
Research on the Control of Multi-Agent Microgrid with Dual Neural Network Based on Priority Experience Storage Policy


Abstract
1. Introduction
- (1)
- In order to solve the nonlinear coupling problem of microgrid systems, this paper proposes an Actor-Critical Neural Network, which combines deep reinforcement learning and the Priority Experience Storage Policy to improve the dual neural network structure algorithm. The control mode adopts distributed method to realize the information transmission between each neighboring agent so that the frequency control of each agent reaches the optimal expectation.
- (2)
- The improved dual neural network adopts the method of strategic gradient updating, iterative optimal adjustment of data deviation caused by primary control layer of the microgrid using target value neural network and predictive value neural network, solves the traditional neural network hoist problem, and ensures load sharing of each agent.
- (3)
- Compared with the traditional control algorithm, this paper combines the method of preemptive experience playback to make the control algorithm have faster convergence speed, and the analysis of plug-and-play characteristics of microgrid ensures better robustness of grid system.
2. Microgrid Control System
2.1. Microgrid Distributed Power Device Model
- Battery model
- 2.
- Gas turbine model
- 3.
- Wind and solar power units
- 4.
- Power balance
2.2. Droop Control of the Microgrid
3. Secondary Control Based on PES-ACNN Model Framework
3.1. Deep Reinforcement Learning Algorithms
3.2. Actor-Critic Neural Network
3.3. Priority Experience Storage Policy
| Algorithm 1: Priority Experience Storage Actor-Critic Algorithm |
| Initialize network parameters randomly Initialize training memory with capacity Initialize agent memory For episode = 1,Max_episodes do: For t = 0, D-1 do: Get initial state Take action a with policy-based On Receive new state and reward Store transition in agent memory End for Calculate for each transition in the agent memory Store in the training memory. Reset agent memory Reset environment If training memory is full: Calculate for the whole batch Perform a gradient descent step on Reset training memory End for |
4. Experimental Validation and Analysis
4.1. Model Simulation
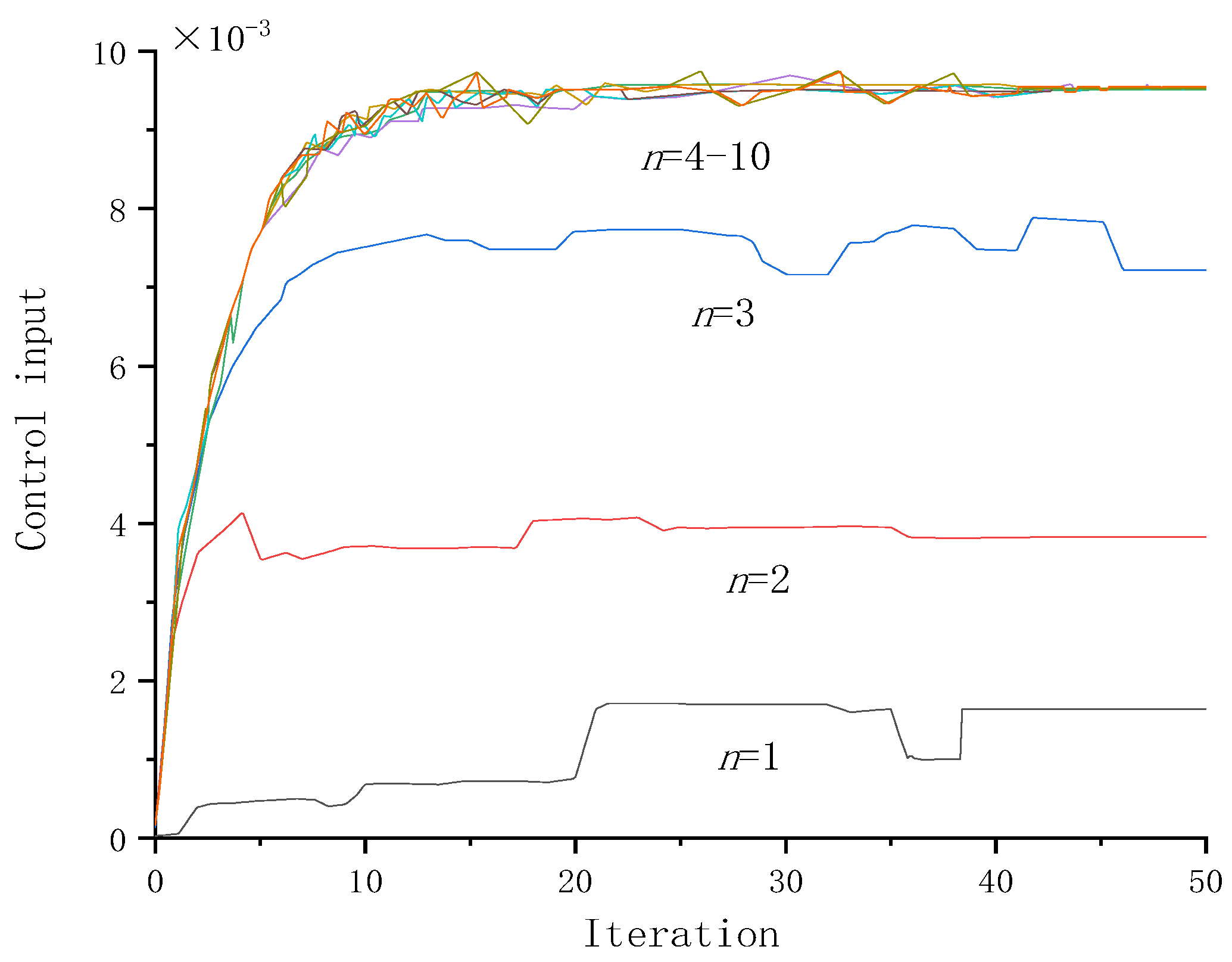
4.2. Neural Network Model Validations
4.3. Distributed Secondary Frequency Control Simulation
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Farrelly, M.A.; Tawfik, S. Engaging in Disruption: A Review of Emerging Microgrids in Victoria, Australia. Renew. Sustain. Energy Rev. 2020, 117, 109491. [Google Scholar] [CrossRef]
- Gao, F.; Bozhko, S.; Asher, G.; Wheeler, P.; Patel, C. An Improved Voltage Compensation Approach in A Droop-Controlled DC Power System for the More Electric Aircraft. IEEE Trans. Power Electron. 2015, 31, 7369–7383. [Google Scholar] [CrossRef]
- Aklilu, Y.T.; Ding, J. Survey on Blockchain for Smart Grid Management, Control, and Operation. Energies 2021, 15, 193. [Google Scholar] [CrossRef]
- De Caro, F.; Andreotti, A.; Araneo, R.; Panella, M.; Rosato, A.; Vaccaro, A.; Villacci, D. A Review of the Enabling Methodologies for Knowledge Discovery from Smart Grids Data. Energies 2020, 13, 6579. [Google Scholar] [CrossRef]
- Dou, C.-X.; Liu, B. Multi-Agent Based Hierarchical Hybrid Control for Smart Microgrid. IEEE Trans. Smart Grid 2013, 4, 771–778. [Google Scholar] [CrossRef]
- Li, F.-D.; Wu, M.; He, Y.; Chen, X. Optimal Control in Microgrid Using Multi-Agent Reinforcement Learning. ISA Trans. 2012, 51, 743–751. [Google Scholar] [CrossRef]
- Wang, Y.; Nguyen, T.L.; Xu, Y.; Li, Z.; Tran, Q.-T.; Caire, R. Cyber-Physical Design and Implementation of Distributed Event-Triggered Secondary Control in Islanded Microgrids. IEEE Trans. Ind. Appl. 2019, 55, 5631–5642. [Google Scholar] [CrossRef]
- Al-Tameemi, Z.H.A.; Lie, T.T.; Foo, G.; Blaabjerg, F. Optimal Coordinated Control of DC Microgrid Based on Hybrid PSO–GWO Algorithm. Electricity 2022, 3, 346–364. [Google Scholar] [CrossRef]
- Ziouani, I.; Boukhetala, D.; Darcherif, A.-M.; Amghar, B.; El Abbassi, I. Hierarchical Control for Flexible Microgrid Based on Three-Phase Voltage Source Inverters Operated in Parallel. Int. J. Electr. Power Energy Syst. 2018, 95, 188–201. [Google Scholar] [CrossRef]
- Bidram, A.; Davoudi, A. Hierarchical Structure of Microgrids Control System. IEEE Trans. Smart Grid 2012, 3, 1963–1976. [Google Scholar] [CrossRef]
- Guo, F.; Xu, Q.; Wen, C.; Wang, L.; Wang, P. Distributed Secondary Control for Power Allocation and Voltage Restoration in Islanded DC Microgrids. IEEE Trans. Sustain. Energy 2018, 9, 1857–1869. [Google Scholar] [CrossRef]
- Ning, C.; You, F. Data-Driven Stochastic Robust Optimization: General Computational Framework and Algorithm Leveraging Machine Learning for Optimization under Uncertainty in the Big Data Era. Comput. Chem. Eng. 2018, 111, 115–133. [Google Scholar] [CrossRef]
- Dou, C.; Li, Y.; Yue, D.; Zhang, Z.; Zhang, B. Distributed Cooperative Control Method Based on Network Topology Optimisation in Microgrid Cluster. IET Renew. Power Gener. 2020, 14, 939–947. [Google Scholar] [CrossRef]
- Lu, R.; Hong, S.H.; Yu, M. Demand Response for Home Energy Management Using Reinforcement Learning and Artificial Neural Network. IEEE Trans. Smart Grid 2019, 10, 6629–6639. [Google Scholar] [CrossRef]
- Du, Y.; Li, F. Intelligent Multi-Microgrid Energy Management Based on Deep Neural Network and Model-Free Reinforcement Learning. IEEE Trans. Smart Grid 2020, 11, 1066–1076. [Google Scholar] [CrossRef]
- Fang, X.; Zhao, Q.; Wang, J.; Han, Y.; Li, Y. Multi-Agent Deep Reinforcement Learning for Distributed Energy Management and Strategy Optimization of Microgrid Market. Sustain. Cities Soc. 2021, 74, 103163. [Google Scholar] [CrossRef]
- Das, S.R.; Ray, P.K.; Sahoo, A.K.; Singh, K.K.; Dhiman, G.; Singh, A. Artificial Intelligence Based Grid Connected Inverters for Power Quality Improvement in Smart Grid Applications. Comput. Electr. Eng. 2021, 93, 107208. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, D.; Gooi, H.B. Optimization Strategy Based on Deep Reinforcement Learning for Home Energy Management. CSEE J. Power Energy Syst. 2020, 6, 572–582. [Google Scholar] [CrossRef]
- Lei, L.; Tan, Y.; Dahlenburg, G.; Xiang, W.; Zheng, K. Dynamic Energy Dispatch Based on Deep Reinforcement Learning in IoT-Driven Smart Isolated Microgrids. IEEE Internet Things J. 2021, 8, 7938–7953. [Google Scholar] [CrossRef]
- Li, H.; Wan, Z.; He, H. Real-Time Residential Demand Response. IEEE Trans. Smart Grid 2020, 11, 4144–4154. [Google Scholar] [CrossRef]
- Wang, J.; Kurth-Nelson, Z.; Tirumala, D.; Soyer, H.; Leibo, J.; Munos, R.; Blundell, C.; Kumaran, D.; Botvinick, M. Learning to Reinforcement Learn. arXiv 2016, arXiv:1611.05763. [Google Scholar]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Harley, T.; Lillicrap, T.P.; Silver, D.; Kavukcuoglu, K. Asynchronous Methods for Deep Reinforcement Learning. Int. Conf. Mach. Learn. 2016, 48, 1928–1937. [Google Scholar]
- Wang, Z.; Bapst, V.; Mnih, V.; Munos, R.; de Freitas, N.; Heess, N.; Kavukcuoglu, K. Sample efficient actor-critic with experience replay. arXiv 2017, arXiv:1611.01224. [Google Scholar]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep Reinforcement Learning with Double Q-Learning. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI-16), Phoenix, AR, USA, 12–17 February 2016; Volume 30. [Google Scholar] [CrossRef]
- Phan, T.V.; Nguyen, T.G.; Bauschert, T. DeepMatch: Fine-Grained Traffic Flow Measurement in SDN with Deep Dueling Neural Networks. IEEE J. Select. Areas Commun. 2021, 39, 2056–2075. [Google Scholar] [CrossRef]
- Bizzarri, F.; del Giudice, D.; Linaro, D.; Brambilla, A. Partitioning-Based Unified Power Flow Algorithm for Mixed MTDC/AC Power Systems. IEEE Trans. Power Syst. 2021, 36, 3406–3415. [Google Scholar] [CrossRef]
- Xia, Y.; Xu, Y.; Wang, Y.; Dasgupta, S. A Distributed Control in Islanded DC Microgrid Based on Multi-Agent Deep Reinforcement Learning. In Proceedings of the IECON 2020 The 46th Annual Conference of the IEEE Industrial Electronics Society, Singapore, 18–21 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 2359–2363. [Google Scholar]
- Liu, W.; Zhuang, P.; Liang, H.; Peng, J.; Huang, Z. Distributed Economic Dispatch in Microgrids Based on Cooperative Reinforcement Learning. IEEE Trans. Neural Netw. Learning Syst. 2018, 29, 2192–2203. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DG1 | DG2 | DG3 | DG4 | |
|---|---|---|---|---|
| DGs | C1/F 15 × 10−5 | C2/F 15 × 10−5 | C3/F 15 × 10−5 | C4/F 15 × 10−5 |
| L1/mH 0.2 | L2/mH 0.2 | L3/mH 0.2 | L4/mH 0.2 | |
| R1/Ω 0.01 | R2/Ω 0.01 | R3/Ω 0.01 | R4/Ω 0.01 | |
| load | Load1 | Load2 | Load3 | Load4 |
| P1/kW 90 | P2/kW 90 | P3 /kW 60 | P4/kW 50 | |
| Q1/kVar 30 | Q2/kVar 20 | Q3 /kVar 30 | Q4/kVar 20 | |
| Line1 | Line2 | Line3 | ||
| routes | R1/Ω 0.18 | R2/Ω 0.21 | R3/Ω 0.20 | |
| L1/mH 0.302 | L2/mH 0.302 | L3/mH 0.82 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, F.; Tong, S.; Li, C.; Du, X. Research on the Control of Multi-Agent Microgrid with Dual Neural Network Based on Priority Experience Storage Policy. Electronics 2023, 12, 565. https://doi.org/10.3390/electronics12030565
Xu F, Tong S, Li C, Du X. Research on the Control of Multi-Agent Microgrid with Dual Neural Network Based on Priority Experience Storage Policy. Electronics. 2023; 12(3):565. https://doi.org/10.3390/electronics12030565
Chicago/Turabian StyleXu, Fengxia, Shulin Tong, Chengye Li, and Xinyang Du. 2023. "Research on the Control of Multi-Agent Microgrid with Dual Neural Network Based on Priority Experience Storage Policy" Electronics 12, no. 3: 565. https://doi.org/10.3390/electronics12030565
APA StyleXu, F., Tong, S., Li, C., & Du, X. (2023). Research on the Control of Multi-Agent Microgrid with Dual Neural Network Based on Priority Experience Storage Policy. Electronics, 12(3), 565. https://doi.org/10.3390/electronics12030565