1. Introduction
With the rapid development of technology and society, human–computer interaction [
1,
2] has improved people’s work efficiency and quality of life, which plays a crucial role in many applications such as virtual reality [
3] and medical research [
4,
5]. Eye detection and tracking is a challenging task in the field of computer vision. It provides useful information for human–computer interaction. The researchers have utilized gaze estimation to study behavior in many domains. It aims to infer people’s focus of attention and behavioral intention by analyzing and understanding the fixation point and direction of the human eye. Sight is the nonverbal information in human communication, which can reveal people’s interests, emotions, and cognitive process. Therefore, gaze estimation has broad application value in fields such as human–computer interaction, intelligent monitoring, medical diagnosis, and intelligent driving.
In human–computer interaction, gaze estimation can be used as an “eye mouse” to control the operation of the computer interface by capturing the fixation point of the human eye, achieving a more natural and intuitive interaction experience. This can be used to improve user interface design. By analyzing the user’s gaze patterns and eye movements, it is possible to understand the user’s attention allocation and interaction behavior toward interface elements. This is very helpful for optimizing interface layout, enhancing the visibility of key features, and providing personalized interactive experiences. For example, in web design, gaze estimation can determine the user’s fixation point and reading path when browsing a webpage, thereby adjusting the layout of content and the position of key information, making it easier for users to find the required information.
In terms of intelligent driving, firstly, gaze estimation can be used for driver fatigue and attention monitoring. By analyzing the driver’s gaze patterns and eye movements, it is possible to detect whether they experience fatigue, distraction, or lack of concentration. Once the driver’s attention drops, the system can issue a warning in a timely manner, reminding the driver to take necessary rest or attention adjustments to avoid traffic accidents. Secondly, gaze estimation can be used for driver behavior analysis. By analyzing drivers’ gaze points and gaze directions during driving, we can understand their attention distribution on roads, traffic signs, and other vehicles. This can provide valuable data support for the development of driver behavior models and the optimization of driving decision systems. In addition, gaze estimation can also be used for monitoring the driver’s emotional and cognitive state. By observing the driver’s gaze patterns and eye movements, one can infer their emotional state, such as anxiety, fatigue, or distraction. This is very important for intelligent driving systems, as it can adjust driving strategies and provide personalized driving experiences based on the driver’s emotional and cognitive state.
In terms of intelligent monitoring, gaze estimation can be used for behavior analysis and anomaly detection. By analyzing people’s gaze patterns and eye movements, we can understand their points of interest and areas of interest in monitoring scenarios. This is very helpful for detecting suspicious behavior, abnormal activities, or potential threats. For example, in a shopping mall monitoring system, if someone’s gaze frequently shifts to a specific area, it may indicate that they are engaging in theft or other improper behavior. Gaze estimation can help intelligent monitoring systems detect and alarm in a timely manner.
In medical diagnosis, the use of eye-tracking technology enables real-time monitoring of patients’ fixation points and directions, providing important information about their attention allocation and cognitive processes. Eye line estimation can be used for ophthalmic diagnosis and treatment. By analyzing the patient’s gaze patterns and eye movements, their eye coordination, eye movement function, and abnormal eye movements can be evaluated. This is very helpful for early detection and treatment of eye diseases. For example, in the diagnosis of strabismus, by observing the patient’s fixation point and eye movements, the type and degree of strabismus can be determined, and an appropriate treatment plan can be developed. In addition, it can be used for neuroscience research and brain function localization. By analyzing patients’ gaze patterns and eye movements, we can understand their attention allocation and cognitive processing processes toward stimuli. This is very helpful for studying the cognitive function of the brain and neurological diseases. For example, in the study of cognitive process, eyesight estimation can determine the cognitive load and attention distribution of patients under different tasks and stimuli, thus revealing the neural mechanism of a cognitive process.
2. Related Work
At first, human gaze estimation information is mainly obtained through mechanical, electrical signals, or traditional algorithms. T. Eggert et al. used a recognition algorithm for electrical signals to achieve human gaze estimation technology. This method mainly uses intelligent sensors to sample electrical signals from skin electrodes and represents the subject’s eye movement through changes in this electrical signal [
6]. This method requires connecting the device to the head position of the subject, which is relatively simple to implement. However, traditional devices are bulky, inconvenient for the subject to move, and have low accuracy. Later, with the continuous development of technology, many researchers began to use image processing algorithms to achieve gaze estimation. Zhang et al. proposed a nonlinear unscented Kalman filter for gaze estimation [
7], which can overcome the difficulties of nonlinear gaze estimation and improve the accuracy of gaze estimation. Jiashu Zhang et al. proposed to use several groups of points to match the posterior probability density function of eye movement [
8], which is more accurate than the estimation effect of the traditional Kalman filter. Although nonlinear Kalman filtering algorithms can improve the accuracy of gaze estimation, they are numerically unstable in practical applications and require more computational time. The process of optimizing the structure is complex and has poor real-time performance. Amudha J et al. used deformable template matching to achieve various challenges in gaze estimation, which achieved a tracking accuracy of 98% [
9]. L. Yu et al. proposed an eye gaze estimation method based on particle swarm optimization [
10], which reduces the restrictive requirements for hardware and improves the practicability of the system. Although the gaze estimation technology based on genetic algorithm and particle swarm optimization algorithm can achieve accurate gaze estimation, the algorithm design is difficult, the parameter adjustment range is wide, and it is time-consuming and laborious.
With the continuous innovation of technology, deep learning methods have gradually attracted more and more attention from researchers. Compared to the Kalman filter algorithm, genetic algorithm, ant colony algorithm, and so on, deep learning advocates direct end-to-end solutions to the problem of gaze estimation, which can be classified into two types:
The model-based gaze estimation is a state-of-the-art computer vision technique that harnesses the power of machine learning algorithms to simulate the intricate movement of human eyes and accurately predict gaze points. B. Yan et al. presented an innovative technique for estimating gaze direction using differential residual networks [
11], which can measure the disparity in gaze between two eyes with higher precision. H. Zhang et al. developed a multitask network model to estimate eye gaze and blinks concurrently [
12]. S. H. Kim et al. proposed a continuous engagement evaluation framework utilizing estimated gaze direction and facial expression data [
13], substantiated by creating a database of gaze estimates. This method effectively expresses fine-grained state information. Liu et al. proposed a 3D gaze estimation model integrating an automatic calibration mechanism [
14], which utilizes eye images to construct a 3D eye model, creating a point cloud with an RGBD camera. This method yields an average precision of 3.7° but requires expensive hardware. J. Ma et al. [
15] proposed an eye-specific offset predictor for humans that enables predicting gaze estimation for multiple target figures. J. Zhuang et al. proposed adding a squeeze-and-excitation (SE) attention mechanism to ResNet networks to predict gaze points of flight simulator operators on the screen [
16], which fills a void in research on multiscreen and multicamera systems. B. Saha et al. developed a real-time gaze estimation interface based on a subjective appearance method to achieve gaze estimation in a free environment using algorithms like decision trees and random forests [
17], which has an accuracy of approximately 98%. However, the error varies in distinct environments and lighting conditions, and the system’s stability is suboptimal. Chang C C et al. proposed a simple facial tagging function based on the YOLO model to locate two facial markers and six facial orientations [
18]. It achieves an average precision of 99% while detecting facial orientations and facial features. However, the accuracy of locational facial marker points is questionable when subjects move significantly. Z. Wan et al. proposed a fractional perceptual gaze estimation method utilizing the actual pupil axis, which regresses the pupil’s spherical coordinates normal to the gaze points [
19]. This technique effectively solves the issue of pupil cornea refraction. However, the method did not detect the pupil contour, producing a less accurate model. H. Huang et al. presented a new framework: GazeAttentionNet [
20], utilizing global and local attention modules to achieve gaze features. The method obtained high accuracy on a dataset with real-time validation. Nevertheless, the method’s accuracy is low, with the average error reaching approximately 2 cm for mobile devices.
- 2.
The appearance-based gaze estimation methods
The appearance-based gaze estimation is a cutting-edge computer vision technique employed to predict a person’s gaze direction accurately. This advanced method relies on the analysis of appearance-based features surrounding the human eye to achieve gaze estimation. Zhao et al. proposed a monocular gaze estimation network utilizing mixed attention to predict gaze points from monocular features and their location information [
21]. Wan et al. introduced a technique for estimating gaze direction utilizing one mapping surface [
22], which accomplished eye-center calibration through the mapping surface, simplifying the model by making assumptions. Zhuang et al. developed a simplified network model for gaze estimation based on the LeNet neural network, called SLeNet [
23], utilizing depth-separable convolution to decrease the number of convolution parameters and improve the speed of the model. Nonetheless, the model design of this technique is too simple, and the accuracy needs to be enhanced.
Zhang et al. presented a gaze data processing model based on artificial neural networks and face recognition techniques [
24], which analyzed gaze estimation from the perspective of data processing, lessened the false recognition rate, and experimentally verified the effectiveness of the method. Murthy et al. designed an end-to-end gaze estimation system to anticipate gaze points employing infrared eyeglass images captured by wearable vision-estimating eyes [
25], which realized comprehensive gaze estimation. Liu et al. developed a technique to predict the disparity in gaze between two eye input images of the same subject by directly training a differential convolutional neural network and predicting the direction of eye gaze using the estimated difference [
26]. This method achieves high accuracy but involves a more complicated process of adjusting the parameters of the differential network when the subject’s eyelids are closed or when the pupils are affected. Suzuki et al. proposed a sight-tracking dataset-based technique for estimating candidate regions for superimposed information in football videos [
27]. Nevertheless, the accuracy of line-of-sight tracking decreases with an increase in superimposed information. Chang et al. proposed a gaze estimation technique based on YOLO and deep learning for localizing and detecting facial orientation by integrating appearance and geometric features [
28], which achieved a robust accuracy of 88% without calibration. However, it suffered from slow real-time tracking due to its inability to locate facial feature coordinates. Senarath et al. proposed a three-stage, three-attention deep convolutional neural network for retail remote gaze estimation using image data [
29]. Luo et al. proposed a collaborative network-based gaze estimation model with an attention mechanism that assigns appropriate weights between eye and facial features and achieved more accurate gaze estimation [
30]. Han et al. proposed a pupil shape-based gaze estimation method, which used a deep network to learn gaze points by extracting various features from the image [
31]. X. Song et al. proposed an end-to-end network using U-Net with residual blocks to retain eye features in high-resolution feature maps for efficient gaze estimation [
32]. Zhao et al. proposed a unified network for simultaneous head detection and gaze estimation, where the two aspects share the same set of features to promote each other and enhance detection accuracy [
33]. However, this method still had limitations in terms of accuracy, with an error of 19.62° at 23 fps.
In summary, the aforementioned algorithms faced two primary challenges. (1) The gaze estimation accuracy is greatly reduced when the subject’s face is obscured or in a different environment with varying lighting conditions. (2) The designed network models or algorithms are simple in structure, leading to decreased gaze estimation accuracy.
To address the above problems, this paper proposes a new attention-based mechanism for the gaze estimation algorithm FPSA_L2CSNet, which integrates L2CSNet with facial feature extractor (FFE) and pyramid squeeze attention (PSA), which has the following contribution:
1. A facial feature extractor is integrated with L2CSNet, enabling retrieval of facial details, location of eye features, extraction of key eye points, and efficient narrowing of eye feature extraction range to enhance gaze estimation accuracy.
2. L2CSNet augmented with PSA incorporates multiscale spatial information and cross-channel attention into the model, selectively highlighting feature regions relevant to vision estimation and suppressing irrelevant weights. Further, it facilitates granular level feature extraction, gaze direction feature extraction, and accurate vision estimation.
3. The proposed model is tested on a real-life dataset and four representative public datasets: the MPIIGaze dataset, the Gaze360 dataset, the ETH-XGaze dataset, and the GazeCapture dataset. The robustness and accuracy of the algorithm are verified by testing on individuals of varying nationalities, skin colors, ages, partial occlusion, genders and complex backgrounds, and lighting conditions.
3. Materials and Methods
First, this paper constructed a feature extractor to obtain the facial features, thereby narrowing down the range of eye feature extraction and accurately locating the key points of the eyes. Then, a high-precision gaze estimation algorithm [
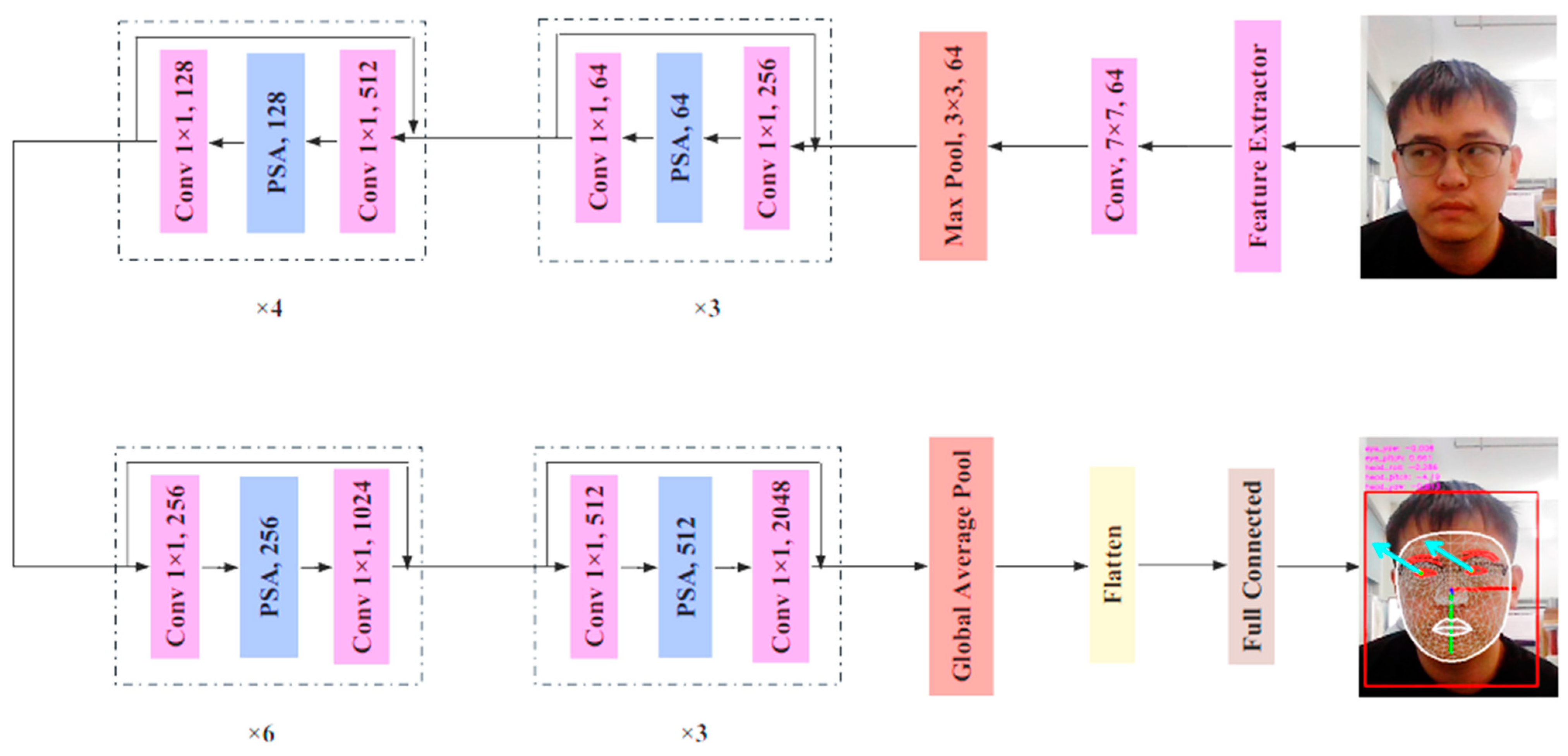
34] is proposed in this paper, which uses ResNet50 as the backbone network, uses a separate loss function to calculate the error of each gaze angle, and regresses the gaze result separately. Furthermore, to further improve the overall performance of the model and reduce the error of gaze results, this paper also introduces the PSA attention module, which combines multiscale spatial information and cross-channel attention into the model and selectively highlights the feature areas related to gaze estimation. Finally, the accuracy and robustness of the algorithm are verified in different environments. The algorithm flowchart of FPSA_L2CSNet is illustrated in
Figure 1.
Therefore, this paper presents a novel attention-based mechanism, FPSA_L2CSNet, for gaze estimation. This approach leverages attention mechanisms to achieve more precise and efficient gaze estimation. The FPSA_L2CSNet algorithm is trained on different datasets, including MPIIGaze, Gaze360, ETH-XGaze, and GazeCapture, and its performance is thoroughly evaluated via comparison with other models. The results confirm the effectiveness and superiority of FPSA_L2CSNet in achieving more accurate and faster gaze estimation.
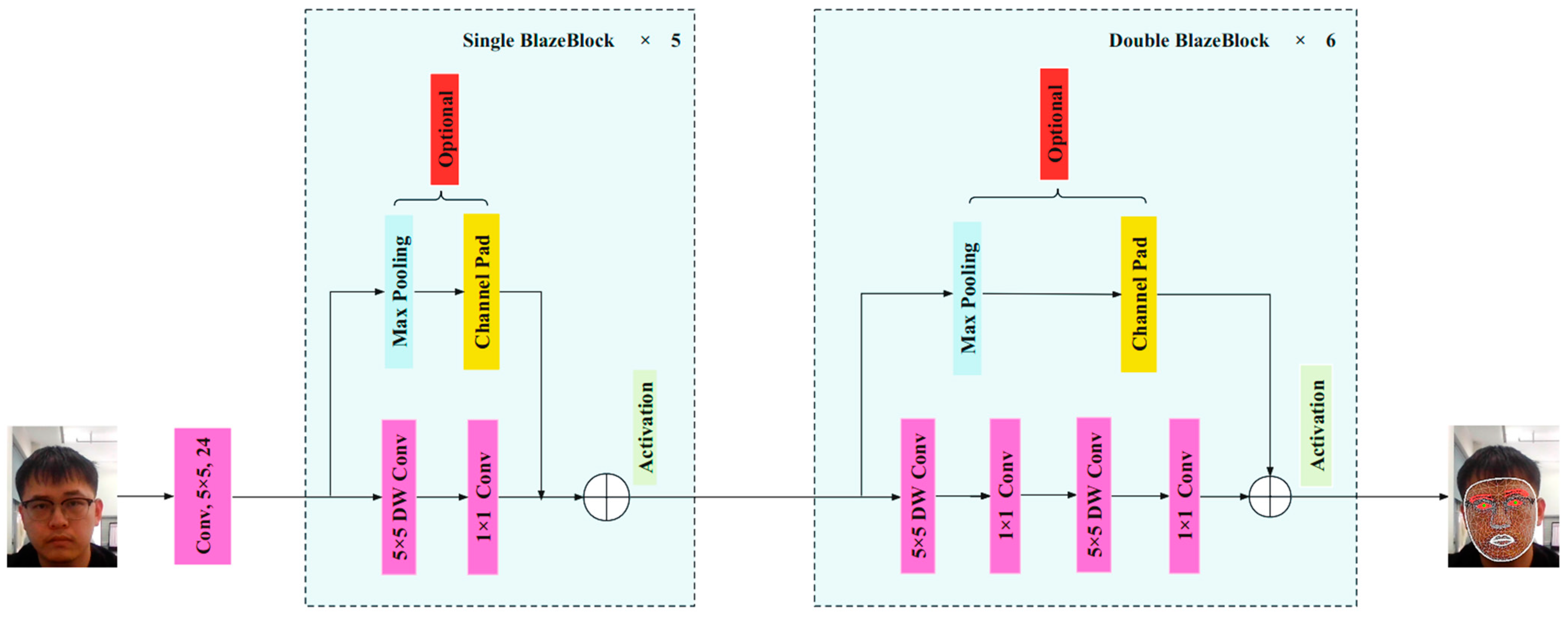
3.1. Acquisition of Facial Feature Points
As depicted in
Figure 2, the FFE (facial feature extractor) in this study utilizes an RGB input image of 128 × 128 pixels to extract facial features. Due to the inherent variation in pixel composition within the dataset, we shall employ the transformative power of the resize () function to preprocess the images. By skillfully applying bilinear interpolation, we shall artfully scale the image, ultimately attaining a harmonious size of 128 × 128 pixels. The results are obtained after passing through 5 single BlazeBlocks and 6 double BlazeBlocks. The main route of the single BlazeBlock consists of a 5 × 5 deep convolution and a 1 × 1 convolution, with the depth-separable convolution layer being the core component. In contrast to traditional convolution layers that perform convolution operations in both the spatial and channel directions, the depthwise separable convolutional layer focuses on these two directions separately to reduce the parameter amount. Specifically, the depthwise separable convolution uses the same convolution kernel to perform convolution on each input channel, resulting in a set of individual output channels. In this way, each convolution kernel is reused, enabling the reduction in a significant number of parameters. The element-wise convolution is the second part of the depthwise separable convolution, using a 1 × 1 convolution kernel to transform each individual output channel into the desired shape. In this way, the depthwise separable convolutional layer establishes the connection between depth and width. The side route of the single BlazeBlock consists of max pooling and channel pad, aiming to increase the convolution kernel size and cover the entire receptive field with fewer convolution layers. The skip connections in the single BlazeBlock allow the model to learn higher-level features that match the input better. Typically, cross-layer connections that span multiple layers help capture globally or partially informative features. Additionally, through skip connections, the single BlazeBlock can integrate with deeper grid structures to enhance the model’s accuracy.
As the network deepens and the features extracted become more advanced, the double BlazeBlock was designed on top of the single BlazeBlock. Compared to the Single BlazeBlock, it simply adds another 5 × 5 deep convolution and a 1 × 1 convolution to the main path. In the double BlazeBlock, the two single BlazeBlock modules are similar in composition to single BlazeBlock in that they both consist of a depthwise separable convolution layer and a skip connection. These modules perform convolutional operations on the input feature map to extract high-level features by using a depthwise separable convolutional layer. The skip connection, on the other hand, ensures that the model learns feature information at a shallower level and allows for a fine-grained combination of feature spectra. The two single BlazeBlock modules in double BlazeBlock are similar in composition to single BlazeBlock in that they both consist of a depth-separable convolutional layer and a skip connection. These modules perform convolutional operations on the input feature map to extract high-level features by using a deeply separable convolutional layer. The skip connection, on the other hand, ensures that the model learns feature information at a shallower level and allows for a fine-grained combination of feature spectra. In double BlazeBlock, after processing by two single BlazeBlock modules, the feature map size and computational burden are then further reduced using the downsampling module. This allows the model to handle large-scale objects better, thus improving the accuracy of the network.
Therefore, the single BlazeBlock can be used for the shallow depth of the network, while the double BlazeBlock can be used for the deeper depth of the network. Through the aforementioned steps, facial feature information, including the feature areas for the left and right eyes, can be obtained.
3.2. ResNet50
Although designing deeper neural networks can lead to better recognition results in the process of deep network design, experiments indicate that as networks become increasingly deep, models will actually perform worse. While overfitting disturbance is eliminated, the real reason behind this problem comes from “vanishing gradients”. Vanishing gradients are inherent defects in the backpropagation training algorithm. As the error is returned, gradients from earlier layers of the network will become increasingly smaller.
Equation (1) presents the loss function of the network, where
X represents the input of the network, and
W represents the weight parameters. The corresponding gradient values from backpropagation are given by Equation (2).
Furthermore, extending to multilayer networks, the loss function is given by Equation (3), where n denotes the number of layers in the network. According to the chain rule, the gradient of layer i can be derived, as shown in Equation (4). It can be observed that as the error is backpropagated, gradients from earlier layers of the network become progressively smaller.
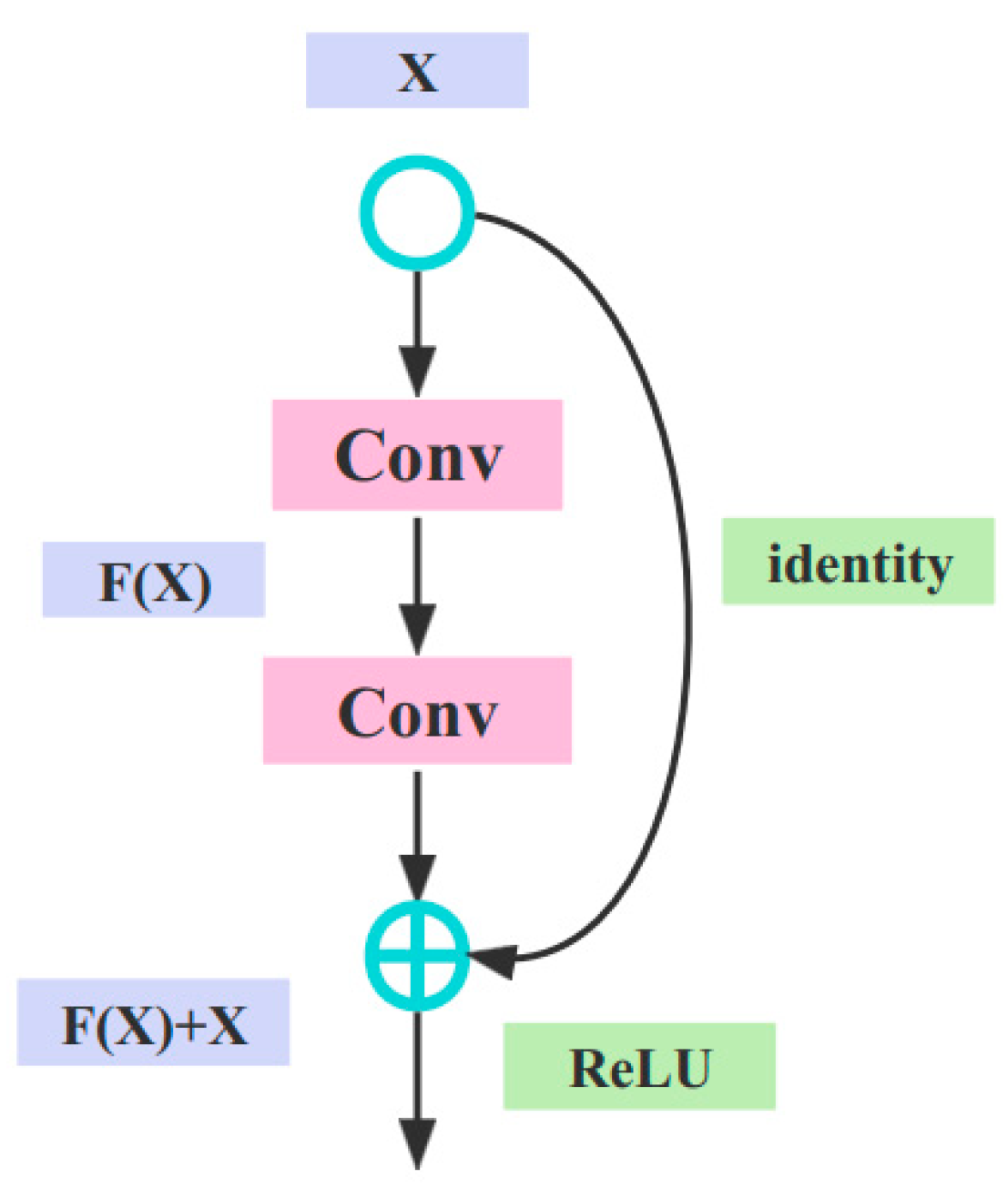
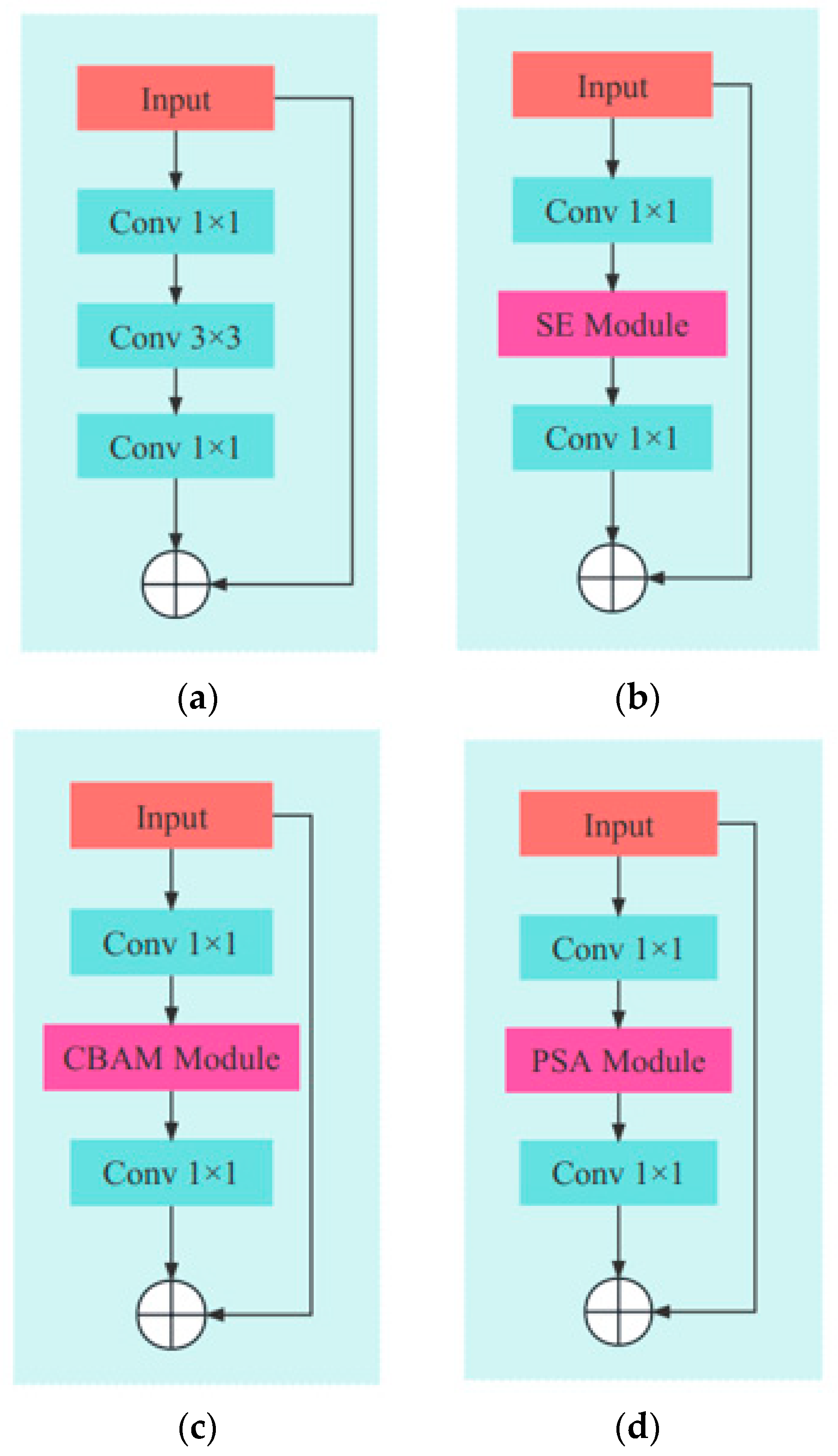
To address this issue, ResNet ingeniously introduced residual structures, as shown in
Figure 3.
This means that the output layer is
y = x + F(x), which implies that, in the process from Equation (4) to Equation (5), the gradient will not vanish even if the network becomes deeper.
The introduction of residual structures in ResNet allows for training neural networks that are deeper and more efficient, reducing the risk of overfitting while improving model performance. Specifically, there are several advantages to using residual structures: mitigate the problem of gradient disappearance, solve the problem of degradation, and avoid the problem of overfitting.
ResNet [
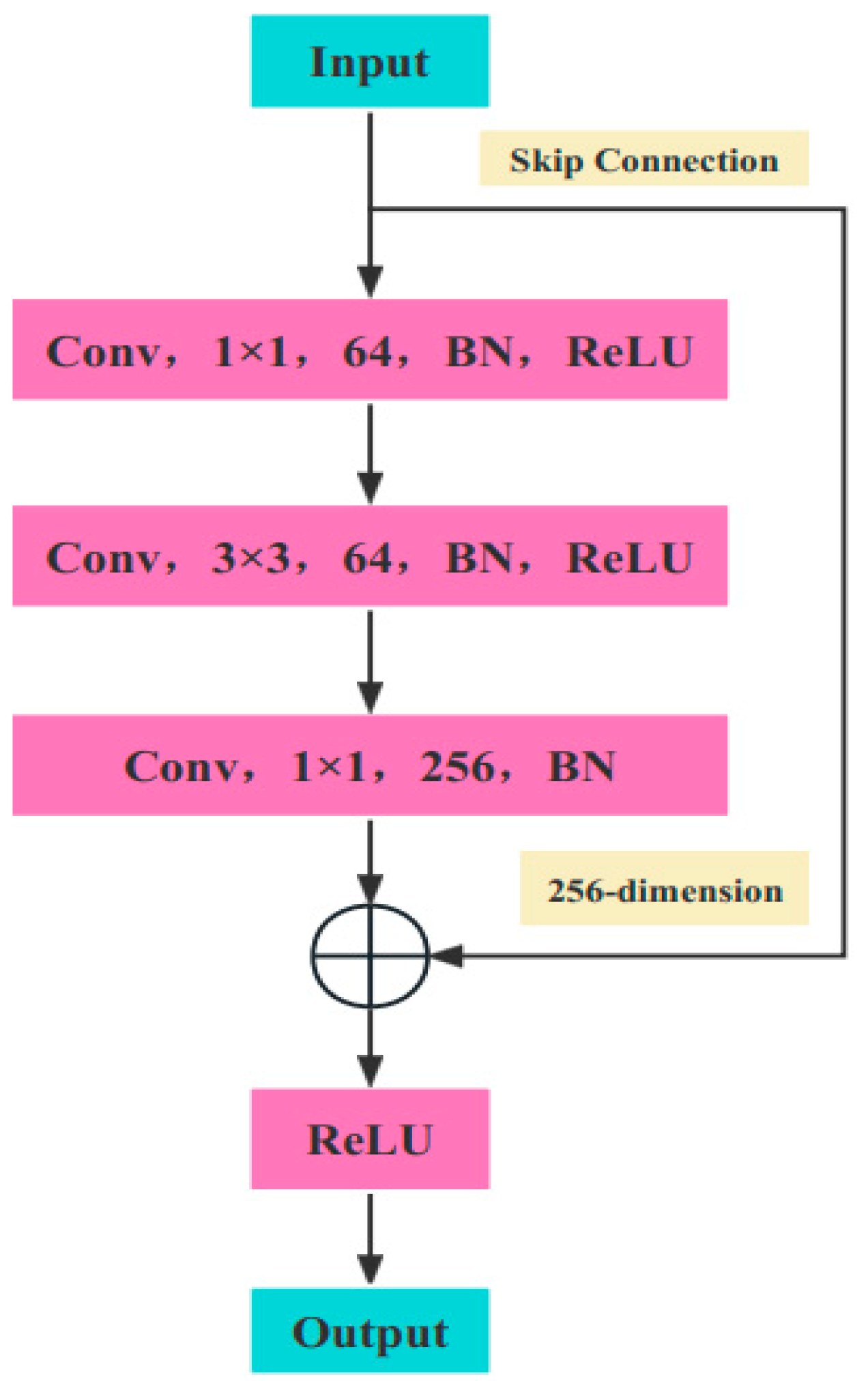
35] has five different structures, namely ResNet18, ResNet34, ResNet50, ResNet101, and ResNet152, representing different model depths and widths. The main differences between them are the depth and number of parameters of the models. ResNet-18 and ResNet-34 have the same basic structure and are relatively shallow networks. The basic structure of the last three models, ResNet-50, ResNet-101, and ResNet-152, is different from ResNet-18 and ResNet-34, representing deeper networks. Overall, the ResNet network structure has a large amount of computation and is complex, although the use of 1 × 1 convolution reduces the number of parameters. The depth of the network determines that the number of parameters is large. Therefore, choosing a network with too many layers may lead to overfitting and difficulty in convergence, while choosing a network with too few layers may result in poor training outcomes and low accuracy. Considering the above, in order to improve the accuracy of the network and prevent overfitting, ResNet50 is chosen as the backbone network in this paper. Its residual structure is shown in
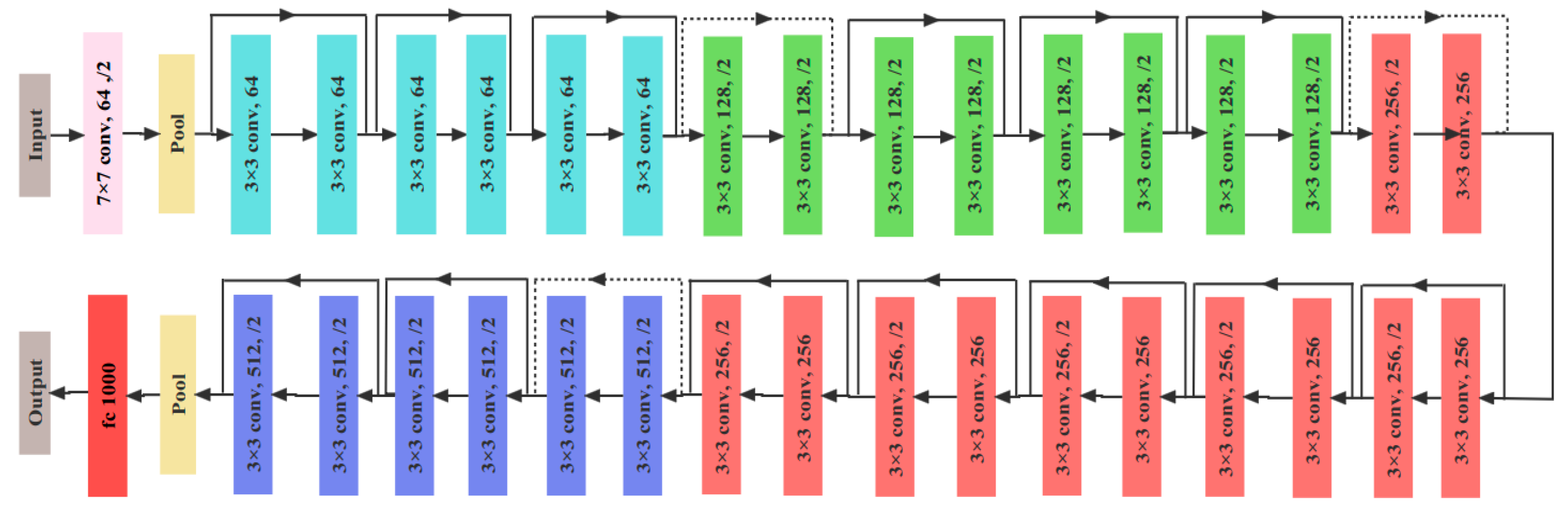
Figure 4.
This model comprises a main branch from top to bottom and skips connections on its right side. Its core idea is to transmit input information directly to the output via skip connections and to learn only the differences between the output and input through the main branch, thereby simplifying the learning process. In the main branch, 1 × 1 convolution is used to reduce the number of dimensions and generate 64 feature maps. Then, 3 × 3 convolution is performed to extract the main features. Subsequently, 1 × 1 convolution is executed to increase dimensionality and generate 256 feature maps. Additionally, batch normalization (BN) is utilized in ResNet to improve the model’s generalization ability by subtracting the mean and dividing by the variance of the same batch of data. Furthermore, rectified linear units (ReLU), a nonlinear activation function, are employed to enhance the model’s nonlinear adaptability.
Figure 5 shows the overall architecture of ResNet50, which adds branches between every two layers of the network and can sample input images with a convolutional sequence of 2. It is evident from the structure that there are four layers in the ResNet50 structure, and each layer is comprised of 3, 4, 6, and 3 residual blocks, respectively. The “3 4 6 3” in the basic block structure refers to the number of residual units in each layer, and these residual units are the basic subelements with interlayer connections. A large number of convolutional layers in ResNet are composed of these basic subelements arranged according to certain rules. Therefore, these numbers actually reflect the overall network depth of ResNet. The advantage of this design is that it enables ResNet to use the depth of the network more effectively and avoids the performance degradation problem that occurs when the number of layers increases in traditional deep networks.
3.3. Attention Mechanism
As a data processing method in machine learning, the attention mechanism mainly focuses the network’s learning on important areas. Studies have shown that embedding attention modules into convolutional neural networks can greatly improve network performance. In recent years, the method has been widely applied in computer vision, such as image classification, object detection, and semantic segmentation. Overall, attention mechanisms are mainly divided into channel attention and spatial attention; the most commonly used methods are the SE attention mechanism module [
36] and the convolutional block attention module (CBAM) [
37], respectively. The former has a simpler structure, consisting of two parts: squeeze and excitation. The main purpose of the squeeze part is to represent the importance of each channel feature, while the excitation part multiplies the feature map channels with the weighted channel importance obtained by the squeeze. Thus, it can make the model aware of the importance of each channel. However, the global average pooling of the squeeze module in the SE attention module is too simple to capture complex global information, and the fully connected layer of the excitation module increases model complexity, ignoring spatial information and leading to long calculation time and overfitting. The characteristic of the CBAM is that it focuses on the densest positions of effective information in an image, concatenates the feature maps generated by max pooling and average pooling, and applies convolutional and activation functions to form spatial attention maps. However, the CBAM has not captured spatial information at different scales to enrich the feature space, and its spatial attention only considers local information, failing to establish long-distance dependencies.
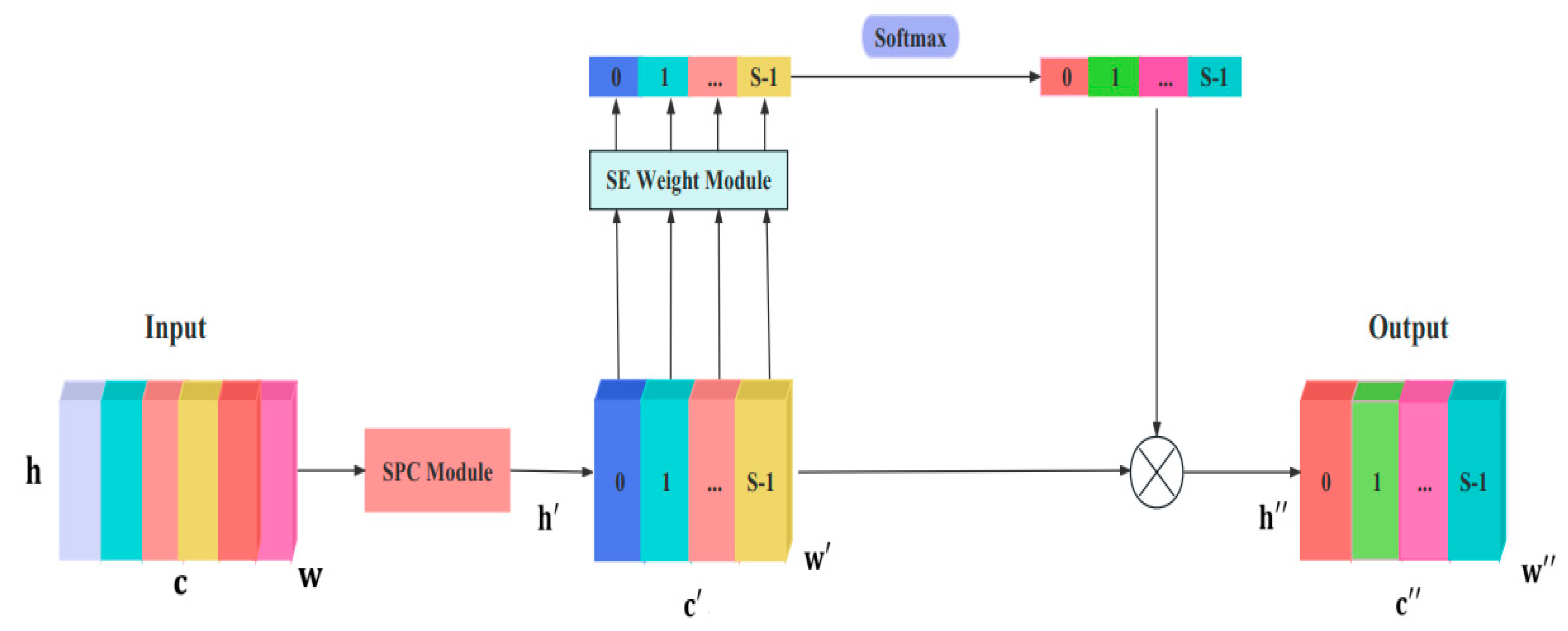
The PSA module not only has the ability to process tensors at multiple scales but also extracts spatial information at different scales by compressing the channel dimension of the input tensor. The PSA attention module [
38] consists of four parts, as shown in
Figure 6. First, the SPC module is used to obtain multiscale feature maps with channel diversity. Then, the SE weight module is used to obtain channel attention across multiple-scale feature maps. Next, the softmax function is used to adjust channel attention again and obtain the weight of multiple-scale channels. Finally, element-wise multiplication is applied to the recalibrated weights and corresponding feature maps. Based on the above four steps, multiscale feature information can be outputted. In this structure, the spatial information of the input feature maps is obtained by using a multibranch method, which can obtain rich position information and conduct parallel processing for multiple scales. Moreover, the pyramid structure generates different spatial resolutions and depths of multiscale convolution kernels, effectively extracting spatial information at different scales on each channel feature map. Therefore, by integrating multiscale spatial information and cross-channel attention into the original model, multiscale spatial information can be extracted at a more granular level.
First, the SPC module is used to obtain feature maps with multiple channel scales. Although each input image in this structure has feature maps with different scales
, they have the same channel dimension
. Their relationship is expressed as follows:
Each branch independently learns multiscale spatial information, allowing them to establish cross-channel interactions in a local manner. The number of parameters changes with the increase in kernel size. In order to handle input tensors with different kernel scales, group convolution is used and applied to the convolution kernel. The quantity n is the kernel size, and
Z is the group size. The relationship between them is expressed as follows:
As a result, the generation function for multiscale feature map is expressed as follows:
The preprocessed multiscale feature map is expressed as follows:
Next, the SE weight module is used to obtain attention across multiple-scale feature maps in order to obtain channel attention. The weight information and weight vector for channel attention are obtained from the preprocessed multiscale feature maps. The attention weight vector is expressed as follows:
The SEWeight module is used to obtain weights from input feature maps at different scales and then to fuse feature information of different scales. In addition, to achieve the interaction of feature information, the vectors across dimensions are fused. Therefore, the multiscale channel attention vector is obtained in the following way:
Here,
refers to the attention value of
, and
Q is the multiscale attention weight vector. Through the above steps, the interaction of local and global channel attention is achieved. Next, the channel attention vector can be obtained by fusing and concatenating channel attention. Its expression is written as follows:
Here, attention refers to the multiscale channel attention weight obtained after the interaction. Next, the weight of multiscale channel attention is multiplied by the feature map, expressed as follows:
The above equation can effectively preserve the original feature map information. After simplification, the final input process is expressed as follows:
The PSA module is a novel attention mechanism that integrates multiscale spatial information and cross-channel attention into each block of feature groups. Thus, the PSA module can achieve better information interaction between local and global channel attention. Its advantages mainly include the following:
1. PSA has more refined weighting, which uses a more detailed monotonic regression algorithm to obtain the relative relationship between features, allowing it to more finely weight feature maps.
2. The PSA module can obtain the feature dependencies of each position in the feature map at different scales, thereby capturing the global and long-range features of the object better.
3. It can adapt to different resolutions: The PSA module adapts to different image inputs of varying resolutions by pyramid pooling, encoding different resolution feature maps through different sizes of pyramid layers, and then weighting them through corresponding convolution operations. This design improves the robustness of the model to different input resolutions.
The introduction of the PSA module can significantly improve the performance of the model in tasks such as object detection and image classification, even outperforming other powerful attention mechanisms. In
Figure 7, the bottleneck module of ResNet consists of two 3 × 3 convolutions and one 1 × 1 convolution. The 1 × 1 convolution is mainly used for dimension reduction or expansion, and the 3 × 3 convolution is mainly used for feature extraction. The purpose of adding the attention module is to improve the feature extraction ability further, and thus, by simply replacing the 3 × 3 convolution of the bottleneck module with the PSA attention module, the EPSANet Bottleneck is obtained.
Next, we adopt two identical loss functions for each gaze angle in this study. Each loss function is a linear combination of cross-entropy loss and mean squared error. The cross-entropy loss is defined as follows:
The cross-entropy loss is defined as follows:
The proposed loss function for each gaze angle is a linear combination of the mean squared error and cross-entropy loss, defined as follows:
where
CLS is the overall loss,
p is the predicted value,
y is the true value, and α is the regression coefficient.
5. Conclusions
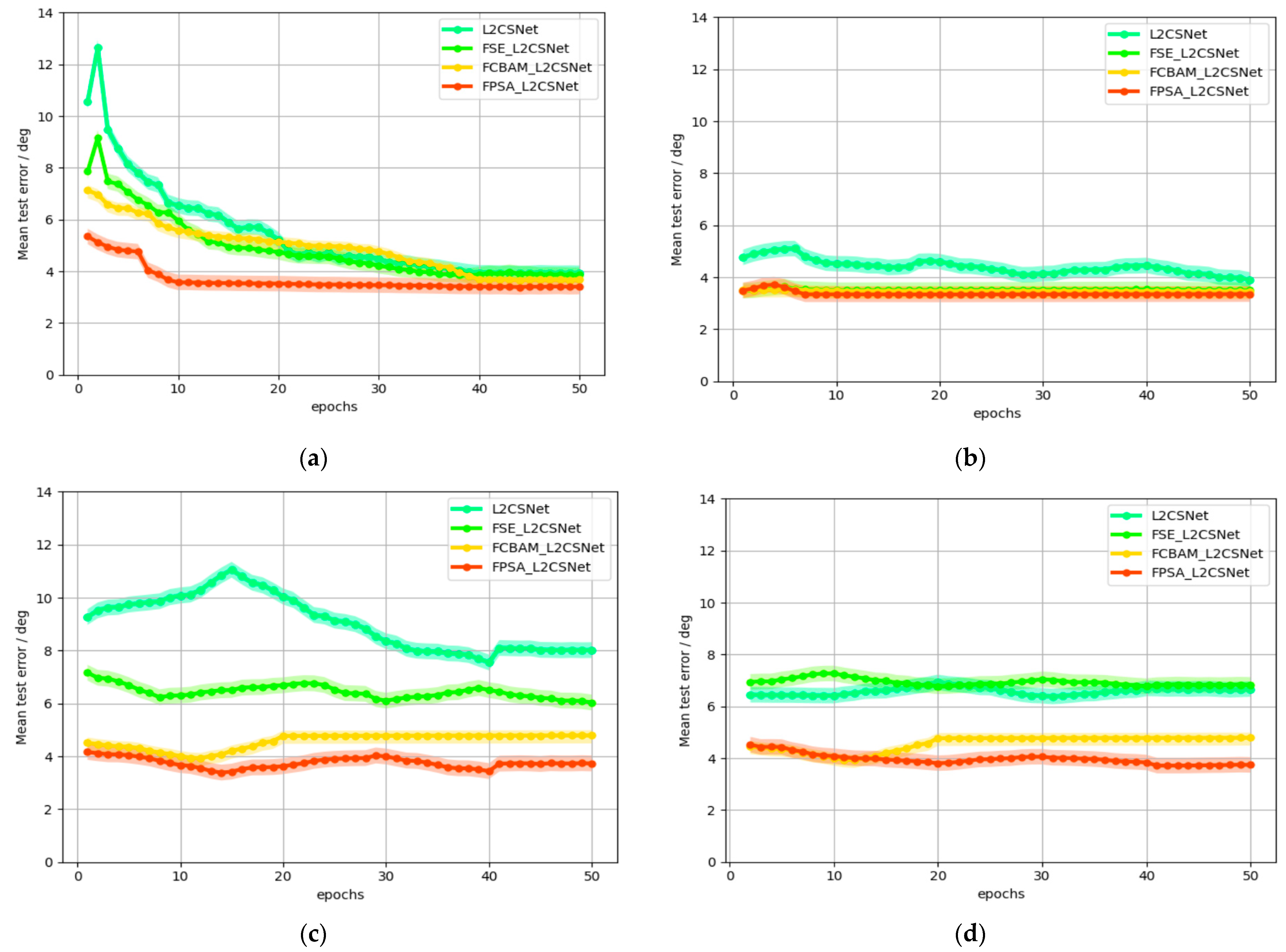
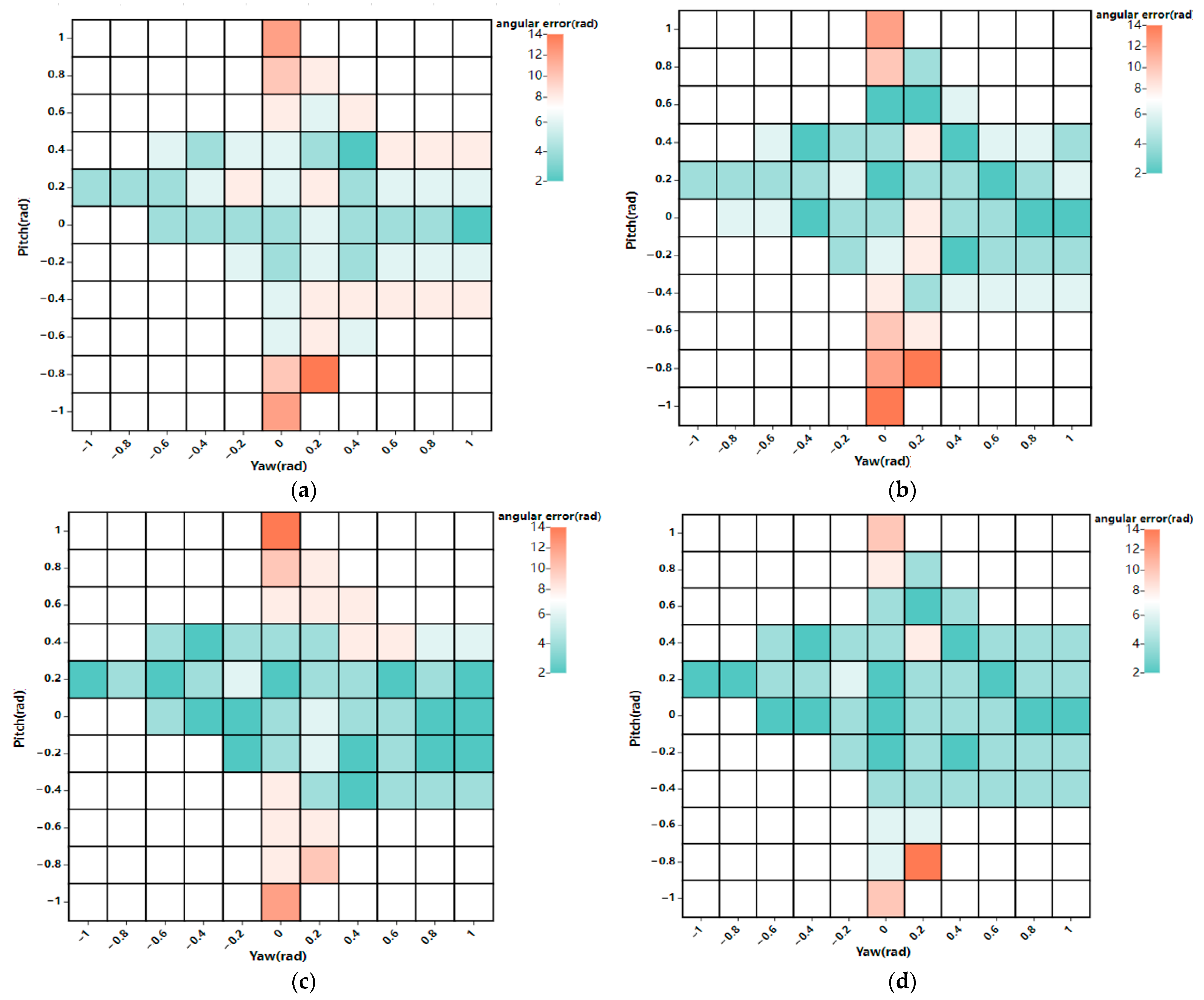
To address the challenge of low gaze estimation accuracy among individuals in different environments, this study proposes a gaze estimation model based on attention mechanisms: FPSA_L2CSNet. The results obtained from testing on the public dataset show that this model exhibits the lowest error and highest accuracy on the MPIIGaze dataset, with errors of 3.41°, 3.35°, 3.73°, and 3.74°, respectively. Compared with L2CSNet, FSE_L2CSNet, and FCBAM_L2CSNet, the accuracy is improved by 13.88%, 11.43%, and 7.34%, respectively. The results obtained from testing on real-world data show that this proposed model achieves precise gaze estimation under different lighting, background, and partial occlusion conditions for individuals of different nationalities, skin tones, ages, and genders, thus verifying the robustness and universality of the model.
In the future, PSA’s attention mechanism could be further enhanced to amalgamate diverse levels of gaze estimation features, which would enable network models to concentrate on line-of-sight information, thereby improving the resilience and precision of the model.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



