
An Adaptive Hybrid Automatic Repeat Request (A-HARQ) Scheme Based on Reinforcement Learning

Abstract
:1. Introduction
2. Related Works
3. Problem Statement and System Framework
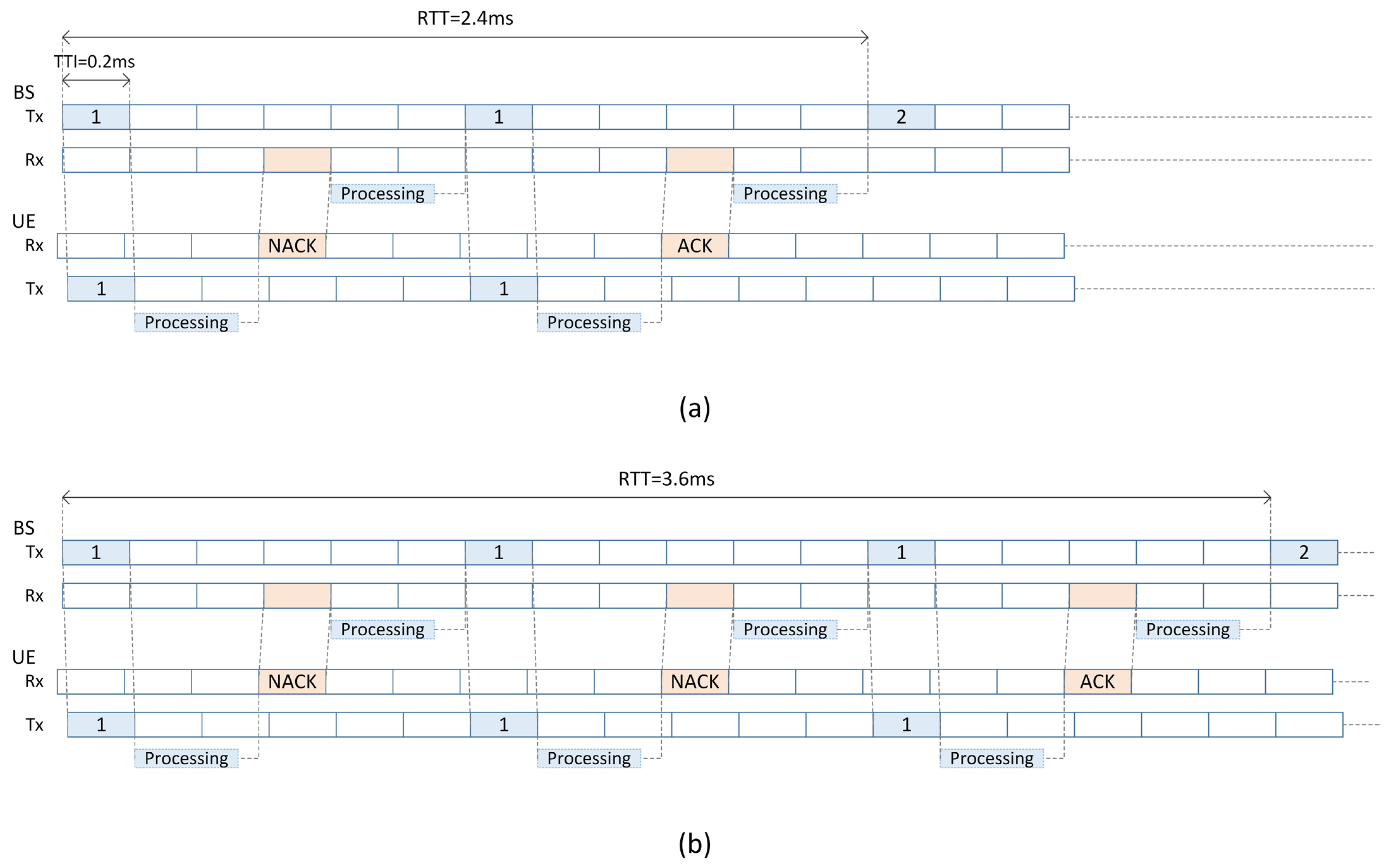
3.1. Problem Statement
3.2. System Overview
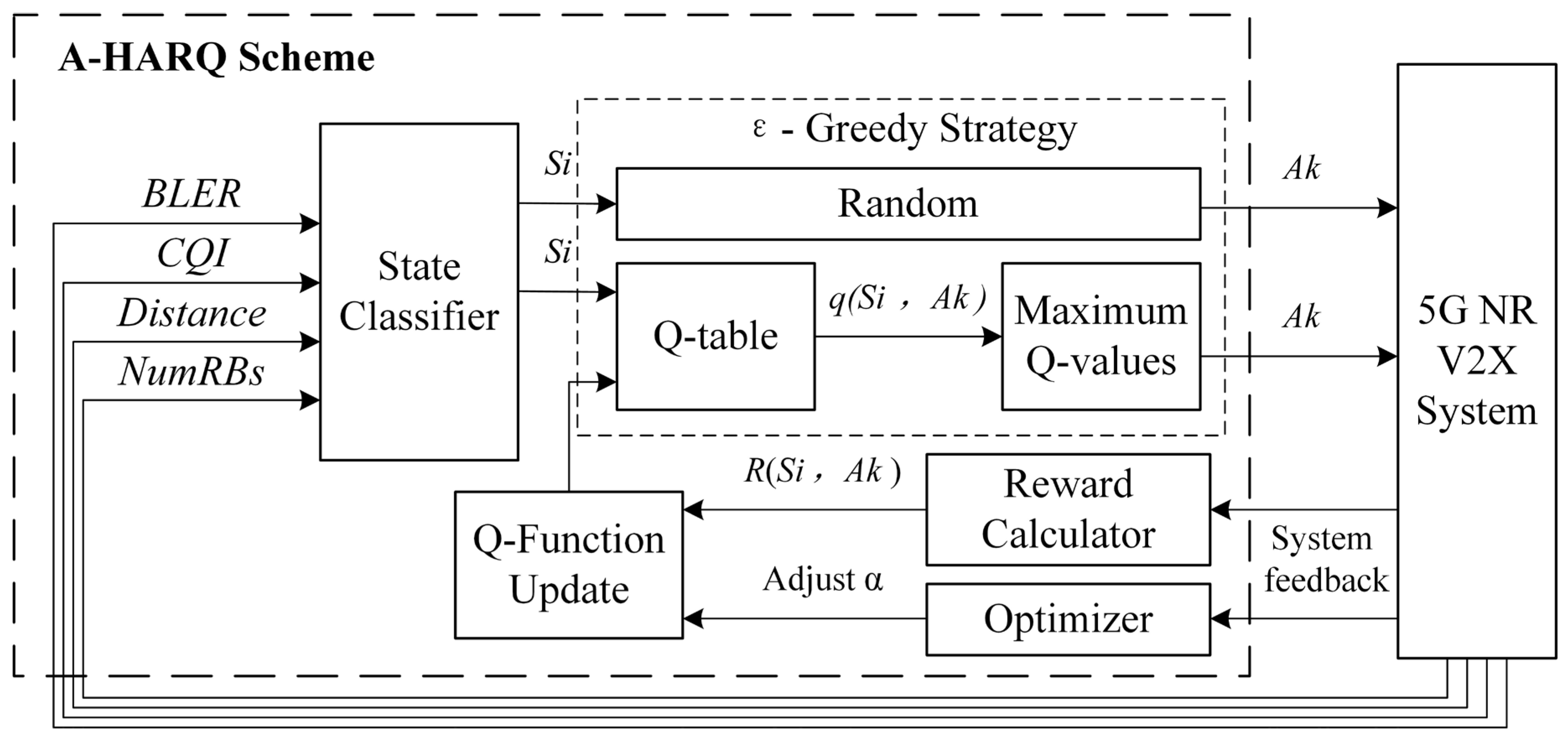
4. The Proposed Adaptive HARQ Q-Learning Model
4.1. Model Description
4.1.1. 5G NR System
4.1.2. State Space
4.1.3. Action Space
4.1.4. Reward Calculator
- The reward rule corresponding to the state that meets the requirements of the BLER, i.e., , is defined as in Equation (3):
- The reward rule corresponding to the state that does not meet the requirements of the BLER, i.e., , is , defined as in Equation (4):
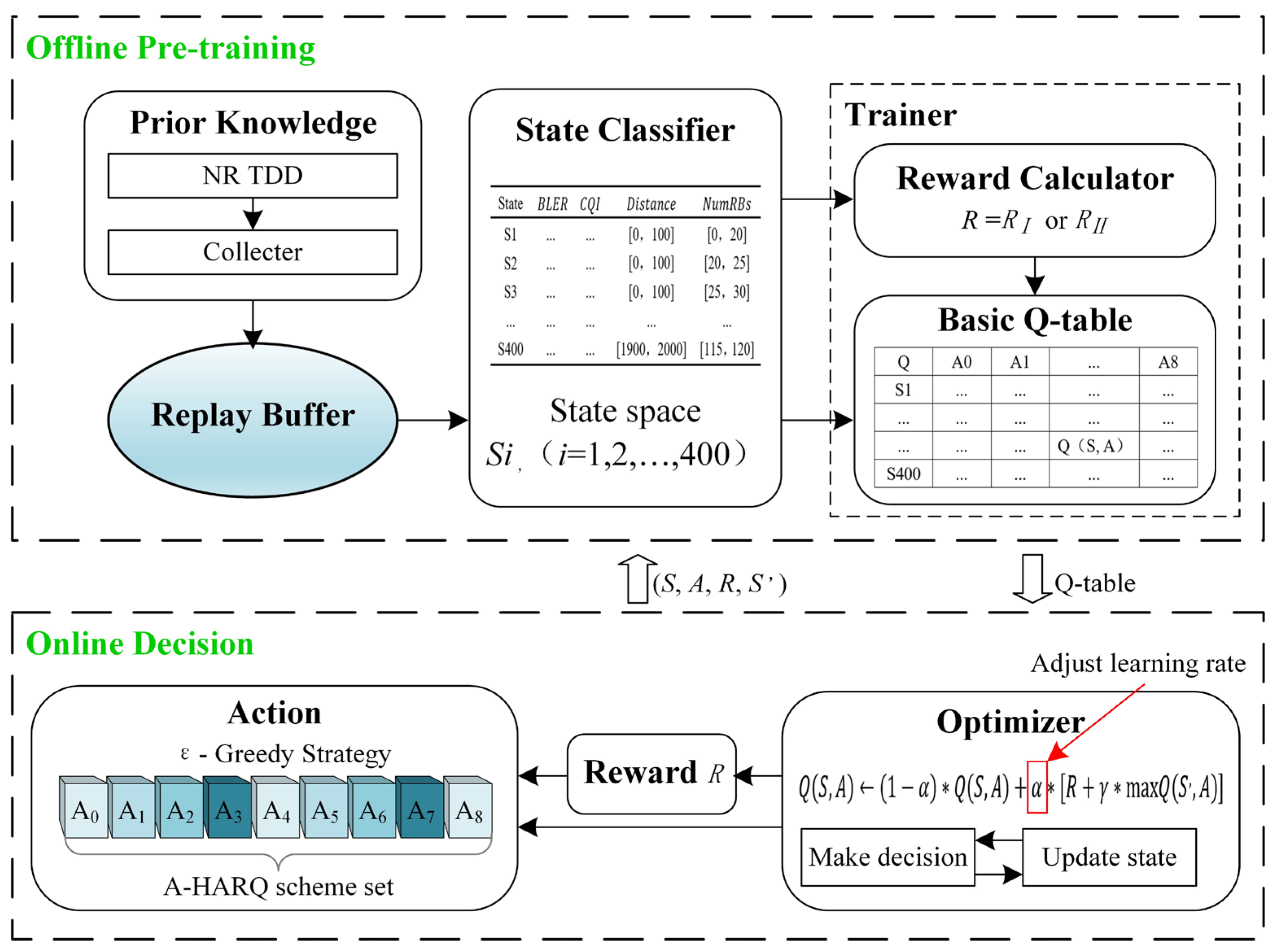
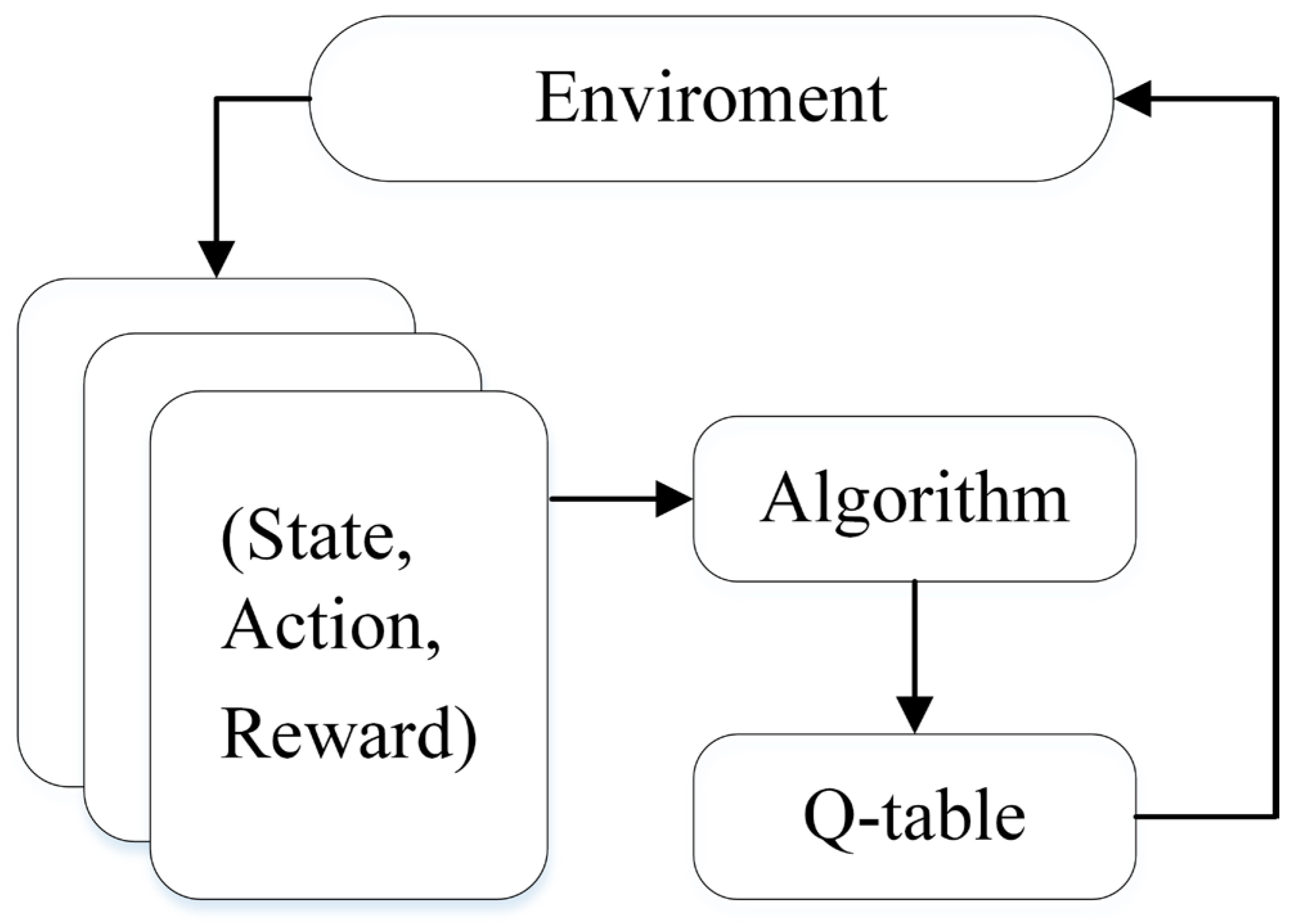
4.2. Q-Learning Model with the 5G NR-V2X System
4.2.1. Offline Training
| Algorithm 1: Offline Training Algorithm for Agent |
 |
4.2.2. Online Decision
| Algorithm 2: Online Decision Algorithm |
 |
5. Performance Evaluation
5.1. Simulation Setup
- The subcarrier spacing: 15 KHz
- Periodicity (in ms) at which the UL packets are generated by UEs: 30 ms
- Size of the UL packets (in bytes) generated by UEs: 5000 B
- Periodicity (in ms) at which the DL packets are generated for UEs at gNB: 20 ms
- Size of the DL packets generated (in bytes) for UEs at gNB: 6000 B
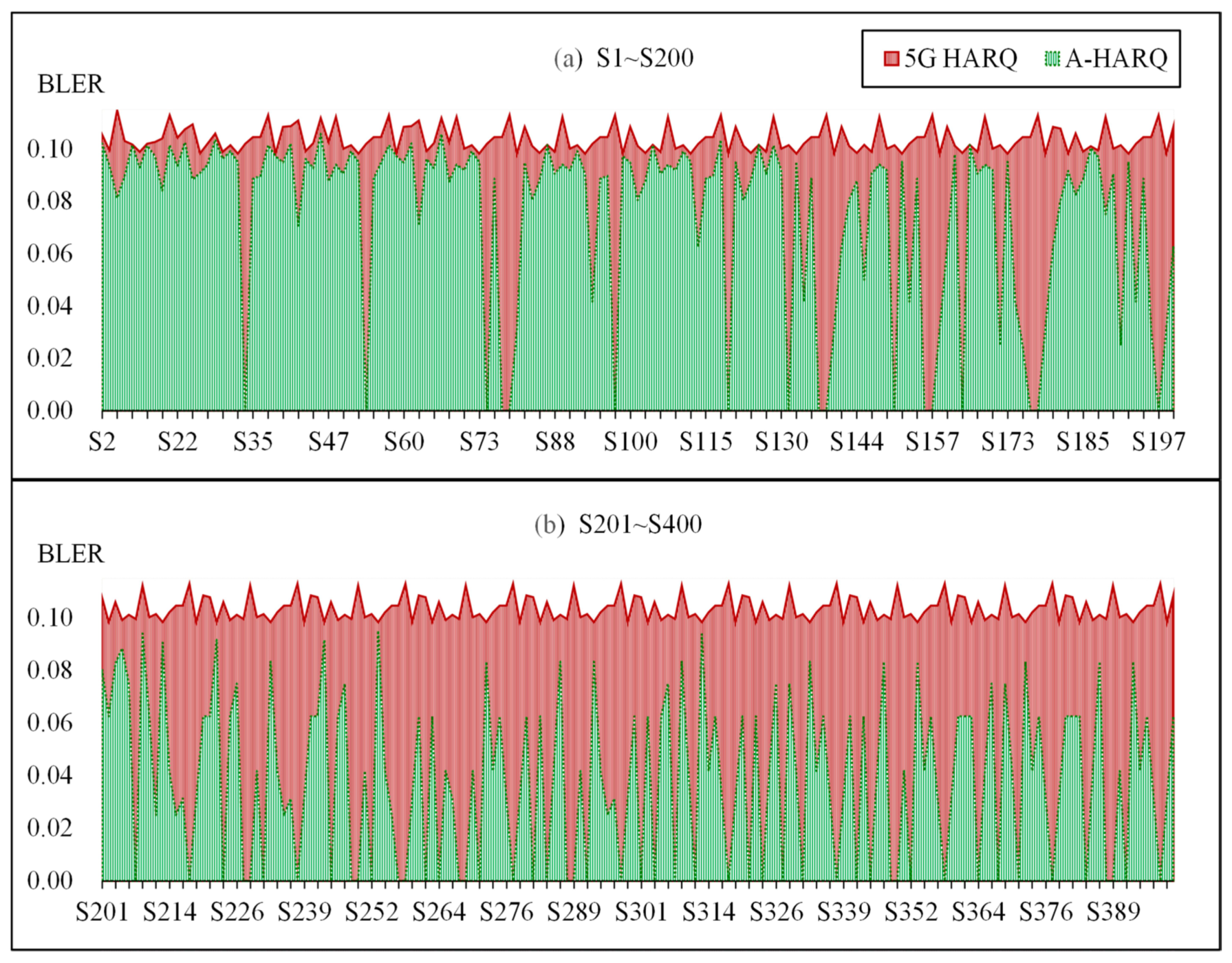
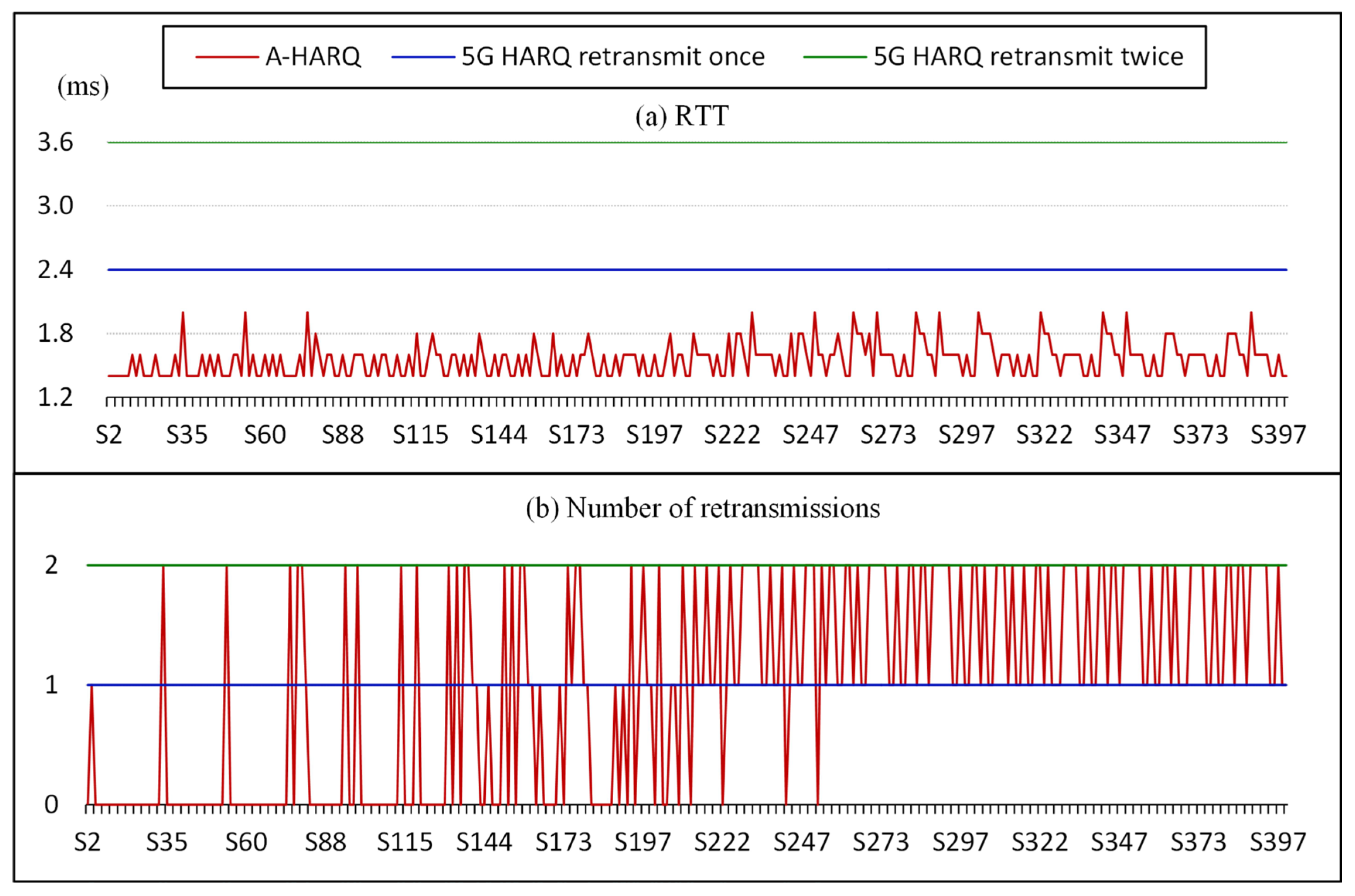
5.2. Performance Analysis
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- 3GPP (3rd Generation Partnership Project). Enhancement of 3GPP Support for V2X Scenarios, 3GPP TS 22.186, v17.0.0; 3GPP: Valbonne, France, 2022. [Google Scholar]
- Vangelista, L.; Centenaro, M. Performance Evaluation of HARQ Schemes for the Internet of Things. Computers 2018, 7, 48. [Google Scholar] [CrossRef]
- Berardinelli, G.; Khosravirad, S.R.; Pedersen, K.I.; Frederiksen, F.; Mogensen, P. Enabling Early HARQ Feedback in 5G Networks. In Proceedings of the IEEE 83rd Vehicular Technology Conference (VTC Spring), Nanjing, China, 15–18 May 2016; pp. 1–5. [Google Scholar]
- AlMarshed, S.; Triantafyllopoulou, D.; Moessner, K. Supervised Learning for Enhanced Early HARQ Feedback Prediction in URLLC. In Proceedings of the IEEE International Conference on Communication, Networks and Satellite, Batam, Indonesia, 17–18 December 2020; pp. 26–31. [Google Scholar]
- Wang, Q.; Cai, S.; Lin, W.; Zhao, S.; Chen, L.; Ma, X. Spatially Coupled LDPC Codes via Partial Superposition and Their Application to HARQ. IEEE Trans. Veh. Technol. 2021, 70, 3493–3504. [Google Scholar] [CrossRef]
- Yeo, J.; Bang, J.; Ji, H.; Kim, Y.; Lee, J. Outer Code-Based HARQ Retransmission for Multicast/Broadcast Services in 5G. In Proceedings of the IEEE 90th Vehicular Technology Conference (VTC2019-Fall), Honolulu, HI, USA, 22–25 September 2019; pp. 1–5. [Google Scholar]
- Shirvanimoghaddam, M.; Khayami, H.; Li, Y.; Vucetic, B. Dynamic HARQ with Guaranteed Delay. In Proceedings of the IEEE Wireless Communications and Networking Conference (WCNC), Seoul, Republic of Korea, 25–28 May 2020; pp. 1–6. [Google Scholar]
- Goektepe, B.; Faehse, S.; Thiele, L.; Schierl, T.; Hellge, C. Subcode-Based Early HARQ for 5G. In Proceedings of the IEEE International Conference on Communications Workshops (ICC Workshops), Kansas City, MO, USA, 20–24 May 2018; pp. 1–6. [Google Scholar]
- Strodthoff, N.; Göktepe, B.; Schierl, T.; Samek, W.; Hellge, C. Machine Learning for Early HARQ Feedback Prediction in 5G. In Proceedings of the IEEE Globecom Workshops (GC Wkshps), Abu Dhabi, United Arab Emirates, 9–13 December 2018; pp. 1–6. [Google Scholar]
- Jang, H.; Kim, J.; Yoo, W.; Chung, J.-M. URLLC Mode Optimal Resource Allocation to Support HARQ in 5G Wireless Networks. IEEE Access 2020, 8, 126797–126804. [Google Scholar] [CrossRef]
- Li, A.; Wu, S.; Jiao, J.; Zhang, N.; Zhang, Q. Age of Information with Hybrid-ARQ: A Unified Explicit Result. IEEE Trans. Commun. 2022, 70, 7899–7914. [Google Scholar] [CrossRef]
- Liu, Y.; Deng, Y.; Elkashlan, M.; Nallanathan, A.; Karagiannidis, G.K. Analyzing Grant-Free Access for URLLC Service. IEEE J. Sel. Areas Commun. 2021, 39, 741–755. [Google Scholar] [CrossRef]
- Fei, Z.; Teng, G. Research on an improved HARQ method based on 5g HARQ. Chang. Inf. Commun. 2023, 36, 210–212. [Google Scholar]
- 3GPP (3rd Generation Partnership Project). 5G; NR; Physical Layer Procedures for Data, 3GPP TS 38.214, v15.9.0; 3GPP: Valbonne, France, 2020. [Google Scholar]
- Hua, G.D.; Li, J.H.; Wang, Z.; Li, N.; Wang, Z. LTE-V2X Test Based on PC5/Uu Mode. Automot. Digest 2022, 08, 24–30. [Google Scholar]
- Wang, W.L.; Shi, S.H.; Zhang, H.B.; Cai, L. Research on Key Communication Technologies for Vehicle-Road Co-ordination. J. Highw. Transp. Sci. Technol. (Appl. Technol. Ed.) 2020, 16, 311–315. [Google Scholar]
- Lin, J.X.; Zheng, L.; Zong, Y.; Wang, Z.J. Port vehicle-road coordination based on dedicated short-range communication. J. Shanghai Inst. Shipp. Transp. Sci. 2021, 44, 56–62. [Google Scholar]
- Han, W.; Wang, Y.H.; Qin, D. Application of URLLC Technology in Electric Vehicles. Electr. Meas. Instrum. 2021, 58, 81–86. [Google Scholar]
- 3GPP (3rd Generation Partnership Project). NR; Medium Access Control (MAC) Protocol Specification, 3GPP TS 38.321, v15.6.0; 3GPP: Valbonne, France, 2019. [Google Scholar]
- 3GPP (3rd Generation Partnership Project). NR; Radio Link Control (RLC) Protocol Specification, 3GPP TS 38.322, v15.5.0; 3GPP: Valbonne, France, 2019. [Google Scholar]
- 3GPP (3rd Generation Partnership Project). NR; Radio Resource Control (RRC) Protocol Specification, 3GPP TS 38.331, v15.6.0; 3GPP: Valbonne, France, 2019. [Google Scholar]
- 3GPP (3rd Generation Partnership Project). NR; Base Station (BS) Radio Transmission and Reception, 3GPP TS 38.104, v16.0.0; 3GPP: Valbonne, France, 2019. [Google Scholar]
- Zhong, L.; Ji, X.; Wang, Z.; Qin, J.; Muntean, G.-M. A Q-Learning Driven Energy-Aware Multipath Transmission Solution for 5G Media Services. IEEE Trans. Broadcast. 2022, 68, 559–571. [Google Scholar] [CrossRef]
- 3GPP (3rd Generation Partnership Project). NR; Packet Data Convergence Protocol (PDCP) Specification, 3GPP TS 38.323, v16.2.0; 3GPP: Valbonne, France, 2020. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| State | BLER | CQI | Distance | NumRBs |
|---|---|---|---|---|
| S1 | … | … | [0, 100] | [0, 20] |
| S2 | … | … | [0, 100] | [20, 25] |
| S3 | … | … | [0, 100] | [25, 30] |
| … | … | … | … | … |
| S400 | … | … | [1900, 2000] | [115, 120] |
| Action | A-HARQ Scheme |
|---|---|
| A0 | 5G HARQ scheme |
| A1 | T-delay scheme where T = 1 slot offset |
| A2 | T-delay scheme where T = 2 slot offset |
| A3 | K-repetition scheme where K = 1 |
| A4 | K-repetition scheme where K = 2 |
| A5 | [T, K]-overlap scheme where [T, K] = [1, 1] |
| A6 | [T, K]-overlap scheme where [T, K] = [1, 2] |
| A7 | [T, K]-overlap scheme where [T, K] = [2, 1] |
| A8 | [T, K]-overlap scheme where [T, K] = [2, 2] |
| Action | |||
|---|---|---|---|
| A1 | |||
| A2 | |||
| A3 | |||
| A4 | |||
| A5 | |||
| A6 | |||
| A7 | |||
| A8 |
| Q | A0 | A1 | … | A8 |
|---|---|---|---|---|
| S1 | … | … | … | … |
| … | … | … | … | … |
| … | … | … | Q(S, A) | … |
| S400 | … | … | … | … |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, S.-Y.; Yang, M.-H.; Jia, S. An Adaptive Hybrid Automatic Repeat Request (A-HARQ) Scheme Based on Reinforcement Learning. Electronics 2023, 12, 4127. https://doi.org/10.3390/electronics12194127
Lin S-Y, Yang M-H, Jia S. An Adaptive Hybrid Automatic Repeat Request (A-HARQ) Scheme Based on Reinforcement Learning. Electronics. 2023; 12(19):4127. https://doi.org/10.3390/electronics12194127
Chicago/Turabian StyleLin, Shih-Yang, Miao-Hui Yang, and Shuo Jia. 2023. "An Adaptive Hybrid Automatic Repeat Request (A-HARQ) Scheme Based on Reinforcement Learning" Electronics 12, no. 19: 4127. https://doi.org/10.3390/electronics12194127
APA StyleLin, S.-Y., Yang, M.-H., & Jia, S. (2023). An Adaptive Hybrid Automatic Repeat Request (A-HARQ) Scheme Based on Reinforcement Learning. Electronics, 12(19), 4127. https://doi.org/10.3390/electronics12194127