1. Introduction
Businesses are constantly looking for ways to offer customized services to directly appeal to customers, build customer loyalty, and achieve a stronger competitive edge. However, customized services cannot be offered without a deep understanding of customers’ behaviors, needs, and preferences. Therefore, there is growing interest in methods that can be used to extract actionable business intelligence (BI) from big data [
1]. The new domain of data analytics has become an important source of competitive advantage for businesses. Data analytics have revolutionized how businesses analyze and utilize data in their decision-making processes [
2]. Analytics helps businesses make better decisions by remodeling how data are used to make decisions [
3]. Many modern businesses use analytics platforms, such as BI systems, to learn about their customers and establish better relationships with them. BI solutions improve businesses’ capacity to process data to discover new knowledge, including customer demographics, preferences, and histories (purchases, contacts, usage, and web activities). In turn, this improved data processing capacity helps businesses customize their offerings to specific conditions. Businesses can build holistic profiles of their customers to explain customers’ current behaviors and expectations and predict future buying behaviors [
3].
Therefore, a customer behavior prediction model with the capacity to recommend suitable forward strategies is of great value to any business. However, analyzing customer behavior is a complex task that requires a well-defined strategy. Intelligent systems cannot simply rely on identifying previous purchases to predict customer behavior. Rather, holistic data must be analyzed to accurately predict future behaviors [
4]. Customer behavior prediction is the process of identifying the behaviors of groups of customers to predict how similar customers will behave under similar circumstances [
1]. A prediction model applies data mining and machine learning techniques to improve the prediction rate [
2]. Machine learning techniques identify customer expectations and requirements by using various learning procedures [
5]. A large volume of data are needed for the training procedure; therefore, big data techniques have been incorporated into BI to increase identification accuracy and to understand customer preferences. Various businesses are interested in creating automated BI systems by integrating big data and machine learning techniques [
6,
7]. This approach minimizes computational complexity and improves the overall prediction rate.
Many studies have argued that traditional machine learning models require considerable time and cannot discover patterns in ideal situations, especially in large chunks of real-world data with different sources and formats. Traditional artificial intelligence (AI) models cannot fully exploit the large volumes of data available in the modern world [
8,
9,
10]. This indicates the importance of exploring new, advanced methods of predicting customer behavior. Indeed, new data learning techniques with minimal computational complexity are required to predict customer behaviors [
10].
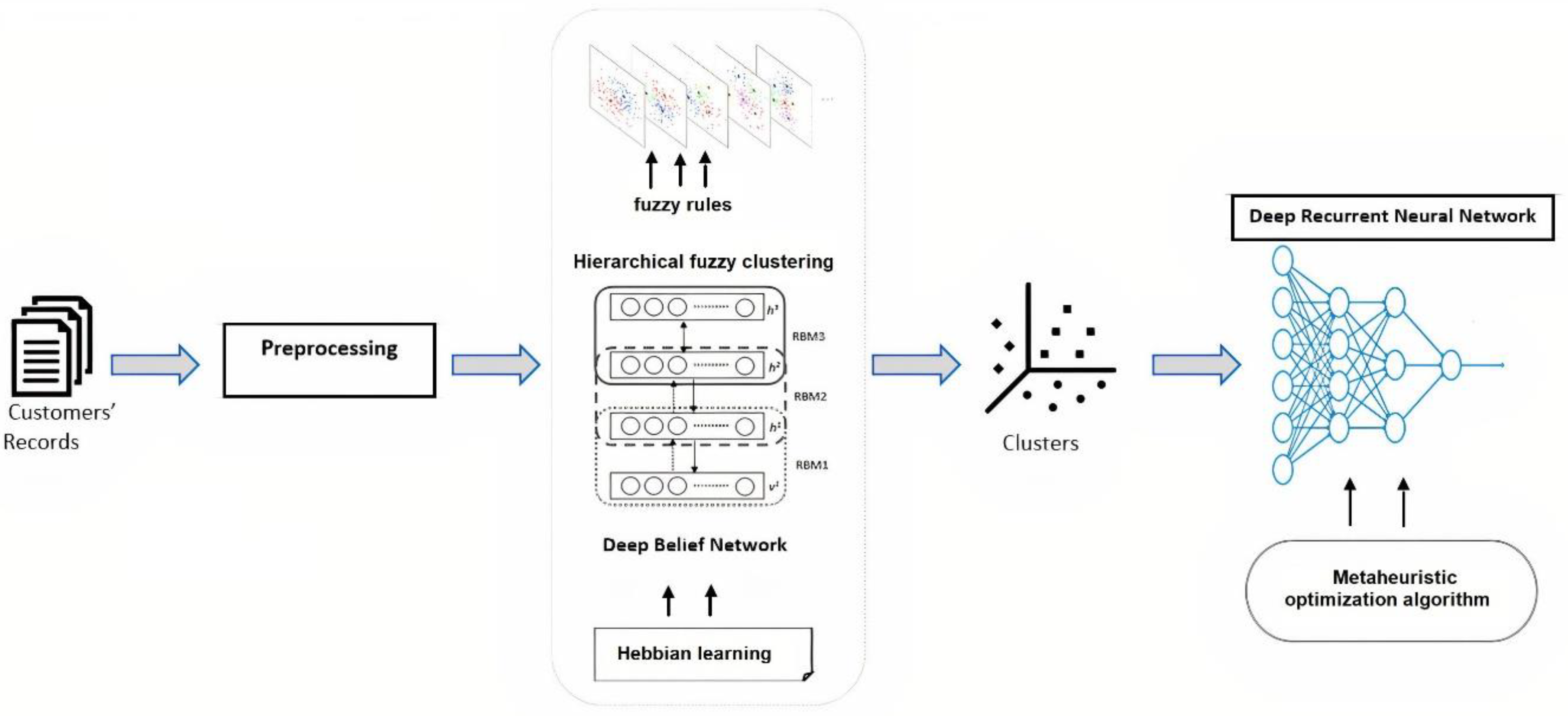
In this work, optimized clustering and deep learning techniques are utilized. Here, the deep belief neural network, Hebbian learning, and fuzzy clustering are combined to examine customer data on customers and their purchasing behaviors. According to similarity, customers are grouped, which helps identify their exact purchasing patterns. The clustered information is analyzed by an optimized deep recurrent neural network (ODRNN) to predict customer behavior. The network parameters are optimized according to a butterfly optimization algorithm (BOA) that minimizes the maximum error classification problem.
The major contributions of this work are as follows. The study (1) proposes a novel clustering approach on the basis of an optimized fuzzy deep belief network and compares it with different hard and fuzzy clustering approaches; (2) adopts an ODRNN that utilizes a BOA to predict customer behavior; (3) proposes a novel hybrid model that comprises two modules, namely a clustering module and a deep recurrent neural network module, and examines it on three benchmark customer datasets; (4) adopts four more advanced machine learning algorithms, specifically K-nearest neighbor, SVM, DNN, and CNN, to predict customer behavior and determine which method works best; and (5) investigates a number of hybrid models to solve customer behavior prediction problems and compare them with the proposed hybrid model. The rest of the paper is organized as follows:
Section 2 elaborates on related work on customer behavior prediction.
Section 3 and
Section 4 explain the working process of the ODRNN-based customer behavior prediction approach.
Section 5 explains the experimentation.
Section 6 analyzes the efficiency of the introduced system. The results are then conclusively explained in
Section 7.
2. Related Works
Customer behavior prediction has been conducted using several prediction methods and techniques. Singh et al. [
11] developed a customer behavior pattern prediction approach by using K-means clustering. Customers’ purchasing patterns were analyzed, after which they were divided into different groups. The clustered information was given as an input to the inferior rule association technique. The a priori algorithm classifies customer patterns by covering enough purchasing patterns. This process improved prediction accuracy and resolved data availability issues effectively. Zare et al. [
12] promoted client satisfaction by incorporating an advanced K-means clustering method. They assessed customer behavioral information by considering malevolent characteristics, criteria of purchase, and demographic details. Sampled characteristics were ranked according to behavioral features. Customers of the Hamkaran company were used to conduct the experiment, and the outcomes indicated that the advanced K-means strategy presented produced higher speed and accuracy than the K-means.
Zheng et al. [
13] introduced an interpretable clustering-based churn identification process from customer transaction and demographic information. The collected details were processed by an inhomogeneous Poisson process that recognized customer churners. This process addresses running time and accuracy issues in the churn detection method.
A study by Yontar et al. [
14] aimed to predict whether users of credit cards would pay off their debts. The support vector machine (SVM) algorithm showed that the potential perils of unpaid debt predicted were accurate and that relevant actions could be taken in due time. In their research, they used the information of 30,000 clients sourced from a major bank in Taiwan. The records contained client details, such as gender, level of education, credit amounts, age, marital status, invoice amount, early payment records, and credit card payments. The evaluation results indicated that SVM provides over 80% accuracy in predicting clients’ payment status in the subsequent month. Sahar and Sabbeh’s [
15] work showed similarities; they evaluated the competence of various machine learning strategies used to solve problems related to customer relationships. Many analytic methods belonging to various learning groups were used in this analysis. These strategies included K-nearest neighbor (KNN), decision trees, SVM, naïve Bayesian, logistic regression, and multi-layer perceptions. They applied models to a telecommunication database containing 3333 records. Realized results indicated 94% accuracy for both multi-layer perception and SVM.
Kim et al. [
16] used unstructured information and a convolutional neural network (CNN) to predict customer behaviors from online storefront information. Their system used a multi-layer perceptron network structure, which combined both structured and unstructured details to improve the learning process. The learning process deduced business problems related to frequent shoppers, churn, frequent refund shoppers, re-shoppers, and high-value shoppers. In addition, the network successfully minimized the deviation between actual and predicted customer behavior. The efficiency of the system was evaluated using Korean-based online storefront information, and the system ensured maximum prediction accuracy.
Ko et al. [
17] incorporated a CNN to create a client retention identification system. They sourced customer information from transaction data, customer satisfaction scores, and purchasing rates. They also obtained conclusive information through the creation of data-driven questionnaires. Furthermore, they evaluated the collected data by using enterprise resource planning, which helps identify client loyalty and trust. This system classified customer retention by ensuring 84% accuracy. Additionally, Tariq et al. [
18] recommended a CNN for creating a distributed model to predict customer churn. The main aim of the study was to monitor customer behavior with maximum accuracy. Their study used the Telco Customer Churn dataset, which was analyzed by data load, pre-processing, and convolutional layer. Along with this, the Apache Spark parallel framework was utilized to improve the data analysis process. The framework minimized validation loss by up to 0.004 and increased prediction rate accuracy by up to 95%.
Fridrich et al. [
19] introduced a genetic algorithm in an artificial neural network (ANN) for optimizing hyper-parameters while recognizing customer churn. Their study aimed to maintain the robustness, trust, and reliability of the classification model. In their study, 10,000 customer lifetime values were collected and processed using neural functions to predict customer churn. During this process, network parameters were optimized according to genetic operators, such as set selection, mutation, and crossover. The optimal parameters helped reduce the deviation between predicted and actual customer behavior. To predict customer churn, Momin et al. [
20] recommended a deep learning model with a multi-layer network. The proposed network uses several layers to examine customer details in an industry to predict churn data. IBM Telco’s customer churn dataset was then utilized for further analysis. This method uses a self-learning algorithm that reduces computation complexity. This implemented system ensured 82.83% accuracy and was compared to the decision tree, K-nearest neighbors (KNN), naive Bayes, and logistic networks. Lalwani et al. [
21] proposed a methodology for prediction of customer churn. Feature selection was performed using a gravitational search algorithm. Various methods were examined in the prediction process, namely, logistic regression, naive Bayes, SVM, random forest, and decision trees. Additional boosting and ensemble mechanisms were applied and examined. The obtained results indicated that Adaboost and XGboost classifiers achieved the highest accuracies of 81.71% and 80.8%, respectively.
Edwine et al. [
22] presented a method for identifying the risk of customer churn based on telecom datasets. The study compared advanced machine learning methods and applied optimization techniques. Hyper-parameter optimization algorithms such as grid search, random search, and genetic algorithms were applied to random forest, SVM, and KNN to predict customer churn. Experimental results showed that the random forest algorithm optimized by grid search achieved the highest numbers compared to the other models, with a maximum accuracy of 95%. Another study conducted by Arivazhagan and Sankara [
23] predicted churn customers by employing a list of important attributes used to measure behavior before churning. The authors of this study focused on three sectors: e-commerce, banking, and telecom. An if–then rule was used to predict churn in addition to the identified attributes. A proposed Bayesian boosting with logistic regression (BLR) was applied to the dataset and compared with logistic regression. The obtained results indicated that the proposed BLR method gave accuracies of 94.42%, 95.54%, and 92.32% for e-commerce, bank, and telecom, respectively. Although the BLR handles bias, it requires a long processing time and needs to be improved.
Another study by Rabieyan et al. [
24] forecasted client value through the application of an improved fuzzy neural network (IFNN). Fuzzy rules favored a continuous investigation of client purchasing details, demographics, and online participant data. Evaluation results comparing classical prediction methods and IFNN showed that the performance of the latter was better. They used root means square error (RMSE) as a measure of performance and their model recorded 0.061 of RMSE.
In their analysis, Sivasankar et al. [
25] incorporated hybrid probabilistic possibility of fuzzy c-means clustering artificial neural networks (PPFCM-ANN) to predict client churn in a commercial enterprise. They gathered customer activity details from the business and applied the clustering technique. Afterward, they computed client relationships, preferences, and relevant probability values to form clusters. Furthermore, they investigated customer information by using a neural network predicting client churn according to similarity. Their model achieved good results among ten samples and accuracy reached 94.62%.
According to various customer behavior prediction models in the literature, machine learning techniques highly influence BI processes. However, some methods require considerable time to recognize behavior patterns, which leads to computational complexity. Other methods struggle with the maximum error classification problem. Existing prediction approaches have recorded low accuracy due to inadequate feature selection [
21,
26]. A feature selection mechanism can improve model performance and increase the predictive power of the applied algorithm. Applying feature selection before data processing leads to more accurate results. Additionally, most recent deep neural network (DNN) models used in customer behavior classification suffer from overfitting, and a prevention technique is not taken into consideration [
21]. Furthermore, a number of studies have concluded that the most accurate results are given by hybrid models rather than single models [
27]. However, most customer behavior prediction models are singular. Moreover, most studies in the field examined their models on private datasets extracted from local businesses. There is a lack of studies using benchmark datasets. Using benchmark datasets organizes researchers around specific research areas and acts as a measure of performance. All these issues are addressed in this study.
In short, there is still room for the improvement of behavior prediction models. This requires optimized and hybrid techniques to analyze customer behavior patterns with maximum accuracy. Combining modalities rather than using a single modality can positively affect the prediction of customer behavioral patterns. The deep learning model has been demonstrated to be a promising solution, especially when combined with the right approaches. As such, clustering and optimized deep learning methods are utilized in this work to improve the overall customer behavior prediction process. The working process of the system proposed in this paper is detailed in the following sections.
4. Customer Behavior Prediction
Following clustering formalization, deep learning is applied in stage two, which decreases the duration of learning and reduces tolerance from the overfitting risk [
35,
36].
Deep learning strategies can learn several representation levels from raw data inputs without involving rules or expert knowledge. A recurrent neural network (RNN) is a feed-forward neural network with an internal memory that retains the processed input [
37]. The memory-based network aids in improving prediction time while investigating new customer details. At this stage, the architecture is a DNN that predicts customer behavior through the use of multiple layers exhibiting temporal feedback loops in every layer, or a DRNN. New information moves up the hierarchy, adding temporal context to every layer in every network update. The DRNN incorporates the DNN concept with the RNN, where every hierarchical layer is an RNN (
Figure 3). Every layer that follows receives the hidden state of the former layer as a series of input times. The automatic assembling of RNNs generates various time scales at different levels, thus producing a temporal hierarchy [
37].
The clustered customer information is given as inputs in this stage, and customer behavior is predicted by applying the ODRNN. The network uses the memory state that saves every processing input detail. The network consists of an input layer, a hidden layer, and an output layer. In every layer, the output is computed to obtain customer behavior. The hidden layer processes the inputs, and the output is obtained using Equation (18).
Here, the hidden layer output is computed from the processing of inputs, the network parameter U, weight W, bias b, and hidden vector . The estimated output is then passed to the next layer to obtain the overall output . The output of the network is obtained from the output layer activation function applied to the output of the hidden layer, the weight multiplication process, and the output layer bias value . During the computation, the sigmoid activation function is utilized to get the output (0 and 1 or 1 and −1). If the output returns a 1, then the customer is considered willing to purchase the product in the future; otherwise (0 or −1), they are not interested in purchasing the product. Additional binary classifications related to customer behavior were studied, including the attractiveness of the customer and product upselling predictions.
This computation is more effective because the clustering process also utilizes the probability value for visible and hidden vectors. This selects the most similar and relevant information; likewise, a recurrent network also uses the
value for every order of customer. The probability value is computed from the customer’s previous purchasing orders to obtain user preferences; therefore, it minimizes the binary classification problem. Parameters tuning effects on improving the performance, such as increasing the number of neurons, batch size, and number of epochs. Hyper-parameter tuning can be performed with multiple trials until the best outcome is found. Nevertheless, the appropriate number of epochs can be selected by an early stopping mechanism, which can stop the training process after a number of epochs when finding the best validation numbers. Furthermore, the system should concentrate on the maximization error rate classification issue. This was resolved by optimizing the network parameters; the optimization was conducted by applying the BOA. The BOA resolves convergence issues by using the objective function, which also diminishes gradient issues. Here, butterfly characteristics are utilized to achieve the objective of the work. Stimulus variance intensity (
SI) and fragrance
characteristics are used to identify the relationship between the network parameters. The
SI of the network parameter is related to the encoded objective function. From the
SI value, the fragrance is estimated using Equation (19).
The fragrance of the network parameter is estimated according to the sensory modality
and dependent modality exponent
values. The range of
and
values varies from (0,1). In the initialization of these parameters, the weight updating process is performed in global and local searching processes.
According to the above solution, the butterfly moves in the search space, and the global solutions are obtained from
in the
-th iterations. From the computation, the best solution
is obtained using Equation (21).
Equation (19) denotes the local search phase of the BOA, where and are the -th and -th butterflies from the solution space. If and butterflies belong to the same swarm and is a random number between the range [0, 1], then Equation (16) becomes a local random walk. A switch probability in BOA helps switch between common global and local searches. This iteration is continued until the stopping criteria are matched. According to the optimization algorithm, the deep recurrent network is trained, and the respective parameters are updated to minimize loss values while predicting customer behavior.
5. Experimentation
The datasets utilized in the research were the KDD Cup 2009 orange small dataset [
38], IBM Telco Customer Churn dataset [
39], and IBM Watson Marketing Customer Value Dataset information [
40]. The collected data consisted of several unwanted, inconsistent, and missing values that reduced the performance of the behavior prediction model. Therefore, missing values were replaced by computing mean values, which successfully removed outliers from the data ets. This pre-processing step reduced unwanted data and noise that might affect prediction accuracy.
The introduced DBN-HBL clustering and ODRNN-based customer behavior prediction were implemented using the MATLAB tool. Here, the neural network used the pre-training and fine-tuning steps to observe the customer information. For every customer order, probability values were computed to determine user preferences. The formed clusters were fed to the BOA-based deep RNN (BOA-DRNN). The network used a 0.05 learning rate, and a batch size of 512 was utilized to classify customer purchasing behavior. The K-fold cross-validation method was chosen as the base validation for comparison and tuning. The system evaluated using different cross-validation methods: test/train splitting, 5-fold cross-validation, and 10-fold cross-validation, and they showed varying results, with 10-fold being the best. The models were therefore trained and validated using 10-fold cross-validation. Initially, a dataset was divided into ten folds to evaluate the effectiveness of the system. The first fold was treated as the test model and the remaining models were considered as the training model. This process was repeated until k = 10. The continuous checking of the data minimized the error rate. In each iteration, grid-search-based hyper-parameter tuning was applied until the training and validation errors were steadied. This process helped solve hyper-parameter overfitting.
The proposed approach was examined and evaluated based on three sets of experiments. They are all explained in the following section.
6. Evaluation and Discussion
6.1. Clustering
In the clustering stage, the results were compared to other clustering methods used in customer behavior prediction, such as K-means, and related forms of fuzzy clustering, such as HFC and probabilistic possibilistic fuzzy c-means clustering (PPFCM) [
25].
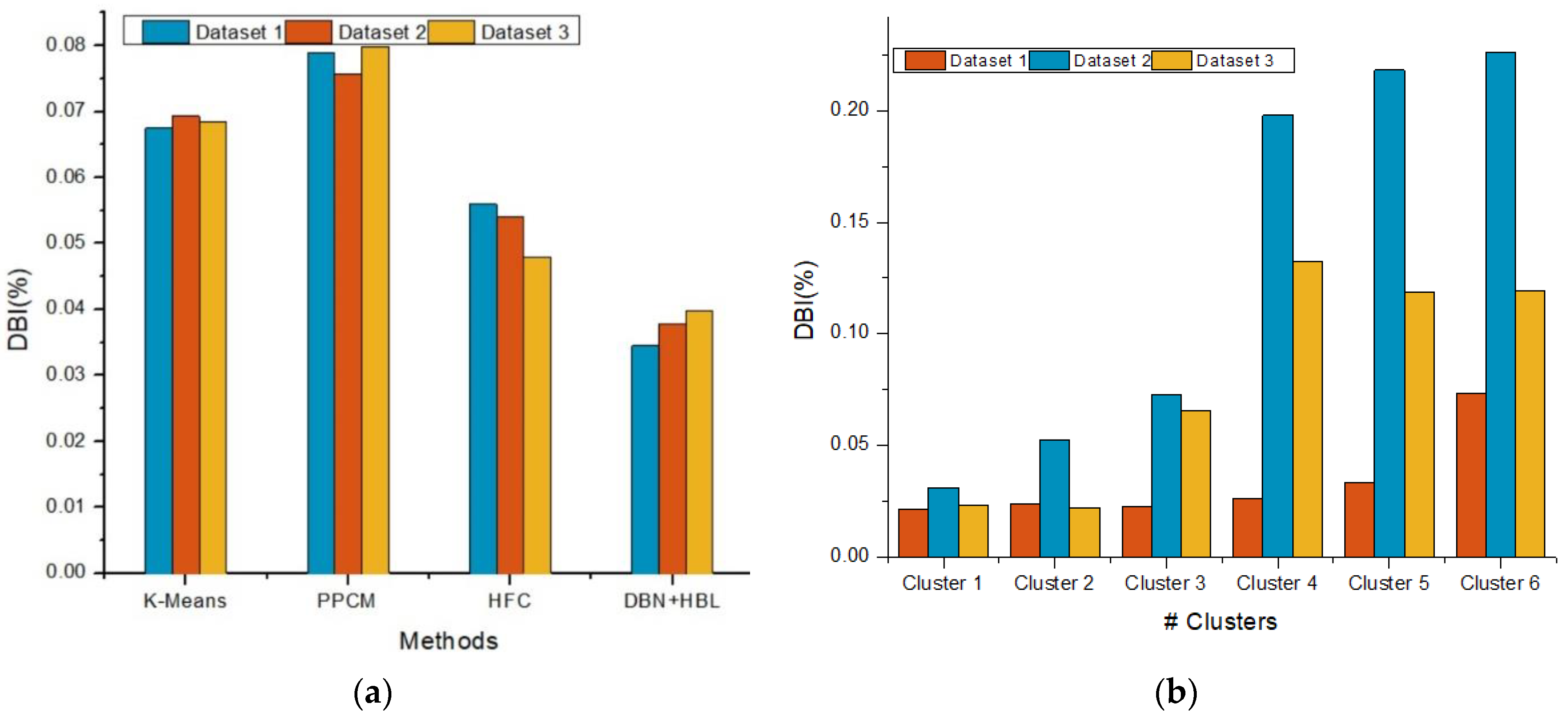
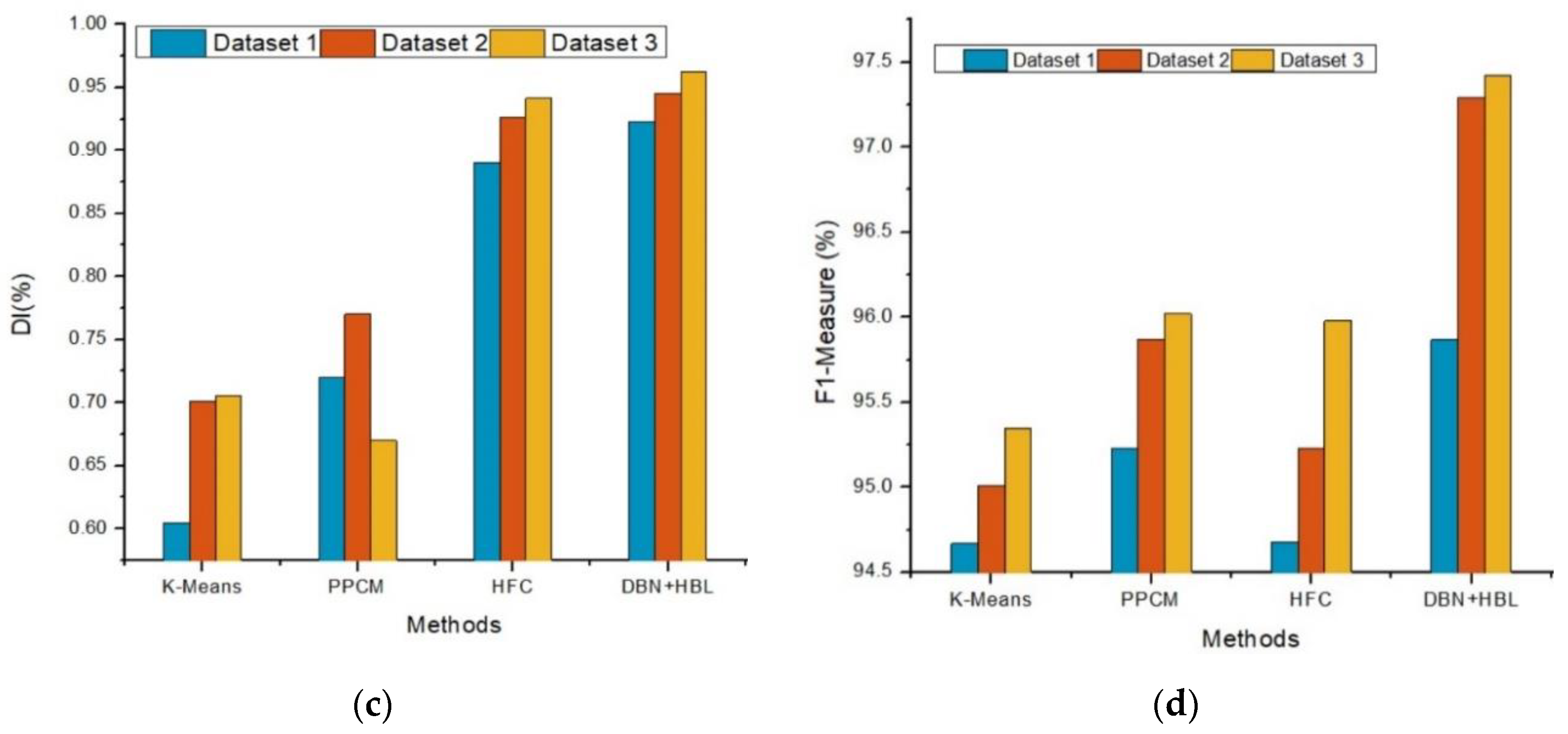
Figure 3,
Figure 4 and
Figure 5 show the clustering evaluation results of the improved clustering approach compared to others based on the Davies–Bouldin index (DBI), Dunn index (DuI), silhouette coefficient (SC), Rand index (RI), Dice index (DI), and F-measure.
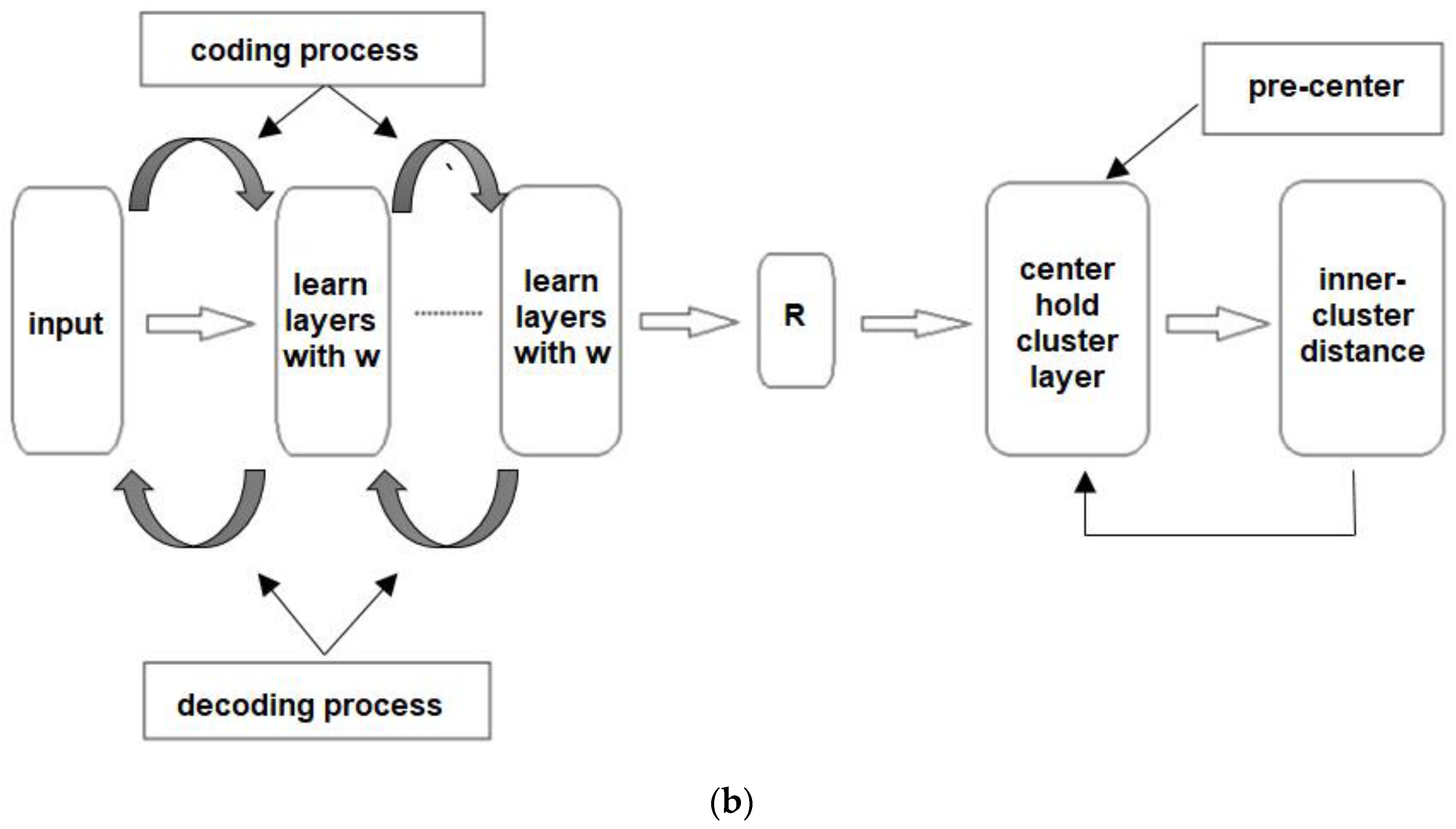
The DBN-HBL approach achieves a low DBI rate because the clustering approach uses the network structure in two phases: pre-training and fine-tuning. These phases are more helpful in predicting the similarities between customer information. In addition, regularized input values during clustering improve the overall cluster process.
Moreover, the DBN-HBL method examines the number of clusters and cluster centers using fuzzy rules and membership values. The effective selection of a cluster center improves the overall effectiveness of the clustering process. Therefore, the system predicts the similarity between customer features with a low DBI value. Here, before clustering, the HBL rule is applied to learn the customer features, and the clusters are formed accordingly. The learning process helps form a more accurate cluster compared to other methods.
Figure 4 illustrates DuI analysis of the DBN-HBL method. DuI is used to evaluate how effectively the method computes similarity value and how effectively the clusters are formed. The DBN-HBL approach attained a higher DuI rate because the clustering centers and fuzzy rules are applied according to the learning process. During this process, visible and hidden layer pair values
are used to identify the probability value. According to the probability measure, customer features are trained and used to identify new customer information. This probability value is assigned for user data, which improves the similarity computation process
. The obtained results of DuI are very highly collated with existing methods.
Based on the results of HFC compared to DBN-HBL, there was an enhancement in clustering efficiency after adding DBN with HBL. DBI was decreased among all three datasets in addition to a higher DuI rate. Here, the DBN approach is utilized to train the features that help improve the overall clustering process compared to the other methods such as K-means and PPCM. After training the features with the Hebbian learning process, the deep belief network utilizes the network layers, which clusters the information effectively.
Thus, the DBN-HBL method attained the highest clustering accuracy metrics due to the similarity computation, probability estimation, and visible–hidden pair data. In addition, fuzzy rules were incorporated into the DBN to select the network centroid value and members of clusters. The regularization of inputs concerning the probability value increased clustering accuracy and reduced deviation error. Here, the learning rule was applied to understand each customer feature, which helped effectively identify the testing features related to the cluster. The effective training process and customer information analysis improved overall clustering efficiency and minimized output deviations. As seen in
Figure 5c, SCs for HFC and DBN-HBL had similar results, with the latter being slightly higher. K-means showed the lowest numbers in the respective metrics compared to the other methods. Although PPFCM showed moderate results in SC, RI, and DI, this method achieved a higher F1-measure compared to K-means and HFC. This can be attributed to the objective function of PPFCM that avoids causing glitches.
The DBN-HBL exhibited the best performance among all metrics. The Hebbian learning process was utilized to examine the customer features used to cluster similar customer information. The effective utilization of learning rules led to the maximization of overall clustering efficiency compared to other methods. The introduced DBN-HBL approach attained maximum prediction accuracy compared to existing methods. Here, the Hebbian learning process was utilized along with the fuzzy rules to improve clustering efficiency. The F-measure rose from 95.5% to 98.89%, indicating 1.068%, 2.013%, and 1.71% improvement while considering overall data analysis in Dataset 1, Dataset 2, and Dataset 3, respectively.
6.2. Single-Model-Based Customer Prediction Models
After the clusters were formed, they were processed using the BOA-DRNN. The network predicts customer behaviors according to network learning functions. During this process, the network parameters were updated by applying a BOA. This updating process reduced the maximum error rate classification problem. The continuous network updating process reduces computation complexity and error rates. The prediction system performance was evaluated using different metrics, such as error rate, sensitivity, specificity, F-measure, and accuracy. The acquired results were compared to other single-model-based prediction models, such as KNN, SVM, DNN, and CNN. To ensure optimal validation, four classifiers were implemented. The system used the tuning parameters shown in
Table 2.
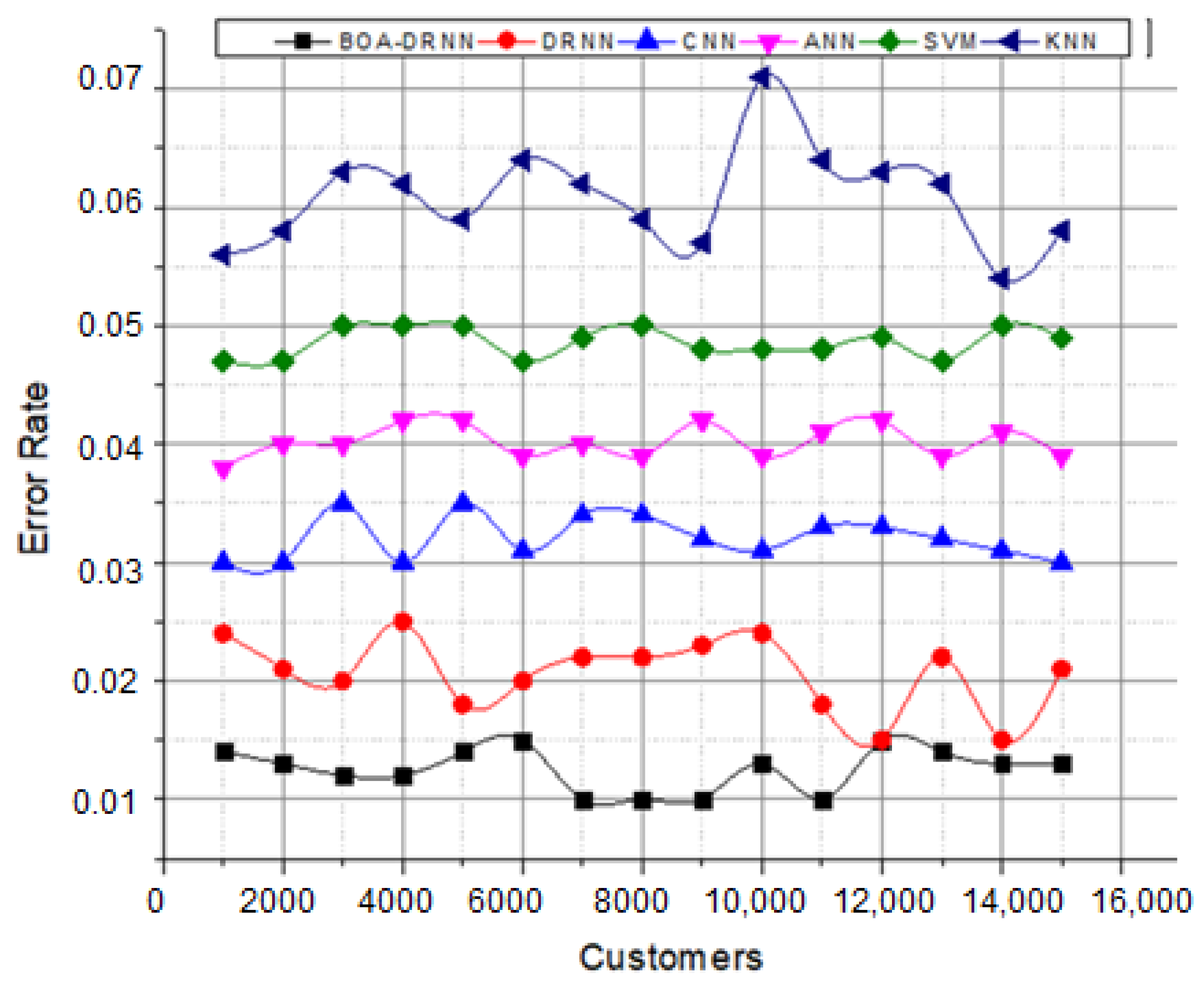
The deviations between the actual and predicted values were computed. A graphical analysis of the error rate is shown in
Figure 6. This figure illustrates the error rate values of actual versus predicted customer behavior patterns. Here, the network uses the memory state for every processed input. The network predicts the output in every layer to reduce the number of deviations because it utilizes the network parameters. Furthermore, the network parameters were updated according to butterfly optimization characteristics
to mitigate the maximum error rate classification problem. Here, the effectiveness of the system was evaluated using different numbers of customers. The minimum error value directly indicated that the introduced system attained high recognition accuracy.
The overall effectiveness of the system results is illustrated in
Table 3. From the table, it can clearly be seen that the introduced approach attained the highest accuracy values compared to the other methods, with Dataset 1 at 97.51%, Dataset 2 at 97.3%, and Dataset 3 at 97.9%. The obtained results directly indicate that successfully utilizing the network parameters, objective functions, and optimization techniques improved the efficiency of the overall system.
As expected, deep learning methods recorded higher numbers in all metrics compared to classical machine learning methods such as KNN and SVM. However, SVM achieved better results than DNN, whereas those of KNN were the lowest. The CNN achieved high numbers compared to SVM, KNN, and DNN models in all metrics, whereas KNN showed the lowest performance. The analysis using the BOA-DRNN improved the accuracy over the widely used SVM model by over 13.78% in Dataset 1, 14.12% in Dataset 2, and 15.12% in Dataset 3. SVM is widely used for prediction-related problems because of its usability and the high interpretability of the produced results. This improvement in the predictive performance of the BOA-DRNN can be attributed to its neural network hyper-parameters (weight, number of layers, number of neurons in each layer, batch size, and number of epochs). The tuning of these hyper-parameters has a strong impact on improving the performance.
The multiple network layers of the DRNN improved the process of feature learning [
41]. Simple features were learned by the initial layers, whereas the later layers were intended to predict the output according to complex combinations of features. Moreover, the network architecture of the DRNN makes it less exposed to the issue of dimensionality, unlike machine learning techniques [
42]. The deep structure of the DRNN enables it to process larger datasets in an efficient manner. The results indicate that, following BOA-DRNN and DRNN, the CNN was able to outperform the others on all explored metrics, with accuracies of 85.29, 85.62, and 85.83 for Datasets 1, 2, and 3, respectively. According to the results, the performance scores of the CNN structure were higher than those of the DNN structure. It is understood that the performances of the two methods are similar in customer behavior prediction problems. Moreover, in such datasets, the number of input features is excessive for a normal DNN structure, which leads to an increase in processing time. In contrast, CNN does not suffer from a large number of features and has a significant advantage because of the feature extraction layer. Therefore, the CNN structure is suitable for problems with large input features, such as customer behavior prediction.
Specificity denotes the portion of negative cases that were classified correctly, while sensitivity denotes the portion of positive cases that were correctly identified. Notably, from
Table 3, BOA-DRNN outperformed the other methods in terms of sensitivity and specificity. BOA improved sensitivity by 3.47%, 3.58%, and 4.77% for Datasets 1, 2, and 3, respectively. In addition, using BOA, the specificity increased by 2.56%, 2.94%, and 3.74% for Datasets 1, 2, and 3, respectively. Notably, there was a large increase in both sensitivity and specificity with a minimum 10% difference when comparing BOA-DRNN with the second-best model, CNN. This can be attributed to the fact that RNNs can use their internal memory to process random sequences of inputs.
According to the precision metric, the introduced approach recognizes customer behavior effectively compared to the other metrics. The high precision value indicates that the system clearly exacts output collated with other metrics. The BOA approach increased the precision value by up to 4.128%, 1.92%, and 4.38% for Dataset 1, Dataset 2, and Dataset 3, respectively.
Moreover, unlike deep learning models, SVM and KNN are capable of directly handling categorical variables [
15]. Basically, SVM has a smaller number of hyper-parameters compared to neural network models, which makes it easier to tune [
14]. Further, the training time for SVM is lowest. Operational efficiency should be considered, as businesses need to predict customers in real time. This is a trade-off between processing efficiency and processing time.
6.3. Hybrid-Model-Based Customer Prediction Models
In this experiment, the proposed approach was compared to other existing hybrid customer prediction models mentioned in the literature, such as PPFCM-ANN [
25] and IFNN [
24]. The performance metrics used here were mean square error rate (MSE), sensitivity, specificity, F-measure, precision and accuracy.
The effectiveness of the system was evaluated using the three datasets, and the respective results are illustrated in
Table 4. For the three datasets, the introduced BOA-DRNN approach attained the maximum prediction accuracy compared to the other methods (Dataset 1: 97.51%, Dataset 2: 97.33, Dataset 3: 97.98%). Followed by PPFCM-ANN, the BOA-DRNN raised the accuracy with 2.95, 3.2, and 7.98 for Dataset 1, Dataset 2, and Dataset 3, respectively. The difference increased gradually along with dataset size, which makes our hybrid model preferable for larger datasets. Specificity denotes the portion of negative cases that were classified correctly while sensitivity denotes the portion of positive cases that were correctly identified. Notably, BOA-DRNN outperforms the other methods in terms of sensitivity and specificity. According to sensitivity, our model achieved the following results: Dataset 1: 96.87, Dataset 2: 96.98, and Dataset 3:97.34. In specificity, BOA-DRNN achieved the following results: Dataset 1: 97.38, Dataset 2: 97.15, and Dataset 3: 97.65. Furthermore, the maximum precision was achieved by BOA-DRNN followed by PPFCM-ANN with differences of 4.6, 4.35, and 5.96 for Dataset 1, Dataset 2 and Dataset 3, respectively. Clearly, IFNN was the lowest performance compared to the other two hybrid models. The MSE numbers were low for all the examined hybrid models. There were only slight differences between them, with BOA-DRNN being the lowest.
The BOA-DRNN network uses the clusters formed by a DBN with HFC as the input to identify customer behavior. Here, the belief network had a set of layers that processed the network according to the learning function. The optimization algorithm was then applied to reduce the deviation between the actual and predicted values. In addition, the optimization algorithm updated the network parameters to regularize network performance effectively.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}