2.2. Text Emotion Recognition Model Based on XLNet
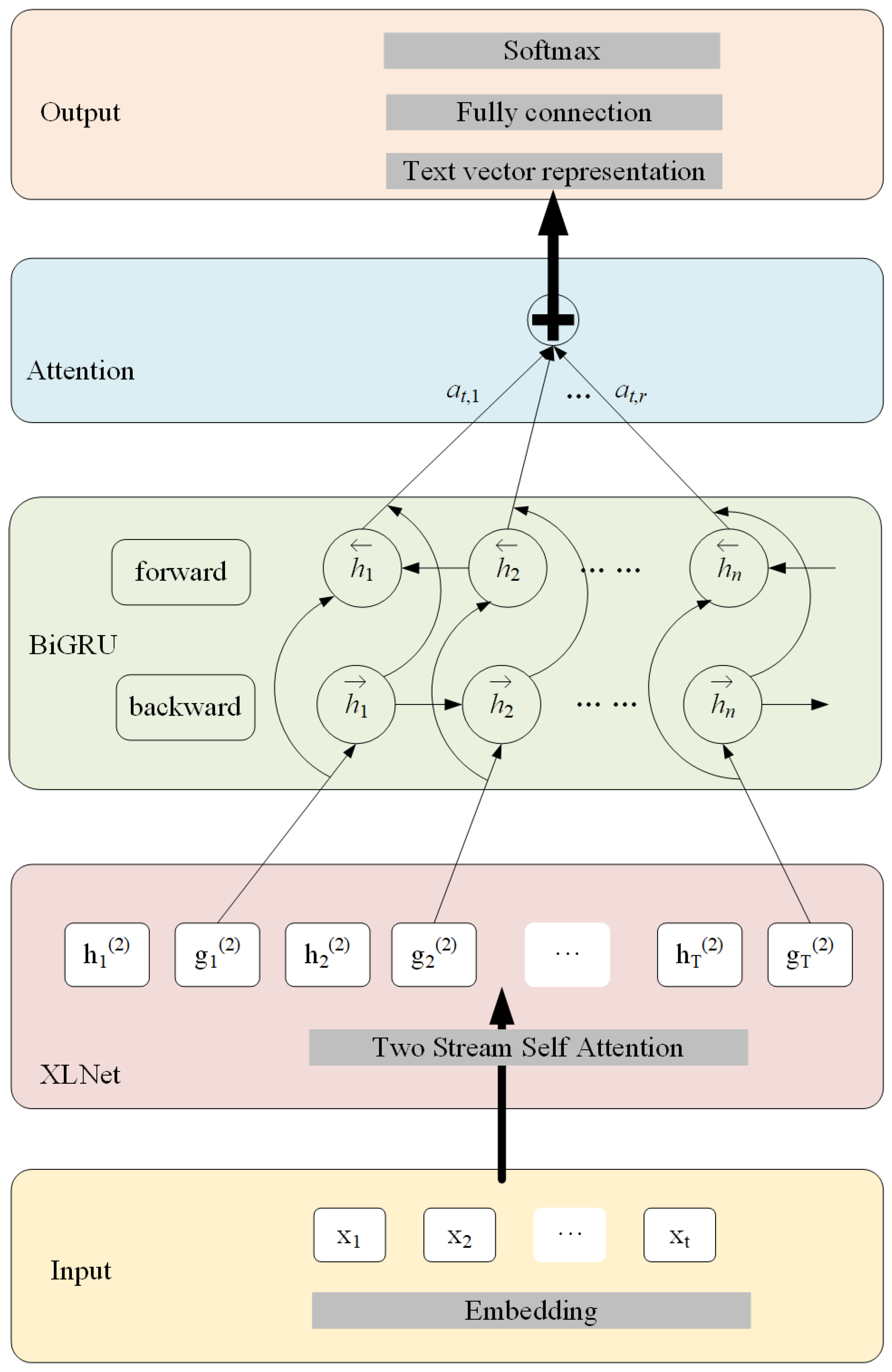
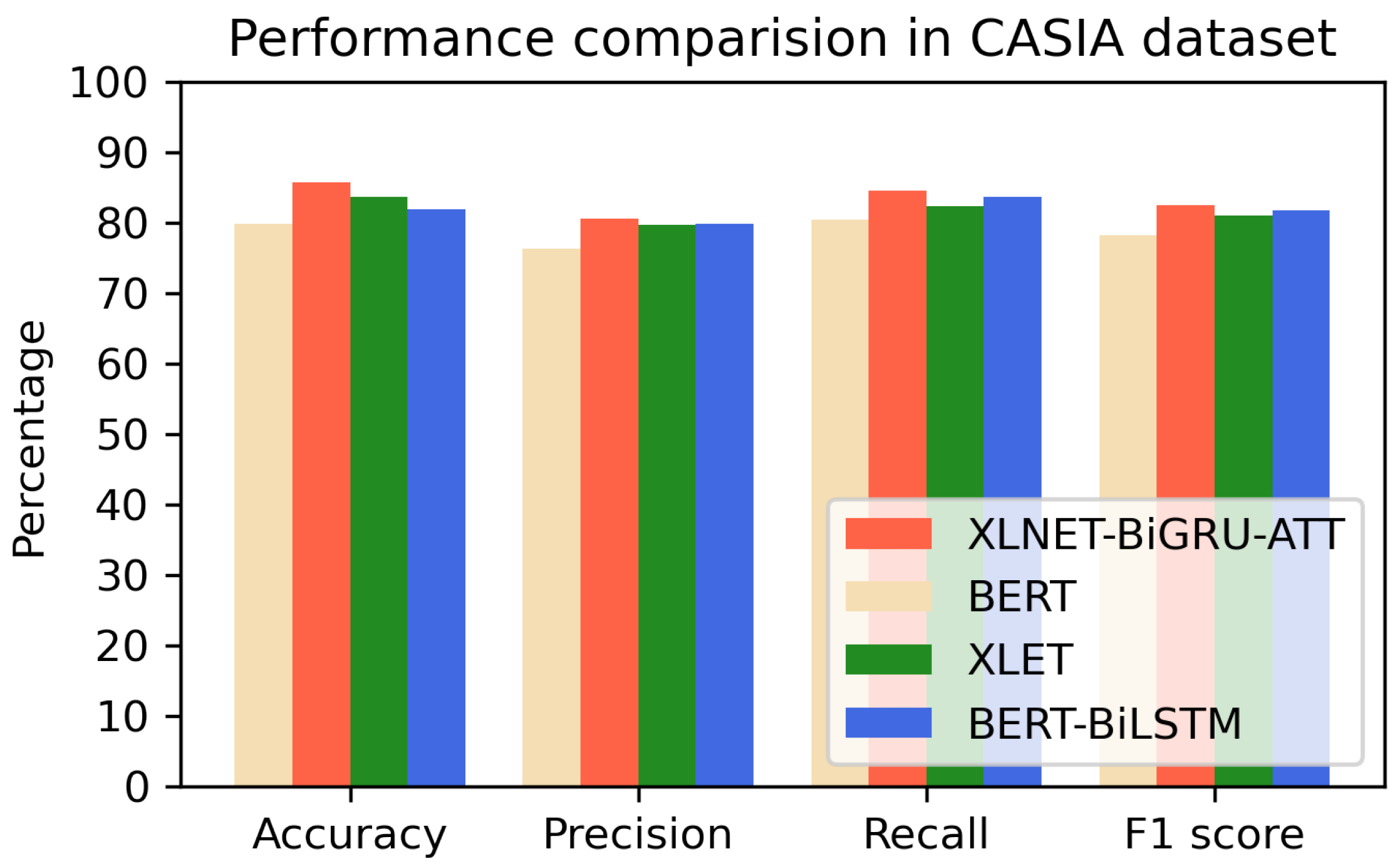
This paper proposes a novel approach to enhance the accuracy of sentiment analysis through the development of a model based on XLNet with bidirectional recurrent unit and attention mechanism (XLNet-BiGRU-Att). The proposed methodology addresses the challenges associated with vectorization of short text sentiment analysis. Unlike traditional language models that only consider unidirectional information, the proposed XLNet model is a two-way modeling language model that simultaneously captures information in context both above and below, making the resulting word vectors more semantically rich. In addition, the BiGRU-Attention network layer effectively filters important information within limited text space and assigns different weights to filtered word vectors in order to enhance their “attention power”. These measures collectively improve the performance of the sentiment analysis model. The architecture of XLNet-BiGRU-Att is shown in
Figure 1, which is mainly composed of thr input layer, XLNet-BIGRU-Att model layer, and output layer. In the input layer, every word in the input sentence is transferred into a word vector by the embedding function, where the raw word vectors
represent the input of XLNet. In XLNet, the raw word vectors are processed by two-stream self-attention and the vectors are calculated concurrently in two channels: the content stream
, and the query stream
. As the query stream contains the position information, it is used as the output of XLNet during the prediction process. The BiGRU layer is used for extraction of deep emotional features; it contains both forward and backward GRUs, as shown in
Figure 1, where
h is the hidden state. Through BiGRU, word vectors can be used to more fully learn the relationships between contexts and perform semantic encoding. The attention layer assigns corresponding probability weights to different word vectors in order to further extract text features and highlight the key information of the text. In the end, the output layer is a fully connected layer and a softmax function is used to provide the emotional classification result.
XLNet is a state-of-the-art model for pre-training in semantic understanding. It builds upon previous models such as mask language models and autoregressive (AR) language models, and addresses specific challenges in the pre-training stage of BERT. One key advantage of XLNet is its ability to handle inconsistencies between the mask flag and the fine-tuning process. Additionally, it effectively resolves the dependency problem between masked words. This is achieved through a unique approach that reconstructs the input text in a permutation and composition manner. Unlike BERT, XLNet applies this approach during the fine-tuning stage, using the Transformer attention mask matrix and double-flow attention mechanism to achieve different combinations and permutations. This allows for the integration of contextual features into the model training process.
XLNet is based on the autoregression (AR) language model. XLnet uses the idea of random sorting to solve the problem of AR models being unable to introduce two-directional text information. The random sorting process simply sorts the sequence number of each position randomly. After sorting, the words prior to each individual word can be used to predict its probability. Here, the previous words may be drawn from either the words prior to the current word in the original sentence or from the words after it, which is equivalent to using the bidirectional sequence information.
First, the Permutation Language Model (PLM) is constructed, which disrupts the order of the original word vectors. Assuming that the original sequence is
, then its arrangement is
and the word order is fully arranged as
,
,
, etc.
Figure 2 presents an example of the prediction of
based on the different orders produced by sequential factorization.
In
Figure 2,
represents the input word vectors,
is the hidden state of the input layer,
is the hidden state of the first layer,
is the predicted result of the
ith word in the first layer,
is the predicted result of the
ith word in the second layer, and
is the output predicted result, which can be understood as a word vector encoding. As shown in
Figure 2a, when the factorization order is
, the prediction of
cannot involve attention to any other words, and can only be predicted based on the previous hidden state
. As shown in
Figure 2b, when the factorization order is
, the semantics of
can be predicted according to the meaning of
and
. Unlike the AR language model, this method captures the contextual semantic information of
, which achieves the purpose of obtaining contextual semantics.
Second, all the factorization orders should be sampled. For a given length
T of text sequence
x,
results can be obtained by fully sorting the sequence. However, when the text sequence is too long, the complexity of the algorithm increases. The random sorting language model needs to randomly sample
results to remove useless sequences. Random sampling of all the factorization orders of the text sequence is realized by Equation (
1):
In Equation (
1),
is the set of sequences with length
T composed of sequences arranged from the original sequence,
z is the sequence sampled from
,
is the value at the position of
t in sequence
z,
represents the
tth element and the preceding
elements in sequence
z, and
is the expectation of the sampling result.
Finally, the later words in the sequence are predicted; for example, the original language sequence is arranged in the order and the language sequence after it is fully arranged as and . When the predicted position is , the word order can only be used to obtain the semantic information of , while when the word order is , the semantic information of , , and can be obtained. Therefore, the model prefers that the predicted words be located at the end of the sentence, as this can provide better contact with the context semantic information.
2.2.1. Attention Mask in XLNet
The principle of the attention mask mechanism is to cover the part to be predicted inside the transformer to ensure that it does not play any role in the prediction process. For example, the original language sequence arrangement is
and the sampling sequence order is
. The first line of the mask is used to predict
, the second line of the mask is used to predict
, and so on. The white dot means that the word in this position is masked, while the black dot means that the information of the word in this position can be contacted. As shown in
Figure 3, when the semantic information of
is predicted, the context of
and
can be used; thus, the positions of
and
in the third line of the mask are shaded. Because the sequence order is
and
is first in the sequence, there is no reference information available for
and the second line is fully masked. Following this theory, the mask matrix of the sequence
is shown in
Figure 3. Black circle indicates the available data, and white circle means the data is masked.
The attention mask approach is used in PLM to realize random sorting and predict word vectors in different sequence orders. On the one hand, PLM solves the shortcoming of AR language models with respect to contacting the contextual semantics; on the other hand, PLM uses a mask matrix to replace the [mask] tag in the BERT model while maintaining the dependency between multiple predictors. For example, for a given sequence (, , , , , , ), for XLNet, to predict and the random sampling sequence can be selected as . Then, the probability of and is . When the model predicts the semantics of the word , the information of does not affect the prediction of . When the semantic information of is predicted, however, the model can use the semantic information of , thereby solving the problem that in other models all of the semantic information is independent and cannot be connected. This makes PLM an important theoretical foundation for the excellent performance of XLNet.
2.2.2. Two-Stream Self-Attention Mechanism
While PLM can allow XLNet to relate to the context semantics, the original AR language model does not consider the location information of the words used in prediction. For example, given a sequence , one of the permutations is . When the predicted statement is , its probability is . The second arrangement order is . When the predicted word is , its probability is . At this time, the semantic equivalent probability of the two is predicted; in fact, however, the semantic content of and is largely different. The main reason for this problem is that AR language models predict words based on the content before the predicted word, and as such do not need to consider the position information of the words in the word order. On the other hand, the random sorting language mechanism requires the word order to be rearranged completely. After the position information of the words is disrupted, the model cannot determine the position information of the predicted words in the original sequence. Therefore, we proposed solving this problem using the two-stream self-attention mechanism.
The two-stream self-attention mechanism can solve the problem of the position of the target prediction word being ambiguous due to the random disordering of the word order by the random sorting language model. Two-stream attention consists of the content stream and query stream. The objective function of the traditional AR language model for a sequence with length
T is shown in Equation (
2):
In the equation,
z is the sequence obtained by full array random sampling from a sequence
x with length
T,
represents the sequence number of the position of
t in the sampling sequence,
x is the word to be predicted, and
is the embedding of
x. The content hidden state
encodes the content of
x and additionally encodes the above information, while not containing any location information, while
demonstrates that for the prediction of words in position
t in the sorting sequence, the probability is calculated from the words corresponding to the sequence number before the position of
t. Because PLM disrupts the sequence order, it is necessary to “explicitly” add the location information of the word to be predicted into the original sequence, meaning that Equation (
2) is updated as Equation (
3):
In the equation,
z represents the query implicit state, including the words before
t position and the position information of the word
x to be predicted; it only encodes the context and location information of the prediction word
x, and does not encode the content information of
x. The updating processes of the content hidden state
and query hidden state
are shown in Equations (
4) and (
5), respectively, where
m represents the number of layers in the network layer. Usually, the query hidden state
is initialized as a variable
w in layer 0 and the content hidden state
is initialized as the embedding of the word, that is,
. The first layer of data is calculated according to layer 0 and then calculated layer by layer, with
Q,
K, and
V being the results of linear transformation of the input data according to different weights.
The purpose of the two-stream self-attention mechanism is to obtain the location information of
without obtaining the content information when predicting a word
. For words other than
, the location information and content information should be provided. For example, if the given sequence is
and the sampling sequence is assumed to be
, the probability of the word with sequence number 1 can be predicted and then its probability can be calculated according to
,
, and
. The working principle used for calculating the probability of
using the content stream and query stream is shown in
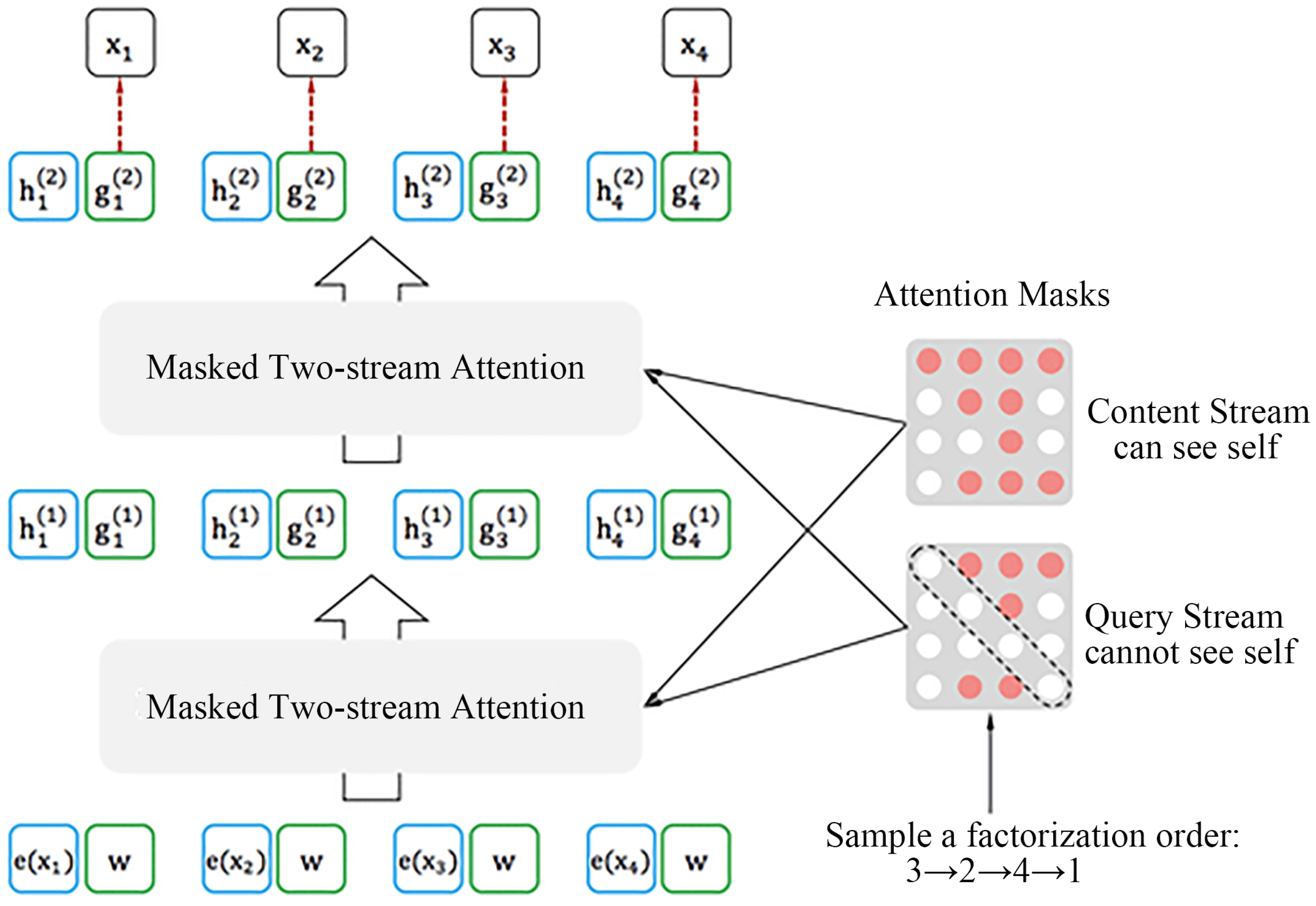
Figure 4.
As shown in
Figure 4a, the content stream encodes both the context information, and the self-information of the predicted word. As shown in
Figure 4b, the query stream encodes the location information of the predicted word and other content information with the exception of the self-information of the predicted word.
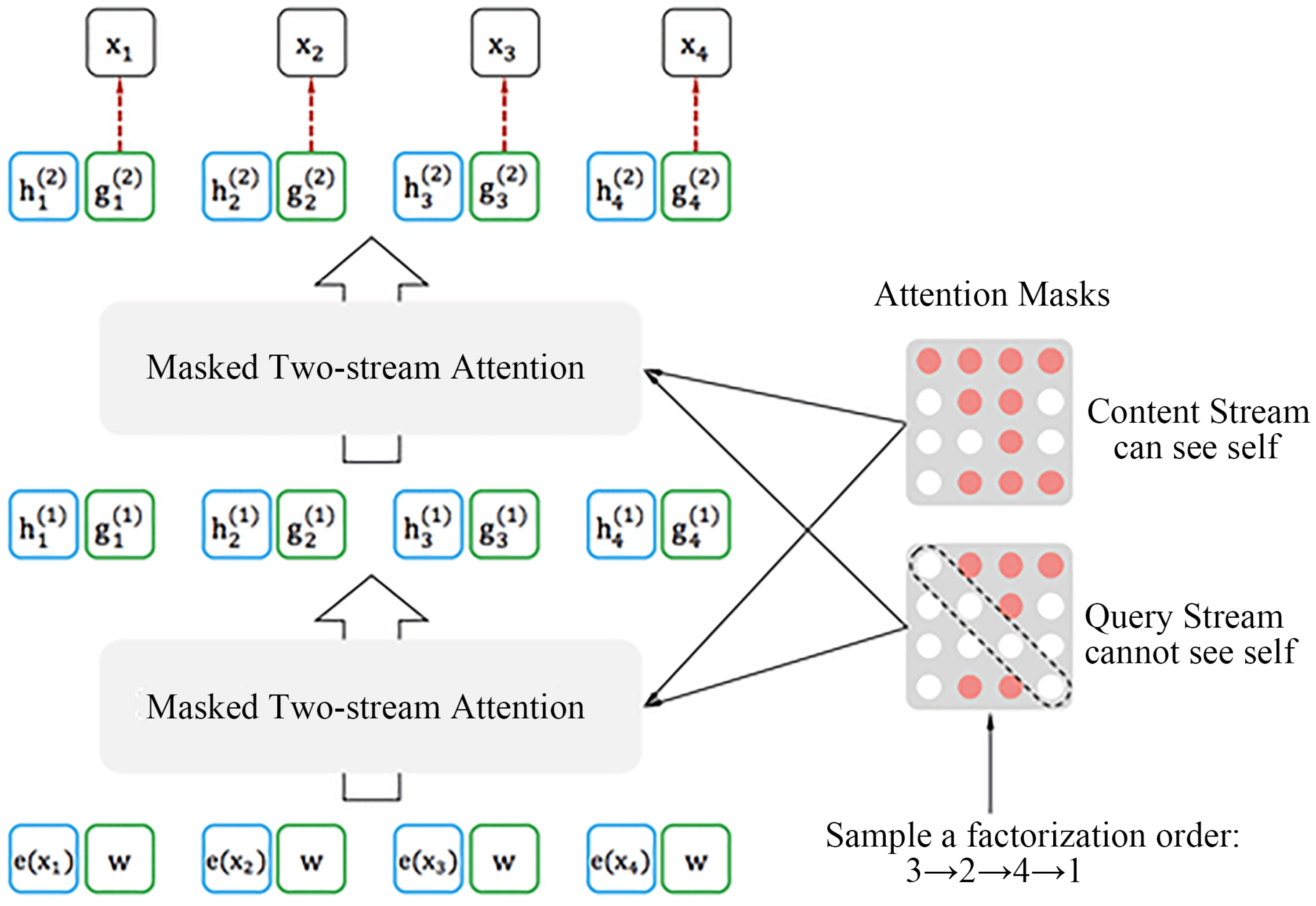
Figure 5 shows the principle of two-stream self-attention when the sampling order of the sequence
is
. From the bottom to the top of
Figure 5, starting from layer 0, the content stream
h and query stream
g are initialized by
and
w, respectively. The first layer output
and
are respectively calculated through the content mask and query mask, then the second layer output is calculated in the same way. It can be observed from the mask matrix on the right that calculating the content stream is a standard transformer calculation process. When predicting the semantics of
, the semantic information of all words can be used, and when predicting the semantics of the word
, the semantic information of
,
, and
can been used. In the content stream, the semantic information of the word itself can participate in predicting itself. When calculating the query stream, the attention mask functions somewhat differently. When predicting the semantic content of word
, its own content is masked, and the word is predicted only through the semantic content of
,
, and
. Similarly, when predicting
, only use the semantic information of
can be used. According to the above explanation, it can be deduced that in the query stream the information of the predicted word itself is not used for its own prediction. The difference between the content stream and query stream is whether the self-semantic information of the predicate itself.
2.3. Bi-Directional Gated Recurrent Unit
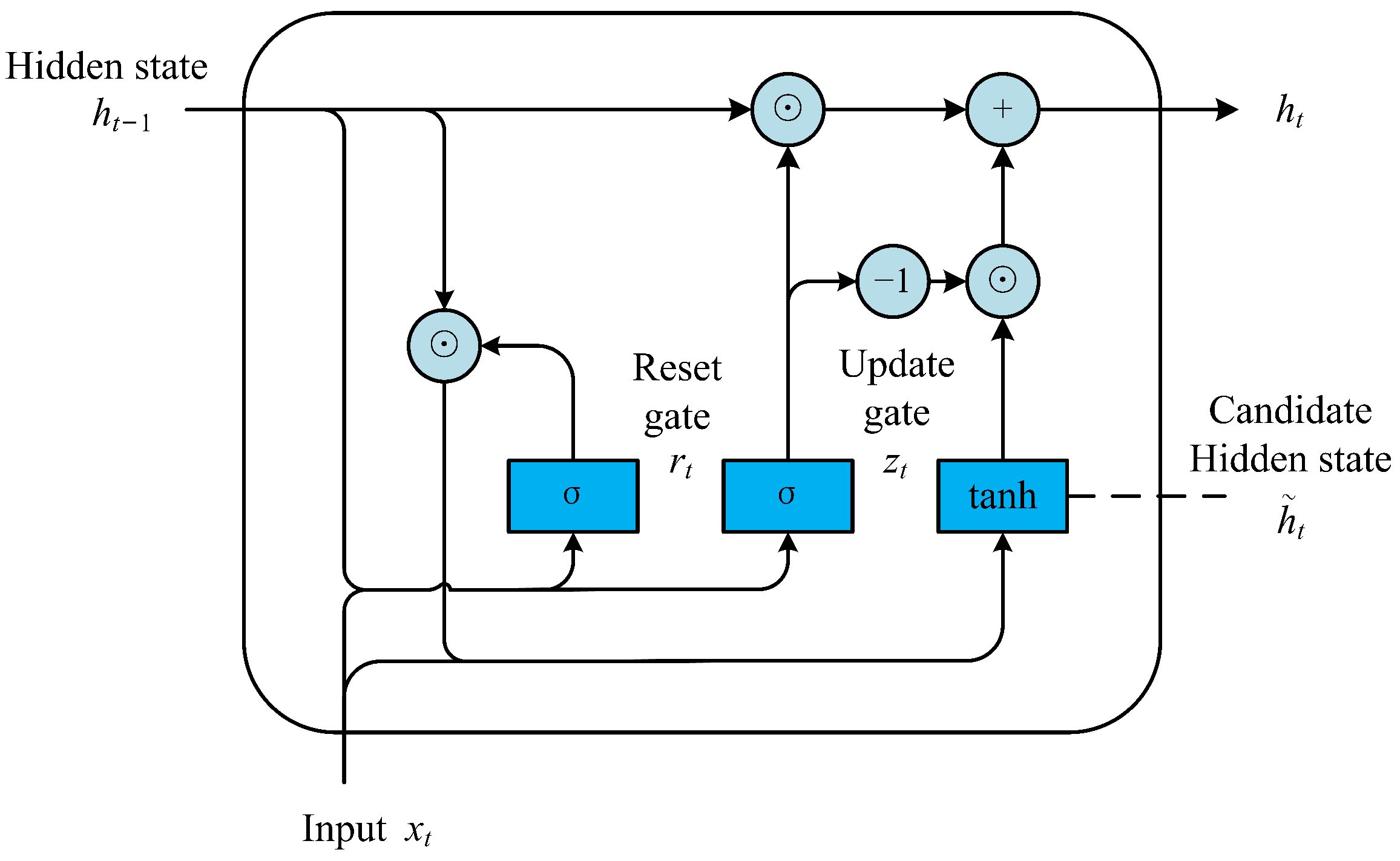
A gated recurrent unit (GRU) is a type of lightweight recurrent neural network that differs from other neural networks due to its internal gate structure. This unique structure enables the network to determine which data are relevant and which data can be discarded based on their relationship. This structure facilitates effective data transmission within the network while effectively controlling redundant information. As a result, the GRU partially addresses the issue of long-term dependence in neural networks. As shown in
Figure 6, the structure of the GRU consists of three main components: the reset gate (
), update gate (
), and hidden state (
); these work together to extract temporal information and obtain long-term dependencies. In addition,
is the hidden state of the prior time point and
is the candidate hidden state. The individual functions of these gates and hidden states are described in further detail below, while the structure of the GRU is displayed in
Figure 6.
The input for the reset and update gates is obtained through the fully connected layer that operates on the current input
and the hidden state of the previous time point
. The reset gate
is calculated by Equation (
6), and
is a Sigmoid function which is used as an activation function. Thus, the result of the reset gate is a vector with a value between 0 and 1 which is similar to the gate in circuit. This value is then used to determine the relevancy of the hidden state of the previous time point. The candidate hidden state
is determined by the input
, reset gate
, and prior hidden state
, as shown in Equation (
7); the prior hidden state contains the information of both the current time and previous time, and is an important component of the current hidden state, although it is not the real current hidden state.
In the above equation,
t is the current time point,
is the last time point,
is the input vector of the current time,
is the hidden state of the previous time point,
and
make up the weight matrix of the reset gate, and
is the bias of the reset gate.
Here, and make up the weight matrix of the candidate hidden state and is the bias of the candidate hidden state.
The update gate
is calculated using Equation (
8) and
is a Sigmoid function which is used as an activation function. Thus, the result of the reset gate is a vector with a value between 0 and 1, which is then used to determine the element of the previous hidden state that should be updated by the current candidate hidden state. For this reason, it is called the update gate.
In this equation, is the current input vector, is the hidden state of the previous time point, and make up the weight matrix of the update gate, and is the bias of the update gate.
The hidden state is the output of the GRU calculated using the candidate hidden state and the previous hidden state in Equation (
9):
Here, is the update gate, is the previous hidden state, is the current candidate hidden state, and is the current hidden state, which is the ouput of the GRU.
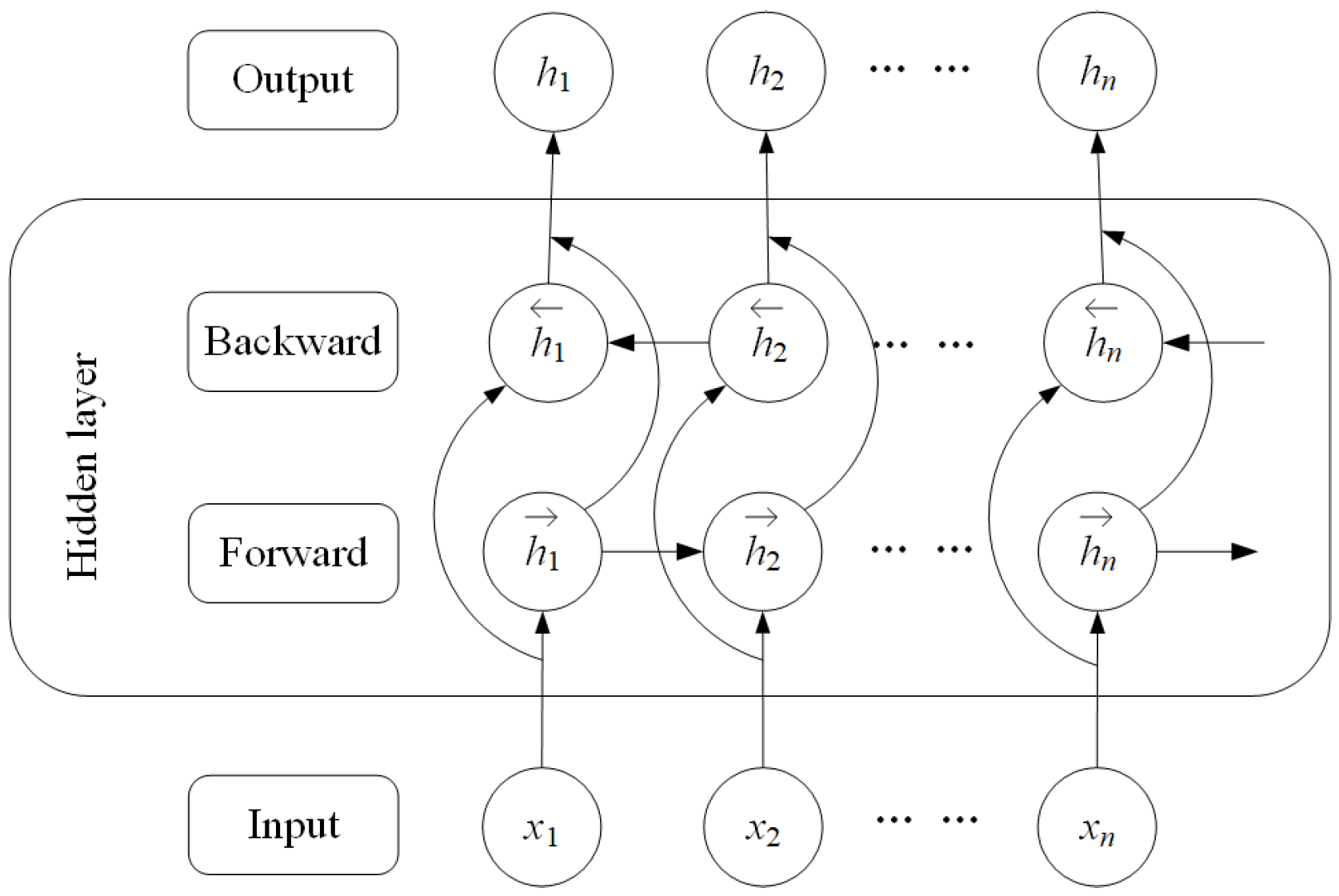
For the GRU, the output is only affected by the current input and the previous hidden state, and is not related to the subsequent state, making the GRU a unidirectional model. However, in order to extract effective features it is necessary to pay attention to the current information, the previous information, and the the subsequent information. It can be easily understood that combining these contexts makes it easier to understand textual information. Based on this idea, BiGRU is proposed to combine forward GRU and backward GRU, making the output result the combination of the two GRUs by weight matrix. The structure of BiGRU is presented in
Figure 7; it is composed of an input layer, forward GRU, backward GRU, and output layer. In the figure,
is the hidden state of the forward GRU,
is the hidden state of the backward GRU,
represents the input vectors of BiGRU,
is the ouput hidden state of BiGRU, and
, where
k is the batch size and
d is the length of the input vectors. The forward hidden state
and the backward hidden state
are calculated using Equations (
10) and (
11).
In the above equations, means the calculation process of the unidirectional GRU, is the input vector, is the hidden state of the forward GRU, and is the hidden state of the backward GRU.
The final output hidden state of the BiGRU combines the outputs of the forward and backward GRUs using a weight matrix calculated by Equation (
12):
In the equation, and make up the weight matrix of the output layer and is the bias of the output layer.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}