


Few-Shot Object Detection with Memory Contrastive Proposal Based on Semantic Priors

Abstract
:1. Introduction
- We introduce semantic information and design the semantic fusion (SF) module, in which we achieve an interaction between semantic and visual information to enhance the representation of feature information and achieve a deeper focus on significant features.
- We designed the memory contrastive proposal (MCP) module to learn increasingly accurate feature representations by continuously updating the class-centered features. Thus, it enhances the intra-class embedding capability, allowing for a more discriminative embedding space to improve the performance of the detector.
- Experiments based on the PASCAL VOC and MS-COCO datasets are conducted to validate the effectiveness of our proposed method. Moreover, we use the visualization methods Grad-CAM and t-SNE for a more intuitive presentation of the experimental results.
2. Related Works
2.1. General Object Detection
2.2. Few-Shot Object Detection
2.3. Semantic in Visual Tasks
2.4. Contrastive Learning
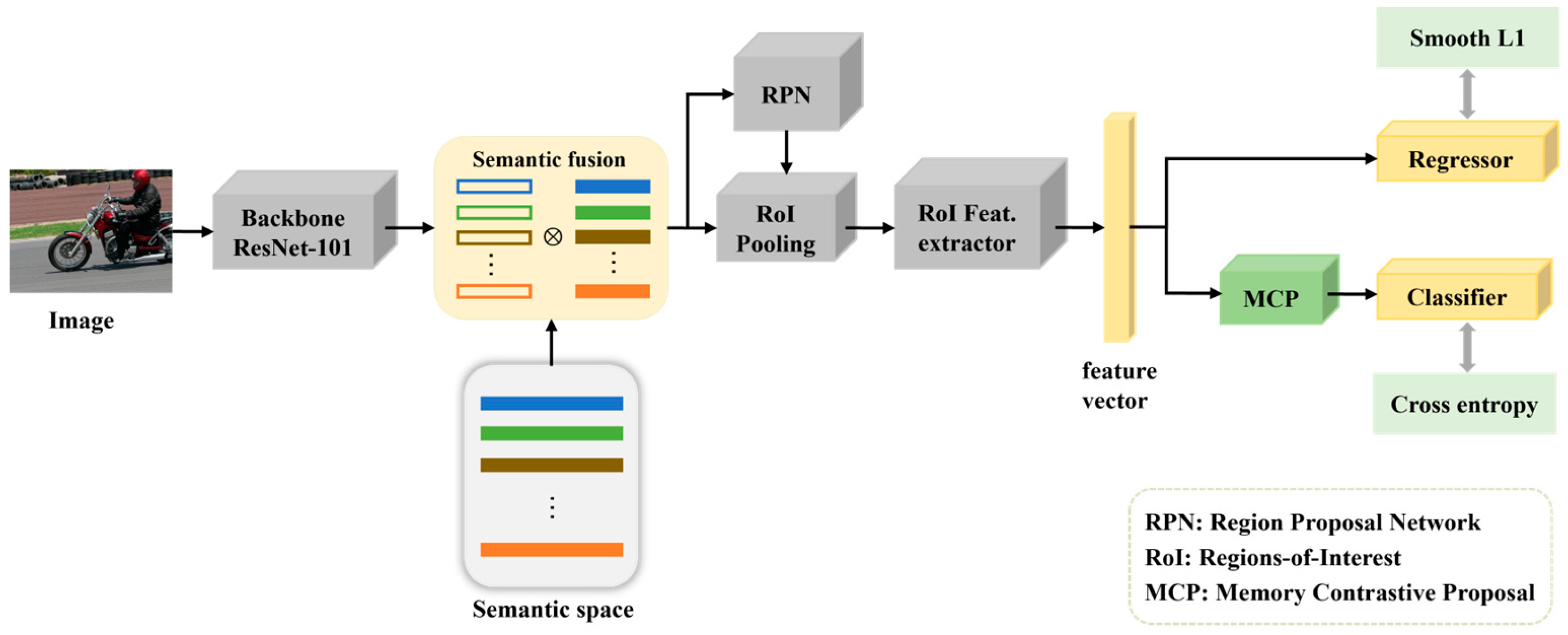
3. The Proposed Method
3.1. Problem Definition
3.2. Semantic Fusion
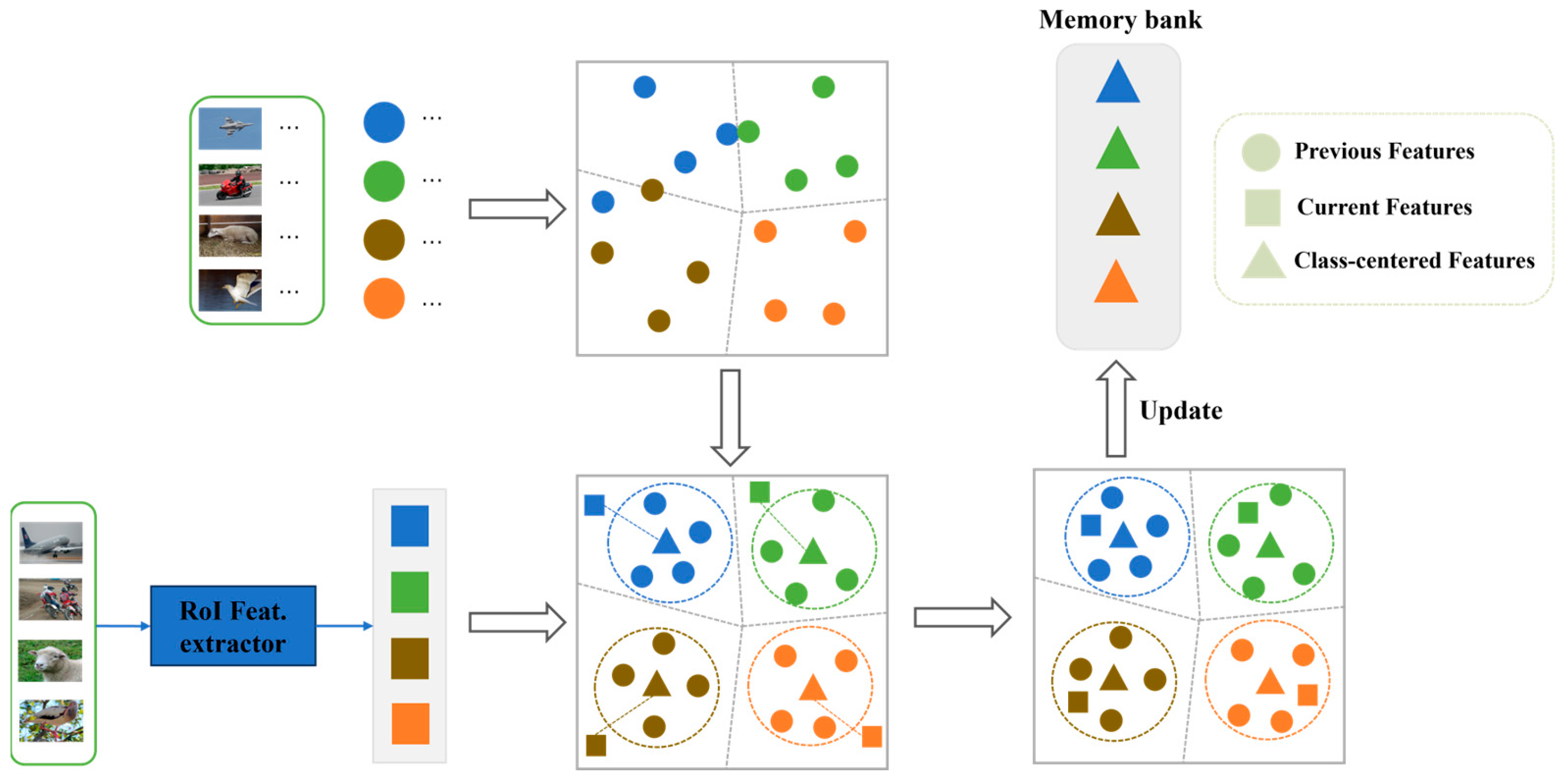
3.3. Memory Contrastive Proposal
| Algorithm 1 Memory contrastive proposal |
| Input: Base set , novel set , image , feature vector is represented as , momentum factor , temperature parameters . Initialize memory bank , where is represented as , and d represents the dimension of the feature vector. |
| Output: Update the memory bank M and contrastive loss . |
| 1: for do 2: RoI extract feature information for RPN: |
| 3: Update the memory bank M by the feature representation with a momentum 4: factor : 5: Calculate memory contrastive proposal loss: 6: where represents the class-centered features corresponding to 7: end for |
3.4. Training Strategy
4. Experiments
4.1. Implementation Details
4.2. Results
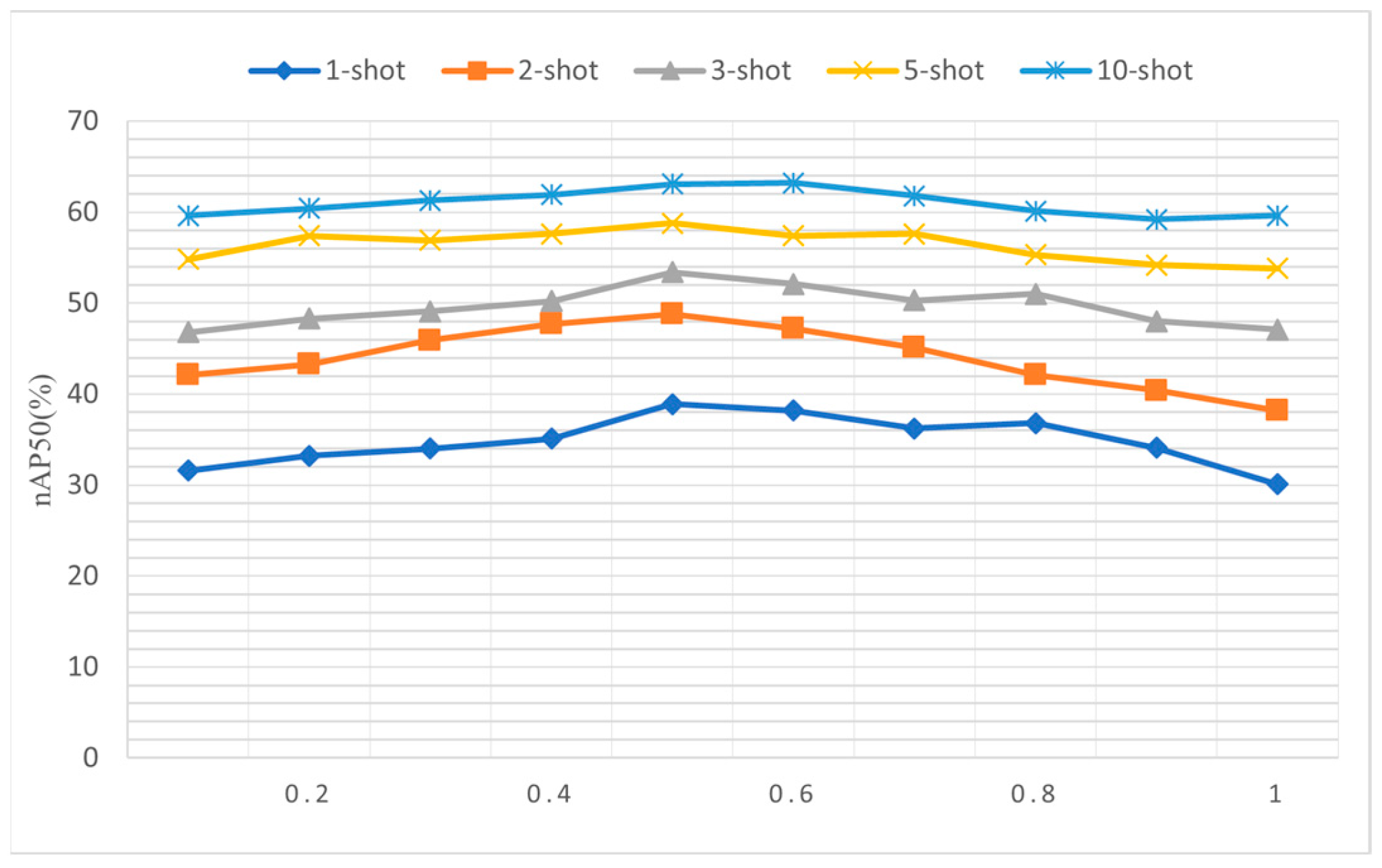
4.3. Ablation Experiment
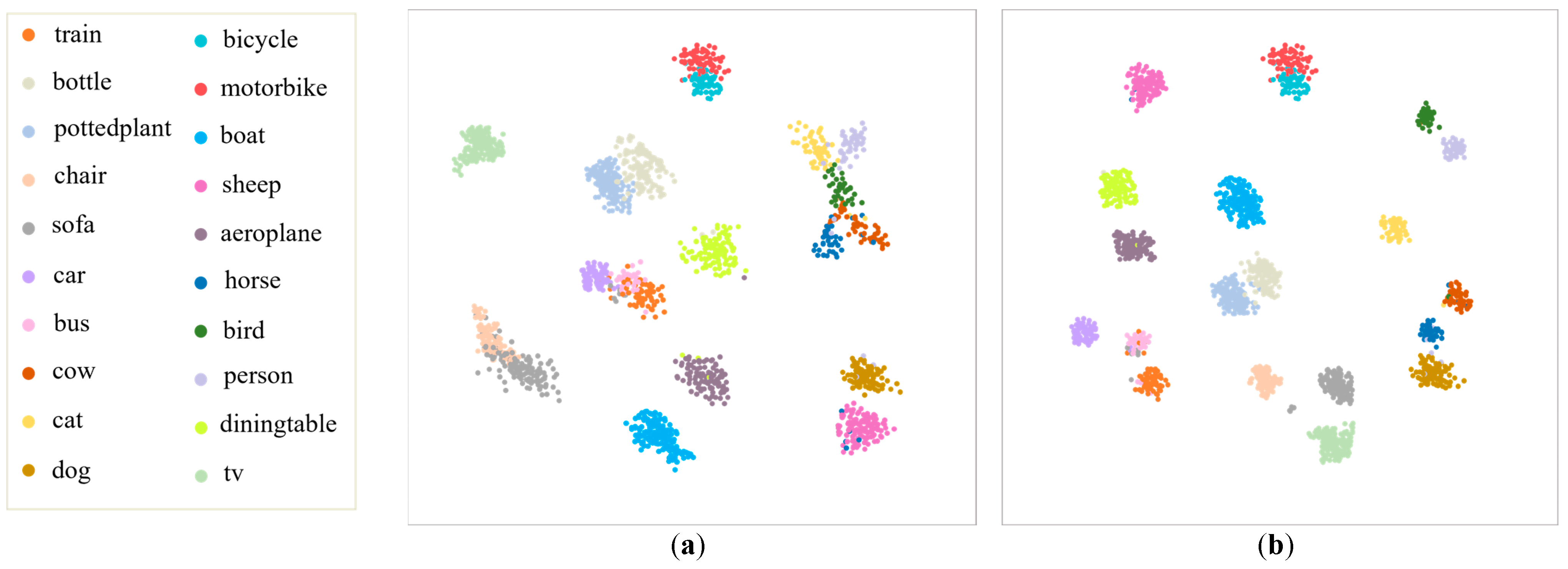
4.4. Visualization Results
5. Limitations
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kong, T.; Yao, A.; Chen, Y.; Sun, F. Hypernet: Towards accurate region proposal generation and joint object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 845–853. [Google Scholar]
- Yu, G.; Fan, H.; Zhou, H.; Wu, T.; Zhu, H. Vehicle target detection method based on improved SSD model. J. Artif. Intell. 2020, 2, 125. [Google Scholar] [CrossRef]
- Micheal, A.A.; Vani, K.; Sanjeevi, S.; Lin, C.-H. Object detection and tracking with UAV data using deep learning. J. Indian Soc. Remote Sens. 2021, 49, 463–469. [Google Scholar] [CrossRef]
- Zhang, X.; Wan, F.; Liu, C.; Ji, X.; Ye, Q. Learning to match anchors for visual object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3096–3109. [Google Scholar] [CrossRef] [PubMed]
- Kang, B.; Liu, Z.; Wang, X.; Yu, F.; Feng, J.; Darrell, T. Few-shot object detection via feature reweighting. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8420–8429. [Google Scholar]
- Yan, X.; Chen, Z.; Xu, A.; Wang, X.; Liang, X.; Lin, L. Meta r-cnn: Towards general solver for instance-level low-shot learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9577–9586. [Google Scholar]
- Hu, H.; Bai, S.; Li, A.; Cui, J.; Wang, L. Dense relation distillation with context-aware aggregation for few-shot object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10185–10194. [Google Scholar]
- Xiao, Y.; Lepetit, V.; Marlet, R. Few-shot object detection and viewpoint estimation for objects in the wild. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 3090–3106. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Huang, T.E.; Darrell, T.; Gonzalez, J.E.; Yu, F. Frustratingly simple few-shot object detection. arXiv 2020, arXiv:2003.06957. [Google Scholar]
- Sun, B.; Li, B.; Cai, S.; Yuan, Y.; Zhang, C. Fsce: Few-shot object detection via contrastive proposal encoding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7352–7362. [Google Scholar]
- Wu, J.; Liu, S.; Huang, D.; Wang, Y. Multi-scale positive sample refinement for few-shot object detection. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XVI 16, 2020. pp. 456–472. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 39, 91–99. [Google Scholar] [CrossRef] [PubMed]
- Schwartz, E.; Karlinsky, L.; Feris, R.; Giryes, R.; Bronstein, A. Baby steps towards few-shot learning with multiple semantics. Pattern Recognit. Lett. 2022, 160, 142–147. [Google Scholar] [CrossRef]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14, 2016. pp. 21–37. [Google Scholar]
- Chen, X.; Yu, J.; Kong, S.; Wu, Z.; Wen, L. Joint anchor-feature refinement for real-time accurate object detection in images and videos. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 594–607. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Li, G.; Zheng, C.; Su, B. Transductive distribution calibration for few-shot learning. Neurocomputing 2022, 500, 604–615. [Google Scholar] [CrossRef]
- Cui, Z.; Wang, Q.; Guo, J.; Lu, N. Few-shot classification of façade defects based on extensible classifier and contrastive learning. Autom. Constr. 2022, 141, 104381. [Google Scholar] [CrossRef]
- Li, B.; Wang, C.; Reddy, P.; Kim, S.; Scherer, S. Airdet: Few-shot detection without fine-tuning for autonomous exploration. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 427–444. [Google Scholar]
- Zhou, Z.; Li, S.; Guo, W.; Gu, Y. Few-Shot Aircraft Detection in Satellite Videos Based on Feature Scale Selection Pyramid and Proposal Contrastive Learning. Remote Sens. 2022, 14, 4581. [Google Scholar] [CrossRef]
- Chen, L.; Zhang, H.; Xiao, J.; Liu, W.; Chang, S.-F. Zero-shot visual recognition using semantics-preserving adversarial embedding networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1043–1052. [Google Scholar]
- Chen, S.; Xie, G.; Liu, Y.; Peng, Q.; Sun, B.; Li, H.; You, X.; Shao, L. Hsva: Hierarchical semantic-visual adaptation for zero-shot learning. Adv. Neural Inf. Process. Syst. 2021, 34, 16622–16634. [Google Scholar]
- Li, Y.; Wang, D.; Hu, H.; Lin, Y.; Zhuang, Y. Zero-shot recognition using dual visual-semantic mapping paths. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3279–3287. [Google Scholar]
- Chen, R.; Chen, T.; Hui, X.; Wu, H.; Li, G.; Lin, L. Knowledge graph transfer network for few-shot recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 10575–10582. [Google Scholar]
- Zhu, C.; Chen, F.; Ahmed, U.; Shen, Z.; Savvides, M. Semantic relation reasoning for shot-stable few-shot object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8782–8791. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- Zeng, H.; Cui, X. Simclrt: A simple framework for contrastive learning of rumor tracking. Eng. Appl. Artif. Intell. 2022, 110, 104757. [Google Scholar] [CrossRef]
- Khosla, P.; Teterwak, P.; Wang, C.; Sarna, A.; Tian, Y.; Isola, P.; Maschinot, A.; Liu, C.; Krishnan, D. Supervised contrastive learning. Adv. Neural Inf. Process. Syst. 2020, 33, 18661–18673. [Google Scholar]
- Quan, J.; Ge, B.; Chen, L. Cross attention redistribution with contrastive learning for few shot object detection. Displays 2022, 72, 102162. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13, 2014. pp. 740–755. [Google Scholar]
- Wang, Y.-X.; Ramanan, D.; Hebert, M. Meta-learning to detect rare objects. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9925–9934. [Google Scholar]
- Wu, A.; Han, Y.; Zhu, L.; Yang, Y. Universal-prototype enhancing for few-shot object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 9567–9576. [Google Scholar]
- Lee, H.; Lee, M.; Kwak, N. Few-shot object detection by attending to per-sample-prototype. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 4–8 January 2022; pp. 2445–2454. [Google Scholar]
- Zhang, S.; Wang, L.; Murray, N.; Koniusz, P. Kernelized few-shot object detection with efficient integral aggregation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 19207–19216. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method/Shots | Novel Split 1 | Novel Split 2 | Novel Split 3 | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 5 | 10 | 1 | 2 | 3 | 5 | 10 | 1 | 2 | 3 | 5 | 10 | |
| Meta-Det | 17.1 | 19.1 | 28.9 | 35.0 | 48.8 | 18.2 | 20.6 | 25.9 | 30.6 | 41.5 | 20.1 | 22.3 | 27.9 | 41.9 | 42.9 |
| Meta R-CNN | 19.9 | 25.5 | 35.0 | 45.7 | 51.5 | 10.4 | 19.4 | 29.6 | 34.8 | 45.4 | 14.3 | 18.2 | 27.5 | 41.2 | 48.1 |
| TFA | 39.8 | 36.1 | 44.7 | 55.7 | 56.0 | 23.5 | 26.9 | 34.1 | 35.1 | 39.1 | 30.8 | 34.8 | 42.8 | 49.5 | 49.8 |
| MPSR | 31.5 | 40.6 | 48.3 | 55.2 | 60.8 | 24.4 | - | 39.2 | 39.9 | 47.8 | 35.6 | - | 42.3 | 48.0 | 49.7 |
| FSCE | 32.9 | 44.0 | 46.8 | 52.9 | 59.7 | 27.3 | 30.6 | 38.4 | 43.0 | 48.5 | 22.6 | 33.4 | 39.5 | 47.3 | 54.0 |
| FSRW | 14.8 | 15.5 | 26.7 | 33.9 | 47.2 | 15.7 | 15.3 | 22.7 | 30.1 | 40.5 | 21.3 | 25.6 | 28.4 | 42.8 | 45.9 |
| FSOD-up | 34.6 | 43.1 | 49.3 | 53.4 | 59.7 | 29.5 | 29.9 | 37.2 | 39.4 | 46.3 | 32.5 | 38.7 | 41.9 | 45.6 | 51.5 |
| CAReD | 36.5 | 45.2 | 47.1 | 50.8 | 58.8 | 26.4 | 31.0 | 37.9 | 43.5 | 51.1 | 20.2 | 33.8 | 41.6 | 48.3 | 55.3 |
| QSAM | 31.1 | 36.1 | 39.2 | 50.7 | 59.4 | 22.9 | 29.4 | 32.1 | 35.4 | 42.7 | 24.3 | 28.6 | 35.0 | 50.0 | 53.6 |
| KFSOD | 44.6 | - | 54.4 | 60.9 | 65.8 | 37.8 | - | 43.1 | 48.1 | 50.4 | 34.8 | - | 44.1 | 52.7 | 53.9 |
| Ours | 45.2 | 49.7 | 55.3 | 61.8 | 66.4 | 32.4 | 34.1 | 43.6 | 48.7 | 50.1 | 34.9 | 41.9 | 46.3 | 53.8 | 56.2 |
| Method | 10-Shot | 30-Shot | ||||
|---|---|---|---|---|---|---|
| AP | AP50 | AP75 | AP | AP50 | AP75 | |
| Meta-Det | 7.1 | 14.6 | 6.1 | 11.3 | 21.7 | 8.1 |
| Meta R-CNN | 8.7 | 19.1 | 6.6 | 12.4 | 25.3 | 10.8 |
| TFA | 10.0 | - | 9.3 | 13.7 | - | 13.4 |
| MPSR | 9.8 | 17.9 | 9.7 | 14.1 | 25.4 | 14.2 |
| FSCE | 11.1 | - | 9.8 | 15.3 | - | 14.2 |
| FSRW | 5.6 | 12.3 | 4.6 | 9.1 | 19.0 | 7.6 |
| FSOD-up | 11.0 | - | 10.7 | 15.6 | - | 15.7 |
| CAReD | 15.5 | 25.1 | 14.9 | 18.4 | 30.1 | 17.7 |
| QSAM | 13.0 | 24.7 | 12.1 | 15.3 | 29.3 | 14.5 |
| Ours | 15.6 | 26.4 | 15.7 | 19.3 | 33.6 | 18.9 |
| SF | MCP | 1-Shot | 2-Shot | 3-Shot | 5-Shot | 10-Shot |
|---|---|---|---|---|---|---|
| - | - | 31.6 | 41.2 | 48.3 | 50.4 | 55.7 |
| √ | - | 34.3 | 44.4 | 50.2 | 50.9 | 56.2 |
| - | √ | 36.1 | 43.8 | 51.7 | 56.3 | 60.2 |
| √ | √ | 39.2 | 45.1 | 52.4 | 59.7 | 61.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, L.; Xu, H.; Xiao, J.; Huang, Y. Few-Shot Object Detection with Memory Contrastive Proposal Based on Semantic Priors. Electronics 2023, 12, 3835. https://doi.org/10.3390/electronics12183835
Xiao L, Xu H, Xiao J, Huang Y. Few-Shot Object Detection with Memory Contrastive Proposal Based on Semantic Priors. Electronics. 2023; 12(18):3835. https://doi.org/10.3390/electronics12183835
Chicago/Turabian StyleXiao, Linlin, Huahu Xu, Junsheng Xiao, and Yuzhe Huang. 2023. "Few-Shot Object Detection with Memory Contrastive Proposal Based on Semantic Priors" Electronics 12, no. 18: 3835. https://doi.org/10.3390/electronics12183835
APA StyleXiao, L., Xu, H., Xiao, J., & Huang, Y. (2023). Few-Shot Object Detection with Memory Contrastive Proposal Based on Semantic Priors. Electronics, 12(18), 3835. https://doi.org/10.3390/electronics12183835