
Speech Emotion Recognition Based on Temporal-Spatial Learnable Graph Convolutional Neural Network



Abstract
1. Introduction
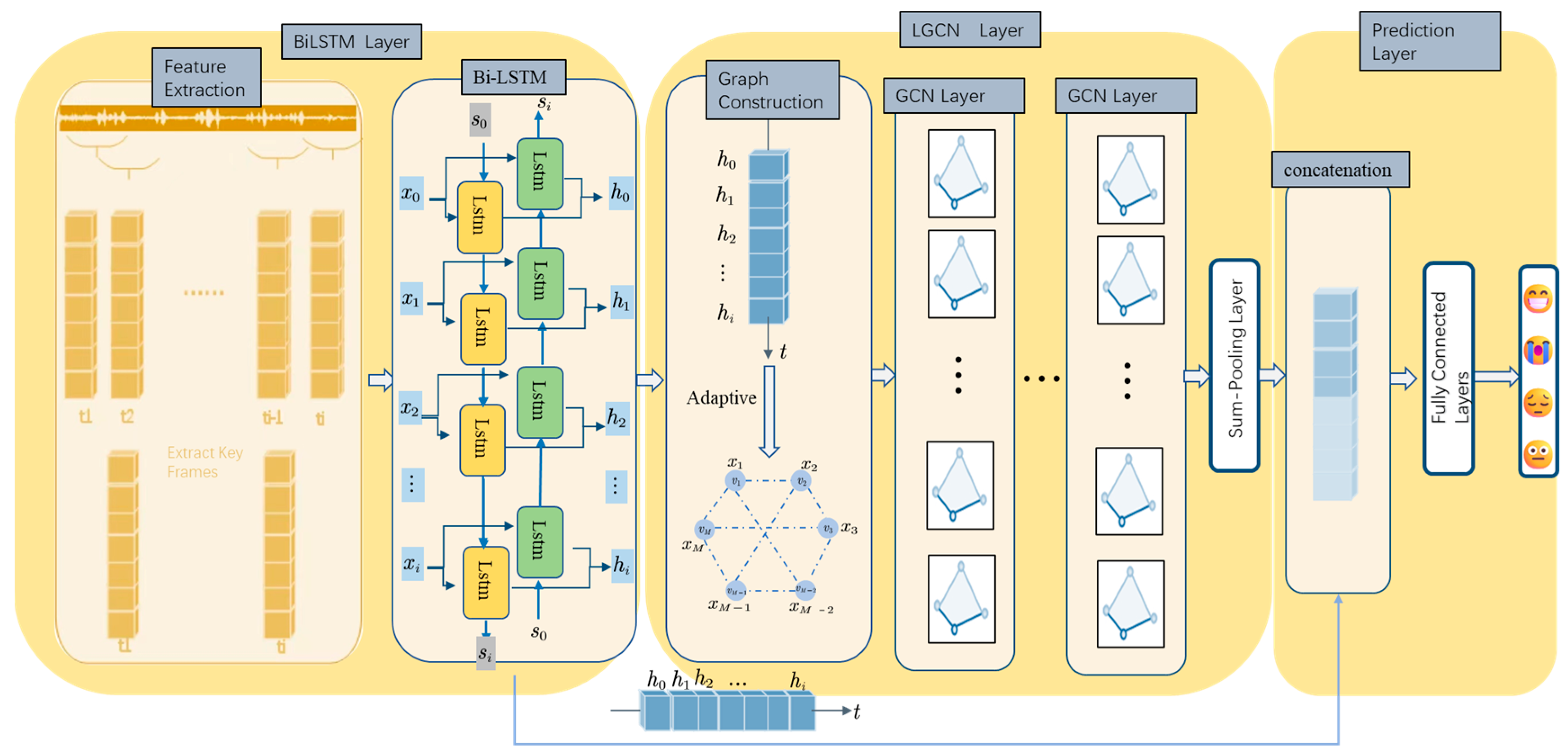
2. Temporal-Spatial Learnable Graph Convolutional Neural Network
2.1. Feature Extraction
2.2. Bi-LSTM
2.3. Learnable Graph Convolutional Neural (LGCN)
2.3.1. Graph Construction
2.3.2. Graph Convolutional Layer
2.3.3. Adaptive Adjacency Matrix
2.3.4. Graph-Level Embedding
3. Datasets, Experiments, and Analysis
3.1. Datasets
3.1.1. IEMOCAP Database
3.1.2. MSP-IMPROV Database
3.2. Implementation Details
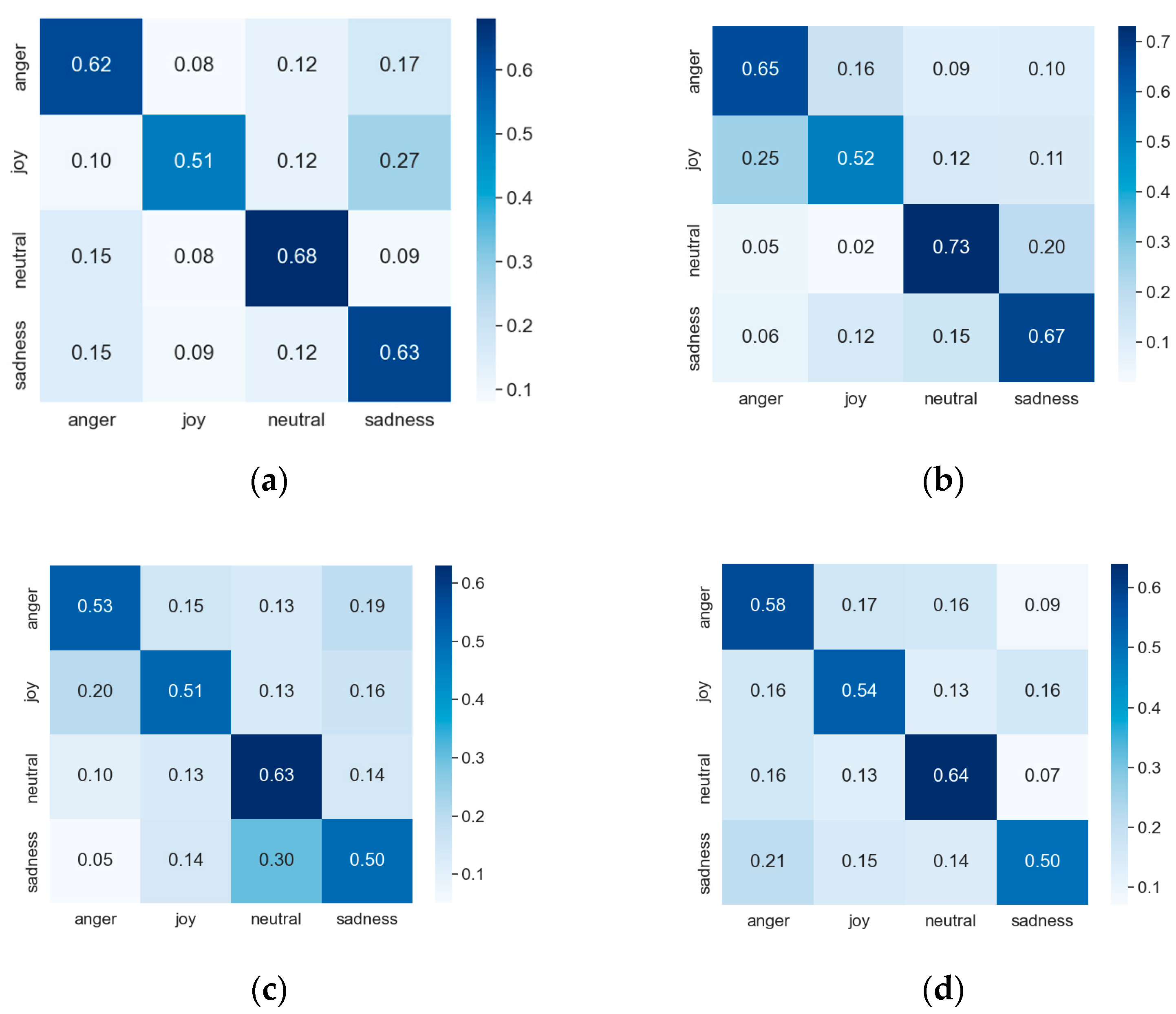
3.3. Results and Analysis
3.4. Ablation Experiments
- During preprocessing, ablation experiments are conducted to investigate whether key frames should be extracted for the emotion features extracted by Open-SMILE;
- Ablation experiments are conducted to evaluate the performance when using LSTM, Bi-LSTM, or no recurrent neural network to extract deep emotion features;
- When obtaining the graph spatial structure, ablation experiments are conducted to assess the impact of using an adaptive adjacency matrix.
3.4.1. Ablation Experiment of Extracting Key Frame Features
3.4.2. LSTM Ablation Experiment
3.4.3. Ablation Experiment of Adaptive Matrix
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kosti, R.; Alvarez, J.M.; Recasens, A.; Lapedriza, A. Emotion Recognition in Context. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1960–1968. [Google Scholar]
- El Ayadi, M.; Kamel, M.S.; Karray, F. Survey on Speech Emotion Recognition: Features, Classification Schemes, and Databases. Pattern Recognit. 2011, 44, 572–587. [Google Scholar] [CrossRef]
- Lakomkin, E.; Zamani, M.A.; Weber, C.; Magg, S.; Wermter, S. On the Robustness of Speech Emotion Recognition for Human-Robot Interaction with Deep Neural Networks. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 854–860. [Google Scholar]
- Li, H.-C.; Pan, T.; Lee, M.-H.; Chiu, H.-W. Make Patient Consultation Warmer: A Clinical Application for Speech Emotion Recognition. Appl. Sci. 2021, 11, 4782. [Google Scholar] [CrossRef]
- Appuhamy, E.J.G.S.; Madhusanka, B.G.D.A.; Herath, H.M.K.K.M.B. Emotional Recognition and Expression Based on People to Improve Well-Being. In Computational Methods in Psychiatry; Springer: Singapore, 2023; pp. 283–307. [Google Scholar]
- Vrigkas, M.; Nikou, C.; Kakadiaris, I.A. Identifying Human Behaviors Using Synchronized Audio-Visual Cues. IEEE Trans. Affect. Comput. 2017, 8, 54–66. [Google Scholar] [CrossRef]
- Ranganathan, H.; Chakraborty, S.; Panchanathan, S. Multimodal Emotion Recognition Using Deep Learning Architectures. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–10 March 2016; pp. 1–9. [Google Scholar]
- Ranganathan, H.; Chakraborty, S.; Panchanathan, S. Transfer of Multimodal Emotion Features in Deep Belief Networks. In Proceedings of the 2016 50th Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 6–9 November 2016; pp. 449–453. [Google Scholar]
- Cámbara, G.; Luque, J.; Farrús, M. Convolutional Speech Recognition with Pitch and Voice Quality Features. arXiv 2020, arXiv:2009.01309. [Google Scholar]
- Farrús, M.; Hernando, J.; Ejarque, P. Jitter and Shimmer Measurements for Speaker Recognition. In Proceedings of the 8th Annual Conference of the International Speech Communication Association (Interspeech 2007), Antwerp, Belgium, 27–31 August 2007. [Google Scholar]
- Al-Dujaili, M.J.; Ebrahimi-Moghadam, A. Speech Emotion Recognition: A Comprehensive Survey. Wirel. Personal Commun. 2023, 129, 2525–2561. [Google Scholar] [CrossRef]
- Vryzas, N.; Vrysis, L.; Matsiola, M.; Kotsakis, R.; Dimoulas, C.; Kalliris, G. Continuous Speech Emotion Recognition with Convolutional Neural Networks. J. Audio Eng. Soc. 2020, 68, 14–24. [Google Scholar] [CrossRef]
- Lieskovská, E.; Jakubec, M.; Jarina, R.; Chmulík, M. A Review on Speech Emotion Recognition Using Deep Learning and Attention Mechanism. Electronics 2021, 10, 1163. [Google Scholar] [CrossRef]
- Lee, J.; Tashev, I. High-Level Feature Representation Using Recurrent Neural Network for Speech Emotion Recognition. In Proceedings of the 16th Annual Conference of the International Speech Communication Association (Interspeech 2015), Dresden, Germany, 6–10 September 2015. [Google Scholar]
- Lim, W.; Jang, D.; Lee, T. Speech Emotion Recognition Using Convolutional and Recurrent Neural Networks. In Proceedings of the 2016 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA), Jeju, Republic of Korea, 13–16 December 2016; pp. 1–4. [Google Scholar]
- Latif, S.; Rana, R.; Khalifa, S.; Jurdak, R.; Epps, J. Direct Modelling of Speech Emotion from Raw Speech. In Proceedings of the 20th Annual Conference of the International Speech Communication Association INTERSPEECH 2019, International Speech Communication Association, Graz, Austria, 15–19 September 2019; pp. 3920–3924. [Google Scholar]
- Luo, D.; Zou, Y.; Huang, D. Investigation on Joint Representation Learning for Robust Feature Extraction in Speech Emotion Recognition. In Proceedings of the 19th Annual Conference of the International Speech Communication (Interspeech 2018), Hyderabad, India, 2–6 September 2018; pp. 152–156. [Google Scholar]
- Zhao, J.; Mao, X.; Chen, L. Speech Emotion Recognition Using Deep 1D & 2D CNN LSTM Networks. Biomed. Signal Process. Control 2019, 47, 312–323. [Google Scholar] [CrossRef]
- Mirsamadi, S.; Barsoum, E.; Zhang, C. Automatic Speech Emotion Recognition Using Recurrent Neural Networks with Local Attention. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 2227–2231. [Google Scholar]
- Le, N.Q.K. Hematoma Expansion Prediction: Still Navigating the Intersection of Deep Learning and Radiomics. Eur. Radiol. 2024, 1–3. [Google Scholar] [CrossRef] [PubMed]
- Le, N.Q.K. Predicting Emerging Drug Interactions Using GNNs. Nat. Comput. Sci. 2023, 3, 1007–1008. [Google Scholar] [CrossRef] [PubMed]
- Zhao, L.; Song, Y.; Zhang, C.; Liu, Y.; Wang, P.; Lin, T.; Deng, M.; Li, H. T-GCN: A Temporal Graph Convolutional Network for Traffic Prediction. IEEE Trans. Intell. Transp. Syst. 2020, 21, 3848–3858. [Google Scholar] [CrossRef]
- Shirian, A.; Guha, T. Compact Graph Architecture for Speech Emotion Recognition. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 6284–6288. [Google Scholar]
- Liu, J.; Wang, H.; Sun, M.; Wei, Y. Graph Based Emotion Recognition with Attention Pooling for Variable-Length Utterances. Neurocomputing 2022, 496, 46–55. [Google Scholar] [CrossRef]
- Yao, L.; Mao, C.; Luo, Y. Graph Convolutional Networks for Text Classification. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 7370–7377. [Google Scholar] [CrossRef]
- Peng, W.; Hong, X.; Chen, H.; Zhao, G. Learning Graph Convolutional Network for Skeleton-Based Human Action Recognition by Neural Searching. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 2669–2676. [Google Scholar] [CrossRef]
- Bai, L.; Yao, L.; Wang, X.; Wang, C. Adaptive Graph Convolutional Recurrent Network for Traffic Forecasting. In Proceedings of the 34th Conference on Neural Information Processing Systems (NeurIPS 2020), Vancouver, BC, Canada, 6–12 December 2020; Advances in Neural Information Processing Systems. Volume 33, pp. 17804–17815. [Google Scholar]
- Su, B.H.; Chang, C.M.; Lin, Y.S.; Lee, C.C. Improving Speech Emotion Recognition Using Graph Attentive Bi-Directional Gated Recurrent Unit Network. In Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH, International Speech Communication Association, Shanghai, China, 25–29 October 2020; pp. 506–510. [Google Scholar]
- Liu, J.; Wang, H. Graph Isomorphism Network for Speech Emotion Recognition. In Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH, International Speech Communication Association, Brno, Czech Republic, 30 August–3 September 2021; Volume 1, pp. 546–550. [Google Scholar]
- Graves, A.; Mohamed, A.; Hinton, G. Speech Recognition with Deep Recurrent Neural Networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 6645–6649. [Google Scholar]
- Eyben, F.; Weninger, F.; Gross, F.; Schuller, B. Recent Developments in OpenSMILE, the Munich Open-Source Multimedia Feature Extractor. In Proceedings of the MM 2013—Proceedings of the 2013 ACM Multimedia Conference, Barcelona, Spain, 21–25 October 2013; pp. 835–838. [Google Scholar]
- Xu, K.; Hu, W.; Leskovec, J.; Jegelka, S. How Powerful Are Graph Neural Networks? In Proceedings of the International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Schuller, B.; Steidl, S.; Batliner, A. The INTERSPEECH 2009 Emotion Challenge. In Proceedings of the INTERSPEECH, Brighton, UK, 6–10 September 2009. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Shuman, D.I.; Narang, S.K.; Frossard, P.; Ortega, A.; Vandergheynst, P. The Emerging Field of Signal Processing on Graphs: Extending High-Dimensional Data Analysis to Networks and Other Irregular Domains. IEEE Signal Process. Mag. 2013, 30, 83–98. [Google Scholar] [CrossRef]
- Defferrard, M.; Bresson, X.; Vandergheynst, P. Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering. In Proceedings of the 30th Conference on Neural Information Processing Systems (NIPS 2016), Barcelona, Spain, 5–10 December 2016. Advances in Neural Information Processing Systems 29. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Busso, C.; Lee, S.; Narayanan, S. Analysis of Emotionally Salient Aspects of Fundamental Frequency for Emotion Detection. IEEE Trans. Audio Speech Lang. Process. 2009, 17, 582–596. [Google Scholar] [CrossRef]
- Busso, C.; Bulut, M.; Lee, C.-C.; Kazemzadeh, A.; Mower, E.; Kim, S.; Chang, J.N.; Lee, S.; Narayanan, S.S. IEMOCAP: Interactive Emotional Dyadic Motion Capture Database. Lang. Resour. Eval. 2008, 42, 335–359. [Google Scholar] [CrossRef]
- Busso, C.; Parthasarathy, S.; Burmania, A.; AbdelWahab, M.; Sadoughi, N.; Provost, E.M. MSP-IMPROV: An Acted Corpus of Dyadic Interactions to Study Emotion Perception. IEEE Trans. Affect. Comput. 2017, 8, 67–80. [Google Scholar] [CrossRef]
- Han, K.; Yu, D.; Tashev, I. Speech Emotion Recognition Using Deep Neural Network and Extreme Learning Machine. In Proceedings of the Interspeech 2014, Singapore, 14–18 September 2014. [Google Scholar]
- Huang, C.-W.; Narayanan, S.S. Attention Assisted Discovery of Sub-Utterance Structure in Speech Emotion Recognition. In Proceedings of the Interspeech 2016, San Francisco, CA, USA, 8–12 September 2016; pp. 1387–1391. [Google Scholar]

{kind=link}
{kind=link}
| IEMOCAP Database | ||
|---|---|---|
| Method | WA (%) | UA (%) |
| GA-GRU [28] | 62.27 | 63.80 |
| GCN-2021 [23] | 64.25 | 61.15 |
| LSTM-GIN [29] | 64.65 | 65.53 |
| GCN-2017 [37] | 56.14 | 52.36 |
| Attn-BLSTM [42] | 59.33 | 49.96 |
| RNN 2017 [19] | 63.50 | 58.80 |
| CRNN 2018 [17] | 63.98 | 60.35 |
| LSTM 2019 [16] | 58.72 | N/A |
| CNN-LSTM 2019 [16] | 59.23 | N/A |
| TLGCNN | 66.82 | 64.21 |
| MSP-IMPROV Database | ||
|---|---|---|
| Method | WA (%) | UA (%) |
| GA-GRU [28] | 56.21 | 57.47 |
| GCN-2021 [23] | 56.24 | 54.32 |
| GCN-2017 [37] | 54.71 | 51.42 |
| CNN 2019 [16] | 50.84 | N/A |
| LSTM 2019 [16] | 51.21 | N/A |
| CNN-LSTM 2019 [16] | 52.36 | N/A |
| TLGCNN | 58.35 | 56.47 |
| IEMOCAP Database | MSP-IMPROV Database | |||
|---|---|---|---|---|
| Experiment Method | WA (%) | UA (%) | WA (%) | UA (%) |
| Not Extracting Key Frames | 65.87 | 63.32 | 56.33 | 54.75 |
| Extracting Key Frames | 66.82 | 64.21 | 58.35 | 56.47 |
| IEMOCAP Database | MSP-IMPROV Database | |||
|---|---|---|---|---|
| Method | WA (%) | UA (%) | WA (%) | UA (%) |
| GCN | 64.25 | 61.15 | 56.24 | 54.32 |
| LSTM + GCN | 65.18 | 62.78 | 56.88 | 54.83 |
| BLSTM + GCN | 65.61 | 62.93 | 57.29 | 55.46 |
| AAM + GCN | 66.03 | 62.13 | 57.33 | 55.18 |
| AAM + BLSTM + GCN | 66.82 | 64.21 | 58.35 | 56.47 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, J.; Li, H.; Xu, F.; Zhou, X.; Liu, Y.; Yang, Y. Speech Emotion Recognition Based on Temporal-Spatial Learnable Graph Convolutional Neural Network. Electronics 2024, 13, 2010. https://doi.org/10.3390/electronics13112010
Yan J, Li H, Xu F, Zhou X, Liu Y, Yang Y. Speech Emotion Recognition Based on Temporal-Spatial Learnable Graph Convolutional Neural Network. Electronics. 2024; 13(11):2010. https://doi.org/10.3390/electronics13112010
Chicago/Turabian StyleYan, Jingjie, Haihua Li, Fengfeng Xu, Xiaoyang Zhou, Ying Liu, and Yuan Yang. 2024. "Speech Emotion Recognition Based on Temporal-Spatial Learnable Graph Convolutional Neural Network" Electronics 13, no. 11: 2010. https://doi.org/10.3390/electronics13112010
APA StyleYan, J., Li, H., Xu, F., Zhou, X., Liu, Y., & Yang, Y. (2024). Speech Emotion Recognition Based on Temporal-Spatial Learnable Graph Convolutional Neural Network. Electronics, 13(11), 2010. https://doi.org/10.3390/electronics13112010