
Selection and Optimization of Hyperparameters in Warm-Started Quantum Optimization for the MaxCut Problem


Abstract
:1. Introduction
2. Related Work
2.1. Warm-Starting
2.2. Alternative Objective Functions for QAOA
2.3. Layer-Wise Training
3. Background
3.1. Quantum Algorithms in the NISQ Era
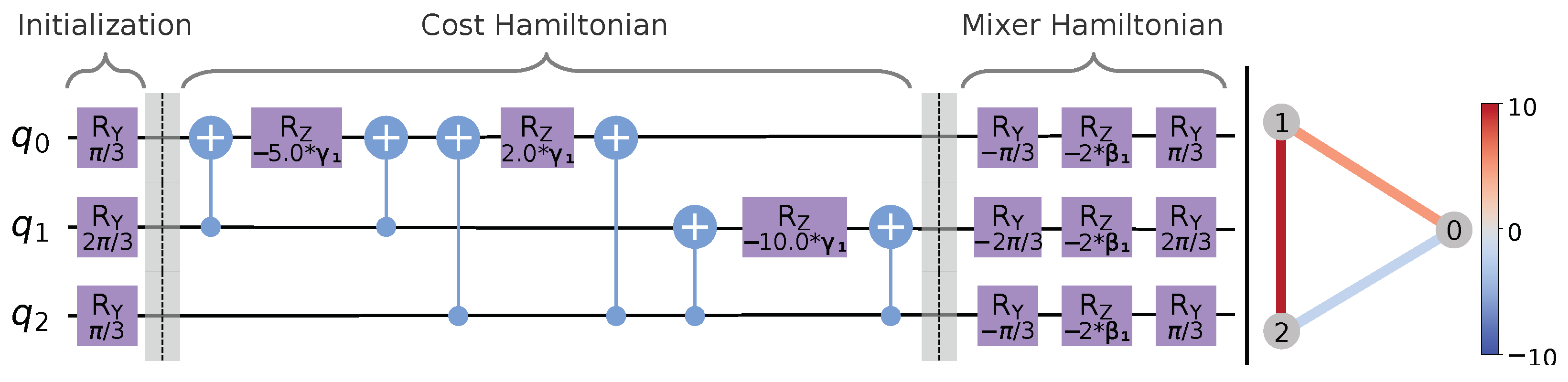
3.2. The Quantum Approximate Optimization Algorithm
3.3. Warm-Started QAOA for Maximum Cut
4. Motivation and Research Questions
- RQ1:
- “How does the regularization parameter ε influence the solution quality, and is it possible and meaningful to delegate the adjustment of ε to a classical optimizer?”
- RQ2:
- “How do different optimization strategies for WS-QAOA influence the solution quality and runtime of the optimization?”
- RQ3:
- “Which alternative objective functions apart from the energy expectation value are suitable for WS-QAOA, and how do they correlate with the solution quality, and are objective functions without additional hyperparameters practical?”
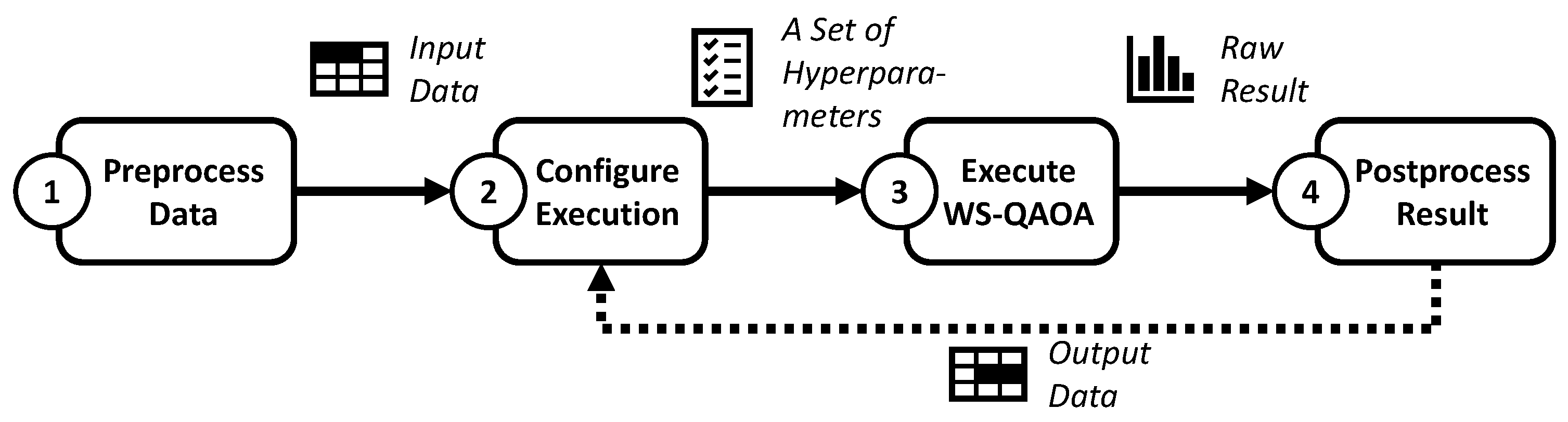
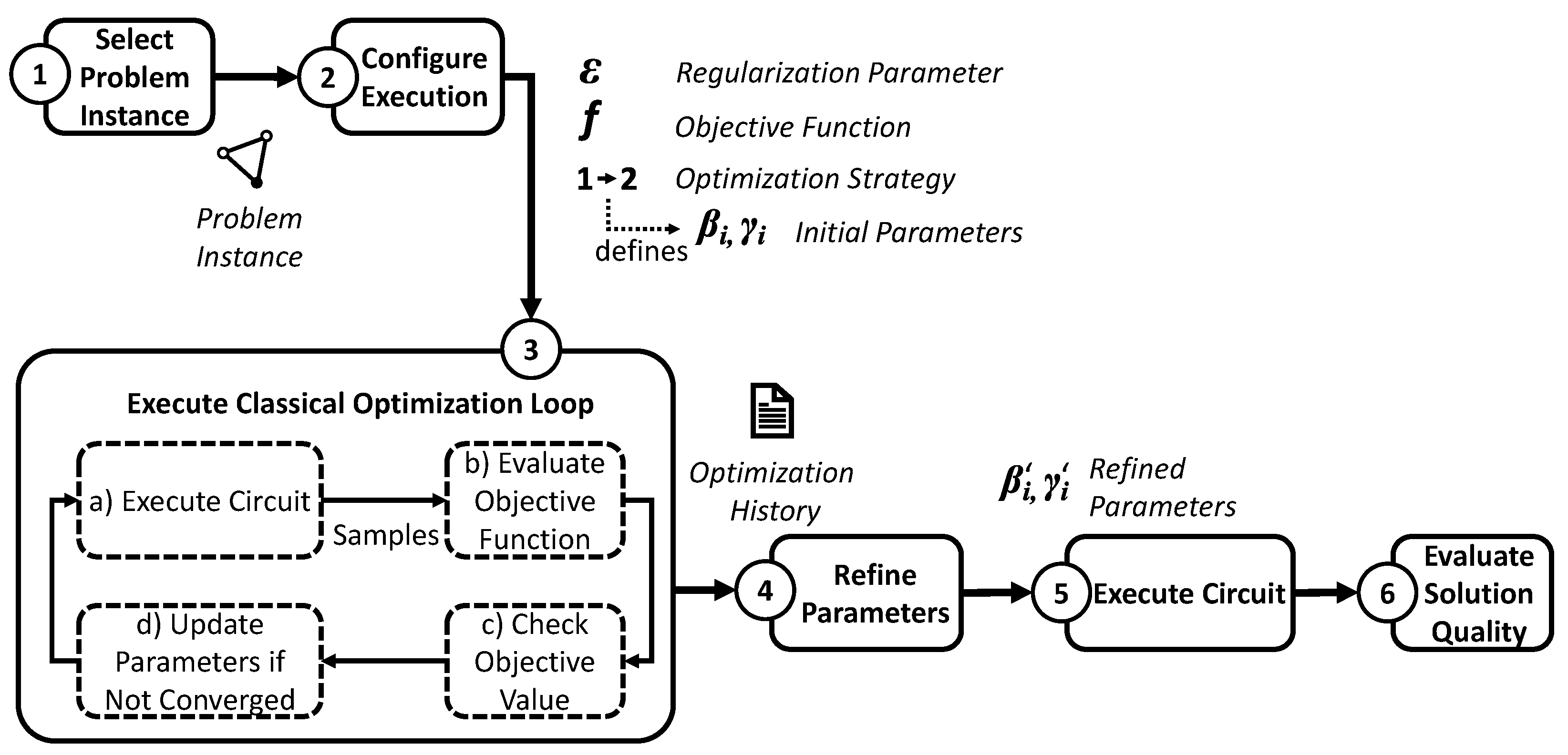
5. Research Design
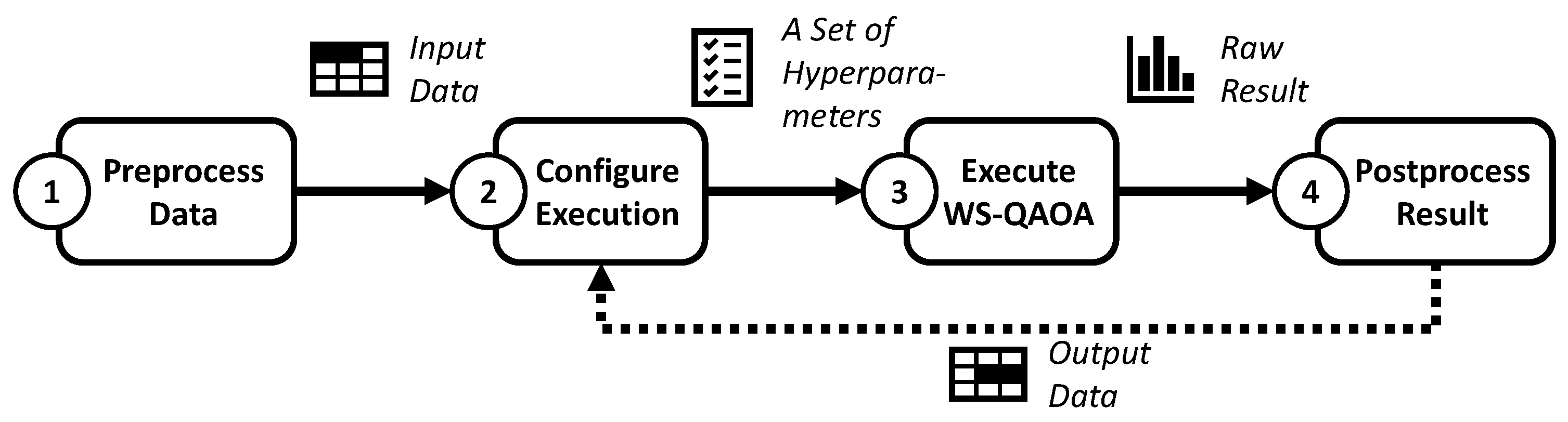
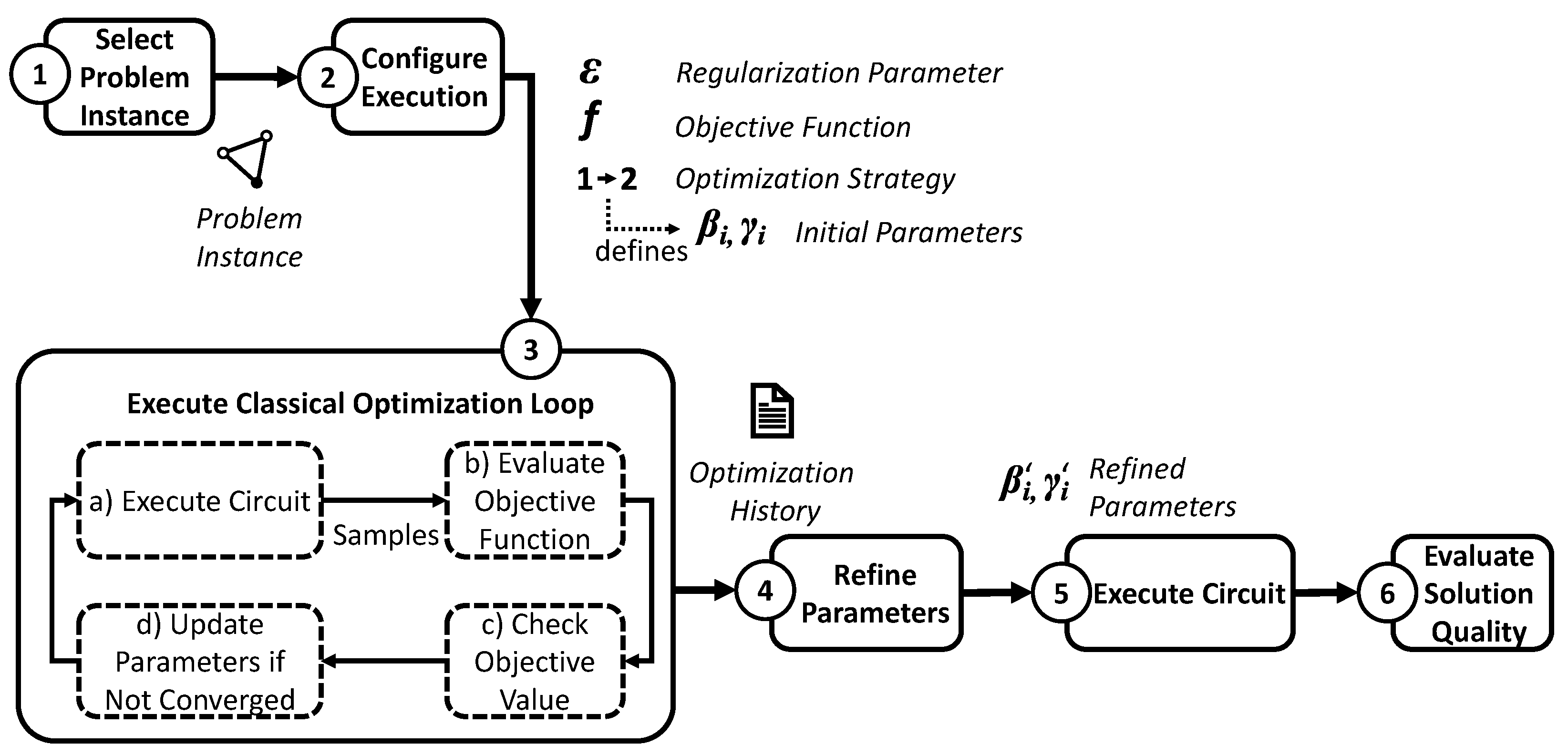
5.1. Overview of the Evaluation Process
5.2. Experiment Designs
- Experiment 1: Influence of the regularization parameter
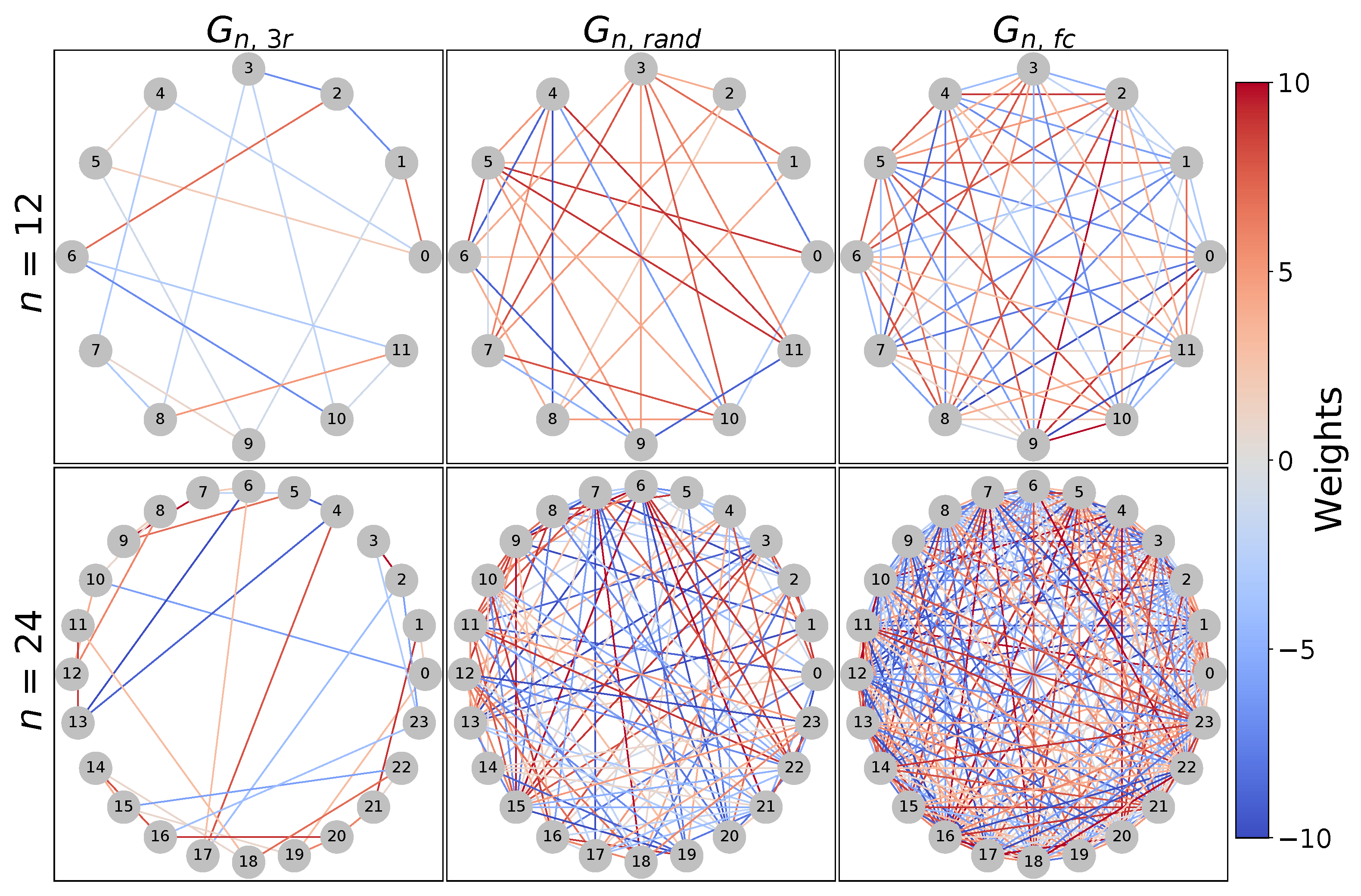
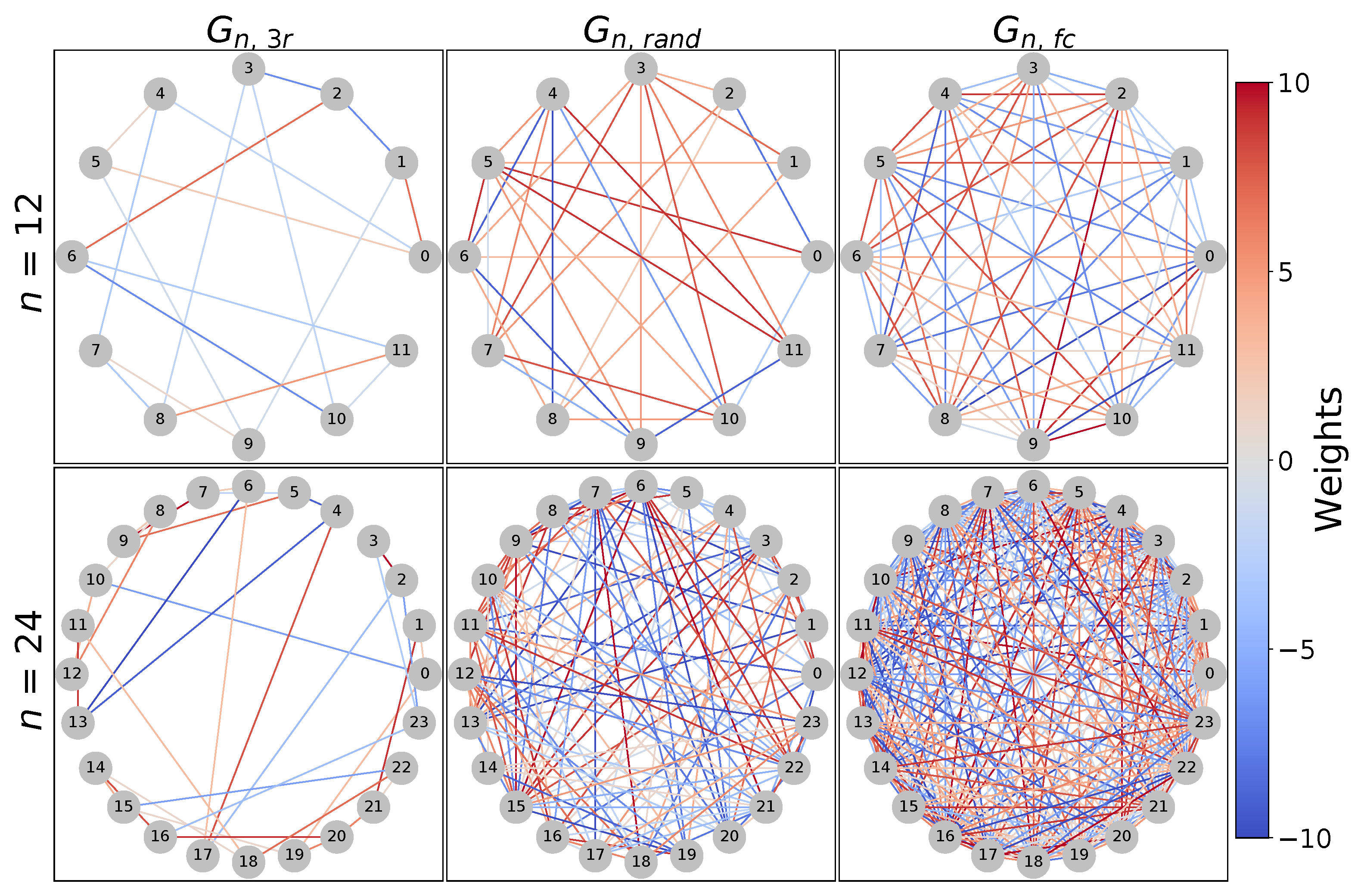
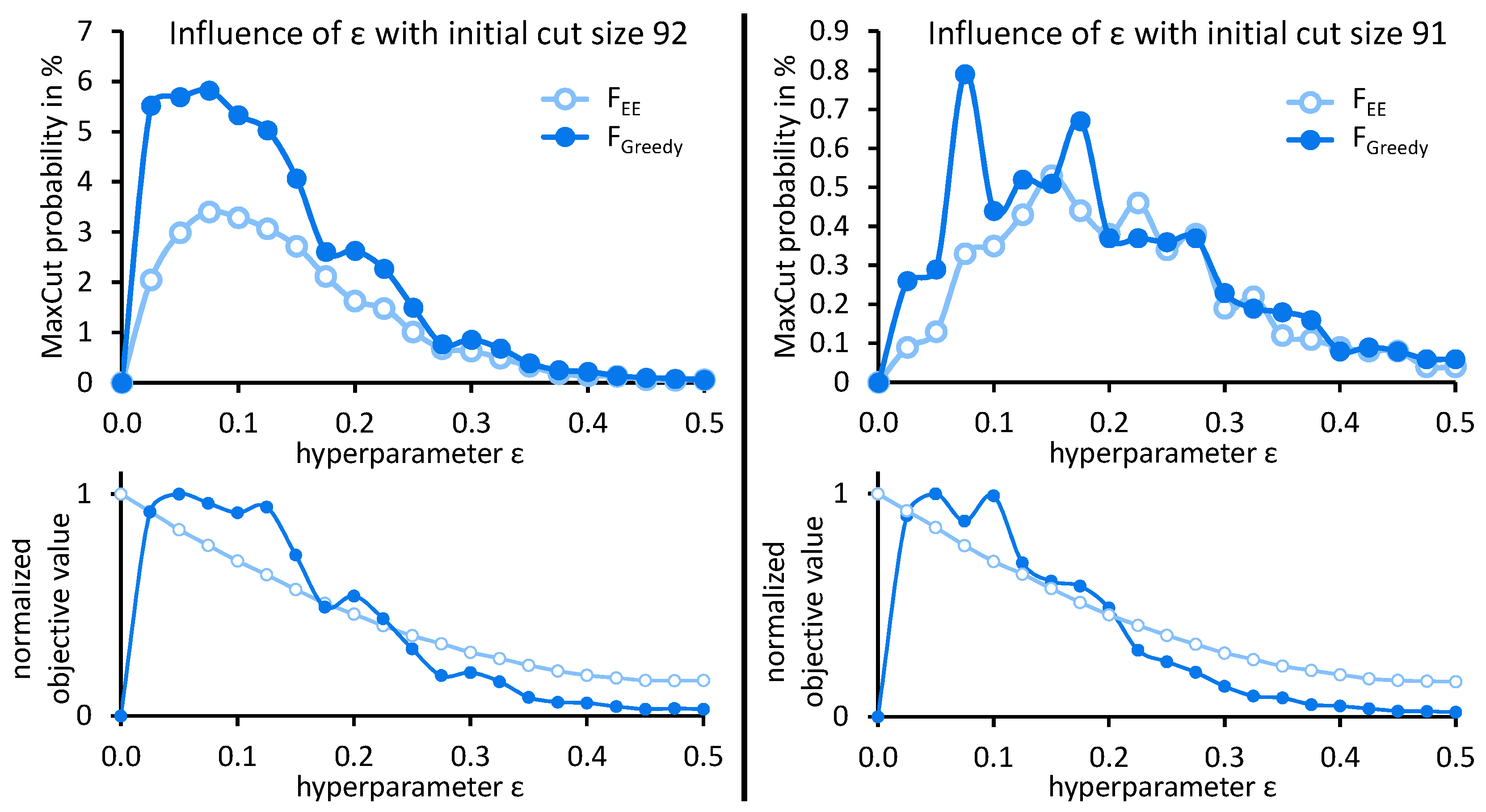
- As the input for WS-QAOA for MaxCut, we use the generated problem instances, each comprising a graph and an initial cut for this graph. For this experiment, we exemplarily focus on as a graph with medium difficulty in our set of generated graphs (Figure 3). The problem instances for this experiment consist of this graph combined with two different initial cuts of size 91 and 92, respectively, as presented in Table 1. Both cuts are below an approximation ratio of , thus creating problem instances for a realistic warm-starting scenario.
- For each of these problem instances, we sequentially fix the regularization parameter to each value in the range of and execute the WS-QAOA algorithm for depth 1 (depth-1 WS-QAOA) using as the objective function.
- We compute the median MaxCut probability achieved with optimized parameters from multiple replications of these executions in order to learn how the MaxCut probability correlates with for different problem instances. Multiple replications are necessary to mitigate the randomness in the measurement of quantum states.
- Finally, to investigate the suitability of the objective functions for delegation of the adjustment of to the classical optimizer, we analyze the correlation of median objective values achieved in each setting with the MaxCut probability. If the values for a high MaxCut probability coincide with high objective values, the classical optimizer could be used to determine based on the objective value.
- Experiment 2: Comparison of Alternative Optimization Strategies
- Depth-0 through depth-3 WS-QAOA are executed and optimized as prescribed by each optimization strategy. Depth-0 WS-QAOA is equivalent to merely sampling solutions from the initialized biased superposition. The regularization value is fixed to an arbitrary value for this experiment to focus on the comparison of optimization strategies for the circuit parameter optimization. and are used, exemplarily, as the objective functions.
- For each depth, we record the number of epochs of the optimization loop as a platform-independent measure for execution time, i.e., the time span taken for the optimization, and the median MaxCut and BetterCut probabilities are determined using the optimized parameters from multiple replications of the optimization loop in order to assess the performance of the optimization strategies.
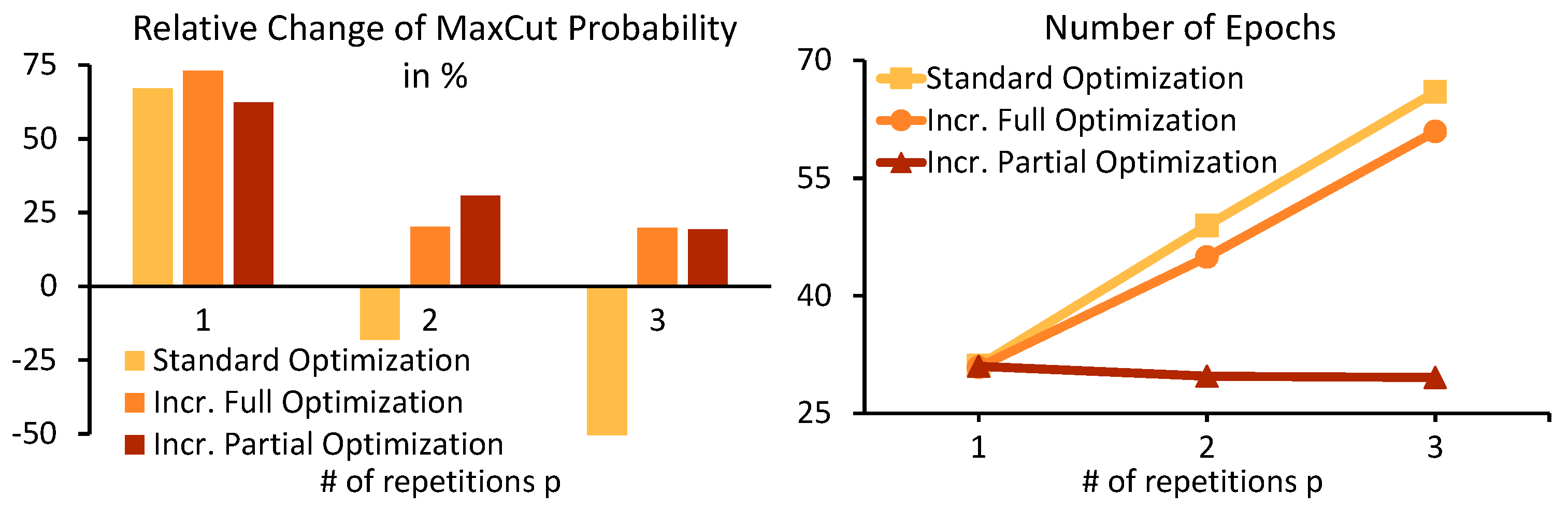
- Additionally, we repeat the same experiment with multiple newly generated problem instances in order to generalize the results obtained for . Therefore, we generate 20 new graphs of each kind (, , and ) and run GW 250 times for each graph. From the resulting list of generated cuts sorted by their cut size, we select the first one of cut size below as the initial cut. For comparability between problem instances, the relative change of the MaxCut probability obtained from depth-0 to depth-1, depth-1 to depth-2, and depth-2 to depth-3 WS-QAOA is considered to assess the suitability of the optimization strategies. The optimization strategies should be able to produce an overall high MaxCut probability, that increases with the depth of the QAOA circuit, and require a low number of optimization epochs, i.e., a short execution time, which indicates high efficiency.
- Experiment 3: Evaluation of Alternative Objective Functions
- We run depth-3 WS-QAOA on each graph and for each objective function. Since we focus on the different objective functions, the optimization strategy is fixed to the most suitable of the three optimization strategies from Experiment 2. Further, we employ the strategy for selecting a viable regularization value as obtained in Experiment 1.
- The median MaxCut and BetterCut probabilities from multiple replications are computed and compared to determine the suitability of objective functions with respect to the obtained solution quality.
6. Results
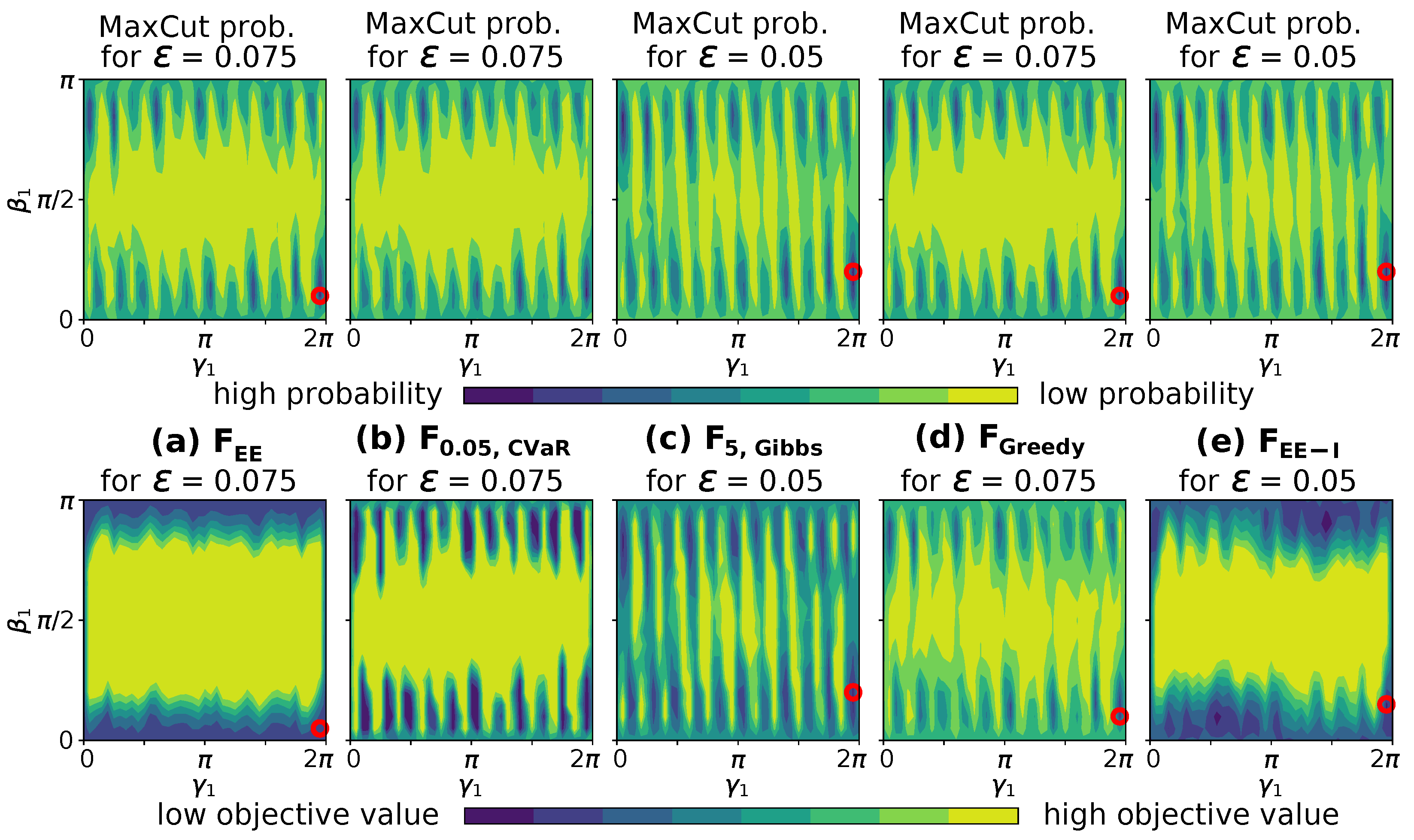
6.1. Experiment 1 Results: Influence of the Regularization Parameter
- The initial cut affects the solution quality independent of the objective function. A minor change in cut size can significantly change MaxCut probabilities.
- Viable regularization values depend on the objective function in use, thus making the selection of specific to the objective function at hand.
- Classical optimizers may be usable with some objective functions to optimize the regularization parameter , however, not with and .
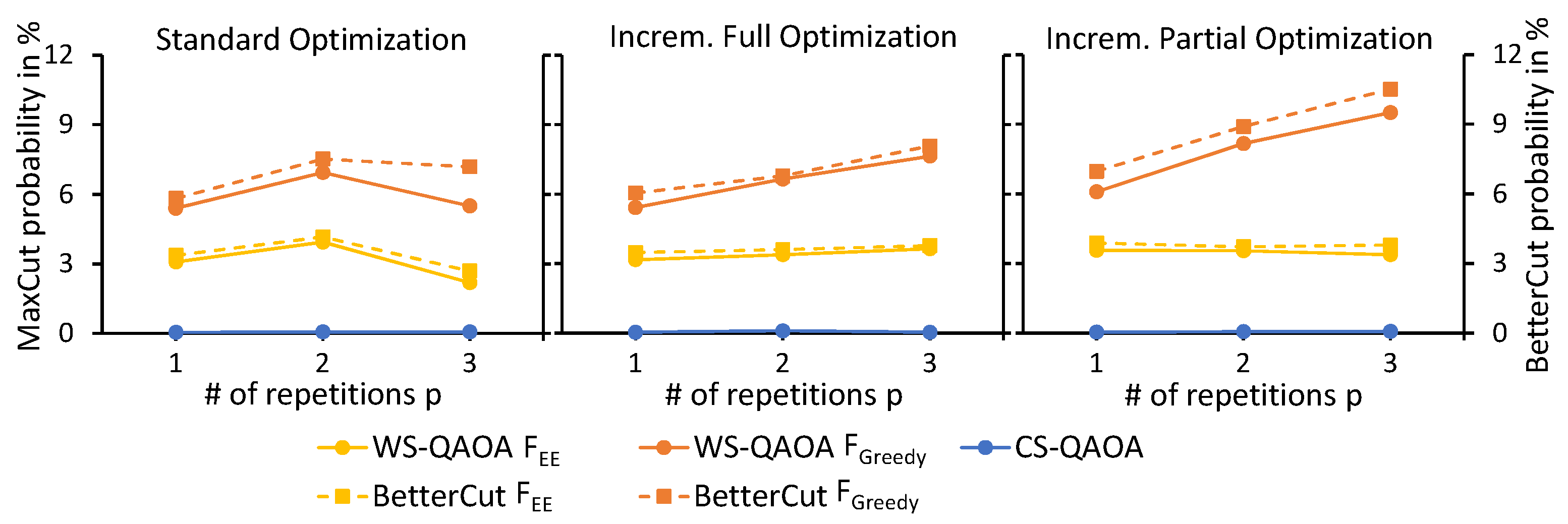
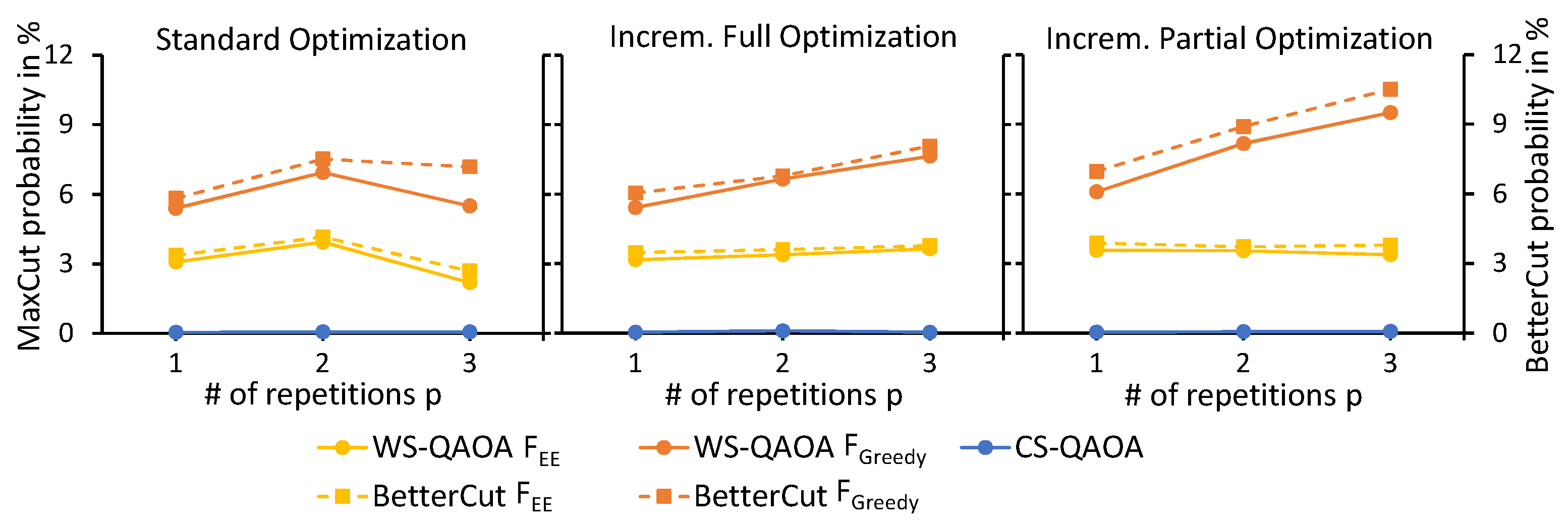
6.2. Experiment 2 Results: Comparison of Alternative Optimization Strategies
- Incremental full and incremental partial optimization lead to higher MaxCut and BetterCut probabilities than the standard optimization strategy.
- Incremental partial optimization requires less epochs of the optimizer than incremental full optimization, thus making it the least resource consuming of both incremental optimization strategies.
- Although the energy expectation objective value () improves, the MaxCut and BetterCut probability may decrease at the same time, indicating a poor correlation between and the solution quality.
6.3. Experiment 3 Results: Evaluation of Alternative Objective Functions
- The overlap of MaxCut probability and objective values is poorer for and than for other objective functions, which consequently led to increased MaxCut probabilities compared to and . Therefore, these alternative objective functions should be preferred for WS-QAOA over the standard energy expectation objective function .
- In our setup, resulted in the highest MaxCut probabilities, while resulted in the highest BetterCut probabilities.
- When the regularization parameter is determined by the optimizer, the performance of and with respect to MaxCut and BetterCut probability, respectively, can increase significantly compared to the fixed value for .
7. Discussion
7.1. Choice of the Regularization Parameter
- A naïve strategy is to fix the regularization parameter to an arbitrary value, thus accepting some loss of solution quality due to sub-optimality for particular combinations of problem instances and objective function. The benefit of this strategy is its simplicity, and the results of Experiment 3 suggest it can produce acceptable solutions.
- As an alternative strategy, selecting the regularization parameter can be delegated to a classical optimizer. However, this requires a suitable objective function. As shown in Experiment 3, the objective functions and are compatible with this strategy. The benefit of this strategy is that it can potentially determine the optimal regularization value for a problem instance automatically and thus achieve a better solution quality compared to setting an arbitrary value. However, it introduces additional optimization difficulty that may lead to increased execution time of the optimization process.
7.2. Choice of the Optimization Strategy
7.3. Choice of the Objective Function
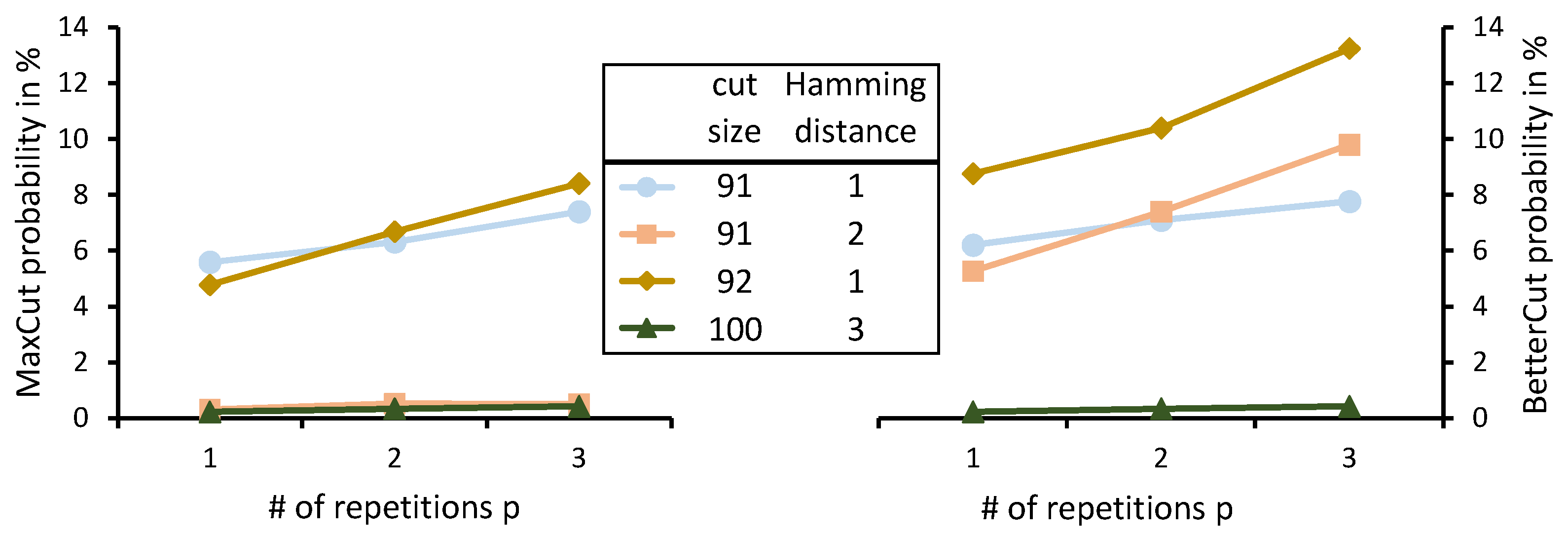
7.4. Influence of Hamming Distance on Solution Quality
8. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cao, Y.; Romero, J.; Olson, J.P.; Degroote, M.; Johnson, P.D.; Kieferová, M.; Kivlichan, I.D.; Menke, T.; Peropadre, B.; Sawaya, N.P.D.; et al. Quantum Chemistry in the Age of Quantum Computing. Chem. Rev. 2019, 119, 10856–10915. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- DeBenedictis, E.P. A Future with Quantum Machine Learning. Computer 2018, 51, 68–71. [Google Scholar] [CrossRef]
- Schuld, M.; Sinayskiy, I.; Petruccione, F. An introduction to quantum machine learning. Contemp. Phys. 2015, 56, 172–185. [Google Scholar] [CrossRef] [Green Version]
- Biamonte, J.; Wittek, P.; Pancotti, N.; Rebentrost, P.; Wiebe, N.; Lloyd, S. Quantum machine learning. Nature 2017, 549, 195–202. [Google Scholar] [CrossRef]
- Arunachalam, S.; de Wolf, R. Guest Column: A Survey of Quantum Learning Theory. SIGACT News 2017, 48, 41–67. [Google Scholar] [CrossRef]
- Khan, T.M.; Robles-Kelly, A. Machine Learning: Quantum vs Classical. IEEE Access 2020, 8, 219275–219294. [Google Scholar] [CrossRef]
- Huang, H.L.; Du, Y.; Gong, M.; Zhao, Y.; Wu, Y.; Wang, C.; Li, S.; Liang, F.; Lin, J.; Xu, Y.; et al. Experimental quantum generative adversarial networks for image generation. Phys. Rev. Appl. 2021, 16, 024051. [Google Scholar] [CrossRef]
- Havlíček, V.; Córcoles, A.D.; Temme, K.; Harrow, A.W.; Kandala, A.; Chow, J.M.; Gambetta, J.M. Supervised learning with quantum-enhanced feature spaces. Nature 2019, 567, 209–212. [Google Scholar] [CrossRef] [Green Version]
- Zahedinejad, E.; Zaribafiyan, A. Combinatorial optimization on gate model quantum computers: A survey. arXiv 2017, arXiv:1708.05294. [Google Scholar]
- Harrigan, M.P.; Sung, K.J.; Neeley, M.; Satzinger, K.J.; Arute, F.; Arya, K.; Atalaya, J.; Bardin, J.C.; Barends, R.; Boixo, S.; et al. Quantum approximate optimization of non-planar graph problems on a planar superconducting processor. Nat. Phys. 2021, 17, 332–336. [Google Scholar] [CrossRef]
- Huang, H.L.; Wu, D.; Fan, D.; Zhu, X. Superconducting quantum computing: A review. Sci. China Inf. Sci. 2020, 63, 1–32. [Google Scholar] [CrossRef]
- Krantz, P.; Kjaergaard, M.; Yan, F.; Orlando, T.P.; Gustavsson, S.; Oliver, W.D. A quantum engineer’s guide to superconducting qubits. Appl. Phys. Rev. 2019, 6, 021318. [Google Scholar] [CrossRef]
- Bruzewicz, C.D.; Chiaverini, J.; McConnell, R.; Sage, J.M. Trapped-ion quantum computing: Progress and challenges. Appl. Phys. Rev. 2019, 6, 021314. [Google Scholar] [CrossRef] [Green Version]
- Blatt, R.; Roos, C.F. Quantum simulations with trapped ions. Nat. Phys. 2012, 8, 277–284. [Google Scholar] [CrossRef]
- Preskill, J. Quantum computing in the NISQ era and beyond. Quantum 2018, 2, 79. [Google Scholar] [CrossRef]
- Leymann, F.; Barzen, J. The bitter truth about gate-based quantum algorithms in the NISQ era. Quantum Sci. Technol. 2020, 5, 044007. [Google Scholar] [CrossRef]
- Farhi, E.; Goldstone, J.; Gutmann, S. A quantum approximate optimization algorithm. arXiv 2014, arXiv:1411.4028. [Google Scholar]
- Cerezo, M.; Arrasmith, A.; Babbush, R.; Benjamin, S.C.; Endo, S.; Fujii, K.; McClean, J.R.; Mitarai, K.; Yuan, X.; Cincio, L.; et al. Variational Quantum Algorithms. arXiv 2020, arXiv:2012.09265. [Google Scholar] [CrossRef]
- Yildirim, E.A.; Wright, S.J. Warm-start strategies in interior-point methods for linear programming. SIAM J. Optim. 2002, 12, 782–810. [Google Scholar] [CrossRef]
- Ralphs, T.; Güzelsoy, M. Duality and warm starting in integer programming. In Proceedings of the 2006 NSF Design, Service, and Manufacturing Grantees and Research Conference, St. Louis, MO, USA, 24–27 July 2006. [Google Scholar]
- John, E.; Yıldırım, E.A. Implementation of warm-start strategies in interior-point methods for linear programming in fixed dimension. Comput. Optim. Appl. 2008, 41, 151–183. [Google Scholar] [CrossRef]
- Shahzad, A.; Kerrigan, E.C.; Constantinides, G.A. A warm-start interior-point method for predictive control. In Proceedings of the UKACC International Conference on CONTROL 2010, Coventry, UK, 7–10 September 2010. [Google Scholar]
- Poloczek, M.; Wang, J.; Frazier, P.I. Warm starting Bayesian optimization. In Proceedings of the 2016 Winter Simulation Conference (WSC), Washington, DC, USA, 11–14 December 2016; pp. 770–781. [Google Scholar]
- Bertsimas, D.; King, A.; Mazumder, R. Best subset selection via a modern optimization lens. Ann. Stat. 2016, 44, 813–852. [Google Scholar] [CrossRef] [Green Version]
- Feurer, M.; Letham, B.; Bakshy, E. Scalable meta-learning for Bayesian optimization. Stat 2018, 1050, 6. [Google Scholar]
- Weigold, M.; Barzen, J.; Leymann, F.; Vietz, D. Patterns for Hybrid Quantum Algorithms. In Proceedings of the Symposium and Summer School on Service-Oriented Computing, Virtual Event, 13–17 September 2021; Springer: Cham, Switzerland, 2021; pp. 34–51. [Google Scholar]
- Egger, D.J.; Mareček, J.; Woerner, S. Warm-starting quantum optimization. Quantum 2021, 5, 479. [Google Scholar] [CrossRef]
- Tate, R.; Farhadi, M.; Herold, C.; Mohler, G.; Gupta, S. Bridging Classical and Quantum with SDP initialized warm-starts for QAOA. arXiv 2020, arXiv:2010.14021. [Google Scholar]
- Goemans, M.X.; Williamson, D.P. Improved approximation algorithms for maximum cut and satisfiability problems using semidefinite programming. J. ACM (JACM) 1995, 42, 1115–1145. [Google Scholar] [CrossRef]
- Barkoutsos, P.K.; Nannicini, G.; Robert, A.; Tavernelli, I.; Woerner, S. Improving Variational Quantum Optimization using CVaR. Quantum 2020, 4, 256. [Google Scholar] [CrossRef]
- Beaulieu, D.; Pham, A. Max-cut Clustering Utilizing Warm-Start QAOA and IBM Runtime. arXiv 2021, arXiv:2108.13464. [Google Scholar]
- Beaulieu, D.; Pham, A. Evaluating performance of hybrid quantum optimization algorithms for MAXCUT Clustering using IBM runtime environment. arXiv 2021, arXiv:2112.03199. [Google Scholar]
- Tate, R.; Gard, B.; Mohler, G.; Gupta, S. Classically-inspired Mixers for QAOA Beat Goemans-Williamson’s Max-Cut at Low Circuit Depths. arXiv 2021, arXiv:2112.11354. [Google Scholar]
- Li, L.; Fan, M.; Coram, M.; Riley, P.; Leichenauer, S. Quantum optimization with a novel Gibbs objective function and ansatz architecture search. Phys. Rev. Res. 2020, 2, 023074. [Google Scholar] [CrossRef] [Green Version]
- Kolotouros, I.; Wallden, P. An evolving objective function for improved variational quantum optimisation. arXiv 2021, arXiv:2105.11766. [Google Scholar]
- Carolan, J.; Mohseni, M.; Olson, J.P.; Prabhu, M.; Chen, C.; Bunandar, D.; Niu, M.Y.; Harris, N.C.; Wong, F.N.; Hochberg, M.; et al. Variational quantum unsampling on a quantum photonic processor. Nat. Phys. 2020, 16, 322–327. [Google Scholar] [CrossRef] [Green Version]
- Skolik, A.; McClean, J.R.; Mohseni, M.; van der Smagt, P.; Leib, M. Layerwise learning for quantum neural networks. Quantum Mach. Intell. 2021, 3, 1–11. [Google Scholar] [CrossRef]
- Sim, S.; Romero, J.; Gonthier, J.F.; Kunitsa, A.A. Adaptive pruning-based optimization of parameterized quantum circuits. Quantum Sci. Technol. 2021, 6, 025019. [Google Scholar] [CrossRef]
- Lyu, C.; Montenegro, V.; Bayat, A. Accelerated variational algorithms for digital quantum simulation of many-body ground states. Quantum 2020, 4, 324. [Google Scholar] [CrossRef]
- Campos, E.; Nasrallah, A.; Biamonte, J. Abrupt transitions in variational quantum circuit training. Phys. Rev. A 2021, 103, 032607. [Google Scholar] [CrossRef]
- Campos, E.; Rabinovich, D.; Akshay, V.; Biamonte, J. Training Saturation in Layerwise Quantum Approximate Optimisation. arXiv 2021, arXiv:2106.13814. [Google Scholar]
- Salm, M.; Barzen, J.; Leymann, F.; Weder, B. About a Criterion of Successfully Executing a Circuit in the NISQ Era: What wd≪1/ϵeff Really Means. In Proceedings of the 1st ACM SIGSOFT International Workshop on Architectures and Paradigms for Engineering Quantum Software (APEQS 2020), Virtual, 13 November 2020; ACM: New York, NY, USA, 2020; pp. 10–13. [Google Scholar] [CrossRef]
- Leymann, F.; Barzen, J.; Falkenthal, M.; Vietz, D.; Weder, B.; Wild, K. Quantum in the Cloud: Application Potentials and Research Opportunities. In Proceedings of the 10th International Conference on Cloud Computing and Service Science (CLOSER 2020), Prague, Czech Republic, 7–9 May 2020; SciTePress: Setúbal, Portugal, 2020; pp. 9–24. [Google Scholar]
- Farhi, E.; Goldstone, J.; Gutmann, S.; Sipser, M. Quantum Computation by Adiabatic Evolution. arXiv 2000, arXiv:0001106. [Google Scholar]
- Dalzell, A.M.; Harrow, A.W.; Koh, D.E.; Placa, R.L.L. How many qubits are needed for quantum computational supremacy? arXiv 2018, arXiv:1805.05224v3. [Google Scholar] [CrossRef]
- Akshay, V.; Philathong, H.; Zacharov, I.; Biamonte, J. Reachability Deficits in Quantum Approximate Optimization of Graph Problems. arXiv 2020, arXiv:2007.09148v2. [Google Scholar] [CrossRef]
- Majumdar, R.; Madan, D.; Bhoumik, D.; Vinayagamurthy, D.; Raghunathan, S.; Sur-Kolay, S. Optimizing Ansatz Design in QAOA for Max-cut. arXiv 2021, arXiv:2106.02812. [Google Scholar]
- Karp, R.M. Reducibility among combinatorial problems. In Complexity of Computer Computations; Springer: Boston, MA, USA, 1972; pp. 85–103. [Google Scholar]
- Khot, S.; Kindler, G.; Mossel, E.; O’Donnell, R. Optimal inapproximability results for MAX-CUT and other 2-variable CSPs? SIAM J. Comput. 2007, 37, 319–357. [Google Scholar] [CrossRef] [Green Version]
- Håstad, J. Some optimal inapproximability results. J. ACM (JACM) 2001, 48, 798–859. [Google Scholar] [CrossRef]
- Barahona, F.; Grötschel, M.; Jünger, M.; Reinelt, G. An application of combinatorial optimization to statistical physics and circuit layout design. Oper. Res. 1988, 36, 493–513. [Google Scholar] [CrossRef] [Green Version]
- Ding, C.H.; He, X.; Zha, H.; Gu, M.; Simon, H.D. A min-max cut algorithm for graph partitioning and data clustering. In Proceedings of the 2001 IEEE International Conference on Data Mining, San Jose, CA, USA, 29 November–2 December 2001; pp. 107–114. [Google Scholar]
- Barzen, J. From Digital Humanities to Quantum Humanities: Potentials and Applications. arXiv 2021, arXiv:2103.11825. [Google Scholar]
- Yang, L.; Shami, A. On hyperparameter optimization of machine learning algorithms: Theory and practice. Neurocomputing 2020, 415, 295–316. [Google Scholar] [CrossRef]
- Claesen, M.; Moor, B.D. Hyperparameter Search in Machine Learning. arXiv 2015, arXiv:1502.02127. [Google Scholar]
- Thimm, G.; Fiesler, E. Neural network initialization. In From Natural to Artificial Neural Computation; Mira, J., Sandoval, F., Eds.; Springer: Berlin/Heidelberg, Germany, 1995; pp. 535–542. [Google Scholar]
- Bengio, Y.; Lamblin, P.; Popovici, D.; Larochelle, H. Greedy layer-wise training of deep networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2006; pp. 153–160. [Google Scholar]
- Nannicini, G. Performance of hybrid quantum-classical variational heuristics for combinatorial optimization. Phys. Rev. E 2019, 99, 013304. [Google Scholar] [CrossRef] [Green Version]
- Documentation on COBYLA and Its Default Parameters in SciPy. Available online: https://docs.scipy.org/doc/scipy/reference/optimize.minimize-cobyla.html (accessed on 24 March 2022).
- Documentation on qiskit.providers.aer.QasmSimulator. Available online: https://qiskit.org/documentation/stubs/qiskit.providers.aer.QasmSimulator.html (accessed on 24 March 2022).
- GitHub Repository with the Prototypical Implementation Used to Obtain the Presented Results. Available online: https://github.com/UST-QuAntiL/WS-QAOA-prototype (accessed on 24 March 2022).
- Hamming, R.W. Error detecting and error correcting codes. Bell Syst. Tech. J. 1950, 29, 147–160. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Graph | ||||||
|---|---|---|---|---|---|---|
| Cut | Size | Cut | Size | |||
| 100010110011 | 18 | 1 | 110111111010011000101000 | 111 | 1 | |
| 100000100111 | 16 | 0.8889 | 101000000101100111110101 | 97 | 0.8739 | |
| 111010100111 | 98 | 1 | 100000001011000111100110 | 166 | 1 | |
| 101111001010 | 86 | 0.8776 | 100000001010100110010111 | 145 | 0.8735 | |
| 111110011010 | 103 | 1 | 110001101001100111001001 | 278 | 1 | |
| 110010111010 | 100 | 0.9709 | 110011101001110111001001 | 246 | 0.8849 | |
| 111110111010 | 92 | 0.8932 | ||||
| 111110001010 | 91 | 0.8835 | ||||
| 111010111010 | 91 | 0.8835 | ||||
| Final MaxCut probabilities after depth-3 WS-QAOA | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| with fixed regularization value | with optimized regularization value | ||||||||||
| F | |||||||||||
| G | |||||||||||
| 0.13% | 0.26% | 0.38% | 0.20% | 0.11% | - | 0.06% | 0.34% | 0.14% | - | ||
| 0.00% | 0.02% | 0.17% | 0.02% | 0.00% | - | 0.01% | 0.28% | 0.02% | - | ||
| 0.37% | 1.00% | 2.03% | 0.60% | 0.54% | - | 0.63% | 1.74% | 0.49% | - | ||
| 0.03% | 0.02% | 0.04% | 0.00% | 0.00% | - | 0.00% | 0.00% | 0.03% | - | ||
| 0.00% | 0.00% | 0.00% | 0.00% | 0.00% | - | 0.00% | 0.00% | 0.00% | - | ||
| 0.08% | 0.08% | 0.16% | 0.08% | 0.08% | - | 0.00% | 0.15% | 0.17% | - | ||
| Final BetterCut probabilities after depth-3 WS-QAOA | |||||||||||
| with fixed regularization value | with optimized regularization value | ||||||||||
| F | |||||||||||
| G | |||||||||||
| 4.54% | 6.46% | 5.20% | 9.11% | 6.34% | - | 5.92% | 2.70% | 12.32% | - | ||
| 1.28% | 3.87% | 0.70% | 3.00% | 1.89% | - | 2.67% | 0.69% | 3.20% | - | ||
| 6.48% | 8.53% | 5.17% | 10.69% | 9.00% | - | 9.03% | 5.33% | 14.13% | - | ||
| 4.23% | 4.04% | 3.01% | 4.59% | 3.56% | - | 0.00% | 2.02% | 11.59% | - | ||
| 1.13% | 1.78% | 1.48% | 1.62% | 1.20% | - | 0.00% | 5.89% | 5.56% | - | ||
| 2.36% | 2.82% | 1.63% | 2.98% | 2.51% | - | 0.00% | 3.02% | 9.40% | - | ||
 | |||||||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Truger, F.; Beisel, M.; Barzen, J.; Leymann, F.; Yussupov, V. Selection and Optimization of Hyperparameters in Warm-Started Quantum Optimization for the MaxCut Problem. Electronics 2022, 11, 1033. https://doi.org/10.3390/electronics11071033
Truger F, Beisel M, Barzen J, Leymann F, Yussupov V. Selection and Optimization of Hyperparameters in Warm-Started Quantum Optimization for the MaxCut Problem. Electronics. 2022; 11(7):1033. https://doi.org/10.3390/electronics11071033
Chicago/Turabian StyleTruger, Felix, Martin Beisel, Johanna Barzen, Frank Leymann, and Vladimir Yussupov. 2022. "Selection and Optimization of Hyperparameters in Warm-Started Quantum Optimization for the MaxCut Problem" Electronics 11, no. 7: 1033. https://doi.org/10.3390/electronics11071033
APA StyleTruger, F., Beisel, M., Barzen, J., Leymann, F., & Yussupov, V. (2022). Selection and Optimization of Hyperparameters in Warm-Started Quantum Optimization for the MaxCut Problem. Electronics, 11(7), 1033. https://doi.org/10.3390/electronics11071033