
Federated Learning for Condition Monitoring of Industrial Processes: A Review on Fault Diagnosis Methods, Challenges, and Prospects

 ,
,  ,
, 
 and
and 
Abstract
1. Introduction
1.1. Motivation
1.2. Methodology
1.3. Related Surveys and Reviews: A General Context
1.3.1. Research in 2019
1.3.2. Research in 2020
1.3.3. Research in 2021
1.3.4. Research in 2022
1.4. Contributions
- Providing a brief background on the main concepts, classification, algorithms, and challenges of FL. This background is limited to the information needed for this review study.
- Analyzing FD methods in the context of the treated problems, FL algorithms, machine-learning algorithms, and datasets.
- On the basis of the obtained results, this review provides challenges facing the evolution of FL in the context of FD.
- This review also gives insight into the future prospects of FD applications in FD.
1.5. Review Outlines
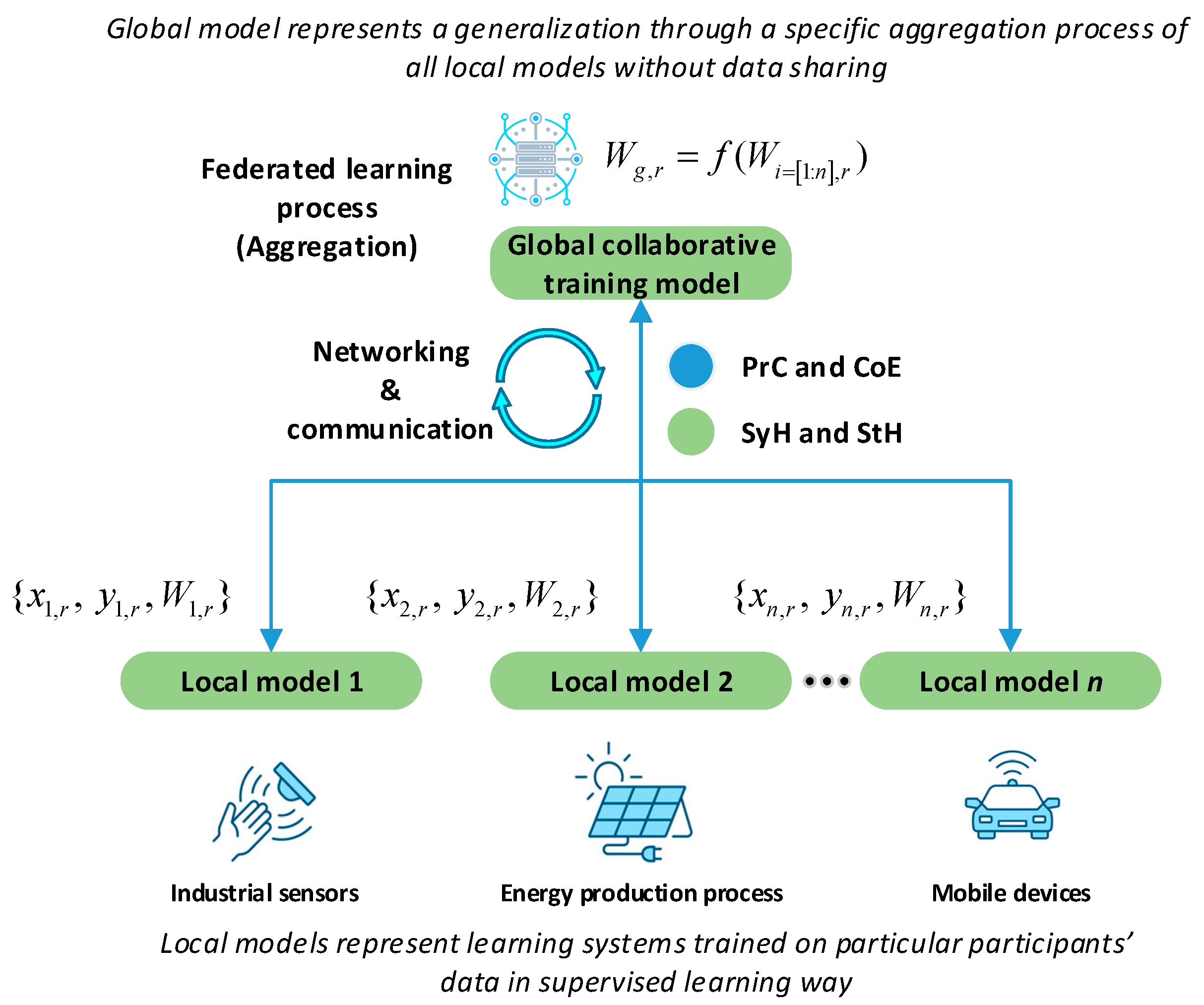
2. Overview of Federated Learning
2.1. Overview
2.2. Classification of FL Algorithms
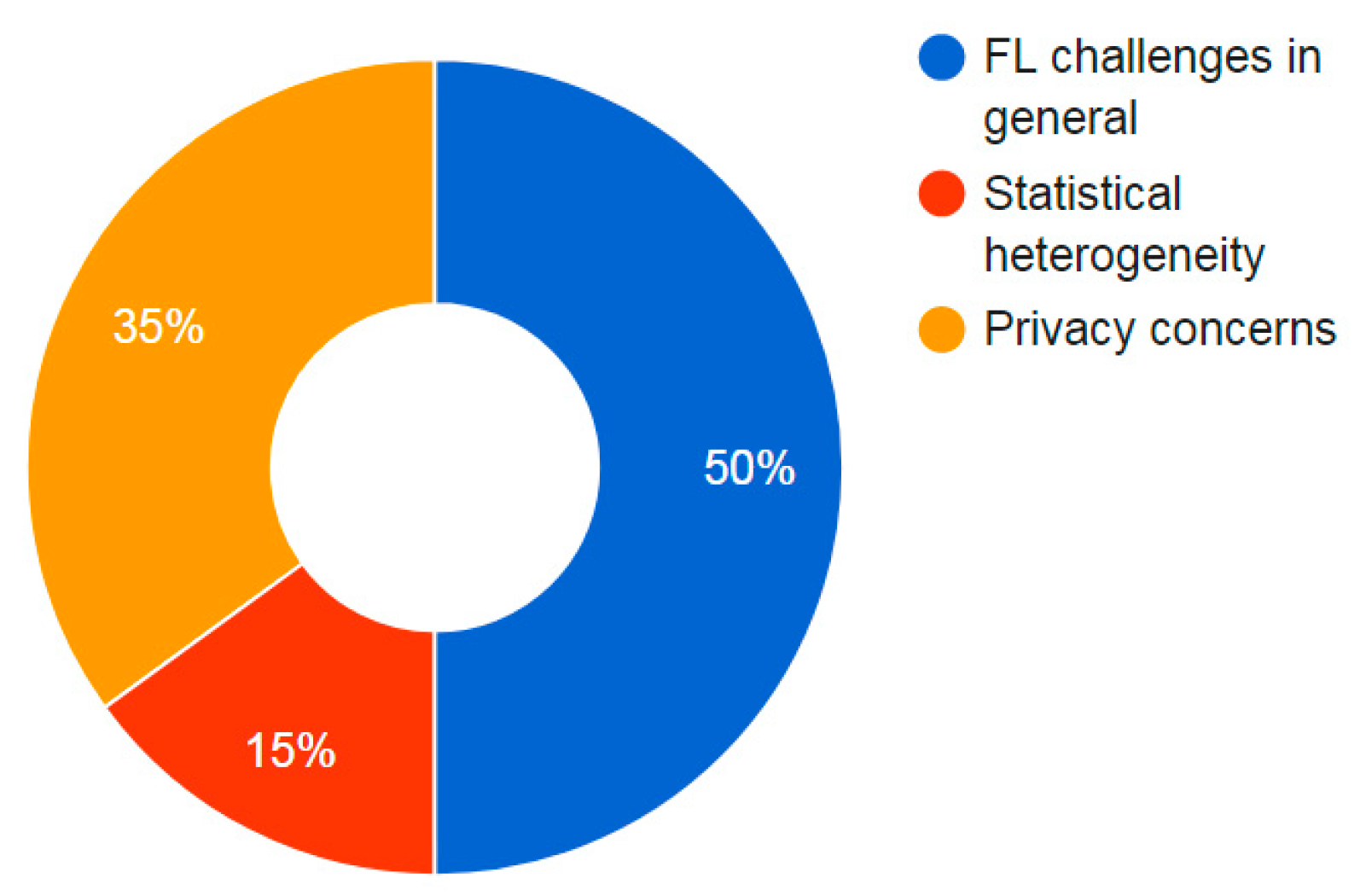
2.3. Challenges
2.4. Enabling Technologies
2.4.1. Algorithms
2.4.2. Software and Platforms
2.4.3. Hardware
3. Works Related to Federated Learning for Fault Diagnosis
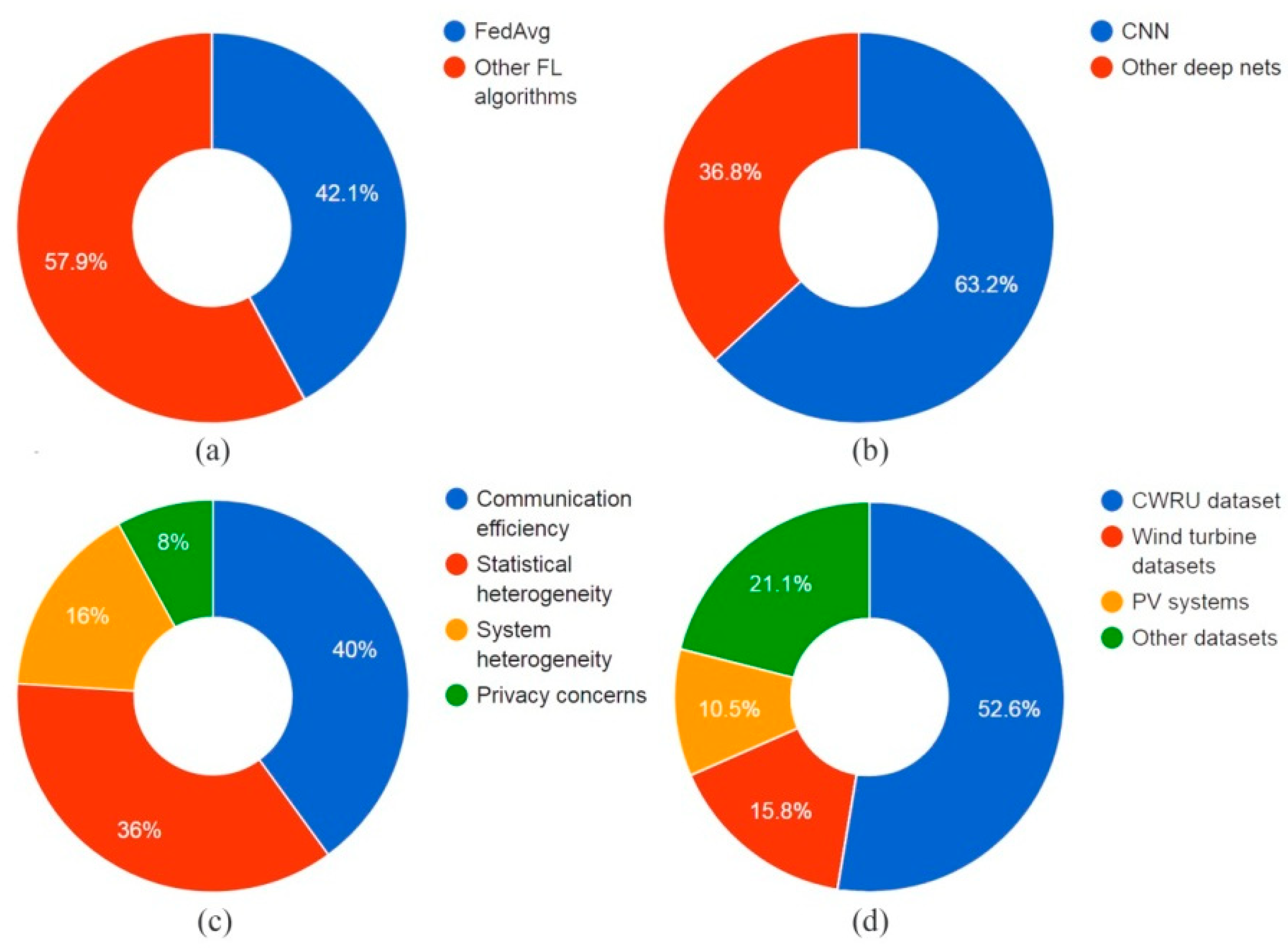
3.1. Analysis
3.1.1. Research in 2020
3.1.2. Research in 2021
3.1.3. Research in 2022
3.2. Discussion
3.3. Challenges
3.4. Future Prospects
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ramu, S.P.; Boopalan, P.; Pham, Q.V.; Maddikunta, P.K.R.; Huynh-The, T.; Alazab, M.; Nguyen, T.T.; Gadekallu, T.R. Federated learning enabled digital twins for smart cities: Concepts, recent advances, and future directions. Sustain. Cities Soc. 2022, 79, 103663. [Google Scholar] [CrossRef]
- Banabilah, S.; Aloqaily, M.; Alsayed, E.; Malik, N.; Jararweh, Y. Federated learning review: Fundamentals, enabling technologies, and future applications. Inf. Process. Manag. 2022, 59, 103061. [Google Scholar] [CrossRef]
- Aledhari, M.; Razzak, R.; Parizi, R.M.; Saeed, F. Federated Learning: A Survey on Enabling Technologies, Protocols, and Applications. IEEE Access 2020, 8, 140699–140725. [Google Scholar] [CrossRef] [PubMed]
- Berghout, T.; Benbouzid, M. A Systematic Guide for Predicting Remaining Useful Life with Machine Learning. Electronics 2022, 11, 1125. [Google Scholar] [CrossRef]
- Berghout, T.; Benbouzid, M.; Muyeen, S.M. Machine Learning for Cybersecurity in Smart Grids: A Comprehensive Review-based Study on Methods, Solutions, and Prospects. Int. J. Crit. Infrastruct. Prot. 2022, 38, 100547. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-Efficient Learning of Deep Networks from Decentralized Data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, AISTATS 2017, Fort Lauderdale, FL, USA, 20–22 April 2017; Volume 54, pp. 1273–1282. [Google Scholar]
- Alazab, M.; RM, S.P.; M, P.; Maddikunta, P.K.R.; Gadekallu, T.R.; Pham, Q.-V. Federated Learning for Cybersecurity: Concepts, Challenges, and Future Directions. IEEE Trans. Ind. Inform. 2022, 18, 3501–3509. [Google Scholar] [CrossRef]
- Agrawal, S.; Sarkar, S.; Aouedi, O.; Yenduri, G.; Piamrat, K.; Alazab, M.; Bhattacharya, S.; Maddikunta, P.K.R.; Gadekallu, T.R. Federated Learning for intrusion detection system: Concepts, challenges and future directions. Comput. Commun. 2022, 195, 346–361. [Google Scholar] [CrossRef]
- Yang, Q.; Liu, Y.; Cheng, Y.; Kang, Y.; Chen, T.; Yu, H. Federated Learning. Synth. Lect. Artif. Intell. Mach. Learn. 2020, 13, 1–207. [Google Scholar] [CrossRef]
- Jatain, D.; Singh, V.; Dahiya, N. A contemplative perspective on federated machine learning: Taxonomy, threats & vulnerability assessment and challenges. J. King Saud Univ.-Comput. Inf. Sci. 2021, 34, 6681–6698. [Google Scholar] [CrossRef]
- Wahab, O.A.; Mourad, A.; Otrok, H.; Taleb, T. Federated Machine Learning: Survey, Multi-Level Classification, Desirable Criteria and Future Directions in Communication and Networking Systems. IEEE Commun. Surv. Tutor. 2021, 23, 1342–1397. [Google Scholar] [CrossRef]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. ACM Trans. Intell. Syst. Technol. 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Li, L.; Fan, Y.; Tse, M.; Lin, K.Y. A review of applications in federated learning. Comput. Ind. Eng. 2020, 149, 106854. [Google Scholar] [CrossRef]
- Google Tensorflow Federated Learning. Available online: https://www.tensorflow.org/federated (accessed on 17 August 2022).
- Webank Federated AI Technology Enabler. Available online: https://github.com/webank (accessed on 17 August 2022).
- Mothukuri, V.; Parizi, R.M.; Pouriyeh, S.; Huang, Y.; Dehghantanha, A.; Srivastava, G. A survey on security and privacy of federated learning. Future Gener. Comput. Syst. 2021, 115, 619–640. [Google Scholar] [CrossRef]
- Yin, X.; Zhu, Y.; Hu, J. A Comprehensive Survey of Privacy-preserving Federated Learning. ACM Comput. Surv. 2021, 54, 1–36. [Google Scholar] [CrossRef]
- Zhang, C.; Xie, Y.; Bai, H.; Yu, B.; Li, W.; Gao, Y. A survey on federated learning. Knowl.-Based Syst. 2021, 216, 106775. [Google Scholar] [CrossRef]
- Blanco-Justicia, A.; Domingo-Ferrer, J.; Martínez, S.; Sánchez, D.; Flanagan, A.; Tan, K.E. Achieving security and privacy in federated learning systems: Survey, research challenges and future directions. Eng. Appl. Artif. Intell. 2021, 106, 104468. [Google Scholar] [CrossRef]
- Jawadur Rahman, K.M.; Ahmed, F.; Akhter, N.; Hasan, M.; Amin, R.; Aziz, K.E.; Muzahidul Islam, A.K.M.; Mukta, M.S.H.; Najmul Islam, A.K.M. Challenges, Applications and Design Aspects of Federated Learning: A Survey. IEEE Access 2021, 9, 124682–124700. [Google Scholar] [CrossRef]
- Nguyen, D.C.; Ding, M.; Pathirana, P.N.; Seneviratne, A.; Li, J.; Vincent Poor, H. Federated Learning for Internet of Things: A Comprehensive Survey. IEEE Commun. Surv. Tutor. 2021, 23, 1622–1658. [Google Scholar] [CrossRef]
- Briggs, C.; Fan, Z.; Andras, P. A Review of Privacy-Preserving Federated Learning for the Internet-of-Things. In Studies in Computational Intelligence; Springer International Publishing: New York, NY, USA, 2021; Volume 965, pp. 21–50. ISBN 9783030706043. [Google Scholar]
- Zhu, H.; Xu, J.; Liu, S.; Jin, Y. Federated learning on non-IID data: A survey. Neurocomputing 2021, 465, 371–390. [Google Scholar] [CrossRef]
- Yang, Q. Toward Responsible AI: An Overview of Federated Learning for User-centered Privacy-preserving Computing. ACM Trans. Interact. Intell. Syst. 2021, 11, 1–22. [Google Scholar] [CrossRef]
- Abreha, H.G.; Hayajneh, M.; Serhani, M.A. Federated Learning in Edge Computing: A Systematic Survey. Sensors 2022, 22, 450. [Google Scholar] [CrossRef]
- Ma, X.; Zhu, J.; Lin, Z.; Chen, S.; Qin, Y. A state-of-the-art survey on solving non-IID data in Federated Learning. Future Gener. Comput. Syst. 2022, 135, 244–258. [Google Scholar] [CrossRef]
- Shaheen, M.; Farooq, M.S.; Umer, T.; Kim, B.-S. Applications of Federated Learning; Taxonomy, Challenges, and Research Trends. Electronics 2022, 11, 670. [Google Scholar] [CrossRef]
- Gupta, R.; Alam, T. Survey on Federated-Learning Approaches in Distributed Environment. Wirel. Pers. Commun. 2022, 125, 1631–1652. [Google Scholar] [CrossRef]
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated Optimization in Heterogeneous Networks. Proc. Mach. Learn. Syst. 2018, 2, 429–450. [Google Scholar]
- Reisizadeh, A.; Mokhtari, A.; Hassani, H.; Jadbabaie, A.; Pedarsani, R. FedPAQ: A Communication-Efficient Federated Learning Method with Periodic Averaging and Quantization. arXiv 2019, arXiv:1909.13014. [Google Scholar] [CrossRef]
- So, J.; Guler, B.; Avestimehr, A.S. Turbo-Aggregate: Breaking the Quadratic Aggregation Barrier in Secure Federated Learning. IEEE J. Sel. Areas Inf. Theory 2021, 2, 479–489. [Google Scholar] [CrossRef]
- Hou, S.; Lu, J.; Zhu, E.; Zhang, H.; Ye, A. A Federated Learning-Based Fault Detection Algorithm for Power Terminals. Math. Probl. Eng. 2022, 2022, 9031701. [Google Scholar] [CrossRef]
- Zhang, W.; Li, X.; Ma, H.; Luo, Z.; Li, X. Federated learning for machinery fault diagnosis with dynamic validation and self-supervision. Knowl.-Based Syst. 2021, 213, 106679. [Google Scholar] [CrossRef]
- Bearing Data Center (CRWU) Seeded Fault Test Data. Available online: https://engineering.case.edu/bearingdatacenter (accessed on 22 December 2022).
- Xue, M.A.; Chenglin, W.E.N. An Asynchronous Quasi-Cloud/Edge/Client Collaborative Federated Learning Mechanism for Fault Diagnosis. Chin. J. Electron. 2021, 30, 969–977. [Google Scholar] [CrossRef]
- Ma, X.; Wen, C.; Wen, T. An Asynchronous and Real-time Update Paradigm of Federated Learning Diagnosisfor Fault. IEEE Trans. Ind. Inform. 2021, 3203, 8531–8540. [Google Scholar] [CrossRef]
- Li, Z.; Li, Z.; Li, Y.; Tao, J.; Mao, Q.; Zhang, X. An intelligent diagnosis method for machine fault based on federated learning. Appl. Sci. 2021, 11, 12117. [Google Scholar] [CrossRef]
- Marins, M.A.; Ribeiro, F.M.L.; Netto, S.L.; da Silva, E.A.B. Improved similarity-based modeling for the classification of rotating-machine failures. J. Franklin Inst. 2018, 355, 1913–1930. [Google Scholar] [CrossRef]
- Wang, Q.; Li, Q.; Wang, K.; Wang, H.; Zeng, P. Efficient federated learning for fault diagnosis in industrial cloud-edge computing. Computing 2021, 103, 2319–2337. [Google Scholar] [CrossRef]
- Gear Fault Data. Available online: https://figshare.com/articles/Gear_Fault_Data/6127874/1 (accessed on 22 December 2022).
- Cao, P.; Zhang, S.; Tang, J. Preprocessing-Free Gear Fault Diagnosis Using Small Datasets With Deep Convolutional Neural Network-Based Transfer Learning. IEEE Access 2018, 6, 26241–26253. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, Y.; Zhu, K.; Zhang, Y.; Li, Y. Diagnosis of Inter-Turn Short Circuit Faults in Permanent Magnet Synchronous Motors Based on Few-Shot Learning under a Federated Learning Framework. IEEE Trans. Ind. Inform. 2021, 3203, 8495–8504. [Google Scholar] [CrossRef]
- Zhang, Z.; Xu, X.; Gong, W.; Chen, Y.; Gao, H. Efficient federated convolutional neural network with information fusion for rolling bearing fault diagnosis. Control Eng. Pract. 2021, 116, 104913. [Google Scholar] [CrossRef]
- Zhang, W.; Li, X. Federated Transfer Learning for Intelligent Fault Diagnostics Using Deep Adversarial Networks with Data Privacy. IEEE/ASME Trans. Mechatron. 2022, 27, 430–439. [Google Scholar] [CrossRef]
- Zhang, W.; Li, X. Data privacy preserving federated transfer learning in machinery fault diagnostics using prior distributions. Struct. Health Monit. 2022, 21, 1329–1344. [Google Scholar] [CrossRef]
- Jiang, G.; Fan, W.P.; Li, W.; Wang, L.; He, Q.; Xie, P.; Li, X. DeepFedWT: A federated deep learning framework for fault detection of wind turbines. Meas. J. Int. Meas. Confed. 2022, 199, 111529. [Google Scholar] [CrossRef]
- Leahy, K.; Hu, R.L.; Konstantakopoulos, I.C.; Spanos, C.J.; Agogino, A.M. Diagnosing wind turbine faults using machine learning techniques applied to operational data. In Proceedings of the 2016 IEEE International Conference on Prognostics and Health Management (ICPHM), Ottawa, ON, Canada, 20–22 June 2016; pp. 1–8. [Google Scholar]
- Yuan, B.; Wang, C.; Luo, C.; Jiang, F.; Long, M.; Yu, P.S.; Liu, Y. WaveletAE: A Wavelet-enhanced Autoencoder for Wind Turbine Blade Icing Detection. arXiv 2019, arXiv:1902.05625. [Google Scholar] [CrossRef]
- Wang, Y.; Yan, J.; Yang, Z.; Dai, Y.; Wang, J.; Geng, Y. A Novel Federated Transfer Learning Framework for Intelligent Diagnosis of Insulation Defects in Gas-Insulated Switchgear. IEEE Trans. Instrum. Meas. 2022, 71, 3517711. [Google Scholar] [CrossRef]
- Zhang, Z.; Guan, C.; Chen, H.; Yang, X.; Gong, W.; Yang, A. Adaptive Privacy-Preserving Federated Learning for Fault Diagnosis in Internet of Ships. IEEE Internet Things J. 2022, 9, 6844–6854. [Google Scholar] [CrossRef]
- Li, Y.; Chen, Y.; Zhu, K.; Bai, C.; Zhang, J. An effective federated learning verification strategy and its applications for fault diagnosis in industrial IOT systems. IEEE Internet Things J. 2022, 9, 16835–16849. [Google Scholar] [CrossRef]
- Liu, Q.; Yang, B.; Wang, Z.; Zhu, D.; Wang, X.; Ma, K.; Guan, X. Asynchronous Decentralized Federated Learning for Collaborative Fault Diagnosis of PV Stations. IEEE Trans. Netw. Sci. Eng. 2022, 9, 1680–1696. [Google Scholar] [CrossRef]
- Geng, D.Q.; He, H.W.; Lan, X.C.; Liu, C. Bearing fault diagnosis based on improved federated learning algorithm. Computing 2022, 104, 1–19. [Google Scholar] [CrossRef]
- Lu, S.; Gao, Z.; Xu, Q.; Jiang, C.; Zhang, A.; Wang, X. Class-Imbalance Privacy-Preserving Federated Learning for Decentralized Fault Diagnosis With Biometric Authentication. IEEE Trans. Ind. Inform. 2022, 18, 9101–9111. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit. 2016, 2016, 770–778. [Google Scholar] [CrossRef]
- Yang, W.; Chen, J.; Chen, Z.; Liao, Y.; Li, W. Federated Transfer Learning for Bearing Fault Diagnosis Based on Averaging Shared Layers. In Proceedings of the 2021 Global Reliability and Prognostics and Health Management (PHM-Nanjing), Nanjing, China, 15–17 October 2021; pp. 1–7. [Google Scholar] [CrossRef]
- Paderborn University. Available online: https://mb.uni-paderborn.de/en/kat/main-research/datacenter/bearing-datacenter/data-sets-and-download (accessed on 22 December 2022).
- Eric, B. Condition Based Maintenance Fault Database for Testing of Diagnostic and Prognostics Algorithms. Available online: https://www.mfpt.org/fault-data-sets/ (accessed on 22 December 2022).
- Chen, J.; Li, J.; Huang, R.; Yue, K.; Chen, Z.; Li, W. Federated Transfer Learning for Bearing Fault Diagnosis With Discrepancy-Based Weighted Federated Averaging. IEEE Trans. Instrum. Meas. 2022, 71, 3514911. [Google Scholar] [CrossRef]
- Berghout, T.; Bentrcia, T.; Ferrag, M.A.; Benbouzid, M. A Heterogeneous Federated Transfer Learning Approach with Extreme Aggregation and Speed. Mathematics 2022, 10, 3528. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | Ref. | Most Important Contributions besides Generalities, e.g., Main Concepts, Classifications, Applications, and Future Prospects | Main Challenges Addressed |
|---|---|---|---|
| 2019 | [12] |
| Challenges of FL in general |
| 2020 | [13] |
| Challenges of FL in general |
| [9] |
| Challenges of FL in general | |
| [16] |
| PrC | |
| 2021 | [17] |
| PrC |
| [18] |
| Challenges of FL in general | |
| [19] |
| PrC | |
| [20] |
| Challenges of FL in general | |
| [21] |
| StH and PrC | |
| [10] |
| Challenges of FL in general and PrC | |
| [22] |
| PrC | |
| [23] |
| StH | |
| [24] |
| PrC | |
| [11] |
| Challenges of FL in general | |
| 2022 | [25] |
| Challenges of FL in general |
| [26] |
| StH | |
| [27] |
| Challenges of FL in general | |
| [28] |
| PrC |
| Year | Ref. | Aggregation Algorithm | Learning Algorithm | Dataset | Solved Challenges |
|---|---|---|---|---|---|
| 2020 | [32] | FedAvg | LSTM | A language-processing-based dataset of a simulated power grid system. The system has cloud computing with 10 edge servers and several terminals. | CoE |
| 2021 | [33] | FedAvg | CNN enhanced with data augmentation algorithm | CWRU [34] and Bogie bearing datasets. | StH |
| [35] | Kalman filter | Kalman filter | Dataset retrieved from a specific rotating mechanical device (type is not specifically revealed). | CoE | |
| [36] | Kalman filtering enhanced by a real-time participant-identification method | Kalman filter | Dataset retrieved from a specific rotating mechanical device (type was not specifically revealed). The CWRU dataset [34] was also studied in this work. | Communication efficiency | |
| [37] | FedAvg | CNN | CWRU [34] and MFD [38]. | StH. | |
| [39] | MBNN | MBNN | CWRU [34] and the gearbox failure diagnostic dataset [40,41]. | CoE and SyH | |
| [42] | FedAvg | SSAE and Siamese networks | Inter-turn short-circuit (ITSC) faults dataset. | Communication efficiency | |
| [43] | FedAvg with some adaptive-learning features | CNN with a dropout layer trained by MGD | CWRU [34]. | CoE | |
| [44] | FedAvg | Deep adversarial semi-supervised network and a CNN | CWRU [34] and Bogie datasets. | SyH | |
| 2022 | [45] | Transfer learning | CNN | CWRU [34] and CRACK datasets. | StH |
| [46] | FedAvg | Multiscale residual attention network and a custom deep network designed for classification | A 3 MW direct-drive wind turbine [47] and 1.5 MW direct-drive WT [48] fault datasets. | StH | |
| [49] | FedMM | CNN with adversarial learning features | Gas-insulated switchgear insulation fault-detection dataset. | StH | |
| [50] | Paillier cryptographic and adaptive control algorithm | CNN | CWRU [34] | PrC, StH, and CoE | |
| [51] | FedAvg and particle swarm optimization for client weighting | Custom deep network designed for classification | Turns in permanent magnet synchronous motor short-circuit fault-detection dataset. | StH, and CoE | |
| [52] | ADFL | CNN | Real PV generator consisting of two PV strings connected in parallel with 22 PV modules. | SyH, StH, and CoE | |
| [53] | FA-FedAvg | CNN | CWRU [34] | CoE | |
| [54] | Biometric authorization mechanism, gradient noise mechanism, and proportional parameter update strategy | ResNet18 [55] | 5 biometric authentication wind farm datasets. | PrC | |
| [56] | FTL-ASL | CNN | PUD [57], MFPT [58], and CWRU [34] datasets. | StH | |
| [59] | D-WFA and MMD | CNN | (NSK) 40BNR10 ball bearing dataset. | SyH |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Berghout, T.; Benbouzid, M.; Bentrcia, T.; Lim, W.H.; Amirat, Y. Federated Learning for Condition Monitoring of Industrial Processes: A Review on Fault Diagnosis Methods, Challenges, and Prospects. Electronics 2023, 12, 158. https://doi.org/10.3390/electronics12010158
Berghout T, Benbouzid M, Bentrcia T, Lim WH, Amirat Y. Federated Learning for Condition Monitoring of Industrial Processes: A Review on Fault Diagnosis Methods, Challenges, and Prospects. Electronics. 2023; 12(1):158. https://doi.org/10.3390/electronics12010158
Chicago/Turabian StyleBerghout, Tarek, Mohamed Benbouzid, Toufik Bentrcia, Wei Hong Lim, and Yassine Amirat. 2023. "Federated Learning for Condition Monitoring of Industrial Processes: A Review on Fault Diagnosis Methods, Challenges, and Prospects" Electronics 12, no. 1: 158. https://doi.org/10.3390/electronics12010158
APA StyleBerghout, T., Benbouzid, M., Bentrcia, T., Lim, W. H., & Amirat, Y. (2023). Federated Learning for Condition Monitoring of Industrial Processes: A Review on Fault Diagnosis Methods, Challenges, and Prospects. Electronics, 12(1), 158. https://doi.org/10.3390/electronics12010158