
A Review of Unmanned Visual Target Detection in Adverse Weather


Abstract
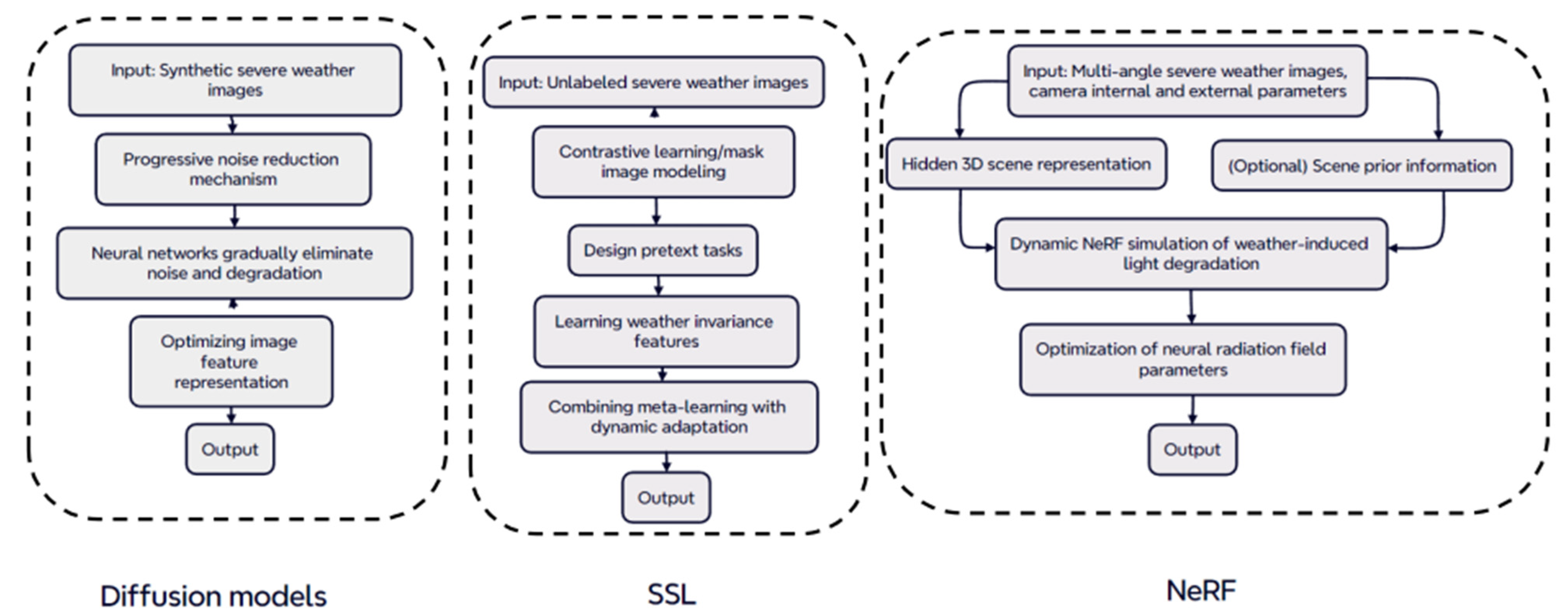
1. Introduction
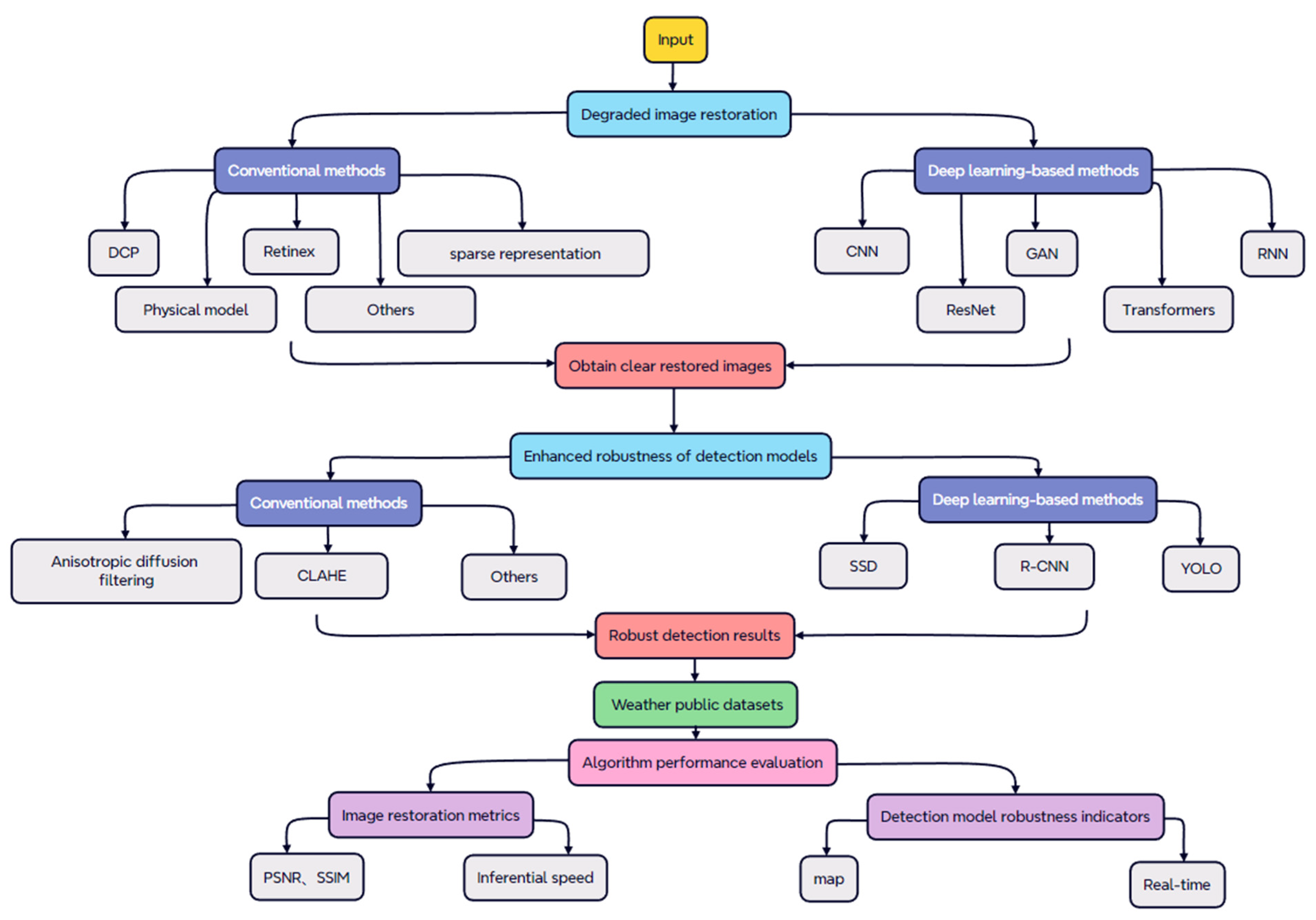
2. Degraded Image Recovery
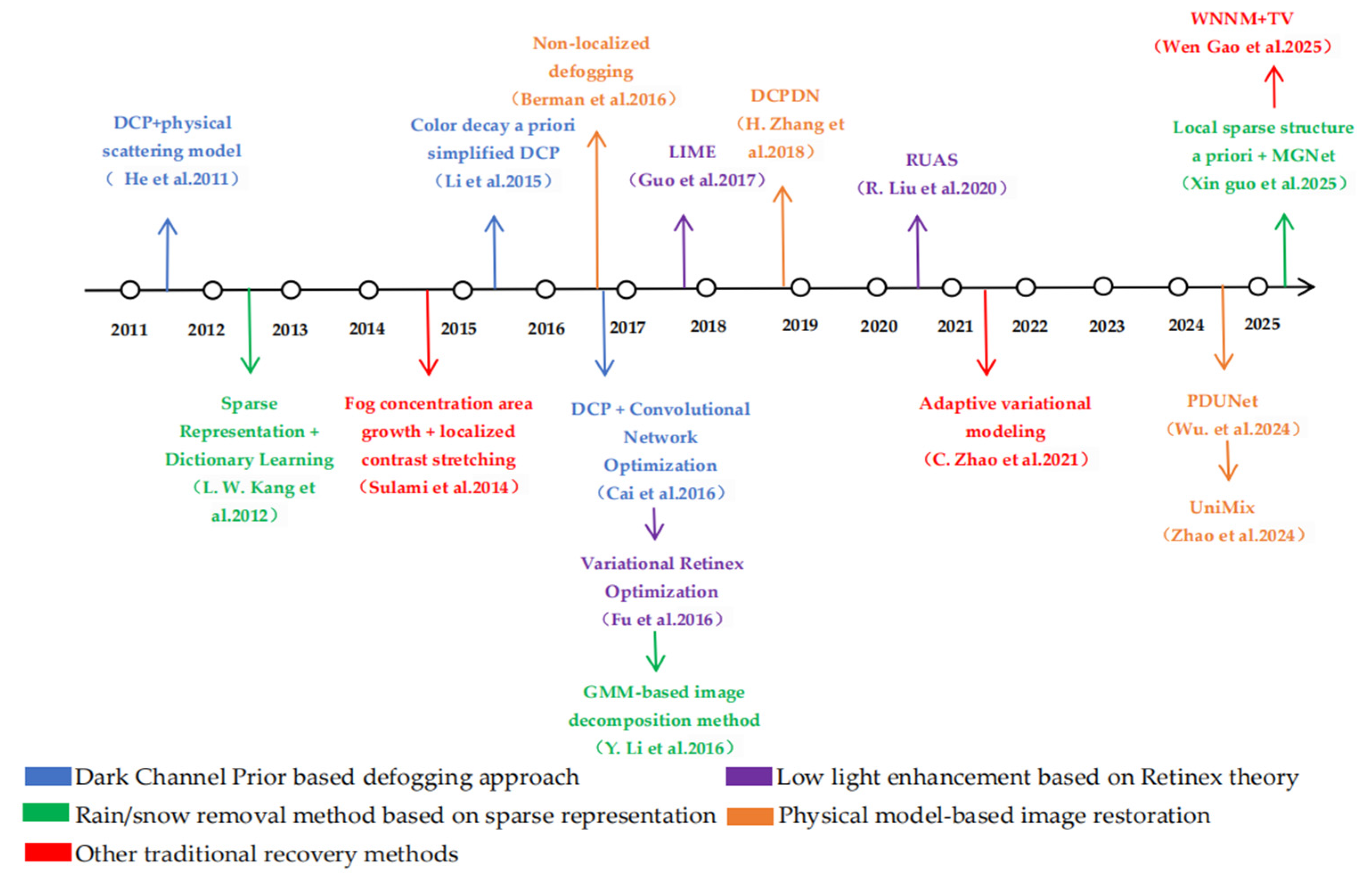
2.1. Traditional Degraded Image Recovery Methods
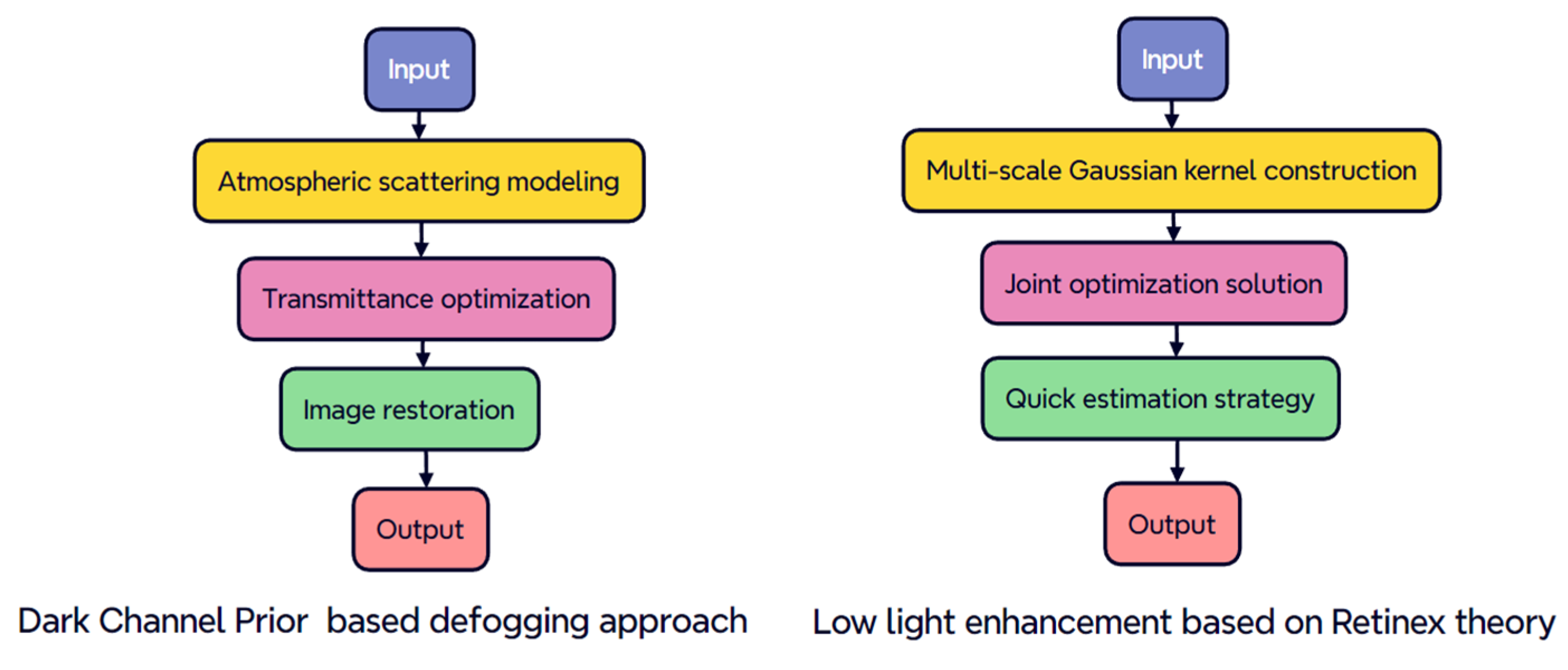
2.1.1. Dark Channel Prior (DCP)-Based Defogging Approach
2.1.2. Low-Light Enhancement Based on Retinex Theory
2.1.3. Rain/Snow Removal Method Based on Sparse Representation
2.1.4. Physical Model-Based Image Restoration
2.1.5. Other Traditional Recovery Methods
2.1.6. Comparison and Analysis
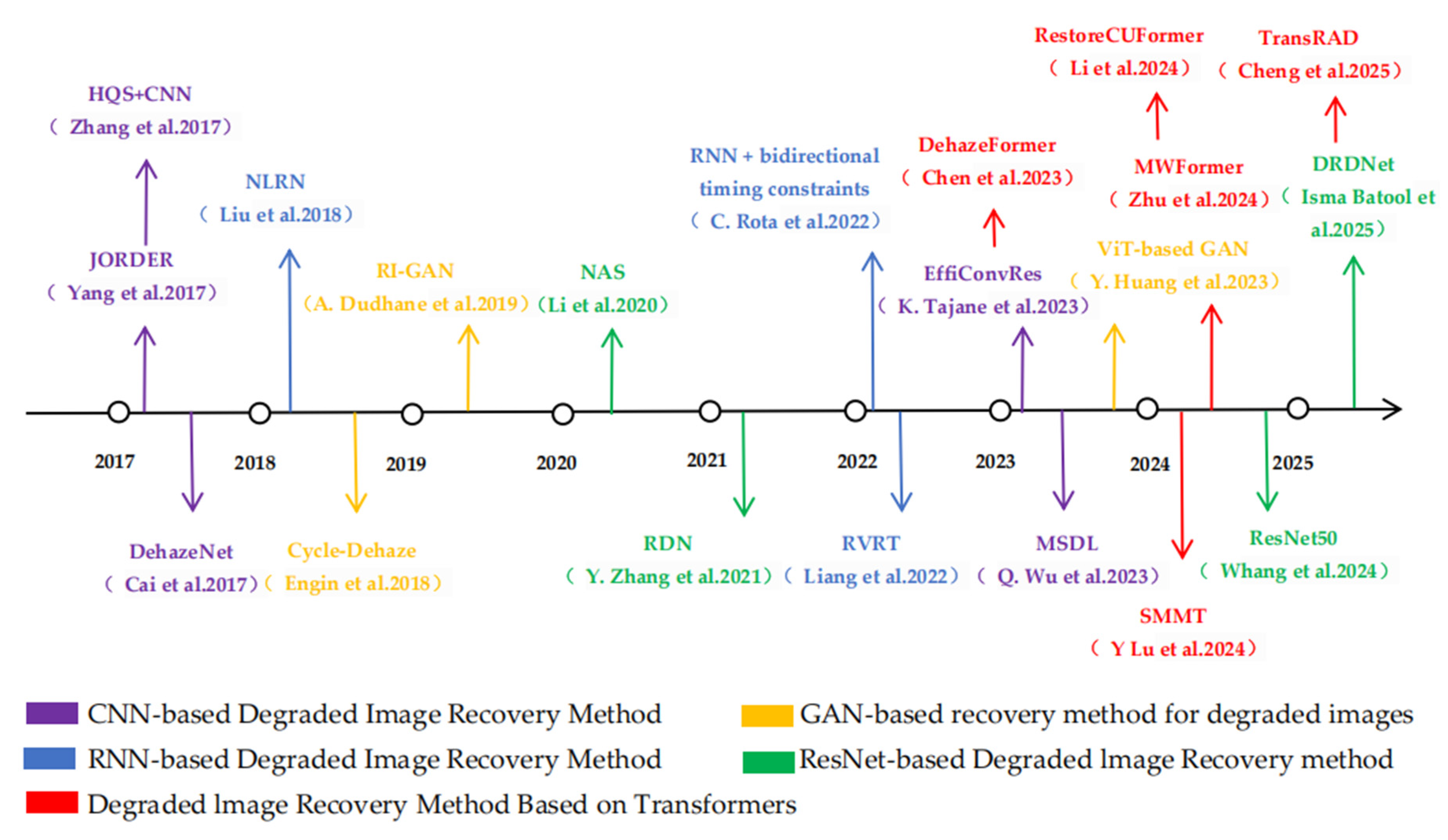
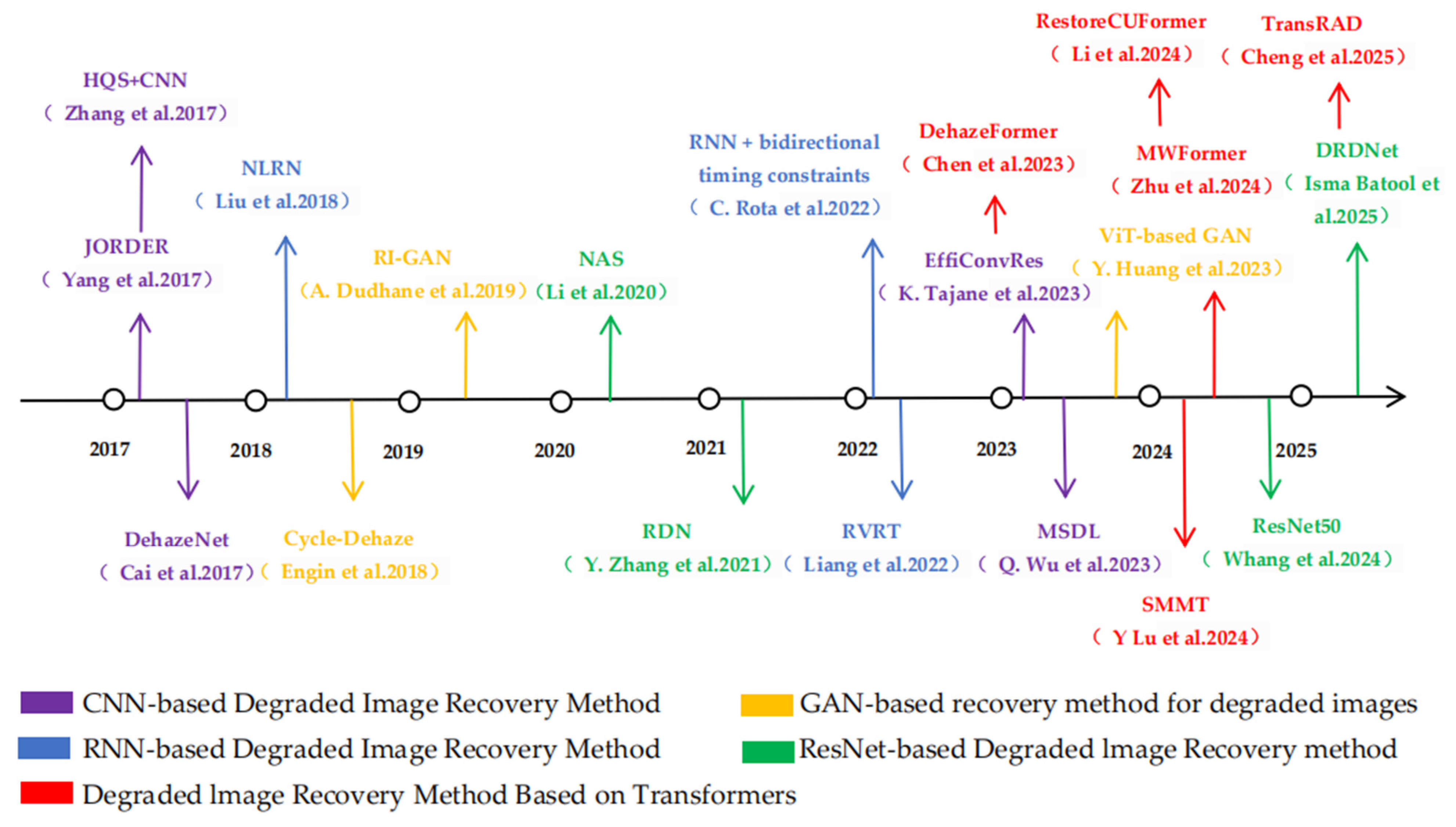
2.2. Deep Learning-Based Degraded Image Recovery Methods
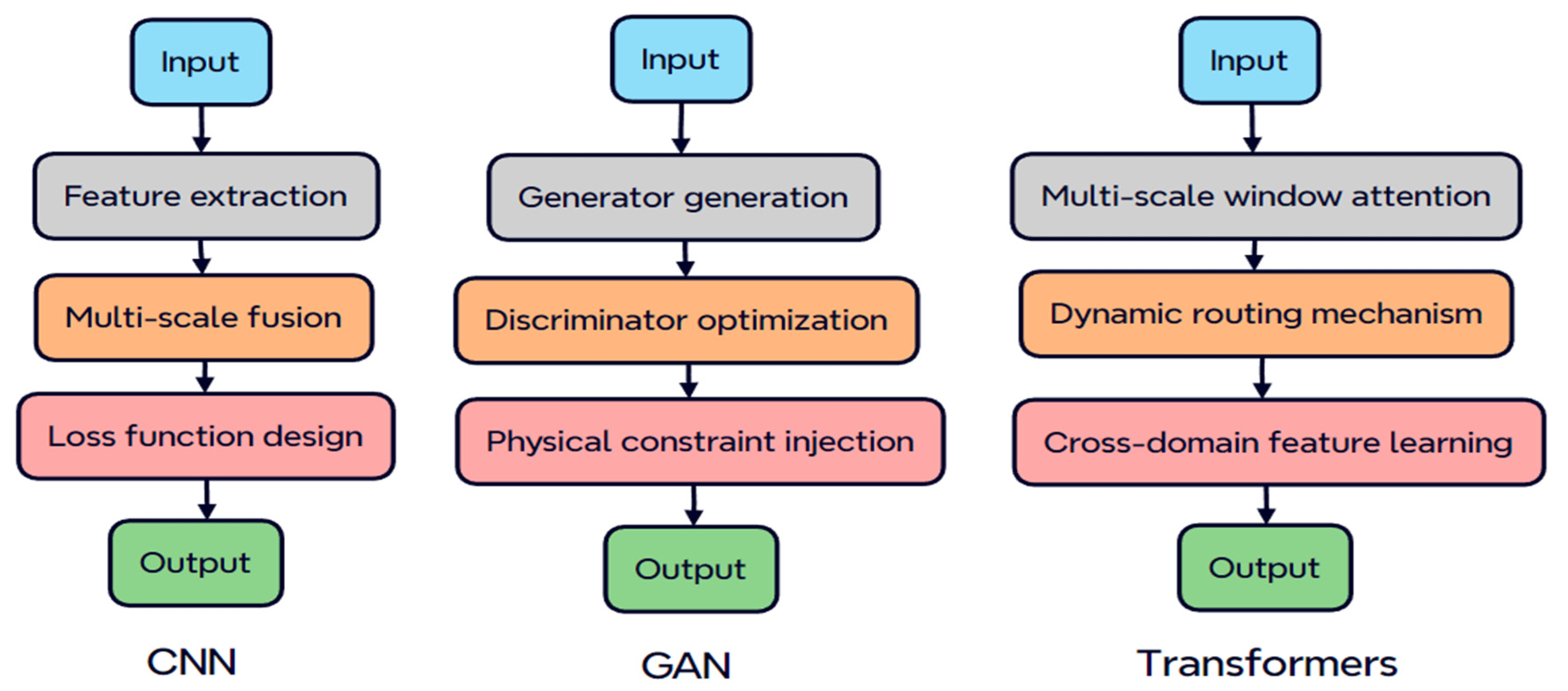
2.2.1. CNN-Based Method for Degraded Image Recovery
2.2.2. Inherent Contradiction Between GAN-Based Degraded Image Recovery Methods and Accuracy
2.2.3. RNN-Based Method for Recovery of Degraded Images
2.2.4. ResNet-Based Degraded Image Recovery Methods
2.2.5. Degraded Image Recovery Method Based on Transformer
2.2.6. Comparison and Analysis
3. Improving Detection Model Robustness
3.1. Traditional Methods for Improving Robustness
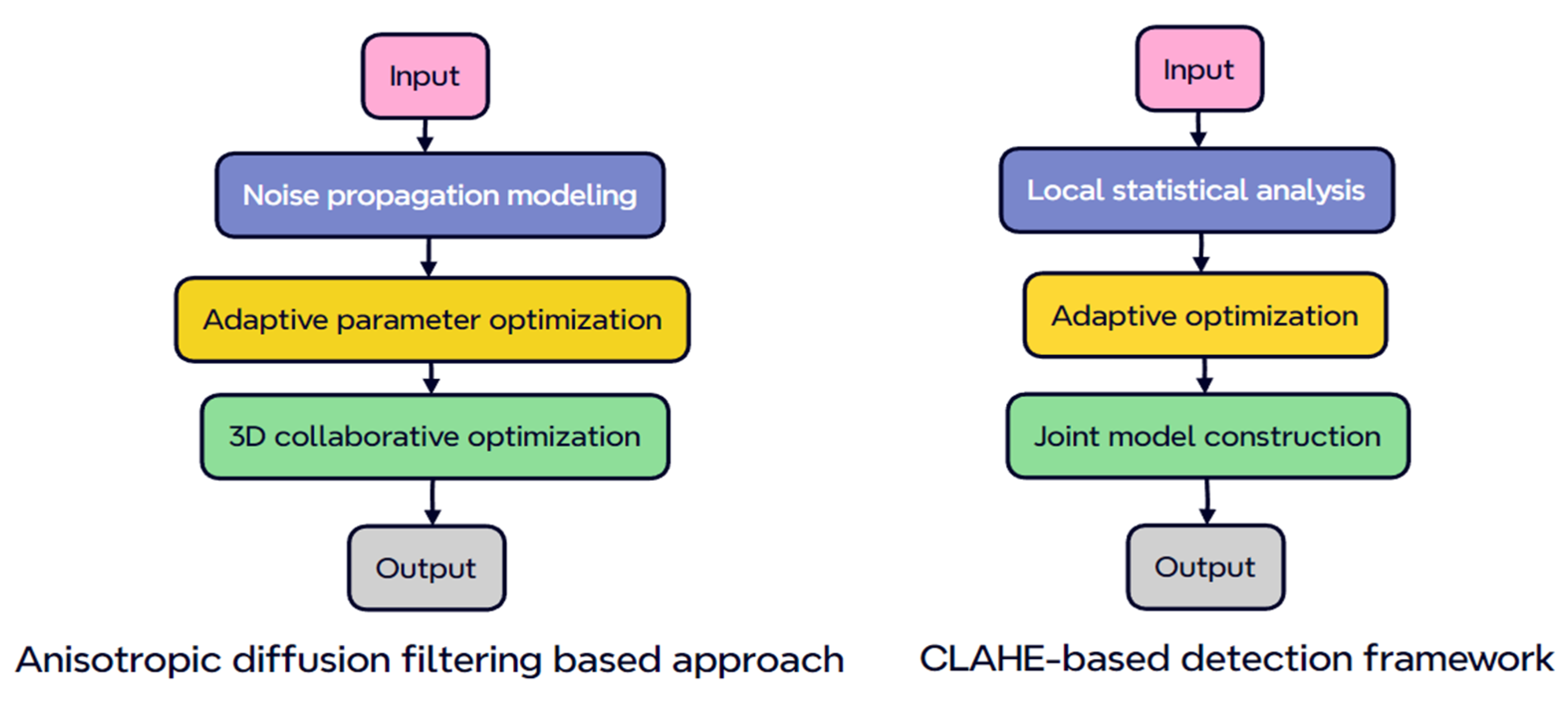
3.1.1. Anisotropic Diffusion Filtering-Based Approach
3.1.2. Contrast Enhancement Method Based on CLAHE
3.1.3. Other Traditional Enhancement Methods
3.1.4. Comparison and Analysis
3.2. Deep Learning-Based Approach to Improve Robustness
3.2.1. SSD-Based Detection Method Improvement
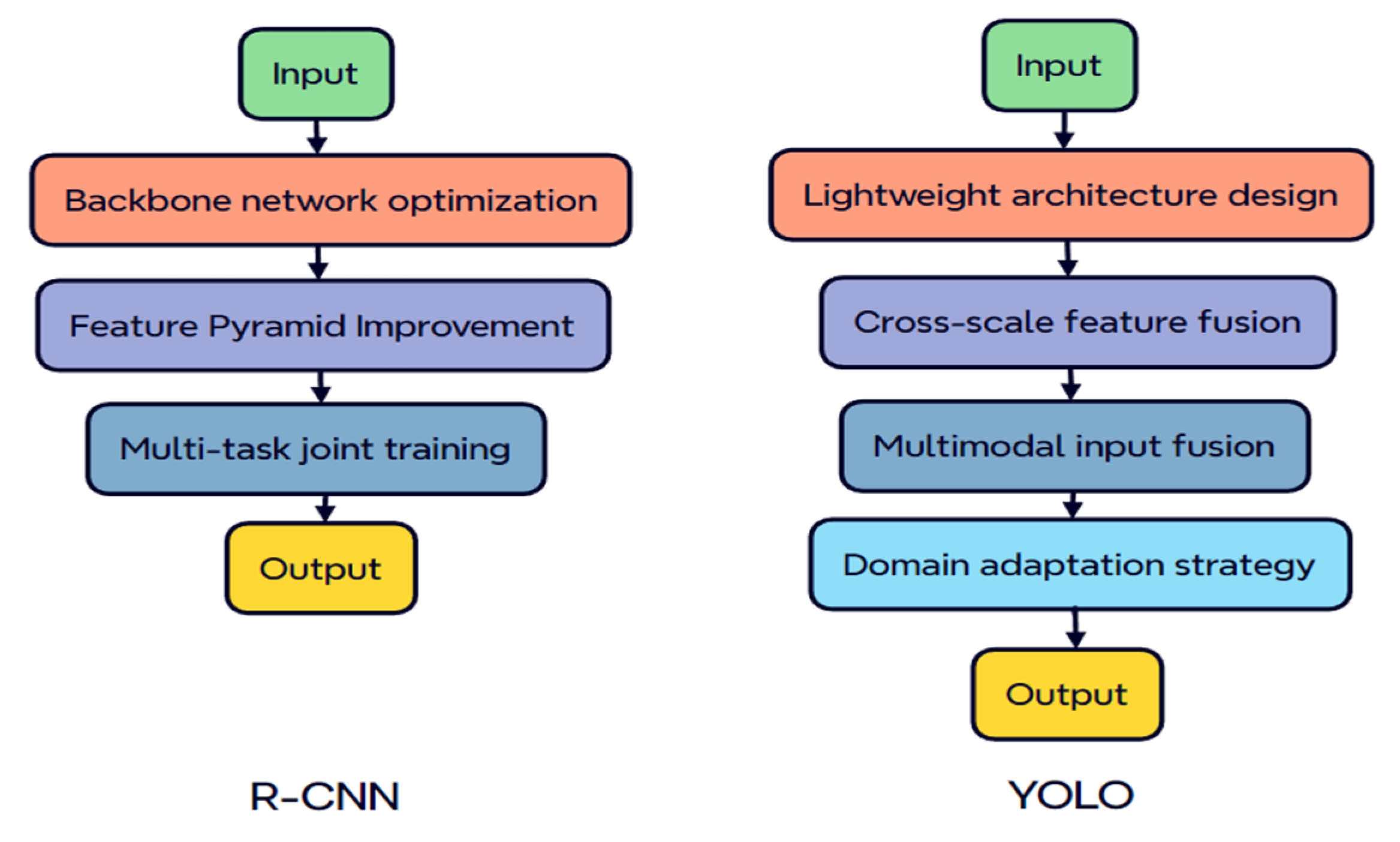
3.2.2. Improvement of R-CNN-Based Detection Methods
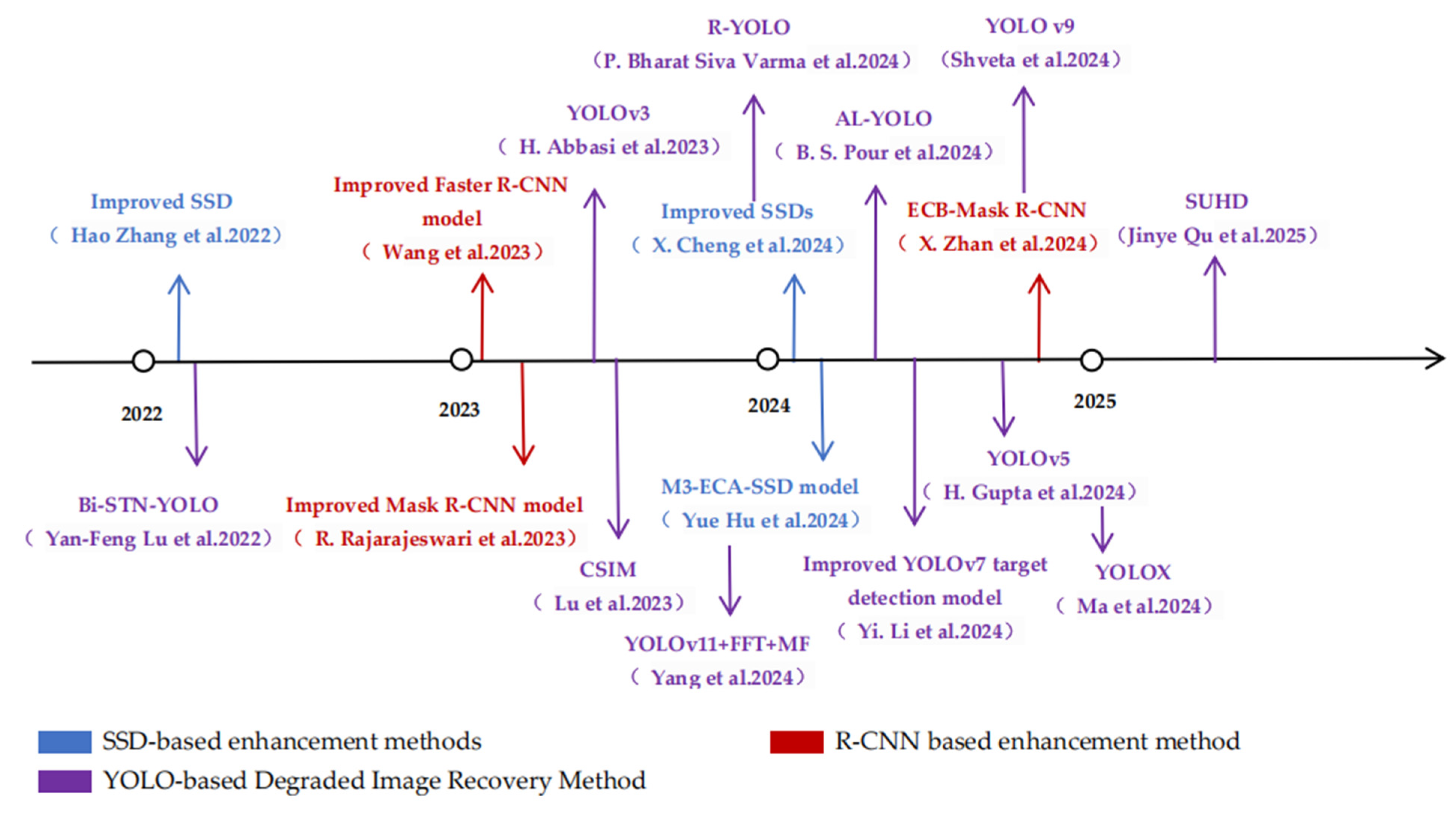
3.2.3. Improvement of YOLO-Based Detection Methods
3.2.4. Comparison and Analysis
4. Weather Public Datasets
5. Performance Comparison and Analysis of Severe Weather-Sensing Algorithms
5.1. Comparison of Degraded Image Recovery Methods
5.1.1. Evaluation of Indicators
- (1)
- PSNR (Peak Signal-to-Noise Ratio). PSNR is a metric that quantifies the global brightness difference by calculating the pixel mean square error (MSE) between the reconstructed image and the reference clear image, expressed in decibels (dB). The numerical meanings are as follows: values ranging from 20 to 30 dB indicate clearly visible distortion; values from 30 to 40 dB suggest visual close to the original; and values exceeding 40 dB signify professional-grade restoration.
- (2)
- SSIM (Structural Similarity Index) evaluates image similarity using three key components: brightness, contrast, and structure. The index value ranges from 0 to 1, with higher values indicating superior quality in visual perception.
- (3)
- Inference speed refers to the total time taken by the model from receiving an input image to producing the output recovery result. It serves as a fundamental indicator of the model’s real-time performance, typically expressed in terms of single-image processing time (ms/image or s/image) or frame rate (FPS).
5.1.2. Traditional Versus Deep Learning Methods
5.2. Comparison of Detection Model Robustness
5.2.1. Evaluation Indicators
- (1)
- mAP (mean Average Precision): mAP serves as the core accuracy index of target detection, quantifying the model’s robustness against variations in target scale, occlusion, and deformation. This is achieved by calculating the average accuracy across categories under varying thresholds of intersection and merging ratios. A smaller fluctuation in mean Average Precision across other situations indicates a more stable detection model.
- (2)
- Real-time performance is a critical aspect of model inference, particularly in the context of processing individual images. This performance is typically quantified by frames per second (FPS), which indicates the number of image frames that can be processed per second. In autonomous driving scenarios, it is imperative to process continuous video streams in real-time; any delays may result in decision-making errors. Therefore, ensuring robust real-time performance is crucial for effective severe weather detection.
5.2.2. Comparison of Robustness of Deep Learning-Based Detection Models
6. Challenges and Prospects
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| DCP | Dark channel a priori |
| PSNR | Peak Signal-to-Noise Ratio |
| NAS | Neural Architecture Search |
| GMM | Gaussian mixture model |
| CLAHE | Contrast Limited Adaptive Histogram Equalization |
References
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1956–1963. [Google Scholar]
- Zhu, Q.; Mai, J.; Shao, L. A Fast Single Image Haze Removal Algorithm Using Color Attenuation Prior. IEEE Trans. Image Process. 2015, 24, 3522–3533. [Google Scholar] [PubMed]
- Cai, B.; Xu, X.; Jia, K.; Qing, C.; Tao, D. DehazeNet: An End-to-End System for Single Image Haze Removal. IEEE Trans. Image Process. 2016, 25, 5187–5198. [Google Scholar] [CrossRef] [PubMed]
- Fu, X.; Zeng, D.; Huang, Y.; Zhang, X.-P.; Ding, X. A Weighted Variational Model for Simultaneous Reflectance and Illumination Estimation. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2782–2790. [Google Scholar]
- Guo, X.; Li, Y.; Ling, H. LIME: Low-Light Image Enhancement via Illumination Map Estimation. IEEE Trans. Image Process. 2017, 26, 982–993. [Google Scholar] [CrossRef] [PubMed]
- Liu, R.; Ma, L.; Zhang, J.; Fan, X.; Luo, Z. Retinex-inspired Unrolling with Cooperative Prior Architecture Search for Low-light Image Enhancement. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 10556–10565. [Google Scholar]
- Kang, L.-W.; Lin, C.-W.; Fu, Y.-H. Automatic Single-Image-Based Rain Streaks Removal via Image Decomposition. IEEE Trans. Image Process. 2012, 21, 1742–1755. [Google Scholar] [CrossRef]
- Li, Y.; Tan, R.T.; Guo, X.; Lu, J.; Brown, M.S. Rain Streak Removal Using Layer Priors. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2736–2744. [Google Scholar]
- Guo, X.; Fu, X.; Zha, Z.-J. Exploring Local Sparse Structure Prior for Image Deraining and Desnowing. IEEE Signal Process. Lett. 2025, 32, 406–410. [Google Scholar] [CrossRef]
- Berman, D.; Treibitz, T.; Avidan, S. Non-local Image Dehazing. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1674–1682. [Google Scholar]
- Zhang, H.; Patel, V.M. Densely Connected Pyramid Dehazing Network. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3194–3203. [Google Scholar]
- Wu, M.; Jiang, A.; Chen, H.; Ye, J. Physical-prior-guided single image dehazing network via unpaired contrastive learning. Multimed. Syst. 2024, 30, 261. [Google Scholar] [CrossRef]
- Zhao, H.; Zhang, J.; Chen, Z.; Zhao, S.; Tao, D. UniMix: Towards Domain Adaptive and Generalizable LiDAR Semantic Segmentation in Adverse Weather. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 17–21 June 2024; pp. 14781–14791. [Google Scholar]
- Sulami, M.; Glatzer, I.; Fattal, R.; Werman, M. Automatic recovery of the atmospheric light in hazy images. In Proceedings of the 2014 IEEE International Conference on Computational Photography (ICCP), Santa Clara, CA, USA, 2–4 May 2014; pp. 1–11. [Google Scholar]
- Zhao, C.; Liu, J.; Zhang, J. A Dual Model for Restoring Images Corrupted by Mixture of Additive and Multiplicative Noise. IEEE Access 2021, 9, 168869–168888. [Google Scholar] [CrossRef]
- Gao, W.; Zhua, J.; Hao, B. Group-based weighted nuclear norm minimization for Cauchy noise removal with TV regularization. Digit. Signal Process. 2025, 156, 104836. [Google Scholar] [CrossRef]
- Jobson, D.J.; Rahman, Z.; Woodell, G.A. Properties and performance of a center/surround retinex. IEEE Trans. Image Process. 1997, 6, 451–462. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.; Gu, S.; Zhang, L. Learning Deep CNN Denoiser Prior for Image Restoration. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2808–2817. [Google Scholar]
- Yang, W.; Tan, R.T.; Feng, J.; Liu, J.; Guo, Z.; Yan, S. Deep Joint Rain Detection and Removal from a Single Image. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Tajane, K.; Rathkanthiwar, V.; Chava, G.; Dhavale, S.; Chawda, G.; Pitale, R. EffiConvRes: An Efficient Convolutional Neural Network with Residual Connections and Depthwise Convolutions. In Proceedings of the 2023 7th International Conference on Computing, Communication, Control and Automation (ICCUBEA), Pune, India, 18–19 August 2023; pp. 1–5. [Google Scholar]
- Wu, Q.; Liu, J.; Feng, M. MSDB-based CNN architecture for image dehazing in driverless cars. In Proceedings of the 2023 IEEE 3rd International Conference on Power, Electronics and Computer Applications (ICPECA), Shenyang, China, 29–31 January 2023; pp. 789–794. [Google Scholar]
- Engin, D.; Genc, A.; Ekenel, H.K. Cycle-Dehaze: Enhanced CycleGAN for Single Image Dehazing. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 938–9388. [Google Scholar]
- Dudhane, A.; Aulakh, H.S.; Murala, S. RI-GAN: An End-To-End Network for Single Image Haze Removal. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019; pp. 2014–2023. [Google Scholar]
- Huang, Y. ViT-R50 GAN: Vision Transformers Hybrid Model based Generative Adversarial Networks for Image Generation. In Proceedings of the 2023 3rd International Conference on Consumer Electronics and Computer Engineering (ICCECE), Guangzhou, China, 6–8 January 2023; pp. 590–593. [Google Scholar]
- Liu, D.; Wen, B.; Fan, Y.; Loy, C.C.; Huang, T.S. Non-local recurrent network for image restoration. In NIPS’18: Proceedings of the 32nd International Conference on Neural Information Processing Systems, Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montréal Canada, 3–8 December 2018; Curran Associates Inc.: Red Hook, NY, USA, 2018; pp. 1680–1689. [Google Scholar]
- Liang, J.; Fan, Y.; Xiang, X.; Ranjan, R.; Ilg, E.; Green, S.; Cao, J.; Zhang, K.; Timofte, R.; Van Gool, L. Recurrent Video Restoration Transformer with Guided Deformable Attention. In Proceedings of the Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Rota, C.; Buzzelli, M.; Bianco, S.; Schettini, R. A RNN for Temporal Consistency in Low-Light Videos Enhanced by Single-Frame Methods. IEEE Signal Process. Lett. 2024, 31, 2795–2799. [Google Scholar] [CrossRef]
- Li, R.; Tan, R.T.; Cheong, L.-F. All in One Bad Weather Removal Using Architectural Search. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 3172–3182. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual Dense Network for Image Restoration. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 2480–2495. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Zhou, Y.; Fu, M. Comprehensive Weather Recognition Using ResNet-50 and a Novel Weather Image Dataset. In Proceedings of the 2024 4th International Signal Processing, Communications and Engineering Management Conference (ISPCEM), Montreal, QC, Canada, 28–30 November 2024; pp. 455–459. [Google Scholar]
- Batool, I.; Imran, M. A dual residual dense network for image denoising. Eng. Appl. Artif. Intell. 2025, 147, 110275. [Google Scholar] [CrossRef]
- Song, Y.; He, Z.; Qian, H.; Du, X. Vision Transformers for Single Image Dehazing. IEEE Trans. Image Process. 2023, 32, 1927–1941. [Google Scholar] [CrossRef] [PubMed]
- Guo, L.; Lu, Y.; Qu, J.; Zheng, S.; Jiang, R.; Lu, Y. Transformer-based Spiking Neural Networks for Multimodal Audio-Visual Classification. IEEE Trans. Cogn. Dev. Syst. 2024, 16, 1077–1086. [Google Scholar] [CrossRef]
- Zhu, R.; Tu, Z.; Liu, J.; Bovik, A.C.; Fan, Y. MWFormer: Multi-Weather Image Restoration Using Degradation-Aware Transformers. IEEE Trans. Image Process. 2024, 33, 6790–6805. [Google Scholar] [CrossRef]
- Li, J.; Wang, Z.; Wan, J.; Si, H.; Wang, X.; Tan, G. RestoreCUFormer: Transformers to Make Strong Encoders via Two-stage Knowledge Learning For Multiple Adverse Weather Removal. In Proceedings of the 2024 International Joint Conference on Neural Networks (IJCNN), Yokohama, Japan, 30 June–5 July 2024; pp. 1–8. [Google Scholar]
- Cheng, L.; Cao, S. TransRAD: Retentive Vision Transformer for Enhanced Radar Object Detection. IEEE Trans. Radar Syst. 2025, 3, 303–317. [Google Scholar] [CrossRef]
- Gautam, K.S.; Tripathi, A.K.; Rao, M.V.S. Vectorization and Optimization of Fog Removal Algorithm. In Proceedings of the 2016 IEEE 6th International Conference on Advanced Computing (IACC), Bhimavaram, India, 27–28 February 2016; pp. 362–367. [Google Scholar]
- Qi, H.; Li, F.; Chen, P.; Tan, S.; Luo, X.; Xie, T. Edge-preserving image restoration based on a weighted anisotropic diffusion model. Pattern Recognit. Lett. 2024, 184, 80–88. [Google Scholar] [CrossRef]
- Palanisamy, V.; Malarvel, M.; Thangakumar, J. Anisotropic Diffusion Method on Multiple Domain Noisy Images: A Recommendation. In Proceedings of the 2024 International Conference on Advances in Data Engineering and Intelligent Computing Systems (ADICS), Chennai, India, 18–19 April 2024; pp. 1–5. [Google Scholar]
- Liu, Y.; Zhu, T.-F.; Luo, Z.; Ouyang, X.-P. 3D robust anisotropic diffusion filtering algorithm for sparse view neutron computed tomography 3D image reconstruction. Nucl. Sci. Tech. 2024, 35, 50. [Google Scholar] [CrossRef]
- Yuan, Z.; Zeng, J.; Wei, Z.; Jin, L.; Zhao, S.; Liu, X.; Zhang, Y.; Zhou, G. CLAHE-Based Low-Light Image Enhancement for Robust Object Detection in Overhead Power Transmission System. IEEE Trans. Power Deliv. 2023, 38, 2240–2243. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, Z.; Wang, H.; Blaabjerg, F. Artificial Intelligence-Aided Thermal Model Considering Cross-Coupling Effects. IEEE Trans. Power Electron. 2020, 35, 9998–10002. [Google Scholar] [CrossRef]
- Lashkov, I.; Yuan, R.; Zhang, G. Edge-Computing-Facilitated Nighttime Vehicle Detection Investigations with CLAHE-Enhanced Images. IEEE Trans. Intell. Transp. Syst. 2023, 24, 3370–13383. [Google Scholar] [CrossRef]
- Kou, F.; Chen, W.; Wen, C.; Li, Z. Gradient Domain Guided Image Filtering. IEEE Trans. Image Process. 2015, 24, 4528–4539. [Google Scholar] [CrossRef] [PubMed]
- Lu, Z.; Long, B.; Li, K.; Lu, F. Effective Guided Image Filtering for Contrast Enhancement. IEEE Signal Process. Lett. 2018, 25, 1585–1589. [Google Scholar] [CrossRef]
- Li, J.; Wang, Y.; Chen, F.; Wang, Y.; Chen, Q.; Sui, X. Multi exposure fusion for high dynamic range imaging via multi-channel gradient tensor. Digit. Signal Process. 2025, 156, 104821. [Google Scholar] [CrossRef]
- Zhang, H.; Huang, W.; Qi, J. Design and implementation of object image detection interface system based on PyQt5 and improved SSD algorithm. In Proceedings of the 2022 IEEE 10th Joint International Information Technology and Artificial Intelligence Conference (ITAIC), Chongqing, China, 17–19 June 2022; pp. 2086–2090. [Google Scholar]
- Cheng, X.; Zhang, X.; Zhao, Z.; Huang, X.; Han, X.; Wu, X. An improved SSD target detection method based on deep separable convolution. In Proceedings of the 2024 6th International Conference on Internet of Things, Automation and Artificial Intelligence (IoTAAI), Guangzhou, China, 26–28 July 2024; pp. 92–96. [Google Scholar]
- Hu, Y.; Zhang, Q. Improved Small Target Detection Algorithm Based on SSD. In Proceedings of the 2024 5th International Conference on Computer Vision, Image and Deep Learning (CVIDL), Zhuhai, China, 19–21 April 2024; pp. 1421–1425. [Google Scholar]
- Wang, Z.; Cao, Y.; Li, J. A Detection Algorithm Based on Improved Faster R-CNN for Spacecraft Components. In Proceedings of the 2023 IEEE International Conference on Image Processing and Computer Applications (ICIPCA), Changchun, China, 11–13 August 2023; pp. 1–5. [Google Scholar]
- Rajarajeswari, R.; Sankaradass, V. Multi-Object Recognition and Segmentation using Enhanced Mask R-CNN for Intricate Image Scenes. In Proceedings of the 2023 International Conference on Data Science, Agents & Artificial Intelligence (ICDSAAI), Chennai, India, 21–23 December 2023; pp. 1–6. [Google Scholar]
- Zhan, X.; Li, C. Study of Mask R-CNN in Target Detection Based on Improved Feature Pyramid Networks. In Proceedings of the 2024 6th International Conference on Frontier Technologies of Information and Computer (ICFTIC), Qingdao, China, 8–10 November 2024; pp. 846–850. [Google Scholar]
- Lu, Y.-F.; Yu, Q.; Gao, J.-W.; Li, Y.; Zou, J.-C.; Qiao, H. Cross Stage Partial Connections based Weighted Bi-directional Feature Pyramid and Enhanced Spatial Transformation Network for Robust Object Detection. Neurocomputing 2022, 513, 70–82. [Google Scholar] [CrossRef]
- Lu, Y.; Gao, J.; Yu, Q.; Li, Y.; Lv, Y.; Qiao, H. A Cross-Scale and Illumination Invariance-Based Model for Robust Object Detection in Traffic Surveillance Scenarios. IEEE Trans. Intell. Transp. Syst. 2023, 24, 6989–6999. [Google Scholar] [CrossRef]
- Abbasi, H.; Amini, M.; Yu, F.R. Fog-Aware Adaptive YOLO for Object Detection in Adverse Weather. In Proceedings of the 2023 IEEE Sensors Applications Symposium (SAS), Ottawa, ON, Canada, 18–20 July 2023; pp. 1–6. [Google Scholar]
- Li, Y.; Lu, Y.; Wu, K.; Fang, Y.; Zheng, C.; Zhang, J. Intelligent Inspection System for Power Insulators based on AAV on Complex Weather Conditions. IEEE Trans. Appl. Supercond. 2024, 34, 1–4. [Google Scholar] [CrossRef]
- Pour, B.S.; Jozani, H.M.; Shokouhi, S.B. AL-YOLO: Accurate and Lightweight Vehicle and Pedestrian Detector in Foggy Weather. In Proceedings of the 2024 14th International Conference on Computer and Knowledge Engineering (ICCKE), Mashhad, Iran, 19–20 November 2024; pp. 131–136. [Google Scholar]
- Gupta, H.; Kotlyar, O.; Andreasson, H.; Lilienthal, A.J. Robust Object Detection in Challenging Weather Conditions. In Proceedings of the 2024 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2024; pp. 7508–7517. [Google Scholar]
- Varma, P.B.S.; Adimoolam, P.; Marna, Y.L.; Vengala, A.; Sundar, V.S.D.; Kumar, M.V.T.R.P. Enhancing Robust Object Detection in Weather-Impacted Environments using Deep Learning Techniques. In Proceedings of the 2024 2nd International Conference on Self Sustainable Artificial Intelligence Systems (ICSSAS), Erode, India, 23–25 October 2024; pp. 599–604. [Google Scholar]
- Rattanpal, S.; Kashish, K.; Kumari, T.; Manvi; Gupta, S. Object Detection in Adverse Weather Conditions using Machine Learning. In Proceedings of the 2024 13th International Conference on System Modeling & Advancement in Research Trends (SMART), Moradabad, India, 6–7 December 2024; pp. 239–247. [Google Scholar]
- Ma, J.; Lin, M.; Zhou, G.; Jia, Z. Joint Image Restoration for Domain Adaptive Object Detection in Foggy Weather Condition. In Proceedings of the 2024 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 27–30 October 2024; pp. 542–548. [Google Scholar]
- Yang, J.; Tian, T.; Liu, Y.; Li, C.; Wu, D.; Wang, L.; Wang, X. A Rainy Day Object Detection Method Based on YOLOv11 Combined with FFT and MF Model Fusion. In Proceedings of the 2024 International Conference on Advanced Control Systems and Automation Technologies (ACSAT), Nanjing, China, 15–17 November 2024; pp. 246–250. [Google Scholar]
- Qu, J.; Gao, Z.; Zhang, T.; Lu, Y.; Tang, H.; Qiao, H. Spiking Neural Network for Ultralow-Latency and High-Accurate Object Detection. IEEE Trans. Neural Netw. Learn. Syst. 2025, 36, 4934–4946. [Google Scholar] [CrossRef]
- Li, B.; Ren, W.; Fu, D.; Tao, D.; Feng, D.; Zeng, W.; Wang, Z. Benchmarking Single-Image Dehazing and Beyond. IEEE Trans. Image Process. 2019, 28, 492–505. [Google Scholar] [CrossRef]
- Hahner, M.; Dai, D.; Sakaridis, C.; Zaech, J.-N.; Gool, L.V. Semantic Understanding of Foggy Scenes with Purely Synthetic Data. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 3675–3681. [Google Scholar]
- Ancuti, C.O.; Ancuti, C.; Timofte, R.; De Vleeschouwer, C. O-HAZE: A Dehazing Benchmark with Real Hazy and Haze-Free Outdoor Images. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 867–8678. [Google Scholar]
- Hu, X.; Fu, C.-W.; Zhu, L.; Heng, P.-A. Depth-Attentional Features for Single-Image Rain Removal. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 8014–8023. [Google Scholar]
- Zhang, H.; Sindagi, V.; Patel, V.M. Image De-Raining Using a Conditional Generative Adversarial Network. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 3943–3956. [Google Scholar] [CrossRef]
- Jiang, K.; Wang, Z.; Yi, P.; Chen, C.; Huang, B.; Luo, Y.; Ma, J.; Jiang, J. Multi-Scale Progressive Fusion Network for Single Image Deraining. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 8343–8352. [Google Scholar]
- Qian, R.; Tan, R.T.; Yang, W.; Su, J.; Liu, J. Attentive Generative Adversarial Network for Raindrop Removal from A Single Image. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2482–2491. [Google Scholar]
- Zhang, K.; Li, R.; Yu, Y.; Luo, W.; Li, C. Deep Dense Multi-Scale Network for Snow Removal Using Semantic and Depth Priors. IEEE Trans. Image Process. 2021, 30, 7419–7431. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.-F.; Jaw, D.-W.; Huang, S.-C.; Hwang, J.-N. DesnowNet: Context-Aware Deep Network for Snow Removal. IEEE Trans. Image Process. 2018, 27, 3064–3073. [Google Scholar] [CrossRef] [PubMed]
- Choi, Y.; Kim, N.; Hwang, S.; Park, K.; Yoon, J.S.; An, K.; Kweon, I.S. KAIST Multi-Spectral Day/Night Data Set for Autonomous and Assisted Driving. IEEE Trans. Intell. Transp. Syst. 2018, 19, 934–948. [Google Scholar] [CrossRef]
- Yu, F.; Chen, H.; Wang, X.; Xian, W.; Chen, Y.; Liu, F.; Madhavan, V.; Darrell, T. BDD100K: A Diverse Driving Dataset for Heterogeneous Multitask Learning. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 2633–2642. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Categorization | Algorithmic Model | Reference | Dataset | Algorithm Characteristics | Summary of Advantages/Disadvantages |
|---|---|---|---|---|---|
| Dark channel prior-based defogging approach | DCP + physical scattering model | He et al. (2009) [1] | Training set: 500 prints Test set: 100 frames | Estimating transmittance and atmospheric light using statistical properties of dark channels in natural scenes without training data | Strong physical interpretability, significant defogging effect, but the sky region is prone to halo, high computational complexity |
| Color decay a priori-simplified DCP | Zhu et al. (2015) [2] | Homemade synthetic data | Fast transmittance estimation based on color attenuation a priori, avoiding dark channel calculations | Computational speed is fast and suitable for real-time processing, but the recovery effect of dense fog scene decreases | |
| DCP + Convolutional Network Optimization | Cai et al. (2016) [3] | Dark Channel Synthesis Data | Combining DCP a priori with shallow CNN to optimize transmittance estimation | Reduces manual parameter adjustment and improves defogging efficiency, but relies on synthetic data and has limited generalization to real scenarios | |
| Low-light enhancement based on Retinex theory | Variational Retinex Optimization | Fu et al. (2016) [4] | Training set: 500 frames Test set: 100 frames | Joint optimization of light reflection components by weighted variational models | Better global illumination consistency, but high computational complexity, need to be solved iteratively |
| LIME | Guo et al. (2017) [5] | Training set: 300 frames Test set: 50 frames | Maximum a priori fast enhancement of low-light regions based on light maps | Strong real-time performance and significant detail enhancement, but noise amplification is a significant problem | |
| RUAS | R. Liu et al. (2021) [6] |
| First to combine Retinex rollout optimization with NAS for lightweight and efficient end-to-end low-light enhancement | Efficient and lightweight with strong robustness, but in extreme noise scenarios, the NRM module may not be able to remove complex noise completely | |
| Rain/snow removal method based on sparse representation | Sparse Representation + Dictionary Learning | L. W. Kang et al. (2012) [7] | Photoshop manually adds rain pattern generation | First combination of MCA and self-learning dictionary for single-image rain removal without external training data | No temporal information is required and dictionary learning is based entirely on the input image itself, but the computational complexity is high |
| GMM-based image decomposition method | Y. Li et al. (2016) [8] | Synthetic data | Dual GMM a priori modeling with a joint optimization framework | In single-image rain pattern removal, a balance between detail preservation and rain pattern suppression is achieved, but the dependence on local region selection limits its practical application. | |
| Local sparse structure a priori + MGNet | Xin guo et al. (2025) [9] |
| Localized sparse structure a priori, two-stage mask-guided recovery network | Local sparse prior with adaptive mask extraction algorithm supports localization of multiple unknown rain and snow types, but heavy rain/blizzard scenarios rely on neighborhood reconstruction | |
| Physical model-based image restoration | Non-localized defogging | Berman et al. (2016) [10] | BSDS300 | Optimizing transmittance using hyperpixel segmentation and non-local similarity | Reduces sky artifacts but relies on superpixel segmentation accuracy |
| DCPDN | H. Zhang et al. (2018) [11] |
| End-to-end joint optimization, multi-scale feature fusion, staged training strategy | Multi-scale detail recovery, joint discriminator reduces color distortion on real images, but has high computational complexity and relies on synthetic data | |
| PDUNet | Wu. et al. (2024) [12] |
| Pre-training (synthetic data) + fine-tuning (real data), hybrid physics a priori | Physical prior fused with deep learning, but with strong two-stage training dependencies and high computational complexity | |
| Other traditional recovery methods | Fog concentration area growth + localized contrast stretching | Sulami et al. (2014) [14] | Training set: none Test set: 100 frames | Segmentation of fog concentration regions based on seed point growth with region-by-region adaptive enhancement | Solve the problem of non-uniform fog concentration, enhance the natural transition of the results, but the seed points need to be initialized manually, but the degree of automation is low |
| Adaptive variational modeling | C. Zhao et al. (2021) [15] | Training set: 5544 frames Test set: House, Lena | Adaptive noise detection, supports multiple regularization methods, and can be adapted to different denoising needs | Superior denoising performance and applicable to multiple scenarios, but insufficient parameter estimation accuracy and high computational complexity | |
| WNNM + TV | Wen Gao et al. (2025) [16] | 8 standard grayscale images | Combining TV and WNNM to balance local smoothness with global structural sparsity | High detail retention, but high computational complexity and memory consumption |
| Categorization | Algorithmic Model | Reference | Dataset | Algorithm Characteristics | Summary of Advantages/Disadvantages |
|---|---|---|---|---|---|
| CNN-based Degraded Image Recovery Method | HQS + CNN | Zhang et al. (2017) [18] |
| Dynamic weights automatically differentiate between additive/multiplicative noise and noise levels without manual intervention | Computationally lightweight and supports real-time processing, but not specifically optimized for weather degradation, with limited recovery effect |
| DehazeNet | Cai et al. (2016) [3] |
| First End-to-End CNN Defogging Scattering Model combined with the introduction of a Density-aware Loss Function | Fast reasoning, unified approach, but shallow network and insufficient detail recovery | |
| JORDER | Yang et al. (2017) [19] |
| Introducing binary rain line maps into the model separates rain line position and intensity information, providing a stronger supervisory signal | Complex Scenarios Adaptable, but improvements needed to balance synthetic data dependency with computational complexity | |
| EffiConvRes | K. Tajane et al. (2023) [20] |
| Multi-architecture convergence, lightweight design, efficient training strategies | High accuracy and efficiency balanced with strong generalization capabilities | |
| MSDL | Q. Wu et al. (2023) [21] |
| Joint parameter estimation, an end-to-end learning framework | Highly efficient defogging effect and optimized computational efficiency, but relies on synthetic data training, and has high graphics memory requirements | |
| GAN-based recovery method for degraded images | Cycle-Dehaze | Engin et al. (2018) [22] | D-HAZY | Unsupervised training via cyclic consistency loss with physical constraints to enhance interpretability | No need for pairs of data or adapting to real scenes, but the cycle training is time-consuming, and the generated images are prone to distortion |
| RI-GAN | A. Dudhane et al. (2019) [23] |
| Bypassing intermediate estimation of transmission maps and atmospheric light to directly generate fog-free images and reduce cascading errors | Strong detail retention and high color fidelity, but relies on synthetic data for training and high computational resource requirements | |
| ViT-based GAN | Y. Huang et al. (2023) [24] |
| Global and local feature fusion with the introduction of StyleGAN2’s nonlinear mapping network | Superior generation quality and hybrid design of discriminators can be adapted to different generators, but with high computational resource requirements | |
| RNN-based Degraded Image Recovery Method | NLRN | Liu et al. (2018) [25] | BSD | Combination of non-local operations with RNN; the same model supports denoising and super-resolution tasks | Strong resistance to degradation, but computational complexity and neighborhood tuning limit its practical application |
| RVRT | Liang et al. (2022) [26] |
| Balancing model efficiency and performance, GDA supports multi-location dynamic aggregation | Superior performance, efficient design, superior robustness, but still high computational complexity | |
| RNN + bidirectional timing constraints | C. Rota et al. (2022) [27] |
| Bidirectional timing modeling; RAFT-based high-precision optical flow estimation, combined with masking masks to reduce ghosting artifacts | Strong fidelity, low computational overhead, but dependent on optical flow accuracy | |
| ResNet-based Degraded Image Recovery method | NAS | Li et al. (2020) [28] | AllWeather | ResNet-152 Backbone + dynamic weather classification branch for adaptive recovery from different weather degradations | A single model handles multiple weather types, and joint classification–recovery training improves generalization, but the number of model parameters is large and hardware acceleration is required for deployment |
| RDN | Y. Zhang et al. (2021) [29] | DIV2K | Enhanced detail recovery through dense connectivity and global fusion to fully extract and fuse shallow to deep features | Lightweight design and multitasking-compatibile, but further optimization is needed for extreme degradation scenarios | |
| ResNet-based Degraded Image Recovery method | ResNet50 | Wang et al. (2024) [30] | Total 1759 images in 7 categories Training set: n/a Test set: n/a | Set out to create a customized dataset, this dataset was specifically designed to identify seven different weather conditions while exploring various machine learning techniques. | The dataset is more comprehensive, providing a greater variety of weather types, and the best models have been identified on this dataset, but the dataset currently only contains indirect weather information images for one type of weather (sunny) |
| DRDNet | Isma Batool et al. (2025) [31] |
| Combining residual learning, dense connectivity, dilated convolution, and BRN for enhanced feature reuse and contextual modeling | High-performance denoising with high computational efficiency, but still needs to be optimized for extreme noise and mobile deployment | |
| Degraded Image Recovery Method Based on Transformers | DehazeFormer | Song et al. (2023) [32] | Training set: 10,000 frames Test set: 2000 frames | Capturing local fog concentration differences with multi-scale window attention to jointly optimize transmittance and atmospheric light | Better detail recovery than CNN in dense fog areas, and is suitable for high-resolution in-vehicle cameras, but the model parameter count is large and real-time performance is limited |
| SMMT | Y Lu et al. (2024) [33] |
| Multimodal fusion advantage, bio-inspired design, and approximation of the gradient of a pulsed neuron by a Sigmoid function to support end-to-end training | High accuracy, low energy consumption, and multimodal complementarity, but with some computational complexity | |
| MWFormer | Zhu et al. (2024) [34] |
| Addressing multi-weather degradation with a single unified architecture | Outperforms previously known multi-weather recovery models without much computational effort, but still has room for improvement | |
| RestoreCUFormer | Li et al. (2024) [35] | RESIDE | Two-stage knowledge learning, joint knowledge transfer, and multi-contrast learning | A method with a unified architecture and pre-trained weights to eliminate the negative effects caused by severe weather is proposed, but there are more parameters within the model architecture | |
| TransRAD | Cheng et al. (2025) [36] | RADDet | Combining attention mechanisms, multi-scale feature fusion, and task decoupling design for RMT | Customized modules for radar data characterization are available but need to be further validated for utility in more complex scenarios and hardware platforms |
| Categorization | Algorithmic Model | Reference | Dataset | Algorithm Characteristics | Summary of Advantages/Disadvantages |
|---|---|---|---|---|---|
| Anisotropic diffusion filtering-based approach | Anisotropic diffusion-based defogging framework | K. S. Gautam et al. (2016) [37] | Customized test images | LUT replacement and memory chunking strategy balances speed and quality | Efficient real-time processing, but accuracy loss and hardware dependency limit its pervasiveness in generalized scenarios |
| Anisotropic diffusion filtering-based approach | Weighted anisotropic diffusion | Huiqing Qi et al. (2024) [38] | Set12 | Edge preservation and artifact suppression, adaptive parameter optimization | Multi-scale feature fusion reduces step effects in uniform regions, but has limitations in complex noise scenes and real-time deployment |
| Improved Perona–Malik modeling | Palanisamy V et al. (2024) [39] | Custom Images | Improved Perona–Malik model for gradient calculation and diffusion coefficient design | Efficient denoising without training, but limited by noise type homogeneity and parameter tuning dependence | |
| OS-SART-ADF | Liu et al. (2024) [40] | 3D Shepp–Logan | Three-dimensional anisotropic diffusion optimization, iterative filtering synergistic mechanism | Compatible with physical model-driven noise suppression strategies, but room for improvement in extreme noise and parameter-optimized automation | |
| CLAHE-based detection framework | ACL-CLAHE | Z. Yuan et al. (2019) [41] | Capturing images | Optimized CLAHE via luminance channel for efficient low-noise enhancement | Detection of task-driven parameter optimization and real-time processing is superior, but generalizability still has room for improvement |
| CLAHE-GIF | Chen et al. (2020) [42] | Self-built haze image set | Balancing contrast restoration and noise suppression in single-image defogging | Process simplicity and edge retention, but limited by dataset size | |
| ACL-CLAHE Enhanced Model | I. Lashkov et al. (2023) [43] | Self-built datasets | Dynamic CLAHE fused with dark channel defogging | Lightweight design and edge device adaptability, but extreme scenario adaptability still needs to be improved | |
| Other traditional enhancement methods | GGIF | F. Kou et al. (2015) [44] |
| Multi-scale, edge-aware weights with explicit first-order gradient constraints | Improvement of parameter robustness and halo suppression for image preprocessing in bad weather, but limitations in extreme noise scenarios |
| EGIF | Z. Lu et al. (2018) [45] |
| Balancing edge preservation and noise suppression through local variance regularization and content-adaptive amplification | Significant halo suppression and good noise control, but optimization for extreme noise and computational efficiency needs to be improved | |
| MGTF | Li et al. (2025) [46] | 30 sets of different exposure images | Innovative combination of multi-channel gradient tensor and WAGGF filtering | Its efficiency and high metrics make it suitable for real-time HDR imaging, but adaptability to dynamic scenes and noise still needs improvement |
| Categorization | Algorithmic Model | Reference | Dataset | Algorithm Characteristics | Summary of Advantages/Disadvantages |
|---|---|---|---|---|---|
| SSD-based enhancement methods | Improved SSD | Hao Zhang et al. (2022) [47] | Mixed datasets | Optimization of small target detection, balancing real-time and accuracy | Multi-scale feature fusion with efficient interactive interfaces, but computational complexity and hardware dependency still need to be optimized |
| Improved SSDs | X. Cheng et al. (2024) [48] | PASCAL VOC | Lightweight design, efficient downsampling strategy, balanced accuracy and speed | Extremely low computational resource requirements and high detection accuracy, but further verification of generalization ability for complex scenarios is needed | |
| M3-ECA-SSD model | Yue Hu et al. (2024) [49] | ADE20k indoor scene dataset | Enhancing detection accuracy and real-time performance through lightweight backbone network and multi-scale feature fusion | Balancing accuracy and speed, but need to further validate cross-scene generalization capability | |
| R-CNN-based enhancement method | Improved Faster R-CNN model | Wang et al. (2023) [50] | Low-Earth orbit spacecraft dataset | Significantly improved detection accuracy by using RegNet as the backbone network | Efficient NAS optimization and lightweight design, but dependent on computational resources |
| Improved Mask R-CNN model | R. Rajarajeswari et al. (2023) [51] | CityScapes | Improved FPN structure supports multi-scale feature fusion to effectively handle dense targets | Complex scene adaptation and high-precision segmentation, but high computational consumption | |
| ECB-Mask R-CNN | X. Zhan et al. (2024) [52] | COCO 2017 | Multi-scale feature fusion enhancement, hybrid convolution strategy, dynamic loss optimization | Dynamic feature fusion and training optimization, but extreme scene adaptation still needs further improvement | |
| YOLO-based Degraded Image Recovery Method | Bi-STN-YOLO | Yan-Feng Lu et al. (2022) [53] |
| Multi-scale feature fusion optimization with high adaptability to spatial deformation, and lightweight and high efficiency | The ESTN module effectively copes with geometric deformations and performs stably in extreme deformation scenarios, but the computational complexity is slightly higher |
| YOLOv3 | H. Abbasi et al. (2023) [54] | Pascal VOC | A proposed knowledge distillation framework to enhance the resilience of computer vision systems under adversarial conditions | Enhances the resilience and robustness of the object detection system, but it requires simulation algorithms to accurately represent unfavorable conditions, as well as a mechanism to classify the input images to specific severe weather conditions | |
| CSIM | Abbasi et al.(2023) [55] |
| Cross-scale feature fusion optimization, light-invariant design, attention mechanism enhancement | Excellent performance in scenes with drastic lighting changes and large-scale deformation, but with slightly reduced computational efficiency | |
| Improved YOLOv7 target detection model | Yi. Li et al. (2024) [56] | Self-built datasets | Supports visible, infrared and fused image inputs, adapting to complex lighting and weather conditions | Stable detection performance under low-light, foggy conditions, etc.; lightweight and efficient, but relies on high-quality data and hardware support | |
| YOLO-based Degraded Image Recovery Method | AL-YOLO | B. S. Pour et al. (2024) [57] | Foggy Cityscape | Proposing a lightweight and accurate object detection model | Achieves better feature extraction and detection accuracy while being computationally efficient for effective severe single weather |
| YOLOv5 | H. Gupta et al. (2024) [58] |
| The approach used is a synthetic weather enhancement strategy that includes physics-based, GAN-based, and style migration methods | Efficient training driven by real data and by multidimensional performance metrics, but the use of high-resolution images and high-volume training has high hardware requirements, which may limit its application in real-time scenarios | |
| YOLO | P. Bharat Siva Varma et al. (2024) [59] |
| Weather domain transformation by QTNet and feature calibration by FCNet | Significantly improves target detection performance in bad weather and maintains advantages in real time and compatibility, but synthetic data dependence and training complexity may limit its application in extreme scenarios | |
| YOLO v9 | Shveta et al. (2024) [60] | Argoverse | NAS-optimized architecture, attention mechanisms, and multi-sensor fusion | Multi-sensor fusion reduces false detection rate and provides fast inference, but reliance on synthetic data and high computational costs limit practical applications | |
| YOLOX | Ma et al. (2024) [61] |
| An end-to-end domain-adaptive framework was designed to manually adjust the defogging module and drop hyperparameters | Outperforms traditional domain-adaptive methods but relies on synthetic fog data for training, extreme weather (e.g., heavy rain) generalizability under YOLOX combined with | |
| YOLOv11 + FFT + MF | Yang et al. (2024) [62] | Customized simulation datasets | Fusion of frequency/space domain preprocessing and dynamic model weighting | improved detection robustness in extreme weather, but needs to tradeoff real-time and computational resources | |
| SUHD | Jinye Qu et al. (2025) [63] |
| Ultra-low latency, high precision, and lossless structural conversion | The problem of high latency and low accuracy of SNNs in target detection has been solved, but improvement in dynamic environment adaptation is still needed |
| Name | Type of Weather | Total Number of Images | Type of Labeling | Particular Year | Reference | Download Address |
|---|---|---|---|---|---|---|
| RESIDE | vapors | 10,000+ | Fogless–foggy image pairs | 2019 | Li et al. [64] | http://sites.google.com/view/reside-dehaze-datasets (all accessed on 10 April 2025) |
| Foggy Cityscapes | vapors | 15,000 | Semantic segmentation, instance segmentation | 2019 | Sakaridis et al. [65] | https://www.cityscapes-dataset.com/downloads/ |
| O-HAZE | vapors | 90 | Fogless–foggy image pairs | 2018 | Ancuti et al. [66] | https://data.vision.ee.ethz.ch/cvl/ntire18//o-haze/ |
| RainCityscapes | rain | 11,400 | Target detection, instance segmentation | 2019 | Hu et al. [67] | https://www.cityscapes-dataset.com/dataset-overview/ |
| Rain800 | rain | 800 | No rain–rain image pairs | 2019 | Yang et al. [68] | https://github.com/hezhangsprinter/ID-CGAN |
| Rain13K | rain | 18,010 | No rain–rain image pairs | 2020 | Fu et al. [69] | https://github.com/kuijiang94/MSPFN |
| RainDrop | rain | 1119 | droplet mask | 2018 | Rui et al. [70] | https://github.com/rui1996/DeRaindrop |
| SnowyKITTI2012 | snowfall | 7488 | 3D target detection, depth estimation | 2021 | Zhang et al. [71] | https://github.com/HDCVLab/Deep-Dense-Multi-scale-Network-for-Snow-Removal/blob/main/kitti.txt |
| Snow-100K | snowfall | 100,000+ | Snowless–snowy image pairs | 2018 | Liu et al. [72] | https://github.com/HDCVLab/Deep-Dense-Multi-scale-Network-for-Snow-Removal/blob/main/snow100k.txt |
| KAIST Multispectral | multi-weather | 95,000+ | Pedestrian detection, target tracking | 2018 | Hwang et al. [73] | https://github.com/yuanmaoxun/Awesome-RGBT-Fusion?tab=readme-ov-file#Multispectral-Pedestrian-Detection |
| BDD100K | all-weather | 100,000+ | Target detection, semantic segmentation, lane detection | 2020 | Yu et al. [74] | http://bdd-data.berkeley.edu |
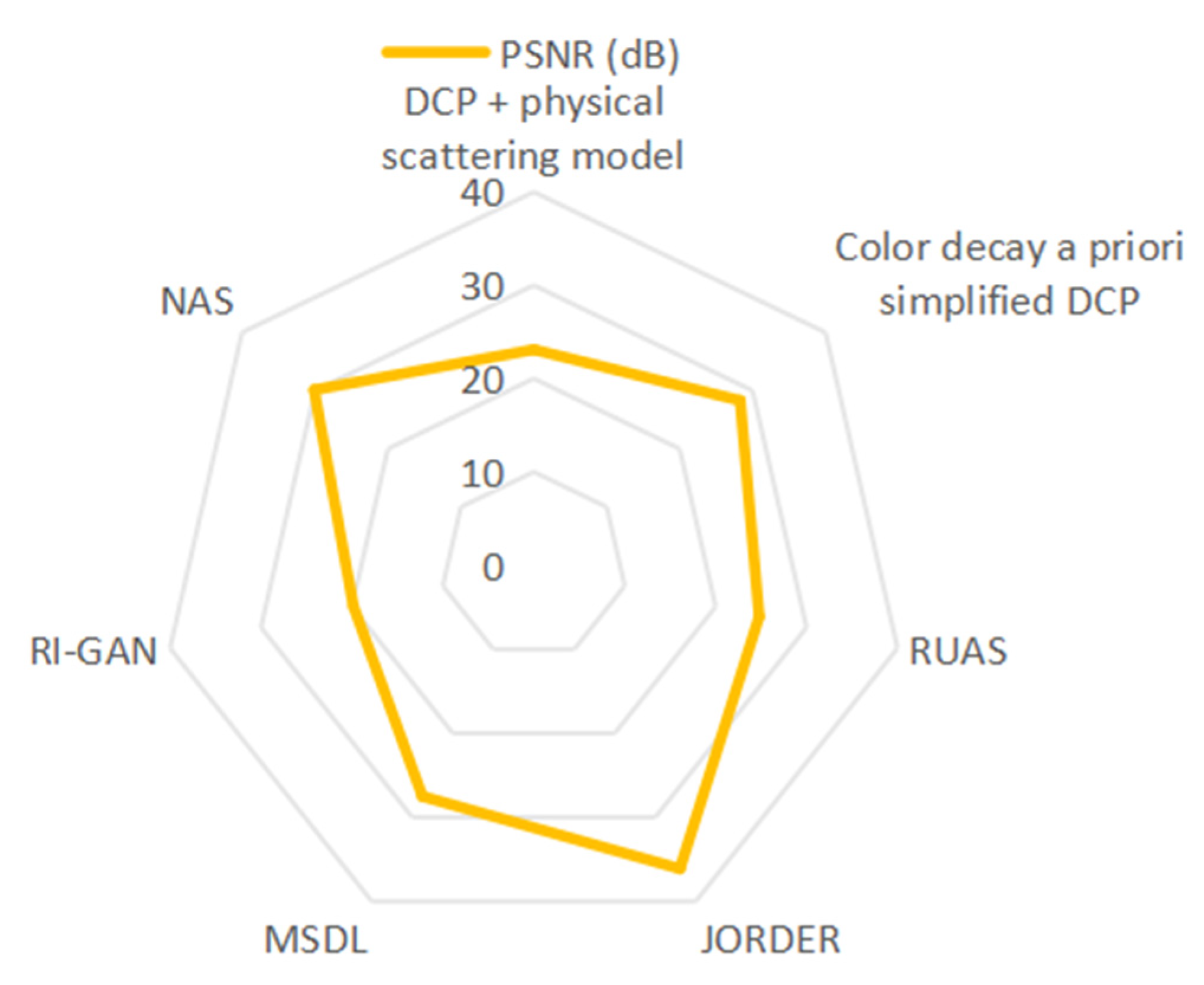
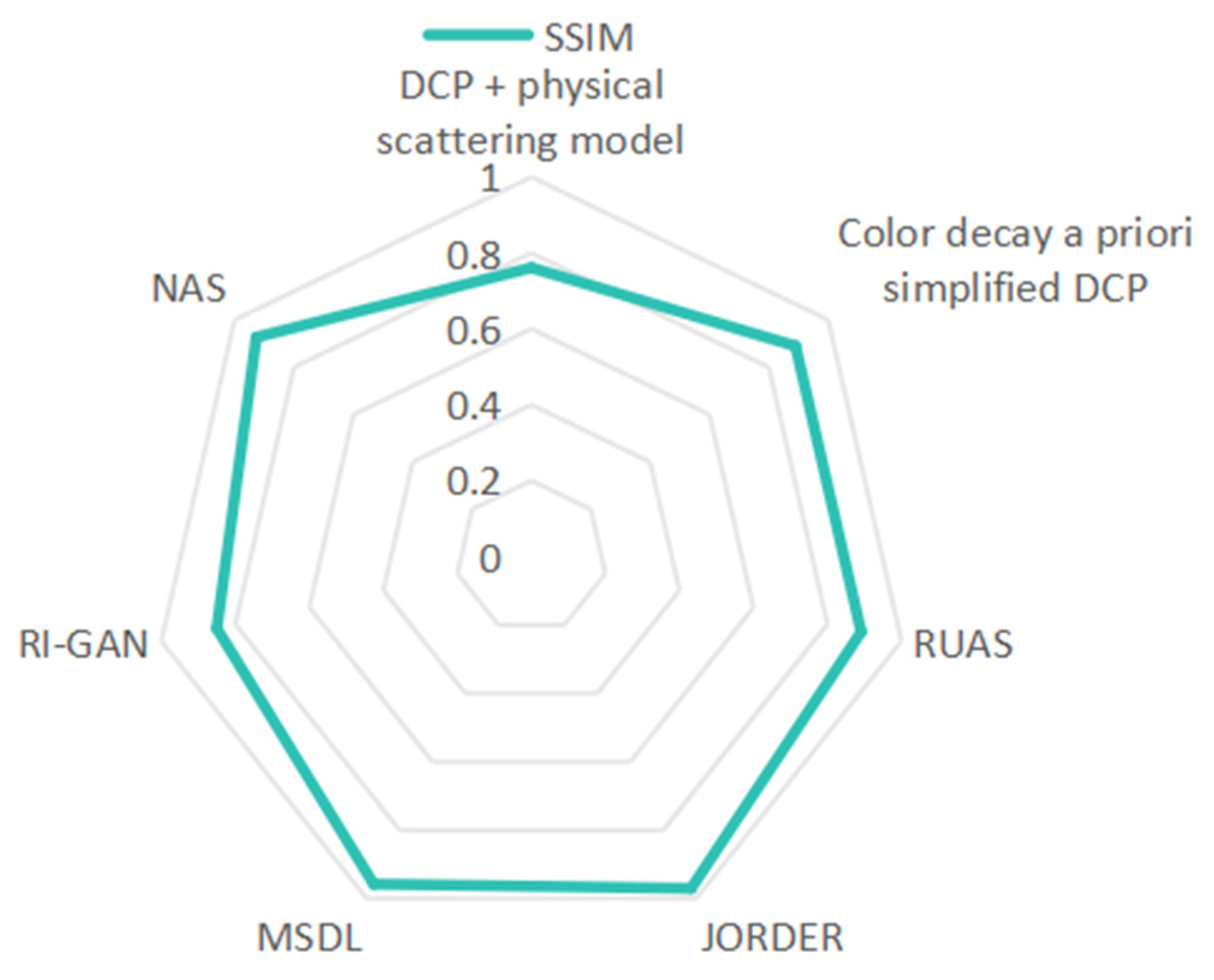
| Categorization | Algorithmic Model | Reference | Dataset | PSNR (dB) | SSIM | Inference Speed |
|---|---|---|---|---|---|---|
| Traditional Methods | DCP + physical scattering model | He et al. (2009) [1] | Composite fog map | 23.1–26.5 | 0.7609 | 6.25 FPS |
| Color decay a priori-simplified DCP | Zhu et al. (2015) [2] | Homemade synthetic data | 28.3 | 0.89 | 14.3 FPS | |
| RUAS | R. Liu et al. (2021) [6] | MIT-Adobe 5K | 24.78 | 0.891 | 20 FPS | |
| Deep Learning | JORDER | Yang et al. (2017) [19] | Rain100L | 36.11 | 0.97 | 0.1 FPS |
| MSDL | Q. Wu et al. (2023) [21] | RESIDE | 27.51 | 0.9576 | 20 FPS | |
| RI-GAN | A. Dudhane et al. (2019) [23] | SOTS | 19.828 | 0.85 | --- | |
| NAS | Li et al. (2020) [28] | Raindrop | 30.12 | 0.9268 | --- |
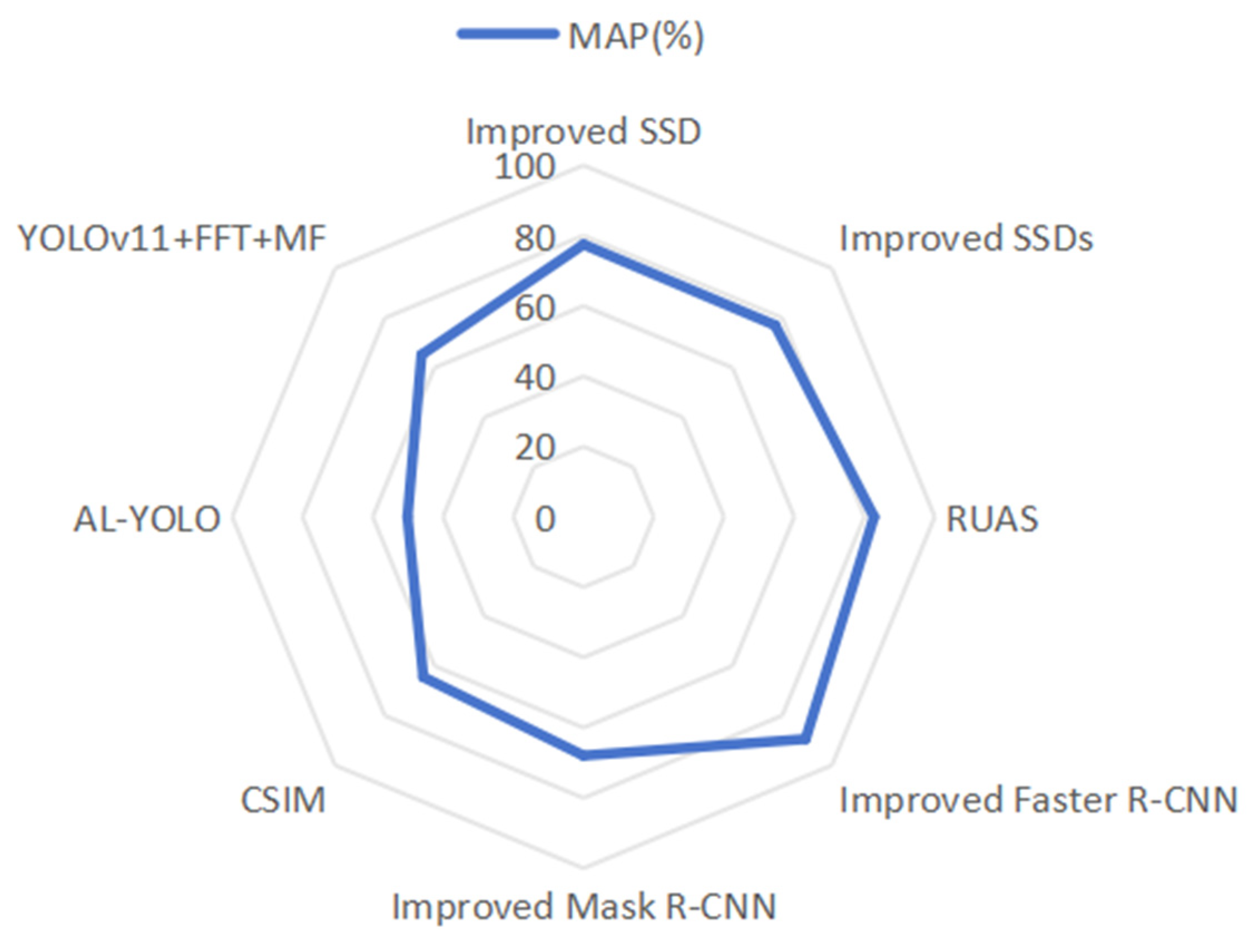
| Organizing Plan | Model Name | Reference | Dataset | MAP (%) | Topicality (FPS) |
|---|---|---|---|---|---|
| SSD Series | Improved SSD | Hao Zhang et al. (2022) [47] | Resnet50 | 77.49 | -- |
| Improved SSDs | X. Cheng et al. (2024) [48] | VOC2007 | 77.1 | -- | |
| RUAS | Yue Hu et al. (2024) [6] | ADE20k | 82.7 | 57.78 | |
| R-CNN Series | Improved Faster R-CNN model | Wang et al. (2023) [50] | Regnet | 89.4 | -- |
| Improved Mask R-CNN model | R. Rajarajeswari et al. (2023) [51] | CityScapes | 67.92 | -- | |
| YOLO Series | CSIM | Abbasi et al. (2023) [55] | UA-DETRAC | 64.47 | 51.1 |
| AL-YOLO | B. S. Pour et al. (2024) [57] | Foggy Cityscape | 50.1 | 114.94 | |
| YOLOv11 + FFT + MF | Yang, J. et al. (2024) [62] | Customized simulation datasets | 65.2 | -- |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, Y.; Lu, Y. A Review of Unmanned Visual Target Detection in Adverse Weather. Electronics 2025, 14, 2582. https://doi.org/10.3390/electronics14132582
Song Y, Lu Y. A Review of Unmanned Visual Target Detection in Adverse Weather. Electronics. 2025; 14(13):2582. https://doi.org/10.3390/electronics14132582
Chicago/Turabian StyleSong, Yifei, and Yanfeng Lu. 2025. "A Review of Unmanned Visual Target Detection in Adverse Weather" Electronics 14, no. 13: 2582. https://doi.org/10.3390/electronics14132582
APA StyleSong, Y., & Lu, Y. (2025). A Review of Unmanned Visual Target Detection in Adverse Weather. Electronics, 14(13), 2582. https://doi.org/10.3390/electronics14132582