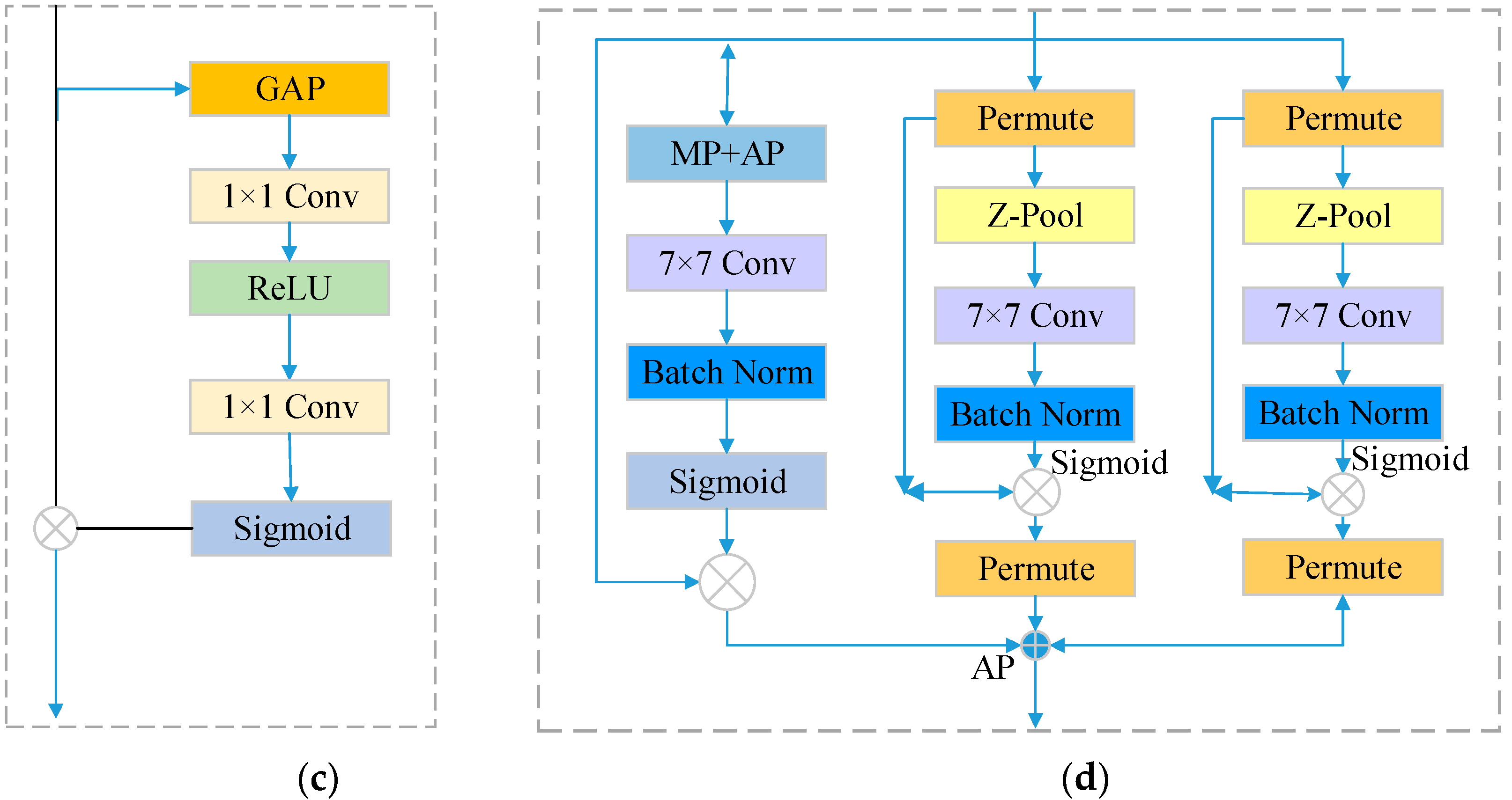
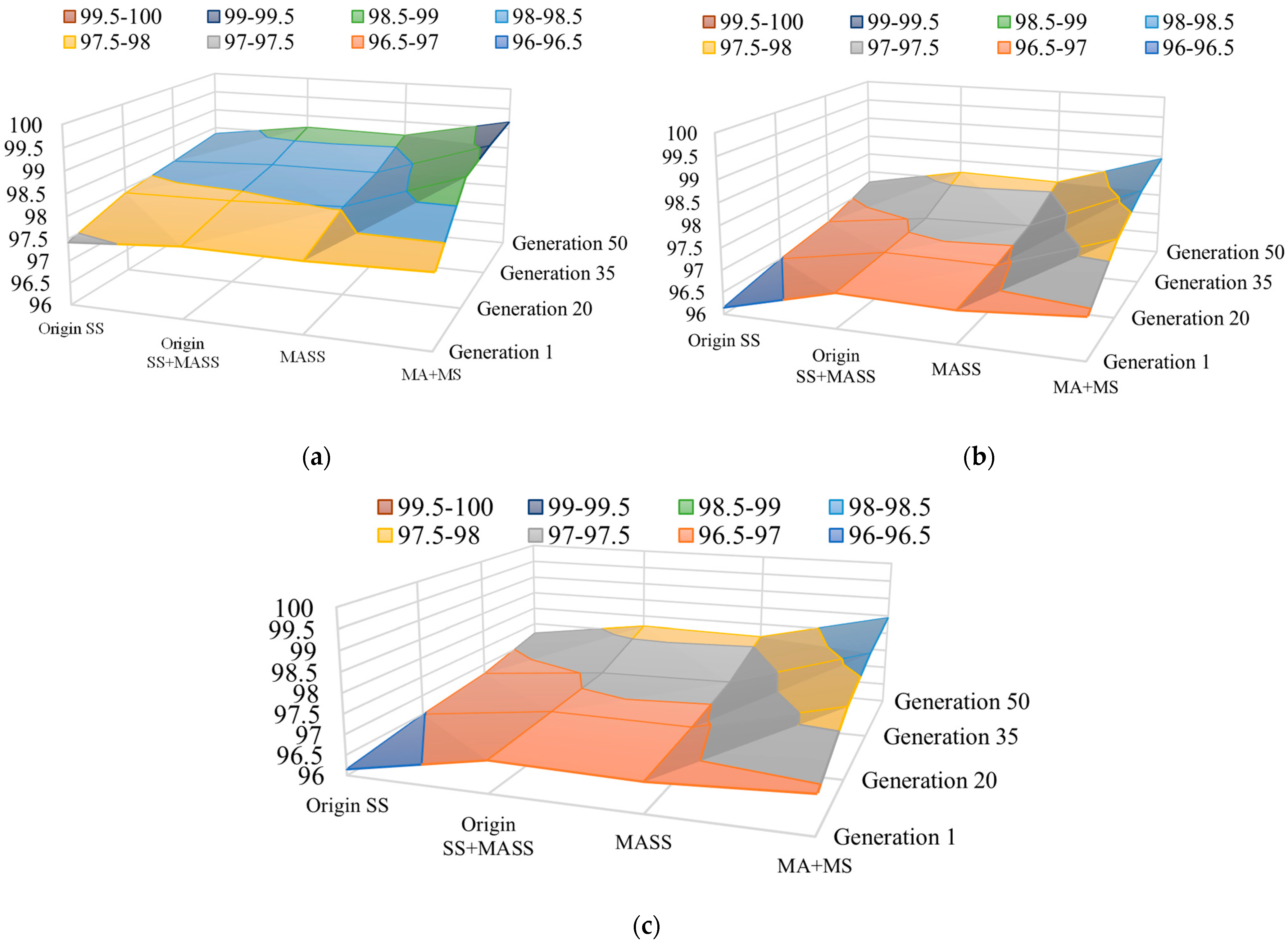
2.2.1. Multi-Scale Attention Mechanism Expanded Search Space
Applying different attention mechanisms to different datasets may face varying challenges. For example, in some HIS datasets, it may be more challenging to use spatial attention mechanisms due to strong correlations between data. In contrast, it may be more difficult to use channel attention mechanisms due to highly variable features. Moreover, the performance of attention mechanisms can also be affected by factors such as dataset size and quality, model architecture, and hyperparameters. Therefore, it is important to choose appropriate attention mechanisms based on different HSI datasets and tasks to achieve optimal performance and effectiveness. In addition, various samples in the HSI dataset exhibit long-tailed distributions, resulting in imbalanced HSI classification results. We propose a multiple search space with rich attention for HSI classification, which can effectively improve classification accuracy and reduce computational complexity. We select four types of attention mechanisms to form it. They are the convolutional block attention module (CBAM) [
38], squeeze-and-excitation (SE) module [
36], triplet attention (TA) module [
39], and coordinate attention mechanism (CA) [
40], as shown in
Figure 2.
To reduce repetition, various attention mechanisms have been proposed in the literature. One such mechanism is the CBAM module, which combines channel attention and spatial attention. It aggregates spatial features by performing max-pooling on top of global average pooling. This allows the network to focus on important spatial information. Another attention mechanism is the SE module, which enhances the network’s sensitivity to informative features. It recalibrates filter responses through squeeze-and-excitation operations, improving the learning ability of convolutional layers. The TA module is composed of three parallel branches, each serving a distinct purpose. The first branch focuses on establishing spatial attention, while the other two branches aim to capture cross-dimensional interactions between the channel and spatial dimensions. The final output is obtained by averaging the outputs from these three branches. The CA mechanism learns weights by combining features at each position with their corresponding coordinate information. This mechanism effectively captures spatial correlations, leading to improved model performance. By incorporating these attention mechanisms, models can effectively reduce redundancy and improve the performance of HSI classification tasks.
As NAS-based HSI classification requires the determination of the search space, we propose search space
. Formally, let
denote a sequence of candidate operations (multiple attention guided operations), where each operation represents a function
to be applied to
. For each cell
, we configure an architecture parameter
for operation
. To ensure continuity of the search space, we relax the search space to allow it to be optimized via gradient descent. Specifically, we relax the architecture parameter
to be continuous, and then compute the operational probabilities for different operations by applying softmax over all
.
Here,
represents the number of candidate operations available. The larger value of
indicates a higher likelihood of selecting the representative operation. The output of the cell is obtained by taking the weighted sum of all possible operations.
The notation
signifies the application of operation
on input
. Consequently, the search process is transformed into a learning process of a set of architectural parameters {
}. Furthermore, as the network weights
also need to be learned, we are required to solve the following bi-level optimization problem.
The purpose of the above formulae is to search for the architectural parameters that minimize the validation loss , and the network weights are obtained by minimizing the training loss . It is important to note that the training loss and the validation loss are identical.
The objective of the aforementioned formulae is to search for architectural parameters that minimize the validation loss , while the network weights are obtained by minimizing the training loss . It is crucial to emphasize that the training loss and the validation loss are indeed the same.
- 2.
Multi-scale attention mechanism search space
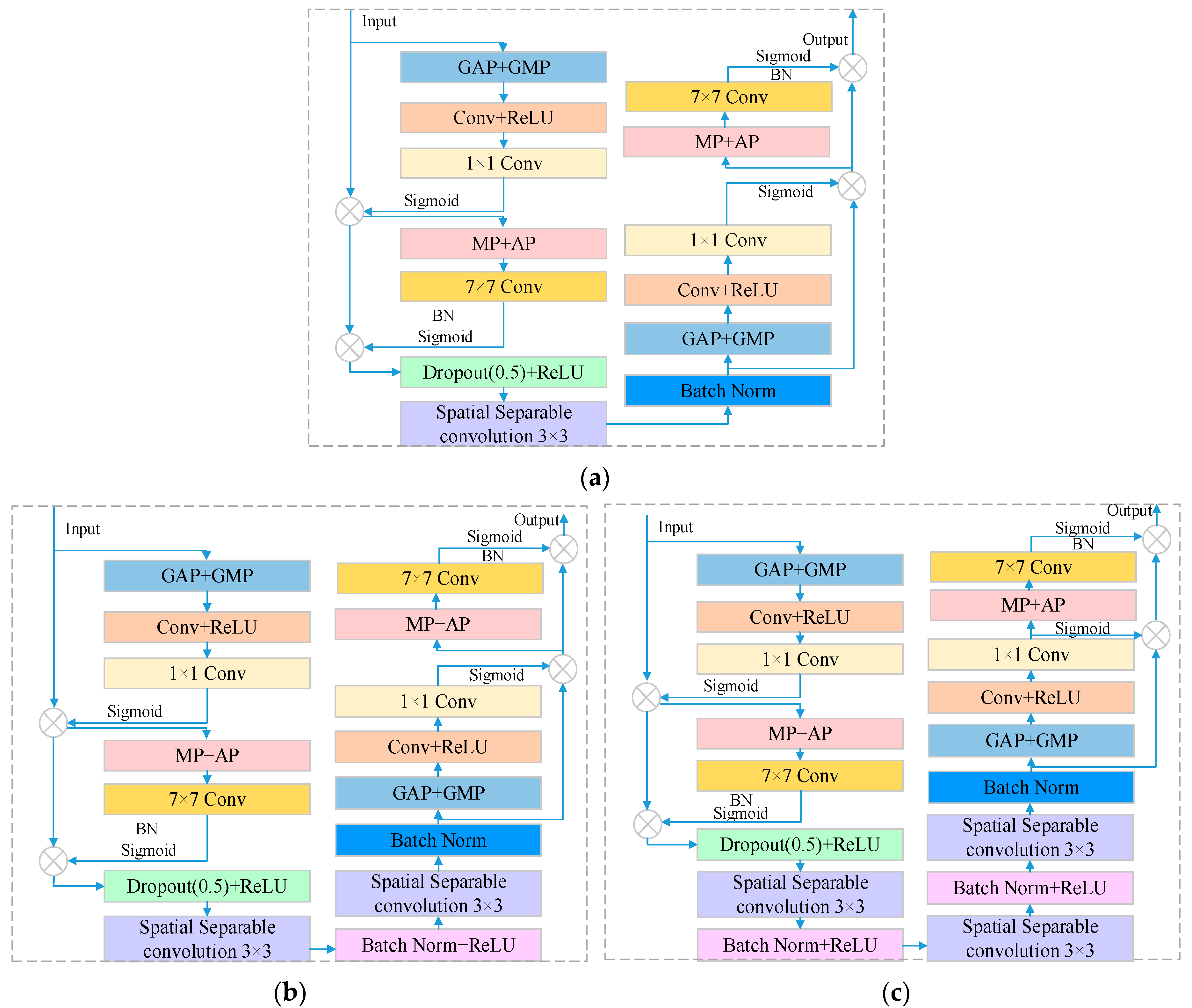
Different types of convolutions have varying computational requirements and parameter counts. Building deeper models can be challenging due to the expensive parameters and time required for high-dimensional convolutions. This can limit the efficiency and feasibility of constructing deeper models. Therefore, high-dimensional convolutions are often replaced with lower-dimensional separable convolutions to alleviate this issue. The novel operation MCS_sepConv_(b × b) (b = 3, 5, 7) in the search space combines spectral–spatial CBAM with spatial separable convolution [
41], which helps to extract deeper spectral–spatial features, and it can enhance the spectral–spatial adaptive learning ability of the I data. In addition, we use small filters to reduce parameters while maintaining a large-scale receptive field. We have strengthened the ability to extract scale spectral–spatial features from data, thereby improving classification performance. MCS_sepConv(b = 3, 5, 7) with different scales are as shown in
Figure 3.
MCS_sepConv_(b × b) refers to a set of convolutional operators that are commonly used in remote sensing and other image-processing tasks to extract deeper spectral–spatial features. These operators consist of two separate convolutional layers, one for processing the spectral dimension and the other for processing the spatial dimension, and they are applied in a cascaded manner. By using MCS_sepConv_(b × b), the model can capture more complex and abstract features by combining spectral and spatial information.
Convolution is a widely used operation in NAS-based methodIor HSI classification. Previous research has primarily concentrated on traditional convolution techniques, depthwise separable convolution, and dilated convolution in order to reduce redundancy. However, the high-dimensional convolutional operations can lead to a large number of parameters and time consumption, making it very difficult to construct an optimal architecture. For example, depthwise separable convolution can be represented as Sep-Conv(b × b) = Conv(1 × 1)(Conv(b × b)(x)), and the parameter and Flops(floating point operations per second) calculations are:
where
is the size of the input x, and
corresponds to the output features, where
and
represent the input and output spectral bands, respectively. Additionally,
P1 and
F1 represent the number of parameters and Flops. Incorporating a pointwise convolution following a depthwise convolution in the CNN can effectively extract both spatial and spectral features in a sequential manner. Assuming
, the number of parameters and Flops for separable convolutions is only
of regular convolutions. If we extend the concept of separable convolution to the spatial dimensions, we can define spatial separable convolution as Spatial_SepConv(b × b) = Conv(1 × 1Conv(1 × b)(Conv(b × 1)(x)). The number of parameters and Flops for a spatial separable convolution is only
of separable convolution:
To reduce redundancy in a convolutional neural network (CNN), one approach is to use small filters instead of large-scale filters. This helps to decrease the number of parameters while still maintaining a large receptive field. This is because, in the CNN, the number of parameters and computations is directly related to the size of the input data and the convolution kernel. By using smaller filters, the number of parameters and computations can be significantly reduced. By using small filters, we can reduce the number of parameters while maintaining a large receptive field, which is important for capturing multi-scale features in HSI classification. This can be achieved by using a combination of small filters with different kernel sizes, which allows us to capture multi-scale features while reducing the number of parameters and computations.
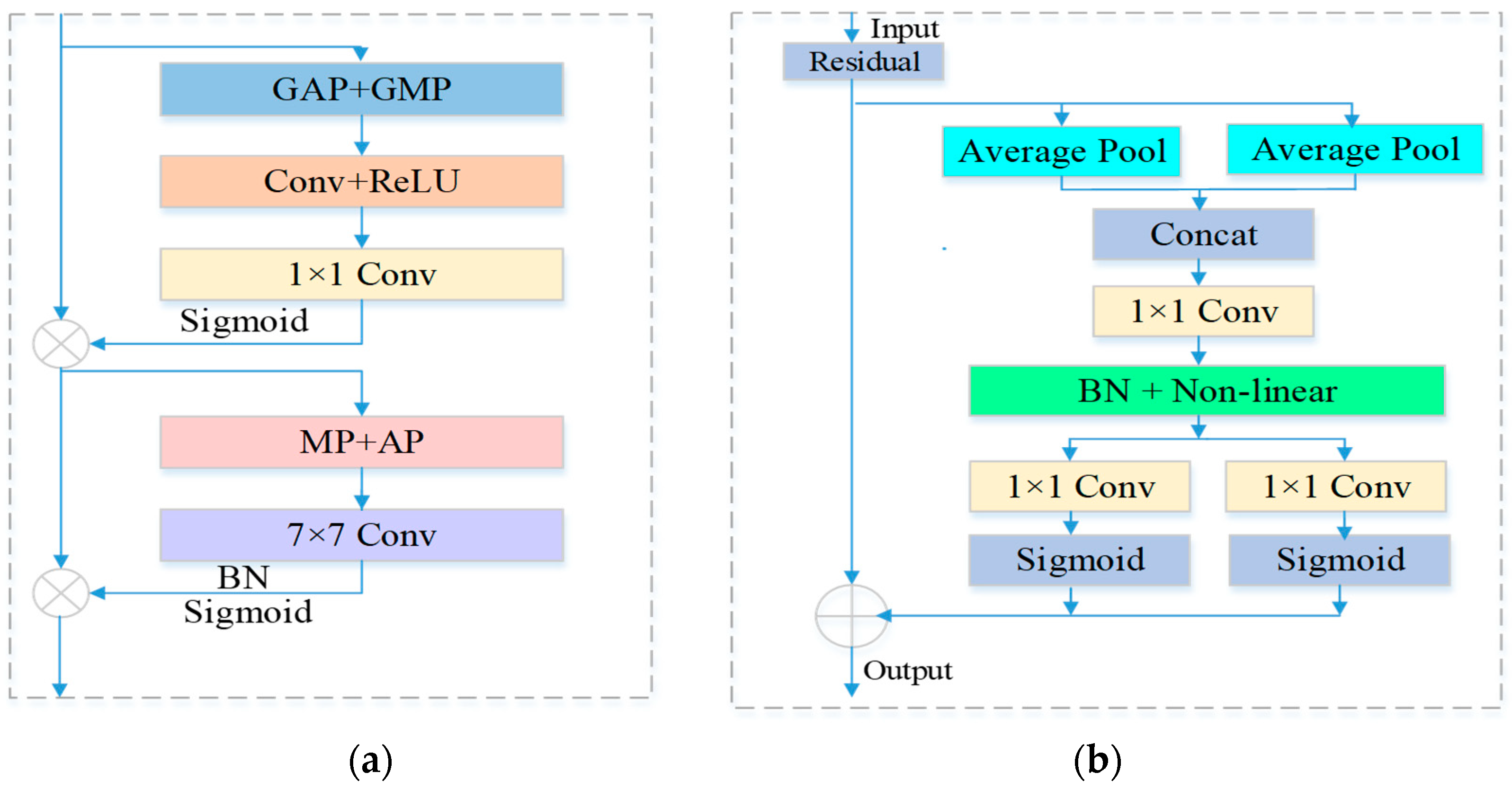
To enhance the adaptive feature extraction capability of the designed convolution operation, a lightweight attention module called CBAM (Multi-scale Channel–Spatial Attention, MCS) is incorporated to enhance the spectral and spatial adaptive learning ability of the data cube. MCS is a combination of the Multi-scale Channel Attention (MS) mechanism and the Multi-scale Spatial Attention (MS) mechanism as follows:
where
represents the spectral–spatial CBAM, which involves element-wise multiplication
,
,
, sigmoid activation
, and the 7 × 7 convolutional
.
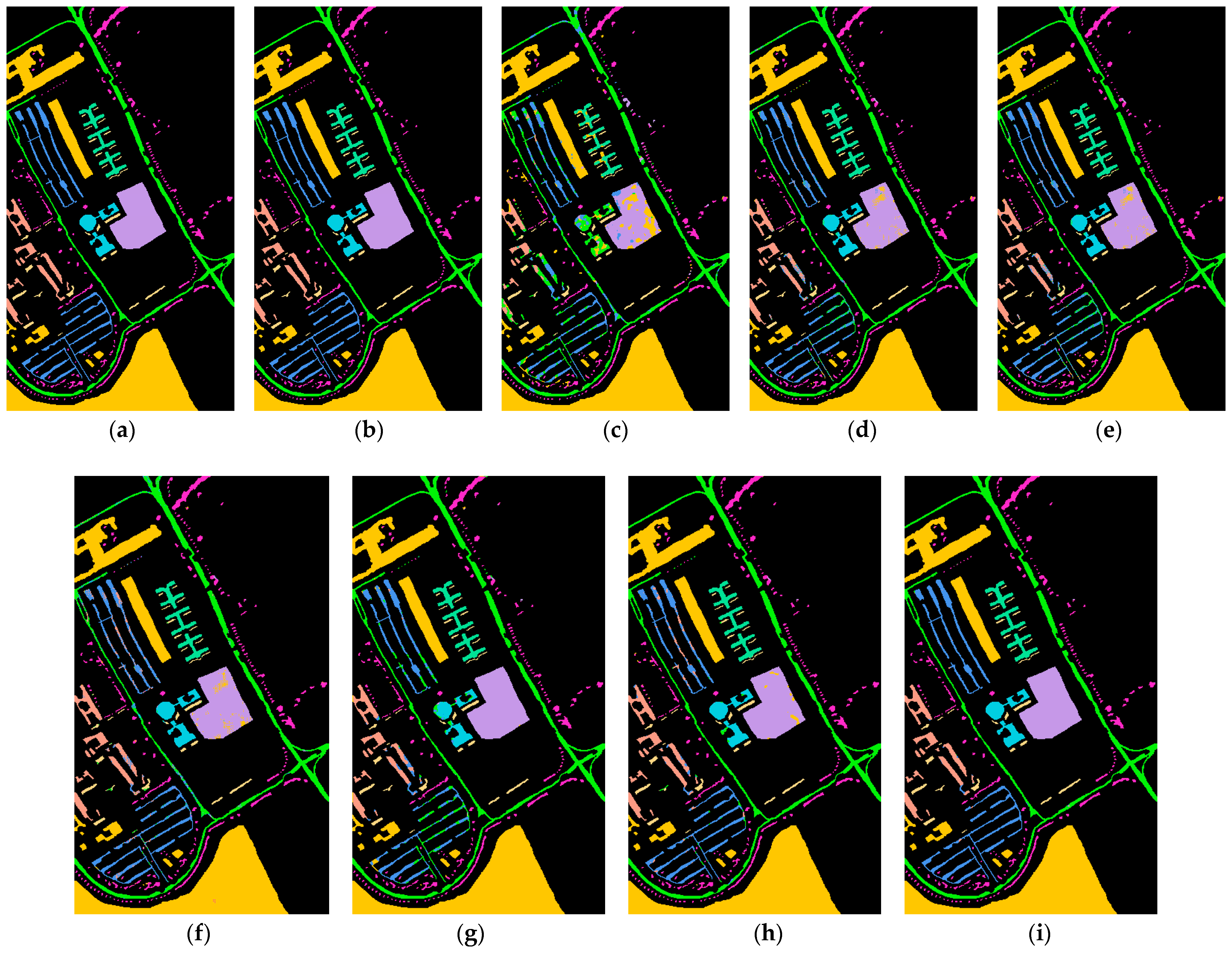
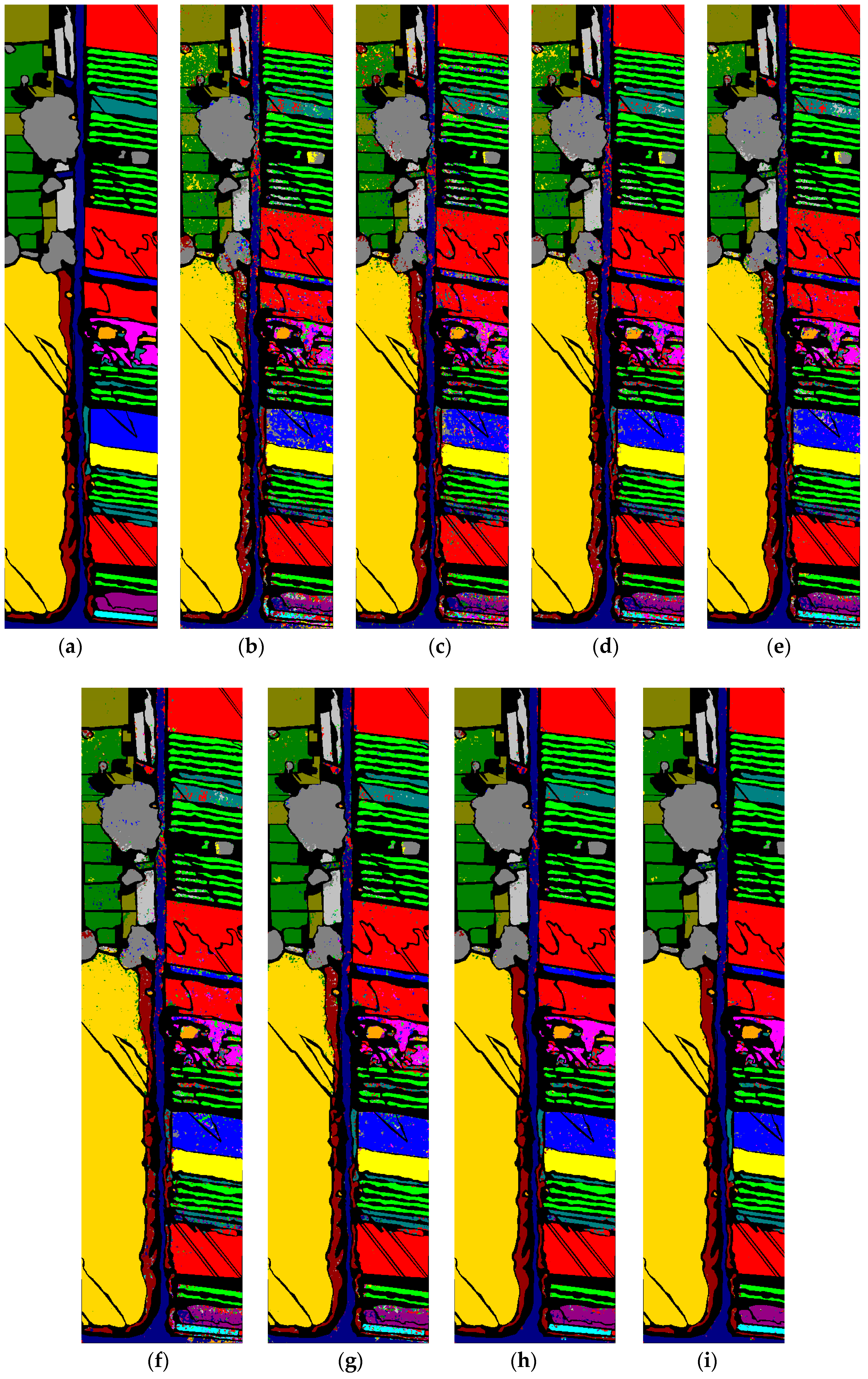
As shown in
Table 1, Conv(5 × 5) and Conv(7 × 7) can be achieved by repeating the Conv(3 × 3) operations for substitution. In addition, Conv(3 × 3) can be replaced with Spatial sepconv(3 × 3) = (Conv(1 × 3)Conv(3 × 1)). Assuming
, when using Spatial sepconv(3 × 3) for equivalent replacement of Conv(5 × 5), the parameter count is reduced by about 25%. After replacing Conv(7 × 7), the parameters were reduced by about 33%. The amount of Flops also showed a significant decrease. It can be explained that we use small filters instead of large ones to effectively reduce parameters while maintaining a large receptive field, which has obvious effectiveness.
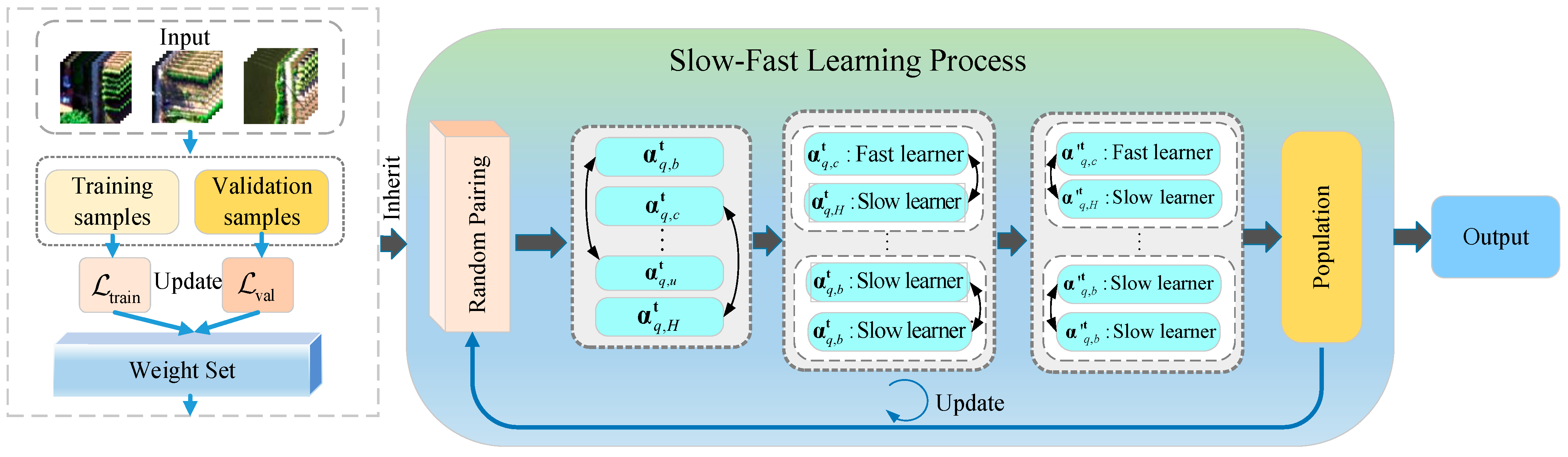
2.2.2. Search Strategy Based on the Slow–Fast Learning Paradigm
In order to further utilize the search space guided by multiple attention mechanisms, we apply the slow–fast learning paradigm to optimize and iteratively update the architecture vector. In addition, the HSI classification involves multiple categories, and the sample size in each category presents the long-tailed distribution, resulting in imbalanced classification results for certain categories in classification tasks. By using the slow–fast paradigm to update the architecture vector, the overall architecture vector can be updated from the perspective of pseudo gradients [
42]. Different hyperspectral imbalanced data can be updated during the construction of the architecture unit to obtain the best results and effectively enhance the generalization of the model. This design is essentially aimed at designing an effective NAS method that benefits from the high efficiency of differentiable NAS and overcomes the drawbacks of high search costs in population-based NAS.
This section optimizes from the perspective of NAS search strategy and effectively updates the population of architecture vectors through pseudo gradient iteration to achieve optimal results. The objective of NAS is to initially search for architecture vectors
. Then, the architecture parameter
is used to minimize the validation loss
, and finally, the weight
, which is associated with the architecture, is obtained by minimizing the training loss
. Therefore, the slow–fast learning is essentially the optimizer for
parameters in our NAS. Specifically, we give the architecture vector
obtained by slow–fast learning in the t
th generation, and its iterative update method is shown in
Figure 4.
where the above equation satisfies
.
To generate pseudo gradient
effectively, this approach suggests utilizing a population of H architecture vectors
. Each generation randomly splits the population into H/2 pairs. Next, for each pair of population q, the order of validation loss values is employed to identify the fast learner
and slow learner
, with smaller loss values indicating slow learner and larger loss values indicating fast learner [
]. Then,
learns from
and updates it.
Here, represents a randomly generated value obtained from a uniform distribution. Specifically, determines the step size for to learn from , and determines the influence of momentum . Finally, all fast–slow learners are aggregated to form a new group of the t + 1th generation. The above pseudo gradient update method is derived from the second derivative of gradient descent in back propagation, so each architecture vector in the search space of the multi-attention mechanism designed in this work will move towards the optimal update direction from the vector that converges faster than them.
After the architecture update process, it is necessary to evaluate the performance of candidate architectures for decoding architecture vectors, so that for each pair of architecture vectors, fast learners can learn and update slow learners by verifying the loss. Subsequently, the candidate architecture
is assessed by solving the following optimization problems:
In the given equation, represents the optimal weight of the candidate architecture, while denotes the iterative optimization process utilized for updating the weights of the neural network.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





























