
Power/Area-Efficient ECC Processor Implementation for Resource-Constrained Devices


Abstract
:1. Introduction
1.1. Existing Works
- System-level relates mostly to the ECC system’s implementation. Some significant ECC hardware implementation are provided below.
- Component-level.
1.2. Research Gap
1.3. Main Contributions
- An efficient GF(2m) digit-serial multiplier based on Bivariate Polynomial Basis representation and mRnIM to reduce booth area and power.
- An efficient ECC architecture based on a multiplier targeting the resource-constrained devices.
- FF operations are built in parallel with the FF multiplier by rearrangement and restructuring of the López–Dahab algorithm.
- An optimized MPM algorithm is used to minimize unnecessary latency/area use.
- Asynchronous counters and clock gating are used to minimize power consumption.
- Xilinx ISE timing closure techniques are used to achieve the best possible high-performance results. The experimental results using FPGA (virtex 7) show the efficiency is about 31%, 18%, 10%, 8%, and 3% compared to the best previous work using GF(2163), GF(2233), GF(2283), GF(2409), and GF(2571), respectively. This has been achieved while the area usage is about 27.43%, 58.47%, and 9.52% less than the best previous work using GF(2163), GF(2283), and GF(2409), respectively.
- Finally, our design used a time-invariant method for each module—including Fermat’s little theorem for field inversion—to complete the point multiplication in constant time, providing security against side-channel attacks.
1.4. Organization
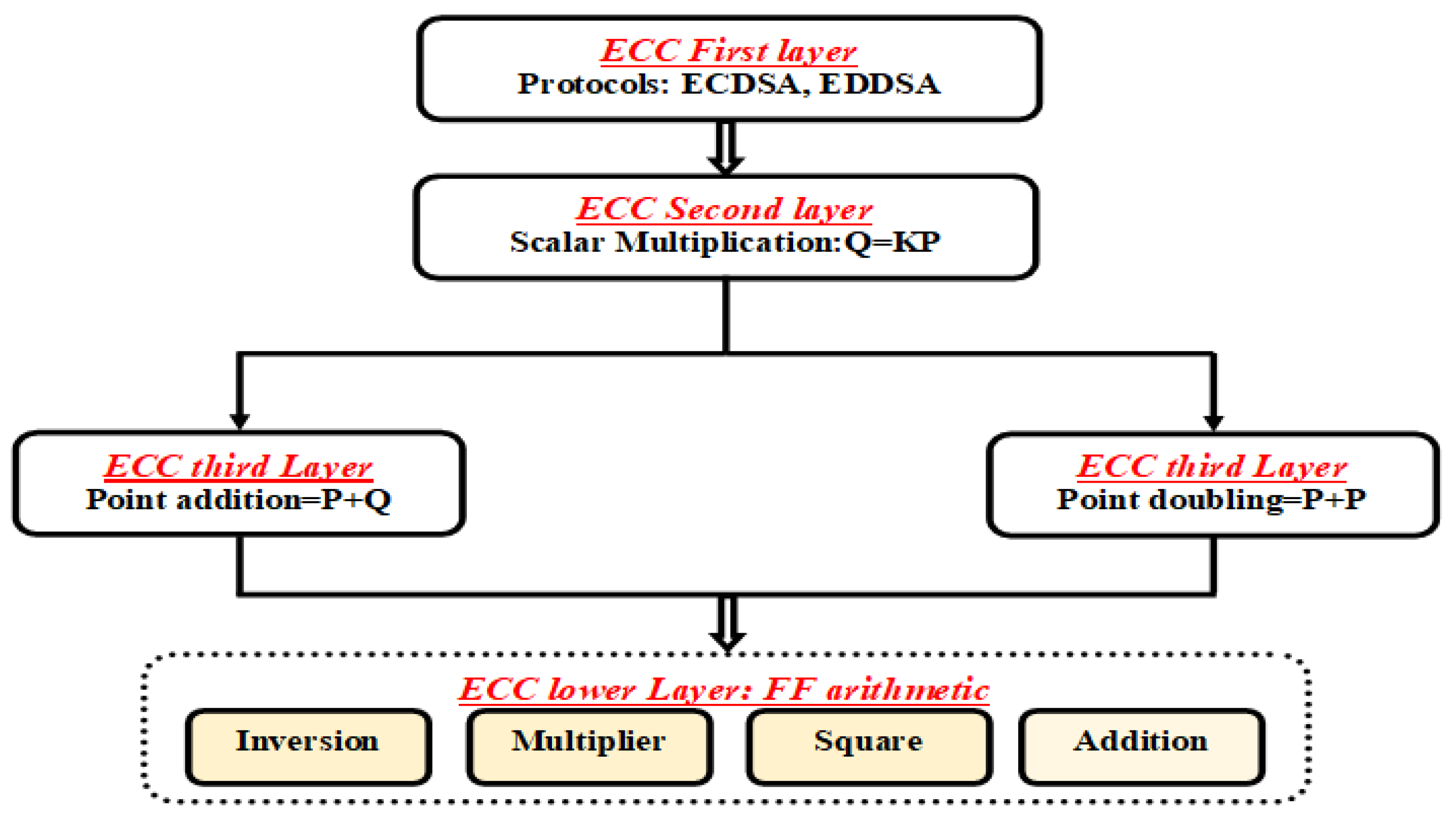
2. ECC over GF(2m) Background
3. Proposed Digit-Serial Multiplier
3.1. Bivariate Polynomial Basis (BPB) Representation Approach
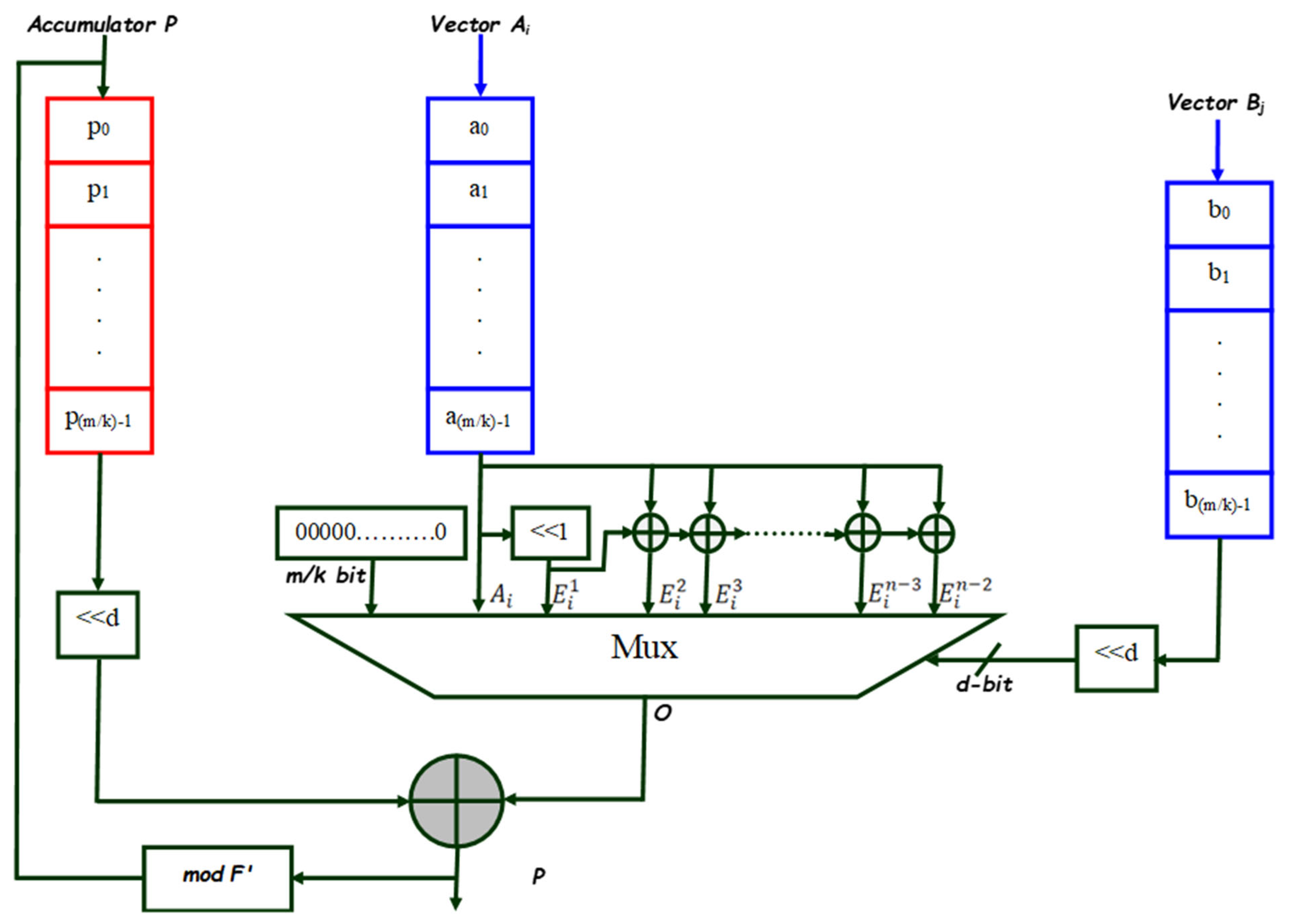
3.2. Digit-Serial Multiplier Algorithm and Design
- ○
- (d-bit left shift mod F′) operation, as specified in step 5.2.
- ○
- Selecting the input to be XORED to the accumulator P based on the bits of a multiplier (step 5.3).
- ○
- XOR operation is specified in step 5.4.
| Algorithm 1. Modifed Radix-n Interleaved Multiplication algorithm. |
|
3.3. Design Space Complexity
4. Low-Cost ECC Processor Design and Implementation
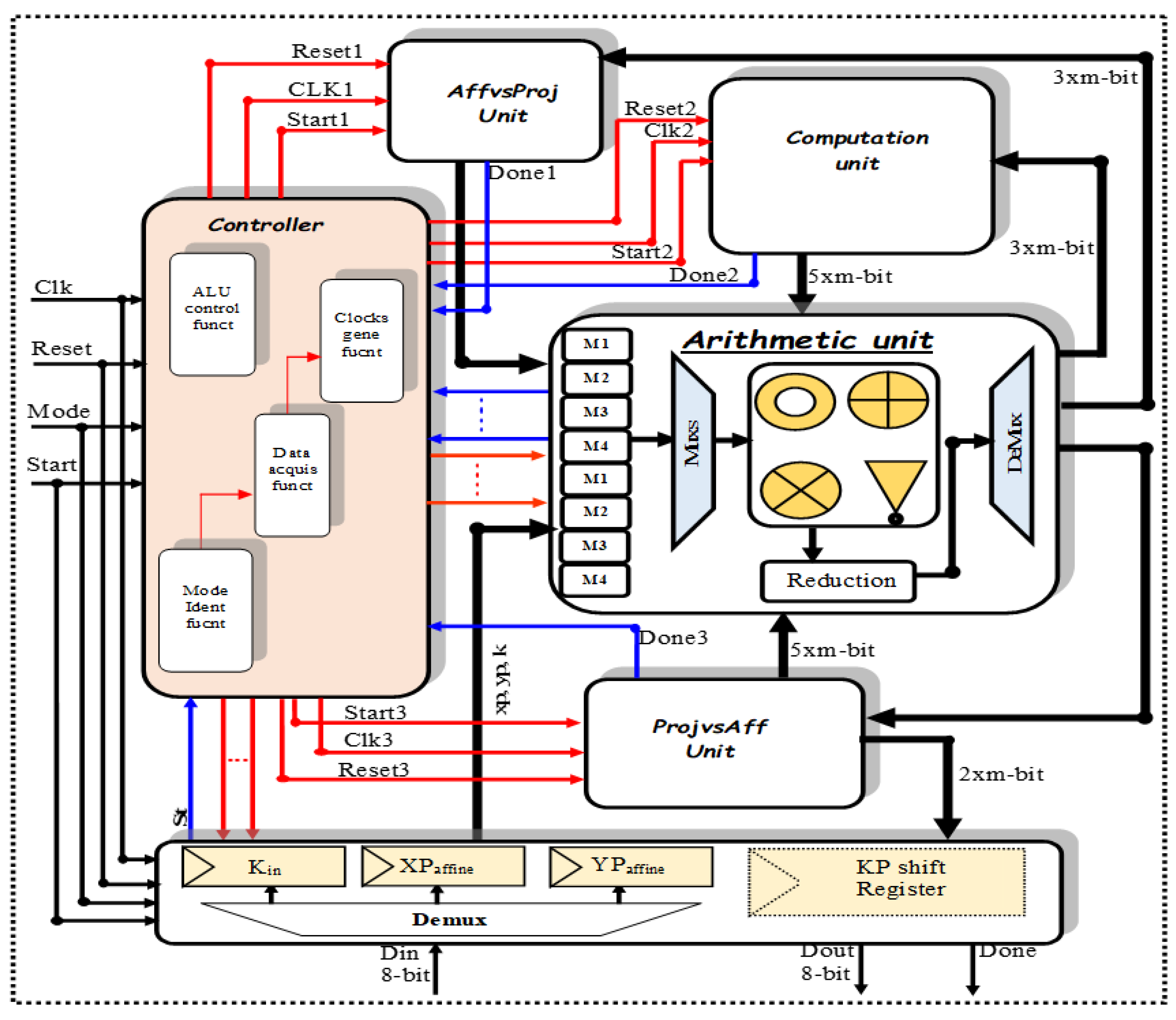
4.1. Low-Cost ECC Processor Design
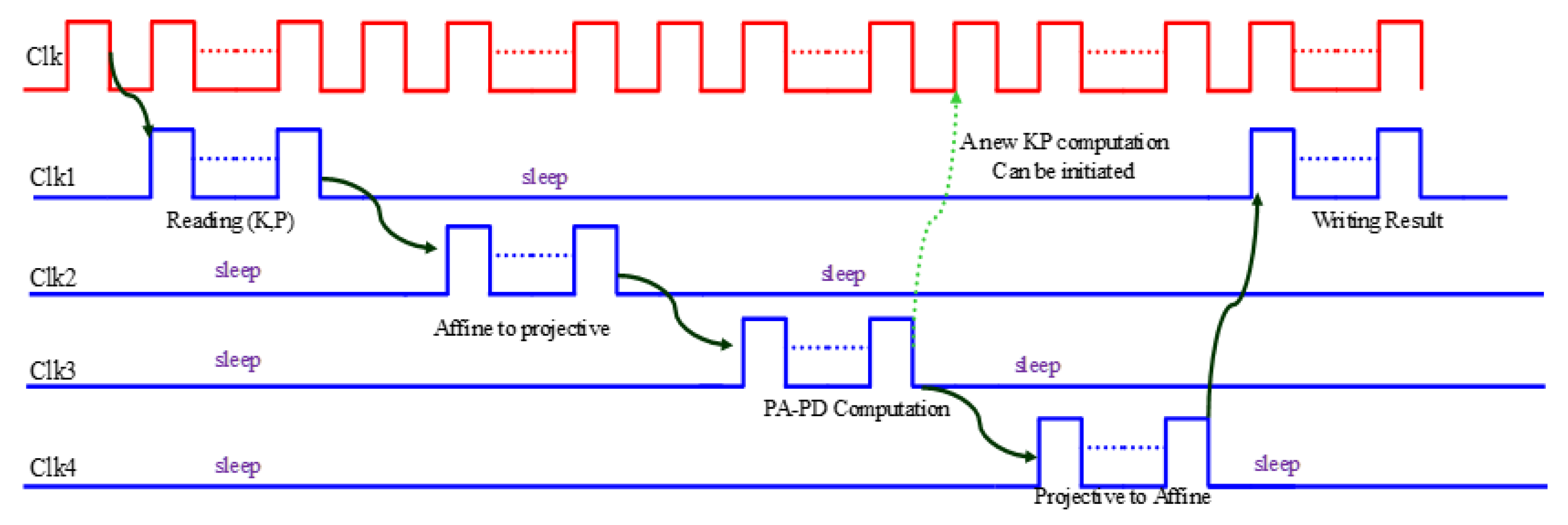
4.2. Processor Implementation
4.2.1. Bus Interface Unit
4.2.2. Conversion Unit: Affine to Projective
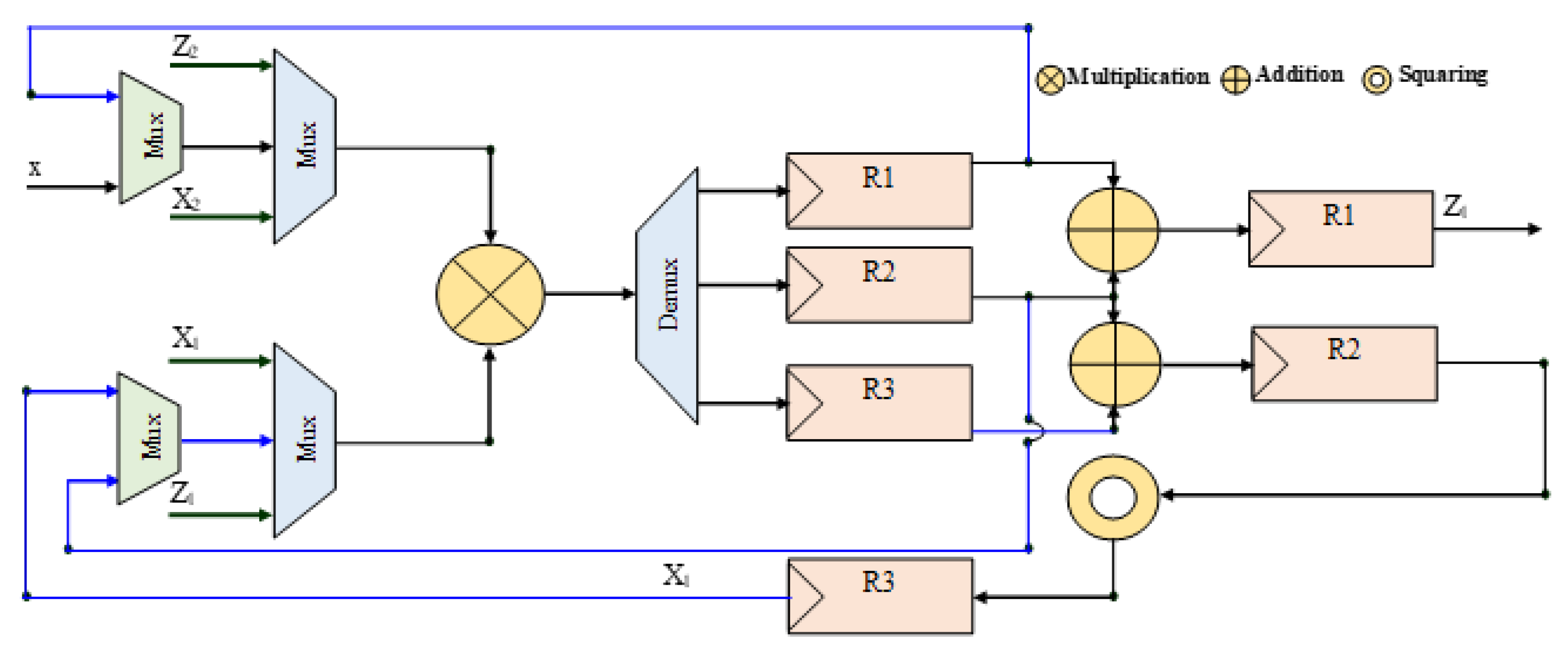
4.2.3. Arithmetic Unit
4.2.4. Computation Unit
| Algorithm 2. LD-Montgomery point multiplication modified algorithm (Mul, Sqr, ADD denote the multiplication, squaring, and addition, respectively). | |
| Input: ; Output: = () | |
| Initial Step: ; | |
| For i from (m-2) to 0 do If ki = ‘1’ then | |
| If ki+1 = ‘1’ then | If ki+1 = ‘0’ then |
| S-1: Z1 = Mul(X2,Z1); | S-1: Z2 = Mul(X1,Z2); |
| S-2: X1 = Mul(X1,Z2) | S-2: X2 = Mul(X2,Z1) |
| S-2: R1 = Sqr2(Z2); R2 = Sqr(X2); | |
| S-3: X2 = Mul(b,R1); Z2 = Sqr(Z2); R4 = Sqr(R2); R3 = Add(X1,Z1); | |
| S-4: Z2 = Mul(R2,Z2); Z1 = Sqr(R3); X2 = ADD(X2, R4); | |
| S-5: R2 = Mul(x, Z1); R1 = X1; R3 = Z1 | |
| S-6: X1 = ADD(Mul(R1,R3), R2) | |
| Conversion Step: | |
- Clock gating: it minimizes power by introducing extra logic to a circuit in order to prune the clock tree [30].
- Asynchronous counter: Many counters are used in our design. Since every register bit is activated on each clock edge, synchronous counters may consume a lot of power. Asynchronous counters only trigger the initial flip-flop using clk. Then the former flip-flops trigger later ones. Therefore, needless register changes may be eliminated and dynamic power may be reduced [31].
4.2.5. Control Unit
4.2.6. Conversion Unit: Projective to Affine
4.2.7. Critical Path Delay and Clock Cycles
5. Results and Comparisons
5.1. Implementation Results over Small Field Sizes
5.1.1. Implementation Results for GF(2163)
5.1.2. Implementation Results over GF(2233)
5.1.3. Implementation Results over GF(2283)
5.2. Implementation Results over Large Field Sizes
5.2.1. Implementation Results over GF(2409)
5.2.2. Implementation Results over GF(2571)
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Astorga, J.; Barcelo, M.; Urbieta, A.; Jacob, E. Revisiting the Feasibility of Public Key Cryptography in Light of IIoT Communications. Sensors 2022, 22, 2561. [Google Scholar] [CrossRef]
- Miller, V.S. Use of elliptic curves in cryptography. In Proceedings of the Advances in Cryptology—CRYPTO’85, Santa Barbara, CA, USA, 18–22 August 1986; pp. 417–426. [Google Scholar]
- IEEE 1363-2000; Standard Specifications for Public Key Cryptography. IEEE Standards: Piscataway, NJ, USA, 2004.
- SEC2; Recommended Elliptic Curve Domain Parameters, Standards for Efficient Cryptography 2. Certicom Research: Mississauga, ON, Canada, 2010.
- Liu, Z.; Liu, D.; Zou, X.; Lin, H.; Cheng, J. Design of an Elliptic Curve Cryptography Processor for RFID Tag Chips. Sensors 2014, 14, 17883–17904. [Google Scholar] [CrossRef]
- Lee, D.-H.; Lee, I.-Y. A Lightweight Authentication and Key Agreement Schemes for IoT Environments. Sensors 2020, 20, 5350. [Google Scholar] [CrossRef] [PubMed]
- Awaludin, A.M.; Larasati, H.T.; Kim, H. High-Speed and Unified ECC Processor for Generic Weierstrass Curves over GF(p) on FPGA. Sensors 2021, 21, 1451. [Google Scholar] [CrossRef]
- Islam, M.M.; Hossain, M.S.; Hasan, M.K.; Shahjalal, M.; Jang, Y.M. Design and Implementation of High-Performance ECC Processor with Unified Point Addition on Twisted Edwards Curve. Sensors 2020, 20, 5148. [Google Scholar] [CrossRef]
- Sajid, A.; Sonbul, O.S.; Rashid, M.; Jafri, A.R.; Arif, M.; Zia, M.Y.I. A Crypto Accelerator of Binary Edward Curves for Securing Low-Resource Embedded Devices. Appl. Sci. 2023, 13, 8633. [Google Scholar] [CrossRef]
- Sutter, G.D.; Deschamps, J.P.; Imana, J.L. Efficient elliptic curve point multiplication using digit-serial binary field operations. IEEE Trans. Ind. Electron. 2013, 60, 217–225. [Google Scholar] [CrossRef]
- Khan, Z.U.A.; Benaissa, M. Throughput/area-efficient ecc processor using Montgomery point multiplication on FPGA. IEEE Trans. Circuits Syst. II Express Briefs 2015, 62, 1078–1082. [Google Scholar] [CrossRef]
- Li, L.; Li, S. High-performance pipelined architecture of elliptic curve scalar multiplication over GF(2m). IEEE Trans. Very Large Scale Integr. Syst. 2016, 24, 1223–1232. [Google Scholar] [CrossRef]
- Rashidi, B.; Sayedi, S.M.; Rezaeian Farashahi, R. High-speed Hardware Architecture of Scalar Multiplication for Binary Elliptic Curve Cryptosystems. Microelectron. J. 2016, 52, 49–65. [Google Scholar] [CrossRef]
- Khan, Z.U.A.; Benaissa, M. High-speed and low-latency ECC processor implementation over GF(2m) on FPGA. IEEE Trans. Very Large Scale Integr. Syst. 2017, 25, 165–176. [Google Scholar] [CrossRef]
- Imran, M.; Rashid, M.; Jafri, A.R.; Kashif, M. Throughput/area optimized pipelined architecture for elliptic curve crypto processor. IET Comput. Digit. Tech. 2019, 13, 361–368. [Google Scholar] [CrossRef]
- Harb, S.; Jarrah, M. FPGA implementation of the ECC over GF(2m) for small embedded applications. ACM Trans. Embed. Comput. Syst. 2019, 18, 1–19. [Google Scholar] [CrossRef]
- Lee, C.Y.; Zeghid, M.; Sghaier, A.; Ahmed, H.Y.; Xie, J. Efficient Hardware Implementation of Large Field-Size Elliptic Curve Cryptographic Processor. IEEE Access 2022, 10, 7926–7936. [Google Scholar] [CrossRef]
- Nadikuda, P.K.G.; Boppana, L. Low area-time complexity point multiplication architecture for ECC over GF(2m) using polynomial basis. J. Cryptogr. Eng. 2023, 13, 107–123. [Google Scholar] [CrossRef]
- Aljaedi, A.; Jamal, S.S.; Rashid, M.; Alharbi, A.R.; Alotaibi, M.; Alanazi, D.J. Area-Efficient Realization of Binary Elliptic Curve Point Multiplication Processor for Cryptographic Applications. Appl. Sci. 2023, 13, 7018. [Google Scholar] [CrossRef]
- Rashid, M.; Sonbul, O.S.; Zia, M.Y.I.; Kafi, N.; Sinky, M.H.; Arif, M. Large Field-Size Elliptic Curve Processor for Area-Constrained Applications. Appl. Sci. 2023, 13, 1240. [Google Scholar] [CrossRef]
- Zeghid, M.; Ahmed, H.Y.; Chehri, A.; Sghaier, A. Speed/Area-Efficient ECC Processor Implementation Over GF(2m) on FPGA via Novel Algorithm-Architecture Co-Design. IEEE Trans. Very Large Scale Integr. Syst. 2023, 31, 1192–1203. [Google Scholar] [CrossRef]
- Xie, J.; Kumar Meher, P.; Sun, M.; Li, Y.; Zeng, B.; Mao, Z.H. Efficient FPGA Implementation of Low-Complexity Systolic Karatsuba Multiplier over GF(2m) Based on NIST Polynomials. IEEE Trans. Circuits Syst. I 2017, 64, 1815–1825. [Google Scholar] [CrossRef]
- Pan, J.; Song, P.; Yang, C. Efficient digit-serial modular multiplication algorithm on FPGA. IET Circuits Devices Syst. 2018, 12, 662–668. [Google Scholar] [CrossRef]
- Lee, C.; Xie, J. Digit-Serial Versatile Multiplier Based on a Novel Block Recombination of the Modified Overlap-Free Karatsuba Algorithm. IEEE Trans. Circuits Syst. I 2019, 66, 203–214. [Google Scholar] [CrossRef]
- Heidarpur, M.; Mirhassani, M. An Efficient and High-Speed Overlap-Free Karatsuba-Based Finite-Field Multiplier for FGPA Implementation. IEEE Trans. Very Large Scale Integr. Syst. 2021, 29, 667–676. [Google Scholar] [CrossRef]
- Li, H.; Ren, S.; Wang, W.; Zhang, J.; Wang, X. A Low-Cost High-Performance Montgomery Modular Multiplier Based on Pipeline Interleaving for IoT Devices. Electronics 2023, 12, 3241. [Google Scholar] [CrossRef]
- Menezes, A.J.; van Oorschot, P.C.; Vanstone, S.A. Handbook of Applied Cryptography; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- Hankerson, D.; Menezes, A. Elliptic curve cryptography. In Encyclopedia of Cryptography, Security and Privacy; Springer: Berlin/Heidelberg, Germany, 2021; pp. 1–2. [Google Scholar]
- Harkelson, D.; Menezes, A.; Vanstone, S. Guide to Elliptic Curve Cryptography; Springer: New York, NY, USA, 2004; pp. 75–152. [Google Scholar]
- Wu, Q.; Pedram, M.; Wu, X. Clock-Gating and its application to low power design of sequential circuits. IEEE Trans. Circuits Syst. I Fundam. Theory Appl. 2000, 47, 415–420. [Google Scholar] [CrossRef]
- Wei, D.; Zhang, C.; Cui, Y.; Chen, H.; Wang, Z. Design of a low-cost low-power baseband-processor for UHF RFID tag with asynchronous design technique. In Proceedings of the 2012 IEEE International Symposium on Circuits and Systems (ISCAS), Seoul, Republic of Korea, 20–23 May 2012. [Google Scholar]
- Imran, M.; Pagliarini, S.; Rashid, M. An Area Aware Accelerator for Elliptic Curve Point Multiplication. In Proceedings of the 2020 27th IEEE International Conference on Electronics, Circuits and Systems (ICECS), Glasgow, UK, 23–25 November 2020. [Google Scholar]
- Zhao, X.; Li, B.; Zhang, L.; Wang, Y.; Zhang, Y.; Chen, R. FPGA Implementation of High-Efficiency ECC Point Multiplication Circuit. Electronics 2021, 10, 1252. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Partial Products | Precomputed Values | Encoded Steps | Encoded Instructions | |||
|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | - | 3-bit left shift | P=SHL(P,3) |
| 0 | 0 | 1 | 1 | - | 3-bit left shift, ⨁ | P=SHL(P,3)⨁ |
| 0 | 1 | 0 | x | 1-bit left shift | 3-bit left shift, ⨁ | P=SHL(P,3)⨁ |
| 0 | 1 | 1 | x+1 | 3-bit left shift, ⨁ | P=SHL(P,3)⨁ | |
| 1 | 0 | 0 | x2 | 2-bit left shift | 3-bit left shift, ⨁ | P=SHL(P,3)⨁ |
| 1 | 0 | 1 | x2+1 | 3-bit left shift, ⨁ | P=SHL(P,3)⨁ | |
| 1 | 1 | 0 | x2+x | 3-bit left shift, ⨁ | P=SHL(P,3)⨁ | |
| 1 | 1 | 1 | x2+x+1 | 3-bit left shift, ⨁ | P=SHL(P,3)⨁ |
| GF(2m) | LUTs | Frequency (MHz) | Computation Time (ns) | Power mW | ADP(10−6) |
|---|---|---|---|---|---|
| (k,d) = (6,4) | |||||
| m = 163 | 570 | 499.523 | 27.19 | 4.175 | 13 |
| m = 233 | 820 | 484.243 | 40.1 | 6.66 | 29 |
| m = 283 | 1006 | 425.412 | 50.67 | 9.85 | 46 |
| m = 409 | 1465 | 415.369 | 78.29 | 12.14 | 100 |
| m = 571 | 1774 | 413.317 | 112.41 | 16.40 | 166 |
| (k,d) = (6,6) | |||||
| m = 163 | 804 | 445.316 | 20.34 | 5.45 | 13 |
| m = 233 | 1145 | 434.739 | 29.78 | 8.175 | 29 |
| m = 283 | 1391 | 429.827 | 36.58 | 11.95 | 44 |
| m = 409 | 1998 | 405.795 | 55.99 | 14.27 | 84 |
| m = 571 | 2353 | 395.847 | 80.14 | 18.18 | 140 |
| (k,d) = (6,8) | |||||
| m = 163 | 968 | 414.275 | 16.39 | 8.585 | 15 |
| m = 233 | 1387 | 395.8 | 24.53 | 12.69 | 30 |
| m = 283 | 1906 | 391.33 | 30.13 | 14.955 | 40 |
| m = 409 | 2440 | 357.744 | 47.64 | 16.45 | 83 |
| m = 571 | 2909 | 351.442 | 67.7 | 20.45 | 137 |
| Ref. | GF(2m) | FPGA Virtex | Area (Slices) | LUTs | FFs | Freq (MHz) | KP Time (µs) | Efficiency (×103) | Efficiency (%) |
|---|---|---|---|---|---|---|---|---|---|
| [10] | 163 | 5 | 6150 | 22,936 | - | 250 | 5.5 | 4.82 | 74 |
| [18] | 163 | 5 | - | 12,566 | - | 261 | 3.9 | - | - |
| [16] | 163 | 6 | 2205 | 5864 | 7176 | 306 | 42.46 | 1.75 | 91 |
| [11] | 163 | 7 | 1476 | 4721 | 1886 | 397 | 10.51 | 10.51 | 43 |
| [13] | 163 | 7 | 5575 | - | - | 437 | 3.97 | 7.37 | 60 |
| [14] | 163 | 7 | 4150 | 14,202 | 3747 | 352 | 3.18 | 12.36 | 32 |
| [21] | 163 | 7 | 4435 | 16,345 | 4590 | 279 | 2.93 | 12.55 | 31 |
| [15] | 163 | 7 | 2207 | 9965 | 1981 | 369 | 10.73 | 6.89 | 63 |
| [32] | 163 | 7 | 1529 | 4162 | - | 383 | 9 | 11.85 | 35 |
| T.W | 163 | 5 | 1205 | 4368 | 1152 | 350 | 9.28 | 14.57 | 19 |
| T.W | 163 | 6 | 1073 | 3681 | 1141 | 369 | 8.8 | 17.26 | 4.8 |
| T.W | 163 | 7 | 1071 | 3872 | 1141 | 387 | 8.39 | 18.14 | |
| [19] | 233 | 7 | 391 | 2346 | - | 161 | 4450 | 0.134 | 98 |
| [15] | 233 | 7 | 5120 | 18,953 | 2764 | 357 | 15.78 | 2.89 | 68 |
| [32] | 233 | 7 | 2048 | 6407 | - | 379 | 14 | 8.13 | 10 |
| T.W | 233 | 7 | 1527 | 5548 | 1626 | 356 | 17 | 8.98 | |
| [10] | 283 | 5 | 7096 | 25,030 | - | 188 | 33.6 | 1.19 | 80 |
| [12] | 283 | 5 | 6286 | 20,256 | - | 213 | 19.9 | 2.27 | 62 |
| [33] | 283 | 5 | - | 116,241 | - | 135 | 22.36 | - | - |
| [15] | 283 | 7 | 5207 | 20,202 | 3210 | 337 | 20.32 | 2.68 | 55 |
| [21] | 283 | 7 | 7096 | 28,033 | 7872 | 241 | 8.24 | 4.85 | 18 |
| T.W | 283 | 5 | 2413 | 9277 | 2316 | 289 | 25.40 | 4.61 | 21 |
| T.W | 283 | 7 | 2162 | 7924 | 2300 | 331 | 22.18 | 5.91 | |
| [10] | 409 | 5 | 10,236 | 28,503 | - | 164 | 102.6 | 0.39 | 85 |
| [12] | 409 | 5 | 11,513 | 35,313 | 13,843 | 172 | 19.4 | 1.84 | 29 |
| [33] | 409 | 6 | - | 116,241 | - | 135 | 41.36 | - | - |
| [11] | 409 | 7 | 6888 | 20,881 | 6038 | 316 | 32.72 | 1.82 | 30 |
| [17] | 409 | 7 | 11,129 | 37,697 | 17,701 | 168 | 21.95 | 1.68 | 35 |
| [20] | 409 | 7 | 4439 | 12,568 | 4129 | 357 | 38.94 | 2.37 | 8 |
| [21] | 409 | 7 | 10,166 | 40,153 | 11,274 | 224 | 16.4 | 2.46 | 3 |
| T.W | 409 | 5 | 4481 | 13,733 | 4305 | 233 | 45.57 | 2.003 | 22 |
| T.W | 409 | 6 | 3709 | 11,701 | 4274 | 244 | 43.51 | 2.54 | 2 |
| T.W | 409 | 7 | 4016 | 11,730 | 4275 | 267 | 39.77 | 2.57 | |
| [12] | 571 | 5 | 18,828 | 58,665 | 19,380 | 127 | 36.5 | 0.84 | 48 |
| [10] | 571 | 5 | 8707 | 30,718 | - | 128 | 352.5 | 0.19 | 89 |
| [33] | 571 | 6 | - | 11,624 | - | 135 | 56.5 | - | - |
| [16] | 571 | 6 | 6738 | 19,158 | 24,730 | 261 | 189.1 | 0.45 | 72 |
| [14] | 571 | 7 | 50,336 | 141,078 | 29,217 | 111 | 34.05 | 0.34 | 79 |
| [11] | 571 | 7 | 12,965 | 38,547 | 10,066 | 250 | 57.61 | 0.77 | 52 |
| [20] | 571 | 7 | 5683 | 14,356 | 5961 | 317 | 64.82 | 1.56 | 3 |
| [17] | 571 | 7 | 17,324 | 57,278 | 23,351 | 147 | 38.89 | 0.85 | 47 |
| [19] | 571 | 7 | 13,789 | 54,470 | 13,275 | 218 | 28.8 | 1.44 | 10 |
| T.W | 571 | 5 | 6422 | 19,263 | 5312 | 198 | 74.88 | 1.18 | 25 |
| T.W | 571 | 6 | 5256 | 16,413 | 5274 | 207 | 71.63 | 1.51 | 5 |
| T.W | 571 | 7 | 5756 | 16,454 | 5275 | 227 | 62.6 | 1.59 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zeghid, M.; Sghaier, A.; Ahmed, H.Y.; Abdalla, O.A. Power/Area-Efficient ECC Processor Implementation for Resource-Constrained Devices. Electronics 2023, 12, 4110. https://doi.org/10.3390/electronics12194110
Zeghid M, Sghaier A, Ahmed HY, Abdalla OA. Power/Area-Efficient ECC Processor Implementation for Resource-Constrained Devices. Electronics. 2023; 12(19):4110. https://doi.org/10.3390/electronics12194110
Chicago/Turabian StyleZeghid, Medien, Anissa Sghaier, Hassan Yousif Ahmed, and Osman Ahmed Abdalla. 2023. "Power/Area-Efficient ECC Processor Implementation for Resource-Constrained Devices" Electronics 12, no. 19: 4110. https://doi.org/10.3390/electronics12194110
APA StyleZeghid, M., Sghaier, A., Ahmed, H. Y., & Abdalla, O. A. (2023). Power/Area-Efficient ECC Processor Implementation for Resource-Constrained Devices. Electronics, 12(19), 4110. https://doi.org/10.3390/electronics12194110