1. Introduction
The Internet is much more encrypted now than it was in the past. Information is much more secure with the widespread application and usage of Internet security protocols, such as elliptic curve cryptography (ECC) in Transport Layer Security (TLS) [
1,
2]. The standard requires many devices, including personal computers, smartphones, and Internet of Things (IoT) devices, to compute cryptography encryption and decryption whenever they communicate over the World Wide Web.
While practical ECC computations are crucial in safeguarding user data privacy on mobile and IoT devices, the primary bottlenecks are the limited processing power and energy resources of these devices. Hardware implementation is designed to increase computational speed and reduce energy consumption through paralleling techniques used on low-power microcontrollers or mobile phones.
Many methods for calculating and processing ECC on hardware differ in performance, area, occupied memory, power consumption, and security level. We focus on putting our design onto a field-programmable gate array (FPGA). Research by Izu et al. [
3] shows a method that applies simple algorithms and utilizes the FPGA structure to achieve high efficiency, which is a trade-off with the area. The above study also builds on the original work of Aoki et al. [
4]. One of the initial adoptions of digital signal processors (DSPs) for modular operation is from [
5]. While using a DSP has the advantage of fast computational speed, it requires the DSP resource to be available and consume more power. To enhance a modular addition, Rogawski et al. suggested using fast carry chain adders [
6] based on a parallel prefix network [
7]. The result is better speed in modular adding and subtracting operations, with a trade-off with latency of pipeline stages. For modular multiplication, the choice is between a high-radix multiplier [
8] or high-density karatsuba with NLP multiplication [
9]. A high radix level increases the complexity of the design, and it is better to compensate for the low radix level with better hardware adders. Redundant binary representation is another notable method for modular multipliers [
10]. P. Kocher et al. pointed out that the vulnerability to power analysis attacks is notable in the hardware design for cryptography processing in FPGAs [
11]. Fischer et al. also gave an example structure against energy analysis [
12].
In the case of Curve25519, Sasdrich et al. presented the first Curve25519 hardware design [
13]. Kopperman et al. presented two Curve25519 hardware implementations that could process ECDHE scalar multiplication under 100
s [
14,
15]. Interleaved modular multipliers were used in research [
16] to reduce power consumption. Niasar et al. [
17] presented three designs with low resource requirements, area–time efficiency, and high performance. Research [
18] showed a hardware–software hybrid design for resource-constrained devices. Research [
19] showed scalable point multiplication for Curve25519. Kudithi et al. [
20] implemented their design with a radix-2 multiplier, using mixed Jacobian coordinates on different FPGA platforms and application-specific integrated circuits (ASIC). With different parameters, Kieu et al. [
21] supported multiple curves on their FPGA and ASIC designs.
Our research is to create a hardware design that handles cryptography operation for the TLS curve Curve25519 [
22]. The ECC operation includes elliptic-curve Diffie–Hellman ephemeral (ECDHE) key generation and computation.
The main contribution of this paper includes creating a hardware design structure that can do the following:
Generate the public key for ECDHE and compute the shared key according to IEEE P1363 [
23] with support for the TLS 256-bit elliptic curve Curve25519 [
2].
Employ a fast elliptic computation unit optimized for modular addition, subtraction, multiplication, and inversion.
Comprise a specialized finite state machine (FSM) that executes point multiplication and ECDHE operations, utilizing a constant-time algorithm and relying on a single consolidated memory block to optimize resource utilization.
The remaining sections of this paper are structured as follows.
Section 2 provides an overview of the mathematical backgrounds and parameters of Curve25519.
Section 3 is the proposed hardware design for implementing Curve25519 elliptic-curve Diffie–Hellman ephemeral (ECDHE) processes. Our findings and results are elaborated upon in
Section 4.
Section 5 discusses our design, including comparisons with relevant references.
Section 6 concludes and summarizes this paper.
2. Backgrounds
2.1. Elliptic Curve Cryptography Mathematics
ECC is based on a finite field in the form of an integer mod p, where p is prime. A field F is a set of elements with addition and multiplication operators. For every element a in field F, except 0, there exists an element so that .
In a finite field of order p (prime field), for a prime number p, a finite field of degree p, , is defined as the set , with the algebraic operations modulo p. Each element in (except 0) has a modular inverse (i.e., there exists z, such that ).
2.2. Curve25519 Parameters
The curve presented in this paper is Curve25519 (Montgomery curve).
Table 1 presents the parameters and corresponding values of Curve25519 from standards [
24,
25,
26]. These are the values used in the hardware design proposed in the paper. The curve is defined in a prime field with the prime
p close to a power of 2 to optimize the efficiency of modulo computations.
2.3. Computation on Montgomery Curve
A Montgomery curve on the field
is in the following form:
On the projective coordinate system, with and , the form is presented in the function below. Notice that Y is no longer needed. is now with . There are two special points and that are converted to and .
This form allows us to use the Montgomery powering ladder algorithm to compute scalar multiplication on the Montgomery curve. A modified version of this algorithm is preferred because of the side-channel attack prevention [
27].
2.4. Elliptic-Curve Diffie–Hellman Ephemeral (ECDHE)
ECDHE is the method used during the key exchange between the server and the client so that the result is a pre-master secret known to both parties. During the handshake, after the server and client have agreed on which cipher suite and curve to use, both of them know the parameter domain, including the following values:
p: prime number p defined for the field
a: parameters of the curve equation
: coordinates of base point (generator)
n: order of S, defined as the smallest integer for which
h: the cofactor
The pre-master secret agreement process is as follows:
The server chooses a random number . Then, the server calculates and sends it to the client.
The client chooses a random number . The client calculates and sends it to the server.
Server and client, after obtaining the ephemeral data k or of the other end, can calculate the pre-master secret
3. Hardware Design
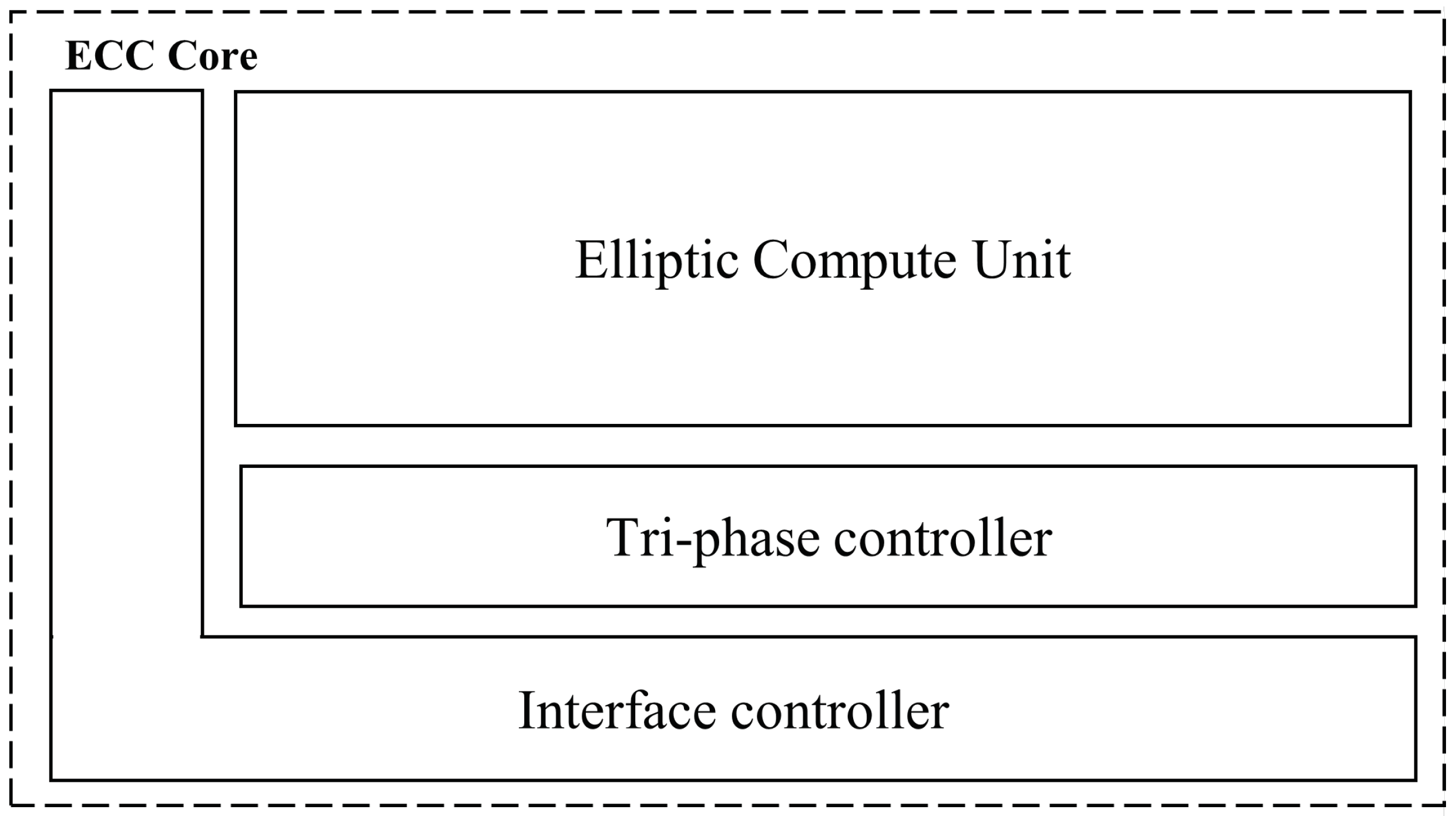
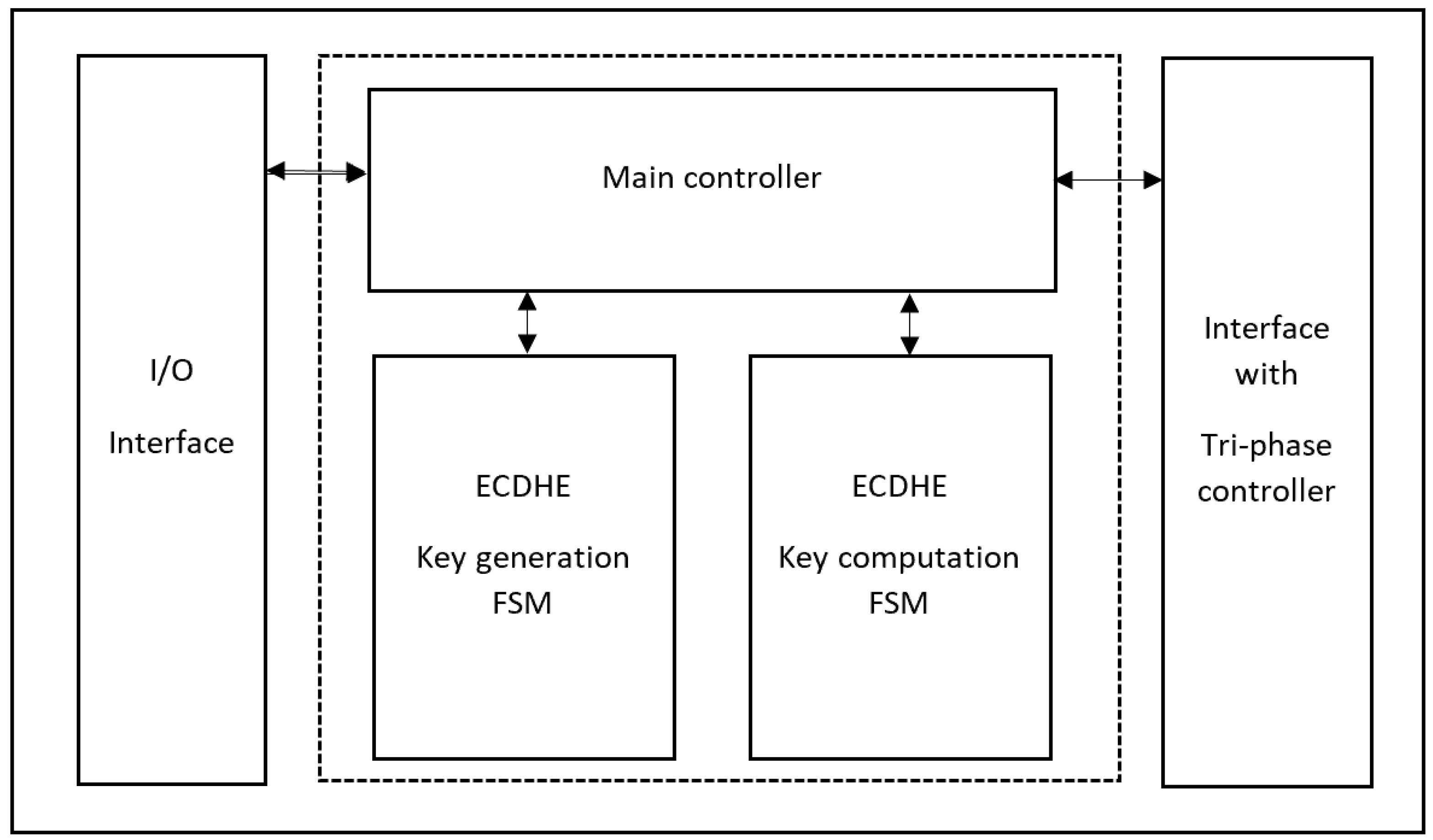
The ECC Core is the proposed hardware structure for implementing elliptic curve cryptography over Curve25519. The ECC Core features a data input bus and start signal along with a mode input for choosing between modes of operation. The calculation status is updated to the output, and the result follows.
The design method is implemented as intuitive, easy-to-modify hardware modules that can work individually with their tasks. The ECU handles modular addition, subtraction, multiplication, and inversion. The
Figure 1 presents the structure of the ECC Core. It includes an interface controller, a tri-phase controller, and an ECU.
The interface controller handles data output and input, mode selection, and testing purposes. The tri-phase controller (TPC) is the finite state machine (FSM) for scalar multiplication, random number generation, memory interface, etc., to serve the ECDHE key generation and computation process. The ECU processes modular arithmetic tasks given by the TPC.
3.1. Interface Controller
The interface controller connects the system’s primary input and output interfaces to the TPC. It also does random number generation and error checking for invalid values during computation.
Figure 2 shows the general structure of the interface controller with dedicated FSMs for receiving the input and processing ECDHE key generation and computation. The input received is 512-bit in parallel for ease of computation. We synthesized our design with another serial-to-parallel interface to eliminate the pin issue. The I/O interface has 32-bit input and output controlled with ready, acknowledge, and a busy flag to receive or output data from the memory in 32-bit chunks. We designed the FSMs so that the state transitions depend only on the current state and mode input, minimizing complex logic. This simplistic FSM architecture provides low-latency performance while minimizing the attack surfaces side-channel leaking and improving security [
28].
For ECDHE key generation and computation, the first 256-bit of the input is
u, and the latest 256-bit is
k.
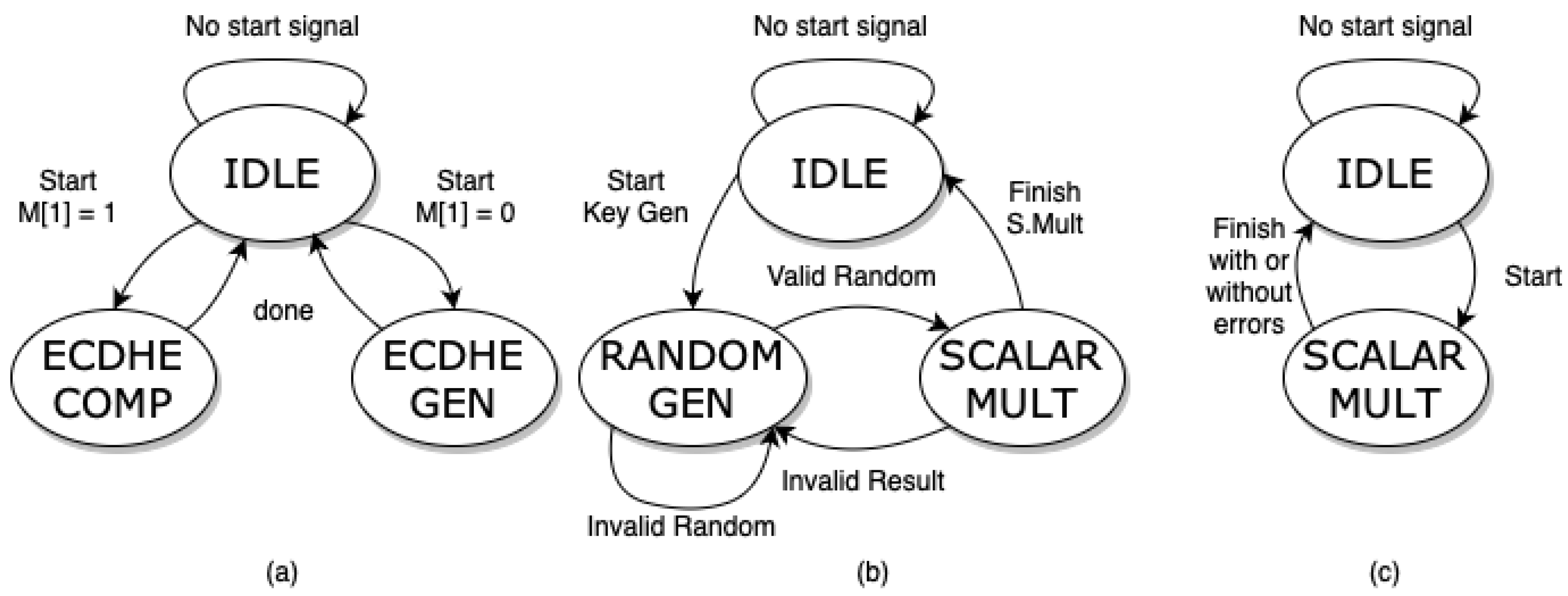
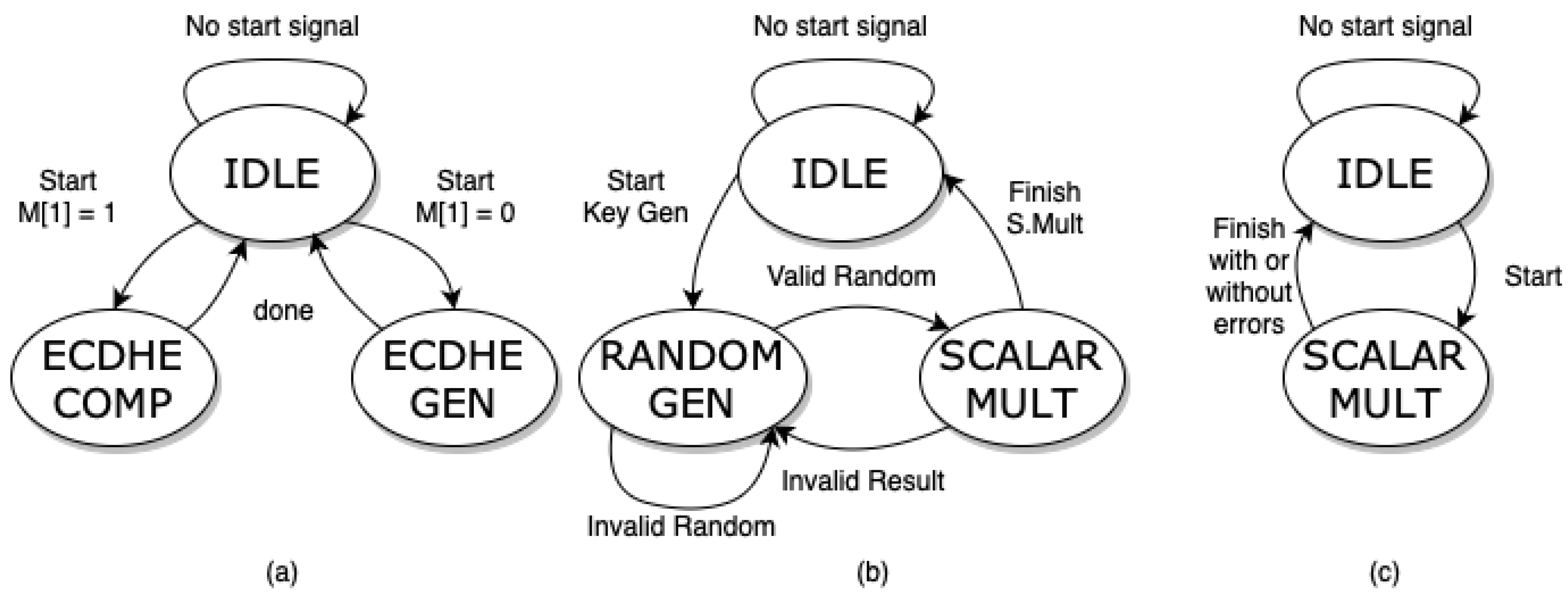
Figure 3 shows the three FSMs.
Figure 3a is the interface controller FSM that interacts with the ECDHE generation FSM (
Figure 3b) and ECDHE computation FSM (
Figure 3c).
The interface controller FSM (a) waits for the start signal and reads the mode input M[1] from the I/O interface to choose between the ECDHE key generation operation or ECDHE key computation. The ECDHE key generation FSM (b) starts with the random generation of
k. If
k is non-zero, we start the scalar multiplication operation with
P from the curve parameter
Table 1. If the result returns an invalid point (point at infinity or zero), the random generation process starts again to obtain another random
k for calculation. The ECDHE computation FSM (c) instructs the tri-phase controller to obtain the data from memory and start the scalar multiplication process.
The ECDHE generation procedure starts with choosing a random
k (and repeating if
k is not valid), computing scalar multiplication, and checking for validation (Q is not point zero) according to
Section 2.4. The ECDHE computation procedure receives data from the input and computes the scalar multiplication. Then, it checks for validation (P is not point zero).
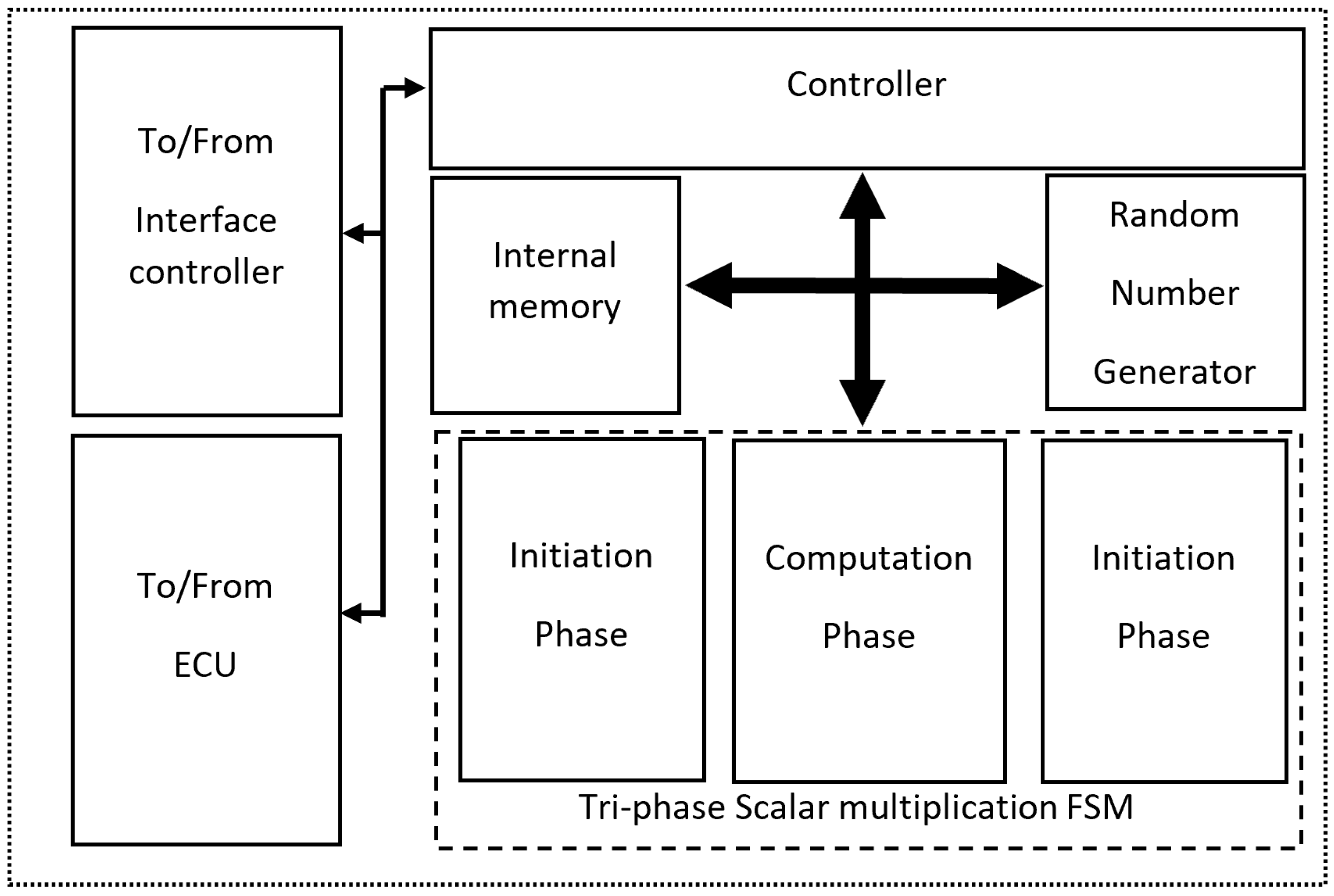
3.2. Tri-Phase Controller
The tri-phase controller interacts with the interface controller and the ECU and controls its internal memory block. We use a BRAM as the internal memory block where values are generated between each operation in the memory. The memory size used is 32 × 256-bit, enough for operations on 256-bit operands of ECDHE key generation and computation.
Figure 4 presents the structural diagram of the tri-phase controller.
3.2.1. Internal Memory Access
We use 32 × 256-bit random access memory with a synchronous read-and-write clock. We use 23 addresses as storage for global variables and 9 as temporary variables. The number is to accommodate the modified scalar multiplication for Montgomery curves.
Table 2 shows how we named each address. The names correspond to the variables in Algorithm 1.
| Algorithm 1 Modified scalar multiplication for Montgomery curves. |
- 1:
121,665 - 2:
for ( down to 0) do - 3:
- 4:
- 5:
- 6:
- 7:
- 8:
- 9:
- 10:
- 11:
- 12:
- 13:
- 14:
- 15:
- 16:
- 17:
- 18:
- 19:
- 20:
end for - 21:
- 22:
- 23:
return
|
3.2.2. Tri-Phase Scalar Multiplication for Montgomery Curves
The algorithm used in the design to perform scalar multiplication for Montgomery elliptic curves (here, we use curve X25519) is S.Turner’s algorithm [
24,
27]. This algorithm ensures the constant-time characteristic for all input values.
Because the original algorithm is written in Python for software, we made some changes to the algorithm to make it suitable for hardware. The modified algorithm is shown in Algorithm 1. The constant is for curve25519/X25519. Specifically, the following process is performed:
Remove the k shift and switch to indexing.
Drop the swap value on the last two swaps because the last 3 bits of k are always zero after correctly decoding in RFC 7748 [
24].
Remove the last exponent. Montgomery exponential can be performed on hardware, but it takes too much time; instead, Montgomery inverse gives the same result, which is proved below:
We can quickly prove that the Montgomery exponential step is the Montgomery inverse.
Given and
This is Fermat’s little theorem [
29].
Montgomery scalar multiplier is divided into three parts. The structural diagram for the multiplier is presented in the tri-phase scalar multiplication FSM in
Figure 4.
Appendix A shows the operations we execute in each step of the finite state machine for each phase in the tri-phase controller. The operation accesses the corresponding address in the internal memory to store or load necessary values for computation.
3.3. Random Number Generator
We utilize a pseudo-random number generator (PRNG) to generate random numbers. Generally, we adopt a linear feedback shift register design, as outlined in [
30], with adjustments to accommodate a 256-bit format. Feedback is incorporated at specific positions: 256, 254, 251, and 246. PRNGs are straightforward and primarily employed for simulation and testing. The structure of the Galois 256-bit LFSR is visually represented in
Figure 5.
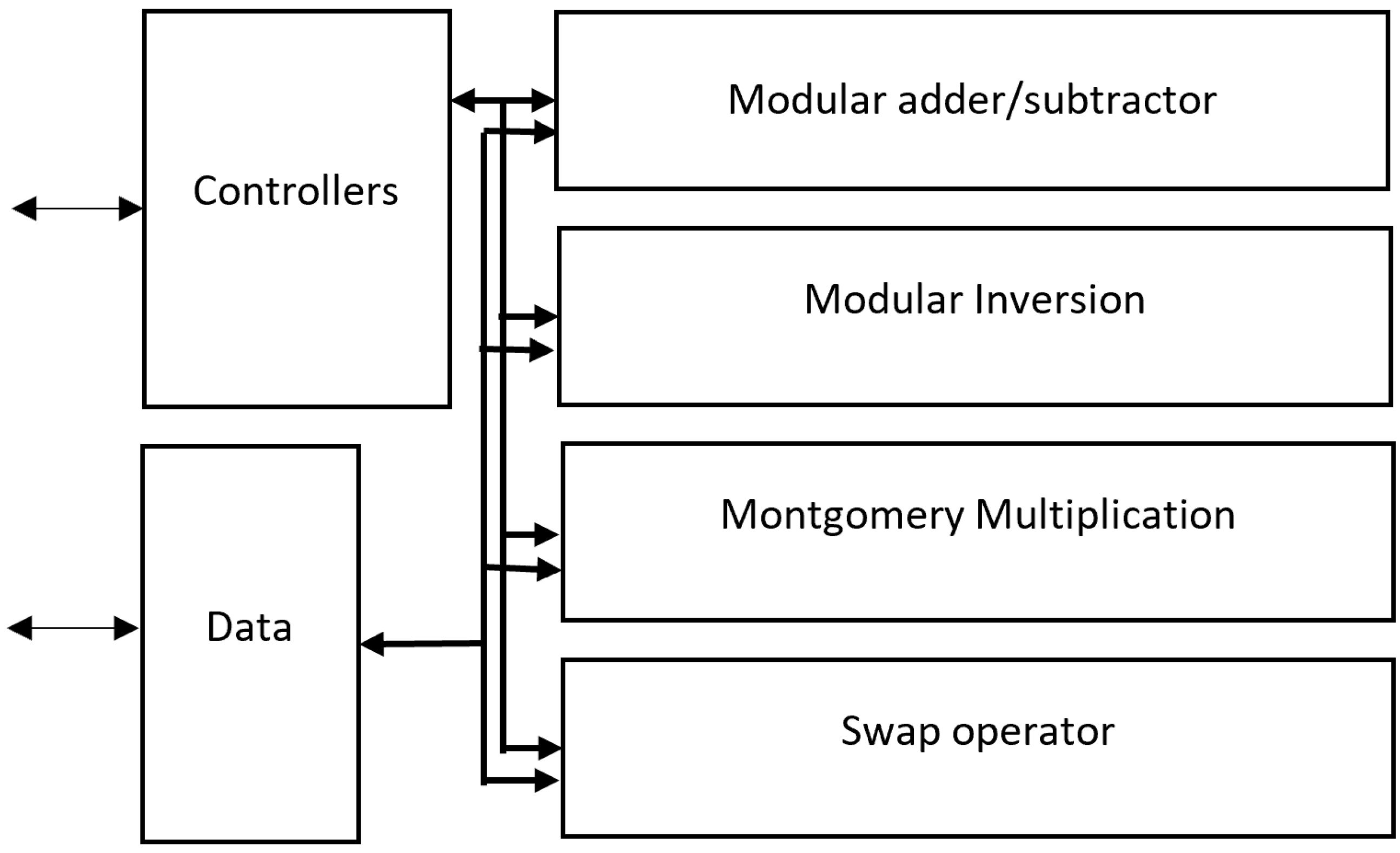
3.4. Elliptic Compute Unit
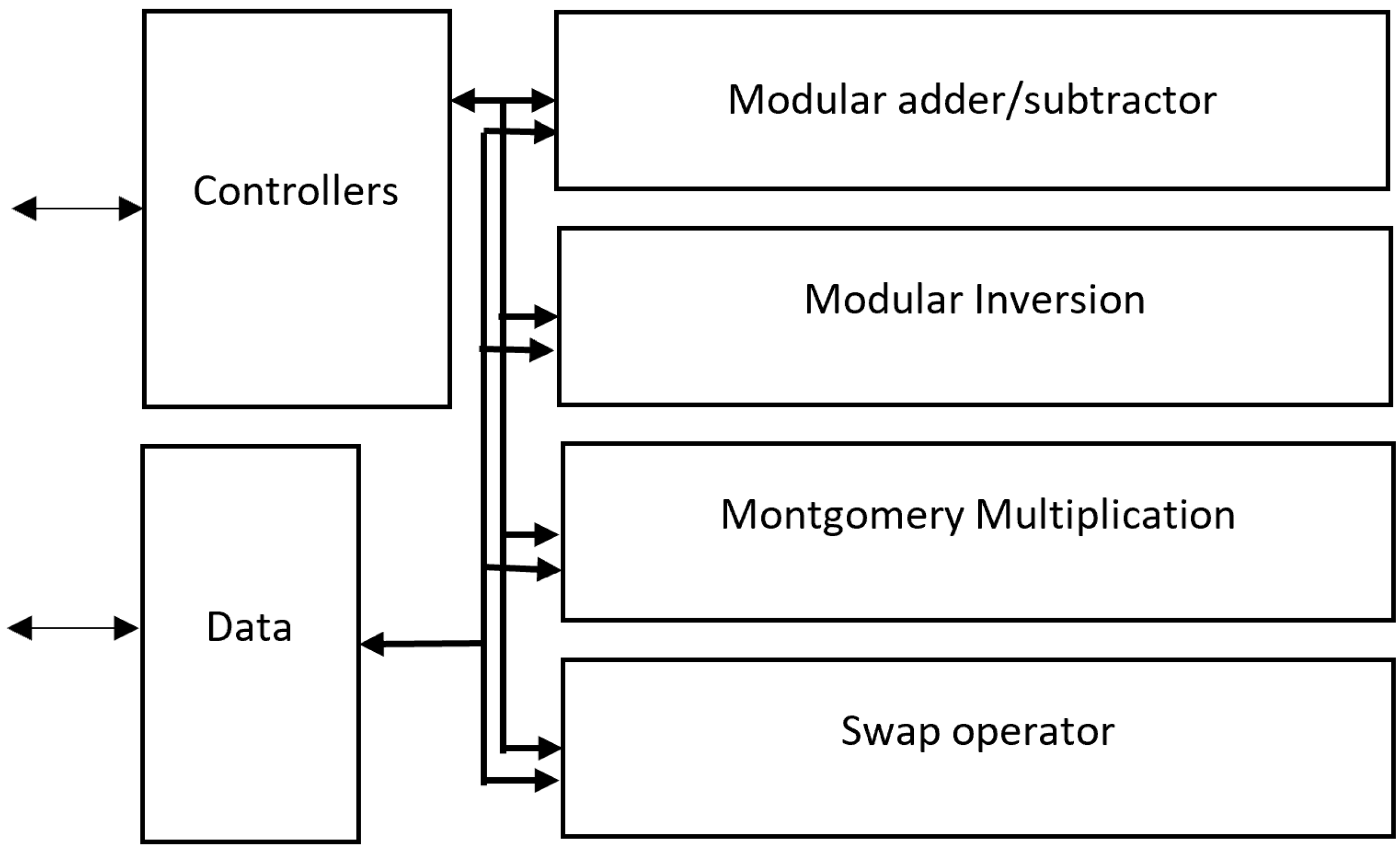
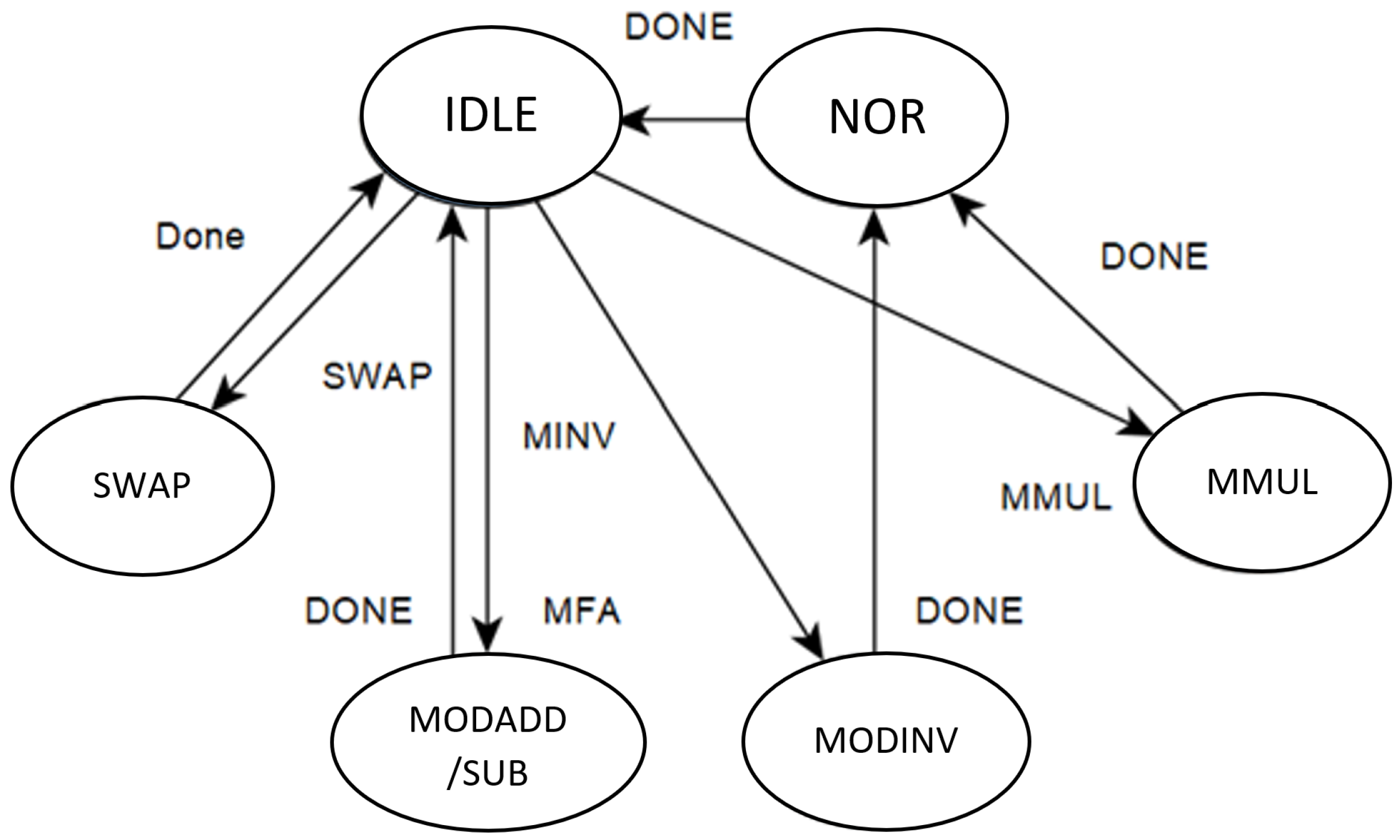
The elliptic compute unit (ECU) receives data and control signals from the tri-phase controller. It consists of four modules for four operations: modular addition, Montgomery multiplication, Montgomery inversion, and swap operator.
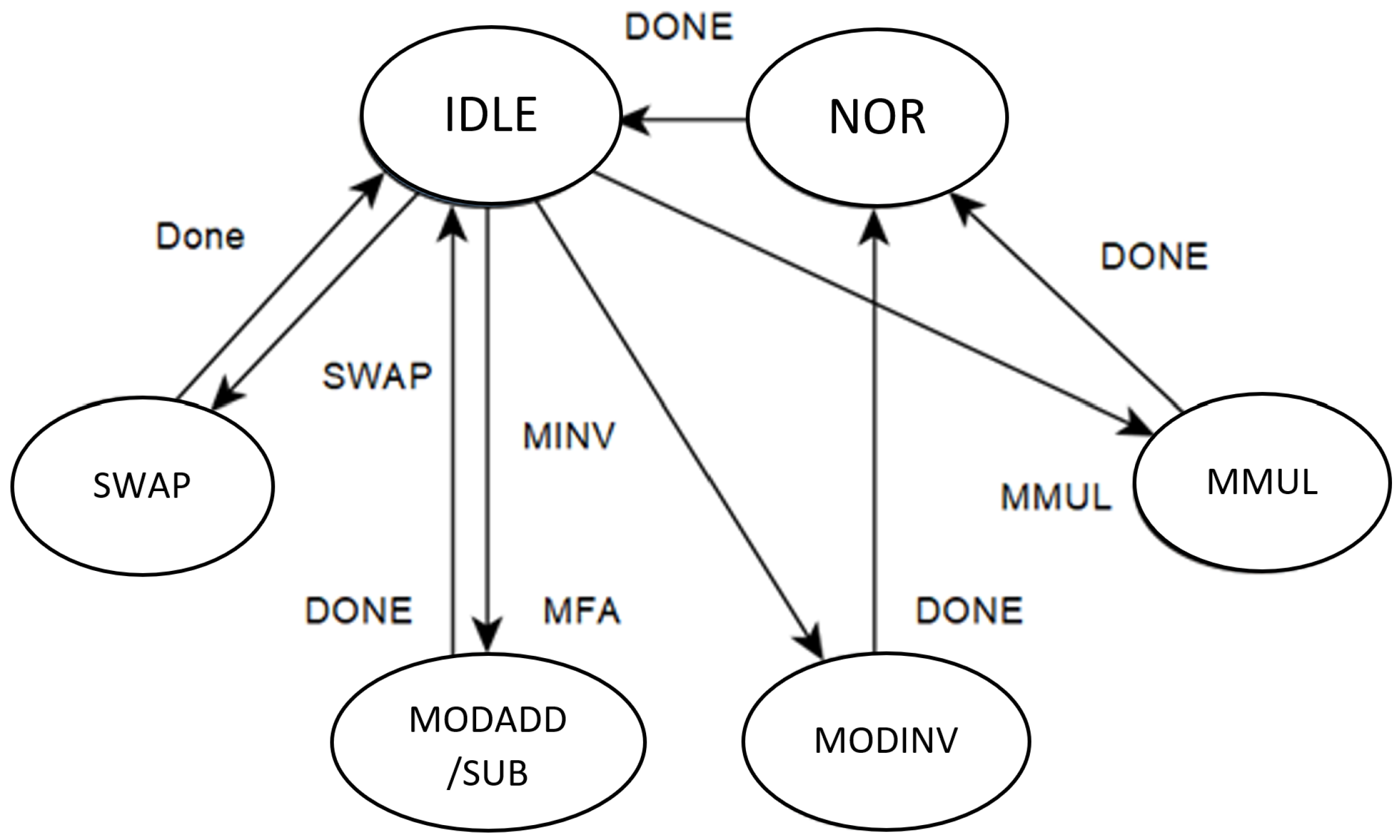
Figure 6 shows the structural diagram of the ECU, and
Figure 7 presents the controller state machine of the ECU. For modular addition, subtraction, and swap state, the state machine starts the corresponding operation based on the mode selection signal and returns when the module finishes. A normalized (NOR) state is needed for modular inverse and multiplication before returning the result. The normalized state removes the excess
from Montgomery multiplication and inversion. Because the ECU affects the critical path of the design heavily, we try to optimize our design on each operation unit of the ECU carefully. Every operation of the ECU is for 256-bit operands and uses a constant-time algorithm to prevent side-channel attacks.
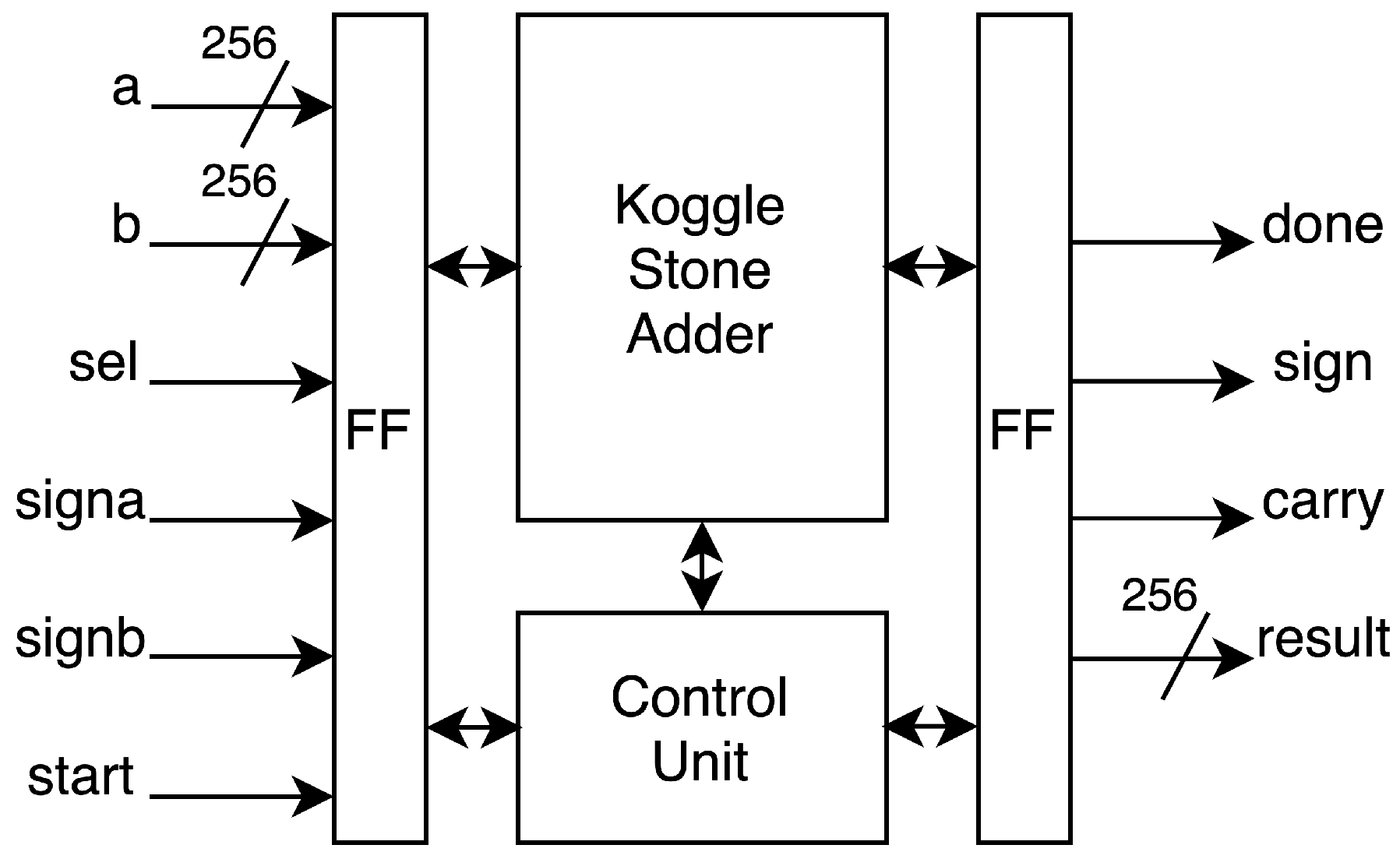
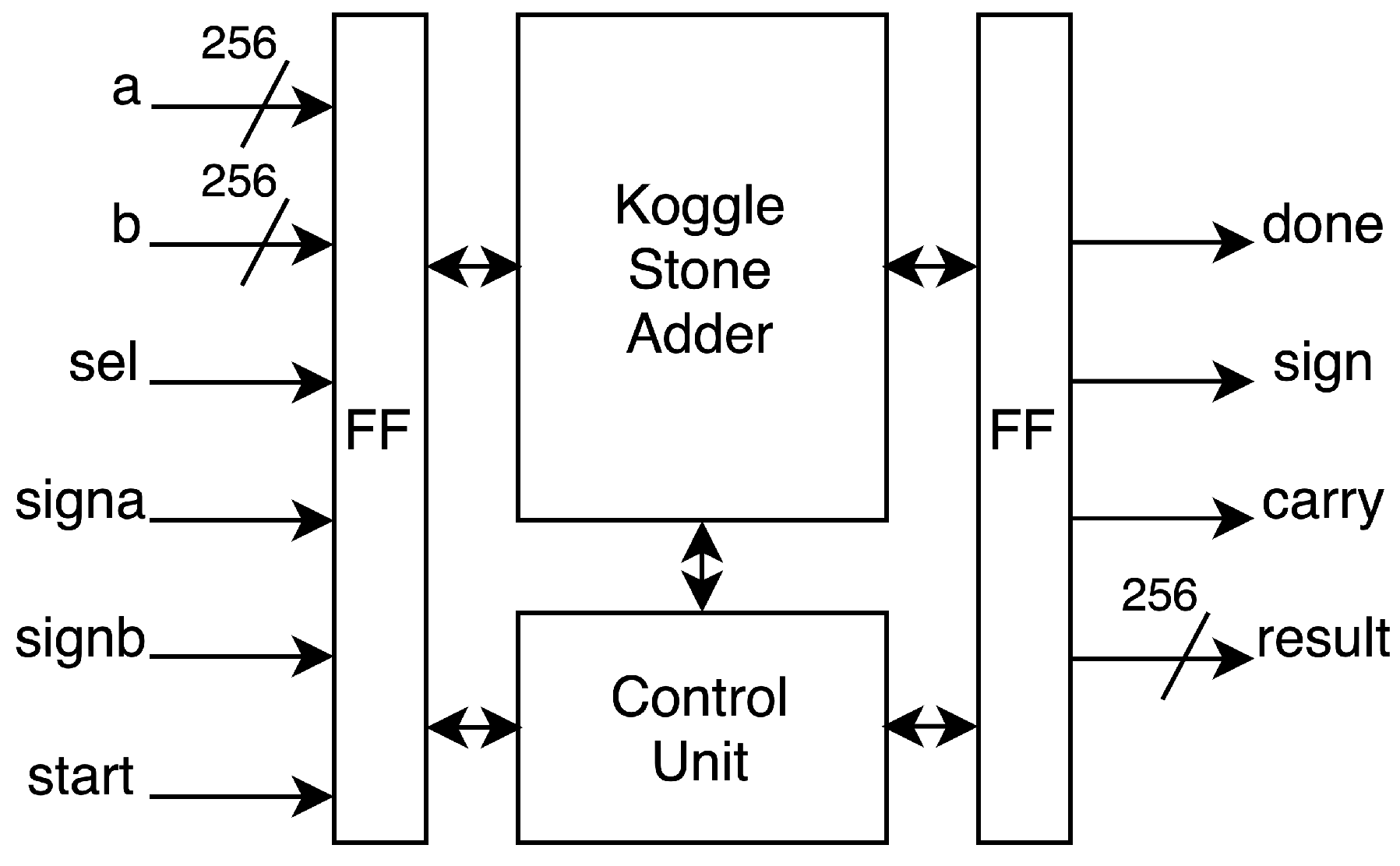
3.5. Modular Adder and Subtractor
To optimize timing for the 256-bit modular adder and subtractor, we use a Kogge–Stone adder (KSA) structure. We designed the dual-purpose modular addition and subtraction unit based on the high-radix parallel prefix network modular adder/subtractor proposed by Rogawski et al. [
6]. This Koggle–Stone parallel prefix network adder/subtractor (KSA) is appropriate for optimizing operating frequency and pipeline.
The adder receives 256-bit input
a and
b with two MSBs processed by the controller. The low 256-bit section is the input for KSA. The controller also processes the
and determines the result’s
and
. Signal
selects the mode between subtraction and addition. The design has 2 clock latencies.
Figure 8 provides the dual-purpose structure packed with a micro finite state machine.
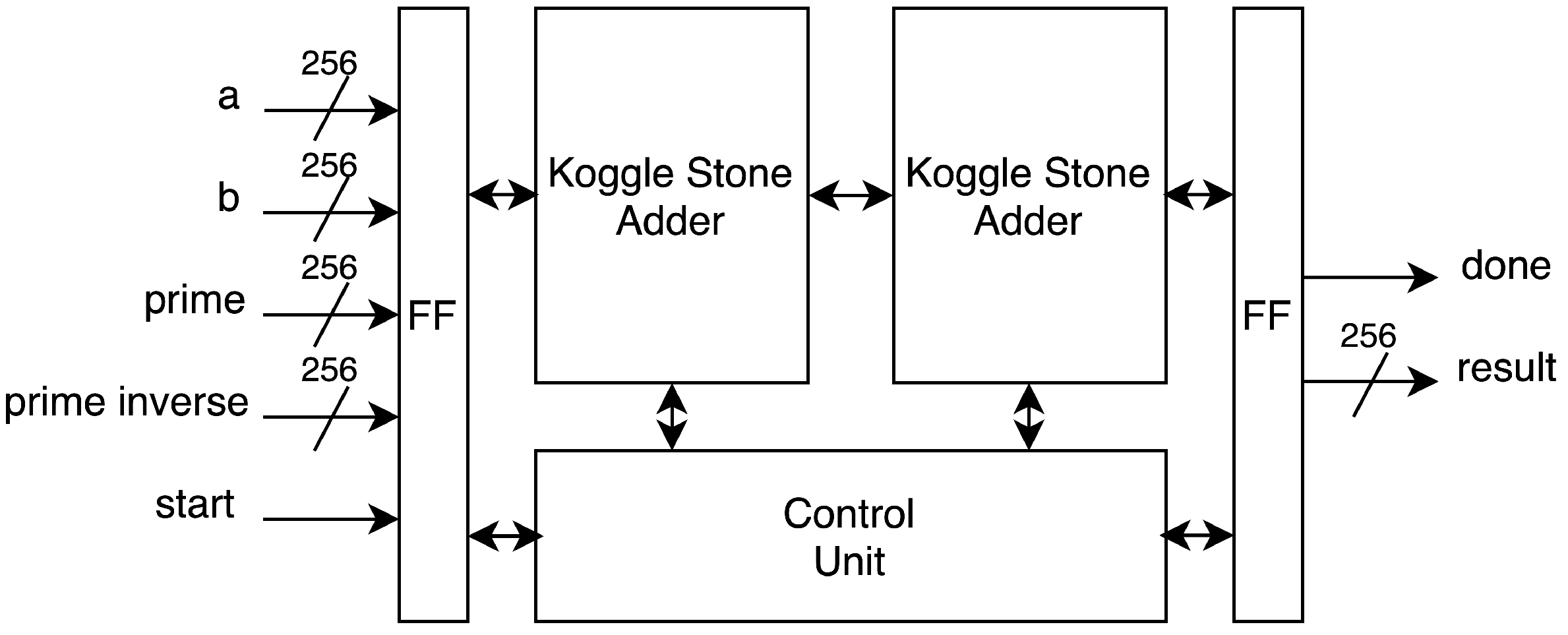
3.6. Montgomery Multiplication
For modular multiplication, we utilize radix-2 Montgomery modular multiplication, as proposed by Xiao et al. [
8], but modified with KSAs instead of 256-bit regular adders for high performance. Algorithm 2 shows the Montgomery modular multiplication used in the proposed design.
The hardware design for the Montgomery multiplication architecture uses the referenced algorithm with
, which uses the mux and carry load adder and the shift register to compute the values of
S through each loop.
computation uses 16-bit adders.
is a constant. It has a 256-bit input port for the Multiplicand and Multiplier
a and
b and the prime and pre-calculated inverse prime number. The start signal starts the operation. It completes the multiplication after 256 loops and outputs the 256-bit result and a done signal.
Figure 9 shows the structural diagram.
| Algorithm 2 Montgomery modular multiplication |
- 1:
Input: , , , - 2:
Output:
- 3:
- 4:
for ( to ) do - 5:
- 6:
- 7:
- 8:
end for - 9:
return
S
|
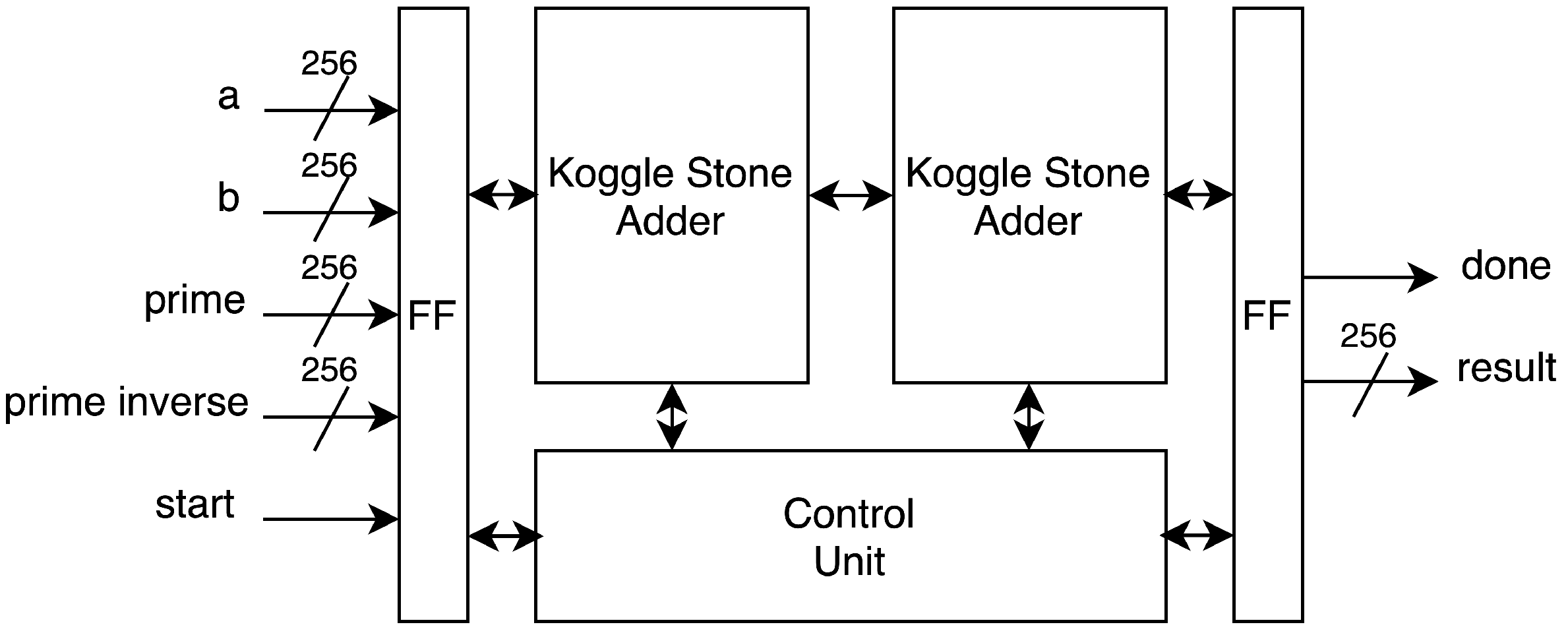
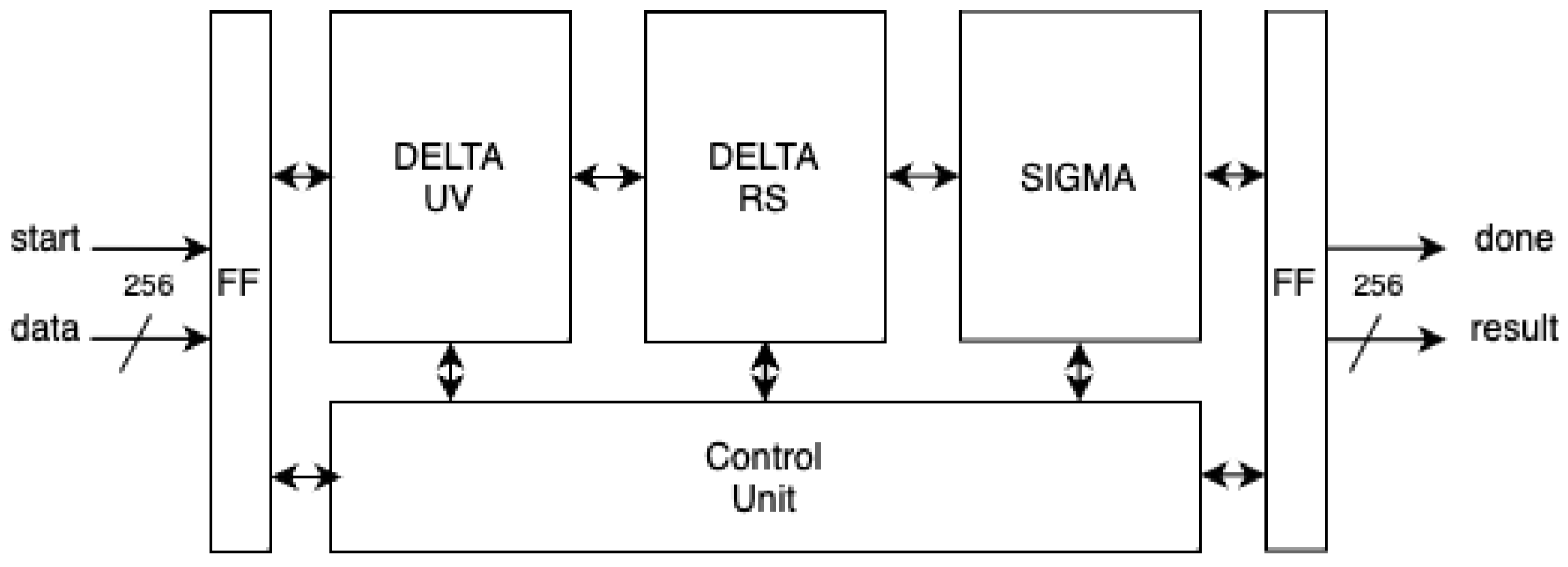
3.7. Montgomery Inversion
We design the modular inversion block based on the constant-time binary extended Euclidean algorithm proposed by Savacs [
31], with modifications including Koggle–Stone adders and optimized control logic. It consists of three consecutive Koggle–Stone adder blocks (DELTA_UV, DELTA_RS, and SIGMA) performing arithmetic operations. An INV_CONTROL finite state machine controls the sequencing and operations of the DELTA_UV, DELTA_RS, and SIGMA blocks.
The algorithm computes the modular inversion result within 512 iterations, with the calculation time depending on the length of our prime value.
Figure 10 shows the structural diagram of the Montgomery inversion unit. It uses a 256-bit data input. The start signal starts the unit and resets the count from the controller to 512 loops, with
. We check for stage jumping between the second and eighth computation steps at each iteration. At each computationstep, delta_uv, delta_rs, and sigma are calculated sequentially. After one iteration, the value is stored and looped back until the counter reaches 0. The output is a 256-bit result and done signal.
5. Discussion
To comprehensively evaluate the efficiency of our proposed hardware architecture designed for elliptic-curve Diffie–Hellman ephemeral (ECDHE) operations on the 256-bit Montgomery Curve25519, we present a comparative analysis to relevant prior works, as summarized in
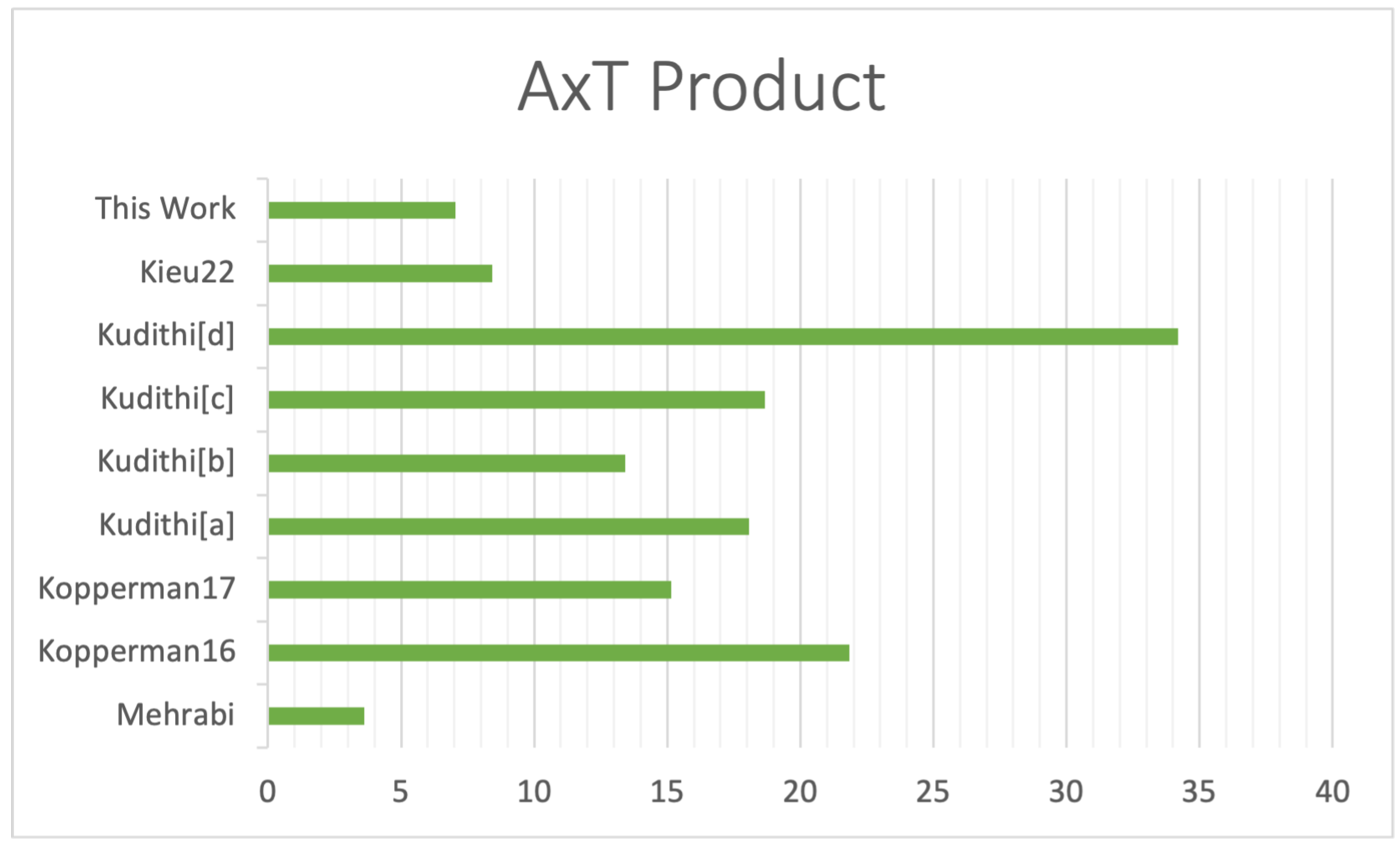
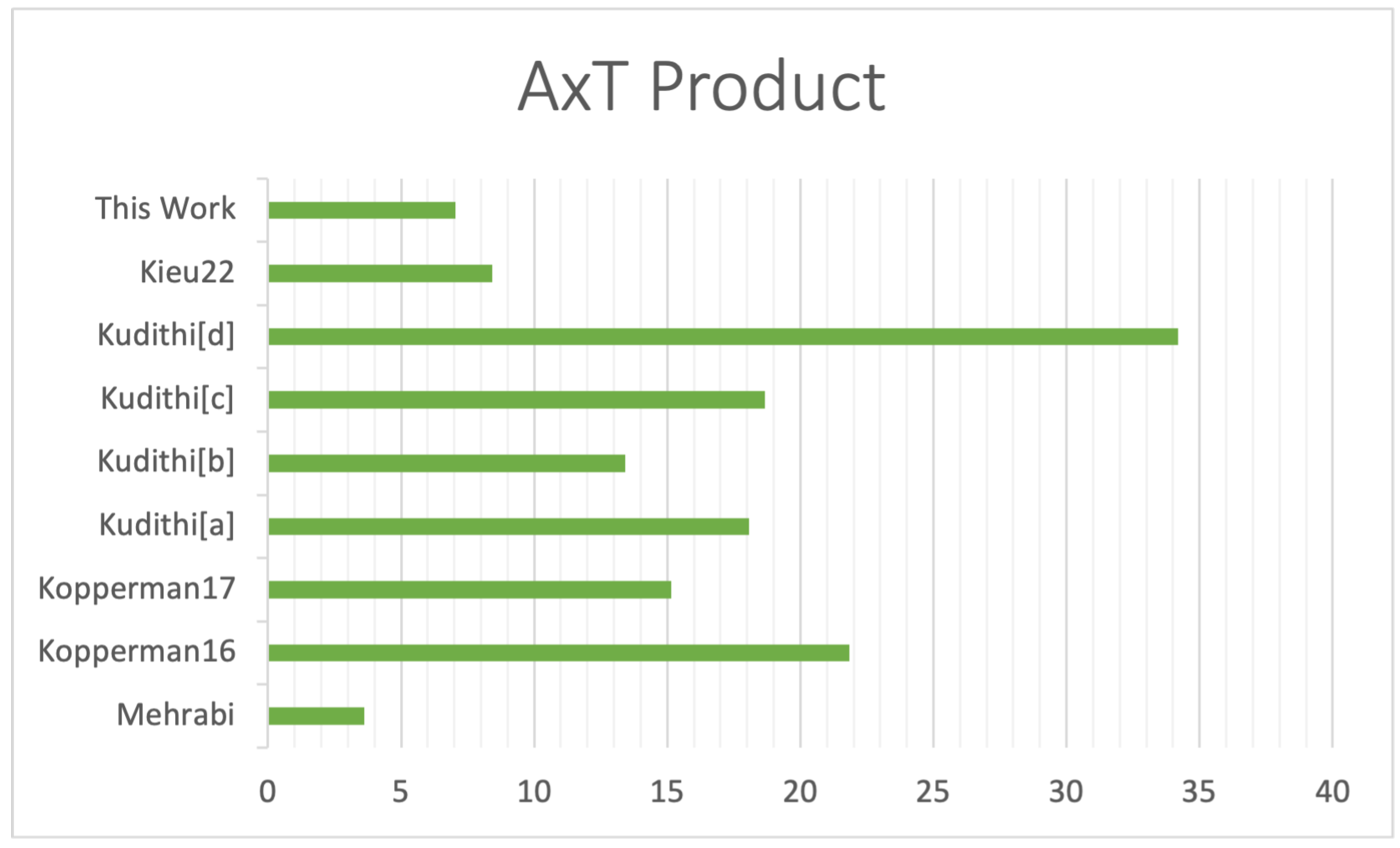
Table 4. The table shows resource utilization (in Slice(s), DSP(s), BRAM(s), latency, and power consumption. To better compare to the previous result, we use a figure of merit called
, or area × time, where the area is in kSlices and time is the latency in
, as shown in Equation (
2), which is normalized to our proposed design.
Our architecture has advantages in terms of resource utilization and power efficiency. With a reduced utilization of 6414 slices and four Block RAMs (BRAM), we achieved a clock frequency of 102 MHz. The latency of 1100 s is competitive among the listed works, even though it may be slightly higher than some implementations. The problem with using only BRAM to store data and temporary values is that it increases the latency with each ECU read-and-write operation.
Figure 11 shows the
products of our work and other implementations. Mehrabi et al. [
16] presented a multiple multipliers implementation that commanded a higher allocation of resources and higher power usage compared to our design. However, their design did not use any BRAM, achieving a better latency and a higher
product than ours. However, in terms of power consumption, our design consumes only half of the power estimation. Our work’s
product is better than the other designs. Koppermann et al. [
14,
15] provided high-performance implementation with heavy DSP usage to improve their latency compared to our design, so their area factor is higher when comparing
values. Different implementations of [
20] use the radix-2 multiplier for modular operation, achieving a good area utilization result but slower latency than ours. The design in [
21] is the smallest hardware implementation in terms of area that supports Curve25519; however, they used the multiple carry saves adder to perform arithmetic operations, so their design speed was considerably slow.
While a higher clock frequency was employed in some prior works to achieve lower latencies, our approach strives for a balance between performance and energy consumption. Our architecture demonstrates efficient resource usage, making it well-suited for scenarios that prioritize secure communication and cryptographic key exchange without sacrificing substantial power resources. Our design proves to be better suited when considering lightweight FPGA and ASIC configurations devoid of DSP blocks.
The security of IoT devices is an important consideration when implementing system designs. As Di Matteo et al. [
33] and Zulberti et al. [
34] discussed, side-channel attacks, such as simple power analysis (SPA) and differential power analysis (DPA), on cryptographic hardware pose a significant threat. While side-channel attack countermeasures are crucial for comprehensive IoT security, an in-depth examination is beyond the scope of this paper. Our implementation focuses instead on core functionality and performance, with security considerations noted as crucial future work.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}