
Multiple Mechanisms to Strengthen the Ability of YOLOv5s for Real-Time Identification of Vehicle Type

 ,
,  , and
, and
Abstract
:1. Introduction
- We have devised a G-CSP module based on YOLOv5s’ cross-stage partial network (CSPNet). It can efficiently extract information from feature maps by using a large-scale separable convolution network to improve the accuracy of detection of types of vehicles.
- We have developed a C_TA module based on the TA module. We used concatenation and convolution operations to fuse multi-dimensional attention-related information, such that the network can assign different attention scores to different dimensions of this information to improve detection performance.
- We propose the DSPPF module based on YOLOv5s’ SPPF module that replaces the maximum pooling operation in the original SPPF module with a dilated convolution operation. It can increase the perceptual field of the network for detecting targets with only a slight increase in the requisite computational effort.
2. Related Work
3. Proposed Approach
3.1. YOLOv5s Module
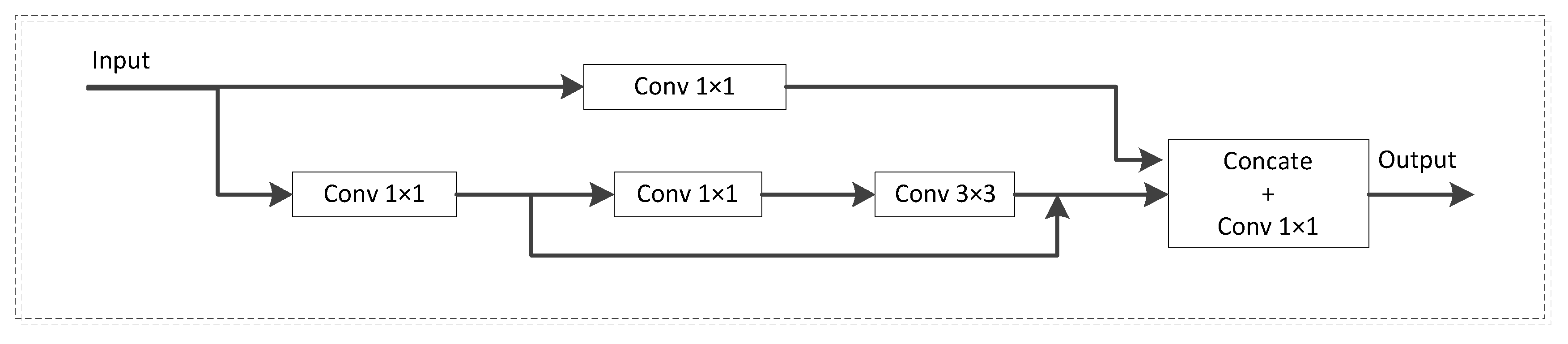
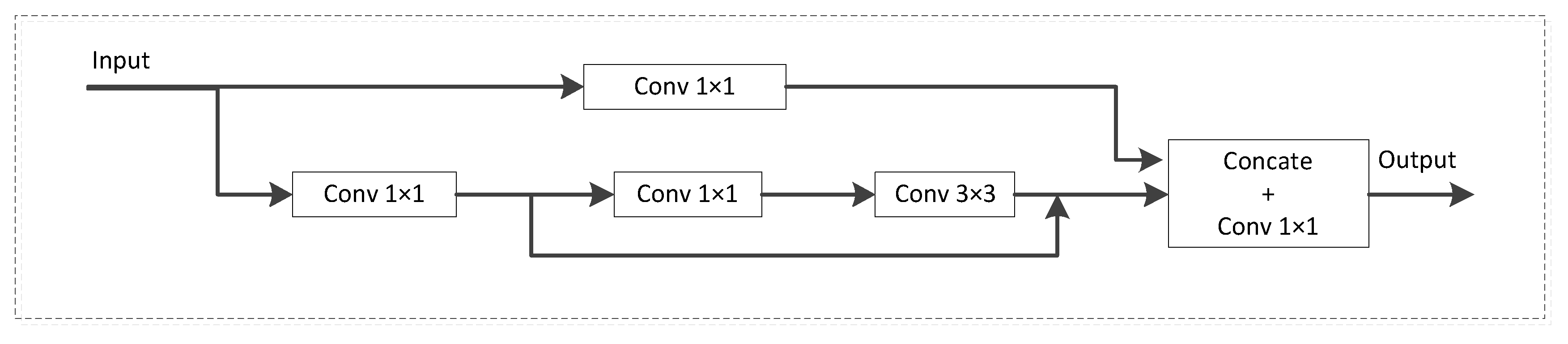
3.2. G_CSP Module
3.3. C_TA Module
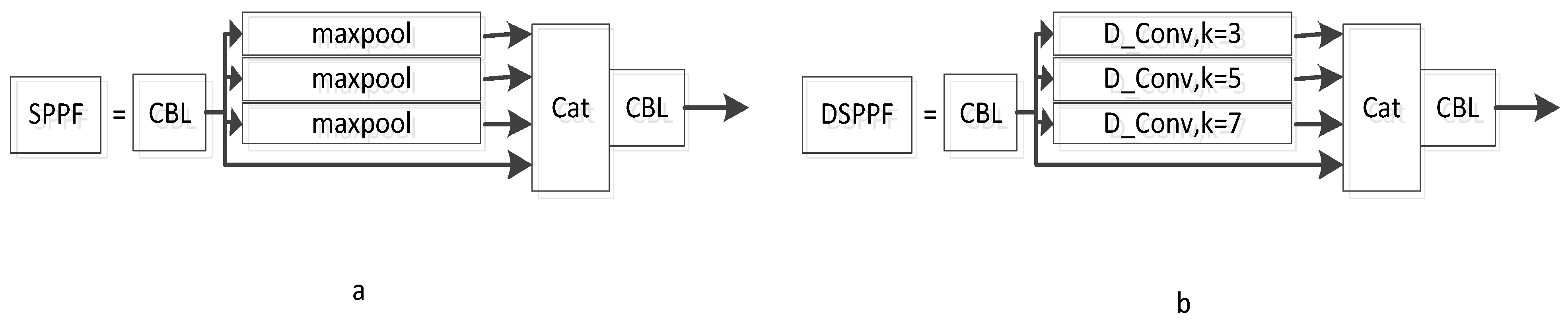
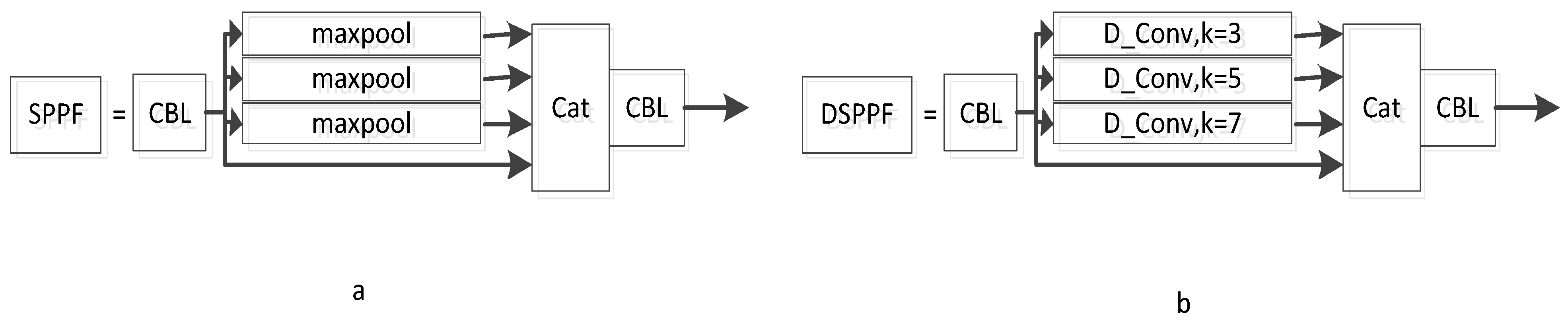
3.4. DSPPF Module
4. Experiments and Results
4.1. Experiment Environment
4.2. Quantitative Evaluation
4.2.1. bdd100k
4.2.2. VOC2019
4.2.3. VOC2007 + 2012
4.3. Ablation Study
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zhao, Z.Q.; Zheng, P.; Xu, S.T.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A review of yolo algorithm developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- Thuan, D. Evolution of Yolo Algorithm and Yolov5: The State-of-the-Art Object Detention Algorithm. Bachelor’s Thesis, Oulu University of Applied Scienc, Oulu, Finland, 2021. [Google Scholar]
- Choi, J.; Chun, D.; Kim, H.; Lee, H.J. Gaussian yolov3: An accurate and fast object detector using localization uncertainty for auton-omous driving. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 502–511. [Google Scholar]
- Kumar, A.; Zhang, Z.J.; Lyu, H. Object detection in real time based on improved single shot multi-box detector algorithm. EURASIP J. Wirel. Commun. Netw. 2020, 2020, 204. [Google Scholar] [CrossRef]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Hunag, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Zhao, J.; Hao, S.; Dai, C.; Zhang, H.; Zhao, L.; Ji, Z.; Ganchev, I. Improved Vision-Based Vehicle Detection and Classification by Optimized YOLOv4. IEEE Access 2022, 10, 8590–8603. [Google Scholar] [CrossRef]
- Khalifa, O.O.; Wajdi, M.H.; Saeed, R.A.; Hashim, A.H.; Ahmed, M.Z.; Ali, E.S. Vehicle Detection for Vision-Based Intelligent Transportation Systems Using Convolutional Neural Network Algorithm. J. Adv. Transp. 2022, 2022, 9189600. [Google Scholar] [CrossRef]
- Park, S.H.; Yu, S.B.; Kim, J.A.; Yoon, H. An all-in-one vehicle type and license plate recognition system using YOLOv4. Sensors 2022, 22, 921. [Google Scholar] [CrossRef]
- Li, X.; Li, X.; Li, Z.; Xiong, X.; Khyam, M.O.; Sun, C. Robust Vehicle Detection in High-Resolution Aerial Images with Imbalanced Data. IEEE Trans. Artif. Intell. 2021, 2, 238–250. [Google Scholar] [CrossRef]
- Li, D.L.; Prasad, M.; Liu, C.L.; Lin, C.T. Multi-view vehicle detection based on fusion part model with active learning. IEEE Trans. Intell. Transp. Syst. 2020, 22, 3146–3157. [Google Scholar] [CrossRef]
- Li, Y.; Liu, Y.; Cui, W.G.; Guo, Y.Z.; Huang, H.; Hu, Z.Y. Epileptic seizure detection in EEG signals using a unified temporal-spectral squeeze-and-excitation network. IEEE Trans. Neural Syst. Rehabil. Eng. 2020, 28, 782–794. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Misra, D.; Nalamada, T.; Arasanipalai, A.U.; Hou, Q. Rotate to attend: Convolutional triplet attention module. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021; pp. 3139–3148. [Google Scholar]
- Singh, V.K.; Abdel-Nasser, M.; Rashwan, H.A.; Akram, F.; Pandey, N.; Lalande, A.; Presles, B.; Romani, S.; Puig, D. FCA-Net: Adversarial learning for skin lesion segmentation based on multi-scale features and factorized channel attention. IEEE Access 2019, 7, 130552–130565. [Google Scholar] [CrossRef]
- Mozaffari, M.H.; Lee, W.S. Semantic Segmentation with Peripheral Vision. In International Symposium on Visual Computing; Springer: Cham, Switzerland, 2020; pp. 421–429. [Google Scholar]
- Bazi, Y.; Bashmal, L.; Rahhal MM, A.; Dayil, R.A.; Ajlan, N.A. Vision transformers for remote sensing image classification. Remote Sens. 2021, 13, 516. [Google Scholar] [CrossRef]
- Wu, X.; Sahoo, D.; Hoi, S.C.H. Recent advances in deep learning for object detection. Neurocomputing 2020, 396, 39–64. [Google Scholar] [CrossRef]
- Asgari Taghanaki, S.; Abhishek, K.; Cohen, J.P.; Cohen-Adad, J.; Hamarneh, G. Deep semantic segmentation of natural and medical images: A review. Artif. Intell. Rev. 2021, 54, 137–178. [Google Scholar] [CrossRef]
- Ouyang, C.; Biffi, C.; Chen, C.; Kart, T.; Qiu, H.; Rueckert, D. Self-supervised Learning for Few-shot Medical Image Segmentation. In IEEE Transactions on Medical Imaging; IEEE: Piscataway, NJ, USA, 2022; pp. 1837–1848. [Google Scholar]
- Su, F.; Zhao, Y.; Wang, G.; Liu, P.; Yan, Y.; Zu, L. Tomato Maturity Classification Based on SE-YOLOv3-MobileNetV1 Network under Nature Greenhouse Environment. Agronomy 2022, 12, 1638. [Google Scholar] [CrossRef]
- Deng, T.; Wu, Y. Simultaneous vehicle and lane detection via MobileNetV3 in car following scene. PLoS ONE 2022, 17, e0264551. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar]
- Zeng, X.; Wang, Z.; Hu, Y. Enabling Efficient Deep Convolutional Neural Network-based Sensor Fusion for Autonomous Driving. arXiv 2022, arXiv:2202.11231. [Google Scholar]
- Bateni, S.; Wang, Z.; Zhu, Y.; Hu, Y.; Liu, C. Co-optimizing performance and memory footprint via integrated cpu/gpu memory management, an implementation on autonomous driving platform. In Proceedings of the 2020 IEEE Real-Time and Embedded Technology and Applications Symposium (RTAS), Sydney, Australia, 21–24 April 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 310–323. [Google Scholar]
- Dong, X.; Yan, S.; Duan, C. A lightweight vehicles detection network model based on YOLOv5. Eng. Appl. Artif. Intell. 2022, 113, 104914. [Google Scholar] [CrossRef]
- Li, Z.; Xie, W.; Zhang, L.; Lu, S.; Xie, L.; Su, H.; Du, W.; Hou, W. Toward Efficient Safety Helmet Detection Based on YoloV5 With Hierarchical Positive Sample Selection and Box Density Filtering. IEEE Trans. Instrum. Meas. 2022, 71, 1–14. [Google Scholar] [CrossRef]
- Li, S.; Cui, X.; Guo, L.; Zhang, L.; Chen, X.; Cao, X. Enhanced Automatic Root Recognition and Localization in GPR Images Through a YOLOv4-based Deep Learning Approach. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Zhou, L.; Rao, X.; Li, Y.; Zuo, X.; Qiao, B.; Lin, Y. A Lightweight Object Detection Method in Aerial Images Based on Dense Feature Fusion Path Aggregation Network. ISPRS Int. J. Geo-Inf. 2022, 11, 189. [Google Scholar] [CrossRef]
- Luo, Q.; Wang, J.; Gao, M.; Lin, H.; Zhou, H.; Miao, Q. G-YOLOX: A Lightweight Network for Detecting Vehicle Types. J. Sens. 2022, 2022, 4488400. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Yu, F.; Xian, W.; Chen, Y.; Liu, F.; Liao, M.; Madhavan, V.; Darrell, T. Bdd100k: A diverse driving video database with scalable annotation tooling. arXiv 2018, arXiv:1805.04687. [Google Scholar]
- Jo, W.; Kim, S.; Lee, C.; Shon, T. Packet Preprocessing in CNN-Based Network Intrusion Detection System. Electronics 2020, 9, 1151. [Google Scholar] [CrossRef]
- Xu, Z.; Lan, S.; Yang, Z.; Cao, J.; Wu, Z.; Cheng, Y. MSB R-CNN: A Multi-Stage Balanced Defect Detection Network. Electronics 2021, 10, 1924. [Google Scholar] [CrossRef]
- Ku, B.; Kim, K.; Jeong, J. Real-Time ISR-YOLOv4 Based Small Object Detection for Safe Shop Floor in Smart Factories. Electronics 2022, 11, 2348. [Google Scholar] [CrossRef]
- Jiang, T.; Li, C.; Yang, M.; Wang, Z. An Improved YOLOv5s Algorithm for Object Detection with an Attention Mechanism. Electronics 2022, 11, 2494. [Google Scholar] [CrossRef]
- Lin, H.-C.; Wang, P.; Chao, K.-M.; Lin, W.-H.; Chen, J.-H. Using Deep Learning Networks to Identify Cyber Attacks on In-trusion Detection for In-Vehicle Networks. Electronics 2022, 11, 2180. [Google Scholar] [CrossRef]
- Parekh, D.; Poddar, N.; Rajpurkar, A.; Chahal, M.; Kumar, N.; Joshi, G.P.; Cho, W. A Review on Autonomous Vehicles: Progress, Methods and Challenges. Electronics 2022, 11, 2162. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Params (M) | Gflops | Weights (MB) | map50 | map50_95 |
|---|---|---|---|---|---|
| YOLOv5s | 7 M | 15.9 | 14.1 | 0.493 | 0.260 |
| YOLOv5s+ (ours) | 10 M | 22.7 | 20.1 | 0.512 | 0.276 |
| Model | Params (M) | Gflops | Weights (MB) | map50 | map50_95 |
|---|---|---|---|---|---|
| YOLOv5s | 7 M | 15.9 | 14.5 | 0.741 | 0.542 |
| YOLOv5s+ (ours) | 10 M | 22.7 | 20.25 | 0.762 | 0.553 |
| Model | Params (M) | Gflops | Weights (MB) | map50 | map50_95 |
|---|---|---|---|---|---|
| YOLOv5s | 7 M | 15.9 | 14.5 | 0.796 | 0.550 |
| YOLOv5s+ (ours) | 10 M | 22.7 | 20.7 | 0.825 | 0.589 |
| Case | Our Basic | G_CSP | Default_TA | C_TA | DSPPF | Params (M) | map50 | map50_95 | FPS |
|---|---|---|---|---|---|---|---|---|---|
| 1 | √ | 7 | 0.796 | 0.550 | 60 | ||||
| 2 | √ | √ | 7.8 | 0.807 | 0.562 | 58 | |||
| 3 | √ | √ | 9.3 | 0.801 | 0.555 | 42 | |||
| 4 | √ | √ | 9.3 | 0.810 | 0.565 | 40 | |||
| 5 | √ | √ | √ | 10 | 0.816 | 0.582 | 37 | ||
| 6 | √ | √ | √ | √ | 10.1 | 0.825 | 0.589 | 35 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, Q.; Wang, J.; Gao, M.; He, Z.; Yang, Y.; Zhou, H. Multiple Mechanisms to Strengthen the Ability of YOLOv5s for Real-Time Identification of Vehicle Type. Electronics 2022, 11, 2586. https://doi.org/10.3390/electronics11162586
Luo Q, Wang J, Gao M, He Z, Yang Y, Zhou H. Multiple Mechanisms to Strengthen the Ability of YOLOv5s for Real-Time Identification of Vehicle Type. Electronics. 2022; 11(16):2586. https://doi.org/10.3390/electronics11162586
Chicago/Turabian StyleLuo, Qiang, Junfan Wang, Mingyu Gao, Zhiwei He, Yuxiang Yang, and Hongtao Zhou. 2022. "Multiple Mechanisms to Strengthen the Ability of YOLOv5s for Real-Time Identification of Vehicle Type" Electronics 11, no. 16: 2586. https://doi.org/10.3390/electronics11162586
APA StyleLuo, Q., Wang, J., Gao, M., He, Z., Yang, Y., & Zhou, H. (2022). Multiple Mechanisms to Strengthen the Ability of YOLOv5s for Real-Time Identification of Vehicle Type. Electronics, 11(16), 2586. https://doi.org/10.3390/electronics11162586