
Performance Evaluation of Parallel Graphs Algorithms Utilizing Graphcore IPU

 ,
,  ,
,  ,
,
Abstract
1. Introduction
2. Literature Overview
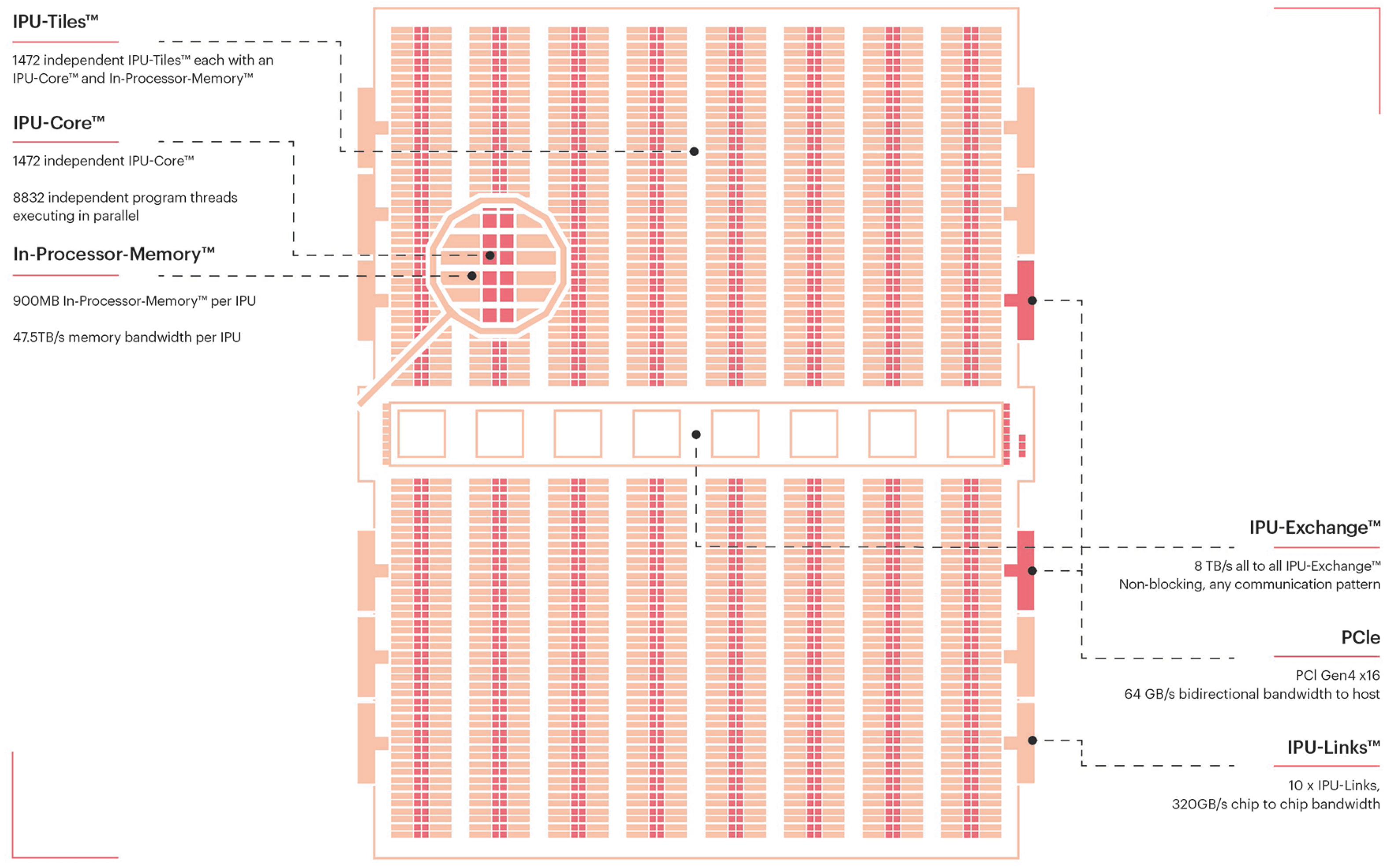
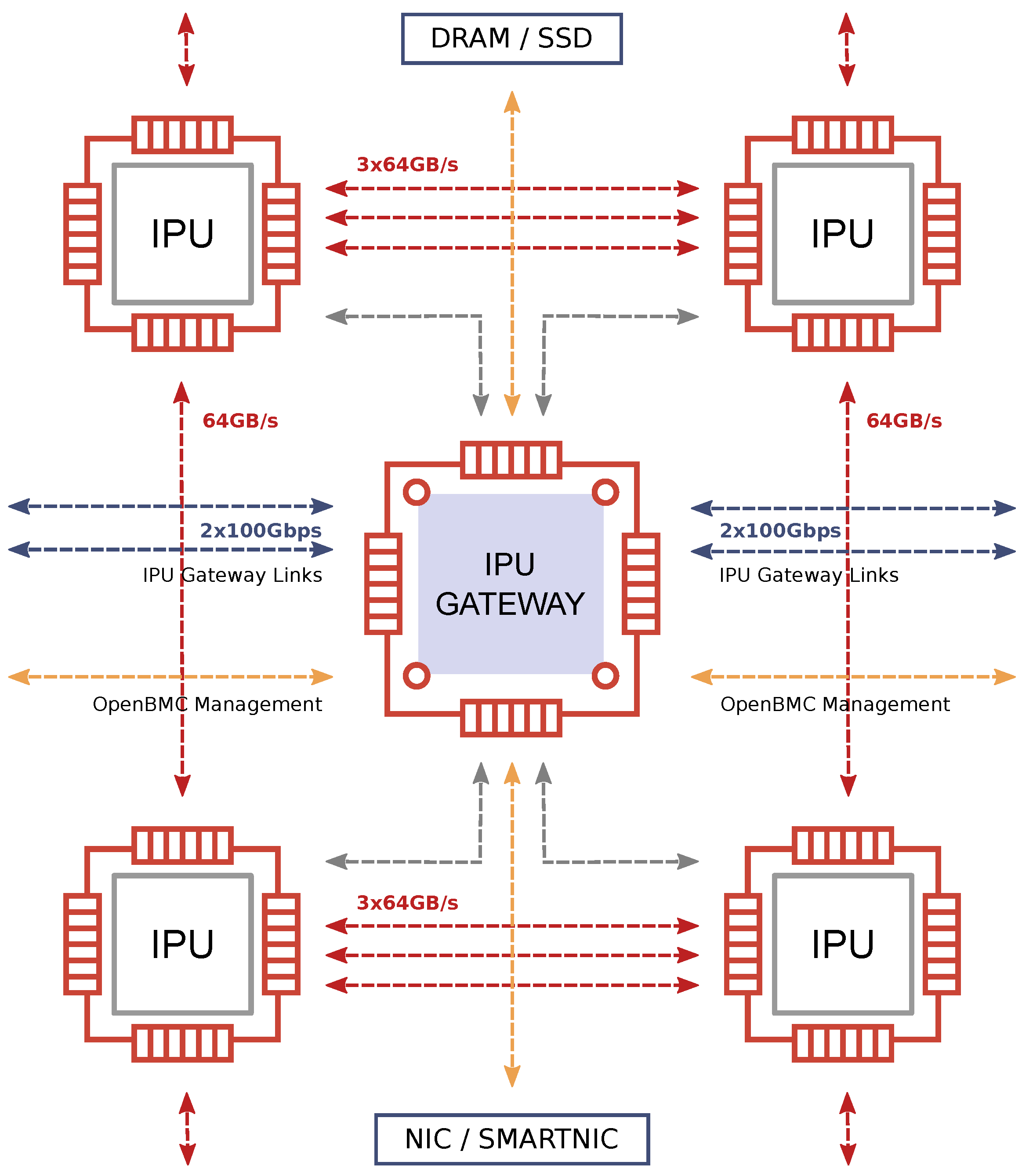
3. Graphcore IPU and Platform Architecture
- Vertices represent programs executed on individual tiles, defining operations integrated into the computation graph. The functionality of a vertex ranges from simple arithmetic operations to complex tensor data reshaping or intricate code execution.
- Computation graph delineates the input–output relationship between variables and operations, offering capabilities for construction, compilation and serialization of the computation graph.
- Control programs oversee argument administration, device selection and execution control of graph operations.
4. Selected Graph Algorithms
| Algorithm 1: PageRank Algorithm |
|
| Algorithm 2: Bellman–Ford Algorithm for Shortest Paths |
|
| Algorithm 3: Breadth-First Search (BFS) Algorithm |
|
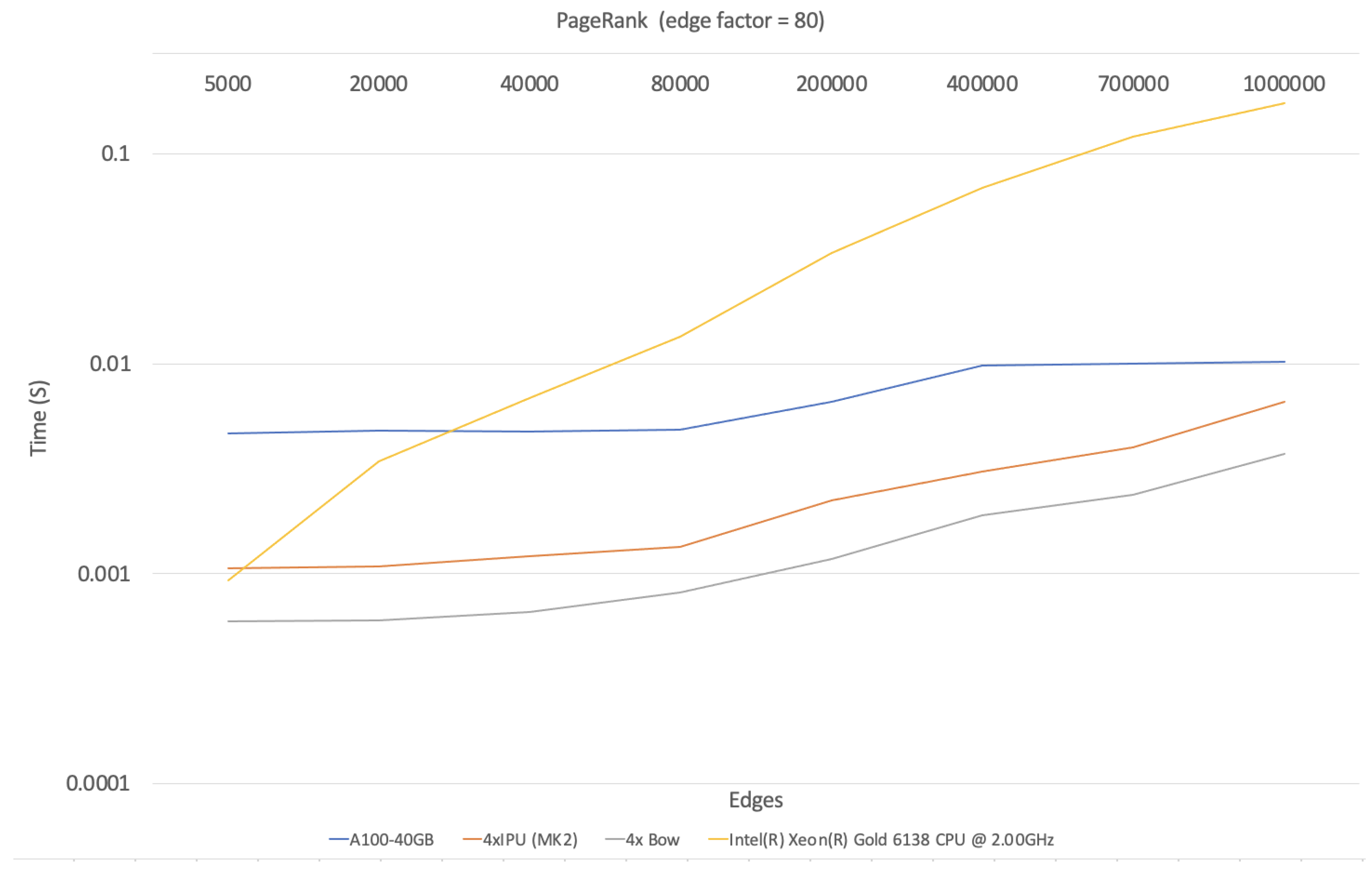
5. Experimental Results and Verification
6. New Insights and Contributions
- IPU Advantage for Specific Tasks: This study reveals a clear performance benefit for Graphcore IPUs (both MK2 and Bow generations) compared to A-100 GPUs and CPUs. This advantage is particularly pronounced for BFS and SSSP algorithms applied to large graphs with hundreds of thousands of edges. While PageRank also shows improvement on IPUs, the performance gap between A-100 and IPU narrows with increasing data size.
- Cross-Platform Performance Comparison: This work offers a valuable comparison of execution times for the three graph algorithms across CPUs, A-100 GPUs and two generations of Graphcore IPUs (MK2 and Bow). This side-by-side analysis highlights the strengths and weaknesses of each platform for tackling graph processing tasks.
- Impact of Graph Density: This research investigates how graph density influences performance. The findings demonstrate that processing efficiency increases for all algorithms as graphs become denser. This is particularly evident for the densest graphs on larger graph sizes.
- IPU Scalability Potential: This study explores the scalability of IPU systems by comparing performance with different numbers of IPUs used for BFS. It reveals a superlinear performance increase (up to 2.5×) when doubling the number of IPUs. This suggests efficient processing of graphs with millions of edges on larger configurations.
- Efficient Data Loading: The experiments confirm the effectiveness of data loading capabilities in the IPU machine. Load times increase linearly, with no significant issues observed related to data size. This indicates a well-configured system for data transfer.
7. Concluding Remarks
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Schulz, F.; Wagner, D.; Zaroliagis, C. Using Multi-level Graphs for Timetable Information in Railway Systems. In Proceedings of the Algorithm Engineering and Experiments, San Francicsco, CA, USA, 4–5 January 2002; Springer: Berlin/Heidelberg, Germany, 2002; pp. 43–59. [Google Scholar]
- Fan, W.; Ma, Y.; Li, Q.; He, Y.; Zhao, E.; Tang, J.; Yin, D. Graph Neural Networks for Social Recommendation. In Proceedings of the Association for Computing Machinery, Atlanta, GA, USA, 29–31 January 2019; pp. 417–426. [Google Scholar] [CrossRef]
- Michael, G.; Rolf, J.; Ypm, F.; Romero-Garcia, R.; Price, S.; Suckling, J. Graph theory analysis of complex brain networks: New concepts in brain mapping applied to neurosurgery. J. Neurosurg. JNS Am. Assoc. Neurol. 2016, 124, 1665–1678. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Liu, S.; Li, Z.; Han, X.; Shi, C.; Hooi, B.; Huang, H.; Cheng, X. FlowScope: Spotting Money Laundering Based on Graphs. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 4731–4738. [Google Scholar] [CrossRef]
- Henderson, R. Using graph databases to detect financial fraud. Comput. Fraud. Secur. 2020, 2020, 6–10. [Google Scholar] [CrossRef]
- Zhang, D.; Liu, Z.; Jia, W.; Liu, H.; Tan, J. Path Enhanced Bidirectional Graph Attention Network for Quality Prediction in Multistage Manufacturing Process. IEEE Trans. Ind. Inform. 2020, 18, 1018–1027. [Google Scholar] [CrossRef]
- Suzumura, T.; Zhou, Y.; Barcardo, N.; Ye, G.; Houck, K.; Kawahara, R.; Anwar, A.; Stavarache, L.; Klyashtorny, D.; Ludwig, H.; et al. Towards Federated Graph Learning for Collaborative Financial Crimes Detection. arXiv 2019, arXiv:1909.12946. [Google Scholar]
- Robinson, D.; Scogings, C. The detection of criminal groups in real-world fused data: Using the graph-mining algorithm, “GraphExtract”. Secur. Inform. 2018, 7, 2. [Google Scholar] [CrossRef]
- Fensel, A.; Akbar, Z.; Kärle, E.; Blank, C.; Pixner, P.; Gruber, A. Knowledge Graphs for Online Marketing and Sales of Touristic Services. Information 2020, 11, 253. [Google Scholar] [CrossRef]
- Gepner, P. Machine Learning and High-Performance Computing Hybrid Systems, a New Way of Performance Acceleration in Engineering and Scientific Applications. In Proceedings of the 16th Conference on Computer Science and Intelligence Systems, Online, 2–5 September 2021; pp. 27–36. [Google Scholar] [CrossRef]
- Superclouds: AI, Cloud-Native Supercomputers Sail into the TOP500. Available online: https://blogs.nvidia.com/blog/2021/06/28/top500-ai-cloud-native/ (accessed on 1 January 2024).
- Hu, L.; Zou, L.; Liu, Y. Accelerating triangle counting on GPU. In Proceedings of the 2021 International Conference on Management of Data, Virtual, 18–22 June 2021; pp. 736–748. [Google Scholar]
- Harish, P.; Narayanan, P. Accelerating large graph algorithms on the GPU using CUDA. In Proceedings of the International Conference on High-Performance Computing, Goa, India, 18–21 December 2007; pp. 197–208. [Google Scholar]
- Lü, Y.; Guo, H.; Huang, L.; Yu, Q.; Shen, L.; Xiao, N.; Wang, Z. GraphPEG: Accelerating graph processing on GPUs. Acm Trans. Archit. Code Optim. (TACO) 2021, 18, 1–24. [Google Scholar] [CrossRef]
- Song, L.; Zhuo, Y.; Qian, X.; Li, H.; Chen, Y. GraphR: Accelerating graph processing using ReRAM. In Proceedings of the 2018 IEEE International Symposium on High-Performance Computer Architecture (HPCA), Vienna, Austria, 24–28 February 2018; pp. 531–543. [Google Scholar]
- Zhong, J.; He, B. Towards GPU-accelerated large-scale graph processing in the cloud. In Proceedings of the IEEE 5th International Conference on Cloud Computing Technology and Science, Bristol, UK, 2–5 December 2013; pp. 9–16. [Google Scholar]
- Betkaoui, B.; Thomas, D.; Luk, W.; Przulj, N. A framework for FPGA acceleration of large graph problems: Graphlet counting case study. In Proceedings of the 2011 International Conference on Field-Programmable Technology, New Delhi, India, 12–14 December 2011; pp. 1–8. [Google Scholar]
- Zhou, S.; Kannan, R.; Zeng, H.; Prasanna, V. An FPGA framework for edge-centric graph processing. In Proceedings of the 15th ACM International Conference on Computing Frontier, Ischia, Italy, 8–10 May 2018; pp. 69–77. [Google Scholar]
- Khoram, S.; Zhang, J.; Strange, M.; Li, J. Accelerating graph analytics by co-optimizing storage and access on an FPGA-HMC platform. In Proceedings of the 2018 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 25–27 February 2018; pp. 239–248. [Google Scholar]
- Zeng, H.; Prasanna, V. GraphACT: Accelerating GCN training on CPU-FPGA heterogeneous platforms. In Proceedings of the 2020 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Seaside, CA, USA, 23–25 February 2020; pp. 255–265. [Google Scholar]
- Wang, Y.; Hoe, J.; Nurvitadhi, E. Processor assisted worklist scheduling for FPGA accelerated graph processing on a shared-memory platform. In Proceedings of the 2019 IEEE 27th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), San Diego, CA, USA, 28 April–1 May 2019; pp. 136–144. [Google Scholar]
- Ma, X.; Zhang, D.; Chiou, D. FPGA-accelerated transactional execution of graph workloads. In Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 22–24 February 2017; pp. 227–236. [Google Scholar]
- Penders, A. Accelerating Graph Analysis with Heterogeneous Systems. Master’s Thesis, University of Twente, Enschede, The Netherlands, 2012. [Google Scholar]
- Zhou, S.; Prasanna, V. Accelerating graph analytics on CPU-FPGA heterogeneous platform. In Proceedings of the 29th International Symposium on Computer Architecture and High-Performance Computing (SBAC-PAD), Campinas, Brazil, 17–20 October 2017; pp. 137–144. [Google Scholar]
- Intel. Katana’s High-Performance Graph Analytics Library. 2021. Available online: https://www.intel.com/content/www/us/en/developer/articles/technical/katana-high-performance-graph-analytics-library.html (accessed on 1 January 2024).
- Sadi, F.; Sweeney, J.; McMillan, S.; Hoe, J.; Pileggi, L.; Franchetti, F. Pagerank acceleration for large graphs with scalable hardware and two-step spmv. In Proceedings of the 2018 IEEE High Performance extreme Computing Conference (HPEC), Waltham, MA, USA, 25–27 September 2018; pp. 1–7. [Google Scholar]
- Angizi, S.; Sun, J.; Zhang, W.; Fan, D. Design, Automation & Test in Europe Conference & Exhibition (DATE). In Proceedings of the GraphS: A Graph Processing Accelerator Leveraging SOT-MRAM, Florence, Italy, 25–29 March 2019; 29 March 2019. [Google Scholar] [CrossRef]
- Kapre, N. Custom FPGA-based soft-processors for sparse graph acceleration. In Proceedings of the 2015 IEEE 26th International Conference on Application-Specific Systems, Architectures and Processors (ASAP), Toronto, ON, Canada, 27–29 July 2015. [Google Scholar] [CrossRef]
- Burchard, L.; Moe, J.; Schroeder, D.; Pogorelov, K.; Langguth, J. iPUG: Accelerating breadth-first graph traversals using manycore Graphcore IPUs. In Proceedings of the International Conference on High Performance Computing, Barcelona, Spain, 10–14 December 2021; pp. 291–309. [Google Scholar]
- Caraballo-Vega, J.; Smith, N.; Carroll, M.; Carriere, L.; Jasen, J.; Le, M.; Li, J.; Peck, K.; Strong, S.; Tamkin, G.; et al. Remote Sensing Powered Containers for Big Data and AI/ML Analysis: Accelerating Science, Standardizing Operations. In Proceedings of the 2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 4034–4037. [Google Scholar] [CrossRef]
- Jia, Z.; Tillman, B.; Maggioni, M.; Scarpazza, D. Dissecting the Graphcore IPU Architecture via Microbenchmarking. arXiv 2019, arXiv:1912.03413. [Google Scholar] [CrossRef]
- Freund, K.; Moorhead, P. The Graphcore Second-Generation IPU. Moor Insights & Strategy. 2020. Available online: https://www.graphcore.ai/hubfs/MK2-%20The%20Graphcore%202nd%20Generation%20IPU%20Final%20v7.14.2020.pdf?hsLang=en (accessed on 1 January 2024).
- cuGraph GPU Graph Analytics. Available online: https://github.com/rapidsai/cugraph (accessed on 1 January 2024).
- Langville, A.; Meyer, C. Google’s PageRank and Beyond: The Science of Search Engine Rankings; Princeton University Press: Princeton, NJ, USA, 2011. [Google Scholar] [CrossRef]
- Brezinski, C.; Redivo-Zaglia, M. The PageRank vector: Properties, computation, approximation, and acceleration. SIAM J. Matrix Anal. Appl. 2006, 28, 551–575. [Google Scholar] [CrossRef]
- Migallón, H.; Migallón, V.; Penadés, J. Non-Stationary Acceleration Strategies for PageRank Computing. Mathematics 2019, 7, 911. [Google Scholar] [CrossRef]
- Nagasinghe, I. Computing Principal Eigenvectors of Large Web Graphs: Algorithms and Accelerations Related to Pagerank and Hits. Ph.D. Dissertation, Southern Methodist University, Dallas, TX, USA, 2010; pp. 1–114. Available online: https://eric.ed.gov/id=ED516370 (accessed on 1 January 2024).
- Liu, C.; Li, Y. A Parallel PageRank Algorithm with Power Iteration Acceleration. Int. J. Grid Distrib. Comput. 2015, 8, 273–284. [Google Scholar] [CrossRef]
- Migallón, H.; Migallón, V.; Penadés, J. Parallel two-stage algorithms for solving the PageRank problem. Adv. Eng. Softw. 2018, 125, 188–199. [Google Scholar] [CrossRef]
- Avrachenkov, K.; Litvak, N.; Nemirovsky, D.; Osipova, N. Monte Carlo methods in PageRank computation: When one iteration is sufficient. SIAM J. Numer. Anal. 2007, 45, 890–904. [Google Scholar] [CrossRef]
- Grützmacher, T.; Cojean, T.; Flegar, G.; Anzt, H.; Quintana-Ortí, E. Acceleration of PageRank with Customized Precision Based on Mantissa Segmentation. Assoc. Comput. Mach. 2020, 7, 1–19. [Google Scholar] [CrossRef]
- Mughrabi, A.; Ibrahim, M.; Byrd, G. QPR: Quantizing PageRank with Coherent Shared Memory Accelerators. In Proceedings of the 2021 IEEE International Parallel and Distributed Processing Symposium, Portland, OR, USA, 17–21 May 2021; pp. 962–972. [Google Scholar] [CrossRef]
- Rungsawang, A.; Manaskasemsak, B. Parallel adaptive technique for computing PageRank. In Proceedings of the 14th Euromicro International Conference on Parallel, Distributed, and Network-Based Processing, Montbeliard-Sochaux, France, 15–17 February 2006. [Google Scholar] [CrossRef]
- Köhler, E.; Möhring, R.; Schilling, H. Acceleration of shortest path and constrained shortest path computation. In Proceedings of the International Workshop on Experimental and Efficient Algorithms, Santorini Island, Greece, 10–13 May 2005; pp. 126–138. [Google Scholar]
- Wei, W.; Yang, W.; Yao, W.; Xu, H. Accelerating the shortest-path calculation using cut nodes for problem reduction and division. Int. J. Geogr. Inf. Sci. 2020, 34, 272–291. [Google Scholar] [CrossRef]
- Daga, M.; Nutter, M.; Meswani, M. Efficient breadth-first search on a heterogeneous processor. In Proceedings of the 2014 IEEE International Conference on Big Data, Washington, DC, USA, 27–30 October 2014; pp. 373–382. [Google Scholar] [CrossRef]
- Fu, Z.; Dasari, H.; Bebee, B.; Berzins, M.; Thompson, B. Parallel breadth first search on GPU clusters. In Proceedings of the 2014 IEEE International Conference on Big Data, Washington, DC, USA, 27–30 October 2014; pp. 110–118. [Google Scholar]
- Merrill, D.; Garland, M.; Grimshaw, A. Scalable GPU graph traversal. ACM SIGPLAN Not. 2012, 47, 117–128. [Google Scholar] [CrossRef]
- Wen, H.; Zhang, W. Improving Parallelism of Breadth First Search (BFS) Algorithm for Accelerated Performance on GPUs. In Proceedings of the 2019 IEEE High Performance Extreme Computing Conference, Waltham, MA, USA, 24–26 September 2019; pp. 1–7. [Google Scholar] [CrossRef]
- Vastenhouw, B.; Bisseling, R. A two-dimensional data distribution method for parallel sparse matrix-vector multiplication. SIAM Rev. 2005, 47, 67–95. [Google Scholar] [CrossRef]
- Jiang, Z.; Liu, T.; Zhang, S.; Guan, Z.; Yuan, M.; You, H. Fast and efficient parallel breadth-first search with power-law graph transformation. arXiv 2020, arXiv:2012.10026. [Google Scholar] [CrossRef]
- Ganzha, M.; Georgiev, K.; Lirkov, I.; Paprzycki, M. An application of the partition method for solving 3D Stokes equation. Comput. Math. Appl. 2015, 70, 2762–2772. [Google Scholar] [CrossRef]
- Bernard, F.; Zheng, Y.; Joubert, A.; Bhatia, S. High Performance Graph Analytics on Graphcore IPUs. In Proceedings of the 2021 IEEE International Conference on High Performance Computing (HiPC), Bengaluru, India, 17–20 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 30–41. [Google Scholar]
- Jia, Z.; Han, S.; Emerling, A.; Qiao, X. Scalable Graph Algorithm Design and Optimization for Graphcore IPUs. In Proceedings of the 41st ACM SIGMOD International Conference on Management of Data, Portland, OR, USA, 12–17 June 2022; pp. 2645–2658. [Google Scholar]
- Tang, Y.; Xu, Z.; Liu, Z.; Li, J. Accelerating Personalized Recommendation with Graph Neural Networks on Graphcore IPUs. In Proceedings of the 2023 International Conference on Information Technology and Computer Applications (ICITACEE), Semarang, Indonesia, 31 August–1 September 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–6. [Google Scholar]
- Xu, L.; Luo, Z.; Li, H.; Chen, J. Scalable Training of Large Graph Neural Networks with Structural Attention on Graphcore IPUs. arXiv 2023, arXiv:2003.03134. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Single Socket Intel Xeon Gold 6138 | CPU+GPU Nvidia A-100 | Dual CPU+4x Graphcore MK2 | Dual CPU+4x Graphcore Bow | |
|---|---|---|---|---|
| Chip speed (Mhz) | 2000 | 765 | 1325 | 1700 |
| Cores number | 20 | 6912 | 1472 | 1472 |
| L1 cache | 32 KB | 192 KB | NA | NA |
| L2 cache | 256 KB | 40,960 KB | NA | NA |
| L3 cache | 27.5 MB | NA | NA | NA |
| RAM | 16 GB | 40 GB | 900 MB | 900 MB |
| OS version | Ubuntu 18.04.4 LTS | Ubuntu 18.04.4 LTS | Ubuntu 18.04.4 LTS | Ubuntu 18.04.4 LTS |
| C++ Compiler | Clang 6.0.0-1 | CUDA 11.7 | Poplar SDK 2.4 | Poplar SDK 2.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gepner, P.; Kocot, B.; Paprzycki, M.; Ganzha, M.; Moroz, L.; Olas, T. Performance Evaluation of Parallel Graphs Algorithms Utilizing Graphcore IPU. Electronics 2024, 13, 2011. https://doi.org/10.3390/electronics13112011
Gepner P, Kocot B, Paprzycki M, Ganzha M, Moroz L, Olas T. Performance Evaluation of Parallel Graphs Algorithms Utilizing Graphcore IPU. Electronics. 2024; 13(11):2011. https://doi.org/10.3390/electronics13112011
Chicago/Turabian StyleGepner, Paweł, Bartłomiej Kocot, Marcin Paprzycki, Maria Ganzha, Leonid Moroz, and Tomasz Olas. 2024. "Performance Evaluation of Parallel Graphs Algorithms Utilizing Graphcore IPU" Electronics 13, no. 11: 2011. https://doi.org/10.3390/electronics13112011
APA StyleGepner, P., Kocot, B., Paprzycki, M., Ganzha, M., Moroz, L., & Olas, T. (2024). Performance Evaluation of Parallel Graphs Algorithms Utilizing Graphcore IPU. Electronics, 13(11), 2011. https://doi.org/10.3390/electronics13112011