


Development of a Hybrid Method for Multi-Stage End-to-End Recognition of Grocery Products in Shelf Images



Abstract
1. Introduction

- A new sequential approach, including a product-independent detection process and a hybrid product recognition concept enhanced by a refinement procedure, is presented to handle a wide variety of products such as constantly renewed packaging and newly added products in grocery products.
- A model in which different feature extraction methods are used together is proposed, since different methods provide better results in different products due to the wide variety of products. Therefore, a combination of these methods can be more promising for such an application.
- The performance of the proposed approach in product recognition is compared with the different methods presented in the product detection and classification stages. In addition, run-time evaluation is included to show that the performance and run-time the proposed system is balanced.
2. Related Works
2.1. Three-Stage Non-End-to-End Product Recognition
2.2. Product Detection Stage
2.3. Product Classification Stage
2.4. Product Detection and Classification Stages Performed Jointly
2.5. Multi-Stage End-to-End Product Recognition
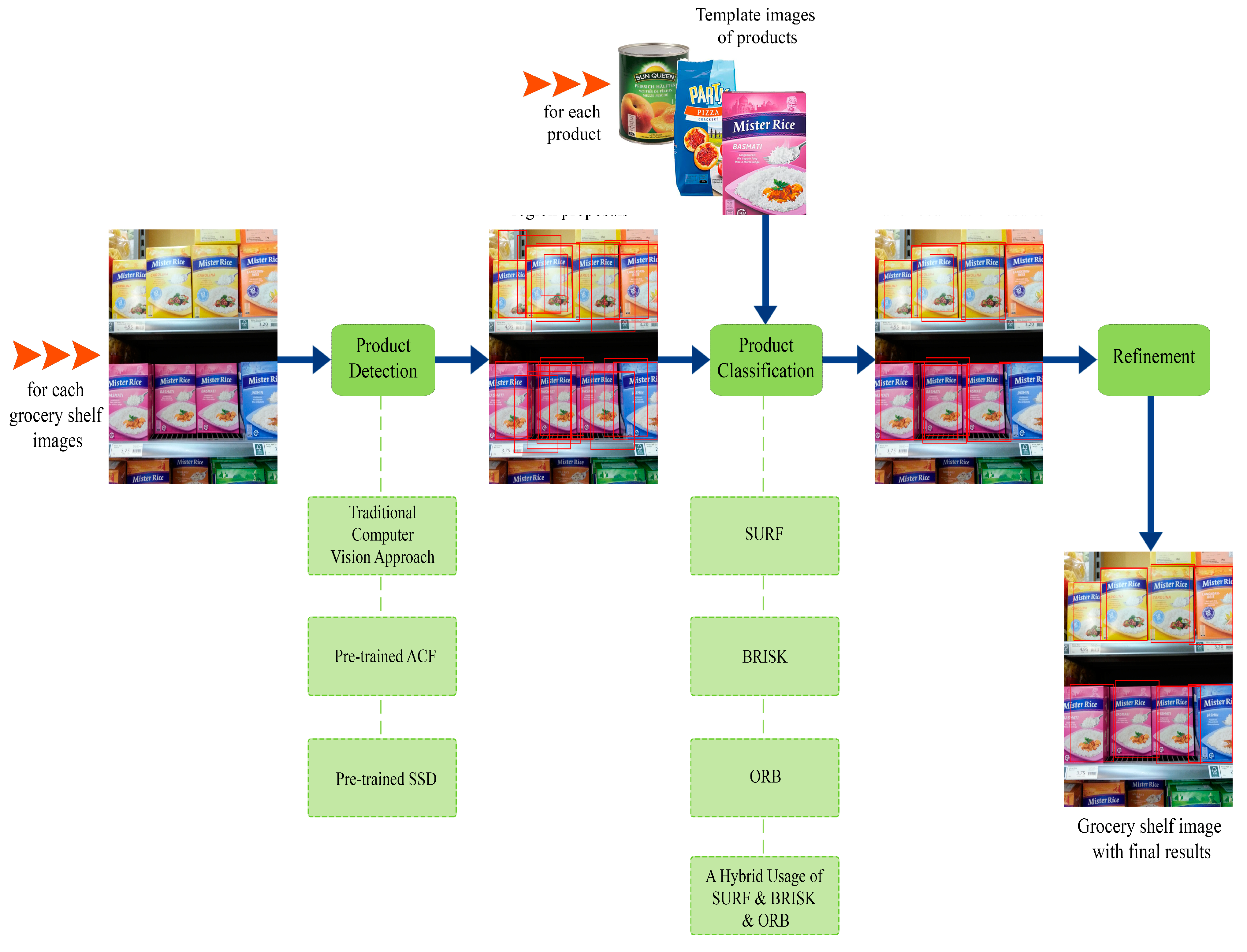
3. Multi-Stage End-to-End Product Recognition Approach
- Although the performance of the state-of-art object detection methods [5,41,44,45] have been improved, the success of object recognition decreases as the number of classes increases [51]. Therefore, product recognition directly with the state-of-art object detection methods is not sufficient for large-scale datasets.
- Data collection for product recognition problem have difficulty due to the high number of classes, in addition to the presence of constantly renewed packaging and newly added products. In the case of an insufficient number of images for each class, product locations can be determined with a single-class object detection algorithm, and then the products can be classified to handle limitations on product recognition datasets [51].
- The presence of constantly renewed packaging and newly added products require re-training the system when product recognition is applied directly. On the contrary, the proposed product-independent detection process is not affected by additional or removed products in grocery stores and provides more flexible detection.
- The similarity between products, different scales of product sizes, and diversity in the color and shape of products lead to an insufficient recognizability for all products with a single method [11]. Therefore, relying on multiple types of features jointly to successfully recognize a wider range of product classes is required. With this aim, the hybrid usage of SURF [6], BRISK [7], and ORB [8] features is proposed in this study.
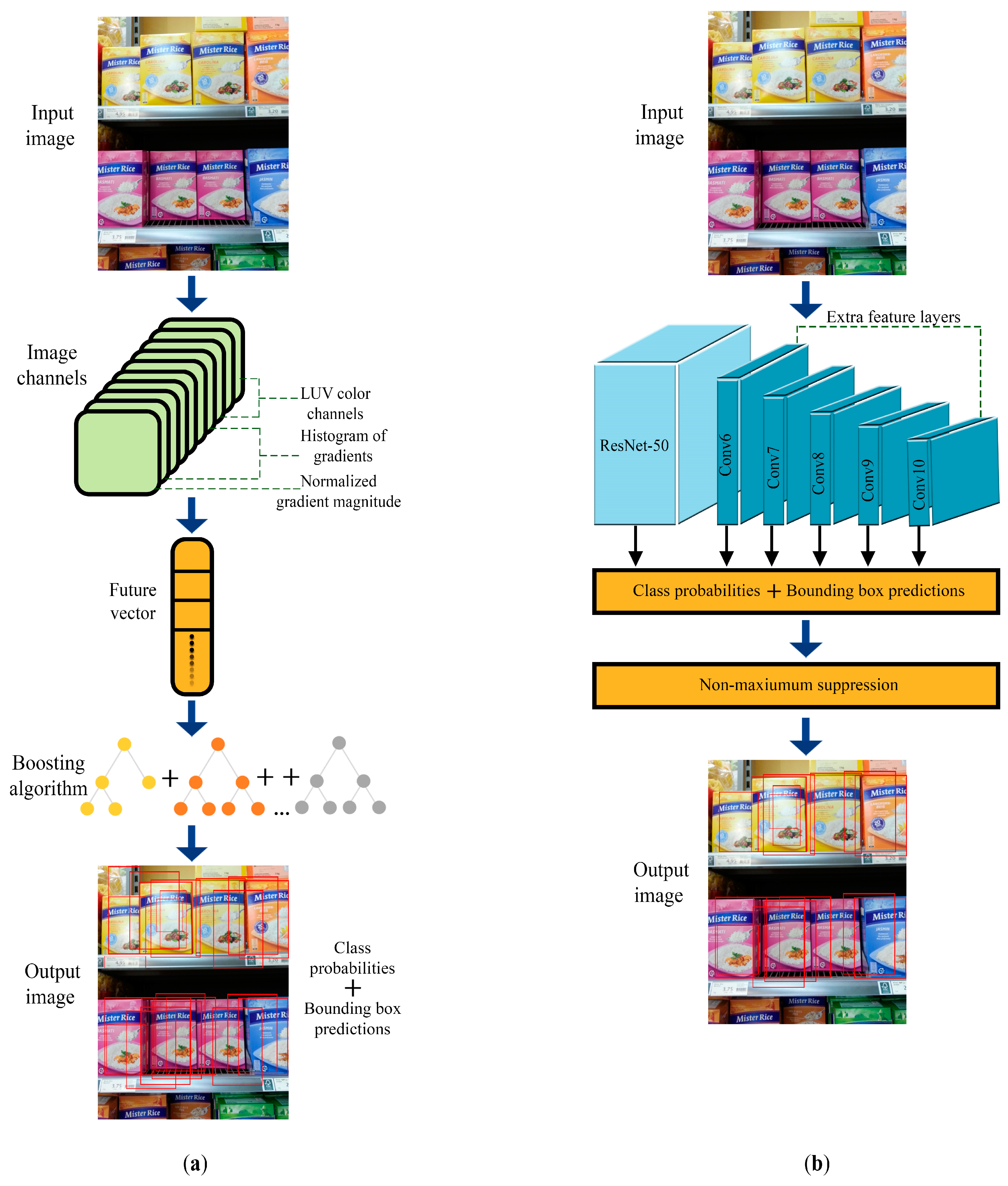
3.1. Product Detection
3.2. Product Classification
3.3. Refinement
- (1)
- The obtained region proposals for each test image are ordered from the highest score to the lowest score.
- (2)
- The region proposal of the highest score is taken as the first element of the first cluster.
- (3)
- If the intersection area of the region proposal in the ranking and any cluster is larger than half of its own area, then these region proposals are included in the same cluster. If a region proposal cannot be assigned to any of the existing clusters, then a new cluster is created.
- (4)
- A cluster is represented by the average of each bounding box values in the same cluster, the maximum of the matching score, and its class information.
- (5)
- These processes continue until there is no non-clustered region proposal.
- (6)
- In order to add neighborhood relations to all the obtained clusters, a distance matrix is calculated between the two closest points of cluster pairs.
- (7)
- In cases where this distance is less than a prefix threshold (half of the width of each cluster), it is assumed that the products are side by side, and the values of matching scores are increased by 1/10 of their own score.
- (8)
- Clusters are eliminated if the new score is less than 40% of the maximum score from all clusters.
4. Experimental Study
4.1. Datasets
4.2. Experimental Results
4.2.1. Results of GP-20
4.2.2. Results of GP-181
4.2.3. Results of Grocery Products
4.3. Running Time Performance Evaluation
5. Conclusions
Author Contributions
Funding
Data Availability Statement
- [Grocery Products] https://sites.google.com/view/mariangeorge/datasets (accessed on 20 June 2023)
- [GP-181] http://vision.disi.unibo.it/index.php?option=com_content&view=article&id=111&catid=78 (accessed on 20 June 2023)
- [Grocery Dataset] https://github.com/gulvarol/grocerydataset (accessed on 20 June 2023)
- [SKU-110K] https://github.com/eg4000/SKU110K_CVPR1912 (accessed on 20 June 2023)
- [GP-20] The GP-20 dataset is a subset of Grocery Products that is created the authors of reference below:
- Franco, A.; Maltoni, D.; Papi, S. Grocery product detection and recognition. Expert Syst. Appl. 2017, 81, 163–176. https://doi.org/10.1016/j.eswa.2017.02.050 (accessed on 20 June 2023).
Conflicts of Interest
References
- Shapiro, M. Executing the Best Planogram; Professional Candy Buyer: Norwalk, CT, USA, 2009. [Google Scholar]
- Gruen, W.T.; Corsten, D.S.; Bharadwaj, S. Retail Out of Stocks: A Worldwide Examination of Extent, Causes, and Consumer Responses; Grocery Manufacturers of Amerika: Washington, DC, USA, 2002. [Google Scholar]
- Berger, R. Optimal Shelf Availability: Increasing Shopper Satisfaction at the Moment of Truth. October 2016. Available online: http://ecr-community.org/wp-content/uploads/2016/10/ecr-europe-osa-optimal-shelf-availability.pdf (accessed on 20 June 2023).
- Dollar, P.; Appel, R.; Belongie, S.; Perona, P. Fast feature pyramids for object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1532–1545. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2016; Volume 9905 LNCS, pp. 21–37. [Google Scholar] [CrossRef]
- Bay, H.; Tuytelaars, T.; Van Gool, L. LNCS 3951—SURF: Speeded Up Robust Features. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Leutenegger, S.; Chli, M.; Siegwart, R.Y. BRISK: Binary Robust invariant scalable keypoints. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 6–13 November 2011; pp. 2548–2555. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 6–13 November 2011; pp. 2564–2571. [Google Scholar] [CrossRef]
- George, M.; Floerkemeier, C. LNCS 8690—Recognizing Products: A Per-exemplar Multi-label Image Classification Approach. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Franco, A.; Maltoni, D.; Papi, S. Grocery product detection and recognition. Expert Syst. Appl. 2017, 81, 163–176. [Google Scholar] [CrossRef]
- Tonioni, A.; Di Stefano, L. Product recognition in store shelves as a sub-graph isomorphism problem. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2017; Volume 10484 LNCS, pp. 682–693. [Google Scholar] [CrossRef]
- Varol, G.; Kuzu, R.S. Toward retail product recognition on grocery shelves. In Proceedings of the 6th International Conference on Graphic and Image Processing (ICGIP 2014), Beijing, China, 24–26 October 2014. [Google Scholar] [CrossRef]
- Goldman, E.; Herzig, R.; Eisenschtat, A.; Goldberger, J.; Hassner, T. Precise detection in densely packed scenes. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5222–5231. [Google Scholar] [CrossRef]
- Fernandcz, W.P.; Xian, Y.; Tian, Y. Image-Based Barcode Detection and Recognition to Assist Visually Impaired Persons. In Proceedings of the 2017 IEEE 7th Annual International Conference on CYBER Technology in Automation, Control, and Intelligent Systems (CYBER), Honolulu, HI, USA, 31 July–4 August 2017; pp. 1241–1245. [Google Scholar] [CrossRef]
- Kulyukin, V.; Kutiyanawala, A. From ShopTalk to ShopMobile: Vision-based barcode scanning with mobile phones for independent blind grocery shopping. In Proceedings of the 2010 Rehabilitation Engineering and Assistive Technology Society of North America Conference (RESNA 2010), Las Vegas, NV, USA, 26–30 June 2010; Volume 703, pp. 1–5. Available online: http://digital.cs.usu.edu/~vkulyukin/vkweb/pubs/RESNA2010_VKulyukin1.pdf (accessed on 20 June 2023).
- Condea, C.; Thiesse, F.; Fleisch, E. RFID-enabled shelf replenishment with backroom monitoring in retail stores. Decis. Support Syst. 2012, 52, 839–849. [Google Scholar] [CrossRef]
- Metzger, C.; Thiesse, F.; Gershwin, S.; Fleisch, E. The impact of false-negative reads on the performance of RFID-based shelf inventory control policies. Comput. Oper. Res. 2013, 40, 1864–1873. [Google Scholar] [CrossRef]
- Wolbitsch, M.; Hasler, T.; Goller, M.; Gutl, C.; Walk, S.; Helic, D. RFID in the Wild—Analyzing Stocktake Data to Determine Detection Probabilities of Products. In Proceedings of the 2019 Sixth International Conference on Internet of Things: Systems, Management and Security (IOTSMS), Granada, Spain, 22–25 October 2019; pp. 251–258. [Google Scholar] [CrossRef]
- Busu, M.F.M.; Ismail, I.; Saaid, M.F.; Norzeli, S.M. Auto-checkout system for retails using Radio Frequency Identification (RFID) technology. In Proceedings of the 2011 IEEE Control and System Graduate Research Colloquium, Shah Alam, Malaysia, 27–28 June 2011; pp. 193–196. [Google Scholar] [CrossRef]
- McCathie, L. The Advantages and Disadvantages of Barcodes and Radio Frequency Identification in Supply Chain Management. Bachelor’s Thesis, University of Wollongong, Wollongong, Australia, 2004; p. 125. [Google Scholar]
- Maulana, F.; Nixon; Putra, R.P.; Hanafiah, N. Self-Checkout System Using RFID (Radio Frequency Identification) Technology: A Survey. In Proceedings of the 2021 1st International Conference on Computer Science and Artificial Intelligence (ICCSAI), Jakarta, Indonesia, 28 October 2021; pp. 273–277. [Google Scholar] [CrossRef]
- Merler, M.; Galleguillos, C.; Belongie, S. Recognizing groceries in situ using in vitro training data. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 18–23 June 2007. [Google Scholar] [CrossRef]
- Winlock, T.; Christiansen, E.; Belongie, S. Toward real-time grocery detection for the visually impaired. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition—Workshops, San Francisco, CA, USA, 13–18 June 2010; pp. 49–56. [Google Scholar] [CrossRef]
- Karlinsky, L.; Shtok, J.; Tzur, Y.; Tzadok, A. Fine-grained recognition of thousands of object categories with single-example training. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; Volume 2017, pp. 965–974. [Google Scholar] [CrossRef]
- Baz, I.; Yoruk, E.; Cetin, M. Context-Aware Confidence Sets for Fine-Grained Product Recognition. IEEE Access 2019, 7, 76376–76393. [Google Scholar] [CrossRef]
- De Feyter, F.; Goedemé, T. Joint Training of Product Detection and Recognition Using Task-Specific Datasets. In Proceedings of the 18th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, Lisbon, Portugal, 19–21 February 2023; VISAPP; SciTePress: Setúbal, Portugal, 2023; Volume 5. [Google Scholar]
- Varol, G. Product Placement Detection Based on Image Processing. In Proceedings of the 2014 22nd Signal Processing and Communications Applications Conference (SIU), Trabzon, Turkey, 23–25 April 2014. [Google Scholar] [CrossRef]
- Pan, X.; Ren, Y.; Sheng, K.; Dong, W.; Yuan, H.; Guo, X.; Ma, C.; Xu, C. Dynamic refinement network for oriented and densely packed object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11204–11213. [Google Scholar] [CrossRef]
- Gökdag, Ü. Planogram Matching Control in Grocery Products by Image Processing. In Proceedings of the 2016 24th Signal Processing and Communication Application Conference (SIU), Zonguldak, Turkey, 16–19 May 2016. [Google Scholar] [CrossRef]
- Srivastava, M.M. Bag of tricks for retail product image classification. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12131 LNCS, pp. 71–82. [Google Scholar] [CrossRef]
- Gokdag, U.; Akpınar, M.Y. Raf Görüntüleri Üzerinde Nesne Tanımaya Dayalı Planogram Eşleştirme. In Proceedings of the Conference: XVIII. AKADEMİK BİLİŞİM KONFERANSI—AB 2016, Aydın, Turkey, February 2019. [Google Scholar]
- Kant, S. Learning Gaussian Maps for Dense Object Detection. 2020, pp. 1–13. Available online: http://arxiv.org/abs/2004.11855 (accessed on 20 June 2023).
- Wang, C.; Huang, C.; Zhu, X.; Zhao, L. One-shot retail product identification based on improved Siamese neural networks. Circuits Syst. Signal Process. 2022, 41, 6098–6112. [Google Scholar] [CrossRef]
- Xu, C.; Zheng, Y.; Zhang, Y.; Li, G.; Wang, Y. A method for detecting objects in dense scenes. Open Comput. Sci. 2022, 12, 75–82. [Google Scholar] [CrossRef]
- Tonioni, A.; Serra, E.; Di Stefano, L. A deep learning pipeline for product recognition on store shelves. In Proceedings of the 2018 IEEE International Conference on Image Processing, Applications and Systems (IPAS), Sophia Antipolis, France, 12–14 December 2018; pp. 25–31. [Google Scholar] [CrossRef]
- Selvam, P.; Koilraj, J.A.S. A deep learning framework for grocery product detection and recognition. Food Anal. Methods 2022, 15, 3498–3522. [Google Scholar] [CrossRef]
- Tiwary, T.; Mahapatra, R.P. Enhancement in web accessibility for visually impaired people using hybrid deep belief network–bald eagle search. Multimed. Tools Appl. 2023, 82, 24347–24368. [Google Scholar] [CrossRef]
- Zhou, Z.; Zhang, B.; Yu, X. Immune coordination deep network for hand heat trace extraction. Infrared Phys. Technol. 2022, 127, 104400. [Google Scholar] [CrossRef]
- Yu, X.; Ye, X.; Zhang, S. Floating pollutant image target extraction algorithm based on immune extremum region. Digit. Signal Process. 2022, 123, 103442. [Google Scholar] [CrossRef]
- Liu, X.; Zhu, X.; Li, M.; Wang, L.; Zhu, E.; Liu, T.; Gao, W. Multiple kernel k-means with incomplete kernels. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 1191–1204. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; Volume 2017, pp. 6517–6525. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 386–397. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as Points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–25 September 1999; Volume 2, pp. 1150–1157. [Google Scholar] [CrossRef]
- Barrington, L.; Marks, T.K.; Hsiao, J.H.W.; Cottrell, G.W. Nimble: A kernel density model of saccade-based visual memory. J. Vis. 2008, 8, 17. [Google Scholar] [CrossRef] [PubMed]
- Lucas, B.D. An Iterative Image Registration Technique with an Application to Stereo Vision. In Proceedings of the Proceedings of the 7th International Joint Conference on Artificial Intelligence, Vancouver, BC, Canada, 24–28 August 1981. [Google Scholar]
- Chatfield, K.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Return of the devil in the details: Delving deep into convolutional nets. In Proceedings of the BMVC 2014—British Machine Vision Conference, Nottingham, UK, 1–5 September 2014; pp. 1–11. [Google Scholar] [CrossRef]
- Wei, Y.; Tran, S.; Xu, S.; Kang, B.; Springer, M. Deep Learning for Retail Product Recognition: Challenges and Techniques. Comput. Intell. Neurosci. 2020, 2020, 8875910. [Google Scholar] [CrossRef]
- Wei, Y.; Yaoran, S.; Tao, D.; Sailing, H. Detecting Retail Products In Situ Using CNN without Human Effort Labeling. arXiv 2019, arXiv:1904.09781. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015—Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Jocher, G. Ultralytics/yolov5: V3.1—Bug Fixes and Performance Improvements. 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 20 February 2023).
- Litman, R.; Anschel, O.; Tsiper, S.; Litman, R.; Mazor, S.; Manmatha, R. SCATTER: Selective context attentional scene text recognizer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 11959–11969. [Google Scholar] [CrossRef]
- Hough, P.V. Method and Means for Recognizing Complex. Patterns. Patent No. 3,069,654, 18 December 1962. [Google Scholar]
- Bastian, B.T.; Jiji, C.V. Integrated feature set using aggregate channel features and histogram of sparse codes for human detection. Multimed. Tools Appl. 2020, 79, 2931–2944. [Google Scholar] [CrossRef]
- Yi, D.; Su, J.; Chen, W. Locust Recognition and Detection via Aggregate Channel Features. In Proceedings of the 2nd UK Robotics and Autonomous Systems Conference (UK-RAS 2019), Loughborough, UK, 24 January 2019. [Google Scholar]
- Zhao, A.; Fu, K.; Sun, H.; Sun, X.; Li, F.; Zhang, D.; Wang, H. An Effective Method Based on ACF for Aircraft Detection in Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 744–748. [Google Scholar] [CrossRef]
- Hermawati, F.A. Combination of Aggregated Channel Features (ACF) Detector and Faster R-CNN to Improve Object Detection Performance in Fetal Ultrasound Images. Int. J. Intell. Eng. Syst. 2018, 11, 65–74. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar] [CrossRef]
- Hsu, W.-Y.; Lin, W.-Y. Adaptive Fusion of Multi-Scale YOLO for Pedestrian Detection. IEEE Access 2021, 9, 110063–110073. [Google Scholar] [CrossRef]
- He, K. Deep Residual Learning for Image Recognition. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Du, C.; Sun, D. Comparison of three methods for classification of pizza topping using different colour space transformations. J. Food Eng. 2005, 68, 277–287. [Google Scholar] [CrossRef]
- Saleem, Z. A Comparative Analysis of SIFT, SURF, KAZE, AKAZE, ORB, and BRISK. In Proceedings of the 2018 International Conference on Computing, Mathematics and Engineering Technologies (iCoMET), Sukkur, Pakistan, 3–4 March 2018; pp. 1–10. [Google Scholar] [CrossRef]
- Mair, E.; Hager, G.D.; Burschka, D.; Suppa, M.; Hirzinger, G. Adaptive and Generic Corner Detection Based on the Accelerated Segment Test. In Proceedings of the ECCV 2010: 11th European Conference on Computer Vision, Heraklion, Crete, Greece, 5–11 September 2010. [Google Scholar]
- Rosten, E.; Drummond, T. Machine learning for high-speed corner detection. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2006; Volume 3951 LNCS, pp. 430–443. [Google Scholar] [CrossRef]
- Calonder, M.; Lepetit, V.; Strecha, C.; Fua, P. BRIEF: Binary Robust Independent Elementary Features. In Proceedings of the ECCV 2010: Computer Vision—ECCV 2010, Heraklion, Crete, Greece, 5–11 September 2010; pp. 778–792. [Google Scholar] [CrossRef]
- Yörük, E.; Öner, K.T.; Akgül, C.B. An efficient Hough transform for multi-instance object recognition and pose estimation. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016. [Google Scholar]
- George, M.; Mircic, D.; Sörös, G.; Floerkemeier, C.; Mattern, F. Fine-Grained Product Class Recognition for Assisted Shopping. In Proceedings of the 2015 IEEE International Conference on Computer Vision Workshop (ICCVW), Santiago, Chile, 7–13 December 2015; Volume 2015, pp. 546–554. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Smith, R. An overview of the Tesseract OCR engine. In Proceedings of the Ninth International Conference on Document Analysis and Recognition (ICDAR 2007), Curitiba, Brazil, 23–26 September 2007. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Publications | Shelf Detection | Product Detection | Product Classification | Product Detection and Classification Performed Jointly | End-to-End | Running Time Performance Evaluation |
|---|---|---|---|---|---|---|
| [10] | - | ✓ | ✓ | - | ✓ | ** |
| [11] | - | ✓ | ✓ | - | ✓ | ✓ |
| [12] | - | ✓ | ✓ | - | - | - |
| [13] | - | ✓ | - | - | - | ✓ |
| [22] | - | - | - | ✓ | ✓ | - |
| [23] | - | - | - | ✓ | ✓ | ✓ |
| [24] | - | - | - | ✓ | ✓ | ✓ |
| [25] | - | - | - | ✓ | ✓ | - |
| [26] | - | - | - | ✓ | ✓ | - |
| [27] | ✓ | ✓ | ✓ | - | - | - |
| [28] | - | ✓ | - | - | - | ✓ |
| [29] | ✓ | ✓ | ✓ | - | - | - |
| [30] | - | ✓ | - | - | - | - |
| [31] | - | ✓ | - | - | - | - |
| [32] | - | ✓ | ✓ | - | - | - |
| [33] | - | - | ✓ | - | - | ✓ |
| [34] | - | ✓ | - | - | - | ✓ |
| [35] | - | ✓ | ✓ | - | ✓ | ** |
| [36] | - | ✓ | ✓ | - | ✓ | - |
| [37] | - | * | * | - | ✓ | ** |
| This paper | ✓ | ✓ | ✓ | - | ✓ | ✓ |
| function: pre_elimination _process(T,R,Thr_Th,Thr_Tl,Thr_ch) Input: T = template image set R = region proposals image set Thr_Th = the highest aspect ratio of template image Thr_Tl = the lowest aspect ratio of template image Thr_ch = threshold value for intersection of color histograms Output: R_new = new region proposals after pre_elimination process for each for each if then if end if end if end for end for return |
| Stage of Study | Dataset | # Product Categories | # of Images | Annotations | Annotated Products |
|---|---|---|---|---|---|
| Training of Stage 1 | Grocery Dataset | 1 | 354 shelf images | item-specific bounding boxes | Annotated with all products |
| SKU-110Kval | 1 | 588 shelf images | item-specific bounding boxes | Annotated with all products | |
| Training of Stage 2 | GP-20 | 20 | one image per product | - | - |
| GP-181 | 181 | one image per product | - | - | |
| Grocery Products | 27 | average of 112 different product images in each category (25–415) | - | - | |
| 3235 | one image per product | - | - | ||
| Testing of end-to-end system | GP-20 | 20 | 71 shelf images | item-specific bounding boxes | Annotated with the selected products |
| GP-181 | 181 | 73 shelf images | item-specific bounding boxes | Annotated with the selected products | |
| Grocery Products | 27 | 680 shelf images | Single bounding box contains multiple instances of products | Annotated with the selected products | |
| 3235 | 680 shelf images | Single bounding box contains multiple instances of products | Annotated with the selected products |
| Methods Used in Product Detection Stage | |||||||
|---|---|---|---|---|---|---|---|
| Traditional Computer Vision Approach | ACF Detector * | SSD * | |||||
| Precision | Recall | Precision | Recall | Precision | Recall | ||
| Methods used in Product Classification Stage | SURF | 61.6 | 82.2 | 59.2 | 72.3 | 71.5 | 78.2 |
| BRISK | 67.6 | 65.2 | 57.7 | 66.8 | 73.7 | 83.2 | |
| ORB | 76.5 | 58.1 | 48.5 | 68.9 | 78.1 | 71.6 | |
| A hybrid usage of SURF & BRISK & ORB | 75.1 | 78.1 | 62.7 | 71.2 | 78.8 | 81.3 | |
| Precision | Recall | |
|---|---|---|
| CA | 78.1 | 77.5 |
| NR_CA | 78.8 | 81.3 |
| Precision | Recall | |
|---|---|---|
| [10] proposed DNN | 73.1 | 73.6 |
| [10] proposed BoW | 77.7 | 76.5 |
| SSD + SURF & BRISK & ORB + NR_CA (ours) | 78.8 | 81.3 |
| mAP | PR | |
|---|---|---|
| [11] | 66.37 | 75.0 |
| [35] | 76.93 | 85.71 |
| SSD + SURF & BRISK & ORB + NR_CA (ours) | 81.23 | 84.57 |
| CA | PA | PP | PR | |
|---|---|---|---|---|
| [9] | - | 21.2 | 23.5 | 43.1 |
| [69] | 84.6 | 32.5 | 57.0 | 41.6 |
| [70] | 61.9 | - | - | - |
| SSD + SURF & BRISK & ORB + NR_CA (ours) | 76.4 | 41.2 | 39.4 | 48.2 |
| SURF | BRISK | ORB | A Hybrid Usage of SURF & BRISK & ORB | |
|---|---|---|---|---|
| GP-20 training set | 0.2094 s | 0.0669 s | 0.0433 s | 0.0934 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Melek, C.G.; Battini Sonmez, E.; Ayral, H.; Varli, S. Development of a Hybrid Method for Multi-Stage End-to-End Recognition of Grocery Products in Shelf Images. Electronics 2023, 12, 3640. https://doi.org/10.3390/electronics12173640
Melek CG, Battini Sonmez E, Ayral H, Varli S. Development of a Hybrid Method for Multi-Stage End-to-End Recognition of Grocery Products in Shelf Images. Electronics. 2023; 12(17):3640. https://doi.org/10.3390/electronics12173640
Chicago/Turabian StyleMelek, Ceren Gulra, Elena Battini Sonmez, Hakan Ayral, and Songul Varli. 2023. "Development of a Hybrid Method for Multi-Stage End-to-End Recognition of Grocery Products in Shelf Images" Electronics 12, no. 17: 3640. https://doi.org/10.3390/electronics12173640
APA StyleMelek, C. G., Battini Sonmez, E., Ayral, H., & Varli, S. (2023). Development of a Hybrid Method for Multi-Stage End-to-End Recognition of Grocery Products in Shelf Images. Electronics, 12(17), 3640. https://doi.org/10.3390/electronics12173640