
Image Forgery Detection Using Deep Learning by Recompressing Images

 ,
,  and
and
Abstract
:1. Introduction
- Image Splicing: A portion of a donor image is copied into a source image. A sequence of donor images can likewise be used to build the final forged image.
- Copy-Move: This scenario contains a single image. Within the image, a portion of the image is copied and pasted. This is frequently used to conceal other objects. The final forged image contains no components from other images.
- A lightweight CNN-based architecture is designed to detect image forgery efficiently. The proposed technique explores numerous artifacts left behind in the image tampering process, and it takes advantage of differences in image sources through image recompression.
- While most existing algorithms are designed to detect only one type of forgery, our technique can detect both image splicing and copy-move forgeries and has achieved high accuracy in image forgery detection.
- Compared to existing techniques, the proposed technique is fast and can detect the presence of image forgery in significantly less time. Its accuracy and speed make it suitable for real-world application, as it can function well even on slower devices.
2. Literature Review
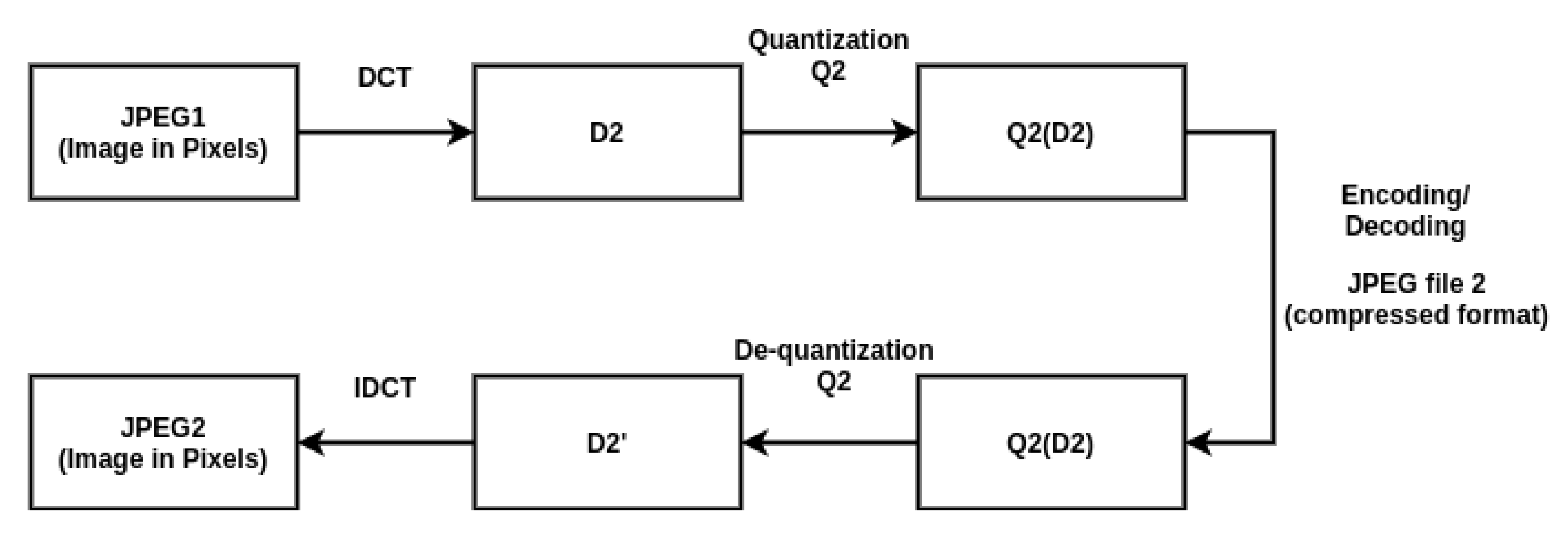
3. Proposed Technique
- The first convolutional layer consists of 32 filters of size 3-by-3, stride size one, and “relu” activation function.
- The second convolutional layer consists of 32 filters of size 3-by-3, stride size one, and “relu” activation function.
- The third convolutional layer consists of 32 filters of size 7-by-7, stride size one, and “relu” activation function, followed by max-pooling of size 2-by-2.
- Then we have the dense layer that has 256 neurons with “relu” activation function, finally which is connected to two neurons (output neurons) with “sigmoid” activation.
| Algorithm 1: Working of the proposed technique for the image forgery detection. |
| 1: /* Model Training (line 2 to 23) */ |
| 2: Input: Image ‘’ (i = 1 to n), with labels ‘’ ( = 1 if is tampered image, else = 0). |
| 3: Output: Trained Model: Image_Forgery_Predictor_Model() |
| 4: /* Prediction Model Description */ |
| 5: Image_Forgery_Predictor_Model(image with size 128 × 128 × 3) |
| 6: { |
| 7: First convo. layer: 32 filters (size 3 × 3, strid size one, activation: “relu”) |
| 8: Second convo. layer: 32 filters (size 3 × 3, strid size one, activation: “relu”) |
| 9: Third convo. layer: 32 filters (size 3 × 3, strid size one, activation: “relu”) |
| 10: Max-pooling of size 2 × 2 |
| 11: Dense layer of 256 neurons with “relu” activation function |
| 12: Two neurons (output neurons) with “sigmoid” activation |
| 13: } |
| 14: for = 1 to do |
| 15: = 0 |
| 16: for i = 1 to n do |
| 17: = |
| 18: = |
| 19: = |
| 20: = ( − Image_Forgery_Predictor_Model()) + |
| 21: end for |
| 22: modify_model(, Image_Forgery_Predictor_Model(), Adam_optimizer) |
| 23: end for |
| 24: /* Image forgery prediction (line 25 to 32) */ |
| 25: Input: Image ‘’ |
| 26: Output: ‘’ labelled as tampered or untampered |
| 27: = |
| 28: = |
| 29: = |
| 30: = Image_Forgery_Predictor_Model() |
| 31: /* If [0][0]> [0][1], then is tampered |
| 32: /* If [0][1]> [0][0], then is untampered |
4. Experimental Results and Discussion
4.1. Experimental Setup
- : The total number of images that were tested.
- (true positive): Correctly identified tampered images.
- (true negative): Correctly identified genuine images.
- (false negative): Wrongly identified tampered images, the tampered images which have been identified as genuine images.
- (false positive): Wrongly identified genuine images, the genuine images which have been identified as tampered images.
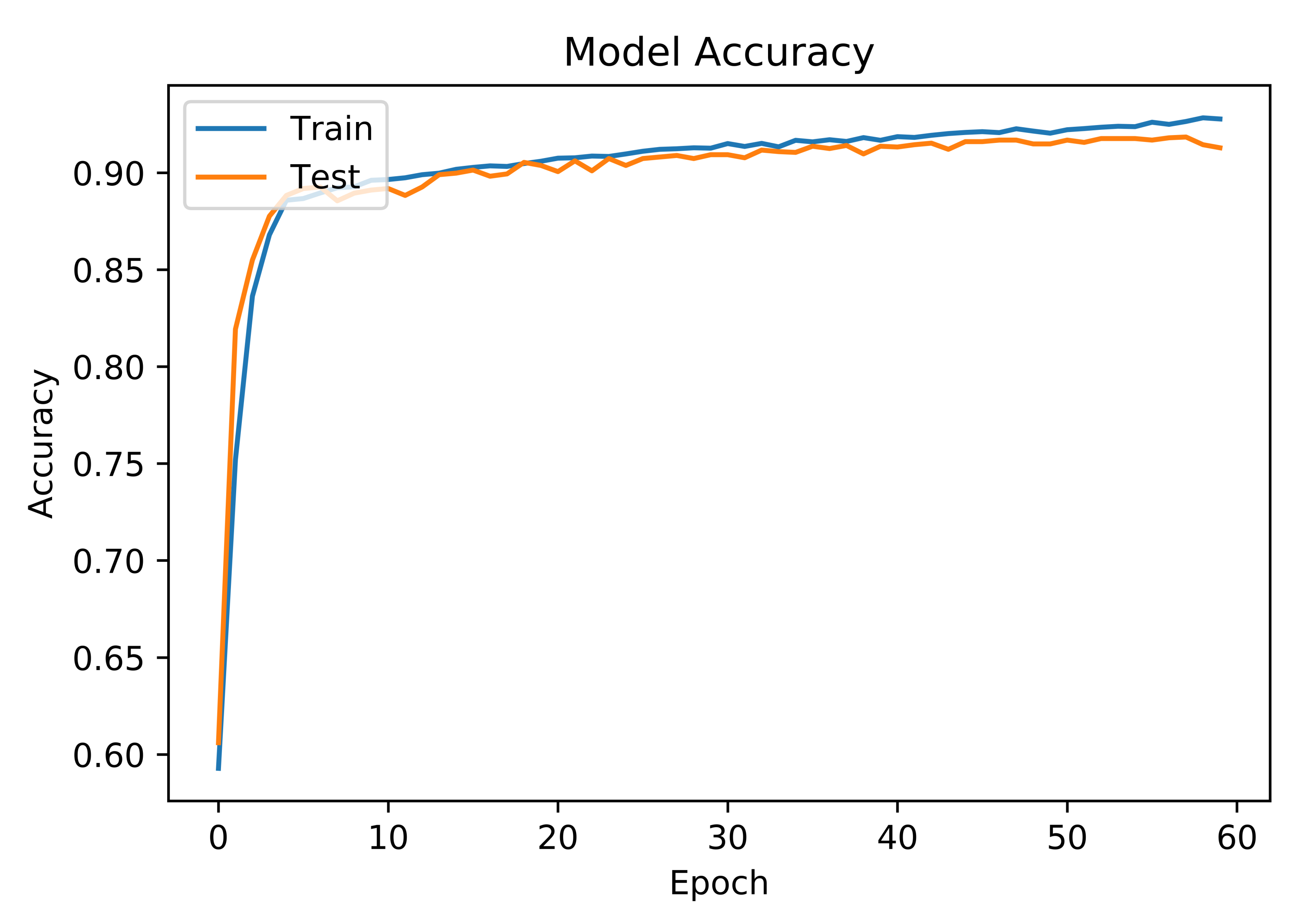
4.2. Model Training and Testing
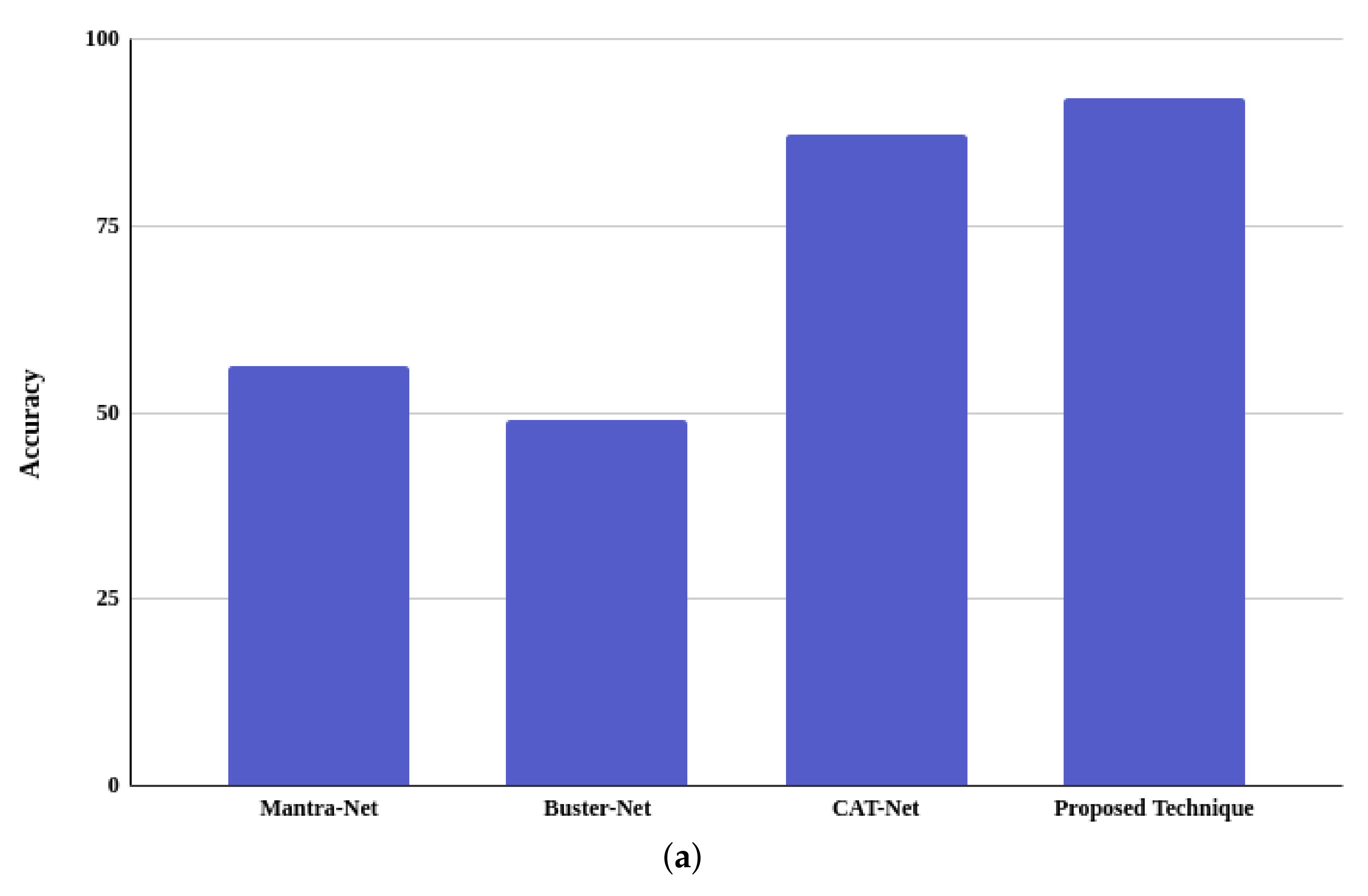
4.3. Comparison with Other Techniques
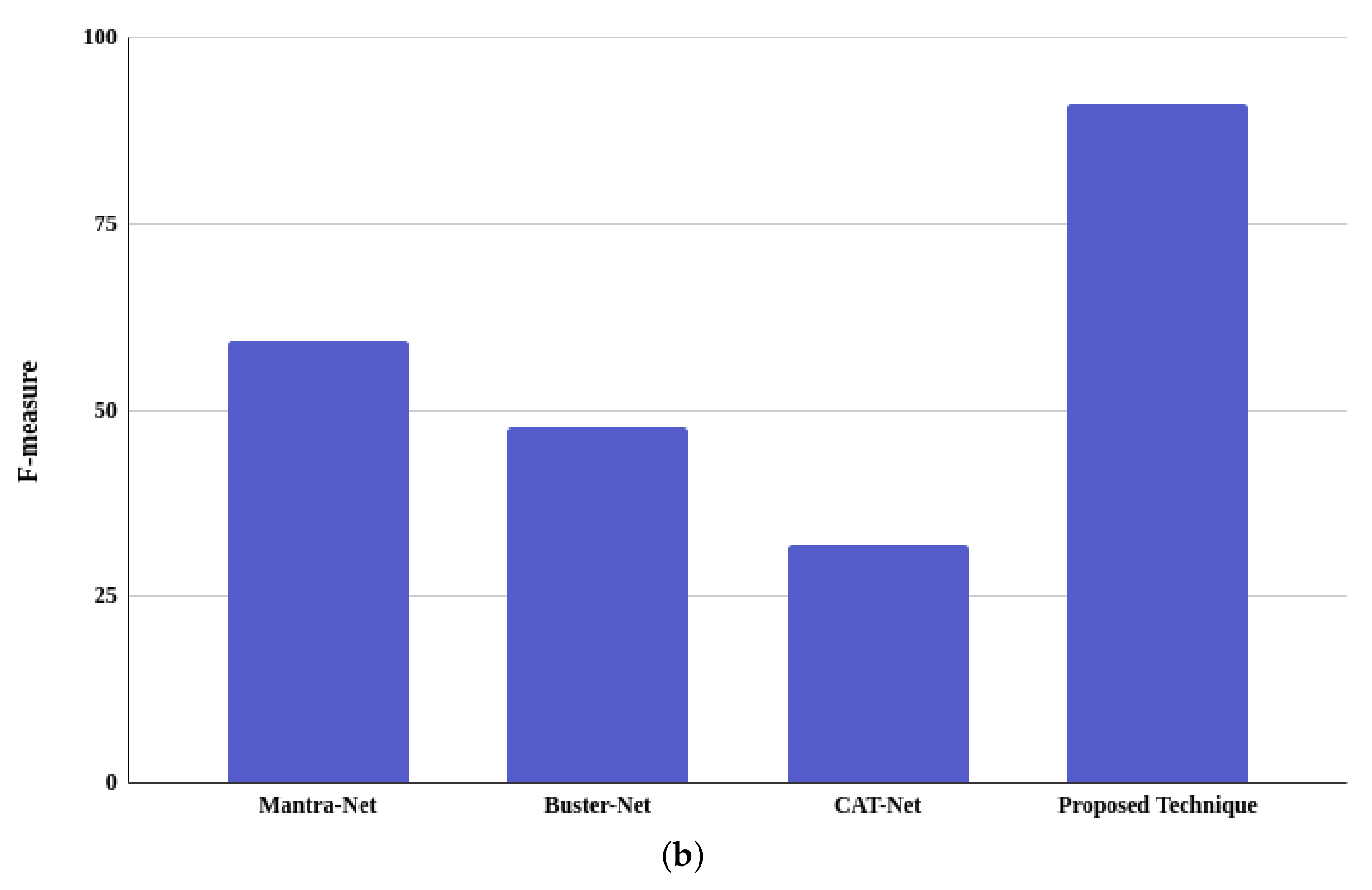
4.3.1. Accuracy Comparison
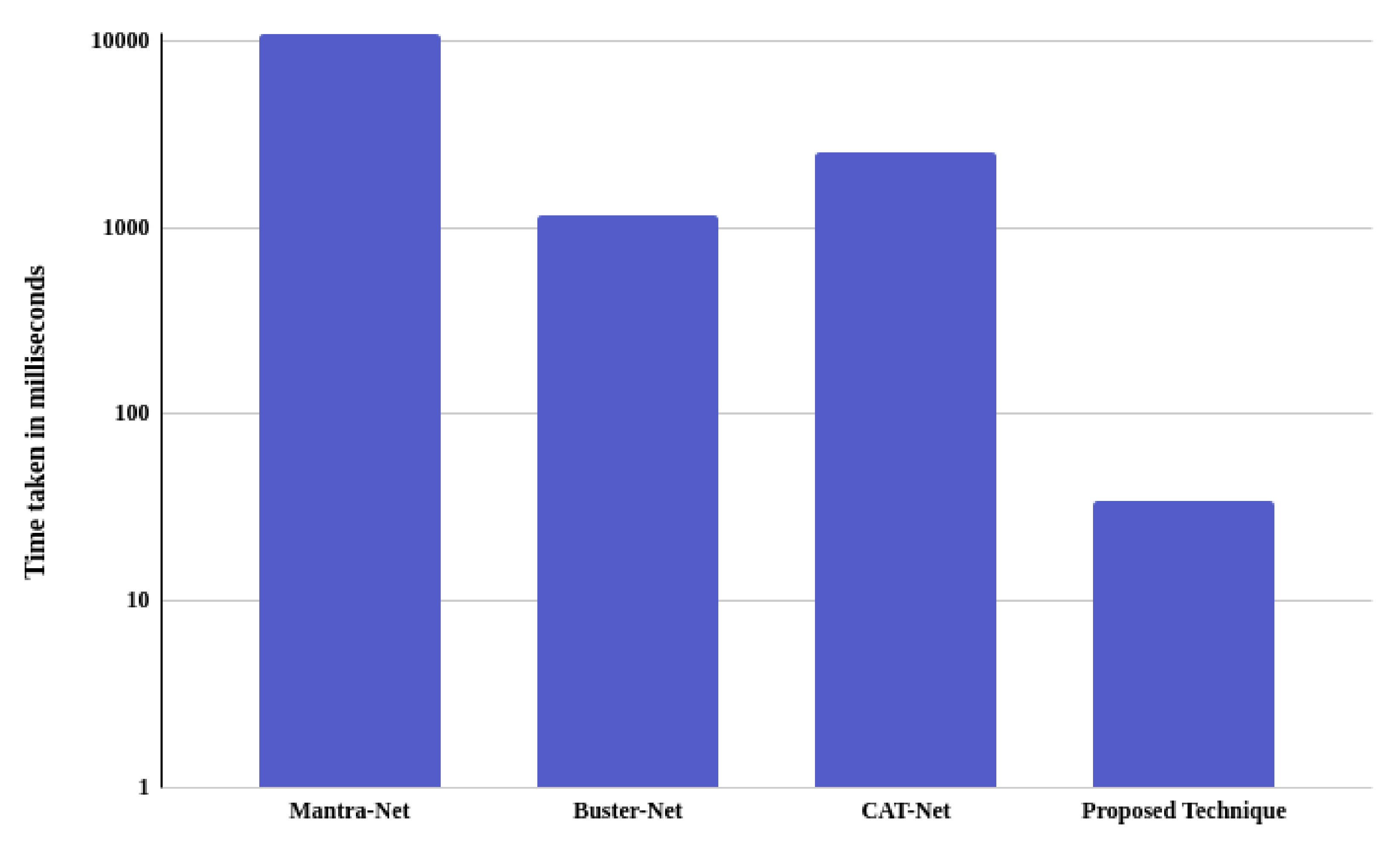
4.3.2. Processing Time Comparison
- Unlike other techniques, the proposed technique works well for both image splicing and copy-move types of image forgeries.
- It is highly efficient for image forgery detection and has exhibited significantly better performance than the other techniques.
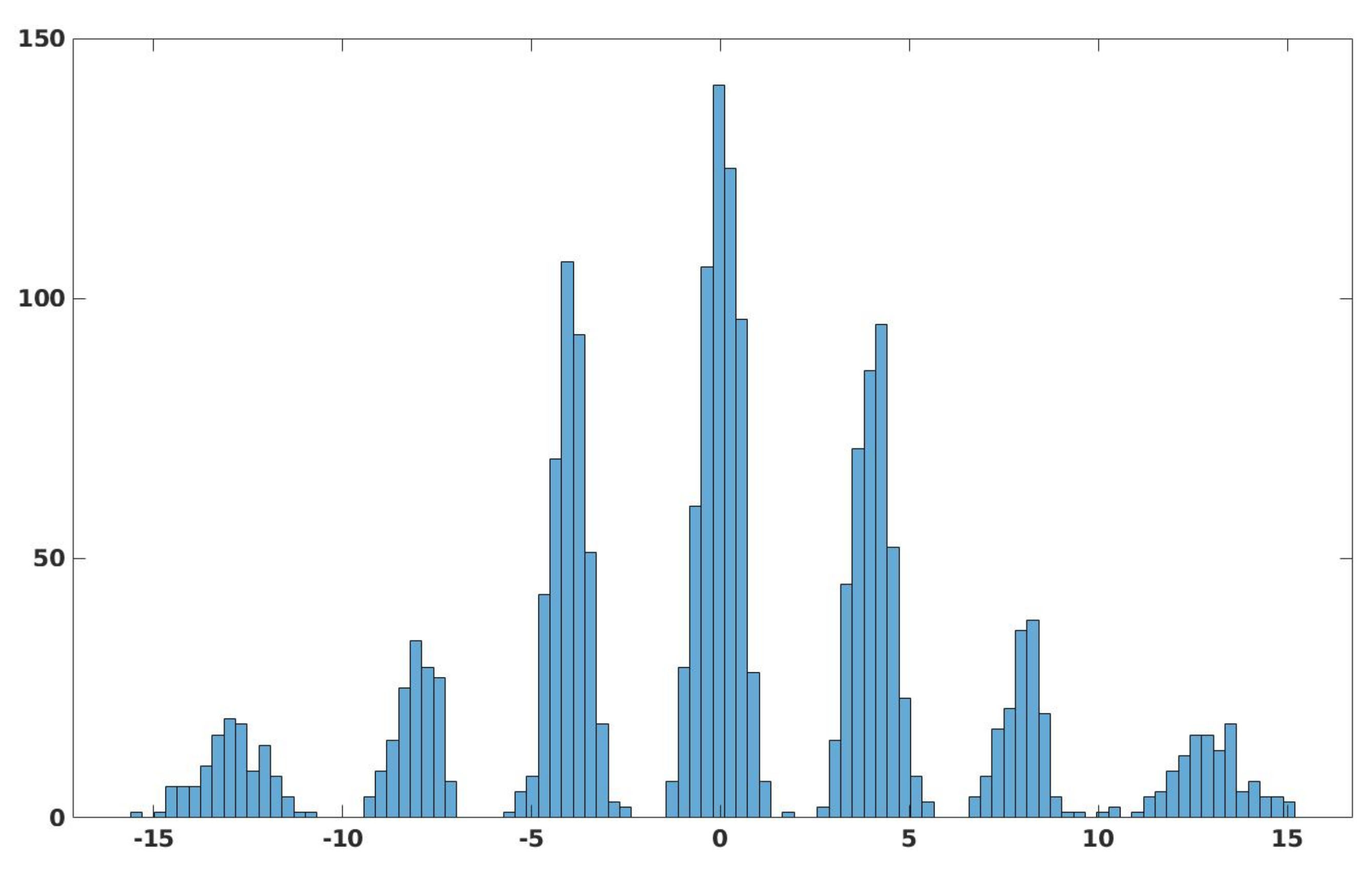
- The difference in the compression of the forged part and the genuine part of the image is a good feature that can be learned by our CNN based model efficiently, which makes the proposed technique more robust in comparison to the other techniques.
- The proposed model is much faster than the other techniques, making it ideal and suitable for real-world usage, as it can be implemented even on slower machines.
5. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Xiao, B.; Wei, Y.; Bi, X.; Li, W.; Ma, J. Image splicing forgery detection combining coarse to refined convolutional neural network and adaptive clustering. Inf. Sci. 2020, 511, 172–191. [Google Scholar] [CrossRef]
- Kwon, M.J.; Yu, I.J.; Nam, S.H.; Lee, H.K. CAT-Net: Compression Artifact Tracing Network for Detection and Localization of Image Splicing. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 5–9 January 2021; pp. 375–384. [Google Scholar]
- Wu, Y.; Abd Almageed, W.; Natarajan, P. ManTra-Net: Manipulation Tracing Network for Detection and Localization of Image Forgeries With Anomalous Features. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 9535–9544. [Google Scholar]
- Ali, S.S.; Baghel, V.S.; Ganapathi, I.I.; Prakash, S. Robust biometric authentication system with a secure user template. Image Vis. Comput. 2020, 104, 104004. [Google Scholar] [CrossRef]
- Castillo Camacho, I.; Wang, K. A Comprehensive Review of Deep-Learning-Based Methods for Image Forensics. J. Imaging 2021, 7, 69. [Google Scholar] [CrossRef] [PubMed]
- Zheng, L.; Zhang, Y.; Thing, V.L. A survey on image tampering and its detection in real-world photos. J. Vis. Commun. Image Represent. 2019, 58, 380–399. [Google Scholar] [CrossRef]
- Jing, L.; Tian, Y. Self-supervised Visual Feature Learning with Deep Neural Networks: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 1. [Google Scholar] [CrossRef]
- Meena, K.B.; Tyagi, V. Image Forgery Detection: Survey and Future Directions. In Data, Engineering and Applications: Volume 2; Shukla, R.K., Agrawal, J., Sharma, S., Singh Tomer, G., Eds.; Springer: Singapore, 2019; pp. 163–194. [Google Scholar]
- Mirsky, Y.; Lee, W. The Creation and Detection of Deepfakes: A Survey. ACM Comput. Surv. 2021, 54, 1–41. [Google Scholar] [CrossRef]
- Rony, J.; Belharbi, S.; Dolz, J.; Ayed, I.B.; McCaffrey, L.; Granger, E. Deep weakly-supervised learning methods for classification and localization in histology images: A survey. arXiv 2019, arXiv:abs/1909.03354. [Google Scholar]
- Lu, Z.; Chen, D.; Xue, D. Survey of weakly supervised semantic segmentation methods. In Proceedings of the 2018 Chinese Control Furthermore, Decision Conference (CCDC), Shenyang, China, 9–11 June 2018; pp. 1176–1180. [Google Scholar]
- Zhang, M.; Zhou, Y.; Zhao, J.; Man, Y.; Liu, B.; Yao, R. A survey of semi- and weakly supervised semantic segmentation of images. Artif. Intell. Rev. 2019, 53, 4259–4288. [Google Scholar] [CrossRef]
- Verdoliva, L. Media Forensics and DeepFakes: An Overview. IEEE J. Sel. Top. Signal Process. 2020, 14, 910–932. [Google Scholar] [CrossRef]
- Luo, W.; Huang, J.; Qiu, G. JPEG Error Analysis and Its Applications to Digital Image Forensics. IEEE Trans. Inf. Forensics Secur. 2010, 5, 480–491. [Google Scholar] [CrossRef]
- Matern, F.; Riess, C.; Stamminger, M. Gradient-Based Illumination Description for Image Forgery Detection. IEEE Trans. Inf. Forensics Secur. 2020, 15, 1303–1317. [Google Scholar] [CrossRef]
- Christlein, V.; Riess, C.; Jordan, J.; Riess, C.; Angelopoulou, E. An Evaluation of Popular Copy-Move Forgery Detection Approaches. IEEE Trans. Inf. Forensics Secur. 2012, 7, 1841–1854. [Google Scholar] [CrossRef] [Green Version]
- Habibi, M.; Hassanpour, H. Splicing Image Forgery Detection and Localization Based on Color Edge Inconsistency using Statistical Dispersion Measures. Int. J. Eng. 2021, 34, 443–451. [Google Scholar]
- Dua, S.; Singh, J.; Parthasarathy, H. Image forgery detection based on statistical features of block DCT coefficients. Procedia Comput. Sci. 2020, 171, 369–378. [Google Scholar] [CrossRef]
- Ehret, T. Robust copy-move forgery detection by false alarms control. arXiv 2019, arXiv:1906.00649. [Google Scholar]
- De Souza, G.B.; da Silva Santos, D.F.; Pires, R.G.; Marana, A.N.; Papa, J.P. Deep Features Extraction for Robust Fingerprint Spoofing Attack Detection. J. Artif. Intell. Soft Comput. Res. 2019, 9, 41–49. [Google Scholar] [CrossRef] [Green Version]
- Balsa, J. Comparison of Image Compressions: Analog Transformations. Proceedings 2020, 54, 37. [Google Scholar] [CrossRef]
- Pham, N.T.; Lee, J.W.; Kwon, G.R.; Park, C.S. Hybrid Image-Retrieval Method for Image-Splicing Validation. Symmetry 2019, 11, 83. [Google Scholar] [CrossRef] [Green Version]
- Bunk, J.; Bappy, J.H.; Mohammed, T.M.; Nataraj, L.; Flenner, A.; Manjunath, B.; Chandrasekaran, S.; Roy-Chowdhury, A.K.; Peterson, L. Detection and Localization of Image Forgeries Using Resampling Features and Deep Learning. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1881–1889. [Google Scholar]
- Bondi, L.; Lameri, S.; Güera, D.; Bestagini, P.; Delp, E.J.; Tubaro, S. Tampering Detection and Localization Through Clustering of Camera-Based CNN Features. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1855–1864. [Google Scholar]
- Yousfi, Y.; Fridrich, J. An Intriguing Struggle of CNNs in JPEG Steganalysis and the OneHot Solution. IEEE Signal Process. Lett. 2020, 27, 830–834. [Google Scholar] [CrossRef]
- Islam, A.; Long, C.; Basharat, A.; Hoogs, A. DOA-GAN: Dual-Order Attentive Generative Adversarial Network for Image Copy-Move Forgery Detection and Localization. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 4675–4684. [Google Scholar]
- Wu, Y.; Abd-Almageed, W.; Natarajan, P. BusterNet: Detecting Copy-Move Image Forgery with Source/Target Localization. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Wu, Y.; Abd-Almageed, W.; Natarajan, P. Image Copy-Move Forgery Detection via an End-to-End Deep Neural Network. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Munich, Germany, 8–14 September 2018; pp. 1907–1915. [Google Scholar]
- Liu, X.; Liu, Y.; Chen, J.; Liu, X. PSCC-Net: Progressive Spatio-Channel Correlation Network for Image Manipulation Detection and Localization. arXiv 2021, arXiv:2103.10596. [Google Scholar]
- Wei, Y.; Bi, X.; Xiao, B. C2R Net: The Coarse to Refined Network for Image Forgery Detection. In Proceedings of the 2018 17th IEEE International Conference On Trust, Security And Privacy in Computing Furthermore, Communication, New York, NY, USA, 1–3 August 2018; pp. 1656–1659. [Google Scholar]
- Bi, X.; Wei, Y.; Xiao, B.; Li, W. RRU-Net: The Ringed Residual U-Net for Image Splicing Forgery Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Younisand, Y.; Xu, M.; Qiao, T.; Wu, Y.; Zheng, N. Image Forgery Detection and Localization via a Reliability Fusion Map. Sensors 2020, 20, 6668. [Google Scholar]
- Abdalla, Y.; Iqbal, M.T.; Shehata, M. Convolutional Neural Network for Copy-Move Forgery Detection. Symmetry 2019, 11, 1280. [Google Scholar] [CrossRef] [Green Version]
- Kniaz, V.V.; Knyaz, V.; Remondino, F. The Point Where Reality Meets Fantasy: Mixed Adversarial Generators for Image Splice Detection. In Advances in Neural Information Processing Systems; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2019; Volume 32. [Google Scholar]
- Mayer, O.; Stamm, M.C. Forensic Similarity for Digital Images. IEEE Trans. Inf. Forensics Secur. 2020, 15, 1331–1346. [Google Scholar] [CrossRef] [Green Version]
- Huh, M.; Liu, A.; Owens, A.; Efros, A.A. Fighting Fake News: Image Splice Detection via Learned Self-Consistency. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Zhang, R.; Ni, J. A Dense U-Net with Cross-Layer Intersection for Detection and Localization of Image Forgery. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 2982–2986. [Google Scholar]
- Liu, Y.; Guan, Q.; Zhao, X.; Cao, Y. Image Forgery Localization Based on Multi-Scale Convolutional Neural Networks. In Proceedings of the 6th ACM Workshop on Information Hiding and Multimedia Security, Innsbruck, Austria, 20–22 June 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 85–90. [Google Scholar]
- Bi, X.; Liu, Y.; Xiao, B.; Li, W.; Pun, C.M.; Wang, G.; Gao, X. D-Unet: A Dual-encoder U-Net for Image Splicing Forgery Detection and Localization. arXiv 2020, arXiv:2012.01821. [Google Scholar]
- Marra, F.; Gragnaniello, D.; Cozzolino, D.; Verdoliva, L. Detection of GAN-Generated Fake Images over Social Networks. In Proceedings of the 2018 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), Miami, FL, USA, 10–12 April 2018; pp. 384–389. [Google Scholar]
- Kadam, K.; Ahirrao, D.S.; Kotecha, D.K.; Sahu, S. Detection and Localization of Multiple Image Splicing Using MobileNet V1, 2021. arXiv 2020, arXiv:2108.09674. [Google Scholar]
- Jaiswal, A.A.K.; Srivastava, R. Image Splicing Detection using Deep Residual Network. In Proceedings of the 2nd International Conference on Advanced Computing and Software Engineering (ICACSE), San Francisco, CA, USA, 13–15 October 2019. [Google Scholar]
- Dang, H.; Liu, F.; Stehouwer, J.; Liu, X.; Jain, A.K. On the Detection of Digital Face Manipulation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 5780–5789. [Google Scholar]
- Nguyen, H.H.; Fang, F.; Yamagishi, J.; Echizen, I. Multi-task Learning for Detecting and Segmenting Manipulated Facial Images and Videos. In Proceedings of the 2019 IEEE 10th International Conference on Biometrics Theory, Applications and Systems (BTAS), Tampa, FL, USA, 23–26 September 2019; pp. 1–8. [Google Scholar]
- Li, Y.; Lyu, S. Exposing DeepFake Videos By Detecting Face Warping Artifacts. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Nashville, TN, USA, 19–25 June 2019. [Google Scholar]
- Komodakis, N.; Gidaris, S. Unsupervised representation learning by predicting image rotations. In Proceedings of the International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Wang, L.; Li, D.; Zhu, Y.; Tian, L.; Shan, Y. Dual Super-Resolution Learning for Semantic Segmentation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 3773–3782. [Google Scholar]
- Yu, L.; Zhang, J.; Wu, Q. Dual Attention on Pyramid Feature Maps for Image Captioning. arXiv 2022, arXiv:2011.01385. [Google Scholar] [CrossRef]
- Dong, J.; Wang, W.; Tan, T. CASIA Image Tampering Detection Evaluation Database. In Proceedings of the 2013 IEEE China Summit and International Conference on Signal and Information Processing, Beijing, China, 6–10 July 2013; pp. 422–426. [Google Scholar]
- Ali, S.S.; Iyappan, G.I.; Prakash, S. Fingerprint Shell construction with impregnable features. J. Intell. Fuzzy Syst. 2019, 36, 4091–4104. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Genuine Images | Tampered Images | Total Images | |
|---|---|---|---|
| CASIA.2.0 | 7491 | 5123 | 12,614 |
| Training (80%) | 5993 | 4098 | 10,091 |
| Testing (20%) | 1498 | 1025 | 2523 |
| Techniques | Accuracy | Precision | Recall | F |
|---|---|---|---|---|
| Mantra-Net [3] | 40.62 | 0.40 | 1 | 57.14 |
| Mantra-Net * [3] | 56.14 | 0.48 | 0.79 | 59.33 |
| Buster-Net [27] | 30.77 | 0.30 | 1 | 46.75 |
| Buster-Net * [27] | 49.06 | 0.35 | 0.77 | 47.74 |
| CAT-Net [2] | 19.33 | 0.19 | 1 | 31.93 |
| CAT-Net * [2] | 87.29 | 0.62 | 0.87 | 72.76 |
| Proposed technique (with normal image) | 72.37 | 0.62 | 0.79 | 70.11 |
| Proposed technique (85% quality) | 87.71 | 0.80 | 0.92 | 85.99 |
| Proposed technique (90% quality) | 91.31 | 0.83 | 0.98 | 90.19 |
| Proposed technique (91% quality) | 91.35 | 0.83 | 0.97 | 90.14 |
| Proposed technique (92% quality) | 91.39 | 0.84 | 0.96 | 90.15 |
| Proposed technique (93% quality) | 90.84 | 0.83 | 0.96 | 89.52 |
| Proposed technique (94% quality) | 91.71 | 0.84 | 0.97 | 90.50 |
| Proposed technique (95% quality) | 91.83 | 0.84 | 0.97 | 90.68 |
| Proposed technique (96% quality) | 92.15 | 0.85 | 0.97 | 90.99 |
| Proposed technique (97% quality) | 91.63 | 0.85 | 0.96 | 90.32 |
| Proposed technique (98% quality) | 92.23 | 0.85 | 0.97 | 91.08 |
| Proposed technique (99% quality) | 91.83 | 0.86 | 0.94 | 90.42 |
| Proposed technique (100% quality) | 91.79 | 0.86 | 0.94 | 90.29 |
| Techniques | Time Taken |
|---|---|
| Mantra-Net [3] | 10,927 |
| Buster-Net [27] | 1160 |
| CAT-Net [2] | 2506 |
| Proposed technique | 34 |
| Sr. No. | Proposed Technique | Other Techniques |
|---|---|---|
| 1 | It focuses on whether the given image is tampered with or genuine (image level forgery detection). | They focus more on where the forgery is present in the given image (pixel level forgery detection). |
| 2 | It uses feature image (difference of original image with its recompressed image), in the feature image the forged part gets highlighted, which helps to detect image forgery better. | They directly use the image in the original pixel format, which makes image forgery detection difficult. |
| 3 | It is utilizes enhanced features, due to which it is able to handle both image splicing and copy-move types image forgeries. | Most of the techniques do not utilize the enhanced features, due to which they are usually able to handle only one type of image forgery. |
| 4 | It attains a high accuracy in classifying the images as tampered or not. | They do pixel level forgery detection. Due to this, they suffer from false positive pixels. Hence, there is degradation in classifying the images as tampered or not. |
| 5 | It is much faster, hence, it is suitable for slow machines as well. | These techniques are much slower, hence, they are not suitable for the slower machines. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ali, S.S.; Ganapathi, I.I.; Vu, N.-S.; Ali, S.D.; Saxena, N.; Werghi, N. Image Forgery Detection Using Deep Learning by Recompressing Images. Electronics 2022, 11, 403. https://doi.org/10.3390/electronics11030403
Ali SS, Ganapathi II, Vu N-S, Ali SD, Saxena N, Werghi N. Image Forgery Detection Using Deep Learning by Recompressing Images. Electronics. 2022; 11(3):403. https://doi.org/10.3390/electronics11030403
Chicago/Turabian StyleAli, Syed Sadaf, Iyyakutti Iyappan Ganapathi, Ngoc-Son Vu, Syed Danish Ali, Neetesh Saxena, and Naoufel Werghi. 2022. "Image Forgery Detection Using Deep Learning by Recompressing Images" Electronics 11, no. 3: 403. https://doi.org/10.3390/electronics11030403
APA StyleAli, S. S., Ganapathi, I. I., Vu, N.-S., Ali, S. D., Saxena, N., & Werghi, N. (2022). Image Forgery Detection Using Deep Learning by Recompressing Images. Electronics, 11(3), 403. https://doi.org/10.3390/electronics11030403