1. Introduction
To represent various sequential blocks, a model of a Mealy finite state machine (FSM) [
1] can be applied. There are many examples of using this model in the implementation of various digital systems [
2]. In this paper, we consider FSM circuits implemented using field-programmable gate arrays (FPGAs) [
3,
4]. This choice is due to the wide use of FPGAs in the implementation of a wide variety of projects [
4,
5]. Leading experts are confident that FPGAs will continue to dominate logic design for at least the next twenty years [
6].
When using any logic basis for the implementation of FSM circuits, a number of optimization problems always arise [
7,
8]. One of the most important tasks is to obtain a circuit that is optimal in terms of hardware costs. By optimal, we mean a circuit that consumes the minimum possible amount of chip resources while simultaneously providing the required level of performance and power consumption. In the case of FPGA-based circuits [
9], the optimization strategy significantly depends on the types of configurable logic blocks (CLBs) used [
10]. In this paper, we discuss the most common CLBs which include look-up table (LUT) elements, programmable flip-flops, and dedicated multiplexers [
10,
11]. To combine these CLBs into an FSM circuit, the following chip resources are used: the synchronization tree, programmable interconnections, and programmable input-outputs [
12,
13]. The method proposed in this paper is aimed at reducing the number of LUTs (LUT count) in a resulting FSM circuit.
It is generally accepted that reducing LUT count leads to improving the spatial characteristics of FSM circuits (reducing the occupied chip areas) [
14,
15]. Area reduction can be achieved by applying structural decomposition (SD) methods [
9] leading to multi-level FSM circuits. However, such a reduction may have an overhead [
9]. This overhead consists of a significant performance degradation compared to equivalent single-level FSM circuits [
14,
16]. However, performance has to be sacrificed if the criterion of design optimality is the minimum occupied chip area.
The best LUT counts can be obtained for three-level FSM circuits when the methods of replacing FSM inputs and encoding collections of FSM outputs [
17] are used together. However, for sufficiently complex FSMs, some of the logic blocks (or even all three blocks) may have a multilevel structure. This leads to an increase in the number of logical levels and interconnections. In turn, this leads to an increase in the occupied area, power consumption and delay time of the FSM circuit. In this paper, we propose a method to reduce the LUT counts of three-level FSM circuits. The proposed method is based on using twofold state assignment [
18]. This approach leads to a decrease in the number of LUTs and their levels in the resulting LUT-based FSM circuits.
There are some leading companies producing FPGA chips. The largest producer is AMD Xilinx [
19]. As follows from [
4], FPGAs from AMD Xilinx are widely used in various projects. Due to this, we structured our approach according to the FPGA families [
19] by AMD Xilinx. In our research, we use FPGAs from the VIrtex-7 family [
10].
The article contains several new scientific results. Firstly, a new architecture of an LUT-based Mealy FSM circuit is proposed. Secondly, methods for the uniform distribution of inputs and state encoding are proposed, which make it possible to reduce the number of LUTs in the circuit of the input replacement block in comparison with the known methods for implementing this block. Thirdly, a new method for stabilizing FSM outputs is proposed, in which the input register is replaced by a register of output collection codes. The noted new approaches led to the main contribution of the article, which is a novel design method aimed at hardware reduction in the multilevel circuits of LUT-based Mealy FSMs. The hardware reduction is achieved due to the use of two types of state codes. The maximum binary state codes are used to replace the FSM inputs. Other partial Boolean functions depend on extended state codes. The proposed approach leads to four-level FSM circuits where any partial function is represented by a single LUT. The conducted experiments show that the resulting FSM circuits include fewer LUTs compared to equivalent three-level circuits [
17]. It is very important that the hardware reduction does not lead to the significant deterioration of temporal characteristics.
The rest of the paper is organized as follows.
Section 2 shows the peculiarities of the LUT-based Mealy FSM design. The analysis of related works is discussed in
Section 3.
Section 4 presents the main idea of our method. In
Section 5, we include a step-by-step example showing how to apply the proposed method.
Section 6 includes the experimental results. The last part of the article is a short conclusion.
2. Peculiarities of LUT-Based Mealy FSM Design
The law of the behaviour of a Mealy FSM can be represented using three sets and two functions [
20]. These sets are the following: a set of internal states
, a set of inputs
, and a set of outputs
. The interstate transitions are represented by a function of transitions. An output function shows the FSM outputs generated during these transitions. In this article, we use a state transition graph (STG) [
1] as an initial tool for FSM design. An STG consists of vertices representing FSM states. The vertices are connected by arcs corresponding to interstate transitions. Each arc is marked by an input signal (the conjunction of inputs leading to a particular transition) and a collection of outputs associated with this transition [
1]. To synthesize the FSM circuit, we transformed this STG into the equivalent state transition table (STT) [
1].
To design an FSM circuit, it is necessary to replace abstract states
with binary codes
. This is the state-assignment step [
1]. To minimize the number of state variables and input memory functions (IMFs), it is necessary to minimize the bitness of state codes. The minimum possible number
of state-code bits corresponds to a maximum state assignment [
20]. This number is determined as
To encode states, state variables creating a set are used. To keep the state codes, a special register, RG, consisting of flip-flops is used as a part of FSM circuit.
In most practical cases [
9], as elements of the state register are used the synchronous D flip-flops. Each state variable is represented by a unique flip-flop. The input of the
r-th flip-flop is connected with an IMF
D where
is a set of IMFs. The initial state code is forcibly loaded into RG. To do this, a special pulse of initialization
Start is used. Set D determines a state code loaded into RG. To load a code
, the pulse of synchronization
Clock is used.
Using either STG or STT, a direct structure table (DST) [
20] can be constructed. There are six columns in the DST [
20]:
,
,
,
,
,
h. The data from these columns have the following meaning:
is an initial state for a given transition;
is a final state for this transition;
is a conjunction of FSM inputs determining the transition
;
is a collection of outputs (CO) produced during the transition
;
is a set of IMFs equal to 1 to execute the
h-th transition (to load the code
into RG); and
h is the transition number
. The DST is a base for constructing the following systems of Boolean functions (SBFs) [
21]:
The SBFs (
2) and (
3) are a base for implementing the so-called P Mealy FSM [
9]. In FPGA-based FSMs, the flip-flops of RG are distributed among the CLBs, including LUTs, generating the functions (
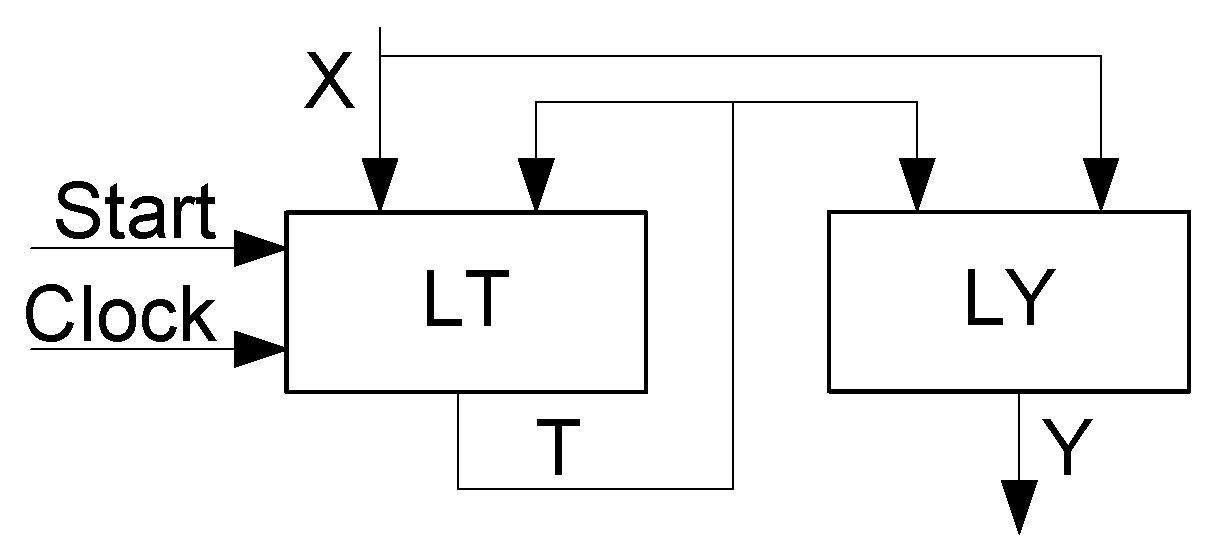
2). Thus, the distributed state-code register is hidden. As a result, there are only two blocks in the structural diagram of LUT-based P Mealy FSM (
Figure 1).
The LUTs of a block LT implement IMFs (
2). The memory elements of LT create the RG. This explains why the pulses
Start and
Clock enter LT. Obviously, the state variables
come out of the block LT. The block LY generates functions (
3) representing the outputs
. Each LUT has
inputs.
The functions (
2) and (
3) are represented by their sum of products (SOPs) [
1]. An SOP of a Boolean function
has
literals. For rather complex FSMs, the following condition may hold:
If (
4) takes place, then the circuit of P Mealy FSM is multi-level. It is known [
9] that multi-level circuits are less efficient than the equivalent single-level circuits (the former are much slower and require more power than the latter). The same is true for the numbers of interconnections in the equivalent single-level and multi-level circuits. The growth in interconnections leads to the further growth in the values of both time of cycle and power consumption. The use of SD-based methods can lead to a significant improvement in the overall circuit quality [
9,
17].
There are two types of literals in SOPs of functions (
2) and (
3): external inputs
and elements of the set
T (the variables
). Each function
depends on
state variables and
inputs. There is only one LUT in the circuit corresponding to the function
, if the following condition is true:
If condition (
5) holds, then the values of function
are generated by a single-LUT circuit. If condition (
5) takes place for all
functions, then the circuit of P Mealy FSM is single-level. A single-level circuit has the best possible values of the required chip area, power consumption and maximum operating frequency.
However, there are FSMs with around 500 states and 30 inputs [
2]. In this case, each function
may depend on up to 39 arguments. Thus, their SOPs can include up to 39 literals. Of course, these SOPs cannot be implemented using only a single LUT with
inputs. Thus, the corresponding circuits will be multi-level with spaghetti-type interconnecting systems. To improve the characteristics of multi-level circuits, various optimization methods should be applied. In this paper, we propose an approach which allows reducing the chip area occupied by the LUT-based FSM circuit when the condition (
5) is violated.
3. Brief Analysis of Related Works
The problem of area reduction is discussed in thousands of monographs and articles. For example, various methods for solving this problem are proposed in the following works (to name but a few): [
14,
22,
23,
24,
25,
26,
27,
28]. As follows from [
23], reducing the required chip area is connected with reducing the LUT count for a corresponding circuit. To achieve this goal, three groups of methods can be used: a proper state assignment, a functional decomposition (FD) of Boolean functions, and SD-based approaches [
9].
The proper state assignment leads to the elimination of some literals from SOPs (
2) and (
3) [
20]. If the elimination of literals results in the fulfilment of condition (
5) for SOPs of all functions (
2) and (
3), then the resulting FSM circuit is single-level. This can be achieved using, for example, the state assignment method JEDI distributed with the CAD system SIS [
29]. JEDI-based optimization is achieved by creating adjacent codes for states whose transitions depend on the same FSM inputs
. As shown in [
30], this allows elimination of up to 3 literals from SOPs representing benchmark FSMs from the library LGSynth93 [
31]. Thus, JEDI can solve the optimization problem if the relation
holds. However, this relation only takes place for rather simple FSMs [
9].
As follows from various research [
32,
33,
34,
35], there is no best universal state-assignment approach. For example, optimization success depends on how many variables
the transitions from each state depend on. For different FSMs, the same state-assignment method may either improve or deteriorate the quality of resulting circuits. In addition, the optimization strategy depends strongly on the peculiarities of the logic elements used [
33]. If LUTs are used, the spatial improvement can be achieved due to an increase in the state-code length [
36]. In the extreme case, the number of bits is equal to
M. This is a one-hot state assignment [
1], when the RG includes
M flip-flops. The results of research reported in [
32] show that the one-hot state assignment can improve the FSM characteristics, if there is
. However, it is necessary to take into account the number of FSM inputs [
34]. As shown in [
32], using MBC improves FSM quality if there is
(compared to FSMs with one-hot codes). This situation stimulates the development of new types of state codes and encoding strategies.
If no state-assignment method allows the implementation of a single-level circuit for a given FSM, then decomposition methods should be applied. In this case, the initial functions (
2) and (
3) are represented as a composition of partial Boolean functions (PBFs). The decomposition is executed till the condition (
4) is satisfied for each partial function. Any kind of decomposition leads to a multi-level FSM circuit.
In the case of FD-based FSM circuits, CLBs are connected by complicated systems of “spaghetti-type” interconnections [
11]. Such circuits have much lower clock rates compared to equivalent single-level solutions. This is connected with the fact that, now, “...wires delay has come to dominate logic delay” [
37]. In addition, compared to single-level circuits, FD-based circuits are more power-consuming. This phenomenon is due to the fact that the interconnections absorb up to 70% of the total power consumed by an FPGA-based FSM circuit [
37]. However, the advantage of FD is that it is applicable to the implementation of Boolean functions of any practical complexity. Therefore, FD-based algorithms are used in all industrial CAD systems aimed at the implementation of FPGA-based digital systems [
38,
39,
40,
41].
In many cases, the methods of structural decomposition [
9] allow the production of FSM circuits with better space-time-energy characteristics than their FD-based counterparts. The SD-based FSM circuits can be viewed as a composition of large logic blocks with unique input-output systems. Such an approach leads to the regularization of interconnections compared to FD-based FSM circuits [
16]. Different methods of SD can be used together. Due to this, the number of blocks can vary from 2 to 4, depending on how many methods are used. The methods of SD and FD can be used together [
9].
Two methods of SD are most commonly used. One of them is the replacement of inputs (RI) with some additional variables [
9]. The second method is the encoding of COs [
9]. Below is a brief description of these methods.
The process of RI comes down to replacing inputs
with the additional variables from a set
. The replacement makes sense if
[
9]. As a result, the SBFs (
2) and (
3) are replaced by the systems
The system (
6) is represented by a block with inputs
and
. In the following text, we denote this block with the symbol LB. Obviously, the circuit of LB consumes some chip resources. The systems (
7) and (
8) are implemented by block LTY. This approach makes sense if the SOPs (
7) and (
8) include much fewer literals than the SOPs (
2) and (
3) [
9]. In this case, the LUT counts in the circuit of P FSM significantly exceed the total number of LUTs necessary to implement SBFs (
6)–(
8).
During the interstate transitions, Q different COs
are generated. Each CO can be represented by a code
. This code includes
bits [
9]:
The COs are encoded using some additional variables creating a set
. If this approach is applied together with the RI, then the SBF (
3) is replaced with the following SBFs:
The system (
10) depends on the same variables as the system (
7). Thus, these two SBFs are implemented using the same block, LTZ. To implement SBF (
11), block LY is used. Sharing these methods turns the original P FSM (
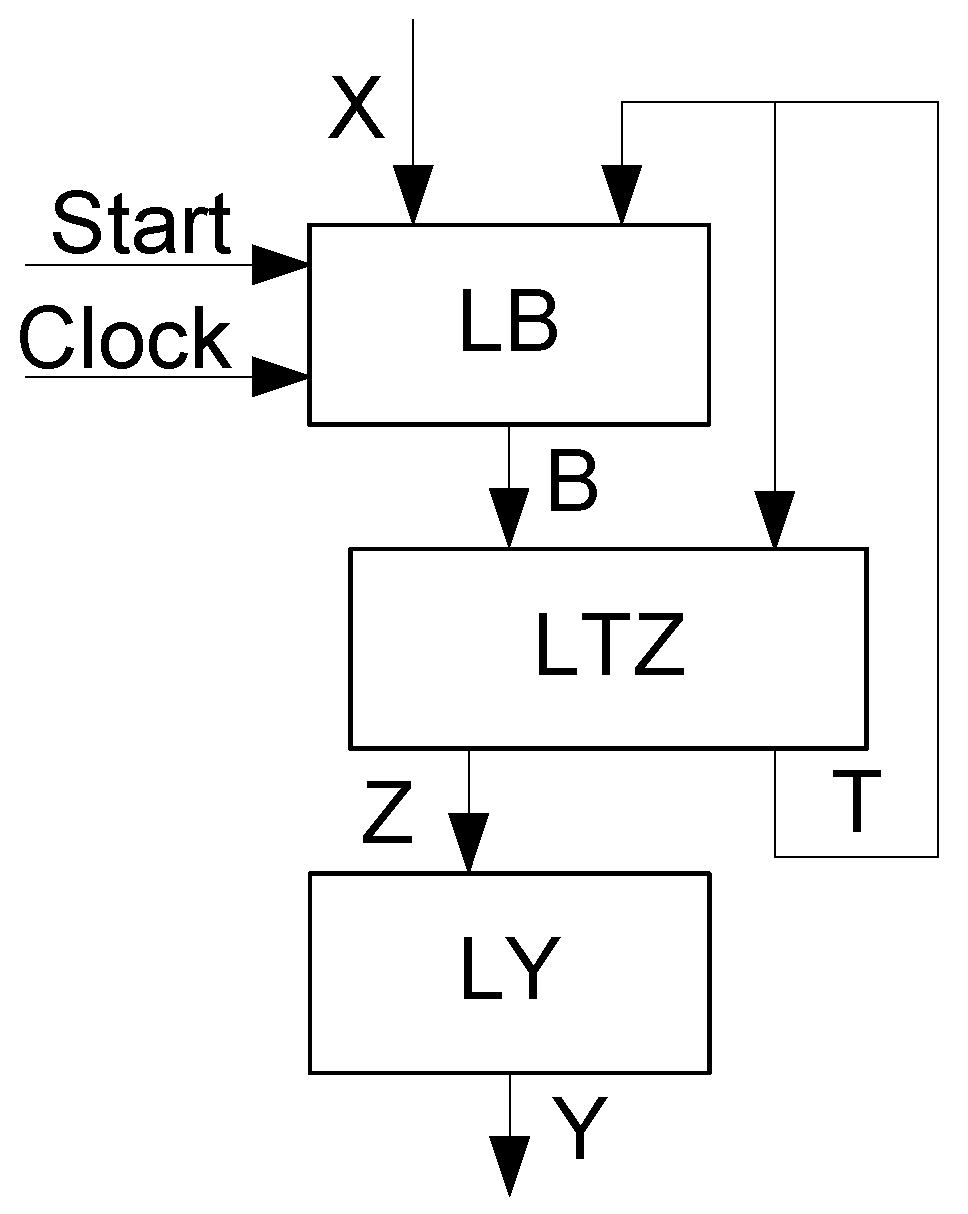
Figure 1) into MPY FSM (
Figure 2).
In MPY FSM, the block LB generates the additional variables (
6). The block LTZ generates IMFs represented by (
7) and additional variables (
10). The block LY generates the FSM outputs (
11). As shown in [
17], the transition from P FSM to MPY FSM allows the reduction in LUT counts in equivalent FSM circuits. Of course, this area reduction leads to a decrease in the value of maximum operating frequency. This decrease can be viewed as the area-reducing overhead.
To obtain SBF (
6), a table of RI should be constructed [
20]. Its columns are marked by states
, whereas additional variables
mark its rows. There is a symbol
written at the intersection of a row
and column
, if the variable
replaces the input
for the state
. In fact, the block LB is a multiplexer, the information inputs of which are connected to inputs
and the control inputs are connected to state variables
.
To obtain SBFs (
7) and (
10), it is necessary to create a transformed DST. In the transformed DST, the column
is replaced by a column
, whereas the column
is replaced by a column
. These new columns are filled in as follows. For example, the first row of DST includes a CO
generated during a transition
caused by the input signal
. Let the following relations take places for the state
and
. In this case, the input signal
is replaced by the conjunction
written in the column
. If
, then the additional variables
are written in the column
. All other rows of the transformed DST are filled in the same manner.
To obtain SBF (
11), it is necessary to create the Karnaugh map whose cells are marked by the variables
. The symbols
are written inside the cells. Using this map, the minimized SOPs (
11) are constructed. The minimization makes sense if some literals are eliminated from all product terms of a SOP representing a function
[
9].
The application of this approach is most efficient if condition (
4) is satisfied for all functions
[
9]. Otherwise, there will be more than a single LUT in the circuits for functions that do not satisfy condition (
4). Moreover, this leads to the multi-levelness of the corresponding blocks, which further reduces the MPY FSM performance. To implement these multi-level circuits, the methods of FD should be applied.
To overcome this shortcoming of MPY FSM, we propose to transform its structural diagram using the method of two-fold state assignment (TSA) [
18]. This idea is discussed in the next section.
4. Main Idea of Proposed Method
To execute the TSA, it is necessary to create a partition
of the set of states. As a result, each state
has two codes. The maximum binary code
has
bits. This code represents a state as some element of the set
S. The partial code
represents a state as some element of a class
. This class includes
elements. To encode them,
bits are sufficient:
In (
12), the value of
is incremented to encode the relation
. We use the code with all zeroes to encode this relation. This code represents the state
for all classes other than
.
The codes
for all classes
form an extended state (ESC) code of the state
. Each ESC includes
bits, where
To create ESCs, the additional variables are used. These variables are elements of a set
. The variables
create the codes
for the states
. To generate ESCs, it is necessary to transform state codes
into codes
for all states
. To transform the codes, it is necessary to create the following SBF:
We discuss a case wherein both the replacement of inputs and encoding of COs are executed. In this case, each class
determines three sets. A set
includes variables
determining transitions from the states
. A set of additional variables
includes elements determining COs generated during transitions from the states
. Finally, the elements of a set
include IMFs equal to 1 in the codes of the states next to states
. Each class
determines the following systems of PBFs:
To obtain the final values of functions
and
, it is necessary to create the following SBFs:
The functions are disjunctions of corresponding PBFs.
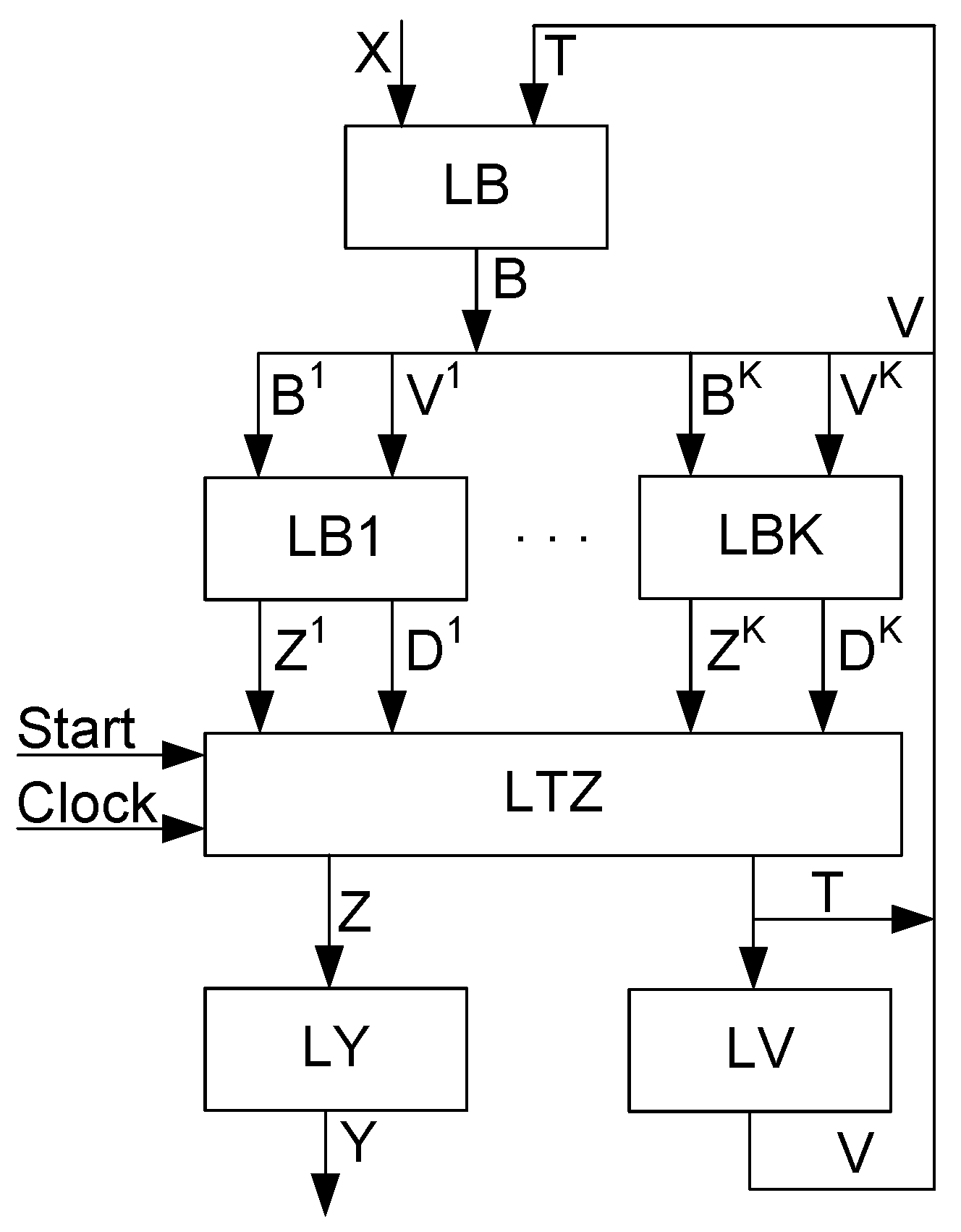
The combined use of these three methods of SD leads to MP
Y Mealy FSMs. The subscript “T” shows that the two-fold state assignment is used. Its structural diagram consists of four logic levels (
Figure 3).
In MP
Y Mealy FSM, the block LB generates functions (
6) to replace FSM inputs using additional variables. The second logic level consists of blocks LB1,
LBK. Each block LBk implements systems of PBFs (
15) and (
16). These functions are transformed into functions
by the block LTZ. This block represents the third logic level of FSM circuit. The block LTZ includes two distributed registers. One of them is the state code register RG. The RG outputs are used as a feedback for the input transformation. In addition, they enter a block LV to create ESCs. The second register (a register RZ) keeps the codes of COs. We discuss the necessity of RZ later. Both registers are zeroed by the pulse
Start and synchronized by the pulse
Clock. The fourth logic level includes two blocks. The block LY generates FSM outputs represented by (
11). The block LV transforms the maximum state codes
into extended state codes
. This block implements SBF (
14).
To reduce the chip area occupied by the LUT-based circuit of MPY Mealy FSM, we propose two new approaches. One of them allows the reduction of the number of LUTs and their levels in the circuit of LB. The second method aims to reduce the number of flip-flops necessary for the stabilization of the FSM operation.
We use the symbol
for a set of FSM inputs replaced by an additional variable
. As a rule, the RI is executed in the following way [
20]: the number of FSM inputs in different sets
should be maximal. At best, identical inputs
should be replaced by the same variable
. Such an approach allows minimization of the chip area if an FSM circuit is implemented using programmable logic arrays (PLAs) [
9]. However, PLAs have a lot of inputs, whereas this number is very limited for LUTs. Thus, we propose distributing inputs
in a way which allows holding the following condition for the maximum possible number of sets
:
Obviously, if (
19) takes place for the set
, then a circuit generating the function
includes only one element. If (
19) takes place for all sets
, then the block LB includes
G elements. In addition, this circuit is single-level.
To increase the value of
, we propose to encode the states in a way that decreases the number of state variables in functions (
6). Let
be a set of states whose transitions depend on the inputs
. We propose to encode the states
in such a way that their codes create the minimum possible number of generalized cubes of
-dimensional Boolean space. This approach allows excluding some state variables as literals of SOPs (
6).
As a rule, FSMs are not stand-alone units. They are used as parts of a digital system. Due to it, the stability of the outputs is one of the very important problems in FSM circuit design [
13,
42,
43]. If an FSM is a part of some digital system, then the FSM outputs are inputs of other system’s blocks. It is known [
1,
20] that outputs of Mealy FSMs are unstable: input fluctuations may lead to output fluctuations. In turn, these fluctuations of FSM outputs may cause failure in some blocks of a digital system. It is possible to avoid such failures by stabilizing the FSM inputs. To do this, it is necessary to introduce a synchronous register of inputs (RI) [
20]. This changes the FSM operation mode.
De facto, the set of inputs consists of outputs of various system blocks. These outputs enter the flip-flops of RI. Till these outputs are transients, the synchronization signal of RI is not active. Due to this, the FSM is disconnected from other blocks. Thus, the RI keeps the values of FSM inputs registered in the previous cycle. After the stabilization of system outputs, they are loaded into the RI using the required edge of synchronization. Thus, eliminating the dependence of the inputs’ stability on the stability of system outputs leads to additional area costs and reduces overall performance. This is an overhead of stability (additional LUTs, flip-flops, interconnections, power consumption and delay). Thus, it makes sense to reduce this overhead.
In our paper, we propose to include a register RZ into block LTZ. There is a flip-flop in each CLB generating a function . Thus, to organize the RZ, there is no need for additional LUTs. In addition, these flip-flops could be controlled by already-existing pulses Start and Clock. Obviously, the proposed approach does not require additional CLBs. This means that it does not require the additional chip area (compared to an FSM architecture which uses either a registration of inputs or a registration of outputs).
A method for the synthesis of MP
Y Mealy FSMs is proposed in this paper. We start the design from an STG [
1]. To create tables representing the blocks of the FSM circuit, the STG is transformed into the equivalent STT [
1]. The proposed method includes the following steps:
Creating STT of Mealy FSM.
Executing replacement of FSM inputs.
Assignment of maximum binary state codes
optimizing SBF (
6).
Creating SBF (
6) representing the block LB.
Finding the partition with the minimum cardinality number.
Assignment of partial codes to states .
Encoding of COs using maximum binary codes.
Creating SBF (
11) representing the block LY.
Constructing tables of LB1–LBK and creating SBFs (
15) and (
16).
Constructing the table of LTZ and creating systems (
17) and (
18).
Constructing table of LV and deriving the system (
14).
Implementing LUT-based circuit of MPY FSM.
If an FSM A is synthesized using the model of MPY Mealy FSM, then we denote such a situation by the symbol MPY(A). Next, we discuss an example of MPY FSM synthesis.
5. Example of Synthesis of MPY Mealy FSM Logic Circuit
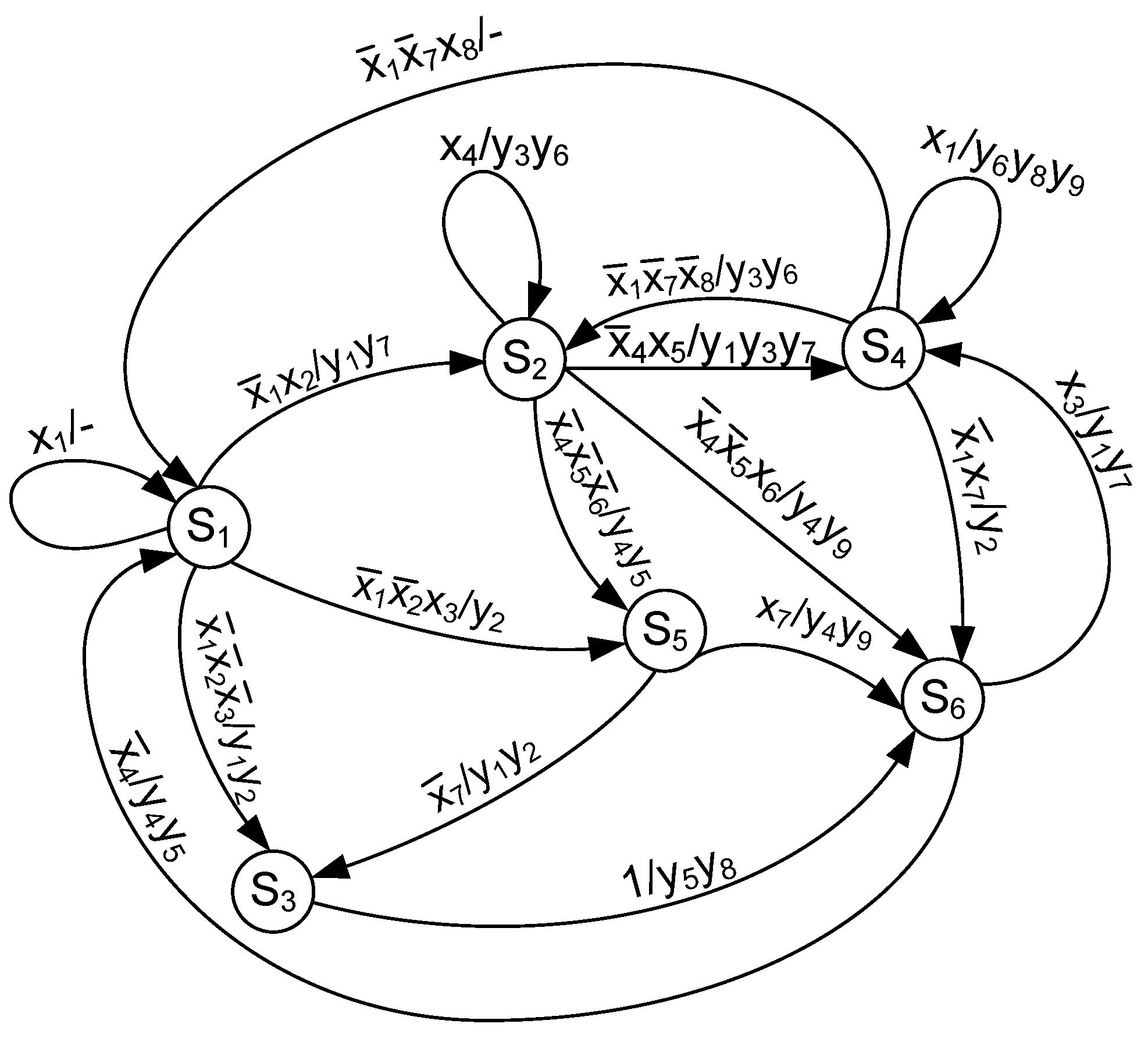
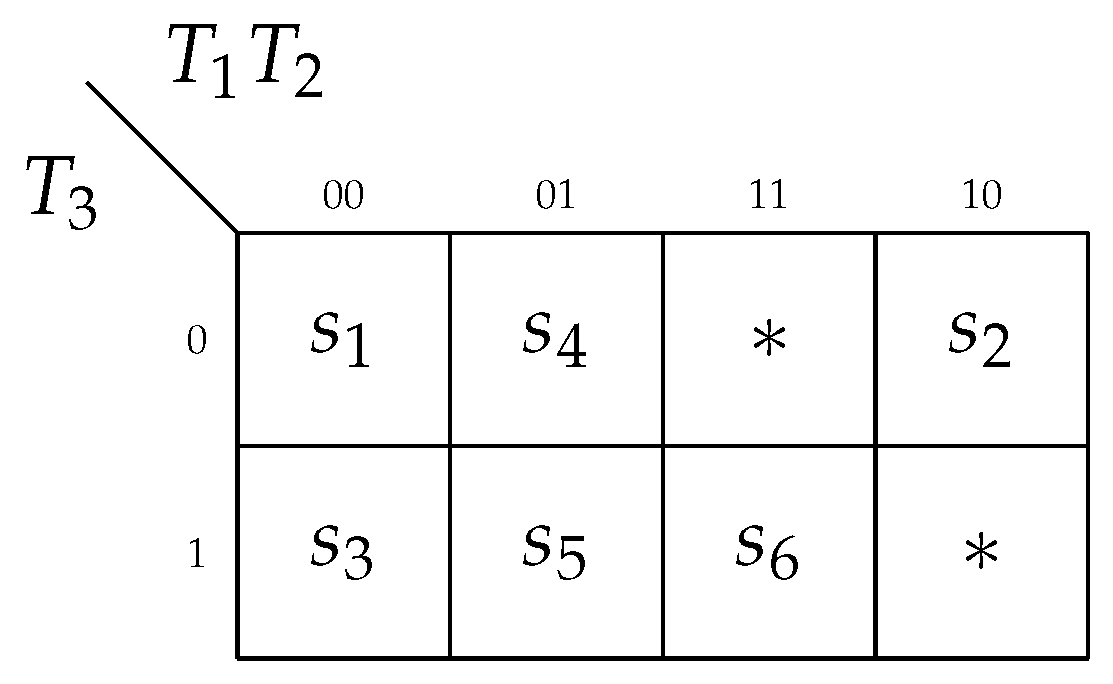
We discuss the synthesis of Mealy FSM MP
Y(A1) using LUTs with
inputs. The STG (
Figure 4) represents the FSM
.
Using STG (
Figure 4), we can derive the sets
(each vertex of STG corresponds to a state);
(these inputs are shown above the STG arcs); and
(these outputs are written above the STG arcs). This gives the following values:
,
, and
. There are
arcs connecting the vertices of STG (
Figure 4). Obviously, there are
rows in the equivalent STT. As follows from (
1),
is necessary to execute the maximum binary state assignment. This gives the sets
and
.
Step 1. The procedure of transformation is executed using the approach shown in [
1]. Each arc of STG determines a row of STT. Each row includes a current state
, a transition state
, an input signal
which determines the transition from
into
, an output collection
, and the row number,
h. In the discussed example, the STG (
Figure 4) is transformed into STT (
Table 1). This table includes an additional column
q containing the subscripts of COs written in each row of the column
.
Step 2. The interstate transitions from
depend on inputs creating the set
with
elements. To find the number,
G, of additional variables
, it is necessary to use the following formula [
20]:
As follows from
Table 1, the existing sets
have the following cardinality numbers:
,
, and
. Using (
20) gives
and
.
Thus, there is
and
. Using (
19) gives
. Thus, the IR should be executed in a way so that the relation
holds for the maximum possible number of sets
. Using the proposed approach gives the distribution of inputs shown in
Table 2.
Step 3. States
should be encoded in a way that minimizes the numbers of literals in SBF (
6). We denote by symbol
a set of states in which FSM inputs
are replaced by the additional variable
. To optimize SBF (
6), we propose placing the codes of states
in the same rows of an
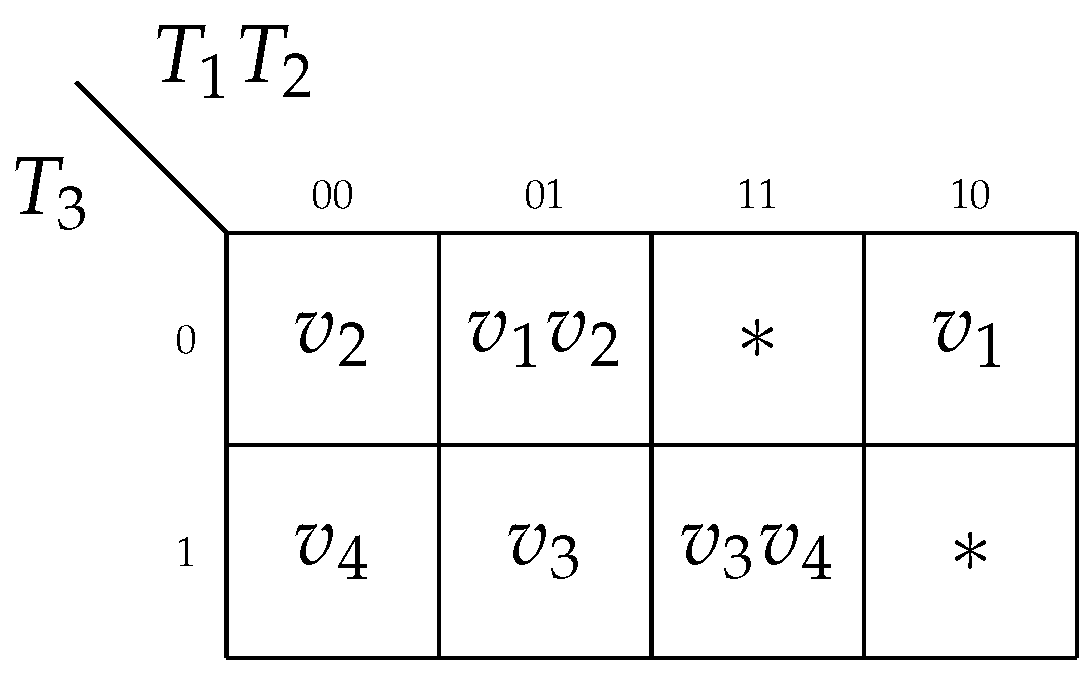
- dimensional Karnaugh map. If an input
is replaced by a variable
for states
, then we propose placing these states into adjusted cells of the map. To optimize the SOP of
, we can use three types of insignificant assignments. They are the following: (1) the states with unconditional transitions; (2) the states which do not belong to a particular set
; and (3) the combinations of state variables which are not used as state codes. For the discussed example, the Karnaugh map (
Figure 5) includes the state codes.
Let us explain how this map was created. There are the sets
and
. As follows from
Figure 5, these states are placed in the same row of the map. For states
and
, the same input
is replaced. So, these states have adjacent codes 000 and 010. The code 001 (state
) can be thought of as insignificant because the transition from this state is unconditional. The code 011 (state
) can be thought of as insignificant because there is no input symbol in the row
( the transaction from this state is unconditional). To optimize the term depended on
, we can use state assignments 110 (no state), 111 (the symbol “–” in the row
) and 101 (no state). As a result, the following Boolean equation is obtained:
.
Step 4. Using the approach discussed above, we can obtain the following SBF:
The analysis of SBF (
21) shows that the circuits implemented into its equations have four LUTs. The circuit for
includes a single LUT, as does the circuit for
. The two-level circuit generating
includes two LUTs. Thus, in the discussed case, there are four LUTs and two have their levels in the circuit of LB.
Step 5. We use the approach proposed in the paper [
18] to create the partition
. Using the method [
18] gives the following sets:
,
and
. Thus,
.
Step 6. As follows from analysis of classes
, each class includes
states. Using (
12) and (
13) gives the following:
,
,
,
and
. It is known that the partial state codes do not affect the number of LUTs in the circuits of LBk [
18]. Thus, we can assign them in the trivial way: codes are assigned as the subscript grows and corresponds to the decimal number of the step to which the code
is assigned. This approach gives the following codes:
, and
.
Step 7. As follows from
Table 1, during the operation of the FSM
, the following COs are generated:
,
,
,
,
,
,
, Y
,
,
. Thus, there are
collections of outputs generated during the interstate transitions of FSM
. Using (
9) gives
and the set
.
The encoding is executed in such a way as to reduce the total number of literals in SOPs (
11). This can be carried out using, for example, the approach from the work [
44]. One of the possible outcomes is shown in (
Figure 6).
Step 8. Using codes
and insignificant input assignments [
1], we can obtain the following SBF:
The SBF (
22) represents the circuit of block LY. Thus, it corresponds to SBF (
11). The maximum number of literals in the SOPs of (
11) is determined as
. In the discussed case, this number is equal to 9 × 4 = 36. The SBF (
22) contains 18 literals. Thus, using the approach [
44] allows a reduction in the number of literals by a factor of 2.0 compared to its maximum possible value. Each literal corresponds to the interconnection between the blocks LTZ and LY. Thus, reducing the number of literals results in reducing the number of interconnections. This is a positive factor because interconnections significantly influence the chip area used, power consumption and performance.
Step 9. To create a table of LBk, it is necessary to use the STT rows representing transitions from states
. For example, to create a table representing LB1, we should choose the rows 1–8 and 10–13 of
Table 1. The column
should be replaced by the column
. This column includes the conjunctions of variables
corresponding the conjunctions of replaced inputs
. The column
is replaced by the column
. This column includes the variables
equal to 1 in the codes
of COs shown the corresponding rows of STT.
In addition, this table includes the columns
(the partial code of the current state),
(the MBC of the next state), and
(IMFs equal to 1 to load the code
into RG). In the discussed case, this table contains H1 = 12 rows (
Table 3).
For example, the second row of
Table 3 is created in the following manner. This row is constructed using the second row of
Table 1. This row describes the transition
executed when the following relation takes place:
. During this transition, the CO
is produced. From the outcome of step 6, we have the code
. This code should be placed in the column
. Using the Karnaugh map (
Figure 5) gives state code
. This code should be placed in the column
. It determines existence of the symbol
in the column
of
Table 3. As follows from the column
of
Table 2, the input
is represented by
and the input
is replaced by the variable
. Thus, the conjunction
is replaced by the conjunction
written in the column
of
Table 3.
A similar approach is used to create all the rows of
Table 3 (block LB1) and
Table 4 (block LB2). These tables represent SBFs (
15) and (
16). There are examples of some SOPs shown below:
Step 10. The table of block LTZ includes the following columns: “Function” (the column includes symbols
and
), LB1, LB2. If a PBF is generated by the block LBk (
), then the intersection of the row with this function and the column LBk is marked by 1. Otherwise, this intersection contains zero. The block LTZ is represented by
Table 5.
To fill the columns LB1 and LB2, we use
Table 3 and
Table 4, respectively. In the discussed case,
Table 5 determines SBFs (
17) and (
18). For example, the following disjunctions may be derived from
Table 5:
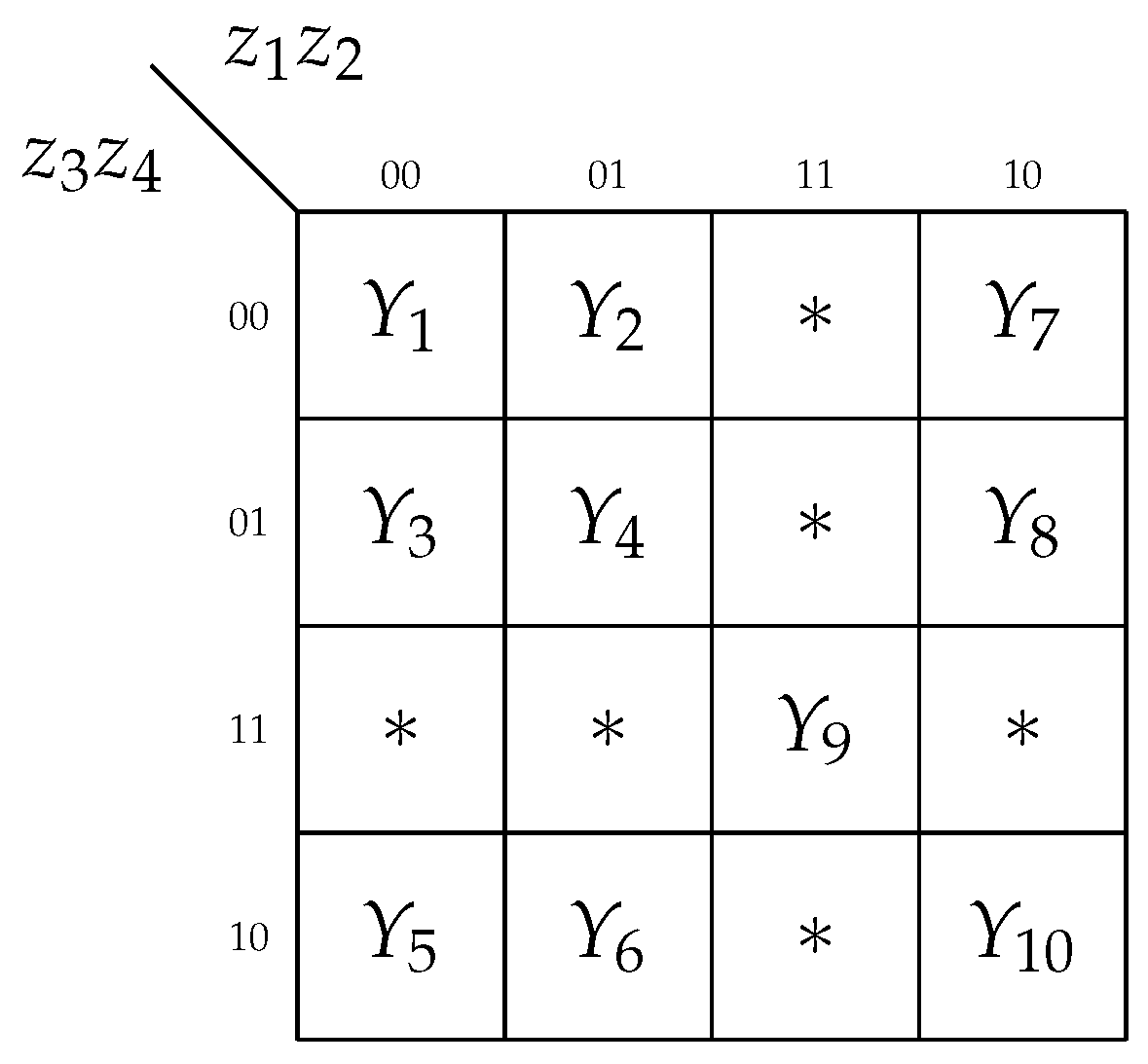
Step 11. The block LV converts MBC codes
into the partial state codes
. The conversion is executed for all states. The table of LV includes the columns
,
,
,
. If there is
for a particular code
, then there is the symbol
in the column
(
Table 6).
Using
Table 6, it is possible to create SBF (
14) represented by its perfect SOPs. To minimize these SOPs, we can create a multi-functional Karnaugh map, as shown in
Figure 7.
This Karnaugh map is created using the codes from
Figure 5. In
Figure 7, the symbols of states
are replaced by symbols of additional variables
. This is performed in the following way: if a particular cell of
Figure 5 includes a state
, then the symbols
are rewritten into the corresponding cell of
Figure 7. Using
Figure 7 gives the following SBF, which determines the contents of LUTs from the block LV:
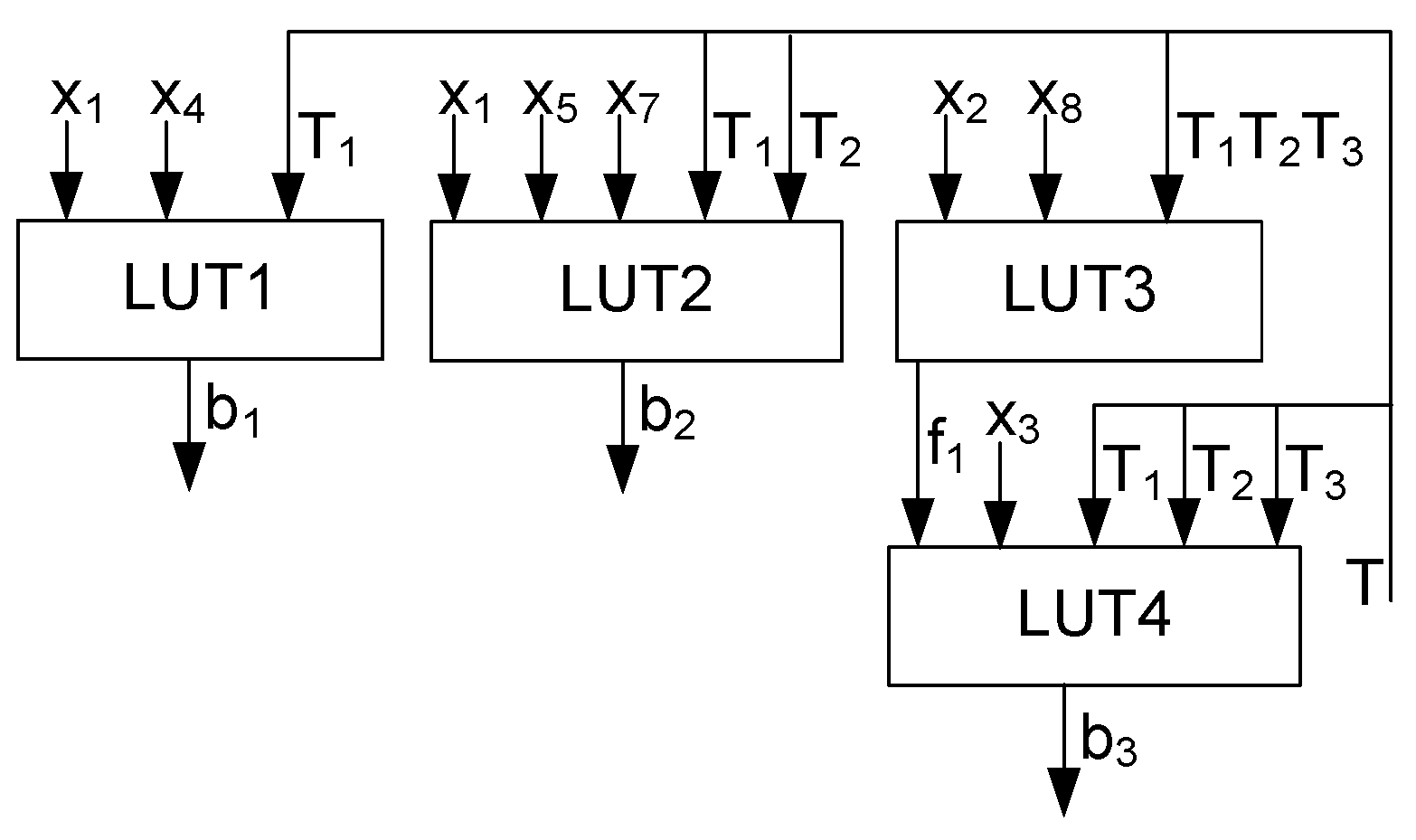
Step 12. Using the obtained SOPs, we can estimate how many LUTs it is necessary to implement in the circuit of MP
Y(A1). As follows from SBF (
21), condition (
19) holds for SOP functions
. Thus, each of these functions is implemented using a single LUT with
. There are six literals in the SOP
. Thus, this SOP should be decomposed. As a result, the corresponding circuit includes two LUTs connected in series. Due to this, the circuit of LB includes four LUTs and has two levels of logic (
Figure 8).
Each of the blocks LB1, LB2 (the second level of logic) and LTZ (the third level of logic) have circuits with seven LUTs. Each of these circuits is single-level. The fourth level consists of circuits for blocks LY (nine LUTs) and LV (four LUTs).
Thus, the resulting circuit has five levels and includes 38 LUTs. Our analysis of Mealy FSM MPY(A1) shows the following. There are the same LUT counts for the circuits of the blocks LB and LY of equivalent MPY and MP
Y FSMs. Thus, in the discussed case, these blocks include 4 + 9 = 13 LUTs. There are
literals in the SOPs of SBFs (
7) and (
10). Using LUTs with five inputs leads to the functional decomposition of these SOPs. As the result, there are three LUTs in a two-level circuit implementing any function from SBFs (
7) and (
10). There are
functions generated by the LTZ of Mealy FSM MPY(A1). Thus, there are 21 LUTs in this circuit. This calculation gives 34 LUTs in the circuit of Mealy FSM MPY(A1). The circuit has five levels of LUTs.
Thus, there is the same number of levels in the circuits of FSMs MPY(A1) and MP
Y(A1). However, the circuit of Mealy FSM MPY(A1) includes fewer LUTs. It is possible to obtain the same LUT count for both circuits if we change the approach for the encoding of states and COs [
16]. However, we do not discuss this approach in our current paper.
Our example is rather simple. It is necessary to compare equivalent FSMs based on various approaches using some benchmarks with a wide range of characteristics. Such a comparison is given in the next Section. This comparison is executed for FPGAs produced by AMD Xilinx. Due to this, the industrial package Vivado [
39] is applied to fulfil all the necessary steps of technology mapping [
7,
26,
45].
6. Experimental Results
To compare the LUT-based circuits produced by our proposed method with circuits obtained using some known design methods, we use 48 benchmarks creating the library LGSsynth93 [
31]. These benchmarks have a wide diapason of their main characteristics such as: the numbers of transitions, internal states, input variables, output functions, collections of FSM outputs. The benchmarks are represented by STTs in the format KISS2. The choice of this library is based on the fact that a lot of FSM designers use it to compare their results with main characteristics of known FSM circuits [
27,
36,
37,
46,
47,
48]. The characteristics of the benchmark FSMs could be found, for example, in our previous articles. Due to this, we do not show them in our current paper.
To conduct the experiments, we use the Virtex-7 VC709 platform (xc7vx690tffg1761-2) [
49] based on FPGA chip xc7vx690tffg1761-2 (AMD Xilinx). The CLBs of this chip include LUTs with six address inputs. To obtain the FSM circuits, we use an industrial package Vivado v2019.1 (64-bit) [
39] produced by AMD Xilinx. To process the benchmarks, we use their VHDL-based models. To transform the KISS2-based benchmarks files into VHDL codes, the CAD tool K2F [
50] is applied.
For each benchmark, we use Vivado reports to find the LUT counts and performance (the values of cycle time and maximum operating frequency). We compare the proposed FSM model with four different FSM models. Three of these models are P FSMs based on: (1) Auto of Vivado (P Mealy FSMs with MBCs); (2) One-hot of Vivado (one-hot-based P Mealy FSMs); (3) JEDI (P Mealy FSMs with MBCs). As the fourth model, we investigate the MPY Mealy FSMs.
In our research, we take into account the fact that FSMs are not stand-alone units. To achieve the stability of the outputs, we use an additional synchronous register. In the cases of P FSMS, the inputs are loaded into this register. Thus, it consists of L flip-flops. Obviously, to implement this register, it is necessary to use L additional LUTs. In the cases of both MPY and FSMs, this register keeps the codes of COs. Thus, it has flip-flops and does not require additional LUTs. In addition, it does not require the additional synchronization pulse. This simplifies the synchronization circuit compared with equivalent P FSMs.
The results of experiments [
16,
17] show that practically all the characteristics of LUT-based FSM circuits strongly depend on the relation between the values of
, on the one hand, and
, on the other hand. In experiments, we use Virtex-7 FPGAs for which
. We divided the set of benchmarks by classes of complexity (CC). If the symbol CCP (
) means a class number, then the benchmarks belonging to a certain class is determined by the expression
For the library used, there are five classes of complexity (CC0-CC4). In each of the following tables, the benchmarks belonging to a certain class are shown in the column “Class of complexity”. The class CC0 includes trivial FSMs. The class CC1 includes simple FSMs. The class CC2 includes average FSMs. The class CC3 includes big FSMs. Finally, the class CC4 includes very big FSMs.
Table 7,
Table 8,
Table 9,
Table 10,
Table 11,
Table 12,
Table 13,
Table 14,
Table 15 and
Table 16 contain the results of the experiments conducted.
Table 7 includes the numbers of LUTs necessary to implement the electrical circuit for a given benchmark. All benchmarks are represented in this table.
Table 8 contains the LUT counts for classes CC0–CC1.
Table 9 contains the LUT counts for classes CC2–CC4. The negative influence of the number of FSM inputs is shown in
Table 10.
Table 11 contains the values of the minimum cycle times for each benchmark. The data for these tables are taken from the Vivado reports. In addition, we show cycle times separately for classes CC0–CC1 (
Table 12) and CC2–CC4 (
Table 13). The values of the maximum operating frequencies are shown in
Table 14. These values are obtained in a simple way using data from
Table 11. In addition, we show the frequencies separately for classes CC0–CC1 (
Table 15) and CC2–CC4 (
Table 16).
Each table is organized in the same manner. The first column includes the benchmarks’ names, the row “Total” and the row “Percentage”. The names of the investigated methods are shown in the next five columns. The classes of complexity are shown in the last column. In the row “Total” are shown the results of the summation of values for a particular column. Finally, the row “Percentage” includes the percentage of the summarized characteristics of various FSM circuits in relation to the summarized characteristics of MP
Y FSMs. We start the discussion of the results starting with
Table 7.
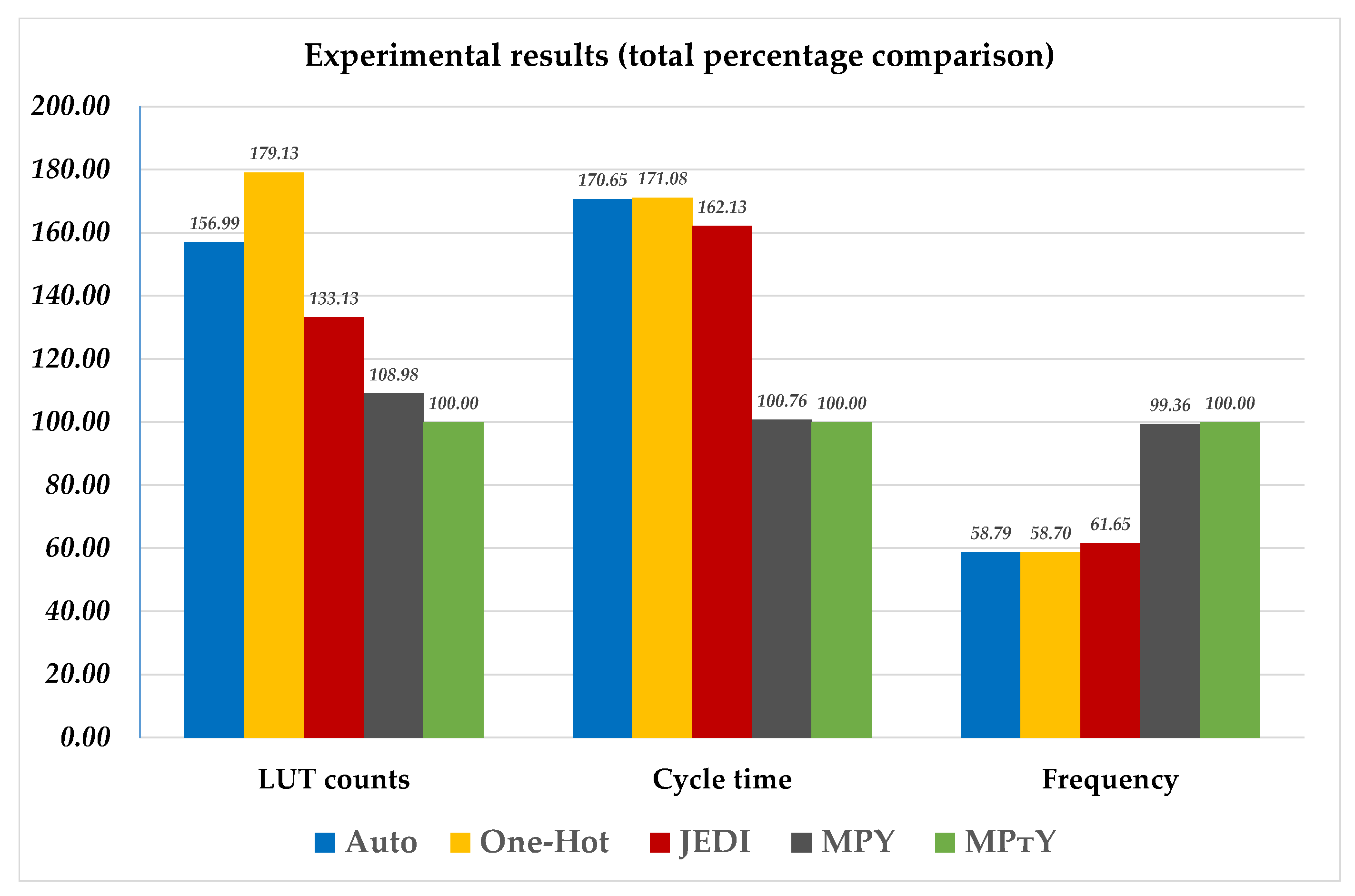
As follows from
Table 8, as compared to other investigated methods, the circuits of MP
Y-based FSMs consist of the minimum number of LUTs. There is the following gain: (1) 56.99% compared to Auto-based FSMs; (2) 79.13% compared to One-hot –based FSMs; (3) 33.13% compared to JEDI-based FSMs; and (4) 8.98% compared to MPY-based FSMs. In second place in terms of gain are MPY-based FSMs. We think this gain is associated with two factors. First, for rather complex FSMs, SD-based circuits always have fewer LUTs than for equivalent FD-based FSMs [
9]. Second, there are an additional L LUTs in the circuits of FD-based FSMs required to stabilize their operation. In the case of both MPY- and MP
Y-based FSMs, the stabilization is achieved by registering the codes of COs. To produce these codes, LUTs of LTZ are used. The outputs of these LUTs are connected with
flip-flops creating the additional register. Thus, there is no need for additional LUTs. Of course, the gain is also associated with replacing FSM inputs with additional variables. We think that this diminishes the number of partial functions compared to equivalent FD-based FSMs.
It is interesting to show how the gain is changed with the change in FSM complexity. Using
Table 7, we created two additional tables.
Table 9 shows LUT counts for trivial and simple FSMs.
Table 9 contains information about LUT counts for average, big and very big FSMs.
Analysis of
Table 8 shows that the proposed approach provides the same LUT counts as for equivalent MPY FSMs. All P-based models require more LUTs. Our approach gives the following gain: (1) 24.89% compared to Auto-based FSMs; (2) 56.11% compared to One-hot—based FSMs; and (3) 9.61% compared to JEDI-based FSMs. We think that this gain is connected to the different stabilization methods used in SD- and FD-based FSMs. The input register of FD-based FSMs requires more LUTs than the output register of SD-based FSMs. However, both MPY- and MP
Y-based FSMs require more LUTs for trivial FSMs (the complexity class CC0). We think this has a very simple explanation. Namely, for trivial FSMs, the condition (
5) holds. Thus, there is no need to apply the SD-based methods. However, these methods are always used during the synthesis of both MPY- and MP
Y-based FSMs. In this case, it is necessary to implement circuits of blocks LB and LY. It is the presence of these absolutely redundant blocks that determines the marked loss of SD-based methods.
The next phenomenon comes from
Table 8: for the class CC0, the circuits of equivalent MPY- and MP
Y-based FSMs have equal amounts of LUTs. We think this is connected with the fact that the partition
consists of one class. Due to this, there is no need to use the blocks LB1–LBK. This means that MP
Y FSMs turn into MPY FSMs. Obviously, these FSM circuits should have equal values for all the other characteristics. This, once again, indicates that it is advisable to use different FSM models for different conditions. Thus, it makes no sense to apply SD-based methods when condition (
5) is met.
Now, we are going to discuss the temporal characteristics of FSM circuits. First of all, we show the negative influence of input register. In all P-based FSMs, the stabilization of operation is achieved due to loading FSM inputs into the additional register. Thus, this approach leads to the use of L additional LUTs and flip-flops. Obviously, the cycle time increases due to the presence of the chain < input-LUTs–flip-flops–LUTs of LB>. In addition, this increases the consumed power. We explored how the number of inputs affects the time and power characteristics of resulting circuits. This information is shown in
Table 10.
As follows from
Table 10, the number of inputs significantly affects the timing and energy characteristics of LUT-based FSM circuits. The more inputs the FSM has, the greater their negative impact. In the case of the investigated SD-based FSMs, the stabilization is achieved due to the registering codes of COs. In this case, the number of additional flip-flops is equal to
. Moreover, there is no need for additional LUTs because the codes of COs are generated by the LUTs of LTZ. As follows, for the studied benchmarks, the following relation holds:
. The validity of this relation determines the gain in time characteristics obtained due to the transition from FD-based FSMs to SD-based FSMs. This gain is shown in
Table 11.
As follows from
Table 11, the SD-based FSMs have the best values of cycle time. Our proposed method produces FSM circuits which are a bit slower than the circuits of MPY-based FSMs (the average loss is 0.76%). However, our method has the following average gain compared to other FSMs: (1) 70.65% compared to Auto-based FSMs; (2) 71.08% compared to One-hot-based FSMs; and (3) 62.13% compared to JEDI-based FSMs. This gain for the SD-based FSMs is explained by the difference in the methods used for stabilizing the FSM outputs, as discussed before.
To show the influence of FSM complexity, we create two additional tables.
Table 12 includes information about the cycle times for trivial and simple FSMs.
Table 13 includes information about the cycle times for average, big and very big FSMs.
As follows from
Table 12, the time characteristics are equal for SD-based trivial and simple FSMs. They have the following gain: (1) 65.63% compared with both Auto- and One-hot—based FSMs and (2) 59.60% compared with JEDI-based FSMs. The reasons for this situation are as discussed before.
As follows from
Table 13, starting from the complexity CC2, our approach wins in performance. There is the following gain: (1) 78.93% compared with Auto-based FSMs; (2) 79.72% compared with One-hot-based FSMs; (3) 66.3% compared with JEDI-based FSMs and (4) 2.0% compared with equivalent MPY FSMs. We think that the superiority of SD-based FSMs is due to the fact that they generate fewer partial Boolean functions. Due to this, their circuits have fewer logic levels and interconnections. In turn, they are faster.
The slight superiority of MPY FSMs (2%) in relation to MPY FSMs is due to the fact that MPY FSMs have fewer interconnections. This is connected with different approaches of stabilization. Since interconnections significantly affect the timing characteristics, our approach produces faster circuits for FSMs from the classes CC2-CC4. Apparently, equivalent SD-based FSMs have the same number of logic levels (the number of series-connected LUTs). Thus, with respect to the other methods under study, the performance of MPY FSMs improves as their complexity increases.
We did not obtain the values of maximum operating frequencies from Vivado reports. However, we calculated them using the values of cycle times. The frequency comparison is represented by
Table 14.
As follows from
Table 14, on average, the circuits of MP
Y-based FSMs are faster in relation to all other models. There is the following gain: (1) 58.79% compared to Auto-based FSMs; (2) 58.7% compared to One-hot-based FSMs; (3) 61.65% compared to JEDI-based FSMs; and (4) 0.64% compared to MPY-based FSMs. Obviously, the reasons for this gain are the same as the ones discussed for the time of cycles. We will not repeat them.
Naturally, the change in the gain in frequency has the same tendencies as the change in the gain in cycle time. This statement is justified by information from
Table 15 and
Table 16.
It should be noted that the gain in operating frequency for our method begins to appear from the complexity CC2. At the same time, the gain grows in the process of the transition to the highest categories of complexity.
Thus, if FSMs belong to the classes CC0-CC1, then equivalent MP
Y and MPY FSMs have the same values of LUT counts, cycle time and maximum operating frequency. For more complex FSMs, MP
Y FSMs require fewer LUTs than for equivalent MPY FSMs. In addition, for FSMs from classes CC0-CC1, both models have the same values of temporal characteristics. However, as the complexity increases, the temporal characteristics of the MP
Y FSMs gradually become slightly better than they are for equivalent MPY FSMs. This gain is rather small; however, the very fact that a decrease in the number of LUTs does not lead to performance degradation is important. The results of the experiments allow us to draw the following conclusion: MP
Y FSMs can replace MPY FSMs for average, big and very big sequential devices. For a more visual assessment of the results, we built a diagram (
Figure 9). This diagram shows a comparison of percentages for the main characteristics of the studied methods.
To construct charts (
Figure 9), we used tables in which the results are shown for all benchmarks, and not for their individual categories. To show the results for LUT counts, we used
Table 7. The times of cycles are taken from
Table 11. At last, the results for the values of maximum operating frequencies are derived from
Table 14. It clearly follows from
Figure 9 that the proposed method allows the improvement in the spatial characteristics of circuits (without the degradation of temporal characteristics).






 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}