


Research on Retinex Algorithm Combining with Attention Mechanism for Image Enhancement


Abstract
1. Introduction
2. Retinex Image Enhancement Algorithm
2.1. Surround Retinex Method
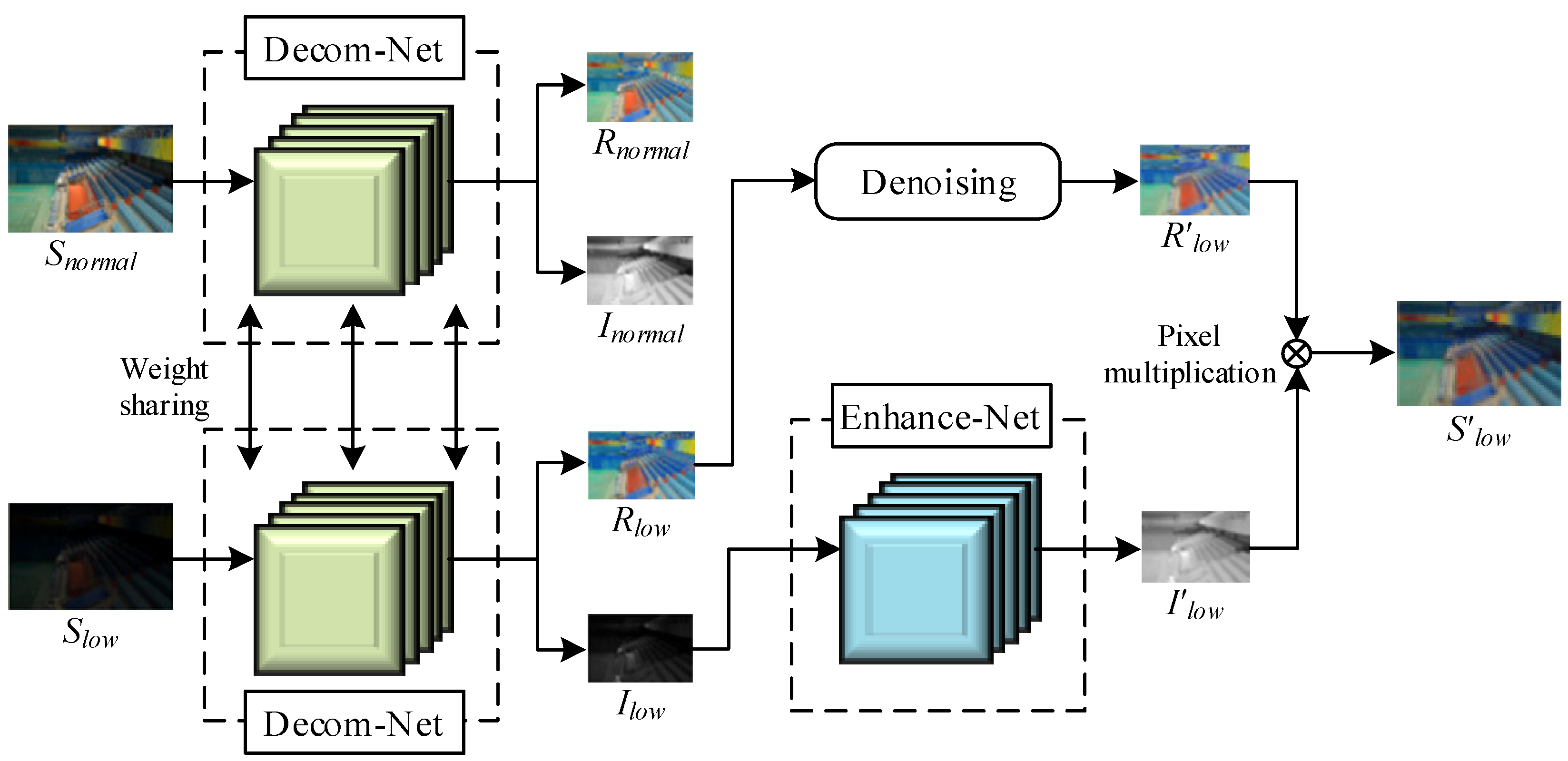
2.2. The Retinex-Net Model
2.3. Image Enhancement Test and Analysis
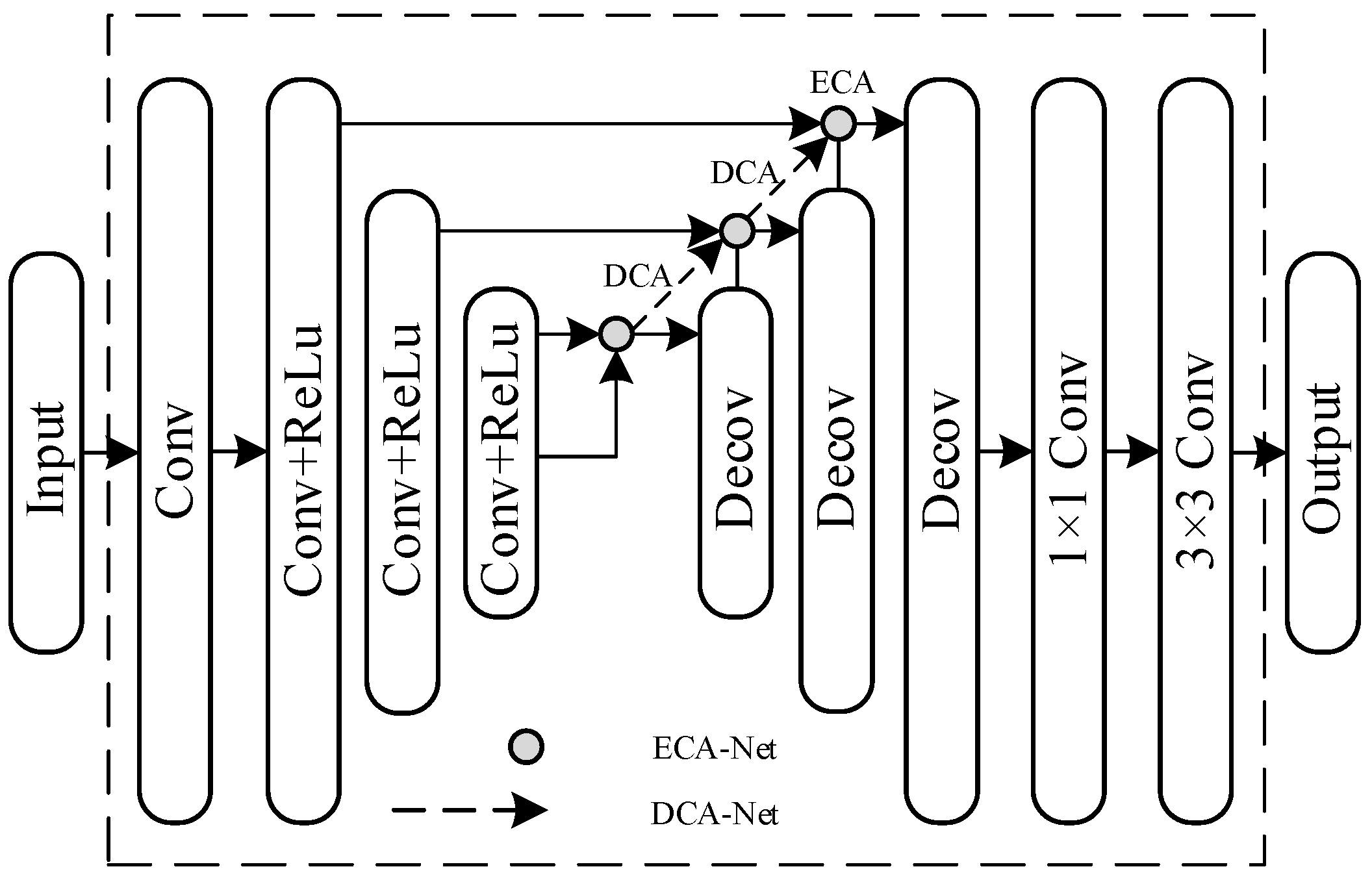
3. The Improved Retinex-Net Model
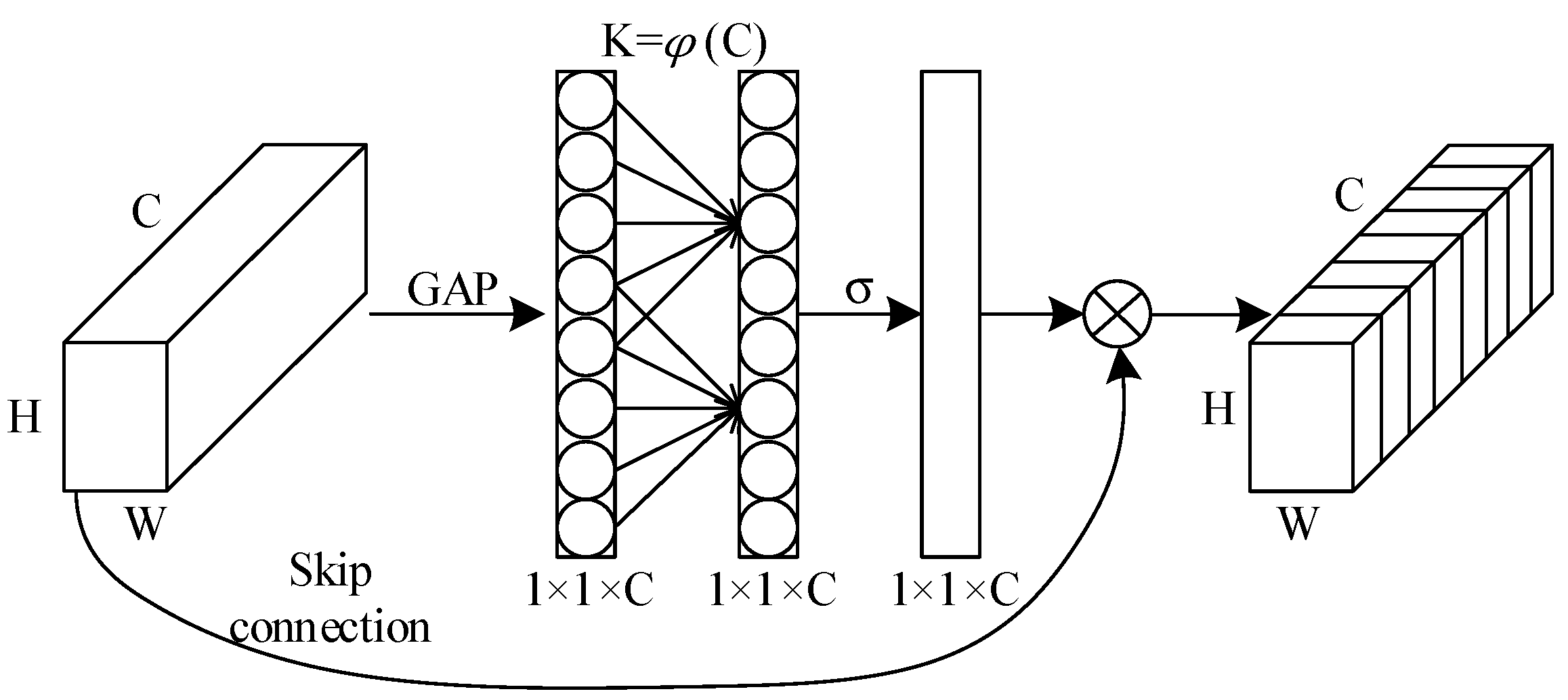
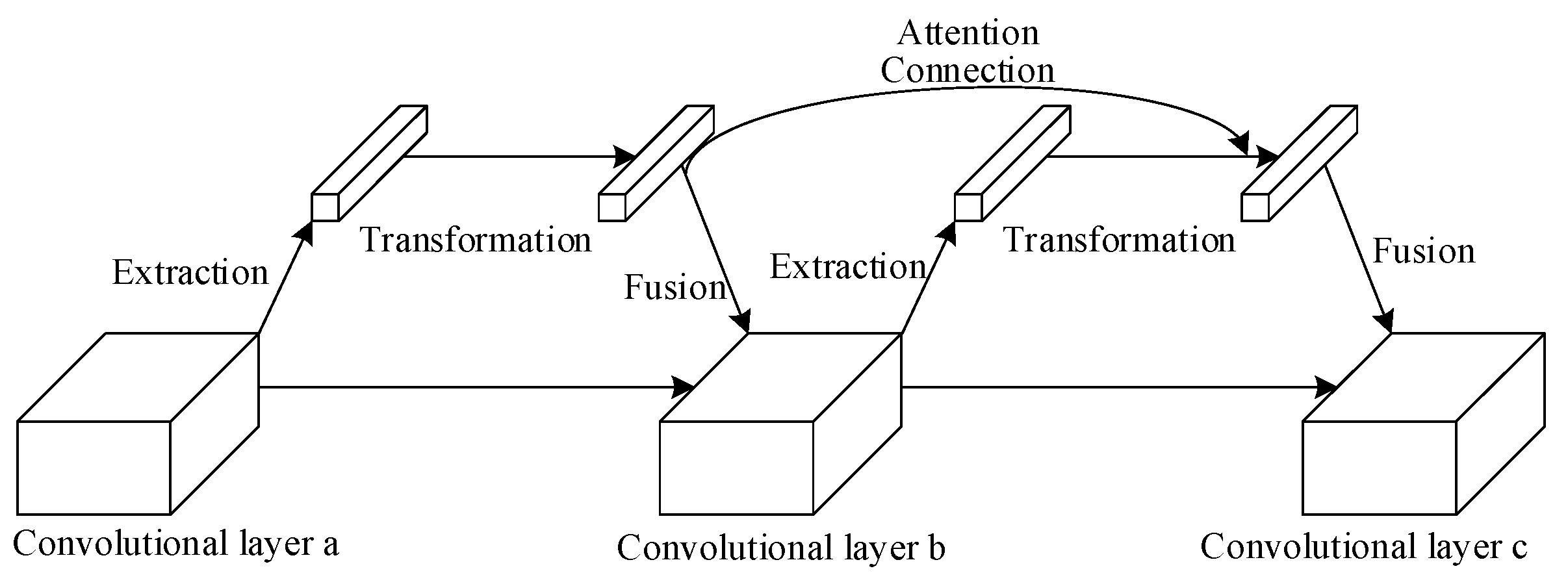
3.1. Introduction of Attention Mechanism and Its Deep Connection
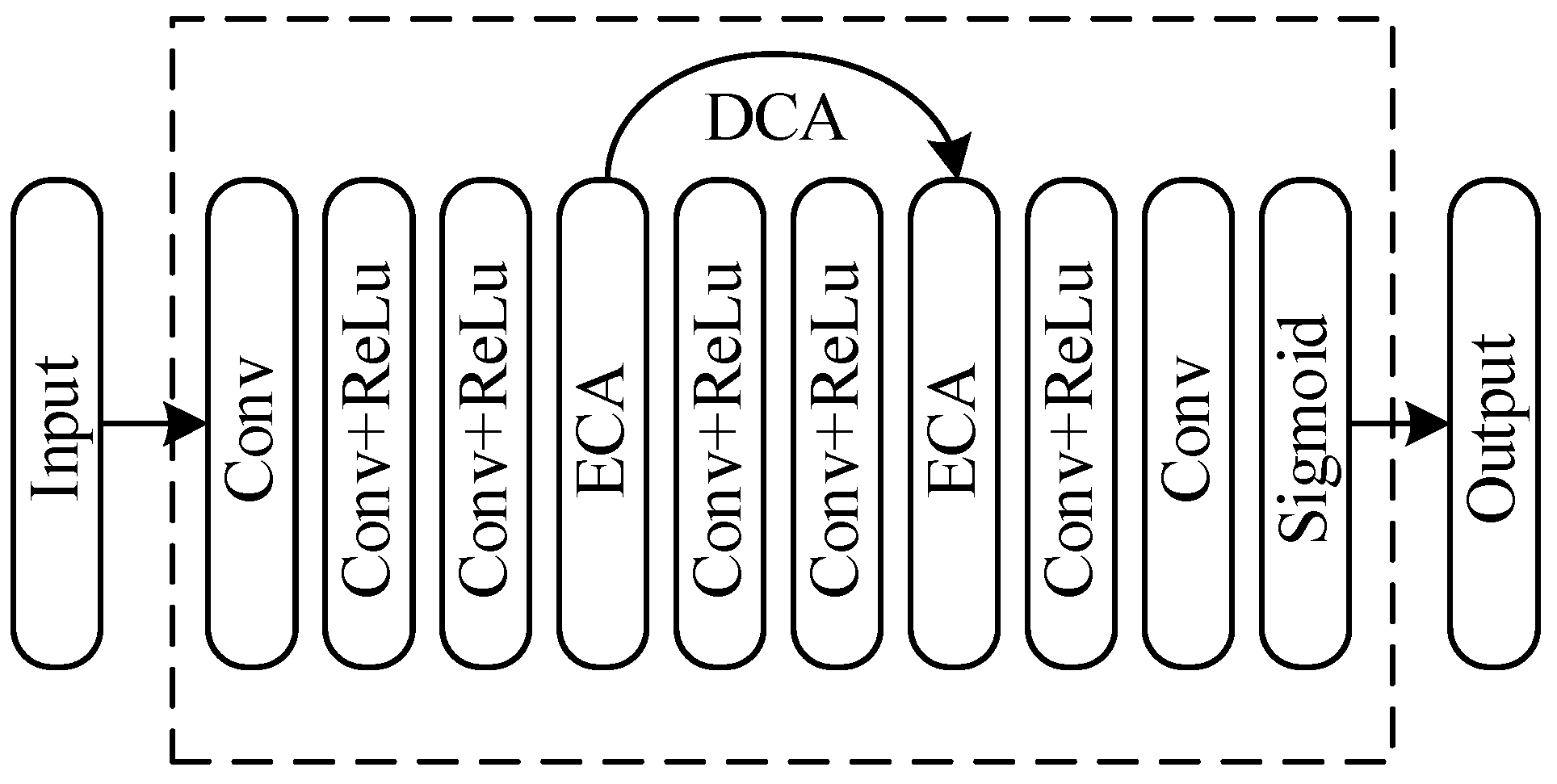
3.2. Improvement of Subnetworks
3.3. Improvement of Loss Functions
4. Experiment and Results Analysis
4.1. Experimental Environment
4.2. Ablation Experiment
4.3. Comparative Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hu, X.; Ma, P.; Mai, Z.; Peng, S.; Yang, Z.; Wang, L. Face hall-ucination from low quality images using definition-scalable inference. Pattern Recognit. 2019, 94, 110–121. [Google Scholar] [CrossRef]
- Pan, R.; Zeng, L.; Wum, S.; Wang, R. Feature detection method for low illumination image. Sens. Microsyst. 2021, 40, 110–113+117. [Google Scholar]
- Liu, M.; Su, T.; Wang, Y. Companding multiscale Research on Retinex image enhancement algorithm. J. Harbin Univ. Sci. Technol. 2020, 25, 93–99. [Google Scholar]
- Jiang, J.L.; Liu, G.M.; Zhu, Z.; Huang, Z.; Zheng, J.Y. Dynamic Multi-Histogram Equalization Based on Fast Fuzzy Clustering. Acta Electron. Sin. 2022, 50, 167–176. [Google Scholar]
- Wang, L.; Chang, X.; Ren, W. Color Image Enhancement Simulation Based on Weighted Histogram Equalization. Comput. Simul. 2021, 38, 126–131. [Google Scholar]
- Xuan, D.; Guan, W.; Yi, P.; Wen, J. Fast Efficient Algorithm for Enhancement of Low Lighting Video. In Proceedings of the 2011 IEEE International Conference on Multimedia and Expo, Barcelona, Spain, 11–15 July 2011; IEEE: Toulouse, France; pp. 1–6. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Single Image Haze Removal Using Dark Channel Prior. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2341–2353. [Google Scholar] [PubMed]
- Land, E.H. The Retinex Theory of Color Vision. Sci. Am. 1978, 237, 108–128. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Xu, Y.; Yue, H.; Jiang, Z.; Li, K. Low-light image enhancement based on Retinex decomposition and adaptive gamma correction. IET Image Process. 2020, 15, 211–220. [Google Scholar] [CrossRef]
- Liu, S.; Long, W.; He, L.; Li, Y.; Ding, W. Retinex-Based Fast Algorithm for Low-Light Image Enhancement. Entropy 2021, 23, 746. [Google Scholar] [CrossRef] [PubMed]
- Lore, K.G.; Akintayo, A.; Sarkar, S. LLNet: A Deep Autoencoder Approach to Natural Low-light Image Enhancement. Pattern Recognit. 2017, 61, 650–662. [Google Scholar] [CrossRef]
- Wei, C.; Wang, W.; Yang, W.; Liu, J. Deep Retinex Decomposition for Low-Light Enhancement. arXiv. Available online: https://arxiv.org/pdf/1808.04560.pdf (accessed on 11 May 2020).
- Ignatov, A.; Kobyshev, N.; Timofte, R.; Vanhoey, K.; Van Gool, L. DSLR-Quality Photos on Mobile Devices with Deep Convolutional Networks. In Proceedings of the IEEE Computer Society, Bochum, Germany, 3–5 July 2017; pp. 3297–3305. [Google Scholar]
- Li, J.; Wang, J.; Wan, G.; Li, Z.; Xu, D.; Cao, H.; Zhang, G. A combination of histogram equalization and A new image enhancement algorithm based on MSRCR. J. Xidian Univ. 2014, 41, 103–109. [Google Scholar]
- Choi, D.H.; Jang, I.H.; Kim, M.H.; Kim, N.C. Color Image Enhancement Based on Single-Scale Retinex With a JND-Based Nonlinear Filter. In Proceedings of the International Symposium on Circuits and Systems (ISCAS 2007), New Orleans, LA, USA, 27 May 2007; IEEE: New York, NY, USA; pp. 1242–1254. [Google Scholar]
- Lin, H.; Shi, Z. Multiscale retinex improvement for nighttime image enhancement. Opt.-Int. J. Light Electron Opt. 2014, 125, 7143–7148. [Google Scholar] [CrossRef]
- Rahman, Z.U.; Jobson, D.J.; Woodell, G.A. Retinex processing for automatic image enhancement. Proc. SPIE-Int. Soc. Opt. Eng. 2004, 13, 100–110. [Google Scholar]
- Jobson, D.J.; Rahman, Z.; Woodell, G.A. A multiscale retinex for bridging the gap between color images and the human observation of scenes. IEEE Trans. Image Process. 2002, 6, 965–976. [Google Scholar] [CrossRef] [PubMed]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image denoising with block-matching and 3D filtering. Proc. SPIE-Int. Soc. Opt. Eng. 2006, 6064, 354–365. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11531–11539. [Google Scholar]
- Ma, X.; Guo, J.; Tang, S.; Qiao, Z.; Chen, Q.; Yang, Q.; Fu, S. DCANet: Learningconnected attentions for convolutional neural networks. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar]
- Zhao, H.; Gallo, O.; Frosio, I.; Kautz, J. Loss Functions for Image Restoration With Neural Networks. IEEE Trans. Comput. Imaging 2017, 3, 633–640. [Google Scholar] [CrossRef]
- Feifan, L.; Bo, L.; Feng, L. Fast Enhancement for Non-Uniform Illumination Images using Light-weight CNNs. In Proceedings of the 28th ACM International Conference on Multimedia, Online, 12 October 2020; Association for Computing Machinery: New York, NY, USA; pp. 1450–1458. [Google Scholar]
- Zhang, R.; Zhu, J.Y.; Isola, P.; Geng, X.; Lin, A.S.; Yu, T.; Efros, A.A. Real-time user-guided image colorization with learned deeppriors. ACM Trans. Graph. (TOG) 2017, 36, 121–131. [Google Scholar] [CrossRef]
- Lehmann, E.L.; Casella, G. Point Estimation Theory; Beijing China Statistics Press: Beijing, China, 2004; p. 11. [Google Scholar]
- Mittal, A.; Moorthy, A.K.; Bovik, A.C. Blind/Referenceless Image Spatial Quality Evaluator. In Proceedings of the 2011 Conference Record of the Forty Fifth Asilomar Conference on Signals, Systems and Computers (ASILOMAR), Pacific Grove, CA, USA, 6–9 November 2011; IEEE: New York, NY, USA; pp. 784–792. [Google Scholar]
- Guo, X.; Li, Y.; Ling, H. LIME: Low-light Image Enhancement via Illumination Map Estimation. IEEE Trans. Image Process. 2016, 26, 982–993. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Evaluation Index | L1 | SSIM | MS − SSIM | Mix |
|---|---|---|---|---|
| PSNR(dB) | 34.42 | 33.15 | 33.29 | 34.61 |
| SSIM | 0.9535 | 0.9500 | 0.9536 | 0.9564 |
| FSIM | 0.9775 | 0.9764 | 0.9782 | 0.9795 |
| Serial No | Basic Framework | Improvement of the Method | PSNR (dB) | SSIM |
|---|---|---|---|---|
| 1 | − | Retinex-Net | 16.7622 | 0.5465 |
| 2 | Retinex-Net | add ECA, do not add DCA | 17.5834 | 0.6945 |
| 3 | add ECA, add DCA | 18.4488 | 0.7249 | |
| 4 | Retinex-Net+ECA+DCA | add, do not add | 18.8743 | 0.749 |
| 5 | , do not add | 18.9616 | 0.7443 | |
| 6 | 19.4536 | 0.7581 |
| SRIE | NPE | GLADNet | EnlightenGAN | Retinex-Net | Proposed Method | |
|---|---|---|---|---|---|---|
| SSIM | 0.4977 | 0.5842 | 0.7115 | 0.6260 | 0.5594 | 0.7581 |
| PSNR (dB) | 11.8550 | 16.8034 | 19.3821 | 19.2303 | 16.7739 | 19.4536 |
| NIQE | 7.2873 | 8.2562 | 6.1744 | 4.528 | 9.7303 | 4.2874 |
| LOE | 575 | 439 | 493 | 445 | 1106 | 417 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, M.; Chen, J.; Han, X. Research on Retinex Algorithm Combining with Attention Mechanism for Image Enhancement. Electronics 2022, 11, 3695. https://doi.org/10.3390/electronics11223695
Liu M, Chen J, Han X. Research on Retinex Algorithm Combining with Attention Mechanism for Image Enhancement. Electronics. 2022; 11(22):3695. https://doi.org/10.3390/electronics11223695
Chicago/Turabian StyleLiu, Mingzhu, Junyu Chen, and Xiaofei Han. 2022. "Research on Retinex Algorithm Combining with Attention Mechanism for Image Enhancement" Electronics 11, no. 22: 3695. https://doi.org/10.3390/electronics11223695
APA StyleLiu, M., Chen, J., & Han, X. (2022). Research on Retinex Algorithm Combining with Attention Mechanism for Image Enhancement. Electronics, 11(22), 3695. https://doi.org/10.3390/electronics11223695