1. Introduction
Salient object detection (SOD) aims to assess salient objects in an image, captured by human visuals. As a means for screening important information, SOD efficiently utilizes limited visual information processing resources, and often serves as a preprocessing approach for downstream vision tasks, such as photo synthesis [
1], visual tracking [
2,
3], semantic segmentation [
4], and image retrieval [
5].
The development of deep learning overcame the issues of traditional models including complex design and poor migration, which considerably boosted the progress of SOD [
6]. In particular, fully convolutional neural networks (FCNs) [
7,
8,
9] stack multiple convolutional and pooling layers to increase the receptive field. This method of gradually extracting features enriches the intermediate information of the model, which plays a vital role in SOD. The FCN consists of two modules: encoder and decoder. (1) The encoder is the backbone of the SOD model for feature extraction. Generally, the encoder is chosen from architectures (such as VGG [
10] or ResNet [
11]) with mature classification performance and multi-level feature supply: the shallow high-resolution feature map contains abundant information, including information regarding spatial, texture and color. The deep low-resolution feature map represents the global semantic information with context-awareness obtained through filtering. (2) The decoder is responsible for integrating the extracted information and inverting to generate the corresponding saliency image. However, as the number of layers increases, the deep module of the simple autoencoder only depends on the previous neighboring layer, and the shallow information is barely perceived, resulting in an inadequate performance.
To overcome this shortcoming, existing methods introduced various constraints, such as the attention mechanism [
12], recurrent architecture [
13,
14], multi-scale feature combination [
15,
16,
17], and boundary loss [
18,
19,
20]. Although, the upgraded method has achieved excellent performance, there is still room for improvement. With regard to the FCN-based model, the quality of the features extracted by the encoder directly determines the capability of the model. Therefore, the optimization of the feature information is highly significant. However, the majority of existing related methods aggregate multi-scale feature layers without distinction, resulting in information redundancy. In addition, inaccurate redundant information may degrade the performance of the model, or even generate incorrect predictions.
In this paper, a novel local and global feature aggregation-aware salient object detection method is proposed. It comprises an encoder with an attention mechanism for efficient feature filtering and an improved decoder based on aggregation-aware features. In the encoder, for local features, the sub-shallow feature map retains high resolution, while eliminating noise interference and combines spatial attention to refine the details of salient objects. For global features, the sub-deep feature map is a context-aware information layer that combines channel attention to quickly locate salient objects. In addition, because the feature contribution of shallow features is less than that of deep features, it is easier to reach saturation. Therefore, the shallow layer selects the sub-shallow layer, and the deep layer selects the sub-deep layer as well as the deepest layer to jointly aggregate the important objects in the perceived image. In the decoder, the symmetrical decoding structure of the encoder chooses the specified feature layer for optimized aggregation to achieve a remarkable prediction effect.
In short, the contributions of this paper are summarized as follows:
A novel attention module is proposed to detect and filter out the crucial salient features. The global features of the context-aware layer aggregate and guide the local features of the detail-aware layer, so as to achieve rapid positioning and detail refinement of salient objects.
An improved decoder based on aggregated perceptual features was proposed to optimize the model. Replacing the complete decoder with specific local and global features enhances the decoder and shifts the emphasis on high-quality features to achieve model simplification and improvement in performance.
2. Related Works
Early methods of estimating saliency values relied on human intuition and heuristic priors to create handcrafted features. Itti et al. [
21] proposed a method for simulating the visual mechanism of primates to obtain the position in the image that first attracts human attention. Achanta et al. [
22] presented a method for determining the salient regions in images, using low-level features of luminance and color. Wei et al. [
23] proposed a model based on background priors to separate saliency objects. Yang et al. [
24] adopted manifold sorting to extract interesting regions in an image. However, most related models do not eliminate excessive dependence on the low-level features of the basic attributes of the image, resulting nearly in a lack of ability to perceive high-level semantic information, which creates the dilemma of insufficient generalization.
Recently, with the developments in deep learning, this defect has been improved owing to its powerful feature perception ability, which has greatly promoted the development of salient object detection. Wang et al. [
25] provided a comprehensive survey covering various aspects to facilitate in-depth understanding of SOD. In the efficiency of feature layer information extraction, Zhao et al. [
26] adopted two groups of multilayer perceptron (MLP) to perceive local and global information, respectively, and the saliency map was predicted through abstract high-level semantic information. Wu et al. [
27] performed cascade optimization on a deep feature layer with high-level semantic information to predict the saliency map. Zhao et al. [
28] proposed a pyramid attention network to enhance high-level context features and low-level spatial structure features. However, the designed model architecture or redundant information is not fully optimized. To further improve the model’s utilization of features, existing methods have studied a variety of information constraint methods. Hou et al. [
16] introduced a skip-connected layer structure to provide deep supervision in the model to improve performance. Qin et al. [
20] fixed a recurrent mechanism after the prediction module to refine an imperfect saliency map. However, such schemes fail to consider the deep optimization of features and use them directly. Therefore, in order to give full play to the functions of each feature layer, an optimization model is proposed in this paper. In the process of improving the efficiency of feature extraction, the model enhances the constraint performance of the model to achieve a reasonable distribution of key information, thereby accurately generating saliency maps.
3. Local and Global Feature Aggregation-Aware Network
This section first describes the overall pipeline of the local and global feature aggregation-aware network (LGFAN), and further elucidates each component module.
3.1. Overview of Network Architecture
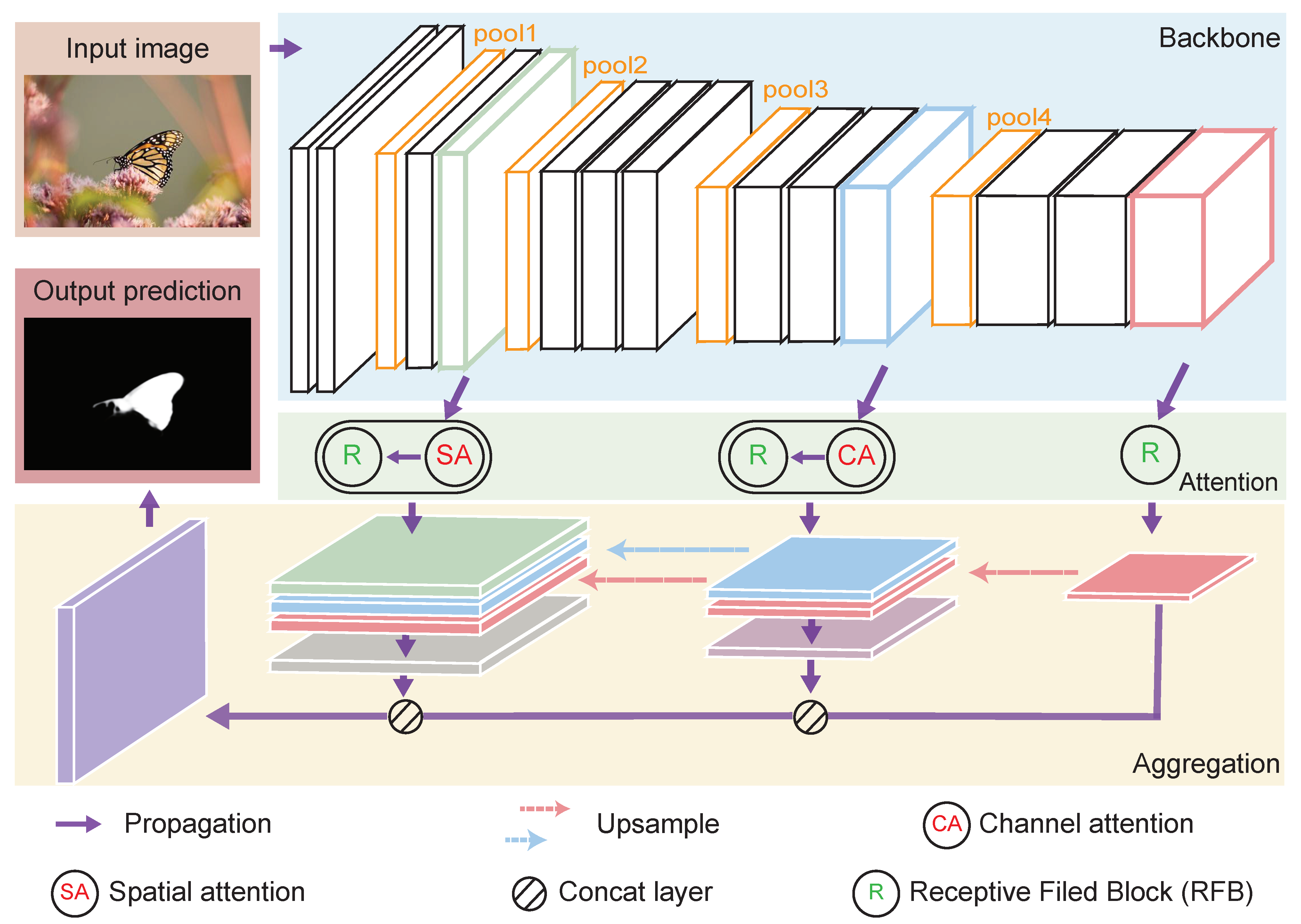
The overall architecture of the network proposed in this paper is shown in
Figure 1. The input image is fed to the backbone network VGG, and the extracted features are filtered by the attention module to obtain important information. Then, the high-quality features are supplied to the aggregation module for prediction of saliency images. The network simulates the human visual perception system in which the neurons analyze visual information while screening significant regions in the global field of vision. First, the visual geometry group (VGG) network, which has an outstanding classification effect in the ImageNet dataset, is extremely consistent with the demand for visual field perception because of the characteristics of its multi-scale feature layer. When VGG extracts features, the shallow layer contains rich information suitable for small target detection and refinement, and the deep layer contains context-aware semantic features used for large target detection and guidance. Furthermore, the spatial attention module and the channel attention module are embedded in the shallow and deep layers of the VGG as branch modules, respectively. The two synchronously filter inaccurate information and guide the network to accurately and quickly locate significant regions. Finally, the aggregated information extracted by the slight autonomous discriminating ability is decoded, and the corresponding saliency image is predicted.
The design of the entire network follows the ultimate goal of seeking salient features. Inspired by the general attention module [
29], a multi-layer separable convolution mechanism [
30] is introduced to lighten the attention module. The optimized attention module embedded in Backbone helps the network eliminate background semantic features and gradually focus on advanced foreground semantic features. The spatial attention mechanism believes that not all areas in the image are important for the contribution of the task, only the region related to the task concerned. Channel attention enhances or suppresses different channels for different tasks by modeling the importance of each feature channel. On the other hand, the RFB module simulates the configuration in terms of the size and eccentricity of RFs in human visual systems, aiming to enhance deep features of lightweight CNN networks [
31]. The improved RFB is to enhance the deep features learned from the lightweight CNN model, making them helpful for fast and accurate detection. It has significant performance gains while still maintaining a controlled computational cost. Furthermore, the multi-scale structure [
32] in the feature layer can fuse the features of different receptive fields on the feature map of the same level, and the multi-scale structure between the feature layers is to fuse low-resolution feature maps into high-resolution. The above modules play an indispensable role in the task of saliency object detection, optimizing the model while achieving accurate and rapid positioning of saliency features.
3.2. Local and Global Attention Module
The local and global attention modules include the network backbone of feature extraction, the network branches of the spatial attention mechanism, and the channel attention mechanism. Because the essence of the attention mechanism is to focus on important information, this property coincides with the purpose of SOD, which helps improve the performance of the model. However, most existing related methods aggregate the multi-scale feature layers extracted by the backbone, without distinction, resulting in information redundancy. In addition, inaccurate redundant information may degrade the performance of the model, or even generate incorrect predictions. Therefore, a reasonable allocation of the feature layers is crucial.
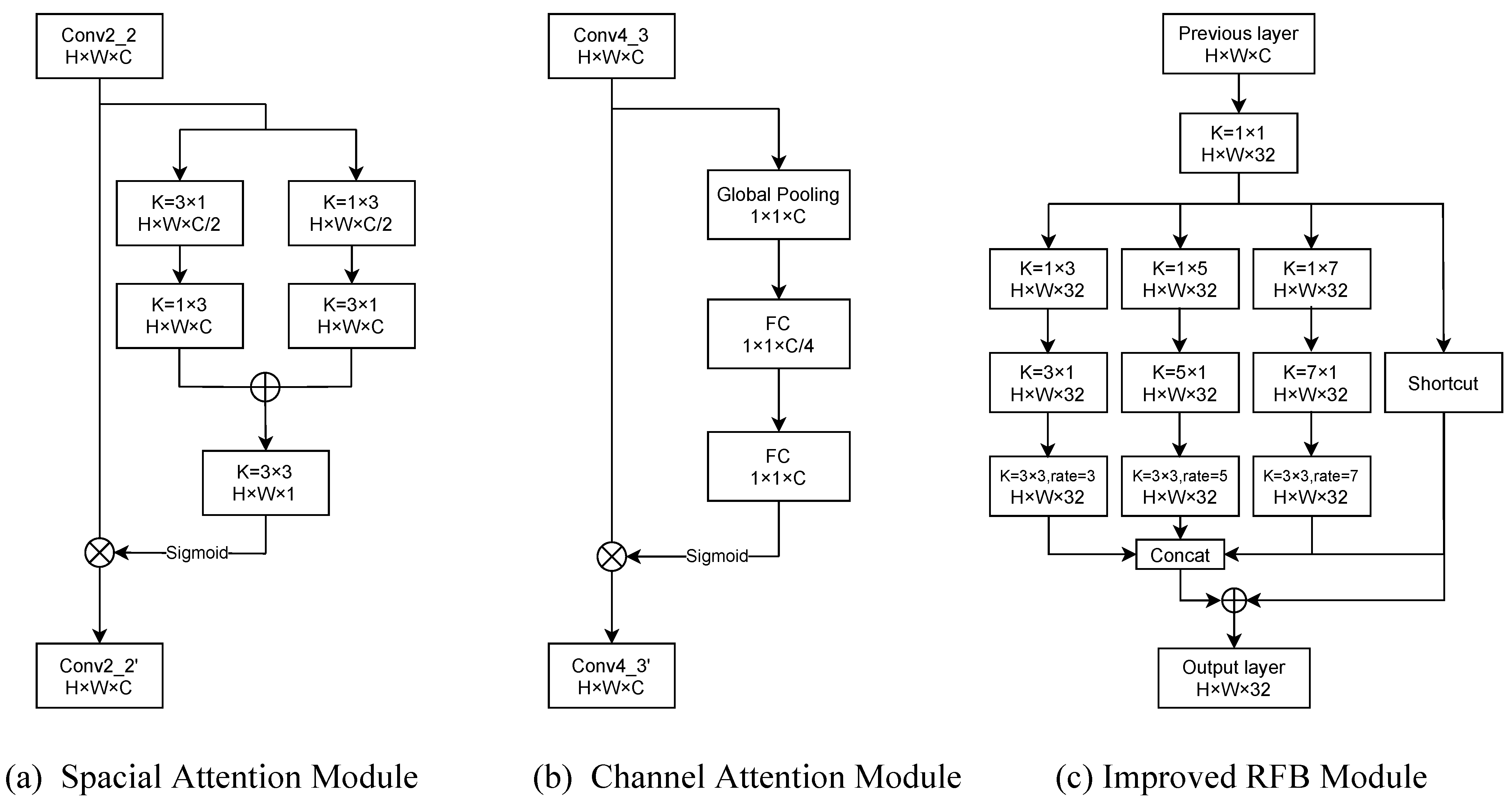
The detailed structure of the local and global attention modules is as follows: VGG16 is the backbone of the network. There are five abstract feature groups, the output of which is denoted by . The layer with complex information could not be processed further. The branch with spatial attention was derived from the layer as a local perception module for a small target location and detailed refinement. The layer generated based on contains a wider receptive field and higher-level features. Simultaneously, was derived from the layer; hence, the layer became suitable for connecting with the channel attention mechanism as a global perception module. Finally, the abstract features generated at the layer perceive the entire field without guidance, which is the critical source for the decoder.
Spatial attention: Instead of treating all spatial information equally, focusing on the object of the image foreground helps produce high-quality saliency predictions. In the proposed model, the information filtering method shown in
Figure 2a is adopted to realize the local saliency information perception, which is defined as follows:
where
and
are lightweight convolutions that utilize a combination of
and
to replace the
, and
and
correspond to their respective convolution kernel parameters. To increase the robustness of the network, two spatial attention perceptions were performed on
. Following the addition of
and
, a sigmoid was performed to assign weights to highlight important features and express them as
layers.
Global attention: The effective global perception channel was highlighted to focus on the guidance of high-level features, which manifested as a high response to salient objects.
Figure 2b presents the module of the channel attention module, and its principle is presented in
where
is obtained by two fully connected layers
and
performing dimensionality reduction and dimensionalization transformation on the result of the global average pooling
of the
layer, which is similar to PCA for feature extraction.
and
are the weights of the two fully connected layers, respectively. The channel perception result ca is normalized by sigmoid and weighted with each channel to stress the saliency perception channel and express them as
layers.
3.3. The Proposed Decoder
To generate a saliency image, a common solution is to exploit fusion decoding on multiple scales of features. However, this not only increases the depth of the network but also incorporates a large amount of redundant information. Instead of the original symmetrical decoder, this study proposes an improved decoder with an improved RBF. The new decoder only decodes the high-quality features provided by the encoder to reduce the network depth, whereas the high-quality features only highlight important information and reduce the amount of information. Moreover, to compensate for the loss of information caused by the decrease in the number of layers, the new decoder also introduces an improved RBF module to enrich the decoding information by increasing the receptive field, thereby generating high-quality saliency detection images.
The RFB module constructed by controlling the dilated convolution parameter provides the corresponding multi-scale feature information source. At the same time, the module combines the key information filtered by the attention module for further enhancement, providing sufficient and reliable feature elements for the model. In addition, the designated feature layers processed by the RFB module are sent to the decoder to form a multi-scale structure when aggregated, which expands the network’s field of vision to form the function of guiding perception.
As shown in
Figure 2c, the improved RFB module splits the feature layer into four branches
, and the corresponding dilated coefficient is
. Among them,
is an ordinary convolution that maintains the continuity of each feature, and the remaining branches are responsible for perceiving more and complete information to ameliorate
. Meanwhile, for acceleration, a 1 × 1 convolution is adopted to repress the number of channels to 32 in each branch. In addition, to reduce the number of parameters, a multi-layer separable convolution technique is applied to optimize the RFB. Finally, the features perceived by multiple groups of this mechanism are concatenated and decoded to predict the saliency image, which is formulated as
where the up-sampled multiple of feature
is identified as
. Conv is a
lightweight convolution. Until the size of the up-sampled feature from the
th layer is the same as that of the
ith layer, they are multiplied and combined.
L represents the feature layer index set for optimization, and
l is its child element. Simultaneously, the number of channels is compressed to output a single-channel feature map.
4. Experimental Results
This section describes the details of the experiment to facilitate the reproduction of follow-up studies. Furthermore, to verify the powerful performance of the model, multiple evaluation schemes were used for comprehensive analysis of multiple public benchmark datasets.
4.1. Datasets and Implementation Details
The images employed for performance evaluation were derived from five standard benchmark datasets: DUT-OMRON [
24], DUTS-TE [
33], ECSSD [
34], HKU-IS [
35], and PASCAL-S [
36]. DUT-OMRON has 5168 images, some of which are more than one object, and some of the foreground objects are complex. DUTS consisted of 10,553 training images (DUTS-TR) and 5019 test images (DUTS-TE), which were utilized for basic training and testing of the model, respectively. The ECSSD was composed of 1000 natural images integrated from the Internet. The HKU-IS comprised 4447 images with multiple targets. PASCAL-S comprised 850 challenging images.
The backbone of the model was selected from the pre-trained VGG on ImageNet, which minimizes the cost function binary cross entropy (BCE) through Adaptive Moment Estimation (Adam) to achieve image feature extraction. The model configuration is as follows: the image feed size was unified to
, the learning rate was based on the initial 1 × e
with a 30/120 epoch decline, and the batch was increased to 20 to shorten the training period. Furthermore, the entire model was implemented by building a torch-1.9 with VS code tool platform on GTX1070 GPU. Once the proposed model was trained using DUTS-TR, the optimal weight parameters were saved to obtain a mature model. The project code can be found in
Supplementary Materials.
4.2. Evaluation Metrics
The optimized model is evaluated based on two types of criteria: model performance or computational efficiency. The performance evaluation indicators include the mean absolute error (
MAE), F-measure (
), and precision-recall (PR). The performance evaluation code can be found in the
Supplementary Materials [
37,
38]. The
MAE be computed as
where
W and
H represent the image size,
x and
y refer to the pixel coordinates,
S is the predicted result, and
G is the expected result.
The F-measure and PR curves obtained by adjusting the classification threshold visualize multiple indicators from the confusion matrix, and take into account the evaluation of small targets in SOD, making the evaluation score convincing. The F-measure is given by
where
is fixed to 0.3 for highlighting the importance of the precision value. Meanwhile, the PR score is calculated through Precision/Recall. The Precision and Recall are written separately as
where true-positive (TP), true-negative (TN), false-positive (FP), and false-negative (FN) are all statistical values from the confusion matrix. In addition, the evaluation indicators used for computational efficiency [
39] are model parameters (Params), floating-point operations (FLOPs), and Time.
4.3. Results and Discussion
The proposed method (LGFAN) is compared with eight state-of-the-art methods, including ASNet [
40], BASNet [
20], CPD [
27], DSS [
16], EAR [
41], GateNet [
42], PoolNet [
19] and
[
43]. To ensure the authenticity of the conclusions, the sources of prediction results adopted for model performance evaluation were all saliency maps published or generated from the original code. Additionally, the utilized evaluation code and its operating environment were consistent.
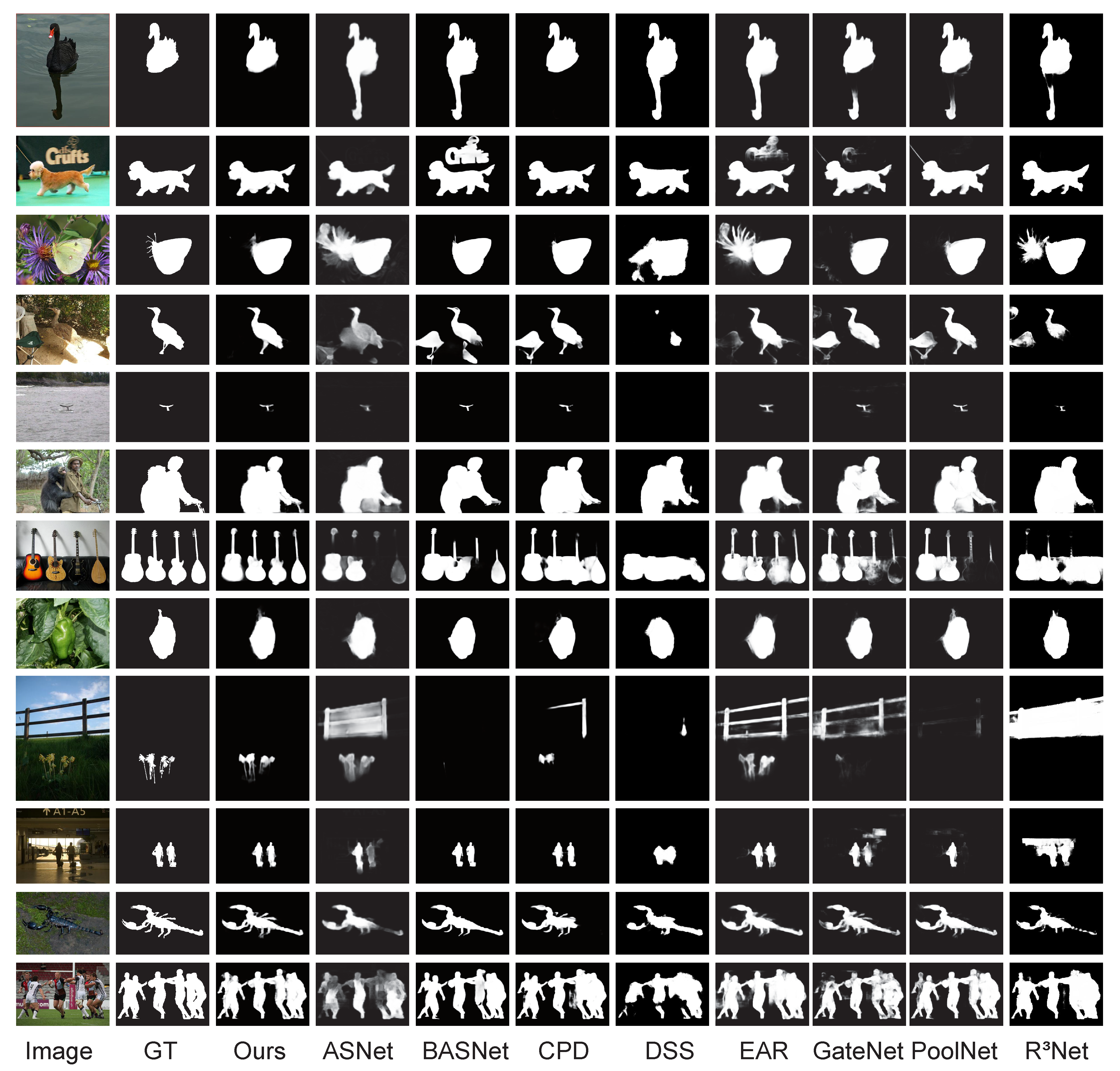
Visual Contrast: To intuitively reflect the superiority of the proposed method as compared to the above methods, we compared their prediction results for the selection of 12 representative images. The selected images include simple or complex backgrounds, large or small objects, more or less things, bright or dark scenes, and low contrast between the foreground and the background. The comparison results are shown in
Figure 3. The GT refers to the ground truth map, and the Ours is used to temporarily refer to the proposed method. The proposed approach not only accurately locates the saliency objects, but also effectively suppresses the object boundary; thus, the prediction is closest to the GT. It is worth noting that the proposed method also has the capability to discriminate when the foreground and background are very similar and the scene is dim.
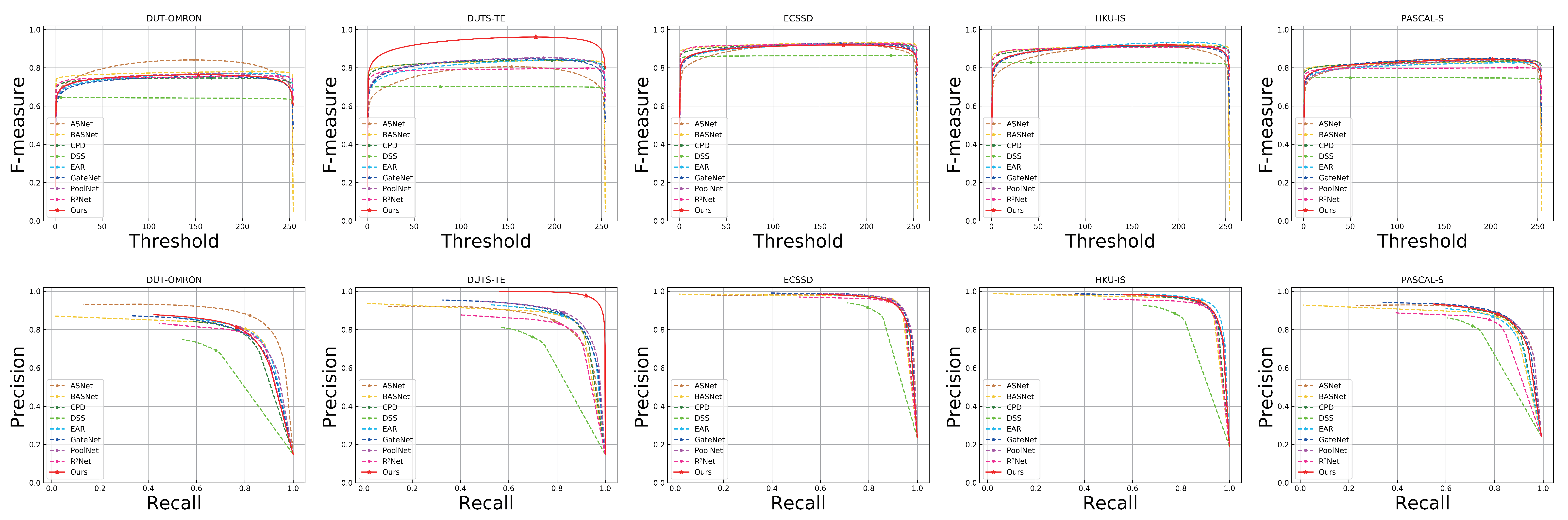
Curve comparison: As compared to the presentation of the prediction results of individual cases of representative images, the F-measure and PR were upgraded to the level of the dataset to compare each model, and were displayed in the form of curves. The curve comparison is shown in
Figure 4. The state-of-the-art algorithms for comparison employ different dashed lines; the proposed method employs a solid red line. It can be further observed that the proposed method performs well on all benchmark datasets; its curve is consistent with mainstream methods, is close to and almost coincides with state-of-the-art methods, outperforming DSS, and
performance is relatively insufficient when compared to other Methods. Particularly striking is that the proposed method exhibits the best evaluation curve on the DUTS-E dataset.
Quantitative analysis: To further verify the powerful effect of the proposed model in predicting the salient object, the model is quantitatively analyzed in terms of predictive performance and efficiency.
Table 1 lists the performance evaluation results that depend on the
and MAE indicators. The upward arrow indicates that the evaluation value is directly proportional to the model performance, and vice versa. The proposed method ranks in the top three on both DUTS-E and PASCAL-S datasets. In particular, it is most prominent on the DUTS-E dataset, where its evaluation scores far outperform other methods. On the other hand, models with light weight and high computational efficiency are generally suitable for most hardware devices to carry, so
Table 2 displays the evaluation results of model parameters and computational efficiency relying on Params, FLOPs, and Time indicators. Compared with the state-of-the-art comparison methods, our method shows excellent performance in terms of the Params, FLOPs, and Time. In general, through rational model structure adjustment and the introduction of novel modules, our method greatly improves the computational efficiency while maintaining high performance.
5. Analysis and Discussion
To investigate the advantages played by different modules in the proposed method, an ablation study was introduced in this section. Subsequently, further improvement directions are discussed.
5.1. Ablation Study
To verify the effectiveness of the model structure improvement program, an ablation study was introduced. First, the proposed LGFAN is split into three major modules including simplified U-Net with the same decoding feature layer as the network as the baseline, attention module, and aggregation module. Then, each module is embedded into the baseline in the manner of control variables, so as to achieve a quantitative comparison of model performance. In the whole process, except that the challenging SOD-data [
44] are employed as the evaluation sample, the other conditions are the same. Finally, the generated quantitative scores are recorded in
Table 3. The excellent scores confirm that the modules embedded in the baseline structure greatly boost the capability in the salient object detection.
5.2. Limitation and Discussion
The LGFAN is constructed through the attention module and aggregation module to enrich key information while extracting features. Due to the collaborative consistency of the embedded modules, this greatly improves the performance of the entire network in the salient object detection, which is confirmed in experiments. Although the improved network shows its excellent quantitative comparison results on the DUT-TE dataset in
Table 1, its performance on other datasets adopted for comparison has a subtle gap with the optimal model. This phenomenon shows that there is still room for improvement. In the future, the designed powerful module unit will be embedded or replaced with the existing state-of-the-art network for further optimization. For example: adding a deep supervision unit, adding a new constraint module in the cost function, etc. Moreover, the overall network architecture is transformed to adapt to the change of the target scene, and the feature layer is activated with the corresponding scene, thereby improving the identification ability of the network. These are the research directions that subsequent researchers are concerned about.
6. Conclusions
This paper proposes a salient object detection method based on local and global feature aggregation awareness. Considering the potential attributes of different feature layers, two modules were designed: the attention module and the RFB module. For the attention module, the spatial attention mechanism is responsible for filtering shallow spatial features, and the channel attention mechanism for filtering deep semantic information to highlight salient features. RFB strengthens the feature extraction capabilities of the network and enriches the saliency features collected for aggregation to predict high-quality saliency images. The experimental results show that, in terms of computational efficiency, the proposed method reduces the Params and Flops by more than 45.15% and 12.08%, respectively, compared with the CPD algorithm with outstanding comprehensive performance among the comparison algorithms, resulting in a saving of 0.52 ms about computational time. In terms of performance, the proposed method fails to comprehensively crush all the comparison algorithms, showing the weakness of insufficient generalization ability. Therefore, how to improve the performance through optimization of parameters or structures on the premise of ensuring good computational efficiency of the model is a research direction worthy of attention.
Author Contributions
Conceptualization, Z.D. and P.W.; methodology, Z.D.; software, Z.D.; validation, Z.D., P.W. and Z.X.; formal analysis, Y.G.; investigation, J.C.; resources, P.W.; data curation, Y.G.; writing—original draft preparation, Z.D.; writing—review and editing, P.W.; project administration, P.W.; funding acquisition, P.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China (number 51574004); Natural Science Foundation of the Higher Education Institutions of Anhui Province, China (number KJ2019A0085); Academic Foundation for Top Talents of the Higher Education Institutions of Anhui Province, China (number 2016041).
Data Availability Statement
The datasets involved in this paper are all from open source links. Researchers in the field have integrated them, and we can query the Object-level Salient Object Detection datasets chapter in the
http://mmcheng.net/socbenchmark/ (accessed on 13 December 2021) to obtain them.
Acknowledgments
Special thanks to reviewers for their valuable comments.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Chen, T.; Cheng, M.M.; Tan, P.; Shamir, A.; Hu, S.M. PhotoSketch: Internet image montage. SIGGRAPH Asia 2009, 28, 1–10. [Google Scholar]
- Lee, H.; Kim, D. Salient region-based online object tracking. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1170–1177. [Google Scholar]
- Hong, S.; You, T.; Kwak, S.; Han, B. Online tracking by learning discriminative saliency map with convolutional neural network. In Proceedings of the International Conference on Machine Learning (ICML) 2015, Lille, France, 7–9 July 2015; pp. 597–606. Available online: http://proceedings.mlr.press/v37/hong15.html (accessed on 13 December 2021).
- Donoser, M.; Urschler, M.; Hirzer, M.; Bischof, H. Saliency driven total variation segmentation. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 817–824. [Google Scholar]
- Gao, Y.; Shi, M.; Tao, D.; Xu, C. Database saliency for fast image retrieval. IEEE Trans. Multimed. 2015, 17, 359–369. [Google Scholar]
- Gupta, A.K.; Seal, A.; Prasad, M.; Khanna, P. Salient object detection techniques in computer vision—A survey. Entropy 2020, 22, 1174. [Google Scholar]
- Borji, A.; Cheng, M.M.; Hou, Q.; Jiang, H.; Li, J. Salient object detection: A survey. Comput. Vis. Media 2019, 5, 117–150. [Google Scholar]
- Borji, A.; Cheng, M.M.; Jiang, H.; Li, J. Salient object detection: A benchmark. IEEE Trans. Image Process. 2015, 24, 5706–5722. [Google Scholar] [PubMed] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Liu, N.; Han, J.; Yang, M.H. Picanet: Pixel-wise contextual attention learning for accurate saliency detection. IEEE Trans. Image Process. 2020, 29, 6438–6451. [Google Scholar]
- Zhang, X.; Wang, T.; Qi, J.; Lu, H.; Wang, G. Progressive attention guided recurrent network for salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 714–722. [Google Scholar]
- Wang, L.; Wang, L.; Lu, H.; Zhang, P.; Ruan, X. Saliency detection with recurrent fully convolutional networks. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 825–841. [Google Scholar]
- Liu, N.; Han, J. Dhsnet: Deep hierarchical saliency network for salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 678–686. [Google Scholar]
- Hou, Q.; Cheng, M.M.; Hu, X.; Borji, A.; Tu, Z.; Torr, P.H. Deeply supervised salient object detection with short connections. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3203–3212. [Google Scholar]
- Zhang, P.; Wang, D.; Lu, H.; Wang, H.; Ruan, X. Amulet: Aggregating multi-level convolutional features for salient object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 202–211. [Google Scholar]
- Luo, Z.; Mishra, A.; Achkar, A.; Eichel, J.; Li, S.; Jodoin, P.M. Non-local deep features for salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6609–6617. [Google Scholar]
- Liu, J.J.; Hou, Q.; Cheng, M.M.; Feng, J.; Jiang, J. A Simple Pooling-Based Design for Real-Time Salient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3917–3926. [Google Scholar]
- Qin, X.; Zhang, Z.; Huang, C.; Gao, C.; Dehghan, M.; Jagersand, M. Basnet: Boundary-aware salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7479–7489. [Google Scholar]
- Itti, L.; Koch, C.; Niebur, E. A model of saliency-based visual attention for rapid scene analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1254–1259. [Google Scholar]
- Achanta, R.; Estrada, F.; Wils, P.; Süsstrunk, S. Salient region detection and segmentation. In International Conference on Computer Vision Systems; Springer: Berlin/Heidelberg, Germany, 2008; pp. 66–75. [Google Scholar]
- Wei, Y.; Wen, F.; Zhu, W.; Sun, J. Geodesic saliency using background priors. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2012; pp. 29–42. [Google Scholar]
- Yang, C.; Zhang, L.; Lu, H.; Ruan, X.; Yang, M.H. Saliency detection via graph-based manifold ranking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 23–28 June 2013; pp. 3166–3173. [Google Scholar]
- Wang, W.; Lai, Q.; Fu, H.; Shen, J.; Ling, H.; Yang, R. Salient object detection in the deep learning era: An in-depth survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 1. [Google Scholar] [CrossRef]
- Zhao, R.; Ouyang, W.; Li, H.; Wang, X. Saliency detection by multi-context deep learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1265–1274. [Google Scholar]
- Wu, Z.; Su, L.; Huang, Q. Cascaded partial decoder for fast and accurate salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3907–3916. [Google Scholar]
- Zhao, T.; Wu, X. Pyramid feature attention network for saliency detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3085–3094. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Liu, S.; Huang, D. Receptive field block net for accurate and fast object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 385–400. [Google Scholar]
- Zhao, Q.; Sheng, T.; Wang, Y.; Tang, Z.; Chen, Y.; Cai, L.; Ling, H. M2det: A single-shot object detector based on multi-level feature pyramid network. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 9259–9266. [Google Scholar]
- Wang, L.; Lu, H.; Wang, Y.; Feng, M.; Wang, D.; Yin, B.; Ruan, X. Learning to detect salient objects with image-level supervision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 136–145. [Google Scholar]
- Yan, Q.; Xu, L.; Shi, J.; Jia, J. Hierarchical saliency detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1155–1162. [Google Scholar]
- Li, G.; Yu, Y. Visual saliency based on multiscale deep features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5455–5463. [Google Scholar]
- Li, Y.; Hou, X.; Koch, C.; Rehg, J.M.; Yuille, A.L. The secrets of salient object segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 280–287. [Google Scholar]
- Zhang, Z.; Jin, W.; Xu, J.; Cheng, M.M. Gradient-induced co-saliency detection. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 455–472. [Google Scholar]
- Fan, D.P.; Lin, Z.; Ji, G.P.; Zhang, D.; Fu, H.; Cheng, M.M. Taking a deeper look at co-salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2020; pp. 2919–2929. [Google Scholar]
- Wang, Y.; Zhou, Q.; Liu, J.; Xiong, J.; Gao, G.; Wu, X.; Latecki, L.J. Lednet: A Lightweight Encoder-Decoder Network for Real-Time Semantic Segmentation. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 1860–1864. [Google Scholar] [CrossRef] [Green Version]
- Wang, W.; Shen, J.; Dong, X.; Borji, A.; Yang, R. Inferring Salient Objects from Human Fixations. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 1913–1927. [Google Scholar] [PubMed]
- Chen, S.; Wang, B.; Tan, X.; Hu, X. Embedding attention and residual network for accurate salient object detection. IEEE Trans. Cybern. 2018, 50, 2050–2062. [Google Scholar] [PubMed]
- Zhao, X.; Pang, Y.; Zhang, L.; Lu, H.; Zhang, L. Suppress and balance: A simple gated network for salient object detection. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 35–51. [Google Scholar]
- Deng, Z.; Hu, X.; Zhu, L.; Xu, X.; Qin, J.; Han, G.; Heng, P.A. R3net: Recurrent residual refinement network for saliency detection. In Proceedings of the 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 684–690. [Google Scholar]
- Movahedi, V.; Elder, J.H. Design and perceptual validation of performance measures for salient object segmentation. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops, San Francisco, CA, USA, 13–18 June 2010; pp. 49–56. [Google Scholar]
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).




{kind=link}
{kind=link}
{kind=link}
{kind=link}