Figure 1.
DANet Architecture.
Figure 1.
DANet Architecture.
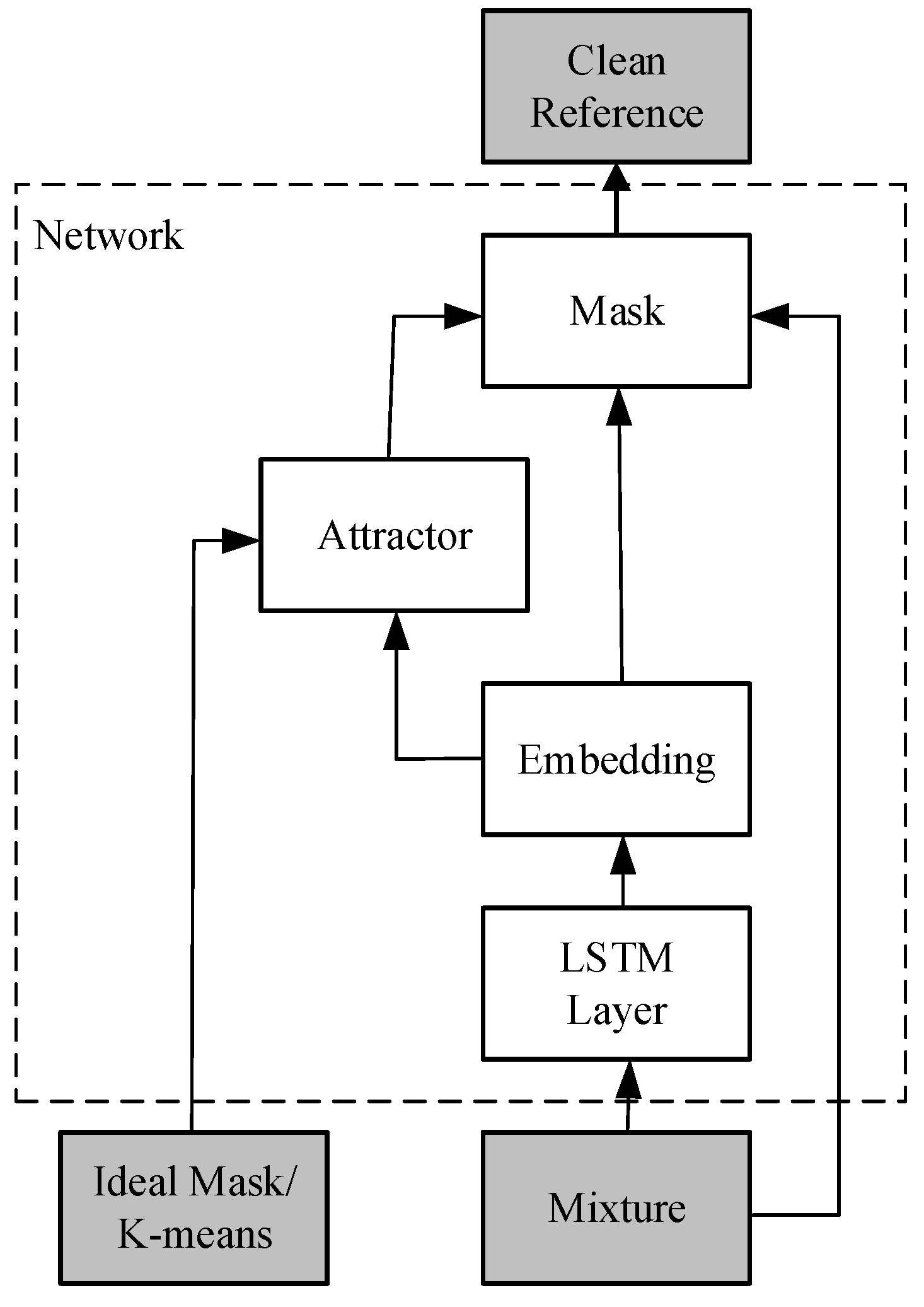
Figure 2.
TasNet Network Architecture.
Figure 2.
TasNet Network Architecture.
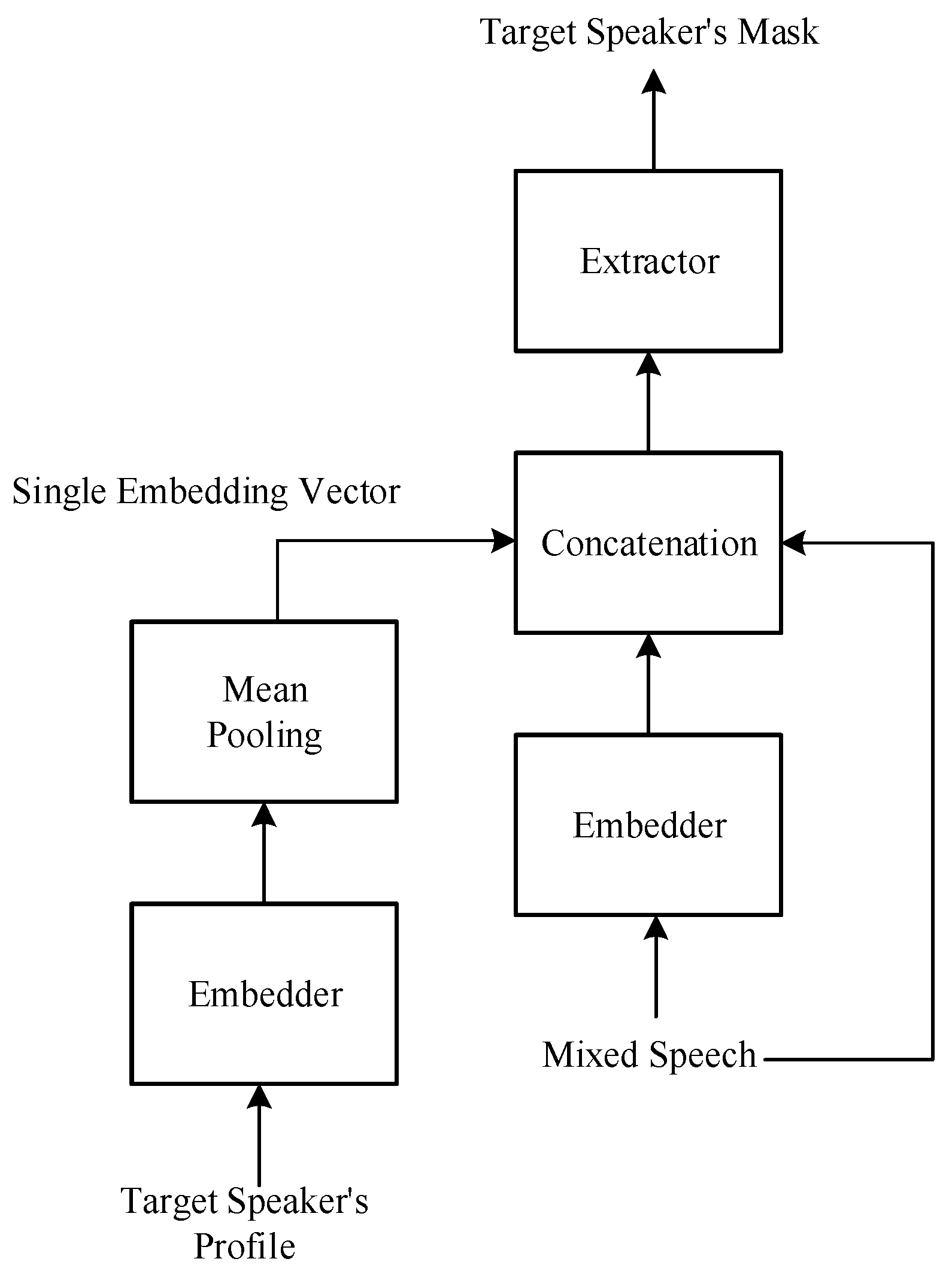
Figure 3.
Basic architecture of the target speech extraction model.
Figure 3.
Basic architecture of the target speech extraction model.
Figure 4.
Proposed system architecture. The system architecture is divided into two stages: the training stage and the testing stage. In the training stage, the source and generation methods of the speech dataset, preprocessing steps, and the overall neural network model are introduced. The neural network model is divided into four blocks: speech encoder, speaker encoder, speaker extractor, and speech decoder. The model structure is based on the SpEx+ baseline model, with additional attention-enhancing mechanisms and delay-reducing methods. In the testing stage, objective evaluation indicators are used to measure the quality and efficiency of the system after processing the testing dataset.
Figure 4.
Proposed system architecture. The system architecture is divided into two stages: the training stage and the testing stage. In the training stage, the source and generation methods of the speech dataset, preprocessing steps, and the overall neural network model are introduced. The neural network model is divided into four blocks: speech encoder, speaker encoder, speaker extractor, and speech decoder. The model structure is based on the SpEx+ baseline model, with additional attention-enhancing mechanisms and delay-reducing methods. In the testing stage, objective evaluation indicators are used to measure the quality and efficiency of the system after processing the testing dataset.
Figure 5.
The role of speech encoder. In the core of this system, the speech encoder plays a crucial role. It acts as the primary entry point, taking in the mixed audio and converting it into a conceptual representation. Simultaneously, a reference input, consisting of a clear, isolated speech signal, undergoes processing using another speech encoder. This second encoder uses the same weights as the first, ensuring that the features it extracts are consistent and aligned. The speaker encoder identifies unique characteristics from the reference, aiding the speaker extractor in isolating the target speaker’s voice. Finally, the speech decoder reconstructs this voice into clear, separated audio, with a weight-sharing strategy across encoders enhancing the system’s effectiveness in noisy environments.
Figure 5.
The role of speech encoder. In the core of this system, the speech encoder plays a crucial role. It acts as the primary entry point, taking in the mixed audio and converting it into a conceptual representation. Simultaneously, a reference input, consisting of a clear, isolated speech signal, undergoes processing using another speech encoder. This second encoder uses the same weights as the first, ensuring that the features it extracts are consistent and aligned. The speaker encoder identifies unique characteristics from the reference, aiding the speaker extractor in isolating the target speaker’s voice. Finally, the speech decoder reconstructs this voice into clear, separated audio, with a weight-sharing strategy across encoders enhancing the system’s effectiveness in noisy environments.
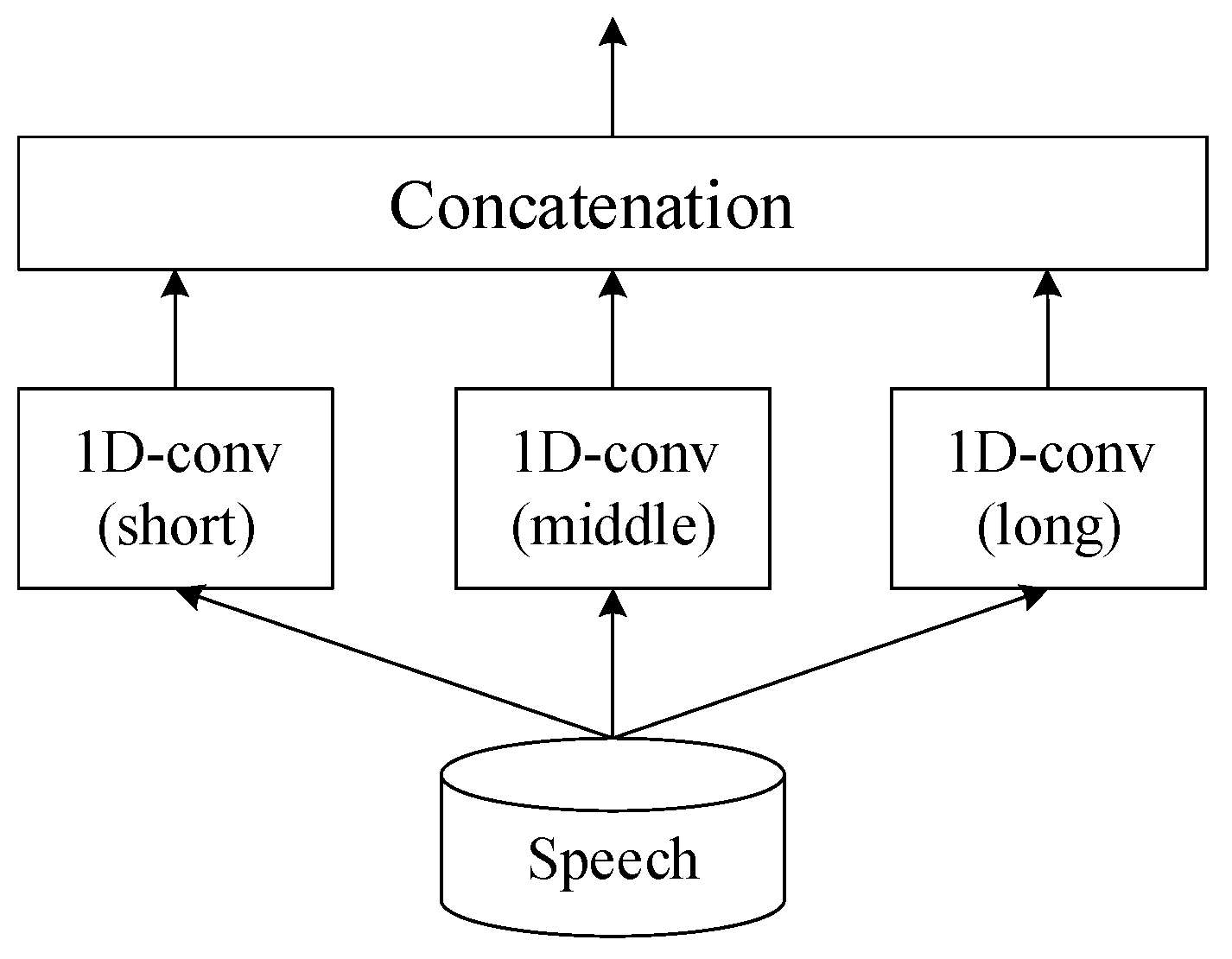
Figure 6.
Architecture of speech encoder outlines an advanced speech encoder framework that precisely extracts features from speech by employing three specialized convolutional layers, each with a unique kernel size. These sizes correspond to different temporal scales: short, medium, and long, allowing the encoder to capture a wide range of speech characteristics.
Figure 6.
Architecture of speech encoder outlines an advanced speech encoder framework that precisely extracts features from speech by employing three specialized convolutional layers, each with a unique kernel size. These sizes correspond to different temporal scales: short, medium, and long, allowing the encoder to capture a wide range of speech characteristics.
Figure 7.
Architecture of speaker encoder to generate speaker-embedding vectors.
Figure 7.
Architecture of speaker encoder to generate speaker-embedding vectors.
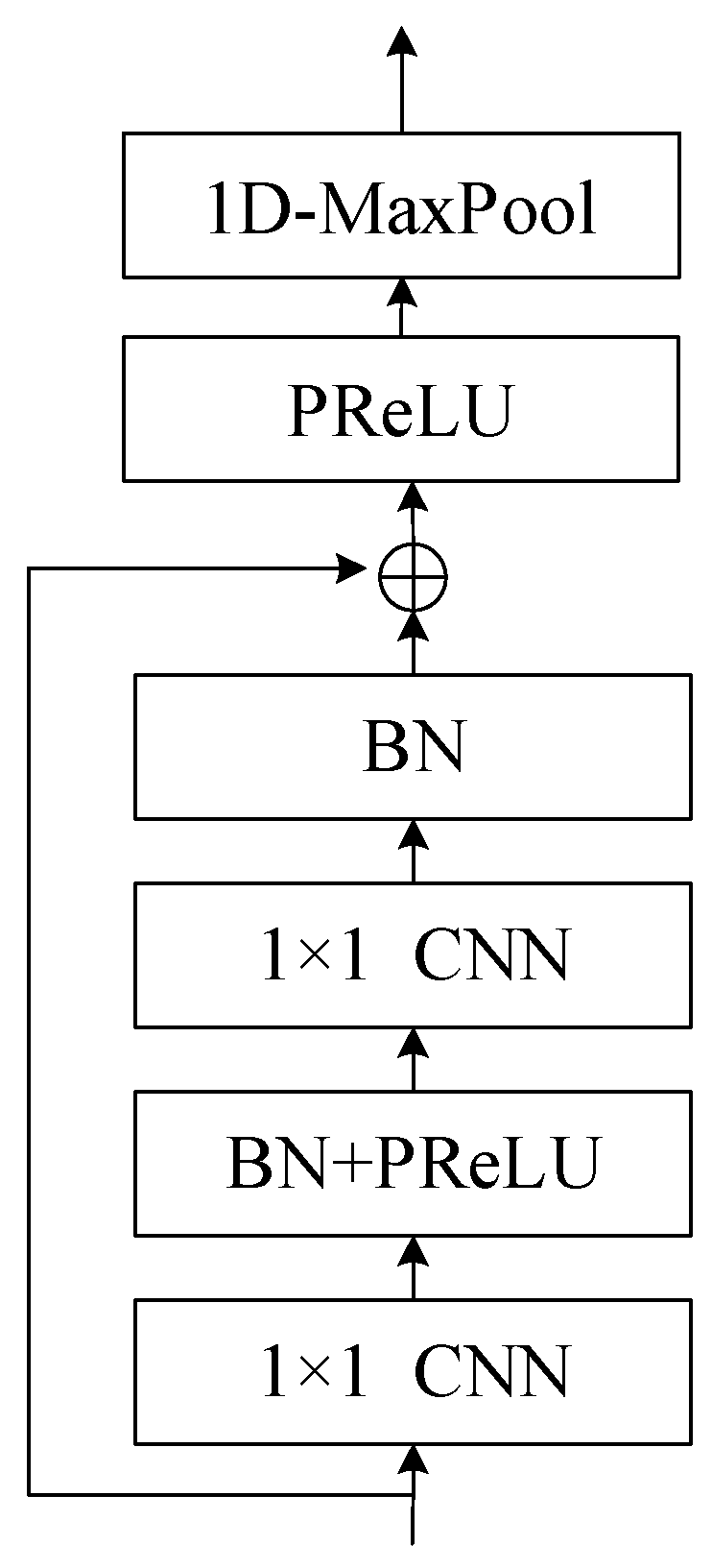
Figure 8.
Structure of ResNet block. The ResNet block employs a residual function to capture the difference between learned features and input, ensuring that important information is preserved and preventing degradation in deep networks. The block incorporates 1x1 convolution layers, batch normalization, and PReLU to enhance learning and convergence, while the skip connection adds the input to the learned residual to obtain features. Additionally, a maximum pooling layer is used to remove silent parts of the audio, contributing to the overall effectiveness of the target speech extraction process.
Figure 8.
Structure of ResNet block. The ResNet block employs a residual function to capture the difference between learned features and input, ensuring that important information is preserved and preventing degradation in deep networks. The block incorporates 1x1 convolution layers, batch normalization, and PReLU to enhance learning and convergence, while the skip connection adds the input to the learned residual to obtain features. Additionally, a maximum pooling layer is used to remove silent parts of the audio, contributing to the overall effectiveness of the target speech extraction process.
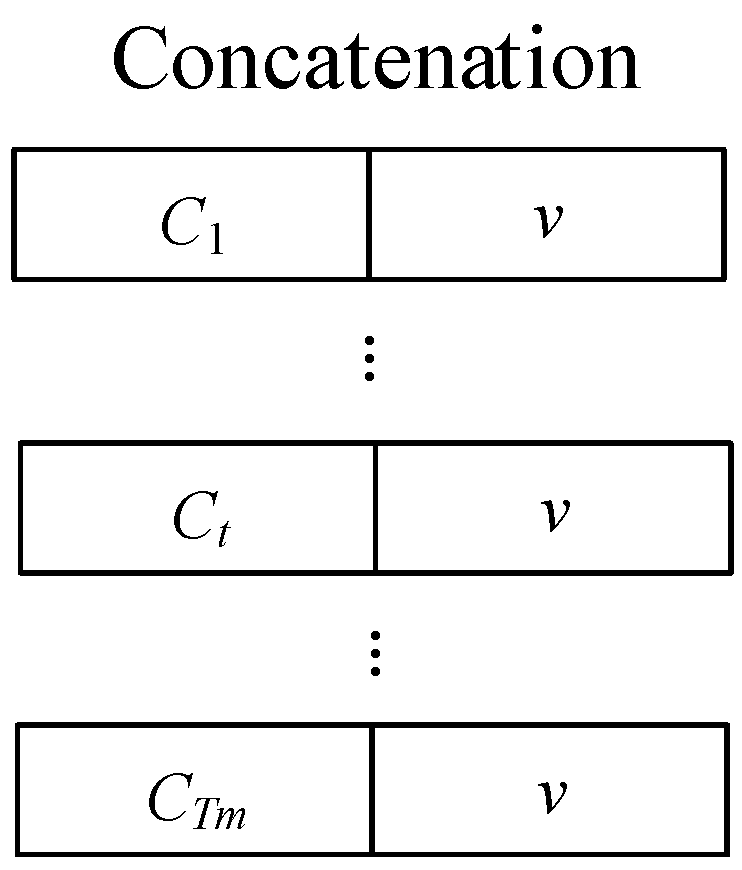
Figure 9.
The process of concatenating the speaker-embedding vector and the context-dependent embedding vector to form the target-embedding vector. This step is a crucial part of the target speech extraction process, as it combines speaker-specific features with context-dependent information to create a comprehensive representation of the target speech, ultimately contributing to the effectiveness of the system.
Figure 9.
The process of concatenating the speaker-embedding vector and the context-dependent embedding vector to form the target-embedding vector. This step is a crucial part of the target speech extraction process, as it combines speaker-specific features with context-dependent information to create a comprehensive representation of the target speech, ultimately contributing to the effectiveness of the system.
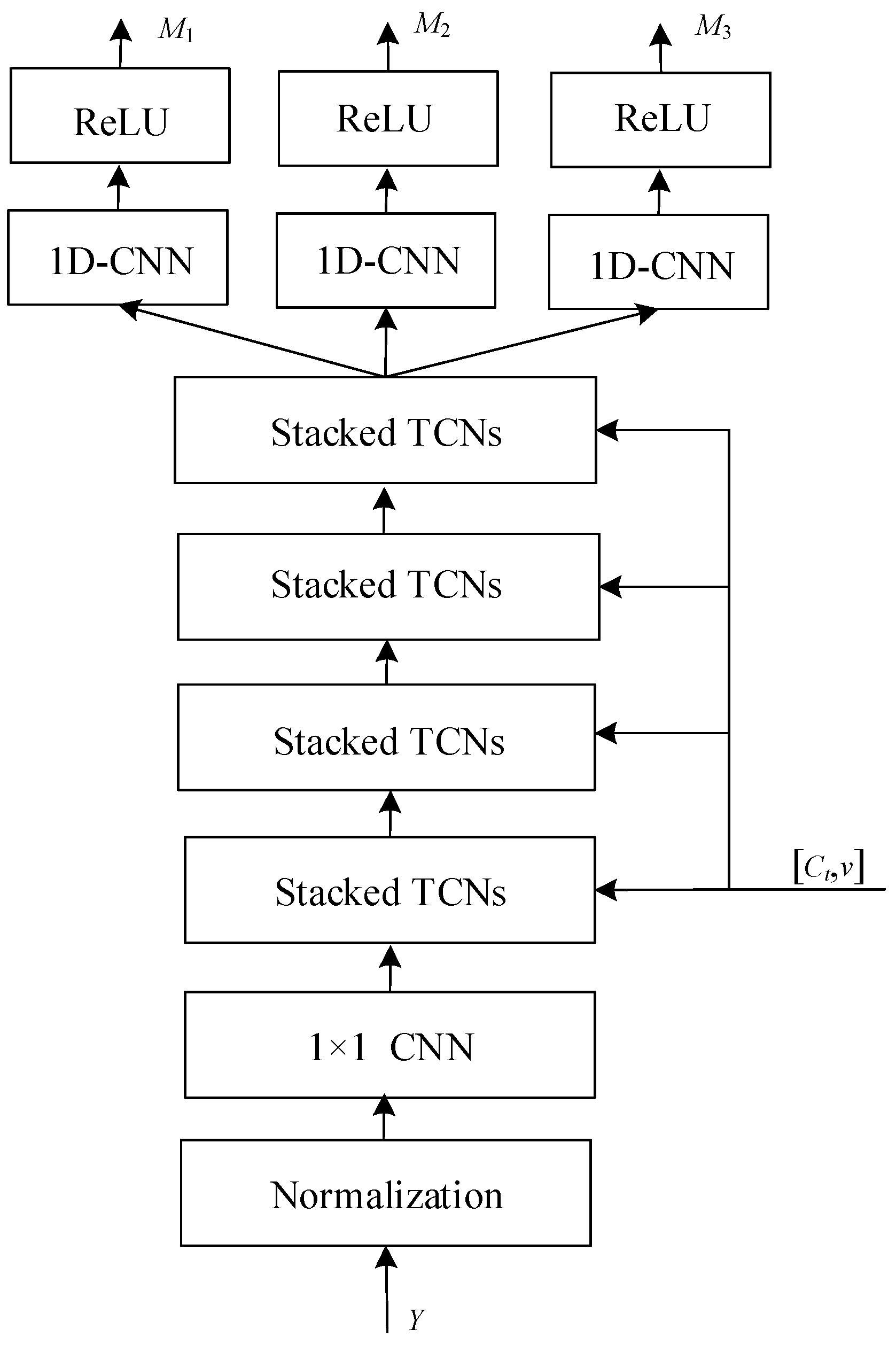
Figure 10.
Architecture of speaker extractor. This figure presents a multi-stage neural network architecture designed for extracting speaker-specific features from an audio input. The process starts with normalization to standardize input data. It is followed by a sequence of 1D-CNN layers, which apply convolutional filters to extract time domain features. These features are then processed through stacked temporal convolutional networks (TCNs), which are adept at capturing long-range temporal dependencies. Post each TCN block, a 1D-CNN layer refines the features further. ReLU activation functions introduce non-linearity, essential for modeling complex patterns. The architecture concludes with multiple output embeddings M1, M2, M3, representing different levels of feature abstraction, which can be utilized for identifying or verifying speakers.
Figure 10.
Architecture of speaker extractor. This figure presents a multi-stage neural network architecture designed for extracting speaker-specific features from an audio input. The process starts with normalization to standardize input data. It is followed by a sequence of 1D-CNN layers, which apply convolutional filters to extract time domain features. These features are then processed through stacked temporal convolutional networks (TCNs), which are adept at capturing long-range temporal dependencies. Post each TCN block, a 1D-CNN layer refines the features further. ReLU activation functions introduce non-linearity, essential for modeling complex patterns. The architecture concludes with multiple output embeddings M1, M2, M3, representing different levels of feature abstraction, which can be utilized for identifying or verifying speakers.
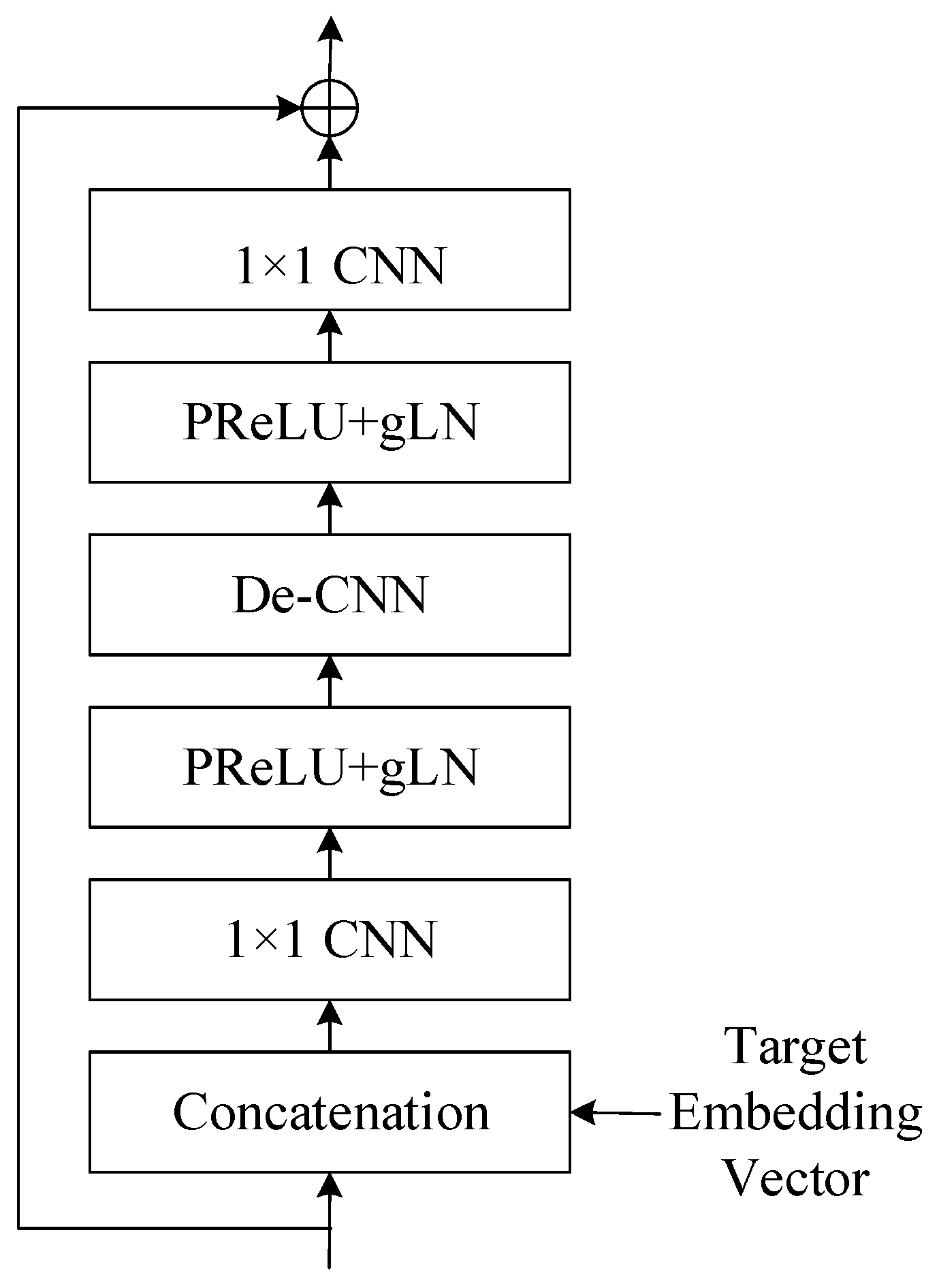
Figure 11.
This figure displays structure of TCN block (cLN ) within a neural network, employing conditional layer normalization for context-specific processing. An embedding vector conditions the input, which then passes through alternating layers of 1 × 1 CNNs and PReLU+gLN for feature extraction and normalization. The structure concludes with a residual connection to ensure smooth training and information flow.
Figure 11.
This figure displays structure of TCN block (cLN ) within a neural network, employing conditional layer normalization for context-specific processing. An embedding vector conditions the input, which then passes through alternating layers of 1 × 1 CNNs and PReLU+gLN for feature extraction and normalization. The structure concludes with a residual connection to ensure smooth training and information flow.
Figure 12.
Dilated convolutional layer with increasing dilation rates at different levels. It allows the network to aggregate information over larger receptive fields without losing resolution. At the bottom level (d = 1), the convolution has no dilation, operating on adjacent data points. As we move up, the dilation rate increases, with d = 2 skipping one data point and d = 4 skipping three, enabling the layer to cover more extensive data spans effectively.
Figure 12.
Dilated convolutional layer with increasing dilation rates at different levels. It allows the network to aggregate information over larger receptive fields without losing resolution. At the bottom level (d = 1), the convolution has no dilation, operating on adjacent data points. As we move up, the dilation rate increases, with d = 2 skipping one data point and d = 4 skipping three, enabling the layer to cover more extensive data spans effectively.
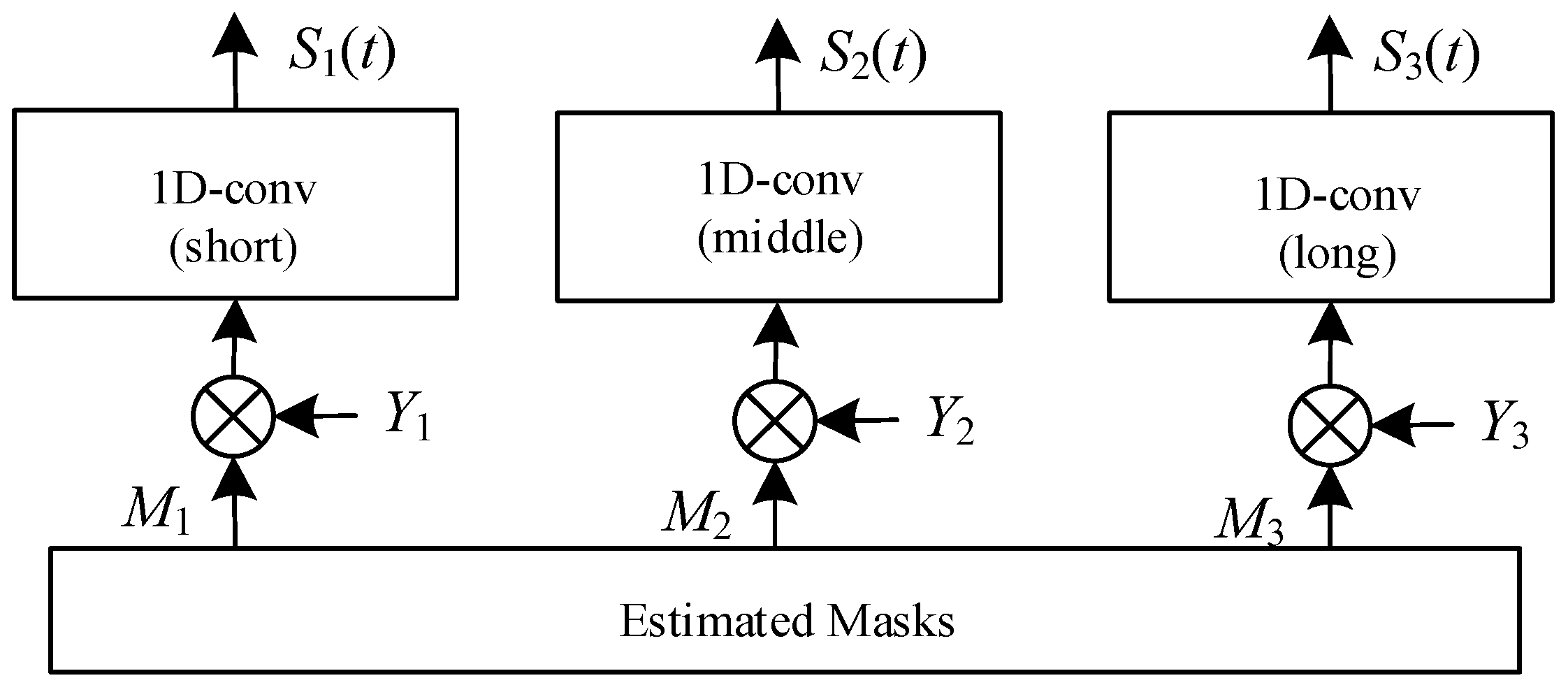
Figure 13.
Architecture of audio decoder (Y3 is missing). It is responsible for differentiating and isolating a target speaker’s voice from a mixture of speech. Within this component, three masks are generated, each associated with convolutional layers of varying lengths—short, middle, and long. These masks play an essential role in the speech separation process.
Figure 13.
Architecture of audio decoder (Y3 is missing). It is responsible for differentiating and isolating a target speaker’s voice from a mixture of speech. Within this component, three masks are generated, each associated with convolutional layers of varying lengths—short, middle, and long. These masks play an essential role in the speech separation process.
Table 1.
Parameters setting for the training model.
Table 1.
Parameters setting for the training model.
| Batch size | 14 |
| Learning rate | 0.001 |
| Learning rate decay | 0.5 |
| Epoch | 50 |
| Optimizer | Adam optimizer |
Table 2.
Kernel length setting for speech encoder.
Table 2.
Kernel length setting for speech encoder.
| Setting | Kernel Length (Samples/Time) |
|---|
| 20 (2.5 ms) |
| 80 (10 ms) |
| 160 (20 ms) |
Table 3.
Parameter setting for the loss function.
Table 3.
Parameter setting for the loss function.
| weight parameter | 0.1 |
| weight parameter | 0.1 |
| proportion parameter | 0.5 |
Table 4.
Hardware and software environments for the experiments.
Table 4.
Hardware and software environments for the experiments.
| CPU | Intel Core i7-9700k @ 3.60GHz |
| GPU | RTX 2080 |
| RAM | 64GB DDR4-3200 MHz |
| OS | Ubuntu 18.04 |
| Software language | Python3.6, Matlab |
| Neural Network tool | Pytorch |
Table 5.
Comparison results of attention mechanisms using different sources.
Table 5.
Comparison results of attention mechanisms using different sources.
| | SI-SDR (dB) | PESQ |
|---|
| Attention (L1) | 3.1465 | 3.1465 |
| Attention (L2) | 14.802 | 3.0877 |
| Attention (L3) | 14.515 | 3.0864 |
Table 6.
Comparisons between the proposed system and other methods.
Table 6.
Comparisons between the proposed system and other methods.
| | Domain | Formula
| SI-SDR (dB) | PESQ |
|---|
| Mixture | - | - | 2.486 | 2.1604 |
| SBF-MTSAL-Concat | Freq. | - | 10.228 | 2.6142 |
| SpEx | Time | - | 13.136 | 2.8866 |
| SpEx+ (Baseline) | Time | SI-SDR | 14.267 | 3.0143 |
| Proposed method |
| Attention (L1) | Time | SI-SDR | 14.974 | 3.0732 |
| Attention (L1) | Time | SD-SDR | 15.041 | 3.1465 |
Table 7.
Comparisons of the effectiveness of the latency reduction method.
Table 7.
Comparisons of the effectiveness of the latency reduction method.
| | Processing Time (s) | SI-SDR (dB) | PESQ |
|---|
| SpEx+ (Baseline) | 0.1428 | 14.267 | 3.0143 |
| SpEx+ (Baseline) * | 0.1147 | 12.581 | 2.8748 |
| Proposed method | | | |
| Non-causal block | 0.1454 | 15.041 | 3.1465 |
| Causal block | 0.1135 | 13.344 | 2.8977 |
Table 8.
Comparisons the effectiveness for different numbers of speakers.
Table 8.
Comparisons the effectiveness for different numbers of speakers.
| | SI-SDR (dB) | PESQ |
|---|
2-speakers
(3-spk-test) | 7.447 | 2.2389 |
| 2-speakers | 15.041 | 3.1465 |
| 3-speakers | 11.624 | 2.5528 |


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}