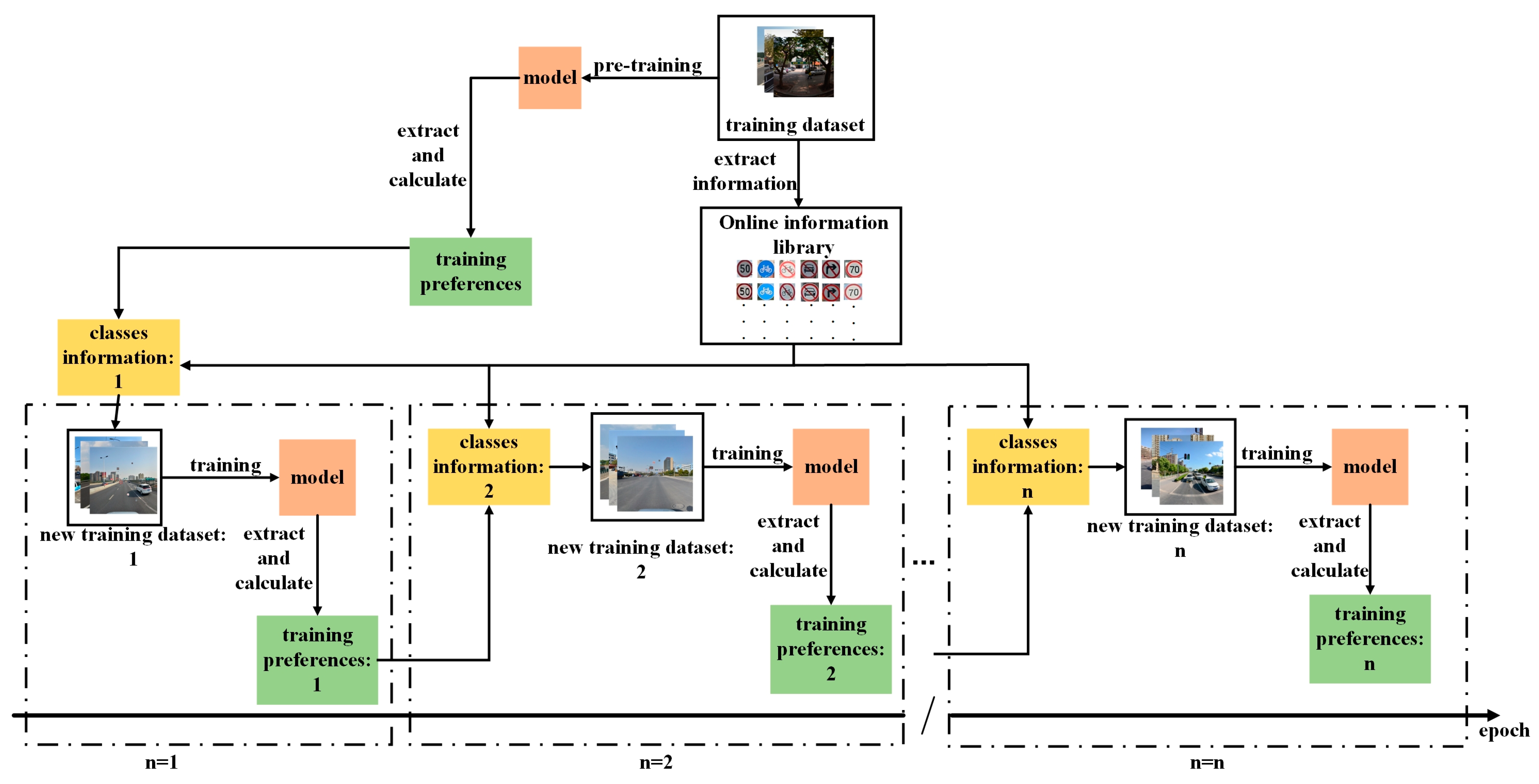
3.2. The Multi-Stage Training Preference of the Model
In the work of CPA [
14], the training preference of the model is proposed. The training preference of the model refers to the model better grasping the features of some classes in training, and giving higher confidence in predicting these classes. Meanwhile, different models are also good at detecting different classes. That is to say, in the same datasets, different models are good at detecting different classes. However, it is found that the training preference of the model is different in different training stages by further experiments. In the CPA algorithm, the model training preference is mainly based on the evaluation results of pre-training. According to the training preference, the CPA algorithm will provide information compensation for each class to alleviate the impact of class imbalance on model training. But this training preference cannot reflect the whole training situation of the model. The expanded sample size may not be suitable for the entire training process of the model.
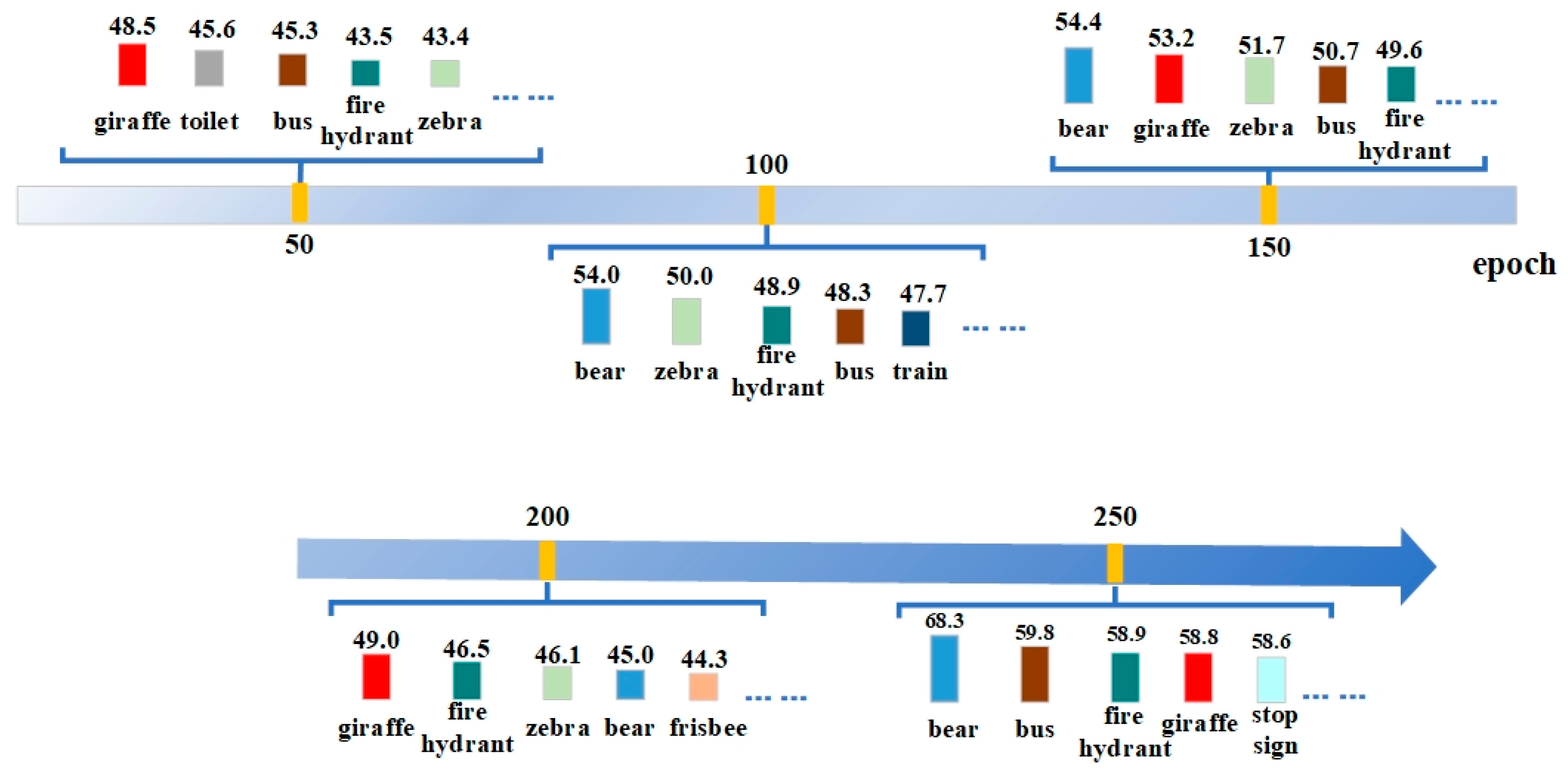
To provide an intuitive explanation of the above analysis, the model YOLOv3 was trained with the original COCO datasets.
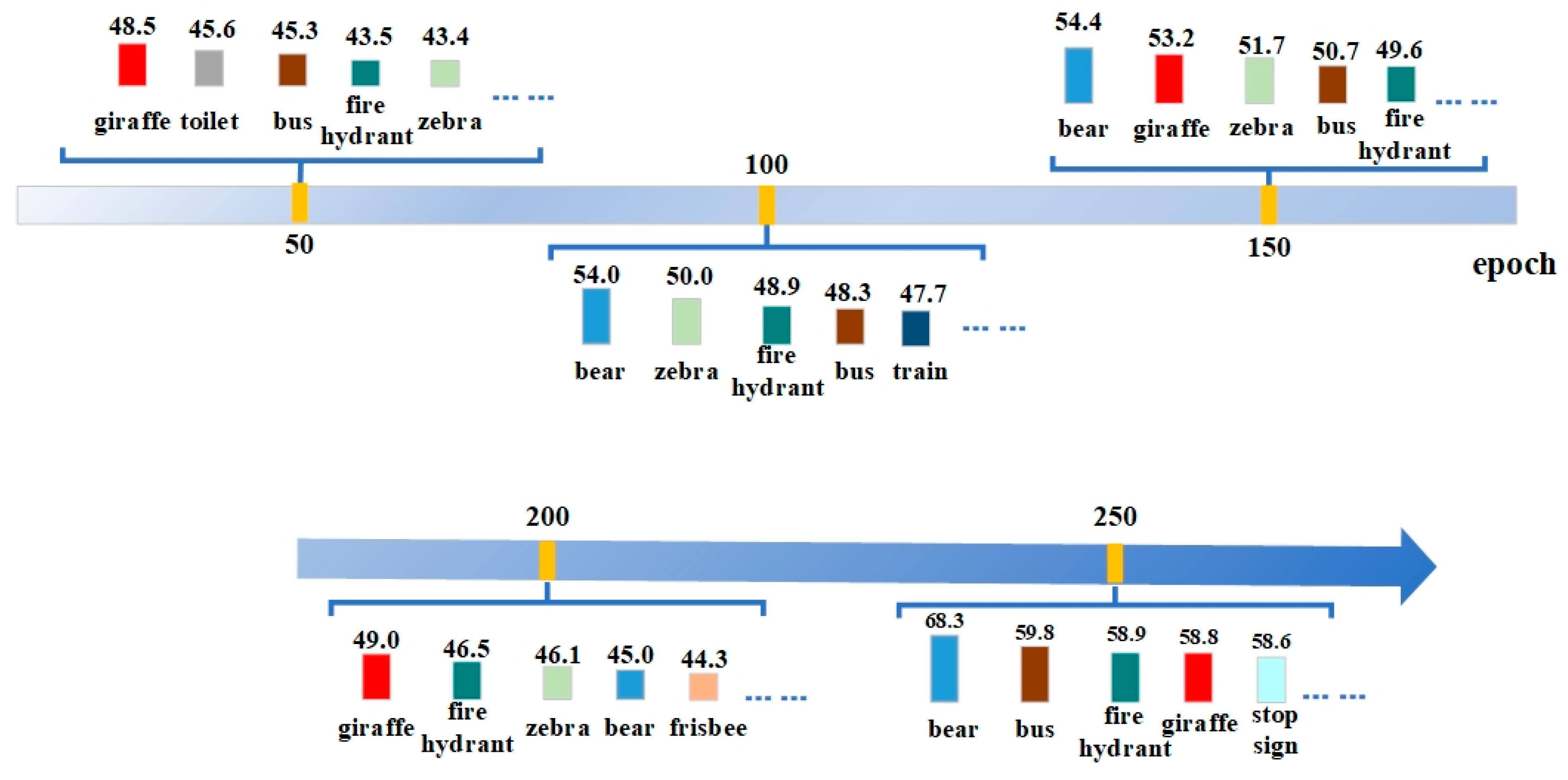
Figure 2 shows the evaluation results of these 5 nodes. The figure only shows the top 5 categories with the highest values. These 5 nodes are the 50th, 100th, 150th, 200th, and 250th epoch, respectively. From the figure, it can be seen that the evaluation results of the 200th epoch show a significant decrease compared to the results of the 100th and 150th epoch, and the training of the model is unstable. For the top five classes, there are differences in the evaluation results between the five epochs. The class giraffe is highest at epoch 50, but does not appear in the top five highest classes at epoch 100. The class bear does not appear in the 50th epoch, but appears in the next four extracts. The class bus does not appear in the top five highest epochs at the 200th epoch, but appears in the other four extractions. The four classes of toilet, train, frisbee, and stop sign appear only once in these five extractions.
The training preferences of the model will be different in different training stages. Therefore, it is not appropriate to reflect the training preference of the model only from the evaluation results of pre-training. In order to master the training preferences of different stages, the commonly used improvement method is to calculate the training preferences based on the evaluation results in real time, and then update the training dataset constantly. This is similar to difficult sample mining, which checks loss values or other indicators in real time to mine the information that the model needs to focus on learning. For the Copy-Paste augmentation algorithm, the main data amplification method is to insert the synthesized image in the training dataset, where the new training dataset is used to train the model. If real-time sampling is applied to the Copy-Paste augmentation algorithm, it means that the training dataset needs to be updated frequently, and it takes time to generate images and import a new training set. The frequent updating of the datasets results in a long training time. If the dataset is updated frequently, it does not give the model much additional class information to learn.
3.3. The Design of MSACP Algorithm
The model in the field of deep learning is usually regarded as a black box because the parameters of the model are uncertain during the training process. How does class imbalance affect model training? For supervised learning, the number of samples in the datasets and the model structure are known, which is a priori knowledge. The probability that the model predicts samples is the posterior probability. The class information such as speed limit signs, warning signs, and so on are in the TT100K dataset and are assumed to be independent of each other. The class information in the training dataset can be written as D = {(
x1,
y1), (
x2,
y2), (
x3,
y3), … …, (
xn,
yn)}, where
x is the sample with class label
y, and
n is the number of classes. If the training dataset contains samples with {m
1, m
2, m
3, … …, m
m}, the probability that a predicted sample m belongs to class
xi can be written as Equation (1):
where
represents the probability that sample m is predicted by the model as class
.
is the prior probability of this class, which represents the proportion of the number of samples in the training dataset.
is the conditional probability, representing the class
of the training dataset. Equation (1) can be further simplified, as shown in Equation (2):
Among them,
is the proportion of the number of samples of class
and the total number of samples in the training dataset. The conditional probability
and prior probability
in the Bayesian model are related to the number of samples in the training dataset, so the class imbalance can affect the magnitude of these two probabilities. If
is used to represent the class with a large number of samples, and
is used to represent the class with a small number of samples, then the posterior probabilities of these two classes can be calculated by Bayes, as shown in Equations (3) and (4):
Because the number of samples for class in the training dataset is small, the values of and are also small, which results in the posterior probability becoming smaller. Because of the influence of class imbalance, the posterior probability of class becomes larger, so the prediction result of the model will be biased to . To reduce the effect of class imbalance, the Copy-Paste enhancement algorithm is used to expand the class information with insufficient samples. This method is used to improve the prior probabilities of these classes and modify the prediction results of the model.
Due to its unique design, the model is easily able to grasp certain categories during training, which forms the training preferences of the model. Under the same dataset, the detection performance of the model is not positively correlated with the number of samples in the dataset. Although the number of samples in the training set is not very large for some categories, the model can accurately detect these categories. Therefore, simply using Copy-Paste enhancement algorithms to increase the sample size of a class lacks the support of principled approaches. After the analysis in
Figure 2, the training preferences will change at different training nodes. These changes are used to update the category information of the training set, correct the training direction of the model, and further improve the detection performance of the model.
How to choose an appropriate time point to update the training dataset and open a new training stage? To ensure the simplicity and generality of MSACP algorithm, the training volume of the model is equally divided into stages. The hyper-parameter n is to represent the number of stages. Before starting the next training stage, MSACP algorithm adaptively adjusts the class information of the training dataset according to the training situation of the current stage. The key of MSACP algorithm is to amplify the appropriate class information according to the training preference of different stages. The computed expression for this training preference is given in Equation (5):
where
reflects the degree of preference of the model in the stage.
is the evaluation result for each class.
i is id of the class.
is the evaluation result of the first epoch in this stage. Then
is the evaluation result of the last epoch in this stage.
serves as an enhancement coefficient to dynamically adjust the preference degree of classes, written as follows:
When
is greater than 1, it means that in this stage, the detection effect of the model for the class is reduced and the training preference is enhanced. When
is less than 1, it means that the detection effect of the model for the class remains stable or has been improved in this stage. The training preference is then kept constant. After obtaining the training preferences for the current stage, the MSACP algorithm calculates the number of samples that need to be expanded in this stage. According to the results, the appropriate amount of amplification is provided for the copy–move augmentation algorithm to adjust the class information in the training dataset. The expression is shown in Formula (7):
is the regulation coefficient. The number of classes to be amplified is adjusted by the size of
. Finally, this result needs to be processed by the normalization, as shown in Formula (8):
(S1, S2) is the normalized range, is the final output result of the class. .





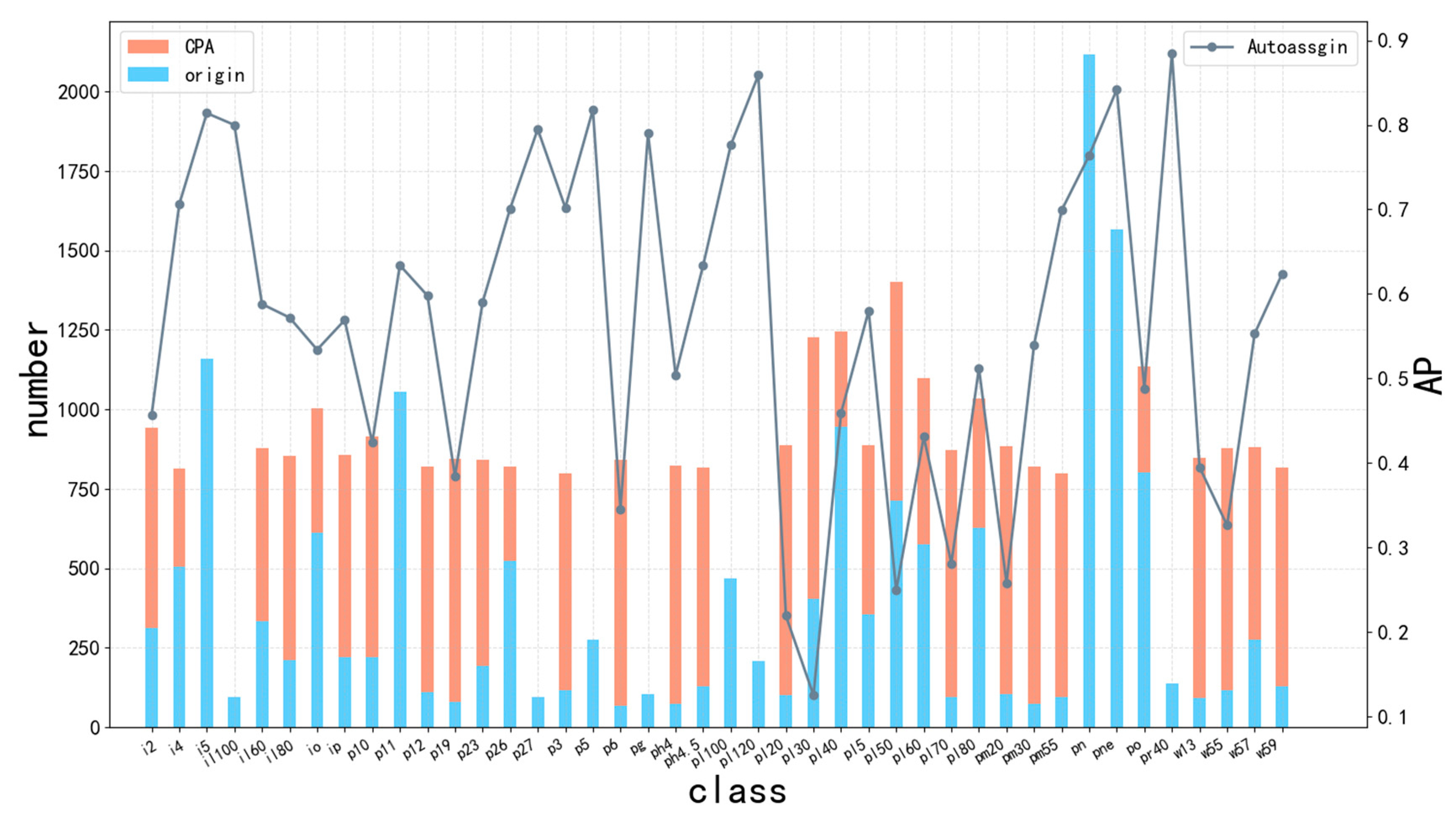
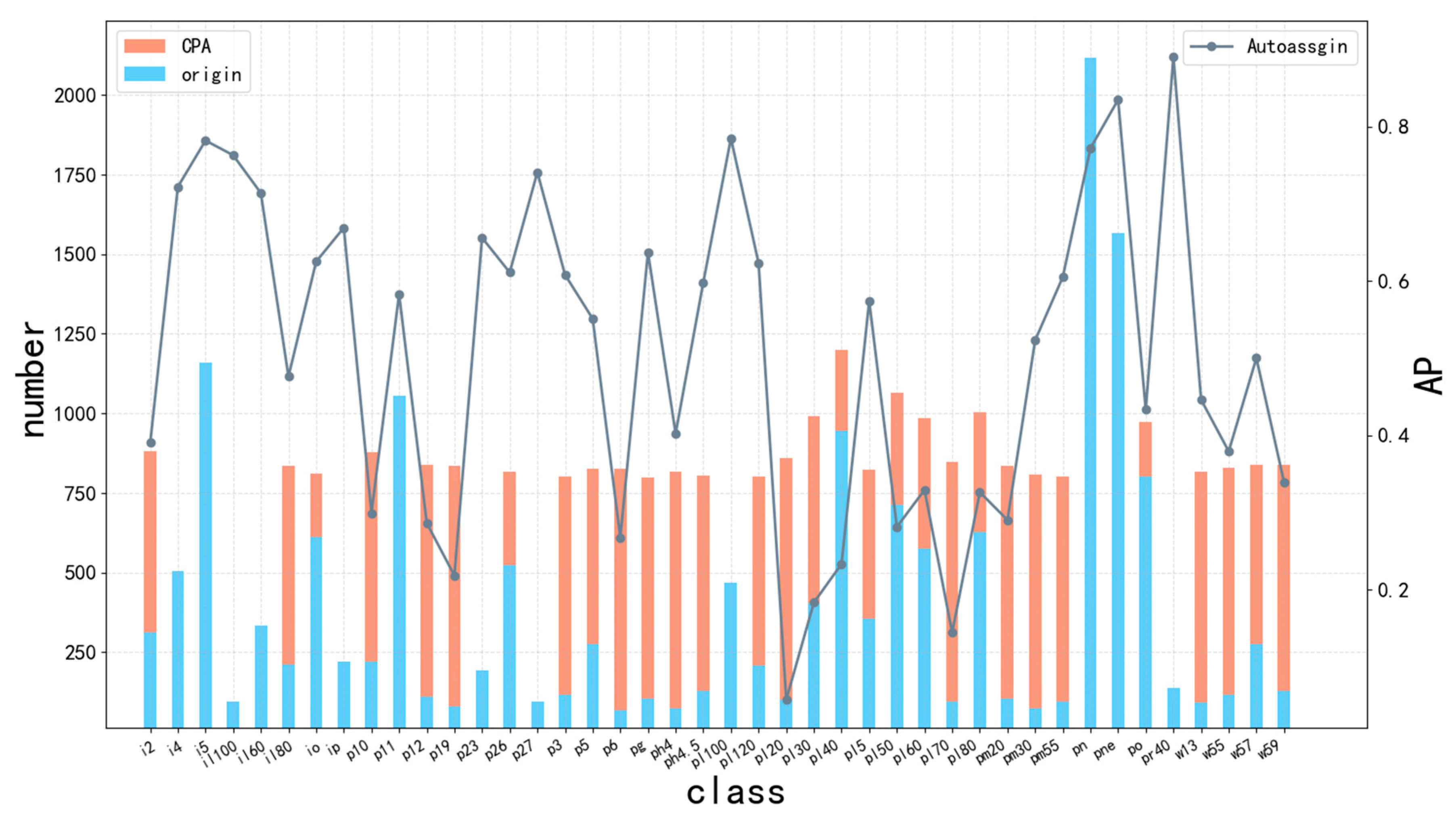





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}