1. Introduction
Natural disasters have a nature of undesirable, unpredictable, and uncontrollable circumstances that may have a widespread hazard in different severities [
1,
2,
3]. A typical damaging disaster is subject to random occurrence periods in specific locations. Unfortunately, nature experiences dramatic suffering as a result of a high-intensity disaster. Due to the random nature of disasters, a precise detection of the onset of a disaster is frequently impossible. With the current abilities of technology, researchers make efforts to monitor disasters in real time [
4,
5] to mitigate the negative impacts and navigate the search and rescue (SAR) activities. The process of real-time monitoring of disaster zones is usually carried out under constrained infrastructure resources due to the inevitable corruption of technological infrastructures. Therefore, designing an efficient monitoring system has a pivotal role in supplying observations in exploring the requirements of a disaster area [
6,
7,
8].
Recently, wildfires have been a critical threatening natural disaster, leading to significant damages in forest zones [
9]. The rise in global climate and human activities have resulted in increased forest fires on a large scale, making a simple monitoring approach impractical when extracting the required information from strategic zones of the area. In recent research, an effective scientific solution in the domain of wildfire monitoring and early detection has placed the main emphasis on the theme of wireless sensor networks (WSNs) [
10]. The main body of WSNs includes a number of nodes with limited capacity, each of which focuses on the completion of a common task such as the timely detection of wildfires [
11]. Taking the vast and harsh forest areas into consideration, deploying a huge amount of nodes for full coverage is imperative, posing financial issues and robust self-organization issues. On the other hand, manned aerial vehicles have the potential to ensure complete and fresh information incurring at the expense of costs and risks.
Currently, the innovations and advancements have extensively attracted the ever-increasing popularity of unmanned aerial vehicles (UAVs) [
12,
13,
14,
15,
16]. An integral task component of UAVs is their ability to collect real-time images of remote zones rendering the implementation of UAVs a feasible and flexible solution in wildfire monitoring [
17]. UAVS are designed to fly at lower altitudes strengthening the assessment of a disaster, with improved quality of real-time data. Therefore, deploying a fleet of UAVs can complete the mission of a full survey of a disaster area of interest [
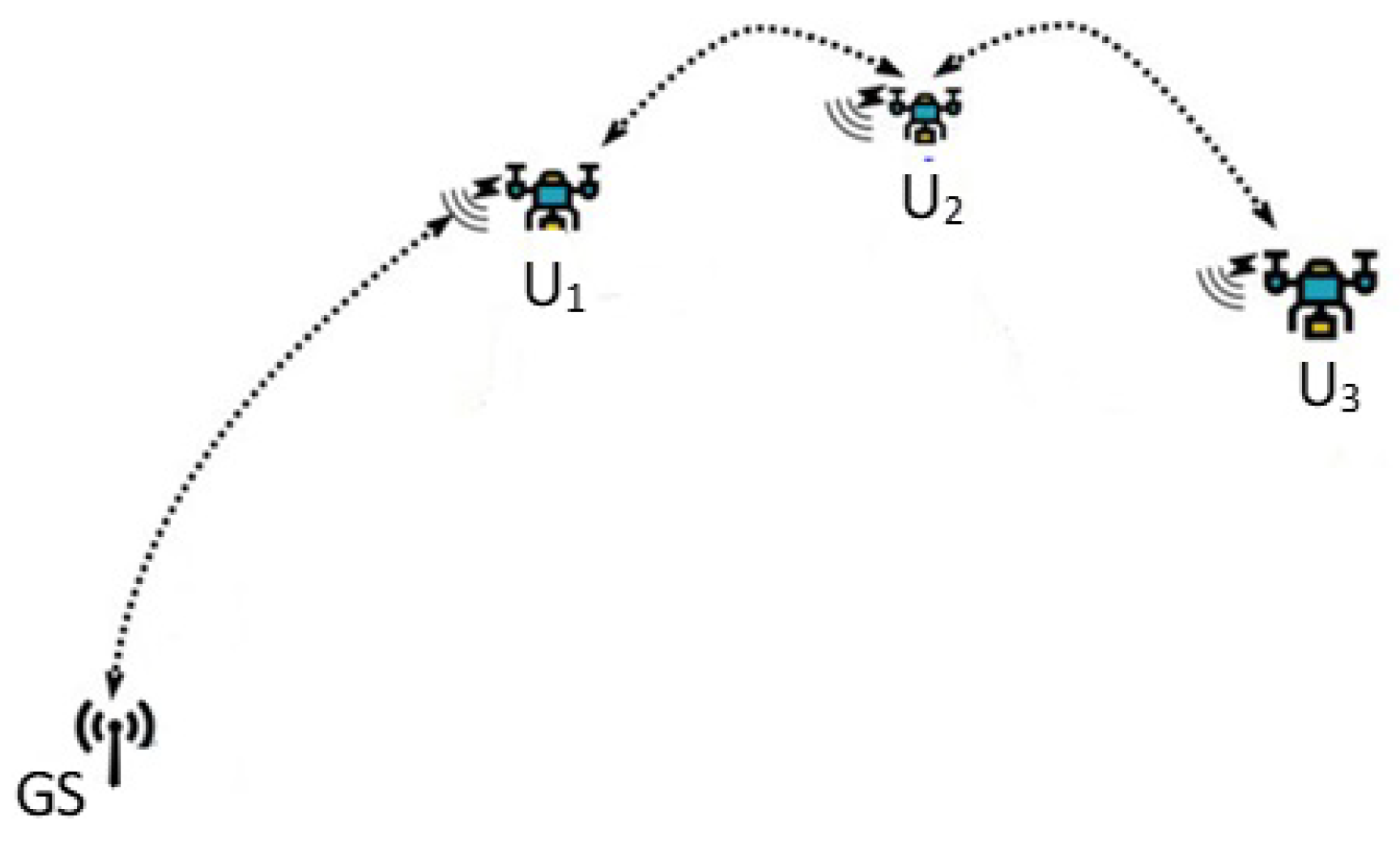
18]. This, of course, allows a fast and accurate detection of the presence of wildfire. The utilization of multiple UAVs poses new challenges, particularly the collaboration of UAVS to harness the potential of the fleet entirely. A prevalent limitation associated with UAVs is the restricted energy sources within the scope of surveillance over a broad disaster area. One notable limitation that often impedes the process of full coverage tasks of UAVs relies on the communication range, necessitating the operation of multiple UAVs in a collaborative manner.
To achieve the goal of maximum coverage under the aforementioned constraints, many of the recent studies for managing a team of UAVs lock on the development of planning trajectories for swarm UAVs. This article has its basics on a deep reinforcement learning (DRL)-based trajectory planning approach to enhance the corresponding monitoring efficiency, treating each UAV as an agent [
19,
20]. The proposed idea formulates trajectory planning specifically for cooperative and homogeneous UAVs, thereby empowering the UAVs to more efficiently observe the area and collect data. The formulation of the proposed DRL algorithm fulfilling wildfire reconnaissance assumes no prior knowledge about the environment. A typical DRL approach utilizes a numerical formation of the reward function for complex environments, letting each agent extract an optimal policy by interacting with the environment via a trial-and-error fashion [
21]. Building on this fact, the proposed DRL approach allows each UAV to autonomously learn a trajectory by maximizing the cumulative reward value and maintaining a time-susceptible data collection structure.
Another important point of the proposed idea to tackle the patrol task of UAVs more precisely is to divide the target disaster area into identical subareas, or so-called grids. This grid-based framework intends to convert the issue of exploring optimum trajectory into enabling UAVs to visit the grids in a periodic cycle. Then, we generate a forest fire risk mapping that forecasts the likelihood of wildfire in a particular grid. In other words, as the probability of fire activities may differ in various parts of a forest area, this kind of mapping indicates the level of forest fire risk in each grid separately. The rationale behind the proposed path planning approach is to create routes with the purpose of fire prevention by letting UAVS visit high-risk grids with an adequately great frequency. The arrangement of risk levels depends mostly on regional and human-made factors such as topographic conditions and unattended campfires.
The specific contributions of this article are the following.
We propose a new trajectory planning algorithm based on reinforcement learning for multi-UAV scenarios within realistic environments with the purpose of early detection of wildfire.
The target area is explicitly split into equal-length sub-areas, and each sub-area is initiated with a risk level through a risk mapping strategy. Therefore, the proposed framework encourages the UAVs to visit high-risk sub-areas more frequently.
A double-deep reinforcement learning-based multi-agent trajectory approach is designed for multiple UAVs providing an efficient coverage of forest areas with high risk in terms of fire.
Extensive performance evaluations to verify the superior capacity of the proposed approach have been conducted in changing practical scenarios.
The remainder of the present paper shall be summarized as follows. The recent research domain in the scope of RL-based trajectory design for multi-UAVs is covered by
Section 2.
Section 3 aims to describe the essential parts of the proposed model. The underlying points of the proposed multi-UAV DDQN trajectory approach are elaborated in
Section 4.
Section 5 demonstrates the performance outputs to display the working principles of the proposed approach. A clear conclusion is provided to mark the remarkable performance measurements in
Section 5.
2. Related Work
The purpose of this section is to study the existing literature pertaining to the relevant scope of this article. A prominent focus has been dedicated to the trajectory design for multiple UAV applications. A recent study proposed a deep-reinforcement learning-based path-planning approach with the extra property of optimizing the transmission power level [
22]. This joint combination of the trajectory and transmission power level of UAVs yields an optimal solution leading to the maximum long-term network utility. The complete problem was treated as a stochastic game to be formulated with respect to the dynamics of the network and the actions of UAVs. To alleviate the burden of computational complexity due to the high volume of action and state spaces, the proposed method employs a deterministic policy gradient technique. Extensive simulations have been carried out to confirm the performance superiority of the proposed method over existing optimization methods. The obtained outputs indicate that the system capacity and network utility can be enhanced by at least 15%.
Data collection from remote zones via multiple UAVs has been an attractive research direction. An autonomous exploration of the most suitable routes for UAVs in smart farming areas with reinforcement learning was thoroughly studied in [
23]. It implements a location and energy-aware Q-learning algorithm to arrange UAV paths for mitigating power consumption, delay performance, and flight duration with increased data collection properties. This work partitions the farm zone of interest into grids, where each grid is further labeled with respect to its geographical features. This sort of mapping assigns a target point to the grids, thereby the grids with a high target point are visited frequently by UAVs to collect attractive agricultural information. Consequently, UAVs are expected to prevent flying over some grids treated as no-fly with no interesting information. A set of simulation experiments has been conducted to prove the efficiency of the proposed method in terms of data collection robustness and UAV resource consumption in comparison to well-known benchmarks.
To accurately detect the propagating trend of the wildfire, a trajectory planning approach of a fleet of UAVs was constructed to offer efficient situational awareness about the current status of an ongoing wildfire perimeter [
24]. The proposed solid idea relies on situation assessment and observation planning (SAOP), operating the activities of perception, decision, and action in turn. The SAOP approach produces a fire map with a prediction of fire spreading through UAV observations. As a centralized approximation, SOAP makes use of a ground station to handle all aforementioned processes. A metaheuristic approach called variable neighborhood search (VNS) is exploited to formulate the wildfire observation problem (WOP), resulting in an output of trajectories depending on application requirements. Realistic and simulation experiments validated the capability of the proposed solution in mapping wildfire spread.
A recent study has made a lot of effort to explore a cost-efficient trajectory through an RL-based path planning strategy with the aid of sensor network (SN) technology [
25]. The target application environment is animal tracking in harsh ambient areas and the Q-learning strategy is the core part of the study to timely acquire the information from the area. A typical sensor network is deployed on the ground to initially detect the animals to be reported to the UAVs. The Q-learning algorithm provides a robust operation for UAVs to visit the sensor nodes containing fresh animal appearance information. A numerical reward function is defined to consider application dynamics that can maximize the total reward value. The proposed strategy reaches an optimal policy that permits the UAVs to fly over the zones with a high animal mobility property. Numerous simulation results proved the applicability of the combination of RL, SN, and UAVs in tracking wild animals in a timely manner.
Quick search and rescue (SAR) activities during a natural disaster have been a research topic with the aid of UAVs achieving the purpose of maximum coverage of the affected zone [
26]. The present study eliminates the coverage issue of a single UAV with a multi-UAV solution with a solid trajectory design algorithm. To accomplish this objective, a target area is split into sub-areas, and each sub-area is associated with a risk level. A multiagent Q-learning-based UAV trajectory strategy is then proposed to enable UAVS to visit sub-areas prioritized with high risk. The proposed learning strategy satisfies the requirements of both the connectivity and energy limitations of UAVs. This is achieved by remaining UAVs connected to a central station on the ground directly or in a multi-hop manner. Comprehensive simulations have been performed to determine the performance efficiency of the designed trajectory with respect to a prioritized map. The supplied results demonstrate a significant performance improvement in ensuring an ideal UAV trajectory over existing ideas such as Monte Carlo and random and greedy algorithms.
Collecting useful information from Internet of Things (IoT) nodes in complex environments by the action of UAVs as central data collection has been thoroughly studied in [
27]. The main goal of the work is to lighten the critical issues faced in UAVs, such as collision avoidance and communication interference between UAVs. An accurate trajectory planning model is established through a three-step approach. The first step implements the K-means algorithm to overcome the task allocation, thereby attaining a collision-free channel among UAVs. The next two steps cover the development of a centralized multi-agent-based DRL algorithm for UAV trajectory design. The effectiveness of the proposed work in simulations has been evaluated for a network setting of 4 UAVs and 30 IoT nodes in comparison to two current multi-agent approaches.
A multi-UAV path planning algorithm with multi-agent RL is proposed to supply robust coordination among UAVs in dynamic environmental conditions [
28]. A recurrent neural network (RNN) is used to collect historical information when the observations can be partially completed with incomplete data. The value of the reward function in the proposed RL architecture was arranged in the light of multi-objective optimization problems with specific attributes such as coverage area and security. A simulation environment with three UAVs is created to simulate multi-UAV reconnaissance tasks with significant performance improvements.
The trajectory design of a group of UAVs for the intention of wireless energy charging to a ground station has been investigated in [
29]. It tries to maximize the total amount of received power on the ground through the optimization of trajectories, taking the main restrictions in terms of flying speed and collision avoidance into consideration. The optimization problem is solved by adapting the Lagrange multiplier method for a specific case of two-UAV-included scenarios. This supports the understanding of the development of trajectories with an increasing number of UAVs, up to 7. The remarkable output of this study suggests deploying the UAVs around a circle, making the radius a safe distance for UAVs. To examine the performance in the sense of the path design coordination of UAVs, simulation results are presented to approve the validity of the proposed trajectory algorithm.
The importance of deployment of UAVs as aerial base stations lying on traditional terrestrial communication network domain has been thoroughly researched with a primary focus on developing a new framework for the joint trajectory design of UAVs [
30]. This scenario includes a high volume of mobile users in the case of dense traffic. The main problems to tackle comprise a joint issue of designing trajectory and controlling power with a satisfied quality of service. To delve into developing a solution, a multi-agent Q-learning-based approach is initially utilized to specify the best positions of the UAVs. Then, real information on the current positions of the users is used to forecast the future positions of the users. Finally, another multi-agent Q-learning-based approach is devised for trajectory design by concurrently assigning the position and transmit power of UAVs. Numerical results in the simulation environment demonstrate a good level of prediction accuracy converging to an ideal steady state.
Similarly, the fundamental goal of another study is to tackle the practical issues of power allocation and trajectory design for multi-UAV communications systems with a DRL-based scheme [
31]. The proposed structure introduces both reinforcement learning and deep learning to discover the optimum behavior of the UAVs, whereby a signaling exchange process is performed among UAVs. Therefore, a network of UAVs is installed to dedicate sufficient bandwidth to fulfilling mission-critical issues in complex practices. As a consequence of this study, two important remarks are pointed out: (1) a centralized structure is committed to the learning process in which UAVs act as the agents, and (2) a decentralized framework is applied to execute the management of bandwidth usage allocating a reliable communication channel among UAVs. To show the benefit of the suggested idea, numerous simulation efforts were carried out with two benchmark methods.
Another study addresses the path-planning challenges of rescue UAVs in multi-regional scenarios with priority constraints [
32]. It introduces a mixed-integer programming model that combines coverage path planning (CPP) and the hierarchical traveling salesman problem (HTSP) to optimize UAV flight paths. The proposed idea suggests an enhanced method for intra-regional path planning using reciprocating flight paths for complete coverage of convex polygonal regions, optimizing these paths with Bezier curves to reduce path length and counteract drone jitter. For inter-regional path planning, a variable neighborhood descent algorithm based on k-nearest neighbors is used to determine the optimal access order of regions according to their priority. The simulation results demonstrate that the proposed algorithm effectively supports UAVs in performing prioritized path-planning tasks, improving the efficiency of information collection in critical areas, and aiding rescue operations by ensuring quicker and safer exploration of disaster sites.
A highly relevant paper presents a comprehensive study on optimizing the flight paths and trajectories of fixed-wing UAVs at a constant altitude [
33]. It is conducted in two primary phases: path planning using the Bezier curve to minimize path length while adhering to curvature and collision avoidance constraints, and flight trajectory planning aimed at minimizing maneuvering time and load factors under various aerodynamic constraints. The study utilizes three meta-heuristic optimization techniques—particle swarm optimization (PSO), genetic algorithm (GA), and grey wolf optimization (GWO)—to determine the optimal solutions for both phases. Results indicate that PSO outperforms GA and GWO in both path planning and trajectory planning, particularly when employing variable speed strategies, which significantly reduce the load factor during maneuvers. Additionally, the paper demonstrates the successful application of these optimized strategies in simultaneous target arrival missions for UAV swarms, highlighting the effectiveness of variable speed in scenarios involving tighter turning radius.
To sum up, recent studies in UAV technology have significantly enhanced wildfire detection and monitoring capabilities. However, these studies often fall short of addressing the energy constraints and communication challenges faced by multi-UAV systems in vast and harsh forest environments. The proposed work addresses these gaps by introducing a novel DRL-based trajectory planning algorithm for multi-UAV scenarios in wildfire reconnaissance. We partition the target area into identical subareas and assign risk levels using a new risk mapping strategy, allowing UAVs to prioritize high-risk areas. Additionally, our double-deep reinforcement learning approach enhances trajectory planning efficiency, ensuring effective coverage of high-risk forest areas. Extensive simulations with real-world datasets validate our approach, demonstrating significant improvements in monitoring efficiency, energy consumption, and data collection accuracy.
4. DDQN-Based Trajectory Planning Approach
In order to mathematically address the objective function stated in the previous part, we apply a decentralized Markov decision process (MDP) as a powerful solution in a finite-state manner. This type of MDP is simply composed via an expandable tuple (S, A, P, R, ), and each piece of the tuple can be defined for the proposed trajectory solution by the following:
S symbolizes the space of a set of states with the aid of environment information such as landing areas (grids).
A is the feasible action list according to the current location of the UAVs, that is, the possible directions of UAV movement when passing a particular grid.
P state transition probability value, which is actually set to 1 due to the deterministic nature of the model.
R represents the reward function, which is calculated upon the arrival of the UAV in a grid.
indicates a discount element in the range of 0 to 1 to decide the weighting ratio of long or short-term rewards, which typically devotes a higher reputation to recently acquired knowledge.
An iterative type of Bellman optimality equation with the purpose of maximizing the reward in solving such an MDP problem has been successfully implemented in [
36]. A series repetition of the Belman equation will eventually result in exploring an optimal policy of choosing the best action for a given state. This correlation can be denoted for state values by the following:
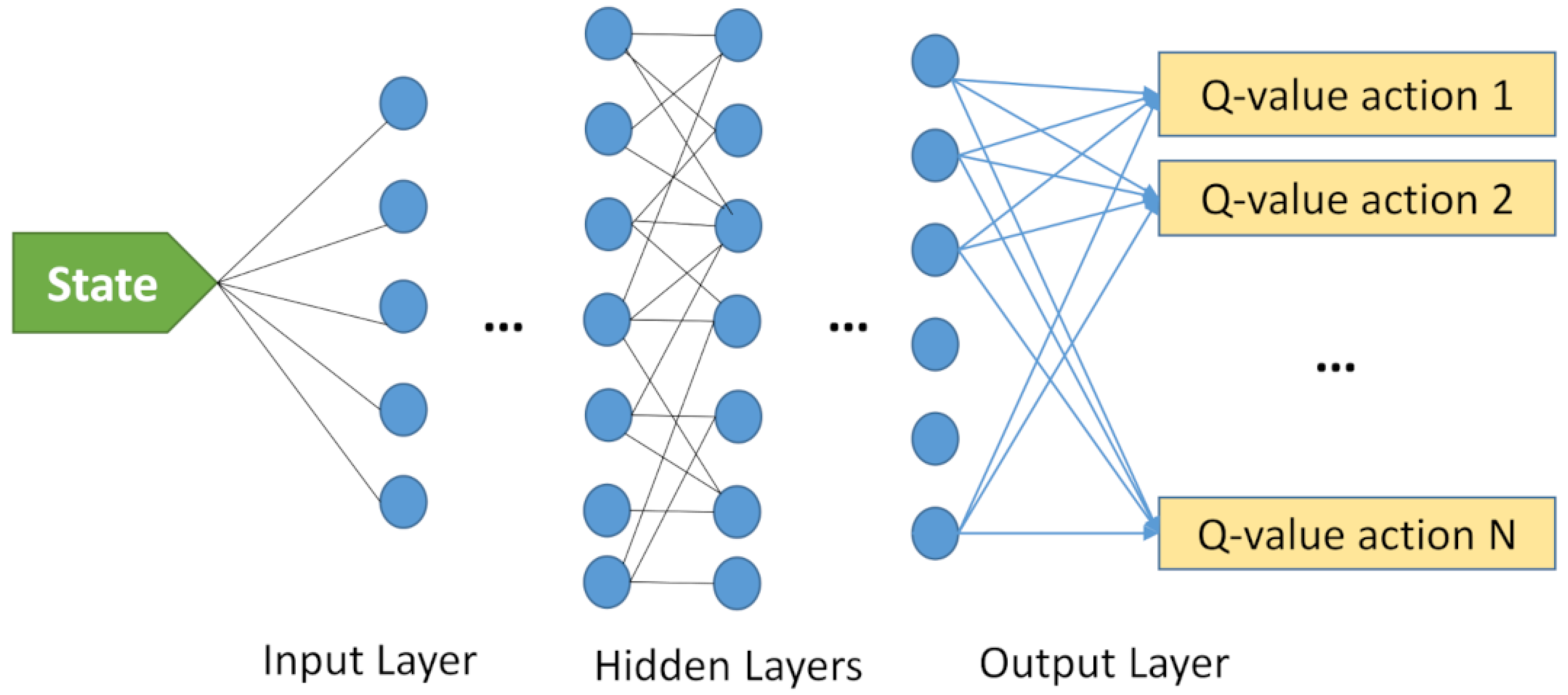
This paper has its basics in Q-learning, as described in the previous section, to solve the defined MDPs, relying on no prior knowledge of both the environment and reward. However, a common problem related to the standard Q-learning structure is its relatively low performance with the increasing number of actions/states. This, in fact, may transfer the problem to a more complex level, impeding the exploration of an optimal policy. To overcome this problem, deep reinforcement learning (DRL) was proposed by incorporating a deep neural network, treating the elements of a typical RL as a neural network. In many practical multi-agent applications, a common policy can be easily obtained by using a single deep network. The main body of a typical DRL model can be represented in
Figure 3. Here, the number of output layers decides the dimension of action space for a given state. In this study, the DQN model is the leading component, and UAVs are the actual agents of the DQN model. The states (
S) in our Q-learning model represent the positions of the UAVs in a three-dimensional plane. Each state corresponds to a specific grid location in the monitored area. The state space encompasses all possible positions that a UAV can occupy during its flight. This allows the model to comprehensively evaluate the environment and determine the best trajectories for the UAVs to follow. The actions (
A) in the Q-learning model correspond to the possible movements of the UAVs from one grid location to another. These actions include movements in various directions such as north, south, east, west, and potentially upward and downward in the 3D space. The UAVs decide on these actions based on the current state and the learned Q-values, aiming to maximize the total reward. The maximum coverage area of UAVs yields reward points, subject to a penalty point when flying to an area beyond the communication range or not returning to the center before exhausting the energy. In this model, at each time step, a UAV evaluates its current state (its position on the grid) and selects an action from the set of possible actions that will maximize its expected reward based on the Q-values stored in the Q-table. It is obvious that pre-flight trajectory determination for a typical multi-UAV system has been delved into a game with the objective of finishing the game with as many points as possible.
DQN may suffer from systematic overestimation, particularly in large or continuous domains of states and actions. This can force the agent to overestimate or underestimate the probability of taking a particular action, thereby learning suboptimal policies. The concept of double DQN (DDQN) has been recently introduced to be a useful algorithm to decrease overestimations [
19]. It uses two distinct Q-value estimators, one for action selection and the other for estimating the value of the selected action. To further support an effective and stable learning process of the DDQN algorithm, the experience replay method was proposed to drop correlations in the training phase and adjust variance in the data distribution [
38]. An agent stores new experiences in a replay memory. Then, a random minibatch from the memory is sampled for the learning process in order to estimate the loss value. The length of the memory is an important hyperparameter that should be carefully regulated according to the dynamics of scenarios. This random process allows an agent to use each experience multiple times and extract more information from previous experiences. Additionally, the resilience level of stability of the learning process is improved through the random selection of the experiences, as a selection of consecutive similar experiences may easily destroy the learning process. The underlying emphasis of this study is placed on the combination of DDQN and experience replay to accelerate the learning process. In addition to experience replay, a different target network is suggested with parameters
for the calculation of the next maximum Q-value. By applying this suggestion, the overestimation of action values satisfying particular circumstances is mitigated with the following loss function [
20]:
where
Y indicates the target value as:
is the parameter of the target network which can be updated with success as:
Here, is the update parameter specifying the adaptation speed in the range of 0 to 1.
In this article, special importance is given to deciding the optimum reward function, possessing a direct impact on the performance. The reward function in our model is designed to encourage UAVs to cover the maximum area while avoiding areas outside the communication range and ensuring they return to the center before depleting their energy. The reward is calculated based on the coverage area and penalties for undesirable actions, which helps guide the UAVs to optimal trajectories. The analytical expression of the reward function can be defined along with the following parts as:
The initial fragment of the sum shows an aggregate reward for FRZI points
collected from the grids through agent
i during the duration of the task
t.
denotes the fire risk values (FRZI) of a grid, which is
kth step of agent
i. The next step is to parameterize the aggregated reward by a multiplication factor
, constituting the shared reward function between all agents.
is a penalty parameter that encourages UAVs to stay within the communication limit. This term penalizes UAVs that navigate outside the predefined communication range, ensuring they maintain connectivity. The next term,
, appoints an exclusive punishment when an action is rejected due to undesirable requests such as border violation and visiting a grid currently being visited by another UAV. It discourages UAVs from taking actions that lead to conflicts or redundancies. The third term,
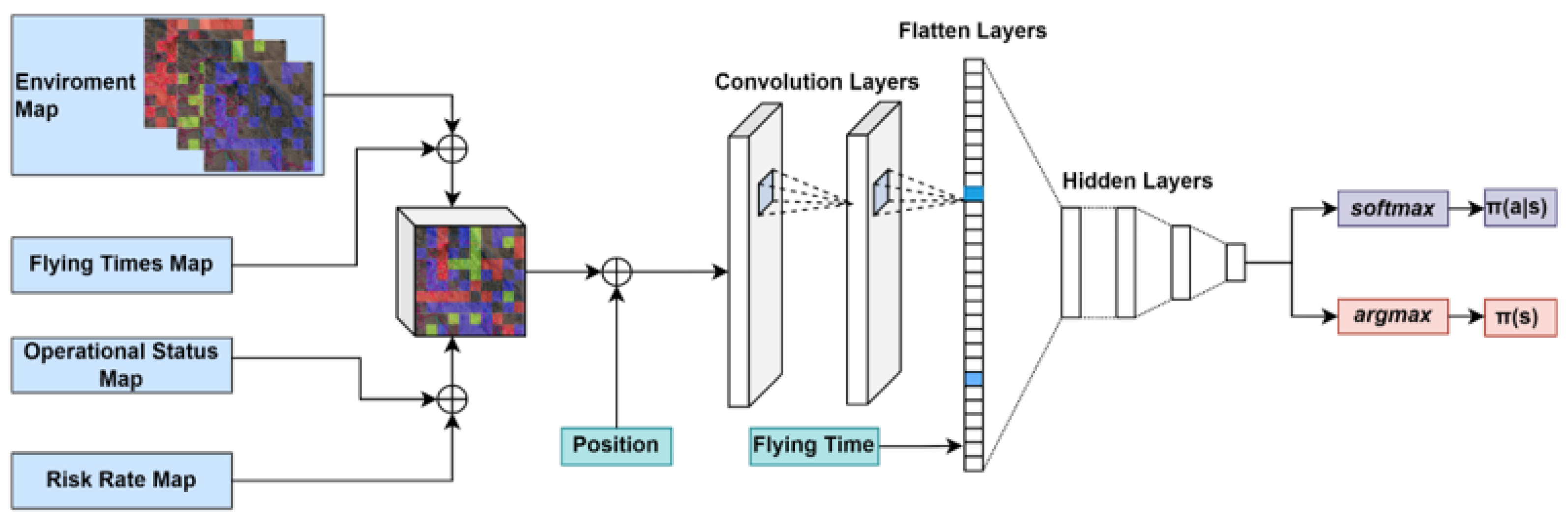
, is another punishment when landing outside the designated time. It ensures that UAVs complete their tasks within a specific timeframe, promoting efficiency in task execution. The last term is a fixed movement punishment for the purpose of encouraging UAVs to shorten their flight durations and giving priority to more efficient trajectories. It acts as a general penalty for unnecessary movements, incentivizing the UAVs to find the shortest and most effective paths. To avoid multiple visits by different UAVs in a visited grid, the risk point of this grid is assigned to 0. The general structure of the neural network model used is inspired by the one successfully implemented in [
39], as shown in
Figure 4.
6. Conclusions and Future Work Directions
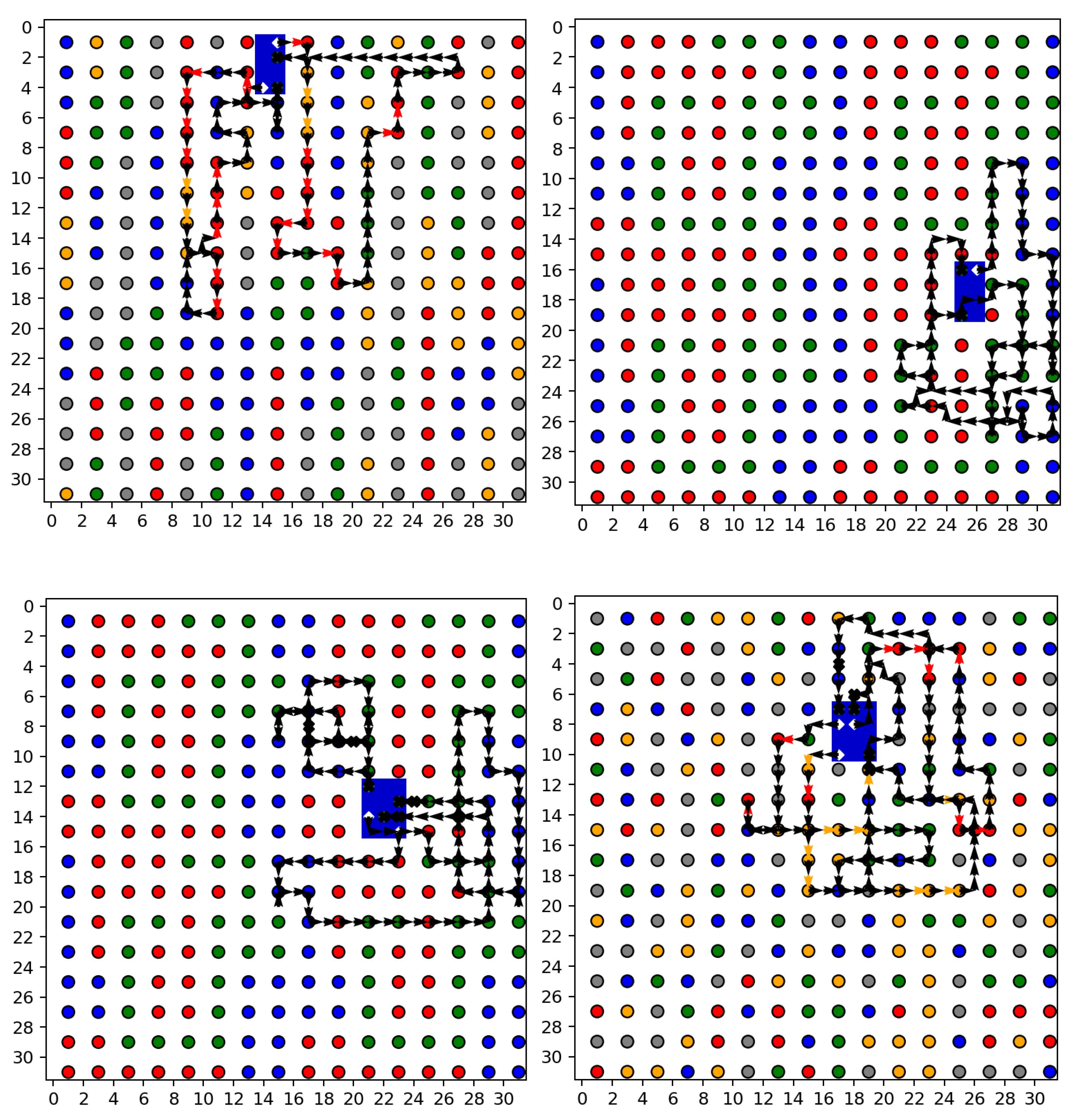
In this article, we explore the application of a novel deep reinforcement learning-based algorithm for the trajectory planning of multi-UAV systems tasked with wildfire reconnaissance and monitoring. The framework effectively partitions a target disaster area into grids, optimizing UAV paths based on calculated fire risk levels to ensure efficient and comprehensive surveillance. The use of multiple UAVs facilitates a collaborative approach to covering extensive forested areas, enhancing detection and monitoring capabilities in regions prone to wildfires. The simulations demonstrate that our approach significantly covers the requirements, particularly in terms of optimizing trajectories under constraints such as limited battery life and communication range. The simulation results reveal substantial improvements in the efficiency and effectiveness of UAV operations, including significant reductions in boundary violations and increases in point collection rates.
Furthermore, the integration of a deep Q-network (DQN) model with double Q-learning ensures that our algorithm adapts to various environmental conditions, continually learning from each interaction to enhance decision-making processes. This adaptability is crucial for managing the dynamic and often unpredictable nature of wildfire spread. The results highlight the potential of advanced machine learning techniques in addressing critical environmental challenges. The successful deployment of such UAV systems could lead to more timely and accurate responses to wildfires, potentially saving vast expanses of forest and wildlife and reducing human and economic losses. In conclusion, this study not only presents a robust technological solution to a pressing environmental issue but also paves the way for further research into the application of machine learning in disaster management and response systems.
It is essential to highlight the possible limitations and drawbacks to give an insight into potential future work directions. The proposed idea is based on small, inexpensive UAVs, allowing for flexibility in terms of complexity and cost. The optimum number of UAVs in practical cases should be carefully arranged. When the application scenario changes, it might take a long time to train the new system again. An important drawback of the proposed method is the lack of practical implementations. We believe that practical scenarios have the potential to experience new problems to be solved, requiring a lot of effort and time to handle. The future work direction of this study will mainly focus on practical implementations and solutions to the problems encountered.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}