1. Introduction
In recent years, with increased maritime traffic and marine resource exploration activities, the risk of maritime accidents has risen significantly, highlighting the critical importance of efficient maritime search and rescue operations [
1,
2]. Traditional maritime rescue methods face several limitations in object detection, such as low efficiency, limited coverage, susceptibility to adverse weather conditions, and substantial reliance on human resources and equipment [
3]. As an emerging solution, Unmanned Aerial Vehicle (UAV) technology enables the rapid coverage of extensive maritime areas from an aerial perspective, significantly improving maritime search and rescue efficiency and reducing operational costs [
4]. However, UAV-based object detection in maritime search and rescue missions still faces a range of significant challenges. Distressed persons, vessels, and floating objects appear relatively small from UAV viewpoints and are subject to complex and varying marine environmental factors such as sea surface reflections and wave fluctuations, making feature extraction and object detection highly complex [
5]. Additionally, due to UAV hardware constraints and real-time operational requirements, the onboard detection models must maintain high accuracy while having limited computational complexity and a small parameter size. Therefore, developing lightweight detection models with high accuracy suitable for UAV deployment is crucial for enhancing maritime search and rescue effectiveness.
Deep learning has played a pivotal role in driving progress in object detection, leading to notable enhancements in both accuracy and computational speed. At present, detection approaches based on deep learning can generally be categorized into two types. The first includes two-stage frameworks, such as the R-CNN series [
6], which initially proposes candidate regions and then performs classification and regression to localize and identify objects. The second comprises single-stage frameworks, including models like the SSD [
7] and the YOLO series [
8], which bypass the region proposal stage and directly infer object classes and positions from input images. While two-stage models tend to be more precise, they often suffer from slower inference, limiting their applicability in real-time scenarios. In contrast, single-stage methods offer faster inference by simplifying the detection pipeline. Consequently, the YOLO series has attracted considerable research attention and numerous improvements. Zhu et al. [
9] proposed TPH-YOLOv5, which improves small-object detection by introducing an extra detection head, replacing the original with Transformer Prediction Heads (TPHs), and incorporating the Convolutional Block Attention Module (CBAM). Wang et al. [
10] presented Sea-YOLOv5s, which adopts high-resolution detection heads derived from YOLOv5 and integrates both the Swin Transformer and CBAM modules to enhance the UAV-based recognition of small targets in maritime rescue scenarios. Zhao et al. [
11] developed YOLOv7-sea, an advanced variant of YOLOv7 that adds a dedicated prediction head for identifying fine-scale objects and leverages the parameter-free SimAM attention mechanism to highlight important regions within maritime environments.
The Detection Transformer (DETR) model [
12] leverages Transformer architectures [
13] to capture global context and reformulates object detection as a set-based prediction task. This approach significantly reduces dependence on handcrafted prior knowledge, removing the reliance on handcrafted components like anchor box generation and non-maximum suppression (NMS), thereby simplifying the detection pipeline and improving detection accuracy. However, DETR suffers from long training durations and slow convergence issues. To overcome these drawbacks and strike a more favorable balance between detection accuracy and processing efficiency, the Real-Time Detection Transformer (RT-DETR) [
14] was proposed as an enhanced version of the original DETR model. It builds upon the Transformer architecture while introducing architectural optimizations that enable real-time, end-to-end object detection. By mitigating the high computational cost and slow convergence issues of DETR, RT-DETR significantly improves efficiency while keeping the high accuracy of the original DETR model, outperforming many widely used detection models.
Nevertheless, RT-DETR faces significant challenges when applied to UAV-based maritime rescue scenarios. Due to its high computational cost and large parameter size, deployment on resource-constrained UAV platforms is difficult. Furthermore, small objects in maritime rescue missions typically occupy fewer pixels in captured images and are highly susceptible to environmental variations such as sea surface changes and object overlap, adversely affecting detection accuracy. Therefore, to further optimize RT-DETR for complex backgrounds, multi-scale object detection, and lightweight design, this paper proposes structural improvements aimed at substantially reducing computational cost and model parameters while maintaining detection performance.
To effectively solve the aforementioned restrictions, we propose Maritime Small Object Detection Transformer (MSO-DETR), a lightweight detection transformer model for small object detection in maritime search and rescue. MSO-DETR achieves a substantial reduction in parameter count and computational cost, thus achieving lightweight deployment while maintaining detection accuracy comparable to RT-DETR. The proposed model enables the efficient utilization of computational resources, making it especially suitable for object detection tasks deployed on UAVs in maritime environments for search and rescue missions with limited onboard resources. The main contributions of this paper are listed below:
StarNet is utilized to redesign the backbone of RT-DETR for enhanced detection efficiency, a lightweight feature extraction backbone based on the Star Operation, substantially reducing parameter and computational cost without significantly compromising detection performance.
The Dynamic-range Histogram Self-Attention (DHSA) mechanism is introduced into the Attention-based Intra-scale Feature Interaction (AIFI) module, forming the DHAIFI module. By incorporating DHAIFI, the model becomes more effective at distinguishing objects from complicated backgrounds, which contributes to improved object perception in tough maritime situations such as those influenced by surface glare and wave interference.
We propose the Scale-Tuned Enhanced Feature Fusion (STEFF) module, which integrates an improved Attentional Scale Sequence Fusion (ASF) structure to improve the representation of fine-grained features. To further improve multi-scale representation within STEFF, a novel Multi-Dilated Convolution Cross-Stage Partial (MDC_CSP) module is designed to replace the RepC3 module, aiming to expand the receptive field and strengthen multi-scale feature extraction. Furthermore, a Parallel Aggregation Downsampling (PAD) module incorporating attention mechanisms is developed for the downsampling stage to better preserve small object information and mitigate interference from background noise. This architecture facilitates cross-scale feature fusion, substantially enhancing small object detection performance with little impact on the overall model computational cost.
2. Materials and Methods
2.1. Overall Architecture
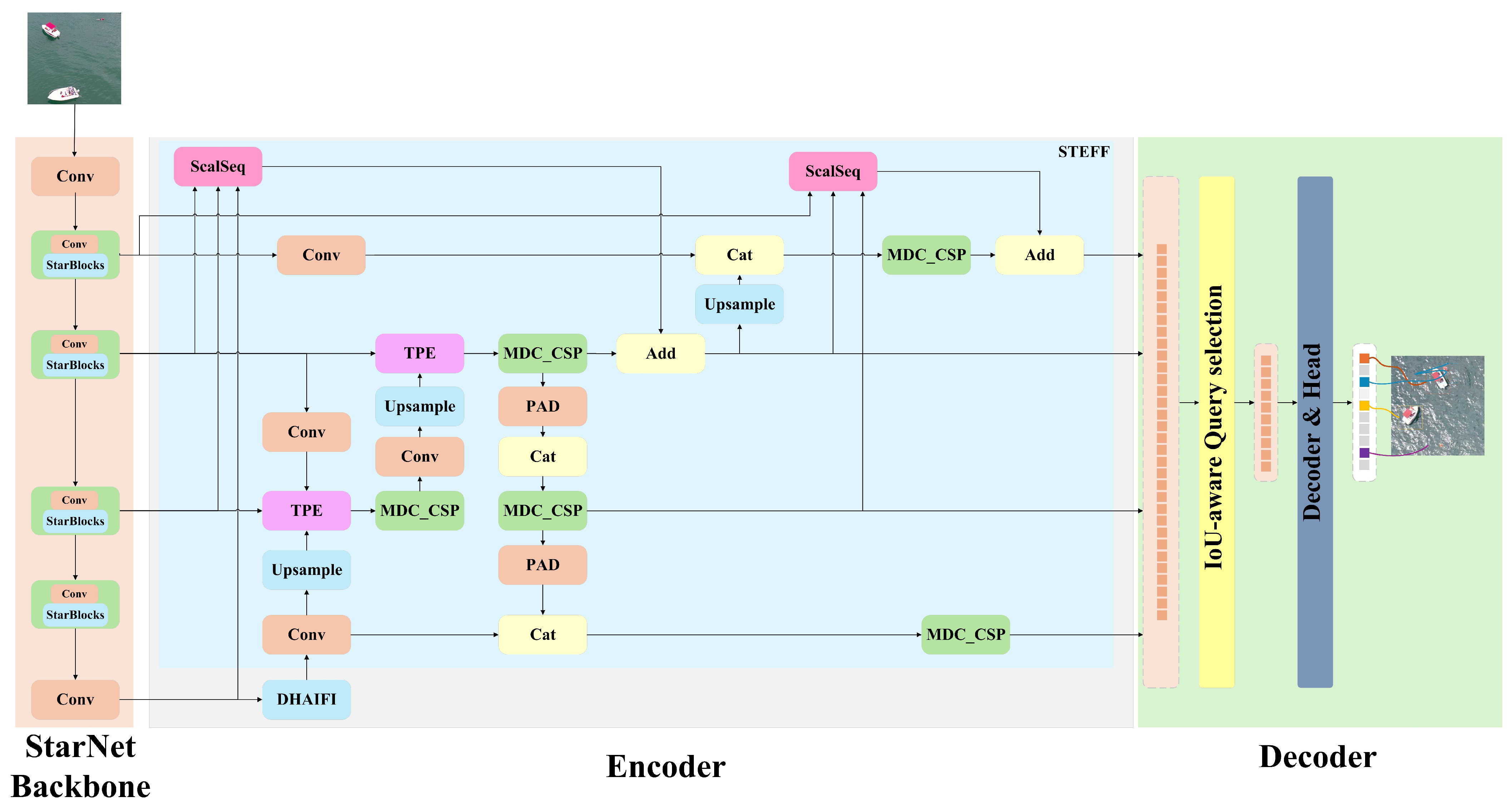
In this paper, we propose MSO-DETR, a lightweight detection transformer model tailored to challenging maritime environments, with a focus on detecting small objects in search and rescue missions. As depicted in
Figure 1, MSO-DETR is a detection transformer model designed to reduce computational cost while maintaining high detection performance under challenging maritime conditions. The proposed MSO-DETR is developed based on the RT-DETR architecture. The RT-DETR model begins by extracting multi-scale features through the backbone, after which a hybrid encoder enhances the feature representations. This encoder employs AIFI to strengthen semantic information and performs multi-scale feature fusion through the CCFF module. Subsequently, a Transformer decoder iteratively updates object queries, generating final bounding boxes and their associated confidence values.
MSO-DETR introduces several key innovations aimed at better meeting the demands of maritime search and rescue scenarios. First, MSO-DETR employs the StarNet [
15] backbone to effectively reduce the computational cost and parameter count, resulting in only minor accuracy degradation. In addition, within the encoder, we enhance the original AIFI module by integrating a DHSA mechanism [
16], forming the novel DHAIFI module. This architectural improvement enhances the model’s capability to detect maritime objects under challenging environmental conditions, including wave interference and sea surface reflections. Furthermore, MSO-DETR replaces the CCFF module in RT-DETR with the proposed STEFF module. STEFF is composed of an improved ASF structure [
17] for fine-grained feature enhancement, MDC_CSP that replaces the original RepC3 to improve multi-scale feature extraction, and PAD designed to better preserve small object features during the downsampling process. This design contributes to the more effective fusion of multi-scale features and the detection of small objects without incurring significant computational cost. As a result, in contrast with the baseline RT-DETR model, MSO-DETR achieves significant lightweighting while retaining the original detection accuracy required for maritime search and rescue scenarios.
2.2. StarNet Backbone
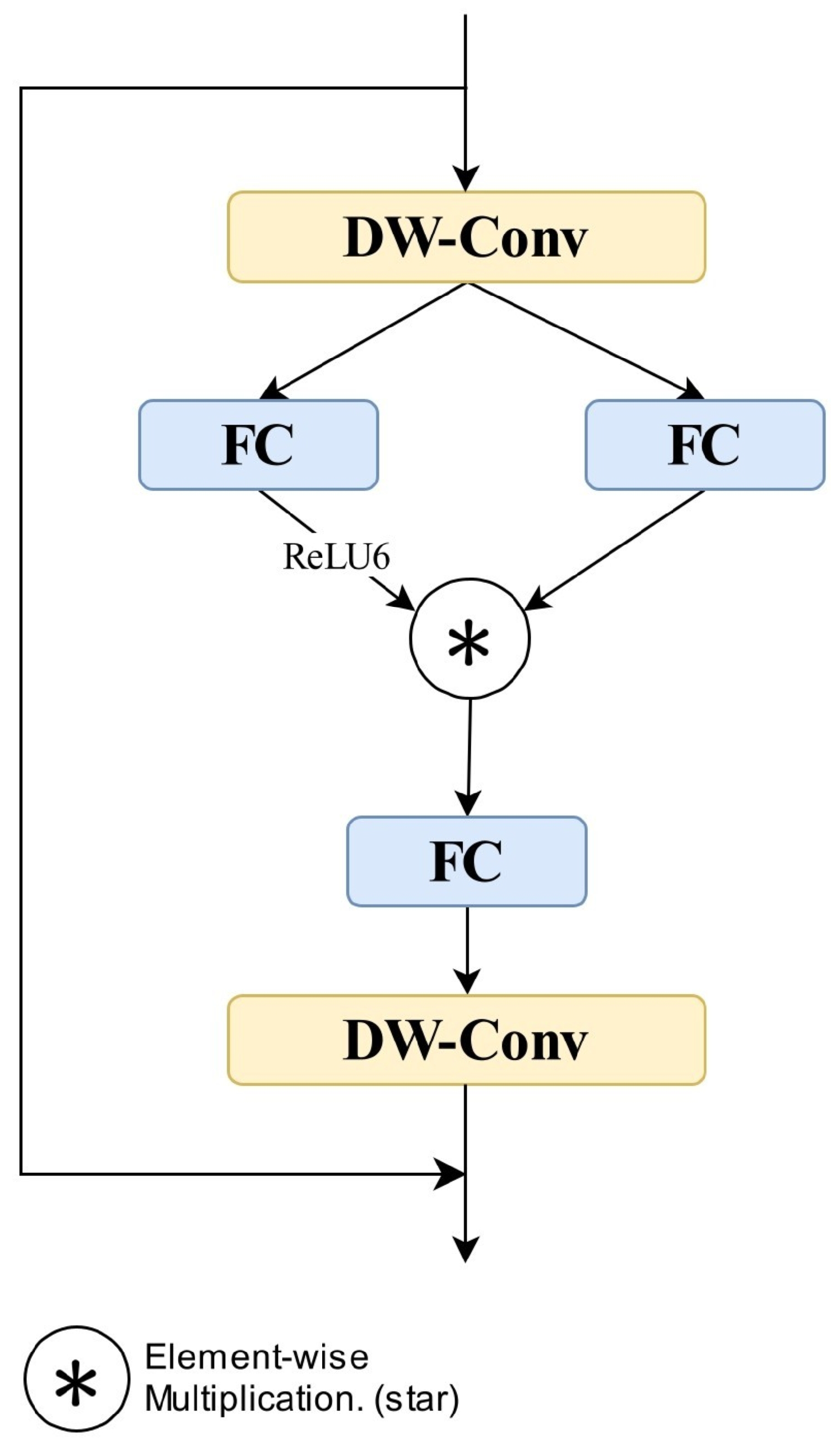
The feature extraction backbone of RT-DETR with ResNet18 has a relatively high computational cost and a large parameter count, making it difficult to deploy on UAV platforms with limited hardware resources. To achieve a lightweight design suitable for edge-device deployment while minimizing performance loss, this study adopts StarNet as the feature extraction backbone. In StarNet, the star operation applies element-wise multiplication to fuse features, leveraging mathematical nonlinearity to transform the input into a higher-dimensional representation space without explicitly increasing dimensionality. This facilitates the modeling of complex feature relationships.
The StarNet architecture utilizes a four-stage hierarchical structure, progressively reducing feature map resolution while increasing channel dimensions. Each stage begins with conventional convolutional layers for downsampling, followed by repeated stacking of Star Blocks for feature extraction. The structure of a Star Block is illustrated in
Figure 2. Initially, the input features pass through depthwise separable convolutions (DW-Conv) and batch normalization layers, extracting local features and normalizing activations. Subsequently, the normalized features enter two parallel fully connected (FC) layers, each expanding the channel dimension by a factor of four. One branch employs ReLU6 activation to enhance nonlinear representation, while the other maintains linear propagation. Finally, the outputs of these two branches are fused through the Star Operation via element-wise multiplication, achieving implicit high-dimensional mapping.
In this paper, the StarNet-S1 variant is employed as the backbone network due to its suitability for deployment in resource-constrained scenarios.
2.3. DHAIFI Module
In UAV-based maritime search and rescue missions, constantly varying sea waves and intense sea surface reflections often result in low contrast between objects and background, substantially increasing the difficulty of detection. To address this issue, this study introduces a Dynamic-range Histogram Self-Attention (DHSA) mechanism integrated into AIFI to form the DHAIFI module. This integration effectively enhances both local and global feature aggregation, mitigating the adverse effects caused by sea waves and surface reflections during object detection.
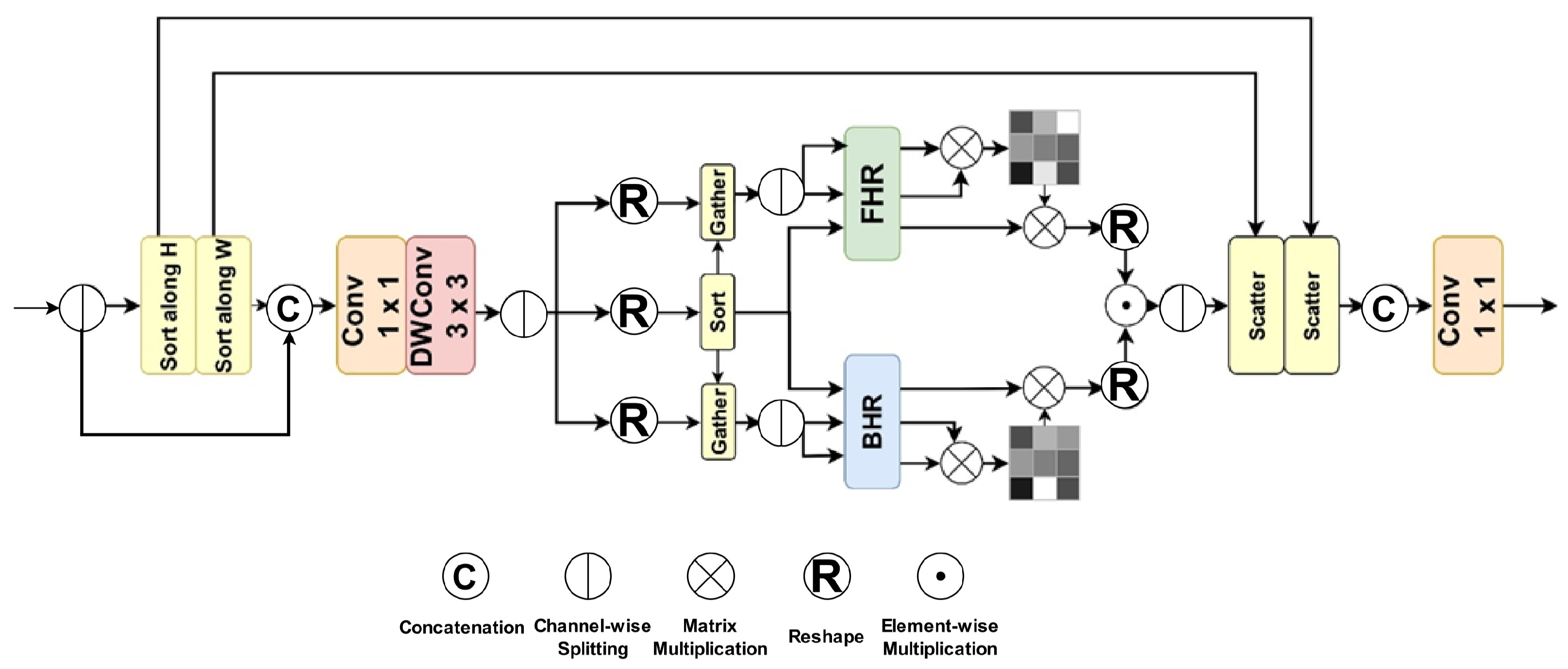
Figure 3 illustrates the DHSA mechanism, which integrates Dynamic-range Convolution and Histogram Self-Attention as its core components. Dynamic-range Convolution first sorts input features
horizontally and vertically, rearranging pixels with similar intensities as
, while preserving the original order of the remaining pixels
. The sorted and unsorted features are concatenated, then refined using a
convolution and a subsequent depthwise
convolution, enabling the convolution operations to focus on retaining clear features and restoring degraded ones within dynamic intensity ranges.
Histogram Self-Attention subsequently partitions features into bins and utilizes Bin-based Histogram Reorganization (BHR) and Frequency-based Histogram Reorganization (FHR) to capture global and local information, respectively. BHR groups pixels of similar intensity into
B bins to extract global dynamic distribution features, while FHR divides neighboring pixels into
B frequency-based groups to obtain fine-grained local features. The attention weights are calculated as follows:
and
denote the reorganization operations for BHR and FHR, respectively, which are applied across multiple attention heads. Finally, DHSA integrates the multi-scale attention outputs and applies them to the value features to generate dynamically modeled feature representations. This module excels in dynamically distinguishing between degraded and clear features, balancing global and local feature extraction, and demonstrating robust feature representation capabilities under complex scenarios.
Building upon the global context modeling capability of AIFI for high-level feature interactions, DHAIFI further enhances the feature representation capacity of the model in dynamically complex scenarios. In UAV-based maritime search and rescue missions, AIFI exhibits certain limitations in differentiating object features from background interference such as waves and sea surface reflections. To overcome these limitations, DHAIFI employs dynamic-range convolution and histogram self-attention to achieve dynamic interval partitioning and multi-scale feature reorganization. Specifically, dynamic-range convolution reorders features horizontally and vertically to adjust their distributions, guiding the convolution operation to focus on restoring degraded regions and enhancing object-relevant features. Meanwhile, histogram self-attention combines BHR and FHR to extract global and local dynamic features and adaptively assign attention weights. Compared to AIFI, DHAIFI demonstrates enhanced robustness in complex maritime environments by suppressing irrelevant background noise and boosting detection performance for small objects.
2.4. STEFF Module
For small object detection, baseline models typically exhibit inadequate performance on detection layers P3, P4, and P5. Traditional methods often enhance detection capability by directly adding a P2 layer to utilize high-resolution shallow features. While effective, this approach significantly increases computational cost, complicating deployment on UAV platforms. To address these challenges in UAV-based maritime search and rescue scenarios, we propose the STEFF module, a novel feature fusion structure designed to enhance small object detection performance without substantially increasing model cost.
2.4.1. Improved ASF Structure
In object detection tasks, effectively combining features from multiple scale levels is a key factor in enhancing object detection performance across varying object sizes. However, UAV aerial images in maritime search and rescue scenarios present significant challenges due to scale variability, scene complexity, and densely distributed small objects. Consequently, the simple fusion strategies employed in conventional feature pyramid networks (FPNs) cannot adequately exploit the correlations between multi-scale feature maps, leading to incomplete feature integration and information loss. Specifically, small object detection heavily relies on shallow-layer features, which contain abundant detailed information but lack global semantic context, rendering them susceptible to interference from complex backgrounds. Additionally, existing methods exhibit limited performance when fusing shallow and deep-level features, further constraining the detection capabilities for small objects.
To address these limitations, we incorporate an improved ASF structure to enhance the original neck architecture of the detection model. This innovative architectural design enhances the detection of small objects without significantly increasing processing costs. The ASF design leverages the scale sequence feature fusion (SSFF) and triple feature encoding (TFE) modules, which collaboratively encode spatial context and multi-scale information.
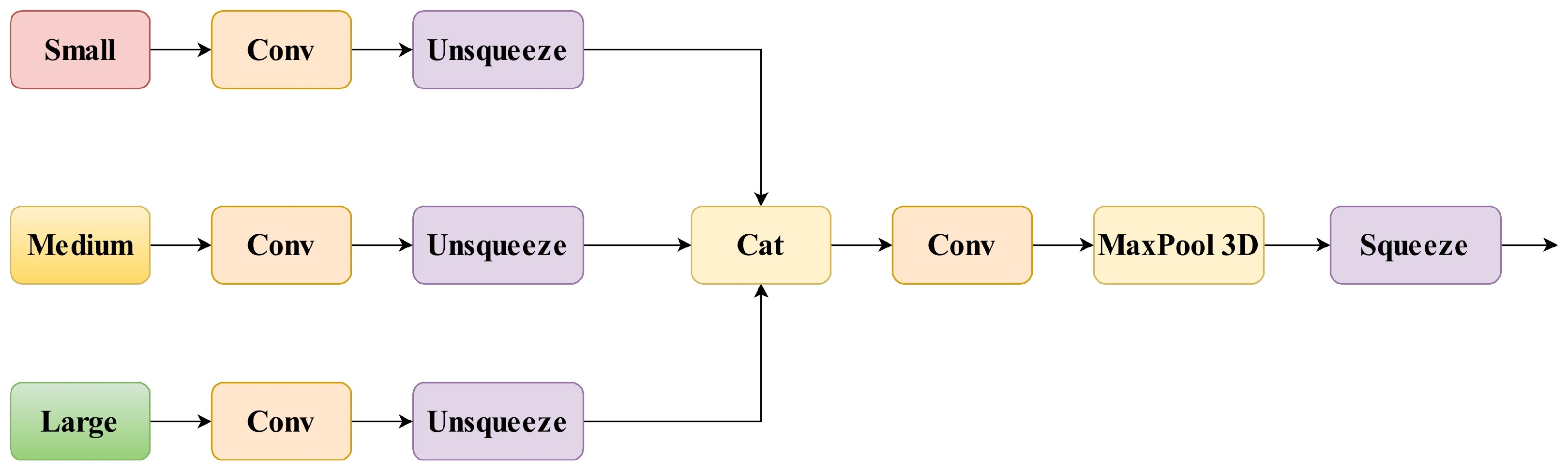
The SSFF module improves the detection of small objects by combining deep-layer semantics together with fine-grained representations from shallow levels. As depicted in
Figure 4, SSFF builds multi-scale feature sequences utilizing feature maps received from the backbone network. Each feature map, specific to a particular scale, is sent through a convolutional layer to unify the channel dimensions and retrieve localized information. These characteristics are then modified to introduce an additional dimension, which facilitates their alignment for further procedures. After alignment, the feature maps are concatenated along the added dimension to generate a 3D volume, which is further processed using 3D convolution and max pooling to model spatial and semantic dependencies across multiple resolution levels. Finally, the extra dimension is eliminated, reverting the feature map to its two-dimensional form while keeping the enriched multi-scale representations.
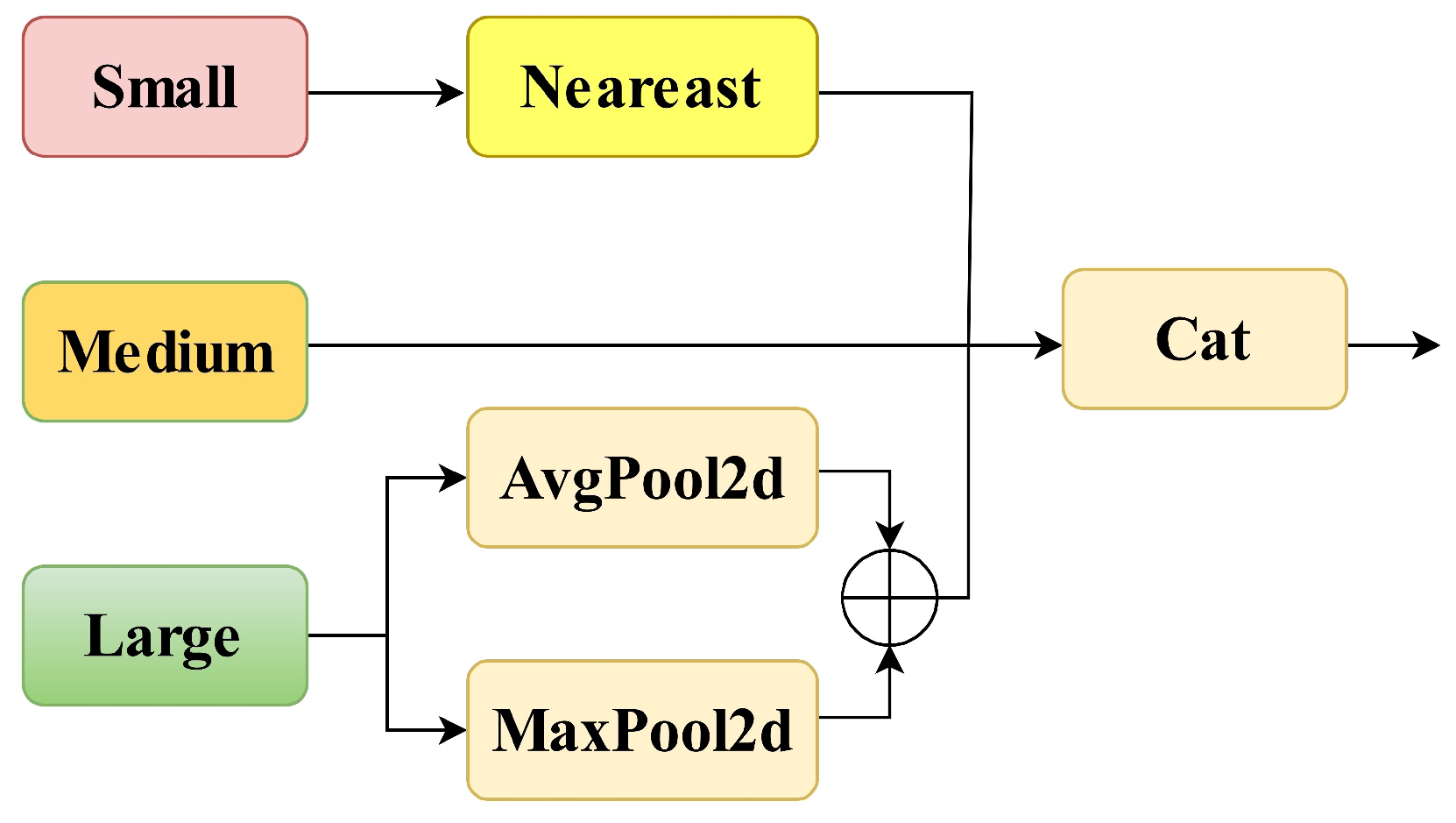
The TFE module processes feature maps across several resolutions, notably big, medium, and small, to preserve detailed representations that are typically degraded by basic upsampling and naive concatenation in conventional feature pyramid architectures. This architecture increases the model’s efficacy in recognizing small objects that are densely scattered over the image. As depicted in
Figure 5, the large-scale feature maps are processed by convolutional modules to alter channel size, followed by downsampling through a hybrid pooling strategy that incorporates both max and average operations. This approach reduces the spatial resolution and enhances resilience against spatial alterations in the input pictures. Small-scale feature maps, after correcting channels using convolutional modules, are upsampled by nearest-neighbor interpolation to maintain local features and avoid the loss of small object information. Subsequently, feature maps from multiple spatial scales are aligned in both channel and resolution dimensions, and then integrated to form a unified feature representation. Output representation of TFE can be computed as
The output feature map of TFE is denoted as , which is obtained by concatenating the large-scale feature map , medium-scale feature map , and small-scale feature map .
In contrast to the original ASF structure, this paper incorporates a small object detection layer into the neck to enhance the representation of shallow-layer features. Additionally, a second SSFF module is introduced to fuse information from shallow-layer features, deep-layer semantic representations, and multi-scale contextual information, which further improves the model’s responsiveness to small objects. The shallow-layer features retain rich edge and texture information, which is beneficial for identifying small objects. The deep-layer semantic representations contribute high-level categorical and contextual cues that enhance detection accuracy; meanwhile, the multi-scale features aggregate information from different levels, maintain fine-grained details across multiple resolutions, and enhance global contextual understanding, allowing the model to interpret complex scenes more effectively.
2.4.2. MDC_CSP Module
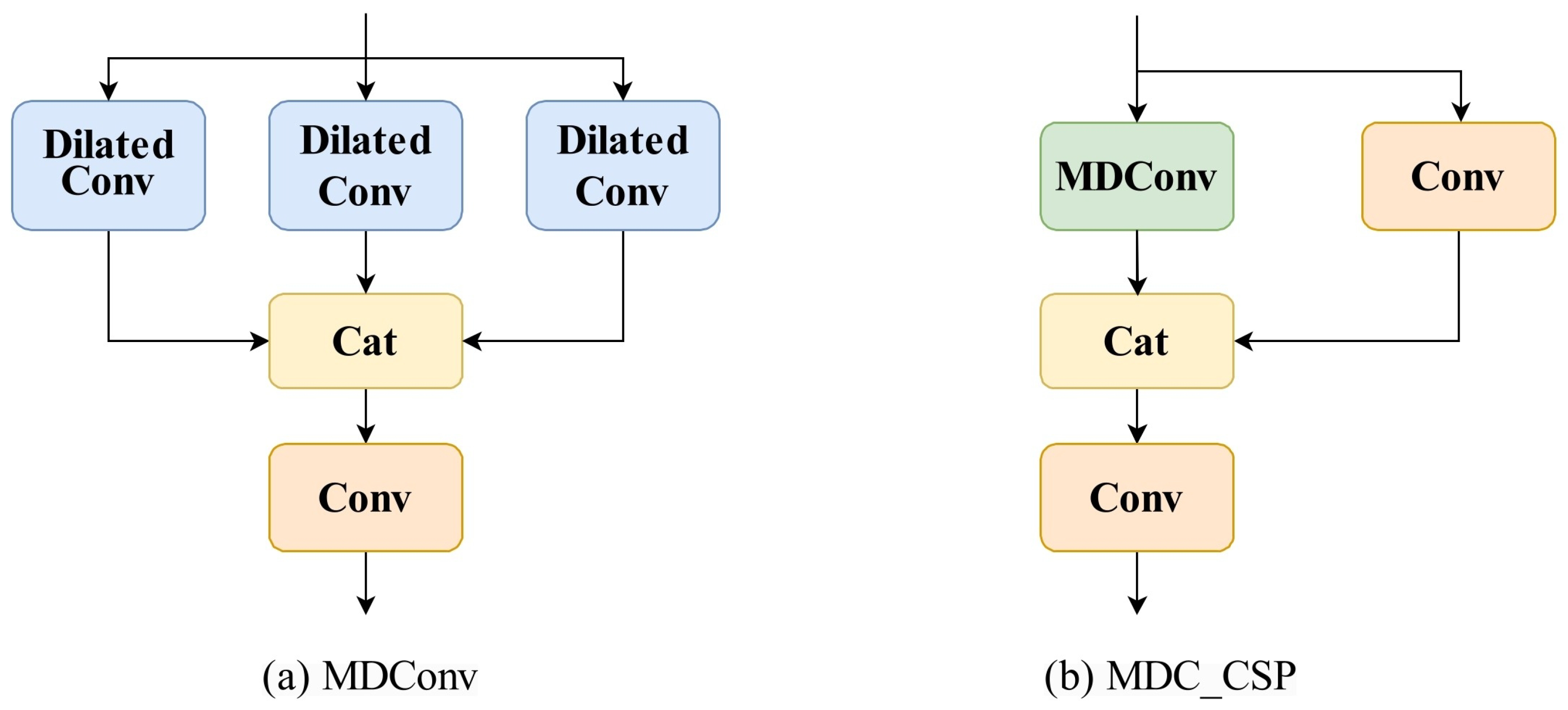
In UAV-based maritime rescue scenarios, the detection of small objects is often challenged by their weak and indistinct features due to constraints such as UAV flying altitude and imaging angles. To improve detection reliability and accuracy, this study introduces a Multi-Dilated Convolution (MDConv) module aimed at fusing shallow-level detail features with high-level semantic representations. The MDConv module is incorporated into the Cross Stage Partial Network (CSPNet) [
18] to form the MDC_CSP module, which is used to replace RepC3 in the baseline architecture.
Figure 6a represents the MDConv module, while
Figure 6b shows the MDC_CSP module.
Standard dilated convolutions [
19] employ a single dilation rate to expand the receptive field but often introduce the “grid effect”, resulting in the incomplete coverage of pixel information and insufficient representation of local details and global context. To mitigate this issue, the proposed MDConv module employs multiple parallel convolutional branches with different dilation rates, thereby preventing information loss and comprehensively capturing both local details and global features. This significantly enhances the richness and effectiveness of feature representations.
The MDC_CSP module integrates the strengths of both CSPNet and MDConv. CSPNet facilitates efficient cross-stage feature interaction, helping to minimize redundant information and improve feature representation. In parallel, MDConv captures multi-scale object characteristics by utilizing multiple branches with different dilation rates. Through this combination, MDC_CSP contributes to enhanced object recognition performance and increased resilience of the model in complex maritime scenarios.
2.4.3. PAD Downsampling Module
Downsampling is commonly performed by fixed convolutional processes, in which high kernel sizes and strides are utilized to reduce feature map resolution. However, such processes do not dynamically modify feature weights based on inter-channel relevance, leading to the dilution or even loss of small object features during the downsampling process. Additionally, conventional single-path designs primarily focus on local feature extraction while lacking the ability to effectively represent multi-scale information and aggregate global context, which may result in small object features being overshadowed by background noise.
In response to the above limitations, the PAD module is introduced, combining channel attention with a multi-branch, as illustrated in
Figure 7. The input feature map is processed through three distinct branches. In the first path, localized spatial information is captured during downsampling via a
convolution operation. The second path conducts spatial reduction via max pooling, subsequently applying a
convolution to unify channel dimensions and preserve global feature information. The third method employs global average pooling to produce channel-wise statistics, which are then processed by a
convolution and a HardSigmoid activation layer to provide attention weights that adaptively modulate the significance of each channel in the resulting feature map.
The global average pooling for channel
c is calculated as
Here,
signifies the average value of channel
c, whereas
H and
W refer to the feature map dimensions along height and width, accordingly. The value of
is then linearly transformed using a
convolution and then processed by the HardSigmoid activation function
, which scales the output to the range
, finally yielding the dynamic channel attention weight
:
Here,
represents the convolutional weights used to learn inter-channel dependencies. Subsequently, the outputs from the first path
and the second path
are fused along the channel axis, allowing the integration of both local and global multi-scale representations. These concatenated features are then element-wise multiplied with the attention weights
from the third path to enhance informative features:
The element-wise multiplication ensures that the channel attention mechanism appropriately weights each channel’s features, highlighting those that contain critical small object information. The weighted feature map is then passed through a final convolution to further compress and fuse information, producing the downsampled output feature.
By incorporating channel attention and a multi-path design, the proposed PAD module effectively preserves and enhances small object features during downsampling while suppressing background noise and redundant information, ultimately enabling more accurate detection of small objects.
3. Results
3.1. Datasets
This study takes the publicly available SeaDronesSee [
20] dataset, a large-scale benchmark built for maritime search and rescue applications. It comprises 14227 RGB photos, of which 8930 are used for training, 1547 for validation, and 3750 for testing. The dataset contains labeled instances of five object categories, namely Boat, Life-saving Appliances, Buoy, Swimmer, and Jetski, with several example images shown in
Figure 8. All photographs were obtained by UAVs from a variety of flying altitudes and viewing perspectives, with heights ranging from 5 to 260 m and camera angles between 0° and 90°. These different imaging settings make the dataset extremely representative of real-world maritime rescue operations.
To further verify the effectiveness of the proposed model in UAV-based maritime object detection, we also conducted experiments on the Aerial Dataset of Floating Objects (AFO) [
21]. The AFO dataset consists of 3647 UAV-captured images with annotations for nearly 40,000 objects, covering categories such as humans, surfers, kayaks, boats, buoys, and sailboats. During data preprocessing, we removed all unannotated images and ensured that each remaining image had a corresponding YOLO-format label file. After cleaning, the dataset consisted of 2031 training images, 319 validation images, and 514 test images, which roughly correspond to 70%, 10%, and 20% of the full dataset. Several representative examples are illustrated in
Figure 9.
3.2. Experimental Environment
The experiments were conducted using Python 3.8.10 and PyTorch 2.0.0, running on a single NVIDIA GeForce RTX 3090 GPU (NVIDIA Corporation, Santa Clara, CA, USA) equipped with CUDA 11.8. The training process was performed over 150 epochs with a batch size of 4, using input images resized to 640 × 640 pixels. Training MSO-DETR for 150 epochs took about 12 h and 30 min on the SeaDronesSee dataset and about 3 h and 45 min min on the AFO dataset.
3.3. Experimental Evaluation Metrics
The experiment adopts Precision (P), Recall (R), Average Precision (AP), mean Average Precision (mAP), model parameters (Param), and giga floating point operations per second (GFLOPs) as evaluation metrics.
Precision (P) denotes the ratio of correctly identified positive cases to the total number of positive predictions, reflecting the reliability of the model’s outputs. Recall (R) represents the capacity of the model to identify all relevant positive cases by estimating the proportion of genuine positives within the actual positive samples. Average Precision (AP) measures the detection performance for a particular category by computing the integral of the Precision–Recall curve, considering precision values at varying recall levels. Mean Average Precision (mAP) is computed by taking the mean of AP scores over all categories, providing an overall evaluation of the model’s detection effectiveness.
The calculation formulas are as follows:
Here, denotes the count of correctly predicted positive instances, while corresponds to false positives generated by the model, refers to the number of missed objects in a given category, and N indicates the total number of categories. Param describes the total number of learnable parameters within the model, and GFLOPs reflect the computational costs of the model. Frames Per Second (FPS) shows the inference speed by counting the images the model can process in one second, therefore representing its real-time performance.
3.4. Backbone Network Comparison Experiments
To achieve model lightweighting without significantly compromising detection performance, this study investigates the use of EfficientViT [
22], FasterNet [
23], GhostNetv2 [
24], MobileNetv3 [
25], and StarNet as backbones. Each backbone replaces the original feature extractor, and their performance is evaluated based on detection accuracy, parameter count, and computational cost. The experimental results are presented in
Table 1. The experimental findings reveal that the model incorporating StarNet as the backbone achieves the best detection accuracy among all candidates, given comparable parameter counts and computational costs. In particular, it outperforms the models based on EfficientViT, FasterNet, GhostNetv2, and MobileNetv3, with gains of 3.9%, 0.3%, 4.1%, and 2.9% in mAP50 and corresponding improvements of 2.6%, 0.9%, 1.5%, and 1.7% in mAP50:95. These results indicate that StarNet effectively balances model compactness and detection precision. Therefore, selecting StarNet as the feature extraction backbone enables significant model lightweighting while ensuring more accurate object identification and localization, thereby improving detection reliability in complex maritime environments.
3.5. Verification of Feature Fusion Modules Effectiveness
To assess how the proposed improvements to the feature fusion network affect model performance, a series of comparison experiments are carried out using models with and without the updated modules. The results are presented in
Table 2. Replacing RepC3 with the MDC_CSP module achieves 0.5% and 0.7% improvements in mAP50 and mAP50:95, respectively, while using PAD as the downsampling component further achieves 0.6% and 0.9% mAP50 and mAP50:95, respectively. Both modules contribute to reductions in parameter count and computational cost. The complete STEFF module, which integrates the ASF structure, a small object detection layer, MDC_CSP, and PAD, achieves 1.4% and 1.2% improvements in mAP50:95, with a 23.6% decrease in parameter count and only a slight increase in computational cost. These results demonstrate that the proposed modules significantly enhance the detection precision of small maritime targets while maintaining a favorable balance between accuracy and efficiency, thereby supporting their effective deployment in resource-constrained maritime search and rescue tasks.
3.6. Ablation Study
The impact of each improved module on overall model performance was investigated through an ablation study based on RT-DETR-R18, and the corresponding results are listed in
Table 3. Replacing the original backbone with the StarNet structure reduces the parameter count and GFLOPs by 43.7% and 47.9%, respectively, and increases FPS by 3.3%, achieving a substantial gain in efficiency with only a slight decline in detection accuracy. Incorporating the DHAIFI module further enhances detection robustness under complex maritime conditions, resulting in a 0.2% increase in mAP50 and a 1.2% improvement in FPS. The STEFF feature fusion module leads to enhanced multi-scale feature integration, accompanied by a reduction in parameter count and limited influence on computational cost, while increasing mAP50 and mAP50:95 by 1.4% and 1.2%, respectively. Through the integration of the above improved modules, MSO-DETR achieves a coordinated balance between model efficiency and detection accuracy, enabling substantial reductions in parameters and computational cost without compromising performance. It reduces the parameter count from 19.9 M to 6.5 M with a 67.3% reduction and lowers the computational cost from 57.0 GFLOPs to 30.5 GFLOPs, representing a 46.5% decrease. At a batch size of one, it achieves an inference speed of 52.7 frames per second, surpassing the baseline in computational efficiency. Meanwhile, the detection accuracy is effectively maintained, with mAP50 decreasing marginally by 0.1 percentage points from 82.1% to 82.0%, and the stricter mAP50:95 increasing by 0.5 percentage points from 48.4% to 48.9%. These results clearly demonstrate that MSO-DETR delivers a favorable trade-off between lightweight design and detection performance, confirming the effectiveness of its overall architecture.
3.7. Comparison with Mainstream Object Detection Models
A comparative study was carried out to benchmark MSO-DETR against several mainstream object detection models. The models involved in the comparison include Faster R-CNN [
26], YOLOv5m, YOLOv6m [
27], YOLOv7 [
28], YOLOv8m, YOLOv9m [
29], YOLOv10m [
30], and YOLOv11m [
31], using the SeaDronesSee dataset. According to the results in
Table 4, it is demonstrated that MSO-DETR outperforms these models in terms of mAP50 by margins of 25.8%, 10.6%, 12.5%, 9.7%, 8.3%, 8.9%, 9.4%, and 8.4%, respectively, while simultaneously achieving lower parameter count and GFLOPs. Compared with YOLOv8s in particular, MSO-DETR not only has fewer parameters and only a 7.4% increase in GFLOPs but also achieves 11.2% and 5.4% improvements in mAP50 and mAP50:95, respectively. Although the inference speed of MSO-DETR is slightly lower than some of the YOLO series models, it still reaches 52.7 frames per second, satisfying the real-time detection requirements. These results indicate that MSO-DETR achieves superior detection performance in UAV-based maritime rescue scenarios, with a more compact architecture and reduced computational cost.
Compared with RT-DETR-R18, MSO-DETR reduces the parameter count and GFLOPs by 67.3% and 46.5%, while maintaining comparable detection accuracy, effectively achieving model lightweighting.
In summary, MSO-DETR displays exceptional performance across numerous major evaluation measures, particularly excelling in lightweight design. These qualities make it well-suited for deployment in UAV-based maritime search and rescue missions, ensuring efficient and precise object detection under resource-constrained scenarios.
3.8. Visualization Results Comparison
The performance of the DHAIFI module, which integrates the DHSA attention mechanism into the AIFI module, is evaluated under complex maritime conditions by applying the Grad-CAM [
32] method to generate heatmaps for models before and after the improvement. This visualization intuitively illustrates the model’s focus on different regions and highlights the key areas considered during prediction.
Figure 10a shows the original input images.
Figure 10b shows the attention regions of RT-DETR-R18, the baseline model, during object detection.
Figure 10c shows the attention map of the baseline model with DHAIFI, indicating the focused areas during detection. As observed from the comparisons, RT-DETR-R18 tends to overlook drowning persons under challenging conditions such as strong sea surface reflections and wave disturbances. In contrast, the model incorporating the DHAIFI module successfully detects all objects in the same scenarios, with attention more concentrated on maritime search and rescue objects. These findings demonstrate that the DHAIFI module, empowered by the DHSA attention mechanism, improves detection robustness under complex environmental interference encountered in maritime search and rescue scenarios.
Figure 11 provides the detection output visualization for RT-DETR-R18 and MSO-DETR on the SeaDronesSee dataset, presenting an intuitive comparison of their detection performance. Under challenging conditions such as strong sea surface reflections, RT-DETR-R18 exhibits the missed detections of people on the sea surface, whereas MSO-DETR successfully detects all objects without omissions. Additionally, for the detected objects, MSO-DETR maintains a confidence level comparable to RT-DETR-R18, demonstrating that it preserves the overall detection accuracy of the baseline model.
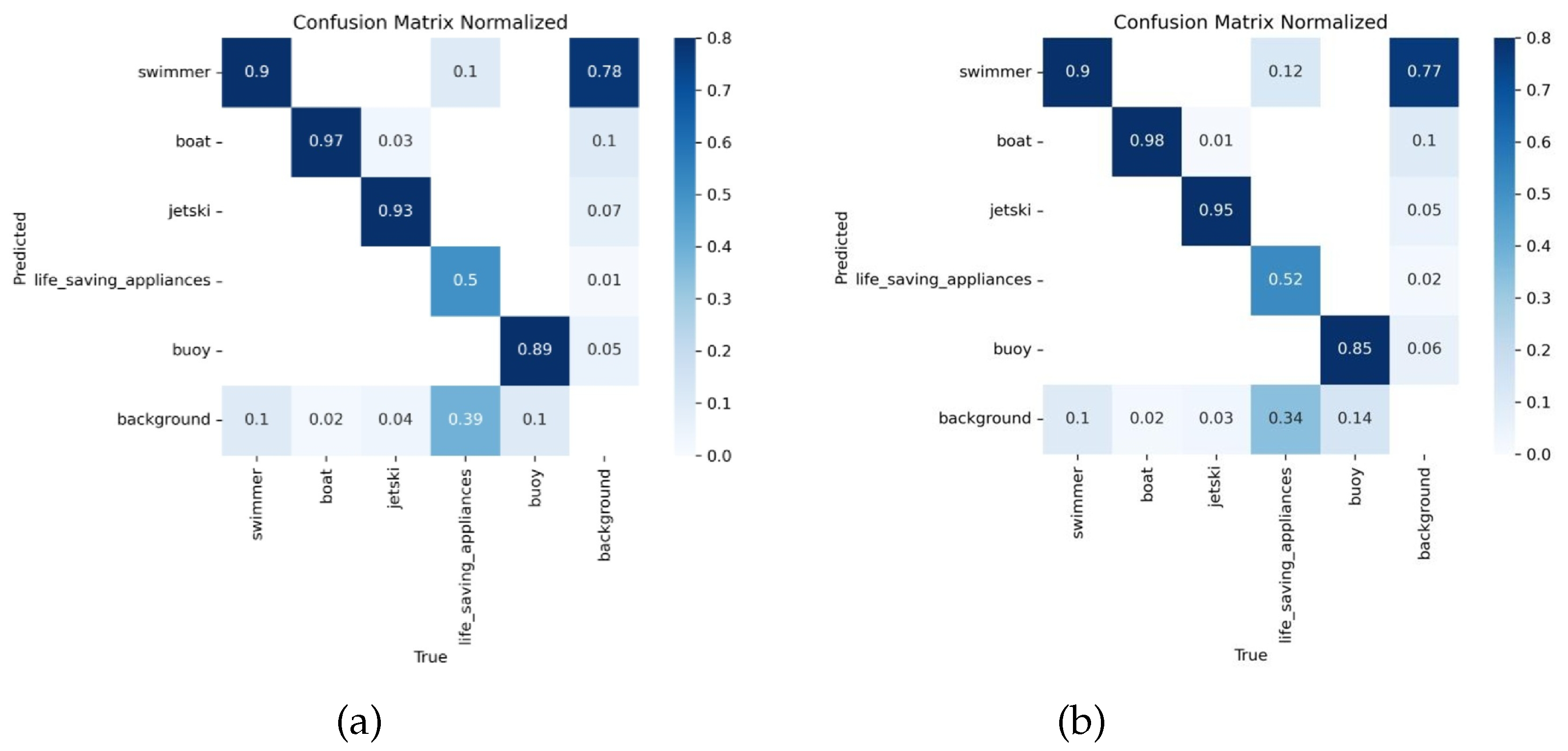
Figure 12 presents a comparative view of the confusion matrices for RT-DETR-R18 and MSO-DETR, reflecting the classification outcomes across different object categories. The diagonal elements indicate correctly predicted instances, whereas the off-diagonal ones correspond to misclassifications or missed detections. The comparison shows that MSO-DETR achieves comparable detection performance to RT-DETR-R18 on the swimmer category while demonstrating improved accuracy in detecting boat, jetski, and life-saving appliances, demonstrating its excellent detection performance.
3.9. Evaluation on an Additional Dataset
To further assess the performance of MSO-DETR in maritime search and rescue scenarios, we conducted a comparative experiment on the AFO dataset. Evaluation was carried out on both the validation and test splits to ensure a comprehensive and unbiased comparison between MSO-DETR and the baseline RT-DETR-R18. The corresponding results are shown in
Table 5. Compared to RT-DETR-R18, MSO-DETR reduces the number of parameters and GFLOPs by 67.3% and 46.5%, respectively, while maintaining detection accuracy at a level comparable to the baseline. These results confirm that MSO-DETR achieves substantial model lightweighting without sacrificing detection accuracy on different maritime datasets, highlighting its potential for UAV-based maritime rescue deployment.
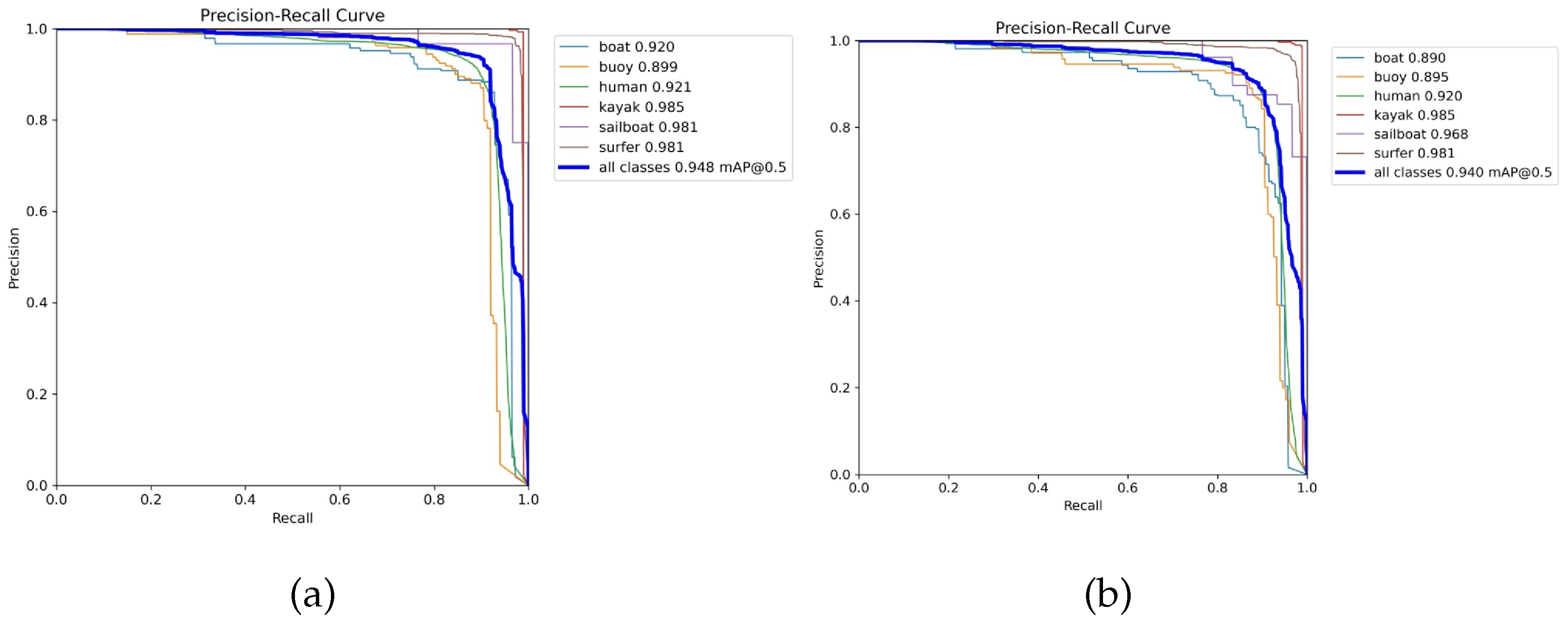
Figure 13 compares the Precision–Recall (PR) curves of the baseline model RT-DETR-R18 and the proposed MSO-DETR, both evaluated on the validation subset of the AFO dataset during training. The baseline model achieved a slightly higher overall mAP50 of 94.8%, while MSO-DETR achieved 94.0%. For several small objects in maritime search and rescue, MSO-DETR demonstrated consistent performance with the baseline. Overall, MSO-DETR provides a substantially more lightweight architecture while maintaining equivalent detection capability on key maritime rescue objects, showing strong potential for deployment object detection in UAV-based maritime search and rescue tasks.
Figure 14 illustrates the detection results for human targets in challenging maritime scenes with wave interference and sunlight reflections. Each image contains two human instances as ground truth. Under these visually complex conditions, RT-DETR-R18 suffers from both missed detections and false positives, indicating its vulnerability to background interference. In contrast, the proposed MSO-DETR successfully detects both targets with fewer redundant boxes and consistent localization. These results show that MSO-DETR performs reliably in maritime rescue scenarios affected by common sea surface disturbances.
4. Conclusions
In this paper, we propose MSO-DETR, a lightweight detection transformer model for small object detection in maritime search and rescue based on an improved RT-DETR architecture. MSO-DETR aims to tackle the limitations encountered when deploying high-precision models on UAVs with restricted computational capacity, as well as the inadequate accuracy of current lightweight detectors under complex maritime conditions. The model’s effectiveness and robustness are comprehensively assessed on the SeaDronesSee dataset, demonstrating consistent results across different maritime object detection datasets.
MSO-DETR integrates multiple innovative architectural components to balance detection accuracy with computational efficiency. First, the StarNet backbone is adopted for feature extraction, achieving a notable reduction in computational load and maintaining comparable detection performance. Within the encoder, the DHAIFI module enhances feature extraction under challenging maritime conditions by mitigating the effects of low object-background contrast caused by sea waves and reflections. Additionally, the proposed STEFF module is composed of the improved ASF structure, MDC_CSP, and PAD. The improved ASF structure is designed to enhance fine-grained feature representation, while MDC_CSP replaces the original RepC3 to strengthen multi-scale feature extraction under complex maritime conditions. PAD is employed during downsampling to preserve small object information and suppress background noise. Experimental results show that MSO-DETR achieves substantial reductions in parameter count and computational cost, while maintaining detection performance comparable to the RT-DETR-R18 on both the SeaDronesSee and AFO datasets, indicating its promising potential for application in maritime small object detection for search and rescue missions.
In future work, we will focus on further compressing the model and improving inference speed to reduce computational overhead and lower processing demands during deployment, thereby improving detection efficiency under the limited onboard computational and energy resources of practical UAV platforms. UAV-based maritime search and rescue missions often face strong winds, heavy rainfall, high sea states, and low-light nighttime conditions, which can cause image instability, background interference, and reduced visibility. We will therefore aim to further improve the model’s detection accuracy and robustness in such complex environments.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}