
Multi-Attention Infused Integrated Facial Attribute Editing Model: Enhancing the Robustness of Facial Attribute Manipulation


Abstract
:1. Introduction
2. Related Work
2.1. Encoder–Decoder Architecture
2.2. Generative Adversarial Networks (GAN)
2.3. Image Translation
2.4. Facial Attribute Manipulation
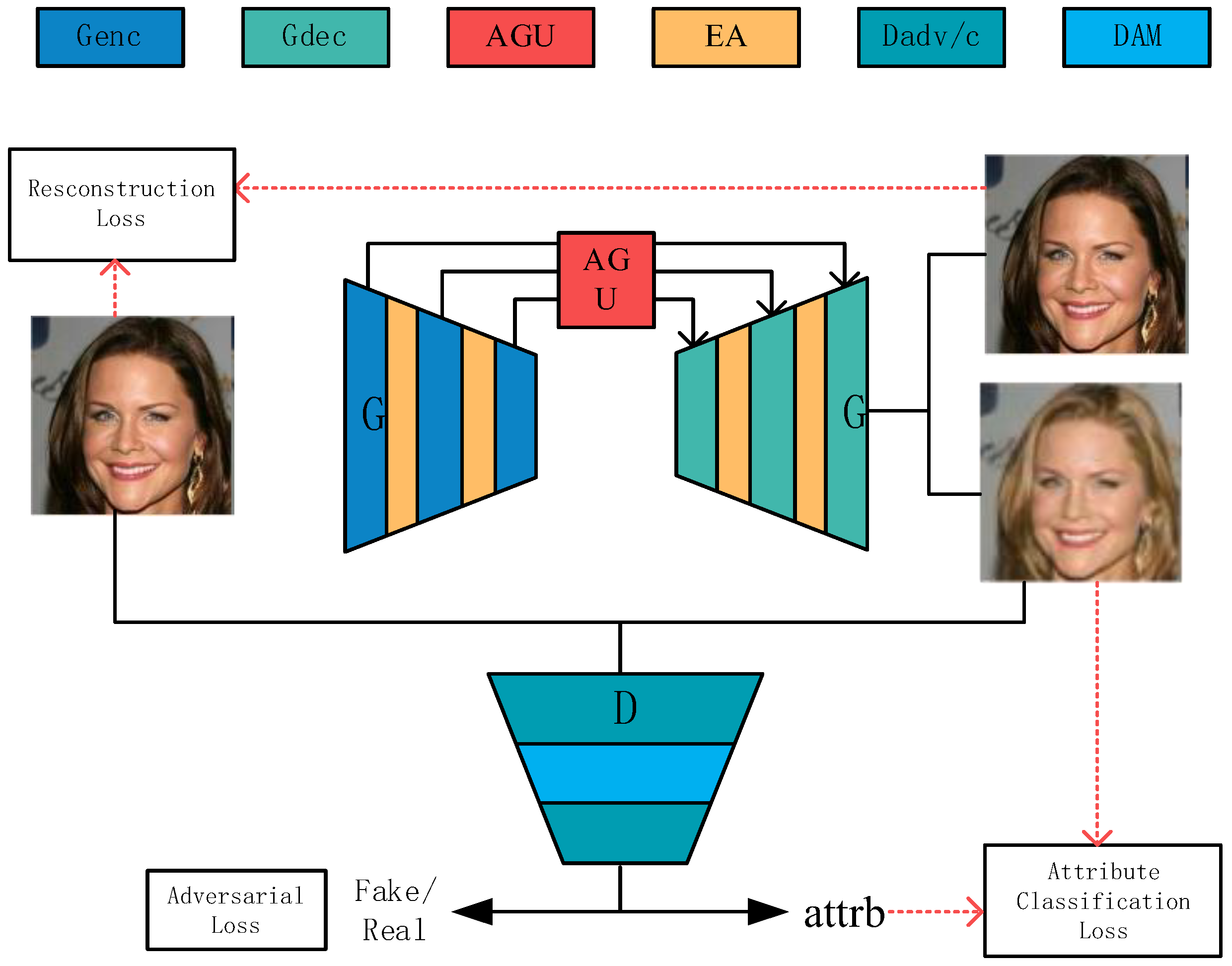
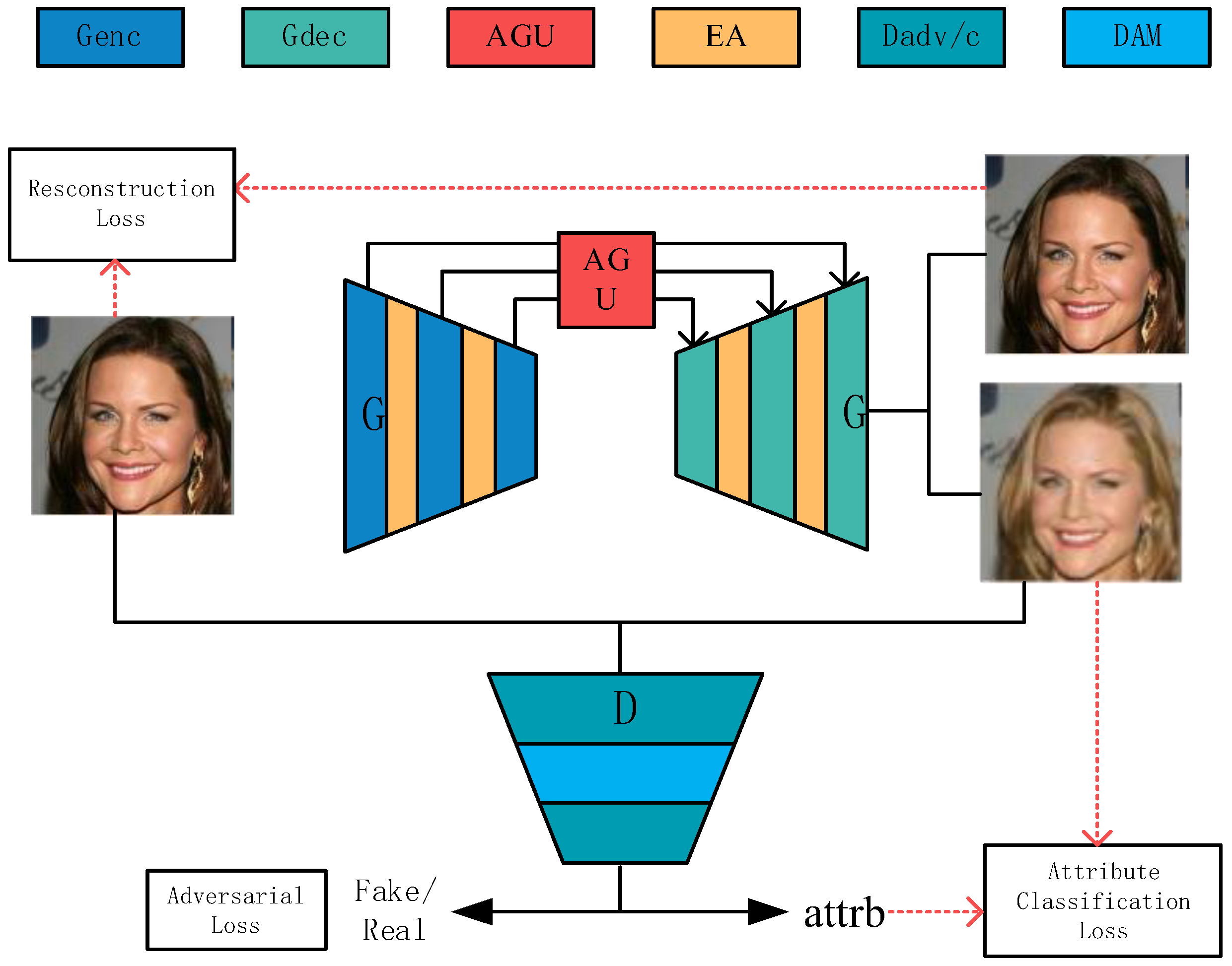
3. Proposed Method
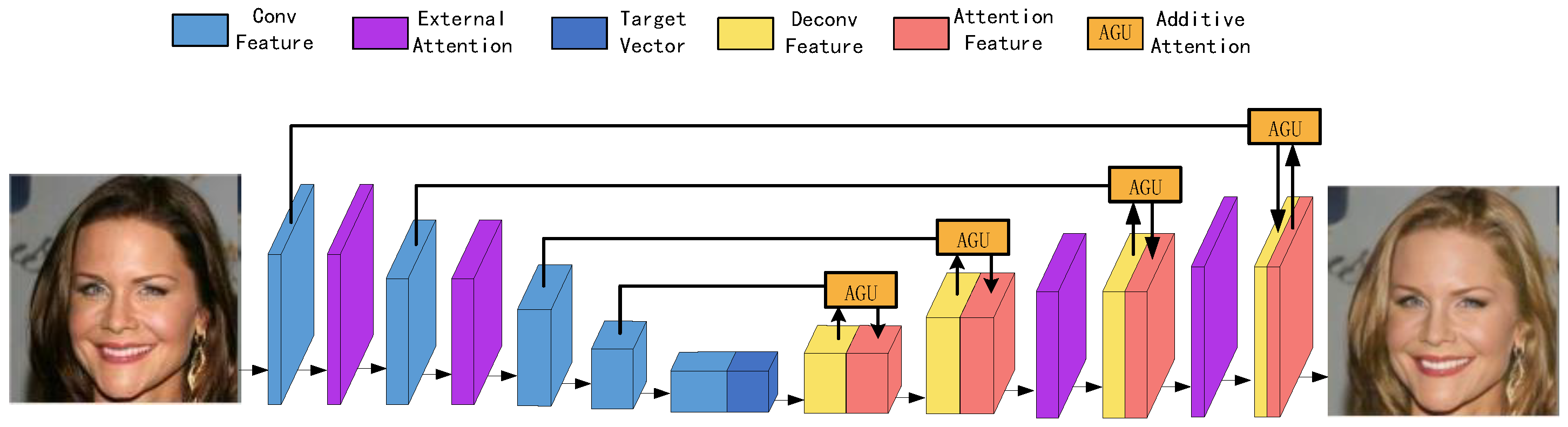
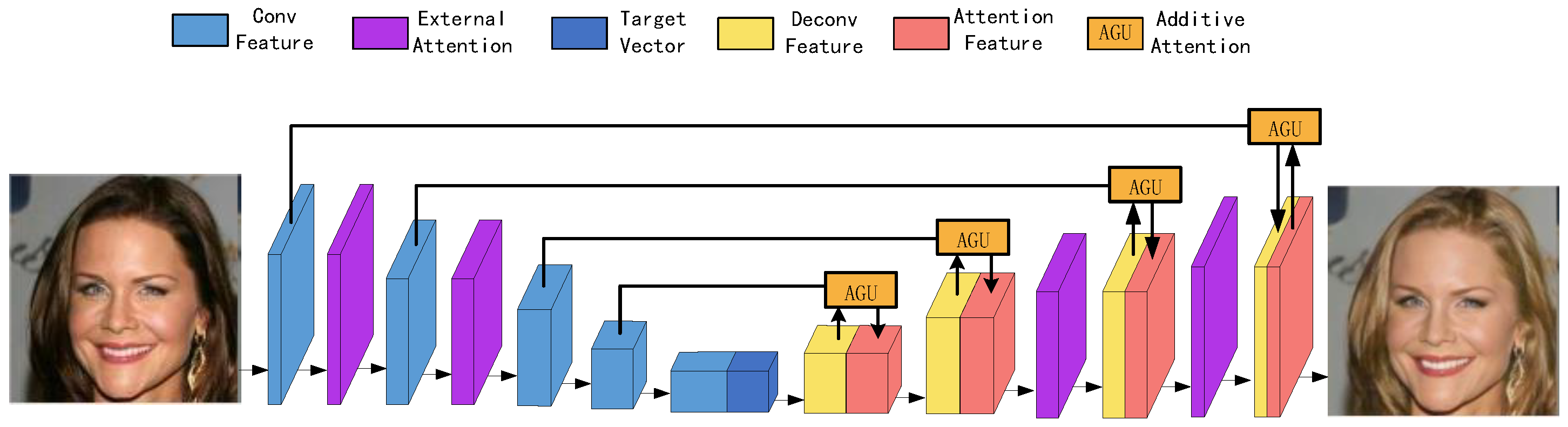
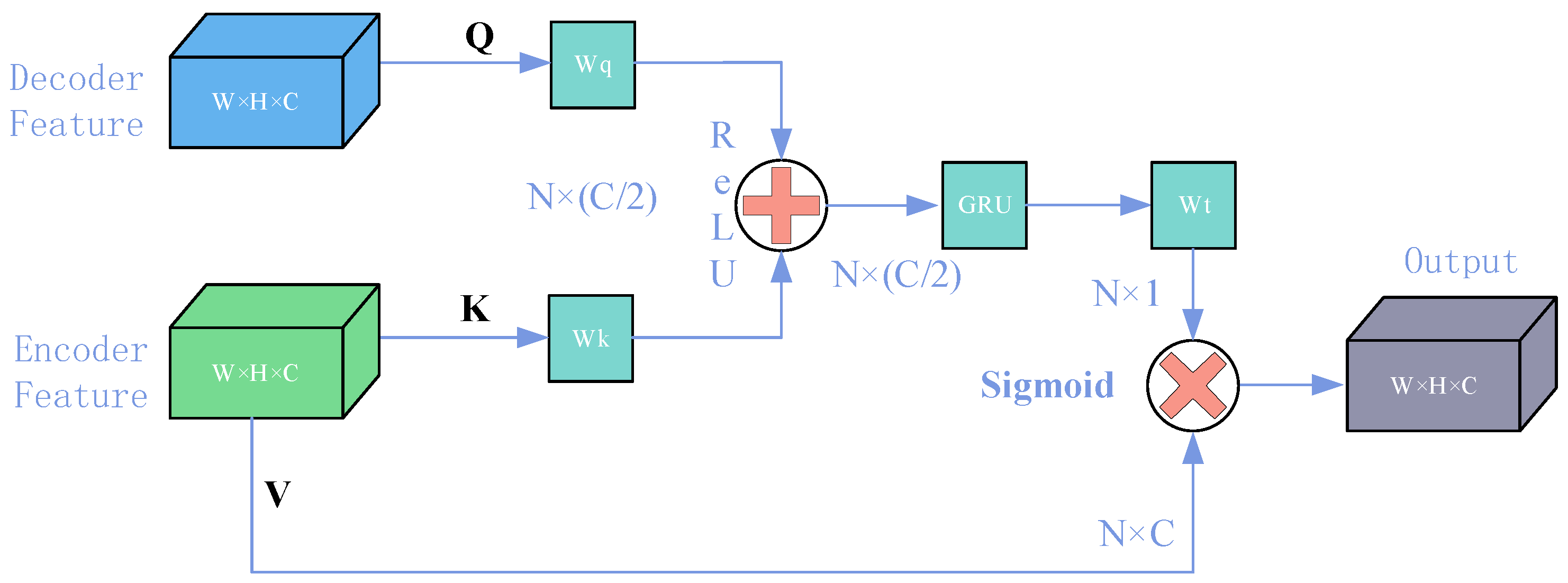
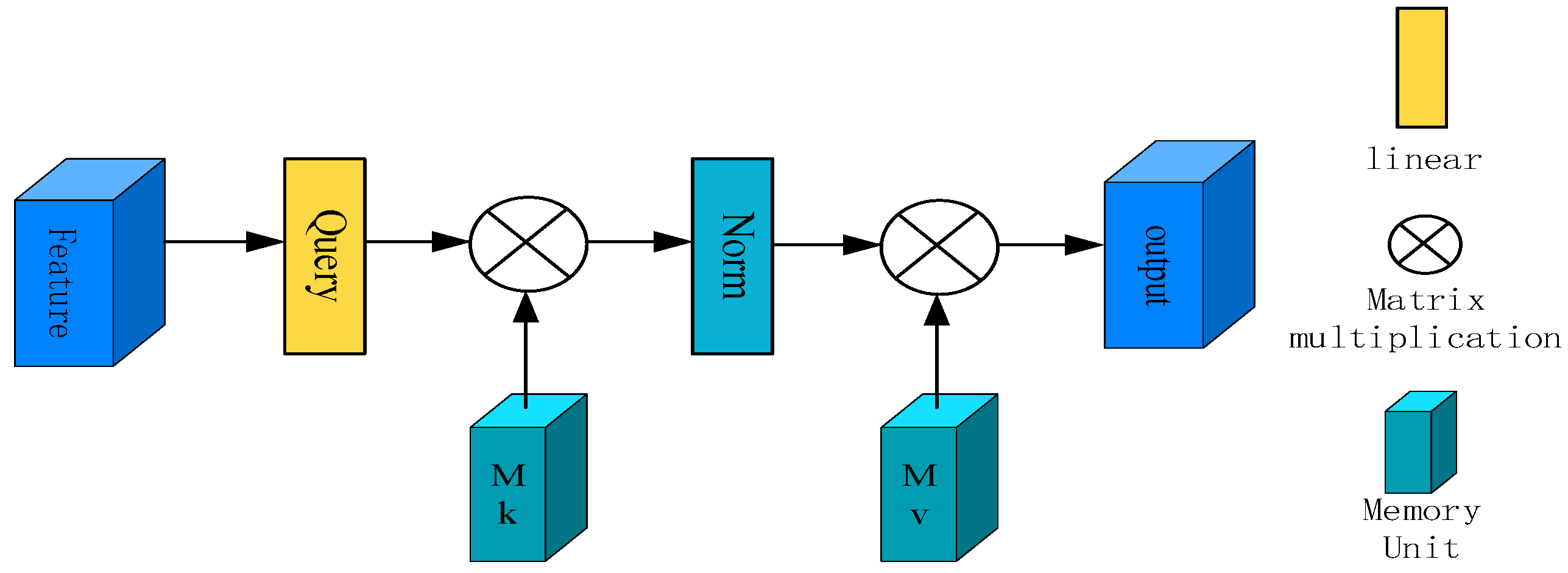
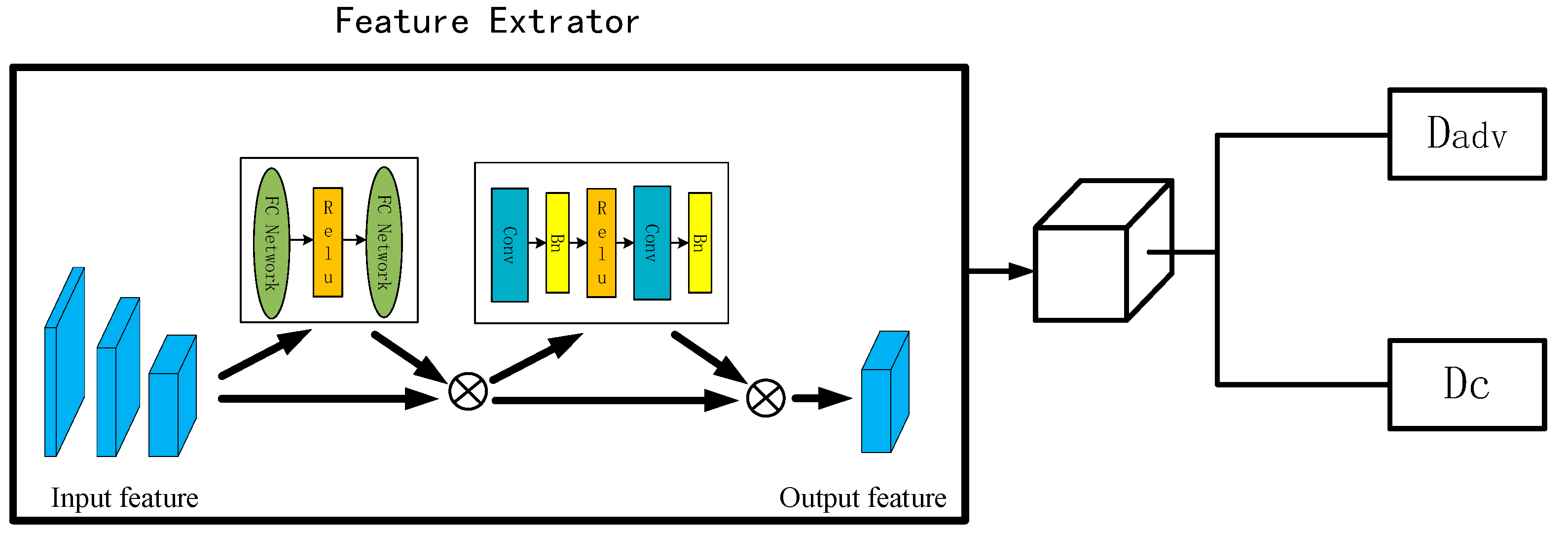
3.1. Generator
3.2. Discriminator
3.3. Loss Functions
4. Experiments
4.1. Dataset and Preprocessing
4.2. Implementation Details
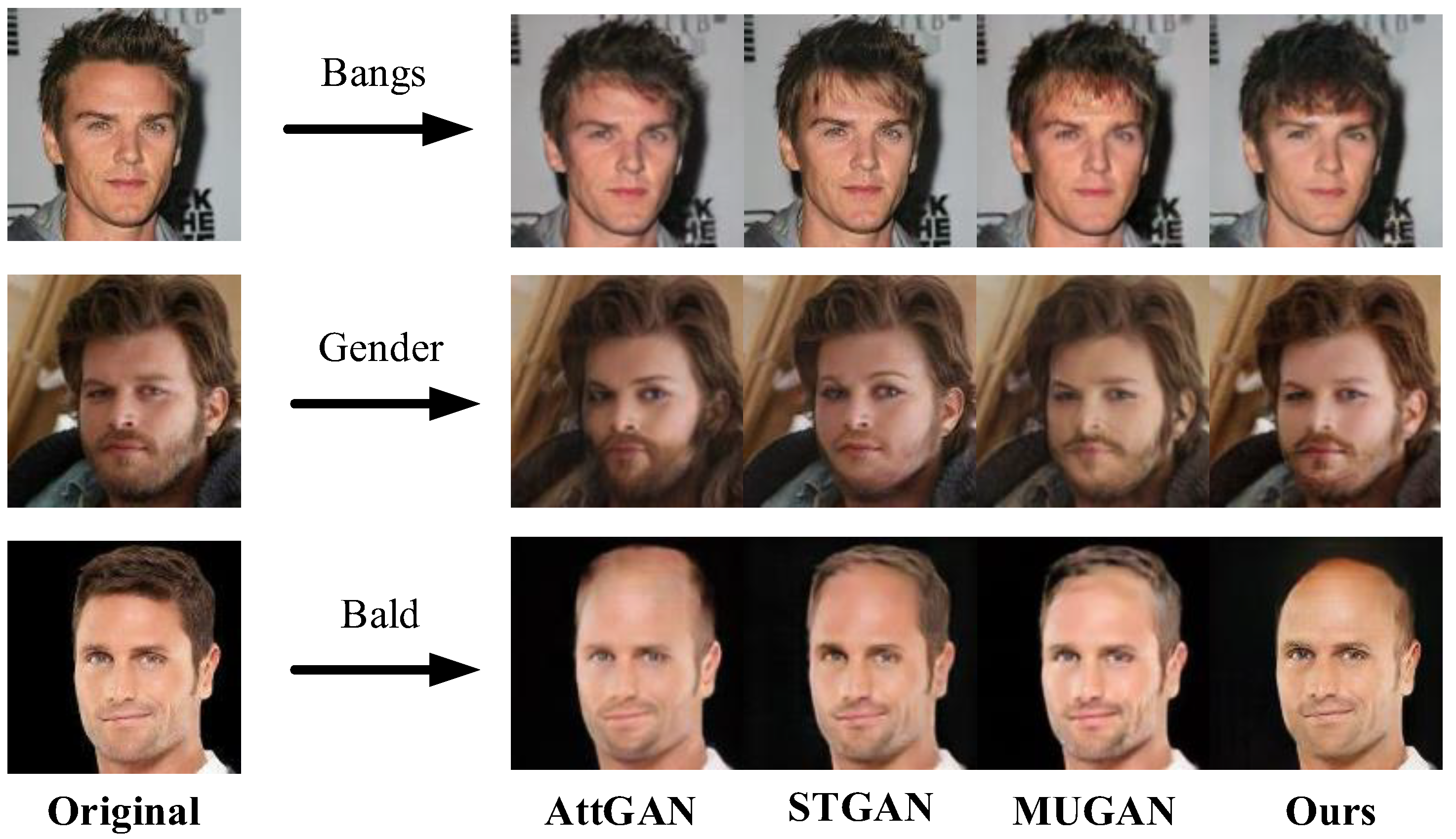
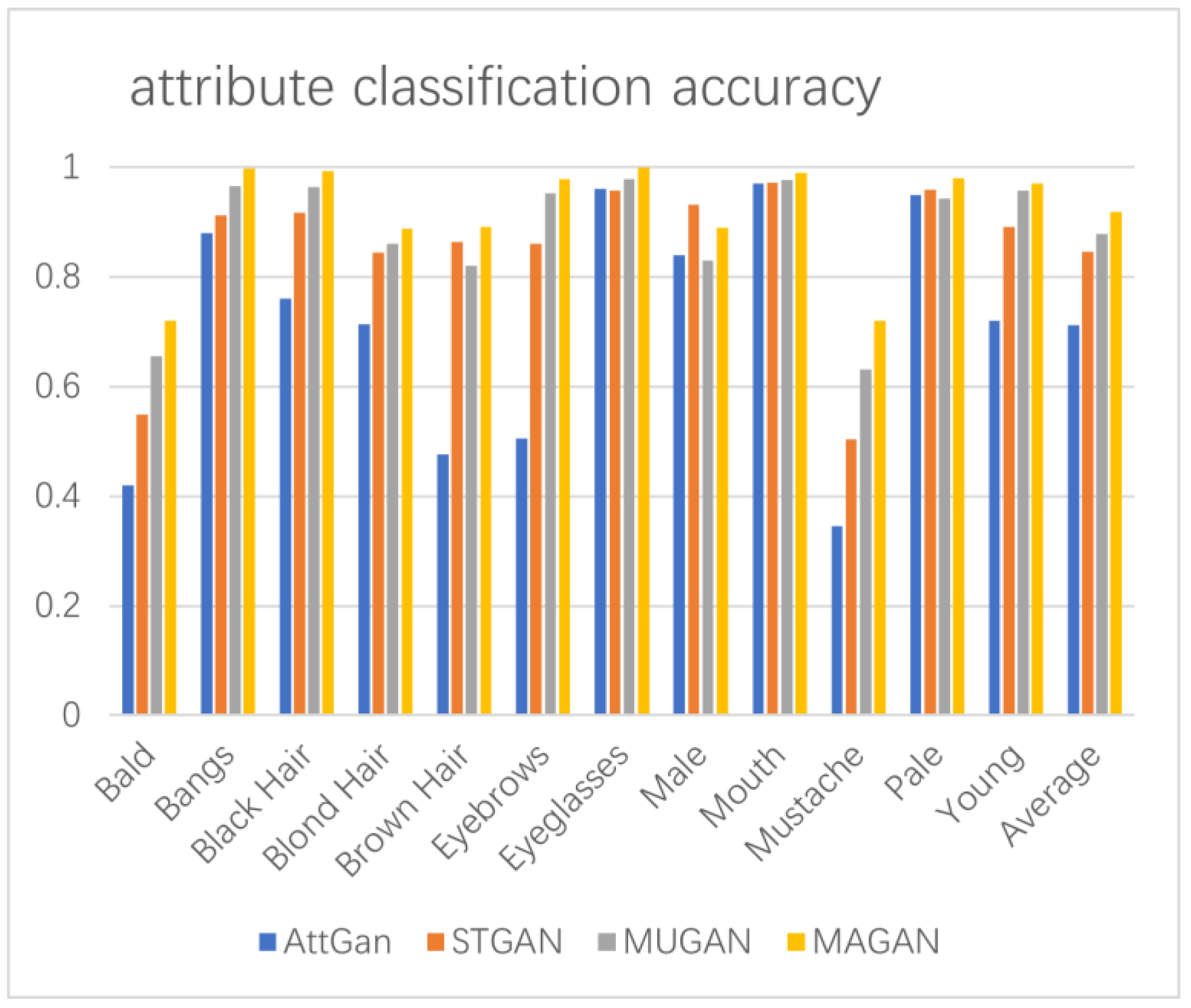
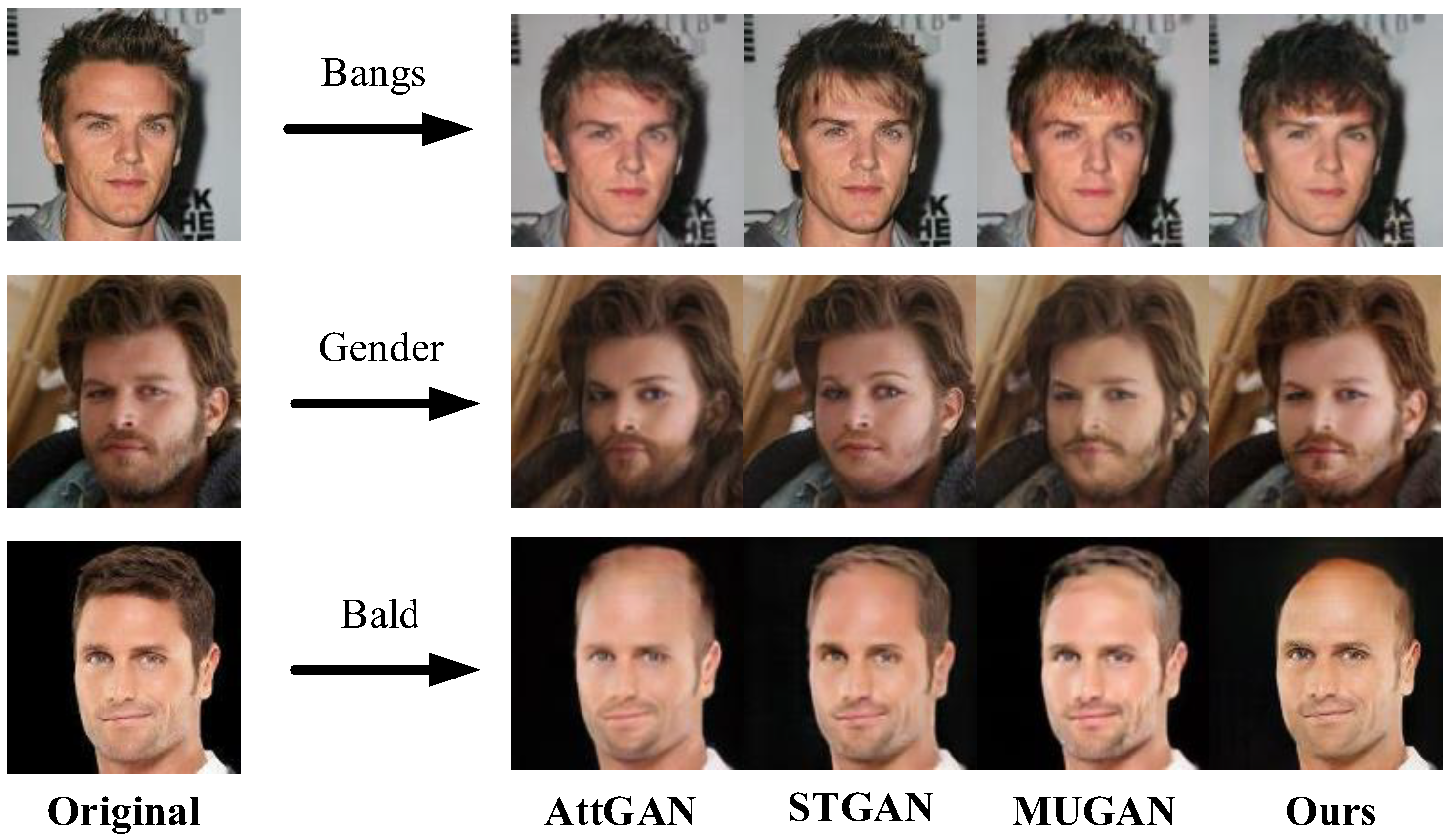
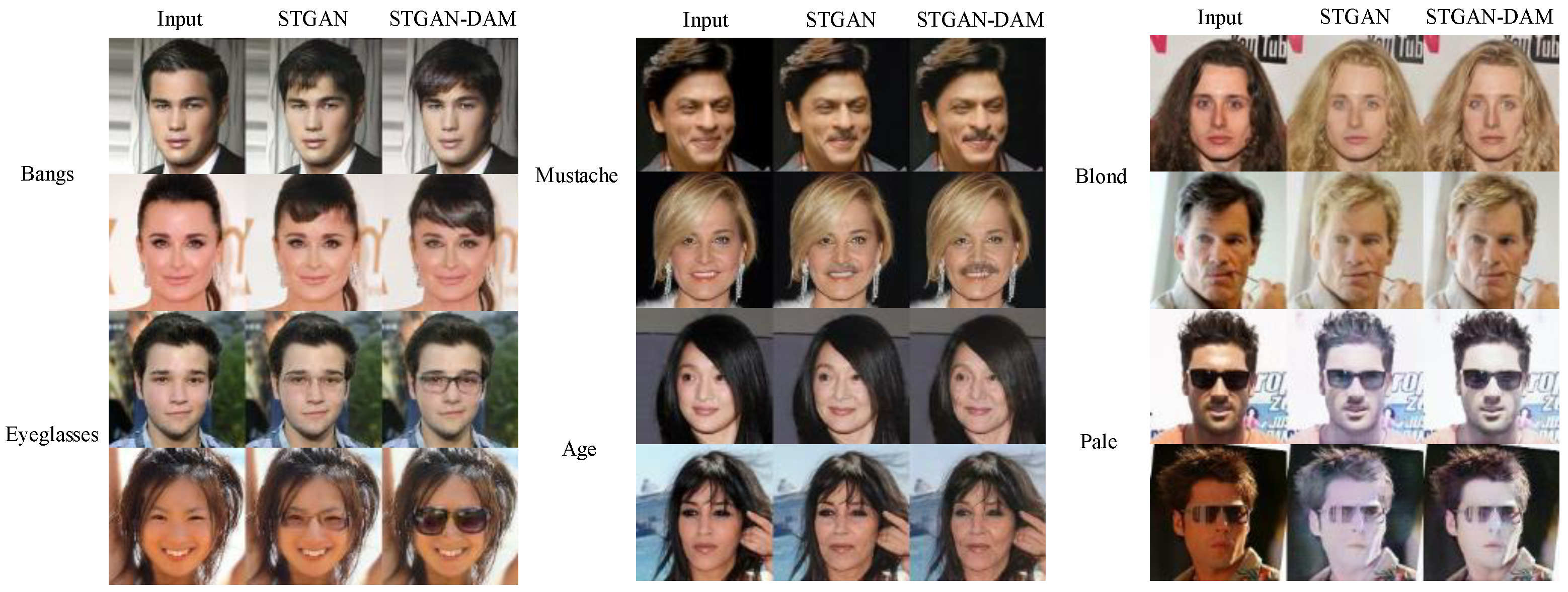
4.3. Results
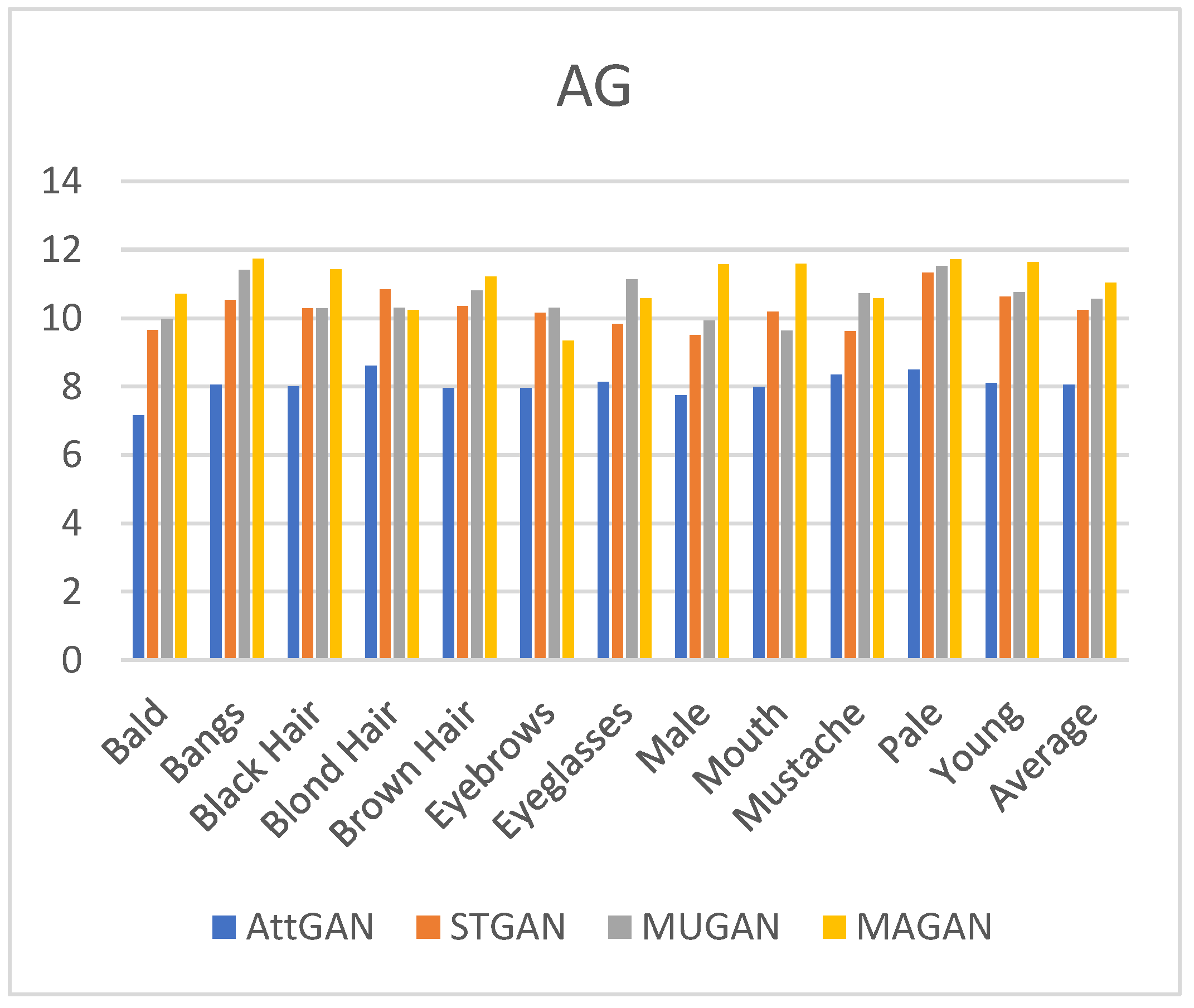
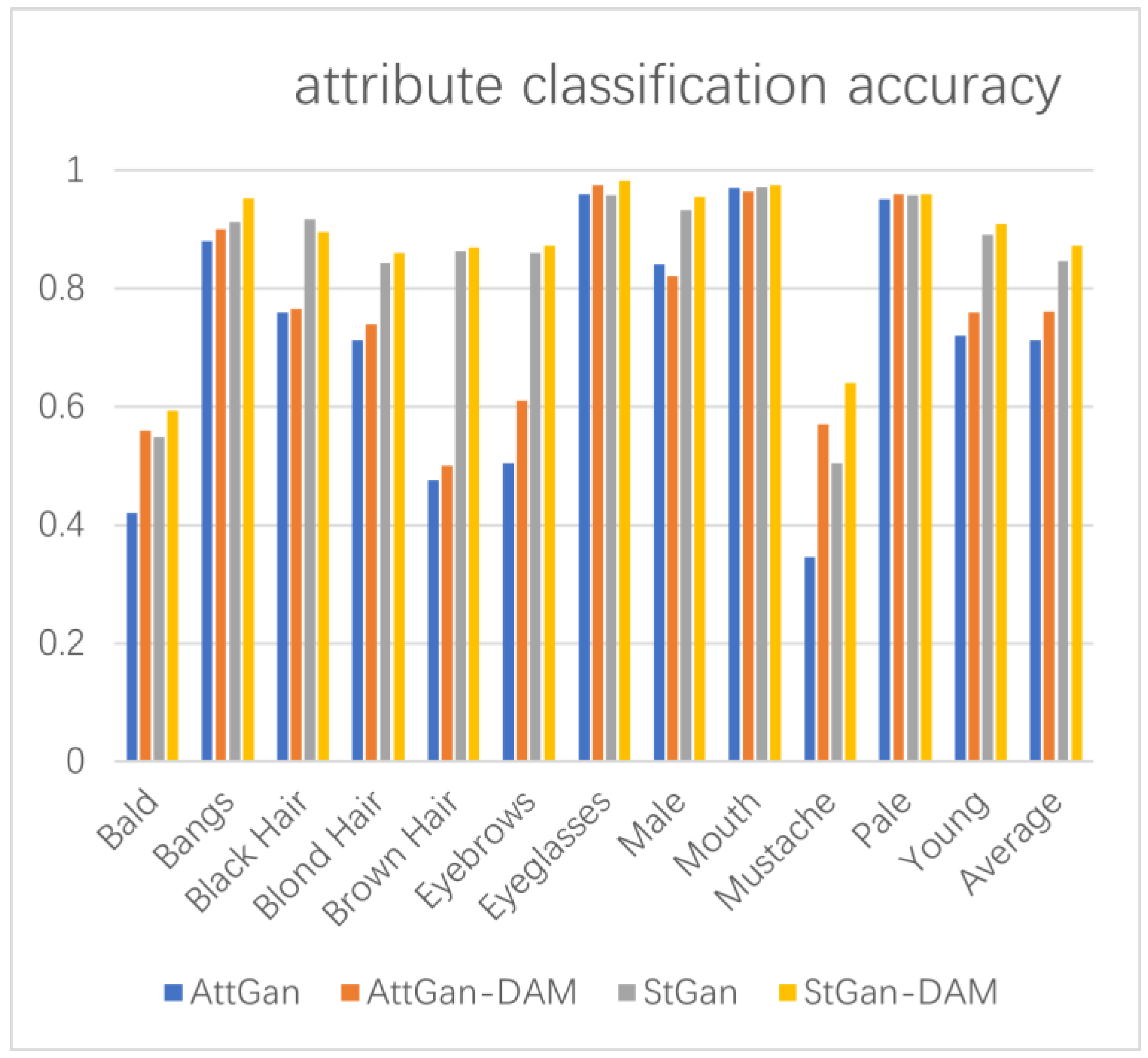
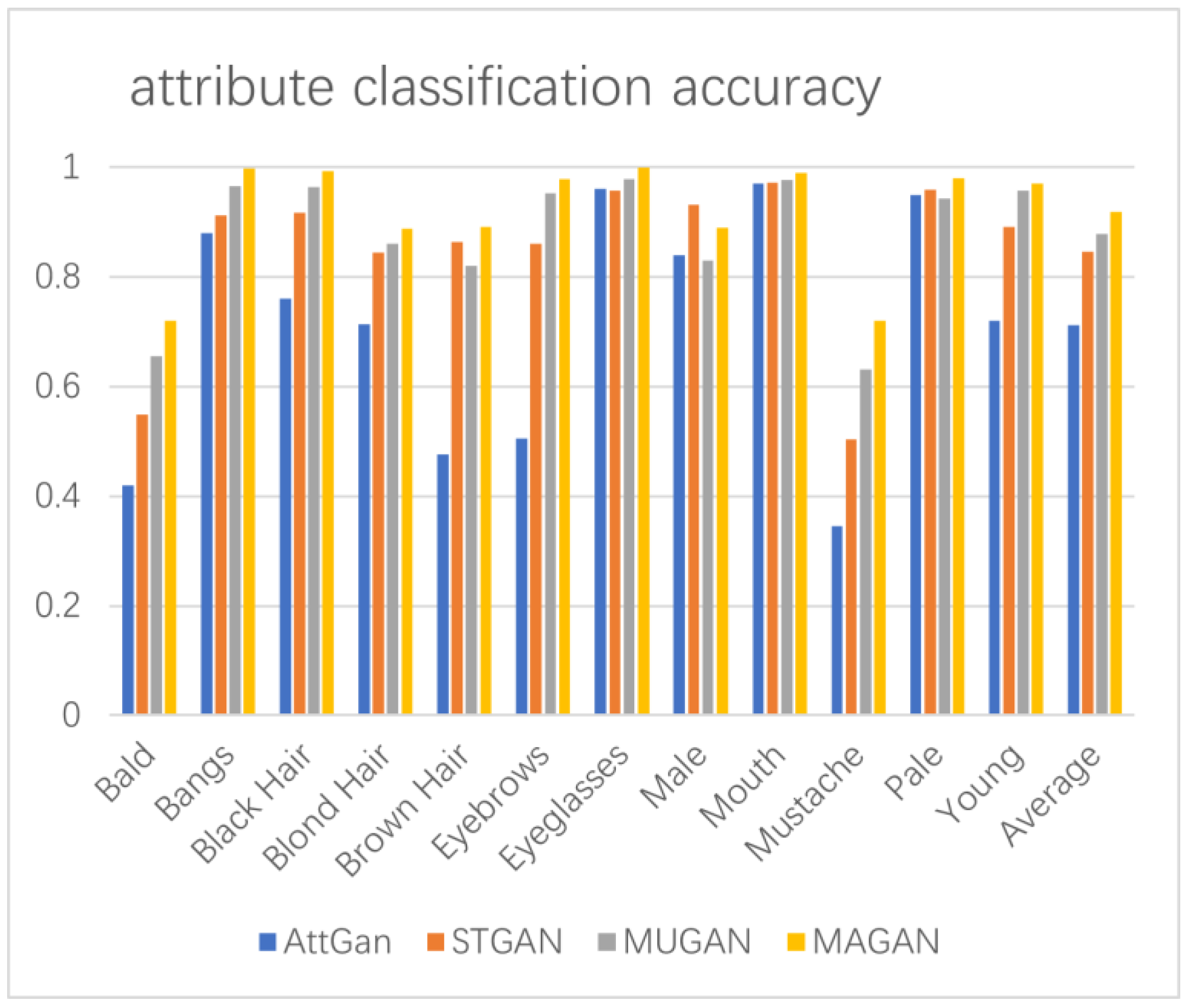
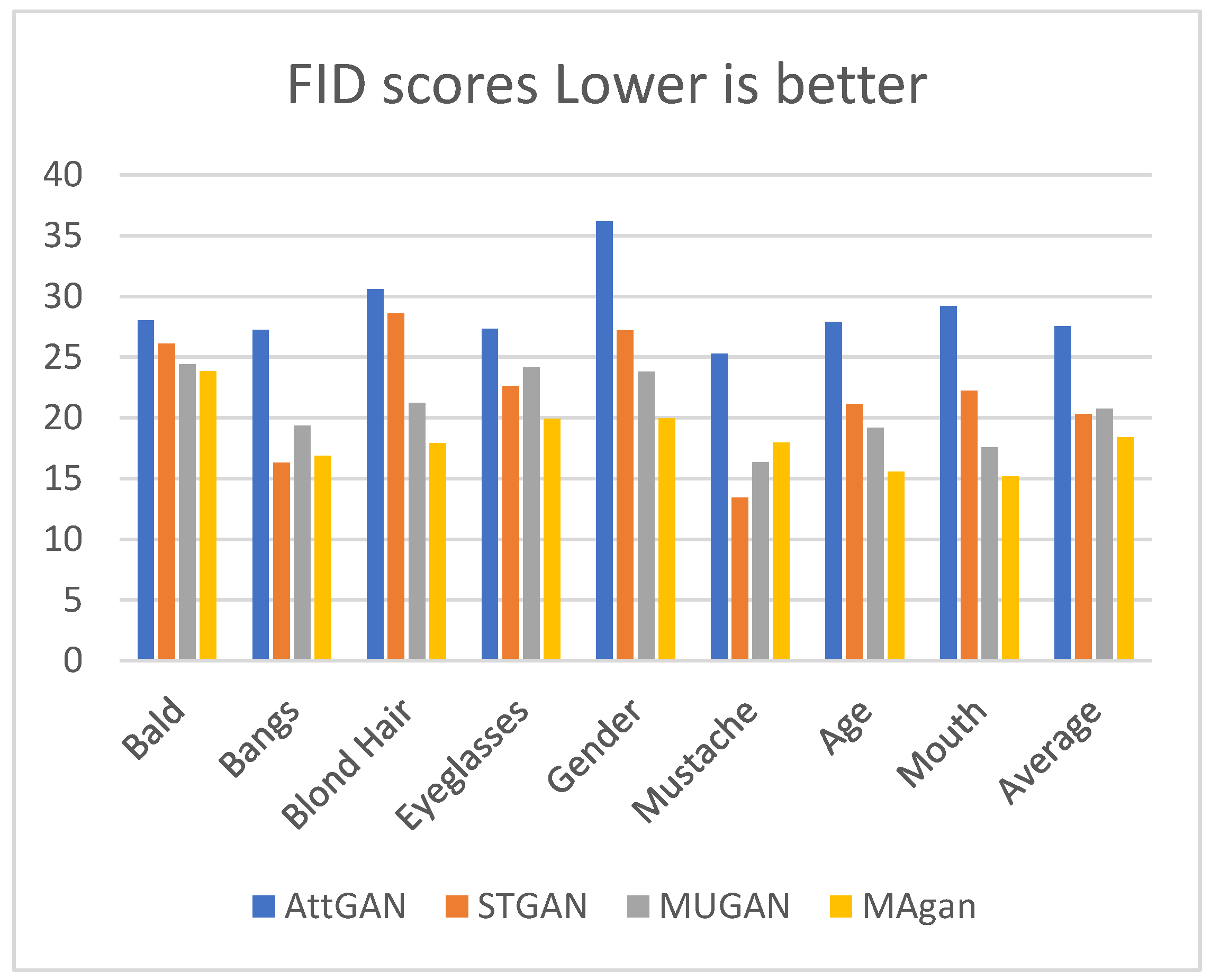
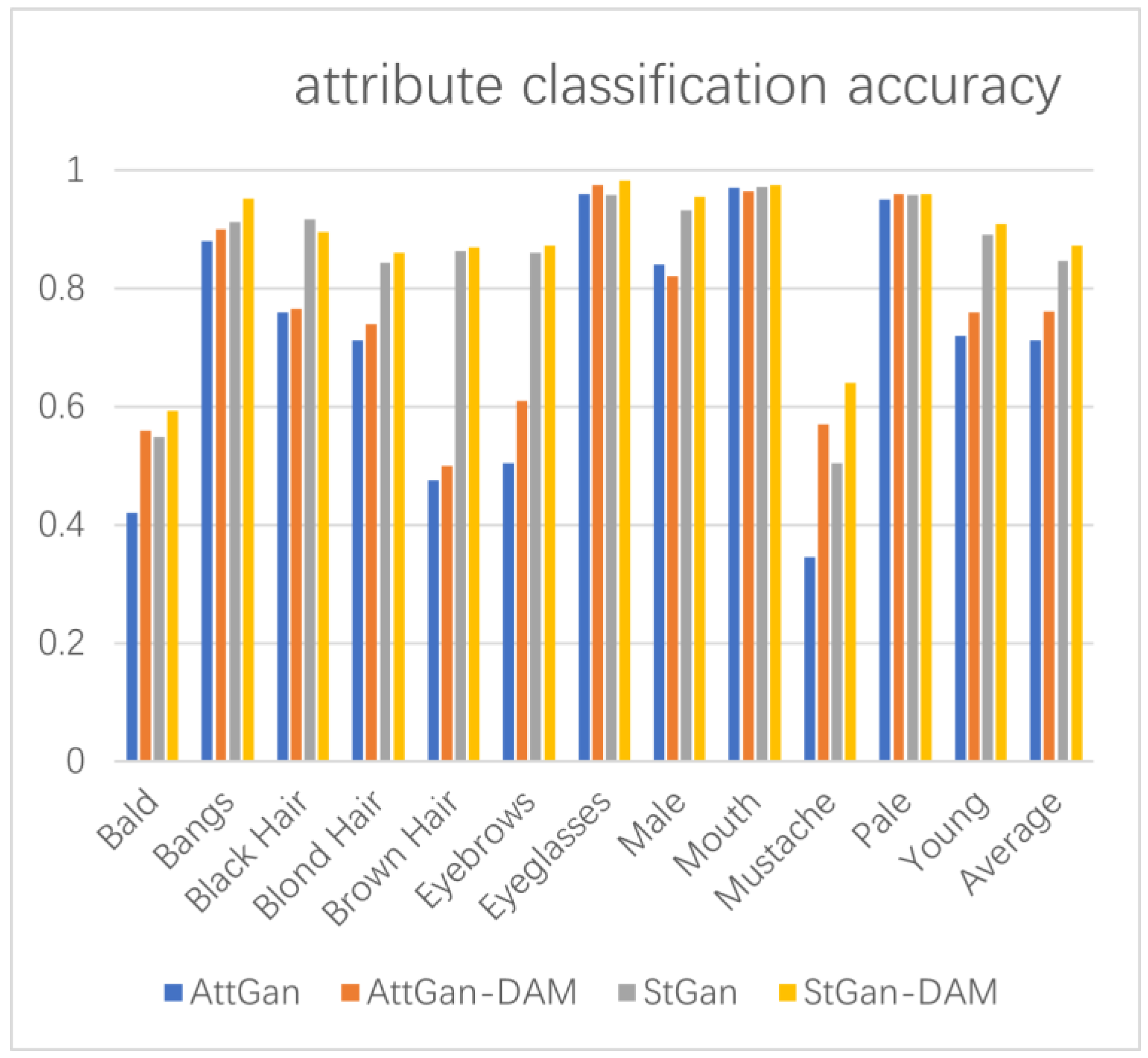
4.4. Evaluation
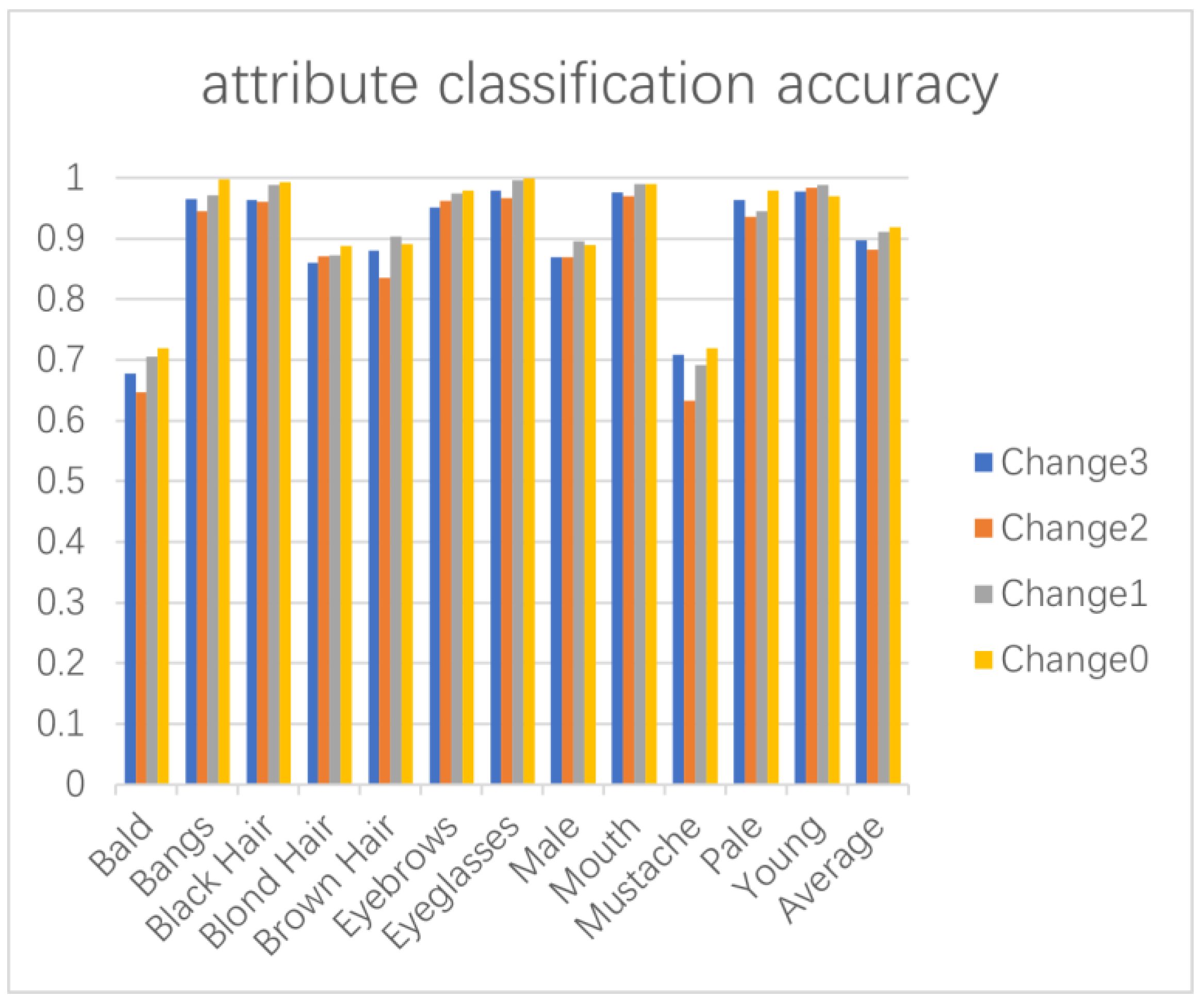
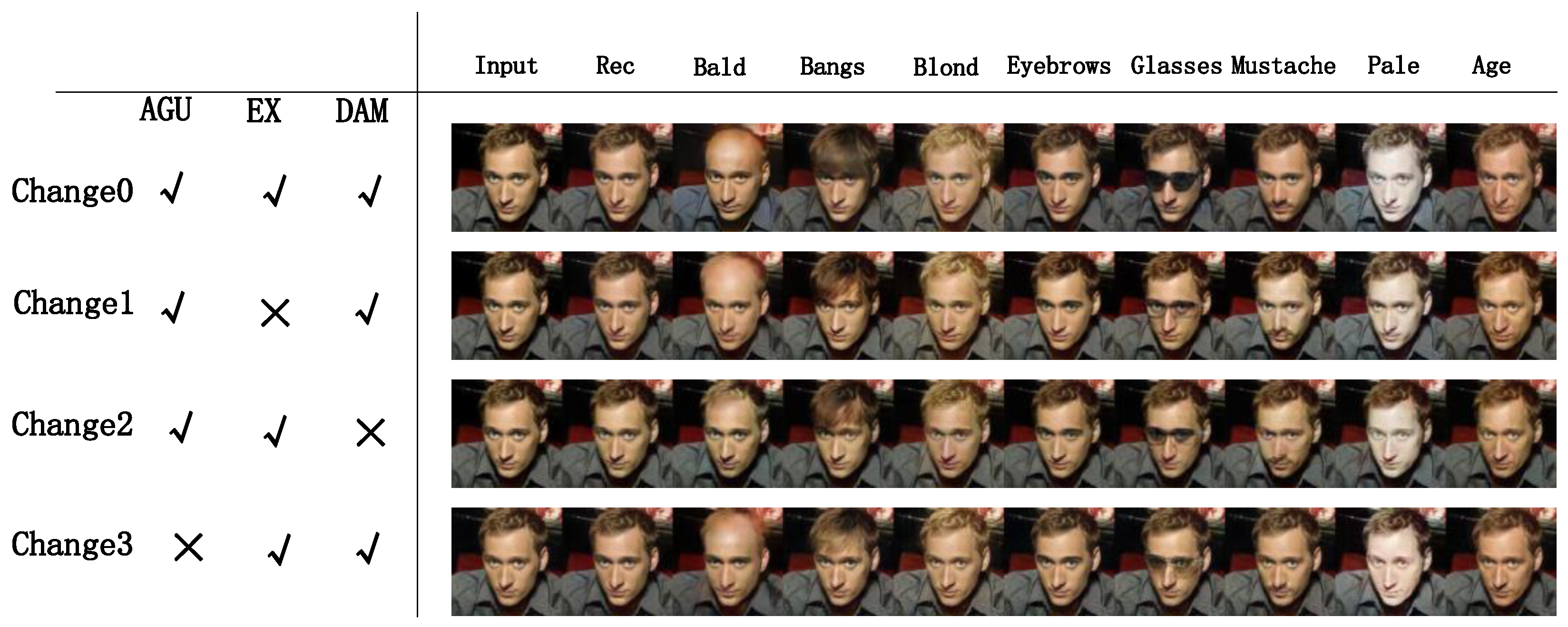
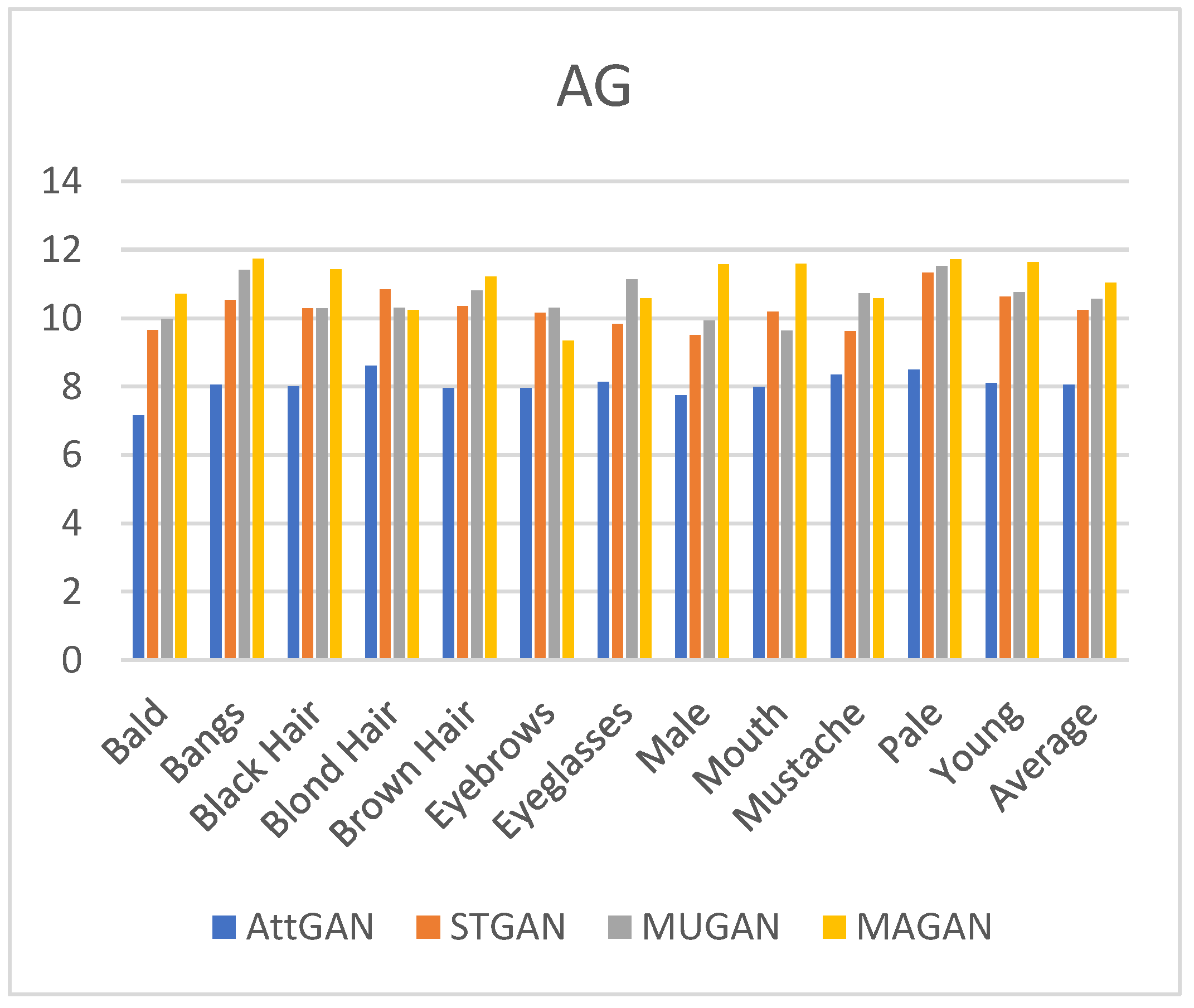
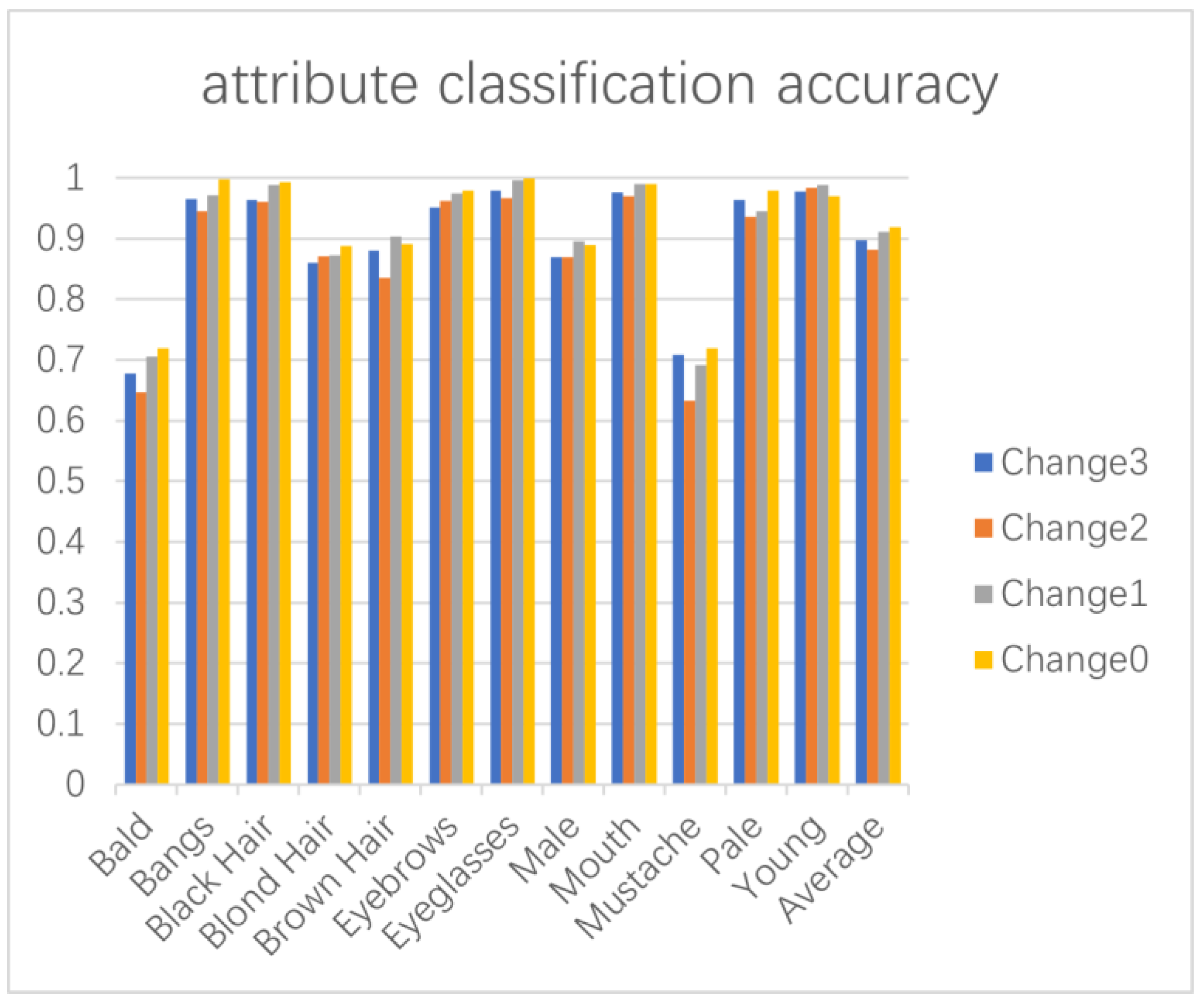
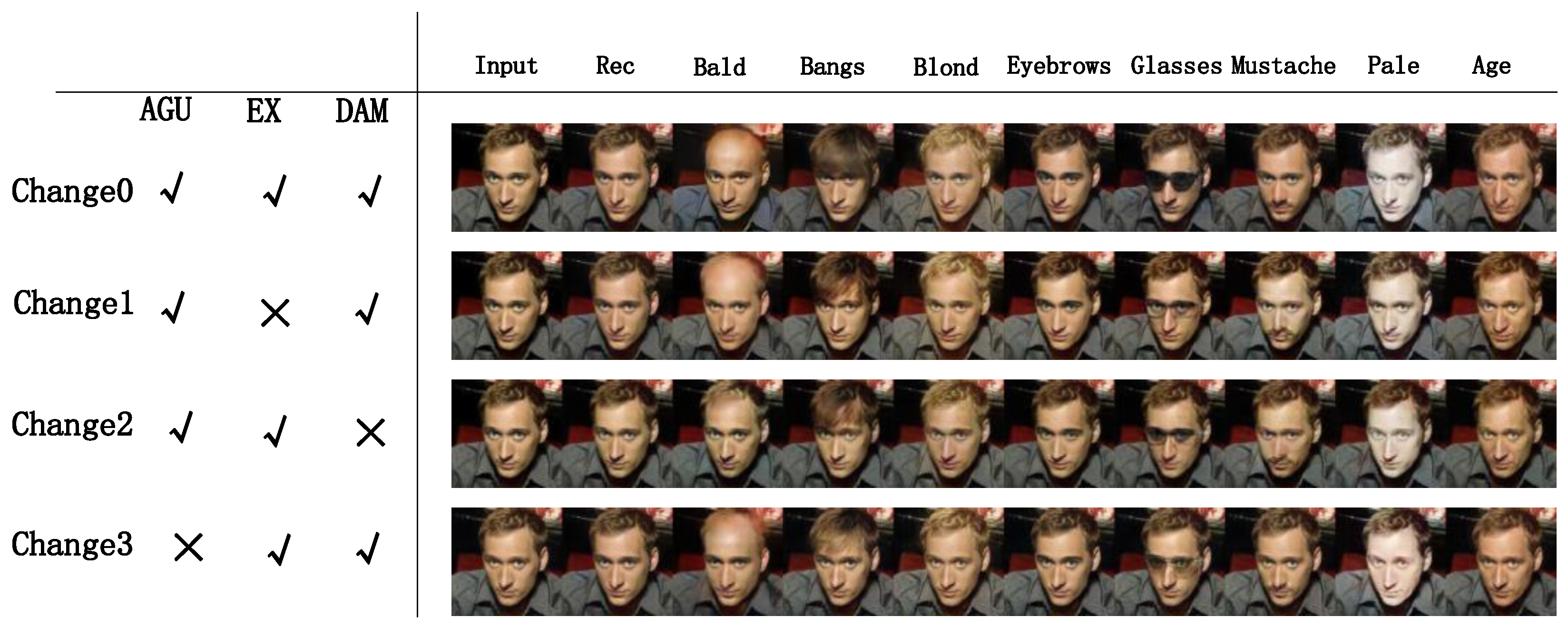
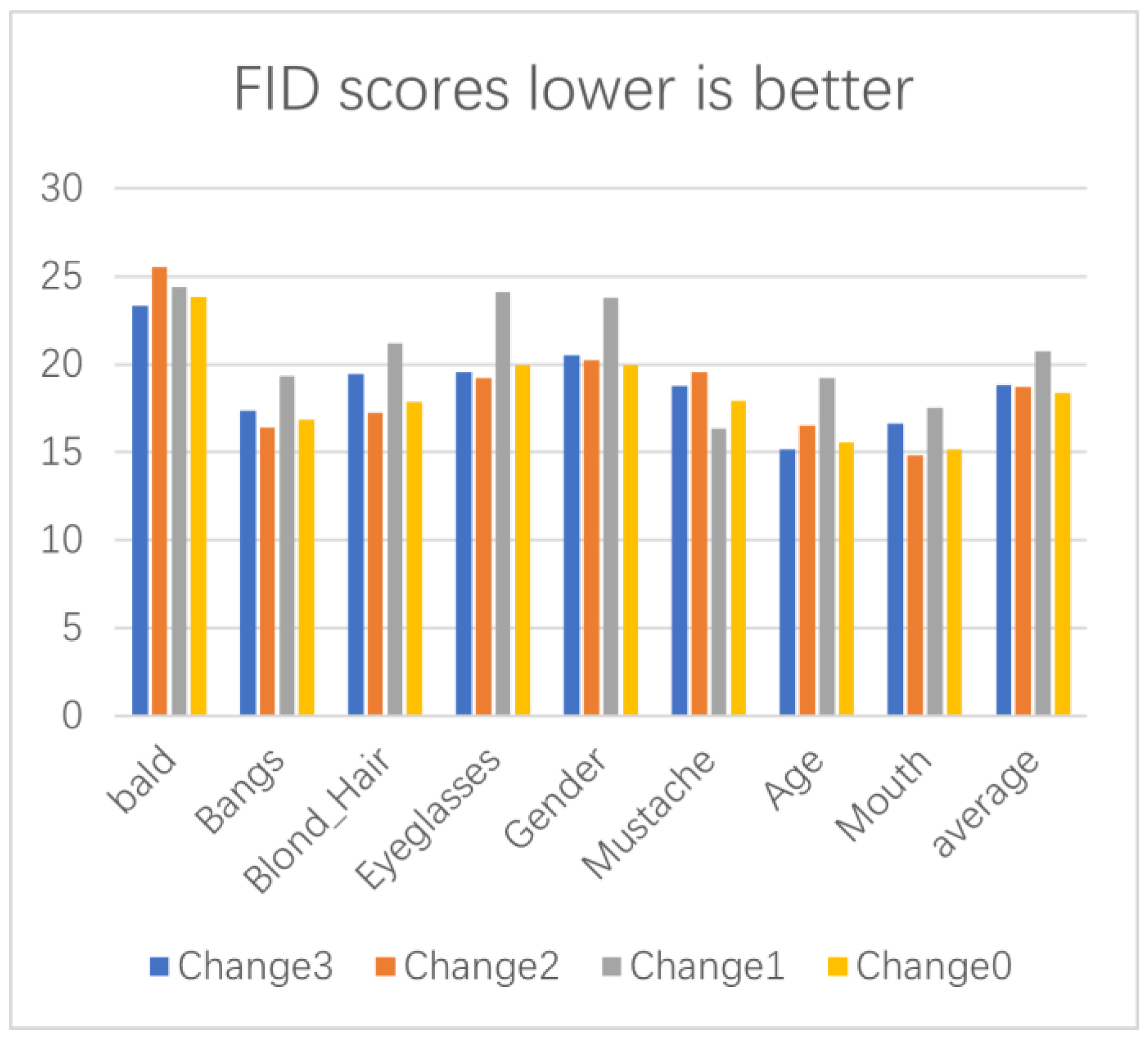
4.5. Ablation Study
4.5.1. Effect of AGU Structure
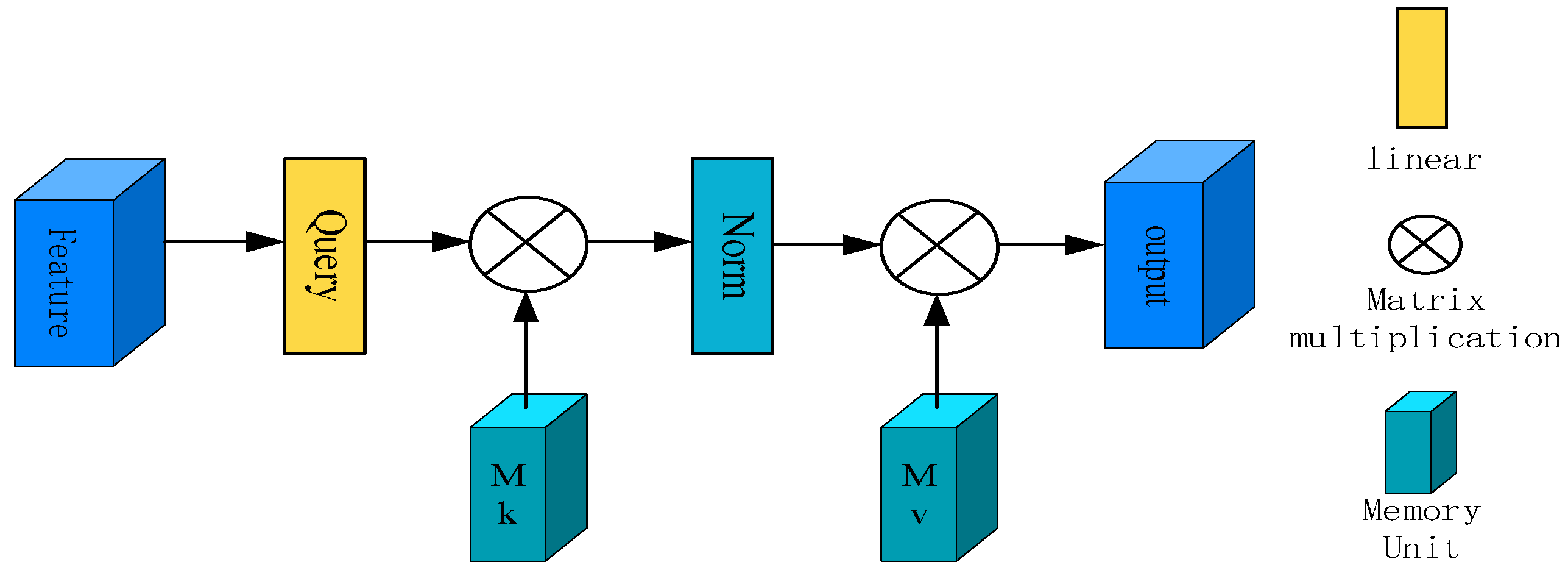
4.5.2. Effect of an External Attention Mechanism
4.5.3. Effect of DAM
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liu, X.; Wang, R.; Peng, H.; Yin, M.; Chen, C.F.; Li, X. Face beautification: Beyond makeup transfer. Front. Comput. Sci. 2022, 4, 910233. [Google Scholar] [CrossRef]
- Gupta, A.; Johnson, J.; Fei-Fei, L.; Savarese, S.; Alahi, A. Social gan: Socially acceptable trajectories with generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 23 June 2018; pp. 2255–2264. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. Stat 2014, 1050, 1. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising Diffusion Probabilistic Models. arXiv 2020, arXiv:2006.11239. [Google Scholar]
- Kim, M.; Liu, F.; Jain, A.; Liu, X. DCFace: Synthetic Face Generation with Dual Condition Diffusion Model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 12715–12725. [Google Scholar]
- Huang, Z.; Chan, K.; Jiang, Y.; Liu, Z. Collaborative Diffusion for Multi-Modal Face Generation and Editing. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 6080–6090. [Google Scholar]
- He, Z.; Zuo, W.; Kan, M.; Shan, S.; Chen, X. Attgan: Facial attribute editing by only changing what you want. IEEE Trans. Image Process. 2019, 28, 5464–5478. [Google Scholar] [CrossRef] [PubMed]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.W.; Kim, S.; Choo, J. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 23 June 2018; pp. 8789–8797. [Google Scholar]
- Liu, M.; Ding, Y.; Xia, M.; Liu, X.; Ding, E.; Zuo, W.; Wen, S. Stgan: A unified selective transfer network for arbitrary image attribute editing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 3673–3682. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Almahairi, A.; Rajeshwar, S.; Sordoni, A.; Bachman, P.; Courville, A. Augmented cyclegan: Learning many-to-many mappings from unpaired data. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 195–204. [Google Scholar]
- Zhang, K.; Su, Y.; Guo, X.; Qi, L.; Zhao, Z. MU-GAN: Facial attribute editing based on multi-attention mechanism. IEEE/CAA J. Autom. Sin. 2020, 8, 1614–1626. [Google Scholar] [CrossRef]
- Guo, M.H.; Liu, Z.N.; Mu, T.J.; Hu, S.M. Beyond self-attention: External attention using two linear layers for visual tasks. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 5436–5447. [Google Scholar] [CrossRef] [PubMed]
- Hinton, G.E.; Zemel, R. Autoencoders, minimum description length and Helmholtz free energy. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 30 November–3 December 1992. [Google Scholar]
- Nie, W.; Wang, Z.; Patel, A.B.; Baraniuk, R.G. An improved semi-supervised VAE for learning disentangled representations. arXiv 2020, arXiv:2006.07460. [Google Scholar]
- Huang, H.; He, R.; Sun, Z.; Tan, T. Introvae: Introspective variational autoencoders for photographic image synthesis. In Proceedings of the Advances in Neural Information Processing Systems 31, Montreal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive growing of gans for improved quality, stability, and variation. arXiv 2017, arXiv:1710.10196. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 4401–4410. [Google Scholar]
- Karras, T.; Aittala, M.; Laine, S.; Härkönen, E.; Hellsten, J.; Lehtinen, J.; Aila, T. Alias-free generative adversarial networks. Adv. Neural Inf. Process. Syst. 2021, 34, 852–863. [Google Scholar]
- Salehi, P.; Chalechale, A. Pix2pix-based stain-to-stain translation: A solution for robust stain normalization in histopathology images analysis. In Proceedings of the 2020 IEEE International Conference on Machine Vision and Image Processing (MVIP), Qom, Iran, 18–20 February 2020; pp. 1–7. [Google Scholar]
- Yang, G.; Fei, N.; Ding, M.; Liu, G.; Lu, Z.; Xiang, T. L2m-gan: Learning to manipulate latent space semantics for facial attribute editing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 2951–2960. [Google Scholar]
- Usman, B.; Dufour, N.; Saenko, K.; Bregler, C. Puppetgan: Cross-domain image manipulation by demonstration. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9450–9458. [Google Scholar]
- Li, M.; Zuo, W.; Zhang, D. Convolutional network for attribute-driven and identity-preserving human face generation. arXiv 2016, arXiv:1608.06434. [Google Scholar]
- Upchurch, P.; Gardner, J.; Pleiss, G.; Pless, R.; Snavely, N.; Bala, K.; Weinberger, K. Deep feature interpolation for image content changes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7064–7073. [Google Scholar]
- Li, M.; Zuo, W.; Zhang, D. Deep identity-aware transfer of facial attributes. arXiv 2016, arXiv:1610.05586. [Google Scholar]
- Shen, W.; Liu, R. Learning residual images for face attribute manipulation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4030–4038. [Google Scholar]
- Zhou, S.; Xiao, T.; Yang, Y.; Feng, D.; He, Q.; He, W. Genegan: Learning object transfiguration and attribute subspace from unpaired data. arXiv 2017, arXiv:1705.04932. [Google Scholar]
- Larsen, A.B.L.; Sønderby, S.K.; Larochelle, H.; Winther, O. Autoencoding beyond pixels using a learned similarity metric. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1558–1566. [Google Scholar]
- Perarnau, G.; Van De Weijer, J.; Raducanu, B.; Álvarez, J.M. Invertible conditional gans for image editing. arXiv 2016, arXiv:1611.06355. [Google Scholar]
- Lample, G.; Zeghidour, N.; Usunier, N.; Bordes, A.; Denoyer, L.; Ranzato, M.A. Fader networks: Manipulating images by sliding attributes. In Proceedings of the Advances in Neural Information Processing Systems 30, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Adler, J.; Lunz, S. Banach wasserstein gan. In Proceedings of the Advances in Neural Information Processing Systems 31, Montreal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep learning face attributes in the wild. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3730–3738. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. In Proceedings of the Advances in neural information processing systems 30, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Schmidt, M.; Le Roux, N.; Bach, F. Minimizing finite sums with the stochastic average gradient. Math. Program. 2017, 162, 83–112. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Average Accuracy | PSNR/SSIM |
|---|---|---|
| AttGAN | 71.16% | 20.65/0.801 |
| STGAN | 84.67% | 30.67/0.927 |
| MUGAN | 87.78% | 31.58/0.934 |
| MAGAN | 91.83% | 32.52/0.957 |
| Method | Average Accuracy | PSNR/SSIM |
|---|---|---|
| AttGAN | 70.59% | 19.35/0.755 |
| STGAN | 82.84% | 29.95/0.903 |
| MUGAN | 85.98% | 30.37/0.916 |
| MAGAN | 89.32% | 31.28/0.933 |
| Method | Average Accuracy |
|---|---|
| Change3 | 89.78% |
| Change2 | 88.17% |
| Change1 | 91.05% |
| Change0 | 91.83% |
| Method | Average AG | PSNR/SSIM |
|---|---|---|
| Change3 | 10.84 | 31.74/0.946 |
| Change2 | 10.68 | 31.58/0.934 |
| Change1 | 10.89 | 31.942/0.951 |
| Change0 | 11.03 | 32.52/0.957 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, Z.; Xu, W.; Ma, X.; Xu, C.; Xiao, H. Multi-Attention Infused Integrated Facial Attribute Editing Model: Enhancing the Robustness of Facial Attribute Manipulation. Electronics 2023, 12, 4111. https://doi.org/10.3390/electronics12194111
Lin Z, Xu W, Ma X, Xu C, Xiao H. Multi-Attention Infused Integrated Facial Attribute Editing Model: Enhancing the Robustness of Facial Attribute Manipulation. Electronics. 2023; 12(19):4111. https://doi.org/10.3390/electronics12194111
Chicago/Turabian StyleLin, Zhijie, Wangjun Xu, Xiaolong Ma, Caie Xu, and Han Xiao. 2023. "Multi-Attention Infused Integrated Facial Attribute Editing Model: Enhancing the Robustness of Facial Attribute Manipulation" Electronics 12, no. 19: 4111. https://doi.org/10.3390/electronics12194111
APA StyleLin, Z., Xu, W., Ma, X., Xu, C., & Xiao, H. (2023). Multi-Attention Infused Integrated Facial Attribute Editing Model: Enhancing the Robustness of Facial Attribute Manipulation. Electronics, 12(19), 4111. https://doi.org/10.3390/electronics12194111