
Diffusion-Based Radio Signal Augmentation for Automatic Modulation Classification



Abstract
1. Introduction
- A novel signal augmentation algorithm, DiRSA, which significantly augments the volume of training data available for AMC models without compromising the intrinsic qualities of the radio signals.
- By incorporating prompt words, the DiRSA technique enhances the accuracy of generating signal data for specific modulation categories, effectively reducing the potential for the confusion commonly associated with generative models. This approach is more adaptable compared to the plain method of training separate models for each modulation category. Utilizing prompt words to dictate the modulation category of generated signals not only simplifies the control mechanism but also significantly decreases the number of model files required, thereby facilitating easier management.
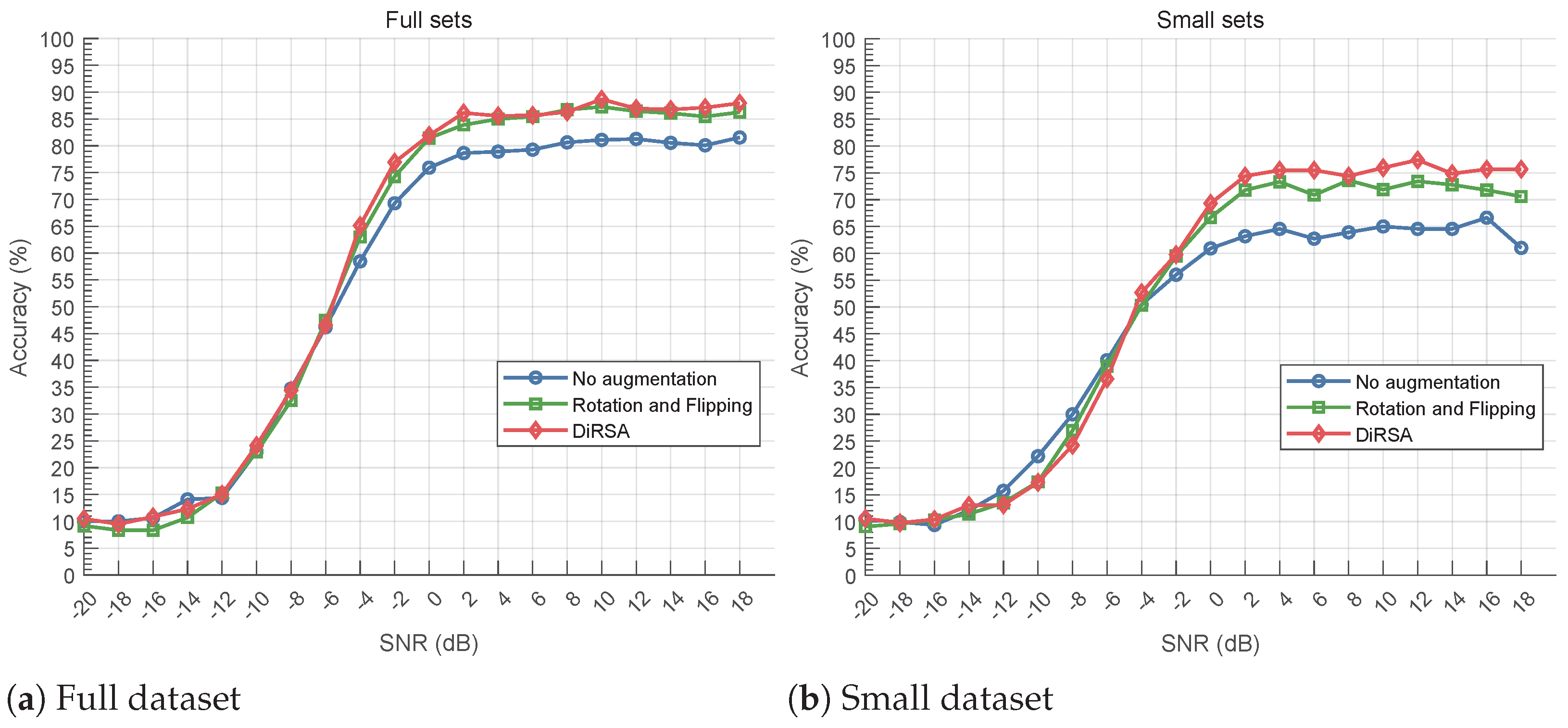
- Compared to traditional signal augmentation methods, such as rotation and flipping, DiRSA-augmented datasets can achieve more effective modulation classification performance. When using long short-term memory (LSTM) [21], CNNs, and convolutional long short-term memory fully connected deep neural networks (CLDNNs) [22], DiRSA performs 2.75–5.92% better than rotation and flipping in small dataset scenarios at an SNR higher than 0 dB.
2. The DiRSA
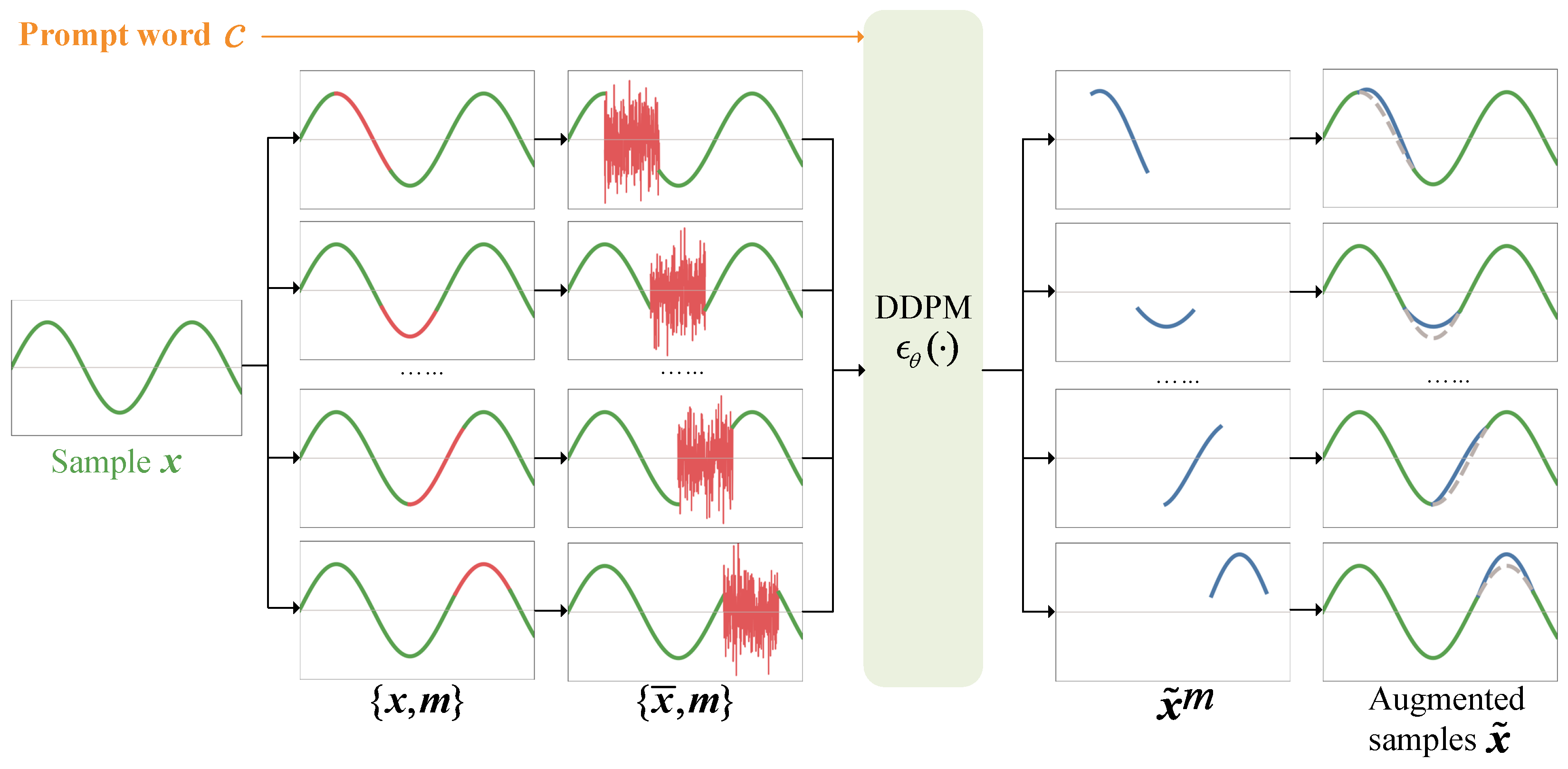
2.1. Overview of DiRSA
- Signal masking. Starting with a sample of radio signals , where L is the length of the sample, we apply a mask . This mask ensures that consecutive elements are set to 1. Each masked signal sample is then split into a masked segment and unmasked segments . As depicted in Figure 1, the masked segments are shown with red lines, while the unmasked segments are displayed with green lines. The masked segments are replaced with pure noise from a standard Gaussian distribution , resulting in a new noised signal sample .
- Signal denoising. An adapted DDPM is employed to reconstruct the signal from the noise. This process is influenced by a prompt word vector , representing the modulation category’s one-hot encoding. The pair and the prompt word are input into the DDPM, which outputs , approximating based on the unmasked segments .
- Signal embedding. The reconstructed segment is then embedded back into the original signal sample by replacing the original masked segment. This produces a new augmented signal sample , shown as blue solid lines in Figure 1, with the original depicted as gray dotted lines.
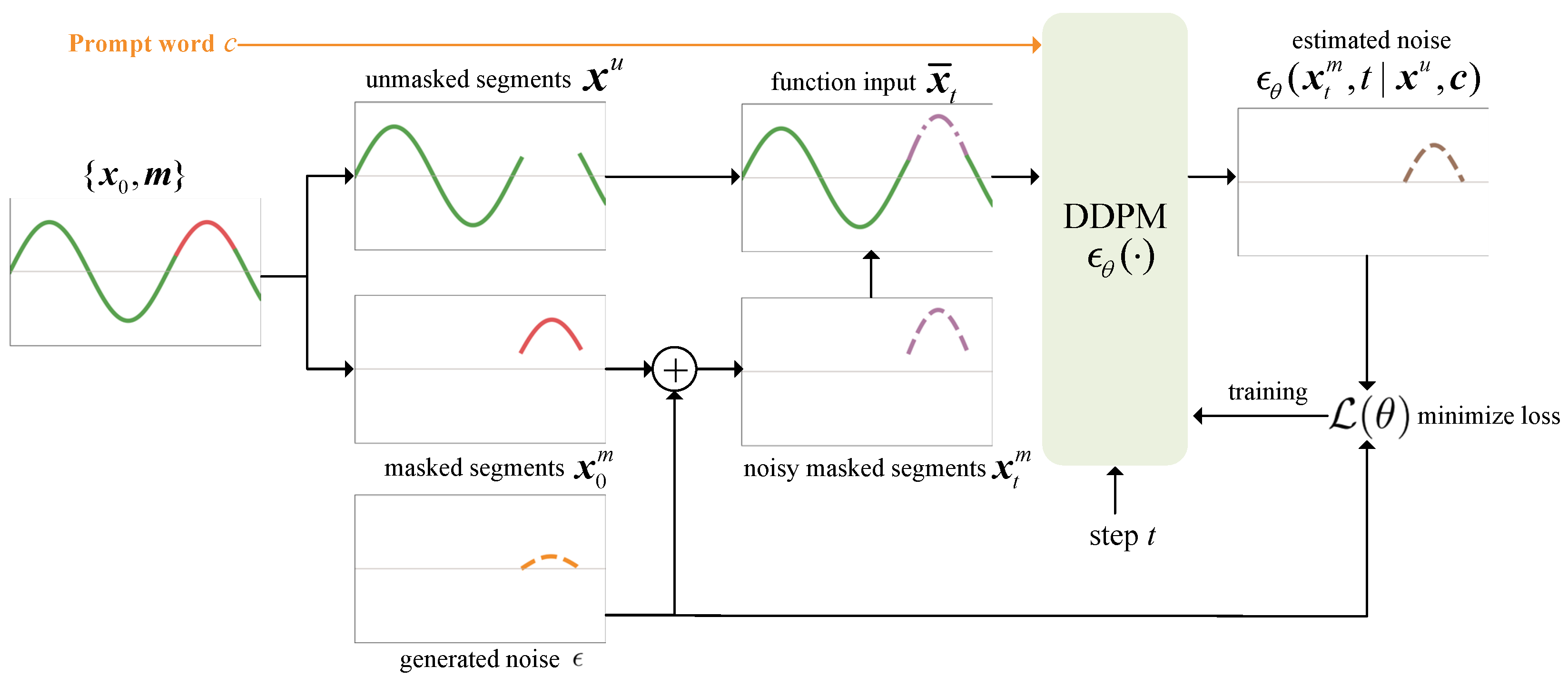
2.2. Prompt-Based Signal Denoising
- Masking and conditional probability: DiRSA employs a novel approach that utilizes masking alongside conditional probabilities. This method allows DiRSA to adapt to IQ signal data and enables the reconstruction of the remaining noise portions of a signal into newly suitable signal segments based on the features of the non-noise portions, thereby achieving the effect of signal augmentation.
- Prompt word for modulation category: Uniquely, DiRSA incorporates the modulation category as a prompt word within its process. Each sample that requires signal augmentation will have a modulation category. It is assigned a unique identifier that ranges from 0 to 10. These identifiers are then transformed into a one-hot encoding format, where each identifier is represented by an 11-element binary vector. In this vector, only the position corresponding to the identifier is marked as “1”, with all other positions set to “0”. This one-hot encoded vector is subsequently used as a prompt word in the input to our model. This innovation allows for the stable generation of signal data corresponding precisely to the specified modulation category. By doing so, DiRSA enhances its utility and accuracy in the field of automatic modulation classification, ensuring that the generated signals are consistently aligned with the desired modulation features.
2.2.1. Denoising Process
| Algorithm 1: Signal Denoising Process for IQ Signals using DiRSA |
 |
2.2.2. Noise Estimation
2.3. Train DiRSA
3. Dataset and Evaluation Method
3.1. Radio Signal Dataset
3.2. Augmented Datasets and Models
3.3. AMC Models
- LSTM Architecture: The LSTM model [21] consists of two layers, each equipped with 128 cells, an input size of 2, and a dropout rate of 0.5. This configuration is designed to effectively process sequential data, making it particularly suitable for time series analysis in modulation classification. The network transitions into a fully connected layer that narrows down from 128 to 11 output channels, corresponding to the different modulation categories present in the dataset.
- CNN Configuration: The CNN employs three convolutional layers that are sequentially arranged, each with a kernel size of 3, ReLU activation, and followed by a MaxPooling layer with a kernel size of 2. This structure is aimed at reducing computational load and simplifying network complexity. Channel depths are progressively increased from 2 to 32, then 64, and finally 128. Subsequent to the convolutional stages, the network includes two fully connected layers that scale down the features from 2048 (128 × 16, presuming full connectivity from the max-pooled outputs) to 128, and finally to 11 output channels.
- CLDNN Model: The CLDNN [12] architecture integrates elements of both the CNN and LSTM models. It starts with two convolutional layers identical to the initial layers of the CNN, which then lead into two LSTM layers configured similarly to those in the standalone LSTM model. This hybrid setup culminates in a fully connected layer that compresses the features to 11 output channels, enhancing the model’s capability for nuanced modulation recognition tasks.
4. Performance
4.1. Evaluation of Prompt Words
4.2. AMC Performance
4.3. Complexity Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ma, H.; Fang, Y.; Chen, P.; Mumtaz, S.; Li, Y. A novel differential chaos shift keying scheme with multidimensional index modulation. IEEE Trans. Wirel. Commun. 2022, 22, 237–256. [Google Scholar] [CrossRef]
- Xiao, L.; Li, S.; Qian, Y.; Chen, D.; Jiang, T. An overview of OTFS for Internet of Things: Concepts, benefits, and challenges. IEEE Internet Things J. 2021, 9, 7596–7618. [Google Scholar] [CrossRef]
- Abdel-Moneim, M.A.; El-Rabaie, S.; Abd El-Samie, F.E.; Ramadan, K.; Abdel-Salam, N.; Ramadan, K.F. Efficient CNN-Based Automatic Modulation Classification in UWA Communication Systems Using Constellation Diagrams and Gabor Filtering. In Proceedings of the 2023 3rd International Conference on Electronic Engineering (ICEEM), Menouf, Egypt, 7–8 October 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Song, G.; Chisom, O.M.; Choi, Y.; Jang, M.; Yoon, D. Deep Learning-Based Automatic Modulation Classification with Prediction Combination in OFDM Systems. In Proceedings of the 2023 8th IEEE International Conference on Network Intelligence and Digital Content (IC-NIDC), Beijing, China, 3–5 November 2023; pp. 336–340. [Google Scholar] [CrossRef]
- Mendis, G.J.; Wei, J.; Madanayake, A. Deep learning-based automated modulation classification for cognitive radio. In Proceedings of the 2016 IEEE International Conference on Communication Systems (ICCS), Kuala Lumpur, Malaysia, 22–27 May 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–6. [Google Scholar]
- Liao, K.; Zhao, Y.; Gu, J.; Zhang, Y.; Zhong, Y. Sequential convolutional recurrent neural networks for fast automatic modulation classification. IEEE Access 2021, 9, 27182–27188. [Google Scholar] [CrossRef]
- Grajal, J.; Yeste-Ojeda, O.; Sanchez, M.A.; Garrido, M.; López-Vallejo, M. Real time FPGA implementation of an automatic modulation classifier for electronic warfare applications. In Proceedings of the 2011 19th European Signal Processing Conference, Barcelona, Spain, 29 August–2 September 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 1514–1518. [Google Scholar]
- Chen, J.; Cui, H.; Miao, S.; Wu, C.; Zheng, H.; Zheng, S.; Huang, L.; Xuan, Q. FEM: Feature extraction and mapping for radio modulation classification. Phys. Commun. 2021, 45, 101279. [Google Scholar] [CrossRef]
- Chen, Z.; Cui, H.; Xiang, J.; Qiu, K.; Huang, L.; Zheng, S.; Chen, S.; Xuan, Q.; Yang, X. SigNet: A novel deep learning framework for radio signal classification. IEEE Trans. Cogn. Commun. Netw. 2021, 8, 529–541. [Google Scholar] [CrossRef]
- Meng, F.; Chen, P.; Wu, L.; Wang, X. Automatic Modulation Classification: A Deep Learning Enabled Approach. IEEE Trans. Veh. Technol. 2018, 67, 10760–10772. [Google Scholar] [CrossRef]
- Hong, D.; Zhang, Z.; Xu, X. Automatic modulation classification using recurrent neural networks. In Proceedings of the 2017 3rd IEEE International Conference on Computer and Communications (ICCC), Chengdu, China, 13–16 December 2017; pp. 695–700. [Google Scholar] [CrossRef]
- Zhang, F.; Luo, C.; Xu, J.; Luo, Y.; Zheng, F.C. Deep learning based automatic modulation recognition: Models, datasets, and challenges. Digit. Signal Process. 2022, 129, 103650. [Google Scholar] [CrossRef]
- Huang, L.; Zhang, Y.; Pan, W.; Chen, J.; Qian, L.P.; Wu, Y. Visualizing deep learning-based radio modulation classifier. IEEE Trans. Cogn. Commun. Netw. 2020, 7, 47–58. [Google Scholar] [CrossRef]
- Harper, C.A.; Thornton, M.A.; Larson, E.C. Automatic Modulation Classification with Deep Neural Networks. Electronics 2023, 12, 3962. [Google Scholar] [CrossRef]
- Brigato, L.; Iocchi, L. A Close Look at Deep Learning with Small Data. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 2490–2497. [Google Scholar] [CrossRef]
- Zang, B.; Gou, X.; Zhu, Z.; Long, L.; Zhang, H. Prototypical Network with Residual Attention for Modulation Classification of Wireless Communication Signals. Electronics 2023, 12, 5005. [Google Scholar] [CrossRef]
- Shi, Y.; Xu, H.; Qi, Z.; Zhang, Y.; Wang, D.; Jiang, L. STTMC: A Few-shot Spatial Temporal Transductive Modulation Classifier. IEEE Trans. Mach. Learn. Commun. Netw. 2024, 2, 546–559. [Google Scholar] [CrossRef]
- Huang, L.; Pan, W.; Zhang, Y.; Qian, L.; Gao, N.; Wu, Y. Data Augmentation for Deep Learning-Based Radio Modulation Classification. IEEE Access 2020, 8, 1498–1506. [Google Scholar] [CrossRef]
- Patel, M.; Wang, X.; Mao, S. Data augmentation with conditional GAN for automatic modulation classification. In Proceedings of the 2nd ACM Workshop on Wireless Security and Machine Learning, Linz, Austria, 13 July 2020; pp. 31–36. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising Diffusion Probabilistic Models. In Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H., Eds.; Curran Associates, Inc.: Scotland, UK, 2020; Volume 33, pp. 6840–6851. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Sainath, T.N.; Vinyals, O.; Senior, A.; Sak, H. Convolutional, long short-term memory, fully connected deep neural networks. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Australia, 19–24 April 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 4580–4584. [Google Scholar]
- Tashiro, Y.; Song, J.; Song, Y.; Ermon, S. CSDI: Conditional Score-based Diffusion Models for Probabilistic Time Series Imputation. In Advances in Neural Information Processing Systems; Ranzato, M., Beygelzimer, A., Dauphin, Y., Liang, P., Vaughan, J.W., Eds.; Curran Associates, Inc.: Scotland, UK, 2021; Volume 34, pp. 24804–24816. [Google Scholar]
- Kong, Z.; Ping, W.; Huang, J.; Zhao, K.; Catanzaro, B. DiffWave: A Versatile Diffusion Model for Audio Synthesis. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 30 April 2020. [Google Scholar]
- Wang, Z.; Gao, G.; Li, J.; Yu, Y.; Lu, H. Lightweight image super-resolution with multi-scale feature interaction network. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar]
- Kenton, J.D.M.W.C.; Toutanova, L.K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, p. 2. [Google Scholar]
- O’Shea, T.; West, N. Radio Machine Learning Dataset Generation with GNU Radio. In Proceedings of the GNU Radio Conference, Boulder, CO, USA, 12–16 September 2016; Volume 1. [Google Scholar]
- Pillai, P.; Pal, P.; Chacko, R.; Jain, D.; Rai, B. Leveraging long short-term memory (LSTM)-based neural networks for modeling structure–property relationships of metamaterials from electromagnetic responses. Sci. Rep. 2021, 11, 18629. [Google Scholar] [CrossRef] [PubMed]
- An, T.T.; Lee, B.M. Robust Automatic Modulation Classification in Low Signal to Noise Ratio. IEEE Access 2023, 11, 7860–7872. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset Scenario | Augmentation Method | Total Samples | Augment Coefficient | Samples per SNR per Modulation |
|---|---|---|---|---|
| Full | No augmentation | 176,000 | 1 | 800 |
| Rotation and Flipping | 1,232,000 | 7 | 5600 | |
| DiRSA | 3,696,000 | 21 | 16,800 | |
| Small | No augmentation | 11,000 | 1 | 50 |
| Rotation and Flipping | 77,000 | 7 | 350 | |
| DiRSA | 308,000 | 28 | 1400 | |
| – | Validation | 22,000 | – | 100 |
| – | Test | 22,000 | – | 100 |
| LSTM | CNN | CLDNN |
|---|---|---|
| LSTM (128 cells, dropout 0.5) | Conv1d () + ReLU | Conv1d () + ReLU |
| LSTM (128 cells, dropout 0.5) | MaxPool1D (kernel = 2) | MaxPool1D (kernel = 2) |
| Fully Connected (128 to 11) | Conv1d () + ReLU | Conv1d () + ReLU |
| MaxPool1D (kernel = 2) | MaxPool1D (kernel = 2) | |
| Conv1d () + ReLU | LSTM (128 cells, dropout 0.5) | |
| MaxPool1D (kernel = 2) | LSTM (128 cells, dropout 0.5) | |
| Fully Connected (128 to 11) + ReLU | Fully Connected (128 to 11) |
| Modulation Category | Prompt Word | MAE |
|---|---|---|
| 8PSK | “8PSK” | 0.588 |
| CPFSK | “CPFSK” | 0.534 |
| AM-DSB | “AM-DSB” | 0.266 |
| GFSK | “GFSK” | 0.272 |
| Modulation Category | Prompt Word | MAE |
|---|---|---|
| 8PSK | “8PSK” | 0.588 |
| 8PSK | “CPFSK” | 0.742 |
| 8PSK | “AM-DSB” | 1.167 |
| 8PSK | “GFSK” | 0.999 |
| Neural Network | Total Params | Estimated Total Size (MB) | Total Mult-Adds (M) |
|---|---|---|---|
| DDPM | 1,052,993 | 2835.83 | 14.97 |
| CNN | 294,827 | 1.28 | 1.48 |
| LSTM | 201,099 | 0.94 | 25.56 |
| CLDNN | 239,275 | 1.19 | 30.45 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Y.; Huang, L.; Zhang, L.; Qian, L.; Yang, X. Diffusion-Based Radio Signal Augmentation for Automatic Modulation Classification. Electronics 2024, 13, 2063. https://doi.org/10.3390/electronics13112063
Xu Y, Huang L, Zhang L, Qian L, Yang X. Diffusion-Based Radio Signal Augmentation for Automatic Modulation Classification. Electronics. 2024; 13(11):2063. https://doi.org/10.3390/electronics13112063
Chicago/Turabian StyleXu, Yichen, Liang Huang, Linghong Zhang, Liping Qian, and Xiaoniu Yang. 2024. "Diffusion-Based Radio Signal Augmentation for Automatic Modulation Classification" Electronics 13, no. 11: 2063. https://doi.org/10.3390/electronics13112063
APA StyleXu, Y., Huang, L., Zhang, L., Qian, L., & Yang, X. (2024). Diffusion-Based Radio Signal Augmentation for Automatic Modulation Classification. Electronics, 13(11), 2063. https://doi.org/10.3390/electronics13112063