1. Introduction
Object recognition, a pivotal process in computer vision, involves the identification of objects within digital images [
1,
2,
3]. Early algorithms in this domain were constrained by limited processing power and primarily focused on binary and grayscale imaging. These early approaches relied on pixel matching and differences [
4], while others were feature-based, leveraging edges [
5], gradients [
6], and histograms [
7]. However, advancements in computing capabilities have led to the development of sophisticated algorithms that can tackle contemporary industrial challenges [
8,
9,
10].
In the evolution of object recognition, the scope has expanded to encompass color object recognition algorithms, which play a crucial role in identifying and localizing objects based on their color features [
11,
12,
13,
14]. Unlike their predecessors, these algorithms take advantage of the rich information provided by color imaging. This evolution has paved the way for applications in various domains, including automated transportation, bioimaging, and object tracking. The integration of color information allows for more nuanced and accurate object identification, enhancing the capabilities of automated systems in diverse fields [
15]. In bioimaging, color recognition algorithms enhance the analysis of biological specimens by leveraging color information to discern different structures and components [
16]. Moreover, in object tracking scenarios, the use of color features provides an additional layer of information, facilitating robust tracking, even in complex and cluttered scenes [
17]. As computing technology continues to advance, color object recognition algorithms are poised to play an increasingly integral role in addressing the demands of modern image processing applications.
Swain and Ballard introduced a pioneering method in computer vision that significantly influenced the field of object recognition. In their seminal paper titled “Color Indexing” published in 1991, they presented an innovative approach to object recognition based on color features [
18]. This method marked a departure from traditional grayscale and binary approaches, introducing the idea that color could serve as a powerful cue for identifying and distinguishing objects in images. The Swain and Ballard method focuses on the concept of color histograms as a means of representing the distribution of colors within an image. By quantizing the color space and creating histograms, they were able to capture the statistical distribution of colors, providing a robust and computationally efficient way to describe the color content of an image. This method was particularly groundbreaking because it allowed for the recognition of objects based on their color patterns, providing a more nuanced and context-aware approach to computer vision.
The color indexing method proposed by Swain and Ballard has several applications, including content-based image retrieval and object recognition. In content-based image retrieval, the color histograms serve as an effective means of comparing and retrieving images based on their visual content. In object recognition, the method demonstrates success in identifying and categorizing objects based on their distinctive color signatures, opening up new possibilities for automated systems to understand and interpret visual information. However, color-matching techniques, including the method of Swain and Ballard, often encounter challenges when applied in real-world scenarios with varying lighting conditions. The reliance on color information for matching or recognition purposes makes these techniques susceptible to inconsistencies introduced by changes in lighting. Fluctuations in illumination levels can result in significant alterations to the perceived colors of objects, leading to mismatches and reduced accuracy in color-based matching. These variations pose a substantial hurdle to achieving robust and reliable performance in applications relying on color information. Addressing the impact of lighting changes remains a crucial aspect in the refinement and development of color-matching methodologies, with the goal of enhancing their adaptability and effectiveness across diverse environmental conditions.
This paper introduces a solution that capitalizes on the benefits of color-based methodologies for object detection while mitigating issues associated with varying lighting conditions. The proposed color histogram contouring (CHC) method prioritizes the effective utilization of unique characteristics found in chrominance components. The underlying principle of this technique is grounded in the belief that chrominance components embody rich features that should be fully leveraged. Thus, the proposed approach advocates for the construction of a chrominance-rich feature vector with a bin size of 1. While color-matching methods suggest that smaller bin sizes offer more precise details at a finer scale but might overlook broader patterns, the proposed technique diverges by asserting that the distinctiveness of chrominance features renders larger bin sizes unnecessary. Larger bins, in this context, could potentially lead to the false detection of objects. Additionally, the recommended chrominance-rich feature vector showcases invariance to changes in lighting conditions, imparting resilience to the analysis. The chrominance-rich feature vector is carefully designed to be analogous to the opponent color axes used by the human visual system [
18]. Each bin is composed of the following illumination-invariant feature vector:
, where
R,
B, and
G are the red, green, and blue components of the pixel, while
H is the hue value of the pixel. The algorithm systematically traverses all non-zero histogram bins that characterize unique colors in the model. It prioritizes those distinctive features whose histogram in the scene corresponds to their respective histogram in the model. The alignment of histograms for these unique features serves as an indicator, confirming the existence of the model in the scene image when there is a full match.
The remainder of this paper is structured as follows.
Section 2 presents a comprehensive review of existing object recognition methods. In
Section 3, the novel color histogram contouring method is introduced, outlining its key principles and contributions. Experimental results, offering insights into the performance of the proposed method, are presented in
Section 4. Finally,
Section 5 serves as the conclusion, summarizing key findings, discussing potential applications, and suggesting avenues for future research.
2. Background on Object Recognition Methods
Classical object recognition approaches rely on handcrafted features [
19,
20,
21,
22]. The extraction of distinctive features, such as edges, corners, or textures, played a central role in these early methods [
23]. Techniques such as Histogram of Oriented Gradients (HOG) [
24] and Scale-Invariant Feature Transform (SIFT) [
25] were employed for feature extraction, but their effectiveness was often constrained by challenges in handling variations in object appearance and sensitivity to complex backgrounds. In [
26], an object recognition technique based on SIFT was proposed. The technique proposed in [
26] focuses on enhancing object recognition efficiency through the utilization of handcrafted features, specifically based on the Oriented Fast and Rotated BRIEF (Binary Robust Independent Elementary Features) and scale-invariant feature transform (SIFT) features. SIFT features prove advantageous in analyzing images with varying orientations and scales. To reduce the dimensionality of the obtained image feature vector, the Locality Preserving Projection (LPP) dimensionality reduction algorithm is investigated. The proposed approach is evaluated using k-NN, decision tree, and random forest classifiers on a dataset comprising 8000 samples of 100-class objects. In experimental trials, precision rates of 69.8% and 76.9% are achieved using the ORB and SIFT feature descriptors, respectively. Additionally, a combination of ORB and SIFT feature descriptors is explored, leading to an enhanced precision rate of 85.6%.
Template matching, another object recognition approach, involves the comparison of predefined templates of objects with different regions of an image [
27]. The template with the best match indicates the presence of an object. Despite its conceptual simplicity, template matching struggles with changes in scale, rotation, and lighting conditions, limiting its robustness in practical scenarios. The authors of [
28] introduced a refined single-shot multi-box Detector (RSSD) for automatic object detection in remote sensing images, addressing challenges related to low confidence of candidates and the generation of unreasonable predicted boxes leading to false positives. The method combines a single-shot multi-box detector (SSD), a refined network (RefinedNet), and a class-specific spatial template-matching (STM) module. During the training stage, the SSD efficiently extracts multiscale features for object classification and location, benefiting from augmented samples with diverse variations. RefinedNet was trained separately with cropped objects to enhance the ability to distinguish between different classes and the background. Additionally, class-specific spatial templates were constructed based on the statistics of objects for each class, providing reliable object templates.
On the other hand, rule-based systems have been constructed around explicit sets of rules or decision trees, often crafted by domain experts [
29]. These rules are based on specific characteristics or patterns associated with each object class. While these systems provide interpretability, their inflexibility hampers adaptation to diverse and evolving datasets. The work reported in [
29] addressed the challenges associated with intraoperative frozen sections in the diagnosis of thyroid nodules by proposing a rule-based system utilizing deep learning techniques. The system comprises the following three key components: (1) automatic localization of tissue regions in Whole Slide Images (WSIs), (2) classification of located tissue regions into predefined categories through Convolutional Neural Networks (CNNs), and (3) integration of predictions from all patches to formulate the final diagnosis using a rule-based system. Specifically, the InceptionV3 model was fine-tuned for thyroid patch classification, with the final layer representing probabilities of being benign, uncertain, or malignant. A rule-based protocol was designed to interpretatively integrate patch predictions into the final diagnosis.
Eigenimages derived through techniques such as Principal Component Analysis (PCA) aim to reduce the dimensionality of image data while retaining essential features [
30]. These methods capture the most significant variations in data, finding applications in facial recognition and object classification. However, their applicability is constrained by assumptions of linearity and Gaussian distribution.
Model-based approaches seek to represent objects using geometric models or shapes, with these models matched to image data for identification. However, these methods are sensitive to variations in pose and scale, presenting challenges in creating accurate models for complex objects. For example, color-based methods incorporate color information for object recognition, recognizing the distinctiveness of color patterns. Frequently, color histograms, representing the distribution of color pixels in an image, are used for this purpose. Despite their utility, these methods are sensitive to changes in illumination and can struggle with variations in object appearance.
The subsequent shift towards machine learning and deep learning addressed many object recognition challenges by enabling the automated learning of hierarchical features directly from data, resulting in improvements in accuracy and robustness. However, a drawback of machine learning methods is their reliance on training, necessitating a substantial amount of labeled data to effectively learn and generalize patterns [
31]. The proposed approach stands apart from machine learning methods by circumventing the need for extensive training data. In contrast to machine learning approaches, the proposed methodology does not rely on a substantial amount of labeled data for training. Despite this departure, the proposed approach consistently delivers advanced and effective results, showcasing its efficiency in achieving robust performance without the prerequisite of extensive training.
3. The Proposed CHC Method
This section presents the proposed CHC technique, an innovative training-less technique for real-time object detection. The proposed CHC method underscores the importance of tapping into the unique features inherent in chrominance components. The rationale behind this technique lies in the belief that chrominance components serve as rich features that warrant maximal exploitation. Therefore, the method advocates for the construction of a chrominance-rich feature vector with a bin size of 1. Conventional color-matching approaches suggest that a smaller bin size provides more precise information about the texture at a finer scale but may overlook broader patterns. The proposed technique challenges this notion by emphasizing the distinctiveness of chrominance features. Thus, it argues against increasing bin sizes, which could potentially lead to the misidentification of objects in object detection techniques.
The proposed CHC method is a color-matching algorithm inspired by the work of Swain and Ballard to detect the existence of an object of interest (model) in a given scene image by comparing the histograms of both, then attempting to localize the detected object of interest within the scene image. The intersection of the image histogram
and model histogram
is defined as the sum of the minimum over all
corresponding bins. The intersection value is normalized by dividing by the number of pixels in the model to obtain a match value
, as per the following equations:
The match value
corresponds to the percentage of pixels from the model that have corresponding pixels of the same color in the image. This match value can be used for object recognition, since a large match value indicates that the model object is present in the image. For example,
means that there is a 90% chance the model appears in the scene image. Next, to localize the detected object, the histogram backprojection method is used, assigning large weights to pixel locations in the image whose color histogram closely resembles the color histogram of the model. A ratio histogram
is backprojected onto the image, replacing the image values with the values of
R that they index. This ratio histogram is defined as follows:
A new image
is created and defined as follows:
where
is the image color value at pixel location
, and
is a histogram function that maps a three-dimensional color value
to a three-dimensional histogram bin, i.e., it finds the bin that represents the color (
). The backprojected image is filtered using a disk shape with a radius equal to the area of the object of interest.
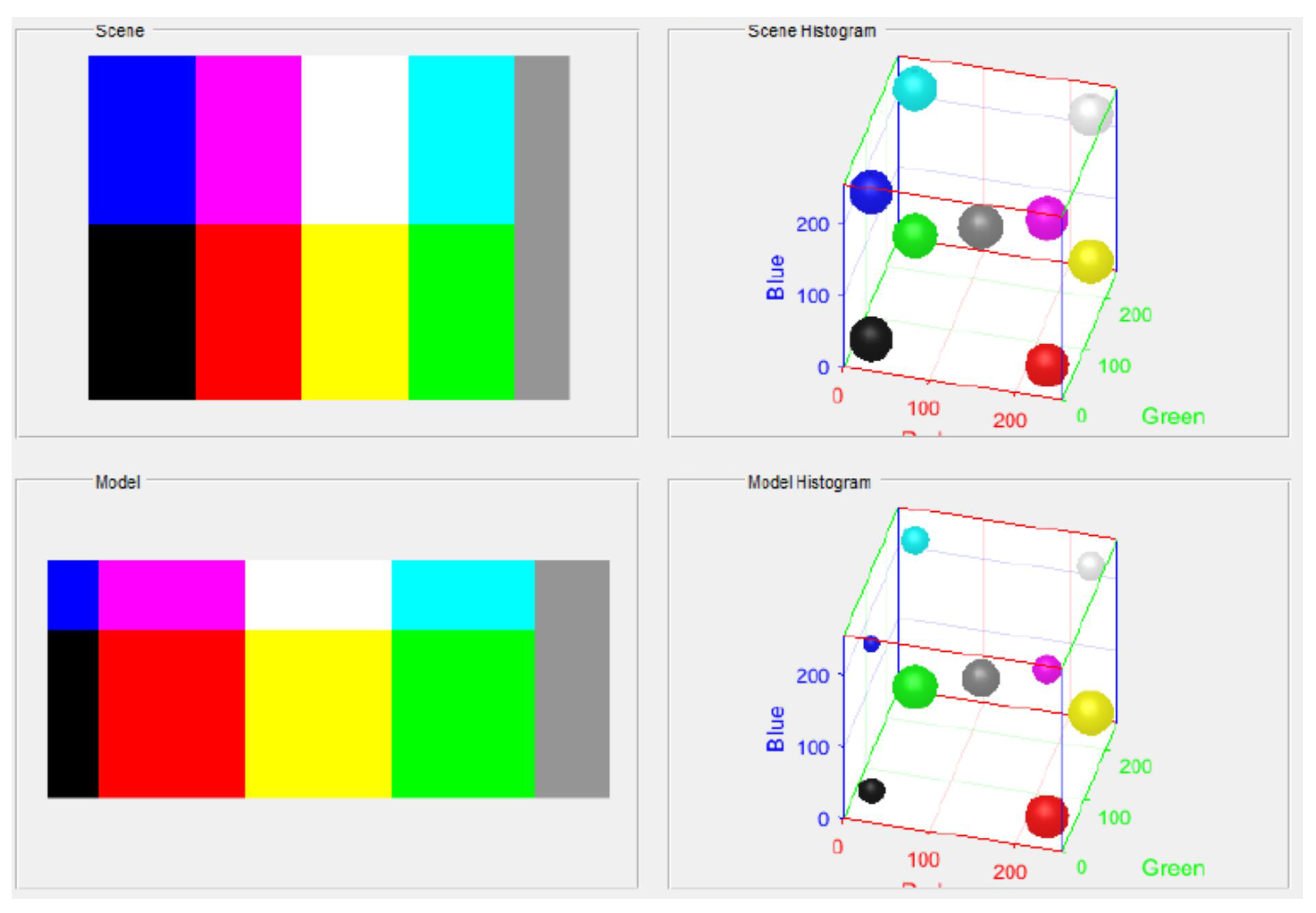
Figure 1 illustrates an example of an RGB histogram cube.
Figure 2 illustrates a block diagram of the proposed CHC technique. The proposed CHC technique involves several key steps for effective object detection. First, the proposed CHC algorithm identifies all unique colors present in the model image. After that, a color from the model is selected. For each color, a chrominance Feature Vector (FV) is computed. The FV consists of the following components: (
), where
R,
G, and
B are the red, green, and blue components of the color, respectively, while H is the Hue value. Hue is a fundamental attribute of color that describes the dominant wavelength or the type of color that we perceive. In simpler terms, it refers to the specific color of an object, such as red, blue, green, or yellow. Hue is one of the three primary color characteristics in the HSL (hue, saturation, lightness) and HSV (hue, saturation, value) color models. As shown in
Figure 3, the hue wheel represents all possible hues in a circular format, where different angles correspond to different colors. In this context, adjusting the hue involves shifting around the color wheel, resulting in a change in the perceived color without altering its saturation or brightness. The hue component is crucial for cases with varying lighting conditions, since the hue component remains relatively consistent with changes in lighting conditions.
The formula to find the hue (H) from RGB values is expressed as follows:
Normalize the RGB values to the range of : ;
Find the maximum and minimum of the normalized RGB values as follows: and ;
Calculate the chroma (C) by subtracting the minimum from the maximum as follows: ;
Calculate the hue (H) based on the following conditions:
For instance, considering a specific color with RGB values
as shown in
Figure 2, the FV is
.
Simultaneously, the algorithm performs a similar operation for the corresponding feature in the scene image, building a histogram with a bin size of 1. It then evaluates whether the histograms match. If the histograms do not align, indicating a lack of similarity between the model and scene for that specific color feature, the corresponding pixels are disregarded in the detection process. Conversely, if the histograms match, signifying feature similarity between the model and scene, the algorithm identifies the indices of these matched pixels in the scene, considering them as integral components of the detected object.
Figure 4 presents a code snippet of the proposed CHC technique.
The proposed method makes several assumptions to facilitate its application. First, it assumes that the model image is rectangular in shape, implying a defined and consistent frame for the image. Secondly, it allows for the rotation of the model image within this rectangular frame, suggesting flexibility in orientation. Lastly, the approach permits the rotation of model objects without modifying pixel values, relying on interpolation methods such as nearest neighbor or bilinear interpolation to maintain the integrity of the image during the rotation process. These assumptions collectively frame the parameters under which the method is designed to operate effectively.
4. Experimental Results
In this section, a thorough evaluation of the proposed object detection method is presented in comparison with the influential Swain and Ballard approach, a benchmark in the field of computer vision. Expanding upon the foundational work laid out by Swain and Ballard, the proposed method incorporates advancements in processing power abilities to enhance the accuracy and generalizability of object detection systems. Swain and Ballard’s method provided a pioneering framework for object detection, and the present work extends and refines their contributions. The objective is to assess the robustness and performance of the proposed approach across a diverse set of challenging scenarios commonly encountered in computer vision applications.
To comprehensively evaluate the proposed method, a series of experiments were designed to span a spectrum of challenging scenarios. Each experiment is tailored to assess specific aspects of object detection performance. The selected scenarios include scenes with varying illumination and shadows (scene with shades), high-intensity lighting and intricate patterns (bright pattern scene), scenes with high-frequency details (high-frequency scene), low-light conditions (dark scene), and more.
This section also compares the performance of the proposed CHC technique with the You Only Look Once (YOLO) technique, showing some advantages of using the proposed technique over such a state-of-the-art AI-based technique.
4.1. Scene with Shades
The scene-with-shades experiment involves applying both the Swain and Ballard method and the proposed CHC method to a model cropped from the ‘shells.png’ scene. This specific scenario is chosen to highlight the challenges posed by varying illumination and shadows, factors known to impact the performance of object detection methods.
Figure 5 illustrates this experiment.
Upon subjecting the model to the Swain and Ballard method, the limitations become apparent. The traditional method, which relies on a holistic analysis of texture and intensity patterns, struggles in the presence of shades. The intricacies of shadows and variations in lighting conditions hinder the Swain and Ballard algorithm from accurately returning the cropped model, leading to a failure in localization.
In contrast, the proposed CHC method excels in scenarios characterized by shades and varying illumination. Leveraging the fixed 256 bins for color histograms, the algorithm adeptly captures nuanced color variations, even in shadowed regions. The emphasis on unique colors, with equal color histograms in both the model and the scene, proves to be a decisive factor.
The fixed 256 bins in the proposed CHC method contribute to heightened color sensitivity. This allows the algorithm to discern subtle variations in color, a crucial aspect in scenes with shades where traditional methods may fail due to reduced texture visibility. Moreover, the emphasis on unique colors and equal color histograms facilitates adaptability to varying lighting conditions. In the presence of shades, the algorithm excels in precisely localizing the model by identifying color patterns, a capability not effectively harnessed by the Swain and Ballard method. The proposed CHC method’s ability to contour the model based on equal color histograms ensures robust performance, even in shadowed regions. This capability is particularly advantageous in real-world scenarios where lighting conditions can be unpredictable.
4.2. Scene of Pattern
The scene-of-pattern experiment involves the examination of a bright pattern scene, specifically focusing on situations where multiple model candidates exist in the scene image. Both the Swain and Ballard method and the proposed CHC method are applied to assess their effectiveness in such complex scenarios.
In this experiment, as illustrated in
Figure 6, the Swain and Ballard method encounters challenges that are characteristic of its limitations. The method, relying on texture and intensity patterns, tends to struggle when multiple model candidates are present in the scene. The inherent difficulty in distinguishing between similar candidates leads to a failure in accurately localizing the model within the bright pattern scene.
On the other hand, the proposed CHC method demonstrates robust performance in scenarios with multiple mode candidates. The approach to comparing full-color histograms, with an emphasis on unique colors and equal histograms between the model and the scene, proves advantageous in resolving ambiguities presented by the bright pattern scene. The method excels in precisely highlighting the localized model, even when faced with the challenges of multiple candidates.
The proposed CHC method leverages the fixed 256 bins to discriminate between unique colors in the model and scene. This allows the algorithm to discern subtle differences between candidates, ensuring that only the correct candidate is highlighted. Moreover, by placing emphasis on unique colors with equal histograms in both the model and the scene, the method effectively narrows down the possibilities, mitigating the ambiguity introduced by multiple candidates. This emphasis acts as a powerful discriminator, ensuring the accurate localization of the model. The reliance on color-based distinctions, rather than relying solely on texture, enables the proposed method to navigate through complex scenes with greater accuracy.
4.3. High-Frequency Scene
The high-frequency Scene experiment introduces a challenging scenario with a high-frequency image, where traditional binary and grayscale segmentation methods, such as edge detection, often struggle to detect objects effectively. In contrast, color object recognition methods are expected to have an advantage in such cases. Both the Swain and Ballard method and the proposed CHC method are applied to assess their capabilities in localizing the model within this intricate scene.
Figure 7 illustrates this experiment.
High-frequency scenes often present challenges for binary and grayscale segmentation methods, particularly those relying on edge detection. The intricate patterns and rapid changes in intensity characteristic of high-frequency images can lead to fragmented and unreliable object boundaries, causing traditional segmentation methods to fail in accurately localizing objects.
Color-based object recognition methods, such as the proposed CHC method, inherently possess an advantage in scenarios with high-frequency content. The utilization of full-color histograms with a fixed number of bins (256 in this case) enables the algorithm to capture and differentiate intricate color patterns that are crucial for distinguishing objects in high-frequency scenes. The sensitivity of the proposed CHC method to color patterns allows it to navigate through the complexities introduced by high-frequency scenes. The fixed 256 bins in the color histograms ensure a detailed representation of color variations, providing the algorithm with the necessary information to accurately recognize and localize objects.
In contrast to binary and grayscale segmentation methods, the color-based approach excels in scenarios with rapid intensity changes, a common characteristic of high-frequency scenes. The algorithm’s emphasis on color distinctions rather than intensity patterns contributes to its adaptability in capturing intricate details. Both color object recognition methods (Swain and Ballard and the proposed technique) showcase robust performance in localizing the model within the high-frequency scene. By focusing on equal color histograms and unique colors, the proposed method ensures precise object contours, overcoming the limitations associated with traditional segmentation techniques.
4.4. Detection in a Dark Scene
The dark-scene experiment involves the analysis of a scene where a basketball shadow blends with a dark background, posing challenges for object detection methods. The Swain and Ballard method, known for its reliance on texture and intensity patterns, encounters difficulties in recognizing the shadow of the basketball, leading to errors in locating the center of the model, as shown in
Figure 8. In contrast, the proposed CHC method is designed to address such challenges and precisely locates the basketball within the dark scene, as illustrated in
Figure 8.
In a dark scene, limitations of the Swain and Ballard method become apparent, particularly when recognizing objects with shadows. The method tends to focus on brighter pixels, potentially overlooking darker regions, leading to errors in localization. In the case of the basketball shadow blending with the dark background, the Swain and Ballard method struggles to accurately identify the center of the model.
The proposed CHC method excels in precisely locating objects within dark scenes. By emphasizing unique colors and equal color histograms between the model and the scene, the algorithm ensures that even subtle variations in color are captured. In the context of the basketball shadow, the method can distinguish between the shadow and the dark background, providing an accurate localization of the center of the basketball. The proposed method’s sensitivity to color allows it to effectively operate in low-light conditions. By capturing subtle color variations, even in dark scenes, the algorithm can discern object boundaries with precision.
While the Swain and Ballard method may be influenced by the brightness of pixels, the proposed CHC method places emphasis on color distinctions. This enables the algorithm to discriminate between the shadow of the basketball and the dark background, mitigating errors in object localization. Moreover, the developed method’s emphasis on equal color histograms and unique colors ensures accurate center localization of the model, even when the object blends with the dark background. This level of precision is crucial for reliable object detection in challenging low-light scenarios.
4.5. Multiple Model Candidates—Proximity
The multiple model candidates—proximity experiment focuses on scenarios where the proximity of multiple model candidates introduces challenges for object detection methods. In
Figure 9, the right-side eye of the girl is selected as the model, and both the Swain and Ballard method and the proposed method are applied to assess their accuracy in locating the model in the presence of proximate candidates.
The Swain and Ballard method encounters difficulties in accurately locating the model when faced with proximity challenges. In this experiment, the right-side eye is selected as the model, but due to the proximity of another model candidate (left eye), the Swain and Ballard method returns an inaccurate location. The holistic analysis of texture and intensity patterns struggles to effectively distinguish between closely situated model candidates, leading to suboptimal localization results. In contrast, the proposed method exhibits superior accuracy in the presence of proximate model candidates.
The Swain and Ballard method relies on global matching strategies that may face challenges when dealing with objects in close proximity. In this case, the proximity of the left eye, another model candidate, likely interferes with the accurate localization of the right-side eye. The method’s global matching approach might struggle to differentiate between the two closely located candidates, leading to an inaccurate selection. On the other hand, the proposed CHC method involves comparing full-color histograms of the model and the scene. This approach, by emphasizing unique colors and considering their respective histograms, demonstrates an ability to capture and utilize local features more effectively. By focusing on color information and considering the entire color distribution, the proposed CHC method is better equipped to discern between closely positioned model candidates, resulting in superior accuracy in the selection of the right-side eye.
4.6. Multiple Model Candidates (Different Orientations)
The multiple model candidates–different orientations experiment shown in
Figure 10 introduces a scenario with varying model orientations within the scene. Both the Swain and Ballard method and the proposed CHC method are employed to assess their respective capabilities in accurately localizing model candidates.
The Swain and Ballard method exhibits notable adaptability in successfully localizing model candidates despite changes in orientation. Its reliance on texture and intensity pattern analysis enables robust handling of scenes with diverse model orientations, ensuring accurate identification and localization. Similarly, the proposed CHC method demonstrates effectiveness in localizing model candidates with varying orientations. Leveraging its sensitivity to color and emphasis on equal color histograms, the algorithm discerns unique colors associated with each model candidate, providing precise localization results. The capacity of the method to capture color-based features proves advantageous in overcoming challenges posed by changes in orientation.
The success of the Swain and Ballard method is attributed to its adeptness in analyzing texture and intensity patterns. This feature-based analysis allows the method to navigate through scenes with model candidates exhibiting different orientations. On the other hand, the precision of the proposed CHC method is derived from its sensitivity to color-based features. By focusing on equal color histograms and unique colors associated with each model candidate, the algorithm excels in discerning variations in orientation, contributing to accurate localization.
Both methods showcase adaptability in the face of varying model orientations. While the Swain and Ballard method relies on traditional texture and intensity pattern analysis, the proposed CHC method introduces a color-centric approach, demonstrating that different methodological strategies can successfully address challenges posed by changes in object orientation within a scene.
4.7. Multiple Color Regions
Figure 11 shows the experiment of the multiple color regions. In this experiment, the scene comprises various reddish regions with differing brightness levels. This complex scenario challenges both the Swain and Ballard method and the proposed CHC method, which are evaluated for their effectiveness in localizing the model within the scene.
Within the experiment, the Swain and Ballard method encounters difficulties in accurately localizing the model amidst multiple color regions. Relying on texture and intensity patterns, this method struggles to differentiate effectively between varying levels of brightness within the reddish regions. The limitations of the Swain and Ballard method become apparent as it fails to provide an accurate localization of the model, displaying a notable discrepancy.
In contrast, the proposed CHC method exhibits superior precision in localizing the model within the scene featuring multiple color regions. Leveraging its sensitivity to color and emphasizing equal color histograms, the algorithm excels in discerning nuanced variations in brightness within the reddish regions. By focusing on unique colors and their equal histograms, the method achieves accurate localization of the model despite the complexity introduced by varying brightness levels.
The reliance of the Swain and Ballard method on texture and intensity patterns is limiting in scenarios with multiple color regions and varying brightness levels, leading to inaccuracies in model localization. In contrast, the sensitivity of the proposed CHC method to color proves advantageous, allowing it to handle scenes with diverse color regions effectively. Emphasizing equal color histograms and unique colors enables the algorithm to accurately capture variations in brightness, ensuring precise model localization. The nuanced color discrimination of the proposed CHC method contributes to its success in scenarios with multiple color regions, overcoming challenges posed by varying brightness levels and providing reliable localization results.
4.8. Low-Contrast Scene Experiment
In the low-contrast scene experiment featuring the coffee.png scene image with low contrasting colors, as shown in
Figure 12, both the Swain and Ballard method and the proposed CHC method are evaluated for their performance in accurately localizing the model.
Within this experiment, the Swain and Ballard method encounters difficulties in accurately localizing the model in the presence of low contrasting colors. Relying on texture and intensity patterns, the method struggles to distinguish between subtle color variations inherent in low-contrast scenes. This challenge becomes evident as the Swain and Ballard method fails to return the correct location, highlighting its limitations in scenarios characterized by minimal color contrast.
In contrast, the proposed CHC method exhibits precision in localizing the model within the low-contrast scene. Leveraging its sensitivity to color and emphasizing equal color histograms, the algorithm excels in discerning subtle color variations, even in low-contrast scenarios. By focusing on unique colors and their equal histograms, the method provides an accurate localization of the model, showcasing its effectiveness in challenging conditions where color contrast is minimal.
The reliance of the Swain and Ballard method on texture and intensity patterns proves challenging in low-contrast scenes, where it struggles to differentiate between subtle color variations, leading to inaccuracies in model localization. Conversely, the sensitivity of the proposed CHC method to color proves advantageous in scenarios with low contrasting colors. Emphasizing equal color histograms and unique colors allows the algorithm to overcome the limitations of the Swain and Ballard method, providing accurate localization results. The robustness of the proposed CHC method in low-contrast conditions is evidenced by its ability to accurately localize the model despite the challenges posed by subtle color variations. The focus on color-centric features enhances the adaptability of the proposed CHC methods in scenarios with low contrasting colors.
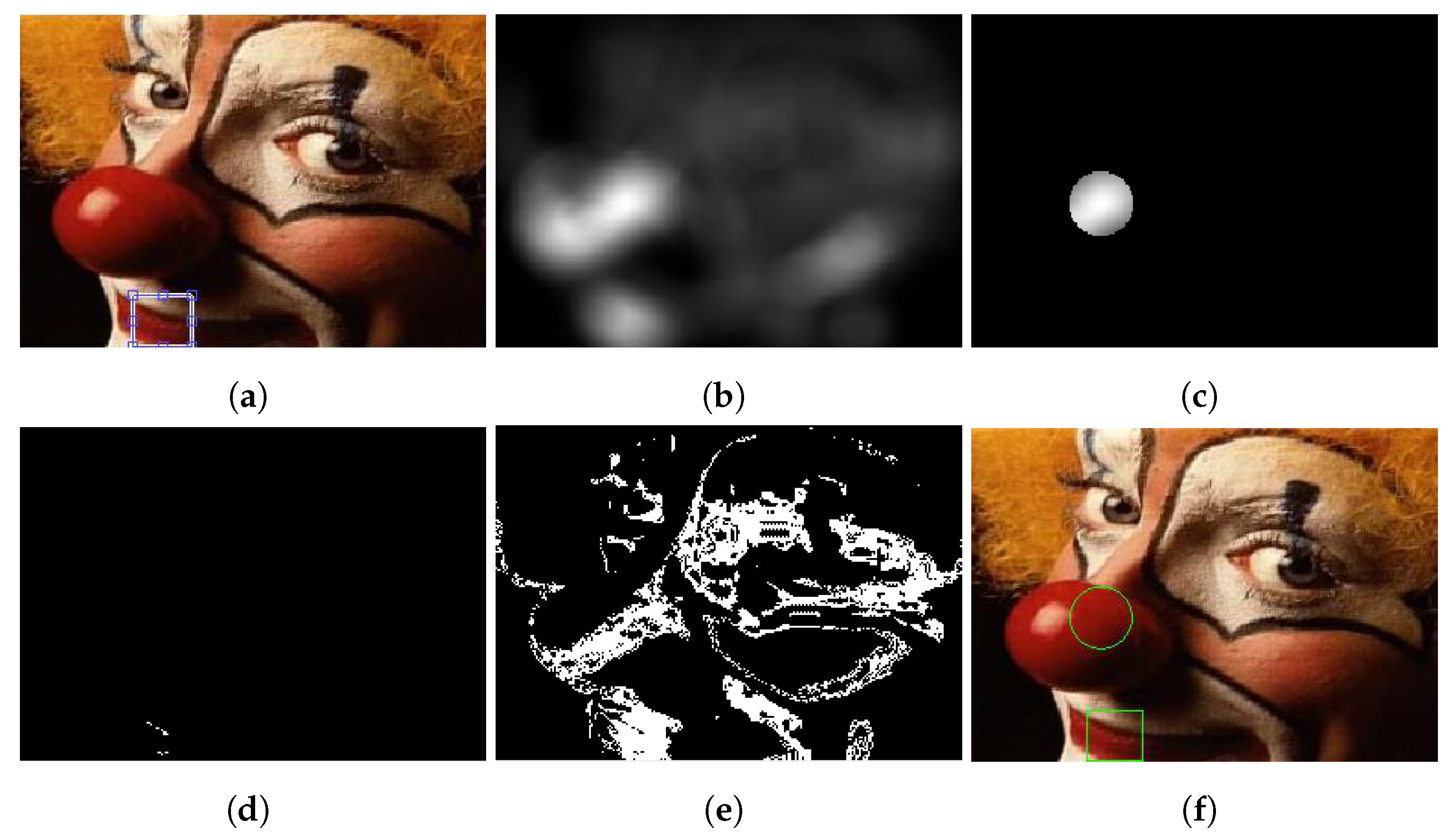
4.9. Neighborhood Pixels Experiment
The neighborhood pixels experiment delves into the influence of neighboring pixels on model localization. Both the Swain and Ballard method and the proposed method undergo scrutiny to evaluate their performance in the presence of neighborhood pixel effects. The accompanying figures illustrate the color object localization outcomes using each method.
In the context of neighborhood pixels, the Swain and Ballard method encounters challenges, resulting in a shifted location for the localized model.
Figure 13a–c showcase color object localization using the Swain and Ballard method, revealing discrepancies and inaccuracies in the ability of the method to precisely identify the position of the model. The impact of neighboring pixels introduces errors, which are evident in representations such as backprojection blobs and highest intensity. Conversely, the proposed method exhibits precision in localizing the model, effectively eliminating the effects of neighboring pixels.
Figure 13e, representing color object localization using the proposed method, showcases the exact location of the cropped model. Despite the challenges introduced by neighboring pixels, the proposed method remains resilient, providing accurate and undistorted model localization results.
The Swain and Ballard method struggles with the impact of neighboring pixels, leading to a shifted location for the localized model. Inaccuracies are evident in representations such as backprojection blobs and highest intensity, indicating challenges in precisely identifying the position of the model. Contrastingly, the proposed method demonstrates precision by eliminating the effects of neighboring pixels. The method successfully returns the exact location of the cropped model, showcasing its resilience to distortions introduced by neighboring pixels.
4.10. Texture Scene Experiment
In the texture scene experiment shown in
Figure 14, the focus is on localizing the pitch of the ground, representing a texture within a scene. The color histograms intersection method and the proposed CHC method are employed to assess their performance in accurately localizing this texture.
The color histograms intersection method of Swain and Ballard encounters challenges in accurately localizing the pitch texture within the scene. Relying on color histogram intersection, the method may struggle to differentiate the pitch texture from other elements, such as the tennis racket or tennis ball. This challenge can lead to inaccuracies as the method identifies regions with intersecting color histograms, resulting in a potentially incorrect localization of the pitch texture.
Conversely, the proposed CHC method demonstrates effectiveness in localizing the pitch texture accurately. Leveraging its sensitivity to color and emphasis on equal color histograms, the algorithm excels in discerning the unique colors associated with the pitch texture. By focusing on equal color histograms and accentuating color-based features, the method returns the exact location of the cropped pitch, showcasing its precision in differentiating texture-rich regions from other elements in the scene.
4.11. Detecting a Rotated or Flipped Model
This section investigates the efficacy of the proposed CHC method in detecting models subjected to rotation, horizontal flipping, and vertical flipping. A comparative analysis with the Swain and Ballard method is presented, emphasizing the color-based nature of both techniques.
Figure 15 visually illustrates the experiment.
Both the proposed CHC and Swain and Ballard methods demonstrate robustness in detecting models, despite geometric transformations. Rotation, horizontal flipping, and vertical flipping are introduced to the models, and both techniques successfully identify them. This resilience is attributed to the color-based nature of the methods, where color information remains unaffected by these transformations.
However, nuanced differences emerge in the precision of detection. The Swain and Ballard method, although successful, exhibits a slight shift in the localized position when confronted with the transformed models. In contrast, the proposed CHC method outperforms the Swain and Ballard method by precisely locating the models without introducing spatial shifts. The distinctive strength of the proposed CHC method lies in its reliance on full-color histograms and the comparison of color distributions between the model and the scene. This approach inherently safeguards against the impact of rotations or flips.
4.12. Execution Speed Comparison
Table 1 presents a comprehensive comparison of the execution speed and the Intersection over Union (IoU) between the proposed CHC technique and the Swain and Ballard method in various challenging scenarios. The experiments evaluate the detection success and time taken for each technique in different scenarios.
The IoU metric is a fundamental metric used to evaluate the accuracy of object detection models, particularly in computer vision tasks such as object detection and segmentation. IoU measures the overlap between two bounding boxes by calculating the ratio of the area of their intersection to the area of their union. Specifically, it is computed as the area of the intersection divided by the area of the union of the predicted and ground-truth bounding boxes. This metric ranges from 0 to 1, where an IoU of 1 indicates perfect overlap, meaning the predicted bounding box exactly matches the ground-truth bounding box, while an IoU of 0 indicates no overlap. A higher IoU value signifies better model performance, as it indicates a greater degree of overlap between the predicted and actual object locations. IoU is widely used because it provides a clear and interpretable measure of the quality of object localization, helping to fine tune models and compare their effectiveness objectively. Its simplicity and robustness make IoU an indispensable tool in the development and evaluation of object detection algorithms.
As shown earlier in this section, the proposed CHC technique consistently demonstrates successful object detection across a range of challenging scenarios, including scenes with shades, patterns, high-frequency elements, dark scenes, and multiple model candidates. Additionally, the proposed technique exhibits advanced accuracy in scenarios involving objects with similar colors and low-contrast scenes. In contrast, the Swain and Ballard technique faces challenges in specific scenarios. Notably, the proposed CHC technique outperforms the Swain and Ballard method in terms of accuracy, successfully detecting objects in scenes where the latter encounters difficulties.
In terms of execution speed, both techniques demonstrate real-time capabilities, as reflected in the time (in seconds) required for each detection. The proposed CHC technique showcases comparable execution speeds to the Swain and Ballard method, emphasizing its ability to achieve similar efficiency while offering superior detection accuracy. This indicates that the proposed technique is a viable real-time solution with enhanced detection capabilities in comparison to the Swain and Ballard method.
Color-based detection methods, exemplified by approaches such as the proposed CHC method, demonstrate real-time execution capability due to their intrinsic computational characteristics. The use of histogram-based representations, as seen in the proposed CHC method, contributes to real-time performance by summarizing color information in a concise and computationally efficient manner. Additionally, the adoption of fixed-size feature representations, such as histograms with a predetermined number of bins, simplifies computational complexity and ensures predictable operations. The reduced dimensionality of color data further enhances the efficiency of these methods, facilitating quicker analysis and comparison of color features. Efficient matching techniques, such as histogram comparison, enable rapid computations crucial for real-time applications.
4.13. Different Lighting Conditions
This section examines the capabilities of the proposed CHC technique in detecting an object of interest when the lighting conditions have changed.
Figure 16 illustrates this experiment. As shown in
Figure 16, a challenging scenario is studied, where the scene shows “AlWasl FC” fans and players all wearing yellow and celebrating. The task is to detect two players from the scene. This is a challenging task, since everyone is wearing yellow and the players have similar uniforms. Moreover, a unique difficulty arises from the need to discern individuals not only based on similar uniforms but also under varying lighting conditions. This requirement makes the task notably arduous, as lighting variations can introduce complexities in color perception. As shown in
Figure 16, the intensity level of the model is changed by −100, −200, +100, and +200.
The exceptional performance of the proposed CHC technique can be attributed to its reliance on color features that exhibit robustness against variations in lighting conditions. The histogram employed by the CHC method is composed of distinctive features, namely (R-G, 2B-R-G, and H), which have proven to be insensitive to changes in illumination. The choice of these specific color features contributes to the method’s ability to withstand challenges posed by different lighting conditions. The utilization of (R-G, 2B-R-G, H) in the histogram ensures that the color representation remains stable and consistent, regardless of variations in brightness or ambient lighting. This insensitivity to changes in illumination enhances the method’s reliability and accuracy in object detection tasks, especially in real-world scenarios where lighting can be unpredictable.
On the other hand, the Swain and Ballard method encounters challenges, as shown in
Figure 16. Color-based techniques such as the Swain and Ballard method often rely on absolute color values, making them more susceptible to changes in illumination. In situations where lighting conditions fluctuate, these methods may struggle to maintain consistent and accurate object detection. The sensitivity of traditional approaches to lighting variations can lead to misinterpretations and inaccuracies in identifying objects, especially in environments where lighting is not controlled or predictable.
4.14. Comparison with Viola-Jones Algorithm
The Viola–Jones algorithm is a cornerstone technique in the field of object detection, particularly noted for its application in face detection. Developed by Paul Viola and Michael Jones [
32,
33], this algorithm introduces a robust and efficient framework that combines several key innovations. It utilizes Haar-like features, which are simple rectangular features resembling convolutional filters, to capture essential structural patterns in images. These features are computed using an integral image representation, allowing for rapid calculation of pixel sums within rectangular regions, significantly enhancing computational efficiency.
The algorithm employs the AdaBoost learning algorithm to select the most informative features from a large pool, effectively creating a strong classifier from a combination of weak classifiers. AdaBoost works by iteratively adjusting the weights of the training examples, emphasizing those that are misclassified and selecting features that minimize classification error. This results in a compact set of features that are highly discriminative for the detection of the target object.
A notable aspect of the Viola–Jones algorithm is its cascading classifier structure, which sequentially applies a series of increasingly complex classifiers. Each stage of the cascade is designed to quickly reject non-object regions, allowing the algorithm to focus computational resources on more promising candidate regions. This hierarchical approach ensures both high detection rates and low false-positive rates, making the algorithm suitable for real-time applications.
Despite its strengths, the Viola–Jones algorithm has limitations, including sensitivity to lighting variations, a fixed detection window size, and reduced effectiveness for non-frontal faces or occluded objects. However, its innovative use of simple features, integral images, and cascading classifiers laid the groundwork for subsequent advancements in object detection, and it remains a significant technique in the field.
Figure 17 shows a comparative analysis between the Viola–Jones algorithm and the proposed technique. It is clear from
Figure 17 that the Viola–Jones algorithm obtains additional false face detections in some cases, as shown in
Figure 17b,d,e. The Viola–Jones algorithm is notably sensitive to lighting variations, which poses a significant challenge in achieving consistent object detection performance across different lighting conditions. This sensitivity primarily arises from the algorithm’s reliance on Haar-like features, which are computed based on pixel intensity values. Haar-like features involve calculating the difference in sums of pixel values over rectangular regions, a process inherently dependent on the brightness and contrast of the image. Consequently, any alteration in lighting can drastically change these pixel intensity values, leading to different computed feature values. For example, shadows or highlights can introduce artificial edges and lines that were not present under uniform lighting, resulting in incorrect feature calculations.
Furthermore, the Viola–Jones algorithm operates under the assumption of relatively uniform lighting conditions across the training and testing images. During the training phase, the algorithm learns features from images with specific lighting conditions. When these conditions change, the learned features may not generalize well to new images with different lighting. This mismatch can significantly degrade the algorithm’s performance, causing it to miss detections or generate false positives in images where the lighting differs from the training dataset.
Another critical factor contributing to this sensitivity is the local nature of Haar-like feature computation. These features are calculated over small, localized regions of the image without considering the broader context. As a result, local changes in lighting, such as a shadow falling across a part of a face, can disproportionately affect the feature values in that region. This localized sensitivity means that even minor lighting changes can lead to significant variations in the feature values, impacting the algorithm’s ability to detect objects accurately.
Moreover, Haar-like features lack inherent invariance to changes in illumination. Unlike more advanced features used in later object detection algorithms, such as scale-invariant feature transform (SIFT), or features learned by deep learning models, Haar-like features do not have mechanisms to normalize or adapt to lighting changes. This limitation makes the Viola–Jones algorithm particularly vulnerable to variations in lighting, as it cannot effectively compensate for differences in brightness or contrast. Consequently, the algorithm’s performance can be inconsistent, making it less reliable for real-world applications where lighting conditions are often unpredictable.
On the other hand, although the proposed CHC relies heavily on chrominance features, the features are carefully designed to be less sensitive to variations in lighting conditions. The selected features
are analogous to the human visual system, which has advanced abilities of recognizing models with varying lighting conditions, as clearly proven in
Figure 17 and
Section 4.13.
4.15. Comparison with State-of-the-Art YOLO-v4
The proposed CHC method offers an approach to object detection that could present advantages in certain scenarios when compared to the YOLO technique, a popular real-time object detection algorithm. While YOLO is known for its impressive accuracy and efficiency, the strength of the proposed CHC technique lies in its training-less nature, which is beneficial in specific contexts.
In this experiment, the aim is to highlight the key advantage of the proposed CHC technique, which is its training-less nature. Unlike deep learning methods such as YOLO, the proposed CHC technique does not require a training phase or a dataset to function. This feature makes the proposed CHC technique particularly valuable in scenarios where collecting a comprehensive dataset is challenging or impractical. It is true that with specifically designed few-shot training, some supervised learning models can provide acceptable results with a small collection of samples. However, in such a case, there is still a need for a diverse, high-quality dataset, which is not always possible. The objective here is to emphasize the fundamental difference between training-dependent and training-less methods. The comparison with YOLO is intended to demonstrate that without sufficient training data, the performance of YOLO can significantly degrade, whereas the proposed CHC technique remains unaffected by the absence of training data.
The YOLO network configuration and experimental setup are detailed in
Table 2. This table outlines the parameters and methods used in training the YOLO model, as well as the data augmentation techniques and dataset splitting strategy. The training process employs the Adam optimizer with a gradient decay factor of 0.9 and a squared gradient decay factor of 0.999. The initial learning rate is set to 0.001, and no learning rate schedule is applied. Training is conducted with a mini-batch size of 4, L2 regularization set to 0.0005, and a maximum of 80 epochs. To ensure efficient processing, the dispatch occurs in the background, and input normalization is reset. The data are shuffled at every epoch, with verbose output provided every 20 iterations and validation checks performed every 1000 iterations. The best validation loss is used to determine the output network, and checkpoints are saved to a temporary directory. Validation data are also provided for periodic performance checks.
The augmentData helper function applies several augmentations to the input data, including color jitter augmentation in HSV space, random horizontal flipping, and random scaling by 10 percent. These augmentations enhance the robustness of the model by introducing variability in the training data. The dataset is split into training, validation, and test sets, with 60% of the data allocated for training, 10% for validation, and the remaining 30% reserved for testing of the trained detector. This ensures a comprehensive evaluation of the model’s performance across different data subsets. The YOLO-v4 model used in this paper was trained using selected images from the COCO dataset [
34].
In scenarios where color information plays a crucial role in distinguishing objects, the proposed CHC technique can outperform YOLO. For instance, in applications where detecting objects based on distinctive color patterns is essential, such as identifying objects in images with intricate artistic designs or complex color variations, the proposed CHC technique might offer superior performance. YOLO, being primarily designed to consider a broad range of object characteristics, may not leverage color information as effectively as the proposed CHC technique in such specific scenarios.
Moreover, the training nature of the proposed CHC technique can be advantageous in scenarios where acquiring and annotating large datasets for training purposes is challenging. In contrast, YOLO requires a substantial training phase with annotated datasets to fine tune its model for specific object detection tasks. In situations where resources for training data are limited, the ability to perform without the need for extensive training could be a compelling advantage.
Another potential scenario where the proposed CHC technique can be beneficial is in environments with distinct color variations or where color is a defining factor for object identification. For example, in applications such as agriculture, where the color of crops or fruits is crucial for assessing ripeness or health, the proposed CHC technique might offer a tailored solution. YOLO, while robust in handling diverse object types, might not exploit color-specific features as explicitly as the proposed CHC technique.
The suitability of the proposed CHC technique over YOLO depends on the nature of the application and the specific requirements of the object detection task. While YOLO excels in versatility and generalization, the emphasis of the proposed CHC technique on color-based features positions it as a promising solution in scenarios where color information is pivotal for accurate and efficient object detection.
Figure 18 presents a comparative analysis of the performance between the state-of-the-art YOLO technique and the proposed CHC technique in detecting the back of a car. The experiment is conducted in three different trials, each represented by a set of
Figure 18a–c for YOLO and
Figure 18d–f for the proposed CHC technique.
In
Figure 18a–c, the YOLO technique is applied to detect the back of a car. However, despite YOLO’s reputation for superior detection capabilities, its accuracy in this specific experiment appears to be dependent on the quality of the training data. The images show that YOLO, trained on only 295 vehicles, does not successfully detect any objects in these instances, as evidenced by the absence of squares drawn around the cars, except for the trail shown in
Figure 18c.
On the contrary,
Figure 18d–f showcase the results of the proposed training-less CHC technique in the same experimental setup. The proposed CHC technique, without the need for an extensive training dataset, demonstrates its ability to successfully detect the objects, marking a notable contrast to the performance of the YOLO technique in this particular scenario.
This experiment emphasizes the potential advantages of the proposed CHC technique, particularly in scenarios where acquiring a large and diverse training dataset may be challenging or impractical. The ability of the proposed CHC technique to detect objects without relying heavily on extensive training data showcases its adaptability and effectiveness, making it a promising solution for real-world applications such as object detection in environments where specific training data might be limited.
4.16. Model Detection in Different Frames
One of the key challenges in color-based object detection techniques is maintaining accuracy when detecting objects across different frames, especially when variations in lighting conditions, shape, appearance, and viewpoint occur. To address these challenges, the proposed CHC method’s robustness is examined by testing its performance on models captured under diverse conditions.
To rigorously assess the proposed CHC technique, an experiment was designed involving objects photographed in different frames, each presenting variations in lighting, shape, and appearance. These frames were captured under various lighting conditions, from bright daylight to dim indoor settings, and include objects viewed from multiple angles to introduce shape and appearance variations. The goal is to simulate real-world scenarios where such variations are inevitable and to test the proposed CHC method’s capability of accurately detecting objects despite these challenges.
The experiments demonstrate that the proposed CHC method can effectively detect objects across different frames with significant variations, as shown in
Figure 19, with some uncertainty. The chrominance-rich feature vector used by the CHC method proves to be robust against changes in lighting conditions. By focusing on distinctive chrominance features, the proposed CHC method maintains high detection accuracy, even when the object’s appearance changes due to different lighting.
Moreover, the proposed CHC method shows resilience to changes in object shape and viewpoint. Although traditional color-based techniques often struggle with such variations, the proposed CHC method’s emphasis on unique color features allows it to correctly identify objects despite these challenges. This robustness is attributed to the method’s ability to highlight and match unique color histograms between the model and scene images, ensuring reliable object detection.
The results affirm the proposed CHC method’s capability of detecting objects across different frames, addressing a significant limitation of traditional color-based techniques. By effectively handling variations in lighting, shape, and appearance, the proposed CHC method demonstrates its potential for robust real-time object detection in dynamic and unpredictable environments. This capability is particularly valuable for applications such as autonomous robot localization and mapping, where consistent and reliable object detection is crucial.
4.17. Limitations and Challenges
Many object detection techniques, such as the well-known Swain and Ballard method, focus only on color histograms for object detection and do not incorporate other parameters. While a method that incorporates different features is usually superior to color-based detection techniques, there are still advantages of color-based object detection techniques that can make them preferred over complex techniques. Color-based object detection techniques can be advantageous because they can efficiently identify and differentiate objects in environments where color is a distinctive and stable feature, making them relatively simple and fast to implement. Additionally, these techniques are computationally less intensive compared to methods that rely on complex feature extraction and machine learning, enabling real-time applications in resource-constrained settings. The proposed technique aims to provide an effective training-less approach. It tends to be used in harsh circumstances and unique scenarios, where datasets are not available or cannot be created. As stated in the Abstract, the proposed technique can be beneficial for robots maneuvering in unknowing environments where detection must be performed on the spot.
The proposed technique is based on Swain and Ballard’s method. Therefore, the main comparison is against the original color indexing technique (Swain and Ballard’s method). We clearly showed that the proposed technique overcomes Swain and Ballard’s method using the same experimental scenario. Therefore, for cases where color detection is sufficient, the proposed technique is an advanced and efficient solution. The proposed technique builds a comprehensive rich feature vector, which is not a simple, straightforward color matching. The feature vector is designed to be analogous to the human visual system, which is invariant to different lighting conditions. Therefore, the results are positive when testing the proposed technique with images with different lighting conditions.
Even though the proposed CHC method offers notable benefits for training-less object detection, it has its limitations. A key challenge is its dependence on distinct features within the chrominance components. This reliance can be problematic in situations where color information is either insufficiently distinctive or highly variable due to environmental factors such as lighting changes, shadows, or reflections. In these cases, the method may have difficulty accurately distinguishing objects, potentially leading to false positives or negatives. As shown in
Figure 20a, the proposed CHC technique is not able to detect the model, since it does not have distinct chrominance features. It is simply an area that is part of a background texture with many surrounding areas with the exact same content. However, such a detection problem is not serious, as it is not intended to detect a specific object.
Another limitation is the proposed CHC method’s sensitivity to the quality and consistency of color data across different frames. Although the method shows robustness against moderate lighting changes, extreme variations or inconsistent color representation between frames can negatively impact its performance. For example, objects that are similar in color but differ in shape or texture may present challenges for the proposed CHC method, which primarily uses color histograms and does not incorporate additional features such as shape or texture information. This limitation indicates the potential benefit of combining the proposed CHC method with other detection techniques to improve overall accuracy and robustness. In
Figure 20b, the intent was to detect the right-back light of the car. However, unlike the experiments described in
Section 4.16, where the model was taken from a different but nearby frame, the model in this experiment is taken from a far frame. This causes large, non-linear variations in light conditions and shape features.
The effectiveness of the proposed CHC method may be restricted in dynamic environments where objects undergo significant transformations or where multiple objects with overlapping color distributions exist. In such complex scenarios, relying solely on color histograms might not be sufficient for reliable object detection and differentiation. Additionally, the computational efficiency of the proposed CHC method could be affected when processing high-resolution images or requiring real-time analysis, as the algorithm processes all non-zero histogram bins. These potential limitations suggest that while the proposed CHC method is a valuable tool for certain applications, it may need to be supplemented with other techniques to address the wide range of object detection challenges in diverse and dynamic environments.

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}