
Robust 12-Lead ECG Classification with Lightweight ResNet: An Adaptive Second-Order Learning Rate Optimization Approach

Abstract
1. Introduction
2. Related Work
3. Adaptive Second-Order Momentum Method (AdaSOM)
| Algorithm 1. AdaSOM. |
| 1: Input: maximum iterations , learning rate , scalar learning rate , momentum coefficient , loss function , training set, and validation set. 2: Initial: , , . 3: . 4: . 5: . 6: while not converged do 7: . 8: . 9: . 10: . 11: . 12: . 13: . 14: . 15: . 16: . 17: . 18: end while 19: return . |
4. Convergence Analysis of AdaSOM Algorithm
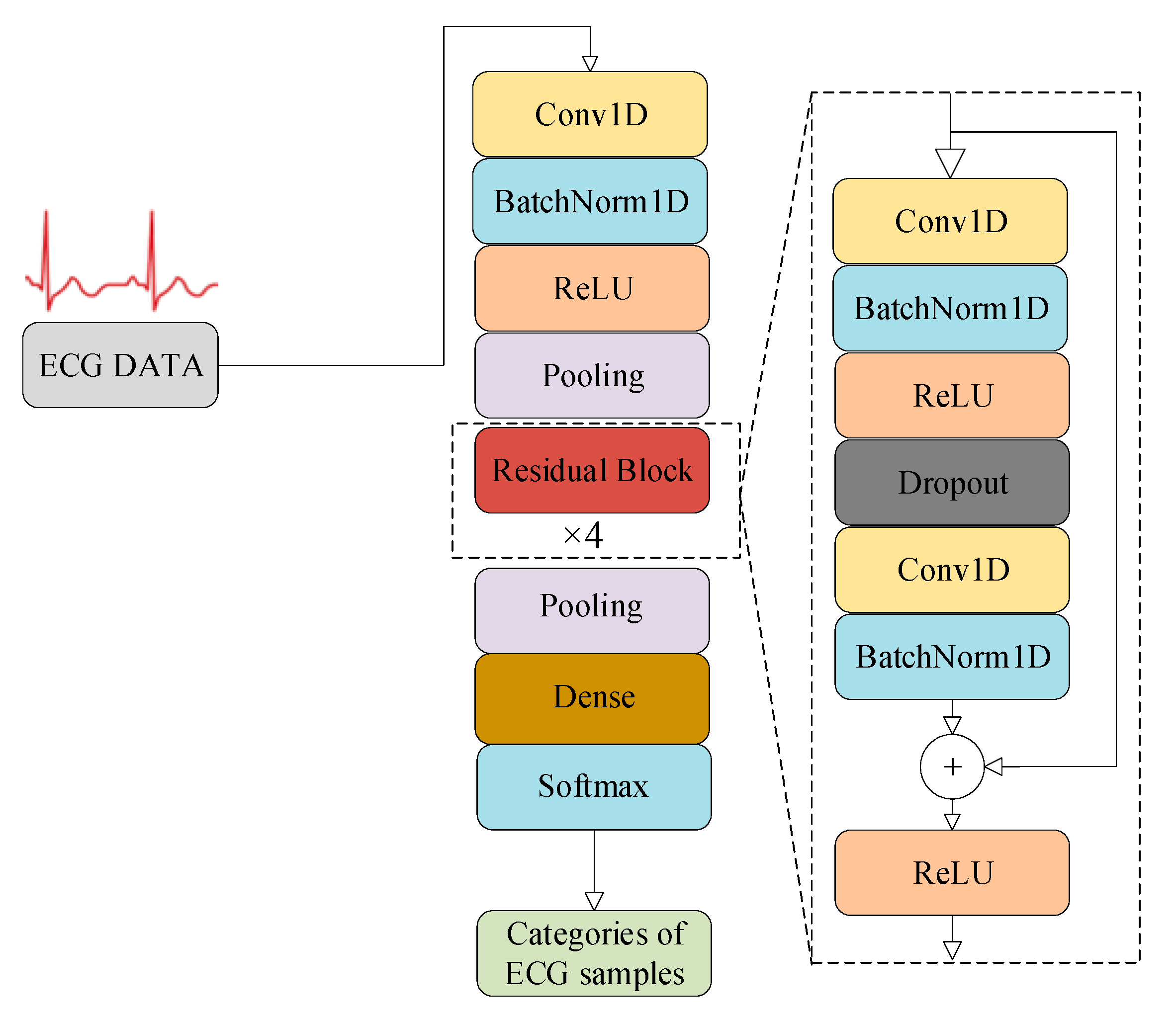
5. Experiments
5.1. Experimental Environment
5.2. Dataset
5.3. Evaluation Metrics
5.4. Results
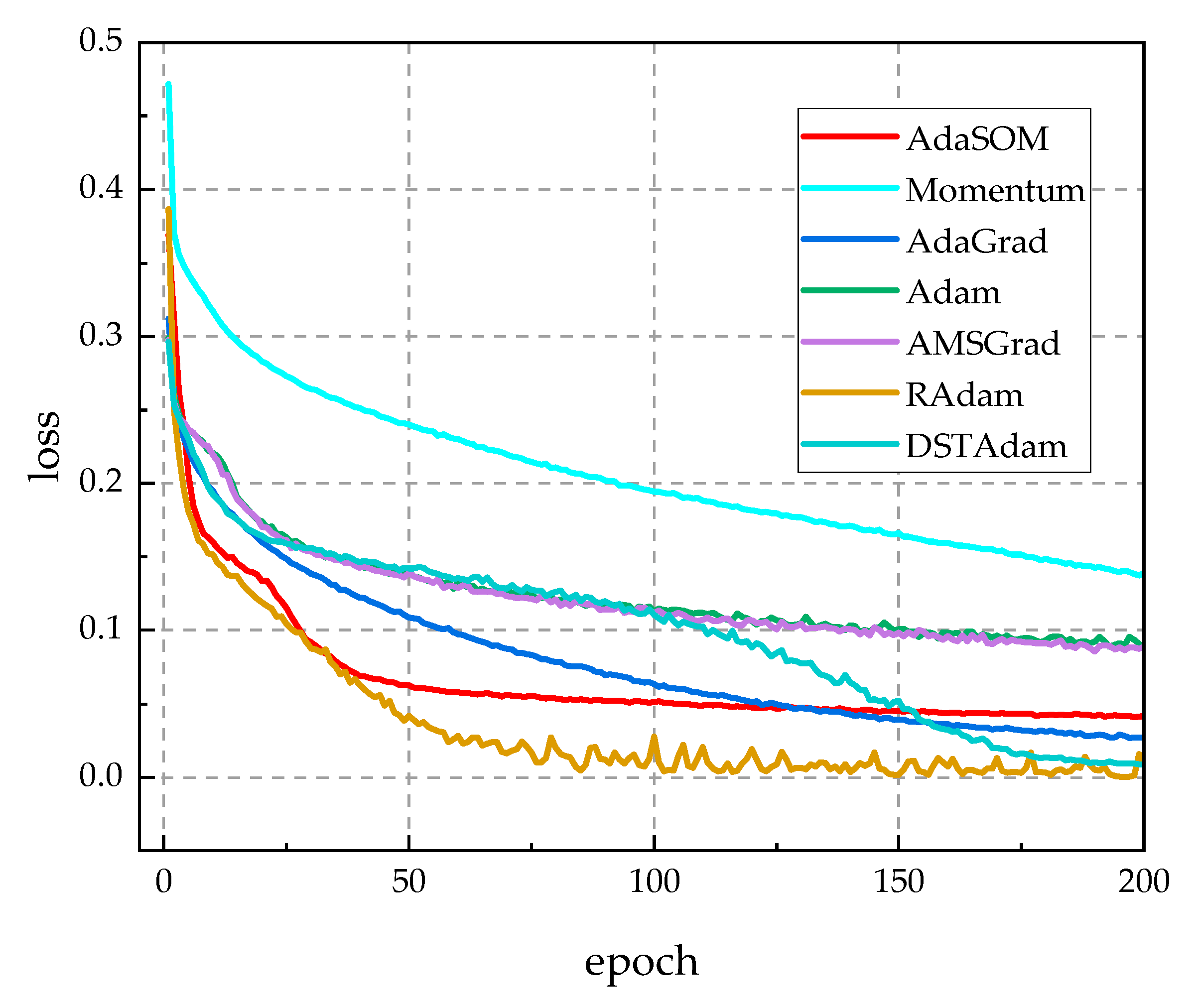
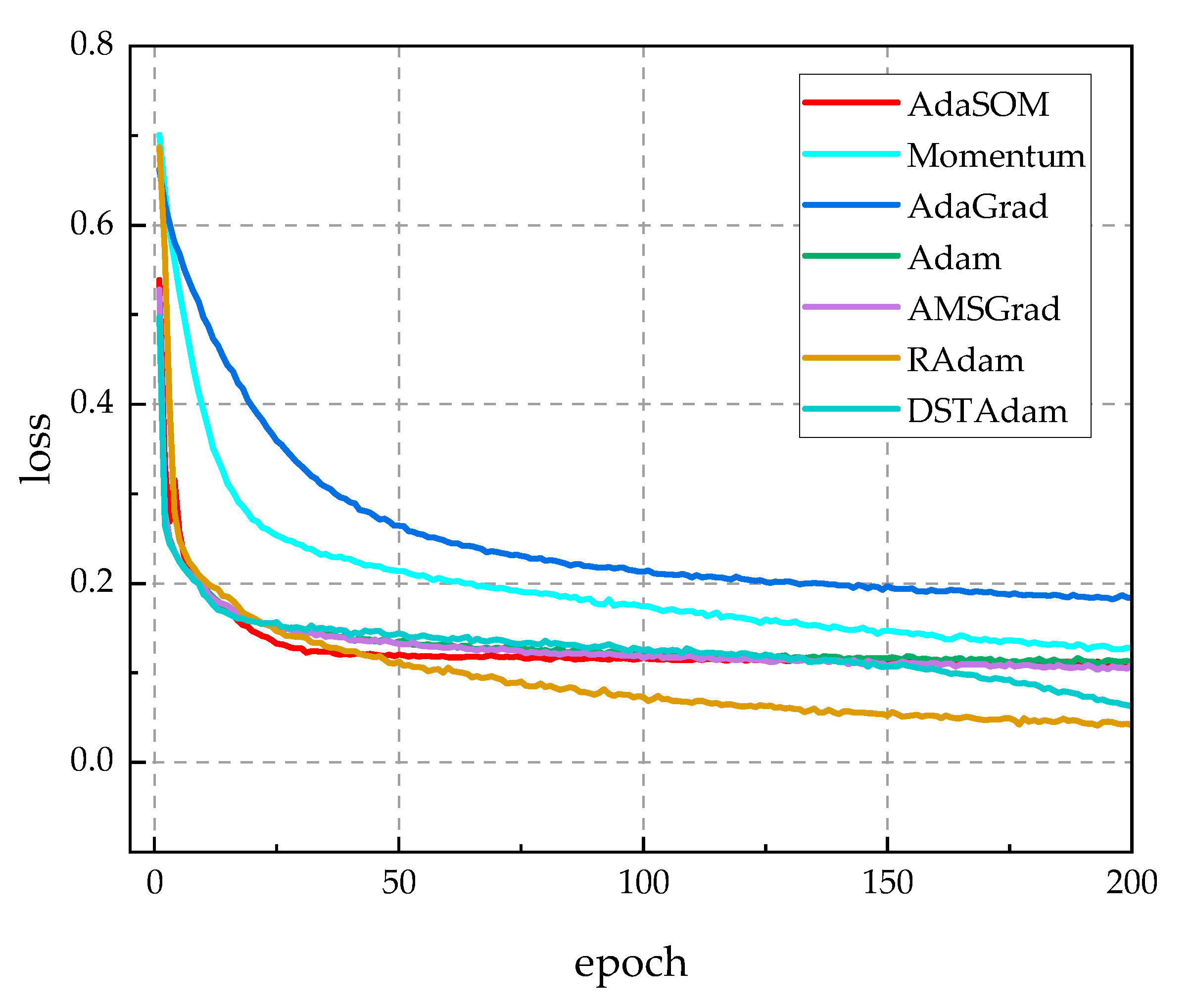
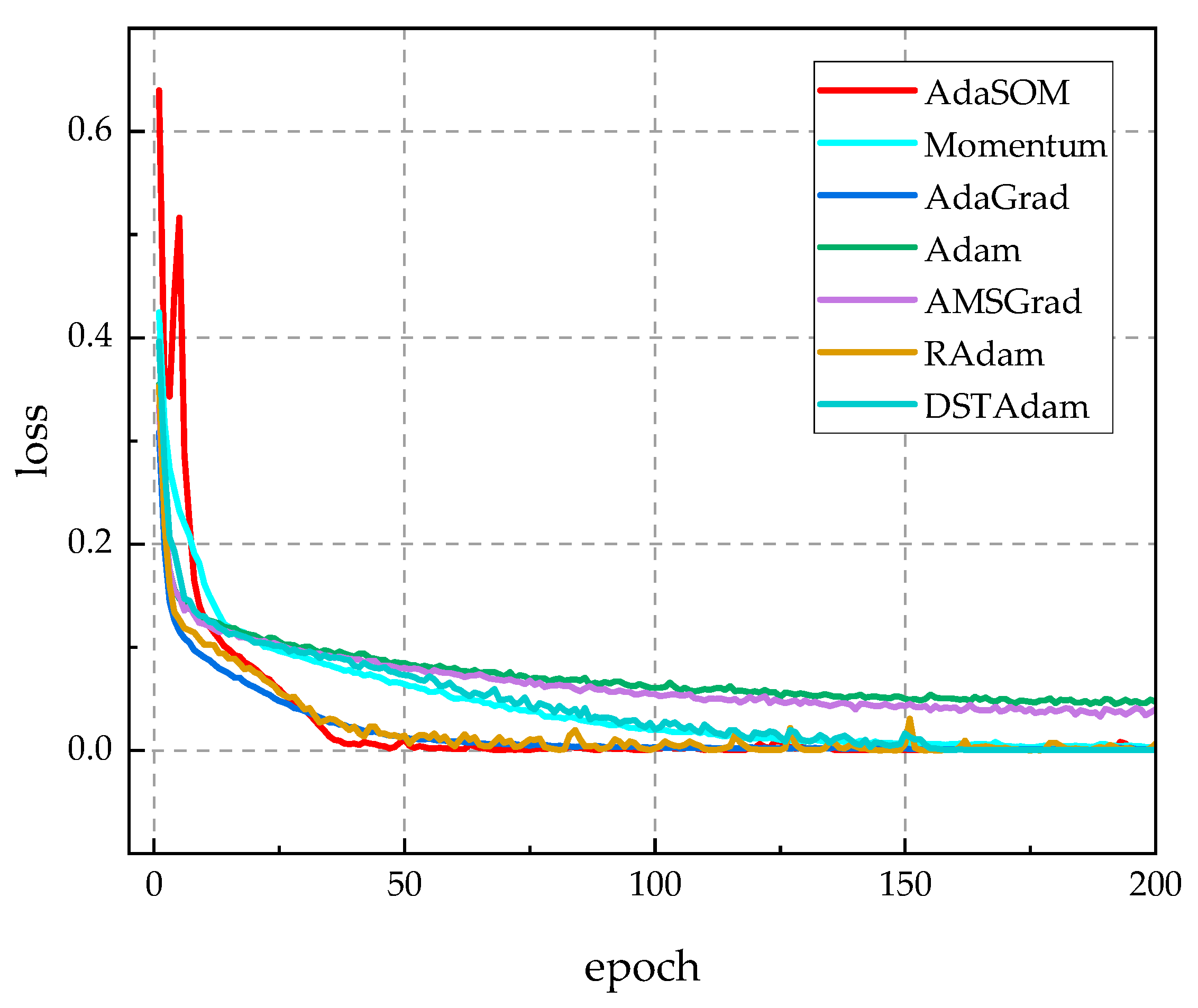
5.4.1. Experimental Results and Analysis
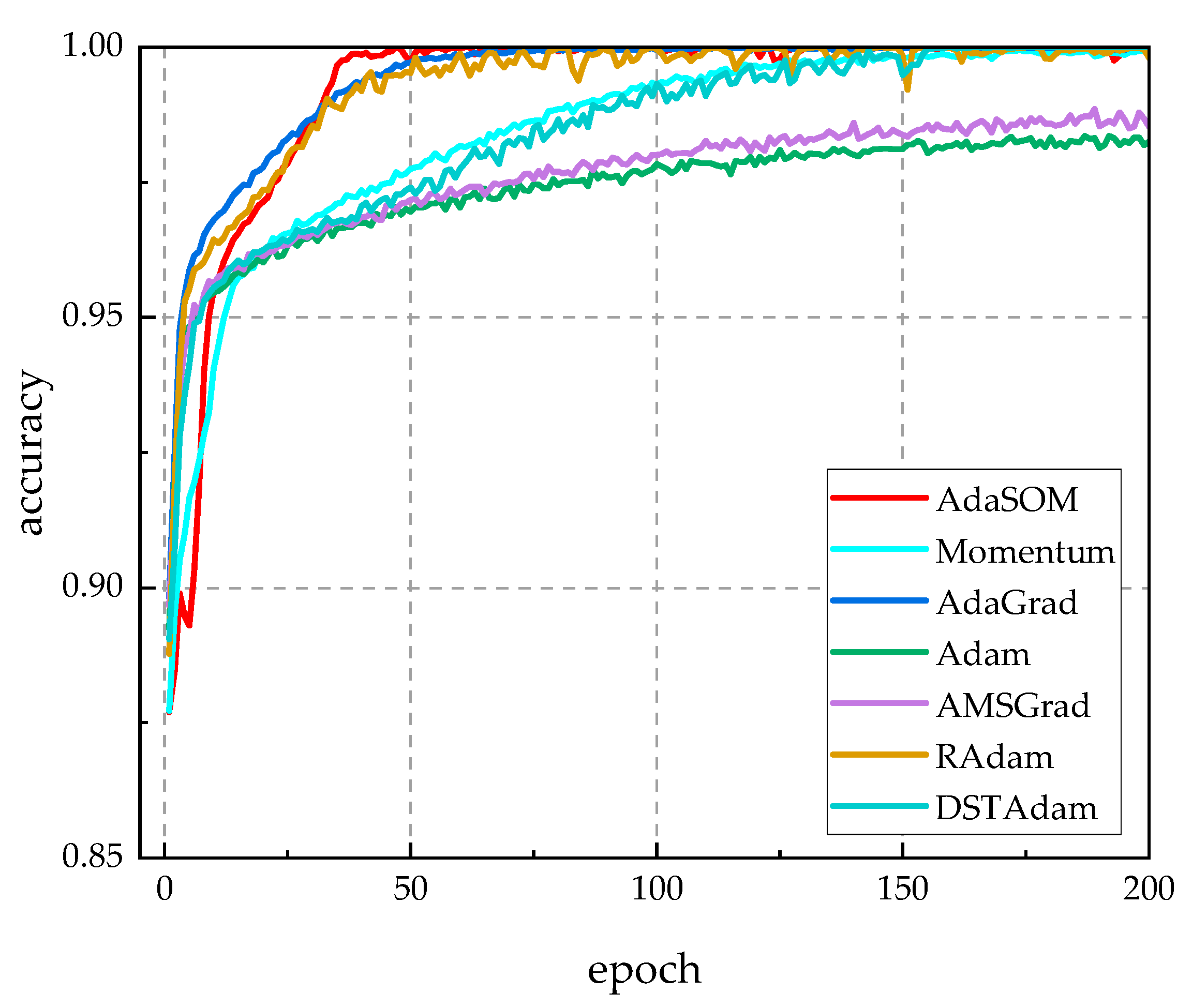
5.4.2. Comparison with Classical Training Algorithms
5.4.3. Comparison with State-of-the-Art Deep-Learning Models
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

References
- Zhang, Q.-x.; Liu, Z.-j.; Liu, X.-h.; Zhao, X.-h.; Li, X.-c. The Correlation between Epicardial Adipose Tissue Thickness Measured by Echocardiography and P-Wave Dispersion and Atrial Fibrillation. Rev. Cardiovasc. Med. 2024, 25, 287. [Google Scholar] [CrossRef] [PubMed]
- Nechita, L.C.; Nechita, A.; Voipan, A.E.; Voipan, D.; Debita, M.; Fulga, A.; Fulga, I.; Musat, C.L. AI-Enhanced ECG Applications in Cardiology: Comprehensive Insights from the Current Literature with a Focus on COVID-19 and Multiple Cardiovascular Conditions. Diagnostics 2024, 14, 1839. [Google Scholar] [CrossRef] [PubMed]
- Kalmady, S.V.; Salimi, A.; Sun, W.; Sepehrvand, N.; Nademi, Y.; Bainey, K.; Ezekowitz, J.; Hindle, A.; McAlister, F.; Greiner, R. Development and validation of machine learning algorithms based on electrocardiograms for cardiovascular diagnoses at the population level. npj Digit. Med. 2024, 7, 133. [Google Scholar] [CrossRef] [PubMed]
- Ameen, A.; Fattoh, I.E.; Abd El-Hafeez, T.; Ahmed, K. Advances in ECG and PCG-based cardiovascular disease classification: A review of deep learning and machine learning methods. J. Big Data 2024, 11, 159. [Google Scholar] [CrossRef]
- Padmavathi, S.; Ramanujam, E. Naïve Bayes classifier for ECG abnormalities using multivariate maximal time series motif. Procedia Comput. Sci. 2015, 47, 222–228. [Google Scholar] [CrossRef]
- Hamidi, A.A.; Robertson, B.; Ilow, J. A new approach for ECG artifact detection using fine-KNN classification and wavelet scattering features in vital health applications. Procedia Comput. Sci. 2023, 224, 60–67. [Google Scholar] [CrossRef]
- Hamza, S.; Ayed, Y.B. Svm for human identification using the ECG signal. Procedia Comput. Sci. 2020, 176, 430–439. [Google Scholar] [CrossRef]
- Ambrish, G.; Ganesh, B.; Ganesh, A.; Srinivas, C.; Mensinkal, K. Logistic regression technique for prediction of cardiovascular disease. Glob. Transit. Proc. 2022, 3, 127–130. [Google Scholar]
- Vimal, C.; Sathish, B. Random forest classifier based ECG arrhythmia classification. Int. J. Healthc. Inf. Syst. Inform. (IJHISI) 2010, 5, 1–10. [Google Scholar] [CrossRef]
- Xu, Y.; Zhang, S.; Cao, Z.; Chen, Q.; Xiao, W. Extreme Learning Machine for Heartbeat Classification with Hybrid Time-Domain and Wavelet Time-Frequency Features. J. Healthc. Eng. 2021, 2021, 6674695. [Google Scholar] [CrossRef]
- El-Khafif, S.H.; El-Brawany, M.A. Artificial Neural Network-Based Automated ECG Signal Classifier. Int. Sch. Res. Not. 2013, 2013, 261917. [Google Scholar] [CrossRef]
- Liu, L.-R.; Huang, M.-Y.; Huang, S.-T.; Kung, L.-C.; Lee, C.-h.; Yao, W.-T.; Tsai, M.-F.; Hsu, C.-H.; Chu, Y.-C.; Hung, F.-H. An Arrhythmia classification approach via deep learning using single-lead ECG without QRS wave detection. Heliyon 2024, 10, e27200. [Google Scholar] [CrossRef] [PubMed]
- Darmawahyuni, A.; Nurmaini, S.; Tutuko, B.; Rachmatullah, M.N.; Firdaus, F.; Sapitri, A.I.; Islami, A.; Marcelino, J.; Isdwanta, R.; Perwira, M.I. An improved electrocardiogram arrhythmia classification performance with feature optimization. BMC Med. Inform. Decis. Mak. 2024, 24, 412. [Google Scholar] [CrossRef]
- Toulni, Y.; Nsiri, B.; Drissi, T.B. ECG signal classification using DWT, MFCC and SVM classifier. Trait. Du Signal 2023, 40, 335. [Google Scholar] [CrossRef]
- Guo, Y.; Liu, Y.; Oerlemans, A.; Lao, S.; Wu, S.; Lew, M.S. Deep learning for visual understanding: A review. Neurocomputing 2016, 187, 27–48. [Google Scholar] [CrossRef]
- Liu, X.; Wang, H.; Li, Z.; Qin, L. Deep learning in ECG diagnosis: A review. Knowl.-Based Syst. 2021, 227, 107187. [Google Scholar] [CrossRef]
- Ahmed, A.A.; Ali, W.; Abdullah, T.A.; Malebary, S.J. Classifying cardiac arrhythmia from ECG signal using 1D CNN deep learning model. Mathematics 2023, 11, 562. [Google Scholar] [CrossRef]
- Hou, B.; Yang, J.; Wang, P.; Yan, R. LSTM-based auto-encoder model for ECG arrhythmias classification. IEEE Trans. Instrum. Meas. 2019, 69, 1232–1240. [Google Scholar] [CrossRef]
- Jahmunah, V.; Ng, E.Y.; Tan, R.-S.; Oh, S.L.; Acharya, U.R. Explainable detection of myocardial infarction using deep learning models with Grad-CAM technique on ECG signals. Comput. Biol. Med. 2022, 146, 105550. [Google Scholar] [CrossRef]
- Strodthoff, N.; Wagner, P.; Schaeffter, T.; Samek, W. Deep learning for ECG analysis: Benchmarks and insights from PTB-XL. IEEE J. Biomed. Health Inform. 2020, 25, 1519–1528. [Google Scholar] [CrossRef]
- Hempel, P.; Ribeiro, A.H.; Vollmer, M.; Bender, T.; Dörr, M.; Krefting, D.; Spicher, N. Explainable AI associates ECG aging effects with increased cardiovascular risk in a longitudinal population study. npj Digit. Med. 2025, 8, 25. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Sutskever, I.; Martens, J.; Dahl, G.; Hinton, G. On the importance of initialization and momentum in deep learning. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; Sanjoy, D., David, M., Eds.; PMLR (Proceedings of Machine Learning Research): New York, NY, USA, 2013; Volume 28, pp. 1139–1147. [Google Scholar]
- Gitman, I.; Lang, H.; Zhang, P.; Xiao, L. Understanding the role of momentum in stochastic gradient methods. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Burdakov, O.; Dai, Y.; Huang, N. Stabilized barzilai-borwein method. J. Comput. Math. 2019, 37, 916–936. [Google Scholar] [CrossRef]
- Castera, C.; Bolte, J.; Févotte, C.; Pauwels, E. Second-order step-size tuning of SGD for non-convex optimization. Neural Process. Lett. 2022, 54, 1727–1752. [Google Scholar] [CrossRef]
- Liu, F.; Liu, C.; Zhao, L.; Zhang, X.; Wu, X.; Xu, X.; Liu, Y.; Ma, C.; Wei, S.; He, Z. An open access database for evaluating the algorithms of electrocardiogram rhythm and morphology abnormality detection. J. Med. Imaging Health Inform. 2018, 8, 1368–1373. [Google Scholar] [CrossRef]
- Zhang, D.; Yang, S.; Yuan, X.; Zhang, P. Interpretable deep learning for automatic diagnosis of 12-lead electrocardiogram. iScience 2021, 24, 102373. [Google Scholar] [CrossRef]
- Ribeiro, A.H.; Ribeiro, M.H.; Paixão, G.M.; Oliveira, D.M.; Gomes, P.R.; Canazart, J.A.; Ferreira, M.P.; Andersson, C.R.; Macfarlane, P.W.; Meira, W., Jr. Automatic diagnosis of the 12-lead ECG using a deep neural network. Nat. Commun. 2020, 11, 1760. [Google Scholar] [CrossRef]
- Jothiaruna, N. SSDMNV2-FPN: A cardiac disorder classification from 12 lead ECG images using deep neural network. Microprocess. Microsyst. 2022, 93, 104627. [Google Scholar]
- Yao, Q.; Wang, R.; Fan, X.; Liu, J.; Li, Y. Multi-class arrhythmia detection from 12-lead varied-length ECG using attention-based time-incremental convolutional neural network. Inf. Fusion 2020, 53, 174–182. [Google Scholar] [CrossRef]
- Baloglu, U.B.; Talo, M.; Yildirim, O.; San Tan, R.; Acharya, U.R. Classification of myocardial infarction with multi-lead ECG signals and deep CNN. Pattern Recognit. Lett. 2019, 122, 23–30. [Google Scholar] [CrossRef]
- Duchi, J.; Hazan, E.; Singer, Y. Adaptive subgradient methods for online learning and stochastic optimization. J. Mach. Learn. Res. 2011, 12, 2121–2159. [Google Scholar]
- Reddi, S.J.; Kale, S.; Kumar, S. On the convergence of adam and beyond. arXiv 2019, arXiv:1904.09237. [Google Scholar]
- Liu, L.; Jiang, H.; He, P.; Chen, W.; Liu, X.; Gao, J.; Han, J. On the variance of the adaptive learning rate and beyond. arXiv 2019, arXiv:1908.03265. [Google Scholar]
- Zeng, K.; Liu, J.; Jiang, Z.; Xu, D. A decreasing scaling transition scheme from Adam to SGD. Adv. Theory Simul. 2022, 5, 2100599. [Google Scholar] [CrossRef]
- Qiu, L.; Cai, W.; Zhang, M.; Zhu, W.; Wang, L. Two-stage ECG signal denoising based on deep convolutional network. Physiol. Meas. 2021, 42, 115002. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Geng, Q.; Liu, H.; Gao, T.; Liu, R.; Chen, C.; Zhu, Q.; Shu, M. An ECG Classification Method Based on Multi-Task Learning and CoT Attention Mechanism. Healthcare 2023, 11, 1000. [Google Scholar] [CrossRef]
- Le, K.H.; Pham, H.H.; Nguyen, T.B.; Nguyen, T.A.; Thanh, T.N.; Do, C.D. Lightx3ecg: A lightweight and explainable deep learning system for 3-lead electrocardiogram classification. Biomed. Signal Process. Control 2023, 85, 104963. [Google Scholar] [CrossRef]
- Cheng, Y.; Zhu, W.; Li, D.; Wang, L. Multi-label classification of arrhythmia using dynamic graph convolutional network based on encoder-decoder framework. Biomed. Signal Process. Control 2024, 95, 106348. [Google Scholar] [CrossRef]
- Yang, Z.; Jin, A.; Li, Y.; Yu, X.; Xu, X.; Wang, J.; Li, Q.; Guo, X.; Liu, Y. A coordinated adaptive multiscale enhanced spatio-temporal fusion network for multi-lead electrocardiogram arrhythmia detection. Sci. Rep. 2024, 14, 20828. [Google Scholar] [CrossRef] [PubMed]
- Cheng, Y.; Li, D.; Wang, D.; Chen, Y.; Wang, L. Multi-label arrhythmia classification using 12-lead ECG based on lead feature guide network. Eng. Appl. Artif. Intell. 2024, 129, 107599. [Google Scholar] [CrossRef]
- Chen, T.-M.; Huang, C.-H.; Shih, E.S.; Hu, Y.-F.; Hwang, M.-J. Detection and classification of cardiac arrhythmias by a challenge-best deep learning neural network model. iScience 2020, 23, 100886. [Google Scholar] [CrossRef]
- Wang, X.; Wang, N.; Liu, D.; Wu, J.; Lu, P. Bean: A Multibranch Network for 12 Leads Electrocardiogram Multilabel Classification Based on Ensemble Learning and Attention. IEEE Trans. Instrum. Meas. 2025, 74, 4005313. [Google Scholar] [CrossRef]
- Wang, Z.; Yan, W.; Oates, T. Time Series Classification from Scratch with Deep Neural Networks: A Strong Baseline. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 1578–1585. [Google Scholar]
- He, T.; Zhang, Z.; Zhang, H.; Zhang, Z.; Xie, J.; Li, M. Bag of Tricks for Image Classification with Convolutional Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 558–567. [Google Scholar]
- Ge, Y.; Zhang, H.; Shi, J.; Luo, D.; Chang, S.; He, J.; Huang, Q.; Wang, H. JAMC: A jigsaw-based autoencoder with masked contrastive learning for cardiovascular disease diagnosis. Knowl.-Based Syst. 2025, 311, 113090. [Google Scholar] [CrossRef]
- Liu, C.; Cheng, S.; Ding, W.; Arcucci, R. Spectral cross-domain neural network with soft-adaptive threshold spectral enhancement. IEEE Trans. Neural Netw. Learn. Syst. 2023, 36, 692–703. [Google Scholar] [CrossRef]
- Zhou, S.; Huang, X.; Liu, N.; Zhang, W.; Zhang, Y.-T.; Chung, F.-L. Open-world electrocardiogram classification via domain knowledge-driven contrastive learning. Neural Netw. 2024, 179, 106551. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | # Recording | Time Length (s) | ||||
|---|---|---|---|---|---|---|
| Mean | SD | Min | Median | Max | ||
| Normal | 918 | 15.43 | 7.61 | 10.00 | 13.00 | 60.00 |
| AF | 1098 | 15.01 | 8.39 | 9.00 | 11.00 | 60.00 |
| IAVB | 704 | 14.32 | 7.21 | 10.00 | 11.27 | 60.00 |
| LBBB | 207 | 14.92 | 8.09 | 9.00 | 12.00 | 60.00 |
| RBBB | 1695 | 14.42 | 7.60 | 10.00 | 11.19 | 60.00 |
| PAC | 556 | 19.46 | 12.36 | 9.00 | 14.00 | 60.00 |
| PVC | 672 | 20.21 | 12.85 | 6.00 | 15.00 | 60.00 |
| STD | 825 | 15.13 | 6.82 | 8.00 | 12.78 | 60.00 |
| STE | 202 | 17.15 | 10.72 | 10.00 | 11.89 | 60.00 |
| Category | Acc | P | R | F1 | AUC |
|---|---|---|---|---|---|
| Normal | 0.9631 ± 0.0125 | 0.8859 ± 0.0115 | 0.8194 ± 0.0106 | 0.8512 ± 0.0110 | 0.9801 ± 0.0127 |
| AF | 0.9821 ± 0.0222 | 0.9612 ± 0.0217 | 0.9303 ± 0.021 | 0.9453 ± 0.0214 | 0.9917 ± 0.0224 |
| IAVB | 0.9791 ± 0.0170 | 0.8705 ± 0.0151 | 0.9192 ± 0.016 | 0.8942 ± 0.0156 | 0.9894 ± 0.0172 |
| LBBB | 0.9969 ± 0.0168 | 0.9071 ± 0.0147 | 0.9071 ± 0.0153 | 0.9072 ± 0.0144 | 0.9962 ± 0.0168 |
| RBBB | 0.9749 ± 0.0182 | 0.9548 ± 0.0178 | 0.9498 ± 0.0177 | 0.9523 ± 0.0178 | 0.9932 ± 0.0185 |
| PAC | 0.9632 ± 0.0184 | 0.8389 ± 0.0160 | 0.6849 ± 0.0131 | 0.7543 ± 0.0144 | 0.9288 ± 0.0178 |
| PVC | 0.9778 ± 0.0201 | 0.8534 ± 0.0175 | 0.8021 ± 0.0164 | 0.8269 ± 0.0170 | 0.9424 ± 0.0193 |
| STD | 0.9616 ± 0.0142 | 0.8709 ± 0.0128 | 0.8537 ± 0.0126 | 0.8622 ± 0.0127 | 0.9569 ± 0.0141 |
| STE | 0.9925 ± 0.0169 | 0.7877 ± 0.0134 | 0.7351 ± 0.0125 | 0.7604 ± 0.013 | 0.9891 ± 0.0169 |
| Average | 0.9768 ± 0.0173 | 0.8812 ± 0.0156 | 0.8446 ± 0.0150 | 0.8616 ± 0.0152 | 0.9742 ± 0.0173 |
| (a) | ||||||
| Category | F1 | |||||
| I | II | III | aVR | aVL | ||
| Normal | 0.6939 ± 0.0083 | 0.7582 ± 0.0088 | 0.6131 ± 0.0075 | 0.7723 ± 0.0091 | 0.6184 ± 0.0076 | |
| AF | 0.9432 ± 0.0113 | 0.9473 ± 0.0109 | 0.9302 ± 0.0113 | 0.9481 ± 0.0112 | 0.9011 ± 0.0111 | |
| IAVB | 0.8697 ± 0.0104 | 0.8947 ± 0.0103 | 0.8609 ± 0.0105 | 0.8901 ± 0.0105 | 0.8854 ± 0.0109 | |
| LBBB | 0.8996 ± 0.0108 | 0.8497 ± 0.0098 | 0.8631 ± 0.0105 | 0.9044 ± 0.0107 | 0.9496 ± 0.0117 | |
| RBBB | 0.8584 ± 0.0103 | 0.8592 ± 0.0099 | 0.7985 ± 0.0097 | 0.8958 ± 0.0106 | 0.8478 ± 0.0104 | |
| PAC | 0.6988 ± 0.0084 | 0.7496 ± 0.0087 | 0.7128 ± 0.0087 | 0.6904 ± 0.0081 | 0.7381 ± 0.0091 | |
| PVC | 0.7774 ± 0.0093 | 0.8482 ± 0.0098 | 0.8298 ± 0.0101 | 0.8159 ± 0.0096 | 0.7918 ± 0.0098 | |
| STD | 0.7606 ± 0.0091 | 0.7996 ± 0.0092 | 0.7242 ± 0.0088 | 0.8354 ± 0.0099 | 0.6369 ± 0.0078 | |
| STE | 0.5329 ± 0.0064 | 0.4996 ± 0.0058 | 0.4135 ± 0.005 | 0.5259 ± 0.0062 | 0.4098 ± 0.0051 | |
| Average | 0.7816 ± 0.0094 | 0.8006 ± 0.0092 | 0.7496 ± 0.0091 | 0.8087 ± 0.0095 | 0.7532 ± 0.0093 | |
| (b) | ||||||
| Category | F1 | |||||
| aVF | V1 | V2 | V3 | V4 | ||
| Normal | 0.6662 ± 0.0083 | 0.6556 ± 0.0088 | 0.6897 ± 0.0075 | 0.7001 ± 0.0091 | 0.7014 ± 0.0076 | |
| AF | 0.9524 ± 0.0113 | 0.9357 ± 0.0109 | 0.9307 ± 0.0113 | 0.9367 ± 0.0112 | 0.9482 ± 0.0111 | |
| IAVB | 0.8871 ± 0.0104 | 0.9163 ± 0.0103 | 0.9112 ± 0.0105 | 0.9086 ± 0.0105 | 0.8868 ± 0.0109 | |
| LBBB | 0.8996 ± 0.0108 | 0.9541 ± 0.0098 | 0.9328 ± 0.0105 | 0.8997 ± 0.0107 | 0.8884 ± 0.0117 | |
| RBBB | 0.8082 ± 0.0103 | 0.9351 ± 0.0099 | 0.8974 ± 0.0097 | 0.8535 ± 0.0106 | 0.8411 ± 0.0104 | |
| PAC | 0.7495 ± 0.0084 | 0.7254 ± 0.0087 | 0.7458 ± 0.0087 | 0.7128 ± 0.0081 | 0.7252 ± 0.0091 | |
| PVC | 0.8347 ± 0.0093 | 0.8078 ± 0.0098 | 0.8451 ± 0.0101 | 0.8205 ± 0.0096 | 0.8279 ± 0.0098 | |
| STD | 0.7853 ± 0.0091 | 0.6303 ± 0.0092 | 0.7196 ± 0.0088 | 0.7225 ± 0.0099 | 0.7138 ± 0.0078 | |
| STE | 0.4663 ± 0.0064 | 0.3806 ± 0.0058 | 0.5362 ± 0.005 | 0.7328 ± 0.0062 | 0.6427 ± 0.0051 | |
| Average | 0.7632 ± 0.0093 | 0.7712 ± 0.0092 | 0.8009 ± 0.0096 | 0.8097 ± 0.0095 | 0.7973 ± 0.0093 | |
| (c) | ||||||
| Category | F1 | |||||
| V5 | V6 | 12-lead | ||||
| Normal | 0.7198 ± 0.0081 | 0.7422 ± 0.0088 | 0.8512 ± 0.0110 | |||
| AF | 0.9325 ± 0.0105 | 0.9561 ± 0.0113 | 0.9453 ± 0.0214 | |||
| IAVB | 0.8687 ± 0.0098 | 0.8607 ± 0.0102 | 0.8942 ± 0.0156 | |||
| LBBB | 0.9521 ± 0.0107 | 0.8778 ± 0.0104 | 0.9072 ± 0.0144 | |||
| RBBB | 0.8535 ± 0.0096 | 0.8511 ± 0.0101 | 0.9523 ± 0.0178 | |||
| PAC | 0.7149 ± 0.0081 | 0.6771 ± 0.008 | 0.7543 ± 0.0144 | |||
| PVC | 0.8259 ± 0.0093 | 0.8328 ± 0.0099 | 0.8269 ± 0.0170 | |||
| STD | 0.7851 ± 0.0088 | 0.7941 ± 0.0094 | 0.8622 ± 0.0127 | |||
| STE | 0.6152 ± 0.0069 | 0.6086 ± 0.0072 | 0.7604 ± 0.013 | |||
| Average | 0.8075 ± 0.0091 | 0.8001 ± 0.0095 | 0.8616 ± 0.0152 | |||
| Algorithm | Acc | P | R | F1 | AUC |
|---|---|---|---|---|---|
| Momentum [23] | 0.9608 ± 0.0126 | 0.8302 ± 0.0108 | 0.8641 ± 0.0112 | 0.8452 ± 0.0110 | 0.9673 ± 0.0125 |
| AdaGrad [35] | 0.9689 ± 0.0127 | 0.8459 ± 0.0111 | 0.8381 ± 0.0113 | 0.8381 ± 0.0112 | 0.9688 ± 0.0127 |
| Adam [25] | 0.9691 ± 0.0118 | 0.8612 ± 0.0105 | 0.8389 ± 0.0102 | 0.8469 ± 0.0103 | 0.9702 ± 0.0118 |
| AMSGrad [34] | 0.9682 ± 0.0105 | 0.8392 ± 0.0091 | 0.8482 ± 0.0092 | 0.8419 ± 0.0091 | 0.9706 ± 0.0105 |
| Radam [36] | 0.9703 ± 0.0101 | 0.8446 ± 0.0088 | 0.8491 ± 0.0088 | 0.8411 ± 0.0087 | 0.9685 ± 0.0100 |
| DSTAdam [37] | 0.9712 ± 0.0105 | 0.8437 ± 0.0091 | 0.8533 ± 0.0092 | 0.8475 ± 0.0092 | 0.9693 ± 0.0105 |
| AdaSOM (Ours) | 0.9768 ± 0.0173 | 0.8812 ± 0.0156 | 0.8446 ± 0.0150 | 0.8616 ± 0.0152 | 0.9742 ± 0.0173 |
| Deep Model | Acc | P | R | AUC | F1 |
|---|---|---|---|---|---|
| MTNN [42] | 0.966 | 0.852 | 0.808 | 0.977 | 0.827 |
| lightX3ECG [43] | 0.963 | 0.821 | 0.786 | — | 0.800 |
| ED-DGCN [44] | — | 0.849 | 0.841 | — | 0.843 |
| STFAC-Net [45] | 0.894 | 0.778 | 0.756 | 0.933 | 0.767 |
| LFG-Net [46] | — | 0.853 | 0.838 | — | 0.842 |
| No. CPSC0236 [47] | 0.970 | — | — | 0.911 | 0.840 |
| Bean [48] | — | 0.706 | 0.715 | 0.928 | 0.711 |
| resnet_wang [48] | — | 0.692 | 0.700 | 0.924 | 0.689 |
| Xresnet1d101 [48] | — | 0.690 | 0.697 | 0.924 | 0.671 |
| JAMC [51] | 0.706 | — | — | 0.915 | 0.666 |
| SCDNN [52] | 0.859 | 0.838 | 0.781 | — | 0.782 |
| Inception-CL [53] | — | — | — | — | 0.710 |
| AlexNet-AdaSOM | 0.963 | 0.811 | 0.813 | 0.969 | 0.811 |
| Inception-AdaSOM | 0.962 | 0.787 | 0.784 | 0.970 | 0.781 |
| VGG11-AdaSOM | 0.949 | 0.729 | 0.793 | 0.963 | 0.756 |
| 1D-ResNet34-AdaSOM | 0.977 | 0.881 | 0.845 | 0.974 | 0.862 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, G.; Zou, S.; Qin, H.; Cao, Y.; Zhang, Z.; Deng, X. Robust 12-Lead ECG Classification with Lightweight ResNet: An Adaptive Second-Order Learning Rate Optimization Approach. Electronics 2025, 14, 1941. https://doi.org/10.3390/electronics14101941
Yang G, Zou S, Qin H, Cao Y, Zhang Z, Deng X. Robust 12-Lead ECG Classification with Lightweight ResNet: An Adaptive Second-Order Learning Rate Optimization Approach. Electronics. 2025; 14(10):1941. https://doi.org/10.3390/electronics14101941
Chicago/Turabian StyleYang, Guolin, Shiyun Zou, Hua Qin, Yuyi Cao, Zihan Zhang, and Xiangyuan Deng. 2025. "Robust 12-Lead ECG Classification with Lightweight ResNet: An Adaptive Second-Order Learning Rate Optimization Approach" Electronics 14, no. 10: 1941. https://doi.org/10.3390/electronics14101941
APA StyleYang, G., Zou, S., Qin, H., Cao, Y., Zhang, Z., & Deng, X. (2025). Robust 12-Lead ECG Classification with Lightweight ResNet: An Adaptive Second-Order Learning Rate Optimization Approach. Electronics, 14(10), 1941. https://doi.org/10.3390/electronics14101941