1. Introduction
Recovering a 3D human mesh from a single image is a core problem in computer vision and computer graphics. The objective is to infer a 3D human model, characterized by realistic geometry and articulated kinematics, as represented by parametric models such as SMPL [
1] and SMPL-X [
2] from a 2D image. This technology plays a vital role in applications including augmented reality, virtual try-on, and sports analysis. However, challenges such as depth ambiguity inherent in monocular imagery, a wide range of complex poses [
3], and occlusions [
4] between the human body and the surrounding environment make it extremely difficult to reconstruct high-precision and physically plausible human meshes from single-view images.
Traditional 3D human modeling technologies [
5] heavily rely on multi-view imaging or depth sensors [
6], requiring specialized equipment (e.g., synchronized multi-camera arrays or LiDAR) and suffering from time-consuming processes and complex deployment. For instance, multi-view reconstruction demands synchronized multi-angle image inputs, yet the intricate environments of live-line power distribution sites—such as densely packed power towers and substation equipment—make it impractical to deploy multi-camera systems or carry professional sensors. This results in high reconstruction latency (typically exceeding 500 ms), failing to meet real-time safety monitoring requirements for live-line operations. In contrast, single-view 3D human reconstruction technology [
7] directly addresses the synergistic demands of real-time performance, precision, and cost-effectiveness in power distribution safety operations. By reconstructing 3D human models in real time from monocular visual data (with MPJPE below 60 mm), pose tracking is enabled for workers in high-risk scenarios (e.g., safety distance alerts during insulator replacement or conductor repair) while eliminating reliance on expensive multi-view hardware systems. With its millisecond-level modeling capability (latency under 50 ms), this technology not only enhances dynamic risk awareness for personnel but also integrates with digital twin platforms to drive intelligent upgrades in power grid maintenance, such as improving equipment inspection efficiency by approximately 40%. Aligned with the strategic goals of “human–machine collaboration and data-driven intelligence” in China’s New Power System initiative, it provides critical technical support for the digital transformation of grid infrastructure, bridging the gap between operational safety and next-generation smart grid development.
Early approaches primarily relied on optimization-based strategies using parametric human models. For example, SMPLify (2015) [
2] iteratively aligned detected 2D keypoints with the SMPL model; however, this method depends heavily on handcrafted priors—such as pose regularization and collision constraints—and suffers from low computational efficiency. With the advent of deep learning, researchers began to explore end-to-end networks that directly regress the parameters of the human model. Representative works include HMR (2018) [
8], which was the first to integrate adversarial training into the 3D human reconstruction process by merging image features with model parameter priors to improve prediction stability, and SPIN (2019) [
9], which combines optimization and regression frameworks by employing a neural network to predict initial parameters, thereby accelerating the traditional optimization procedure.
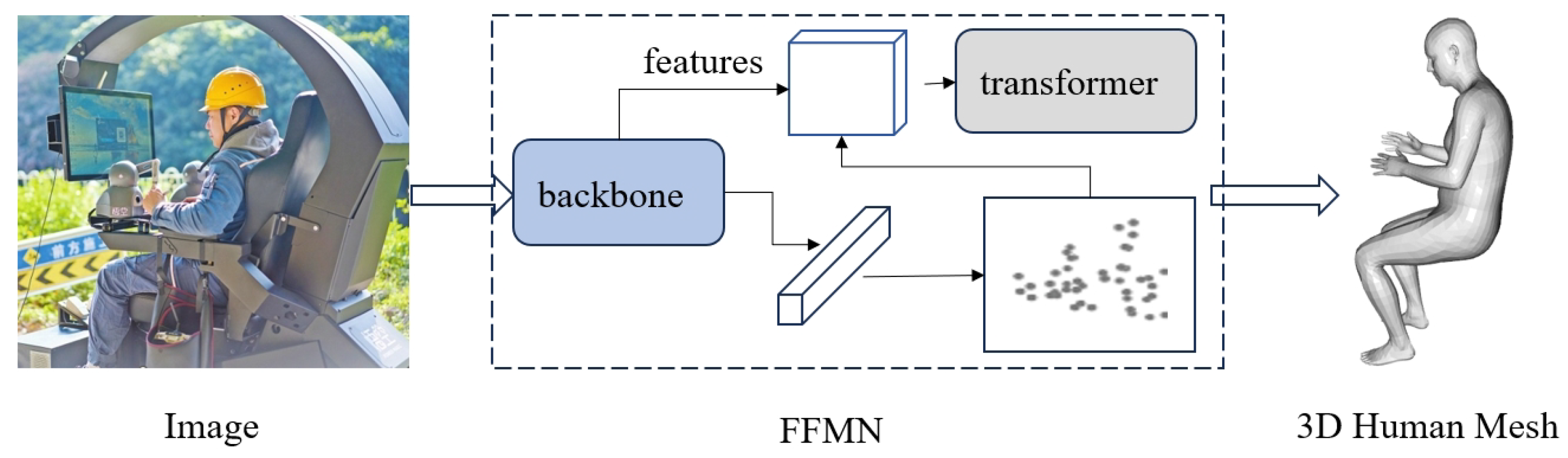
In this paper, we propose an architecture for 3D human reconstruction: fast fitting mesh network (FFMN). FFMN reformulates the regression problem as a learning-to-optimize task, and thanks to its lightweight network design, it achieves faster training and higher inference speeds while maintaining competitive accuracy compared to existing frameworks.
FFMN is inspired by ReFit [
10], but it differs in several important aspects. (1) FFMN employs a more lightweight backbone—an improved version of YOLO [
11]—to extract image features efficiently. (2) It utilizes a transformer module to control keypoints, which decouples the recurrent structure and allows keypoint reprojection to occur only once. (3) A self-attention module is integrated into the keypoint reprojection process, enabling the model to focus on feature information in the vicinity of the keypoints. This novel design facilitates the rapid fitting of a 3D human mesh (
Figure 1).
For model fitting, the objective function computes the L2 distance between the reprojected points and the detected keypoints [
12,
13]. In FFMN, each reprojected keypoint queries a window on the feature map, where the window encodes first-order information corresponding to the derivative of the L2 objective. The extracted features are then passed to a transformer-based update module to compute the necessary updates for the human model.
The transformer update module of FFMN is designed to learn decoupled update rules for three groups of parameters. These include a hidden state vector for pose (), a shape vector (), and a camera parameter vector (). Each of these three parameter groups is first encoded with positional encodings before being processed in batch matrix operations, facilitating efficient training and inference.
Unlike previous architectures, FFMN leverages reprojection-based query feedback rather than using a static global feature vector [
14]. Moreover, in contrast to conventional learning-to-optimize techniques that rely on explicit skeleton keypoint detection, FFMN utilizes learned features for end-to-end training, further enhancing its efficiency and performance.
The main contributions of this work are as follows:
We propose FFMN, a novel fast fitting mesh network for monocular 3D human reconstruction, specifically designed for real-time applications in live-line work scenarios.
FFMN introduces a lightweight backbone based on an improved YOLO architecture for efficient multi-scale feature extraction, and a transformer-based update module that decouples the optimization of pose, shape, and camera parameters, achieving rapid and accurate mesh fitting through parallel processing.
A keypoint reprojection feedback mechanism is developed, which leverages mocap marker-based features and dropout regularization to enhance robustness against occlusions and improve fitting accuracy.
2. Related Work
Monocular 3D human mesh recovery is one of the core tasks in computer vision, aiming to reconstruct 3D human models with plausible poses and shapes from a single RGB image. With the widespread adoption of parametric human models (e.g., SMPL [
1], SMPL-X [
2]), two principal technical routes—optimization-based and regression-based—have emerged, which have further spawned hybrid methods, novel network architectures, and extensions to multiple scenarios.
Optimization-based approaches were prominent in the early work. For instance, SMPLify [
2] optimized the SMPL parameters via gradient descent to align the detected 2D keypoints, relying on manually designed priors (such as pose regularization and collision penalties) to avoid implausible outputs. However, this method is sensitive to noise in 2D detections. Subsequent work improved robustness by incorporating multimodal cues: HMR-2D [
8] combined DensePose and semantic segmentation, while Bodynet [
15] integrated volumetric features and contour alignment to reinforce shape constraints. Moreover, to reduce the dependency on handcrafted priors, some studies incorporated deep learning techniques [
16,
17,
18] into the optimization process.
End-to-end regression-based methods directly map images to 3D mesh parameters or vertex coordinates through deep neural networks, thereby eliminating iterative optimization and enabling efficient inference. HMR [
8] pioneered this approach by employing adversarial training to regress the SMPL rotation parameters (represented in the axis-angle format) and leveraged unpaired 3D data to mitigate the scarcity of annotated data. Subsequent studies improved rotation representations (e.g., 6D continuous vectors [
19] and rotation matrices [
20]) to address the discontinuity inherent in the axis-angle representation. ProHMR [
21] further modeled the distribution of pose parameters using conditional normalization flows, supporting multi-hypothesis generation, while Sengupta et al. [
22] employed an autoregressive model to encode the hierarchical dependencies among joint rotations [
23], thereby enhancing pose consistency.
Hybrid iterative methods combine the strengths of optimization and regression, progressively refining predictions through multi-step iterations to balance data-driven flexibility and physical plausibility [
24]. ReFit [
10] introduced an iterative update module based on GRUs that decouples the parameter update streams—each GRU unit is responsible for adjusting specific joint or shape parameters—and employs a feedback mechanism to extract local error signals from image features. Its multi-view extension improves consistency through cross-view parameter averaging. Similarly, PyMAF [
19] constructed a multi-scale feature pyramid and, starting from a coarse prediction, projected the mesh onto high-resolution feature maps to extract local cues for progressively refining joint alignment.
In contrast, our proposed FFMN is based on a hybrid optimization and regression approach that directly outputs predictions without requiring multiple iterations. By leveraging a lightweight backbone and decoupled outputs, FFMN achieves strong real-time performance. The use of keypoint reprojection to update joint and shape parameters further enhances its accuracy.
3. Methods
Given an input image of a person, our objective is to predict the parameters of the SMPL human model. In this process, FFMN’s backbone network first extracts feature representations from the image (
Section 3.1), which are then processed by a multilayer perceptron to obtain a coarse-grained representation of the human model. These coarse outputs are reprojected onto the feature space for comparative evaluation (
Section 3.2) and subsequently updated by transformer and regression perceptron layers to yield a refined, fine-grained human model (
Section 3.3). An overview of the method is illustrated in
Figure 2. We provide an overview of the key steps involved in the FFMN method, as illustrated in Algorithm 1.
| Algorithm 1 FFMN Algorithm Overview |
Input: Monocular image I Output: SMPL parameters (pose and shape) Extract multi-scale features using the backbone network Initial SMPL model Keypoint While do Reproject EndWhile Update features , where T is the transformer module Update parameters Return: Refined SMPL parameters
|
3.1. Feature Extraction
The proposed lightweight feature extraction network is an improved design based on the YOLO [
11] framework, incorporating a multi-scale feature fusion mechanism along with attention enhancement modules. The overall architecture consists of an efficient multi-feature extraction layer and a hierarchical feature fusion pathway, which are balanced in terms of model accuracy and inference speed using a re-parameterization design, as shown in
Figure 3.
The multi-feature extraction layer employs a three-stage hierarchical structure that progressively downsamples the input to construct a multi-scale feature space: (1) Shallow Feature Extraction.This stage consists of a 5-layer convolution module that includes 2 standard convolution layers (with stride = 2) and 3 C3k2 bottleneck modules, producing a 512-dimensional feature map. It preserves rich spatial details, which are critical for the preliminary localization of human contours. (2) Mid-level Feature Extraction. Two stages of downsampling are employed to obtain a 1024-dimensional feature map. Residual-connected C3k2 modules are used in this stage to enhance feature reuse, thereby improving the robustness of the extracted features. (3) Deep Semantic Extraction. An SPPF (Spatial Pyramid Pooling Fast) module is introduced to expand the receptive field, coupled with a dual-channel C2PSA attention module to amplify keypoint-responsive features. The final output of this stage is a 1024-dimensional feature map enriched with high-level semantic information.
Notably, to achieve a lightweight design, the network utilizes dynamic downsampling and feature compression. Specifically, strided convolutions are employed in lieu of pooling operations to reduce information loss while improving hardware parallel efficiency. At the network’s end, global average pooling compresses the spatial feature map into a compact 512-dimensional vector, which serves as an efficient representation for subsequent pose classification tasks.
3.2. Reprojection Feedback
Based on the preliminary estimates obtained in
Section 3.1, the keypoints derived from the SMPL model are reprojected onto the feature map F to retrieve spatial features. In this design, each keypoint is mapped to a single feature channel, resulting in K channels corresponding to K keypoints. The rationale is to enable the feature extraction module to capture distinctive information for each keypoint.
Given a reprojected point
(where u and v denote the pixel coordinates), we extract a window of features centered according to the following formulation:
where r = 3 pixels represents the radius of the window. By integrating the feedback from all keypoints and concatenating it with the current estimate parameters, as well as the bounding box center
and scale
, the final feedback vector is constructed as follows:
It is important to note that each channel in the keypoint feature map does not directly detect a keypoint; rather, it learns features associated with a particular keypoint. There are three types of keypoints available: semantic keypoints (K = 24), mocap markers (K = 67), and evenly sampled mesh vertices (K = 231). Our objective is to design a lightweight model without compromising accuracy; therefore, one of the mocap markers is selected because they provide more reliable pose and shape information than semantic keypoints and contain less redundancy compared to mesh vertices. We adopt the same mocap marker definitions as in AMASS [
25], where the markers are defined on the mesh surface by choosing the nearest vertices.
In current monocular human regression methods, a common paradigm is to use a square crop centered on the human body as the model input, under the assumption that the optical axis of the imaging system passes through the geometric center of the crop. However, in practical scenarios, input data often originate from full-frame images with varying optical centers. This systematic discrepancy between the assumed condition and the actual data acquisition can significantly affect the accuracy of the rotation matrix estimation.
In contrast to CLIFF [
26], we adjust the reprojected points from the full-frame back to the cropped image. Specifically, the transformation is defined as follows:
where cbbox and sbbox denote the position and scale of the bounding box corresponding to the person. Although this operation might appear trivial, it confers two distinct advantages. Firstly, it normalizes the scale of the reprojected points, ensuring that the reprojection error remains independent of the person’s size in the original image. Secondly, since each keypoint reprojected generates a feedback signal, we employ dropout [
27] to mitigate an over-reliance on global keypoint signals and enhance the robustness of the network during testing in cases where some keypoints are occluded. Specifically, a dropout rate of 0.25 was applied during training, meaning that there is a 25% chance that the feedback will be set to zero.
Our approach shares conceptual similarities with spatial dropout [
28] in terms of regularization, as both methods suppress specific feature responses to improve model generalizability. However, there is a fundamental implementation difference: spatial dropout conducts random channel-wise deactivation (typically with a dropout rate of 0.2–0.5 [
28]), whereas the keypoint feedback dropout proposed here implements a global, spatial-wise all-or-nothing strategy. In practice, when a keypoint’s confidence falls below an adaptive threshold, the entire gradient backpropagation path for that keypoint is completely terminated.
3.3. Transformer Update Module
The update module takes the feedback signal f as input (refer to Equation (2)), which integrates feature-layer information with the coarse-grained human model data. It employs parallel transformer encoder branches to separately process three key streams—human pose, shape, and camera parameters—thereby achieving a collaborative update of multi-dimensional state information.
The module’s input comprises the hidden state vectors
,
, and
, along with the current frame feature layers (which are obtained by concatenating information related to localization, pose, shape, and camera parameters). The core component consists of three independently designed transformer processing branches (illustrated in
Figure 4):
Pose Encoding Branch: This branch uses a transformer structure with 24-dimensional joint positional encodings. Initially,
is linearly projected from
to
and then added to the spatially expanded frame features. Next, positional encodings based on trigonometric functions [
29] are injected. An 8-head self-attention mechanism is used to model spatial dependencies at the joint level, and the branch eventually outputs new
.
Shape Encoding Branch: A single-token processing architecture is designed for the shape stream. Here, is first projected to and then fused with the frame features. A layer-normalized transformer encoder is applied to capture the global representation of the shape parameters. After a subsequent linear layer reduces the dimensionality, the branch outputs a refined shape representation, the new .
Camera Parameter Branch: This branch is similar in structure to the shape branch but maintains its own independent hidden state space. The feature interaction incorporates residual connections to ensure numerical stability during the optimization of camera extrinsics. Additionally, a multi-head attention mechanism effectively models the implicit correlations among camera parameters.
Each branch produces an intermediate representation of unified dimensions, and LayerNorm is applied after the transformer layers to standardize the outputs. This design enables the independent learning of each modality while facilitating cross-modal information exchange by sharing the lower-level frame features. Experimental results demonstrate that the inclusion of positional encoding reduces the pose estimation error. While merging the three modality-specific branches (pose, shape, and camera) through shared weight reduces model complexity, cross-modal interference enhances MPJPE error compared to isolated modality processing, as shown in
Section 4.3.
3.4. Train FFMN
Three-dimensional Joints Loss. During training, this loss function quantifies the discrepancy between predicted and ground-truth joint coordinates using the L1 norm. The 3D joint regression loss
is formulated as follows:
where
denotes the ground-truth 3D joint coordinates,
represents the fine-grained predicted 3D joints, and
is derived from the coarse-grained SMPL mesh via linear regression. Here, K corresponds to the number of body joints (K = 24).
Two-Dimensional Joint Projection Loss. To align the reconstructed 3D human mesh with the input 2D image, we adopt the weakly supervised projection loss methodology established in prior works [
8,
10,
30]. The model predicts weak-perspective camera parameters s, t from camera-aware features extracted by the transformer encoder, where
is a scaling factor and
denotes the 2D translation vector. Using the estimated camera model, we orthographically project both the original 3D joints
and their augmented variant
onto the 2D image plane:
where
implements the orthographic projection via the matrix
. The projection loss
enforces consistency between projected joints and ground-truth 2D annotations
using the L1 norm:
This dual-projection strategy constrains both the initial 3D pose estimation and its refined counterpart, enhancing robustness to camera parameter variations under weak 2D supervision.
SMPL Refinement Loss. This loss regularizes the deviation between the coarse-grained SMPL parameters
and their fine-grained counterparts
optimized through the transformer-based refinement module:
Total Loss. Inspired by the iterative refinement paradigm in RAFT [
31], we employ a multi-task learning framework combining 3D and 2D supervisory signals from diverse training datasets. The composite loss
is defined as follows:
where
are empirically tuned fixed weighting coefficients to balance the loss components.
4. Experiments
Datasets. We trained our FFMN model on 3DPW [
32], Human3.6M [
33], MPI-INF-3DHP [
34], COCO [
35], and MPII [
36], where SMPL pseudo-labels from EFT [
16] were utilized for COCO and MPII datasets. The evaluation was conducted on 3DPW and Human3.6M validation sets using two metrics: MPJPE (mean per-joint position error) and PA-MPJPE (Procrustes-aligned MPJPE).
Implementation Details. FFMN was trained for 40 epochs on the combined dataset, with periodic validation on a subset of the 3DPW validation set. We employed the Adam optimizer with a learning rate of 1 × 10
−4 and batch size 64. Input images were resized to 256 × 256 resolution, and Pascal-style occlusion augmentation [
37] was applied. All experiments were conducted on a PC equipped with dual RTX 3090 GPUs and 128 GB RAM.
4.1. Quantitative Evaluation
The quantitative results are presented in
Table 1, which compares our method with prior works on 3DPW and Human3.6M. To enable comprehensive analysis, we additionally report parameter counts and per-image inference time.
To further validate the effectiveness of FFMN, we compare it with recent state-of-the-art methods on the 3DPW and Human3.6M benchmarks. As shown in
Table 1, FFMN achieves a favorable balance between accuracy and efficiency. Specifically, FFMN attains a PA-MPJPE of 43.9 mm on 3DPW and 32.7 mm on Human3.6M, which is competitive with or better than most existing approaches. Notably, FFMN’s inference time is significantly lower than that of ReFit [
10] and other iterative optimization-based methods, making it suitable for real-time applications.
Compared to regression-based models such as HMR [
8], PyMAF [
19], and CLIFF [
26], FFMN demonstrates improved accuracy while maintaining a lightweight architecture. Although ReFit achieves slightly better accuracy, its computational cost is much higher, with inference times exceeding 200 ms per image. In contrast, FFMN processes each image in just 15 ms, enabling real-time deployment in safety-critical scenarios such as live-line work monitoring.
These results highlight the practical advantages of FFMN: it delivers state-of-the-art accuracy with a fraction of the computational resources required by previous methods, thus bridging the gap between research and real-world deployment for monocular 3D human mesh recovery.
4.2. Qualitative Evaluation
We present qualitative results across multiple datasets in
Figure 5, categorized into three occlusion levels: unoccluded, partially occluded, and heavily occluded. The results include both the original image alignment and multi-view visualizations of 3D human meshes rendered in virtual environments using Open3D, demonstrating pose consistency across perspectives.
In the unoccluded scenarios, FFMN accurately reconstructs the 3D human mesh with precise alignment to the subject’s body contours and articulated joints, even in challenging poses such as squatting or arm extension. For partially occluded cases, such as when limbs are blocked by equipment or other objects, the model maintains plausible mesh predictions by leveraging contextual cues and robust feature extraction, resulting in anatomically reasonable reconstructions. In heavily occluded situations, where large portions of the body are not visible, FFMN still produces coherent mesh structures, indicating strong generalization and the effectiveness of the feedback dropout mechanism in handling missing keypoint information.
To validate temporal coherence, we evaluate sequential human motion reconstructed by our FFM-Net model using continuous image sequences. As shown in
Figure 6, eight consecutive frames from the MHHI dataset [
41] are processed to generate temporally smooth 3D human animations. The results exhibit natural motion transitions in 3D space, confirming our model’s capability for dynamic human mesh recovery.
In particular, FFMN demonstrates strong temporal consistency across frames, with reconstructed meshes maintaining anatomical plausibility and smooth articulation even during rapid or complex movements. As shown in
Table 2, the model effectively suppresses jitter and discontinuities that often arise in frame-by-frame predictions, thanks to its robust feature extraction and feedback mechanisms. This temporal stability is crucial for downstream applications such as motion analysis, behavior recognition, and real-time safety monitoring, where reliable tracking of human pose and shape over time is essential.
4.3. Ablation Study
We conduct ablation experiments on core components of FFMN. All models are trained with identical datasets and evaluated on 3DPW [
32]. The time and parametric quantities in
Table 3 are the overhead of the module during the inference process.
Backbone Architecture. The backbone network critically impacts performance. As shown in
Table 3, our Pose* network (adapted from YOLO [
11]) achieves 1.8% lower MPJPE error and 2.8× faster inference speed compared to the widely used HRNet baseline. This demonstrates Pose*’s superior feature extraction capability and computational efficiency.
Keypoint Reprojection. Our results confirm that employing keypoint reprojection for supervision enhances accuracy [
26]. The proposed full-frame adjusted reprojection extends this benefit to the feedback stage. Optimal performance is achieved when the camera model faithfully participates in all image formation stages.
Feedback Dropout. Implementing dropout () during feedback feature aggregation yields 5.5 MPJPE improvement. This regularization prevents co-adaptation of keypoint signals and enhances robustness to occlusions, as evidenced by improved performance in partially occluded scenarios.
Update Module. Our experiments compare transformer and GRU modules for iterative prediction updates. While the GRU-based variant achieves marginally higher accuracy (3.0 mm lower MPJPE), its inference latency exceeds that of the transformer module by an order of magnitude. When applying shared-weight disentanglement to transformer modules across branches, although the parameter count is reduced, the model performance degrades. This occurs because preliminary SMPL estimates introduce interference when fusing and updating features from heterogeneous dimensions. Given the critical requirement for real-time performance in practical applications, we prioritize computational efficiency, ultimately selecting the transformer architecture. This design choice sacrifices <3% absolute accuracy to achieve 10× faster inference speeds, ensuring viable deployment in latency-sensitive systems.
5. Conclusions
This paper presents fast fitting mesh network (FFMN), a monocular 3D human mesh reconstruction framework based on parametric human models such as SMPL. FFMN integrates an optimization–regression hybrid strategy for end-to-end learning: it leverages transformer-based self-attention mechanisms to model long-range dependencies between global image features and human joints for direct parameter regression, while simultaneously incorporating a differentiable fitting module to refine outputs through implicit geometric constraints. The framework achieves real-time inference through an efficient parallel computation architecture that processes multi-scale voxel features during training. Experimental results demonstrate that FFMN maintains reconstruction accuracy comparable to state-of-the-art methods (e.g., CLIFF [
26], ReFit [
10]) on challenging datasets 3DPW, while achieving a improvement in inference speed. This work bridges the efficiency–accuracy gap in monocular mesh recovery, offering practical value for real-world applications requiring high-speed 3D human analysis.
In the context of distribution network safety monitoring, FFMN enables real-time 3D pose estimation of workers from monocular images, overcoming the limitations of traditional multi-view or sensor-based systems that are difficult to deploy in complex power grid environments. By providing accurate and efficient human mesh recovery (MPJPE < 50 mm), FFMN supports dynamic risk assessment, safety distance alerts, and intelligent operation in live-line work scenarios, thus offering practical value for the digital transformation and intelligent upgrade of power grid maintenance.
Limitations and Future Work
The current implementation has several limitations. Firstly, the model struggles with complex pose variations, particularly in occluded or truncated human bodies. Secondly, the computational cost remains relatively high for edge device deployment despite the optimizations. Future work will focus on addressing these issues by (1) incorporating more robust feature extraction mechanisms to handle occlusions and (2) exploring model quantization and pruning techniques for further efficiency improvements.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}