Abstract
Format-Preserving Encryption (FPE) algorithms are symmetric cryptographic algorithms that encrypt an arbitrary-length plaintext into a ciphertext of the same size. Standardisation bodies recognised the first FPE algorithms (FEA-1, FEA-2, FF1 and FF3-1) in the last decade, and they have not been used for network layer privacy protection so far. However, their ability to encrypt arbitrary-length plaintext makes them suitable for encrypting selected packet header fields and replacing their original value with ciphertext of the same size without storing excessive information on the network element. If the encrypted fields carry personally identifiable information, it is possible to protect the privacy of the endpoints in the communication. This paper presents our research on using FPE for network layer privacy protection and describes LISPP, a lightweight, stateless network layer privacy protection system. The system was developed for programmable smart network interface cards (NIC) and thoroughly tested in a real network environment. We have created several implementations ranging from pure P4 to a mix of P4 and C implementations, exploring their performance and the suitability of target-independent P4 language for such processor-intensive applications. Finally, LISPP achieved line rate TCP throughput, up to 4.5 million packets per second, with the penalty of only 30 to 60 microseconds of additional one-way delay, proving that it is adequate for use in production networks. The most efficient implementation was with the FF3-1 algorithm developed in C and carefully adapted to the specific hardware configuration of the NIC.
1. Introduction
The impact of communication services and applications on our lives and the reliance on the Internet is increasing daily. This is also followed by the evidence that this usage is being extensively monitored and analysed and that a lot of personal data is gathered for either security or commercial purposes. Therefore, privacy protection and internet usage anonymisation have been important research topics for several decades. Personal data can be gathered from various sources, most directly from operating systems and applications and through analysing network traffic patterns and protocols. This paper focuses on the latter—protecting from network layer profiling and personal data leakage. Assume an Internet user communicates using a permanent public IP address or can be unambiguously linked to some public IP address in a specific period. In that case, adversaries can track the user’s behaviour and habits by monitoring the set of visited IP addresses [1]. Even more accurate information can be obtained by tracking users’ DNS requests [2,3]. Although IPv6 has some privacy protection mechanisms like prefix rotation and IPv6 privacy extensions, a recent study showed that the privacy of a substantial fraction of end-users is still at risk [4]. Therefore, the European Union’s General Data Protection Regulation (GDPR) regulation considers IP addresses as Personally Identifiable Information (PII) [5], and special care must be taken to protect them.
Since web-based applications are the most popular internet services used nowadays, various proxy/VPN services have emerged that enable hiding the original source IP address when visiting a website. However, such systems have a single point of failure and rely on trust in the proxy/VPN provider, which can reside in a foreign legislation environment. The low-latency onion routing system Tor is probably the best-known and widely used network layer anonymisation system [6]. It allows anonymous web page browsing through the onion router circuits, which consist of three servers (called onion routers) and three layers of packet data encryption. It also enables access to hidden web content. By using Tor, a web server or an observer on any single point on the Internet cannot tell which are both endpoints of the web session, preserving user anonymity on a network layer. However, such protection comes with a performance cost. Each packet is split into Tor cells with additional headers, decreasing the useful part of the packet. Each cell processing includes three encryptions and decryptions between the endpoints. The path between the endpoints is (intentionally) not optimal. This additional cost is seen as often slow and annoying web browsing. Also, despite the heavy use of encryption, it is well known that Tor circuits are susceptible to end-to-end timing and rogue Tor router attacks owned by an adversary. Former is an attack in which an adversary monitoring traffic on multiple points in the network can discover the endpoints by correlating traffic patterns. This non-ideal situation inspired new proposals for providing network layer anonymity, which will be more thoroughly described in the next section.
More than 20 years have passed since the first Tor release, and some internet usage patterns have changed since then. Nowadays, almost all web traffic is encrypted [7], raising questions about whether additional data field encryption layers are needed and justified, primarily because they do not provide additional security against timing and rogue onion router attacks. In this paper, we propose a lightweight, stateless system for network layer anonymity which encrypts and obfuscates only the necessary parts of the packet headers to protect the user’s privacy. Such an approach using well-known symmetric algorithms (e.g., Advanced Encryption Standard—AES) is not quite feasible because packet header fields are usually shorter and do not align with the block size for block ciphers nor a byte boundary for stream ciphers. For example, if a 12-bit plaintext is encrypted using AES-128, it will have to be padded to the size of the block—128 bits (usually with zeros or a random tweak), and the encryption will produce a 128-bit ciphertext. In order to decrypt back the initial 12-bit plaintext, one has to store the whole 128-bit ciphertext somewhere to perform decryption and later remove the padding (Figure 1a). Suppose a 12-bit plaintext is a packet header field or part of it (e.g., host part of the IP address with mask /20), which is to be encrypted. In that case, storing the encrypted version of that field takes additional space, which implies additional headers, protocols, or storage space. Therefore, we explored using Format-Preserving Encryption (FPE) for network layer privacy protection. FPE enables the encryption of arbitrary-length fields in a manner which allows the replacement of a protocol field with its encrypted version of the same size. This difference between the FPE and block ciphers is shown in Figure 1. Recently, the first such protocols, FEA-1 and FEA-2 [8] in South Korea and FF1 and FF3-1 [9] in the United States, passed the evaluation and adoption by the relevant standardisation bodies. To the best of our knowledge, this is the first use of FPE to protect network packet header fields. We believe its successful and performant implementation demonstrated in this paper through the design and deployment of a LIghtweight Stateless Privacy Protection system (LISPP) will pave the way for further use in networking applications for the privacy protection of all applications, not just the web.
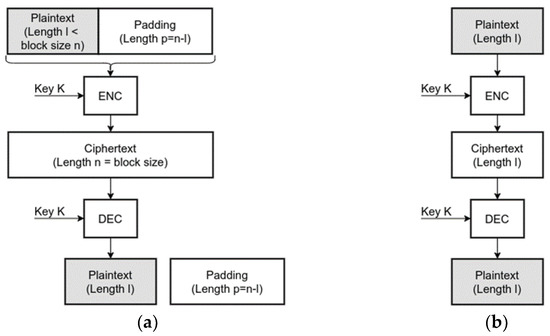
Figure 1.
(a) Block cipher encryption vs (b) Format-preserving encryption of plaintext of length l.
Programmable network devices (e.g., switches, smart network interface cards (NICs) or switches filled with the bump-in-the-wire SmartNICs) became very popular in the last decade among network professionals, with the P4 language as one of the most popular recent innovations. Their programmability and flexibility enabled innovation and boosted research in the field. SmartNICs can be programmed using various programming languages and styles (e.g., P4, C, assembler or a combination of those), and in this way, offload a part of traffic processing from the central server processors and cores. Programmable NICs enable computing tasks execution and traffic processing closer to the data path, shortening processing times and enabling high-speed traffic processing and new applications or packet modifications without sacrificing network traffic performance. We developed the LISPP system and evaluated its performance on Netronome Agilio CX programmable network interface card. LISPP was developed in several implementations ranging from pure P4 to a combination of P4 and Micro-C to explore the performance of portable P4 code and its dependence on the specific hardware configuration of the card.
Our research differs from the previous network layer privacy protection proposals in several important points. This is the first study on the use of the FPE for network layer privacy protection. Unlike previous proposals described in Section 2, the implemented LISPP system is fully stateless, which implies low memory requirements, simple multihoming, fully transparent, and fast line-rate operation on contemporary programmable hardware, as described in the paper. The performance of the proposed system is proven through the experimental evaluation of actual devices within a real network environment. The LISPP achieved line rate TCP throughput, up to 4.5 million packets per second, with the penalty of only 30 to 60 microseconds of additional one-way delay under the conditions described in the remainder of the paper. Such throughput on low-cost SmartNICs proves that FPE is adequate for network layer privacy protection. The LISPP is network layer protocol-independent, ready to protect the privacy of both IPv4 and IPv6 header data, which was not a feature of the previously proposed systems. Finally, we have made three implementations of LISPP using different combinations of P4 and Micro-C code. The analysis of these implementations presented in this paper revealed less than optimal performance of the P4 code on the target system we used and indicated that further work on the P4 compiler optimisation is needed.
The paper is structured as follows: Section 2 gives an overview of the recent research in the field of network layer privacy protection, with special attention on the issues of the proposed solutions, which are a consequence of the use of classic encryption algorithms. Section 3 describes the architecture and principles of privacy protection using LISPP. Section 4 introduces FPE algorithms and presents FPE implementation challenges on network accelerator cards. Section 5 discusses LISPP performance and obtained experimental results, while Section 6 concludes the paper.
2. Related Work
Two recent overview papers of applied research in the field of data plane programming [10,11], among other work, listed the most recent efforts on network layer privacy protection that use novel network programmability mechanisms. Systems like HORNET [12], TARANET [13], PHI [14], LAP [15], or Dovetail [16] aim to provide solutions similar to Tor with multiple cooperating routers/servers along the packet path, usually in conjunction with some Next Generation Internet technology that enhances security. In some cases (e.g., LAP, HORNET), packets are additionally encrypted by the system. In the other (e.g., Dovetail), there is no additional encryption, and the system relies on another protection mechanism. Similarly to Tor, all these systems are vulnerable to timing correlation attacks, but newer systems like HORNET also turned out to have other previously unknown vulnerabilities [17].
A series of papers on network layer privacy from a research group from Princeton University primarily inspired our work. SPINE [18] is a system for IP address, TCP sequence, and acknowledgement numbers obfuscation. It encrypts the source IP address from the original IPv4 packet header and encodes the encrypted data into the newly created IPv6 packet while discarding the original IPv4 packet header. To avoid encrypting one IP address always into the same encrypted value using a single key, SPINE adds a random nonce to the address encryption process. The nonce is different for each packet and randomises the encrypted address values. To achieve reversible decryption, SPINE encodes the encrypted IP address and the used nonce into a newly created IPv6 packet. An IPv6 address that is longer than the IPv4 address can store both the encrypted IPv4 address and the nonce. In order to ensure high-speed operation, SPINE uses a simple XOR-based encryption scheme. SPINE is a VPN-like system in which two or more collaborating autonomous systems are the endpoints of the newly created IPv6 tunnels. Encrypting original IPv4 addresses and storing them in the new IPv6 header hides original communication details from the intermediate autonomous systems. The SPINE system is stateless because it does not need to store the mapping between the original IPv4 and newly created IPv6 addresses—the encryption/decryption process provides the mapping. However, mapping between the destination IPv4 address and the corresponding IPv6 endpoint prefix is needed for the operation, as well as the previous key exchange.
Wang et al. [19], in the P4-based PINOT system for address obfuscation, proposed a scheme in which the source IP address is padded with random padding up to the size of the block of the cryptographic algorithm and then encrypted. The encryption scheme is more complex than in the case of SPINE but still non-standard. PINOT uses a simplified 56 or 64-bit wide two-stage substitution-permutation network to achieve high packet rates. As in SPINE, because the length of the ciphertext is longer than the IPv4 address, and in order to make the process reversible once the packets return from the opposite endpoint, the encrypted data is encoded in the IPv6 packet. The system is stateless for egress source IP addresses for which there is no need for a table lookup—they are just encrypted using a local key. However, the lookup is needed for the destination IPv6 address, which has to be found based on the destination IPv4 address. The PINOT authors assumed that some sort of DNS snooping is used, in which both A and AAAA records are intercepted at the network device and mapped so that the appropriate destination IPv6 address can be created. However, this process does not seem trivial on a network element or without a performance penalty. Cryptographic keys in the PINOT system do not have to be exchanged. They are local to the network element if the egress and ingress points to the network are the same and as long as there are no multiple entries into the network.
Unfortunately, today, privacy-preserving systems like PINOT and SPINE, which use IPv4 to IPv6 translation, do not ensure full Internet connectivity. At the moment of writing this paper, only about one-third of all the autonomous systems on the Internet support IPv6 [20]. Further, once IPv6 becomes fully adopted and the predominant IP protocol on the Internet, applying the same approach for the IPv6 address and transport layer would be challenging, if not impossible. PINOT and SPINE used the fact that IPv6 addresses are longer than IPv4, which enabled storing the ciphertext of the IPv4 address and random nonce in the IPv6 address. However, when a random nonce is padded to an IPv6 address, the resulting ciphertext will be longer than the available space in the IPv6 address. The question is where the excess bits of the ciphertext would be stored—either in a new protocol header or using a stateful operation is required.
Another older IP address mixing system [21] is a stateful system that encrypts the host part of the class B IPv4 address and source port using an RC5-based scheme with the addition of a random number—tweak. Since the output of the RC5 is 128-bit, and the plaintext input, which is replaced with the encrypted value, is only 32 bits long, the solution for the excess ciphertext was to make the system stateful. The system keeps records of all flow to 32-bit encrypted value mappings to perform decryption/replacement operations on the backward packet path. In that case, an encrypted pair (src IP, src port) is used as a key. Although not reported in the paper, the system suffers from the birthday problem and experiences collisions with 64 thousand concurrent flows with a probability of 0.5.
To summarise, the previous research that proposed the encryption of the critical packet header fields using classic block encryption algorithms showed that such an approach successfully hides users’ IP addresses. However, block ciphers require a stateful operation or IPv4–IPv6 translation, which poses significant implementation and usage issues, as explained above. This paper explored FPE for packet header field obfuscation and created the LISPP system. This fully stateless system efficiently scrambles packet flow data using FPE, hiding the source IP address from the observers on the Internet and disabling user profiling. The system is built for low-cost programmable SmartNICs for IPv4 and IPv6 and achieves line rate throughput on 10 Gbit/s links, proving that the concept can be used in real networking environments. We have tested the performance of several development and deployment options (pure P4, mixed P4 and C and pure C implementation). LISPP achieved line rate operation on 10 Gbit/s interfaces. Our analysis also showed performance issues in pure P4 deployments. P4 performance, especially for processor-demanding tasks like encryption, still heavily depends on the underlying hardware architecture. The P4 compiler we used does not optimise the executable code most efficiently.
3. LISPP System Architecture
An IP address consists of two inseparable parts: the network part, which determines the host’s location on the Internet (the autonomous system) and the host part, which identifies the exact sender or recipient of the packet in that network. Since the information about the location is needed to route the packet properly, IP addresses are usually sent unprotected or unchanged. Some of the previous protection mechanisms use either fully stateful address swapping (e.g., in NAT) or full packet encryption (like in Tor or IPsec). However, such approaches are not always scalable for general Internet usage patterns.
LISPP processes packets at the network boundary. It encrypts the host part of the source IP address and source port in packets that exit the protected network and decrypts them in the opposite direction. In the egress direction, the host part of the original source IP address from the protected network (designated as P—plaintext in Figure 2) and source port are replaced with their encrypted values (designated as C—ciphertext and new port number). The network part of the IP address (Net) remains the same, ensuring proper packet routing back to the protected network. In the ingress direction, decryption using the same key is performed, restoring addresses and ports to their original values.
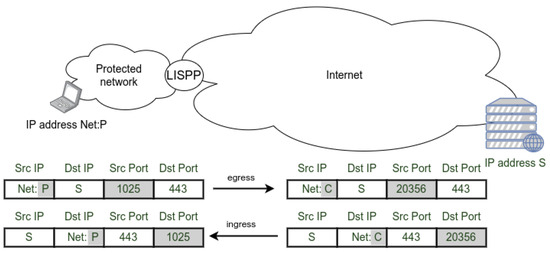
Figure 2.
LISPP header field modification at the network boundary.
This way, when the user from the protected network communicates with the external devices, external devices can only know the user’s location (network part of the IP address) but not the exact user’s original source IP address. The encrypted version of the plaintext changes in every session because the source port takes a new value in subsequent TCP or UDP sessions. Every time a client from the protected network accesses the same external server, the client will appear to have a different IP address with a high probability, ensured by the use of encryption algorithms. Such a behaviour prevents the destination, or an observer in any location between the protected network and the destination, from tracking the behaviour of any specific user in the protected network on a network level because his network sessions will appear to be coming from different IP addresses. LISPP behaviour is similar to Port Address Translation (PAT) because it changes the source IP address and port on the network entry/exit point. However, unlike PAT, which maps a pool of private IP addresses onto a single or a smaller number of public IP addresses, LISPP makes a bijection of a pool of public IP addresses onto that same IP address set. Also, unlike PAT, LISPP is fully stateless, implying that mappings between the original and encrypted pairs of addresses and ports do not have to be stored at the network element because the mapping is performed using encryption/decryption. From this brief description, it is clear that LISPP does not strive to replace or present an alternative to Tor, as it assumes a single point which obfuscates the addresses. However, there are several clear use cases, as described in the remainder of this section, in which LISPP can protect user privacy.
3.1. Packet Processing
In both directions, after packet parsing and checksum verification, LISPP filters packets which will be processed (Figure 3). Since LISPP uses a source port as a part of the plaintext in the egress direction, LISPP can be used to protect any TCP or UDP packet. However, it is possible to program the match filter to push to the encryption phase packets with any specific destination port value (e.g., TCP 443 for TLS or UDP 53 for DNS requests/responses) while all the other packets pass the system unchanged.
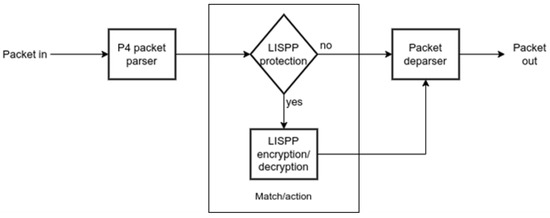
Figure 3.
LISPP packet processing diagram.
3.2. Packet Header Field Encryption
Figure 4 shows how LISPP encrypts the packet header elements using FPE. The host part of the source IP address and source port are concatenated and encrypted using a secret key. Since FPE is used, n bits of plaintext are encrypted into exactly n bits of the ciphertext regardless of the number of bits n. In that case, it is possible to obtain a reversible one-to-one mapping between the (src IP, src port) and (enc(src IP), enc(src port)) pairs regardless of the network mask size (and IP version). It is possible to achieve fully transparent and stateless operation in both directions.
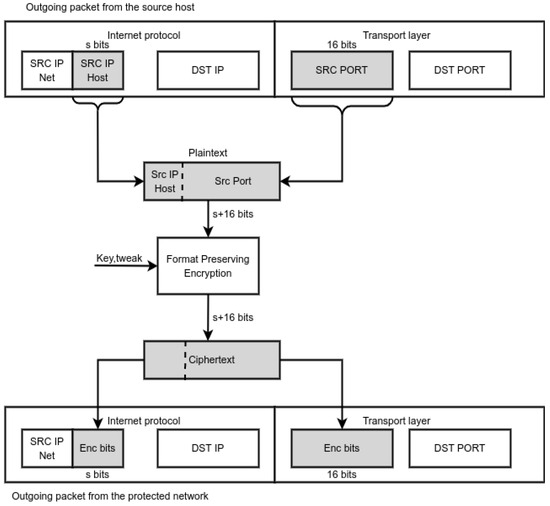
Figure 4.
LISPP address and port encryption.
An illustration of LISPP address obfuscation in operation is given in Figure 5. This figure shows the empirical probability of the appearance of encrypted values of host parts of the IP address (enc(src IP)) obtained from a single source IP address with mask /23 and the full range of source ports from 0 to 65,535. Visual inspection shows that LISPP achieves uniform distribution of the encrypted source IP addresses across all possible 512 values of a 9-bit host part of the address. More rigorous randomness testing is presented in Section 5.
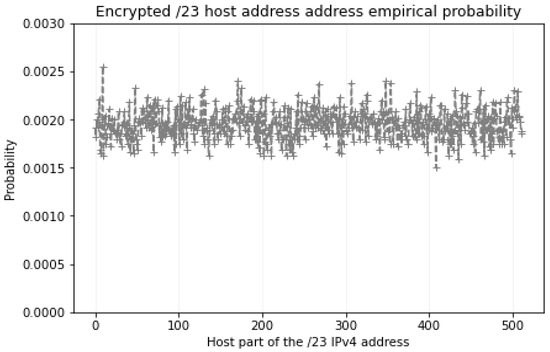
Figure 5.
Empirical probability of the appearance of host part values of the IP address obtained from a single source IP address with mask /23 and the full range of source ports using LISPP.
FPE algorithms require a secret cryptographic key and tweak (described in Section 4) to be used to encrypt and decrypt header fields. This cryptographic material can be created directly on a network element using a pseudorandom derivation from a seed defined by the user or taken from some source of randomness on the network element. In the case of a single entry point into the protected network, key and tweak do not have to leave that network element because both encryption and decryption are performed on the same device. However, when a network has multiple entry points and asymmetric ingress and egress flow paths, all devices on the network boundary must use the same cryptographic material. In that case, one boundary network element would create the key and tweak, while the others would receive that material through some secure connection (e.g., TLS or IPsec). In any of these cases, the tweak is not sent along the encrypted header fields, which further strengthens the security of the proposed solution.
Since cryptographic material has a limited operational lifetime, the key and tweak have to be changed periodically (e.g., daily) or after some number of packets are processed. In moments when the key and/or tweak are changed, network flows active in that period will be broken because packet header fields in the egress direction would be encrypted with the old key, while in the ingress would be decrypted with the new, yielding wrong IP address and port numbers for that flow. This transient behaviour, although short, disrupts network operation and has to be planned for quiet periods of network operation. There is a trade-off between stronger data privacy (often key/tweak changes) and reliable network operation.
3.3. Threat Model
LISPP is a network layer privacy protection mechanism that cannot protect privacy at the application level. Like PINOT, it hides the client’s IP addresses and flow identifiers from the server side and the intermediate networks while accessing services on the Internet. LISPP assumes trust in the local network operator and does not hide connection/flow details from it or the devices that perform the encryption. An intermediate network between the protected network and the destination or the destination itself can reveal the actual IP address of the client, either by obtaining the encrypted–plaintext mapping or an encryption key through collusion with the client’s network provider or by breaking the encryption algorithm, which is computationally hard at the moment of writing this paper.
3.4. LISPP Use Case
LISPP is applicable and is desirable in all cases where the user has a public IP address given by the Internet Service Provider (ISP). ISPs might use mechanisms like stateless, temporary IPv6 address assignment [22], which periodically leases and changes temporary IP addresses. However, by default, this period is one day, giving the adversary a sufficiently large time window to analyse user behaviour and cross-correlate this behaviour with other sources of private data. There is also evidence that despite the use of such mechanisms, there are still substantial privacy leaks [4]. Since LISPP provides per-session address randomisation, it completely breaks any chance of network layer user tracking.
One clear use of LISPP is to mitigate the threat of private information leakage and user profiling by public DNS resolvers (e.g., Google Public DNS: 8.8.8.8, Quad9: 9.9.9.9, Cloudflare: 1.1.1.1 and similar). DNS resolvers receive the set of symbolic names of sites a user visits regardless of how symbolic names are sent to the resolver (encrypted by DNS over TLS or HTTPS or in plaintext). Therefore, for a user behind the specific IP address, DNS resolvers can gather information about the interests and the sites visited. There were some previous attempts to hide the symbolic names from the public resolvers by encrypting and encapsulating them into the regular DNS queries and redirecting them to another resolver [23]. By varying the source IP address for each user’s DNS request, LISPP successfully disables such profiling, and the system is significantly simpler than the previous solutions. The ISP can offer LISPP as an additional privacy protection service that prevents third parties (external sites and services) on the Internet from tracking the users and analysing their behaviour on the network layer. An example of LISPP performing DNS request source obfuscation is given in Figure 6. This figure shows eight consecutive DNS requests from a single computer in a /23 network and the set of addresses and ports to which LISPP converted the original data. It is evident that for the DNS server operator, it is difficult, if not impossible, to tell which device it is talking to at any given time. The effect of using LISPP would be the same for any other network protocol (e.g., web, SSH, FTP, etc.).
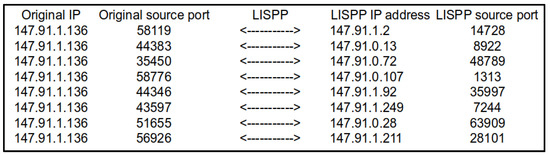
Figure 6.
LISPP translation of 8 consecutive DNS requests coming from a device with the address 147.91.1.136/23.
Furthermore, because of the ever-increasing number of cybersecurity threats and difficulties in identifying the attackers when the attack comes behind the Carrier-grade NAT devices, there are recent incentives to mandate the retention of the metadata that gives the mapping between the user and the IP address [24]. If such regulations are adopted, LISPP can easily comply with them and preserve privacy against third parties. Unlike large logs of NAT mappings, in the case of LISPP, only cryptographic material used by the FPE during the lifetime of that material needs to be kept to reconstruct the actual IP address of the users upon request from the legal authorities.
3.5. LISPP Design Goals
LISPP was designed with the following properties in mind:
- Transparency. Users from the protected network do not have to employ any dedicated application. They are generally unaware of any privacy protection system on the packet path (except for added minimal latency due to the packet processing).
- Stateless operation. The network element does not have to store any state, i.e., mappings between the plaintext and encrypted fields’ values or any tables. The stateless operation further brings simple multihoming because there is no need to synchronise states among the entry/exit points.
- Seamless multihoming. Suppose the protected network has multiple entry/exit points, and packet paths are not symmetric in the ingress and egress direction. In that case, LISPP should be deployed on all entry/exit points with the need to exchange only cryptographic material (keys and tweaks, as described in Section 4.1) between the entry/exit points. Deploying LISPP on all entry/exit points is easily achievable using any key exchange mechanism or through already-established cryptographic channels between the endpoints (e.g., IPsec).
- Effortless reconfigurability. LISPP can be configured to protect any TCP or UDP protocol port. Only the appropriate packet filter should be defined to select packets for which the obfuscation will be performed.
- Protocol independence. LISPP works with both IPv4 and IPv6 without any network layer protocol modifications.
- Legal compliance. Operators of the LISPP-protected network can easily reconstruct true packet origins upon legitimate requests from legal authorities.
Another side effect of using LISPP is that port scanning a device in a protected network from the outside is significantly more difficult. Suppose an adversary scans the entire port range for a single destination address in the protected network. In that case, these packets will pass the decryption and be scattered across the whole IP address segment, as shown in Figure 5, hitting various devices on ports which are not the same as those that an adversary sent, making the analysis significantly more difficult for the external observer. Further, with frequent changes of the cryptographic key and/or tweaks, the scanned footprint will completely change, making the analysis or the attacks even more difficult. LISPP can, in this case, be considered one of the tools and techniques for the Moving Target Defence strategy [25].
4. Format-Preserving Encryption
FPE is a type of encryption that preserves the format (alphabet) and size of the plaintext in the ciphertext. For example, with FPE, the ciphertext of a 16-digit decimal payment card number is also a 16-digit decimal number. The symbol sets and lengths for the plaintext and ciphertext are the same. One of the first algorithms that allowed variable bit size input and the same size output was a Hasty Pudding Cipher (HPC) [26], one of the candidates at the AES algorithm contest. The HPC algorithm did not pass to the later stages of the AES algorithm contest because of its complex and unusual structure. As a result, the cryptographic community did not widely test the HPC, so its resistance to various attacks was not well known.
The first, and so far only, FPE algorithms that passed as a recommendation of a standardisation body are South Korean FEA-1 and FEA-2, as well as FF1 and FF3 from the National Institute of Standards and Technology (NIST). FF3-1 is a revision of FF3 created after finding a security flaw in FF3 [27]. All these FPE algorithms have a very similar Feistel structure with different options for the random function, as will be described in the next section. The cryptanalysis of standardised FPE algorithms showed that the attacks on the FPE algorithms using differential distinguishers are more complex and require more data for the FF3-1 algorithm compared to the FEA standards [28]. In addition, linear cryptanalysis of the FPE algorithms [29] revealed that attacks on FF3-1 are more time-consuming compared to other algorithms in terms of encryption operations, thereby highlighting its enhanced security. Finally, the FF3-1 algorithm’s ability to encrypt binary words ranging from 20 to 192 bits in length made it particularly suitable for encrypting specific protocol fields in our system.
FPE specifications, although relatively young compared to the well-known block cipher symmetric cryptographic algorithms, have attracted attention from cryptanalysts. These experts have identified potential vulnerabilities in FPE schemes, particularly highlighting a decrease in the complexity of attacks, especially for shorter plaintext lengths and under specific circumstances, such as when the adversary has knowledge of the tweak parameter [29,30]. In the context of LISPP, these issues are effectively mitigated, as the plaintext lengths utilised exceed those susceptible to such vulnerabilities, and the tweak parameter never leaves the network element, ensuring its confidentiality. Consequently, the attacks reported in the literature are not applicable to LISPP. Nevertheless, we believe that finding such issues in the current algorithms will only improve their future versions and not jeopardise the use of FPE in general.
4.1. FF1 and FF3-1 Algorithm
FF1 and FF3-1 are Feistel-structure tweakable symmetric algorithms. Feistel structure is a well-known primitive block for symmetric algorithm design, known since the time before the Digital Encryption Standard (DES). Tweakable means that the algorithm uses an additional component called tweak as an input to the encryption and decryption process. The tweak does not necessarily have to be kept secret. It is used to increase the input variability because, with the FPE, input strings can be short with a limited set of values. Encrypting as few plaintexts as possible under any given tweak is recommended. However, changing the tweak during network operation can break existing sessions (one endpoint will change), and it should be conducted in carefully defined moments.
The FF3-1 achieves greater throughput because it has eight rounds, two fewer compared to the FF1, while the FF1 supports a wider range of lengths for the plaintext and flexibility in the tweak length [9]. Since per-packet processing time should be as low as possible, we focused on the FF3-1. In the core of each FF3-1 round is an approved block cipher used as a round function (Fk) to create a pseudorandom output. Figure 7 shows two Feistel rounds of FF3-1 encryption and decryption. Plaintext input is divided into two parts (Ai and Bi), which have the same size in case of an even number of plaintext characters or differ in size by one character in case of an odd number of plaintext characters. In our case, one character corresponds to one bit because packet header fields are binary words. The second part (Bi) is copied into the first part of the next round (Ai+1), while the first part is added to the output of the Fk round function. The inputs to the round function are one part of the previous block, round number i, random tweak T and the plaintext size n.
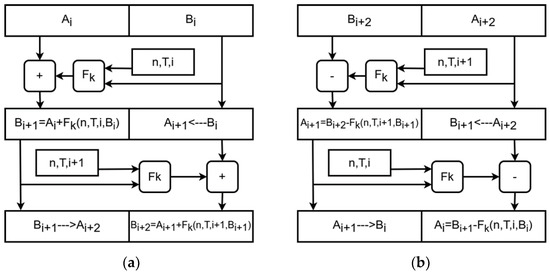
Figure 7.
Two Feistel rounds of the FF3-1 (a) encryption and (b) decryption.
According to the FF3-1 specification, an approved block cipher with secret key K should be used as the Fk, and at this moment, only the AES block cipher fits this profile. However, there are deployments with other lightweight algorithms [31]. Unlike FF1 and FF3-1, FEA-1 and FEA-2 use a modification of the SHARK cryptographic algorithm as a round function. FF3-1 does not use AES-128 to encrypt the data but provides a pseudorandom output truncated to the required number of bits and added to half of the plaintext. Therefore, only AES encryption is used for both FF3-1 encryption and decryption, simplifying the algorithm’s implementation. However, as described, FF3-1 consists of 8 rounds in which AES encryption of a 128-bit block is invoked, which means that standard-based FF3-1 implementation is roughly comparable to the encryption of 1024 bits (8 blocks) with AES, and that could present a challenge for the system performance. However, in Section 5, we show that even with the pure software implementation of the cryptographic algorithms, it was possible to achieve line rate performance on SmartNIC.
The FF3-1 algorithm has several parameters which define its behaviour. The base is the number of characters in a plaintext alphabet denoted as the radix. For binary plaintext, radix is 2. For an English plaintext consisting only of letters, the radix is 26. The number of plaintext characters and their base define the domain size of the plaintext as radixlength. For example, for a 16-digit debit card number, the theoretical domain size is 1016. Still, the actual domain size is somewhat smaller because some fields, like the issuer identification number, are fixed. FF3-1 specifies the minimum domain size of the plaintext to be at least 1 million. Therefore, for binary inputs, any plaintext that is longer or equal to 20 bits complies with the algorithm specification. For LISPP, this limit implies that the longest network prefix that could be used as an input is /28 (4 bits for the host part of the address + 16-bit source port). However, such a small network with only 14 devices might present a different privacy risk to users. Since the number of users using the network is small, side-channel attacks that analyse the user’s activity at a certain period are more likely to happen. Better results are obtained for larger networks with shorter prefixes and more users (we consider a mask of at least /24 as recommended). Another FF3-1 limit is the maximum plaintext length, which must be smaller than 2logradix296. For binary inputs, this is 192 bits—enough for almost all uses in packet headers for both IPv4 and IPv6. In the context of LISPP header field encryption, this implies that the source port and the whole IPv6 address can be encrypted using the FF3-1 without reaching the theoretical limit of the algorithm. It is interesting to notice that since the output of the AES algorithm is applied to half of the plaintext, which is of the maximal size of 96 bits, in all cases, regardless of the plaintext size, in each FF3-1 round, only one AES encryption is used, and the algorithm performance will be the same. Our experimental evaluation proved that the system’s performance was the same regardless of the IP address mask length.
4.2. FF3-1 Implementation (Target Netronome)
The implementation targets the Netronome Agilio CX 2 × 10GbE NFP-4000 series SmartNIC [32]. The SmartNIC consists of 12 clusters, i.e., islands of different architecture. Islands can be roughly divided into two categories depending on the purpose of the contained Flow Processor Cores (FPC), i.e., Microengines (ME). The first category includes islands containing only multi-threaded MEs for packet processing. There are eight cooperative threads within the ME, with only one thread running at any time; each has its own set of 32 32-bit wide general-purpose registers. Each ME has its Code Store and Local Memory following the Harvard architecture. In addition to its own Local Memory, which stores the data needed for processing every packet, the ME has access to four other kinds of memory. The size and data access time expressed in clock cycles for each kind of memory are given in Table 1 [33]. Cluster Local Scratch is meant to store the data needed to process the majority of packets and smaller tables. Cluster Target Memory stores packet headers and coordinates ME and other subsystems. Internal Memory stores the packet payload and medium-sized tables. External Memory stores large tables.

Table 1.
Types of Netronome Agilio CX memories and their access times.
The second category includes islands that contain accelerators (ILA, PCIe, Crypto, ARM) and multi-threaded MEs managing those accelerators. The SmartNIC used in the experimental evaluation contained no islands with a cryptographic accelerator. That is why we implemented the FF3-1 algorithm entirely in the software. Netronome Agilio CX cards without crypto accelerators use Linear Feedback Shift Register (LFSR) to generate a pseudorandom number, which can be used by Microengine software as an FF3-1 key and a tweak. It can be initialised using a timestamp and some user-defined value as a pseudorandom seed.
As described above, the FF3-1 algorithm can be used with an arbitrary alphabet or character set. In the case of a binary alphabet whose radix is 2, the following primitive operations of the FF3-1 algorithm were simplified:
- NUMradix(X), the number that the numeral string X represents in base radix when the numerals are valued in decreasing order of significance, has precisely the value X,
- STRmradix(X), which is the representation of X as a string of m numerals in base radix, in decreasing order of significance, given a nonnegative integer X less than radixm, is X at bit-width m,
- NUM(X) equals the integer that a bit string X represents. When the bits are valued in decreasing order of significance, it is essentially X itself,
- Modulo operation X mod radixm is implemented by a bit masking as X & ((1 << m)—1).
P4 is a hardware-independent network programming language where users can write the forwarding behaviour of the network devices using the standard forwarding model defined in the P4 architecture [34]. The user does not need to know Network flow processor (NFP) specific data structures. The P4 compiler automatically maps the different parts of the P4 program into the NFP internal resources. The P4 front-end compiler first compiles a P4 program to an intermediate representation (IR). The Netronome’s P4 back-end compiler transpiles the IR into the Micro-C program, which can be compiled and linked to generate the NFP firmware using the network flow C compiler (NFCC) [35]. The firmware generated from the P4 code is loaded on multiple MEs, each of which can independently process packets according to the packet processing code written as a P4 program. Motivated by the portability of the implementation to a larger number of devices, i.e., P4 targets, the aim was to explore portable implementation purely in the P4 language. Netronome supports executing P4 programs written for the v1model architecture [36], a variation of a theoretical model defined by Portable Switch Architecture (PSA) [37,38]. Theoretically, the implementation would be portable to any P4 target with a v1model architecture, such as the Behavioral Model (BMv2). We used tools from Netronome SDK version 6.1-preview, the first version that supports the P4-16 language. The code of all LISPP implementations described in the following sections is publicly accessible [39].
4.2.1. Pure P4 Implementation
The biggest challenges in the P4-based FF3-1 implementation were the limitations directly imposed by the P4 language [40]. P4 language does not have the loop construct, which presents a serious challenge in implementing symmetric cryptographic algorithms consisting of many rounds to achieve data confusion and diffusion. Unrolling loops of the entire algorithm is not an option due to the size limit of the Code Store where the program code resides. The size limit of the Code Store comes to the fore due to the design limit specified in the Netronome SDK documentation that a maximum of 256 actions may be defined, meanwhile expecting an increased Code Store usage. For each action invocation, the Netronome P4 back-end compiler defines a new Micro-C function that provides the given action with the context (arguments) and invokes the action. Defining a new Micro-C function for each action invocation leads to a non-negligible increase in the program code size. Saving Code Store space becomes even more critical, considering that the Netronome P4 front-end compiler does not support P4 functions. That is why we had to overcome the non-existent loop construct limitation by resubmitting the packet for each round of the FF3-1 algorithm. Instead of replicating code for an entire FF3-1 round multiple times, invocation of the resubmit extern function from the v1model architecture returns the packet to the start of the ingress pipeline, representing a single FF3-1 round. The internal state of the FF3-1 algorithm is stored in the packet’s metadata to save it across resubmission.
To implement AES encryption, we used a solution based on scrambled lookup tables [41]. The upside of this solution is that it performs all AES encryption in just one packet pass through the ingress pipeline and uses a pre-expanded AES key. The downside of this solution is the need for 160 match-action tables, a necessity arising from the P4 language’s absence of array support. Each byte of the AES algorithm state requires an individual table because the same table cannot be applied more than once during a single packet pass through the ingress pipeline. All sixteen tables must be replicated for every round of the AES algorithm, resulting in the 160 tables mentioned above. Such a large number of tables harms latency [42], especially given that the P4 back-end compiler places all tables in External Memory, which has the longest access time.
The required number of tables exceeds Netronome SmartNIC’s limit on the number of match-action tables used in the ingress pipeline of a P4 program [43]. That is why we had to reduce the number of tables to only five: four distinct for standard AES rounds and one for the last AES round. Table number reduction implies introducing additional packet resubmissions to implement AES encryption successfully. The most straightforward implementation would pass the packet through the ingress pipeline once for each of the 16 bytes in the AES state for every round of the AES algorithm. Such a naive implementation requires even 8 × (1 + 9×16 + 1×16 + 1) = 1296 resubmissions for each incoming packet. With a slightly more complex implementation, applying all four distinct tables for standard AES rounds in a single ingress pipeline pass, it is possible to reduce the packet resubmissions down to 8 × (1 + 9×4 + 1×16 + 1) = 432.
4.2.2. Packet Control and FF3-1 in P4 and AES in Micro-C Implementation
A large number of packet resubmissions causes a throughput well below the link capacity, as shown in Section 5. We tried to improve the throughput by replacing the parts of the P4 code with Micro-C. The Micro-C programming language is the most efficient way of programming the Agilio SmartNIC as it can take advantage of NFP architecture-specific data structures [44]. The Micro-C programming on the NFP slightly differs from the host-based generic C programming, as the NFP data structures and memories are specific to the NFP architecture.
We decided to port the complete AES encryption to the Micro-C language because AES encryption represents the most complex part of the FF3-1 algorithm and, in some SmartNICs, can be implemented using hardware acceleration. In order to achieve the highest possible throughput, the implementation is still based on scrambled lookup tables. The algorithm is considerably sped up by pre-computing part of the internal operations performed by the AES algorithm and storing the results in lookup tables [45]. Since the content of lookup tables is immutable, they do not have to be thread-local. Sharing these tables between threads leads to better memory space utilisation. Therefore, tables are explicitly marked as shared and placed in memories with the smallest latency. Only one of four tables for standard AES rounds is allocated to the fastest Local Memory because there is no more free space in the Local Memory due to its usage for register spilling. The remaining tables for standard AES rounds and the table for the last AES round are allocated to the slightly slower Cluster Local Scratch. All functions are inlined directly at the place of their invocation to gain an execution speedup.
Great attention has been paid to the types of data used due to the specifics of SmartNIC’s hardware. The compiler supports 8-bit and 16-bit data types and their appropriate pointers, although at some potential performance cost. Still, users should not use 8-bit and 16-bit data types because access to quantities less than 32 bits (64 bits in MEM) generally involves additional operations to extract the appropriate bytes from the longword or quadword. Access through pointers to 8-bit and 16-bit types may also require runtime alignment of data, which is even more inefficient. Therefore, we have neither used 8-bit and 16-bit data types nor pointers. The AES state is defined as a 128-bit structure with four fields of 32-bit data type, and the given structure is transmitted exclusively by value. Implementing AES in Micro-C resulted in approximately 45 times increased throughput compared to the pure P4 implementation, as described in Section 5.
4.2.3. P4 Packet Control and Entire FF3-1 in Micro-C implementation
Finally, we ported the entire FF3-1 algorithm implementation from the P4-16 to the Micro-C language, leaving only packet parsing and filtering to the P4 code. The same coding principles imposed by SmartNIC’s architecture were used for the FF3 implementation in Micro-C. In addition, an FF3-1 specific bit reversal operation was realised using lookup tables instead of bit masking and shifting. This implementation resulted in line rate LISPP operation.
5. Experimental Evaluation
LISPP performance was rigorously assessed using actual physical network devices rather than within a simulated environment. Two bare metal servers with dual Intel® Xeon® CPU E5-2660 processors and 40 GB of RAM each were used as the source and sink of the test traffic. These servers were connected through a Netronome Agilio CX programmable network interface card with two 10 Gbit/s ports installed in another bare metal server with dual Intel® Xeon® CPU E5-2680 processors and 64 GB of RAM, as depicted in Figure 8. The connections between the servers were through 10 Gbit/s ports on a switch. These ports were used solely in the testbed, so there was no interference of other cross traffic with the test traffic. MTU on all interfaces remained at 1500 bytes in all the experiments.
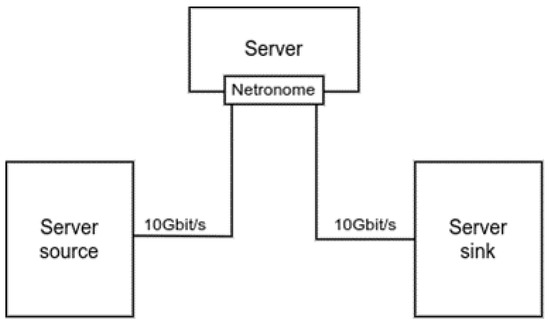
Figure 8.
Testbed setup.
5.1. LISPP Performance Evaluation
In our performance evaluation, we employed three state-of-the-art tools for active network monitoring: iPerf2 [46] for the TCP throughput tests, PF_RING Zero Copy-based packet rate tests [47] and Sockperf [48] for latency tests. Each of these tools actively monitors by injecting test traffic to measure the performance characteristics of the underlying network. iPerf2 is designed to assess the maximum achievable TCP or UDP bandwidth. It establishes TCP sessions between the source and sink of the test traffic to gauge the highest achievable throughput. iPerf2 can achieve throughputs higher than 10 Gbit/s with default parameters and a single TCP stream [49]. PF_RING is a new type of network socket that improves the packet capture speed by avoiding any kernel intervention and can achieve up to 100 Gbit/s wire speed at any packet size. Sockperf is a network benchmarking utility designed for testing latency at a sub-nanosecond resolution. It is able to measure the latency of every single packet, even under a load of millions of packets per second.
Test packets were sent from the source to the sink server through the LISPP system on the Netronome SmartNIC. Table 2 gives iPerf2 TCP throughput for three different FF3-1 implementations described in Section 4.2. All measurements were made for IPv4 and IPv6 using /24 and /64 address masks, making the size of the encrypted and plaintext 24 and 80 bits, respectively. As a baseline measurement, we measured TCP throughput for a code which only passes the traffic between the two card interfaces without any modification (pass-through column).
Table 2.
TCP throughput for three different FF3-1 implementations.
Measurement results reveal that the last implementation (entire FF3-1 in Micro-C) achieves maximum TCP throughput, equal to the wire speed. In contrast, the first two implementations—pure P4 and the one with only AES in Micro-C show significantly lower throughputs. Such a performance difference suggests that the compiling from P4 to the executable code in the domain of complex packet processing for the particular hardware configuration is not optimal. Therefore, while it is possible to achieve code portability to the other platforms by using only P4, the performance of the code is not assured. Results also show a difference in IPv4 and IPv6 TCP throughput. This difference can be attributed to the difference in header sizes, which is larger for IPv6, thus yielding less useful data bandwidth for the TCP stream, although the endpoint processing effects should not be neglected. In addition to the TCP throughput tests, one-way throughput tests using PF_RING Zero Copy-based packet streams showed that the system can achieve line rate throughput, i.e., 10 Gbit/s throughput, when the entire FF3-1 implementation is in Micro-C.
The per-packet processing overhead introduced by LISPP remains constant across all packet sizes, as it exclusively involves the encryption/decryption of specific packet header fields. These fields maintain the same size in every packet processed by the LISPP device. As a result, this overhead is not influenced by the size of the packet’s payload, ensuring uniformity regardless of changes in payload dimensions. Therefore, the performance constraints of LISPP are more aptly gauged by the maximum achievable packet rate rather than by standard throughput measures. This aspect gains particular significance in the context of TCP, which often employs packets sized at the MTU for large-scale data transfers, a trend commonly observed in TCP throughput testing. It is also important to emphasise that the LISPP system is fully operational on the Netronome network interface card, without requiring any interaction with the hosting server apart from the initial code compilation and subsequent configuration upload, resulting in negligible CPU usage on the host computer to which the Netronome network interface card is connected.
We conducted tests to assess the impact of the test packet size on achievable packet rates and packet latency using the LISPP implementation with FF3-1 in Micro-C. Figure 9a displays the achieved throughput and packet rate using PF_RING Zero Copy-based packet streams. With packet sizes exceeding 600 bytes, the traffic fully saturates the links between the test servers at 10 Gbit/s, resulting in lower recorded packet rates (e.g., a 10 Gbit/s link is completely saturated by sending either 1.25 million 1000 byte-size packets or approximately 0.9 million 1400 byte-size packet per second). Tests with packets smaller than 600 bytes reveal the highest packet rates attainable with LISPP on Netronome cards, reaching 2.64 Mpps for IPv6 and 2.15 Mpps for IPv4. Figure 9b presents the one-way latency incurred by LISPP for packet sizes ranging from 100 to 1400 bytes. As a reference, we have measured one-way latency for packets that pass through the Netronome card without any LISPP processing (measurement denoted as “wire” latency in Figure 9b). Notably, the LISPP implementation with a complete FF3-1 in Micro-C consistently adds approximately 60 microseconds of latency, irrespective of packet size, thereby validating the hypothesis outlined in the previous paragraph.
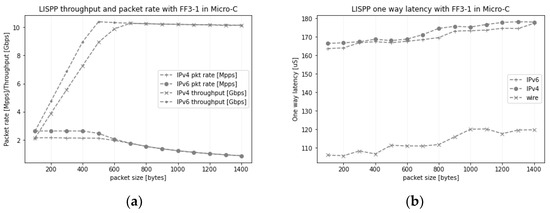
Figure 9.
(a) Throughput and achieved packet rate for various packet sizes; (b) Per-packet one-way latency for various packet sizes.
The data presented in Figure 9b also indicates that the latency induced by LISPP is independent of the ciphertext size. The added latency remained consistent for IPv4, with a 24-bit ciphertext, and IPv6, featuring an 80-bit ciphertext. This finding suggests that LISPP is scalable with the size (number of devices) of the protected network, which defines the size of the host part of the address to be encrypted. Ultimately, the key parameter that defines the performance limits of the system is the number of packets per second that the system can forward. For handling larger packet throughputs, additional testing with more powerful network accelerators and implementation of load balancing are necessary.
5.2. Lower Number of AES Rounds
FF3-1 is an 8-round algorithm that invokes the AES algorithm in each round, which has ten internal rounds. In our implementation, in which FF3-1 is entirely developed in Micro-C, AES takes 54% of the processor time. Decreasing the number of rounds in any of these algorithms would improve processing time and overall algorithm throughput. However, such an intervention comes with a potential decrease in algorithm security. Recent cryptanalytic papers showed that the complexity of the attack on FPE [29] depends on the number of Feistel rounds, which means that lowering the number of Feistel rounds will decrease attack complexity, which is not a viable option.
On the other hand, during the evaluation of the last stage candidates for the AES algorithm, it was discovered that the output of the Rijndael algorithm (which later became AES) appeared to be random after three rounds. Subsequent rounds produce randomness similar to that already obtained at round 3 [50]. Since the AES algorithm in FF3-1 is used as a random number generator rather than for data encryption, we argue that performance gains can be obtained by lowering the number of rounds in the AES algorithm without sacrificing the strength of the FPE algorithm. We conducted randomness tests on the series of FF3-1 encrypted host addresses. Address series were obtained by encrypting a 9-bit host address and 16-bit port. In each run, we picked 20 random host addresses for which we iterated all 65,536 different ports and analysed the series of obtained encrypted address values. We did the same tests for FF3-1 implementations with AES with 3 to 10 rounds. Runs and Discrete Fourier Transform (DFT) spectral analysis tests from the common randomness batteries of tests [51] were performed. In each case, the hypothesis that the output series is random was confirmed. Figure 10a shows the standard deviations of empirical frequencies of appearance of all possible IP addresses in the 9-bit address range for varying numbers of AES rounds. As can be seen from the image, standard deviations have approximately the same value regardless of the number of rounds, meaning that the variability of empirical frequencies does not change with the number of rounds. Figure 10b shows a DFT magnitude of an encrypted address series obtained using FF3-1 with 3-round AES. Visual inspection shows that the spectrum seems flat for the whole range of frequency values without a single value exceeding the peak threshold value, confirming that the encrypted address series behaves like a random series. This suggests that with FF3-1, performance gains can be obtained by lowering the number of AES rounds without sacrificing the algorithm’s security. However, a more detailed analysis of this hypothesis in the field of cryptanalysis is needed.
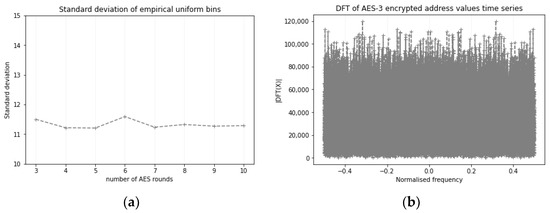
Figure 10.
(a) The standard deviation of empirical frequencies of appearance of all possible encrypted IP addresses in the 9-bit address range for varying numbers of AES rounds; (b) DFT magnitude of an encrypted address series obtained using FF3-1 with 3-round AES.
In the third batch of performance tests, we analysed the potential packet rate increase by reducing the number of FF3-1 rounds. We pushed 10,000,000 100-byte packets per second through the LISPP system and measured the number of packets that arrived on the sink side. Figure 11a shows the number of packets the system can process per second. The entire FF3-1 implementation in Micro-C can process more than 2 million packets per second, while the packet rate can be almost doubled using 3-round AES as a round function. It is interesting to notice that the network interface card achieved higher packet rates for IPv6 packets, which is probably a consequence of the simpler IPv6 header processing in the card (no header checksum).
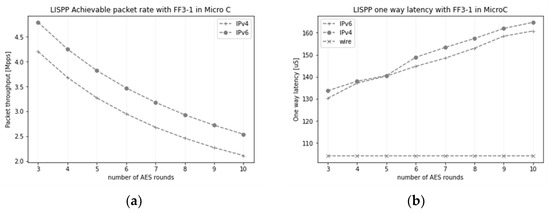
Figure 11.
(a) The number of packets per second the LISPP system can process for IPv4 and IPv6; (b) Per-packet one-way latency.
Finally, we measured the additional latency introduced due to the LISPP packet header field encryption with fewer FF3-1 rounds. Figure 11b gives the per-packet one-way latency measured by the Sockperf tool. The latency added by LISPP packet processing is between 30 and 60 microseconds for the FF3-1 implementations with 3-round and 10-round AES, respectively. Such an additional latency is negligible compared to the latencies on international links and corresponds to the signal propagation latency between the nodes, which are only 10 to 20 km away.
6. Conclusions
In this paper, we report on the research results of using FPE algorithms for privacy protection on the network layer. Designed and implemented system, LISPP, based on the FF3-1 FPE algorithm, can obfuscate source IP addresses and ports fully transparently with minimal additional one-way latency for both IPv4 and IPv6. Its performance on SmartNICs in real network environments is adequate for use in production networks. Therefore, the key conclusion is that the FPE algorithms are a viable option for packet header obfuscation and privacy protection.
Other important conclusions from this research are related to the experiences from the system implementation. Although P4 language is advertised as target-independent, its performance for processor-intensive applications on the particular target device is still highly dependent on the underlying hardware architecture. While code functionality is the same on different targets, its performance is far from optimal, and there are no automated optimisation options. This suggests that the compilation process from P4 to the specific hardware architectures, especially for processor-intensive applications like novel cryptographic algorithms without hardware acceleration, can be significantly improved.
Our further research activities will be in two key directions: integrating LISPP with the onion routing control plane to achieve lower latency than traditional onion routing systems and further optimising the FPE performance on multiprocessor targets using lightweight cryptographic algorithms.
Author Contributions
M.M.: investigation, methodology, software, validation, visualisation, and writing the original draft; U.R.: investigation, validation, and writing-review and editing; P.V.: conceptualisation, methodology, visualisation, supervision and writing the original draft. All authors have read and agreed to the published version of the manuscript.
Funding
This research was partially financially supported by the Ministry of Science, Technological Development, and Innovation of the Republic of Serbia (contract number 451-03-68/2022-14/200103).
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Acknowledgments
The authors want to express their thanks to Marinos Dimolianis from the National Technical University of Athens, Greece, for his valuable advice and help with the code deployment on Netronome cards.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Hoang, N.P.; Niaki, A.A.; Gill, P.; Polychronakis, M. Domain Name Encryption Is Not Enough: Privacy Leakage via IP-Based Website Fingerprinting. In Proceedings of the Privacy Enhancing Technologies (PETS), Virtual Event, 12–16 July 2021; pp. 420–440. [Google Scholar] [CrossRef]
- Yan, Z.; Lee, J.H. The Road to DNS Privacy. Future Gener. Comput. Syst. 2020, 112, 604–611. [Google Scholar] [CrossRef]
- Khormali, A.; Park, J.; Alasmary, H.; Anwar, A.; Saad, M.; Mohaisen, D. Domain Name System Security and Privacy: A Contemporary Survey. Comput. Netw. 2021, 185, 107699. [Google Scholar] [CrossRef]
- Saidi, S.J.; Gasser, O.; Smaragdakis, G. One Bad Apple Can Spoil Your IPv6 Privacy. ACM SIGCOMM Comput. Commun. Rev. 2022, 52, 10–19. [Google Scholar] [CrossRef]
- GDPR.Eu. What Is Considered Personal Data under the EU GDPR? Available online: https://gdpr.eu/eu-gdpr-personal-data/ (accessed on 17 October 2023).
- Tor Project | Anonymity Online. Available online: https://www.torproject.org/ (accessed on 17 October 2023).
- HTTPS Encryption on the Web–Google Transparency Report. Available online: https://transparencyreport.google.com/https/overview?hl=en (accessed on 17 October 2023).
- Lee, J.K.; Koo, B.; Roh, D.; Kim, W.H.; Kwon, D. Format-Preserving Encryption Algorithms Using Families of Tweakable Blockciphers; Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2014; Volume 8949, pp. 132–159. [Google Scholar] [CrossRef]
- Dworkin, M. Recommendation for Block Cipher Modes of Operation: Methods for Format-Preserving Encryption; NIST: Gaithersburg, MD, USA, 2016. [Google Scholar] [CrossRef]
- AlSabeh, A.; Khoury, J.; Kfoury, E.; Crichigno, J.; Bou-Harb, E. A Survey on Security Applications of P4 Programmable Switches and a STRIDE-Based Vulnerability Assessment. Comput. Netw. 2022, 207, 108800. [Google Scholar] [CrossRef]
- Hauser, F.; Häberle, M.; Merling, D.; Lindner, S.; Gurevich, V.; Zeiger, F.; Frank, R.; Menth, M. A Survey on Data Plane Programming with P4: Fundamentals, Advances, and Applied Research. J. Netw. Comput. Appl. 2023, 212, 103561. [Google Scholar] [CrossRef]
- Chen, C.; Asoni, D.E.; Barrera, D.; Danezis, G.; Perrig, A. HORNET: High-Speed Onion Routing at the Network Layer. In Proceedings of the ACM Conference on Computer and Communications Security 2015, Denver, CO, USA, 12–16 October 2015; pp. 1441–1454. [Google Scholar] [CrossRef]
- Chen, C.; Asoni, D.E.; Perrig, A.; Barrera, D.; Danezis, G.; Troncoso, C. TARANET: Traffic-Analysis Resistant Anonymity at the Network Layer. In Proceedings of the 3rd IEEE European Symposium on Security and Privacy, London, UK, 24–26 April 2018; pp. 137–152. [Google Scholar] [CrossRef]
- Chen, C.; Perrig, A. PHI: Path-Hidden Lightweight Anonymity Protocol at Network Layer. In Proceedings of the Privacy Enhancing Technologies, Minneapolis, MN, USA, 18–21 July 2017; pp. 100–117. [Google Scholar] [CrossRef]
- Hsiao, H.C.; Kim, T.H.J.; Perrig, A.; Yamada, A.; Nelson, S.C.; Gruteser, M.; Meng, W. LAP: Lightweight Anonymity and Privacy. In Proceedings of the 2012 IEEE Symposium on Security and Privacy, San Francisco, CA, USA, 20–23 May 2012; pp. 506–520. [Google Scholar] [CrossRef]
- Sankey, J.; Wright, M. Dovetail: Stronger Anonymity in Next-Generation Internet Routing; Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2014; Volume 8555, pp. 283–303. [Google Scholar] [CrossRef]
- Kuhn, C.; Beck, M.; Strufe, T. Breaking and (Partially) Fixing Provably Secure Onion Routing. In Proceedings of the 2020 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 18–21 May 2020; pp. 168–185. [Google Scholar] [CrossRef]
- Datta, T.; Feamster, N.; Rexford, J.; Wang, L. {SPINE}: Surveillance Protection in the Network Elements. In Proceedings of the 9th USENIX Workshop on Free and Open Communications on the Internet (FOCI 19), Santa Clara, CA, USA, 13 August 2019. [Google Scholar]
- Wang, L.; Kim, H.; Mittal, P.; Rexford, J. Programmable In-Network Obfuscation of Traffic. arXiv 2020, arXiv:2006.00097. [Google Scholar]
- AS6447-IPv6 BGP Table Statistics. Available online: https://bgp.potaroo.net/v6/as6447/ (accessed on 17 October 2023).
- Raghavan, B.; Kohno, T.; Snoeren, A.C.; Wetherall, D. Enlisting ISPs to Improve Online Privacy: Ip Address Mixing by Default; Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2009; Volume 5672, pp. 143–163. [Google Scholar] [CrossRef]
- Gont, F.; Krishnan, S.; Narten, T.; Draves, R. Temporary Address Extensions for Stateless Address Autoconfiguration in IPv6; Internet Engineering Task Force RFC: Fremont, CA, USA, 2021. [Google Scholar] [CrossRef]
- Herrmann, D.; Fuchs, K.P.; Lindemann, J.; Federrath, H. EncDNS: A Lightweight Privacy-Preserving Name Resolution Service; Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2014; Volume 8712, pp. 37–55. [Google Scholar] [CrossRef]
- Non-Paper on the Way Forward on Data Retention. Council of the European Union on June 2021. Available online: https://www.statewatch.org/media/2592/eu-council-data-retention-com-non-paper-wk-7294-2021.pdf (accessed on 17 October 2023).
- Nguyen, T.A.; Kim, M.; Lee, J.; Min, D.; Lee, J.W.; Kim, D. Performability Evaluation of Switch-over Moving Target Defence Mechanisms in a Software Defined Networking Using Stochastic Reward Nets. J. Netw. Comput. Appl. 2022, 199, 103267. [Google Scholar] [CrossRef]
- Hasty Pudding Specification. Available online: https://web.archive.org/web/20111007174344/http://richard.schroeppel.name:8015/hpc/hpc-spec (accessed on 17 October 2023).
- Durak, F.B.; Vaudenay, S. Breaking the FF3 Format-Preserving Encryption Standard over Small Domains; Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2017; Volume 10402, pp. 679–707. [Google Scholar] [CrossRef]
- Dunkelman, O.; Kumar, A.; Lambooij, E.; Sanadhya, S.K. Cryptanalysis of Feistel-Based Format-Preserving Encryption; Paper 2020/1311; IACR Cryptology ePrint Archive: Bellevue, WA, USA, 2020. [Google Scholar]
- Beyne, T. Linear Cryptanalysis of FF3-1 and FEA; Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2021; Volume 12825, pp. 41–69. [Google Scholar] [CrossRef]
- Amon, O.; Dunkelman, O.; Keller, N.; Ronen, E.; Shamir, A. Three Third Generation Attacks on the Format Preserving Encryption Scheme FF3; Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2021; Volume 12697, pp. 127–154. [Google Scholar] [CrossRef]
- Jang, W.; Lee, S.Y. A Format-Preserving Encryption FF1, FF3-1 Using Lightweight Block Ciphers LEA and, SPECK. In Proceedings of the ACM Symposium on Applied Computing, Brno, Czech Republic, 30 March–3 April 2020; pp. 369–375. [Google Scholar] [CrossRef]
- NFP-4000 Theory of Operation. Available online: https://www.netronome.com/static/app/img/products/silicon-solutions/WP_NFP4000_TOO.pdf (accessed on 17 October 2023).
- The Joy of Micro-C, Netronome. Available online: https://cdn.open-nfp.org/media/documents/the-joy-of-micro-c_fcjSfra.pdf (accessed on 17 October 2023).
- Bosshart, P.; Daly, D.; Gibb, G.; Izzard, M.; McKeown, N.; Rexford, J.; Schlesinger, C.; Talayco, D.; Vahdat, A.; Varghese, G.; et al. P4: Programming Protocol-Independent Packet Processors. ACM SIGCOMM Comput. Commun. Rev. 2014, 44, 87–95. [Google Scholar] [CrossRef]
- Programming Netronome Agilio® SmartNICs. Available online: https://www.netronome.com/media/documents/WP_NFP_Programming_Model.pdf (accessed on 17 October 2023).
- Architecture for Simple Switch-V1model.P4. Available online: https://github.com/p4lang/p4c/blob/main/p4include/v1model.p4 (accessed on 17 October 2023).
- P416 Portable Switch Architecture (PSA) Version 1.2. The P4.Org Architecture Working Group 2022-12-22. Available online: https://p4.org/p4-spec/docs/PSA-v1.2.pdf (accessed on 17 October 2023).
- Gomez, J.; Kfoury, E.F.; Crichigno, J.; Srivastava, G. A Survey on TCP Enhancements Using P4-Programmable Devices. Comput. Netw. 2022, 212, 109030. [Google Scholar] [CrossRef]
- LISPP: A Lightweight Stateless Network Layer Privacy Protection System. Available online: https://github.com/marko-micovic/lispp (accessed on 17 October 2023).
- Kaur, S.; Kumar, K.; Aggarwal, N. A Review on P4-Programmable Data Planes: Architecture, Research Efforts, and Future Directions. Comput. Commun. 2021, 170, 109–129. [Google Scholar] [CrossRef]
- Chen, X. Implementing AES Encryption on Programmable Switches via Scrambled Lookup Tables. In Proceedings of the 2020 ACM SIGCOMM Workshop on Secure Programmable Network Infrastructure (SPIN), Virtual Event, 10–14 August 2020; pp. 8–14. [Google Scholar] [CrossRef]
- Harkous, H.; Jarschel, M.; He, M.; Priest, R.; Kellerer, W. Towards Understanding the Performance of P4 Programmable Hardware. In Proceedings of the 2019 ACM/IEEE Symposium on Architectures for Networking and Communications Systems, ANCS 2019, Cambridge, UK, 24–25 September 2019. [Google Scholar] [CrossRef]
- Viegas, P.B.; de Castro, A.G.; Lorenzon, A.F.; Rossi, F.D.; Luizelli, M.C. The Actual Cost of Programmable SmartNICs: Diving into the Existing Limits; Lecture Notes in Networks and Systems; Springer: Berlin/Heidelberg, Germany, 2021; Volume 225, pp. 181–194. [Google Scholar] [CrossRef]
- Programming NFP with P4 and C. Available online: https://www.netronome.com/media/documents/WP_Programming_with_P4_and_C.pdf (accessed on 17 October 2023).
- Bertoni, G.; Breveglieri, L.; Fragneto, P.; Macchetti, M.; Marchesin, S. Efficient Software Implementation of AES on 32-Bit Platforms; Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2003; Volume 2523, pp. 159–171. [Google Scholar] [CrossRef]
- A TCP, UDP, and SCTP Network Bandwidth Measurement Tool. Available online: https://github.com/esnet/iperf (accessed on 17 October 2023).
- PF_RING ZC (Zero Copy), Multi-10 Gbit RX/TX Packet Processing from Hosts and Virtual Machines. Available online: https://www.ntop.org/products/packet-capture/pf_ring/ (accessed on 17 October 2023).
- Mellanox Network Benchmarking Utility. Available online: https://github.com/Mellanox/sockperf (accessed on 17 October 2023).
- Lopes, R.; Rand, D.; Chown, T.; Golub, I.; Vuletic, P. Network Performance Tests over the 100G BELLA Link between GÉANT and RNP. 2023. Available online: https://resources.geant.org/wp-content/uploads/2023/02/GN4-3_White-Paper_Network-Performance-Tests-Over-100G-BELLA-Link.pdf (accessed on 15 November 2023).
- Randomness Testing of the Advanced Encryption Standard Finalist Candidates. Booz-Allen and Hamilton Inc Mclean Va. Available online: https://nvlpubs.nist.gov/nistpubs/Legacy/IR/nistir6483.pdf (accessed on 17 October 2023).
- Random Number Generators: An Evaluation and Comparison of Random.Org and Some Commonly Used Generators. Management Science and Information Systems Studies Project Report, the Distributed Computing Group, Trinity College Dublin, Ireland. Available online: https://www.random.org/analysis/Analysis2005.pdf (accessed on 17 October 2023).
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).