



Crowd Counting by Multi-Scale Dilated Convolution Networks

Abstract

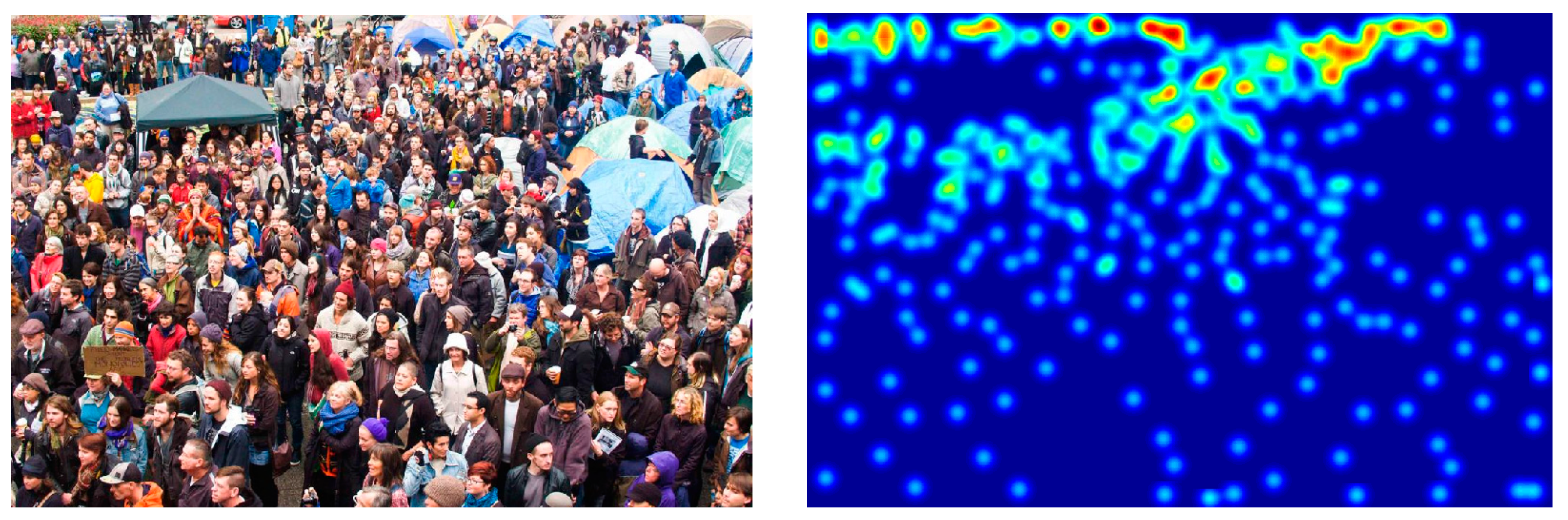
1. Introduction
- We propose a multi-scale dilated convolution network (MSDCNet) to estimate the density map of an input crowd image. A multi-scale feature extraction network is designed as the core component of MSDCNet.
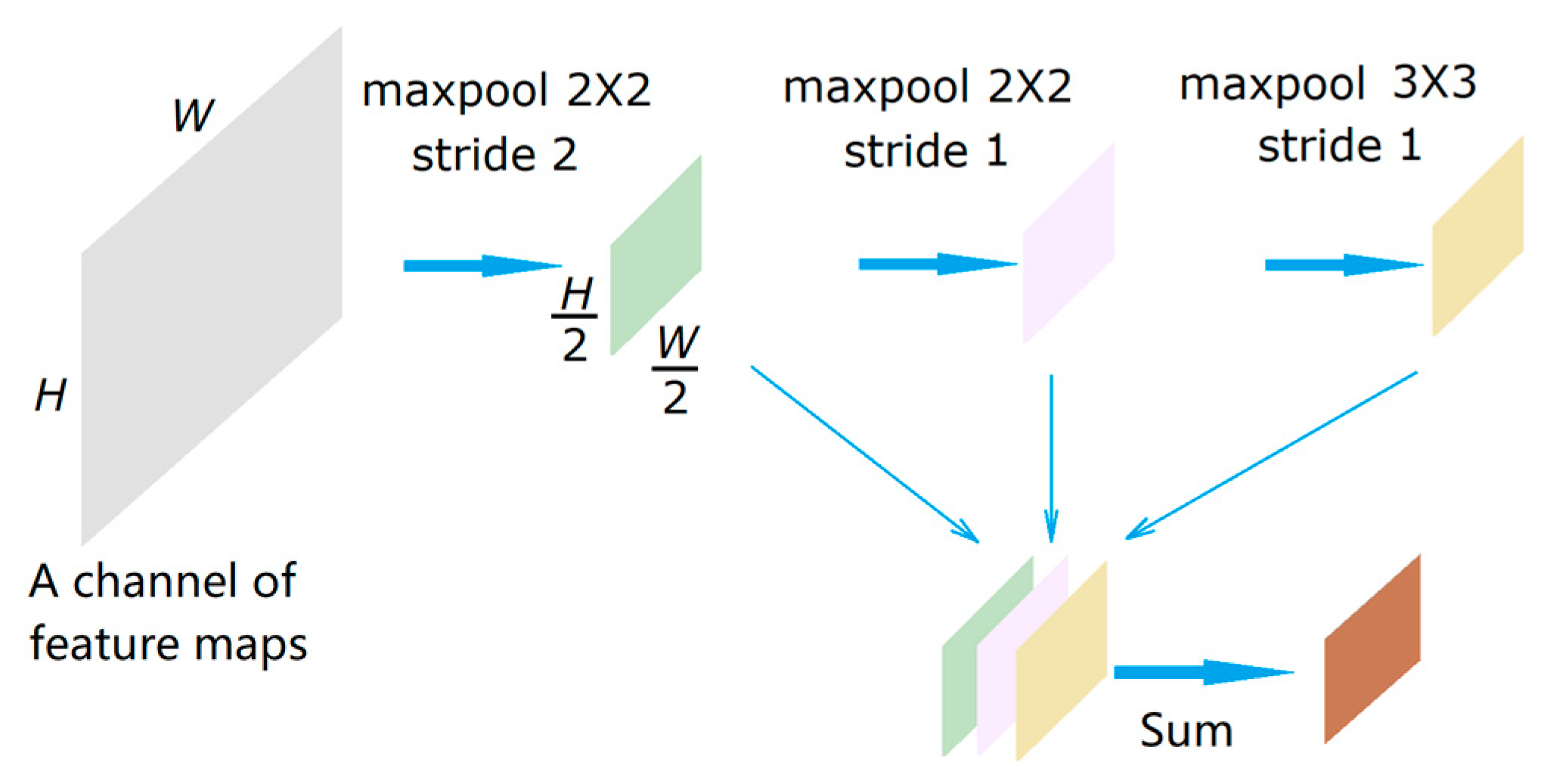
- In the front-end network of MSDCNet, we propose SPP modules to replace max- pooling layers of VGG16 that can extract features with scale invariance. In the back-end network of MSDCNet, we use the dilated convolution layers to replace the traditional alternate convolution and pooling to expand the receptive field, extract high-level semantic information and avoid the loss of spatial information at the same time.
- The effectiveness of our approach is validated on three public datasets, Shanghai_Tech, UCF_CC_50, and UCF_QNRF. Compared with other representative crowd counting models, our model has a better counting performance.
2. Related Work
2.1. Density Map
2.2. Generating Density Map Based on Gaussian Kernel
2.3. Crowd Counting Models
3. Proposed Approach
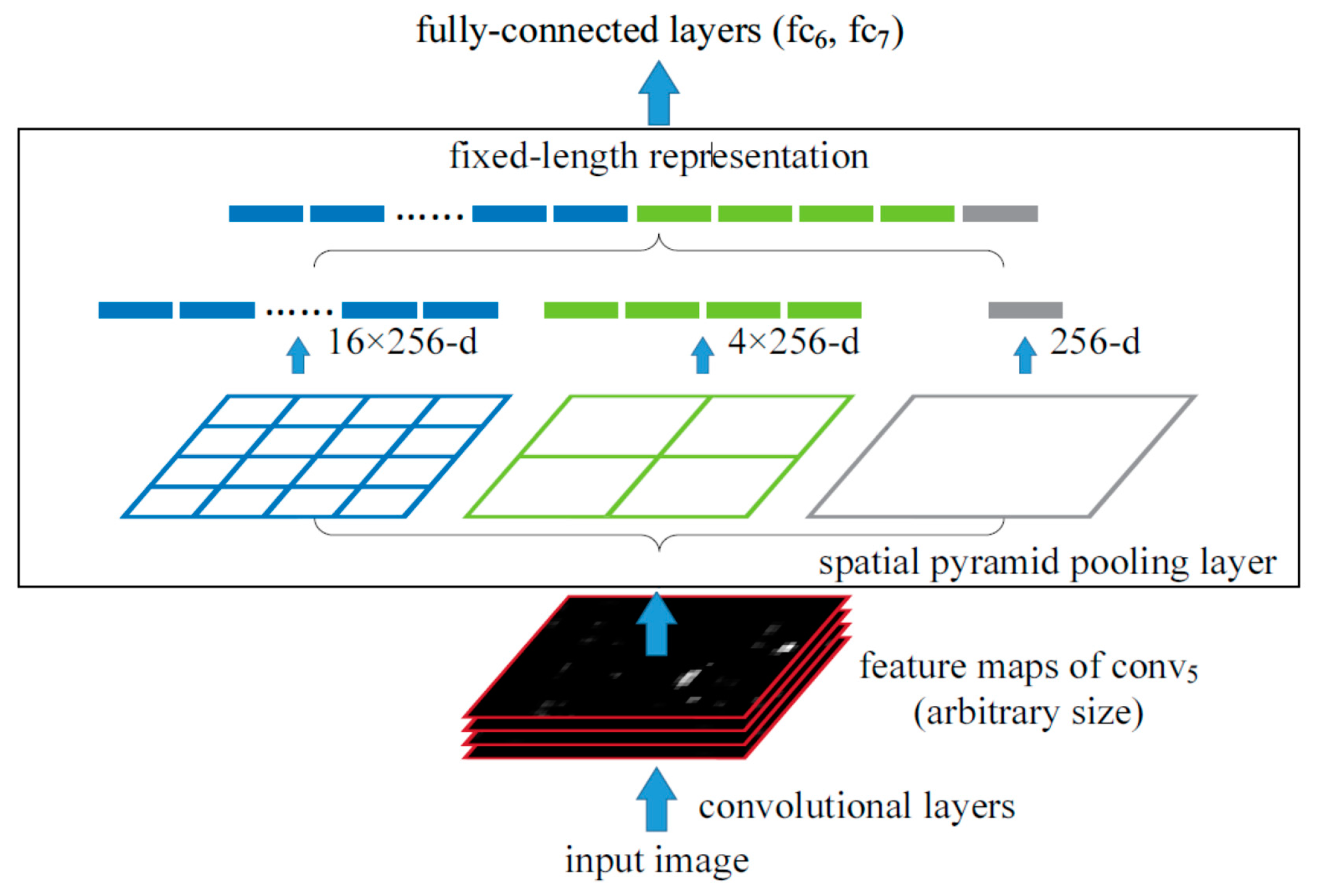
3.1. Front-end Network
3.1.1. SPP Module
3.1.2. Architecture of Front-End Network
3.2. Multi-Scale Feature Extraction Network (MFENet)
3.3. Back-End Network
3.4. Discussion on Number of Parameters
4. Experimental Results and Discussions
4.1. Datasets and Data Augmentation
4.2. Evaluation Metrics
4.3. Network Training
- Training the back-end network. The dimensions of MFENet’s input and output are same (H/8 × W/8 × 512), so we can remove it first and connect the back end to the front end directly. The front-end network adopts VGG16’s pretrained model on ImageNet. We then freeze the front end and set the back end to trainable. We then obtain a preliminary back end.
- Fine-tuning the front-end network. We freeze the back end, and train the front end from the pretrained weights of VGG16.
- Training MFENet column to column. We put MFENet back into our model. At first, we froze the front end, back end, and column 2, 3, and 4 of MFENet, and only set column1 to trainable. After column1 was trained, we trained column 2 starting at part of the weights coming from column1. After four columns had been trained one by one, we trained them together.
- Fine-tuning the model in order from back end to front end and then to MFENet.
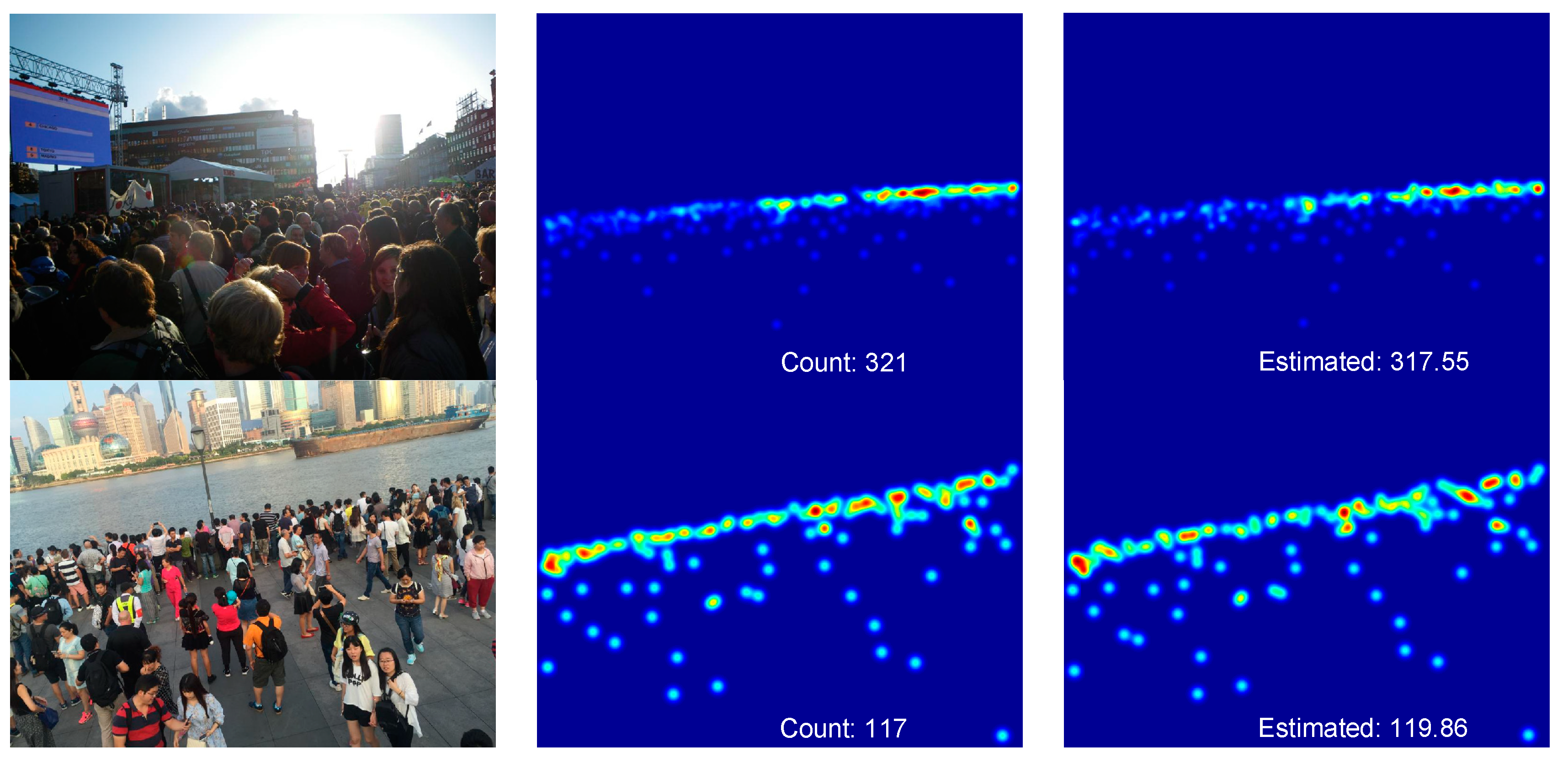
4.4. Experimental Results on the ShanghaiTech Dataset
4.5. Experimental Results on the UCF_CC_50 Dataset
4.6. Experimental Results on the UCF-QNRF Dataset
4.7. Ablation Experiments
- From the counting errors of the two experimental models and MSDCNet, it can be seen that after removing MFENet and the SPP, the counting accuracy of MSDCNet significantly decreased. Without MFENet, the MAE of model-A increased by 84.2 (about 45% of model-A’s MAE), and the MSE increased by 97.2 (about 36% of model-A’s MSE). Without the SPP module, the MAE of model-B increased by 61.9 (about 38% of the MAE of model-B), and the MSE increased by 67.8 (about 28% of the MSE of model-B). Without dilated conv layers, the MAE of model-C increased by 15.7 (about 13% of the MAE of model-C), and the MSE increased by 14.6 (about 8% of the MSE of model-C). These fully demonstrate the effectiveness of MFENet, the SPP modules and the dilated conv layers in our model.
- From the counting errors of the three experimental models, it can be seen that the counting error of model-A is higher than that of model-B and model-C, indicating that MFENet makes a greater contribution to the counting accuracy of the entire network than the SPP modules and dilated conv layers.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, J.; Liu, J.; Wang, Z. Convolutional Neural Network for Crowd Counting on Metro Platforms. Symmetry 2021, 13, 703. [Google Scholar] [CrossRef]
- de Silva, E.M.K.; Kumarasinghe, P.; Indrajith, K.K.D.A.K.; Pushpakumara, T.V.; Vimukthi, R.D.Y.; de Zoysa, K.; Gunawardana, K.; de Silva, S. Feasibility of using convolutional neural networks for individual-identification of wild Asian elephants. Mamm. Biol. 2022, 102, 931–941. [Google Scholar] [CrossRef]
- Lu, W.G.; Tan, Z. Research on Crowded Trampling Accident Prevention and Disposal in Urban Public Places: The Case of Itaewon Trampling Accident in Korea. China Emerg. Rescue 2023, 1, 4–10. [Google Scholar]
- Gao, G.; Gao, J.; Liu, Q.; Wang, Q.; Wang, Y. CNN-based Density Estimation and Crowd Counting: A Survey. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Zhao, R.; Dong, D.; Wang, Y.; Li, C.; Ma, Y.; Enriquez, V.F. Image-Based Crowd Stability Analysis Using Improved Multi-Column Convolutional Neural Network. IEEE Trans. Intell. Transp. Syst. 2021, 23, 5480–5489. [Google Scholar] [CrossRef]
- Chan, A.B.; Liang, Z.S.; Vasconcelos, N. Privacy preserving crowd monitoring: Counting people without people models or tracking. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Anchorage, AK, USA, 23–28 June 2008. [Google Scholar]
- Chan, A.B.; Vasconcelos, N. Bayesian Poisson regression for crowd counting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 6 May 2010. [Google Scholar]
- Wan, H.L.; Wang, X.M.; Peng, Z.W.; Bai, Z.; Yang, X.; Sun, J. A dense crowd counting algorithm based on a novel multi-scale attention mechanism. J. Electron. Imaging 2022, 44, 1129–1136. [Google Scholar]
- Jiang, N.; Zhou, O.; Yu, F.H. A review of computer vision-based target counting methods. Laser Optoelectron. Prog. 2021, 58, 43–59. [Google Scholar]
- Meng, Y.B.; Chen, X.R.; Liu, G.H.; Xu, S.J. Crowd density estimation method based on multi-feature information fusion. Laser Optoelectron. Prog. 2021, 58, 276–287. [Google Scholar]
- Wang, Y.; Zhang, W.; Huang, D.; Liu, Y.; Zhu, J. Multi-scale features fused network with multi-level supervised path for crowd counting. Expert Syst. Appl. 2022, 59, 200–212. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–8 December 2012. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Zhang, Y.; Zhou, D.; Chen, S.; Gao, S.; Ma, Y. Single-image crowd counting via multi-column convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June-1 July 2016. [Google Scholar]
- Li, Y.; Zhang, X.; Chen, D. CSRNet: Dilated Convolutional Neural Networks for Understanding the Highly Congested Scenes. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1091–1100. [Google Scholar]
- Jiang, X.L.; Xiao, Z.H.; Zhang, B.C.; Zhen, X.; Cao, X.; Doermann, D.; Shao, L. Crowd counting and density estimation by trellis encoder-decoder networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Yang, Y.; Li, G.; Wu, Z.; Su, L.; Huang, Q.; Sebe, N. Reverse Perspective Network for Perspective-Aware Object Counting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Zhou, J.T.; Zhang, L.; Du, J.; Peng, X.; Fang, Z.; Xiao, Z.; Zhu, H. Locality-Aware Crowd Counting. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 3602–3613. [Google Scholar] [CrossRef] [PubMed]
- Song, Q.; Wang, C.; Jiang, Z.; Wang, Y.; Tai, Y.; Wang, C.; Li, J.; Huang, F.; Wu, Y. Rethinking Counting and Localization in Crowds: A Purely Point-Based Framework. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Wan, J.; Liu, Z.; Chan, A.B. A Generalized Loss Function for Crowd Counting and Localization. In Proceedings of the Computer Vision and Pattern Recognition, Online; 2021. [Google Scholar]
- Lin, H.; Ma, Z.H.; Ji, R.R. Boosting Crowd Counting via Multifaceted Attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- 24. Fisher, Y.; Koltun, V. Muti-scale context aggregation by dilated convolutions. In Proceedings of the International Conference on Learning Representations (ICLR), San Juan, Puerto Rico, 2–5 May 2016. [Google Scholar]
- Liu, W.; Salzmann, M.; Fua, P. Context-aware crowd counting. In Proceedings of the IEEE Conference Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Sam, D.B.; Surya, S.; Babu, R.V. Switching convolutional neural network for crowd counting. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zeng, L.; Xu, X.; Cai, B.; Qiu, S.; Zhang, T. Multi-scale convolutional neural networks for crowd counting. In Proceedings of the IEEE International Conference on Image Proceeding (ICIP), Beijing, China, 17–20 September 2017. [Google Scholar]
- Sindagi, V.A.; Patel, V.M. Generating high-quality crowd density maps using contextual pyramid CNNs. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Cao, X.; Wang, Z.; Zhao, Y.; Su, F. Scale Aggregation Network for Accurate and Efficient Crowd Counting. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Oh, M.H.; Olsen, P.; Ramamurthy, K.N. Crowd Counting with Decomposed Uncertainty. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Liu, C.; Weng, X.; Mu, Y. Recurrent Attentive Zooming for Joint Crowd Counting and Precise Localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layers | Kernel | Stride |
|---|---|---|
| Conv1 | conv3-64 | 1 |
| Conv2 | conv3-64 | 1 |
| SPP modules | maxpool 2 × 2 | 2 |
| maxpool 2 × 2 | 1 | |
| maxpool 3 × 3 | 1 | |
| Conv3 | conv3-128 | 1 |
| Conv4 | conv3-128 | 1 |
| SPP modules | maxpool 2 × 2 | 2 |
| maxpool 2 × 2 | 1 | |
| maxpool 3 × 3 | 1 | |
| Conv5 | conv3-256 | 1 |
| Conv6 | conv3-256 | 1 |
| Conv7 | conv3-256 | 1 |
| SPP modules | maxpool 2 × 2 | 2 |
| maxpool 2 × 2 | 1 | |
| maxpool 3 × 3 | 1 | |
| Conv8 | conv3-512 | 1 |
| Conv9 | conv3-512 | 1 |
| Conv10 | conv3-512 | 1 |
| Layers | Kernel |
|---|---|
| Column1 | conv1-128 |
| Column2 | conv1-128 |
| conv3-128 | |
| Column3 | conv1-128 |
| conv3-128 | |
| conv3-128 | |
| Column4 | conv1-128 |
| conv3-128 | |
| conv3-128 | |
| conv3-128 |
| Layers | Kernel | Dilation Rate |
|---|---|---|
| Dilated conv1 | Dilated conv3-256 | 1 |
| Dilated conv2 | Dilated conv3-128 | 2 |
| Dilated conv3 | Dilated conv3-64 | 2 |
| Dilated conv4 | Dilated conv3-32 | 2 |
| Conv | conv1-1 | - |
| Component | Parameters (M) | ||
|---|---|---|---|
| Front-end network | 7.633 | ||
| MFENet | Column1 | 65,536 | 0.360 |
| Column2 | 81,920 | ||
| Column3 | 98,304 | ||
| Column4 | 114,688 | ||
| Back-end network | 1.567 | ||
| Total | 9.560 | ||
| Dataset | Number of Samples | Average Resolution | Annotations | |||||
|---|---|---|---|---|---|---|---|---|
| Total | Training Set | Test Set | Training Set | Test Set | Total | Ave | Max | |
| ShanghaiTech_Part_A | 482 | 300 | 182 | 872 × 598 | 861 × 574 | 241,677 | 501 | 3139 |
| ShanghaiTech_Part_B | 716 | 400 | 316 | 1024 × 768 | 88,488 | 123 | 578 | |
| UCF_CC_50 | 50 | - | - | 902 × 653 | 63,974 | 1279 | 4633 | |
| UCF-QNRF | 1535 | 1201 | 334 | 2896 × 2006 | 2910 × 2038 | 1,251,642 | 815 | 12,865 |
| Method | Part_A | Part_B | |||||
|---|---|---|---|---|---|---|---|
| MAE↓ | MSE | Parameters (M) | MACs (G) | MAE | MSE | MACs (G) | |
| MCNN [15] | 110.2 | 173.2 | 0.133 | 13.989 | 26.4 | 41.3 | 21.097 |
| SwitchCNN [26] | 90.4 | 135.0 | 15.108 | 164.182 | 21.6 | 33.4 | 247.610 |
| MSCNN [27] | 83.8 | 127.4 | 3.084 | 288.706 | 17.7 | 30.2 | 435.412 |
| CP-CNN [28] | 73.6 | 106.4 | 17.137 | 254.311 | 20.1 | 30.1 | 383.537 |
| CSRNet [16] | 68.2 | 115.0 | 16.259 | 215.405 | 10.6 | 16.0 | 324.862 |
| SANet [29] | 67.0 | 104.5 | 1.146 | 49.334 | 8.4 | 13.6 | 74.403 |
| TEDNet [17] | 64.2 | 109.1 | 8.863 | 367.193 | 8.2 | 12.8 | 553.780 |
| DUBNet [30] | 64.6 | 106.8 | 18.827 | 52.172 | 7.7 | 12.5 | 78.683 |
| MSDCNet (Ours) | 60.9 | 97.2 | 9.560 | 160.804 | 6.9 | 11.2 | 242.516 |
| Method | MAE↓ | MSE | Parameters (M) | MACs (G) |
|---|---|---|---|---|
| MCNN [15] | 377.6 | 509.1 | 0.133 | 15.801 |
| MSCNN [27] | 363.7 | 468.4 | 3.084 | 326.106 |
| SwitchCNN [26] | 318.1 | 439.2 | 15.108 | 185.450 |
| CP-CNN [28] | 295.8 | 320.9 | 17.137 | 287.254 |
| CSRNet [16] | 266.1 | 397.5 | 16.259 | 243.308 |
| SANet [29] | 258.4 | 334.9 | 1.146 | 55.725 |
| DUBNet [30] | 243.8 | 329.3 | 18.827 | 58.930 |
| MSDCNet (ours) | 206.9 | 271.3 | 9.560 | 181.635 |
| Method | MAE↓ | MSE | Parameters (M) | MACs (G) |
|---|---|---|---|---|
| SwitchCNN [26] | 228 | 445 | 15.108 | 1829.095 |
| RAZ-Net [31] | 116 | 195 | 24.465 | 4848.993 |
| TEDNet [17] | 113 | 188 | 8.863 | 4090.777 |
| DUBNet [30] | 105.6 | 180.5 | 18.827 | 581.231 |
| MSDCNet (ours) | 101.4 | 170.9 | 9.560 | 1791.465 |
| Model | MAE | MSE |
|---|---|---|
| model-A (MSDCNet without MFENet) | 185.6 | 268.1 |
| model-B (MSDCNet without SPP module) | 163.3 | 238.7 |
| model-C (MSDCNet without dilated conv) | 117.1 | 185.5 |
| MSDCNet | 101.4 | 170.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dong, J.; Zhao, Z.; Wang, T. Crowd Counting by Multi-Scale Dilated Convolution Networks. Electronics 2023, 12, 2624. https://doi.org/10.3390/electronics12122624
Dong J, Zhao Z, Wang T. Crowd Counting by Multi-Scale Dilated Convolution Networks. Electronics. 2023; 12(12):2624. https://doi.org/10.3390/electronics12122624
Chicago/Turabian StyleDong, Jingwei, Ziqi Zhao, and Tongxin Wang. 2023. "Crowd Counting by Multi-Scale Dilated Convolution Networks" Electronics 12, no. 12: 2624. https://doi.org/10.3390/electronics12122624
APA StyleDong, J., Zhao, Z., & Wang, T. (2023). Crowd Counting by Multi-Scale Dilated Convolution Networks. Electronics, 12(12), 2624. https://doi.org/10.3390/electronics12122624