This section presents the simulation results that evaluate the effectiveness of the proposed advanced intelligent frame generation (AIFG) algorithm under different delay constraints. The main goals of the simulation are to validate the adaptability of AIFG in varying network conditions, and to compare its performance against three benchmark algorithms: AFG + HEFG, IFG + HEFG, and FIFO + FIFO. Additionally, to strengthen the evaluation from the perspective of reinforcement learning methodologies, we introduce a Deep Q-Network-combined framing policy (DQN + HEFG) as an additional comparative baseline. This inclusion supplements the analysis with a machine learning-based benchmark, allowing for a more comprehensive performance assessment of AIFG against both traditional and contemporary intelligent algorithms. The simulation scenario emulates data traffic in an AOS, incorporating delay-sensitive and non-delay-sensitive services with dynamic arrival patterns.
The evaluation focuses on three critical performance indicators: average queue delay, frame multiplexing efficiency, and throughput. To explore the robustness of AIFG, the simulations are conducted under four different delay threshold settings: 5 ms, 10 ms, 15 ms, and 20 ms.
Beyond the standard evaluations, this section further investigates the scalability and practical applicability of AIFG. We extend the simulation environment by varying the number of network nodes (from 25 up to 200), altering the MPDU payload length (ranging from 800 to 1800 bytes), and adjusting satellite link bandwidth (from 3 Mbps to 20 Mbps). These additional experiments serve to analyze the computational overhead, convergence behavior, and performance resilience of AIFG under more realistic and heterogeneous system conditions.
The results demonstrate that AIFG can dynamically adjust its frame generation policy based on real-time feedback from the system environment, effectively balancing delay and efficiency. The subsequent subsections provide detailed discussions of the simulation setup, algorithm configurations, and quantitative comparisons under each experimental scenario.
6.2. Simulation Results and Analysis
Under different delay requirements, the AOS automatically adjusts and produces varying network performance results, leading to changes in parameters such as the final threshold values, delay, multiplexing efficiency, and throughput. To achieve more accurate results from the advanced intelligent frame generation algorithm, the simulation sets four different delay requirements : 5 ms, 10 ms, 15 ms, and 20 ms. At the same time, according to the delay requirements, iteration parameters, reward function parameters, and final reward values of the old and new policy are flexibly adjusted to train the agent to obtain a more optimized delay threshold.
In the simulation of this algorithm, the change in the delay requirement combined with adjustments to the reward function parameters can guide the correct training and learning of the agent, which makes the agent complete. Then, the agent is able to make the optimal policy. The difference in the four parameter settings in the reward function will greatly affect the performance of the algorithm. Therefore, the numerical selection of the parameter group is particularly important. This simulation takes the setting delay requirement of 5 ms as an example. Multiple parameter sets of reward functions are as shown in
Table 3. For each case, the reward function, throughput, average delay, and multiplexing efficiency are observed. The optimal parameter group value is obtained via a comparison, and the reward value convergence curve changes as shown in
Figure 5.
Different parameter settings will bring different changes in the value of the reward function.
Figure 5 clearly shows the mainstream trend of the reward function, which gradually rises in the early stage of training. When the number of iterations is about 40, it begins to stabilize and enters the platform period, indicating the convergence of the reward function. Among the four parameter groups selected, the growth rate of the convergence function is the fastest in the case of Parameter Group 3, and the growth rate of the Parameter Group 2 is slower. At the same time, the convergence effect of Parameter Groups 1, 3 and 4 is better, but the convergence effect of Parameter Group 2 is poor.
From
Figure 6, it can be observed that the average delay and throughput are optimal for Parameter Group 3, while the multiplexing efficiency is highest for Parameter Group 4. Overall, selecting Parameter Group 3 for AIFG algorithm training is the most optimal choice.
For the four different network processing strategies, different simulation performances are observed under varying delay threshold requirements. Except for the FIFO + FIFO algorithm, which cannot accurately set delay requirements, the other strategies produce a single result under each delay requirement. In this simulation, the parameter groups of the optimal reward function are set for the four delay requirements, and the specific values are shown in
Table 4. These sets determine the weights for delay and efficiency trade-offs in the agent’s learning process. The detailed values of
,
,
, and
for each delay condition are summarized in
Table 4, covering thresholds of 5 ms, 10 ms, 15 ms, and 20 ms, respectively. The following series of figures provides the frame generation delay, throughput, and multiplexing efficiency for the four strategies under different delay requirements.
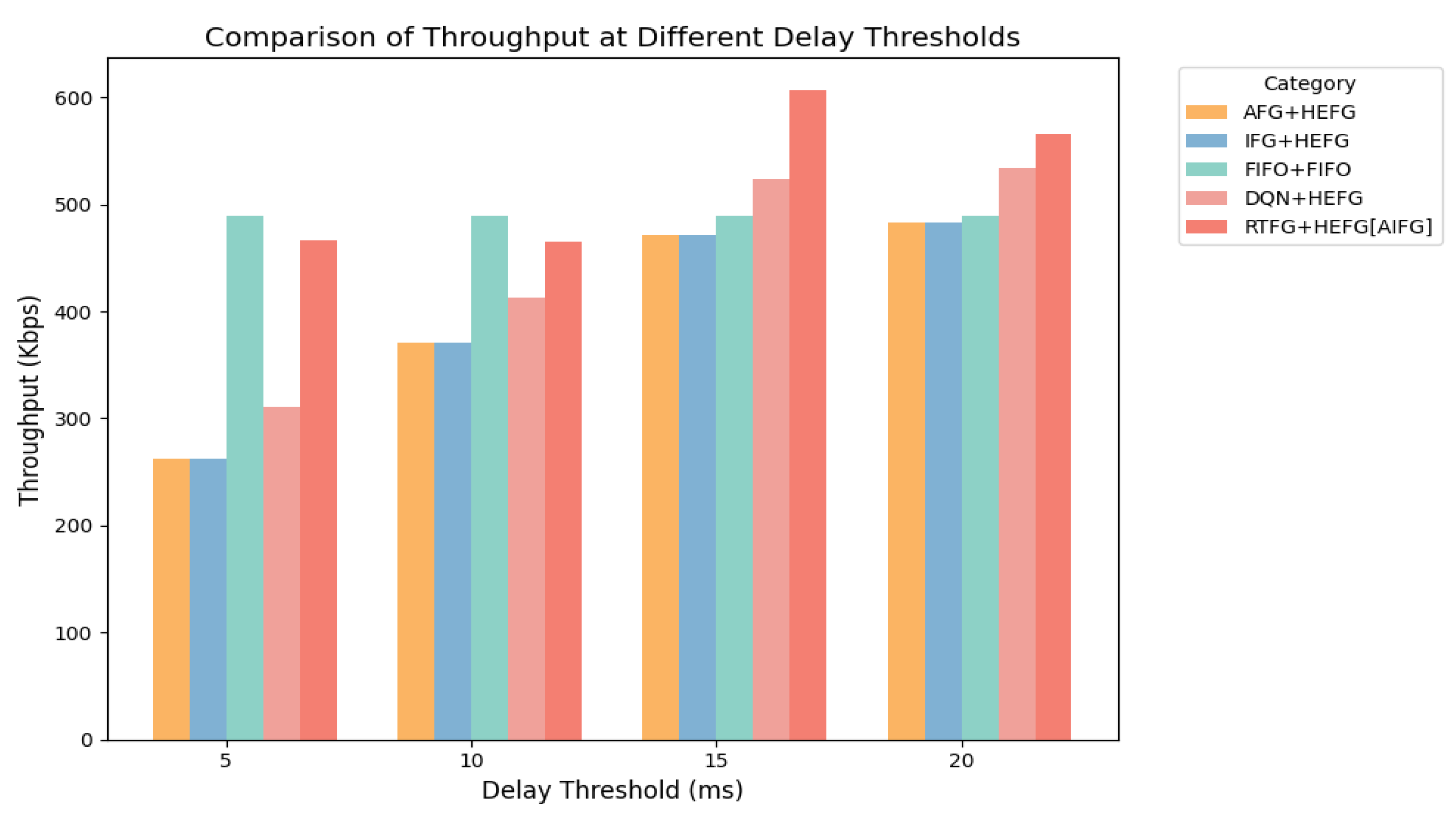
From
Figure 7, it can be seen that the throughput of the AIFG algorithm is generally higher compared to other frame generation algorithms. When the delay requirement is 5 ms, the throughput of the AIFG algorithm is 466 Kbps, which is an increase of 78.05% over both the AFG + HEFG and IFG + HEFG algorithms. With a delay requirement of 10 ms, the throughput of AIFG is 464 Kbps, which is an increase of 25.37% compared to that of AFG + HEFG and IFG + HEFG. When the delay requirement is 15 ms, the AIFG algorithm achieves the maximum throughput of 606.456 Kbps, which is 28.66% higher than that of the AFG + HEFG and IFG + HEFG algorithms. At a delay requirement of 20 ms, the throughput of AIFG also improves, with an increase of 17.18% compared to both AFG + HEFG and IFG + HEFG. The AIFG consistently exhibits superior throughput, especially under 5 ms and 10 ms delay thresholds, where it outperforms DQN + HEFG by margin of 49.9% and 12.7% respectively. Under 15 ms and 20 ms delay thresholds, the throughput of AIFG is 15.8% and 6.1% higher than that of DQN + HEFG, respectively. When the delay requirement is low, AIFG shows a higher throughput improvement rate, and its performance change is optimal. Conversely, when the delay requirement is high, AIFG is able to achieve a larger throughput value. This highlights the effectiveness of PPO in guiding reward shaping and decision making over longer time horizons.
Due to the FIFO transmission mechanism, the queue’s multiplexing efficiency is always 100%. As shown in
Figure 8, the multiplexing efficiency of the AIFG algorithm is higher compared to the IFG + HEFG, AFG + HEFG and DQN + HEFG algorithms under smaller delay requirements. With a delay requirement of 5 ms, AIFG’s multiplexing efficiency is 69.25%, which is an increase of 92.36% over both AFG + HEFG and IFG + HEFG, and an increase of 63.2% over DQN + HEFG. Under a delay requirement of 10 ms, the multiplexing efficiency of the AIFG algorithm is 69.1%, which is 52.47% higher than that of the AFG + HEFG and IFG + HEFG algorithms, and an increase of 35.5% over DQN + HEFG. At a 15 ms delay requirement, AIFG’s multiplexing efficiency is 12.26% higher than that of AFG + HEFG and IFG + HEFG, while it is only 3.2% higher than that of DQN + HEFG. When the delay requirement is 20 ms, the multiplexing efficiency of AIFG reaches its maximum value of 94.7%, with an increase of 1.4% compared to DQN + HEFG, but with a slight decrease compared to AFG + HEFG and IFG + HEFG. When the delay requirement is high, the multiplexing efficiency improvement rate of AIFG decreases. This is constrained by the time threshold and influenced by the fixed AOS transmission frame size. Nevertheless, the overall trend in multiplexing efficiency remains upward. Among learning-based methods, AIFG shows better multiplexing efficiency than DQN + HEFG, especially under strict delay conditions (5 ms, 10 ms), indicating a more refined policy learned through PPO.
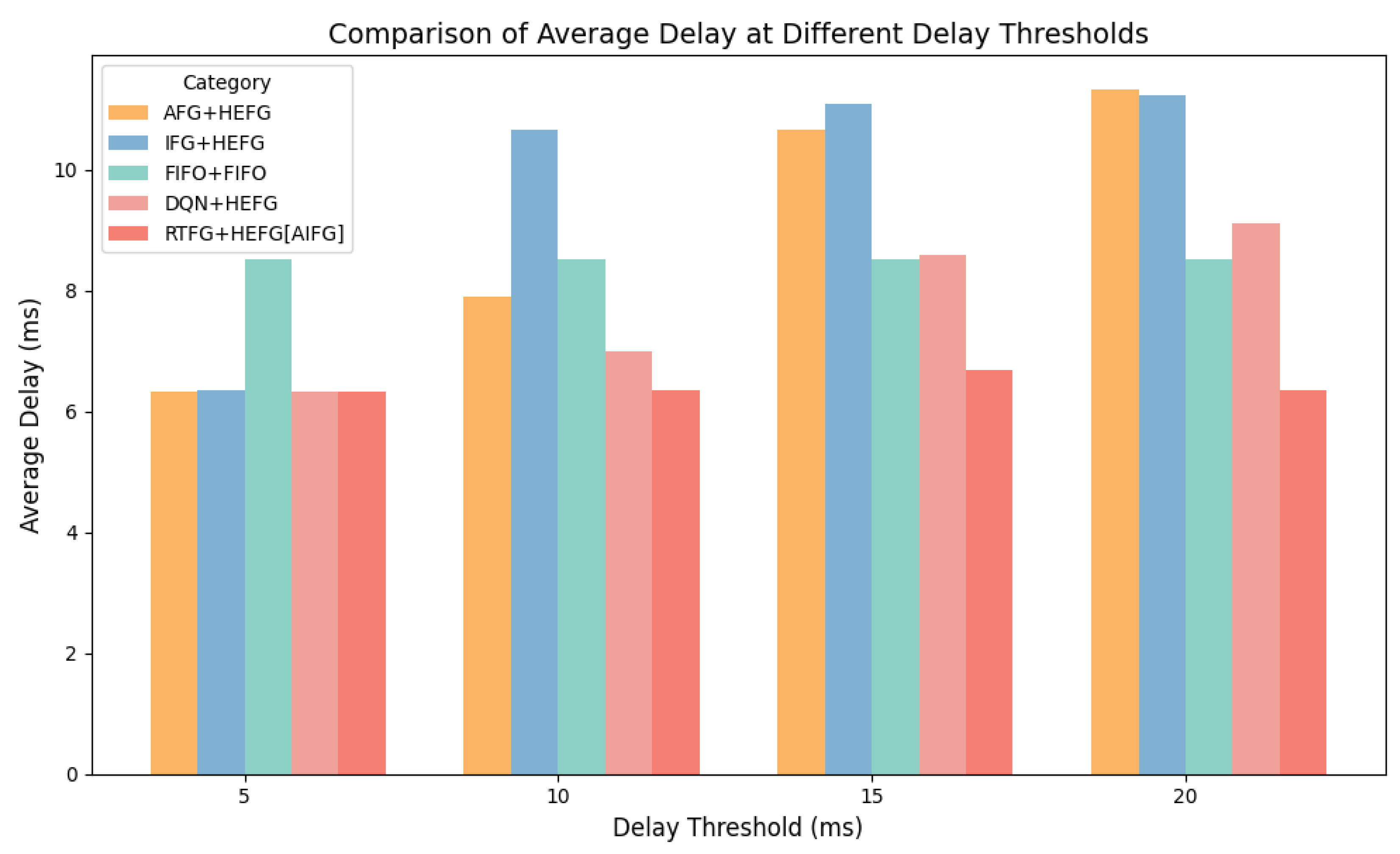
Figure 9 shows that AIFG consistently exhibits the lowest delay across all time requirements, outperforming all other methods. This is especially noticeable under higher time requirements (15 ms and 20 ms), where the delay is substantially smaller. Meanwhile, the FIFO-based method exhibits slower processing times due to its inherent characteristics. With a delay requirement of 5 ms, the average queue delay for AIFG, DQN + HEFG, AFG + HEFG, and IFG + HEFG is almost the same, ranging from 6 to 7 ms. However, at a 10 ms delay requirement, AIFG’s average queue delay is reduced by 19.39% compared to AFG + HEFG and by 40.33% compared to IFG + HEFG and by 8.9% compared to DQN + HEFG. At a 15 ms delay requirement, AIFG’s average queue delay decreases by 37.30% compared to AFG + HEFG and by 39.62% compared to IFG + HEFG and by 22.1% compared to DQN + HEFG. At a 20 ms delay requirement, AIFG’s average queue delay is 43.90% lower than AFG + HEFG and 43.45% lower than IFG + HEFG and 30.3% lower than DQN + HEFG. When the delay requirement is low (e.g., 5 ms), the queue length typically does not exceed the AFG threshold, so the algorithm’s performance is similar to that of AFG, and the advantages of AIFG are not fully manifested. However, when the delay requirement is high, AIFG dynamically optimizes the gap between frames, reducing delays and improving overall performance by adapting to changing conditions in the transmission environment. In this part, DQN + HEFG performs better than traditional rule-based approaches (AFG/IFG + HEFG) but does not reach the stability and optimization level of PPO-based AIFG. The simulation results validate the adaptability of the AIFG algorithm under varying delay requirements and the advantage of AIFG in reducing average queue delay.
Based on the analysis of the above results, in the face of time-sensitive service queues, the AIFG algorithm proposed in this paper can effectively adjust the framing threshold according to the queue state. Compared with the traditional algorithm, it achieves a better multiplexing efficiency and a lower queuing delay while ensuring excellent throughput, which is an effective performance improvement. In terms of throughput performance, the AIFG algorithm has an average increase of 31.92% compared with the AFG + HEFG, IFG + HEFG and DQN + HEFG algorithms. In terms of the multiplexing efficiency, the AIFG algorithm has an average increase of 74.93% compared with the AFG + HEFG, IFG + HEFG and DQN + HEFG algorithms when the delay requirement is below 5 ms. In terms of the average queuing delay, the AIFG algorithm is 33.53% lower than the AFG + HEFG algorithm and 41.13% lower than the IFG + HEFG algorithm and 20.43% lower than the DQN + HEFG algorithm when the delay requirement is above 5 ms. In reinforcement learning applications, while DQN provides improvements over heuristic baselines, the PPO-based AIFG exhibits higher adaptability, stability, and better global optimization performance, making it more suitable for diverse and dynamic space network environments.
To evaluate the scalability and robustness of the proposed AIFG algorithm under varying network sizes, we expand the simulation to assess performance across different network sizes, including 25–25, 50–50, 100–100, and 200–200 transmitter–receiver pairs. We maintain the same satellite relay architecture. These different simulation situations are all performed under the condition that the delay requirement is 20 ms. To further validate the scalability of the proposed AIFG algorithm, we specifically focus on the PPO training time, training memory consumption, convergence iterations, and resulting performance metrics such as delay, multiplexing efficiency, and throughput. The key performance metrics observed include the following:
Training computational overhead, measured as the cumulative time and training memory consumption required for PPO training to reach a stable policy.
Convergence time, quantified as the number of iterations needed for the reward function to stabilize within a defined tolerance range.
As shown in
Figure 10, the reward sum becomes negative in large-scale cases due to an increased queuing delay. In contrast, for smaller networks (25 and 50 nodes), the algorithm achieves convergence within fewer episodes and yields positive reward values. Notably, the algorithm’s accumulated reward converges well even in large-scale environments.
As summarized in
Table 5, the training time increases with the node scale, reaching approximately 798 s in the 200-node configuration, compared to just 41.5 s for 50 nodes. Similarly, the number of PPO training iterations required for reward convergence increases from 40 to 80. Nonetheless, AIFG still delivers high efficiency and throughput across all scenarios. Although the computational cost increases as the network grows, the performance in delay remains acceptable.
These results, summarized in
Figure 10 and
Table 5, demonstrate that AIFG remains computationally viable and robust under scale expansion, offering consistent performance and QoS adaptability even in dense satellite constellations. In summary, the AIFG algorithm demonstrates strong scalability with a predictable computational cost growth and robust convergence behavior, indicating its feasibility in large-scale deployment.
To further investigate the robustness and adaptability of the proposed AIFG algorithm under varying network configurations, two additional simulation scenarios were conducted. The first scenario explores the influence of different MPDU sizes on system performance. Specifically, MPDU sizes were varied across 800, 1200, 1500 (default), and 1800 bytes. As shown in
Table 6, the AIFG algorithm maintains consistently high throughput and multiplexing efficiency across different MPDU sizes. The results show that while increasing MPDU size improves multiplexing efficiency up to a point, overly large frame sizes (e.g., 1800 bytes) lead to degraded throughput, likely due to transmission and fragmentation inefficiencies. The default size of 1500 bytes strikes a good balance among the average delay (10.77 ms), efficiency (99.49%), and throughput (566.45 Kbps), confirming the appropriateness of the default setting. Interestingly, even when reducing the frame size to 800 bytes, the algorithm achieves strong performance with an average delay of only 7.23 ms and a throughput of 559.61 Kbps. These results indicate that the AIFG algorithm is capable of dynamically adjusting the frame threshold to maintain high performance, even under less efficient framing conditions.
In the second scenario, the satellite link bandwidth was adjusted across 3, 6 (default), 9, 15, and 20 Mbps to simulate the variability caused by orbital distance, channel fading, or dynamic scheduling. As summarized in
Table 7, the AIFG algorithm continues to demonstrate resilient performance, with stable average delay and throughput across all bandwidth conditions. Although slight improvements in throughput are observed as bandwidth increases, the average delay and efficiency remain within a narrow and acceptable range. The default configuration of 6 Mbps achieved the highest throughput at 575.18 Kbps and the best multiplexing efficiency at 99.52%. Even in constrained link scenarios (e.g., 3 Mbps), the algorithm sustains efficient operation, with a throughput of 566.86 Kbps. These findings confirm the algorithm’s robustness under dynamic bandwidth constraints and validate its practical applicability in real-world spaceborne communication environments.
These extended experiments further support that the AIFG algorithm not only provides adaptive framing under differentiated QoS demands but also maintains high levels of delay control, bandwidth efficiency, and throughput under fluctuating MPDU configurations and varying relay link conditions. This reinforces the algorithm’s suitability for deployment in dynamic space networking environments with heterogeneous service profiles.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}