
A Generative Learning Steganalysis Network against the Problem of Training-Images-Shortage

Abstract
1. Introduction
2. Materials and Methods
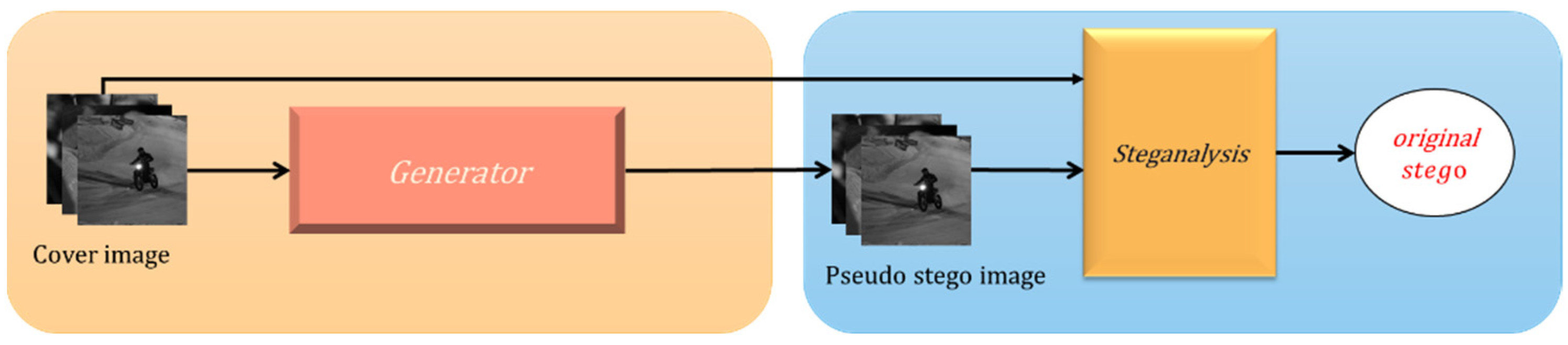
2.1. Architecture
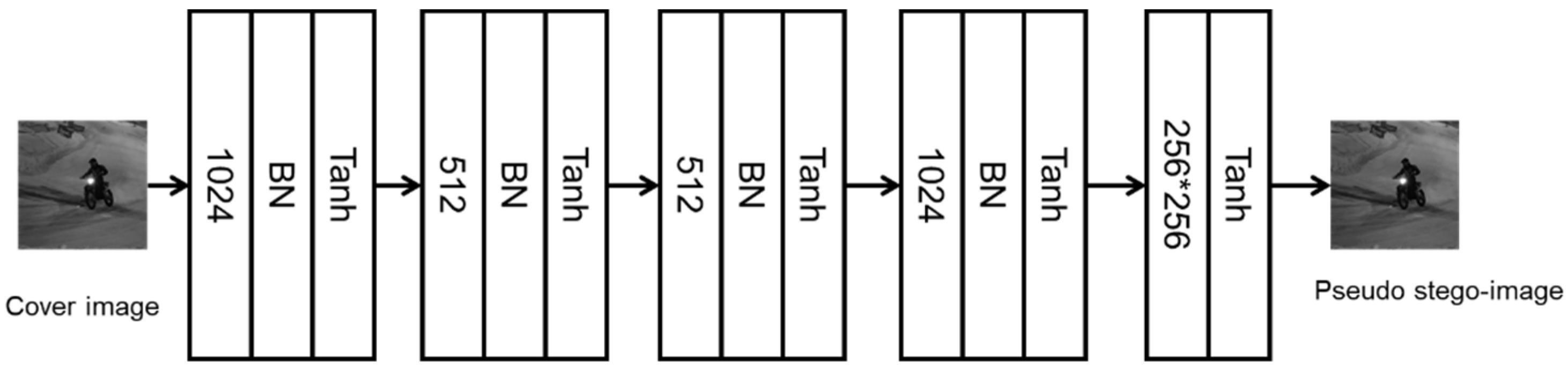
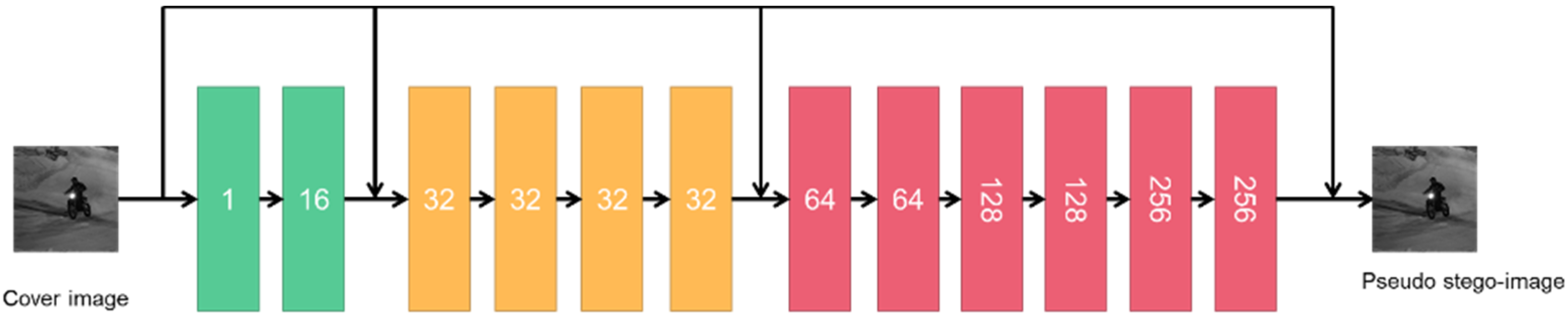
2.2. Details of the Generator
2.3. Dataset and Steganographic Method
2.4. Parameters and Evaluation Metric
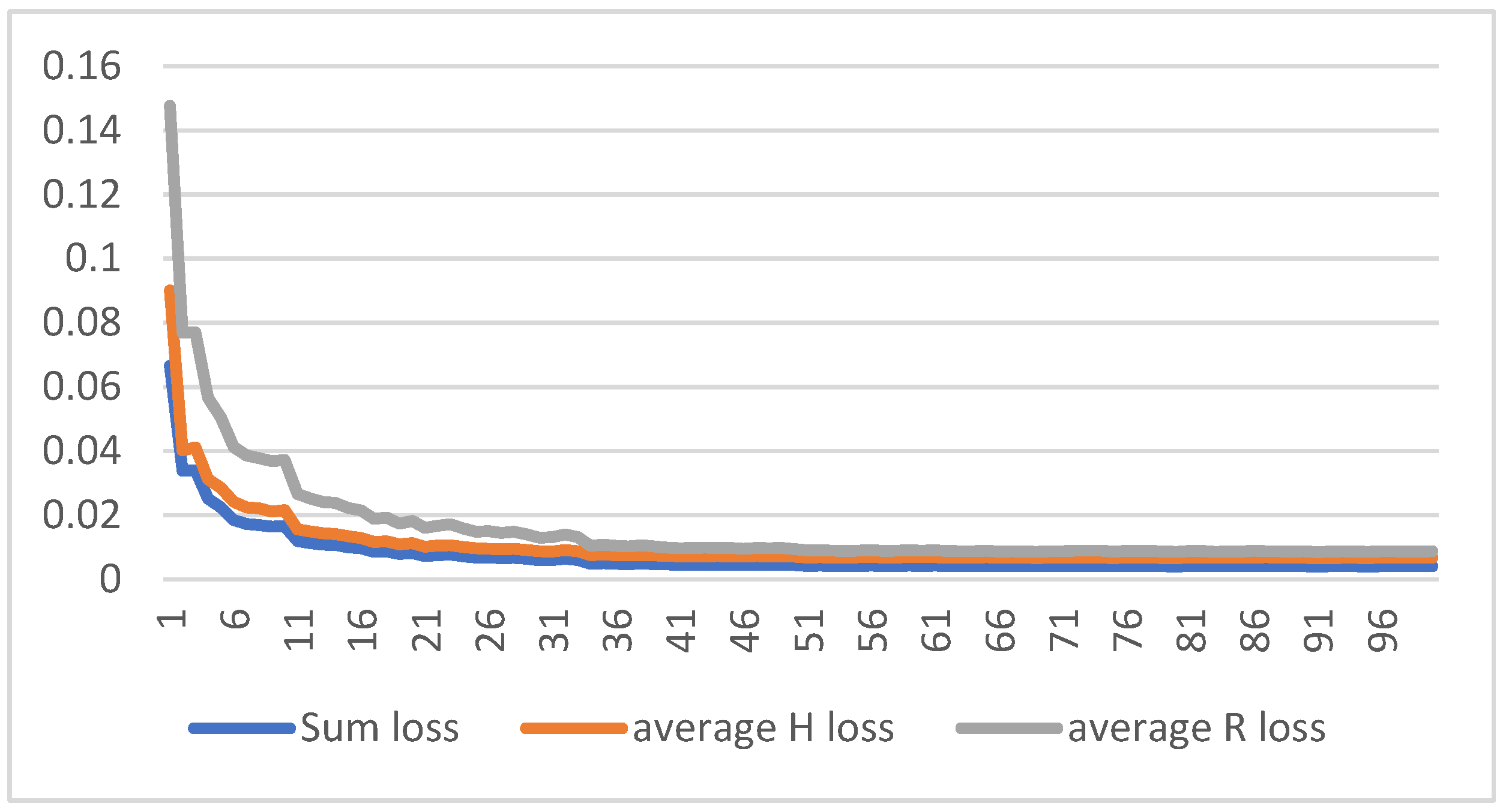
3. Results
4. Discussion
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Baluja, S. Hiding Images in Plain Sight: Deep Steganography. In Advances in Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2017; Volume 30, Available online: https://proceedings.neurips.cc/paper/2017/file/838e8afb1ca34354ac209f53d90c3a43-Paper.pdf (accessed on 8 August 2022).
- Holub, V.; Fridrich, J.J.; Denemark, T. Universal distortion function for steganography in an arbitrary domain. EURASIP J. Inf. Secur. 2014, 2014, 1–13. [Google Scholar] [CrossRef]
- Holub, V.; Fridrich, J. Designing steganographic distortion using directional filters. In Proceedings of the 2012 IEEE International Workshop on Information Forensics and Security (WIFS), Costa Adeje-Tenerife, Spain, 2–5 December 2012; pp. 234–239. [Google Scholar]
- Filler, T.; Fridrich, J. Gibbs Construction in Steganography. IEEE Trans. Inf. Forensics Secur. 2010, 5, 705–720. [Google Scholar] [CrossRef]
- Sedighi, V.; Fridrich, J.; Cogranne, R. Content-adaptive pentary steganography using the multivariate generalized Gaussian cover model. In Media Watermarking, Security, and Forensics; SPIE: San Francisco, CA, USA, 2015; Volume 9409, pp. 144–156. [Google Scholar] [CrossRef]
- Hu, D.; Wang, L.; Jiang, W.; Zheng, S.; Li, B. A Novel Image Steganography Method via Deep Convolutional Generative Adversarial Networks. IEEE Access 2018, 6, 38303–38314. [Google Scholar] [CrossRef]
- Shi, H.; Dong, J.; Wang, W.; Qian, Y.; Zhang, X. SSGAN: Secure Steganography Based on Generative Adversarial Networks. In Advances in Multimedia Information Processing—PCM 2017; Springer International Publishing: Cham, Switzerland, 2018; pp. 534–544. [Google Scholar]
- Tang, W.; Tan, S.; Li, B.; Huang, J. Automatic Steganographic Distortion Learning Using a Generative Adversarial Network. IEEE Signal Process. Lett. 2017, 24, 1547–1551. [Google Scholar] [CrossRef]
- Avcibas, I.; Memon, N.D.; Sankur, B. Steganalysis using image quality metrics. IEEE Trans. Image Process. 2003, 12 2, 221–229. [Google Scholar] [CrossRef]
- Avcıbaş, İ.; Kharrazi, M.; Memon, N.; Sankur, B. Image Steganalysis with Binary Similarity Measures. EURASIP J. Adv. Signal Process. 2005, 2005, 679350. [Google Scholar] [CrossRef]
- Kodovský, J.; Fridrich, J.J.; Holub, V. Ensemble Classifiers for Steganalysis of Digital Media. IEEE Trans. Inf. Forensics Secur. 2012, 7, 432–444. [Google Scholar] [CrossRef]
- Denemark, T.; Sedighi, V.; Holub, V.; Cogranne, R.; Fridrich, J. Selection-channel-aware rich model for Steganalysis of digital images. In Proceedings of the 2014 IEEE International Workshop on Information Forensics and Security (WIFS), Atlanta, GA, USA, 3–5 December 2014; pp. 48–53. [Google Scholar] [CrossRef]
- Tang, W.; Li, H.; Luo, W.; Huang, J. Adaptive Steganalysis against WOW Embedding Algorithm. In Proceedings of the 2nd ACM Workshop on Information Hiding and Multimedia Security, Salzburg, Austria, 11–13 June 2014; pp. 91–96. [Google Scholar] [CrossRef]
- Dengpan, Y.; Shunzhi, J.; Shiyu, L.; ChangRui, L. Faster and transferable deep learning steganalysis on GPU. J. Real-Time Image Process. 2019, 16, 623–633. [Google Scholar] [CrossRef]
- Padmasiri, A.T.; Hettiarachchi, S. Impact on JPEG Image Steganalysis using Transfer Learning. In Proceedings of the 2021 10th International Conference on Information and Automation for Sustainability (ICIAfS), Negombo, Sri Lanka, 3–5 May 2021; pp. 234–239. [Google Scholar] [CrossRef]
- Boroumand, M.; Chen, M.; Fridrich, J.J. Deep Residual Network for Steganalysis of Digital Images. IEEE Trans. Inf. Forensics Secur. 2019, 14, 1181–1193. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Xu, G.; Wu, H.; Shi, Y.Q. Structural Design of Convolutional Neural Networks for Steganalysis. IEEE Signal Process. Lett. 2016, 23, 708–712. [Google Scholar] [CrossRef]
- Yang, J.; Liu, K.; Kang, X.; Wong, E.; Shi, Y. Steganalysis based on awareness of selection-channel and deep learning. In Digital Forensics and Watermarking—16th International Workshop, IWDW 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 263–272. [Google Scholar] [CrossRef]
- Li, B.; Wei, W.; Ferreira, A.; Tan, S. ReST-Net: Diverse Activation Modules and Parallel Subnets-Based CNN for Spatial Image Steganalysis. IEEE Signal Process. Lett. 2018, 25, 650–654. [Google Scholar] [CrossRef]
- Huang, S.; Zhang, M.; Ke, Y.; Bi, X.; Kong, Y. Image steganalysis based on attention augmented convolution. Multimed. Tools Appl. 2022, 81, 19471–19490. [Google Scholar] [CrossRef]
- Zhang, L.; Abdullahi, S.M.; He, P.; Wang, H. Dataset mismatched steganalysis using subdomain adaptation with guiding feature. Telecommun. Syst. 2022, 80, 263–276. [Google Scholar] [CrossRef]
- Itzhaki, T.; Yousfi, Y.; Fridrich, J. Data Augmentation for JPEG Steganalysis. In Proceedings of the 2021 IEEE International Workshop on Information Forensics and Security (WIFS), Montpellier, France, 7–10 December 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Yu, I.-J.; Ahn, W.; Nam, S.-H.; Lee, H.-K. {BitMix}: Data augmentation for image steganalysis. Electron. Lett. 2020, 56, 1311–1314. [Google Scholar] [CrossRef]
- Yedroudj, M.; Chaumont, M.; Comby, F.; Amara, A.O.; Bas, P. Pixels-off: Data-augmentation Complementary Solution for Deep-learning Steganalysis. In Proceedings of the 2020 ACM Workshop on Information Hiding and Multimedia Security, Denver, CO, USA, 22–24 June 2020; pp. 39–48. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; Volume 37, pp. 448–456. Available online: https://proceedings.mlr.press/v37/ioffe15.html (accessed on 8 August 2022).
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer Normalization. 2016. Available online: http://arxiv.org/abs/1607.06450 (accessed on 8 August 2022).
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V.S. Instance Normalization: The Missing Ingredient for Fast Stylization. CoRR 2016, abs/1607.0. Available online: http://arxiv.org/abs/1607.08022 (accessed on 8 August 2022).
- Wu, Y.; He, K. Group Normalization. In Computer Vision—ECCV 2018; Springer International Publishing: Cham, Switzerland, 2018; pp. 3–19. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input | 256 |
| Layer1 | Tanh |
| Layer2 | Tanh |
| Layer3 | Tanh |
| Layer4 | Tanh |
| Layer5 | Tanh |
| Layer6 | Tanh |
| Layer7 | maxPool2D (3,1) |
| Layer8 | maxPool2D (3,1) |
| Layer9 | maxPool2D (3,1) |
| Layer10 | maxPool2D (3,1) |
| Layer11 | maxPool2D (3,1) |
| Layer12 | maxPool2D(3,1) |
| Output | 256 |
| Notes |
|
| Steganography | Generator | No. of Original Cover-Stego Image Pairs | |||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 5 | 10 | 20 | 50 | 100 | 300 | ||
| Baluja-Net | RES | 77.75% | 81.92 | 86.33% | 88.11% | 89.08% | 90.75% | 85.58% | 91.33% |
| FC | 50.00% | 50.00% | 50.00% | 50.12% | 50.26% | 51.51% | 50.21% | 51.18% | |
| CNN | 50.56% | 51% | 55.69% | 63.32% | 64.96% | 66.26% | 67.56% | 68.66% | |
| Non | 62.83% | 68.17% | 71.37% | 79.92% | 79.68% | 94.78% | 95.00% | 92.59% | |
| S_UNIWARD (0.2 bpp) | RES | 59.37% | 59.93% | 63.38% | 64.05% | 69.36% | 72.73% | 81.50% | 87.75% |
| FC | 50.00% | 50.00% | 50.00% | 50.00% | 50.11% | 50.15% | 51.25% | 51.63% | |
| CNN | 50.00% | 50.00% | 50.00% | 50.00% | 52.43% | 58.29% | 59.58% | 58.66% | |
| Non | 50.00% | 50.00% | 52.13% | 52.59% | 58.01% | 59.35% | 67.57% | 83.39% | |
| S_UNIWARD (0.4 bpp) | RES | 63.17% | 63.68% | 66.83% | 64.17% | 71.00% | 79.33% | 88.50% | 91% |
| FC | 50.00% | 50.00% | 50.00% | 50.00% | 51.17% | 51.11% | 52.00% | 52.36% | |
| CNN | 50.00% | 50.00% | 50.00% | 50.05% | 60.36% | 65.13% | 65.5% | 63.33% | |
| Non | 56.61% | 58.33% | 57.83% | 60.54% | 68.17% | 74.60% | 92.00% | 98.51% | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Song, Z.; Xing, Q.; Feng, B.; Lin, X. A Generative Learning Steganalysis Network against the Problem of Training-Images-Shortage. Electronics 2022, 11, 3331. https://doi.org/10.3390/electronics11203331
Zhang H, Song Z, Xing Q, Feng B, Lin X. A Generative Learning Steganalysis Network against the Problem of Training-Images-Shortage. Electronics. 2022; 11(20):3331. https://doi.org/10.3390/electronics11203331
Chicago/Turabian StyleZhang, Han, Zhihua Song, Qinghua Xing, Boyu Feng, and Xiangyang Lin. 2022. "A Generative Learning Steganalysis Network against the Problem of Training-Images-Shortage" Electronics 11, no. 20: 3331. https://doi.org/10.3390/electronics11203331
APA StyleZhang, H., Song, Z., Xing, Q., Feng, B., & Lin, X. (2022). A Generative Learning Steganalysis Network against the Problem of Training-Images-Shortage. Electronics, 11(20), 3331. https://doi.org/10.3390/electronics11203331