Generating Artistic Portraits from Face Photos with Feature Disentanglement and Reconstruction



Abstract
1. Introduction
- We propose a novel method for generating artistic portraits from face photos with feature disentanglement and reconstruction.
- We used the wavelet transform to perform feature disentanglement and reconstruction from an information perspective.
- We designed a fusion module to combine features from different modalities (wavelet coefficients and original images).
- We conducted extensive experiments on the APDrawing dataset and show that our method outperforms existing methods in various aspects.
2. Related Work
2.1. GAN-Based Image Synthesis
2.2. Image Style Transfer
2.3. Non-Photorealistic Rendering of Portraits
2.4. Recent Advancements in Image Synthesis
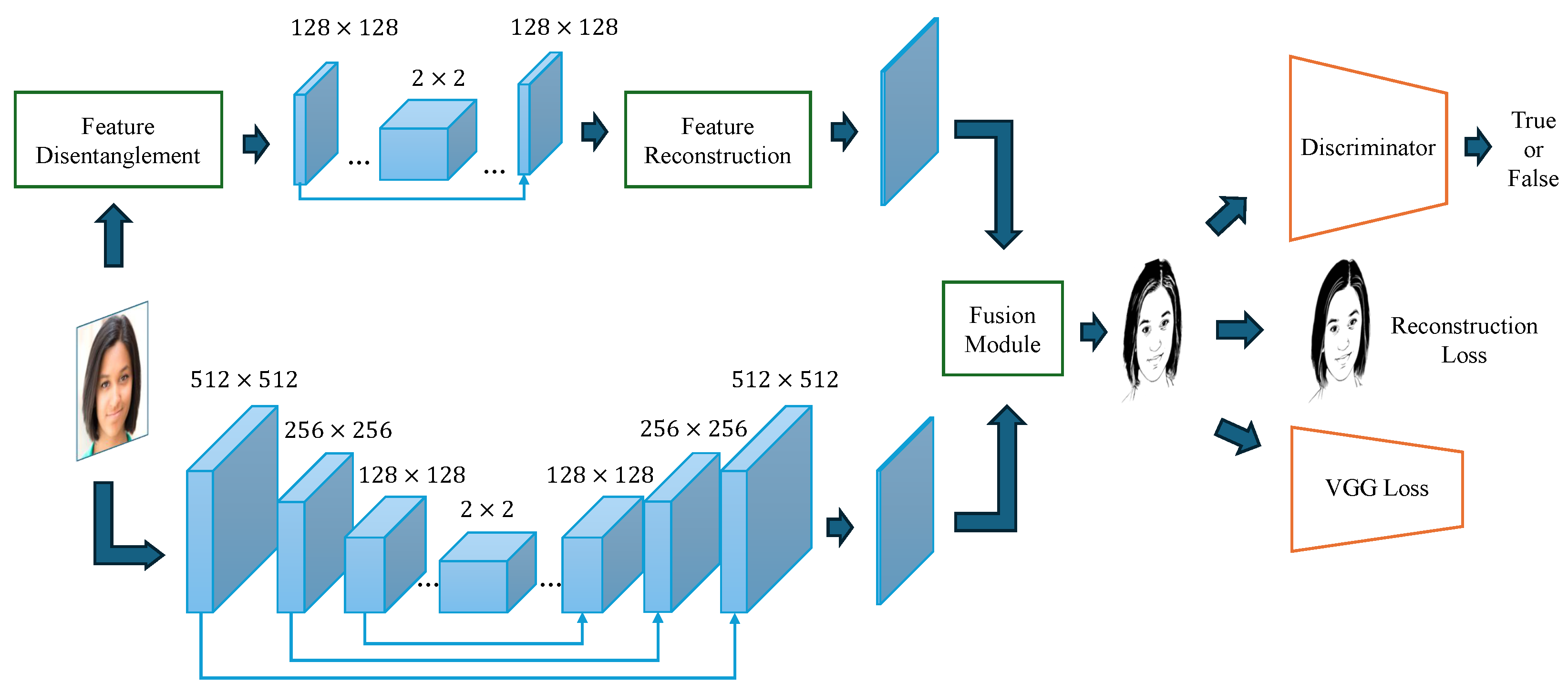
3. Method
3.1. U-Net-Based Image Generator
3.2. Feature-Disentanglement Module
3.3. U-Net-Based Information Generator
3.4. Feature-Reconstruction Module
3.5. Cross-Modal Fusion Module
3.6. Image Discriminator
3.7. Loss Function
4. Experiments
4.1. Dataset
4.2. Implementation Details
4.3. Comparison with State-of-the-Art
4.4. Ablation Study
4.5. Case Study
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yi, R.; Liu, Y.; Lai, Y.; Rosin, P.L. APDrawingGAN: Generating Artistic Portrait Drawings From Face Photos with Hierarchical GANs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, 16–20 June 2019; pp. 10743–10752. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.C.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.P.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 105–114. [Google Scholar] [CrossRef]
- Yu, J.; Lin, Z.; Yang, J.; Shen, X.; Lu, X.; Huang, T.S. Generative Image Inpainting with Contextual Attention. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5505–5514. [Google Scholar] [CrossRef]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. Image Style Transfer Using Convolutional Neural Networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 2414–2423. [Google Scholar] [CrossRef]
- Karras, T.; Laine, S.; Aila, T. A Style-Based Generator Architecture for Generative Adversarial Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 4217–4228. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Liu, M.; Li, X.; Yang, M.; Kautz, J. A Closed-form Solution to Photorealistic Image Stylization. arXiv 2018, arXiv:1802.06474. [Google Scholar]
- Zhu, J.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision, ICCV 2017, Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar] [CrossRef]
- Chen, D.; Yuan, L.; Liao, J.; Yu, N.; Hua, G. StyleBank: An Explicit Representation for Neural Image Style Transfer. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 2770–2779. [Google Scholar] [CrossRef]
- Ronneberger, O. Invited Talk: U-Net Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Bildverarbeitung für die Medizin 2017—Algorithmen—Systeme—Anwendungen. Proceedings des Workshops vom 12. bis 14. März 2017 in Heidelberg; Maier-Hein, K.H., Deserno, T.M., Handels, H., Tolxdorff, T., Eds.; Informatik Aktuell; Springer: Berlin/Heidelberg, Germany, 2017; p. 3. [Google Scholar] [CrossRef]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. In Proceedings of the 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Kurach, K.; Lucic, M.; Zhai, X.; Michalski, M.; Gelly, S. A Large-Scale Study on Regularization and Normalization in GANs. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 3581–3590. [Google Scholar]
- Zhang, H.; Goodfellow, I.J.; Metaxas, D.N.; Odena, A. Self-Attention Generative Adversarial Networks. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 7354–7363. [Google Scholar]
- Zhou, Y.; Long, G. Improving Cross-modal Alignment for Text-Guided Image Inpainting. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, EACL 2023, Dubrovnik, Croatia, 2–6 May 2023; pp. 3437–3448. [Google Scholar]
- Zhou, Y.; Tao, W.; Zhang, W. Triple Sequence Generative Adversarial Nets for Unsupervised Image Captioning. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2021, Toronto, ON, Canada, 6–11 June 2021; pp. 7598–7602. [Google Scholar] [CrossRef]
- Zhuang, P.; Koyejo, O.; Schwing, A.G. Enjoy Your Editing: Controllable GANs for Image Editing via Latent Space Navigation. In Proceedings of the 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- Zhou, Y.; Geng, X.; Shen, T.; Zhang, W.; Jiang, D. Improving Zero-Shot Cross-lingual Transfer for Multilingual Question Answering over Knowledge Graph. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2021, Online, 6–11 June 2021; pp. 5822–5834. [Google Scholar] [CrossRef]
- Brock, A.; Donahue, J.; Simonyan, K. Large Scale GAN Training for High Fidelity Natural Image Synthesis. In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Shang, Q.; Hu, L.; Li, Q.; Long, W.; Jiang, L. A Survey of Research on Image Style Transfer Based on Deep Learning. In Proceedings of the 3rd International Conference on Artificial Intelligence and Advanced Manufacture, AIAM 2021, Manchester, UK, 23–25 October 2021; pp. 386–391. [Google Scholar] [CrossRef]
- Liu, B.; Zhu, Y.; Song, K.; Elgammal, A. Towards Faster and Stabilized GAN Training for High-fidelity Few-shot Image Synthesis. In Proceedings of the 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and Improving the Image Quality of StyleGAN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, 13–19 June 2020; pp. 8107–8116. [Google Scholar] [CrossRef]
- Zhu, J.; Zhao, D.; Zhang, B.; Zhou, B. Disentangled Inference for GANs with Latently Invertible Autoencoder. Int. J. Comput. Vis. 2022, 130, 1259–1276. [Google Scholar] [CrossRef]
- Kumar, M.P.P.; Poornima, B.; Nagendraswamy, H.S.; Manjunath, C. A comprehensive survey on non-photorealistic rendering and benchmark developments for image abstraction and stylization. Iran J. Comput. Sci. 2019, 2, 131–165. [Google Scholar] [CrossRef]
- Zhou, Y.; Shi, B.E. Photorealistic facial expression synthesis by the conditional difference adversarial autoencoder. In Proceedings of the Seventh International Conference on Affective Computing and Intelligent Interaction, ACII 2017, San Antonio, TX, USA, 23–26 October 2017; pp. 370–376. [Google Scholar] [CrossRef]
- Li, Y.; Fang, C.; Yang, J.; Wang, Z.; Lu, X.; Yang, M. Diversified Texture Synthesis with Feed-Forward Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 266–274. [Google Scholar] [CrossRef]
- Chen, J.; Liu, G.; Chen, X. AnimeGAN: A Novel Lightweight GAN for Photo Animation. In Proceedings of the Artificial Intelligence Algorithms and Applications—11th International Symposium, ISICA 2019, Guangzhou, China, 16–17 November 2019; Volume 1205, pp. 242–256. [Google Scholar] [CrossRef]
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. Lora: Low-rank adaptation of large language models. arXiv 2021, arXiv:2106.09685. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 6626–6637. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019; pp. 8024–8035. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Miyato, T.; Kataoka, T.; Koyama, M.; Yoshida, Y. Spectral Normalization for Generative Adversarial Networks. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Wei, X.; Gong, B.; Liu, Z.; Lu, W.; Wang, L. Improving the Improved Training of Wasserstein GANs: A Consistency Term and Its Dual Effect. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Isola, P.; Zhu, J.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar] [CrossRef]
- Yi, R.; Xia, M.; Liu, Y.J.; Lai, Y.K.; Rosin, P.L. Line drawings for face portraits from photos using global and local structure based GANs. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3462–3475. [Google Scholar] [CrossRef] [PubMed]
- Richardson, E.; Alaluf, Y.; Patashnik, O.; Nitzan, Y.; Azar, Y.; Shapiro, S.; Cohen-Or, D. Encoding in style: A stylegan encoder for image-to-image translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2287–2296. [Google Scholar]


{kind=link}
{kind=link}
| Methods | FID | SSIM | IS |
|---|---|---|---|
| CycleGAN | 87.82 | 0.70 | 15 |
| Pix2Pix | 75.30 | 0.72 | 16 |
| APDrawingGAN | 62.14 | 0.78 | 22 |
| StyleGAN-based method | 61.89 | 0.80 | 24 |
| APDrawingGAN++ | 61.56 | 0.82 | 25 |
| Ours | 61.23 | 0.85 | 27 |
| Real (training vs. test) | 49.72 | / | / |
| Methods | FID |
|---|---|
| CycleGAN | 90.87 |
| Pix2Pix | 88.63 |
| APDrawingGAN | 70.56 |
| StyleGAN-based method | 66.89 |
| APDrawingGAN++ | 65.47 |
| Ours | 63.69 |
| Real (training vs. test) | 52.51 |
| Methods | FID |
|---|---|
| Our proposed method without the feature-disentanglement module | 76.88 |
| Ours w/o U-Net-based information generator | 64.39 |
| Our proposed method | 61.23 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, H.; Ma, Z.; Chen, X.; Wang, X.; Xu, J.; Zheng, Y. Generating Artistic Portraits from Face Photos with Feature Disentanglement and Reconstruction. Electronics 2024, 13, 955. https://doi.org/10.3390/electronics13050955
Guo H, Ma Z, Chen X, Wang X, Xu J, Zheng Y. Generating Artistic Portraits from Face Photos with Feature Disentanglement and Reconstruction. Electronics. 2024; 13(5):955. https://doi.org/10.3390/electronics13050955
Chicago/Turabian StyleGuo, Haoran, Zhe Ma, Xuhesheng Chen, Xukang Wang, Jun Xu, and Yangming Zheng. 2024. "Generating Artistic Portraits from Face Photos with Feature Disentanglement and Reconstruction" Electronics 13, no. 5: 955. https://doi.org/10.3390/electronics13050955
APA StyleGuo, H., Ma, Z., Chen, X., Wang, X., Xu, J., & Zheng, Y. (2024). Generating Artistic Portraits from Face Photos with Feature Disentanglement and Reconstruction. Electronics, 13(5), 955. https://doi.org/10.3390/electronics13050955