
IE-Net: Information-Enhanced Binary Neural Networks for Accurate Classification


Abstract
:1. Introduction
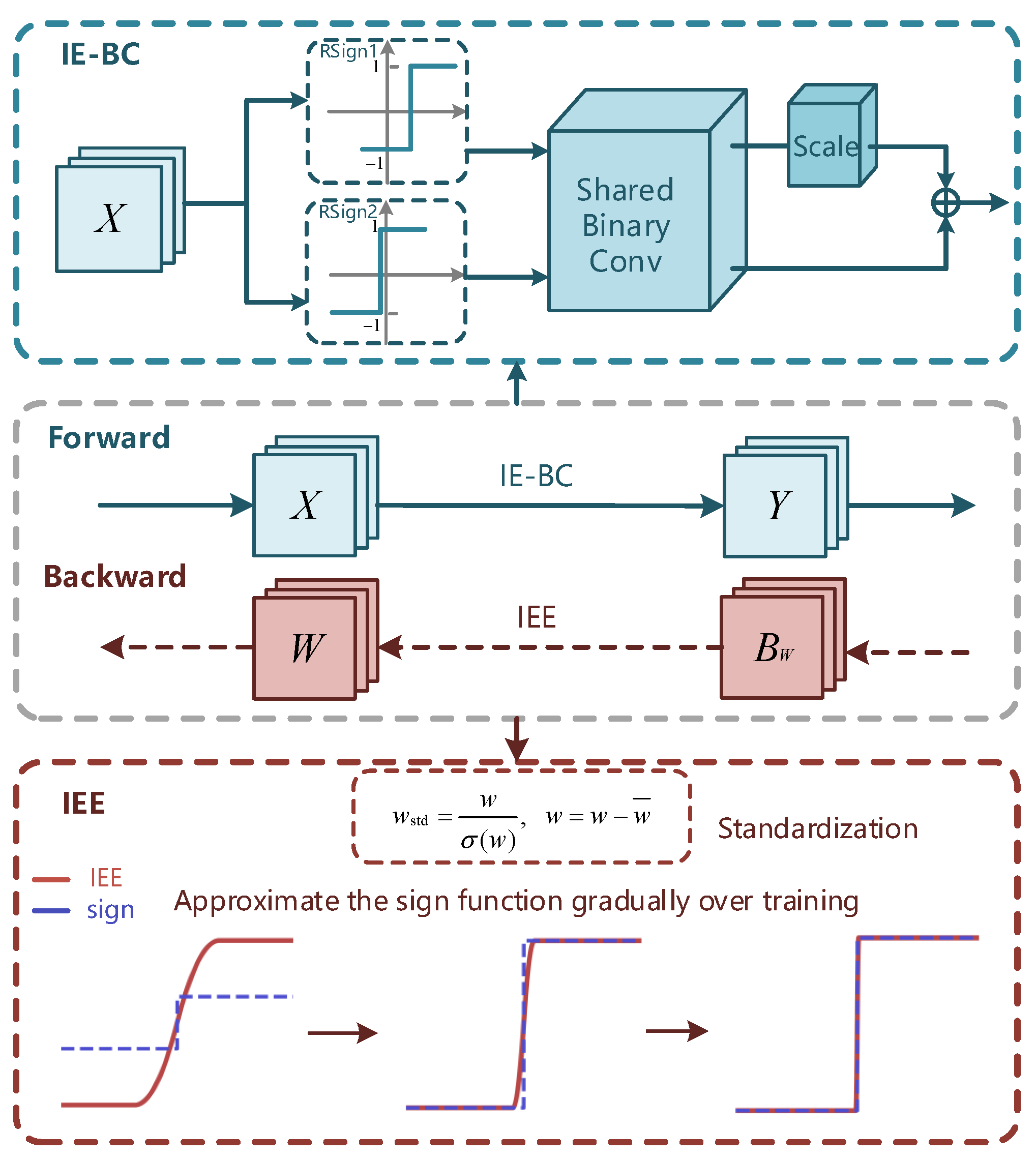
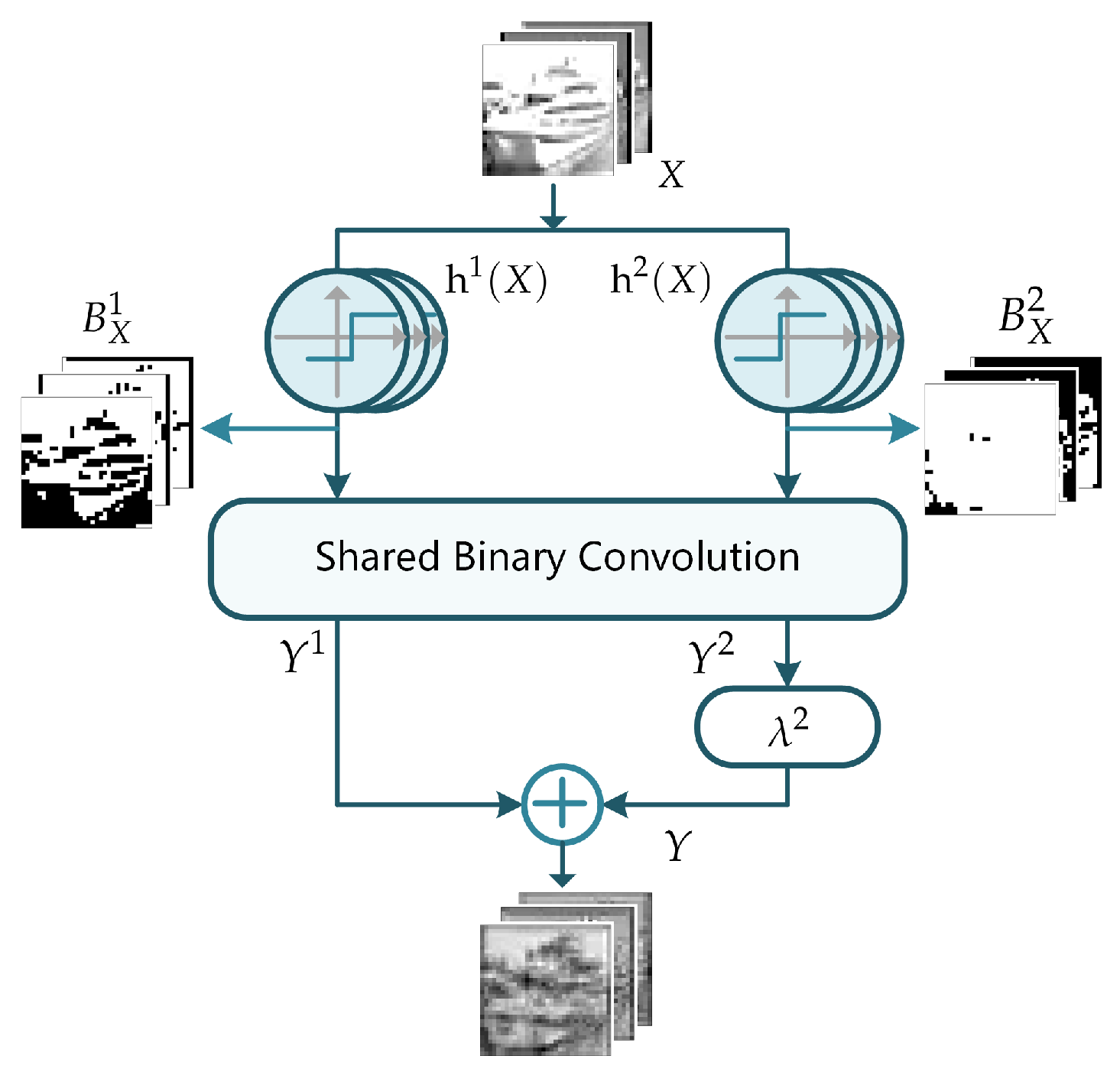
- To enhance the information of binary activations and improve the representational power of the binary model, we present the novel binary function IE-BC, which employs multiple sign functions with different learnable thresholds, a shared binary convolution, and following scaling operations. The diverse binary activations generated by IE-BC retain the information of the original input, and the novel convolution in IE-BC could combine the multiple binary features effectively with information enhancement. In addition, the IE-BC improves the model performance with minor memory and computation requirements increase.
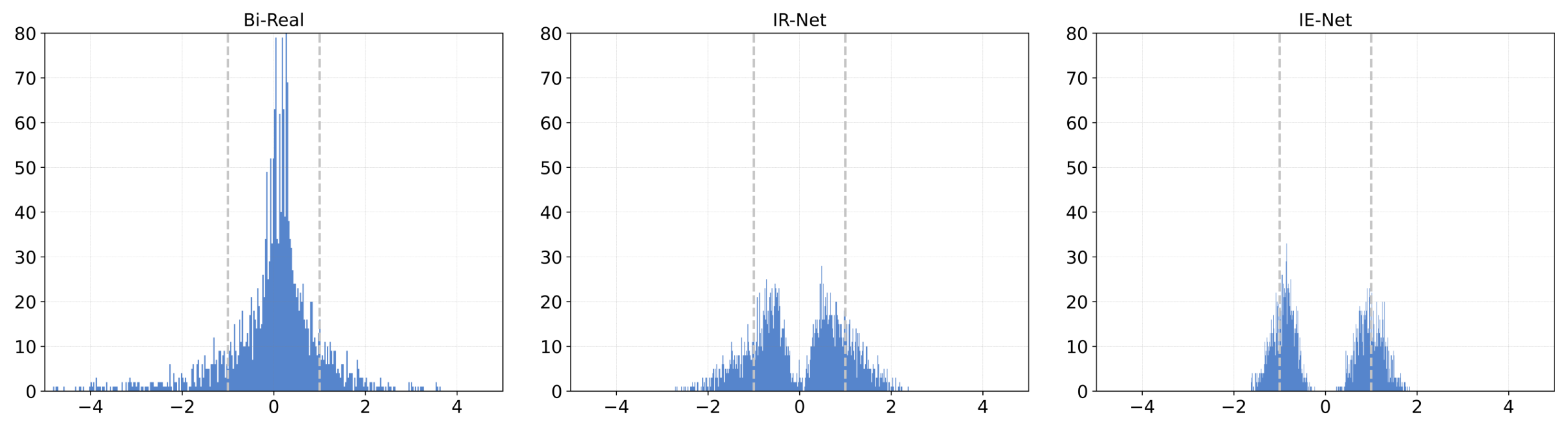
- To help weights decide their signs and achieve better information gain on binary weights, we propose to replace the STE method with the IEE fucntion that approximates the original sign function as training proceeds. With the help of the proposed method, the gradients of the weights are adapted according to different training stages and strong enough to help the weights update. The IEE could shape the weights distributions around +1 and −1, which reduces the quantization error that introduces information loss and maximizes the information entropy of weights in each layer.
- The experimental results show that our proposed IE-Net increases the mean accuracy of the baseline model Bi-Real [21] by 2.8% and outperforms the other state-of-the-art (SOTA) BNN methods on the CIFAR-10 dataset. Besides, we evaluate our method with the ResNet-18 and ResNet-34 [1] structures on the ImageNet dataset and the results show that the IE-Net achieves the best performance compared with other SOTA models, which proves the effectiveness of the proposed method.
2. Materials and Methods
2.1. Binary Neural Networks
2.2. Information Enhanced Binary Convolution (IE-BC)
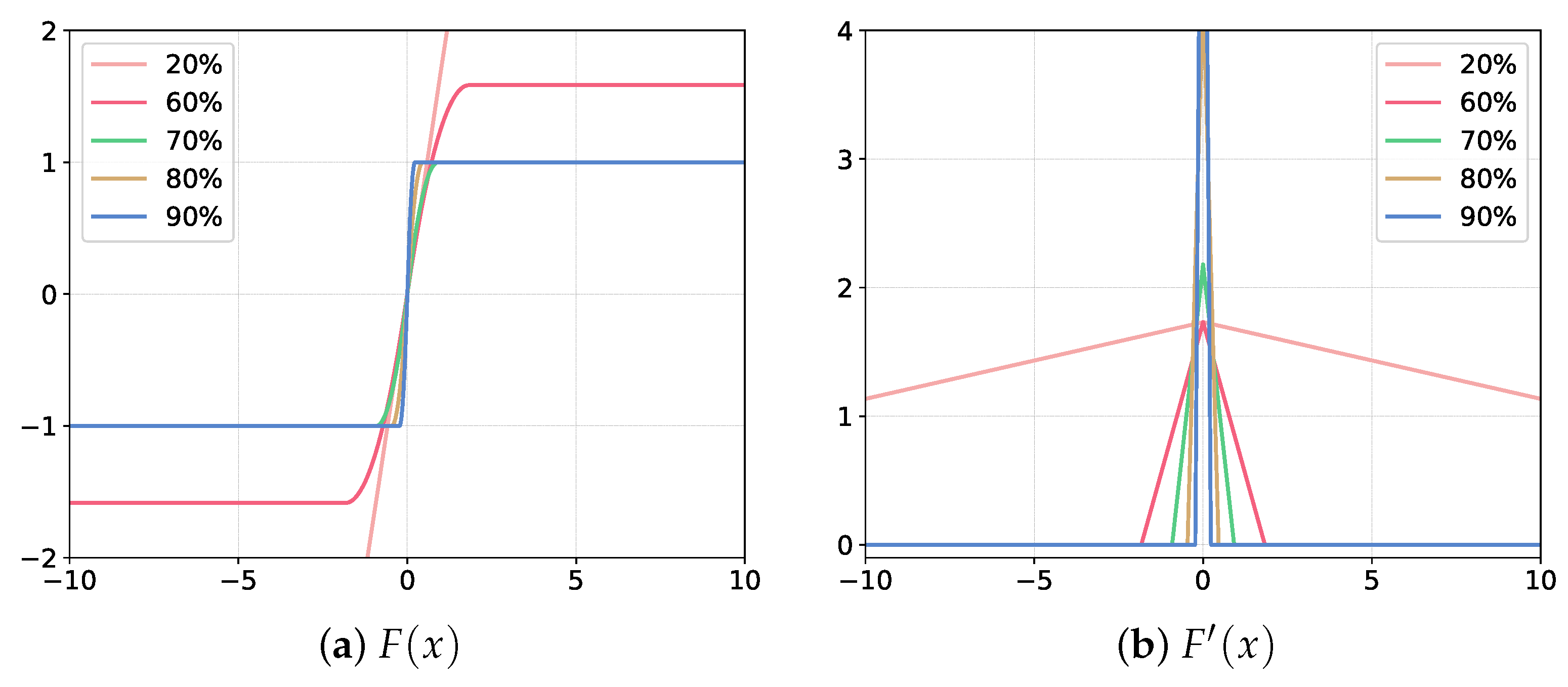
2.3. Information-Enhanced Estimator (IEE)
3. Experiments and Discussion
3.1. Experimental Settings
3.1.1. Datasets
3.1.2. Implementation Details
3.2. Ablation Study
3.2.1. Effectiveness of Information Enhanced Binary Convolution (IE-BC)
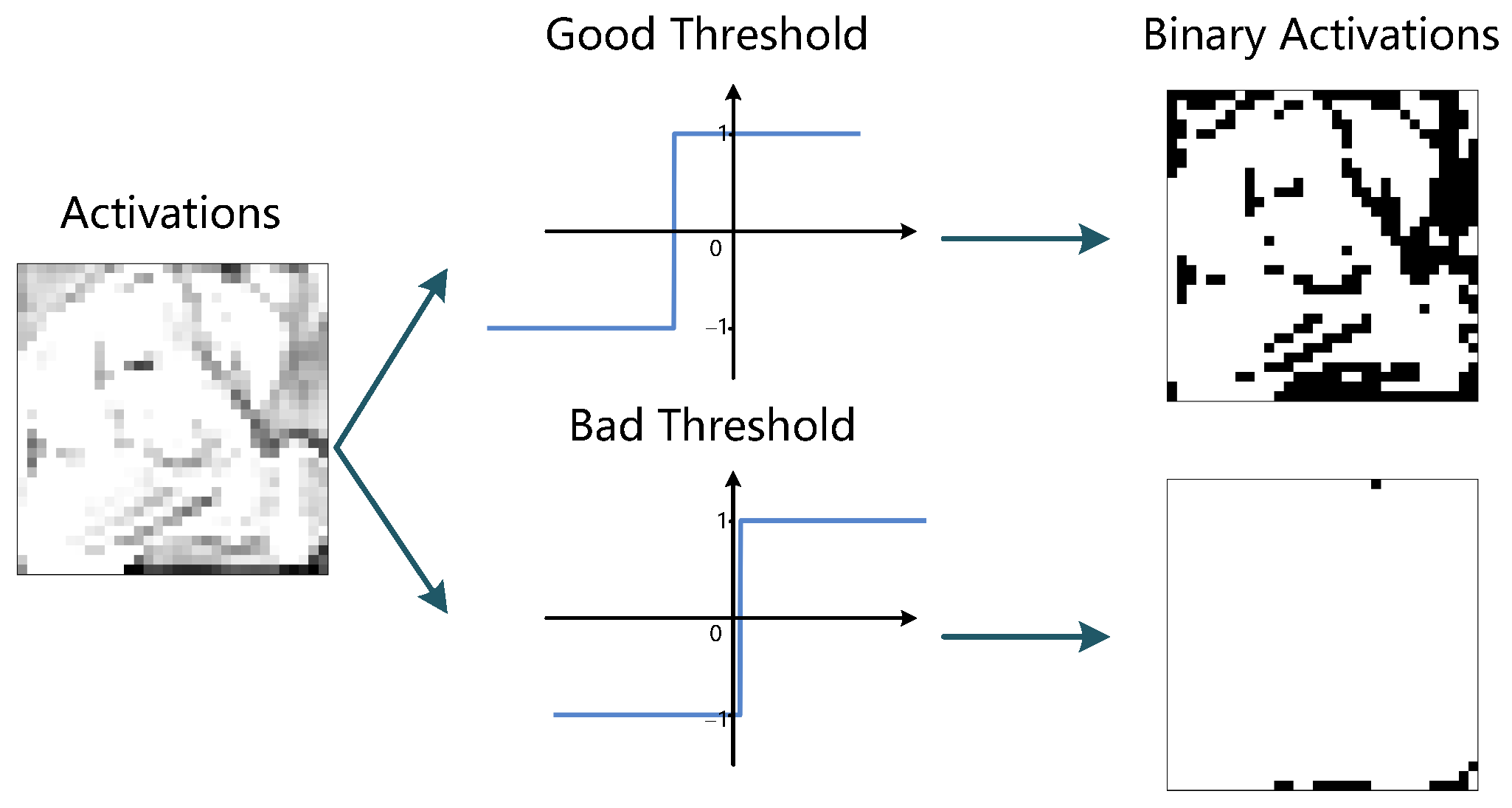
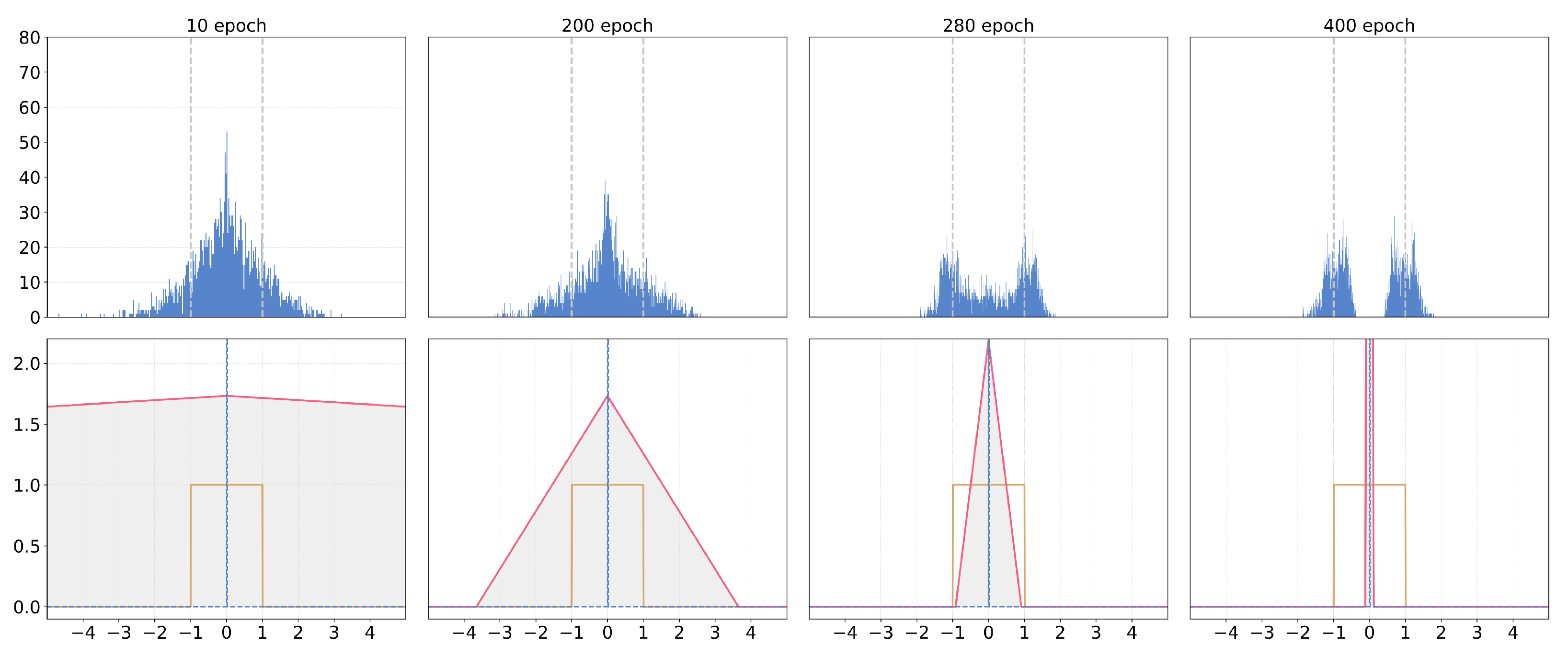
- For the same full-precision inputs, the binarized inputs generated by the sign functions with different thresholds present diverse features. In particular, the information of binary inputs in the 1 channel is completely different, which helps the binary model learn more meaningful patterns.
- Meanwhile, as feature maps from the 2 channel show, the sign function with a bad threshold will generate meaningless binary activations as shown in the third row which induces large information loss. By using the IE-BC method, the binary activations from another sign function with a different threshold could compensate the missing feature as shown in the second row at channel, which proves the effectiveness of the proposed technology.
- In conclusion, the different activation binarized functions could generate multiple diversified binary patterns to help enhance the information of binary activations and boost the representational power of the normal binary convolution, which increases the final classification accuracy of the binary models.
3.2.2. Influence of Hyperparameter K
3.2.3. Effectiveness of Information-Enhanced Estimator (IEE)
3.2.4. Ablation Performance
3.3. Comparison with State-of-the-Art Methods
3.3.1. Comparisons on CIFAR-10
3.3.2. Comparisons on ImageNet
3.4. Memory and Computation Complexity Analyses
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Wang, X.; Ren, H.; Wang, A. Smish: A Novel Activation Function for Deep Learning Methods. Electronics 2022, 11, 540. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Guo, J.M.; Yang, J.S.; Seshathiri, S.; Wu, H.W. A Light-Weight CNN for Object Detection with Sparse Model and Knowledge Distillation. Electronics 2022, 11, 575. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Xie, X.; Bai, L.; Huang, X. Real-Time LiDAR Point Cloud Semantic Segmentation for Autonomous Driving. Electronics 2022, 11, 11. [Google Scholar] [CrossRef]
- Zhang, D.; Yang, J.; Ye, D.; Hua, G. Lq-nets: Learned Quantization for Highly Accurate and Compact Deep Neural Networks. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 365–382. [Google Scholar]
- Vandersteegen, M.; Van Beeck, K.; Goedemé, T. Integer-Only CNNs with 4 Bit Weights and Bit-Shift Quantization Scales at Full-Precision Accuracy. Electronics 2021, 10, 2823. [Google Scholar] [CrossRef]
- Han, S.; Mao, H.; Dally, W.J. Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Stewart, R.; Nowlan, A.; Bacchus, P.; Ducasse, Q.; Komendantskaya, E. Optimising Hardware Accelerated Neural Networks with Quantisation and a Knowledge Distillation Evolutionary Algorithm. Electronics 2021, 10, 396. [Google Scholar] [CrossRef]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. In Proceedings of the Advances in Neural Information Processing Systems Workshop, Montreal, QC, Canada, 12–13 December 2014; pp. 1–9. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–21 June 2018; pp. 6848–6856. [Google Scholar]
- Hubara, I.; Courbariaux, M.; Soudry, D.; El-Yaniv, R.; Bengio, Y. Binarized Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 4107–4115. [Google Scholar]
- Rastegari, M.; Ordonez, V.; Redmon, J.; Farhadi, A. Xnor-net: Imagenet Classification using Binary Convolutional Neural Networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 525–542. [Google Scholar]
- Qin, H.; Gong, R.; Liu, X.; Shen, M.; Wei, Z.; Yu, F.; Song, J. Forward and Backward Information Retention for Accurate Binary Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Virtual, 14–19 June 2020; pp. 2250–2259. [Google Scholar]
- Liu, Z.; Shen, Z.; Savvides, M.; Cheng, K.T. ReActNet: Towards Precise Binary Neural Network with Generalized Activation Functions. In Proceedings of the European Conference on Computer Vision, Virtual, 23–28 August 2020. [Google Scholar]
- Lin, X.; Zhao, C.; Pan, W. Towards Accurate Binary Convolutional Neural Network. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 345–353. [Google Scholar]
- Zhu, S.; Dong, X.; Su, H. Binary Ensemble Neural Network: More Bits per Network or More Networks per Bit? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4923–4932. [Google Scholar]
- Zhuang, B.; Shen, C.; Tan, M.; Liu, L.; Reid, I. Structured Binary Neural Networks for Accurate Image Classification and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 413–422. [Google Scholar]
- Liu, C.; Ding, W.; Xia, X.; Zhang, B.; Gu, J.; Liu, J.; Ji, R.; Doermann, D. Circulant Binary Convolutional Networks: Enhancing the Performance of 1-bit Dcnns with Circulant Back Propagation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 2691–2699. [Google Scholar]
- Liu, Z.; Wu, B.; Luo, W.; Yang, X.; Liu, W.; Cheng, K.T. Bi-real Net: Enhancing the Performance of 1-bit Cnns with Improved Representational Capability and Advanced Training Algorithm. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 722–737. [Google Scholar]
- Lin, M.; Ji, R.; Xu, Z.; Zhang, B.; Wang, Y.; Wu, Y.; Huang, F.; Lin, C.W. Rotated Binary Neural Network. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 6–12 December 2020; pp. 1–12. [Google Scholar]
- Xu, S.; Zhao, J.; Lu, J.; Zhang, B.; Han, S.; Doermann, D. Layer-wise Searching for 1-bit Detectors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 5682–5691. [Google Scholar]
- Bengio, Y.; Léonard, N.; Courville, A. Estimating or Propagating Gradients through Stochastic Neurons for Conditional Computation. arXiv 2013, arXiv:1308.3432. [Google Scholar]
- Courbariaux, M.; Bengio, Y.; David, J.P. Binaryconnect: Training Deep Neural Networks with Binary Weights during Propagations. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Li, Z.; Ni, B.; Zhang, W.; Yang, X.; Gao, W. Performance Guaranteed Network Acceleration via High-order Residual Quantization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2584–2592. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images; Technical Report; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F. Imagenet: A Large-scale Hierarchical Image Database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Zou, W.; Cheng, S.; Wang, L.; Fu, G.; Shang, D.; Zhou, Y.; Zhan, Y. Increasing Information Entropy of Both Weights and Activations for the Binary Neural Networks. Electronics 2021, 10, 1943. [Google Scholar] [CrossRef]
- Ding, R.; Chin, T.W.; Liu, Z.; Marculescu, D. Regularizing Activation Distribution for Training Binarized Deep Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11408–11417. [Google Scholar]
- Zhou, S.; Wu, Y.; Ni, Z.; Zhou, X.; Wen, H.; Zou, Y. Dorefa-net: Training Low Bitwidth Convolutional Neural Networks with Low Bitwidth Gradients. arXiv 2016, arXiv:1606.06160. [Google Scholar]
- Gong, R.; Liu, X.; Jiang, S.; Li, T.; Hu, P.; Lin, J.; Yu, F.; Yan, J. Differentiable Soft Quantization: Bridging Full-precision and Low-bit Neural Networks. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 4852–4861. [Google Scholar]
- Yang, Z.; Wang, Y.; Han, K.; Xu, C.; Xu, C.; Tao, D.; Xu, C. Searching for Low-bit Weights in Quantized Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 7–12 September 2020; pp. 4091–4102. [Google Scholar]
- Wan, D.; Shen, F.; Liu, L.; Zhu, F.; Qin, J.; Shao, L.; Shen, H.T. Tbn: Convolutional Neural Network with Ternary Inputs and Binary Weights. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 315–332. [Google Scholar]
- Gu, J.; Li, C.; Zhang, B.; Han, J.; Cao, X.; Liu, J.; Doermann, D. Projection Convolutional Neural Networks for 1-bit Cnns via Discrete Back Propagation. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 8344–8351. [Google Scholar]
- Gu, J.; Zhao, J.; Jiang, X.; Zhang, B.; Liu, J.; Guo, G.; Ji, R. Bayesian Optimized 1-bit Cnns. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 4909–4917. [Google Scholar]

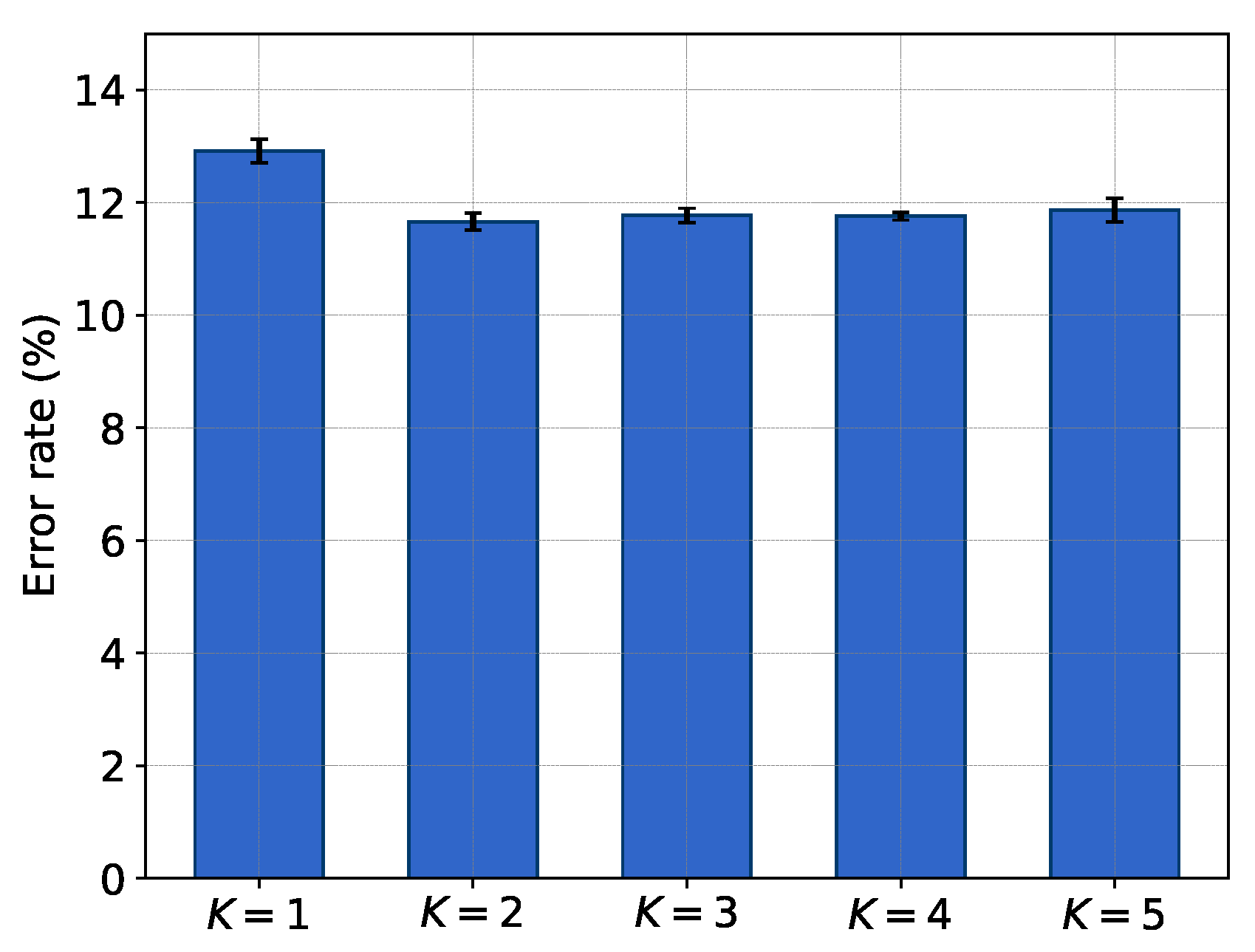

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Bi-Real Baseline [21] | Bi-Real+RSign [16] | Bi-Real+IE-BC | |
|---|---|---|---|
| Mean Accuracy (%) | 85.74 | 86.88 | 88.34 |
| Std (%) | 0.19 | 0.27 | 0.15 |
| Metric | Bi-Real [21] | IR-Net [15] | BiReal+ML [29] | Bi-Real+IEE |
|---|---|---|---|---|
| 5.39 | 5.42 | 5.41 | 5.42 |
| Topology | Method | Bit-Width (W/A) | Accuracy (%) |
|---|---|---|---|
| ResNet-20 | Bi-Real | 1/1 | 85.74 ± 0.19 |
| +IE-BC | 1/1 | 88.34 ± 0.15 | |
| +IEE | 1/1 | 86.47 ± 0.09 | |
| +IE-BC+IEE (IE-Net) | 1/1 | 88.54 ± 0.14 |
| Topology | Method | Bit-Width (W/A) | Accuracy (%) |
|---|---|---|---|
| ResNet-18 | Full-Precision | 32/32 | 94.8 |
| RAD | 1/1 | 90.5 | |
| IR-Net | 1/1 | 91.5 | |
| RBNN | 1/1 | 92.2 | |
| Ours | 1/1 | 92.9 | |
| ResNet-20 | Full-Precision | 32/32 | 92.1 |
| DoReFa | 1/1 | 79.3 | |
| DSQ | 1/1 | 84.1 | |
| XNOR+ML+BMA | 1/1 | 85.00 | |
| SLB | 1/1 | 85.5 | |
| IR-Net | 1/1 | 86.5 | |
| RBNN | 1/1 | 87.8 | |
| Ours | 1/1 | 88.5 | |
| VGG-Small | Full-Precision | 32/32 | 94.1 |
| XNOR-Net | 1/1 | 89.8 | |
| BNN | 1/1 | 89.9 | |
| IR-Net | 1/1 | 90.4 | |
| RAD | 1/1 | 90.4 | |
| RBNN | 1/1 | 91.3 | |
| DSQ | 1/1 | 91.7 | |
| Ours | 1/1 | 92.0 |
| Topology | Method | Bit-Width (W/A) | Top-1 (%) | Top-5 (%) |
|---|---|---|---|---|
| ResNet-18 | Full-Precision | 32/32 | 69.6 | 89.2 |
| XNOR-Net | 1/1 | 51.2 | 73.2 | |
| DoReFa | 1/2 | 53.4 | - | |
| TBN | 1/2 | 55.6 | 79.0 | |
| Bi-Real | 1/1 | 56.4 | 79.5 | |
| PDNN | 1/1 | 57.3 | 80.0 | |
| IR-Net | 1/1 | 58.1 | 80.0 | |
| BONN | 1/1 | 59.3 | 81.6 | |
| RBNN | 1/1 | 59.9 | 81.9 | |
| Ours | 1/1 | 61.4 | 83.0 | |
| ResNet-34 | Full-Precision | 32/32 | 73.3 | 91.3 |
| ABC-Net | 1/1 | 52.4 | 76.5 | |
| Bi-Real | 1/1 | 62.2 | 83.9 | |
| IR-Net | 1/1 | 62.9 | 84.1 | |
| RBNN | 1/1 | 63.1 | 84.4 | |
| Ours | 1/1 | 64.6 | 85.2 |
| Topology | Method | Bit-Width (W/A) | Memory Cost (Mbit) | FLOPs |
|---|---|---|---|---|
| ResNet-18 | Full-Precision | 32/32 | 374.1 | 1.81 × |
| XNOR-Net | 1/1 | 33.7 | 1.67 × | |
| Bi-Real | 1/1 | 33.6 | 1.63 × | |
| IR-Net | 1/1 | 33.6 | 1.63 × | |
| Ours | 1/1 | 33.8 | 1.63 × | |
| ResNet-34 | Full-Precision | 32/32 | 697.3 | 3.66 × |
| XNOR-Net | 1/1 | 43.9 | 1.98 × | |
| Bi-Real Net | 1/1 | 43.7 | 1.93 × | |
| IR-Net | 1/1 | 43.7 | 1.93 × | |
| Ours | 1/1 | 44.1 | 1.93 × |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, R.; Liu, H.; Zhou, X. IE-Net: Information-Enhanced Binary Neural Networks for Accurate Classification. Electronics 2022, 11, 937. https://doi.org/10.3390/electronics11060937
Ding R, Liu H, Zhou X. IE-Net: Information-Enhanced Binary Neural Networks for Accurate Classification. Electronics. 2022; 11(6):937. https://doi.org/10.3390/electronics11060937
Chicago/Turabian StyleDing, Rui, Haijun Liu, and Xichuan Zhou. 2022. "IE-Net: Information-Enhanced Binary Neural Networks for Accurate Classification" Electronics 11, no. 6: 937. https://doi.org/10.3390/electronics11060937
APA StyleDing, R., Liu, H., & Zhou, X. (2022). IE-Net: Information-Enhanced Binary Neural Networks for Accurate Classification. Electronics, 11(6), 937. https://doi.org/10.3390/electronics11060937