

Digital Face Manipulation Creation and Detection: A Systematic Review

Abstract
1. Introduction
1.1. Relevant Surveys
1.2. Contributions
- This review categorizes and discusses the latest studies that have achieved state-of-the-art results in face manipulation generation and detection.
- Covering over 160 studies on the creation and detection of face manipulation, this survey categorizes them into smaller subtopics and provides a comprehensive discussion.
- The review focuses on the emerging field of DL-based deepfake content generation and detection.
- The survey uncovers challenges, addresses open research questions, and suggests upcoming research trends in the domain of digital face manipulation generation and detection.
1.3. Research Scope and Collection
1.3.1. Scope
1.3.2. Research Collection
2. Background
3. Types of Digital Face Manipulation and Datasets
3.1. Digitally Manipulated Face Types
- Face synthesis encompasses a series of methods that utilize efficient GANs to generate human faces that do not exist, resulting in astonishingly realistic facial images. Figure 2 introduces various examples of entire face synthesis created using the PGGAN structure [39]. While face synthesis has revolutionized industries like gaming and fashion [40], it also carries potential risks, as it can be exploited to create fake identities on social networks for spreading false information.
- Face swapping involves a collection of techniques used to replace specific regions of a person’s face with corresponding regions from another face to create a new composite face. Presently, there are two main methods for face swapping: (i) traditional CV-based methods (e.g., FaceSwap), and (ii) more sophisticated DL-based methods (e.g., deepfake). Figure 2 illustrates highly realistic examples of this type of manipulation. Despite its applications in various industrial sectors, particularly film production, face swapping poses the highest risk of manipulation due to its potential for malevolent use, such as generating pornographic deepfakes, committing financial fraud, and spreading hoaxes.
- Face attribute editing involves using generative models, including GANs and variational autoencoders (VAEs), to modify various facial attributes, such as adding glasses [33], altering skin color and age [34], and changing gender [33]. Popular social media platforms like TikTok, Instagram, and Snapchat feature examples of this manipulation, allowing users to experiment with virtual makeup, glasses, hairstyles, and hair color transformations in a virtual environment.
- Facial re-enactment is an emerging topic in conditional face synthesis, aimed at two main concurrent objectives: (1) transferring facial expressions from a source face to a target face, and (2) retaining the features and identity of the target face. This type of manipulation can have severe consequences, as demonstrated by the popular fake video of former US President Barack Obama speaking words that were not real [41].
3.2. Datasets
3.2.1. Face Synthesis and Face Attribute Editing

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Name | Year | Source | T:O | Dataset Size | Consent | Reference |
|---|---|---|---|---|---|---|---|
| Face synthesis and face attribute editing | Diverse Fake Face Dataset (DFFD) | 2020 | StyleGAN and PGGAN | 300 K images | ✔ | [50] | |
| iFakeFaceDB | 2020 | StyleGAN and PGGAN | 330 K images | ✔ | [51] | ||
| 100K-Generated-Images | 2019 | StyleGAN | 100 K images | ✔ | [48] | ||
| PGGAN | 2018 | PGGAN | 100 K images | ✔ | [39] | ||
| 100K-Faces | 2018 | StyleGAN | 100 K images | ✔ | [49] | ||
| Face swapping and facial re-enactment | ForgeryNIR | 2022 | CASIA NIR-VIS 2.0 [52] | 1:4.1 | 50 K identities | ✕ | [53] |
| Face Forensics in the Wild () | 2021 | YouTube | 1:1 | 40 K videos | ✕ | [54] | |
| OpenForensics | 2021 | Google open images | 1:0.64 | 115 K BBox/masks | ✔ | [55] | |
| ForgeryNet | 2021 | CREMAD [56], RAVDESS [57], VoxCeleb2 [58], and AVSpeech [59] | 1:1.2 | 221 K videos | ✔ | [60] | |
| Korean Deepfake Detection (KoDF) | 2021 | Actors | 1:0.35 | 238 K videos | ✔ | [61] | |
| Deepfake Detection Challenge (DFDC) | 2020 | Actors | 1:0.28 | 128 K videos | ✔ | [62] | |
| Deepfake Detection Challenge Preview (DFDC_P) | 2020 | Actors | 1:0.28 | 5K videos | ✔ | [63] | |
| DeeperForensics-1.0 | 2020 | Actors | 1:5 | 60 K videos | ✕ | [64] | |
| A large-scale challenging dataset for deepfake (Celeb-DF) | 2020 | YouTbe | 1:0.1 | 6.2 K videos | ✕ | [65] | |
| WildDeepfake | 2020 | Internet | 707 videos | ✕ | [66] | ||
| FaceForensics++ | 2019 | YouTube | 1:4 | 5 K videos | Partly | [67] | |
| Google DFD | 2019 | Actors | 1:0.1 | 3 K videos | ✔ | [68] | |
| UADFV | 2019 | YouTube | 1:1 | 98 videos | ✕ | [69] | |
| Media Forensic Challenge (MFC) | 2019 | Internet | 100 K images 4 K videos | ✕ | [70] | ||
| Deepfake-TIMIT | 2018 | YouTube | Only fake | 620 videos | ✕ | [71] |
3.2.2. Face Swapping and Facial Re-Enactment
4. Face Synthesis
4.1. Generation Techniques
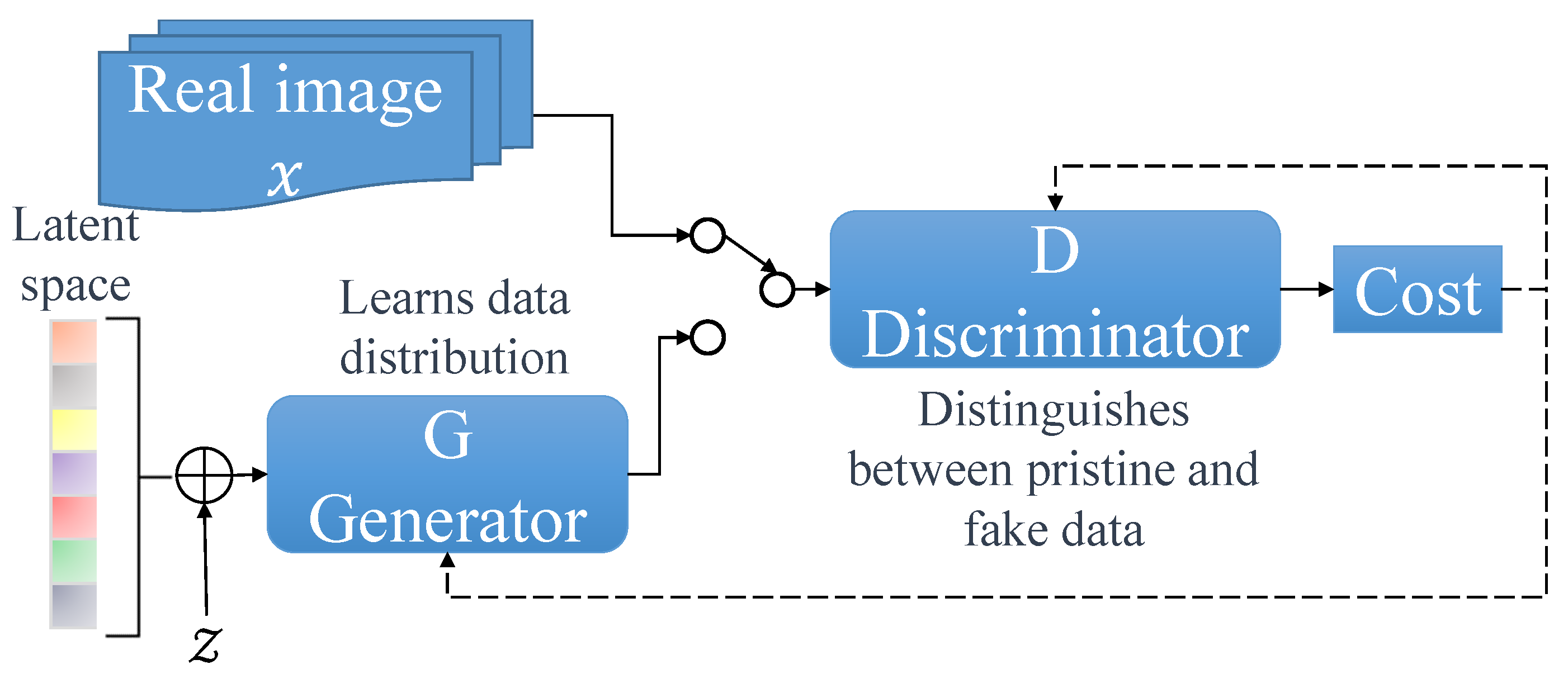
- Generative modeling in GANs aims to learn a generator distribution that closely resembles the target data distribution . Instead of explicitly assigning a probability to each variable x in the data distribution, GAN constructs a generator network G that creates samples by converting a noise variable into a sample from the generator distribution.
- Discrimination modeling in GANs seeks to generate an adversarial discriminator network D that can effectively discriminate between samples from the generator’s distribution and the true data distribution . The discriminator’s role is to distinguish between real data samples and those generated by the generator, thus creating a competitive learning dynamic.
4.2. Detection Techniques
5. Face Attribute Editing
5.1. Generation Techniques
5.2. Detection Techniques
6. Face Swapping
6.1. Generation Techniques
6.1.1. Traditional Approach
6.1.2. Deep Learning Approach
6.2. Detection Techniques
| Features | Classifier | Dataset | Performance | Reference |
|---|---|---|---|---|
| Deep | Transformer | FF++ | ACC = 98.56% | [144] |
| DFDC | ACC = 93.7% | |||
| DeeperForensics | ACC = 93.57% | |||
| Deep | AE (multi-task learning) | FaceSwap | ACC = 83.71%/EER = 15.7% | [142] |
| Deep | CNN (attention mechanism) | DFFD | ACC = 99.4%/EER = 3.1% | [50] |
| Deep | CNN | DFDC | Precision = 93%/Recall = 8.4% | [63] |
| Steganalysis and deep | CNN SVM | SwapMe | AUC = 99.5% | [143] |
| FaceSwap | AUC = 99.9% | |||
| Steganalysis and deep | CNN | FF++ (FaceSwap, LQ) | ACC = 93.7% | [67] |
| FF+ (FaceSwap, HQ) | ACC = 98.2% | |||
| FF+ (FaceSwap, Raw) | ACC = 99.6% | |||
| FF+ (Deepfake, HQ) | ACC = 98.8% | |||
| FF+ (Deepfake, Raw) | ACC = 99.5% | |||
| Facial | CNN | UADFV | ACC = 97.4% | [151] |
| DeepfakeTIMIT (LQ) | ACC = 99.9% | |||
| DeepfakeTIMIT (HQ) | ACC = 93.2% | |||
| Facial (source) | CNN | FF++ (Deepfake, -) | AUC = 100% | [145] |
| FF++ (FaceSwap, -) | AUC = 100% | |||
| DFDC | AUC = 94.38% | |||
| Celeb-DF | AUC = 99.98% | |||
| Facial | Multilayer perceptron (MLP) | Own | AUC = 85.1% | [152] |
| Facial | Face-cutout + CNN | DFDC | AUC = 92.71% | [146] |
| FF++ (LQ) | AUC = 98.77% | |||
| Celeb-DF | AUC = 99.54% | |||
| Head pose | SVM | MFC | AUC = 84.3% | [69] |
| Temporal | CNN + RNN | FF++ (Deepfake, LQ) | ACC = 96.9% | [147] |
| FF++ (FaceSwap, LQ) | ACC = 96.3% | |||
| Temporal | CNN | DFDC (HQ) | AUC = 91% | [146] |
| DCeleb-DF (HQ) | AUC = 84% | |||
| Spatial and temporal | CNN | FF++ (LQ) | AUC = 90.9% | [148] |
| FF++ (HQ) | AUC = 99.2% | |||
| DeeperForensics | AUC = 90.08% | |||
| Spatial, temporal, and steganalysis | 3D CNN | FF++ | ACC = 99.83% | [149] |
| DeepfakeTIMIT (LQ) | ACC = 99.6% | |||
| DeepfakeTIMIT (HQ) | ACC = 99.28% | |||
| Celeb-DF | ACC = 98.7% | |||
| Textural | CNN | FF++ (HQ) | AUC = 99.29% | [153] |
7. Facial Re-Enactment
7.1. Generation Techniques
7.2. Detection Techniques
8. Deepfake Evolution
9. Challenges and Future Trends
- Face synthesis. Current face synthesis research typically relies on GAN structures, such as WGAN and PGGAN, to generate highly realistic results [192]. However, it has been demonstrated that face synthesis detectors can easily distinguish between authentic and synthesized images due to GAN-specific fingerprints. The primary challenge in face synthesis is to eliminate GAN-specific artifacts or fingerprints that can be easily detected by face synthesis detectors. The continuous evolution of GAN structures indicates that in the near future, it may become possible to eliminate these GAN fingerprints or add noise patterns to challenge the detectors while simultaneously improving the quality of the generated images [127]. Recent studies have focused on this trend, as it poses a challenge even for state-of-the-art face synthesis detectors. In addition, current face synthesis models struggle to generate facial expressions with high fidelity [193]. Future research should focus on developing methods to improve the realism and naturalness of generated facial expressions in synthesized faces.
- Face attribute editing. Similar to face synthesis, this type of manipulation also relies mainly on GAN architectures, so GAN fingerprint reduction can also be applied here [194]. Another challenge in face attribute editing is disentangling different facial attributes to independently control and manipulate them without affecting other attributes [195]. Finally, it is worth noting that there is a lack of benchmark datasets and standard evaluation protocols for a fair comparison between different studies.
- Face swapping. Even though various face-swapping databases have been described in this review, it may be hard for readers to determine the best one due to many issues. First of all, previous systems have generally shown promising performance because they were explicitly trained on a database with a fixed compression level. However, most of them demonstrated poor generalization ability when tested under unseen conditions. Moreover, each face-swapping generation study has used different experimental protocols and evaluation metrics, such as accuracy, AUC, and EER, and experimental protocols, making it hard to produce a fair comparison between studies. As a result, it is necessary to introduce a uniform evaluation protocol in order to advance the field further. Likewise, it is worth noting that face-swapping detectors have already obtained AUC values near 100% for the first generation of benchmark datasets, such as FaceForensics++ and UADFV [69]. However, most detectors have shown a considerable performance degradation, with AUC values under 60%, for the second-generation face-swapping datasets, particularly DFDC [63] and Celeb-DF [65]. As a result, novel ideas are required in the next generation of fake identification techniques, for example, through large-scale challenges, like the recent DFDC.
- Facial re-enactment. To the best of our knowledge, the most well-known facial re-enactment benchmark dataset is FaceForensics++, though such datasets are relatively scarce compared to those for face-swapping manipulation [67]. The FaceForensics++ dataset contains observable artifacts that can be easily detected using DL models, resulting in the highest AUC value of nearly 100% in various studies. Consequently, there is a pressing need for researchers to develop and introduce a large-scale facial re-enactment public dataset that includes highly realistic and high-quality images/videos. Such a dataset would enable the more comprehensive evaluation and benchmarking of facial re-enactment detection methods, fostering the advancement of this important area of research.
10. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Pidhorskyi, S.; Adjeroh, D.A.; Doretto, G. Adversarial latent autoencoders. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 14104–14113. [Google Scholar]
- Deepnude. 2021. Available online: https://www.vice.com/en/article/kzm59x/deepnude-app-creates-fake-nudes-of-any-woman (accessed on 20 December 2021).
- FaceApp. 2021. Available online: https://www.faceapp.com/ (accessed on 24 May 2021).
- Snapchat. 2021. Available online: https://www.snapchat.com/ (accessed on 24 May 2021).
- FaceSwap. 2021. Available online: https://faceswap.dev/ (accessed on 24 May 2021).
- Gupta, S.; Mohan, N.; Kaushal, P. Passive image forensics using universal techniques: A review. Artif. Intell. Rev. 2021, 55, 1629–1679. [Google Scholar] [CrossRef]
- Media Forensics (MediFor). 2019. Available online: https://www.darpa.mil/program/media-forensics (accessed on 9 February 2022).
- Goljan, M.; Fridrich, J.; Kirchner, M. Image manipulation detection using sensor linear pattern. Electron. Imaging 2018, 30, art00003. [Google Scholar] [CrossRef]
- Vega, E.A.A.; Fernández, E.G.; Orozco, A.L.S.; Villalba, L.J.G. Image tampering detection by estimating interpolation patterns. Future Gener. Comput. Syst. 2020, 107, 229–237. [Google Scholar] [CrossRef]
- Li, B.; Zhang, H.; Luo, H.; Tan, S. Detecting double JPEG compression and its related anti-forensic operations with CNN. Multimed. Tools Appl. 2019, 78, 8577–8601. [Google Scholar] [CrossRef]
- Mohammed, T.M.; Bunk, J.; Nataraj, L.; Bappy, J.H.; Flenner, A.; Manjunath, B.; Chandrasekaran, S.; Roy-Chowdhury, A.K.; Peterson, L.A. Boosting image forgery detection using resampling features and copy-move analysis. arXiv 2018, arXiv:1802.03154. [Google Scholar] [CrossRef]
- Long, C.; Smith, E.; Basharat, A.; Hoogs, A. A c3d-based convolutional neural network for frame dropping detection in a single video shot. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1898–1906. [Google Scholar]
- Yu, P.; Xia, Z.; Fei, J.; Lu, Y. A Survey on Deepfake Video Detection. IET Biom. 2021, 10, 607–624. [Google Scholar] [CrossRef]
- Kwon, M.J.; Nam, S.H.; Yu, I.J.; Lee, H.K.; Kim, C. Learning JPEG compression artifacts for image manipulation detection and localization. Int. J. Comput. Vis. 2022, 130, 1875–1895. [Google Scholar] [CrossRef]
- Minh, D.; Wang, H.X.; Li, Y.F.; Nguyen, T.N. Explainable artificial intelligence: A comprehensive review. Artif. Intell. Rev. 2021, 55, 3503–3568. [Google Scholar] [CrossRef]
- Abdolahnejad, M.; Liu, P.X. Deep learning for face image synthesis and semantic manipulations: A review and future perspectives. Artif. Intell. Rev. 2020, 53, 5847–5880. [Google Scholar] [CrossRef]
- Dang, L.M.; Hassan, S.I.; Im, S.; Moon, H. Face image manipulation detection based on a convolutional neural network. Expert Syst. Appl. 2019, 129, 156–168. [Google Scholar] [CrossRef]
- Dang, L.M.; Min, K.; Lee, S.; Han, D.; Moon, H. Tampered and computer-generated face images identification based on deep learning. Appl. Sci. 2020, 10, 505. [Google Scholar] [CrossRef]
- Juefei-Xu, F.; Wang, R.; Huang, Y.; Guo, Q.; Ma, L.; Liu, Y. Countering malicious deepfakes: Survey, battleground, and horizon. Int. J. Comput. Vis. 2022, 130, 1678–1734. [Google Scholar] [CrossRef] [PubMed]
- Malik, A.; Kuribayashi, M.; Abdullahi, S.M.; Khan, A.N. DeepFake Detection for Human Face Images and Videos: A Survey. IEEE Access 2022, 10, 18757–18775. [Google Scholar] [CrossRef]
- Deshmukh, A.; Wankhade, S.B. Deepfake Detection Approaches Using Deep Learning: A Systematic Review. Intell. Comput. Netw. 2021, 146, 293–302. [Google Scholar]
- Mirsky, Y.; Lee, W. The creation and detection of deepfakes: A survey. ACM Comput. Surv. (CSUR) 2021, 54, 1–41. [Google Scholar] [CrossRef]
- Thakur, R.; Rohilla, R. Recent advances in digital image manipulation detection techniques: A brief review. Forensic Sci. Int. 2020, 312, 110311. [Google Scholar] [CrossRef]
- Tolosana, R.; Vera-Rodriguez, R.; Fierrez, J.; Morales, A.; Ortega-Garcia, J. Deepfakes and beyond: A survey of face manipulation and fake detection. Inf. Fusion 2020, 64, 131–148. [Google Scholar] [CrossRef]
- Verdoliva, L. Media forensics and deepfakes: An overview. IEEE J. Sel. Top. Signal Process. 2020, 14, 910–932. [Google Scholar] [CrossRef]
- Kietzmann, J.; Lee, L.W.; McCarthy, I.P.; Kietzmann, T.C. Deepfakes: Trick or treat? Bus. Horizons 2020, 63, 135–146. [Google Scholar] [CrossRef]
- Zheng, X.; Guo, Y.; Huang, H.; Li, Y.; He, R. A survey of deep facial attribute analysis. Int. J. Comput. Vis. 2020, 128, 2002–2034. [Google Scholar] [CrossRef]
- Walia, S.; Kumar, K. An eagle-eye view of recent digital image forgery detection methods. In Proceedings of the International Conference on Next Generation Computing Technologies, Dehradun, India, 30–31 October 2017; Springer: Singapore, 2017; pp. 469–487. [Google Scholar]
- Asghar, K.; Habib, Z.; Hussain, M. Copy-move and splicing image forgery detection and localization techniques: A review. Aust. J. Forensic Sci. 2017, 49, 281–307. [Google Scholar] [CrossRef]
- Barni, M.; Costanzo, A.; Nowroozi, E.; Tondi, B. CNN-based detection of generic contrast adjustment with JPEG post-processing. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 3803–3807. [Google Scholar]
- Qian, S.; Lin, K.Y.; Wu, W.; Liu, Y.; Wang, Q.; Shen, F.; Qian, C.; He, R. Make a face: Towards arbitrary high fidelity face manipulation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 10033–10042. [Google Scholar]
- Xu, Z.; Yu, X.; Hong, Z.; Zhu, Z.; Han, J.; Liu, J.; Ding, E.; Bai, X. FaceController: Controllable Attribute Editing for Face in the Wild. Proc. AAAI Conf. Artif. Intell. 2021, 35, 3083–3091. [Google Scholar] [CrossRef]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep Learning Face Attributes in the Wild. In Proceedings of the International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Westerlund, M. The emergence of deepfake technology: A review. Technol. Innov. Manag. Rev. 2019, 9, 39–52. [Google Scholar] [CrossRef]
- Kwok, A.O.; Koh, S.G. Deepfake: A social construction of technology perspective. Curr. Issues Tour. 2021, 24, 1798–1802. [Google Scholar] [CrossRef]
- Another Fake Video of Pelosi Goes Viral on Facebook. 2020. Available online: https://www.washingtonpost.com/technology/2020/08/03/nancy-pelosi-fake-video-facebook/ (accessed on 9 February 2022).
- Paris, B.; Donovan, J. Deepfakes and Cheap Fakes. 2019. Available online: https://apo.org.au/node/259911 (accessed on 9 February 2022).
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive Growing of GANs for Improved Quality, Stability, and Variation. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Liu, Y.; Chen, W.; Liu, L.; Lew, M.S. Swapgan: A multistage generative approach for person-to-person fashion style transfer. IEEE Trans. Multimed. 2019, 21, 2209–2222. [Google Scholar] [CrossRef]
- Murphy, G.; Flynn, E. Deepfake false memories. Memory 2022, 30, 480–492. [Google Scholar] [CrossRef]
- Kazemi, V.; Sullivan, J. One millisecond face alignment with an ensemble of regression trees. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1867–1874. [Google Scholar]
- Yi, D.; Lei, Z.; Liao, S.; Li, S.Z. Learning face representation from scratch. arXiv 2014, arXiv:1411.7923. [Google Scholar]
- Cao, Q.; Shen, L.; Xie, W.; Parkhi, O.M.; Zisserman, A. Vggface2: A dataset for recognising faces across pose and age. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; pp. 67–74. [Google Scholar]
- Huang, G.B.; Mattar, M.; Berg, T.; Learned-Miller, E. Labeled faces in the wild: A database forstudying face recognition in unconstrained environments. In Proceedings of the Workshop on Faces in ‘Real-Life’ Images: Detection, Alignment, and Recognition, Marseille, France, 12–18 October 2008. [Google Scholar]
- Zhang, G.; Kan, M.; Shan, S.; Chen, X. Generative adversarial network with spatial attention for face attribute editing. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 417–432. [Google Scholar]
- Wang, L.; Chen, W.; Yang, W.; Bi, F.; Yu, F.R. A state-of-the-art review on image synthesis with generative adversarial networks. IEEE Access 2020, 8, 63514–63537. [Google Scholar] [CrossRef]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4401–4410. [Google Scholar]
- 100KGenerated. 100,000 Faces Generated by AI. 2018. Available online: https://mymodernmet.com/free-ai-generated-faces/ (accessed on 24 May 2021).
- Dang, H.; Liu, F.; Stehouwer, J.; Liu, X.; Jain, A.K. On the detection of digital face manipulation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5781–5790. [Google Scholar]
- Neves, J.C.; Tolosana, R.; Vera-Rodriguez, R.; Lopes, V.; Proença, H.; Fierrez, J. Ganprintr: Improved fakes and evaluation of the state of the art in face manipulation detection. IEEE J. Sel. Top. Signal Process. 2020, 14, 1038–1048. [Google Scholar] [CrossRef]
- Li, S.; Yi, D.; Lei, Z.; Liao, S. The casia nir-vis 2.0 face database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Portland, OR, USA, 23–28 June 2013; pp. 348–353. [Google Scholar]
- Wang, Y.; Peng, C.; Liu, D.; Wang, N.; Gao, X. ForgeryNIR: Deep Face Forgery and Detection in Near-Infrared Scenario. IEEE Trans. Inf. Forensics Secur. 2022, 17, 500–515. [Google Scholar] [CrossRef]
- Zhou, T.; Wang, W.; Liang, Z.; Shen, J. Face Forensics in the Wild. arXiv 2021, arXiv:2103.16076. [Google Scholar]
- Le, T.N.; Nguyen, H.H.; Yamagishi, J.; Echizen, I. OpenForensics: Large-Scale Challenging Dataset For Multi-Face Forgery Detection And Segmentation In-The-Wild. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10117–10127. [Google Scholar]
- Cao, H.; Cooper, D.G.; Keutmann, M.K.; Gur, R.C.; Nenkova, A.; Verma, R. Crema-d: Crowd-sourced emotional multimodal actors dataset. IEEE Trans. Affect. Comput. 2014, 5, 377–390. [Google Scholar] [CrossRef] [PubMed]
- Livingstone, S.R.; Russo, F.A. The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS): A dynamic, multimodal set of facial and vocal expressions in North American English. PLoS ONE 2018, 13, e0196391. [Google Scholar] [CrossRef]
- Chung, J.S.; Nagrani, A.; Zisserman, A. Voxceleb2: Deep speaker recognition. arXiv 2018, arXiv:1806.05622. [Google Scholar]
- Ephrat, A.; Mosseri, I.; Lang, O.; Dekel, T.; Wilson, K.; Hassidim, A.; Freeman, W.T.; Rubinstein, M. Looking to listen at the cocktail party: A speaker-independent audio-visual model for speech separation. ACM Trans. Graph. (TOG) 2018, 37, 1–11. [Google Scholar] [CrossRef]
- He, Y.; Gan, B.; Chen, S.; Zhou, Y.; Yin, G.; Song, L.; Sheng, L.; Shao, J.; Liu, Z. Forgerynet: A versatile benchmark for comprehensive forgery analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4360–4369. [Google Scholar]
- Kwon, P.; You, J.; Nam, G.; Park, S.; Chae, G. KoDF: A Large-scale Korean DeepFake Detection Dataset. arXiv 2021, arXiv:2103.10094. [Google Scholar]
- Dolhansky, B.; Bitton, J.; Pflaum, B.; Lu, J.; Howes, R.; Wang, M.; Canton Ferrer, C. The deepfake detection challenge dataset. arXiv 2020, arXiv:2006.07397. [Google Scholar]
- Dolhansky, B.; Howes, R.; Pflaum, B.; Baram, N.; Ferrer, C.C. The deepfake detection challenge (dfdc) preview dataset. arXiv 2019, arXiv:1910.08854. [Google Scholar]
- Jiang, L.; Li, R.; Wu, W.; Qian, C.; Loy, C.C. Deeperforensics-1.0: A large-scale dataset for real-world face forgery detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2889–2898. [Google Scholar]
- Li, Y.; Sun, P.; Qi, H.; Lyu, S. Celeb-DF: A Large-scale Challenging Dataset for DeepFake Forensics. In Proceedings of the IEEE Conference on Computer Vision and Patten Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Zi, B.; Chang, M.; Chen, J.; Ma, X.; Jiang, Y.G. Wilddeepfake: A challenging real-world dataset for deepfake detection. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 2382–2390. [Google Scholar]
- Rossler, A.; Cozzolino, D.; Verdoliva, L.; Riess, C.; Thies, J.; Nießner, M. Faceforensics++: Learning to detect manipulated facial images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1–11. [Google Scholar]
- Google DFD. 2020. Available online: https://ai.googleblog.com/2019/09/contributing-data-to-deepfake-detection.html (accessed on 17 December 2021).
- Yang, X.; Li, Y.; Lyu, S. Exposing deep fakes using inconsistent head poses. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 8261–8265. [Google Scholar]
- Guan, H.; Kozak, M.; Robertson, E.; Lee, Y.; Yates, A.N.; Delgado, A.; Zhou, D.; Kheyrkhah, T.; Smith, J.; Fiscus, J. MFC datasets: Large-scale benchmark datasets for media forensic challenge evaluation. In Proceedings of the 2019 IEEE Winter Applications of Computer Vision Workshops (WACVW), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 63–72. [Google Scholar]
- Korshunov, P.; Marcel, S. Deepfakes: A new threat to face recognition? assessment and detection. arXiv 2018, arXiv:1812.08685. [Google Scholar]
- Deepfakes. 2021. Available online: https://github.com/deepfakes/faceswap (accessed on 18 December 2021).
- Thies, J.; Zollhofer, M.; Stamminger, M.; Theobalt, C.; Nießner, M. Face2face: Real-time face capture and reenactment of rgb videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2387–2395. [Google Scholar]
- Faceswap. 2016. Available online: https://github.com/MarekKowalski/FaceSwap/ (accessed on 18 December 2021).
- Thies, J.; Zollhöfer, M.; Nießner, M. Deferred neural rendering: Image synthesis using neural textures. ACM Trans. Graph. (TOG) 2019, 38, 1–12. [Google Scholar] [CrossRef]
- Lahasan, B.; Lutfi, S.L.; San-Segundo, R. A survey on techniques to handle face recognition challenges: Occlusion, single sample per subject and expression. Artif. Intell. Rev. 2019, 52, 949–979. [Google Scholar] [CrossRef]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A. Improved training of wasserstein GANs. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5769–5779. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Gauthier, J. Conditional generative adversarial nets for convolutional face generation. Cl. Proj. Stanf. CS231N Convolutional Neural Netw. Vis. Recognit. Winter Semester 2014, 2014, 2. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 1–9. [Google Scholar]
- Luo, G.; Xiong, G.; Huang, X.; Zhao, X.; Tong, Y.; Chen, Q.; Zhu, Z.; Lei, H.; Lin, J. Geometry Sampling-Based Adaption to DCGAN for 3D Face Generation. Sensors 2023, 23, 1937. [Google Scholar] [CrossRef]
- Wang, Y.; Dantcheva, A.; Bremond, F. From attribute-labels to faces: Face generation using a conditional generative adversarial network. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Bau, D.; Zhu, J.Y.; Wulff, J.; Peebles, W.; Strobelt, H.; Zhou, B.; Torralba, A. Seeing what a gan cannot generate. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4502–4511. [Google Scholar]
- Liu, B.; Zhu, Y.; Song, K.; Elgammal, A. Towards faster and stabilized gan training for high-fidelity few-shot image synthesis. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Neyshabur, B.; Bhojanapalli, S.; Chakrabarti, A. Stabilizing GAN training with multiple random projections. arXiv 2017, arXiv:1705.07831. [Google Scholar]
- Shahriar, S. GAN computers generate arts? A survey on visual arts, music, and literary text generation using generative adversarial network. Displays 2022, 73, 102237. [Google Scholar] [CrossRef]
- Brock, A.; Donahue, J.; Simonyan, K. Large Scale GAN Training for High Fidelity Natural Image Synthesis. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Jeong, Y.; Kim, D.; Min, S.; Joe, S.; Gwon, Y.; Choi, J. BiHPF: Bilateral High-Pass Filters for Robust Deepfake Detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 48–57. [Google Scholar]
- Dzanic, T.; Shah, K.; Witherden, F. Fourier spectrum discrepancies in deep network generated images. Adv. Neural Inf. Process. Syst. 2020, 33, 3022–3032. [Google Scholar]
- Dang, L.M.; Hassan, S.I.; Im, S.; Lee, J.; Lee, S.; Moon, H. Deep learning based computer generated face identification using convolutional neural network. Appl. Sci. 2018, 8, 2610. [Google Scholar] [CrossRef]
- Chen, B.; Ju, X.; Xiao, B.; Ding, W.; Zheng, Y.; de Albuquerque, V.H.C. Locally GAN-generated face detection based on an improved Xception. Inf. Sci. 2021, 572, 16–28. [Google Scholar] [CrossRef]
- Liu, Z.; Qi, X.; Torr, P.H. Global texture enhancement for fake face detection in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8060–8069. [Google Scholar]
- Wang, R.; Juefei-Xu, F.; Ma, L.; Xie, X.; Huang, Y.; Wang, J.; Liu, Y. Fakespotter: A simple yet robust baseline for spotting ai-synthesized fake faces. arXiv 2019, arXiv:1909.06122. [Google Scholar]
- Nataraj, L.; Mohammed, T.M.; Manjunath, B.; Chandrasekaran, S.; Flenner, A.; Bappy, J.H.; Roy-Chowdhury, A.K. Detecting GAN generated fake images using co-occurrence matrices. arXiv 2019, arXiv:1903.06836. [Google Scholar] [CrossRef]
- Yang, X.; Li, Y.; Qi, H.; Lyu, S. Exposing gan-synthesized faces using landmark locations. In Proceedings of the ACM Workshop on Information Hiding and Multimedia Security, Paris, France, 3–5 July 2019; pp. 113–118. [Google Scholar]
- McCloskey, S.; Albright, M. Detecting gan-generated imagery using color cues. arXiv 2018, arXiv:1812.08247. [Google Scholar]
- Marra, F.; Gragnaniello, D.; Verdoliva, L.; Poggi, G. Do gans leave artificial fingerprints? In Proceedings of the 2019 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), San Jose, CA, USA, 29–30 March 2019; pp. 506–511. [Google Scholar]
- Mi, Z.; Jiang, X.; Sun, T.; Xu, K. GAN-Generated Image Detection With Self-Attention Mechanism Against GAN Generator Defect. IEEE J. Sel. Top. Signal Process. 2020, 14, 969–981. [Google Scholar] [CrossRef]
- Marra, F.; Gragnaniello, D.; Cozzolino, D.; Verdoliva, L. Detection of gan-generated fake images over social networks. In Proceedings of the 2018 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), Miami, FL, USA, 10–12 April 2018; pp. 384–389. [Google Scholar]
- Wang, M.; Deng, W. Deep face recognition: A survey. Neurocomputing 2021, 429, 215–244. [Google Scholar] [CrossRef]
- Karkkainen, K.; Joo, J. FairFace: Face Attribute Dataset for Balanced Race, Gender, and Age for Bias Measurement and Mitigation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual. 5–9 January 2021; pp. 1548–1558. [Google Scholar]
- Lu, Z.; Hu, T.; Song, L.; Zhang, Z.; He, R. Conditional expression synthesis with face parsing transformation. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018; pp. 1083–1091. [Google Scholar]
- Liu, S.; Li, D.; Cao, T.; Sun, Y.; Hu, Y.; Ji, J. GAN-based face attribute editing. IEEE Access 2020, 8, 34854–34867. [Google Scholar] [CrossRef]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.W.; Kim, S.; Choo, J. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8789–8797. [Google Scholar]
- Liu, M.; Ding, Y.; Xia, M.; Liu, X.; Ding, E.; Zuo, W.; Wen, S. STGAN: A unified selective transfer network for arbitrary image attribute editing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3673–3682. [Google Scholar]
- Tripathy, S.; Kannala, J.; Rahtu, E. Facegan: Facial attribute controllable reenactment gan. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual. 5–9 January 2021; pp. 1329–1338. [Google Scholar]
- Muhammad, S.; Dailey, M.N.; Farooq, M.; Majeed, M.F.; Ekpanyapong, M. Spec-Net and Spec-CGAN: Deep learning models for specularity removal from faces. Image Vis. Comput. 2020, 93, 103823. [Google Scholar] [CrossRef]
- Antipov, G.; Baccouche, M.; Dugelay, J.L. Face aging with conditional generative adversarial networks. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 2089–2093. [Google Scholar]
- Perarnau, G.; Van De Weijer, J.; Raducanu, B.; Álvarez, J.M. Invertible conditional gans for image editing. arXiv 2016, arXiv:1611.06355. [Google Scholar]
- Ardizzone, L.; Lüth, C.; Kruse, J.; Rother, C.; Köthe, U. Guided image generation with conditional invertible neural networks. arXiv 2019, arXiv:1907.02392. [Google Scholar]
- Pumarola, A.; Agudo, A.; Martinez, A.M.; Sanfeliu, A.; Moreno-Noguer, F. Ganimation: Anatomically-aware facial animation from a single image. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 818–833. [Google Scholar]
- Thomas, C.; Kovashka, A. Persuasive faces: Generating faces in advertisements. arXiv 2018, arXiv:1807.09882. [Google Scholar]
- Mobini, M.; Ghaderi, F. StarGAN Based Facial Expression Transfer for Anime Characters. In Proceedings of the 2020 25th International Computer Conference, Computer Society of Iran (CSICC), Tehran, Iran, 1–2 January 2020; pp. 1–5. [Google Scholar]
- Lee, C.H.; Liu, Z.; Wu, L.; Luo, P. Maskgan: Towards diverse and interactive facial image manipulation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5549–5558. [Google Scholar]
- Kim, H.; Choi, Y.; Kim, J.; Yoo, S.; Uh, Y. Exploiting spatial dimensions of latent in gan for real-time image editing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 852–861. [Google Scholar]
- Xiao, T.; Hong, J.; Ma, J. Dna-gan: Learning disentangled representations from multi-attribute images. arXiv 2017, arXiv:1711.05415. [Google Scholar]
- He, Z.; Zuo, W.; Kan, M.; Shan, S.; Chen, X. Attgan: Facial attribute editing by only changing what you want. IEEE Trans. Image Process. 2019, 28, 5464–5478. [Google Scholar] [CrossRef] [PubMed]
- Collins, E.; Bala, R.; Price, B.; Susstrunk, S. Editing in style: Uncovering the local semantics of gans. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5771–5780. [Google Scholar]
- Xu, Y.; Yin, Y.; Jiang, L.; Wu, Q.; Zheng, C.; Loy, C.C.; Dai, B.; Wu, W. TransEditor: Transformer-Based Dual-Space GAN for Highly Controllable Facial Editing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 7683–7692. [Google Scholar]
- Guarnera, L.; Giudice, O.; Battiato, S. Deepfake detection by analyzing convolutional traces. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 666–667. [Google Scholar]
- Tariq, S.; Lee, S.; Kim, H.; Shin, Y.; Woo, S.S. Detecting both machine and human created fake face images in the wild. In Proceedings of the 2nd International Workshop on Multimedia Privacy and Security, Toronto, ON, Canada, 15–19 October 2018; pp. 81–87. [Google Scholar]
- Jain, A.; Singh, R.; Vatsa, M. On detecting gans and retouching based synthetic alterations. In Proceedings of the 2018 IEEE 9th International Conference on Biometrics Theory, Applications and Systems (BTAS), Redondo Beach, CA, USA, 22–25 October 2018; pp. 1–7. [Google Scholar]
- Bharati, A.; Singh, R.; Vatsa, M.; Bowyer, K.W. Detecting facial retouching using supervised deep learning. IEEE Trans. Inf. Forensics Secur. 2016, 11, 1903–1913. [Google Scholar] [CrossRef]
- Jain, A.; Majumdar, P.; Singh, R.; Vatsa, M. Detecting GANs and retouching based digital alterations via DAD-HCNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 672–673. [Google Scholar]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8110–8119. [Google Scholar]
- Yu, N.; Davis, L.S.; Fritz, M. Attributing fake images to gans: Learning and analyzing gan fingerprints. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7556–7566. [Google Scholar]
- Bitouk, D.; Kumar, N.; Dhillon, S.; Belhumeur, P.; Nayar, S.K. Face swapping: Automatically replacing faces in photographs. ACM Trans. Graph. (TOG) 2008, 27, 1–8. [Google Scholar] [CrossRef]
- Li, L.; Bao, J.; Yang, H.; Chen, D.; Wen, F. Faceshifter: Towards high fidelity and occlusion aware face swapping. arXiv 2019, arXiv:1912.13457. [Google Scholar]
- Yan, S.; He, S.; Lei, X.; Ye, G.; Xie, Z. Video face swap based on autoencoder generation network. In Proceedings of the 2018 International Conference on Audio, Language and Image Processing (ICALIP), Shanghai, China, 16–17 July 2018; pp. 103–108. [Google Scholar]
- Xingjie, Z.; Song, J.; Park, J.I. The image blending method for face swapping. In Proceedings of the 2014 4th IEEE International Conference on Network Infrastructure and Digital Content, Beijing, China, 19–21 September 2014; pp. 95–98. [Google Scholar]
- Chen, D.; Chen, Q.; Wu, J.; Yu, X.; Jia, T. Face swapping: Realistic image synthesis based on facial landmarks alignment. Math. Probl. Eng. 2019, 2019, 8902701. [Google Scholar] [CrossRef]
- Dale, K.; Sunkavalli, K.; Johnson, M.K.; Vlasic, D.; Matusik, W.; Pfister, H. Video face replacement. In Proceedings of the 2011 SIGGRAPH Asia Conference, Hong Kong, China, 12–15 December 2011; pp. 1–10. [Google Scholar]
- Perov, I.; Gao, D.; Chervoniy, N.; Liu, K.; Marangonda, S.; Umé, C.; Dpfks, M.; Facenheim, C.S.; RP, L.; Jiang, J.; et al. Deepfacelab: A simple, flexible and extensible face swapping framework. arXiv 2020, arXiv:2005.05535. [Google Scholar]
- Nirkin, Y.; Keller, Y.; Hassner, T. Fsgan: Subject agnostic face swapping and reenactment. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7184–7193. [Google Scholar]
- Liu, K.; Wang, P.; Zhou, W.; Zhang, Z.; Ge, Y.; Liu, H.; Zhang, W.; Yu, N. Face Swapping Consistency Transfer with Neural Identity Carrier. Future Internet 2021, 13, 298. [Google Scholar] [CrossRef]
- Zhu, Y.; Li, Q.; Wang, J.; Xu, C.Z.; Sun, Z. One Shot Face Swapping on Megapixels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4834–4844. [Google Scholar]
- Naruniec, J.; Helminger, L.; Schroers, C.; Weber, R.M. High-resolution neural face swapping for visual effects. In Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2020; Volume 39, pp. 173–184. [Google Scholar]
- Xu, Y.; Deng, B.; Wang, J.; Jing, Y.; Pan, J.; He, S. High-resolution face swapping via latent semantics disentanglement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 7642–7651. [Google Scholar]
- Chen, R.; Chen, X.; Ni, B.; Ge, Y. Simswap: An efficient framework for high fidelity face swapping. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 2003–2011. [Google Scholar]
- Xu, Z.; Hong, Z.; Ding, C.; Zhu, Z.; Han, J.; Liu, J.; Ding, E. MobileFaceSwap: A Lightweight Framework for Video Face Swapping. arXiv 2022, arXiv:2201.03808. [Google Scholar] [CrossRef]
- Nguyen, H.H.; Fang, F.; Yamagishi, J.; Echizen, I. Multi-task Learning For Detecting and Segmenting Manipulated Facial Images and Videos. In Proceedings of the 10th IEEE International Conference on Biometrics: Theory, Applications, and Systems (BTAS 2019), Tampa, FL, USA, 23–16 September 2020. [Google Scholar]
- Zhou, P.; Han, X.; Morariu, V.I.; Davis, L.S. Two-stream neural networks for tampered face detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1831–1839. [Google Scholar]
- Dong, X.; Bao, J.; Chen, D.; Zhang, T.; Zhang, W.; Yu, N.; Chen, D.; Wen, F.; Guo, B. Protecting Celebrities from DeepFake with Identity Consistency Transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 9468–9478. [Google Scholar]
- Zhao, T.; Xu, X.; Xu, M.; Ding, H.; Xiong, Y.; Xia, W. Learning Self-Consistency for Deepfake Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 15023–15033. [Google Scholar]
- Das, S.; Seferbekov, S.; Datta, A.; Islam, M.; Amin, M. Towards Solving the DeepFake Problem: An Analysis on Improving DeepFake Detection using Dynamic Face Augmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3776–3785. [Google Scholar]
- Sabir, E.; Cheng, J.; Jaiswal, A.; AbdAlmageed, W.; Masi, I.; Natarajan, P. Recurrent convolutional strategies for face manipulation detection in videos. Interfaces (GUI) 2019, 3, 80–87. [Google Scholar]
- Trinh, L.; Tsang, M.; Rambhatla, S.; Liu, Y. Interpretable and trustworthy deepfake detection via dynamic prototypes. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual. 5–9 January 2021; pp. 1973–1983. [Google Scholar]
- Liu, J.; Zhu, K.; Lu, W.; Luo, X.; Zhao, X. A lightweight 3D convolutional neural network for deepfake detection. Int. J. Intell. Syst. 2021, 36, 4990–5004. [Google Scholar] [CrossRef]
- Dong, S.; Wang, J.; Liang, J.; Fan, H.; Ji, R. Explaining Deepfake Detection by Analysing Image Matching. arXiv 2022, arXiv:2207.09679. [Google Scholar]
- Li, Y.; Lyu, S. Exposing DeepFake Videos By Detecting Face Warping Artifacts. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Matern, F.; Riess, C.; Stamminger, M. Exploiting visual artifacts to expose deepfakes and face manipulations. In Proceedings of the 2019 IEEE Winter Applications of Computer Vision Workshops (WACVW), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 83–92. [Google Scholar]
- Zhao, H.; Zhou, W.; Chen, D.; Wei, T.; Zhang, W.; Yu, N. Multi-attentional deepfake detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2185–2194. [Google Scholar]
- Zhang, J.; Zeng, X.; Wang, M.; Pan, Y.; Liu, L.; Liu, Y.; Ding, Y.; Fan, C. Freenet: Multi-identity face reenactment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5326–5335. [Google Scholar]
- Rössler, A.; Cozzolino, D.; Verdoliva, L.; Riess, C.; Thies, J.; Nießner, M. Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv 2018, arXiv:1803.09179. [Google Scholar]
- Averbuch-Elor, H.; Cohen-Or, D.; Kopf, J.; Cohen, M.F. Bringing portraits to life. ACM Trans. Graph. (TOG) 2017, 36, 1–13. [Google Scholar] [CrossRef]
- Wang, T.C.; Mallya, A.; Liu, M.Y. One-shot free-view neural talking-head synthesis for video conferencing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10039–10049. [Google Scholar]
- Zakharov, E.; Shysheya, A.; Burkov, E.; Lempitsky, V. Few-shot adversarial learning of realistic neural talking head models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9459–9468. [Google Scholar]
- Gu, Z.; Chen, Y.; Yao, T.; Ding, S.; Li, J.; Ma, L. Delving into the local: Dynamic inconsistency learning for deepfake video detection. Proc. AAAI Conf. Artif. Intell. 2022, 36, 744–752. [Google Scholar] [CrossRef]
- Wang, J.; Wu, Z.; Chen, J.; Jiang, Y.G. M2TR: Multi-modal Multi-scale Transformers for Deepfake Detection. arXiv 2021, arXiv:2104.09770. [Google Scholar]
- Qian, Y.; Yin, G.; Sheng, L.; Chen, Z.; Shao, J. Thinking in frequency: Face forgery detection by mining frequency-aware clues. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 86–103. [Google Scholar]
- Zhang, B.; Li, S.; Feng, G.; Qian, Z.; Zhang, X. Patch Diffusion: A General Module for Face Manipulation Detection. Proc. Assoc. Adv. Artif. Intell. (AAAI) 2022, 36, 3243–3251. [Google Scholar] [CrossRef]
- Afchar, D.; Nozick, V.; Yamagishi, J.; Echizen, I. Mesonet: A compact facial video forgery detection network. In Proceedings of the 2018 IEEE International Workshop on Information Forensics and Security (WIFS), Hong Kong, China, 11–13 December 2018; pp. 1–7. [Google Scholar]
- Kumar, P.; Vatsa, M.; Singh, R. Detecting face2face facial reenactment in videos. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 2589–2597. [Google Scholar]
- Liu, H.; Li, X.; Zhou, W.; Chen, Y.; He, Y.; Xue, H.; Zhang, W.; Yu, N. Spatial-phase shallow learning: Rethinking face forgery detection in frequency domain. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 772–781. [Google Scholar]
- Amerini, I.; Galteri, L.; Caldelli, R.; Del Bimbo, A. Deepfake video detection through optical flow based cnn. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Cozzolino, D.; Rossler, A.; Thies, J.; Nießner, M.; Verdoliva, L. Id-reveal: Identity-aware deepfake video detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 15108–15117. [Google Scholar]
- Khan, S.; Naseer, M.; Hayat, M.; Zamir, S.W.; Khan, F.S.; Shah, M. Transformers in vision: A survey. ACM Comput. Surv. (CSUR) 2021, 54, 1–41. [Google Scholar] [CrossRef]
- These Deepfake Videos of Putin and Kim Have Gone Viral. 2020. Available online: https://fortune.com/2020/10/02/deepfakes-putin-kim-jong-un-democracy-disinformation/ (accessed on 9 February 2022).
- This Disturbingly Realistic Deepfake Puts Jeff Bezos and Elon Musk in a Star Trek Episode. 2020. Available online: https://www.theverge.com/tldr/2020/2/20/21145826/deepfake-jeff-bezos-elon-musk-alien-star-trek-the-cage-amazon-tesla (accessed on 9 February 2022).
- Deepfake’ Voice Tech Used for Good in David Beckham Malaria Campaign. 2019. Available online: https://www.prweek.com/article/1581457/deepfake-voice-tech-used-good-david-beckham-malaria-campaign (accessed on 9 February 2022).
- How a Deepfake Tom Cruise on TikTok Turned into a Very Real AI Company. 2021. Available online: https://edition.cnn.com/2021/08/06/tech/tom-cruise-deepfake-tiktok-company/index.html (accessed on 9 February 2022).
- Adobe. Adobe Photoshop. 2021. Available online: https://www.adobe.com/products/photoshop.html (accessed on 24 May 2021).
- Faceswap. 2021. Available online: https://faceswap.dev/download/ (accessed on 24 May 2021).
- Xpression. 2021. Available online: https://xpression.jp/ (accessed on 24 May 2021).
- REFACE. 2021. Available online: https://hey.reface.ai/ (accessed on 24 May 2021).
- Impressions. 2021. Available online: https://appadvice.com/app/impressions-face-swap-videos/1489186216 (accessed on 24 May 2021).
- Myheritage. 2021. Available online: https://www.myheritage.com/ (accessed on 24 May 2021).
- Wombo. 2021. Available online: https://www.wombo.ai/ (accessed on 24 May 2021).
- Reflect. 2021. Available online: https://oncreate.com/en/portfolio/reflect#:~:text=A%20first%2Dever%20artificial%20intelligence,picture%20in%20a%20split%20second (accessed on 24 May 2021).
- DEEPFAKES WEB. 2021. Available online: https://deepfakesweb.com/ (accessed on 24 May 2021).
- FaceswapGAN. 2021. Available online: https://github.com/shaoanlu/faceswap-GAN (accessed on 24 May 2021).
- DeepFaceLab. 2021. Available online: https://github.com/iperov/DeepFaceLab (accessed on 24 May 2021).
- Deepware Scanner. 2019. Available online: https://scanner.deepware.ai/ (accessed on 9 February 2022).
- Face2face. 2021. Available online: https://github.com/datitran/face2face-demo (accessed on 24 May 2021).
- Dynamixyz. 2021. Available online: https://www.dynamixyz.com/ (accessed on 24 May 2021).
- GeneratedPhotos. 2021. Available online: https://generated.photos/ (accessed on 24 May 2021).
- Deepfake Bots on Telegram Make the Work of Creating Fake Nudes Dangerously Easy. 2021. Available online: https://www.theverge.com/2020/10/20/21519322/deepfake-fake-nudes-telegram-bot-deepnude-sensity-report (accessed on 9 February 2022).
- Microsoft Launches a Deepfake Detector Tool ahead of US Election. 2020. Available online: https://techcrunch.com/2020/09/02/microsoft-launches-a-deepfake-detector-tool-ahead-of-us-election/ (accessed on 9 February 2022).
- Synthetic and Manipulated Media Policy. 2020. Available online: https://help.twitter.com/en/rules-and-policies/manipulated-media (accessed on 9 February 2022).
- Reddit, Twitter Ban Deepfake Celebrity Porn Videos. 2018. Available online: https://www.complex.com/life/a/julia-pimentel/twitter-reddit-and-more-ban-deepfake-celebrity-videos (accessed on 9 February 2022).
- Mokhayeri, F.; Kamali, K.; Granger, E. Cross-domain face synthesis using a controllable GAN. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 252–260. [Google Scholar]
- Fu, C.; Hu, Y.; Wu, X.; Wang, G.; Zhang, Q.; He, R. High-fidelity face manipulation with extreme poses and expressions. IEEE Trans. Inf. Forensics Secur. 2021, 16, 2218–2231. [Google Scholar] [CrossRef]
- Wang, J.; Alamayreh, O.; Tondi, B.; Barni, M. Open Set Classification of GAN-based Image Manipulations via a ViT-based Hybrid Architecture. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 953–962. [Google Scholar]
- Shen, Y.; Yang, C.; Tang, X.; Zhou, B. Interfacegan: Interpreting the disentangled face representation learned by gans. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 2004–2018. [Google Scholar] [CrossRef] [PubMed]
- Tursman, E.; George, M.; Kamara, S.; Tompkin, J. Towards untrusted social video verification to combat deepfakes via face geometry consistency. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 654–655. [Google Scholar]
- Tursman, E. Detecting deepfakes using crowd consensus. XRDS Crossroads ACM Mag. Stud. 2020, 27, 22–25. [Google Scholar] [CrossRef]







| ID | Ref. | Year | Contributions |
|---|---|---|---|
| 1 | [20] | 2022 |
|
| 2 | [21] | 2022 |
|
| 3 | [22] | 2021 |
|
| 4 | [23] | 2021 |
|
| 5 | [14] | 2021 |
|
| 6 | [24] | 2020 |
|
| 7 | [25] | 2020 |
|
| 8 | [26] | 2020 |
|
| 9 | [27] | 2020 |
|
| 10 | [17] | 2020 |
|
| 11 | [28] | 2020 |
|
| Name | Year | Source | Number of Images | Reference |
|---|---|---|---|---|
| VGGFace2 | 2018 | Google Images | 3.31 M | [44] |
| CelebFaces Attributes (CelebA) | 2015 | Internet | 500 K | [34] |
| Flickr-Faces-HQ dataset (FFHQ) | 2014 | Flickr | 70 K | [42] |
| CASIA-WebFace | 2014 | Internet | 500 K | [43] |
| Labeled Faces in the Wild (LFW) | 2007 | Internet | 13 K | [45] |
| Features | Classifier | Dataset | Performance | Reference |
|---|---|---|---|---|
| Frequency discrepancy | CNN | ProGAN | ACC = 90.7% | [89] |
| StarGAN | ACC = 94.4% | |||
| Frequency discrepancy | CNN | StyleGAN | ACC = 99.9% | [90] |
| PGGAN | ACC = 97.4% | |||
| Deep | CNN | Own (PCGAN and BEGAN) | ACC = 98.0% | [91] |
| Deep | CNN + attention mechanism | DFFD (ProGAN, StyleGAN) | AUC = 100% EER = 0.1% | [50] |
| Deep | CNN | 100K-Faces (StyleGAN) | EER = 0.3% | [51] |
| iFakeFaceDB | EER = 4.5% | |||
| Multi-level | CNN | Own (reconstruction) | ACC = 94% | [92] |
| Textural | CNN | StyleGAN | ACC = 95.51% | [93] |
| PGGAN | ACC = 92.28% | |||
| Layer-wise neuron | Support vector machine (SVM) | Own (InterFaceGAN, StyleGAN) | ACC = 84.7% | [94] |
| Steganalysis | CNN | 100K-Faces (StyleGAN) | EER = 1.23% | [95] |
| Landmark | SVM | Own (PCGAN) | ACC = 94.13% | [96] |
| GAN | SVM | NIST MFC2018 | AUC = 70.0% | [97] |
| Features | Classifier | Dataset | Performance | Reference |
|---|---|---|---|---|
| Steganalysis | CNN | StarGAN | AUC = 93.4% | [95] |
| Layer-wise neuron | SVM | StarGAN | ACC = 88% | [94] |
| STGAN | ACC = 90% | |||
| Expectation— maximization (EM) | CNN | StarGAN | ACC = 93.17% | [121] |
| AttGAN | ACC = 92.67% | |||
| GDWCT | ACC = 88.4% | |||
| STYLEGAN2 | ACC = 99.81% | |||
| Deep | CNN + attention mechanism | FF++ | AUC = 99.4% EER = 3.4% | [50] |
| Deep | CNN | ProGAN | ACC = 99% | [122] |
| Adobe Photoshop | AUC = 74.9% | |||
| Facial patches | CNN | ND-IIITD | ACC = 99.65% | [123] |
| StarGAN | ACC = 99.83% | |||
| Facial patches | Supervised restricted Boltzmann machine (SRBM) | ND-IIITD | ACC = 87.1% | [124] |
| Celebrity | ACC = 96.2% | |||
| Facial patches | Hierarchical CNN | StarGAN | ACC = 99.98% | [125] |
| Features | Classifier | Dataset | Performance | Reference |
|---|---|---|---|---|
| Deep | CNN | FF++ (NeuralTextures, HQ) | ACC = 94.2% | [159] |
| FF++ (Face2Face, HQ | ACC = 95.7% | |||
| Deep | AE | FF++ (Face2Face, RAW) | ACC = 86.6% | [152] |
| Deep | CNN | DFFD | AUC = 99.4% EER = 3.4% | [50] |
| Deep | AE | FF++ (Face2Face, HQ) | AUC = 92.7% EER = 7.8% | [142] |
| Deep | Transformer | FF++ (LQ) | AUC = 94.2% | [160] |
| FF++ (HQ) | AUC = 99.4% | |||
| FF++ (Raw) | AUC = 99.9% | |||
| Steganalysis + deep | CNN | FF++ (NeuralTextures, LQ) | ACC = 82.1% | [67] |
| FF+ (NeuralTextures, HQ) | ACC = 94.5% | |||
| FF++ (NeuralTextures, Raw) | ACC = 99.36% | |||
| FF++ (Face2Face, LQ) | ACC = 91.5% | |||
| FF+ (Face2Face, HQ) | ACC = 98.3% | |||
| FF++ (Face2Face, Raw) | ACC = 99.6% | |||
| Frequency | CNN | FF++ (Face2Face, LQ) | AUC = 95.8% | [161] |
| FF++ (NeuralTextures, LQ) | AUC = 86.1% | |||
| Patch | CNN | FF++ (NeuralTextures, HQ) | ACC = 92% | [162] |
| FF++ (Face2Face, HQ | ACC = 99.6% | |||
| Mesoscopic | CNN | FF++ (Face2Face, LQ) | ACC = 81.3% | [163] |
| FF+ (Face2Face, HQ) | ACC = 93.4% | |||
| FF++ (Face2Face, Raw) | ACC = 96.8% | |||
| Facial | CNN | FF++ (Face2Face, LQ) | AUC = 91.2% | [164] |
| FF+ (Face2Face, HQ) | AUC = 98.1% | |||
| FF++ (Face2Face, Raw) | AUC = 99.96% | |||
| Facial (source) | CNN | FF++ (Face2Face, -) | AUC = 98.97% | [145] |
| FF+ (NeuralTextures, -) | AUC = 97.63% | |||
| Low-level texture | CNN | FF++ (Face2Face, LQ) | AUC = 94.6% | [165] |
| FF++ (NeuralTextures, LQ) | AUC = 80.4% | |||
| Temporal | CNN + RNN | FF++ (Face2Face, LQ) | ACC = 94.3% | [147] |
| Optical flow | CNN | FF++ (Face2Face, -) | AUC = 81.61% | [166] |
| Temporal + semantic | CNN | DFD (Facial re-enactment, LQ) | AUC = 90% | [167] |
| DFD (Facial re-enactment, HQ) | AUC = 87% |
| Type | Name | Face Swapping | Re-enactment | Attribute Editing | Face Synthesis | Reference | Note |
|---|---|---|---|---|---|---|---|
| CS | Adobe Photoshop | ✔ | ✔ | [173] | Commercial application | ||
| Faceswap | ✔ | [174] | For learning and training purposes Faster with GPU | ||||
| MA | FaceApp | ✔ | [4] | ||||
| Xpression | ✔ | [175] | |||||
| Reface | ✔ | [176] | Simple process Relies on face embeddings | ||||
| Impressions | ✔ | [177] | |||||
| Myheritage | ✔ | [178] | Animates historical photos | ||||
| Wombo | ✔ | [179] | Ensures users’ privacy | ||||
| WA | Reflect | ✔ | [180] | ||||
| Deepfake WEB | ✔ | ✔ | [181] | Learns various features of the face datacTakes hours to render the data | |||
| OS | Faceswap-GAN | ✔ | [182] | ||||
| DeepFaceLab | ✔ | ✔ | ✔ | [183] | Advanced application Needs a powerful PC | ||
| Deepware scanner | ✔ | ✔ | ✔ | [184] | Supports API Hosted website | ||
| Face2Face | ✔ | [185] | |||||
| Dynamixyz | ✔ | [186] | |||||
| Generated Photos | ✔ | [187] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dang, M.; Nguyen, T.N. Digital Face Manipulation Creation and Detection: A Systematic Review. Electronics 2023, 12, 3407. https://doi.org/10.3390/electronics12163407
Dang M, Nguyen TN. Digital Face Manipulation Creation and Detection: A Systematic Review. Electronics. 2023; 12(16):3407. https://doi.org/10.3390/electronics12163407
Chicago/Turabian StyleDang, Minh, and Tan N. Nguyen. 2023. "Digital Face Manipulation Creation and Detection: A Systematic Review" Electronics 12, no. 16: 3407. https://doi.org/10.3390/electronics12163407
APA StyleDang, M., & Nguyen, T. N. (2023). Digital Face Manipulation Creation and Detection: A Systematic Review. Electronics, 12(16), 3407. https://doi.org/10.3390/electronics12163407