
Multi-Stream General and Graph-Based Deep Neural Networks for Skeleton-Based Sign Language Recognition

 ,
, 

Abstract
1. Introduction
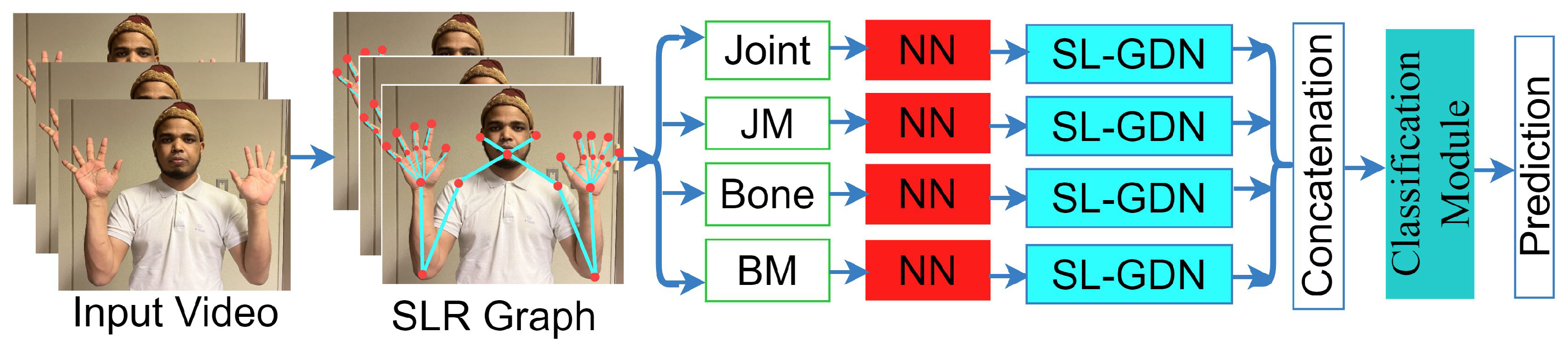
- We construct a skeleton graph for large-scale SLR using 27 key points selected among the whole-body key points. The main purpose of this graph is to construct a unified graph to dynamically optimize the nodes and edges based on different actions due to the minimum number of the skeleton key points being selected among the whole-body points, and extract features from four streams that can be solved to increase the model’s performance accuracy and generalizability.
- We extract hybrid features from the multiple streams, including joints, joint motion, bones, and bone motion of the skeleton by combining the graph-based SL-GDN and general neural network features. After concatenating the features, we use a classification module to refine the concatenated features for prediction.
- We use two large-scale data sets with four modalities (i.e., joint, joint motion, bone, and bone motion) to evaluate the model, and our model presents superior performance when compared to an existing system.
2. Related Work
3. Data Sets
3.1. AUTSL Data Set
3.2. CSL Data Set
4. Proposed Methodology
4.1. Key Point Selection and Graph Construction
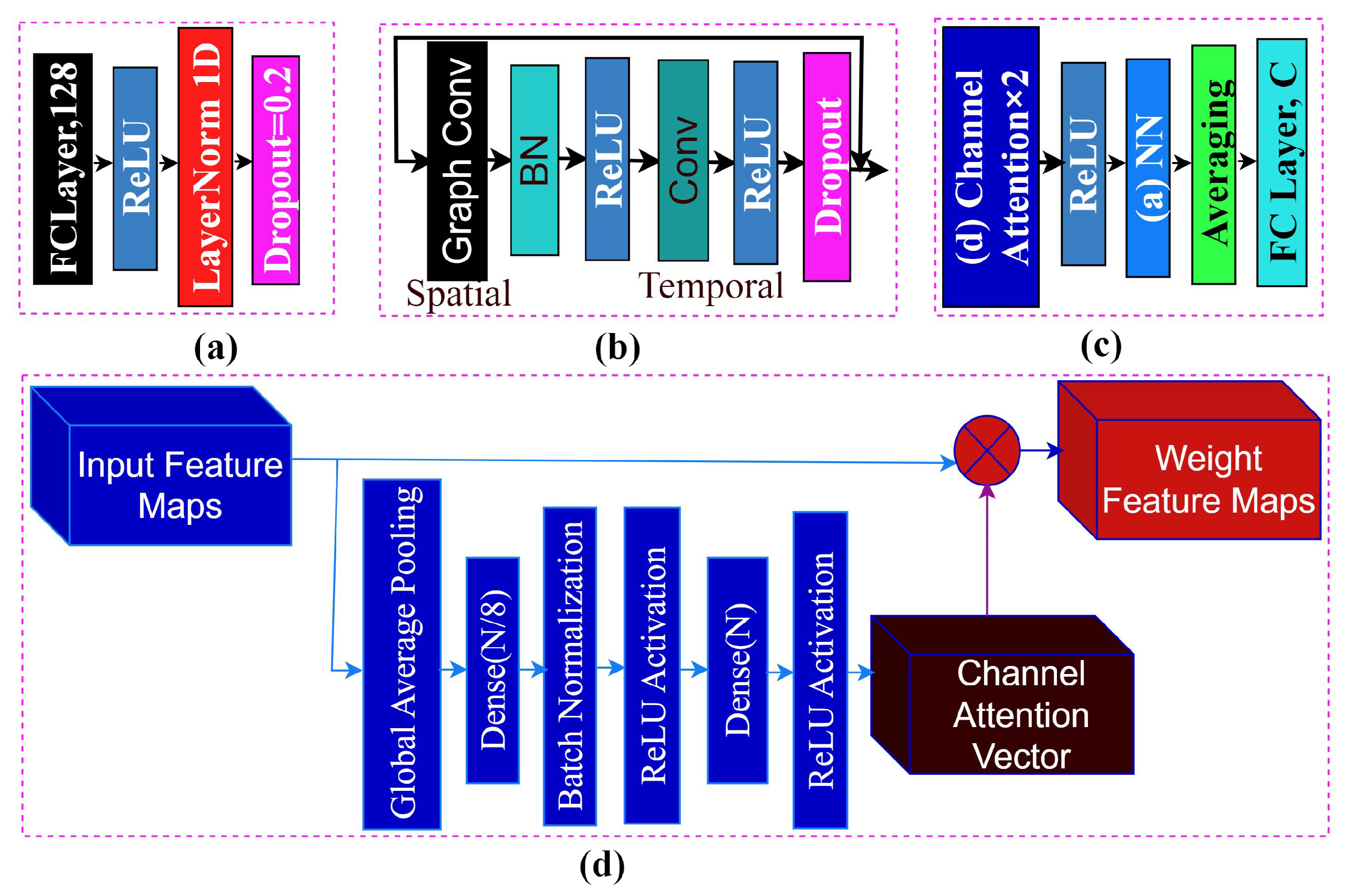
4.2. Neural Network (NN)
4.3. Graph Convolution
4.4. SL-GDN Architecture Block
4.5. Four-Stream Approach
4.6. Classification Module
5. Experimental Results
5.1. Experimental Setting
5.2. Performance Accuracy of SL-GDN on Benchmark Data Set
5.3. Ablation Study
5.4. Comparison of the Proposed Model with State-of-the-Art on the AUTSL Data Set
5.5. Comparison of the Proposed Model with State-of-the-Art on the CSL Data Set
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Miah, A.S.M.; Hasan, M.A.M.; Shin, J. Dynamic Hand Gesture Recognition using Multi-Branch Attention Based Graph and General Deep Learning Model. IEEE Access 2023, 11, 4703–4716. [Google Scholar] [CrossRef]
- Miah, A.S.M.; Hasan, M.A.M.; Shin, J.; Okuyama, Y.; Tomioka, Y. Multistage Spatial Attention-Based Neural Network for Hand Gesture Recognition. Computers 2023, 12, 13. [Google Scholar] [CrossRef]
- Miah, A.S.M.; Shin, J.; Hasan, M.A.M.; Rahim, M.A. BenSignNet: Bengali Sign Language Alphabet Recognition Using Concatenated Segmentation and Convolutional Neural Network. Appl. Sci. 2022, 12, 3933. [Google Scholar] [CrossRef]
- Miah, A.S.M.S.J.; Hasan, M.A.M.; Rahim, M.A.; Okuyama, Y. Rotation, Translation And Scale Invariant Sign Word Recognition Using Deep Learning. Comput. Syst. Sci. Eng. 2023, 44, 2521–2536. [Google Scholar] [CrossRef]
- Miah, A.S.M.; Shin, J.; Islam, M.M.; Molla, M.K.I. Natural Human Emotion Recognition Based on Various Mixed Reality (MR) Games and Electroencephalography (EEG) Signals. In Proceedings of the 2022 IEEE 5th Eurasian Conference on Educational Innovation (ECEI), Taipei, Taiwan, 10–12 February 2022; IEEE: New York, NY, USA, 2022; pp. 408–411. [Google Scholar]
- Miah, A.S.M.; Mouly, M.A.; Debnath, C.; Shin, J.; Sadakatul Bari, S. Event-Related Potential Classification Based on EEG Data Using xDWAN with MDM and KNN. In Proceedings of the International Conference on Computing Science, Communication and Security, Gujarat, India, 6–7 February 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 112–126. [Google Scholar]
- Emmorey, K. Language, Cognition, and the Brain: Insights from Sign Language Research; Psychology Press: London, UK, 2001. [Google Scholar]
- Jiang, S.; Sun, B.; Wang, L.; Bai, Y.; Li, K.; Fu, Y. Skeleton aware multi-modal sign language recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3413–3423. [Google Scholar]
- Yang, Q. Chinese sign language recognition based on video sequence appearance modeling. In Proceedings of the 2010 5th IEEE Conference on Industrial Electronics and Applications, Taichung, Taiwan, 5–17 June 2010; IEEE: New York, NY, USA, 2010; pp. 1537–1542. [Google Scholar]
- Valli, C.; Lucas, C. Linguistics of American Sign Language: An Introduction; Gallaudet University Press: Washington, DC, USA, 2000. [Google Scholar]
- Mindess, A. Reading between the Signs: Intercultural Communication for Sign Language Interpreters; Nicholas Brealey: Boston, MA, USA, 2014. [Google Scholar]
- Shin, J.; Musa Miah, A.S.; Hasan, M.A.M.; Hirooka, K.; Suzuki, K.; Lee, H.S.; Jang, S.W. Korean Sign Language Recognition Using Transformer-Based Deep Neural Network. Appl. Sci. 2023, 13, 3029. [Google Scholar] [CrossRef]
- Miah, A.S.M.; Shin, J.; Hasan, M.A.M.; Molla, M.K.I.; Okuyama, Y.; Tomioka, Y. Movie Oriented Positive Negative Emotion Classification from EEG Signal using Wavelet transformation and Machine learning Approaches. In Proceedings of the 2022 IEEE 15th International Symposium on Embedded Multicore/Many-Core Systems-on-Chip (MCSoC), Penang, Malaysia, 19–22 December 2022; IEEE: New York, NY, USA, 2022; pp. 26–31. [Google Scholar]
- Miah, A.S.M.; Rahim, M.A.; Shin, J. Motor-imagery classification using Riemannian geometry with median absolute deviation. Electronics 2020, 9, 1584. [Google Scholar] [CrossRef]
- Miah, A.S.M.; Islam, M.R.; Molla, M.K.I. Motor imagery classification using subband tangent space mapping. In Proceedings of the 2017 20th International Conference of Computer and Information Technology (ICCIT), Dhaka, Bangladesh, 22–24 December 2017; IEEE: New York, NY, USA, 2017; pp. 1–5. [Google Scholar]
- Zobaed, T.; Ahmed, S.R.A.; Miah, A.S.M.; Binta, S.M.; Ahmed, M.R.A.; Rashid, M. Real time sleep onset detection from single channel EEG signal using block sample entropy. Iop Conf. Ser. Mater. Sci. Eng. 2020, 928, 032021. [Google Scholar] [CrossRef]
- Kabir, M.H.; Mahmood, S.; Al Shiam, A.; Musa Miah, A.S.; Shin, J.; Molla, M.K.I. Investigating Feature Selection Techniques to Enhance the Perfor-mance of EEG-Based Motor Imagery Tasks Classification. Mathematics 2023, 11, 1921. [Google Scholar] [CrossRef]
- Miah, A.S.M.; Islam, M.R.; Molla, M.K.I. EEG classification for MI-BCI using CSP with averaging covariance matrices: An experimental study. In Proceedings of the 2019 International Conference on Computer, Communication, Chemical, Materials and Electronic Engineering (IC4ME2), Rajshahi, Bangladesh, 11–12 July 2019; IEEE: New York, NY, USA, 2019; pp. 1–5. [Google Scholar]
- Joy, M.M.H.; Hasan, M.; Miah, A.S.M.; Ahmed, A.; Tohfa, S.A.; Bhuaiyan, M.F.I.; Zannat, A.; Rashid, M.M. Multiclass mi-task classification using logistic regression and filter bank common spatial patterns. In Proceedings of the Computing Science, Communication and Security: First Interna-tional Conference, COMS2 2020, Gujarat, India, 26–27 March 2020; Revised Selected Papers. Springer: Berlin/Heidelberg, Germany, 2020; pp. 160–170. [Google Scholar]
- Cheng, K.; Zhang, Y.; Cao, C.; Shi, L.; Cheng, J.; Lu, H. Decoupling gcn with dropgraph module for skeleton-based action recognition. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXIV 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 536–553. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Skeleton-based action recognition with multi-stream adaptive graph convolutional networks. IEEE Trans. Image Process. 2020, 29, 9532–9545. [Google Scholar] [CrossRef] [PubMed]
- Song, Y.F.; Zhang, Z.; Shan, C.; Wang, L. Stronger, faster and more explainable: A convolutional graph baseline for skeleton-based action recognition. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 1625–1633. [Google Scholar]
- Wang, H.; Wang, L. Modeling temporal dynamics and spatial configurations of actions using two-stream recurrent neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 499–508. [Google Scholar]
- Yan, S.; Xiong, Y.; Lin, D. Spatial, temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Oberweger, M.; Lepetit, V. Deepprior++: Improving fast and accurate 3d hand pose estimation. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 585–594. [Google Scholar]
- Shin, J.; Matsuoka, A.; Hasan, M.A.M.; Srizon, A.Y. American sign language alphabet recognition by extracting feature from hand pose estimation. Sensors 2021, 21, 5856. [Google Scholar] [CrossRef]
- Jin, S.; Xu, L.; Xu, J.; Wang, C.; Liu, W.; Qian, C.; Ouyang, W.; Luo, P. Whole-body human pose estimation in the wild. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part IX 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 196–214. [Google Scholar]
- Xiao, Q.; Qin, M.; Yin, Y. Skeleton-based Chinese sign language recognition and generation for bidirectional communication between deaf and hearing people. Neural Netw. 2020, 125, 41–55. [Google Scholar] [CrossRef]
- Mejía-Peréz, K.; Córdova-Esparza, D.M.; Terven, J.; Herrera-Navarro, A.M.; García-Ramírez, T.; Ramírez-Pedraza, A. Automatic recognition of Mexican Sign Language using a depth camera and recurrent neural networks. Appl. Sci. 2022, 12, 5523. [Google Scholar] [CrossRef]
- Jiang, S.; Sun, B.; Wang, L.; Bai, Y.; Li, K.; Fu, Y. Sign language recognition via skeleton-aware multi-model ensemble. arXiv 2021, arXiv:2110.06161. [Google Scholar]
- Lim, K.M.; Tan, A.W.C.; Lee, C.P.; Tan, S.C. Isolated sign language recognition using convolutional neural network hand modelling and hand energy image. Multimed. Tools Appl. 2019, 78, 19917–19944. [Google Scholar] [CrossRef]
- Shi, B.; Del Rio, A.M.; Keane, J.; Michaux, J.; Brentari, D.; Shakhnarovich, G.; Livescu, K. American sign language fingerspelling recognition in the wild. In Proceedings of the 2018 IEEE Spoken Language Technology Workshop (SLT), Athens, Greece, 18–21 December 2018; IEEE: New York, NY, USA, 2018; pp. 145–152. [Google Scholar]
- Li, Y.; Wang, X.; Liu, W.; Feng, B. Deep attention network for joint hand gesture localization and recognition using static RGB-D images. Inf. Sci. 2018, 441, 66–78. [Google Scholar] [CrossRef]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Corfu, Greece, 20–25 September 1999; IEEE: New York, NY, USA, 1999; Volume 2, pp. 1150–1157. [Google Scholar]
- Zhu, Q.; Yeh, M.C.; Cheng, K.T.; Avidan, S. Fast human detection using a cascade of histograms of oriented gradients. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; IEEE: New York, NY, USA, 2006; Volume 2, pp. 1491–1498. [Google Scholar]
- Dardas, N.H.; Georganas, N.D. Real-time hand gesture detection and recognition using bag-of-features and support vector machine techniques. IEEE Trans. Instrum. Meas. 2011, 60, 3592–3607. [Google Scholar] [CrossRef]
- Memiş, A.; Albayrak, S. A Kinect based sign language recognition system using spatio-temporal features. In Proceedings of the Sixth International Conference on Machine Vision (ICMV 2013), London, UK, 16–17 November 2013; Volume 9067, pp. 179–183. [Google Scholar]
- Rahim, M.A.; Miah, A.S.M.; Sayeed, A.; Shin, J. Hand gesture recognition based on optimal segmentation in human-computer interaction. In Proceedings of the 2020 3rd IEEE International Conference on Knowledge Innovation and Invention (ICKII), Kaohsiung, Taiwan, 21–23 August 2020; IEEE: New York, NY, USA, 2020; pp. 163–166. [Google Scholar]
- Tur, A.O.; Keles, H.Y. Isolated sign recognition with a siamese neural network of RGB and depth streams. In Proceedings of the IEEE EUROCON 2019-18th International Conference on Smart Technologies, Novi Sad, Serbia, 1–4 July 2019; IEEE: New York, NY, USA, 2019; pp. 1–6. [Google Scholar]
- Cai, Z.; Wang, L.; Peng, X.; Qiao, Y. Multi-view super vector for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 596–603. [Google Scholar]
- Neverova, N.; Wolf, C.; Taylor, G.; Nebout, F. Moddrop: Adaptive multi-modal gesture recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 1692–1706. [Google Scholar] [CrossRef]
- Pu, J.; Zhou, W.; Li, H. Iterative alignment network for continuous sign language recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4165–4174. [Google Scholar]
- Koller, O.; Zargaran, S.; Ney, H.; Bowden, R. Deep sign: Enabling robust statistical continuous sign language recognition via hybrid CNN-HMMs. Int. J. Comput. Vis. 2018, 126, 1311–1325. [Google Scholar] [CrossRef]
- Huang, J.; Zhou, W.; Li, H.; Li, W. Attention-based 3D-CNNs for large-vocabulary sign language recognition. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 2822–2832. [Google Scholar] [CrossRef]
- Venugopalan, S.; Rohrbach, M.; Donahue, J.; Mooney, R.; Darrell, T.; Saenko, K. Sequence to sequence-video to text. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4534–4542. [Google Scholar]
- Pigou, L.; Van Den Oord, A.; Dieleman, S.; Van Herreweghe, M.; Dambre, J. Beyond temporal pooling: Recurrence and temporal convolutions for gesture recognition in video. Int. J. Comput. Vis. 2018, 126, 430–439. [Google Scholar] [CrossRef]
- Huang, J.; Zhou, W.; Zhang, Q.; Li, H.; Li, W. Video-based sign language recognition without temporal segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Li, D.; Rodriguez, C.; Yu, X.; Li, H. Word-level deep sign language recognition from video: A new large-scale dataset and methods comparison. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 1459–1469. [Google Scholar]
- Cui, R.; Liu, H.; Zhang, C. A deep neural framework for continuous sign language recognition by iterative training. IEEE Trans. Multimed. 2019, 21, 1880–1891. [Google Scholar] [CrossRef]
- Guo, D.; Zhou, W.; Li, H.; Wang, M. Hierarchical LSTM for sign language translation. In Proceedings of the AAAI Conference on Artificial Intelligence, Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Parelli, M.; Papadimitriou, K.; Potamianos, G.; Pavlakos, G.; Maragos, P. Exploiting 3D Hand Pose Estimation in Deep Learning-Based Sign Language Recognition from RGB Videos. In Proceedings of the Computer Vision—ECCV 2020 Workshops, Glasgow, UK, 23–28 August 2020; Bartoli, A., Fusiello, A., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 249–263. [Google Scholar]
- Cai, J.; Jiang, N.; Han, X.; Jia, K.; Lu, J. JOLO-GCN: Mining Joint-Centered Light-Weight Information for Skeleton-Based Action Recognition. In Proceedings of the IEEE/CVF winter conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2021; pp. 2734–2743. [Google Scholar] [CrossRef]
- Li, M.; Chen, S.; Chen, X.; Zhang, Y.; Wang, Y.; Tian, Q. Actional-structural graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3595–3603. [Google Scholar]
- Li, S.; Li, W.; Cook, C.; Zhu, C.; Gao, Y. Independently recurrent neural network (indrnn): Building a longer and deeper rnn. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5457–5466. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Two-stream adaptive graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12026–12035. [Google Scholar]
- de Amorim, C.C.; Macêdo, D.; Zanchettin, C. Spatial-temporal graph convolutional networks for sign language recognition. In Proceedings of the Artificial Neural Networks and Machine Learning–ICANN 2019: Workshop and Special Sessions: 28th International Conference on Artificial Neural Networks, Munich, Germany, 17–19 September 2019; Proceedings 28. Springer: Berlin/Heidelberg, Germany, 2019; pp. 646–657. [Google Scholar]
- Sincan, O.M.; Keles, H.Y. Autsl: A large scale multi-modal turkish sign language dataset and baseline methods. IEEE Access 2020, 8, 181340–181355. [Google Scholar] [CrossRef]
- Huang, J. Chinese Sign Language Recognition Dataset. 2017. Available online: http://home.ustc.edu.cn/~hagjie/ (accessed on 23 June 2023).
- Sincan, O.M.; Tur, A.O.; Keles, H.Y. Isolated sign language recognition with multi-scale features using LSTM. In Proceedings of the 2019 27th Signal Processing and Communications Applications Conference (SIU), Sivas, Turkey, 24–26 April 2019; IEEE: New York, NY, USA, 2019; pp. 1–4. [Google Scholar]
- Pagliari, D.; Pinto, L. Calibration of kinect for xbox one and comparison between the two generations of microsoft sensors. Sensors 2015, 15, 27569–27589. [Google Scholar] [CrossRef]
- Liu, J.; Shahroudy, A.; Xu, D.; Wang, G. Spatio-temporal lstm with trust gates for 3d human action recognition. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part III 14. Springer: New York, NY, USA, 2016; pp. 816–833. [Google Scholar]
- Hirooka, K.; Hasan, M.A.M.; Shin, J.; Srizon, A.Y. Ensembled Transfer Learning Based Multichannel Attention Networks for Human Activity Recognition in Still Images. IEEE Access 2022, 10, 47051–47062. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. In Proceedings of the Advances in Neural Information Processing Systems 32, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Tock, K. Google CoLaboratory as a platform for Python coding with students. RTSRE Proc. 2019, 2. Available online: https://www.rtsre.org/index.php/rtsre/article/view/63 (accessed on 23 June 2023).
- Gollapudi, S. Learn Computer Vision using OpenCV; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Dozat, T. Incorporating Nesterov Momentum into Adam 2016. Available online: https://cs229.stanford.edu/proj2015/054_report.pdf (accessed on 23 June 2023).
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Set | Language | Year | Signs | Subjects | Total Sample | Each Sign Word |
|---|---|---|---|---|---|---|
| AUTSL [57] | Turkish | 2020 | 226 | 43 | 38,336 | 169 (on average) |
| CSL [48,58] | Chinese | 2019 | 500 | 50 | 125,000 | 250 |
| Stream | Testing Accuracy on AUTSL [%] | Testing Accuracy on CSL [%] |
|---|---|---|
| Joint | 96.00 | 88.70 |
| Joint Motion | 95.00 | 87.00 |
| Bone | 94.00 | 86.00 |
| Bone Motion | 93.00 | 86.50 |
| Multi-Stream | 96.00 | 89.45 |
| Method Name | No. of SL-GDN in Series | No.of Channel Attention Newly Added | Datasets | Performance Accuracy [%] |
|---|---|---|---|---|
| Two Stream [55] | 9 | 1 | AUTSL | 94.00 |
| Two Stream [55] | 9 | 1 | CSL | 88.00 |
| Four Stream [8] | 10 | 2 | AUTSL | 96.00 |
| Four Stream [8] | 10 | 2 | CSL | 88.50 |
| Proposed Four Stream | 13 | 2 | AUTSL | 96.45 |
| Proposed Four Stream | 13 | 2 | CSL | 89.45 |
| Data Set Type | Method Name | Sign Recognition Accuracy [%] |
|---|---|---|
| RGB+Depth | CNN+FPM+LSTM+Attention [57] | 83.93 |
| Skeleton | Two Stream CNN [55] | 93.70 |
| Skeleton Joint | Jiang [8] | 95.02 |
| Skeleton Joint Motion | Jiang [8] | 94.70 |
| Skeleton Bone | Jiang [8] | 93.10 |
| Skeleton Bone Motion | Jiang [8] | 92.49 |
| Skeleton Multi-Stream | Jiang [8] | 95.45 |
| Skeleton Joint | Proposed Model | 96.00 |
| Skeleton Joint Motion | Proposed Model | 95.00 |
| Skeleton Bone | Proposed Model | 94.00 |
| Skeleton Bone Motion | Proposed Model | 93.00 |
| Skeleton Multi-Stream | Proposed Model | 96.45 |
| Data Set Name | Data Set Type | Methodology | Sign Recognition Accuracy [%] |
|---|---|---|---|
| CSL | RGB-D+Skeleton | 3D-CNN [44] | 88.70 |
| Proposed Model | Skeleton | SL-GDN | 89.45 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Miah, A.S.M.; Hasan, M.A.M.; Jang, S.-W.; Lee, H.-S.; Shin, J. Multi-Stream General and Graph-Based Deep Neural Networks for Skeleton-Based Sign Language Recognition. Electronics 2023, 12, 2841. https://doi.org/10.3390/electronics12132841
Miah ASM, Hasan MAM, Jang S-W, Lee H-S, Shin J. Multi-Stream General and Graph-Based Deep Neural Networks for Skeleton-Based Sign Language Recognition. Electronics. 2023; 12(13):2841. https://doi.org/10.3390/electronics12132841
Chicago/Turabian StyleMiah, Abu Saleh Musa, Md. Al Mehedi Hasan, Si-Woong Jang, Hyoun-Sup Lee, and Jungpil Shin. 2023. "Multi-Stream General and Graph-Based Deep Neural Networks for Skeleton-Based Sign Language Recognition" Electronics 12, no. 13: 2841. https://doi.org/10.3390/electronics12132841
APA StyleMiah, A. S. M., Hasan, M. A. M., Jang, S.-W., Lee, H.-S., & Shin, J. (2023). Multi-Stream General and Graph-Based Deep Neural Networks for Skeleton-Based Sign Language Recognition. Electronics, 12(13), 2841. https://doi.org/10.3390/electronics12132841