

Detection and Classification of Obstructive Sleep Apnea Using Audio Spectrogram Analysis





Abstract
1. Introduction
- Increasing the subgroup of patients from 25 to 192;
- Performing the training and testing of the networks using a separate subset of data related to the patients (i.e., no data from patients used in the training appears in the test);
- Presenting the bi-LSTM architecture and performance comparisons in terms of confusion matrix for the identification of OSAHS;
- Providing results related to AHI prediction and AHI severity classification.
2. Related Works
3. OSAHS Dataset
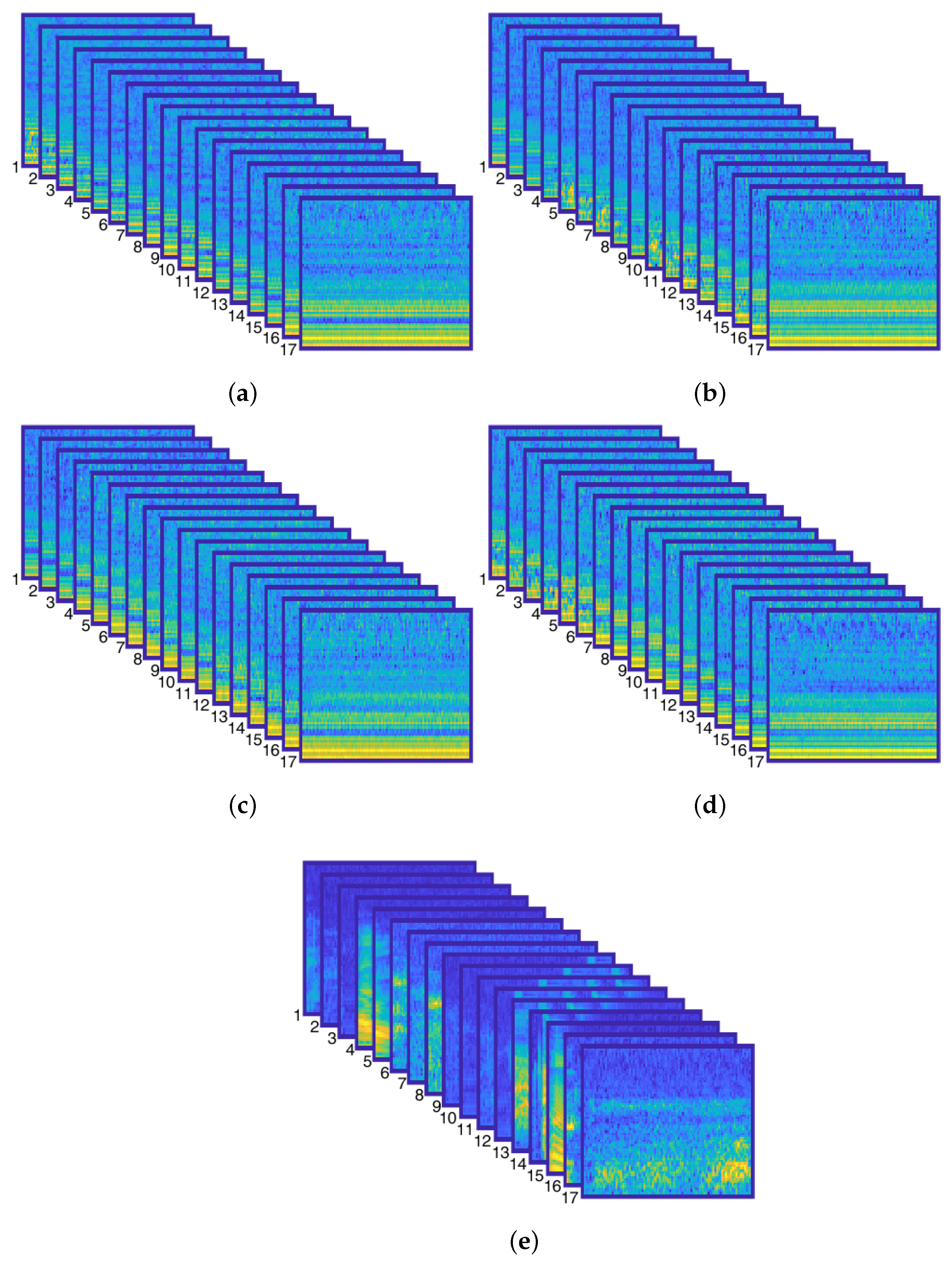
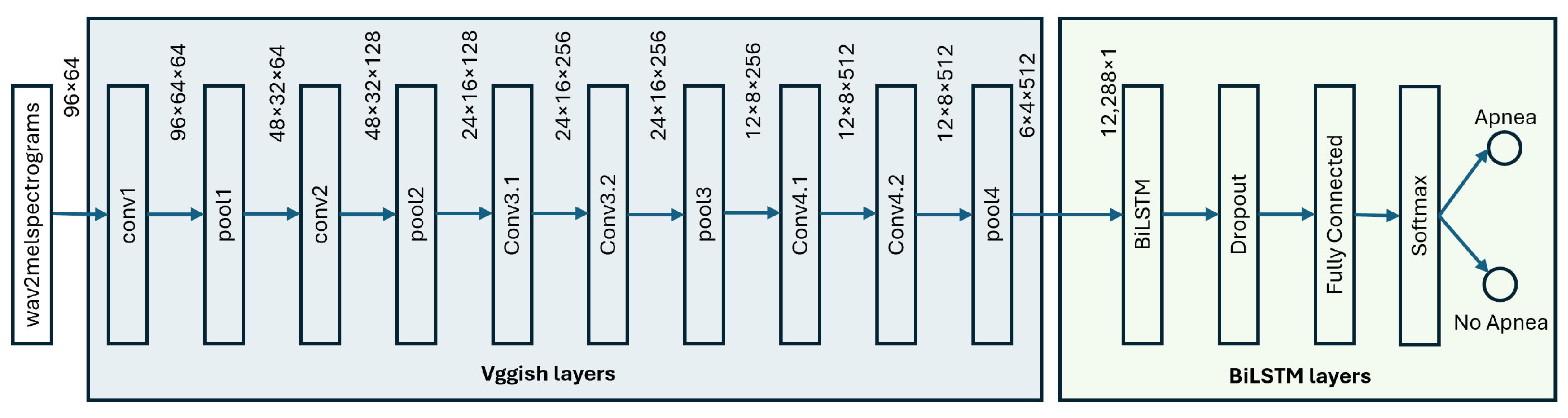
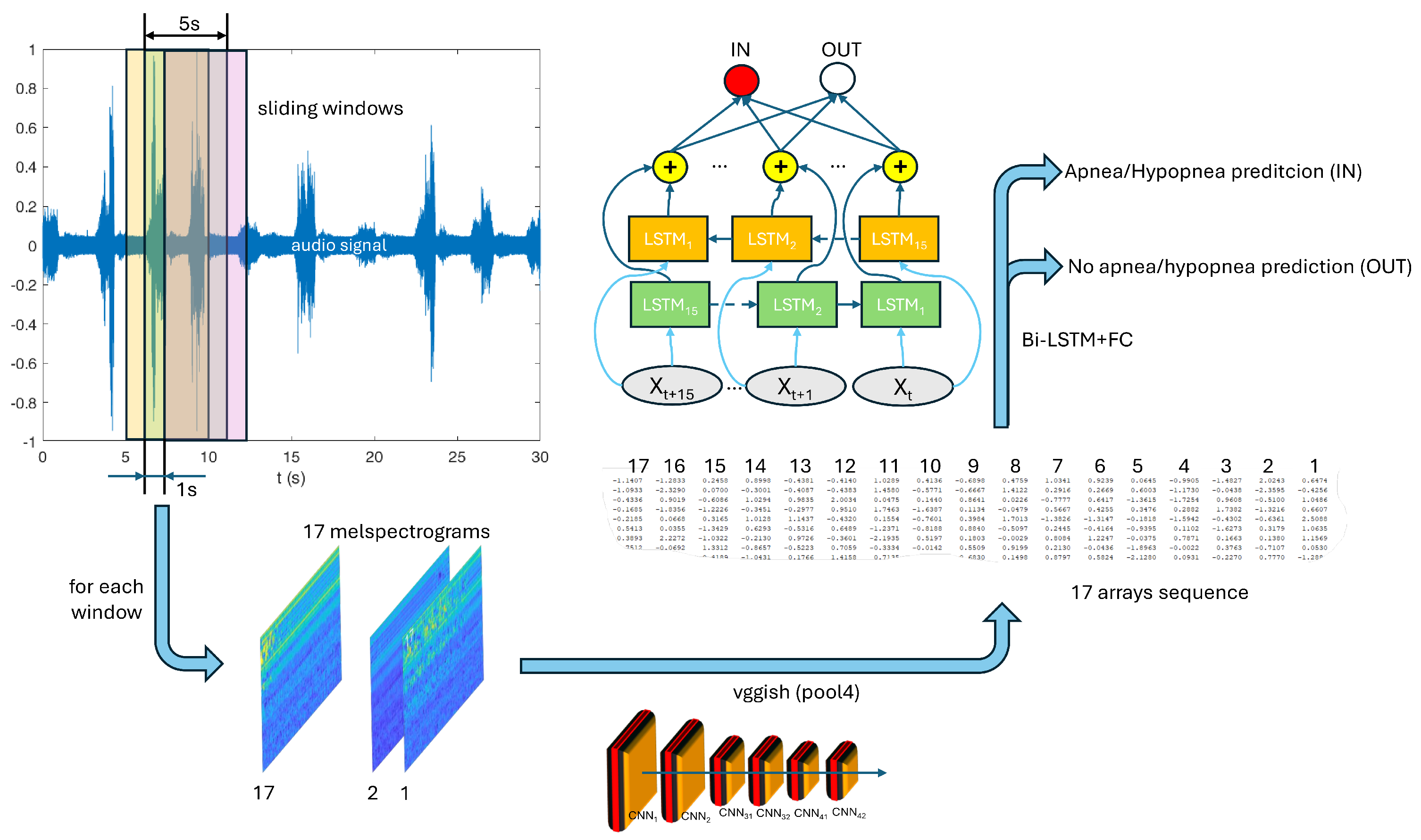
4. Proposed Methodology: Deep Neural Networks for Audio Processing
- The first submodel consists of the VGGish convolutional stages up to the “pool4” layer; this submodel is not trained further and it works with the same hyperparameters of the original VGGish;
- On the top of the previous submodel, a bi-LSTM network runs: it uses as input the output of the VGGish at the “pool4” layer and it is specifically trained to classify “Apnea” and “No-Apnea” events.
5. Experimentation and Results
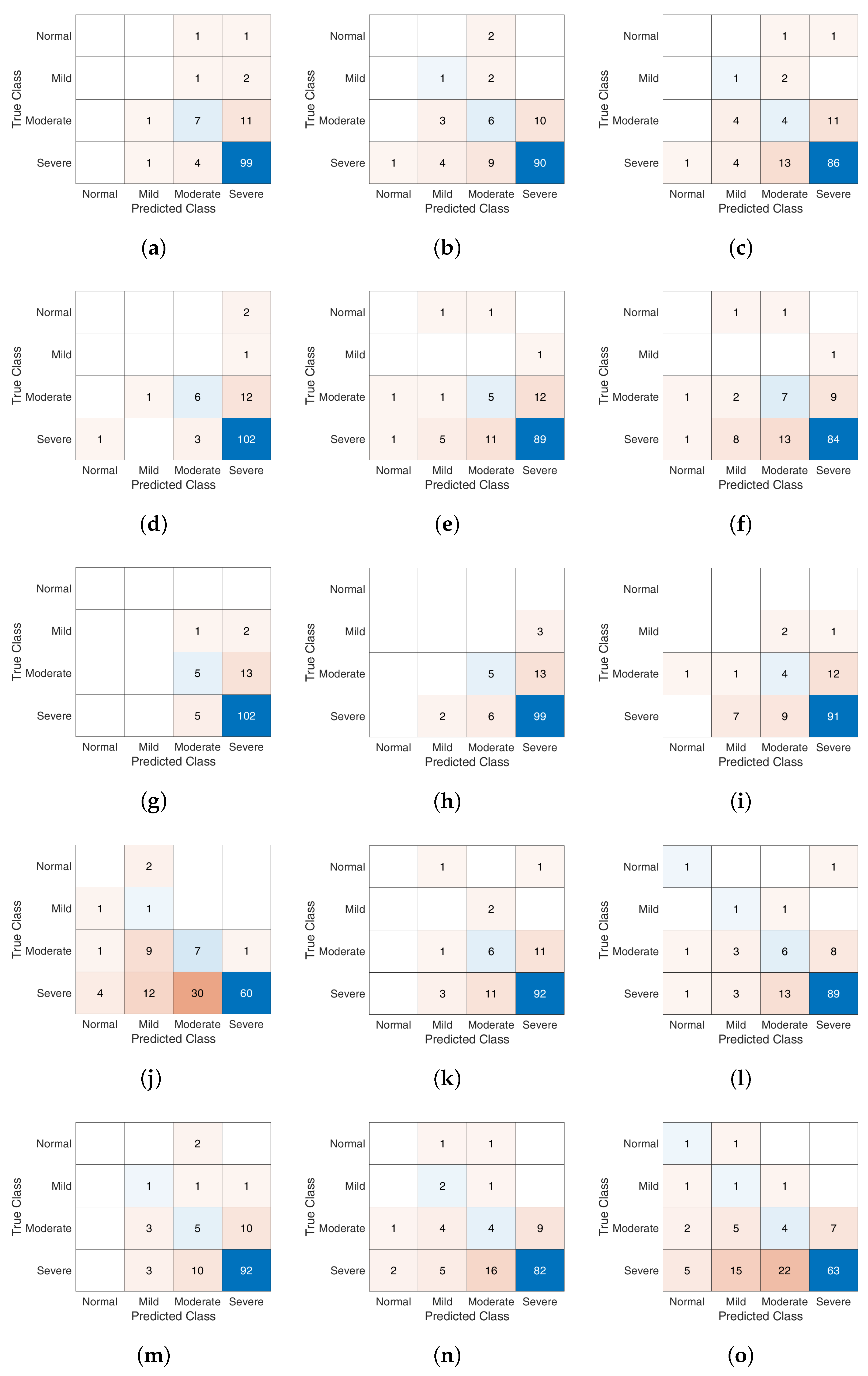
5.1. Classification Results
- Precision: The ability to properly identify positive samples ;
- Recall: The fraction of positive samples correctly classified ;
- Specificity: The fraction of negative samples correctly classified ;
- Accuracy: The fraction of patterns correctly classified ;
- F1-score: The harmonic mean between precision and recall .
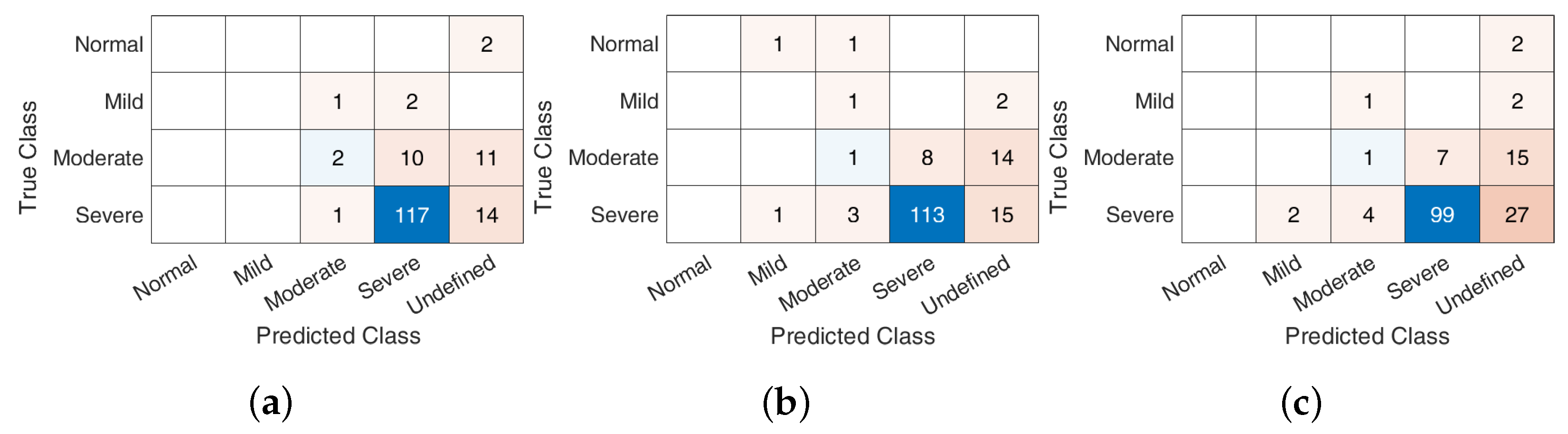
5.1.1. Discussion
- SSS versus SSP: For this experiment, the snoring sounds of all subjects were randomly divided into training, validation, and test sets in the ratio 8:1:1;
- NSP versus ASP: To conduct this experiment, snoring sounds from OSAHS patients were randomly divided into training, validation and test sets with a ratio of 8:1:1;
- NSP versus ASP-LOSOCV: For this experiment, snoring sounds of one subject were selected as the test set, and the remaining 39 subjects were used as the training set. This process was repeated 40 times, rating the subject under test, to calculate the average metrics.
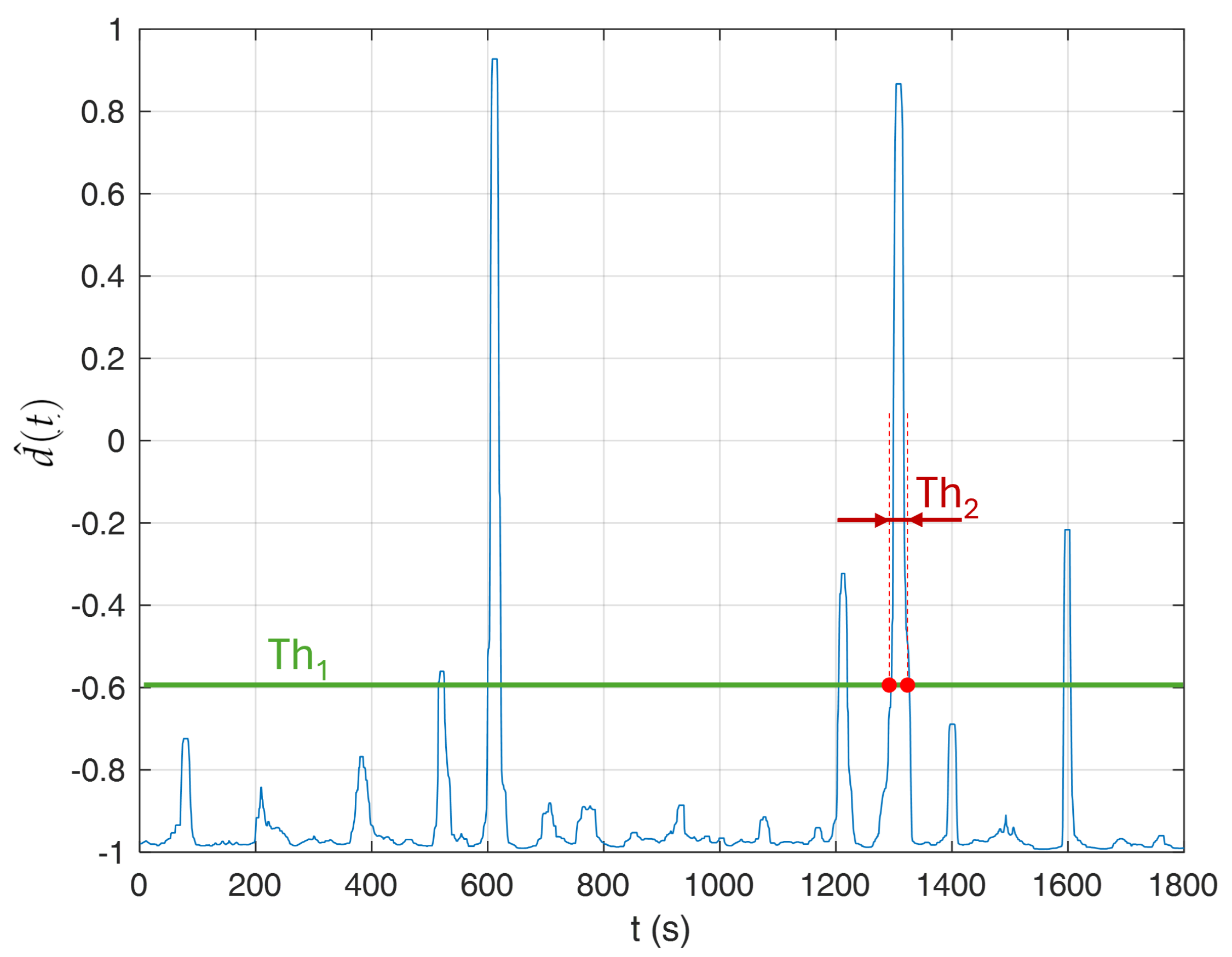
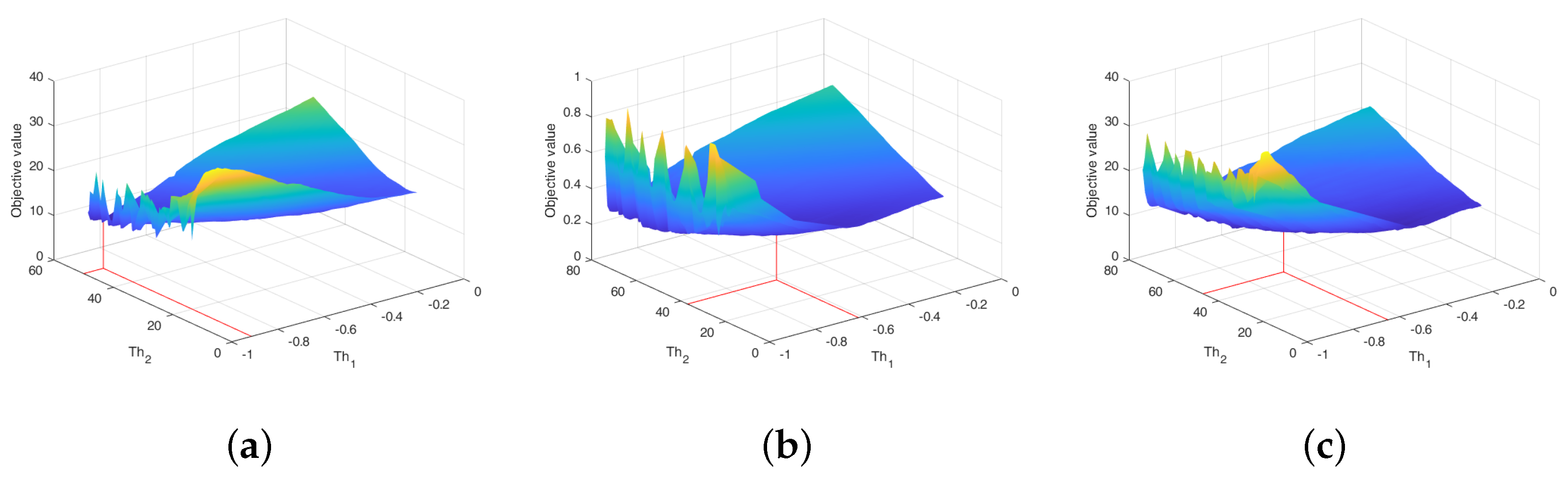
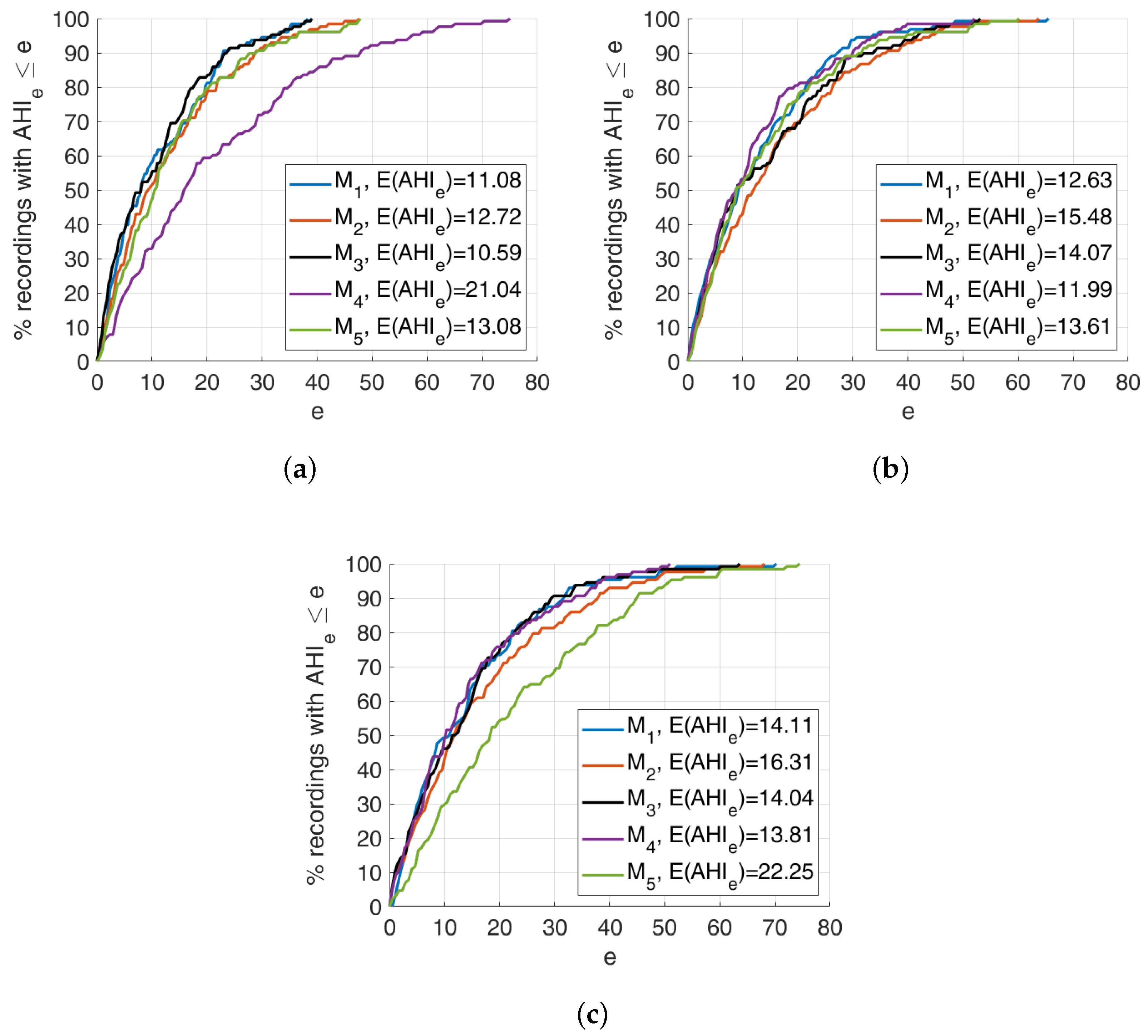
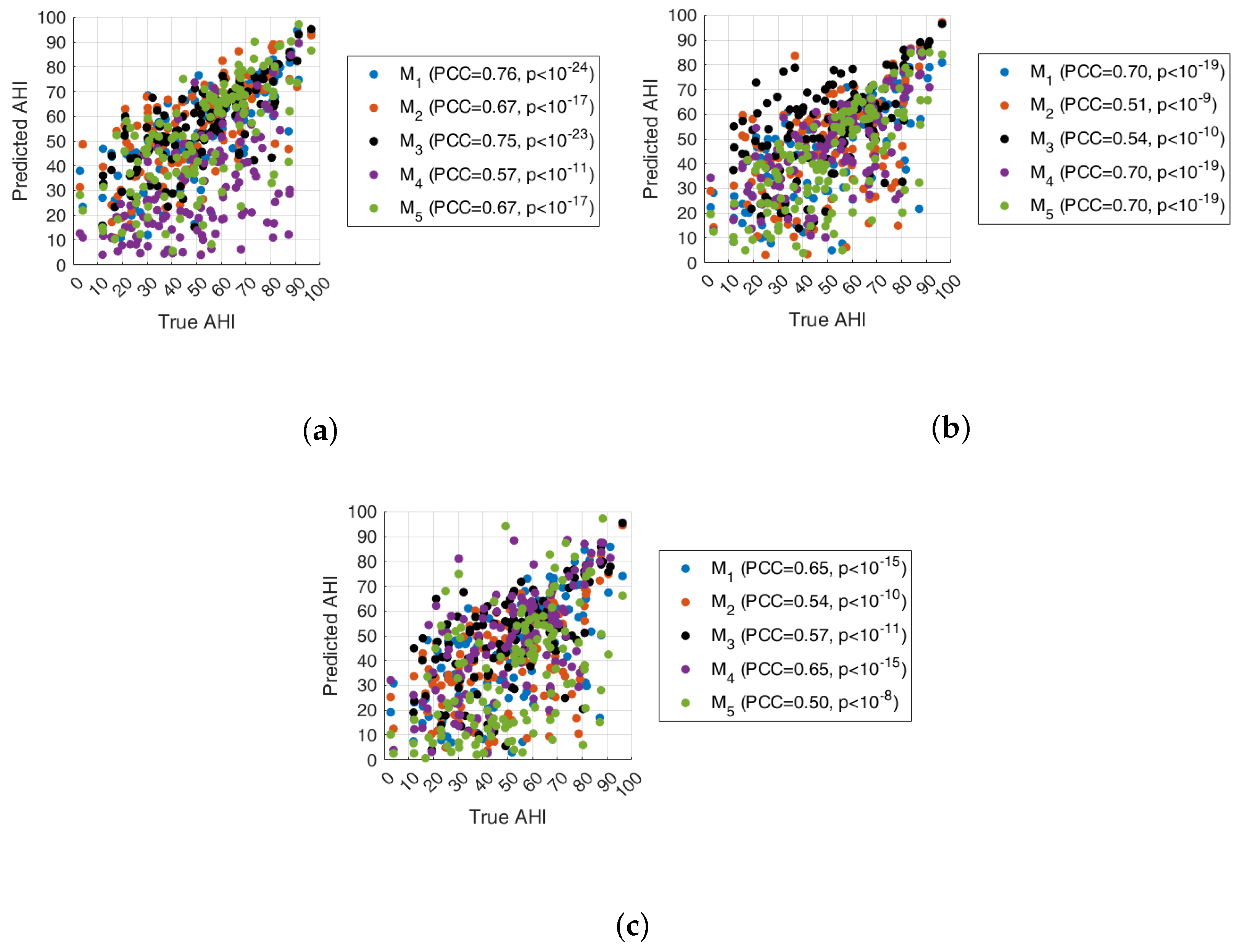
5.2. AHI Estimation and Classification
- The absolute value of the AHI error averaged over all recordings
- The relative absolute value of the AHI error, averaged over all recordings
- The class-weighted absolute value of the AHI error, averaged over all recordings
Discussion
5.3. Models Aggregation
- :
- :
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Pavlova, M.K.; Latreille, V. Sleep disorders. Am. J. Med. 2019, 132, 292–299. [Google Scholar] [CrossRef] [PubMed]
- Armstrong, M.; Wallace, C.; Marais, J. The effect of surgery upon the quality of life in snoring patients and their partners: A between-subjects case-controlled trial. Clin. Otolaryngol. Allied Sci. 1999, 24, 510–522. [Google Scholar] [CrossRef] [PubMed]
- Gall, R.; Isaac, L.; Kryger, M. Quality of life in mild obstructive sleep apnea. Sleep 1993, 16, S59–S61. [Google Scholar] [CrossRef] [PubMed]
- Zhu, K.; Li, M.; Akbarian, S.; Hafezi, M.; Yadollahi, A.; Taati, B. Vision-based heart and respiratory rate monitoring during sleep—A validation study for the population at risk of sleep apnea. IEEE J. Transl. Eng. Health Med. 2019, 7, 1900708. [Google Scholar] [CrossRef] [PubMed]
- Imtiaz, S.A. A systematic review of sensing technologies for wearable sleep staging. Sensors 2021, 21, 1562. [Google Scholar] [CrossRef]
- Sabil, A.; Glos, M.; Günther, A.; Schöbel, C.; Veauthier, C.; Fietze, I.; Penzel, T. Comparison of apnea detection using oronasal thermal airflow sensor, nasal pressure transducer, respiratory inductance plethysmography and tracheal sound sensor. J. Clin. Sleep Med. 2019, 15, 285–292. [Google Scholar] [CrossRef] [PubMed]
- Fietze, I.; Laharnar, N.; Obst, A.; Ewert, R.; Felix, S.B.; Garcia, C.; Gläser, S.; Glos, M.; Schmidt, C.O.; Stubbe, B.; et al. Prevalence and association analysis of obstructive sleep apnea with gender and age differences—Results of SHIP-Trend. J. Sleep Res. 2019, 28, e12770. [Google Scholar] [CrossRef]
- Berry, R.B.; Brooks, R.; Gamaldo, C.E.; Harding, S.M.; Marcus, C.; Vaughn, B.V. The AASM manual for the scoring of sleep and associated events. Rules Terminol. Tech. Specif. Darien Illinois Am. Acad. Sleep Med. 2012, 176, 2012. [Google Scholar]
- Bhutada, A.M.; Broughton, W.A.; Garand, K.L. Obstructive sleep apnea syndrome (OSAS) and swallowing function—A systematic review. Sleep Breath. 2020, 24, 791–799. [Google Scholar] [CrossRef]
- Almazaydeh, L.; Elleithy, K.; Faezipour, M. Obstructive sleep apnea detection using SVM-based classification of ECG signal features. In Proceedings of the 2012 Annual International Conference of the IEEE Engineering in Medicine and Biology Society, San Diego, CA, USA, 28 August–1 September 2012; pp. 4938–4941. [Google Scholar]
- Mendonca, F.; Mostafa, S.S.; Ravelo-Garcia, A.G.; Morgado-Dias, F.; Penzel, T. A review of obstructive sleep apnea detection approaches. IEEE J. Biomed. Health Inform. 2018, 23, 825–837. [Google Scholar] [CrossRef]
- Zhou, Q.; Shan, J.; Ding, W.; Wang, C.; Yuan, S.; Sun, F.; Li, H.; Fang, B. Cough Recognition Based on Mel-Spectrogram and Convolutional Neural Network. Front. Robot. AI 2021, 8, 580080. [Google Scholar] [CrossRef] [PubMed]
- Castro-Ospina, A.E.; Solarte-Sanchez, M.A.; Vega-Escobar, L.S.; Isaza, C.; MartÃnez-Vargas, J.D. Graph-Based Audio Classification Using Pre-Trained Models and Graph Neural Networks. Sensors 2024, 24, 2106. [Google Scholar] [CrossRef] [PubMed]
- Serrano, S.; Patanè, L.; Scarpa, M. Obstructive Sleep Apnea identification based on VGGish networks. In Proceedings of the Proceedings—European Council for Modelling and Simulation, ECMS, Florence, Italy, 20–23 June 2023; pp. 556–561. [Google Scholar]
- Korompili, G.; Amfilochiou, A.; Kokkalas, L.; Mitilineos, S.A.; Tatlas, N.A.; Kouvaras, M.; Kastanakis, E.; Maniou, C.; Potirakis, S.M. PSG-Audio, a scored polysomnography dataset with simultaneous audio recordings for sleep apnea studies. Sci. Data 2021, 8, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Yang, C.; Cheung, G.; Stankovic, V.; Chan, K.; Ono, N. Sleep apnea detection via depth video and audio feature learning. IEEE Trans. Multimed. 2016, 19, 822–835. [Google Scholar] [CrossRef]
- Amiriparian, S.; Gerczuk, M.; Ottl, S.; Cummins, N.; Freitag, M.; Pugachevskiy, S.; Baird, A.; Schuller, B. Snore sound classification using image-based deep spectrum features. In Proceedings of the INTERSPEECH 2017, Stockholm, Sweden, 20–24 August 2017. [Google Scholar]
- Dong, Q.; Jiraraksopakun, Y.; Bhatranand, A. Convolutional Neural Network-Based Obstructive Sleep Apnea Identification. In Proceedings of the 2021 IEEE 6th International Conference on Computer and Communication Systems (ICCCS), Chengdu, China, 23–26 April 2021; pp. 424–428. [Google Scholar]
- Wang, L.; Guo, S.; Huang, W.; Qiao, Y. Places205-vggnet models for scene recognition. arXiv 2015, arXiv:1508.01667. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Targ, S.; Almeida, D.; Lyman, K. Resnet in resnet: Generalizing residual architectures. arXiv 2016, arXiv:1603.08029. [Google Scholar]
- Maritsa, A.A.; Ohnishi, A.; Terada, T.; Tsukamoto, M. Audio-based Wearable Multi-Context Recognition System for Apnea Detection. In Proceedings of the 2021 6th International Conference on Intelligent Informatics and Biomedical Sciences (ICIIBMS), Kyushu, Japan, 25–27 November 2021; Volume 6, pp. 266–273. [Google Scholar]
- Maritsa, A.A.; Ohnishi, A.; Terada, T.; Tsukamoto, M. Apnea and Sleeping-state Recognition by Combination Use of Openair/Contact Microphones. In Proceedings of the INTERACTION 2022; Information Processing Society of Japan (IPSJ): Tokyo, Japan, 2022; pp. 87–96. [Google Scholar]
- Wang, C.; Peng, J.; Song, L.; Zhang, X. Automatic snoring sounds detection from sleep sounds via multi-features analysis. Australas. Phys. Eng. Sci. Med. 2017, 40, 127–135. [Google Scholar] [CrossRef] [PubMed]
- Shen, F.; Cheng, S.; Li, Z.; Yue, K.; Li, W.; Dai, L. Detection of snore from OSAHS patients based on deep learning. J. Healthc. Eng. 2020, 2020, 8864863. [Google Scholar] [CrossRef] [PubMed]
- Wu, D.; Tao, Z.; Wu, Y.; Shen, C.; Xiao, Z.; Zhang, X.; Wu, D.; Zhao, H. Speech endpoint detection in noisy environment using Spectrogram Boundary Factor. In Proceedings of the 2016 9th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Datong, China, 15–17 October 2016; pp. 964–968. [Google Scholar] [CrossRef]
- Cheng, S.; Wang, C.; Yue, K.; Li, R.; Shen, F.; Shuai, W.; Li, W.; Dai, L. Automated sleep apnea detection in snoring signal using long short-term memory neural networks. Biomed. Signal Process. Control 2022, 71, 103238. [Google Scholar] [CrossRef]
- Sun, X.; Ding, L.; Song, Y.; Peng, J.; Song, L.; Zhang, X. Automatic identifying OSAHS patients and simple snorers based on Gaussian mixture models. Physiol. Meas. 2023, 44, 045003. [Google Scholar] [CrossRef]
- Song, Y.; Sun, X.; Ding, L.; Peng, J.; Song, L.; Zhang, X. AHI estimation of OSAHS patients based on snoring classification and fusion model. Am. J. Otolaryngol. 2023, 44, 103964. [Google Scholar] [CrossRef] [PubMed]
- Ding, L.; Peng, J.; Song, L.; Zhang, X. Automatically detecting apnea-hypopnea snoring signal based on VGG19 + LSTM. Biomed. Signal Process. Control 2023, 80, 104351. [Google Scholar] [CrossRef]
- SoX-Sound eXchange. Available online: https://sourceforge.net/projects/sox/ (accessed on 29 May 2024).
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef] [PubMed]
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. Deep reinforcement learning: A brief survey. IEEE Signal Process. Mag. 2017, 34, 26–38. [Google Scholar] [CrossRef]
- Luong, N.C.; Hoang, D.T.; Gong, S.; Niyato, D.; Wang, P.; Liang, Y.C.; Kim, D.I. Applications of deep reinforcement learning in communications and networking: A survey. IEEE Commun. Surv. Tutor. 2019, 21, 3133–3174. [Google Scholar] [CrossRef]
- Bkassiny, M.; Li, Y.; Jayaweera, S.K. A survey on machine-learning techniques in cognitive radios. IEEE Commun. Surv. Tutor. 2012, 15, 1136–1159. [Google Scholar] [CrossRef]
- Serrano, S.; Scarpa, M.; Maali, A.; Soulmani, A.; Boumaaz, N. Random sampling for effective spectrum sensing in cognitive radio time slotted environment. Phys. Commun. 2021, 49, 101482. [Google Scholar] [CrossRef]
- Bithas, P.S.; Michailidis, E.T.; Nomikos, N.; Vouyioukas, D.; Kanatas, A.G. A survey on machine-learning techniques for UAV-based communications. Sensors 2019, 19, 5170. [Google Scholar] [CrossRef]
- Grasso, C.; Raftopoulos, R.; Schembra, G.; Serrano, S. H-HOME: A learning framework of federated FANETs to provide edge computing to future delay-constrained IoT systems. Comput. Netw. 2022, 219, 109449. [Google Scholar] [CrossRef]
- Serrano, S.; Sahbudin, M.A.B.; Chaouch, C.; Scarpa, M. A new fingerprint definition for effective song recognition. Pattern Recognit. Lett. 2022, 160, 135–141. [Google Scholar] [CrossRef]
- Sahbudin, M.A.B.; Chaouch, C.; Scarpa, M.; Serrano, S. IOT based song recognition for FM radio station broadcasting. In Proceedings of the 2019 7th International Conference on Information and Communication Technology (ICoICT), Kuala Lumpur, Malaysia, 24–26 July 2019; pp. 1–6. [Google Scholar]
- Sahbudin, M.A.B.; Scarpa, M.; Serrano, S. MongoDB clustering using K-means for real-time song recognition. In Proceedings of the 2019 International Conference on Computing, Networking and Communications (ICNC), Honolulu, HI, USA, 18–21 February 2019; pp. 350–354. [Google Scholar]
- Serrano, S.; Scarpa, M. Fast and Accurate Song Recognition: An Approach Based on Multi-Index Hashing. In Proceedings of the 2022 International Conference on Software, Telecommunications and Computer Networks (SoftCOM), Split, Croatia, 22–24 September 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Alharbi, S.; Alrazgan, M.; Alrashed, A.; Alnomasi, T.; Almojel, R.; Alharbi, R.; Alharbi, S.; Alturki, S.; Alshehri, F.; Almojil, M. Automatic speech recognition: Systematic literature review. IEEE Access 2021, 9, 131858–131876. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Hershey, S.; Chaudhuri, S.; Ellis, D.P.W.; Gemmeke, J.F.; Jansen, A.; Moore, C.; Plakal, M.; Platt, D.; Saurous, R.A.; Seybold, B.; et al. CNN Architectures for Large-Scale Audio Classification. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017. [Google Scholar]
- The MathWorks Inc. MATLAB Version: 23.2.0.2515942 (R2023b) Update 7. Available online: https://www.mathworks.com (accessed on 29 May 2024).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | # Excerpts |
|---|---|
| OUT | 247,542 |
| IN | 104,777 |
| IN(CA) | 3696 |
| IN(HA) | 21,819 |
| IN(MA) | 15,987 |
| IN(OA) | 63,219 |
| IN(PR) | 56 |
| Fold #1 () | Fold #2 () | Fold #3 () | Fold #4 () | Fold #5 () | Fold #6 () | |
|---|---|---|---|---|---|---|
| #1 | 00001000 | 00001014 | 00001028 | 00001008 | 00000995 | 00000999 |
| #2 | 00001010 | 00001022 | 00001041 | 00001016 | 00001037 | 00001006 |
| #3 | 00001039 | 00001093 | 00001088 | 00001059 | 00001045 | 00001018 |
| #4 | 00001069 | 00001104 | 00001116 | 00001082 | 00001084 | 00001020 |
| #5 | 00001097 | 00001131 | 00001122 | 00001089 | 00001086 | 00001024 |
| #6 | 00001106 | 00001147 | 00001126 | 00001139 | 00001095 | 00001026 |
| #7 | 00001108 | 00001155 | 00001135 | 00001151 | 00001110 | 00001043 |
| #8 | 00001120 | 00001172 | 00001137 | 00001153 | 00001112 | 00001057 |
| #9 | 00001157 | 00001176 | 00001169 | 00001161 | 00001127 | 00001071 |
| #10 | 00001195 | 00001197 | 00001210 | 00001171 | 00001129 | 00001073 |
| #11 | 00001249 | 00001198 | 00001222 | 00001178 | 00001143 | 00001118 |
| #12 | 00001250 | 00001202 | 00001224 | 00001193 | 00001145 | 00001163 |
| #13 | 00001258 | 00001206 | 00001245 | 00001219 | 00001174 | 00001186 |
| #14 | 00001265 | 00001215 | 00001263 | 00001228 | 00001182 | 00001191 |
| #15 | 00001295 | 00001217 | 00001268 | 00001230 | 00001204 | 00001200 |
| #16 | 00001310 | 00001234 | 00001276 | 00001247 | 00001239 | 00001208 |
| #17 | 00001314 | 00001270 | 00001294 | 00001252 | 00001241 | 00001226 |
| #18 | 00001318 | 00001284 | 00001312 | 00001262 | 00001254 | 00001232 |
| #19 | 00001327 | 00001287 | 00001329 | 00001282 | 00001274 | 00001256 |
| #20 | 00001344 | 00001299 | 00001335 | 00001285 | 00001290 | 00001301 |
| #21 | 00001355 | 00001303 | 00001369 | 00001288 | 00001292 | 00001308 |
| #22 | 00001361 | 00001331 | 00001373 | 00001306 | 00001305 | 00001316 |
| #23 | 00001374 | 00001340 | 00001384 | 00001358 | 00001320 | 00001324 |
| #24 | 00001378 | 00001342 | 00001396 | 00001360 | 00001322 | 00001337 |
| #25 | 00001386 | 00001376 | 00001398 | 00001367 | 00001333 | 00001357 |
| #26 | 00001406 | 00001380 | 00001402 | 00001371 | 00001408 | 00001365 |
| #27 | 00001419 | 00001382 | 00001411 | 00001392 | 00001440 | 00001388 |
| #28 | 00001424 | 00001412 | 00001414 | 00001432 | 00001451 | 00001390 |
| #29 | 00001434 | 00001436 | 00001438 | 00001449 | 00001461 | 00001400 |
| #30 | 00001442 | 00001447 | 00001455 | 00001453 | 00001474 | 00001428 |
| #31 | 00001444 | 00001463 | 00001459 | 00001457 | 00001486 | 00001430 |
| #32 | 00001488 | 00001476 | 00001478 | 00001480 | 00001494 | 00001492 |
| Hyperparameter | Value |
|---|---|
| Training/validation percentage | |
| Mini-batch size | 64 |
| Max epochs | 60 |
| Initial learn rate | |
| Gradient threshold | 2 |
| Number of hidden units (bi-LSTM layer) | 15 |
| Probability to drop out input elements (dropout layer) | |
| Output size (fully connected layer) | 2 |
| P (%) | R (%) | S (%) | A (%) | F1 (%) | |
|---|---|---|---|---|---|
| 71.06 | |||||
| AHI Class | F #1 | F #2 | F #3 | F #4 | F #5 | F #6 | ALL |
|---|---|---|---|---|---|---|---|
| Normal | 0 | 0 | 2 | 0 | 0 | 0 | |
| Mild | 0 | 2 | 0 | 1 | 0 | 1 | |
| Moderate | 4 | 4 | 5 | 5 | 5 | 2 | |
| Severe | 28 | 26 | 25 | 26 | 27 | 29 |
| 49 | 62 | 59 | ||||
| 47 | 50 | 66 | ||||
| 50 | 37 | 47 | ||||
| 47 | 58 | 25 | ||||
| 47 | 58 | 35 | ||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Serrano, S.; Patanè, L.; Serghini, O.; Scarpa, M. Detection and Classification of Obstructive Sleep Apnea Using Audio Spectrogram Analysis. Electronics 2024, 13, 2567. https://doi.org/10.3390/electronics13132567
Serrano S, Patanè L, Serghini O, Scarpa M. Detection and Classification of Obstructive Sleep Apnea Using Audio Spectrogram Analysis. Electronics. 2024; 13(13):2567. https://doi.org/10.3390/electronics13132567
Chicago/Turabian StyleSerrano, Salvatore, Luca Patanè, Omar Serghini, and Marco Scarpa. 2024. "Detection and Classification of Obstructive Sleep Apnea Using Audio Spectrogram Analysis" Electronics 13, no. 13: 2567. https://doi.org/10.3390/electronics13132567
APA StyleSerrano, S., Patanè, L., Serghini, O., & Scarpa, M. (2024). Detection and Classification of Obstructive Sleep Apnea Using Audio Spectrogram Analysis. Electronics, 13(13), 2567. https://doi.org/10.3390/electronics13132567