

Moral Judgment with a Large Language Model-Based Agent

Abstract
1. Introduction
- MoralAgent is proposed as an agentic approach using LLMs for moral judgment. We systematically sort and summarize many moral judgment theories and design a four-step analysis plan. In addition, dynamic prompt templates, moral principles, and the memory module are designed to support the analysis.
- An information processing method is designed. The memory module summarizes and stores the results obtained from the analysis plan. Subsequently, the variable fields in the next prompt template are automatically updated based on what is memorized. The two interact synergistically to ensure the orderly progression of each step in the analysis plan and the efficient delivery of important information.
- The paper’s experiments demonstrate that the MoralAgent method outperforms previous related methods, and the moral judgment process is demonstrated through a sample.
2. Related Works
2.1. Theoretical Research on Human Moral Judgment
2.2. Research on Moral Judgment in LLMs
2.3. Research on LLM Agents
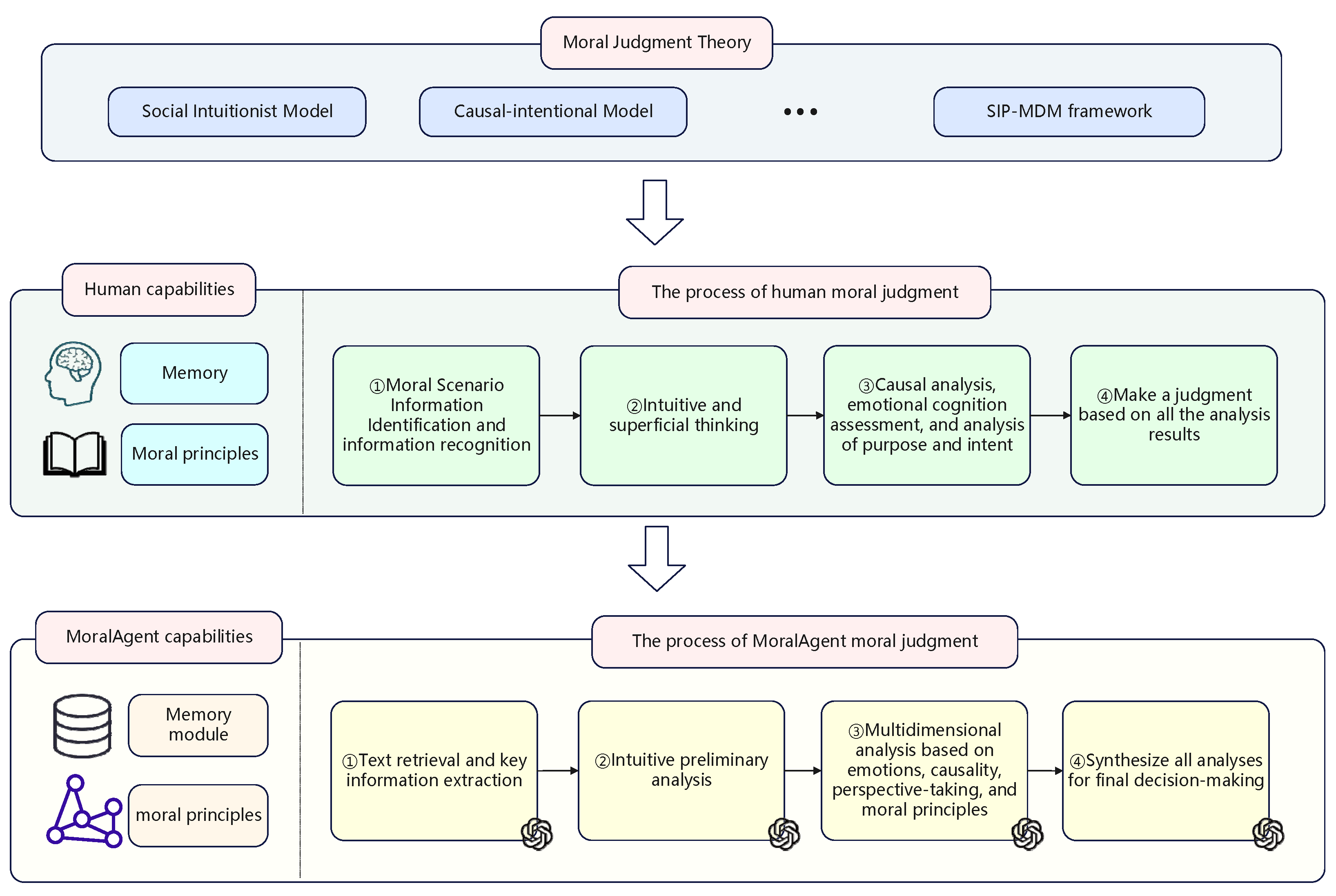
3. Methodology
3.1. Task Definition
3.2. Design of the MoralAgent Method
3.2.1. Design of the Analysis Process
3.2.2. Design of the Memory Module
3.2.3. Formulation of the Moral Principles
3.3. Execution Process of the MoralAgent
3.3.1. Key Information Extraction
3.3.2. Preliminary Analysis
3.3.3. Multidimensional Analysis
3.3.4. Comprehensive Decision-Making
4. Experimental Design
4.1. Introduction to the Dataset
4.2. Baseline Methods
- 1.
- Simple Baseline Methods. This includes Random Baseline and Always No. Random Baseline is the result of randomly choosing in moral scenarios. Always No is the result of choosing inappropriate in all scenarios.
- 2.
- 3.
- Delphi Family of Models [44]. Delphi is trained on 1.7 million moral judgment datasets, while Delphi++ is a model trained on top of Delphi with an additional 200,000 pieces of data.
- 4.
- 5.
- Chain of Thought (CoT). The CoT method [47] adds “Let’s think step by step” to the instruction to guide the model in step-by-step reasoning. MORALCoT [9], based on contractualism, evaluates whether an action violates moral principles. Self-Ask [48] prompts the model to generate and answer relevant questions sequentially before making moral judgments. The “emotion-cognition” collaborative reasoning method proposed by ECMoral [10]. Auto-ECMoral [10] is an automatic reasoning chain for “emotion-cognition” collaboration, which enables LLMs to automatically generate and answer reasoning questions under guidance.
4.3. Experimental Metrics
5. Analysis of Experimental Results
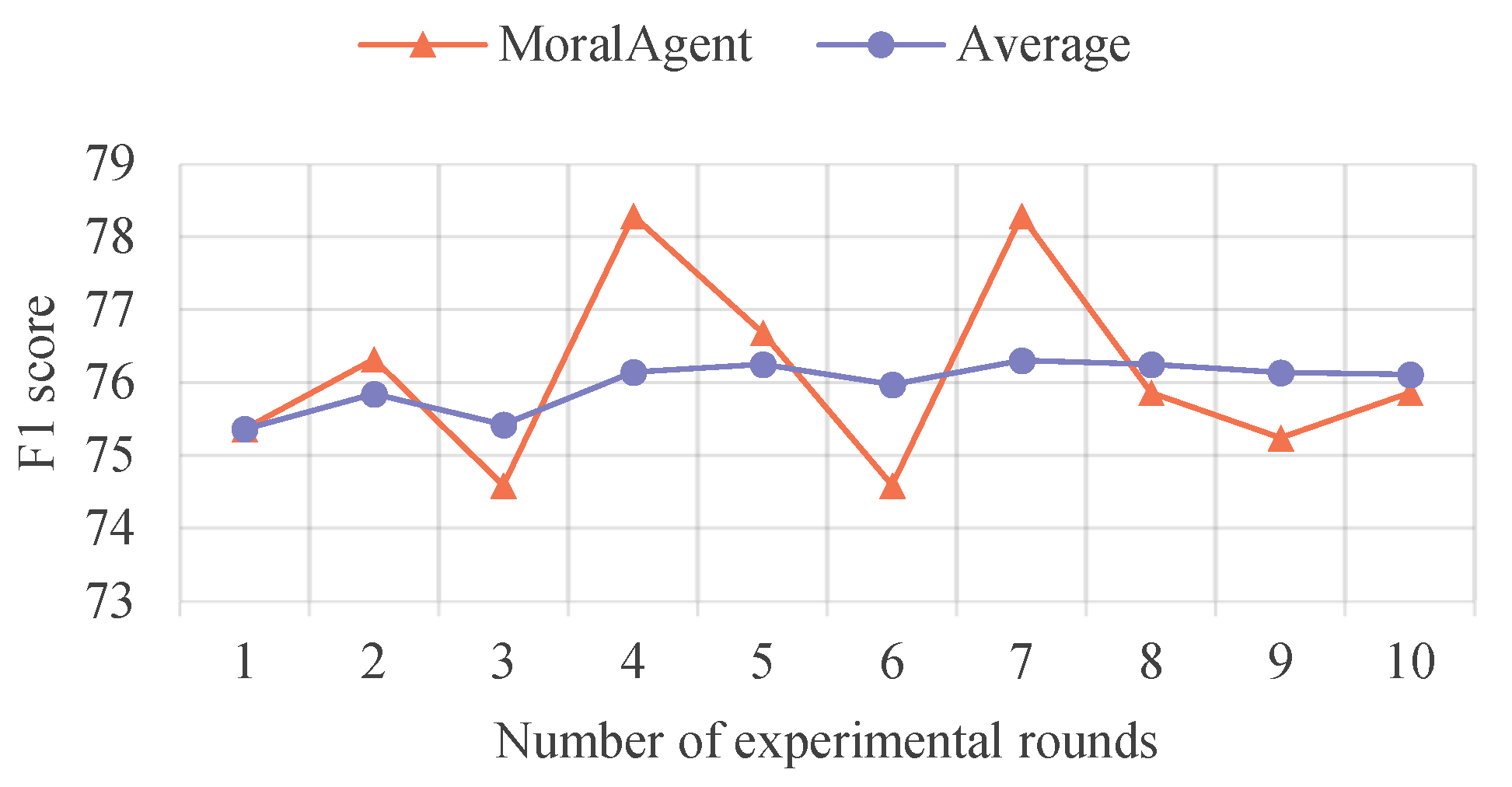
5.1. Comparative Experiment
5.2. Ablation Study
5.3. Generalization Ability of the MoralAgent
5.4. Sample Analysis
6. Conclusions
6.1. Summary of This Study
6.2. Limitations and Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| LLMs | Large Language Models |
| LLM | Large Language Model |
| AI | Artificial Intelligence |
| MM | Memory Model |
| CoT | Chain of Thought |
| TP | True Positive |
| TN | True Negative |
| FP | False Positive |
| FN | False Negative |
References
- Sheng, E.; Chang, K.-W.; Natarajan, P.; Peng, N. Towards Controllable Biases in Language Generation. arXiv 2020, arXiv:2005.00268. [Google Scholar] [CrossRef]
- Cheng, P.; Hao, W.; Yuan, S.; Si, S.; Carin, L. FairFil: Contrastive Neural Debiasing Method for Pretrained Text Encoders. arXiv 2021, arXiv:2103.06413. [Google Scholar] [CrossRef]
- Berg, H.; Hall, S.M.; Bhalgat, Y.; Yang, W.; Kirk, H.R.; Shtedritski, A.; Bain, M. A Prompt Array Keeps the Bias Away: Debiasing Vision-Language Models with Adversarial Learning. arXiv 2022, arXiv:2203.11933. [Google Scholar] [CrossRef]
- Qian, J.; Dong, L.; Shen, Y.; Wei, F.; Chen, W. Controllable Natural Language Generation with Contrastive Prefixes. arXiv 2022, arXiv:2202.13257. [Google Scholar] [CrossRef]
- Wang, Y.; Kordi, Y.; Mishra, S.; Liu, A.; Smith, N.A.; Khashabi, D.; Hajishirzi, H. Self-Instruct: Aligning Language Models with Self-Generated Instructions. arXiv 2023, arXiv:2212.10560. [Google Scholar] [CrossRef]
- A Public and Large-Scale Expert Information Fusion Method and Its Application: Mining Public Opinion via Sentiment Analysis and Measuring Public Dynamic Reliability. Information Fusion 2022, 78, 71–85. [CrossRef]
- Sun, Z.; Shen, Y.; Zhou, Q.; Zhang, H.; Chen, Z.; Cox, D.; Yang, Y.; Gan, C. Principle-Driven Self-Alignment of Language Models from Scratch with Minimal Human Supervision. Adv. Neural Inf. Process. Syst. 2023, 36, 2511–2565. [Google Scholar]
- Liu, H.; Sferrazza, C.; Abbeel, P. Chain of Hindsight Aligns Language Models with Feedback. arXiv 2023, arXiv:2302.02676. [Google Scholar] [CrossRef]
- Jin, Z.; Levine, S.; Gonzalez Adauto, F.; Kamal, O.; Sap, M.; Sachan, M.; Mihalcea, R.; Tenenbaum, J.; Schölkopf, B. When to Make Exceptions: Exploring Language Models as Accounts of Human Moral Judgment. Adv. Neural Inf. Process. Syst. 2022, 35, 28458–28473. [Google Scholar]
- Wu, D.; Zhao, Y.; Qin, B. A Joint Emotion-Cognition Based Approach for Moral Judgement. Available online: https://crad.ict.ac.cn/article/doi/10.7544/issn1000-1239.202330812 (accessed on 16 June 2025).
- Hua, W.; Fan, L.; Li, L.; Mei, K.; Ji, J.; Ge, Y.; Hemphill, L.; Zhang, Y. War and Peace (WarAgent): Large Language Model-Based Multi-Agent Simulation of World Wars. arXiv 2024, arXiv:2311.17227. [Google Scholar] [CrossRef]
- Yang, J.; Fu, J.; Zhang, W.; Cao, W.; Liu, L.; Peng, H. MoE-AGIQA: Mixture-of-Experts Boosted Visual Perception-Driven and Semantic-Aware Quality Assessment for AI-Generated Images. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 17–18 June 2024; pp. 6395–6404. [Google Scholar] [CrossRef]
- Yang, J.; Fu, J.; Zhang, Z.; Liu, L.; Li, Q.; Zhang, W.; Cao, W. Align-IQA: Aligning Image Quality Assessment Models with Diverse Human Preferences via Customizable Guidance. In Proceedings of the MM ‘24: The 32nd ACM International Conference on Multimedia, Melbourne, VIC, Australia, 28 October–1 November 2024. [Google Scholar]
- Dong, L.; Jiang, F.; Peng, Y.; Wang, K.; Yang, K.; Pan, C.; Schober, R. LAMBO: Large AI Model Empowered Edge Intelligence. IEEE Commun. Mag. 2025, 63, 88–94. [Google Scholar] [CrossRef]
- Li, X.; Deng, R.; Wei, J.; Wu, X.; Chen, J.; Yi, C.; Cai, J.; Niyato, D.; Shen, X. AIGC-Driven Real-Time Interactive 4D Traffic Scene Generation in Vehicular Networks. IEEE Netw. 2025, early access. [Google Scholar] [CrossRef]
- Shaver, K.G. The Attribution of Blame: Causality, Responsibility, and Blameworthiness; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Weiner, B. Judgments of Responsibility: A Foundation for a Theory of Social Conduct; Guilford Press: New York, NY, USA, 1995. [Google Scholar]
- Cushman, F. Crime and Punishment: Distinguishing the Roles of Causal and Intentional Analyses in Moral Judgment. Cognition 2008, 108, 353–380. [Google Scholar] [CrossRef] [PubMed]
- Knobe, J. Person as Scientist, Person as Moralist. Behav. Brain Sci. 2010, 33, 315–329. [Google Scholar] [CrossRef]
- Haidt, J.; Hersh, M.A. Sexual Morality: The Cultures and Emotions of Conservatives and Liberals. J. Appl. Soc. Pyschol. 2001, 31, 191–221. [Google Scholar] [CrossRef]
- Greene, J.D. The Secret Joke of Kant’s Soul. Moral Psychol. 2008, 3, 35–79. [Google Scholar]
- Malle, B.F.; Guglielmo, S.; Monroe, A.E. A Theory of Blame. Psychol. Inq. 2014, 25, 147–186. [Google Scholar] [CrossRef]
- Garrigan, B.; Adlam, A.L.; Langdon, P.E. Moral Decision-Making and Moral Development: Toward an Integrative Framework. Dev. Rev. 2018, 49, 80–100. [Google Scholar] [CrossRef]
- Crick, N.R.; Dodge, K.A. A Review and Reformulation of Social Information-Processing Mechanisms in Children’s Social Adjustment. Psychol. Bull. 1994, 115, 74–101. [Google Scholar] [CrossRef]
- Van Bavel, J.; FeldmanHall, O.; Mende-Siedlecki, P. The Neuroscience of Moral Cognition: From Dual Processes to Dynamic Systems. Curr. Opin. Psychol. 2015, in press. [Google Scholar] [CrossRef]
- Yang, Z.; Yi, X.; Li, P.; Liu, Y.; Xie, X. Unified Detoxifying and Debiasing in Language Generation via Inference-Time Adaptive Optimization. arXiv 2023, arXiv:2210.04492. [Google Scholar] [CrossRef]
- Lu, K.; Mardziel, P.; Wu, F.; Amancharla, P.; Datta, A. Gender Bias in Neural Natural Language Processing. In Logic, Language, and Security; Nigam, V., Ban Kirigin, T., Talcott, C., Guttman, J., Kuznetsov, S., Thau Loo, B., Okada, M., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2020; Volume 12300, pp. 189–202. [Google Scholar] [CrossRef]
- Ganguli, D.; Askell, A.; Schiefer, N.; Liao, T.I.; Lukošiūtė, K.; Chen, A.; Goldie, A.; Mirhoseini, A.; Olsson, C.; Hernandez, D.; et al. The Capacity for Moral Self-Correction in Large Language Models. arXiv 2023, arXiv:2302.07459. [Google Scholar] [CrossRef]
- Saunders, W.; Yeh, C.; Wu, J.; Bills, S.; Ouyang, L.; Ward, J.; Leike, J. Self-Critiquing Models for Assisting Human Evaluators. arXiv 2022, arXiv:2206.05802. [Google Scholar] [CrossRef]
- Jiang, W.; Wang, Y.; Jiang, Y.; Chen, J.; Xu, Y.; Tan, L. Research on Mobile Internet Mobile Agent System Dynamic Trust Model for Cloud Computing. China Commun. 2019, 16, 174–194. [Google Scholar] [CrossRef]
- Jiang, W.; Liu, W.; Xia, H.; Xu, Y.; Cao, D.; Liang, G. Research on Intelligent Mobile Commerce Transaction Security Mechanisms Based on Mobile Agent. CMC 2020, 65, 2543–2555. [Google Scholar] [CrossRef]
- Bang, Y.; Cahyawijaya, S.; Lee, N.; Dai, W.; Su, D.; Wilie, B.; Lovenia, H.; Ji, Z.; Yu, T.; Chung, W.; et al. A Multitask, Multilingual, Multimodal Evaluation of ChatGPT on Reasoning, Hallucination, and Interactivity. arXiv 2023, arXiv:2302.04023. [Google Scholar] [CrossRef]
- Zhu, G.; Cai, C.; Pan, B.; Wang, P. A Multi-Agent Linguistic-Style Large Group Decision-Making Method Considering Public Expectations. Int. J. Comput. Intell. Syst. 2021, 14, 188. [Google Scholar] [CrossRef]
- Jiang, F.; Dong, L.; Wang, K.; Yang, K.; Pan, C. Distributed Resource Scheduling for Large-Scale MEC Systems: A Multiagent Ensemble Deep Reinforcement Learning with Imitation Acceleration. IEEE Internet Things J. 2022, 9, 6597–6610. [Google Scholar] [CrossRef]
- Xi, Z.; Chen, W.; Guo, X.; He, W.; Ding, Y.; Hong, B.; Zhang, M.; Wang, J.; Jin, S.; Zhou, E.; et al. The Rise and Potential of Large Language Model Based Agents: A Survey. Sci. China Inf. Sci. 2025, 68, 121101. [Google Scholar] [CrossRef]
- Bran, A.M.; Cox, S.; Schilter, O.; Baldassari, C.; White, A.D.; Schwaller, P. ChemCrow: Augmenting Large-Language Models with Chemistry Tools. arXiv 2023, arXiv:2304.05376. [Google Scholar] [CrossRef]
- Swan, M.; Kido, T.; Roland, E.; dos Santos, R.P. Math Agents: Computational Infrastructure, Mathematical Embedding, and Genomics. arXiv 2023, arXiv:2307.02502. [Google Scholar] [CrossRef]
- Kiley Hamlin, J.; Wynn, K.; Bloom, P. Three-month-olds Show a Negativity Bias in Their Social Evaluations. Dev. Sci. 2010, 13, 923–929. [Google Scholar] [CrossRef]
- Hamborg, F.; Breitinger, C.; Schubotz, M.; Lachnit, S.; Gipp, B. Extraction of Main Event Descriptors from News Articles by Answering the Journalistic Five W and One H Questions. In Proceedings of the 18th ACM/IEEE on Joint Conference on Digital Libraries, Fort Worth, TX, USA, 3–7 June 2018; pp. 339–340. [Google Scholar] [CrossRef]
- Jin, P.; Mu, L.; Zheng, L.; Zhao, J.; Yue, L. News Feature Extraction for Events on Social Network Platforms. In Proceedings of the 26th International Conference on World Wide Web Companion—WWW ’17 Companion, Perth, Australia, 3–7 April 2017; pp. 69–78. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-Training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1 (long and short papers), pp. 4171–4186. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar] [CrossRef]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. ALBERT: A Lite BERT for Self-Supervised Learning of Language Representations. arXiv 2020, arXiv:1909.11942. [Google Scholar] [CrossRef]
- Jiang, L.; Hwang, J.D.; Bhagavatula, C.; Bras, R.L.; Liang, J.; Dodge, J.; Sakaguchi, K.; Forbes, M.; Borchardt, J.; Gabriel, S.; et al. Can Machines Learn Morality? The Delphi Experiment. arXiv 2022, arXiv:2110.07574. [Google Scholar] [CrossRef]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models Are Few-Shot Learners. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: New York, NY, USA, 2020; Volume 33, pp. 1877–1901. [Google Scholar]
- Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Ray, A. Training Language Models to Follow Instructions with Human Feedback. Adv. Neural Inf. Process. Syst. 2022, 35, 27730–27744. [Google Scholar]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Xia, F.; Chi, E.; Le, Q.V.; Zhou, D. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. Adv. Neural Inf. Process. Syst. 2022, 35, 24824–24837. [Google Scholar]
- Press, O.; Zhang, M.; Min, S.; Schmidt, L.; Smith, N.A.; Lewis, M. Measuring and Narrowing the Compositionality Gap in Language Models. arXiv 2023, arXiv:2210.03350. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Number of Scenes |
| Do not cut in line (Line) | 66 |
| Do not damage others’ property (Prop) | 54 |
| Do not throw firecrackers into the pool (Cann) | 28 |
| Total | 148 |
| Model/Method | Overall Performance | F1 on Each Subset | |||||||
|---|---|---|---|---|---|---|---|---|---|
| F1(↑) | Accuracy (↑) | Cons | MAE (↓) | CE (↓) | Line (↑) | Prop (↑) | Cann (↑) | ||
| Simple Baseline Methods | Random Baseline | 49.37 (4.50) | 48.82 (4.56) | 40.08 (2.85) | 0.35 (0.02) | 1.00 (0.09) | 44.88 (7.34) | 57.55 (10.34) | 48.36 (1.67) |
| Always No | 45.99 (0.00) | 60.81 (0.00) | 100.00 (0.00) | 0.258 (0.00) | 0.70 (0.00) | 33.33 (0.00) | 70.60 (0.00) | 33.33 (0.00) | |
| BERT Family of Models. | BERT-base | 45.28 (6.41) | 48.87 (10.52) | 64.16 (21.36) | 0.26 (0.02) | 0.82 (0.19) | 40.81 (8.93) | 51.65 (22.04) | 43.51 (11.12) |
| BERT-large | 52.49 (1.95) | 56.53 (2.73) | 69.61 (16.79) | 0.27 (0.01) | 0.71 (0.01) | 42.53 (2.72) | 62.46 (6.46) | 45.46 (7.20) | |
| RoBERTa-large | 23.76 (2.02) | 39.64 (0.78) | 0.75 (0.65) | 0.30 (0.01) | 0.76 (0.02) | 34.96 (3.42) | 6.89 (0.00) | 38.32 (4.32) | |
| ALBERT-xxlarge | 22.07 (0.00) | 39.19 (0.00) | 0.00 (0.00) | 0.46 (0.00) | 1.41 (0.04) | 33.33 (0.00) | 6.89 (0.00) | 33.33 (0.00) | |
| Delphi Family of Models | Delphi | 48.51 (0.42) | 61.26 (0.78) | 97.70 (1.99) | 0.42 (0.01) | 2.92 (0.23) | 33.33 (0.00) | 70.60 (0.00) | 44.29 (2.78) |
| Delphi++ | 58.27 (0.00) | 62.16 (0.00) | 76.79 (0.00) | 0.34 (0.00) | 1.34 (0.00) | 36.61 (0.00) | 70.60 (0.00) | 40.81 (0.00) | |
| GPT Family of Models | GPT3 | 52.32 (3.14) | 58.95 (3.72) | 80.67 (15.50) | 0.27 (0.02) | 0.72 (0.03) | 36.53 (3.70) | 72.58 (6.01) | 41.20 (7.54) |
| text-davinci-002 | 53.94 (5.48) | 64.36 (2.43) | 98.52 (1.91) | 0.38 (0.04) | 1.59 (0.43) | 42.40 (7.17) | 70.00 (0.00) | 50.48 (11.67) | |
| GPT-3.5-turbo-instruct | 53.13 (6.27) | 62.84 (3.41) | 70.45 (10.10) | 0.39 (0.03) | 1.57 (0.37) | 37.66 (6.12) | 48.01 (3.04) | 65.75 (7.32) | |
| Chain of Thought | CoT | 62.02 (4.68) | 62.84 (6.02) | 58.46 (17.5) | 0.40 (0.02) | 4.87 (0.73) | 54.4 (4.30) | 72.50 (11.11) | 59.57 (5.07) |
| MORALCoT | 64.47 (5.31) | 66.05 (4.43) | 66.96 (2.11) | 0.38 (0.02) | 3.20 (0.30) | 62.10 (5.13) | 70.68 (5.14) | 54.04 (1.43) | |
| Self-Ask | 53.58 (2.46) | 62.84 (1.23) | 93.62 (1.14) | 0.40 (0.02) | 4.57 (0.85) | 42.50 (4.26) | 72.44 (2.68) | 46.90 (1.20) | |
| ECMoral | 71.98 (1.76) | 72.13 (1.50) | 50.16 (12.87) | 0.29 (0.02) | 1.78 (0.27) | 66.24 (3.90) | 85.56 (8.03) | 53.95 (4.44) | |
| Auto-ECMoral | 67.70 (2.14) | 68.58 (2.79) | 59.53 (19.75) | 0.31 (0.01) | 1.75 (0.37) | 59.46 (2.94) | 81.30 (5.69) | 55.26 (4.94) | |
| MoralAgent | 76.11 (1.60) | 81.76 (1.54) | 53.26 (8.87) | 0.29 (0.02) | 1.77 (0.29) | 75.76 (3.23) | 80.00 (5.78) | 74.07 (3.92) | |
| Ablation Component | F1 | Line | Prop | Cann |
|---|---|---|---|---|
| MoralAgent | 76.11 | 75.76 | 80.00 | 74.07 |
| Ablation of Key Information Extraction | 66.67 | 61.54 | 73.68 | 74.07 |
| Ablation of Preliminary Analysis | 73.21 | 73.85 | 76.19 | 69.23 |
| Ablation of Multidimensional Analysis | 59.65 | 59.70 | 55.56 | 62.07 |
| Ablation of Multidimensional Analysis | 61.11 | 56.25 | 66.67 | 69.23 |
| Method | F1 | Line | Prop | Cann |
|---|---|---|---|---|
| GPT4o | 76.64 | 71.43 | 85.71 | 80.00 |
| MORALCoT | 76.92 | 76.17 | 75.68 | 75.68 |
| ECMoral | 77.78 | 76.19 | 86.96 | 75.68 |
| MoralAgent | 81.16 | 77.65 | 85.71 | 87.50 |
| Method | F1 | Accuracy |
|---|---|---|
| GPT-3.5-turbo-instruct | 61.41 | 60.23 |
| MORALCoT | 51.33 | 57.52 |
| ECMoral | 63.89 | 61.17 |
| MoralAgent | 68.67 | 63.32 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiong, S.; Gu, H.; Liang, W.; Yin, L. Moral Judgment with a Large Language Model-Based Agent. Electronics 2025, 14, 2580. https://doi.org/10.3390/electronics14132580
Xiong S, Gu H, Liang W, Yin L. Moral Judgment with a Large Language Model-Based Agent. Electronics. 2025; 14(13):2580. https://doi.org/10.3390/electronics14132580
Chicago/Turabian StyleXiong, Shuchu, Haozhan Gu, Wei Liang, and Lu Yin. 2025. "Moral Judgment with a Large Language Model-Based Agent" Electronics 14, no. 13: 2580. https://doi.org/10.3390/electronics14132580
APA StyleXiong, S., Gu, H., Liang, W., & Yin, L. (2025). Moral Judgment with a Large Language Model-Based Agent. Electronics, 14(13), 2580. https://doi.org/10.3390/electronics14132580