
P-Raft: An Efficient and Robust Consensus Mechanism for Consortium Blockchains

 ,
,
Abstract
1. Introduction
- We introduced an enhanced election algorithm that assessed the performance of individual nodes. The election algorithm evaluated the performance of nodes. It could correctly select the node with the best machine performance as the Leader and satisfy the data consistency and availability.
- We proposed a leader verification mechanism based on the BLS signature to prevent the malicious Byzantine node from becoming the Leader during the election by pretending that it had received enough votes.
2. Related Work
3. Materials and Methods
3.1. Raft Algorithm
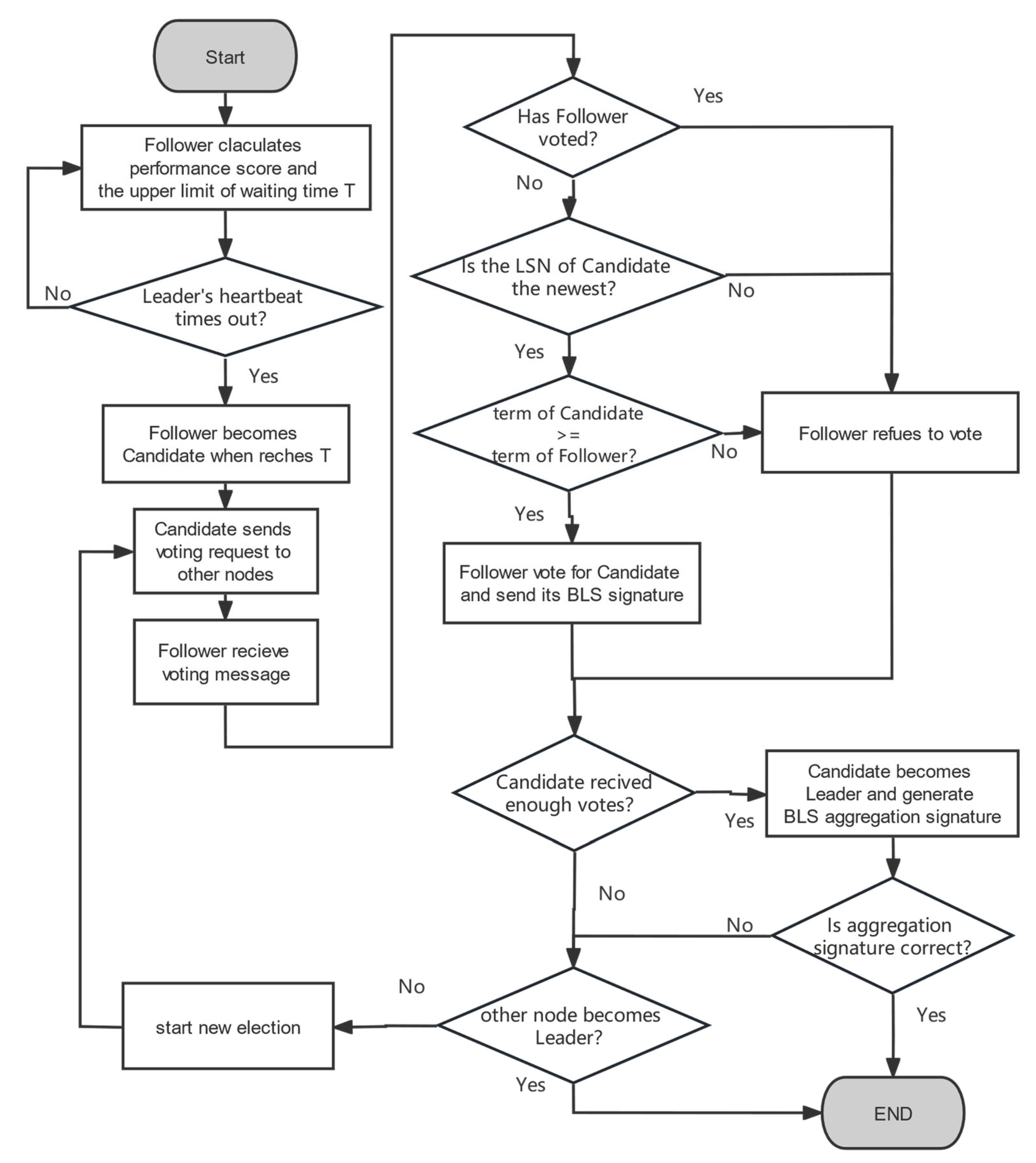
3.2. P-Raft Consensus Mechanism
3.3. Evaluation Model of Node’s Performance: Yasa Model
3.4. Leader Verification Mechanism
4. Results
4.1. Experimental Environment
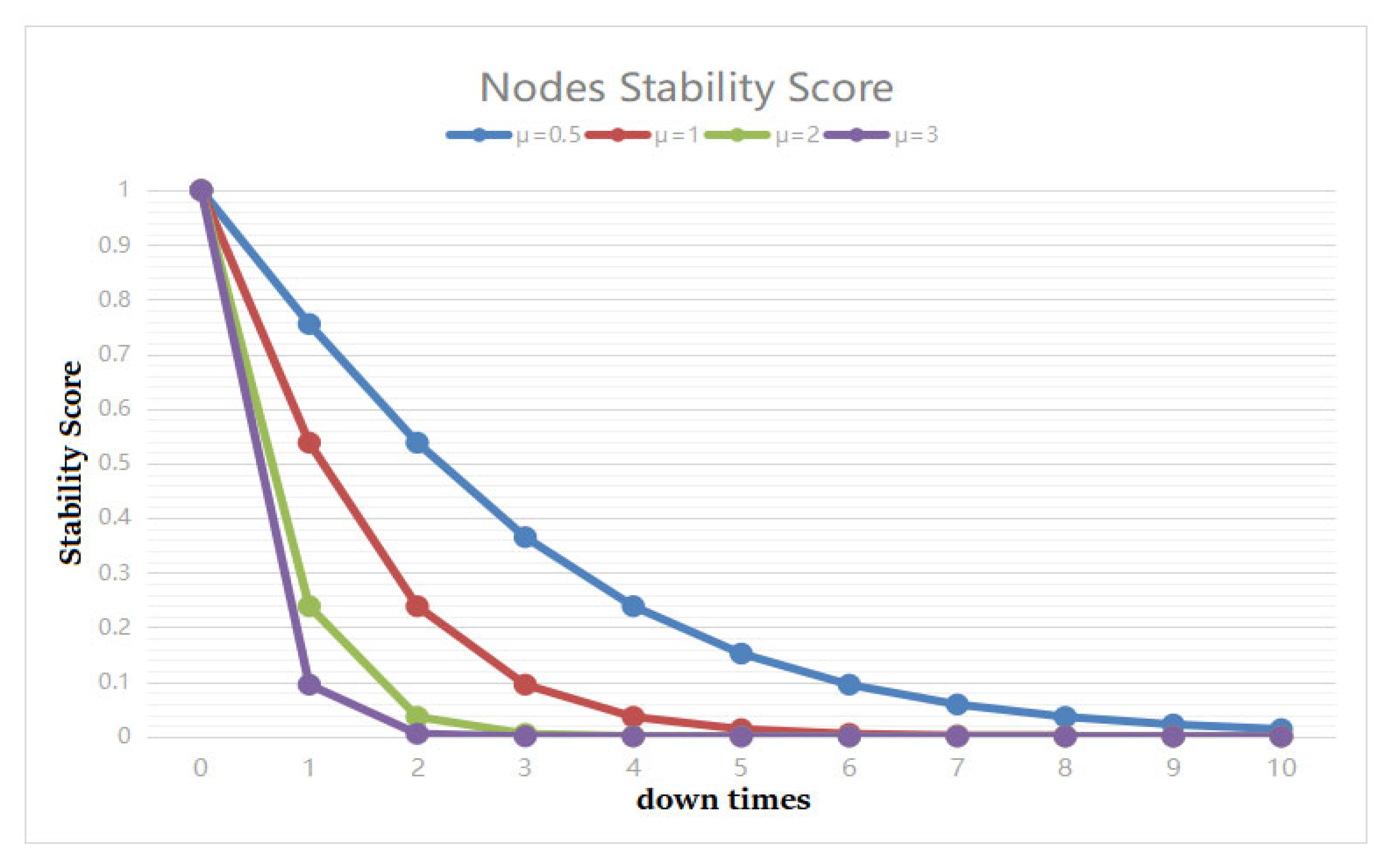
4.2. Changes in Nodes’ Stability Score
4.3. Performance of P-Raft
4.3.1. Election Result
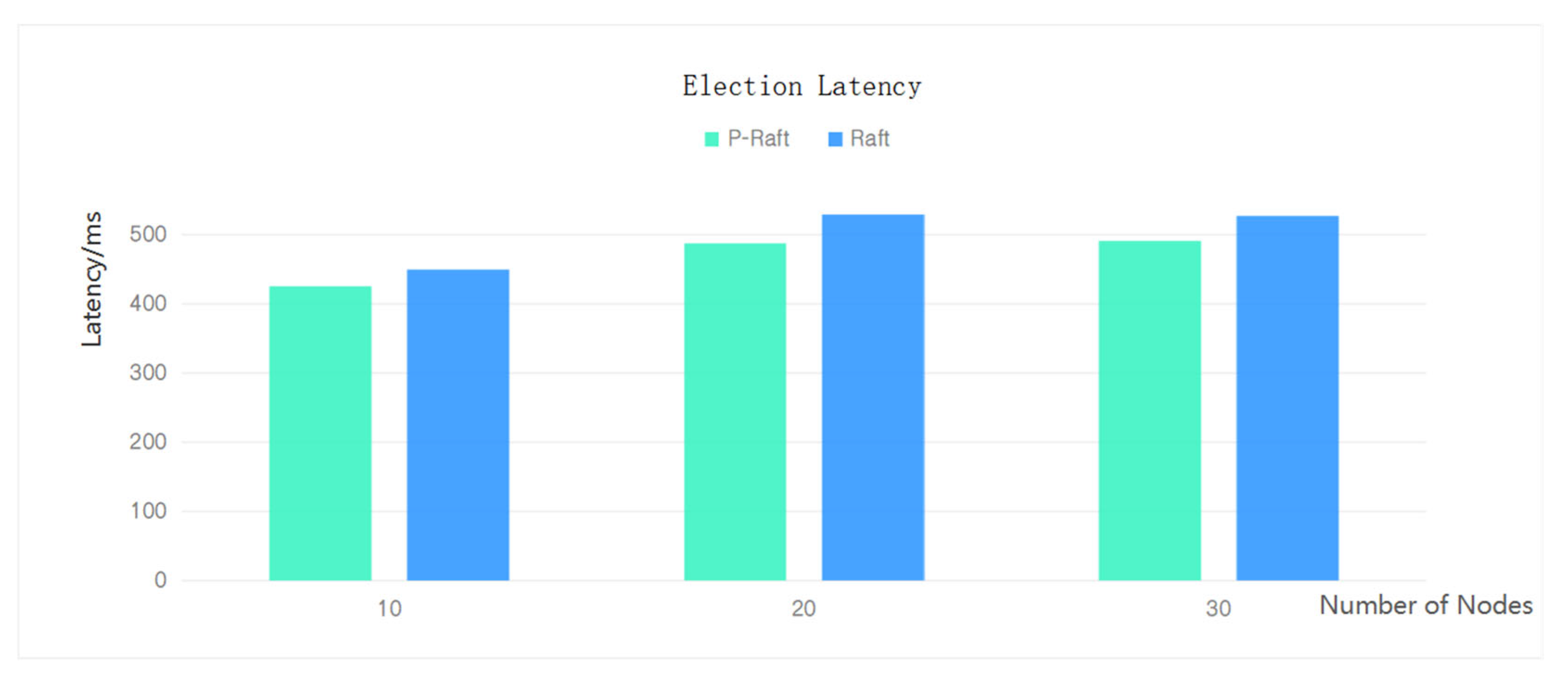
4.3.2. Efficiency of Leader Election
4.3.3. Byzantine Fault-Tolerance
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cui, S.; Lu, Y.; Chang, X. Research on model of blockchain-enabled power carbon emission trade considering credit scoring mechanism. Electr. Power Constr. 2019, 40, 104–111. [Google Scholar]
- Lamport, L.; Shostak, R.; Pease, M. The Byzantine generals problem. ACM Trans. Program. Lang. Syst. 1982, 4, 382–401. [Google Scholar] [CrossRef]
- Zheng, Z.; Xie, S.; Dai, H.; Chen, X.; Wang, H. An overview of blockchain technology: Architecture, consensus, and future trends. In Proceedings of the 2017 IEEE International Congress on Big Data (BigData Congress), Honolulu, HI, USA, 25–30 June 2017; pp. 557–564. [Google Scholar]
- Lu, S.; Pei, J.; Zhao, R.; Yu, X.; Zhang, X.; Li, J.; Yang, G. CCIO: A Cross-Chain Interoperability Approach for Consortium Blockchains Based on Oracle. Sensors 2023, 23, 1864. [Google Scholar] [CrossRef] [PubMed]
- Guerrero-Sanchez, A.E.; Rivas-Araiza, E.A.; Gonzalez-Cordoba, J.L.; Toledano-Ayala, M.; Takacs, A. Blockchain Mechanism and Symmetric Encryption in A Wireless Sensor Network. Sensors 2020, 20, 2798. [Google Scholar] [CrossRef] [PubMed]
- Singh, A.; Saha, R.; Conti, M.; Kumar, G. PoSC: Combined Score for Consensus in Internet-of-Things Applications. In Proceedings of the 2022 Fourth International Conference on Blockchain Computing and Applications (BCCA), San Antonio, TX, USA, 5–7 September 2022; pp. 173–180. [Google Scholar]
- Chen, Y.; Liu, P.; Zhang, W. Raft consensus algorithm based on credit model in consortium blockchain. Wuhan Univ. J. Nat. Sci. 2020, 2. [Google Scholar]
- Wang, R.; Zhang, L.; Xu, Q.; Zhou, H. K-Bucket based Raft-like consensus algorithm for permissioned blockchain. In Proceedings of the 2019 IEEE 25th International Conference on Parallel and Distributed Systems (ICPADS), Tianjin, China, 4–6 December 2019; pp. 996–999. [Google Scholar]
- Xu, H.; Zhang, L.; Liu, Y.; Cao, B. Raft based wireless blockchain networks in the presence of malicious jamming. IEEE Wirel. Commun. Lett. 2020, 9, 817–821. [Google Scholar] [CrossRef]
- Wu, Y.S.; Wu, Y.S.; Liu, Y.R.; Shi, T.J. The research of the optimized solutions to Raft consensus algorithm based on a weighted PageRank algorithm. In Proceedings of the 2022 Asia Conference on Algorithms, Computing and Machine Learning, Hangzhou, China, 25–27 March 2022; pp. 784–789. [Google Scholar]
- Tian, S.; Liu, Y.; Zhang, Y.; Zhao, Y. A byzantine fault-tolerant Raft algorithm combined with Schnorr signature. In Proceedings of the 2021 15th International Conference on Ubiquitous Information Management and Communication (IMCOM), Seoul, Republic of Korea, 4–6 January 2021; IEEE: New York, NY, USA, 2021; pp. 1–5. [Google Scholar]
- Jiang, X.; Sun, A.; Sun, Y.; Luo, H.; Guizani, M. A Trust-Based Hierarchical Consensus Mechanism for Consortium Blockchain in Smart Grid. Tsinghua Sci. Technol. 2022, 28, 69–81. [Google Scholar] [CrossRef]
- Saaty, T.L. Decision making with the analytic hierarchy process. Int. J. Serv. Sci. 2008, 1, 83–98. [Google Scholar] [CrossRef]
- Boneh, D.; Lynn, B.; Shacham, H. Short signatures from the Weil pairing. In Proceedings of the 2001 International Conference on the Theory and Application of Cryptology and Information Security, LNCS 2248, Gold Coast, Australia, 9–13 December 2001; Springer: Berlin/Heidelberg, Germany; pp. 514–532. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Q | CPU | GPU | Memory | Net |
|---|---|---|---|---|
| CPU | 1 | 1 | 1 | 3 |
| GPU | 1 | 1 | 1 | 3 |
| Memory | 1 | 1 | 1 | 3 |
| Net | 1 |
| Server Type | A | B | C | D | E |
|---|---|---|---|---|---|
| vCPU | 1 | 2 | 4 | 2 | 2 |
| CPU Clock Speed/Turbo | 2.5 GHz/ 3.2 GHz | -/3.5 GHz | -/3.5 GHz | 2.5 GHz/2.7 GHz | 2.5 GHz/- |
| Memory | 2G | 4G | 8G | 8G | 8G |
| GPU | - | - | - | - | NVIDIAP4 |
| Region | Hangzhou | Guangzhou | Guangzhou | Shanghai | Shenzhen |
| Amount | 7 | 8 | 2 | 12 | 1 |
| Network Bandwidth | 50 Mbps | ||||
| OS | Ubuntu 16.04 | ||||
| HyperLedger Fabric | v2.0.0 | ||||
| Docker | 1.8.2 | ||||
| Algorithms | A1 | A2 | A3 | A4 | A5 | A6 | A7 | B1 | B2 | B3 | B4 | B5 | B6 | B7 | B8 | C1 | C2 | D1 | D2 | D3 | D4 | D5 | D6 | D7 | D8 | D9 | D10 | D11 | D12 | E1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Raft | 41 | 32 | 30 | 1 | 36 | 42 | 33 | 37 | 36 | 36 | 37 | 31 | 31 | 45 | 36 | 47 | 47 | 28 | 32 | 32 | 1 | 27 | 32 | 33 | 32 | 43 | 31 | 31 | 39 | 41 |
| P-Raft | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 591 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 409 |
| Algorithms | A1 | A2 | A3 | A4 | A5 | A6 | A7 | B1 | B2 | B3 | B4 | B5 | B6 | B7 | C1 | C2 | D1 | D2 | D3 | E1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Raft | 55 | 58 | 62 | 47 | 53 | 64 | 56 | 60 | 12 | 51 | 44 | 50 | 43 | 33 | 12 | 61 | 60 | 61 | 54 | 64 |
| P-Raft | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 8 | 699 | 0 | 0 | 0 | 293 |
| Algorithms | A1 | B1 | C1 | C2 | D1 |
|---|---|---|---|---|---|
| Raft | 0 | 0 | 0 | 1000 | 0 |
| P-Raft | 0 | 0 | 1000 | 0 | 0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, S.; Zhang, X.; Zhao, R.; Chen, L.; Li, J.; Yang, G. P-Raft: An Efficient and Robust Consensus Mechanism for Consortium Blockchains. Electronics 2023, 12, 2271. https://doi.org/10.3390/electronics12102271
Lu S, Zhang X, Zhao R, Chen L, Li J, Yang G. P-Raft: An Efficient and Robust Consensus Mechanism for Consortium Blockchains. Electronics. 2023; 12(10):2271. https://doi.org/10.3390/electronics12102271
Chicago/Turabian StyleLu, Shaofei, Xuyang Zhang, Renke Zhao, Lizhi Chen, Junyi Li, and Guanzhong Yang. 2023. "P-Raft: An Efficient and Robust Consensus Mechanism for Consortium Blockchains" Electronics 12, no. 10: 2271. https://doi.org/10.3390/electronics12102271
APA StyleLu, S., Zhang, X., Zhao, R., Chen, L., Li, J., & Yang, G. (2023). P-Raft: An Efficient and Robust Consensus Mechanism for Consortium Blockchains. Electronics, 12(10), 2271. https://doi.org/10.3390/electronics12102271