
Optimized URL Feature Selection Based on Genetic-Algorithm-Embedded Deep Learning for Phishing Website Detection


Abstract
:1. Introduction
- The genetic-algorithm-embedded convolutional recurrent network works well for classifying benign and phishing URLs, resulting the best recall and accuracy for phishing website detection;
- We formulated the task of regulating the learning process of a deep learning model to enhance a specific metric as an optimization problem, and solved it effectively by extending the existing genetic algorithm.
2. Related Works
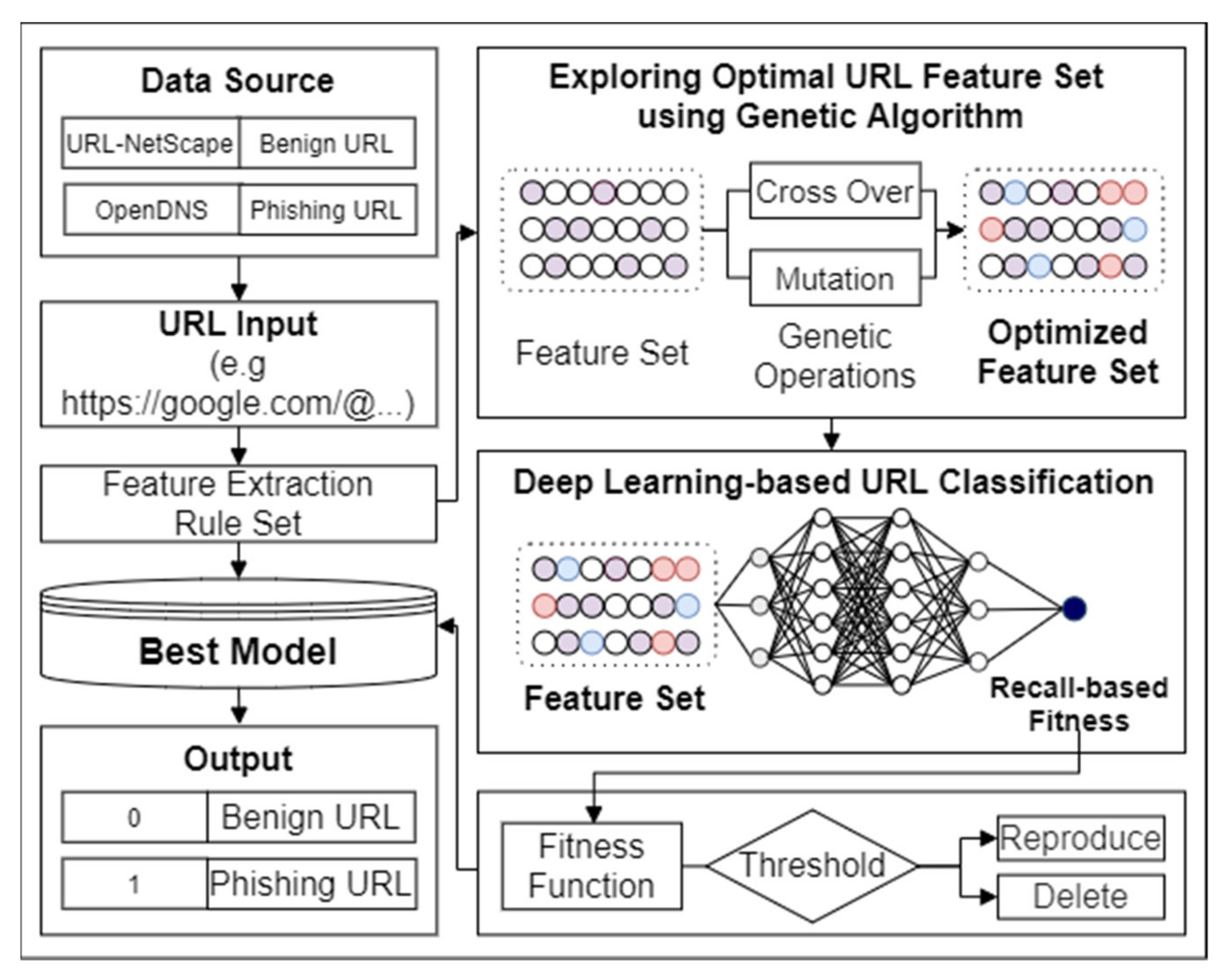
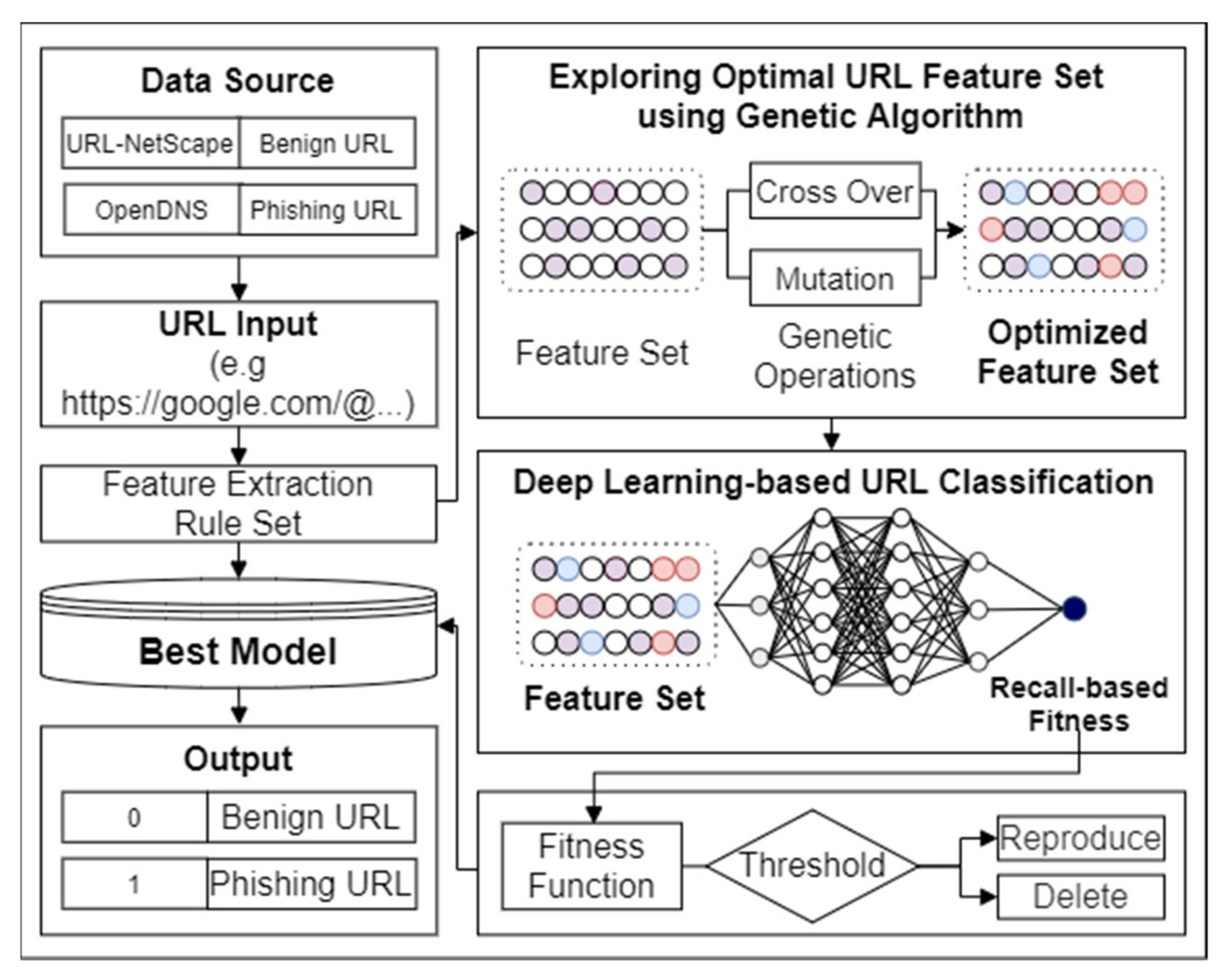
3. Proposed Method
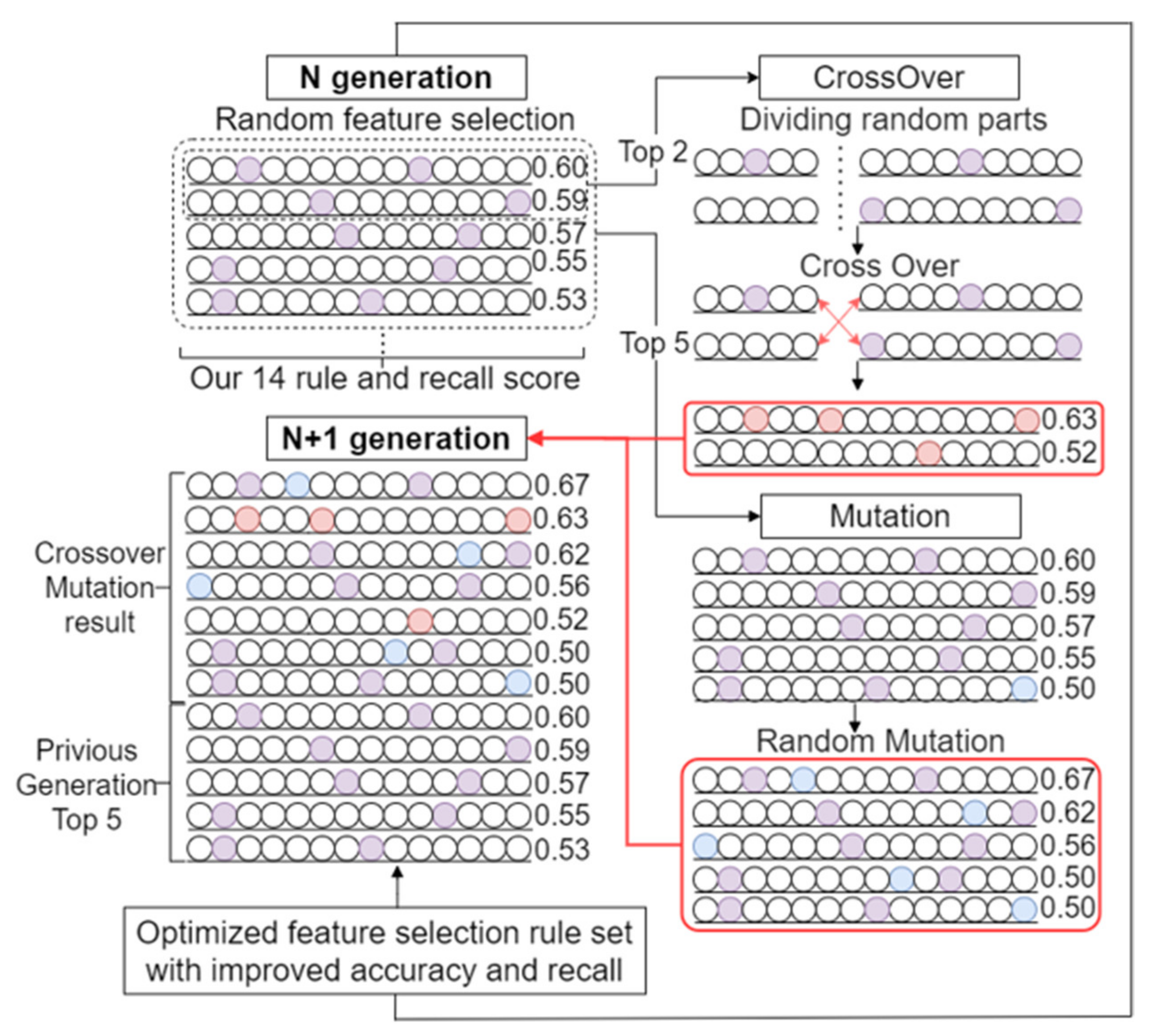
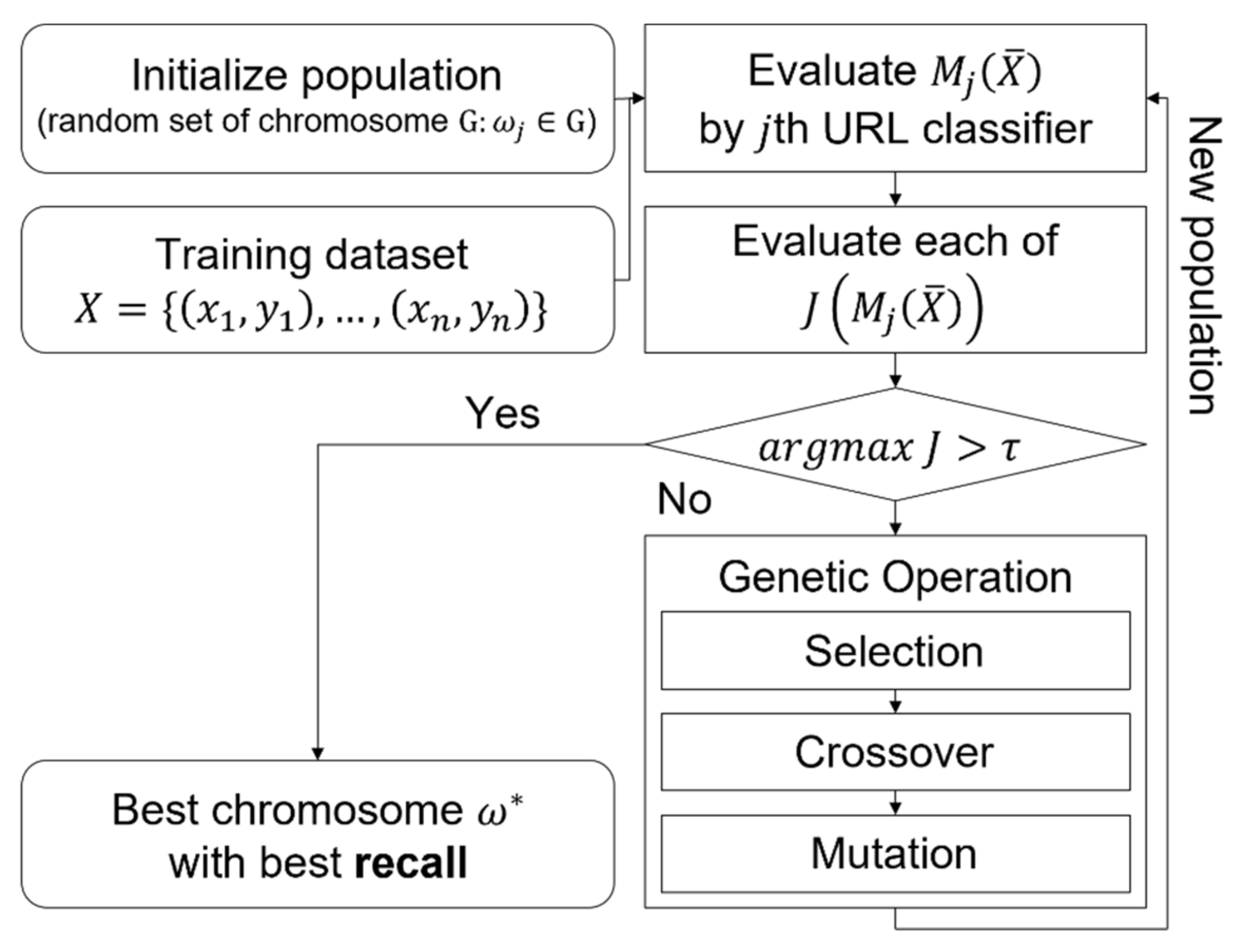
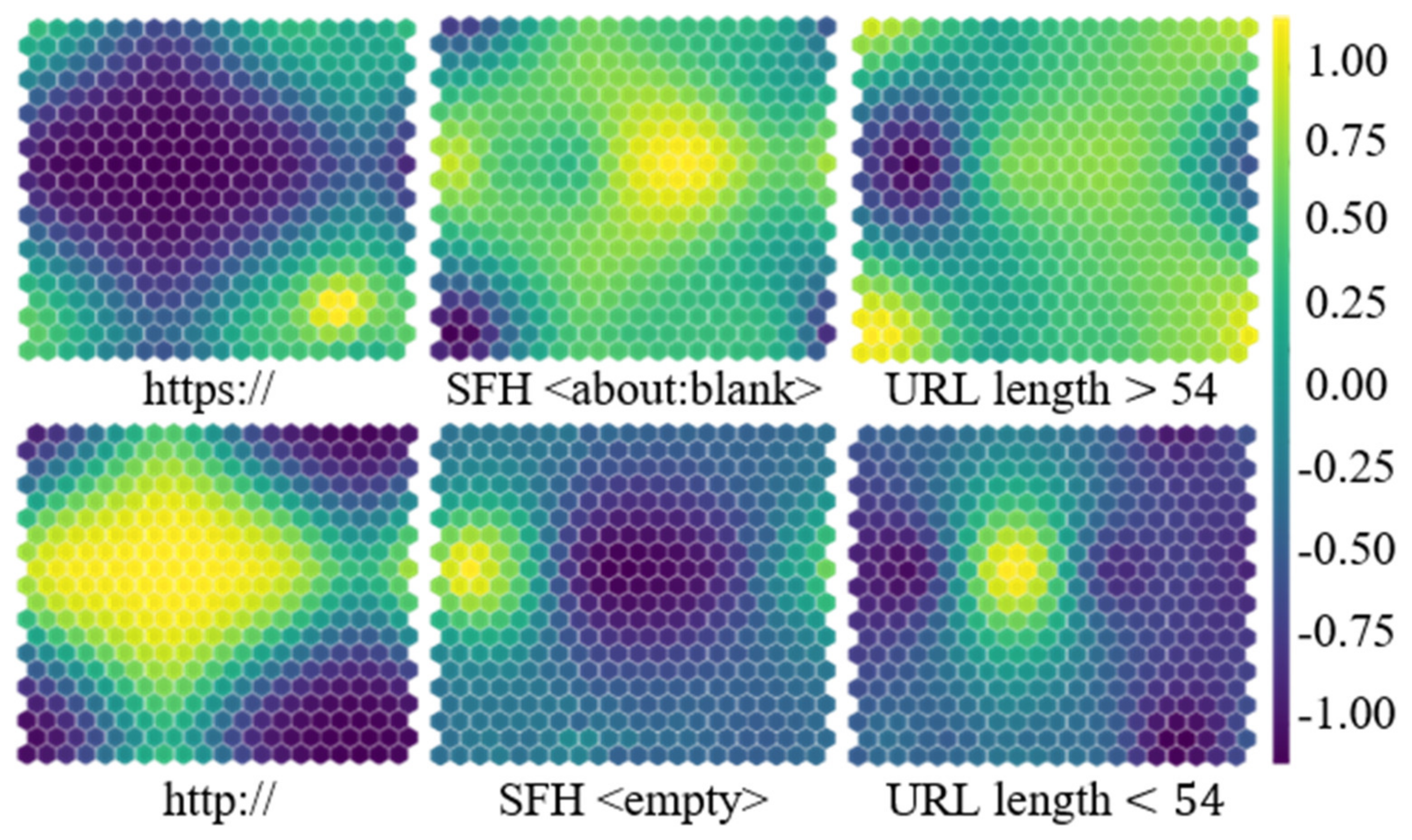
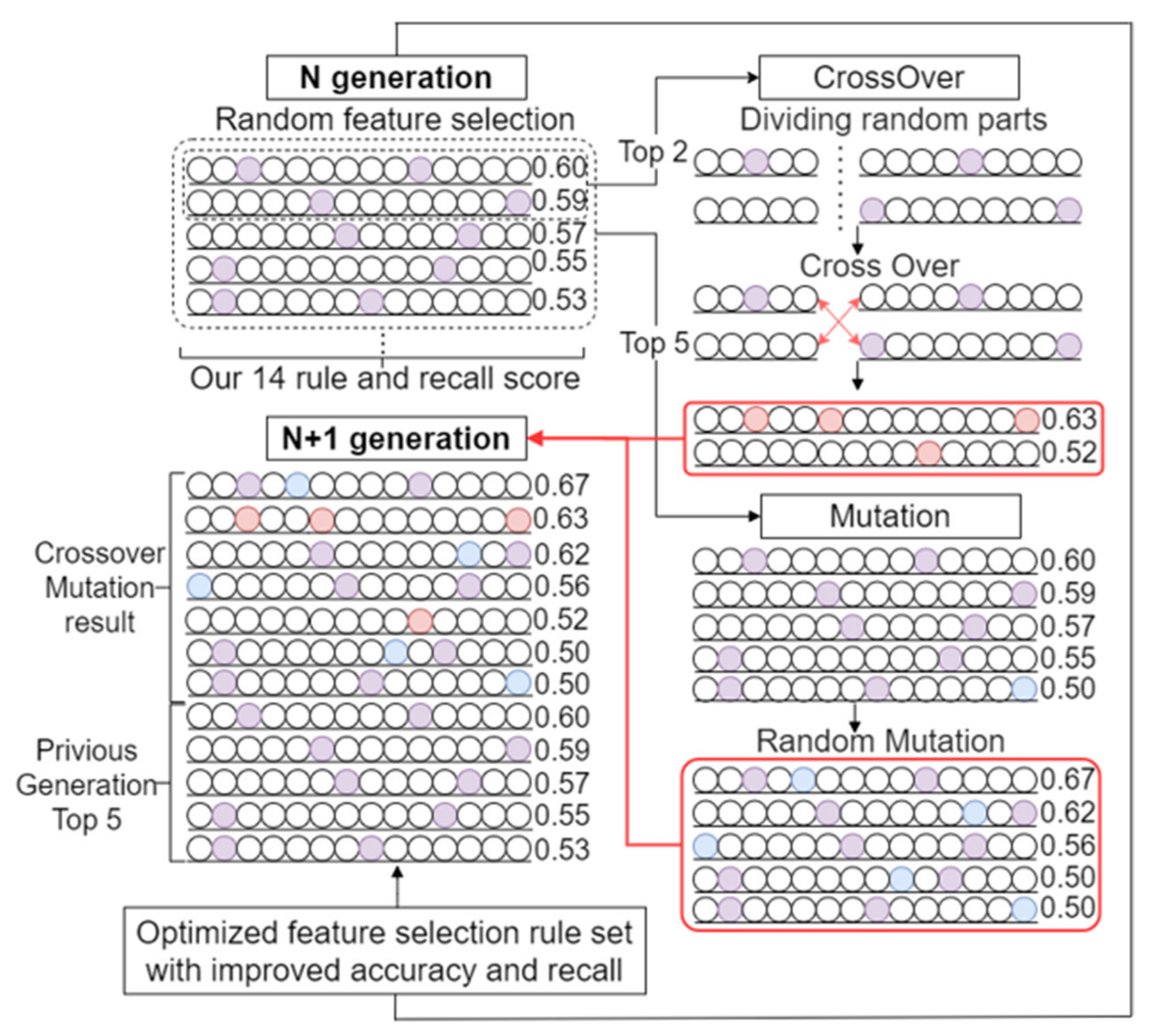
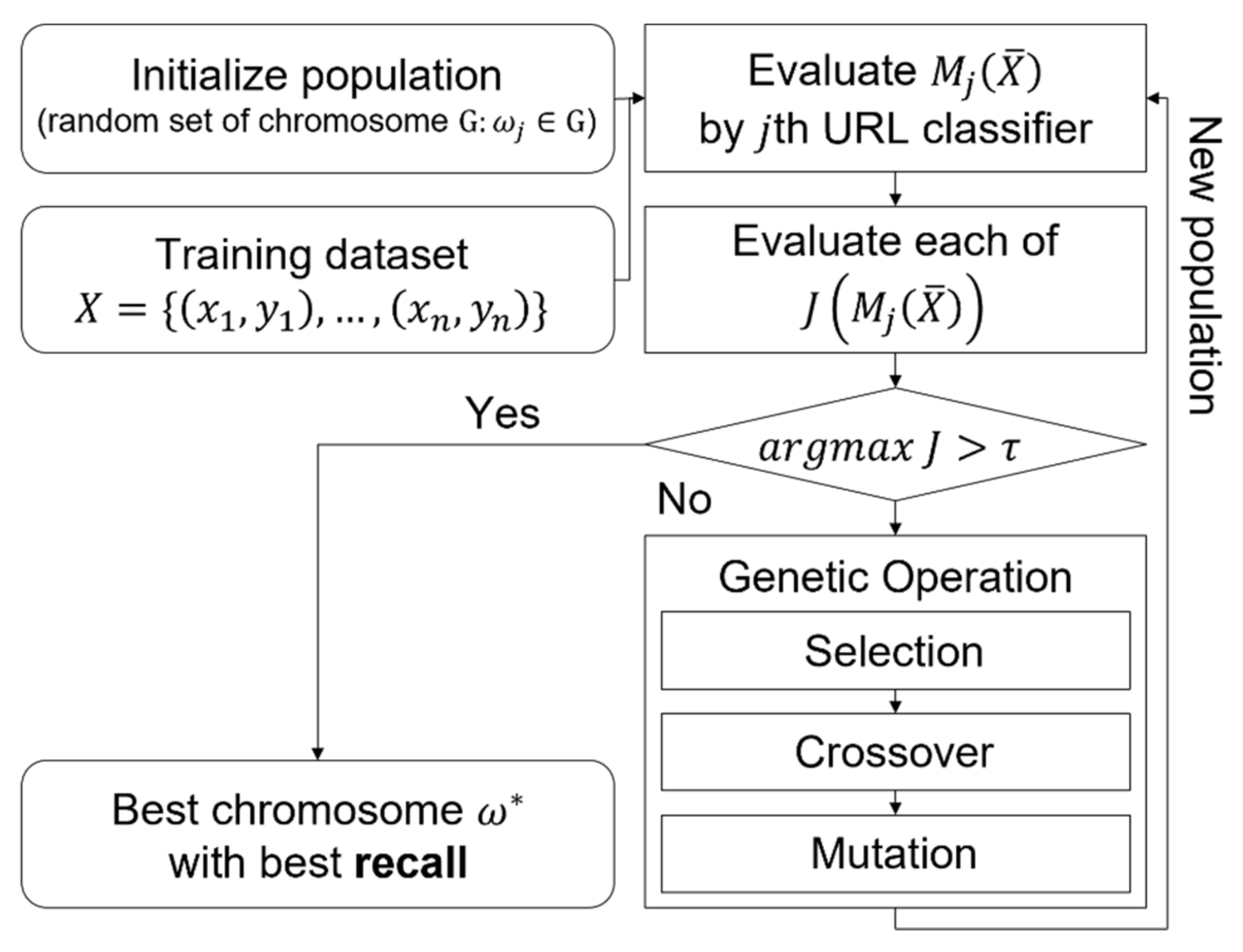
3.1. Genetic-Algorithm-Based URL Feature Optimization
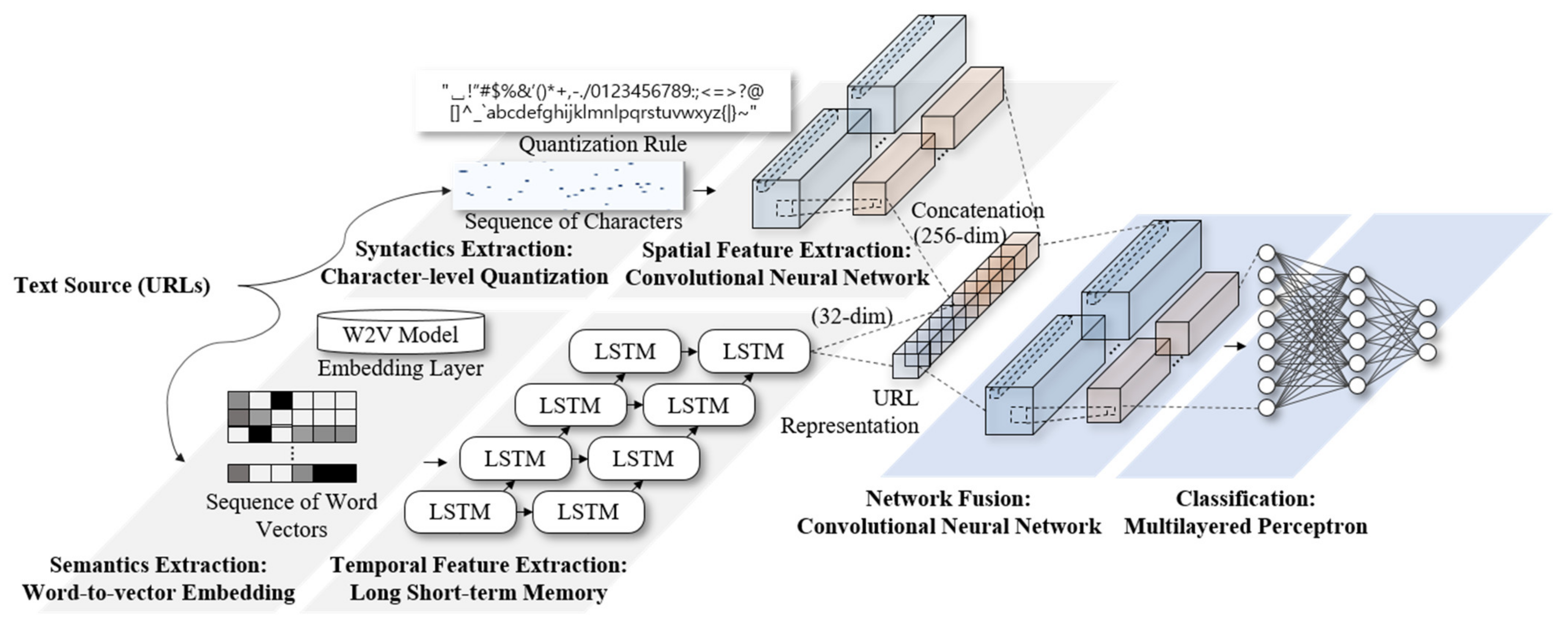
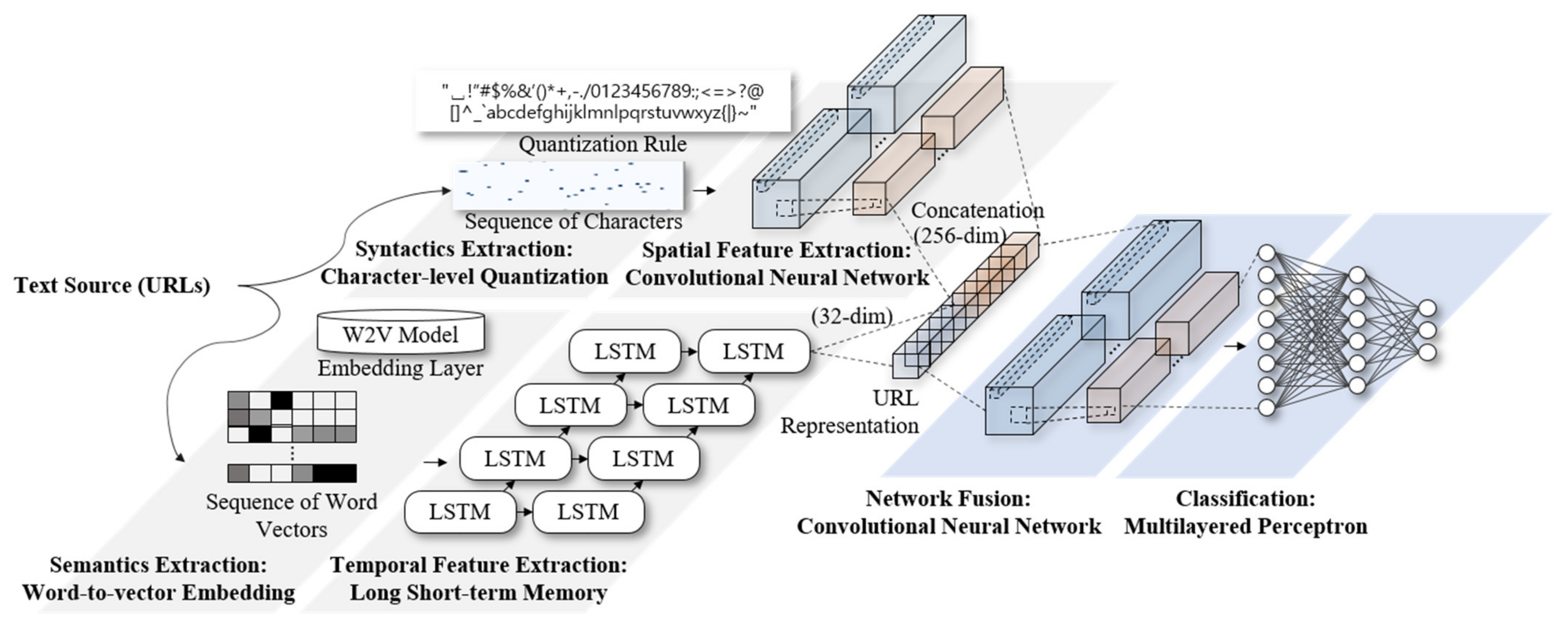
3.2. Convolutional–Recurrent Neural-Network-Based URL Classification
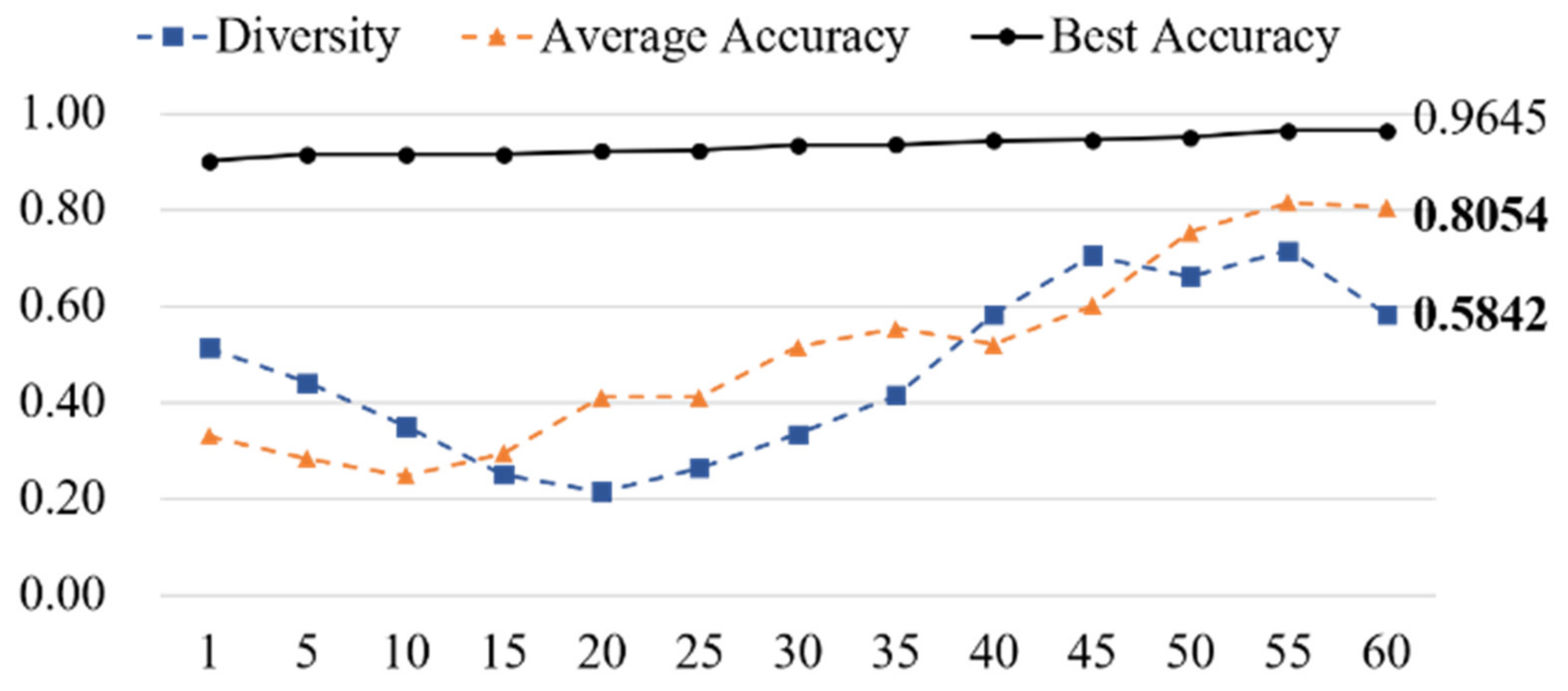
4. Experimental Results
4.1. Dataset and Implementation
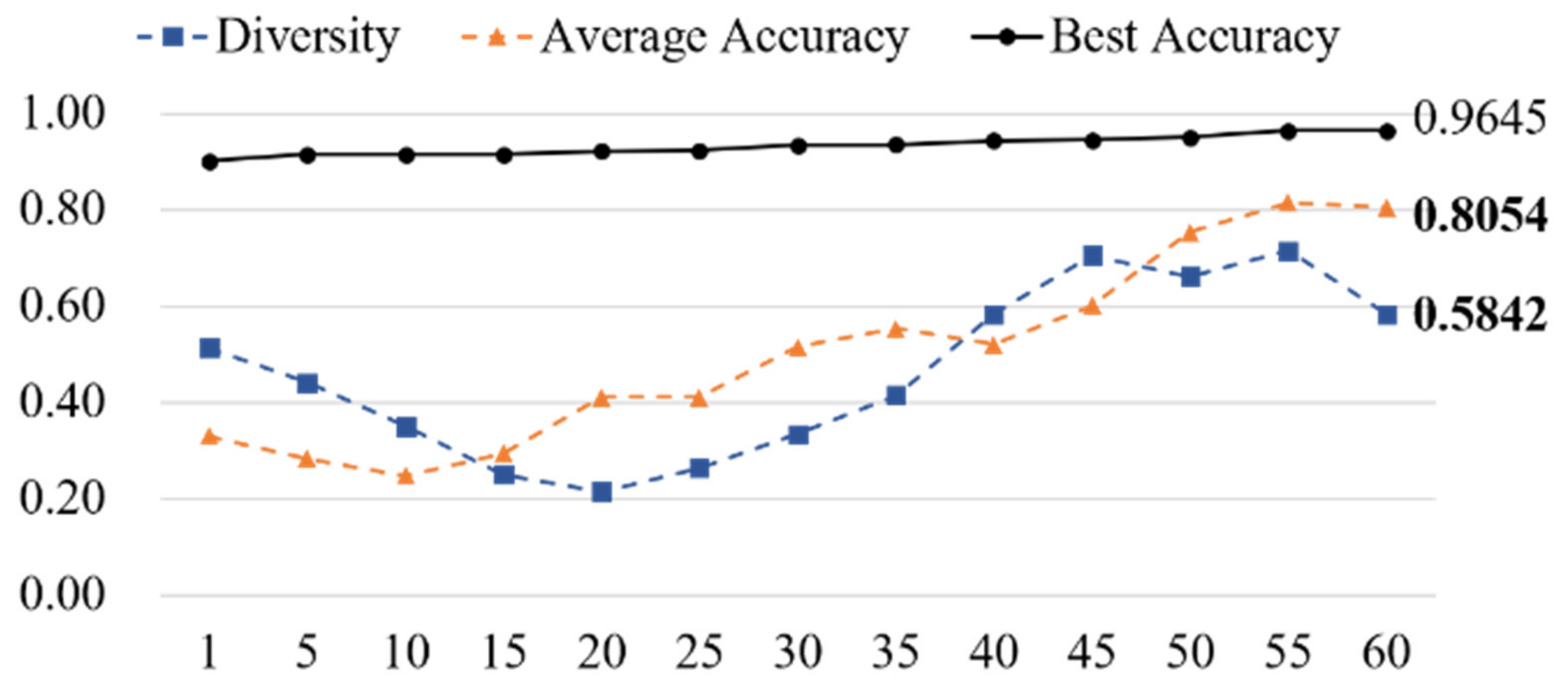
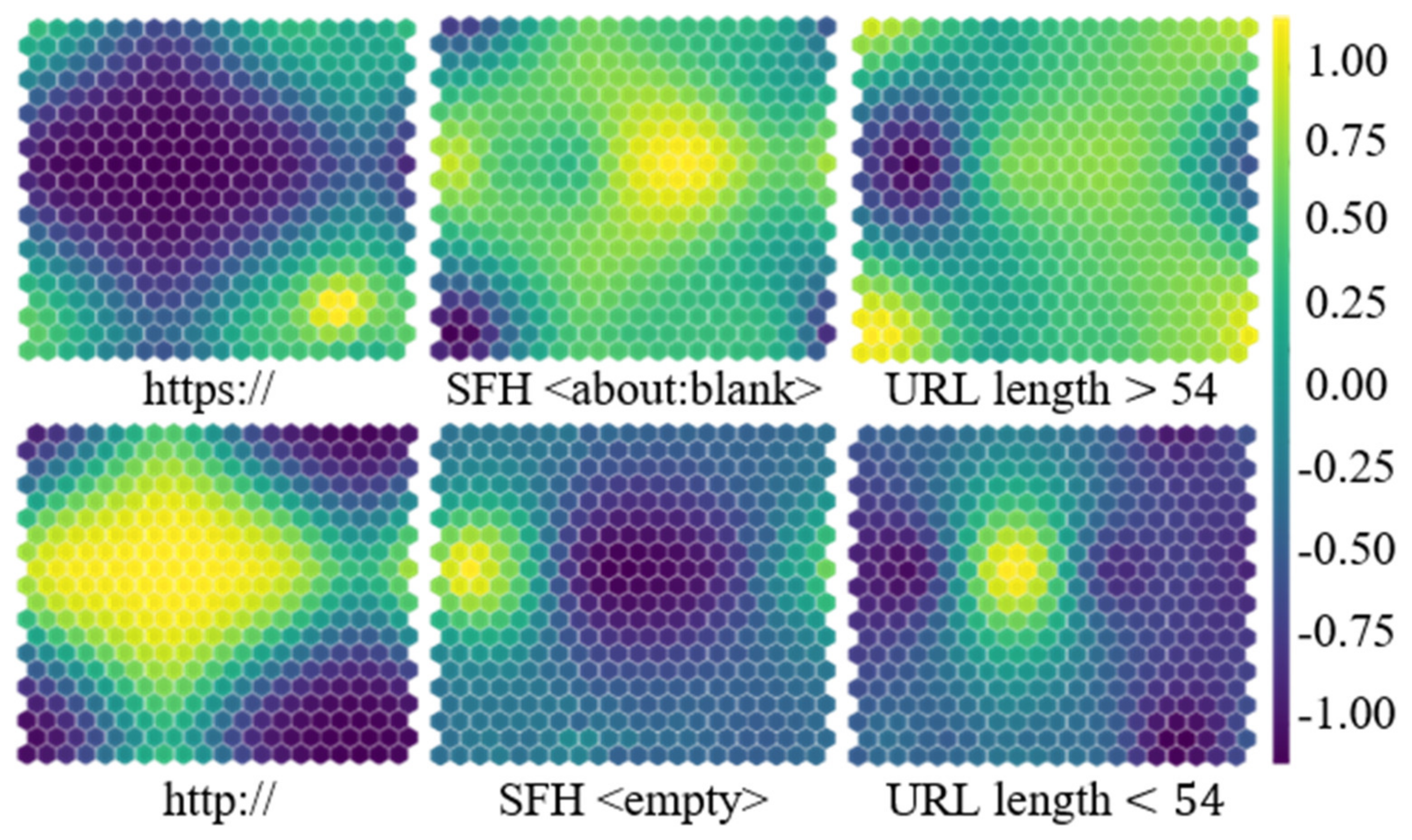
4.2. Phishing Detection Performance
5. Concluding Remarks
Author Contributions
Funding
Conflicts of Interest
References
- Marchal, S.; François, J.; State, R.; Engel, T. PhishStorm: Detecting phishing with streaming analytics. IEEE Trans. Netw. Serv. Manag. 2014, 11, 458–471. [Google Scholar] [CrossRef] [Green Version]
- Bu, S.-J.; Cho, S.-B. Deep character-level anomaly detection based on a convolutional autoencoder for zero-day phishing URL detection. Electronics 2021, 10, 1492. [Google Scholar] [CrossRef]
- Bu, S.-J.; Cho, S.-B. Integrating deep learning with first-order logic programmed constraints for zero-day phishing attack detection. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 2685–2689. [Google Scholar]
- Wei, W.; Ke, Q.; Nowak, J.; Korytkowski, M.; Scherer, R.; Woźniak, M. Accurate and fast URL phishing detector: A convolutional neural network approach. Comput. Netw. 2020, 178, 107275. [Google Scholar] [CrossRef]
- Le, H.; Pham, Q.; Sahoo, D.; Hoi, S.C. URLNet: Learning a URL representation with deep learning for malicious URL detection. arXiv 2018, arXiv:1802.03162. [Google Scholar]
- Tajaddodianfar, F.; Stokes, J.W.; Gururajan, A. Texception: A character/word-level deep learning model for phishing URL detection. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 2857–2861. [Google Scholar]
- Muntasir, M.; Rahman, S.S.M.M.; Jahan, N.; Siddikk, A.B.; Islam, T. AntiPhishTuner: Multi-level approaches focusing on optimization by parameters tuning in phishing URLs detection. In Artificial Intelligence and Blockchain for Future Cybersecurity Applications; Springer: Berlin/Heidelberg, Germany, 2021; pp. 161–180. [Google Scholar]
- Le, A.; Markopoulou, A.; Faloutsos, M. Phishdef: Url names say it all. In Proceedings of the 2011 Proceedings IEEE INFOCOM, Shanghai, China, 10–15 April 2011; pp. 191–195. [Google Scholar]
- Mohammad, R.M.; Thabtah, F.; McCluskey, L. An assessment of features related to phishing websites using an automated technique. In Proceedings of the 2012 International Conference for Internet Technology and Secured Transactions, London, UK, 10–12 December 2012; pp. 492–497. [Google Scholar]
- Iuga, C.; Nurse, J.R.; Erola, A. Baiting the hook: Factors impacting susceptibility to phishing attacks. Hum.-Cent. Comput. Inf. Sci. 2016, 6, 8. [Google Scholar] [CrossRef] [Green Version]
- Bahnsen, A.C.; Bohorquez, E.C.; Villegas, S.; Vargas, J.; González, F.A. Classifying phishing URLs using recurrent neural networks. In Proceedings of the 2017 APWG Symposium on Electronic Crime Research (eCrime), Scottsdale, AZ, USA, 25–27 April 2017; pp. 1–8. [Google Scholar]
- Zhao, J.; Wang, N.; Ma, Q.; Cheng, Z. Classifying malicious URLs using gated recurrent neural networks. In Proceedings of the International Conference on Innovative Mobile and Internet Services in Ubiquitous Computing, Matsue, Japan, 3–5 July 2018; pp. 385–394. [Google Scholar]
- Zhang, X.; Zhao, J.; LeCun, Y. Character-level convolutional networks for text classification. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 649–657. [Google Scholar]
- Anand, A.; Gorde, K.; Moniz, J.R.A.; Park, N.; Chakraborty, T.; Chu, B.-T. Phishing URL detection with oversampling based on text generative adversarial networks. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 1168–1177. [Google Scholar]
- Bu, S.-J.; Cho, S.-B. A convolutional neural-based learning classifier system for detecting database intrusion via insider attack. Inf. Sci. 2020, 512, 123–136. [Google Scholar] [CrossRef]
- Suleman, M.-T.; Awan, S.M. Optimization of URL-based phishing websites detection through genetic algorithms. Autom. Control. Comput. Sci. 2019, 53, 333–341. [Google Scholar] [CrossRef]
- Park, K.-W.; Bu, S.-J.; Cho, S.-B. Evolutionary optimization of neuro-symbolic integration for phishing URL detection. In Proceedings of the International Conference on Hybrid Artificial Intelligence Systems, Bilbao, Spain, 22–24 September 2021; pp. 88–100. [Google Scholar]
- Da Silva, C.M.R.; Fernandes, B.J.T.; Feitosa, E.L.; Garcia, V.C. Piracema.io: A rules-based tree model for phishing prediction. Expert Syst. Appl. 2022, 191, 116239. [Google Scholar] [CrossRef]
- Shreeram, V.; Suban, M.; Shanthi, P.; Manjula, K. Anti-phishing detection of phishing attacks using genetic algorithm. In Proceedings of the 2010 International Conference on Communication Control and Computing Technologies, Nagercoil, India, 7–9 October 2010; pp. 447–450. [Google Scholar]
- Moghimi, M.; Varjani, A.Y. New rule-based phishing detection method. Expert Syst. Appl. 2016, 53, 231–242. [Google Scholar] [CrossRef]
- Sun, Y.; Xue, B.; Zhang, M.; Yen, G.G.; Lv, J. Automatically designing CNN architectures using the genetic algorithm for image classification. IEEE Trans. Cybern. 2020, 50, 3840–3854. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mamun, M.S.I.; Rathore, M.A.; Lashkari, A.H.; Stakhanova, N.; Ghorbani, A.A. Detecting malicious urls using lexical analysis. In Proceedings of the International Conference on Network and System Security, Taipei, Taiwan, 28–30 September 2016; pp. 467–482. [Google Scholar]
- Cui, Q.; Jourdan, G.-V.; Bochmann, G.V.; Couturier, R.; Onut, I.-V. Tracking phishing attacks over time. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 667–676. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | URL Features |
|---|---|
| Address-bar-based | Usage of IP address |
| Digit count | |
| Character length | |
| Special characters count | |
| http:// or https:// | |
| Abnormal request-based | URL request count |
| Server form handler | |
| Domain-based | Age of domain |
| Registered top domain | |
| Subdomain count | |
| Typosquatted URL (e.g., google → goggle.com) | |
| Script-based | Usage of mouseover script |
| Usage of popup window | |
| Disabling right click |
| Authors | URL Feature | Model | Dataset |
|---|---|---|---|
| Le [8] | Bag-of-words | SVM | VirusTotal |
| Mohammad [9] | Address bar, HTTP request, Domain, Script | Hierarchical classifier based on feature groups | PhishTank |
| Bhansen [11] | Word embeddings | LSTM | PhishTank |
| Zhao [12] | GRU | PhishTank | |
| Anand [14] | Character-level URL features | GAN | PhishTank |
| Bu [2] | Convolutional autoencoder | PhishTank, PhishStorm, ISCX-URL-2016 | |
| Le [5] | Character-level, Word vector-level URL features | Character-CNN with W2V-LSTM | VirusTotal |
| Tajaddodianfar [6] | CNN-LSTM with Attention | MS anonymized browsing data | |
| Suleman [16] | Address bar, HTTP request, Domain, Script | Machine learning with genetic algorithm | UCI phishing website dataset |
| Park [17] | Character-level URL features, Address bar, HTTP request, Domain, Script | CNN-LSTM with genetic algorithm | PhishTank, PhishStorm, ISCX-URL-2016 |
| Bu [3] | Character-level URL features, Address bar, HTTP request, Domain, Script | Transformer-style network with first-order logics | PhishTank, PhishStorm, ISCX-URL-2016 |
| Source | Desc. | Instances | Examples (Accessed Date: 19 October 2020) |
|---|---|---|---|
| ISCX-URL-2016 [22] | Benign | 35,000 | http://metro.co.uk/2015/05... |
| Phishing | 9000 | http://standardprincipal.pt/... | |
| Malware | 11,000 | http://9779.info/%E5%88%... | |
| Spam | 12,000 | http://adverse*s.co.uk/scr/cl... | |
| PhishStorm [1] | Benign | 47,682 | en.wikipedia.org/wiki/dead... |
| Phishing | 47,859 | nobell.it/70ffb52d079109dc... | |
| PhishTank [23] | DMOZ Open Directory (Benign) | 45,000 | http://geneba**.org/ftp/... |
| OpenDNS (Phishing) | 15,000 | http://droopbxoxx.com/@@@.. |
| Objective | Hyperparameter | Choice of Value Range | Best Model for Phishing Detection |
|---|---|---|---|
| Genetic algorithm configurations | Population per generation | 50, 100, 150, 200, 250, 300 | 300 |
| Number of generations | 16, 32, 64, 128, 256 | 64 | |
| Chromosome selection strategy | Roulette, Rank, Elitism | Elitism | |
| Network architecture | Activation functions | relu, sigmoid, tanh | relu |
| Embedding dimension | 32, 64, 128, 256, 512 | 64 | |
| Dropout rate | 0.25, 0.5 | 0.5 | |
| Learning strategy | Batch size | 32, 64, 128, 256, 512 | 32 |
| Loss optimizer | adam, adadelta, sgd | adam |
| Dataset | ISCX-URL-2016 | PhishStorm | PhishTank | |||
|---|---|---|---|---|---|---|
| Metrics | Acc. | Recall | Acc. | Recall | Acc. | Recall |
| Base network | ||||||
| Character-CNN | 0.9363 | 0.8909 | 0.9016 | 0.8565 | 0.8852 | 0.8034 |
| LSTM [10] | 0.9175 | 0.8803 | 0.8777 | 0.8440 | 0.8544 | 0.7865 |
| CNN-LSTM | 0.9424 | 0.9015 | 0.9229 | 0.8785 | 0.9070 | 0.8374 |
| Comparative studies | ||||||
| URLNet [5] | 0.9450 | 0.9390 | 0.9395 | 0.8864 | 0.9226 | 0.8785 |
| Texception Net [6] | 0.9765 | 0.9462 | 0.9710 | 0.9227 | 0.9319 | 0.9075 |
| GA-based URL feature set optimization (Proposed) | ||||||
| Ours | 0.9685 | 0.9510 | 0.9505 | 0.9332 | 0.9483 | 0.9081 |
| Type | URL Features | Selected URL Features |
|---|---|---|
| Address-bar-based | Usage of IP address | is_ip_address |
| Digit count | digits >50 | |
| Character length | length >30 | |
| Special character count | special_characters >10 | |
| dots >5 | ||
| http:// or https:// | is_https | |
| Abnormal-request-based | URL request count | - |
| SFH | SFH_blank | |
| SFH_empty | ||
| Domain-based | Age of domain | domain_age > average_domain_age |
| Registered top domain | is_registered | |
| Subdomain count | subdomains >5 | |
| Typo-squatted domain | is_typosquatted | |
| Suspicious TLD | suspicious_tld | |
| Script-based | Usage of mouseover | is_mouseover_available |
| Usage of pop-up | - | |
| Disabling right click | is_rightclick_available |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bu, S.-J.; Kim, H.-J. Optimized URL Feature Selection Based on Genetic-Algorithm-Embedded Deep Learning for Phishing Website Detection. Electronics 2022, 11, 1090. https://doi.org/10.3390/electronics11071090
Bu S-J, Kim H-J. Optimized URL Feature Selection Based on Genetic-Algorithm-Embedded Deep Learning for Phishing Website Detection. Electronics. 2022; 11(7):1090. https://doi.org/10.3390/electronics11071090
Chicago/Turabian StyleBu, Seok-Jun, and Hae-Jung Kim. 2022. "Optimized URL Feature Selection Based on Genetic-Algorithm-Embedded Deep Learning for Phishing Website Detection" Electronics 11, no. 7: 1090. https://doi.org/10.3390/electronics11071090
APA StyleBu, S.-J., & Kim, H.-J. (2022). Optimized URL Feature Selection Based on Genetic-Algorithm-Embedded Deep Learning for Phishing Website Detection. Electronics, 11(7), 1090. https://doi.org/10.3390/electronics11071090