
Automatic RTL Generation Tool of FPGAs for DNNs


Abstract
:1. Introduction
- (1)
- This study proposes DNN implementation via an auto-generated automation tool, which maps the DNN design process from a deep learning framework to FPGA. As the structure of DNNs changes rapidly, it is difficult for their hardware design to keep up with the software design. Therefore, our proposition allows users to perform resource allocation and optimization during register-transfer level (RTL) design when deploying a DNN on FPGAs.
- (2)
- A DNN model was generated according to developer performance guidelines during the design process. An automatic DNN model optimization engine is proposed based on this process, by implementing a long short-term memory (LSTM) that can effectively generate DNN models that meet the performance requirements of FPGA design.
- (3)
- Highly optimized RTL network components can be automatically generated for building DNN layers. Since different FPGA manufacturers use different intellectual property (IP) cores for multiplication in digital signal processing (DSP), we propose a multiplier optimization for DNN processing elements (PEs) with improved energy consumption. The engine can be configured to provide the best performance within the constraints of the FPGA.
2. Related Work
3. Materials and Methods
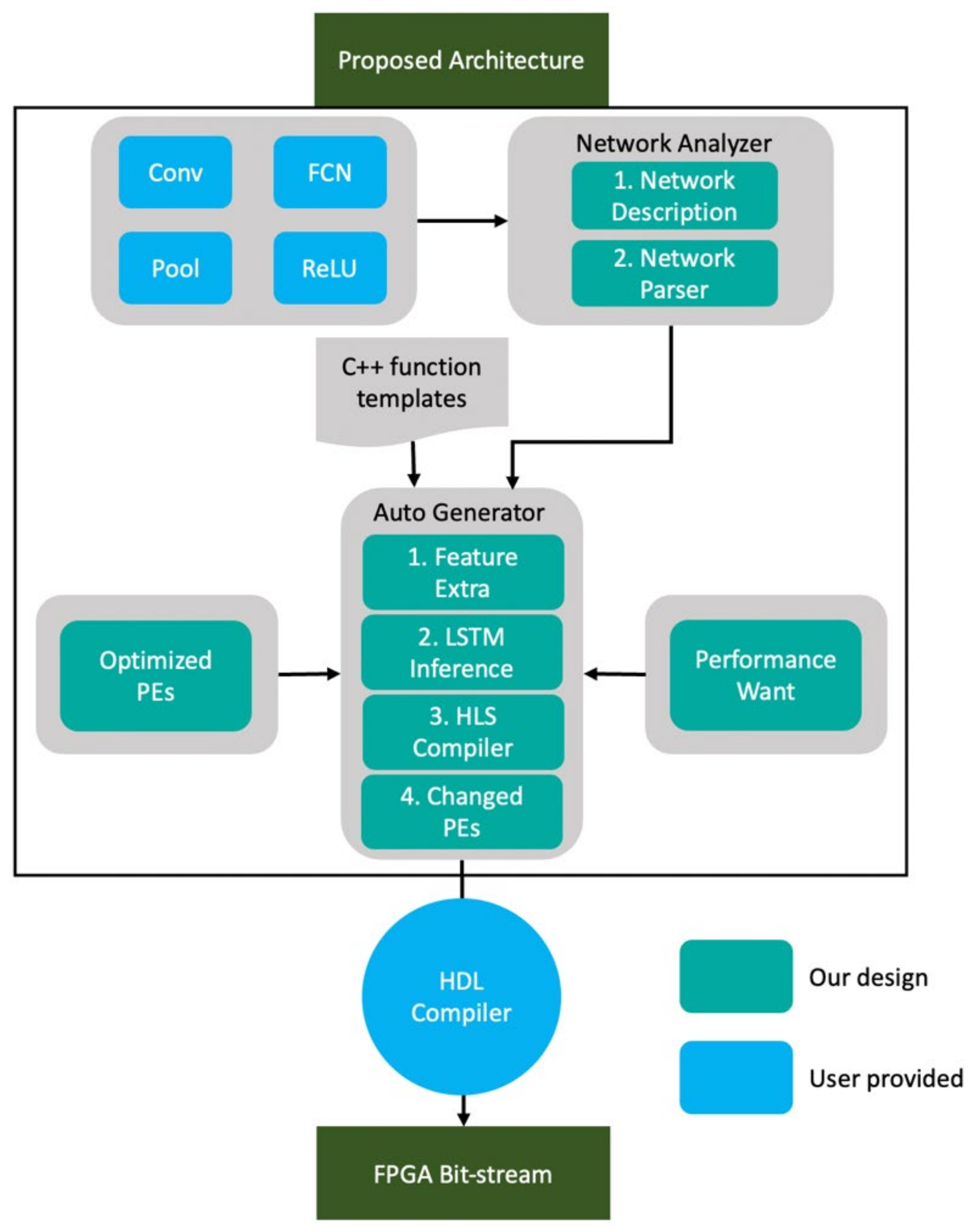
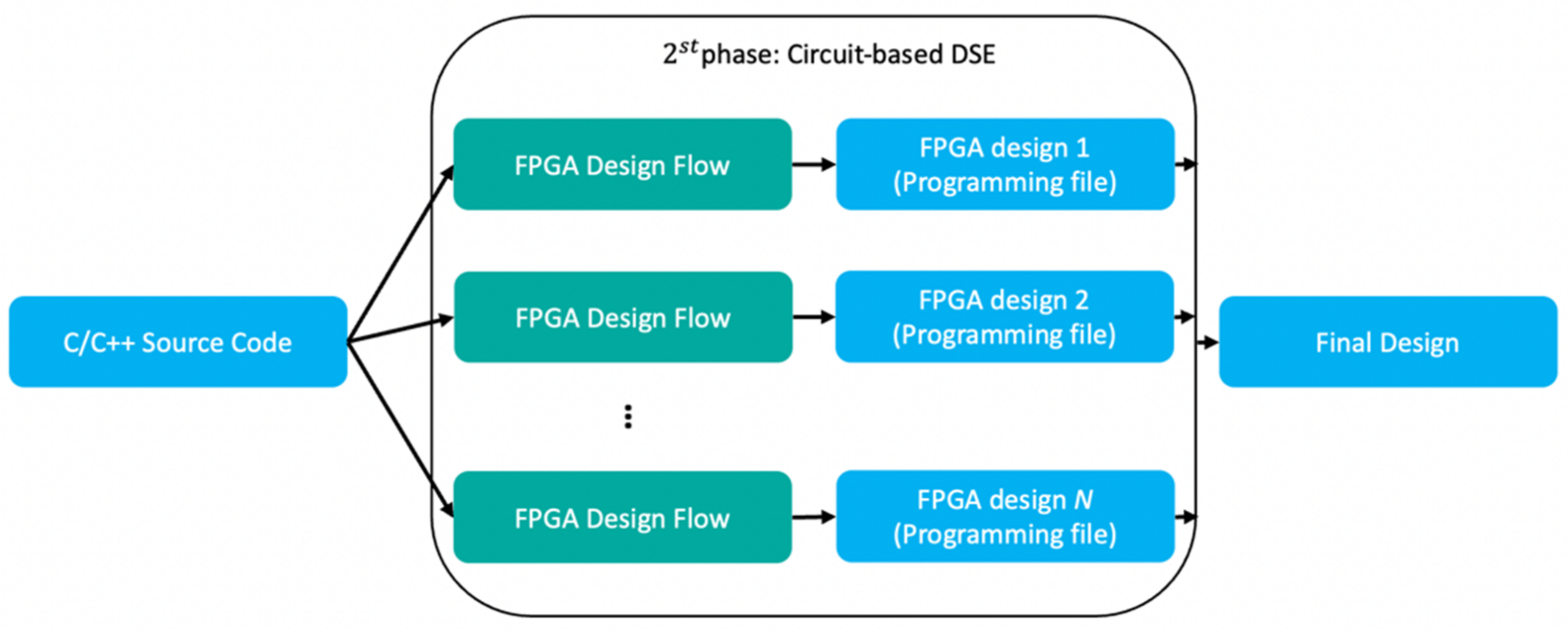
3.1. Proposed Automation Flow
- (1)
- Developers first use a deep learning open neural network exchange (ONNX) framework to design and train the DNN target network during the design process. After training, the DNN network definition file is passed to the DNN network analyzer [19].
- (2)
- A network analysis decomposes network layers from the network model, such as the conv, pooling, and FC layers. Then, it maps them to the HLS template. The network analyzer retains the operation logic and bit size in the conv, pooling, and FC layers to ensure that logic remains as designed.
- (3)
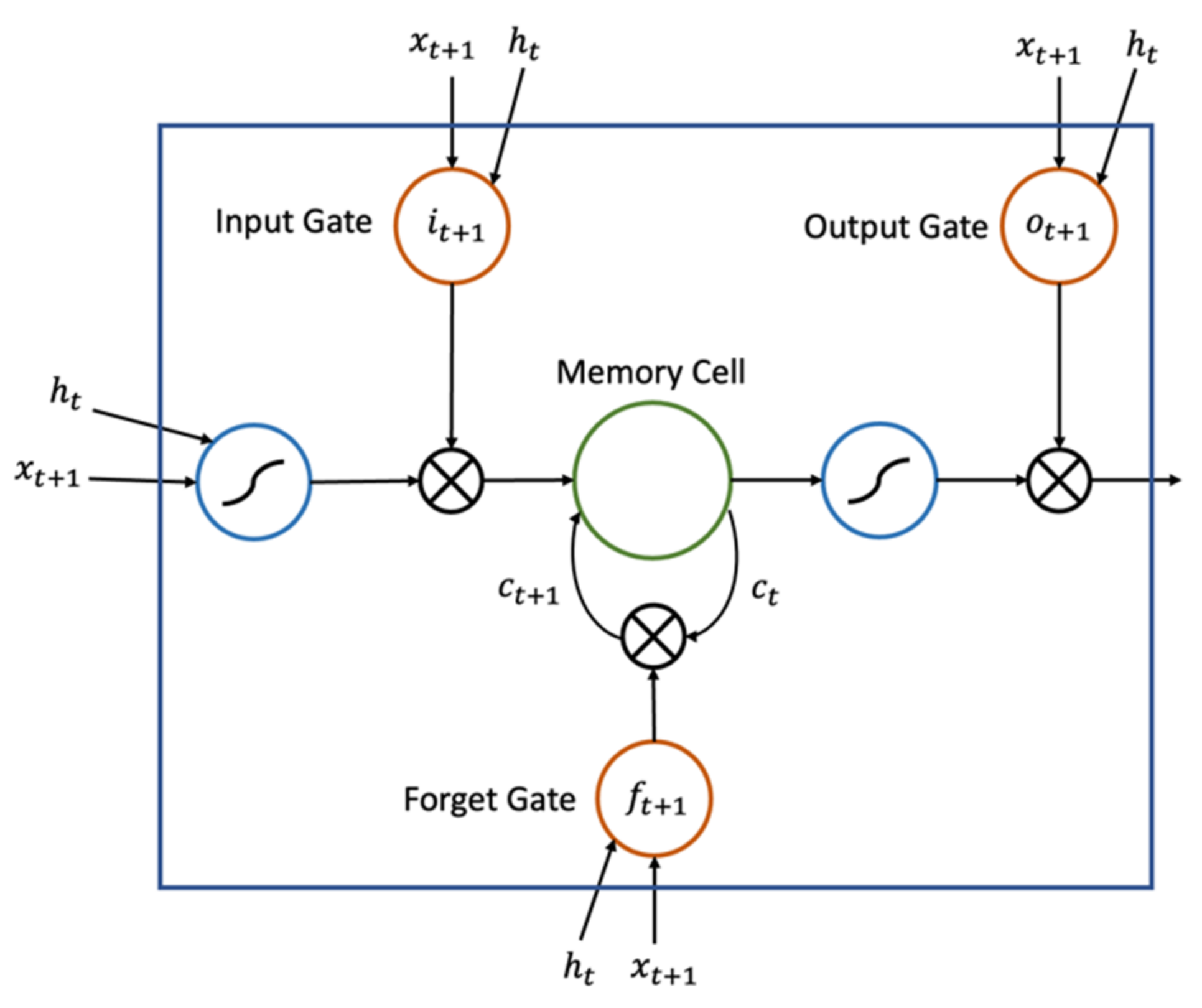
- In the third step, the LSTM-based generator automatically designs the optimized DNN HLS.
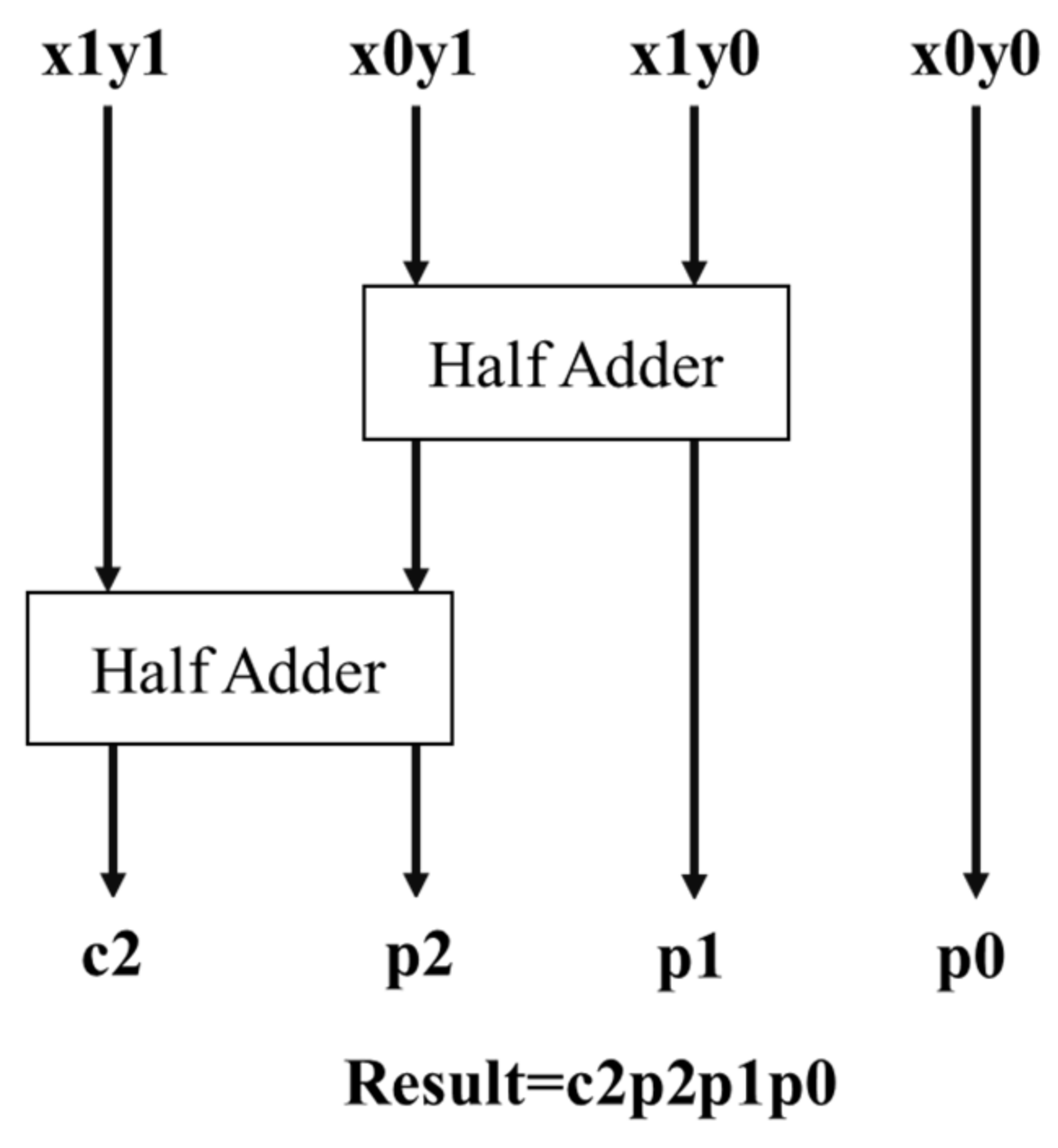
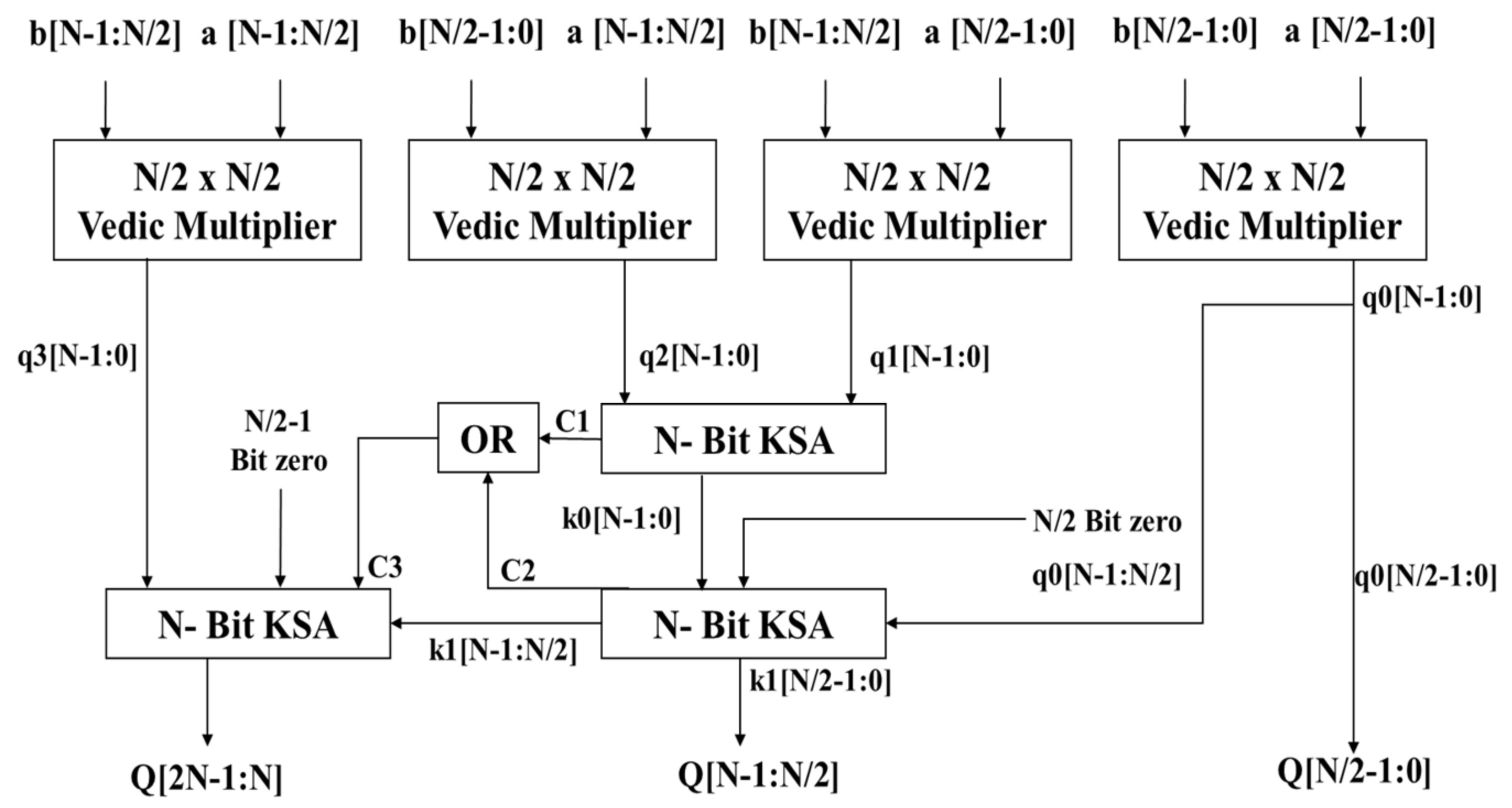
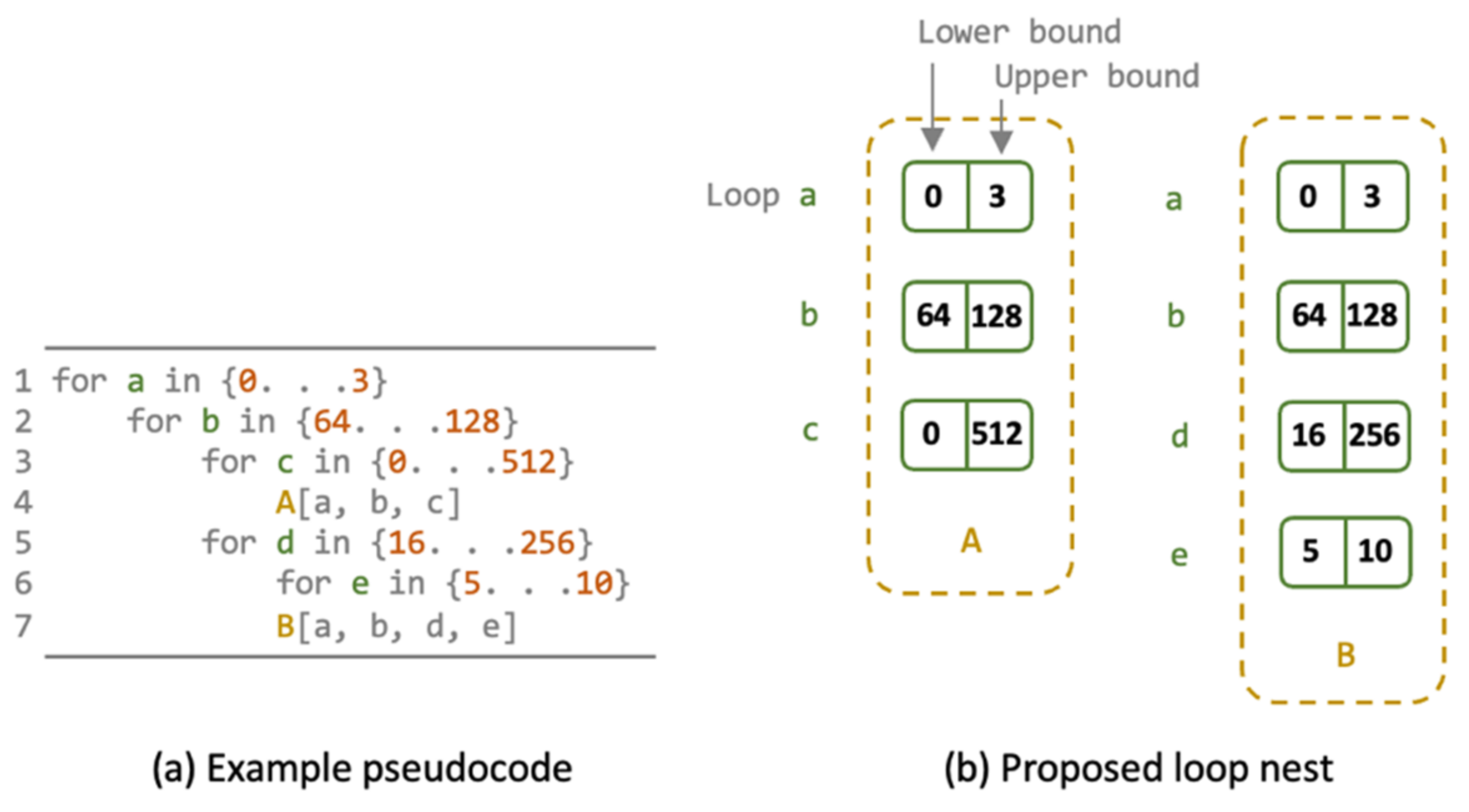
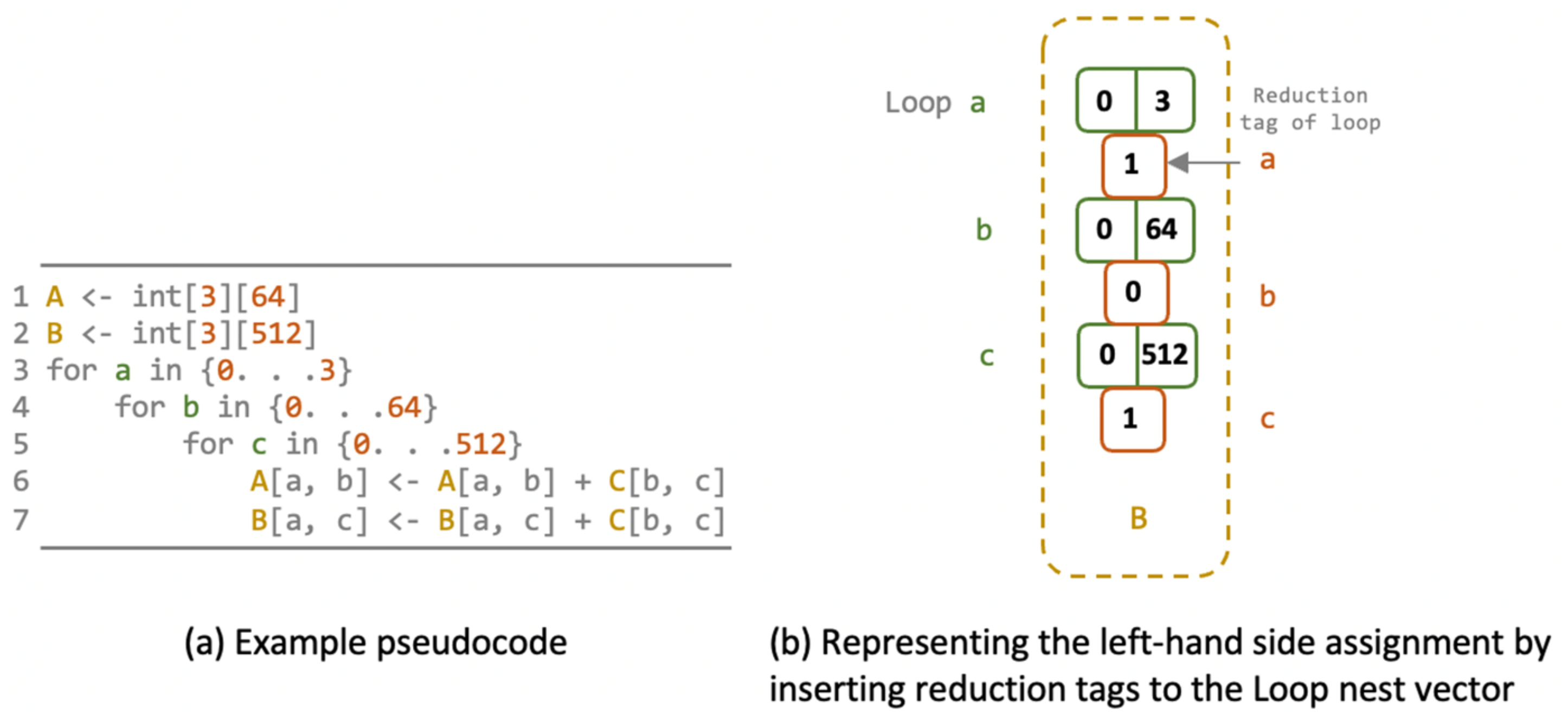
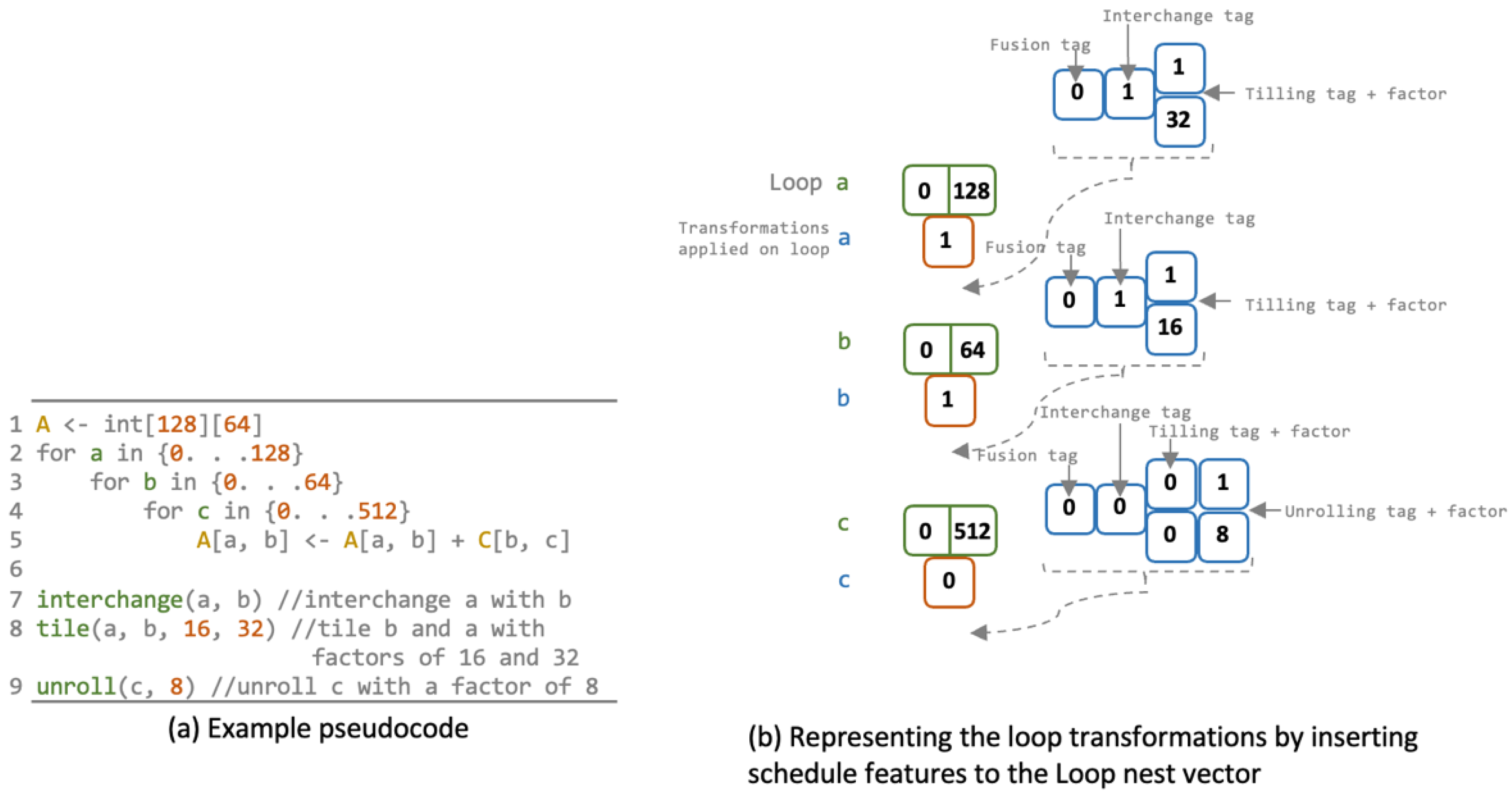
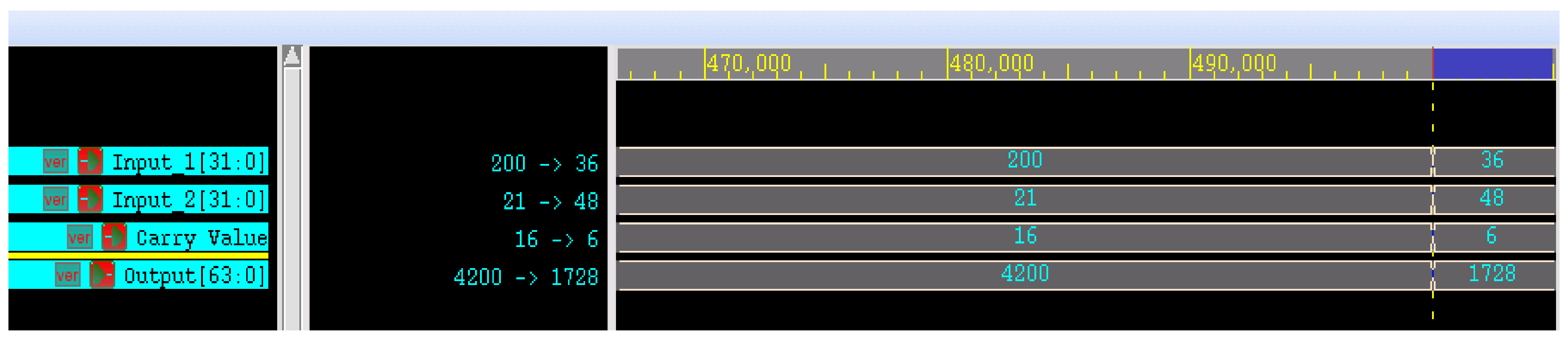
3.2. N-Bit Vedic Multiplier for DNN PEs
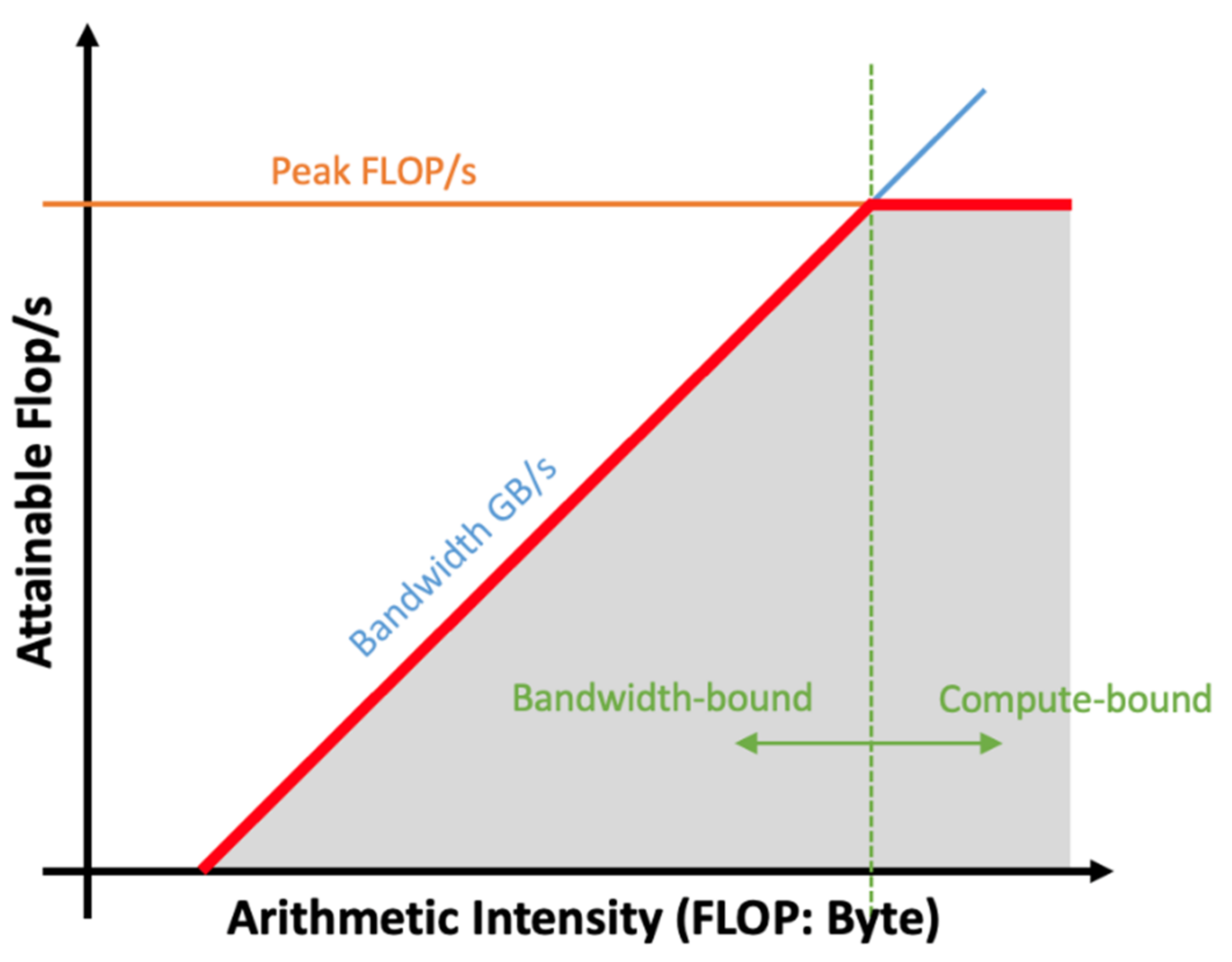
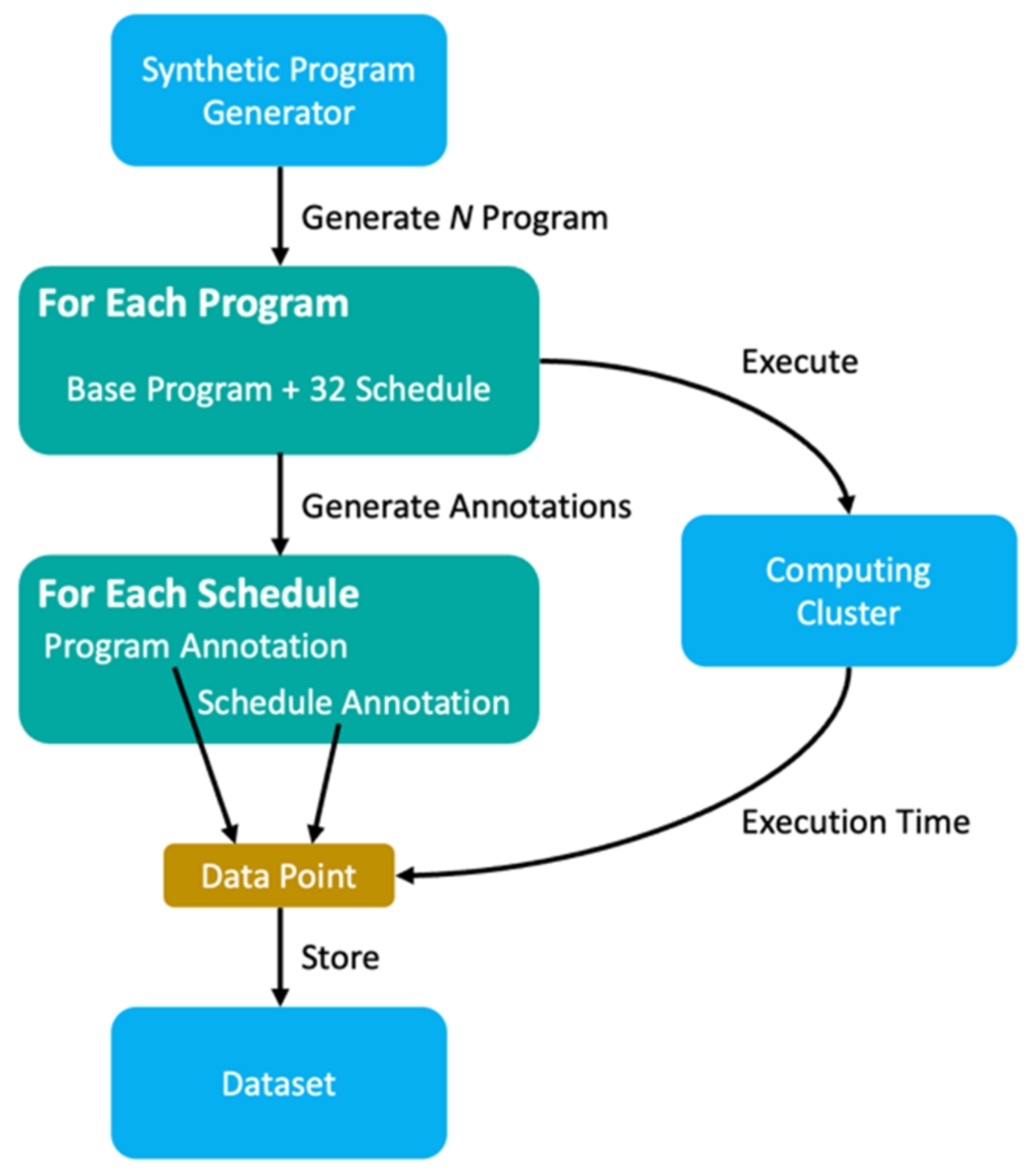
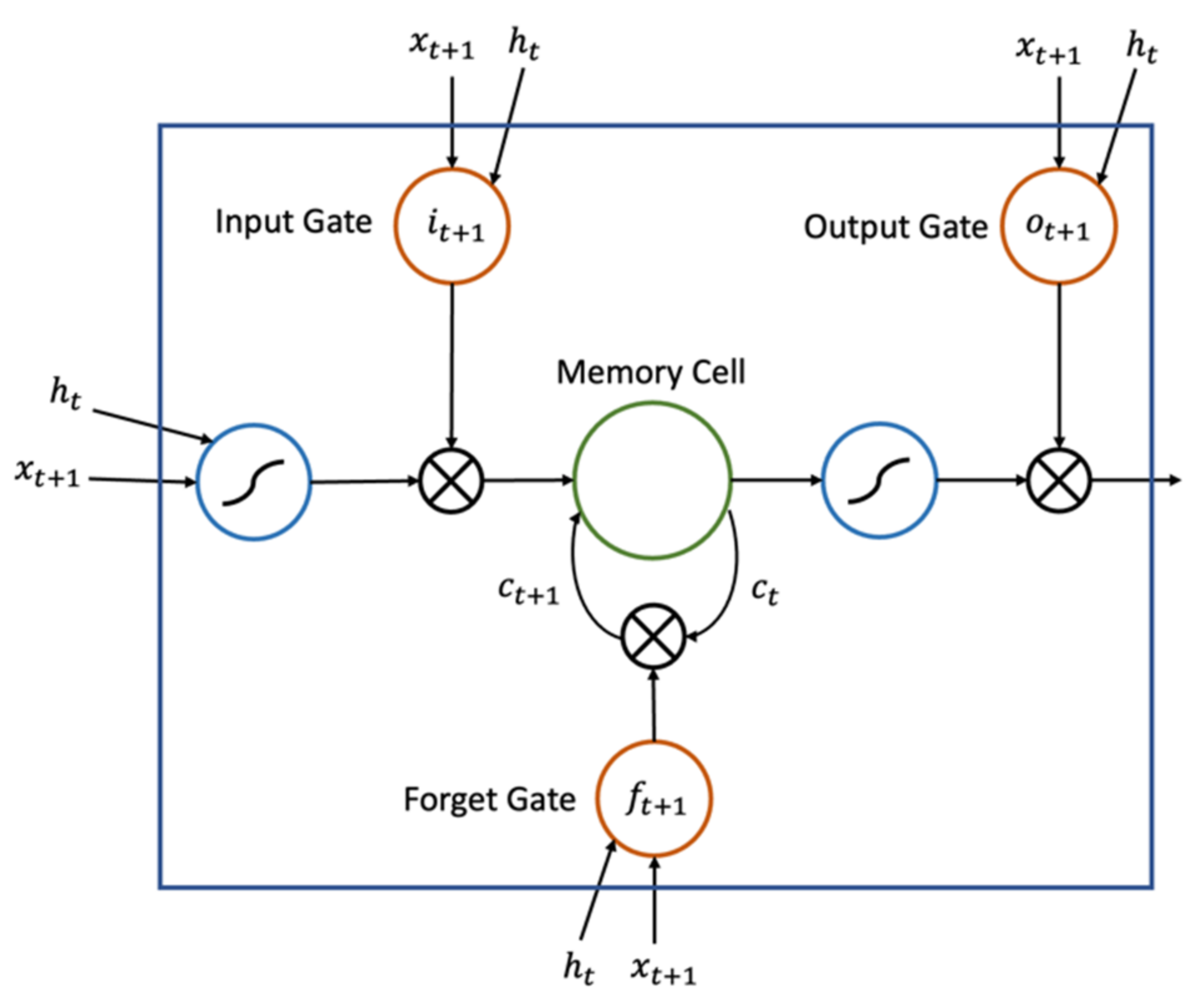
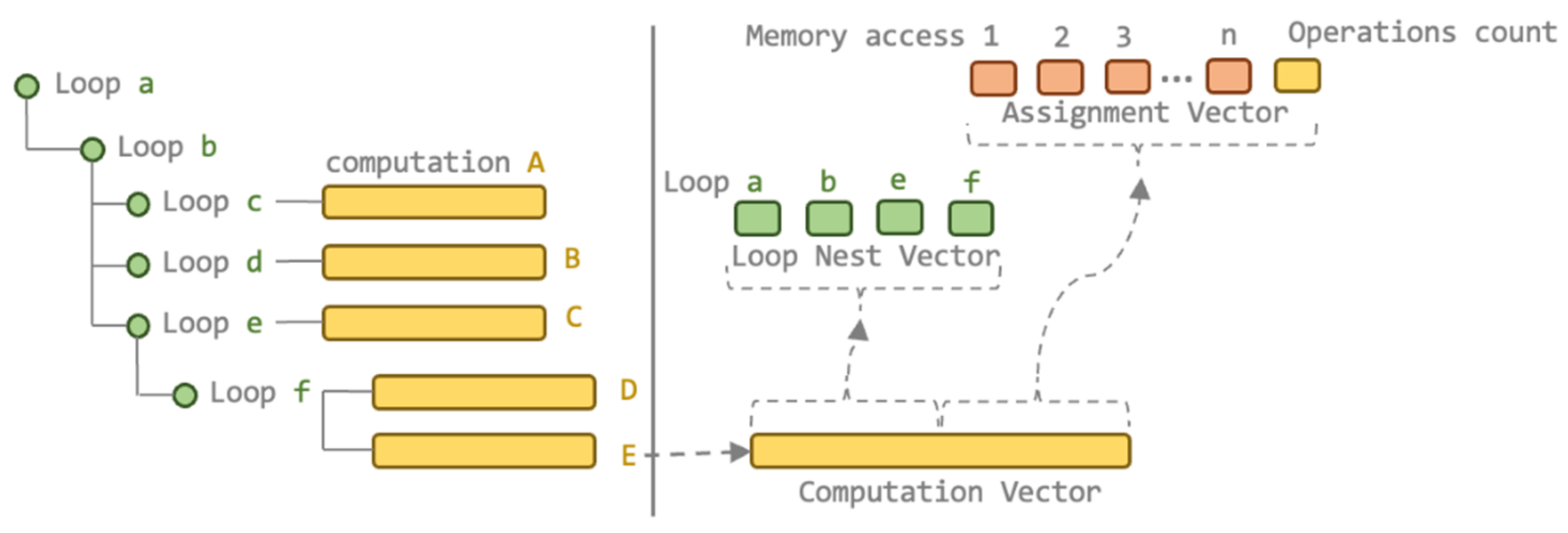
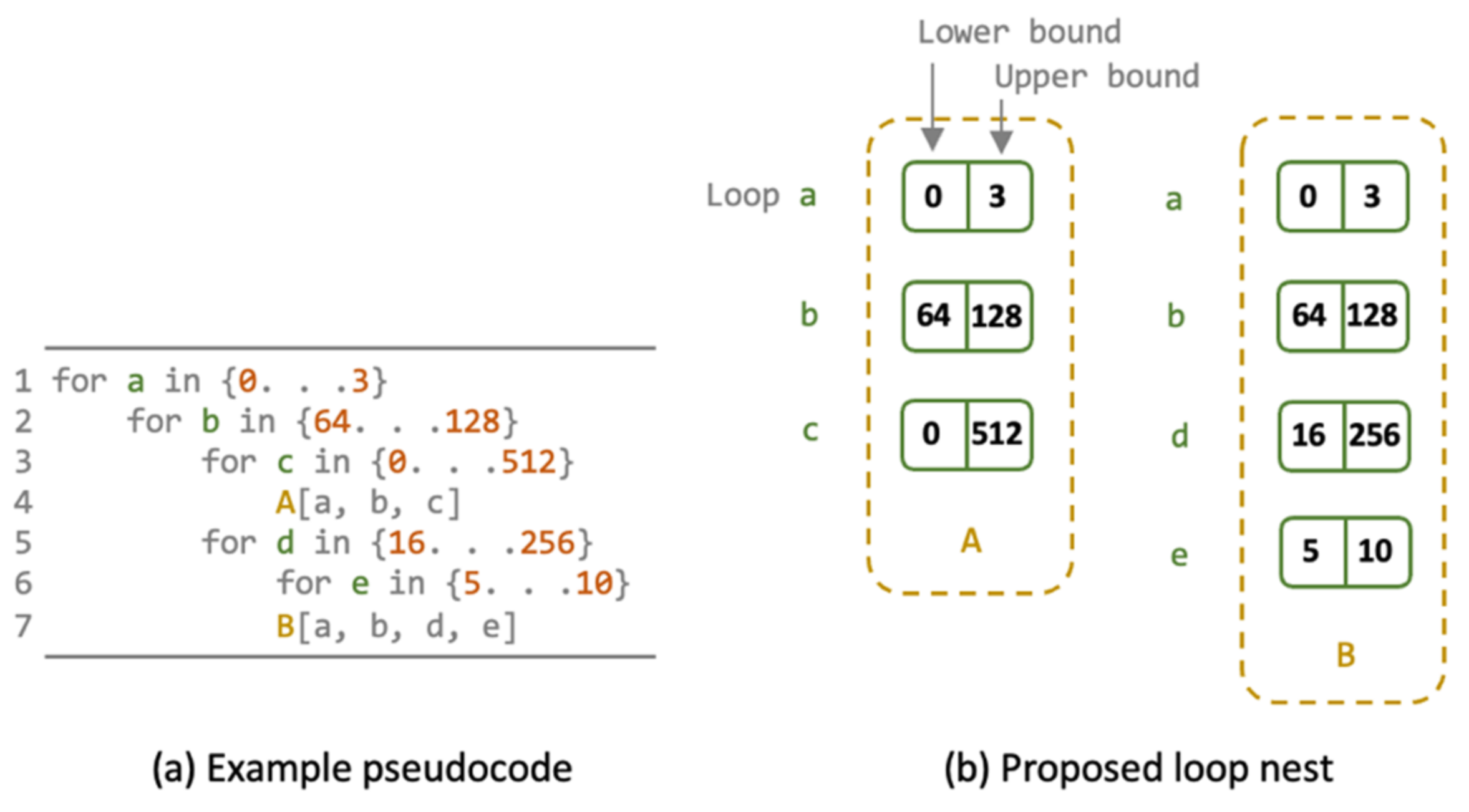
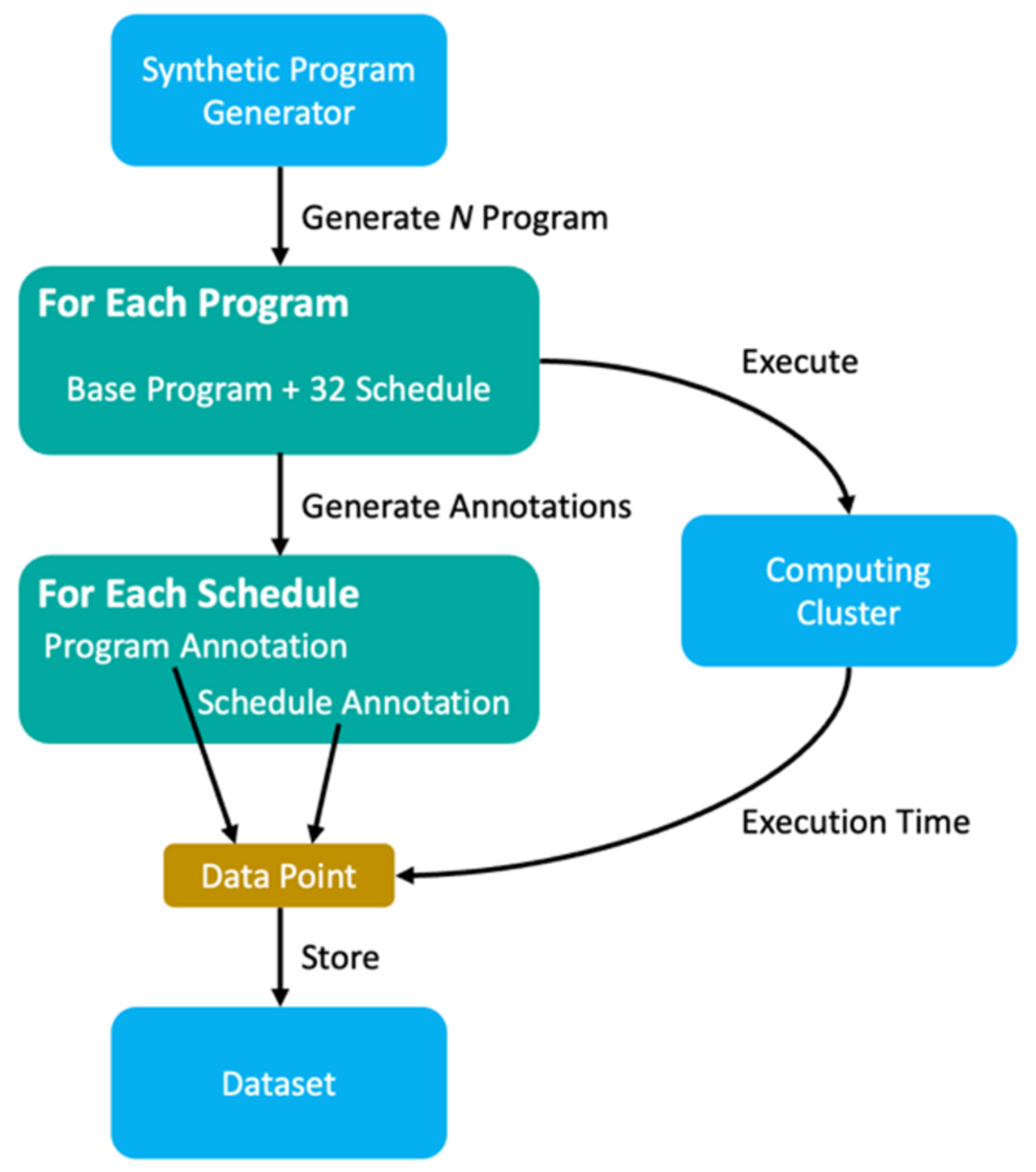
3.3. Performance-Based Auto-Generator
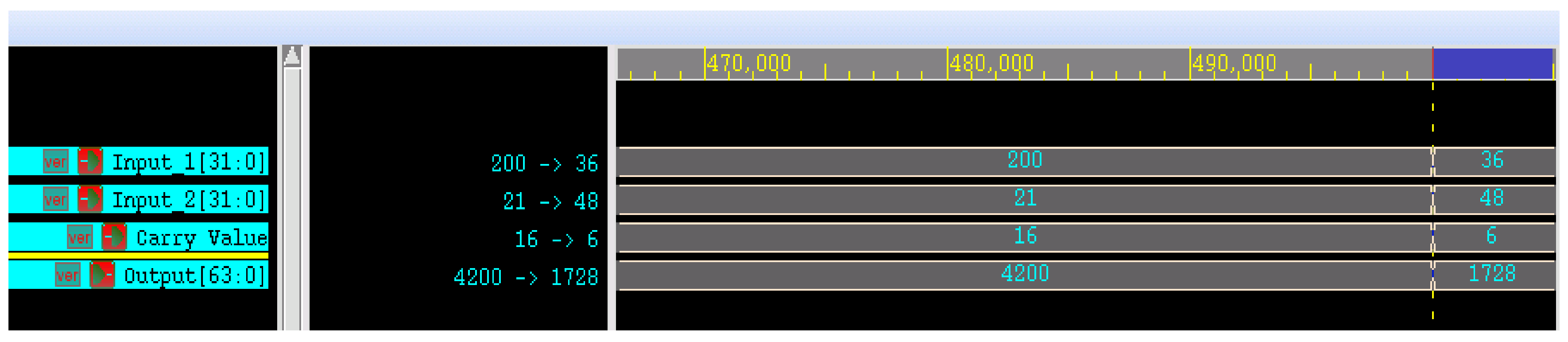
4. Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zhang, C.; Li, P.; Sun, G.; Guan, Y.; Xiao, B.; Cong, J. Optimizing FPGA-based accelerator design for deep convolutional neural networks. In Proceedings of the 2015 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 22–24 February 2015. [Google Scholar]
- Kim, T.; Park, S.; Cho, Y. Study on the Implementation of a Simple and Effective Memory System for an AI Chip. Electronics 2021, 10, 1399. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, J.; Zhu, C.; Lin, Y.; Xiong, J.; Hwu, W.M.; Chen, D. Dnnbuilder: An automated tool for building high-performance dnn hardware accelerators for fpgas. In Proceedings of the 2018 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), San Diego, CA, USA, 5–8 November 2018. [Google Scholar]
- Li, Q.; Zhang, X.; Xiong, J.; Hwu, W.M.; Chen, D. Implementing neural machine translation with bi-directional GRU and attention mechanism on FPGAs using HLS. In Proceedings of the 24th Asia and South Pacific Design Automation Conference, Tokyo, Japan, 21–24 January 2019. [Google Scholar]
- He, D.; He, J.; Liu, J.; Yang, J.; Yan, Q.; Yang, Y. An FPGA-Based LSTM Acceleration Engine for Deep Learning Frameworks. Electronics 2021, 10, 681. [Google Scholar] [CrossRef]
- Qi, X.; Liu, C. Enabling Deep Learning on IoT Edge: Approaches and Evaluation. In Proceedings of the IEEE/ACM Symposium on Edge Computing (SEC), Seattle, WA, USA, 25–27 October 2018. [Google Scholar] [CrossRef]
- Zhang, X.; Ramachandran, A.; Zhuge, C.; He, D.; Zuo, W.; Cheng, Z.; Rupnow, K.; Chen, D. Machine learning on FPGAs to face the IoT revolution. In Proceedings of the 2017 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), Irvine, CA, USA, 13–16 November 2017. [Google Scholar]
- Wang, J.; Lou, Q.; Zhang, X.; Zhu, C.; Lin, Y.; Chen, D. Design flow of accelerating hybrid extremely low bit-width neural network in embedded FPGA. In Proceedings of the 2018 28th International Conference on Field Programmable Logic and Applications (FPL), Dublin, Ireland, 27–31 August 2018. [Google Scholar]
- Aydonat, U.; O’Connell, S.; Capalija, D.; Ling, A.C.; Chiu, G.R. An opencl™ deep learning accelerator on arria 10. In Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 22–24 February 2017. [Google Scholar]
- Tan, M.; Chen, B.; Pang, R.; Vasudevan, V.; Sandler, M.; Howard, A.; Le, Q.V. Mnasnet: Platform-aware neural architecture search for mobile. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Cai, H.; Zhu, L.; Han, S. Proxylessnas: Direct neural architecture search on target task and hardware. In Proceedings of the 2019 7th International Conference on Learning Representation (ICLR), New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Qiu, J.; Wang, J.; Yao, S.; Guo, K.; Li, B.; Zhou, E.; Yu, J.; Tang, T.; Xu, N.; Song, S.; et al. Going deeper with embedded fpga platform for convolutional neural network. In Proceedings of the 2016 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 21–23 February 2016. [Google Scholar]
- Han, S.; Kang, J.; Mao, H.; Hu, Y.; Li, X.; Li, Y.; Xie, D.; Luo, H.; Yao, S.; Wang, Y.; et al. Ese: Efficient speech recognition engine with sparse lstm on fpga. In Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 22–24 February 2017. [Google Scholar]
- Zhang, M.; Li, L.; Wang, H.; Liu, Y.; Qin, H.; Zhao, W. Optimized Compression for Implementing Convolutional Neural Networks on FPGA. Electronics 2019, 8, 295. [Google Scholar] [CrossRef] [Green Version]
- Zeng, H.; Chen, R.; Zhang, C.; Prasanna, V. A framework for generating high throughput CNN implementations on FPGAs. In Proceedings of the 2018 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 25–27 February 2018. [Google Scholar]
- Sharma, H.; Park, J.; Mahajan, D.; Amaro, E.; Kim, J.K.; Shao, C.; Mishra, A.; Esmaeilzadeh, H. From high-level deep neural models to FPGAs. In Proceedings of the 2016 49th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Taipei, Taiwan, 15–19 October 2016. [Google Scholar]
- Ma, Y.; Cao, Y.; Vrudhula, S.; Seo, J.S. An automatic RTL compiler for high-throughput FPGA implementation of diverse deep convolutional neural networks. In Proceedings of the 2017 27th International Conference on Field Programmable Logic and Applications (FPL), Ghent, Belgium, 4–8 September 2017. [Google Scholar]
- Guan, Y.; Liang, H.; Xu, N.; Wang, W.; Shi, S.; Chen, X.; Sun, G.; Zhang, W.; Cong, J. FP-DNN: An automated framework for mapping deep neural networks onto FPGAs with RTL-HLS hybrid templates. In Proceedings of the 2017 IEEE 25th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), Napa, CA, USA, 30 April–2 May 2017. [Google Scholar]
- Lin, W.F.; Tsai, D.Y.; Tang, L.; Hsieh, C.T.; Chou, C.Y.; Chang, P.H.; Hsu, L. ONNC: A compilation framework connecting ONNX to proprietary deep learning accelerators. In Proceedings of the 2019 IEEE International Conference on Artificial Intelligence Circuits and Systems (AICAS), Hsinchu, Taiwan, 18–20 March 2019. [Google Scholar]
- Kumm, M.; Abbas, S.; Zipf, P. An efficient softcore multiplier architecture for Xilinx FPGAs. In Proceedings of the 2015 IEEE 22nd Symposium on Computer Arithmetic, Lyon, France, 22–24 June 2015. [Google Scholar]
- Tiwari, H.D.; Gankhuyag, G.; Kim, C.M.; Cho, Y.B. Multiplier design based on ancient Indian Vedic Mathematics. In Proceedings of the 2008 International SoC Design Conference, Busan, Korea, 24–25 November 2008. [Google Scholar]
- Karthik, V.K.; Govardhan, Y.; Reddy, V.K.; Praveena, K. Design of Multiply and Accumulate Unit using Vedic Multiplication Techniques. Int. J. Sci. Res. 2013, 4, 756. [Google Scholar]
- Jayanthi, A.N.; Ravichandran, C.S. Comparison of performance of high speed VLSI adders. In Proceedings of the 2013 International Conference on Current Trends in Engineering and Technology (ICCTET), Coimbatore, India, 3 July 2013. [Google Scholar]
- Akhter, S.; Saini, V.; Saini, J. Analysis of Vedic multiplier using various adder topologies. In Proceedings of the 2017 4th International Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, 2–3 February 2017. [Google Scholar]
- Suda, N.; Chandra, V.; Dasika, G.; Mohanty, A.; Ma, Y.; Vrudhula, S.; Seo, J.S.; Cao, Y. Throughput-optimized OpenCL-based FPGA accelerator for large-scale convolutional neural networks. In Proceedings of the 2016 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 21–23 February 2016. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Conventional Multiplier | Conventional Vedic Multiplier | Proposed Vedic Multiplier |
|---|---|---|---|
| Power (µW) | 26.351 | 27.235 | 23.33 |
| Speed (ns) | 6.213 | 5.327 | 4.1 |
| Area (µm2) | 3567 | 4283 | 3958 |
| Parameter | Slice | LUT | DSP | IOB |
|---|---|---|---|---|
| Xilinx IP | 415 | 93 | 2 | 102 |
| Ours | 287 | 107 | 0 | 86 |
| ZCU 104 (ms) | ZCU 102 (ms) | Cyclone V SoC (ms) | Jetson Tx1 (ms) | Jetson Tx2 (ms) | |
|---|---|---|---|---|---|
| ResNet18 | 1.78 | 2.16 | 4.1 | 21 | 14.7 |
| VGG-16 | 12.9 | 15.52 | 29.1 | 151 | 105.7 |
| MobileNetV2 | 1.77 | 2.15 | 3.95 | 20.5 | 14.3 |
| DenseNet-121 | 5.67 | 6.79 | 12.8 | 66.4 | 46.4 |
| Oiu [12] | Suda [25] | Ours | |||
|---|---|---|---|---|---|
| CNN Models | VGG | ||||
| Device | Zynq 7Z45 | Stratix V GSD8 | ZCU 104 | ZCU 102 | Cyclone V SoC |
| Precision | Fixed 16 bit | Fixed 16 bit | Fixed 16 bit | Fixed 16 bit | Fixed 16 bit |
| Overall CONV GOPs | 187.8 | 136.5 | 304.2 | 253.3 | 144.7 |
| Peak CONV | 254.8 | - | 368.5 | 304.7 | 260.6 |
| Platform | CPU (SIMD) | GPU | FPGA | |||
|---|---|---|---|---|---|---|
| Device | Kirin 970 | Jetson Tx1 | Jetson Tx2 | ZCU 104 | ZCU 102 | Cyclone V SoC |
| Precision | Float32 | Float32 | Float32 | Fixed 16 | Fixed 16 | Fixed 16 |
| Batch size | 1 | 1 | 1 | 1 | 1 | 1 |
| Latency | 720.9 | 151 | 105.7 | 12.9 | 15.52 | 29.1 |
| Speedup | 1× | 4.77× | 6.82× | 55.88× | 46.44× | 24.77× |
| Power (Watt) | 8 | 10 | 7.5 | 6.3 | 7.6 | 8.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jang, S.; Liu, W.; Park, S.; Cho, Y. Automatic RTL Generation Tool of FPGAs for DNNs. Electronics 2022, 11, 402. https://doi.org/10.3390/electronics11030402
Jang S, Liu W, Park S, Cho Y. Automatic RTL Generation Tool of FPGAs for DNNs. Electronics. 2022; 11(3):402. https://doi.org/10.3390/electronics11030402
Chicago/Turabian StyleJang, Seojin, Wei Liu, Sangun Park, and Yongbeom Cho. 2022. "Automatic RTL Generation Tool of FPGAs for DNNs" Electronics 11, no. 3: 402. https://doi.org/10.3390/electronics11030402
APA StyleJang, S., Liu, W., Park, S., & Cho, Y. (2022). Automatic RTL Generation Tool of FPGAs for DNNs. Electronics, 11(3), 402. https://doi.org/10.3390/electronics11030402