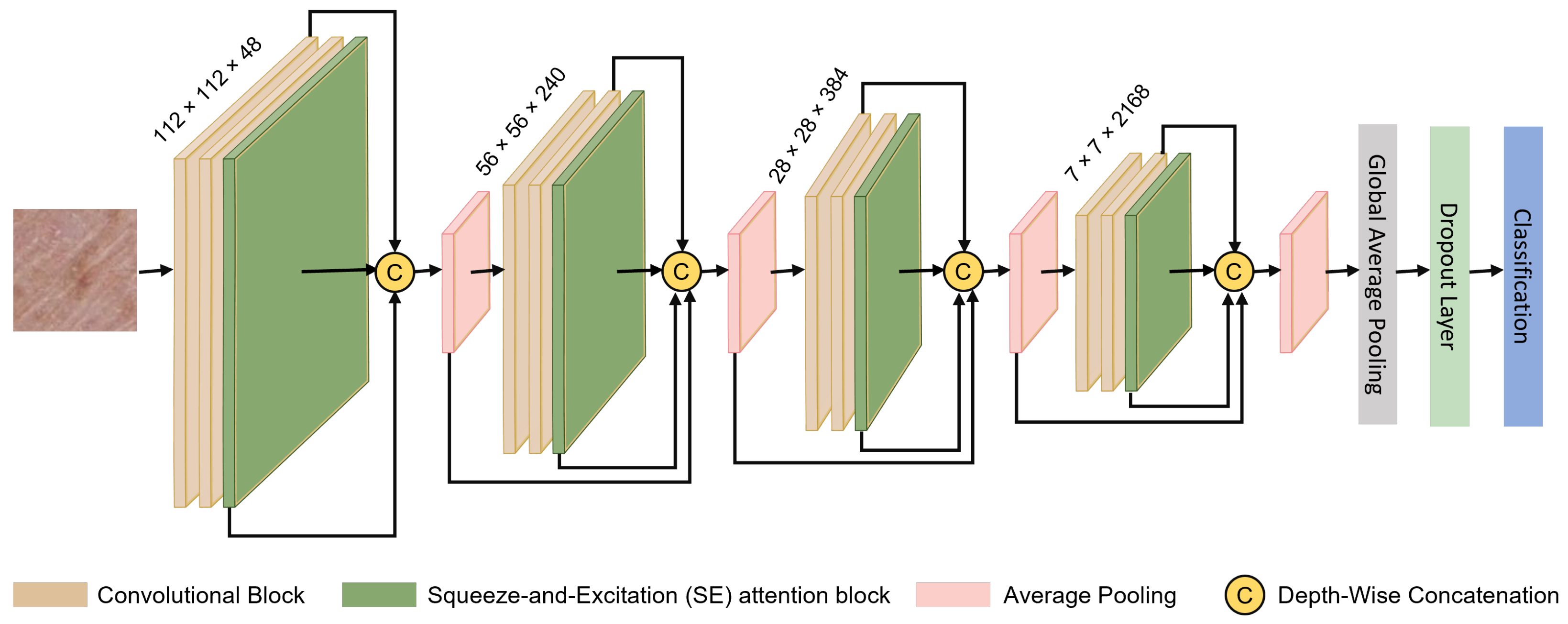
The network design, represented in
Figure 1, utilizes a hierarchical framework for feature aggregation, integrated with channel-wise attention for improved accuracy in classification tasks. This attention is achieved through the Squeeze-and-Excitation (SE) method, which emphasizes refining feature representations. The model operates on resized input images as
pixels, enabling the extraction of key discriminative features that are subsequently aggregated and re-calibrated across hierarchical levels. The architecture is structured with four convolutional groups, each composed of two convolutional blocks, culminating in a total of eight convolutional blocks. Additionally, four SE blocks, complemented by eight dual SE blocks, as depicted in
Figure 2, further improve feature aggregation and refinement. The upcoming section provides an in-depth breakdown of the proposed network’s architecture, highlighting key components such as feature aggregation, the functionality of SE blocks, and their integration within the framework. This explanation is aimed at offering a complete interpretation of the model’s design and operational goals.
3.2. Deep Feature Aggregation
CNNs are composed of multiple layers, each designed to fulfill a specific function within the overall architecture. The performance of a CNN depends heavily on the hierarchical organization and interaction of these layers, as no single layer can independently capture the full complexity of input features. While many existing CNN architectures have sought to enhance performance by increasing network depth and width, such expansions do not inherently guarantee optimal feature representation in the final layers [
42]. To address this limitation, skip connections have been widely adopted, proving effective in mitigating performance degradation and improving feature propagation. These connections, however, require a careful architectural design to realize their full potential.
In this study, we propose a deep learning framework that enhances feature representation by hierarchically aggregating information across different network depths [
43]. The proposed architecture fuses features from both shallow and deep layers to generate more discriminative and contextually enriched representations. Within each hierarchical level, features are progressively aggregated and propagated to deeper layers, facilitating continuous refinement. Moreover, to preserve spatial resolution and mitigate information loss typically caused by downsampling, features from earlier stages are merged into the final feature map via strategically placed skip connections. This design ensures that critical spatial details are retained while enabling robust and expressive feature learning. The hierarchical deep feature aggregation across network layers is formally defined as follows:
where
F signifies the final feature map, while
denotes the aggregated feature map at a specific depth
d. The variables
d,
A, and
x correspond to the depth of the network, the aggregation function, and the feature map at level
x, respectively. Additionally, the terms
L and
R, as defined in Equations (
2) and (
3), describe left- and right-propagated features across network layers. The aggregated feature map
is generated through the aggregation function
A, which operates on transformed feature maps from both preceding and succeeding layers.
The aggregation function
A dynamically integrates feature representations across different network depths, ensuring optimal feature fusion between shallow and deep layers. The function employs learnable weights
W that are adjusted during training via backpropagation. Batch normalization is applied to stabilize weight distributions, preventing vanishing or exploding gradients. The adaptive nature of
A ensures that lower layers emphasize fine-grained spatial details, while deeper layers focus on high-level semantic feature fusion. The recursive structure, as defined in Equations (
2) and (
3), ensures continuous refinement through left- and right-propagated feature maps, enhancing classification robustness.
Specifically, right-propagated features
for
and left-propagated features
for
facilitate bi-directional feature flow across layers. This design supports multi-scale feature integration by merging contextual information from various network depths, augmenting the model’s capability to encapsulate complex relationships and patterns.
Equation (
2) outlines the recursive process used to construct left-propagated feature maps
through a series of transformation operations. At depth
, the left-propagated feature map
is computed using
, which represents a transformation operator such as convolution combined with normalization and activation. The recursive application of
C begins with the right-propagated feature map
and continues with the left-propagated feature map from the preceding depth
. This hierarchical design allows for effective information flow across layers, enabling the network to capture both shallow and deep contextual features. Residual connections are embedded within this structure to counteract issues like vanishing or exploding gradients, thereby ensuring stable gradient propagation in deeper networks. However, as noted by [
44], a shallow network hierarchy—characterized by limited depth or insufficient intermediate layers—may reduce the efficacy of residual learning, potentially diminishing overall performance. Therefore, maintaining a well-structured and adequately hierarchical design is critical for maximizing the benefits of residual connections in deep feature aggregation networks.
In the attention-guided deep feature aggregation network, the integration of feature representations across multiple hierarchical levels addresses challenges commonly encountered in deep neural networks, such as gradient misrepresentation. This hierarchical aggregation improves discriminative learning by ensuring robust gradient flow and introducing alternative short pathways, which enable more efficient backpropagation during training. The right-propagated features, represented as
, are recursively computed as defined in Equation (
3). Here,
signifies the features propagated from depth
m towards depth
d. The function
is typically a learnable module, such as a convolutional block or an attention-improved feature encoder, applied at level
m. For the deepest level, where
,
directly outputs the encoded features. Otherwise, it operates on the output of the subsequent deeper layer
, establishing a recursive feature flow. This framework facilitates the progressive integration of high-level semantic information from deeper layers to shallower ones. The network uses a weighted fusion strategy, described in Equation (
4), to combine multi-scale features effectively, enhancing both classification accuracy and feature representation.
Here,
and
b are learnable parameters that adaptively scale feature contributions at different depths. The function
represents a non-linear activation (such as ReLU) ensuring effective feature fusion. This structure enables multi-scale feature integration, reinforcing hierarchical representation and boosting classification accuracy. In this formulation,
acts as the aggregation function, while
and
b represent learnable parameters, and
denotes a non-linear activation function such as ReLU. This setup equips the network with the capability to learn adaptive weights, enhancing its efficiency in combining features across various depths. Consequently, the model excels at encapsulating both detailed, fine-grained patterns and high-level contextual data essential for accurate skin lesion classification. The proposed network architecture incorporates eight convolutional blocks, each comprising two separable convolution layers [
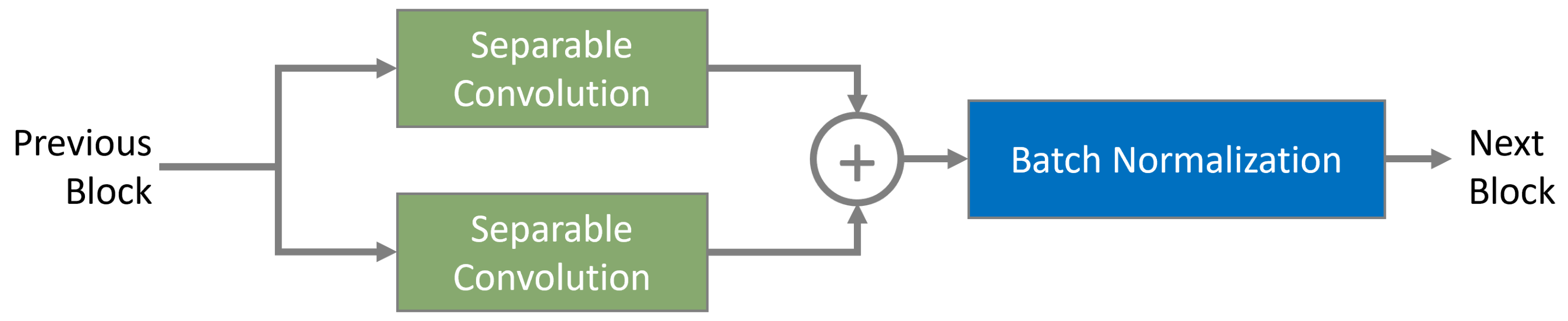
45]. As depicted in
Figure 3, the proposed architecture employs depthwise separable convolution layers with 3 × 3 and 5 × 5 kernels arranged in a parallel configuration. Each kernel independently extracts multi-scale spatial features, capturing fine-grained textures with the 3 × 3 kernel while the 5 × 5 kernel enhances broader contextual details. The outputs of these kernels are element-wise added to ensure complementary feature fusion, reinforcing hierarchical feature representation. This structure is depicted in (
Figure 4), where individual depthwise paths contribute to a balanced mix of local and global feature extraction. These layers employ convolutional kernels of sizes
and
, ensuring the network captures multi-scale spatial features effectively. The structure is depicted in Equation (
2), highlighting the hierarchical organization and feature refinement approach adopted by the model.
Convolutional layers are critical for determining both the effectiveness and computational efficiency of deep learning models [
46]. While early architectures, such as AlexNet, Attention-Guided VGG [
47], DenseNet, and ResNet, relied heavily on standard convolutional layers, recent innovations have introduced advanced alternatives. Depthwise separable and group convolutions, in particular, have emerged as efficient options to reduce model complexity without sacrificing accuracy [
48]. In the proposed method, depthwise separable convolution is utilized to decrease trainable parameters, inference time, and overall model size. This approach splits a typical convolution into two discrete operations: (i) depthwise convolution, which relates spatial filtering separately across each input channel, and (ii) pointwise convolution, employing
kernels to map depthwise outputs into a new feature space. As depicted in
Figure 3, the convolutional block is designed for multi-scale feature extraction using kernels of size
and
. The resulting feature maps from each depthwise separable convolutional path undergo element-wise addition and are then controlled with batch normalization layers. To further improve multi-scale representation, features from the initial and concluding convolutional blocks are concatenated at the final aggregation node. Complementing this structure is a channel-wise attention module, implemented through the Squeeze-and-Excitation (SE) block, which recalibrates feature responses, strengthening the network’s overall representation capability.
3.3. Squeeze and Excitation Block (SE)
The squeeze-and-excitation (SE) block, as introduced by Hong et al. [
49], is a lightweight yet effective architectural unit designed to enhance feature representations by explicitly modeling channel-wise dependencies in CNNs. Conventional CNNs primarily rely on convolution, pooling, and batch normalization to extract and abstract spatial features. While these techniques are effective for spatial pattern learning, early CNN designs often overlooked the interdependence between feature channels, a factor critical to capturing rich contextual information. The SE block addresses this gap through an adaptive channel recalibration mechanism, composed of two sequential operations. The recalibration of feature channels through the squeeze-and-excitation mechanism plays a crucial role in dermatological image analysis. By dynamically adjusting channel importance, the model enhances sensitivity to critical lesion characteristics, such as pigmentation variations, asymmetry, and texture irregularities, which are key indicators in skin cancer classification. This ensures that diagnostically relevant features receive higher attention while suppressing background noise, improving classification accuracy. First, a squeeze operation performs global average pooling to distill spatial information into a compact channel descriptor. This is followed by an excitation operation that captures non-linear channel interdependencies through a lightweight gating mechanism, producing channel-wise attention weights. These weights are then applied to the original feature maps, amplifying informative features while suppressing less relevant ones [
16]. A key advantage of the SE block lies in its modularity and computational efficiency, allowing seamless integration into existing CNN architectures with minimal overhead. When incorporated into early layers, it enhances general-purpose features such as texture and edges; in deeper layers, it refines high-level, class-specific semantic representations. This adaptability across the network hierarchy contributes to improved feature discrimination and overall model accuracy, particularly in tasks demanding fine-grained classification. Due to its compact design and significant performance gains, the SE block has become a foundational component in modern CNN-based systems across diverse application domains [
50].
The SE block, illustrated in
Figure 4, operates as a lightweight and highly effective attention module designed to address channel-wise interdependencies in CNNs. It improves the network’s feature representation by adaptively recalibrating the importance of each channel. The SE block consists of three core mechanisms: squeeze, excitation, and scale. During the squeeze phase, comprehensive spatial information is condensed by applying global average pooling to each individual channel of the input tensor. This reduces the spatial dimensions, yielding a compact feature descriptor of size
, where
C is the number of channels. This descriptor serves as a statistical summary of the channel-wise activation values, forming the foundation for the excitation phase. The subsequent excitation stage utilizes this compact descriptor to capture non-linear relationships among channels, generating attention weights that highlight significant features. These weights are then applied during the scaling phase to adaptively improve salient channels while blocking less related ones. This mechanism is integral for refining feature representations and improving classification accuracy in CNNs.
The excitation phase of the SE block features is a dynamic mechanism that captures channel-wise dependencies. The process begins with the squeezed descriptor, which is delivered through a bottleneck comprising two fully connected (FC) layers. The first layer decreases the dimensionality by a predefined reduction ratio
r, and the second reinstates it to
C. A non-linear activation function (e.g., ReLU) is applied between these layers, followed by a sigmoid activation at the output. This sequence generates modulation weights in the range of
, representing the relative significance of respective channels. In the scale stage, attention weights are applied to the original input tensor through channel-wise multiplication. This step improves salient features while diminishing irrelevant ones, enabling the network to learn more discriminative feature representations. This mechanism proves particularly valuable for tasks like medical image analysis, e.g., skin lesion classification, where fine-grained features—texture, color, and boundaries—are critical for precise diagnosis. As demonstrated in
Figure 4, the SE block efficiently integrates channel dependencies into the network, boosting both performance and robustness. This adaptive attention mechanism significantly improves the network’s capability to handle complex visual recognition challenges.
The operations within the SE block—namely, the squeeze, excitation, and scaling modules—are formally defined in Equations (
5), (
6), and (
7), respectively. In this context, the input tensor
represents spatial dimensions
and
, the number of input channels. A convolutional transformation
F is applied to generate the feature map
, where each
corresponds to the spatial representation of the
channel. The resulting tensor
serves as the input to the SE block, capturing both spatial and channel-wise information for further refinement through attention-based recalibration. This architectural design allows the SE block to dynamically adjust the importance of each channel by leveraging global contextual information. Specifically, the squeeze operation condenses spatial information into a channel descriptor via global average pooling. The excitation step models non-linear channel dependencies and generates attention weights that are subsequently used in the scaling operation to recalibrate the original feature maps. Integrated into the attention-guided deep feature aggregation network, the SE block plays a pivotal role in enhancing the model’s ability to capture and emphasize diagnostically relevant patterns in skin lesion images. By assigning adaptive importance to different channels, the SE mechanism suppresses redundant information while amplifying salient features that contribute most to accurate classification. This is particularly beneficial for handling the complex visual characteristics inherent in dermoscopic medical images, thereby improving both diagnostic precision and network robustness. The squeeze operation is expressed as follows:
In this context,
refers to the spatial feature map associated with the
channel after the convolutional layer, where
W and
H characterize the width and height of the feature map one-to-one. To effectively capture the global context of each channel, the methodology applies global average pooling. This operation condenses the dimensions into a single scalar value for each channel, summarizing the distribution of activation values. This scalar serves as a channel descriptor, allowing the network to influence global spatial information for further attention-based refinements within the squeeze-and-excitation block. The concise representation provided by global average pooling improves the model’s ability to concentrate on significant patterns within the feature space. The excitation step is expressed as follows:
In the proposed model,
represents the output of the squeeze operation, capturing global channel-wise information. The ReLU activation function,
, initiates non-linearity between transformations, while the sigmoid function,
, scales the output to the range
. The weight matrices
and
handle dimensionality decrease and expansion,
r, defining the reduction ratio and ensuring efficient computation. This bottleneck mechanism effectively learns non-linear dependencies across channels while maintaining computational efficiency. The recalibration of the feature map is performed via element-wise multiplication, as elaborated in Equation (
7), selectively enhancing salient channel-wise features to improve the network’s discriminative capabilities. This process significantly contributes to accurate and robust feature representation in tasks like skin lesion classification.
The SE block’s flexibility and architecture-agnostic nature make it a valuable improvement for deep learning models. By adaptively scaling each channel using learned attention weights , where corresponds to the feature map , this module boosts the network’s discriminative ability. It selectively amplifies significant features while suppressing less pertinent ones, refining the overall representation. Its integration within the proposed attention-guided deep feature aggregation network has proven beneficial. By reinforcing attention-guided feature aggregation, the SE block improves the network’s capability to capture subtle variations in dermoscopic medical images. This adaptability significantly improves classification performance, particularly in challenging fine-grained tasks like skin lesion diagnosis. With its lightweight design and computational efficiency, the SE block becomes a pivotal element for advancing automated diagnostic systems.
The architectural improvement integrating double SE blocks into the attention-guided deep feature aggregation network presents a significant leap in optimizing feature discrimination for skin lesion classification. By employing two SE blocks after each pair of convolutional layers, rather than the standard single SE block, the modified design aims to refine channel-wise attention at finer levels. This approach is particularly effective in enhancing sensitivity to subtle lesion patterns, which are critical for accurate classification. The modified architecture features four convolutional groups, each consisting of two convolutional blocks, subsequent in a total of eight convolutional blocks and eight SE blocks. With each group incorporating two SE modules, this configuration allows for a more profound recalibration of feature channels across multiple hierarchical levels. Such in-depth recalibration strengthens the network’s capability to obtain and amplify diagnostically significant features while suppressing less relevant ones. Only the most optimal hyperparameter settings were selected throughout training, therefore
Table 1 contains more details of the final outcomes. As highlighted in
Table 2,
Table 3,
Table 4,
Table 5 and
Table 6, the performance of this improved architecture demonstrates noticeable improvements in classification accuracy when compared to the baseline single SE block configuration. This augmented attention mechanism not only boosts the network’s robustness but also offers a scalable solution for addressing complex datasets with intricate lesion patterns.



{kind=link}
{kind=link}
{kind=link}
{kind=link}