Research on Data Quality Governance for Federated Cooperation Scenarios


Abstract
1. Introduction
- First, this paper proposes an innovative “Two-stage” quality governance framework, which can be widely applied to real-world federated learning cooperation scenarios.
- Second, The DQ-FedAvg method is proposed, incorporating outlier processing and model quality assessment, resulting in a new federated aggregation approach.
- Third, we conducted experiments on the proposed framework to verify its feasibility. Our results show that in the process of federated cooperation, it is necessary to check the data quality of each participant, and monitor the quality of the local models and local parameters provided by each participant in the training process, so as to promote the effective implementation of federated training.
2. Related Research
2.1. Federated Scenario
2.2. Data Quality Governance
2.3. Blockchain Technology
3. Problem Analysis
3.1. Stage 1 Problem Analysis
3.2. Stage 2 Problem Analysis
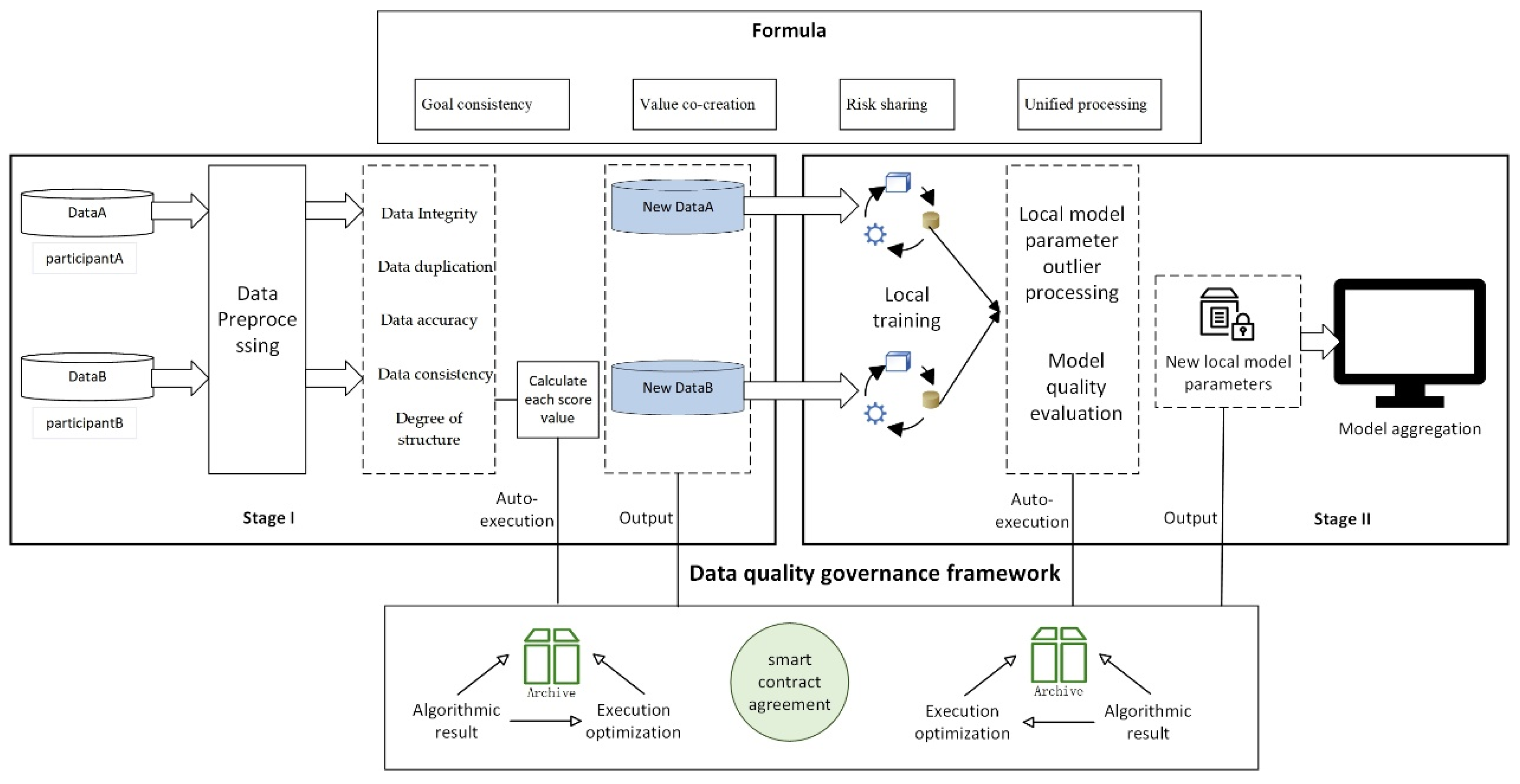
4. “Two-Stage” Quality Governance Framework
4.1. General Framework
- Goal consistency
- Value co-creation
- Risk sharing
- Unified processing
4.2. Smart Contract
4.3. Stage 1: Local Data Quality Governance

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| One-Dimensional | Two-Dimensional | Description of the Metric | Measure | Indicator Sources |
|---|---|---|---|---|
| Intrinsic quality | The amount of data | The total number of datasets (how many pieces of data are in the dataset provided by the participants | The sum of the data entries in the dataset | [25,26] |
| Data Integrity | Whether there are null values in the dataset measures whether the data is complete | Quantitative assessment | [25,26,27,28,29,30,31,32] | |
| Data duplication | Whether there are duplicate data entries in the dataset provided by the participant | Quantitative assessment | [29,30,31] | |
| Data accuracy | A measure of the accuracy of the data, such as how accurate it is to the actual situation | Quantitative assessment | [25,26,27,28,30,31,32] | |
| Data consistency | Measure the consistency of data, including consistency in data fields and formats, as well as logical consistency between data | Quantitative assessment | [25,26,27,28,29,30,31,32] | |
| Degree of structure | Measure how well your data is organized and formatted when stored locally | Quantitative assessment | [28] | |
| Contextual quality | Timeliness | How often and time delays the data is updated | Quantitative assessment | [25,26,28,29,30,31,32] |
- Completeness score . Each participant calculates the completeness of the dataset in which it participates in training, counting the number of missing values in the sample data, and calculates the ratio of the null value data to the total number of entries. The formula is as follows:where refers to the number of null values in sample data D, and refers to the total number of null values in sample data set D. Assuming that Participant A has a total number of total samples, in which there is a total null value, , then the integrity score of Participant A is , and Participant B has a total of total samples, in which there is a total null value, , and the integrity score of Participant B is . The higher the integrity score, the more complete and easier the dataset is to process.
- Repeatability score . The number of duplicate samples of each feature column in the participant statistical sample dataset is added and denoted as , and the ratio of the number of duplicate samples of each feature column to the total number of samples is calculated by the following formula:where is the total number of duplicate samples in sample data D, and is the total number of sample data set D. The higher the repeatability score of Participant A, the fewer duplicates appeared in the sample.
- Accuracy score . Accuracy is used to measure the degree to which each feature dimension of the data conforms to the actual situation, in this paper, the accuracy degradation caused by not conforming to the normal distribution and pattern of the data set is considered as an outlier analysis, so the outliers of each dimension feature are counted. For continuous data, we use the interquartile range (IQR) method (a non-parametric method) to identify outliers. For categorical data, if the data is encoded, outliers are defined as values that fall outside the range of encoded values (exceeding upper and lower limits or with undefined encoding). Next, the proportion of outlier samples in each feature dimension to the total sample size was calculated, and the data accuracy was evaluated by this. The formula is as follows:where indicates the number of abnormal samples in sample data D, and refers to the total number of sample data set D. The higher the accuracy score, the higher the quality of the dataset data provided by the participants.
- Consistency score . The data consistency index is evaluated by checking the consistency of data values and data formats, where the consistency of data values is to check whether the value range of the same data field in different datasets or sources is consistent, and data format consistency refers to whether the format and unit of the data field are consistent. Calculate the number of data entries in feature columns that do not meet the consistency of data values and data formats, and their proportion to the total number of data entries in feature columns. The consistency scoring formula is expressed as follows:where refers to the number of data entries in the feature column that does not meet the consistency of data values and data formats, and refers to the total number of sample dataset D. The higher the consistency score, the easier it is for the data to be used for model training.
- Degree of structuring score . Participants evaluate the degree of structuring for their respective datasets used in federated training. Structured data refers to data stored in databases that can be logically expressed in a two-dimensional table structure. In this paper, the degree of structuring is assessed by calculating the total amount of data in formats other than “int64” and “float64”. The structured degree scoring formula is expressed as follows:where refers to the data samples in unstructured format, and refers to the total number of samples in the sample dataset D. The higher the structuring score, the easier the data is to process, indicating the higher the quality of the dataset used for training.
- Timeliness score . The timeliness of the current dataset is known according to the time difference of the dataset or the degree of time covered by the dataset, and the newer the data, the more the generalization ability of the model can be enhanced.
4.4. Stage 2: Federated Training Phase
| Algorithm 1. Aggregation method: DQ-FedAvg |
| 1: Server steps: |
| 2: initialize the global model with parameters |
| 3: for do: |
| 4: for do: |
| 5: The client trains the model locally and obtains the model parameters |
| 6: The client updates the local model parameters locally using the outlier handling mechanism |
| 7: Calculate the quality of the client’s local model, |
| 8: Comparing the quality of the local model in the previous round, |
| 9: Determine whether is greater than 0 in ∆, and adjust the model parameters according to Equation (10). |
| 10: Aggregate model parameters that have been updated after quality governance into the global model |
5. Experiments
5.1. Experimental Data
5.2. Details of the Experiment
5.3. Experimental Evaluation Indicators
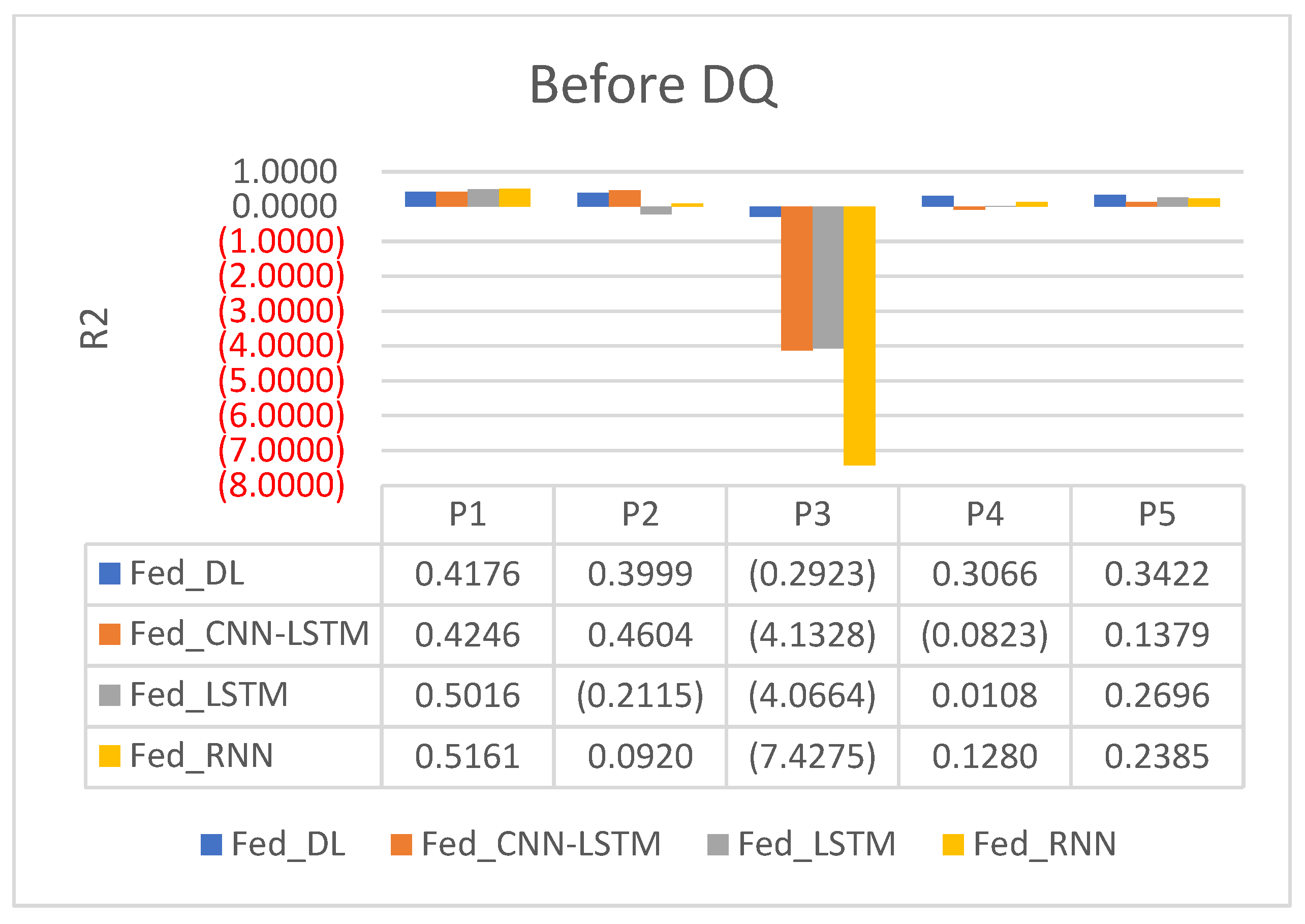
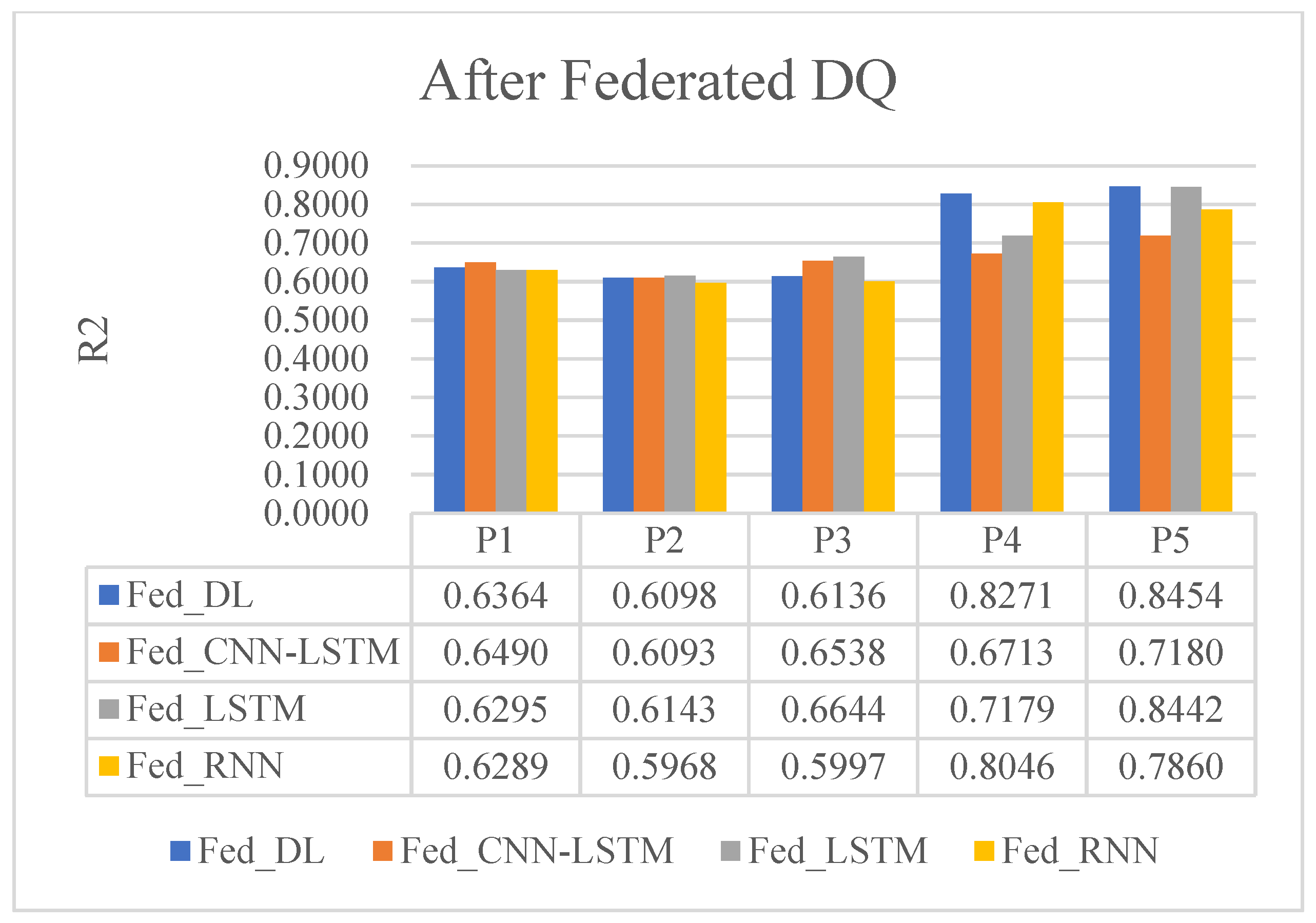
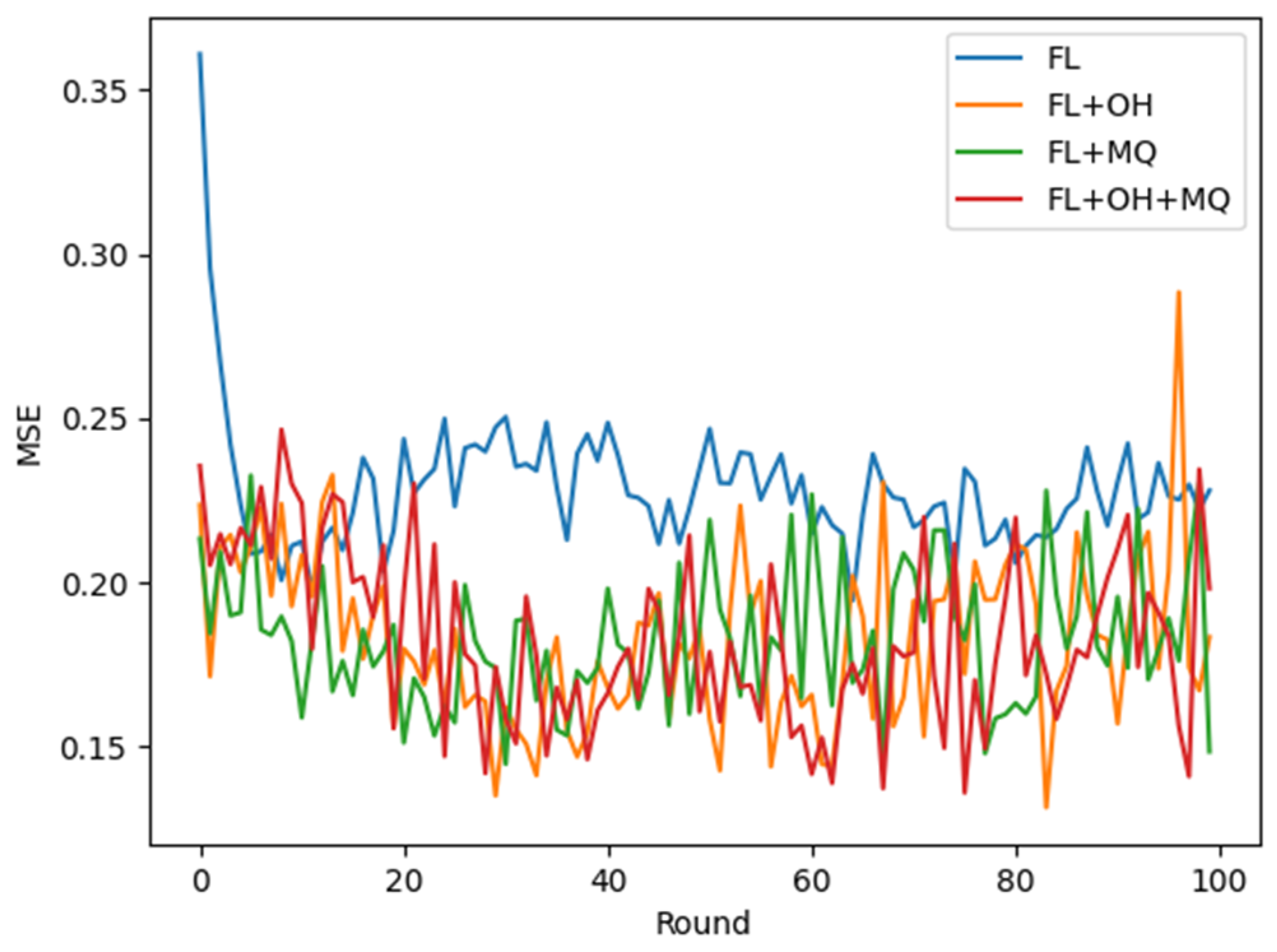
5.4. Experimental Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Peregrina, J.A.; Ortiz, G.; Zirpins, C. Data Governance for Federated Machine Learning in Secure Web-Based Systems. In Actas de las Jornadas de Investigación Predoctoral en Ingeniería Informática: Proceedings of the Doctoral Consortium in Computer Science (JIPII 2021), Online, 3–29 September 2021; Universidad de Cádiz: Puerto Real, Spain, 2021; pp. 36–39. ISBN 978-84-89867-47-5. [Google Scholar]
- Janssen, M.; Brous, P.; Estevez, E.; Barbosa, L.S.; Janowski, T. Data Governance: Organizing Data for Trustworthy Artificial Intelligence. Gov. Inf. Q. 2020, 37, 101493. [Google Scholar] [CrossRef]
- Rieke, N.; Hancox, J.; Li, W.; Milletarì, F.; Roth, H.R.; Albarqouni, S.; Bakas, S.; Galtier, M.N.; Landman, B.A.; Maier-Hein, K.; et al. The Future of Digital Health with Federated Learning. Npj Digit. Med. 2020, 3, 1–7. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Zheng, D.; Zhang, C.; Huang, L.; Chen, G.; Huang, W. Literature Review on Federated Learning Application: Based on “Element-Process” Framework-All Databases. J. Ind. Eng. Eng. Manag. 2023, 38, 14–30. [Google Scholar]
- Thiruneelakandan, A.; Umamageswari, A. Federated Learning Approach for Analyzing Electric Vehicle Sales in the Indian Automobile Market. In Proceedings of the 2023 International Conference on Research Methodologies in Knowledge Management, Artificial Intelligence and Telecommunication Engineering (RMKMATE), Chennai, India, 1 November 2023; pp. 1–6. [Google Scholar]
- Jia, Y.; Xiong, L.; Fan, Y.; Liang, W.; Xiong, N.; Xiao, F. Blockchain-Based Privacy-Preserving Multi-Tasks Federated Learning Framework. Connect. Sci. 2024, 36, 2299103. [Google Scholar] [CrossRef]
- Liu, S.; Xu, X.; Wang, M.; Wu, F.; Ji, Y.; Zhu, C.; Zhang, Q. FLGQM: Robust Federated Learning Based on Geometric and Qualitative Metrics. Appl. Sci. 2024, 14, 351. [Google Scholar] [CrossRef]
- Yang, X.; Li, T. A Blockchain-Based Federated Learning Framework for Secure Aggregation and Fair Incentives. Connect. Sci. 2024, 36, 2316018. [Google Scholar] [CrossRef]
- Xu, S.; Xia, H.; Zhang, R.; Liu, P.; Fu, Y. FedNor: A Robust Training Framework for Federated Learning Based on Normal Aggregation. Inf. Sci. 2024, 684, 121274. [Google Scholar] [CrossRef]
- Kim, D.S.; Ahmad, S.; Whangbo, T.K. Federated Regressive Learning: Adaptive Weight Updates through Statistical Information of Clients. Appl. Soft Comput. 2024, 166, 112043. [Google Scholar] [CrossRef]
- Prigent, C.; Costan, A.; Antoniu, G.; Cudennec, L. Enabling Federated Learning across the Computing Continuum: Systems, Challenges and Future Directions. Future Gener. Comput. Syst. 2024, 160, 767–783. [Google Scholar] [CrossRef]
- Morbey, G. Data Quality for Decision Makers: A Dialog between a Board Member and a DQ Expert, 2nd ed.; Springer Gabler: Wiesbaden, Germany, 2013; ISBN 978-3-658-01822-1. [Google Scholar]
- Liu, Y.; Ma, S.; Yang, Z.; Zou, X.; Shi, S. A Data Quality and Quantity Governance for Machine Learning in Materials Science. J. Chin. Ceram. Soc. 2023, 51, 427–437. [Google Scholar]
- Pahl, C.; Azimi, S.; Barzegar, H.R.; Ioini, N.E. A Quality-Driven Machine Learning Governance Architecture for Self-Adaptive Edge Clouds. In Proceedings of the CLOSER 2022—12th International Conference on Cloud Computing and Services Science, Virtual, 26–28 April 2022; pp. 305–312. [Google Scholar]
- Peregrina, J.A.; Ortiz, G.; Zirpins, C. Towards Data Governance for Federated Machine Learning. In Proceedings of the Advances in Service-Oriented and Cloud Computing, Virtual, 22–24 March 2022; Zirpins, C., Ortiz, G., Nochta, Z., Waldhorst, O., Soldani, J., Villari, M., Tamburri, D., Eds.; Springer Nature: Cham, Switzerland, 2022; pp. 59–71. [Google Scholar]
- Peregrina, J.A.; Ortiz, G.; Zirpins, C. Towards a Metadata Management System for Provenance, Reproducibility and Accountability in Federated Machine Learning. In Proceedings of the Advances in Service-Oriented and Cloud Computing, Virtual, 22–24 March 2022; Zirpins, C., Ortiz, G., Nochta, Z., Waldhorst, O., Soldani, J., Villari, M., Tamburri, D., Eds.; Springer Nature: Cham, Switzerland, 2022; pp. 5–18. [Google Scholar]
- Navaz, A.N.; Serhani, M.A.; El Kassabi, H.T. Federated Quality Profiling: A Quality Evaluation of Patient Monitoring at the Edge. In Proceedings of the 2022 International Wireless Communications and Mobile Computing (IWCMC), Dubrovnik, Croatia, 30 May–3 June 2022; pp. 1015–1021. [Google Scholar]
- Chen, L.; Guo, Y.; Ge, C.; Zheng, B.; Gao, Y. Cross-Source Data Error Detection Approach Based on Federated Learning. J. Softw. 2023, 13, 1126–1147. [Google Scholar] [CrossRef]
- Zhang, Z.; Chen, G.; Xu, Y.; Huang, L.; Zhang, C.; Xiao, S. FedDQA: A Novel Regularization-Based Deep Learning Method for Data Quality Assessment in Federated Learning. Decis. Support Syst. 2024, 180, 114183. [Google Scholar] [CrossRef]
- Jeon, K.-C.; Han, G.-S.; Han, C.-Y.; Chong, I. Federated Learning Model for Contextual Sensitive Data Quality Applications: Healthcare Use Case. In Proceedings of the 2023 31st Signal Processing and Communications Applications Conference (SIU), Istanbul, Turkey, 5–8 July 2023; pp. 1–4. [Google Scholar]
- Bejenar, I.; Ferariu, L.; Pascal, C.; Caruntu, C.-F. Aggregation Methods Based on Quality Model Assessment for Federated Learning Applications: Overview and Comparative Analysis. Mathematics 2023, 11, 4610. [Google Scholar] [CrossRef]
- Li, R.; Wang, Z.; Fang, L.; Peng, C.; Wang, W.; Xiong, H. Efficient Blockchain-Assisted Distributed Identity-Based Signature Scheme for Integrating Consumer Electronics in Metaverse. IEEE Trans. Consum. Electron. 2024, 70, 3770–3780. [Google Scholar] [CrossRef]
- Wang, W.; Han, Z.; Gadekallu, T.R.; Raza, S.; Tanveer, J.; Su, C. Lightweight Blockchain-Enhanced Mutual Authentication Protocol for UAVs. IEEE Internet Things J. 2024, 11, 9547–9557. [Google Scholar] [CrossRef]
- Wang, W.; Yang, Y.; Yin, Z.; Dev, K.; Zhou, X.; Li, X.; Qureshi, N.M.F.; Su, C. BSIF: Blockchain-Based Secure, Interactive, and Fair Mobile Crowdsensing. IEEE J. Sel. Areas Commun. 2022, 40, 3452–3469. [Google Scholar] [CrossRef]
- Wang, R.Y.; Strong, D.M. Beyond Accuracy: What Data Quality Means to Data Consumers. J. Manag. Inf. Syst. 1996, 12, 5–33. [Google Scholar] [CrossRef]
- Stahl, F.; Vossen, G. Data Quality Scores for Pricing on Data Marketplaces. In Proceedings of the Intelligent Information and Database Systems, Da Nang, Vietnam, 14–16 March 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 215–224. [Google Scholar]
- Yang, Y.; Yuan, Y.; Li, B. Data Quality Evaluation: Methodology and Key Factors. In Proceedings of the Smart Computing and Communication, Erode, India, 14–15 December 2018; Qiu, M., Ed.; Springer International Publishing: Cham, Switzerland, 2018; pp. 222–230. [Google Scholar]
- Cai, L.; Zhu, Y. The Challenges of Data Quality and Data Quality Assessment in the Big Data Era. Data Sci. J. 2015, 14, 2. [Google Scholar] [CrossRef]
- Xiaojuan, B.; Shurong, N.; Zhaolin, X.; Peng, C. Novel Method for the Evaluation of Data Quality Based on Fuzzy Control. J. Syst. Eng. Electron. 2008, 19, 606–610. [Google Scholar] [CrossRef]
- An, X.; Huang, J.; Xu, J.; Wang, L.; Hong, X.; Wang, Z.; Han, X. Construction of Panoramic Big Data Quality Evaluation Indicator Framework-All Databases. J. Manag. Sci. China 2023, 26, 138–153. [Google Scholar]
- Huang, Q.; Zhao, Z.; Liu, Z. Comprehensive Management System and Technical Framework of Data Quality in the Data Circulation Transaction Scenario-All Databases. Data Anal. Knowl. Discov. 2022, 6, 22–34. [Google Scholar]
- Batini, C.; Cappiello, C.; Francalanci, C.; Maurino, A. Methodologies for Data Quality Assessment and Improvement. ACM Comput. Surv. 2009, 41, 16:1–16:52. [Google Scholar] [CrossRef]
- Lin, W.-C.; Tsai, C.-F. Missing Value Imputation: A Review and Analysis of the Literature (2006–2017). Artif. Intell. Rev. 2020, 53, 1487–1509. [Google Scholar] [CrossRef]
- Xia, W.; Jiang, H.; Feng, D.; Douglis, F.; Shilane, P.; Hua, Y.; Fu, M.; Zhang, Y.; Zhou, Y. A Comprehensive Study of the Past, Present, and Future of Data Deduplication. Proc. IEEE 2016, 104, 1681–1710. [Google Scholar] [CrossRef]
- Hodge, V.; Austin, J. A Survey of Outlier Detection Methodologies. Artif. Intell. Rev. 2004, 22, 85–126. [Google Scholar] [CrossRef]
- Sun, Y.; Zhao, G.; Liao, Y. Evolutionary Game Model for Federated Learning Incentive Optimization-All Databases. J. Chin. Comput. Syst. 2024, 45, 718–725. [Google Scholar]
- Shalabi, L.A.; Shaaban, Z.; Kasasbeh, B. Data Mining: A Preprocessing Engine. J. Comput. Sci. 2006, 2, 735–739. [Google Scholar] [CrossRef]
- Gao, L.; Li, L.; Chen, Y.; Zheng, W.; Xu, C.; Xu, M. FIFL: A Fair Incentive Mechanism for Federated Learning. In ICPP ′21: Proceedings of the 50th International Conference on Parallel Processing, Lemont, IL, USA, 9–12 August 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 1–10. [Google Scholar]

| Study | Topic | Contributions | Limitations |
|---|---|---|---|
| [15,16] | This paper discusses how to improve the quality, traceability, and stability of a federated learning system through a data governance framework. | Propose a preliminary data governance architecture, covering model quality assessment, access control, etc. [15] A comprehensive framework combining data governance and metadata management is proposed for federated machine learning [16] | It is limited to theoretical models, has not been practiced, and lacks verification in practical scenarios. |
| [17] | The methods of quality assessment of patient monitoring data in an edge computing environment were discussed. | A federated data quality analysis model was proposed, and the effect of FDQ analysis in improving data quality was demonstrated through experiments. | The main focus is on the quality of the dataset. The data quality dimensions considered are incomplete. |
| [18] | This paper discusses how to use federated learning technology to improve the accuracy of cross-source data error detection under the premise of protecting data privacy. | The FeLeDetect method is proposed to improve error detection accuracy under the premise of privacy protection by using cross-source data, which directly promotes the improvement of data quality. | There is no explicit mention of the limitations of the method in error detection for specific types of data. |
| [19] | This paper discusses how to assess the quality of cross-source data while protecting data privacy. | The proposed method evaluates and controls the data quality according to the training task, prevents the bias of the dataset from affecting the decision-making, and enhances the robustness and effectiveness of the business decision-making of the federated learning service. | The adaptability of FedDQA to other federated learning constructs and low-quality data warrants further investigation. |
| [20] | Explores how to evaluate and improve data quality in a federated learning environment for specific business applications, such as healthcare scenarios. | A new federated learning framework considering the quality of data in the local context is proposed. | The generalizability of the model and its applicability to other fields have not been verified. |
| ours | Data quality issues across the federal collaboration scenarios are discussed and respective governance strategies are adopted. | This paper proposes a “Two-stage” data quality governance framework based on the problems of local data quality and model quality in the federated training process, and verifies the feasibility of the framework and the effectiveness of the method through experiments. | There is no discussion of what kind of data quality governance should be adopted when there are malicious actors. |
| One-Dimensional | Two-Dimensional | The Reason Why These Metrics Were Chosen in the Federated Cooperation Scenario |
|---|---|---|
| Intrinsic quality | The amount of data | In federated learning scenarios, the amount of training data of different participants is inconsistent, and the results will also be inconsistent (both the quantity and quality of training data will affect the accuracy of the model) |
| Data Integrity | In the federated learning scenario, some fields may be missing in the data that each client participates in training, so it is necessary to check the missing values and comprehensively consider the integrity of the dataset provided by the participants | |
| Data duplication | In federated training, repeatability evaluation can help us filter the data with duplicate records in the participating datasets, so as to better manage data quality and provide the generalization ability of the model | |
| Data accuracy | In federated learning, accuracy evaluation can help us determine whether the data trained by the model is authentic and reliable, so as to avoid the degradation of model performance due to data error | |
| Data consistency | In federated learning, because the data is distributed among different participants, consistency evaluation is used to ensure that the model can accurately extract information from the data | |
| Degree of structure | In federated learning, structured data is good for better training of models, and if it is unstructured data, more preprocessing work is required, which affects efficiency and the smooth flow of the cooperation process | |
| Contextual quality | Timeliness | In federated learning, timeliness evaluation can help us determine whether the data is fresh enough to reflect the current situation to ensure that |
| Index | Contrast | P1 | P2 | P3 | P4 | P5 |
|---|---|---|---|---|---|---|
| (Integrity) | previous | 1.0000 | 1.0000 | 1.0000 | 0.9673 | 0.9628 |
| after | 1.0000 | 1.0000 | 1.0000 | 1.0000 ↑ | 1.0000 ↑ | |
| (Repeatability) | previous | 1.0000 | 1.0000 | 1.0000 | 0.9540 | 0.9686 |
| after | 1.0000 | 1.0000 | 1.0000 | 1.0000 ↑ | 1.0000 ↑ | |
| (Consistency) | previous | 0.3295 | 0.3289 | 0.3262 | 0.2281 | 0.2093 |
| after | 1.0000 ↑ | 1.0000 ↑ | 0.9991 ↑ | 1.0000 ↑ | 1.0000 ↑ | |
| (Structured) | previous | 0.8235 | 0.8235 | 0.8235 | 0.5000 | 0.5000 |
| after | 0.9231 ↑ | 0.9231 ↑ | 0.9231 ↑ | 0.8846 ↑ | 0.8846 ↑ | |
| (Accuracy) | previous | 0.9729 | 0.9742 | 0.9825 | 0.9775 | 0.9743 |
| after | 0.9786 ↑ | 0.9778 ↑ | 0.9886 ↑ | 0.9811↑ | 0.9875 ↑ | |
| (Timeliness) | 0.0351 | 0.0353 | 0.0338 | 0.5646 | 0.5578 | |
| (Number) | 0.4408 | 0.2644 | 0.1765 | 0.0708 | 0.0474 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shen, J.; Zhou, S.; Xiao, F. Research on Data Quality Governance for Federated Cooperation Scenarios. Electronics 2024, 13, 3606. https://doi.org/10.3390/electronics13183606
Shen J, Zhou S, Xiao F. Research on Data Quality Governance for Federated Cooperation Scenarios. Electronics. 2024; 13(18):3606. https://doi.org/10.3390/electronics13183606
Chicago/Turabian StyleShen, Junxin, Shuilan Zhou, and Fanghao Xiao. 2024. "Research on Data Quality Governance for Federated Cooperation Scenarios" Electronics 13, no. 18: 3606. https://doi.org/10.3390/electronics13183606
APA StyleShen, J., Zhou, S., & Xiao, F. (2024). Research on Data Quality Governance for Federated Cooperation Scenarios. Electronics, 13(18), 3606. https://doi.org/10.3390/electronics13183606