
Efficient Low-Complexity Turbo-Hadamard Code in UAV Anti-Jamming Communications


Abstract
:1. Introduction
- 1.
- An improved turbo-Hadamard code based on tail-biting is proposed. The proposed codes outperform the conventional terminate-state-zeroturbo-Hadamard codes in terms of the coding gain and anti-jamming performance. Since we introduced no redundant bits, our algorithm has proven to be more efficient than other low-rate codes, especially in the UAV communication scenarios requiring extremely short code lengths.
- 2.
- A corresponding decoding scheme is proposed. For easy implementation on the hardware platforms of resource-limited UAVs, we employ addition operations instead of multiplication, division, exponential and logarithm operations. We prove that the proposed algorithm consumes fewer resources than the existing concatenated low-rate codes FPGA platform.
- 3.
- The expression of the computational complexity and transmission efficiency are given in closed form. Meanwhile, we analyze the complexity and efficiency of the proposed tail-biting turbo-Hadamard codes in detail.
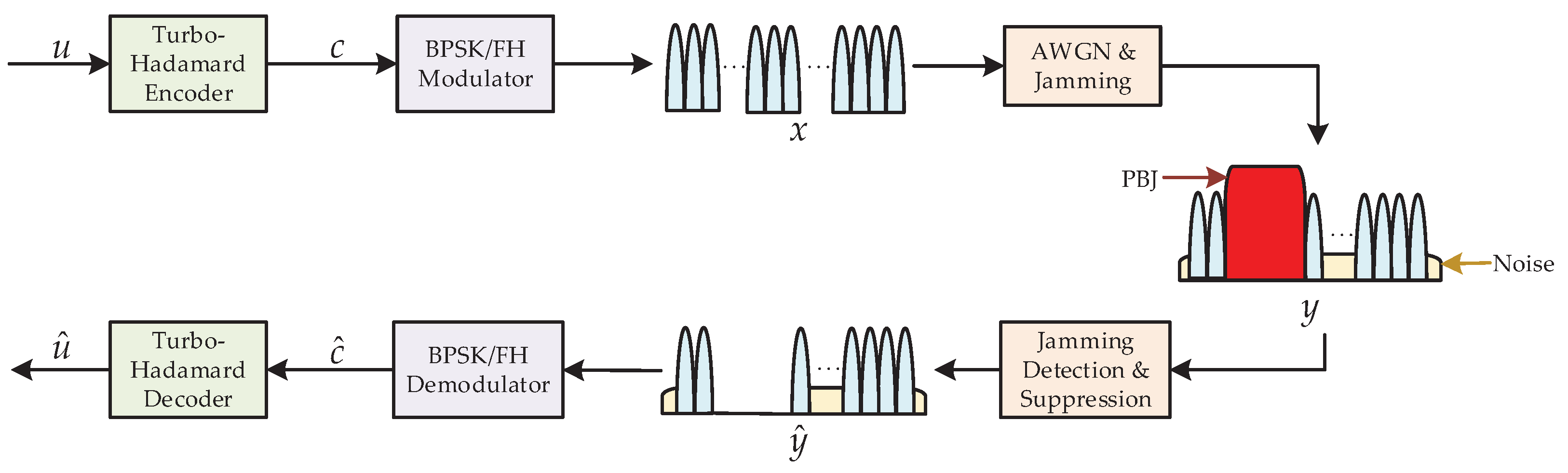
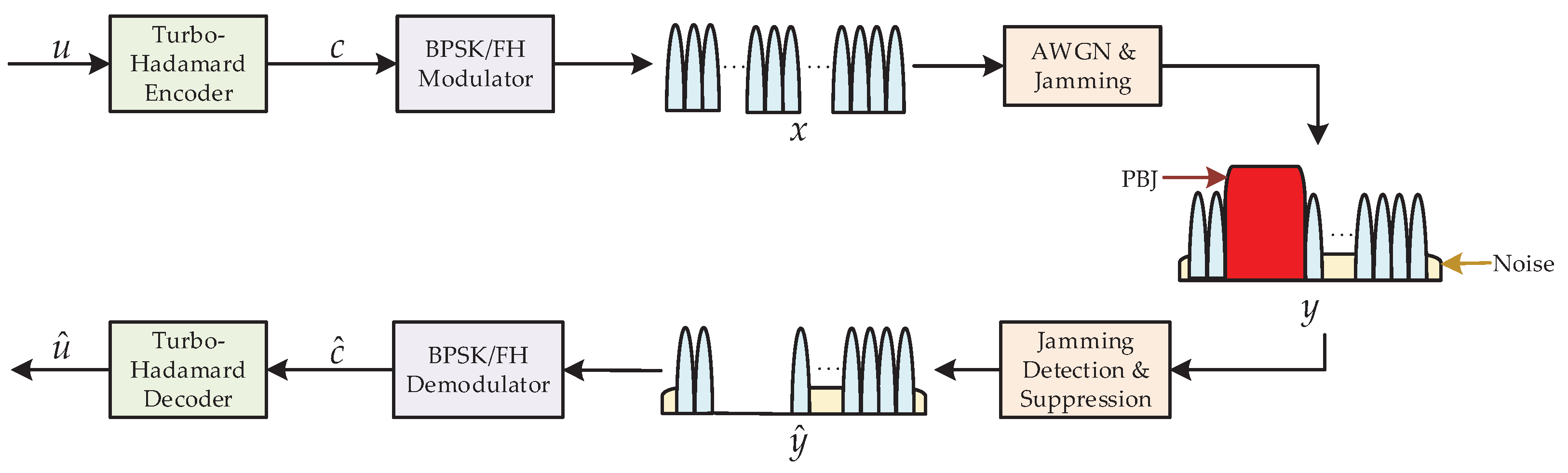
2. System Model
3. Low-Complexity Turbo-Hadamard Codes Based on Tail-Biting
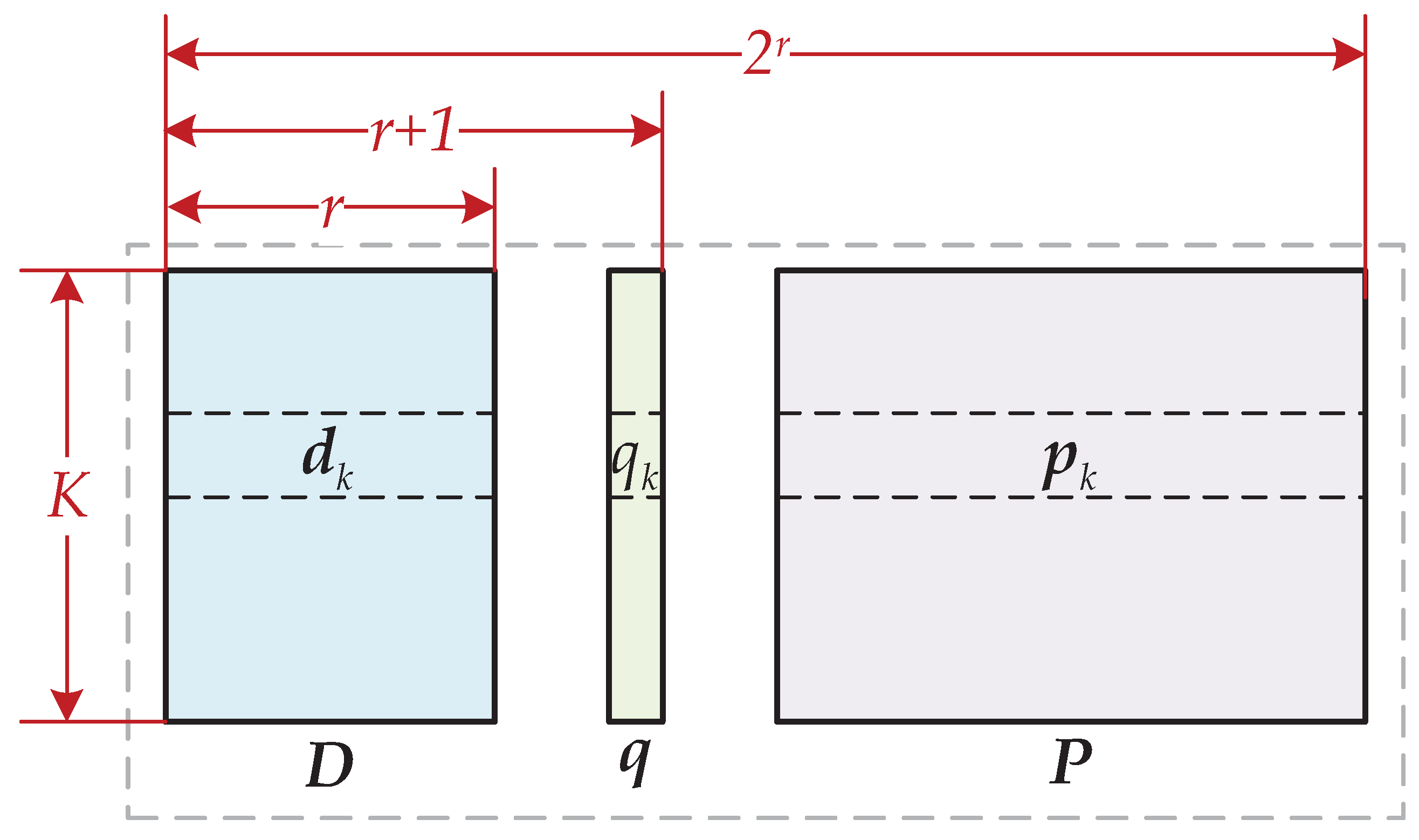
3.1. The Tail-Biting Convolutional-Hadamard Encoder
| Algorithm 1 Tail-Biting Convolutional-Hadamard Encoder Algorithm. |
| Input: Block information bit of size . Tail-biting convolutional generator . Output: Tail-biting convolutional-Hadamard code .
|
- Input: For ease of description, the length-W uncoded bits are segmented into . Each row consists of r bits, where r is the order of Hadamard codes. It is worth noting that .
- Line 3: Cyclic state is the key to keeping the convolutional trellis start state and end state once the input is . is calculated by with the initial state being all zeros. The details of how to generate are as follows, and as illustrated in Figure 2.The feedback coefficients of convolutional generator can be represented as the state recursive matrix . Moreover, if the generator is described in the mode of a fraction, the denominator of is denoted as . For example, the state recursive matrix of can be given byIt is essential to guarantee that the matrix is nonsingular, where denotes the order- identity matrix, denotes the memory depth of convolutional generator and denotes the inverse operator. Thus, we can obtain the final state after K-step precoding with from the state-0. The cyclic state is calculated bySince the precoder calculates the cyclic state of the convolutional code, the initial state and the terminal state of the convolutional code trellis are same. The states are explained as follows,
- Line 5: Encode length- using order-r Hadamard code, which outputs the length- bitstream .
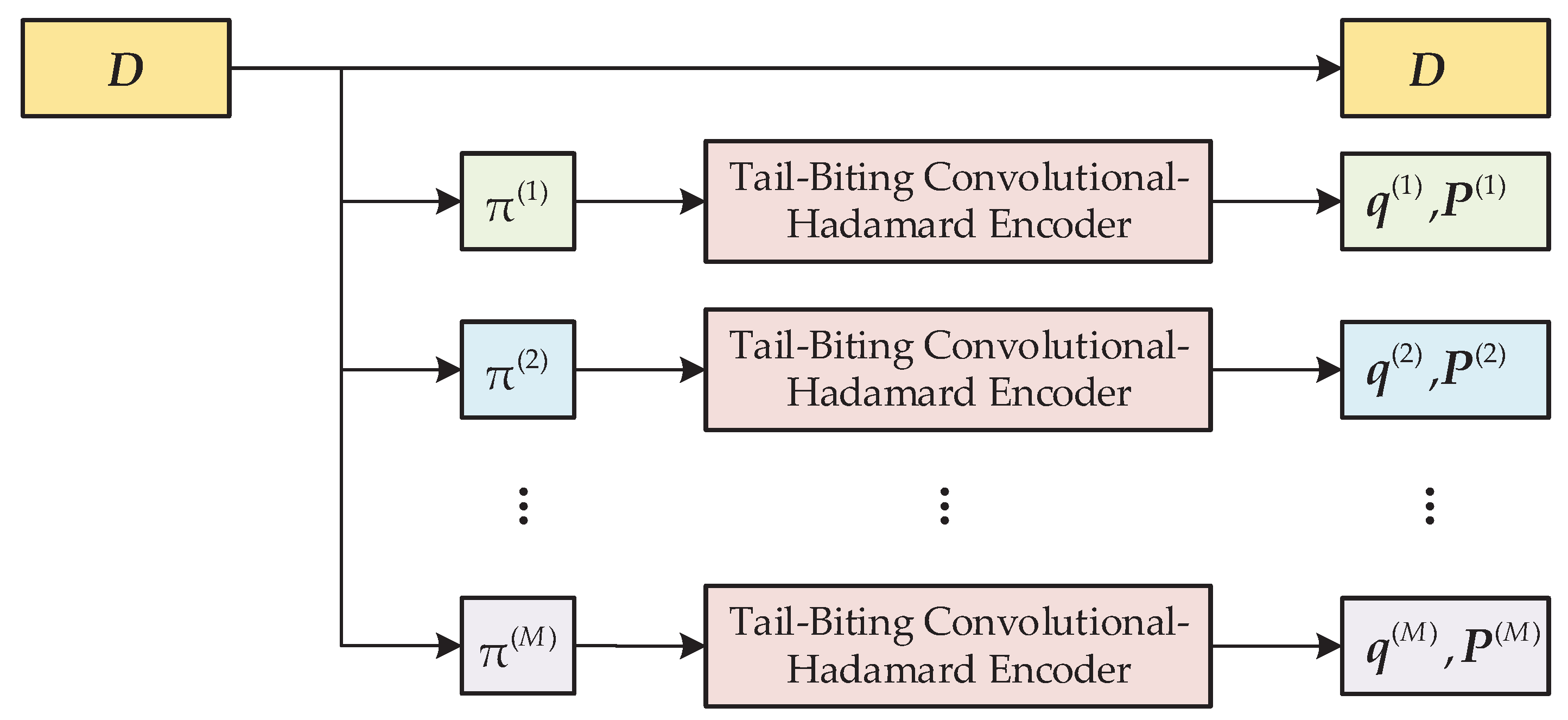
3.2. The Tail-Biting Turbo-Hadamard Encoder
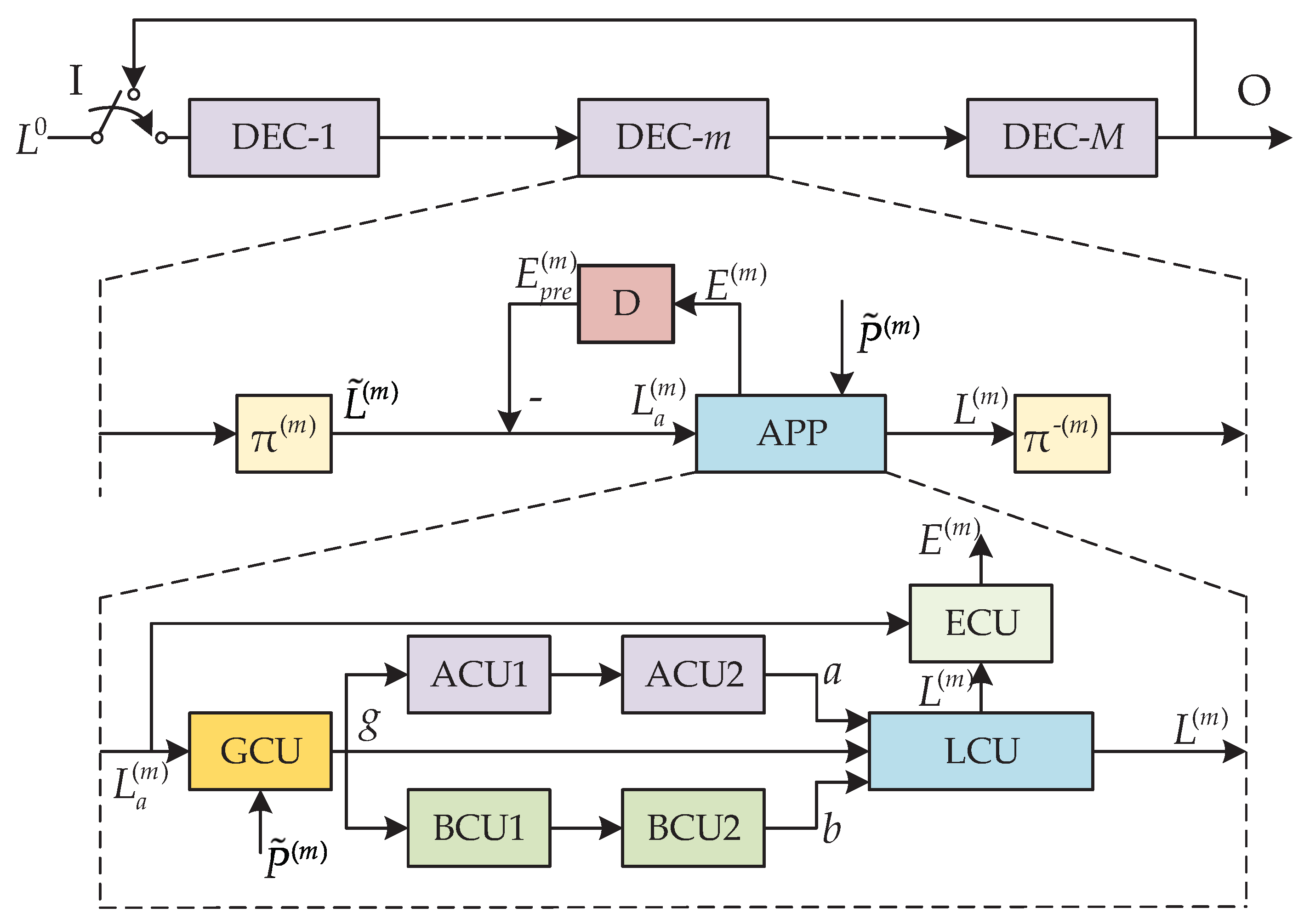
3.3. The Tail-Biting Turbo-Hadamard Decoder
| Algorithm 2 Tail-Biting Convolutional-Hadamard APP Decoder Algorithm. |
| Input: Block extrinsic prior LLR of information bits of size , and block prior LLR of parity bits of size . Output: Block extrinsic LLR of information bits of size , and block posterior LLR of information bits of size .
|
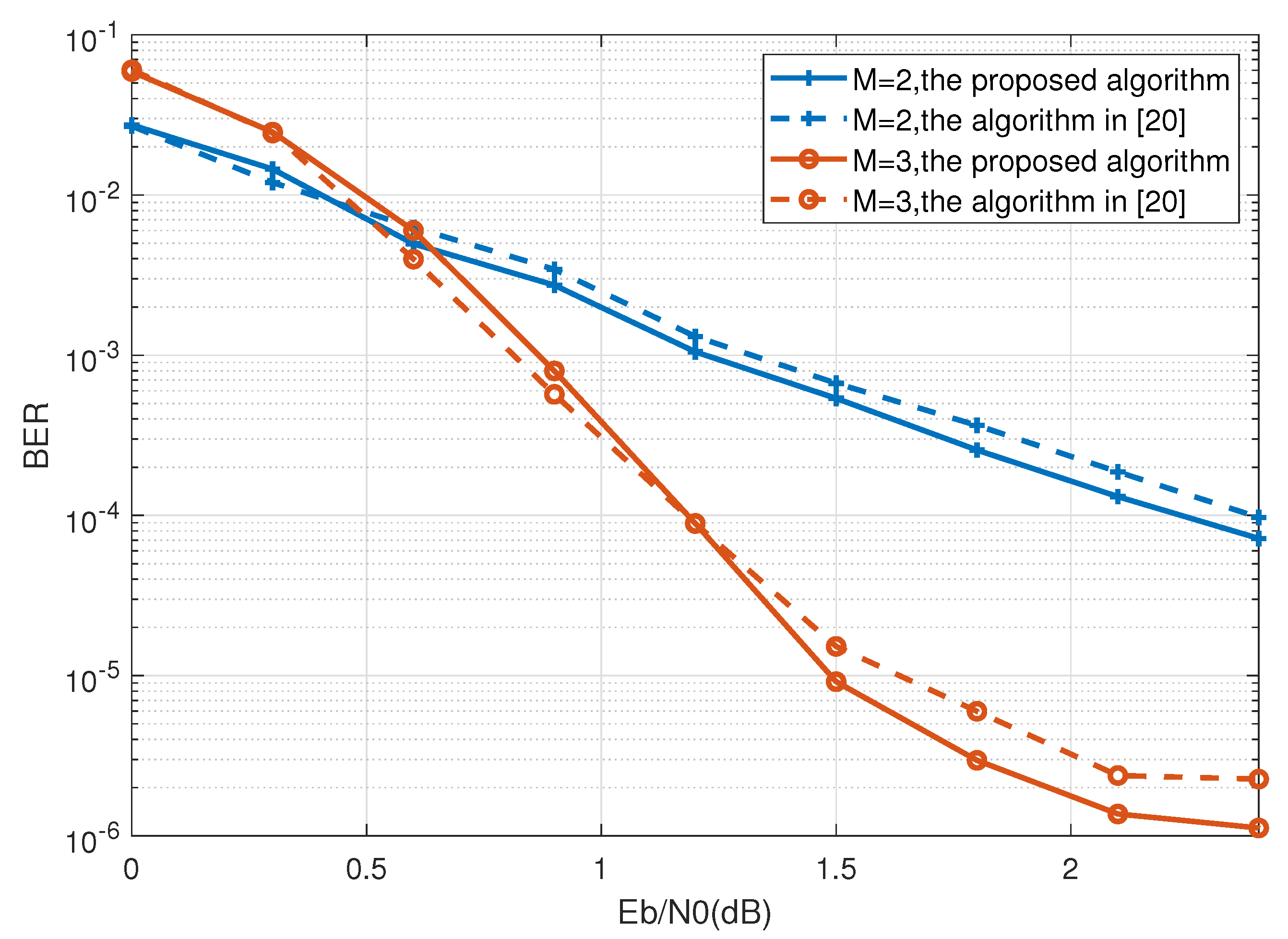
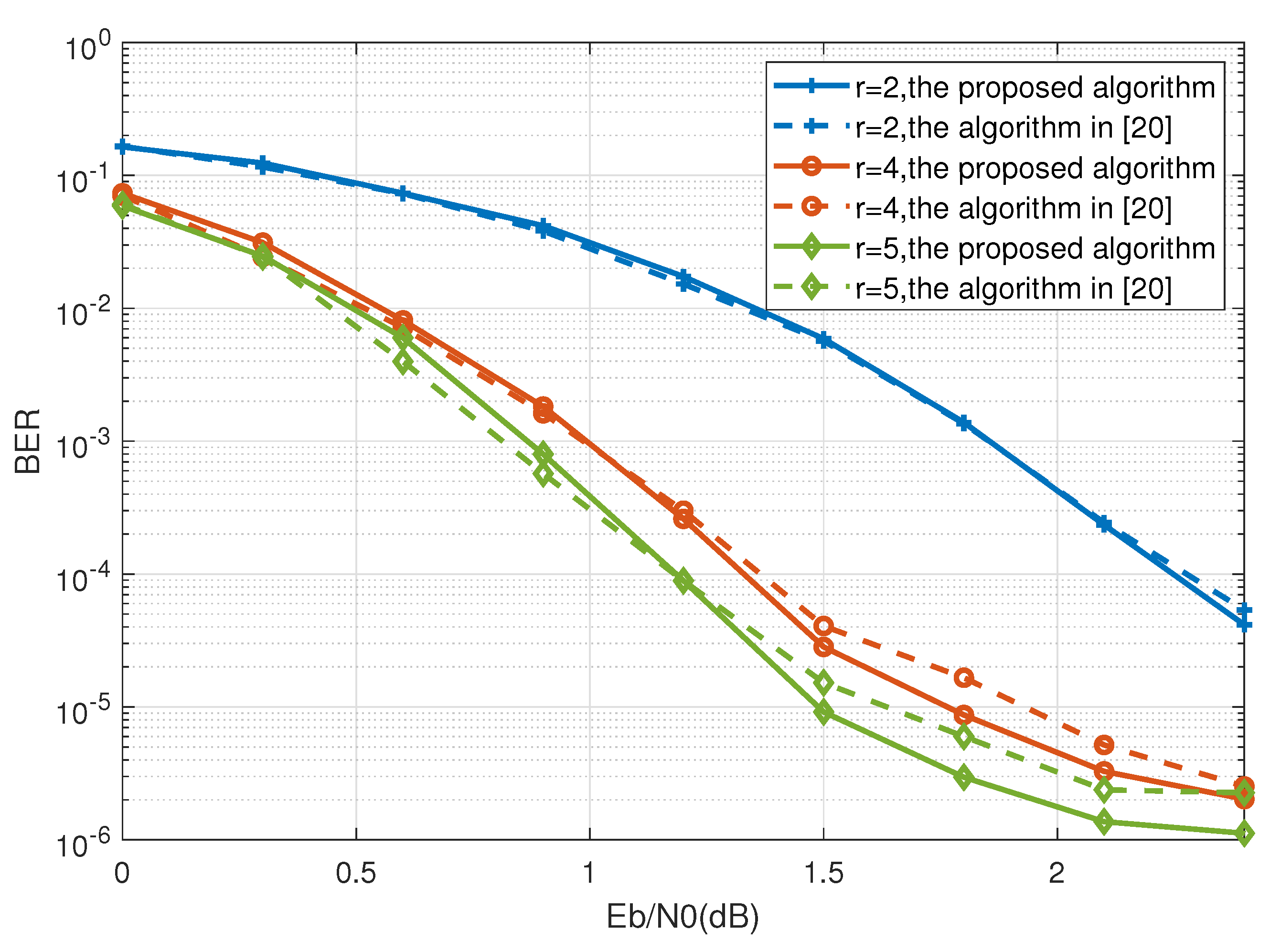
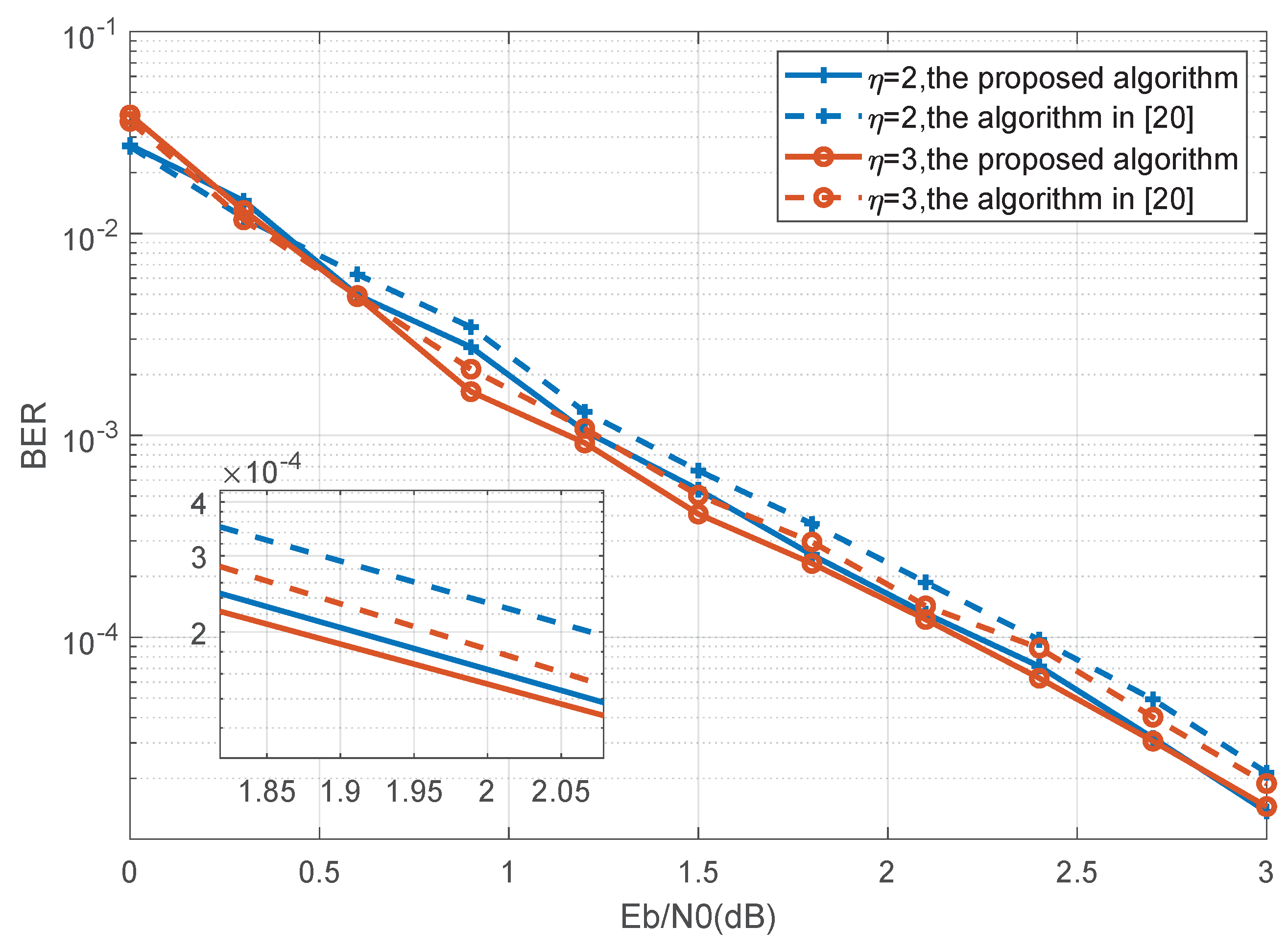
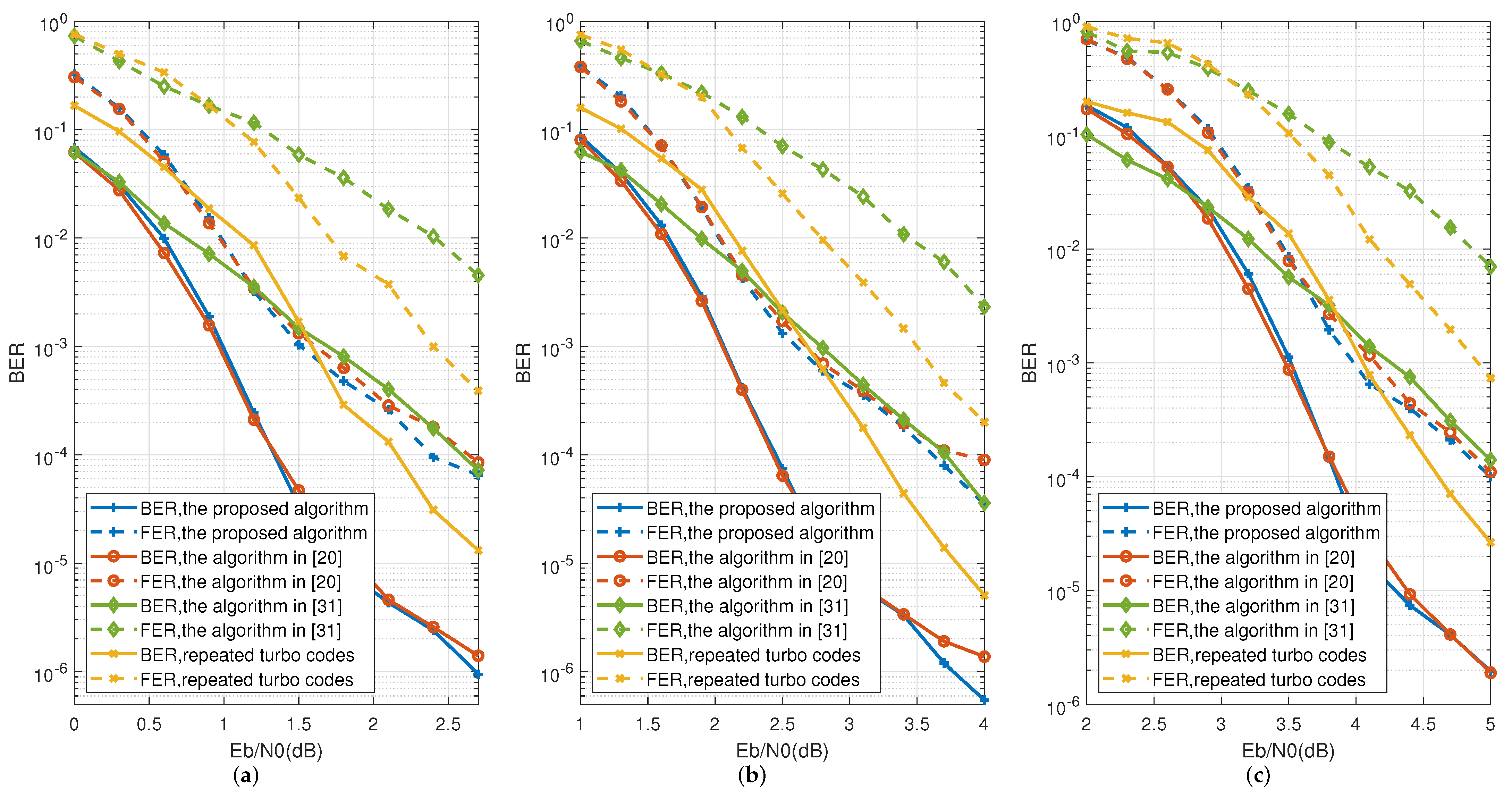
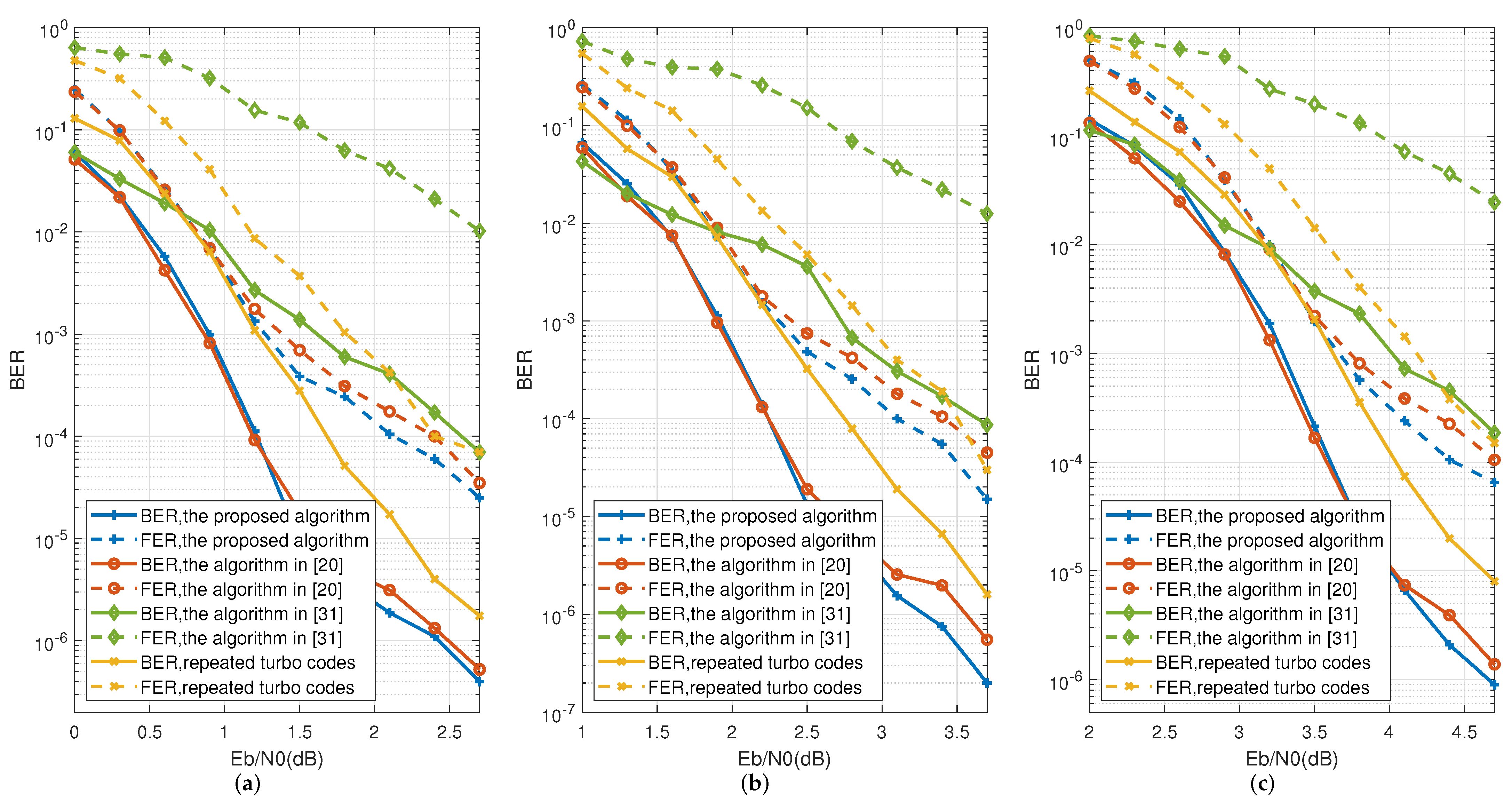
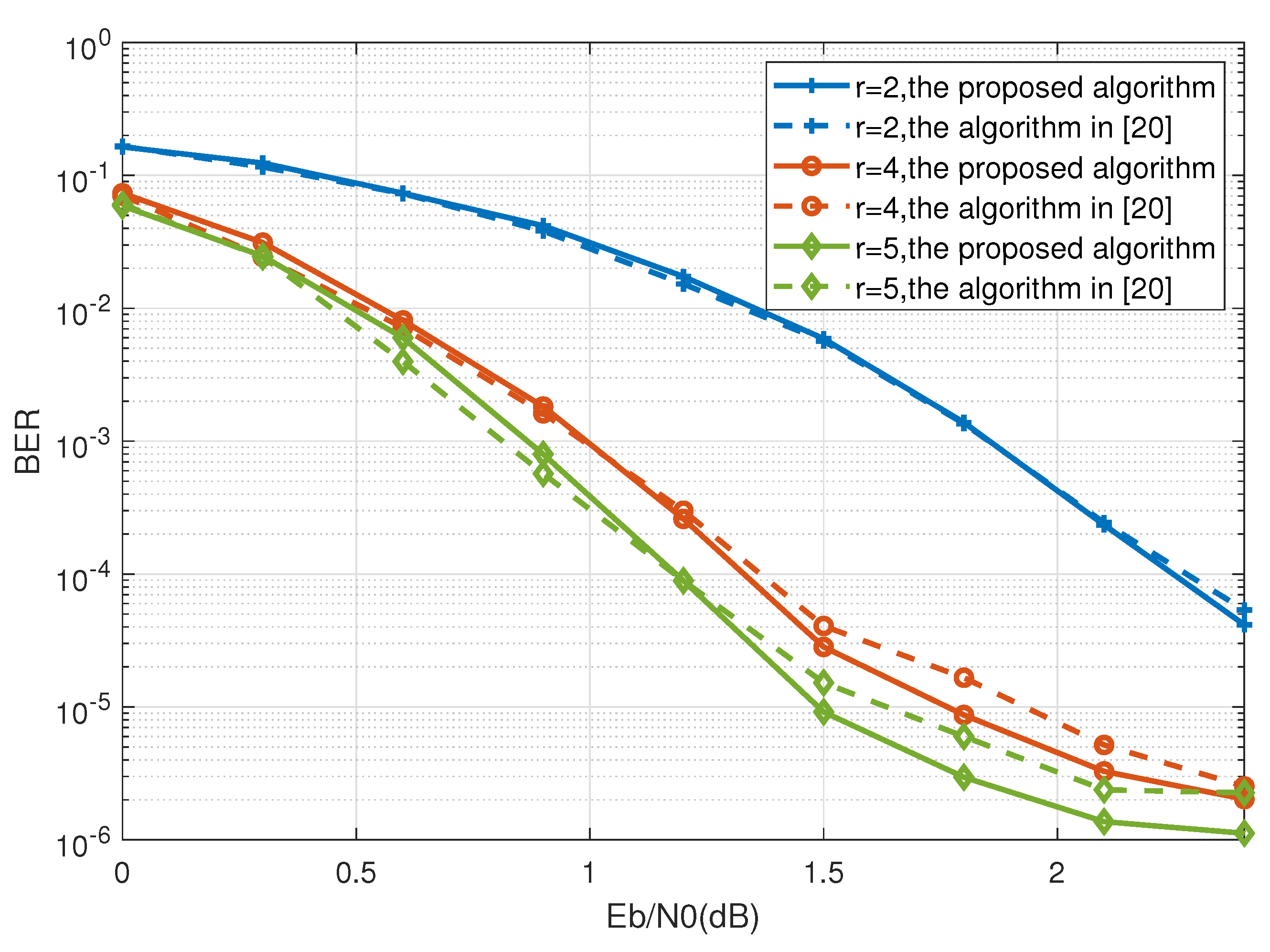
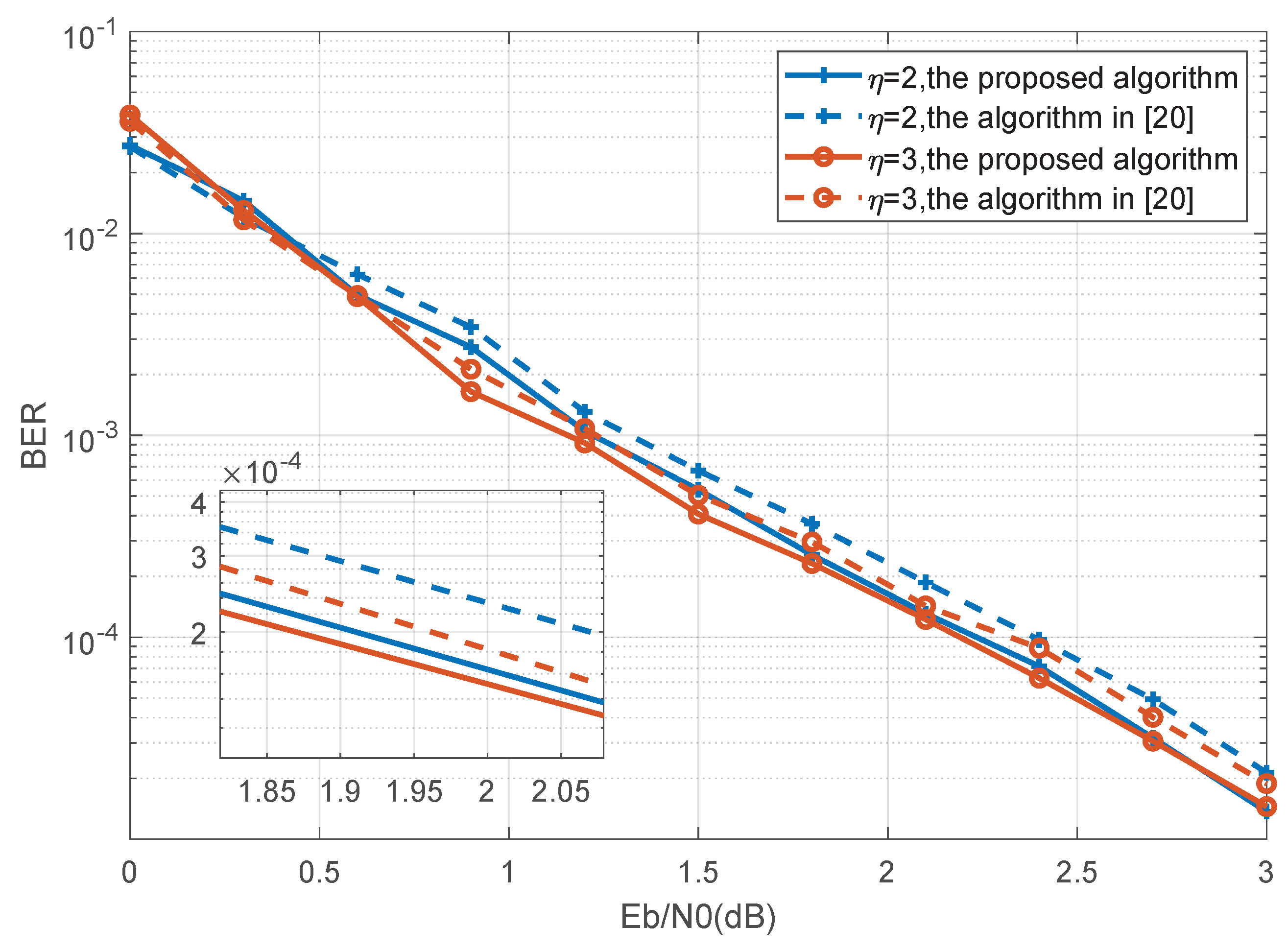
4. Simulation Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Iscold, P.; Pereira, G.A.S.; Torres, L.A.B. Development of a hand-launched small UAV for ground reconnaissance. IEEE Trans. Aerosp. Electron. Syst. 2010, 46, 335–348. [Google Scholar] [CrossRef]
- Semsch, E.; Jakob, M.; Pavlicek, D.; Pechoucek, M. Autonomous UAV surveillance in complex urban environments. In Proceedings of the 2009 IEEE/WIC/ACM International Joint Conference on Web Intelligence and Intelligent Agent Technology, Milan, Italy, 15–18 September 2009; Volume 2, pp. 82–85. [Google Scholar]
- Schesvold, D.; Tang, J.; Ahmed, B.M.; Altenburg, K.; Nygard, K.E. POMDP planning for high level UAV decisions: Search vs. strike. In Proceedings of the 16th International Conference on Computer Applications in Industry and Engineering, Las Vegas, NV, USA, 11–13 November 2003; pp. 1–4. [Google Scholar]
- Nguyen, L.D.; Nguyen, K.K.; Kortun, A.; Duong, T.Q. Real-time deployment and resource allocation for distributed UAV systems in disaster relief. In Proceedings of the 2019 IEEE 20th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Cannes, France, 2–5 July 2019; pp. 1–5. [Google Scholar]
- Gonzalo, P. Overview and current status of remote sensing applications based on unmanned aerial vehicles (UAVs). Am. Soc. Photogramm. Remote Sens. Photogramm. Eng. Remote Sens. 2015, 81, 281–330. [Google Scholar]
- Thibbotuwawa, A.; Bocewicz, G.; Nielsen, P.; Zbigniew, B. Planning deliveries with UAV routing under weather forecast and energy consumption constraints. In Proceedings of the 9th IFAC Conference on Manufacturing Modelling, Management and Control MIM, Berlin, Germany, 28–30 August 2019; Volume 52, pp. 820–825. [Google Scholar]
- Grover, K.; Lim, A.; Yang, Q. Jamming and anti–jamming techniques in wireless networks: A survey. Int. J. Ad Hoc Ubiquitous Comput. 2014, 17, 197–215. [Google Scholar] [CrossRef] [Green Version]
- Do, D.; Nguyen, T.T.; Le, C.; Voznak, M.; Kaleem, Z.; Rabie, A.K. UAV relaying enabled NOMA network with hybrid duplexing and multiple antennas. IEEE Access 2020, 8, 186993–187007. [Google Scholar] [CrossRef]
- Deng, D.; Li, X.; Menon, V.; Piran, M.J.; Chen, H.; Jan, M.A. Learning-based joint UAV trajectory and power allocation optimization for secure IoT networks. Digit. Commun. Netw. 2021. [Google Scholar] [CrossRef]
- Li, X.; Wang, Q.; Liu, Y.; Tsiftsis, T.A.; Ding, Z.; Nallanathan, A. UAV-aided multi-way NOMA networks with residual hardware impairments. IEEE Wirel. Commun. Lett. 2020, 9, 1538–1542. [Google Scholar] [CrossRef]
- Do, D.; Le, A.; Liu, Y.; Jamalipour, A. User grouping and energy harvesting in UAV-NOMA system with AF/DF relaying. IEEE Trans. Veh. Technol. 2021, 70, 11855–11868. [Google Scholar] [CrossRef]
- Yu, M.; Yu, L.; Li, C.; Xu, B. A time-frequency information based method for BSS output FH signal recognition. In Proceedings of the 2021 13th International Conference on Communication Software and Networks (ICCSN), Chongqing, China, 4–7 June 2021; pp. 343–347. [Google Scholar]
- Yang, K.; Zhang, B.; Wang, H.; Guo, D. The performance analysis of LDPC coded SFH/BPSK anti-jamming system. In Proceedings of the 2015 International Conference on Wireless Communications Signal Processing (WCSP), Nanjing, China, 15–17 October 2015; pp. 1–5. [Google Scholar]
- Xue, D.; Zhou, X. Performance study on a DS/FH hybrid system with concatenated coding in strong partial band noise. In Proceedings of the 2011 IEEE International Conference on Signal Processing, Communications and Computing (ICSPCC), Xi’an, China, 14–16 September 2011; pp. 1–6. [Google Scholar]
- Lee, Y.H. Concatenated codes in frequency-hopping spread-spectrum multiple access (FH-SSMA) packet radio communications. In Proceedings of the 2017 International Conference on Information and Communications (ICIC), Hanoi, Vietnam, 26–28 June 2017; pp. 264–265. [Google Scholar]
- Dai, J.; Xu, D.; Jing, Y. The performance of LDPC coded FFH/BFSK system over Rayleigh fading channel under multitone jamming. In Proceedings of the Fifth International Conference on Computing, Communications and Networking Technologies (ICCCNT), Dallas-Fortworth, TX, USA, 13–15 July 2014; pp. 1–5. [Google Scholar]
- Dai, J.; Jing, Y.; Yao, M. Analysis of LDPC code in the FH system with partial-band interference. IET Commun. 2017, 11, 2585–2595. [Google Scholar] [CrossRef]
- Herzog, R.; Hagenauer, J.; Schmidbauer, A. Soft-in/soft-out Hadamard despreader for iterative decoding in the IS-95(A) system. In Proceedings of the 1997 IEEE 47th Vehicular Technology Conference. Technology in Motion, Phoenix, AZ, USA, 4–7 May 1997; pp. 1219–1222. [Google Scholar]
- Berrou, C.; Glavieux, A.; Thitimajshima, P. Near Shannon limit error-correcting coding and decoding: Turbo-codes. 1. In Proceedings of the ICC ’93—IEEE International Conference on Communications, Geneva, Switzerland, 23–26 May 1993; pp. 1064–1070. [Google Scholar]
- Li, P.; Leung, W.K.; Wu, K.Y. Low-rate turbo-Hadamard codes. IEEE Trans. Inf. Theory 2003, 49, 3213–3224. [Google Scholar]
- Vaezi, M.; Azari, A.; Khosravirad, S.R.; Shirvanimoghaddam, M.; Azari, M.M.; Chasaki, D.; Popovski, P. Cellular, wide-area, and non-terrestrial IoT: A survey on 5G advances and the road towards 6G. IEEE Commun. Surv. Tutor. 2022. [Google Scholar] [CrossRef]
- Robertson, P.; Villebrun, E.; Hoeher, P. A comparison of optimal and sub-optimal MAP decoding algorithms operating in the log domain. In Proceedings of the IEEE International Conference on Communications ICC ’95, Seattle, WA, USA, 18–22 June 1995; pp. 1009–1013. [Google Scholar]
- Jiang, S.; Zhang, P.W.; Lau, F.C.M.; Sham, C.W.; Huang, K. A turbo-Hadamard encoder/decoder system with hundreds of Mbps throughput. In Proceedings of the 2018 IEEE 10th International Symposium on Turbo Codes Iterative Information Processing (ISTC), Hong Kong, China, 3–7 December 2018; pp. 1–5. [Google Scholar]
- Jiang, S.; Lau, F.C.M.; Sham, C.W. Hardware design of concatenated zigzag Hadamard encoder/decoder system with high throughput. IEEE Access 2020, 8, 165298–165306. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, Y.; Yu, B.; Diao, X.; Cai, Y. Minimizing age of information based on predictions and short packet communications in UAV relay systems. In Proceedings of the 2021 13th International Conference on Wireless Communications and Signal Processing (WCSP), Changsha, China, 20–22 October 2021; pp. 1–5. [Google Scholar]
- Ma, H.; Wolf, J. On tail biting convolutional codes. IEEE Trans. Commun. 1986, 34, 104–111. [Google Scholar] [CrossRef]
- Wu, X.; Yang, Z.; Yan, J.; Cui, J. Low-rate turbo-Hadamard coding approach for narrow-band interference suppression. In Proceedings of the 2014 IEEE International Conference on Communications (ICC), Sydney, NSW, Australia, 10–14 June 2014; pp. 2130–2134. [Google Scholar]
- Wu, X.; Yang, Z. Coding versus spreading for narrowband interference suppression. IEEE Trans. Veh. Technol. 2016, 65, 2129–2141. [Google Scholar] [CrossRef] [Green Version]
- Bahl, L.; Cocke, J.; Jelinek, F.; Raviv, J. Optimal decoding of linear codes for minimizing symbol error rate. IEEE Trans. Inf. Theory 1974, 20, 284–287. [Google Scholar] [CrossRef] [Green Version]
- Weiss, C.; Bettstetter, C.; Riedel, S. Code construction and decoding of parallel concatenated tail-biting codes. IEEE Trans. Inf. Theory 2001, 47, 366–386. [Google Scholar] [CrossRef]
- Leung, W.K.R.; Yue, G.; Li, P.; Wang, X. Concatenated zigzag Hadamard codes. IEEE Trans. Inf. Theory 2006, 52, 1711–1723. [Google Scholar] [CrossRef]


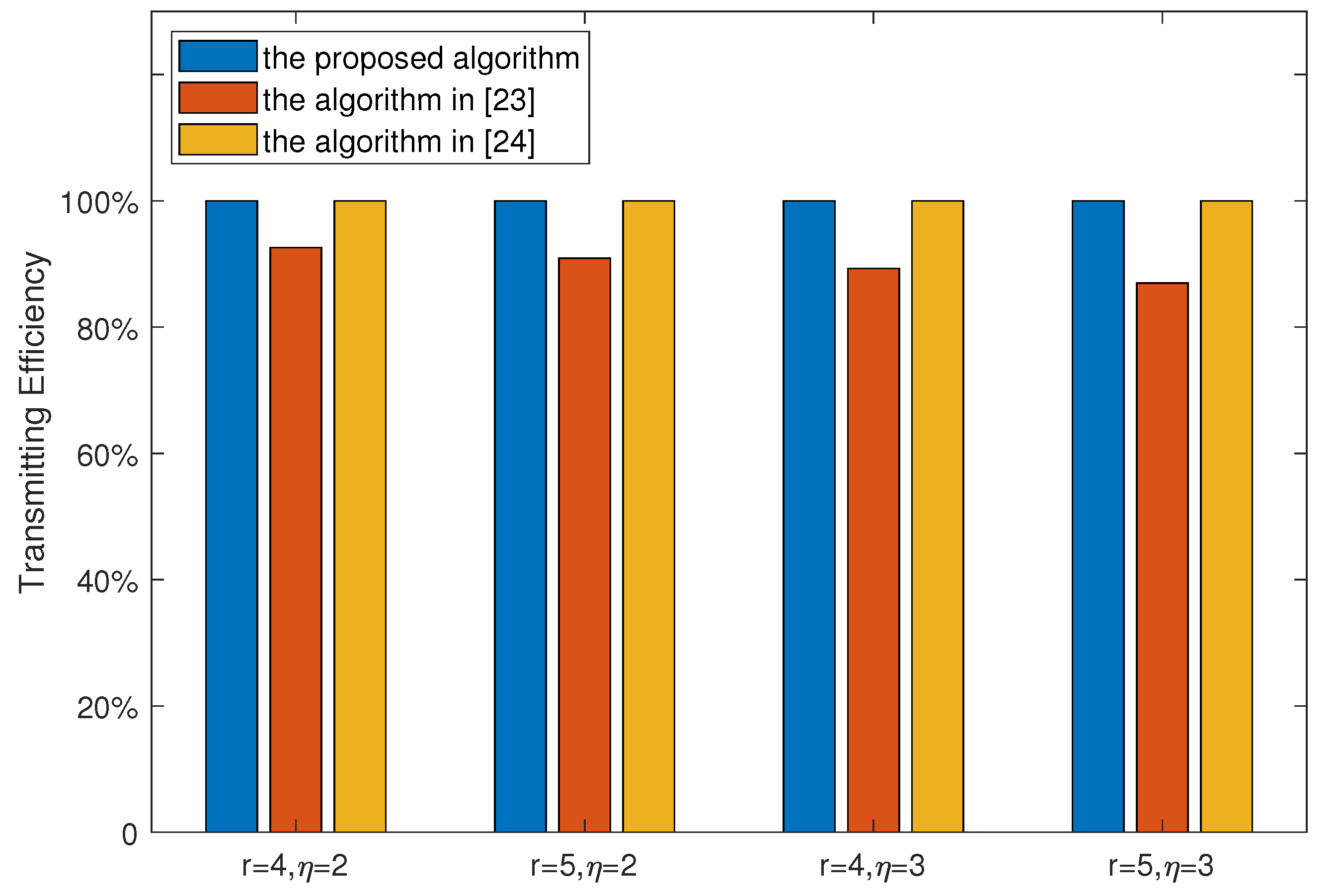

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Calculation Process | The Proposed Code | Code in [20] | Code in [31] |
|---|---|---|---|
| Branch Metric | ADD: | ADD: | ADD: |
| EXP: | EXP: | ||
| Full Branch Metric | ADD: | ADD: | - |
| Forward Recursion | ADD: | ADD: | ADD: |
| MULT: | DIV:K | ||
| LOG:K | |||
| Backward Recursion | ADD: | ADD: | ADD: |
| MULT: | DIV:K | ||
| LOG:K | |||
| LLR of Information Bits | ADD: | ADD: | ADD: |
| MULT: | DIV: | ||
| DIV: | LOG: | ||
| LOG: | |||
| Total | ADD: | ADD: | ADD: |
| MULT: | DIV: | ||
| DIV: | EXP: | ||
| EXP: | LOG: | ||
| LOG: |
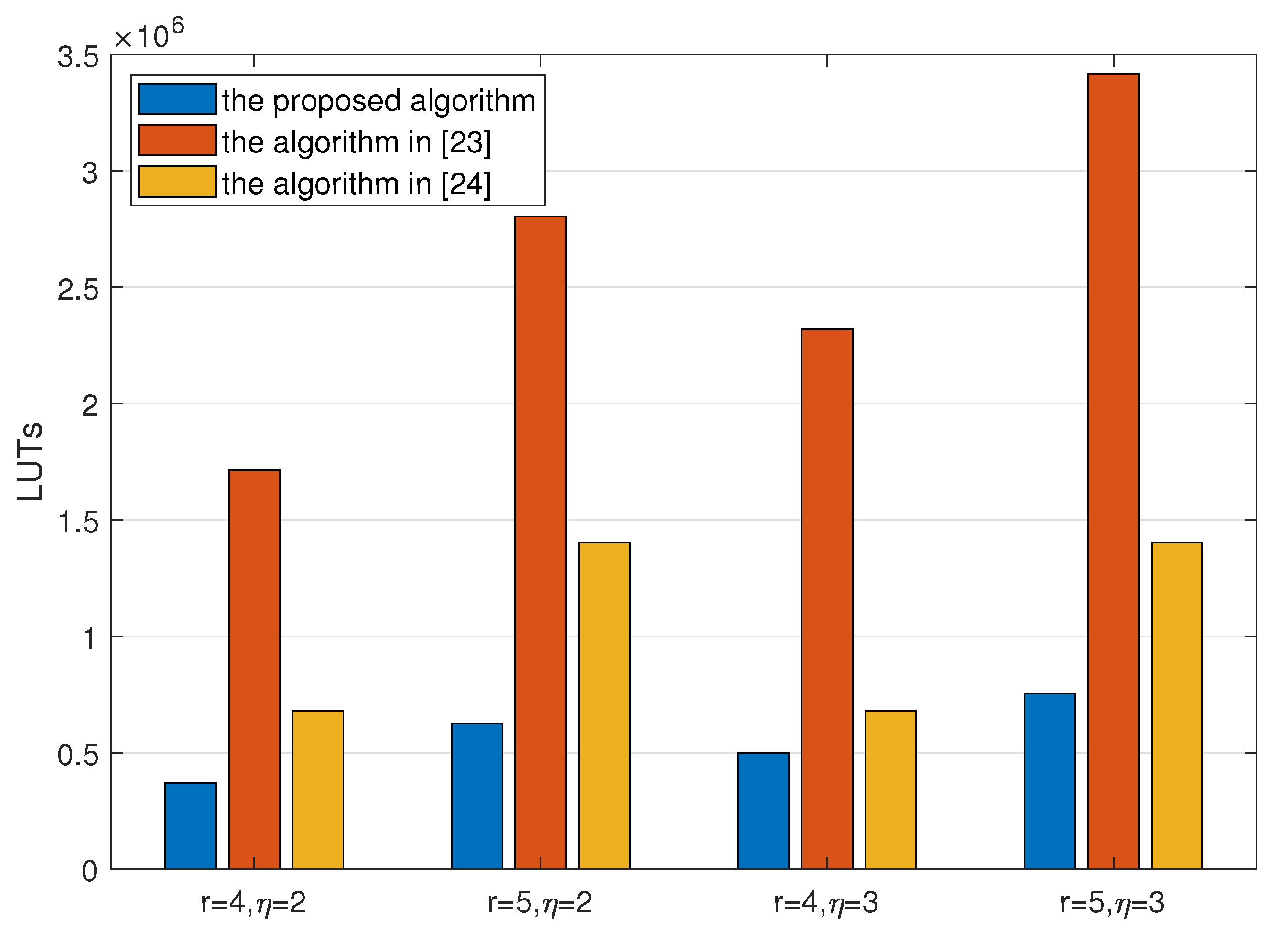
| Code Parameters | The Proposed Code | Code in [20] | Code in [31] |
|---|---|---|---|
| k = 200, r = 4, = 2 | 370,000 LUTs | 1,712,960 LUTs | 679,200 LUTs |
| 1.0 BRAMs | 1.0 BRAMs | ||
| k = 200, r = 5, = 2 | 626,000 LUTs | 2,805,376 LUTs | 1,402,400 LUTs |
| 1.0 BRAMs | 1.0 BRAMs | ||
| k = 200, r = 4, = 3 | 498,000 LUTs | 2,319,072 LUTs | 679,200 LUTs |
| 1.0 BRAMs | 1.0 BRAMs | ||
| k = 200, r = 5, = 3 | 754,000 LUTs | 3,416,896 LUTs | 1,402,400 LUTs |
| 1.0 BRAMs | 1.0 BRAMs |
| Parameter | Value |
|---|---|
| System Clock | 245.76 MHz |
| Symbol Rate | 0.96 MHz |
| Interpolation Rate | 256 |
| Modulation Filter | Root Raised Cosine |
| Roll-Off Factor | 0.35 |
| Frequency Hopping Numbers | 200 |
| Frequency Hopping Rate | 960,000 hop/s |
| Total Bandwidth | 192 MHz |
| Interference Bandwidth | 38.4 MHz, 76.8 MHz |
| Proportion of Jammed Frequency Bins | 20%, 40% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dong, X.; He, M.; Yang, X.; Miao, X. Efficient Low-Complexity Turbo-Hadamard Code in UAV Anti-Jamming Communications. Electronics 2022, 11, 1088. https://doi.org/10.3390/electronics11071088
Dong X, He M, Yang X, Miao X. Efficient Low-Complexity Turbo-Hadamard Code in UAV Anti-Jamming Communications. Electronics. 2022; 11(7):1088. https://doi.org/10.3390/electronics11071088
Chicago/Turabian StyleDong, Xinhu, Minjue He, Xuanhe Yang, and Xiaqing Miao. 2022. "Efficient Low-Complexity Turbo-Hadamard Code in UAV Anti-Jamming Communications" Electronics 11, no. 7: 1088. https://doi.org/10.3390/electronics11071088
APA StyleDong, X., He, M., Yang, X., & Miao, X. (2022). Efficient Low-Complexity Turbo-Hadamard Code in UAV Anti-Jamming Communications. Electronics, 11(7), 1088. https://doi.org/10.3390/electronics11071088