


Few-Shot Classification with Dual-Model Deep Feature Extraction and Similarity Measurement



Abstract
:1. Introduction
2. Related Work
2.1. Conventional Approaches
2.2. Meta Learning Models
2.3. Self-Supervised Learning Models
- (1)
- As the few-shot classification relies on learning from a few ground-truth data, the proposed work focusses on the development of optimal pretrained models, which can be generalized and fine-tuned to any datasets with limited training. In this work, four prominent SSL techniques such as SimCLR, SimSiam, BYOL, and BTs were trained and analyzed to obtain best pretrained backbone.
- (2)
- For further improvisation, more augmentation techniques such as random jigsaw and random patch swap were added to obtain more diversity and robustness, during the pretraining stages.
- (3)
- From the model perspective, the proposed work is based on the latest ConvNeXt backbone, and a new dual-model configuration is proposed with different depths, complementing the few-shot training. The new training strategies practiced in the latest vision transformer and convolution models were also integrated.
- (4)
- Finally, a new training approach is proposed, in which the distance between the feature embedding of the query set and the most representative feature vector of each category is used to determine the query set category. In addition, the progressive model training was performed using multiple few-shot extraction and feature similarity assessment.
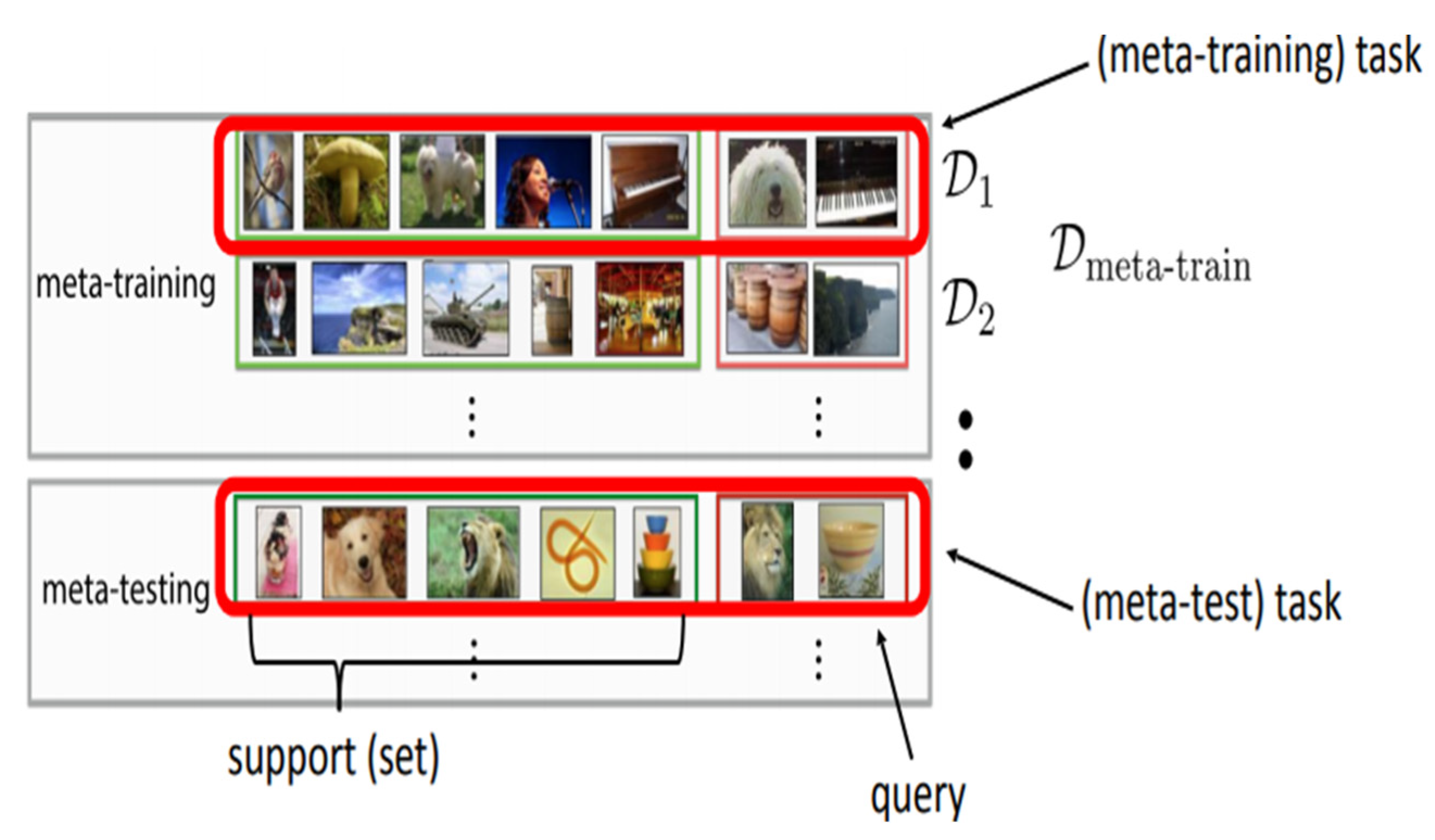
3. Few-Shot Learning Datasets
4. Proposed Method
4.1. Self-Supervised Learning
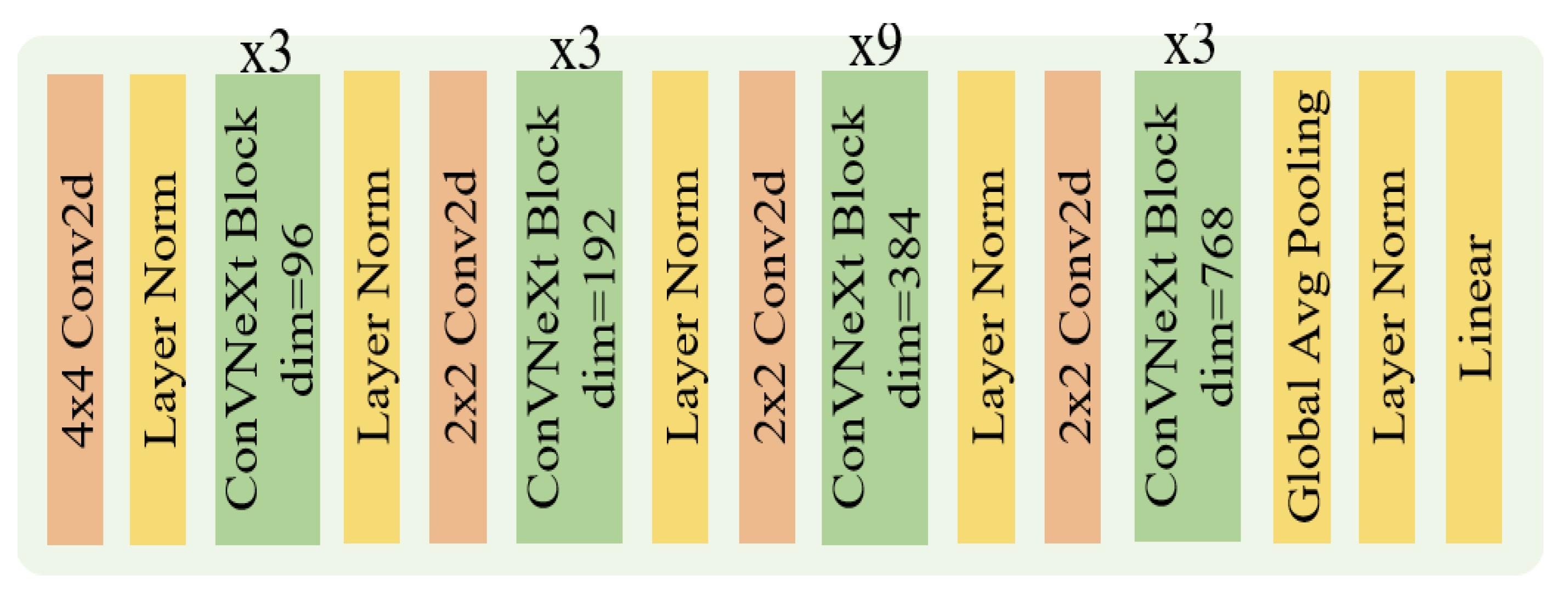
4.2. Dual-Model Architecture
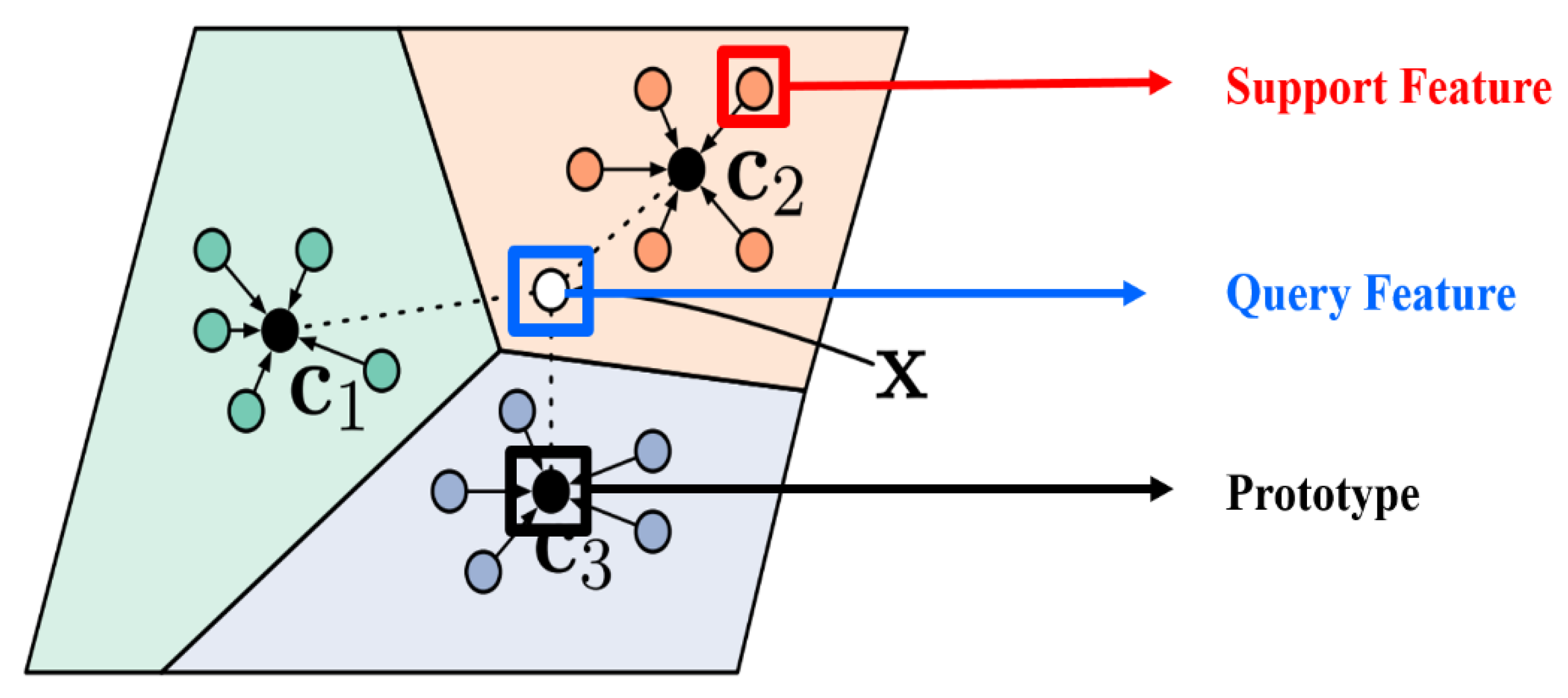
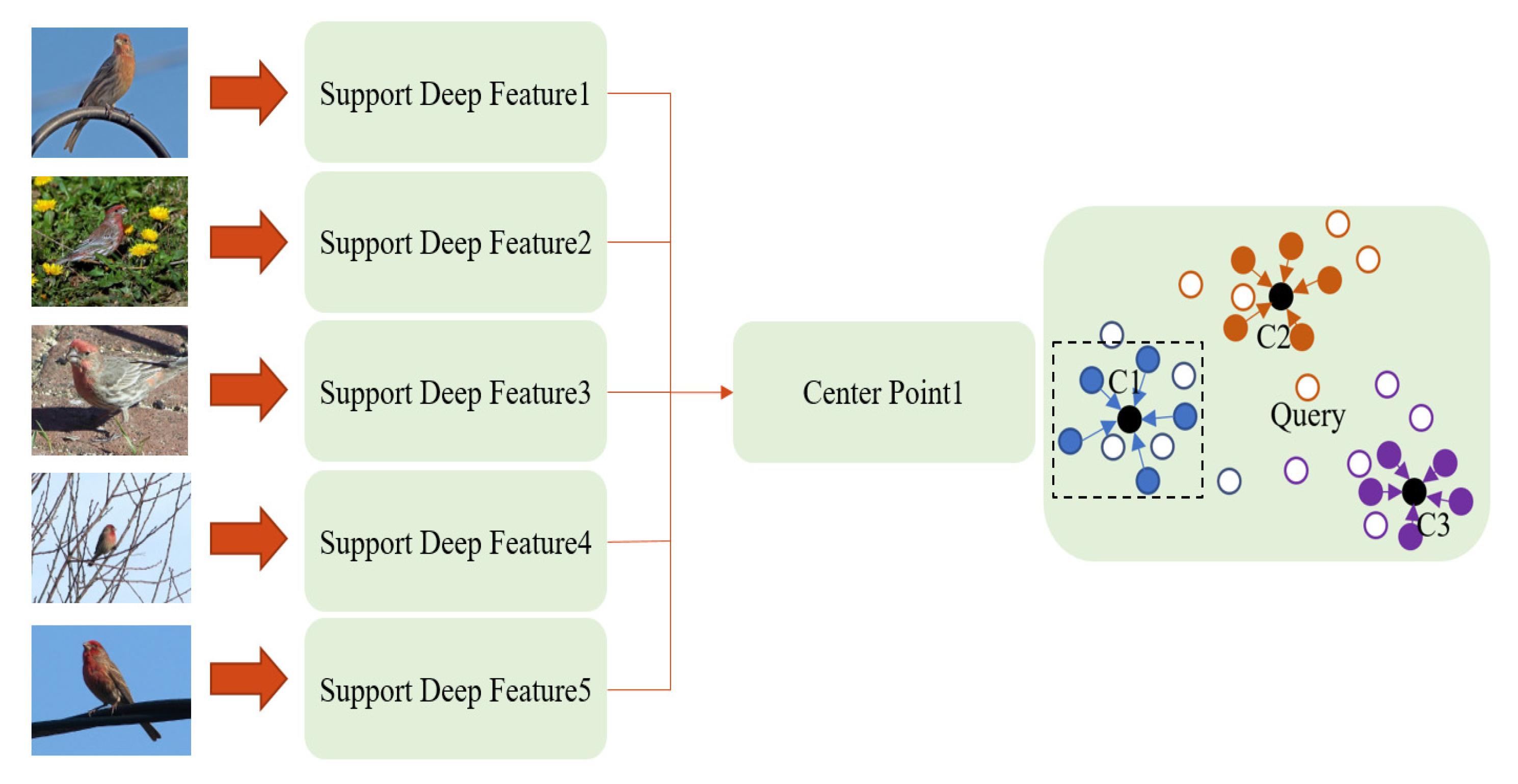
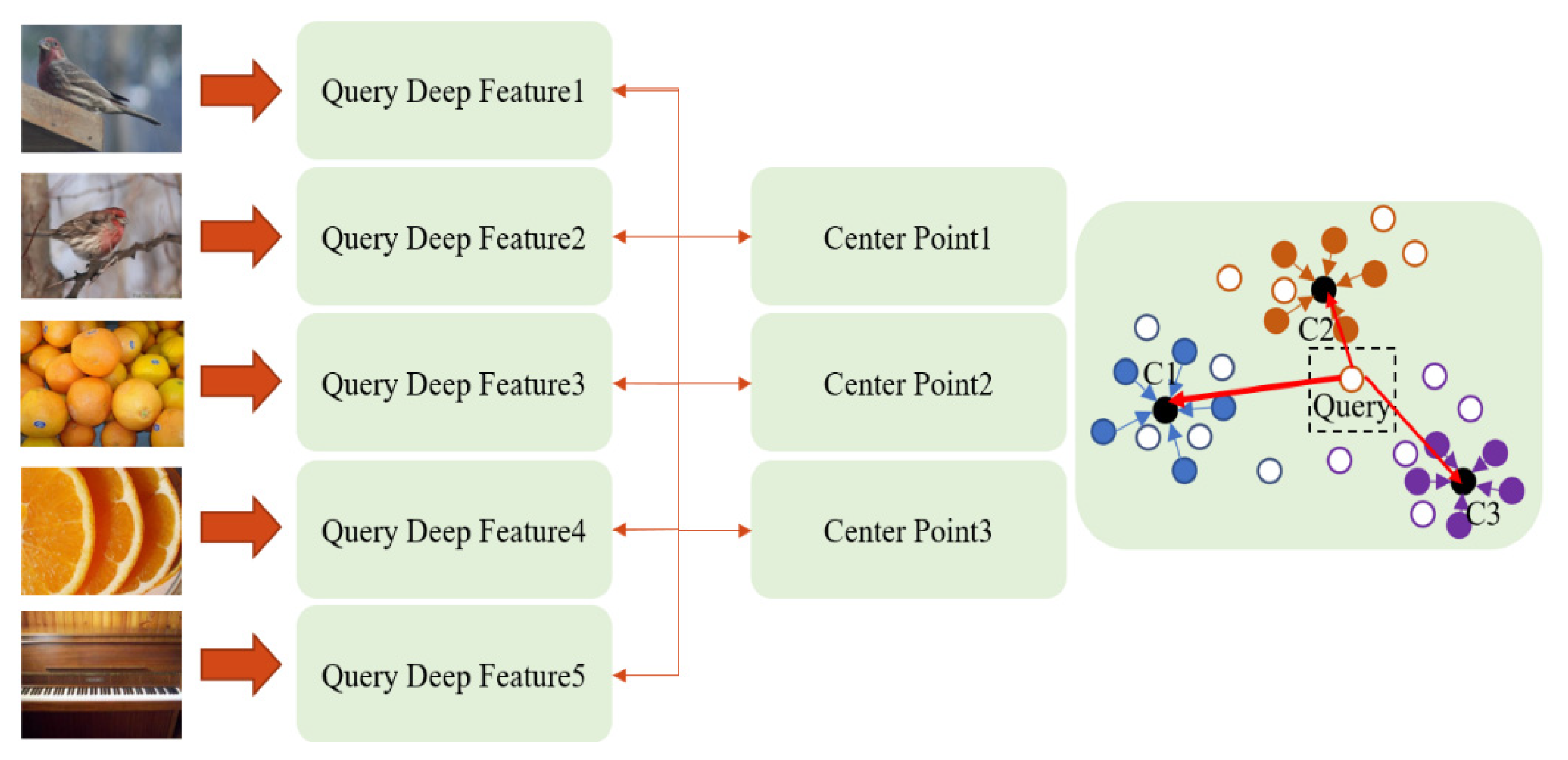
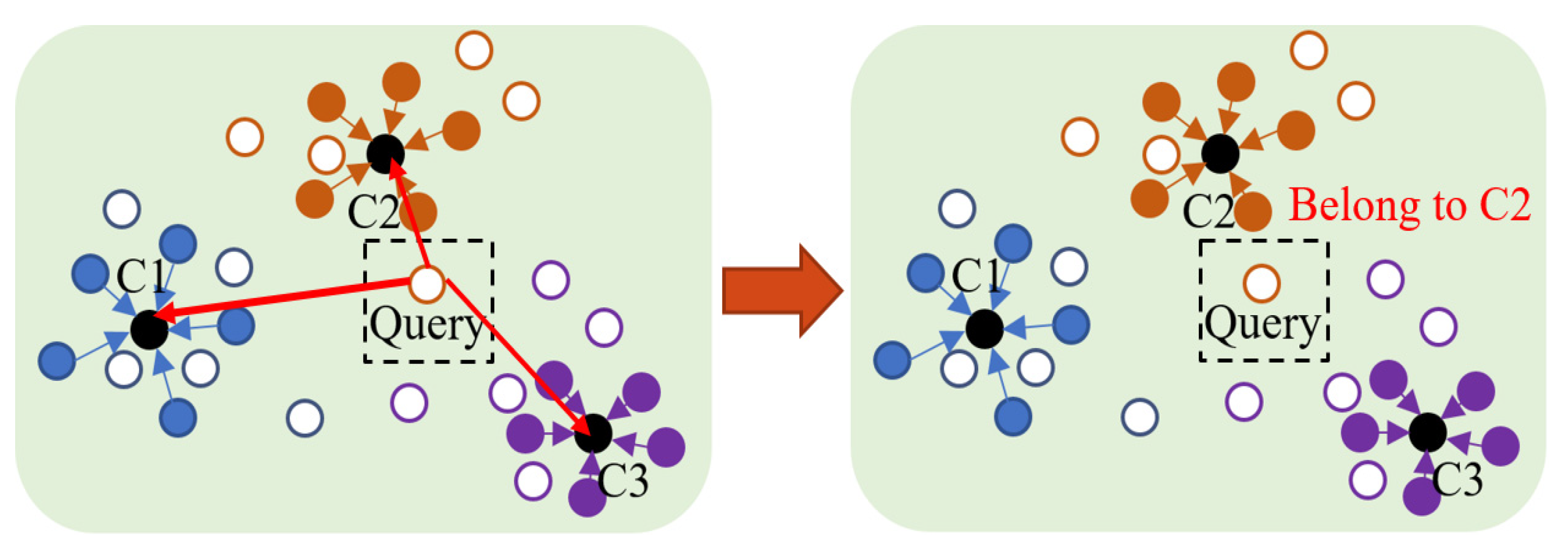
4.3. Feature Extraction and Similarity Assessment
5. Results and Analysis
5.1. Pretrained Model Optimization
5.2. Model Ablation Studies
5.3. Few-Shot Classification Results
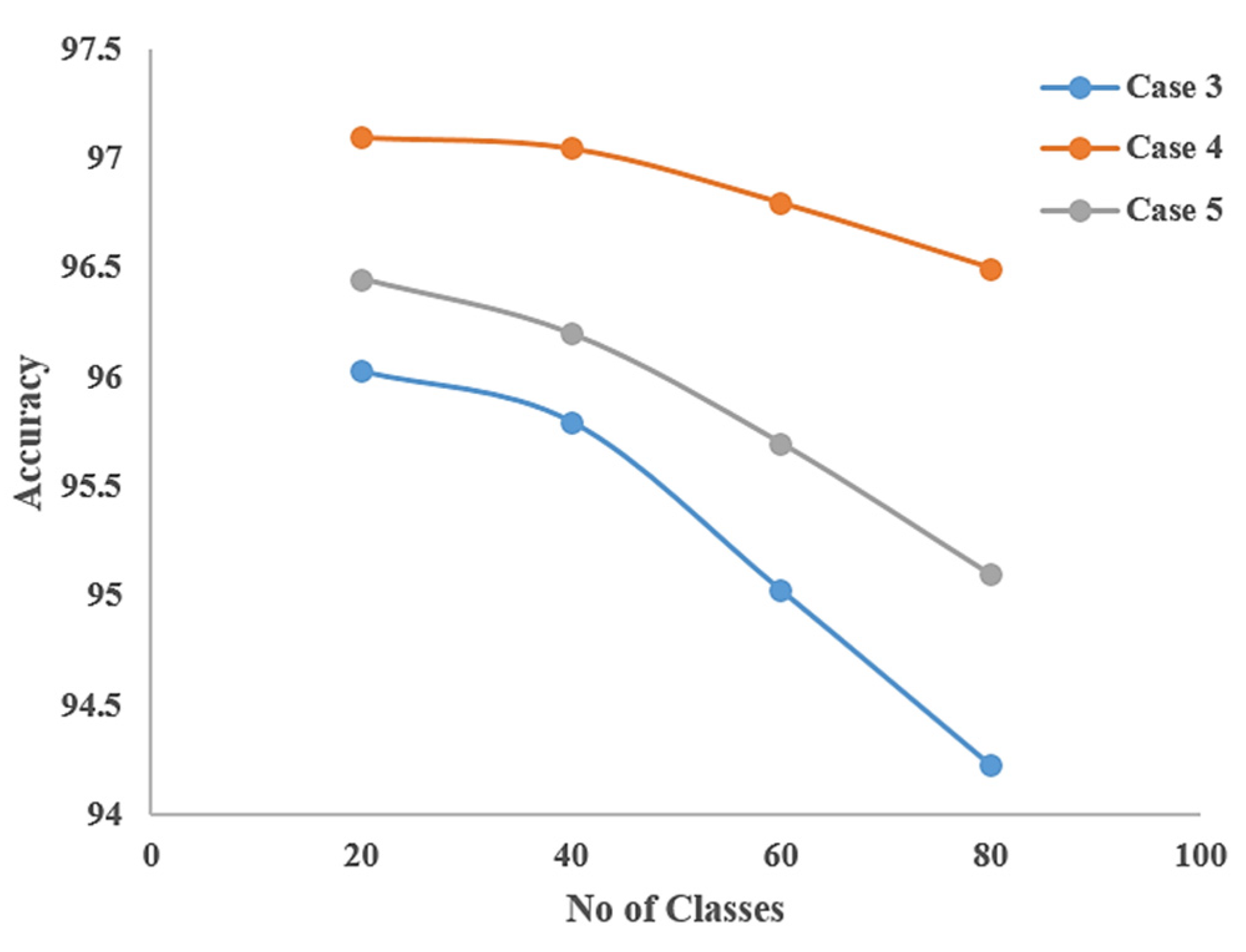
5.4. Case Studies
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26–30 June 2016; pp. 770–778. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26–30 June 2016; pp. 779–788. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Region-based convolutional networks for accurate object detection and segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 142–158. [Google Scholar] [CrossRef]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the International Conference on Machine Learning. PMLR, Sydney, Australia, 6–11 August 2017; pp. 1126–1135. [Google Scholar]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Kavukcuoglu, K.; Wierstra, D. Matching networks for one shot learning. Adv. Neural Inf. Process. Syst. 2016, 3637–3645. [Google Scholar] [CrossRef]
- Sung, F.; Yang, Y.; Zhang, L.; Xiang, T.; Torr, P.H.S. Learning to compare: Relation network for few-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1199–1208. [Google Scholar]
- Zhang, H.; Cao, Z.; Yan, Z.; Zhang, C. Sill-net: Feature augmentation with separated illumination representation. arXiv 2021, arXiv:2102.03539. [Google Scholar]
- Chen, X.; Wang, G. Few-shot learning by integrating spatial and frequency representation. In Proceedings of the 18th Conference on Robots and Vision (CRV), Burnaby, BC, Canada, 26–28 May 2021; pp. 49–56. [Google Scholar]
- Snell, J.; Swersky., K.; Zemel., R. Prototypical networks for few-shot learning. Adv. Neural Inf. Process. Syst. 2017, 4080–4090. Available online: https://dl.acm.org/doi/10.5555/3294996.3295163 (accessed on 25 October 2022).
- Chobola, T.; Vašata, D.; Kondik, P. Transfer learning based few-shot classification using optimal transport mapping from preprocessed latent space of backbone neural network. AAAI Workshop Meta-Learn. Meta-DL Chall. PMLR 2021, 29–37. [Google Scholar] [CrossRef]
- Hu, Y.; Pateux, S.; Gripon, V. Squeezing Backbone Feature Distributions to the Max for Efficient Few-Shot Learning. Algorithms 2022, 15, 147. [Google Scholar] [CrossRef]
- Bateni, P.; Barber, J.; Van de Meent, J.W.; Wood, F. Enhancing few-shot image classification with unlabelled examples. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, New Orleans, LA, USA, 18–24 June 2022; pp. 2796–2805. [Google Scholar]
- Bendou, Y.; Hu, Y.; Lafargue, R.; Lioi, G.; Pasdeloup, B.; Pateux, S.; Gripon, V. EASY: Ensemble Augmented-Shot Y-shaped Learning: State-Of-The-Art Few-Shot Classification with Simple Ingredients. arXiv 2022, arXiv:2201.09699. [Google Scholar]
- Shalam, D.; Korman, S. The Self-Optimal-Transport Feature Transform. arXiv 2022, arXiv:2204.03065. [Google Scholar]
- Chen, D.; Chen, Y.; Li, Y.; Mao, F.; He, Y.; Xue, H. Self-supervised learning for few-shot image classification. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 1745–1749. [Google Scholar]
- Ravi, S.; Larochelle, H. Optimization as a Model for Few-Shot Learning. In Proceedings of the ICLR, Toulan, France, 24–26 April 2017. [Google Scholar]
- Bertinetto, L.; Henriques, J.F.; Torr, P.H.; Vedaldi, A. Meta-learning with differentiable closed-form solvers. arXiv 2018, arXiv:1805.08136. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, Vienna, Austria, 12–18 July 2020; pp. 1597–1607. [Google Scholar]
- Chen, X.; He, K. Exploring Simple Siamese representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15750–15758. [Google Scholar]
- Grill, J.B.; Strub, F.; Altché, F.; Tallec, C.; Richemond, P.H.; Buchatskaya, E.; Doersch, C.; Pires, B.A.; Daniel Guo, Z.; Gheshlaghi Azar, M.; et al. Bootstrap your own latent-a new approach to self-supervised learning. Adv. Neural Inf. Process. Syst. 2021, 21271–21284. Available online: https://dl.acm.org/doi/abs/10.5555/3495724.3497510 (accessed on 25 October 2022).
- Zbontar, J.; Jing, L.; Misra, I.; LeCun, Y.; Deny, S. Barlow twins: Self-supervised learning via redundancy reduction. In Proceedings of the International Conference on Machine Learning, Seoul, Korea, 18–24 July 2021; pp. 12310–12320. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11976–11986. [Google Scholar]
- Wightman, R.; Touvron, H.; Jégou, H. Resnet strikes back: An improved training procedure in timm. arXiv 2021, arXiv:2110.00476. [Google Scholar]
- Zhou, D.; Kang, B.; Jin, X.; Yang, L.; Jiang, Z.; Hou, Q.; Feng, J. Deepvit: Towards deeper vision transformer. arXiv 2021, arXiv:2103.11886. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Breiki, F.A.; Ridzuan, M.; Grandhe, R. Self-Supervised Learning for Fine-Grained Image Classification. arXiv 2021, arXiv:2107.13973. [Google Scholar]
- Hu, Y.; Pateux, S.; Gripon, V. Adaptive Dimension Reduction and Variational Inference for Transductive Few-Shot Classification. arXiv 2022, arXiv:2209.08527. [Google Scholar]
- Singh, A.; Jamali-Rad, H. Transductive Decoupled Variational Inference for Few-Shot Classification. arXiv 2022, arXiv:2208.10559. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Augmentations | Accuracy |
|---|---|---|
| SimCLR | Set 1: crop, resize, flipping, rotation, cutout, gaussian and color jitter | 63.5% |
| SimSiam | 64.21% | |
| BYOL | 66.72% | |
| BTs | 67.85% | |
| BTs | Set 1 + RPS + RJ | 68.9% |
| Case | Support Set | Query Set | Accuracy (Training) | Accuracy (Test) |
|---|---|---|---|---|
| 1 | 6,6,27,6 | 6,6,27,6 | 96.28 | 91.63 |
| 2 | 6,6,27,6 | 6,6,9,6 | 96.53 | 92.63 |
| 3 | 3,3,27,3 | 3,3,27,3 | 95.78 | 93.05 |
| 4 | 3,3,27,3 | 3,3,9,3 | 96.10 | 95.50 |
| 5 | 3,3,9,3 | 3,3,27,3 | 94.35 | 93.15 |
| Method | Accuracy (5-Way 5-Shot) | Accuracy (5-Way 1-Shot) |
|---|---|---|
| Matching Nets [5] | 60 | 46.6 |
| MAML [4] | 63.1 | 48.7 |
| Relation Network [6] | 65.32 | 49.42 |
| Prototypical Networks [9] | 68.2 | 50.44 |
| PT + MAP [8] | 88.82 | 76.82 |
| Sill-Net [7] | 89.14 | 79.9 |
| EASY 3xResNet12 [13] | 89.14 | 82.99 |
| AmdimNet [15] | 90.98 | 84.04 |
| SOT [12] | 91.34 | 84.81 |
| CNAPS + FETI [14] | 91.5 | 85.54 |
| PEMnE-BMS * [11] | 91.53 | 85.59 |
| BAVARDAGE [27] | 91.65 | 84.80 |
| TRIDENT [28] | 95.95 | 86.11 |
| Dual-Model (Proposed) | 94.64 | 88.3 |
| Dual-Model (Proposed) + BTs-Pretrained Model + Set 1 | 95.83 | 88.91 |
| Dual-Model (Proposed-Final) + BTs-Pretrained Model + Set 1 + RPS + RJ | 95.98 | 88.96 |
| Method | Accuracy (5-Way 5-Shot) | Accuracy (5-Way 1-Shot) |
|---|---|---|
| EASY 3xResNet12 [13] | 90.47 | 87.16 |
| PT + MAP [8] | 90.68 | 87.69 |
| LST + MAP [10] | 90.73 | 87.73 |
| Sill-Net [7] | 91.09 | 87.79 |
| PEMnE-BMS * [11] | 91.86 | 88.44 |
| SOT [12] | 92.83 | 89.94 |
| Dual-Model (Proposed) | 94.74 | 91.4 |
| Dual-Model (Proposed-Final) + BTs-Pretrained Model + Set 1 + RPS + RJ | 95.16 | 92.35 |
| Method | Accuracy (5-Way 5-Shot) | Accuracy (5-Way 1-Shot) |
|---|---|---|
| Relation Network [6] | 65.32 | 50.44 |
| AmdimNet [15] | 89.18 | 77.09 |
| EASY 3xResNet12 [13] | 91.93 | 90.56 |
| PT + MAP [8] | 93.99 | 91.68 |
| LST + MAP [10] | 94.09 | 94.73 |
| Sill-Net [7] | 96.28 | 94.78 |
| PEMnE-BMS * [11] | 96.43 | 95.48 |
| SOT [12] | 97.12 | 95.8 |
| Dual-Model (Proposed) | 98.35 | 96.82 |
| Dual-Model (Proposed-Final) + BTs-Pretrain Model + Set 1 + RPS + RJ | 98.56 | 97.23 |
| Framework | Datasets | Accuracy | |
|---|---|---|---|
| 5-Way 1-Shot | 5-Way 5-Shot | ||
| Single-Model (Query Backbone) | Mini-ImageNet | 82.81 | 89.89 |
| CIFAR-FS | 85.68 | 90.44 | |
| CUB 200 | 92.56 | 93.99 | |
| Single-Model (Support Backbone) | Mini-ImageNet | 86.31 | 93.83 |
| CIFAR-FS | 89.68 | 93.72 | |
| CUB 200 | 95.1 | 97.43 | |
| Dual-Model (Proposed Method-Final) | Mini-ImageNet | 88.96 | 95.98 |
| CIFAR-FS | 92.35 | 95.16 | |
| CUB 200 | 97.23 | 98.56 | |
| Dataset | Sample 1 | Sample 2 | Variations |
|---|---|---|---|
| Mini-ImageNet |  Ground-Truth: Trifle Model Predicted: Trifle |  Ground-Truth: Trifle Model Predicted: Trifle |
|
 Ground-Truth: Scoreboard Model Predicted: Scoreboard |  Ground-Truth: Scoreboard Model Predicted: Scoreboard |
| |
| CIFAR-FS |  Ground-Truth: Plain Model Predicted: Plain |  Ground-Truth: Plain Model Predicted: Plain |
|
 Ground-Truth: Bicycle Model Predicted: Bicycle |  Ground-Truth: Bicycle Model Predicted: Bicycle |
| |
| CUB 200 |  Ground-Truth: Baird Sparrow Model Predicted: Baird Sparrow |  Ground-Truth: Baird Sparrow Model Predicted: Baird Sparrow |
|
 Ground-Truth: Fox Sparrow Model Predicted: Fox Sparrow |  Ground-Truth: Fox Sparrow Model Predicted: Fox Sparrow |
|
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, J.-M.; Seshathiri, S.; Chen, W.-H. Few-Shot Classification with Dual-Model Deep Feature Extraction and Similarity Measurement. Electronics 2022, 11, 3502. https://doi.org/10.3390/electronics11213502
Guo J-M, Seshathiri S, Chen W-H. Few-Shot Classification with Dual-Model Deep Feature Extraction and Similarity Measurement. Electronics. 2022; 11(21):3502. https://doi.org/10.3390/electronics11213502
Chicago/Turabian StyleGuo, Jing-Ming, Sankarasrinivasan Seshathiri, and Wen-Hsiang Chen. 2022. "Few-Shot Classification with Dual-Model Deep Feature Extraction and Similarity Measurement" Electronics 11, no. 21: 3502. https://doi.org/10.3390/electronics11213502
APA StyleGuo, J.-M., Seshathiri, S., & Chen, W.-H. (2022). Few-Shot Classification with Dual-Model Deep Feature Extraction and Similarity Measurement. Electronics, 11(21), 3502. https://doi.org/10.3390/electronics11213502