1. Introduction
With the 2024 release of the Apple Vision Pro and its Persona digital avatar system, 3D telepresence has become more widely desired and accessible than ever. Apple’s Persona system is technically very impressive, but it does not stream any live-captured 3D data. Despite a recent proliferation of 3D capture hardware and advances in methods that allow for the real-time capture of 3D range data at high resolutions and frame rates, the vast majority of mainstream use cases can only use this data locally. This is because, without compression, a 3D data stream could be on the order of gigabits per second, a data rate that cannot be reliably sustained on a typical wireless broadband connection.
In order to encourage the development and adoption of novel 3D streaming use cases, such as 3D telepresence, performance capture, and telerobotics, more efficient methods of compressing this 3D information are required. Optimally, this 3D information could be stored in a way that allows compression by modern 2D image or video codecs, which are already highly optimized to exploit spatiotemporal redundancies and are very often hardware-accelerated. Unfortunately, values within a conventional depth image generally have higher bit depths (e.g., 16-bit, 32-bit) than color image channels, so they cannot be accurately compressed with the most common lossy image formats. Depth value bits can be directly split across multiple image channels, but this results in rapid spatial oscillations and discontinuities that do not compress well. Instead, an efficient, compression-resilient depth encoding scheme is required to smoothly and intelligently spread the depth information across the red, green, and blue color channels of a regular 2D image so that modern image and video codecs can be leveraged.
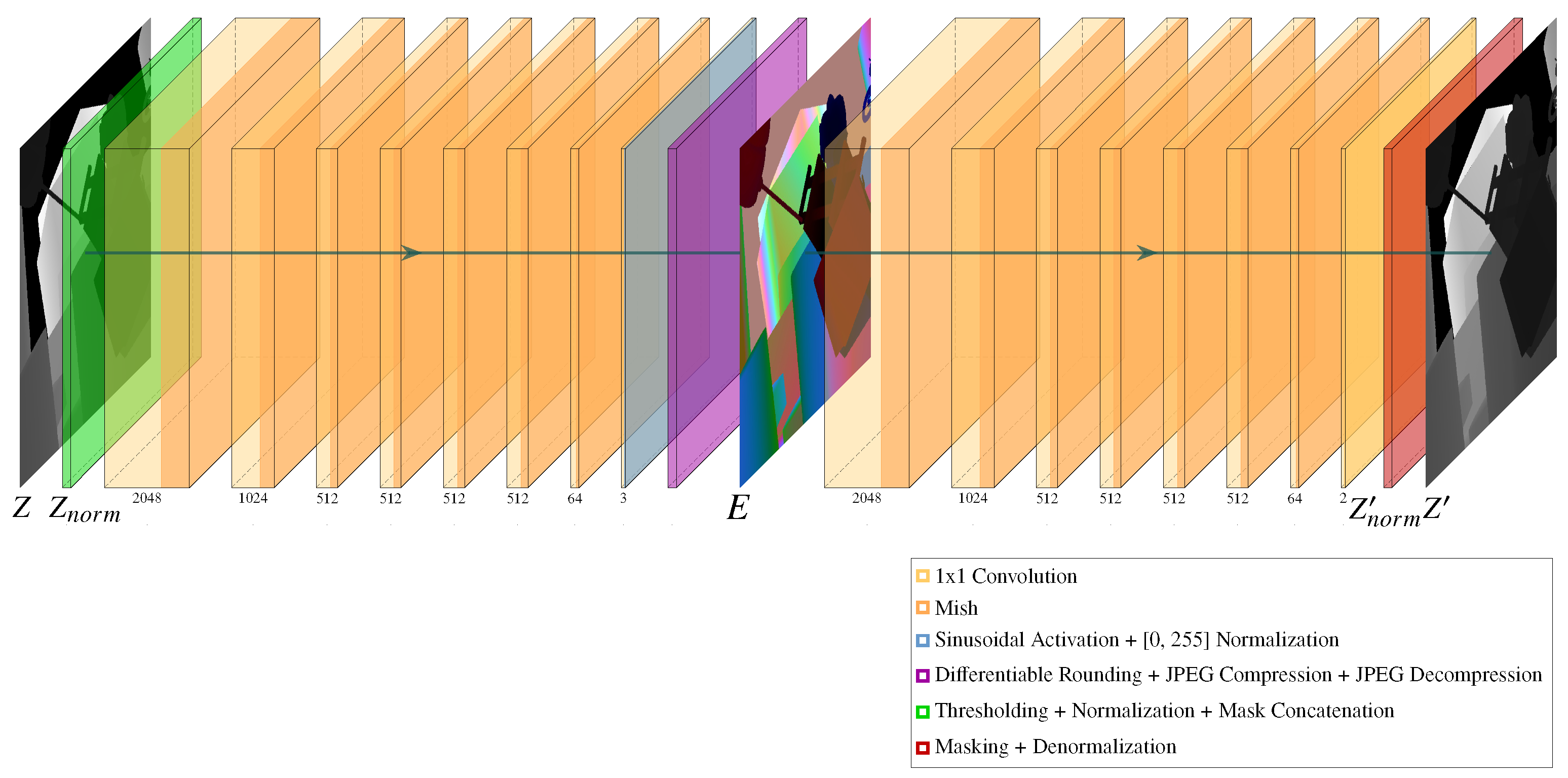
This paper proposes N-DEPTH, the first learned depth-to-RGB encoding scheme that is directly optimized for a lossy image compression codec. The key to this encoding scheme is a fully differentiable pipeline that includes a pair of neural networks sandwiched around a differentiable approximation of JPEG. An illustration of this pipeline can be seen in
Figure 1. When trained end-to-end, the proposed system is able to minimize depth reconstruction losses and outperform a state-of-the-art, handcrafted algorithm. Furthermore, the proposed method is directly applicable to modern video codecs (e.g., H.264), making this neural encoding suitable for 3D data streaming applications.
Contributions
We introduce N-DEPTH, a novel neural depth encoding scheme optimized for lossy compression codecs to efficiently encode depth maps into 24-bit RGB representations.
We utilize a fully differentiable pipeline, sandwiched around a differentiable approximation of JPEG, allowing end-to-end training and optimization.
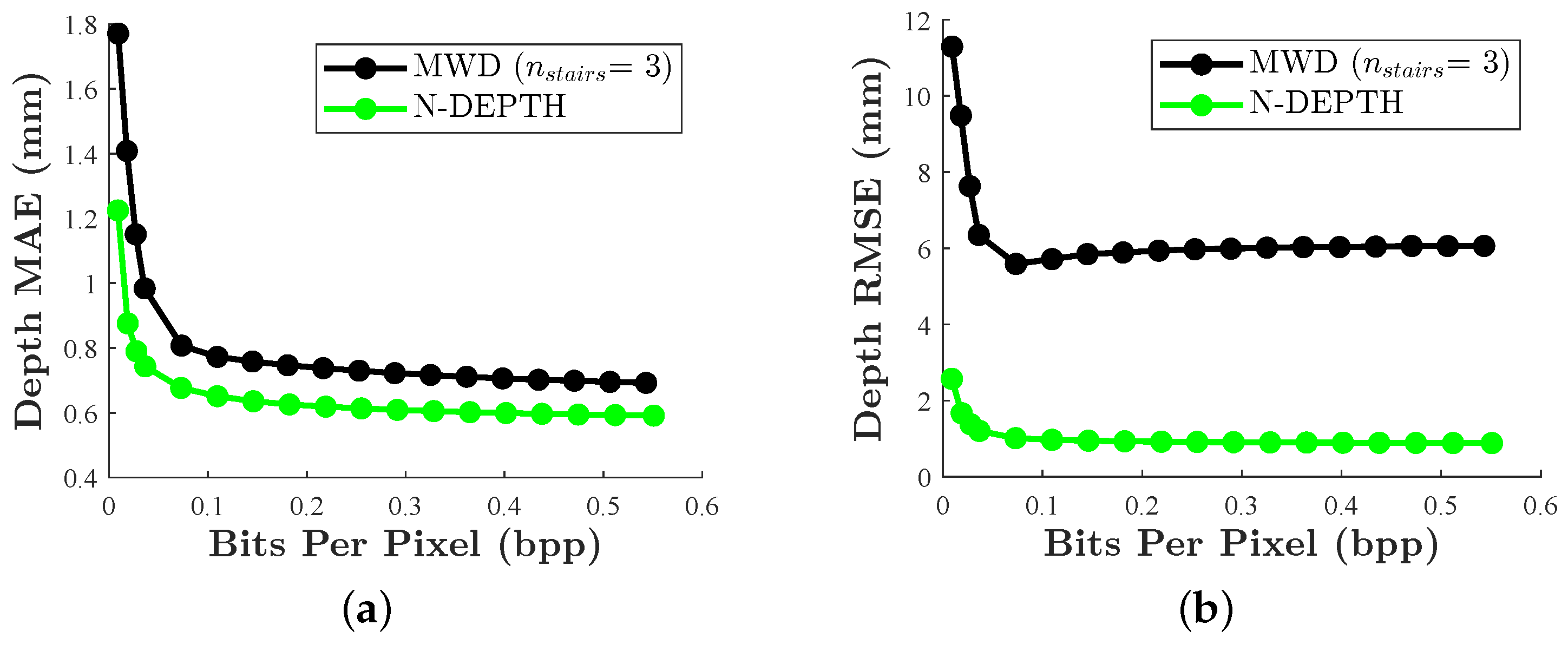
We demonstrate significant performance improvements over a state-of-the-art method in various depth reconstruction error metrics across a wide range of image and video qualities, while also achieving lower file sizes.
We offer a solution for emerging 3D streaming and telepresence applications, enabling high-quality and efficient 3D depth data storage and transmission.
In the remainder of this paper,
Section 2 introduces related research up to the development of the proposed method,
Section 3 describes the principle of the method,
Section 4 provides experimental results for the method,
Section 5 offers a discussion of the method, and
Section 6 concludes the work. A preliminary version of this research was published in the proceedings of the 3D Imaging and Applications conference at the Electronic Imaging Symposium 2024 [
1].
2. Related Work
Devices capable of reconstructing high-precision and high-resolution 3D geometry at real-time speeds have widely proliferated over the past decade [
2,
3]. Given this, such RGB-D and 3D imaging devices are being adopted within numerous applications in industry, entertainment, manufacturing, security, forensic sciences, and more. While the added spatial dimension has brought improvement to many domains, they are typically limited to working with the data at the capture source. That is, due to the high volume of data that 3D devices can produce, it is a practical challenge to store these 3D data or to transmit these 3D data to a remote location in real time [
4] (e.g., for remote archival, processing, or visualization). Such functionality could be particularly beneficial for many applications, such as security, telepresence, entertainment, communications, robotics, and more. Given this, researchers have sought a robust and efficient method with which to compress 3D data.
While there has been much research proposed in the context of generic 3D mesh compression [
5], such methods might unnecessarily impose too much overhead when the data to be compressed are produced by a single-perspective 3D imaging device. These devices (e.g., stereo vision, structured light, time-of-flight) often represent their data within a single depth map [
6]. This depth map (
Z) can be used to recover complete 3D coordinates (i.e., values
and
for each
) if the imaging system’s calibration parameters are known. This means that if the depth map (
Z) can be efficiently compressed then the 3D geometry can be recovered.
Storing only the depth map simplifies the task of 3D data compression. Since depth maps are often represented with 16-bit or 32-bit precision, whereas a regular RGB image typically uses 24 bits per pixel (i.e., 8 bits per channel), there are two prevailing approaches to storing depth maps as images. Some image-based depth encoding schemes ameliorate the bit-depth problem by using high dynamic range (HDR) image and video codecs. For instance, in Project Starline [
7], a seminal 3D telepresence system, the depth streams were stored directly within the 10-bit luminance channels of a series of H.265 video streams. This, however, limited this system to a maximum of only 10 bits of precision for each depth stream. An alternative approach is to spread the depth map’s high bit-depth information over each of the red, green, and blue channels’ 8 bits. There have been a variety of approaches proposed for encoding 3D geometry data into the RGB values of a 2D image [
8,
9,
10]. Ultimately, these methods attempt to intelligently distribute the 3D geometry’s data across the 2D output image’s RGB channels, such that (1) the resulting RGB image can be efficiently stored with 2D compression techniques and (2) the 3D geometry can be robustly reconstructed (i.e., decoded) from the signals in the compressed RGB channels.
Multiwavelength depth (MWD) [
11] is one of the few state-of-the-art methods for encoding depth data across the red, green, and blue color channels of a typical RGB image that is robust to both lossless (e.g., PNG) and lossy (e.g., JPEG) image compression. Our previous work [
12] also explored MWD’s robustness against various levels of video compression (i.e., H.264), using it to enable a real-time, two-way holographic 3D video conferencing application over standard wireless internet connections at 3–30 Mbps. MWD works by storing two sinusoidal encodings of the depth information, along with a normalized version of the depth information, into the RGB channels of a color image. More specifically, the red channel is a sinusoidal encoding of the normalized depth map, the green channel is a complementary cosinusoidal encoding, and the blue channel simply stores the normalized depth map. The frequency of the sinusoidal encodings can be tuned to balance compressibility and accuracy [
13] (by adjusting MWD’s
parameter), while the normalized depth map guides the phase unwrapping process during decoding.
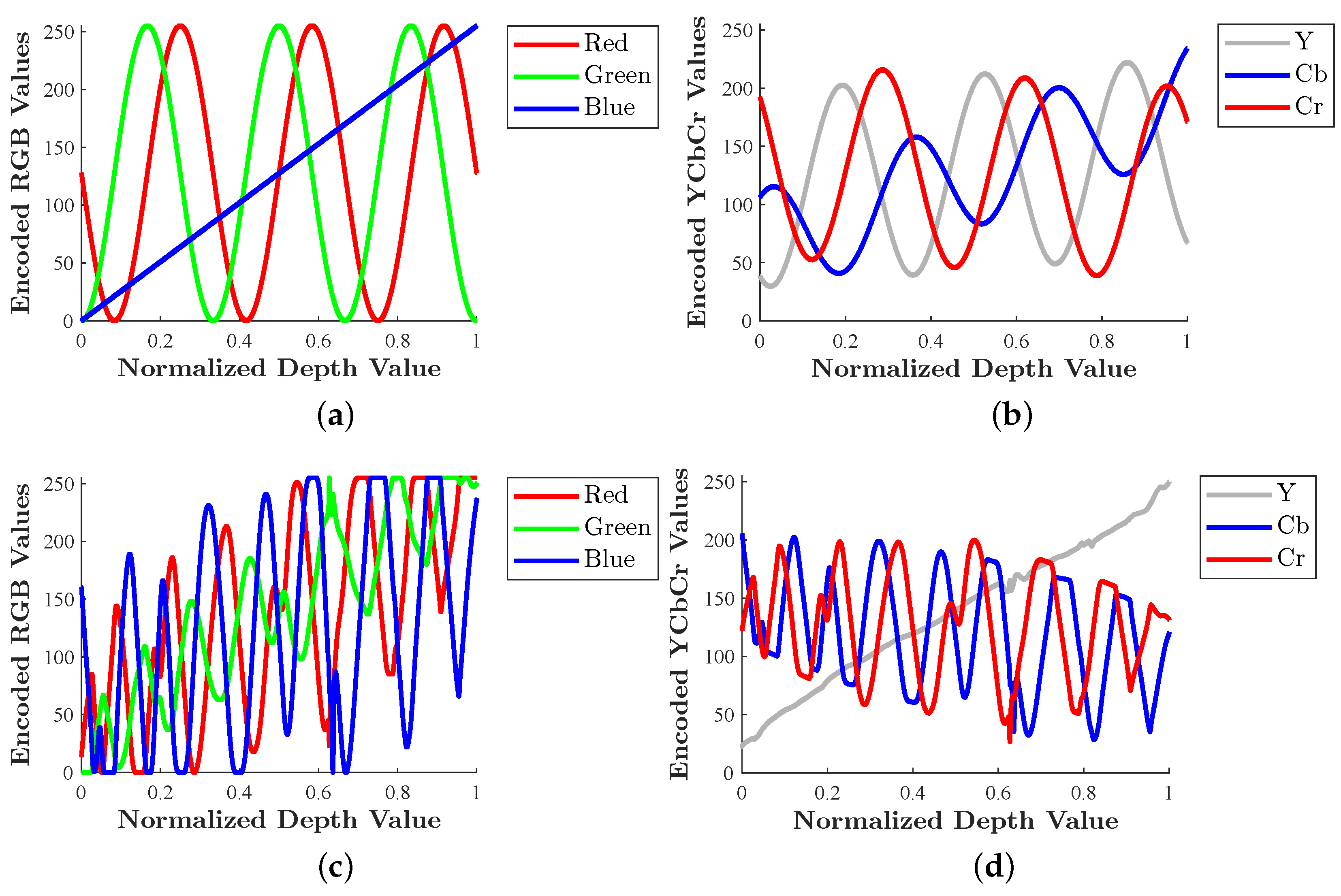
Figure 2a illustrates how MWD encodes a normalized depth range across the red, green, and blue color channels when
is set to 3, meaning that three periodic repetitions occur across the depth range (as can be seen in the encodings in the red and green channels).
While MWD proved to be quite efficient and robust against compression artifacts, subsequent works have attempted to decrease the effective file size of its compressed images by minimizing the number of encoding channels [
14,
15], reducing the depth range to be encoded [
16], using a variable number of
to offer a balance between targeted precision and improved compressibility [
13,
17], and decreasing the resolution of the output image [
18]. In general, MWD’s ability to achieve small compressed file sizes while remaining robust against compression artifacts is due to its encodings being smoothly varying. That said, this handcrafted encoding scheme was never directly optimized for the image-compression codecs that it sought to exploit. While deep learning technologies have been used to train on a domain-specific dataset in the depth decoding pipeline of SCDeep [
19] (another method derived from MWD), no published work in the area of depth-to-RGB encoding has leveraged deep learning throughout the entire encoding and decoding pipeline. This work proposes just that: an end-to-end image-based depth map compression method directly optimized for lossy image compression.
3. Methods
3.1. Overview
Figure 1 gives an overview of the full neural depth encoding, compression, and decoding pipeline. Fundamentally, this pipeline needs to take in a depth map, encode it into an RGB image, compress this image with a lossy codec such as JPEG, and then recover the depth map on the other end with as few end-to-end depth losses as possible. Unlike traditional, handcrafted algorithms that naively operate on the depth values to be stored, our encoding scheme leverages a pair of neural networks for the depth-to-RGB encoding and RGB-to-depth decoding, sandwiched around a differentiable approximation of JPEG compression. This system is, to our knowledge, the first depth-to-RGB encoding scheme that is directly optimized against a lossy image compression codec. Due to the exclusive use of 1 × 1 convolutions, the encoder and decoder neural networks can be succinctly understood as a pair of multilayer perceptrons (MLP) of similar structure. Together, they form N-DEPTH, a depth autoencoder where the bottleneck layer is an RGB image.
3.2. Encoding
Starting with a raw depth frame, the depth values are first thresholded within a desired depth range to form
Z and then normalized to the range
to form
. Additionally, values within the thresholding range are marked with a 1, while out-of-range values are marked with a 0 in a ground truth mask, which is concatenated to
to form the input for the neural encoder network. The neural encoder employs a series of 1 × 1 convolutions that encode each depth and mask value pair into three floating-point numbers destined for the red, green, and blue color channels. Mish activations [
20] are used in all layers except after the final encoder convolution, which uses a sinusoidal activation function. The sinusoidal activation primarily serves to restrict the outputs to the range
. Additionally, experimental findings have indicated that using Mish and sinusoidal activation functions promotes faster and more optimal solution convergence compared to using only ReLU and sigmoid activations in the network. Finally, the outputs of the sinusoidal activation function are normalized to the
range of an 8-bit unsigned integer, which ensures compatibility with the subsequent differentiable JPEG layer.
Figure 3 demonstrates how both N-DEPTH and MWD spread depth information across various color channels in both the RGB and YCbCr color spaces. The depth map being encoded here can be thought of as a tilted plane that samples the full
normalized depth range, with a depth of 0 in the top-left corner and a depth of 1 in the bottom-right corner. MWD clearly exhibits smooth sinusoidal spatial oscillations in the red and green color channels, with the blue channel serving as a quantized version of the normalized depth map. In contrast, the N-DEPTH encoding appears to exhibit higher-frequency spatial oscillations than MWD in the RGB color space. However, when converted to the YCbCr color space, the luminance channel (Y) of the N-DEPTH encoding is largely smooth and approximates the original normalized depth map. In this YCbCr color space, N-DEPTH appears to encode the high-frequency information almost exclusively in the chrominance channels (Cb, Cr). Conversely, MWD exhibits sinusoidal oscillations in all channels of the YCbCr color space, without any strong specialization among the channels. These behaviors become even more starkly apparent in
Figure 2. A parallel can clearly be drawn between the MWD RGB encoding scheme in
Figure 2a and the N-DEPTH YCbCr encoding scheme in
Figure 2d. N-DEPTH effectively stores an approximation of the normalized depth value in the luminance channel, very similarly to how MWD employs the blue channel to store a quantized version of the normalized depth value in the RGB color space. Furthermore, the chrominance channels of the N-DEPTH encoding plot strongly resemble the sinusoidal and cosinusoidal encoding pattern used by the red and green color channels in MWD.
More intuition about these encoding schemes can be gleaned by plotting their depth encoding functions in 3D. When plotted in an RGB color volume in
Figure 4a, it becomes apparent that the equations defining MWD trace a helix that rotates about the blue color axis. Although the function is not as smooth, N-DEPTH also forms a distinctly helical shape that rotates about the luminance axis in
Figure 4b. This learned behavior will be further discussed in
Section 5.1.
3.3. Compression
In addition to being normalized to
, the outputs of the neural encoder need to be rounded to the nearest integer to simulate the quantization loss that occurs when attempting to store floating-point numbers in 8-bit color channels. Unfortunately, rounding is not a differentiable operation, so we need to use a differentiable quantizer proxy. We have elected to use the same “straight-through” quantizer proxy used in [
21]. This quantizer proxy rounds inputs to the nearest integer during the forward pass but treats the operation as an identity function when calculating gradients during the backward pass of training. The lossless neural RGB encoding generated is next fed into a differentiable approximation of JPEG, DiffJPEG [
22].
At this point, the bottleneck image of the autoencoder is an RGB encoding that has not yet been compressed. However, JPEG and most video codecs do not ordinarily store pixels in the RGB color space. Instead, a conversion to the YCbCr color space is more commonly used in lossy image and video-compression codecs. With JPEG, the “full-swing” version of YCbCr color space is ordinarily used, but video codecs usually use the “studio-swing” range for conversion to YCbCr. In this work, we will use the full-swing YCbCr range for both image and video compression for the sake of consistency, although the studio-swing conversions could also be employed at the cost of some numerical precision. In the YCbCr color space, the Y component represents luminance, which is the brightness of the grayscale information of the image. Humans are perceptually more sensitive to luminance information than chrominance, so the preservation of the luminance channel is often prioritized over the chrominance when performing lossy compression. We are focusing on JPEG image compression and H.264 video compression, both of which commonly employ 4:2:0 chroma subsampling of the YCbCr information to downsample the chrominance channels by a factor of 2 in both the horizontal and vertical directions. Since low-level control of chroma subsampling settings is often unavailable in video-streaming software solutions, all image and video compression methods in this paper employ 4:2:0 chroma subsampling for the widest-possible compatibility.
Note that we have modified the current publicly available version of DiffJPEG to use bilinear interpolation instead of nearest-neighbor interpolation for the chroma upsampling operation in order to more closely follow the JPEG specification. While training, there is no need to actually store a compressed JPEG file, so the lossless compression algorithms used in JPEG (i.e., run-length encoding and Huffman coding) are not explicitly simulated. After encoding and decoding are performed by DiffJPEG, the lossy RGB encoding E is generated, which has been normalized to a range in preparation for the neural decoding step.
3.4. Decoding
The neural decoder has a similar series of 1 × 1 convolutions as the encoder and takes the RGB encoding E as input. Mish activations are used after every 1 × 1 convolution in the decoder, with the exception of the final convolution, which directly outputs a two-channel image. These two channels correspond to a recovered mask and normalized depth map. During training, is recovered by applying the ground truth mask to the recovered depth channel. In contrast, for testing, the system applies a threshold to the recovered mask channel, which is then applied against the recovered depth channel to form . It is the thresholded mask channel that is responsible for filtering the out-of-range background regions during testing. Lastly, the masked is denormalized back to the original depth range to recover .
3.5. Training
To enable the neural network to learn a compression-resilient encoding scheme across a variety of input depth maps, a diverse data set was chosen. FlyingThings3D [
23] is a synthetic dataset of over 25,000 stereo image pairs of digital objects flying along randomized 3D trajectories. The included disparity maps were approximately inversely proportional to depth maps, so they were easily made into an acceptable substitute for training the neural depth autoencoder pipeline. The depth map analogs were randomly cropped and resized to 224 × 224 during training. Image histogram equalization was used to ensure relatively even sampling of the normalized depth range. A randomized threshold was applied to both the lower and upper bound of the depth range, after which the values were normalized. For training, the normalized depth range was expanded to
to improve the accuracy of depth reconstructions at the extrema of the
testing inference range.
The JPEG quality levels were randomized and uniformly sampled from the range
. Periodic calibrations were performed during training in order to equalize the losses across the JPEG quality range, ensuring that training samples with low JPEG qualities did not dominate the losses and have an outsized impact on the solution convergence. An Adam optimizer with a cosine annealing learning rate scheduler with warm restarts [
24] was used to minimize the L1 loss between
and
as well as the binary cross-entropy (BCE) loss between the ground truth mask and the recovered mask. In practice, the BCE loss was implemented as a single BCE with a logits loss layer that included an integrated sigmoid activation for improved numerical stability. Importantly, the original ground truth mask was not the exclusive source of data for training the outputs of the mask layer. Instead, a new form of ground truth mask was created by removing from the original ground truth mask those regions where the inferred depth had errors exceeding 3% of the normalized depth range. This combined mask enabled N-DEPTH to effectively filter out both background pixels and pixels whose RGB values it had low confidence in accurately decoding into depth. Using PyTorch (v2.3), the model was trained to convergence with an NVIDIA GeForce RTX 4090 with a batch size of 1.
The cosine annealing learning rate scheduler with warm restarts was configured with a period of 5000 iterations, after which the learning rate restarted to its full original learning rate (). This is a relatively aggressive learning rate schedule that helps to find solutions closer to the global minimum in a difficult-to-navigate loss landscape. Due to the thorough sampling of the input parameter space and data-augmentation techniques, we did not encounter issues with overfitting. Since end-to-end numerical precision was very important to the accuracy of the depth map recoveries, we employed a progressive training approach with increasing precision levels. The network was initially trained using mixed precision, followed by PyTorch’s default precision mode (which allows the use of TensorFloat32 tensor cores on recent NVIDIA GPUs for certain operations, which reduces numerical precision) and, finally, using full 32-bit floating-point precision for every operation. Each precision level was utilized until the loss metric plateaued. This approach allowed for faster initial training while ensuring high numerical precision in the final stages. Training took approximately three days to complete.
6. Conclusions
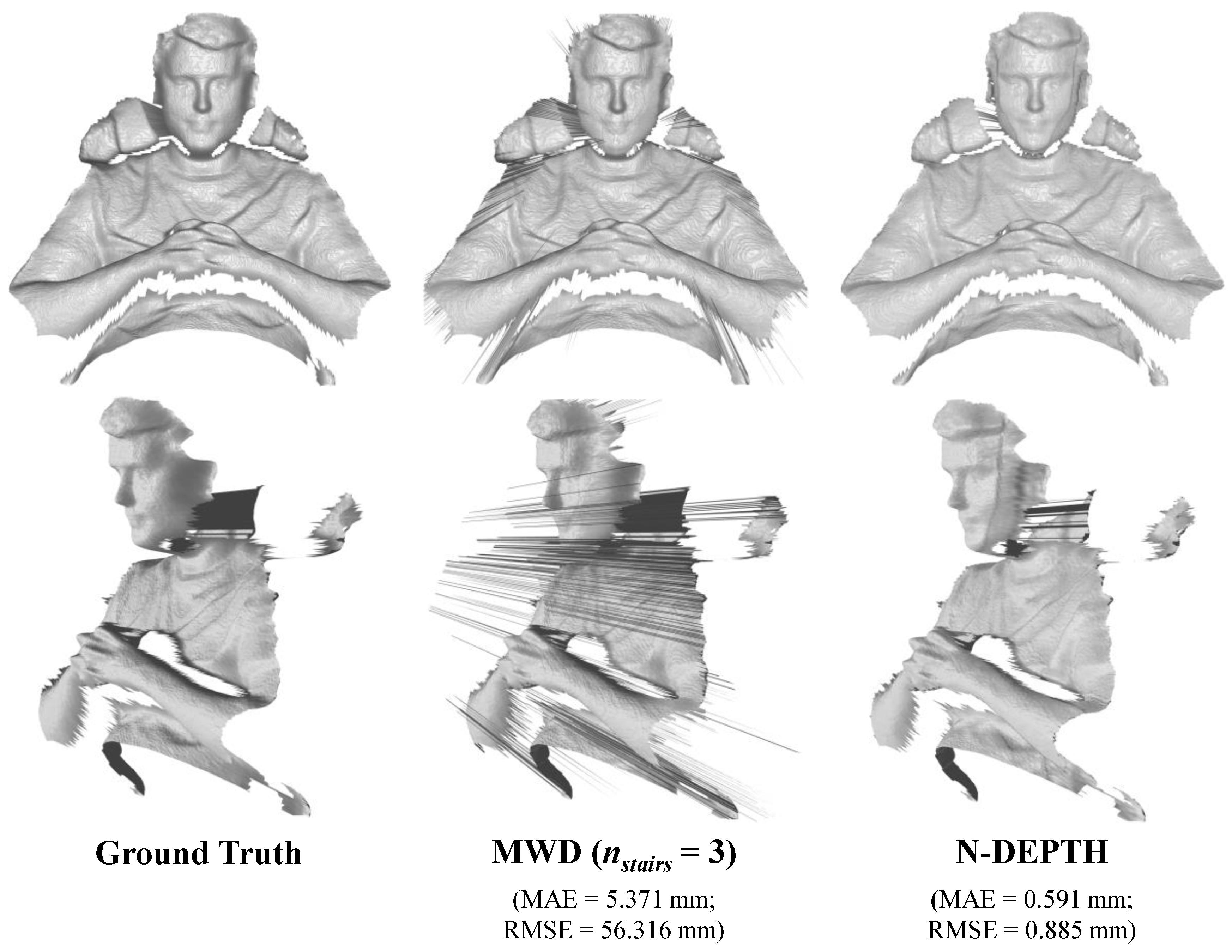
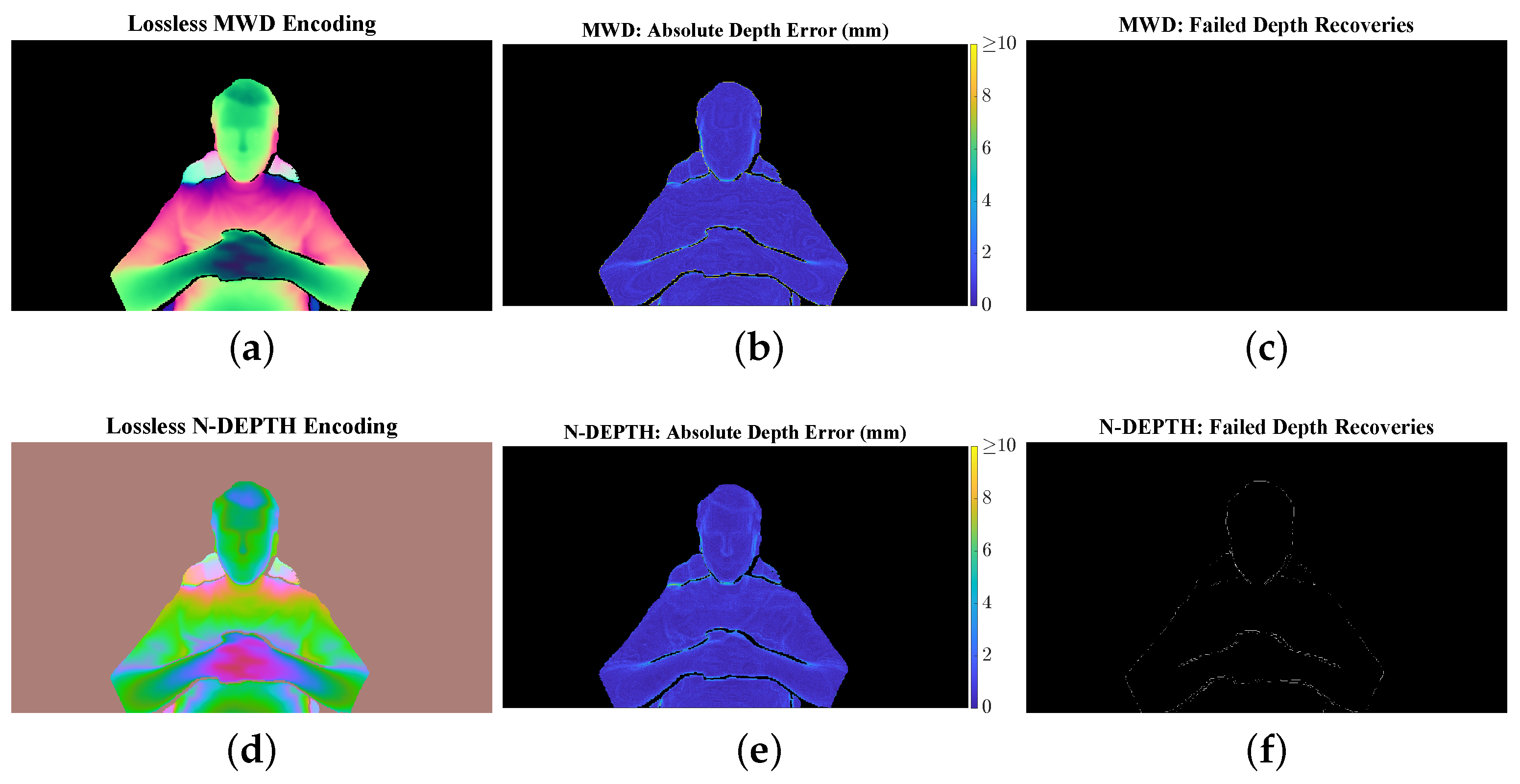
In summary, the proposed neural depth encoding method, N-DEPTH, demonstrates very promising results. To our knowledge, this is the first depth-to-RGB encoding scheme directly optimized for a lossy image compression codec. The learned depth encoding scheme consistently outperforms MWD, in terms of MAPE and NRMSE across a wide range of JPEG image qualities, and it achieves this with compressed image sizes that are, on average, more than 20% smaller. In addition, N-DEPTH similarly outperforms MWD, in terms of both MAE and RMSE, when sandwiched around H.264 video compression.
A key strength of N-DEPTH is its specialization in handling the types of errors that occur during lossy image and video compression, particularly artifacts derived from chroma subsampling and upsampling. This allows it to seamlessly integrate with off-the-shelf image compression and video streaming solutions. The method’s implicit filtering capabilities stand in stark contrast to those of MWD, since the filtering is so effective that further post-processing is essentially optional. However, a dedicated filtering neural network with spatial kernels could potentially further improve these results, albeit at the cost of increased computational complexity.
Future work could involve training N-DEPTH on a video compression analog, to better understand the temporal implications of compression artifacts. Matching the precision and quantization behavior of specific video codec implementations will also be important, particularly at higher quality levels. Additionally, the impact of using studio swing versus full swing in the YCbCr color space should be further investigated. While N-DEPTH shows excellent performance in applications involving color space transformations and chroma subsampling, MWD may still be better suited for scenarios without these operations.
The insights gained from N-DEPTH’s learned helical encoding strategy could drive the development of improved handcrafted depth encoding algorithms. It is worth noting that the neural network’s need for smoothness and differentiability may impose certain limitations on the functions it can learn. In addition, N-DEPTH is quite computationally complex to run, despite encoding smooth functions that could easily be approximated with a set of lookup tables or high-order polynomial approximations. Future research could explore the development of neural-inspired handcrafted algorithms that can more easily be implemented in real-time streaming applications. Overall, N-DEPTH offers a unique and effective solution for emerging 3D streaming and telepresence applications, enabling high-quality depth data storage and transmission in a manner that is resilient to lossy compression. The method’s learned encoding strategies provide valuable insights that can guide the development of even more advanced depth encoding techniques.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}