
Efficient Detailed Routing for FPGA Back-End Flow Using Reinforcement Learning



Abstract
1. Introduction
- Enhancement proposed to speed up the detailed routing of FPGA back-end flow through an RL-based framework;
- Extensive experimentation, exploration, and analysis of the proposed enhancement by using two sets of open-source large heterogeneous benchmarks;
- Evaluation of the proposed enhancement through comparison with the conventional negotiation-based congestion-driven routing approach.
2. Related Work
- To make the FPGA CAD flow more efficient, we apply an RL technique to a negotiation-based routing approach;
- We further refine the reward function and explore its effect on the routing result through an enhanced exploration technique;
- We use two sets of comprehensive benchmarks for experimentation, perform extensive analysis of the results, comparing them with existing routing techniques.
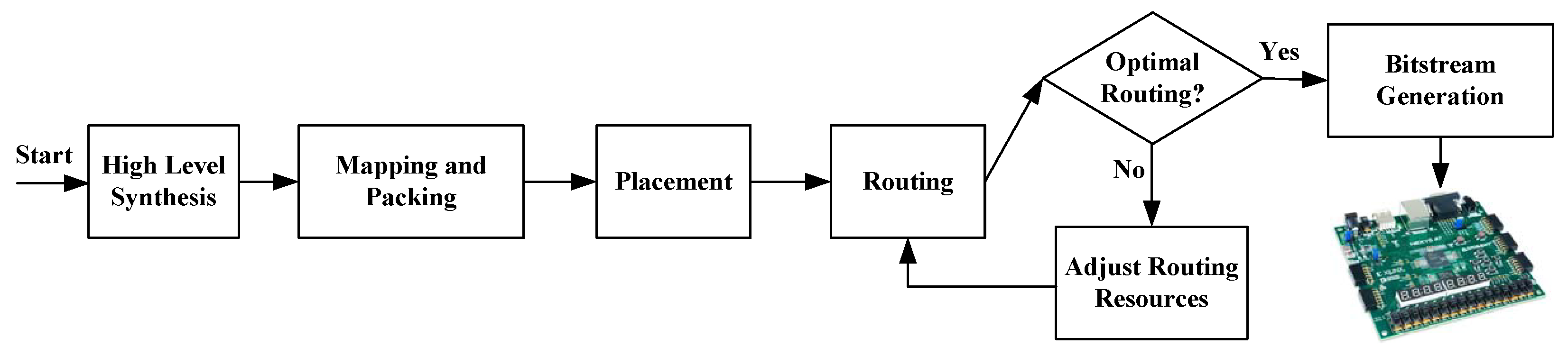
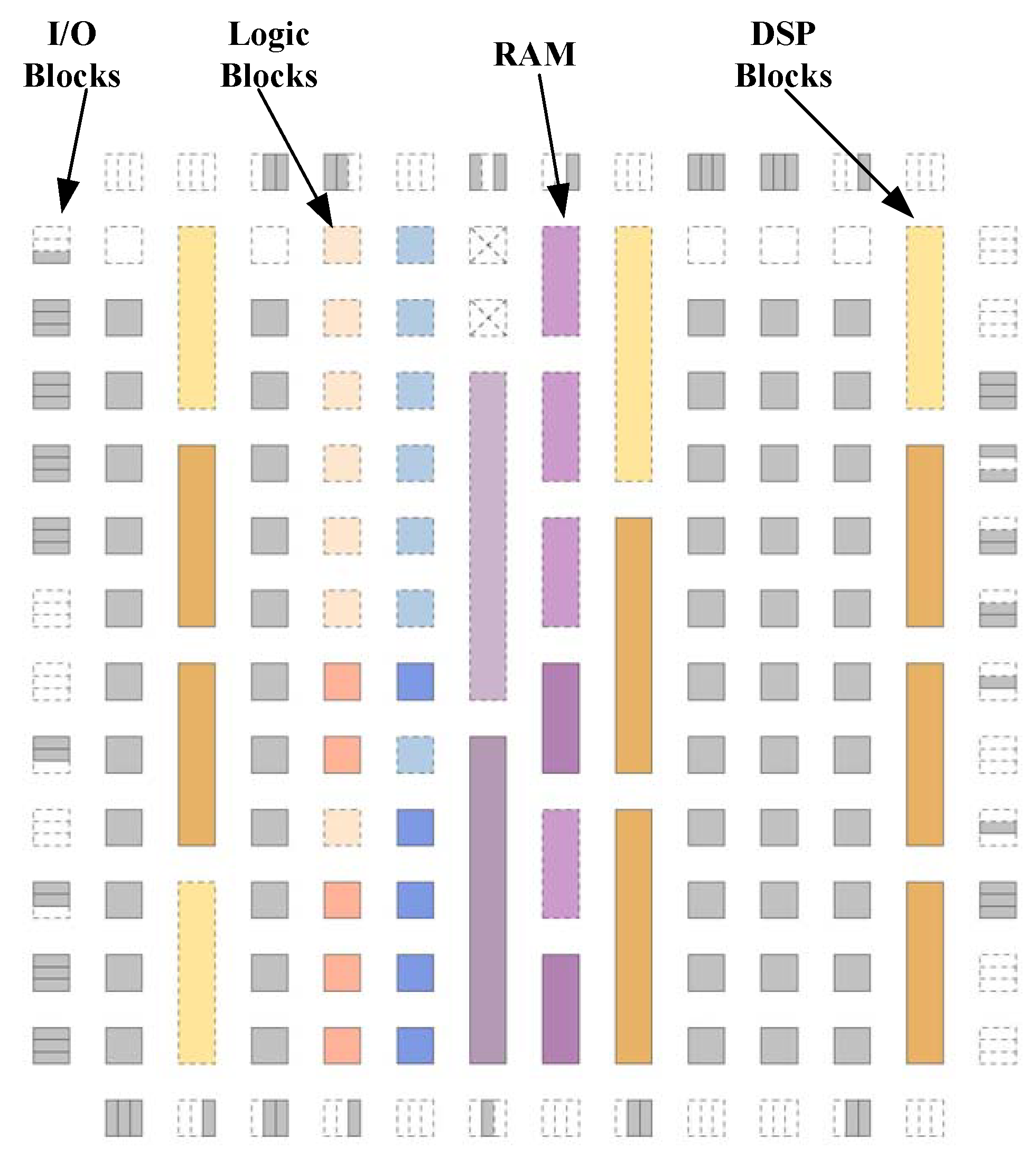
3. FPGA Back-End Flow
3.1. Synthesis, Mapping, and Packing
3.2. Placement
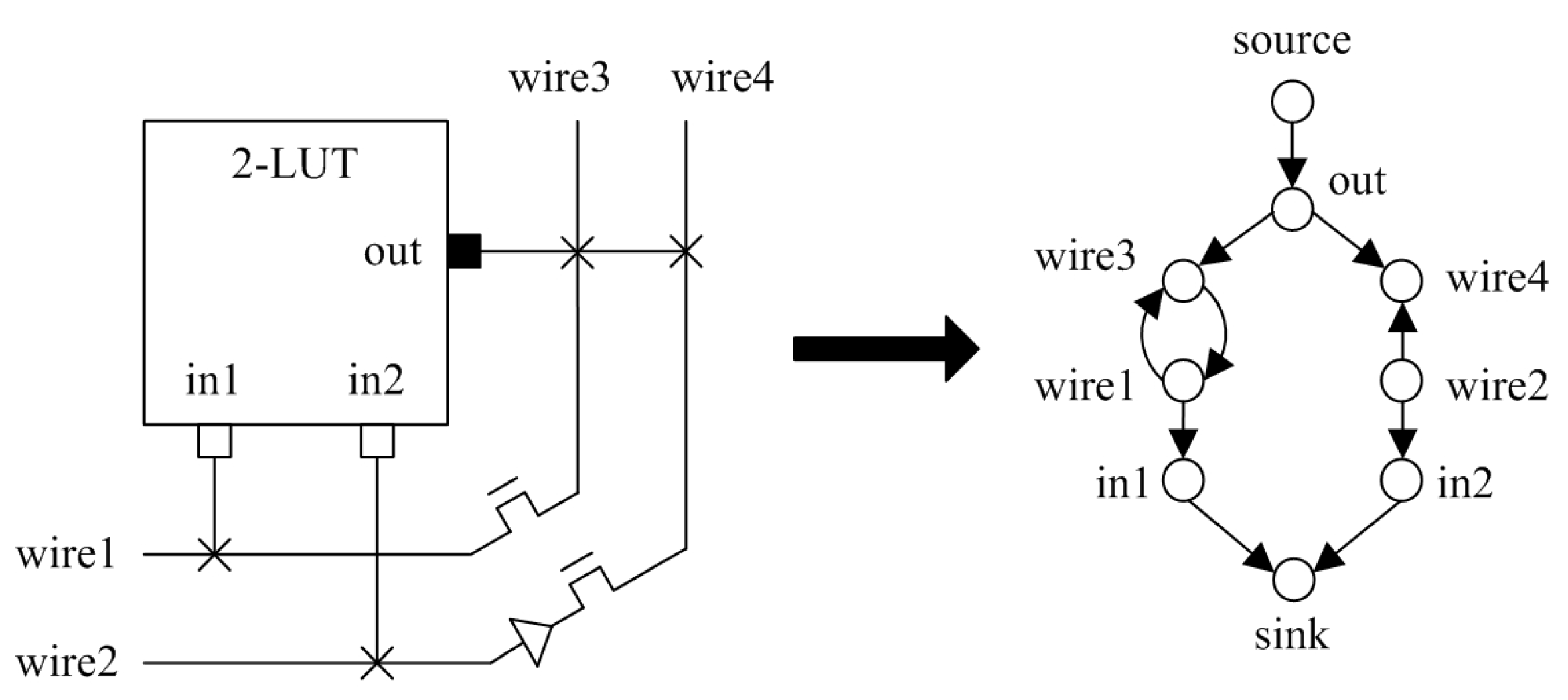
3.3. Routing
4. Proposed Enhancements
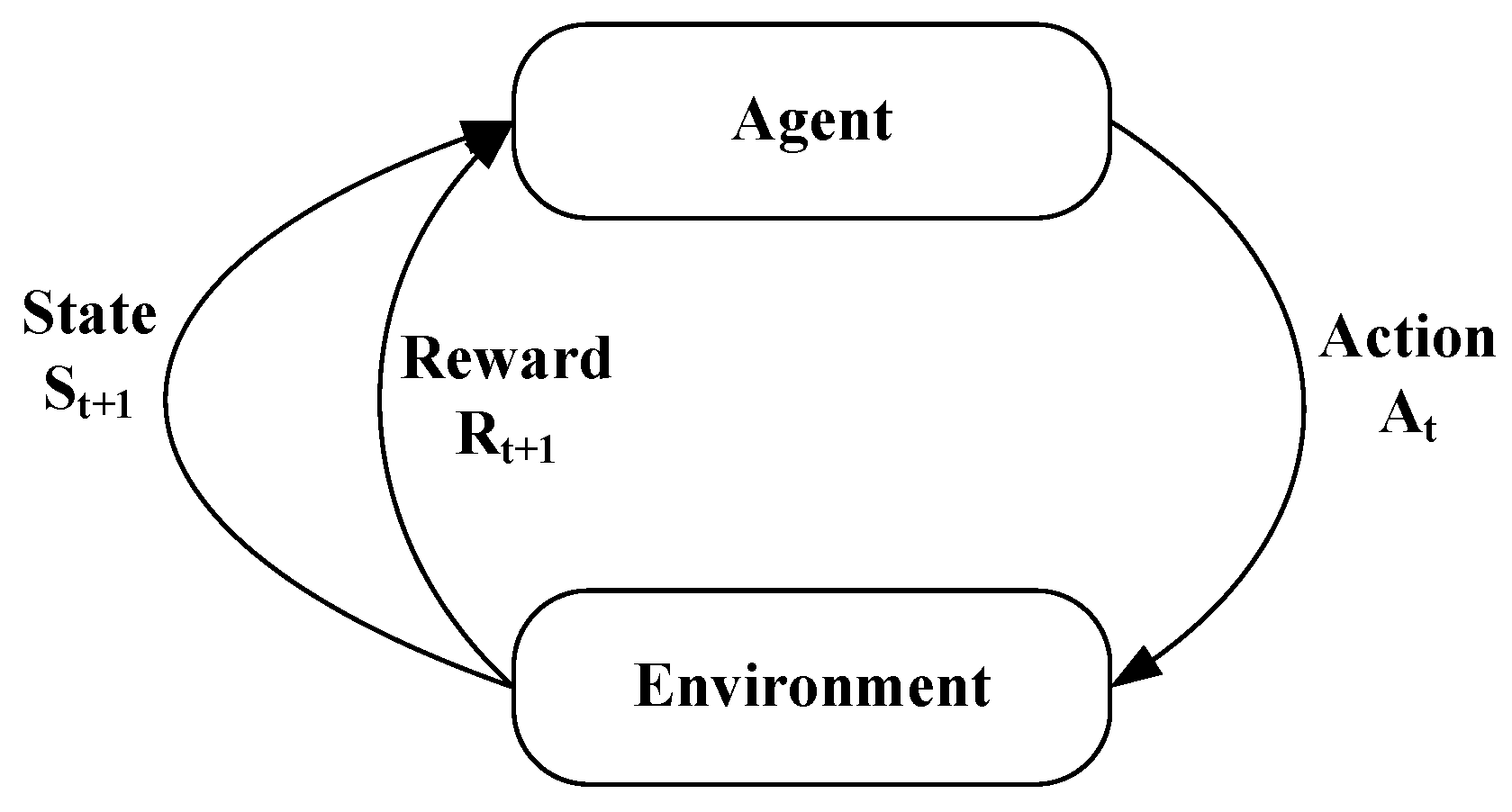
4.1. Reinforcement Learning
4.2. Routing Enhancement
| Algorithm 1: Pseudo-code of the FPGA routing algorithm [20]. |
 |
5. Experimentation, Results, and Analysis
5.1. Benchmarks
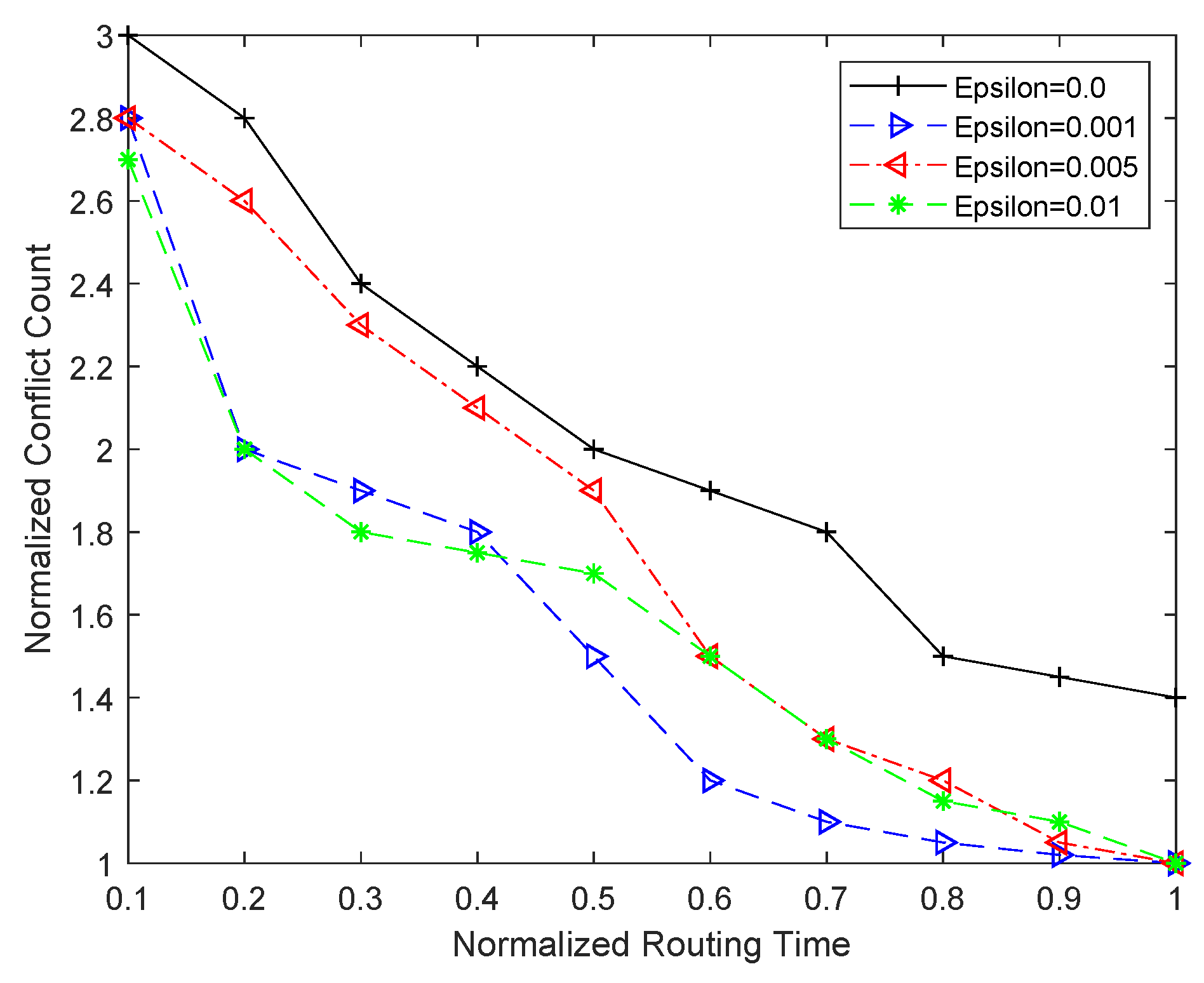
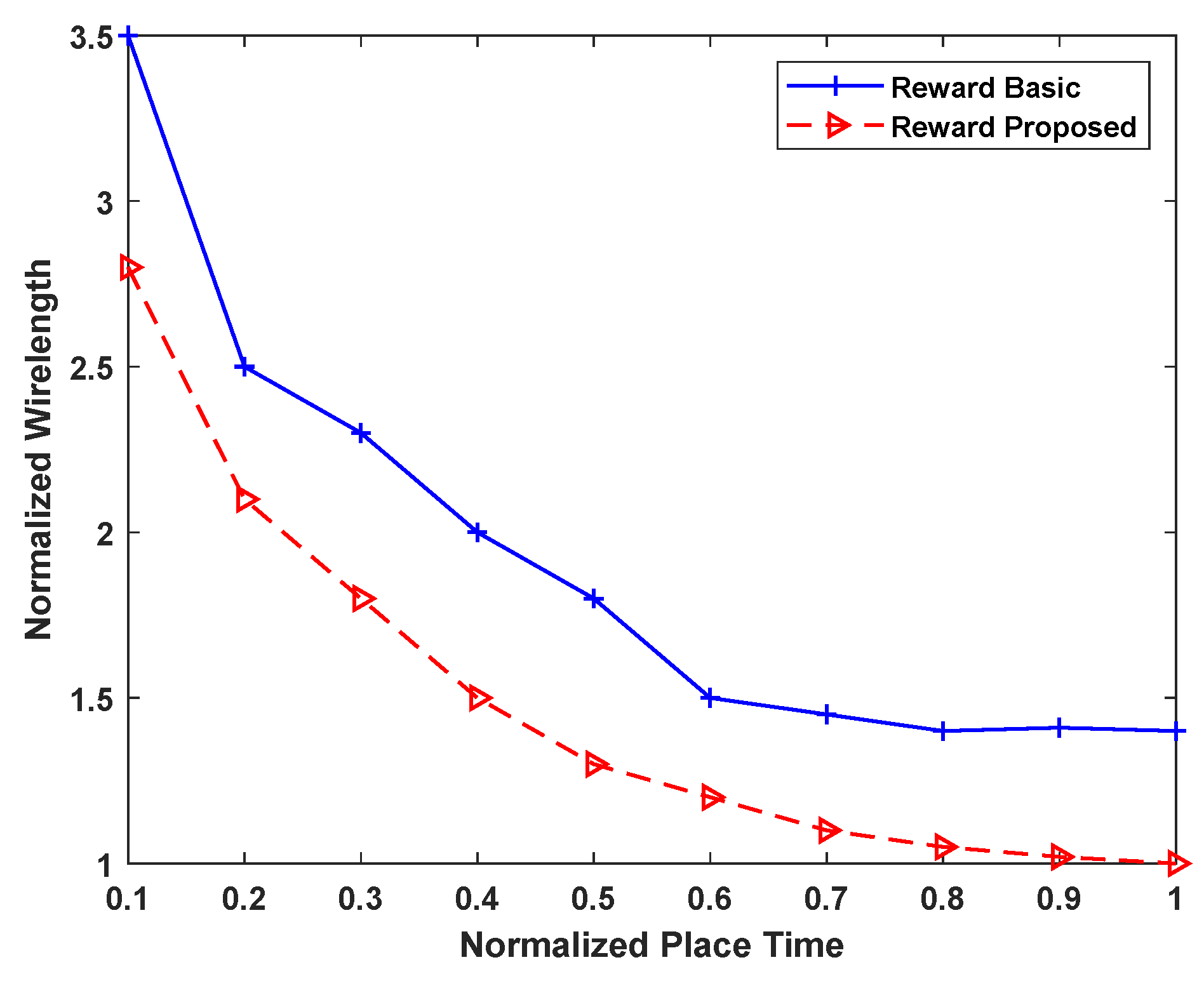
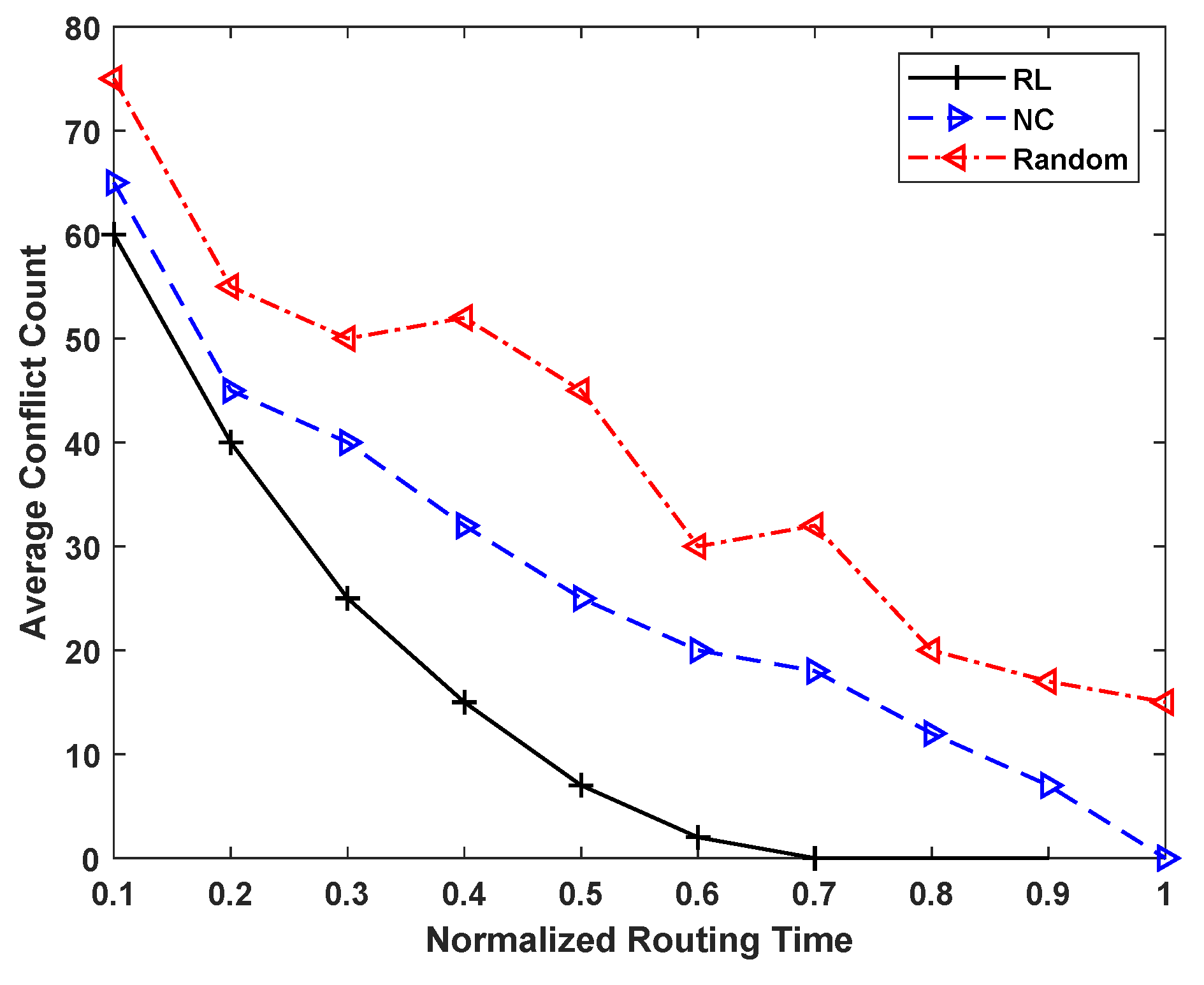
5.2. Proposed Enhancements—Exploration and Discussion
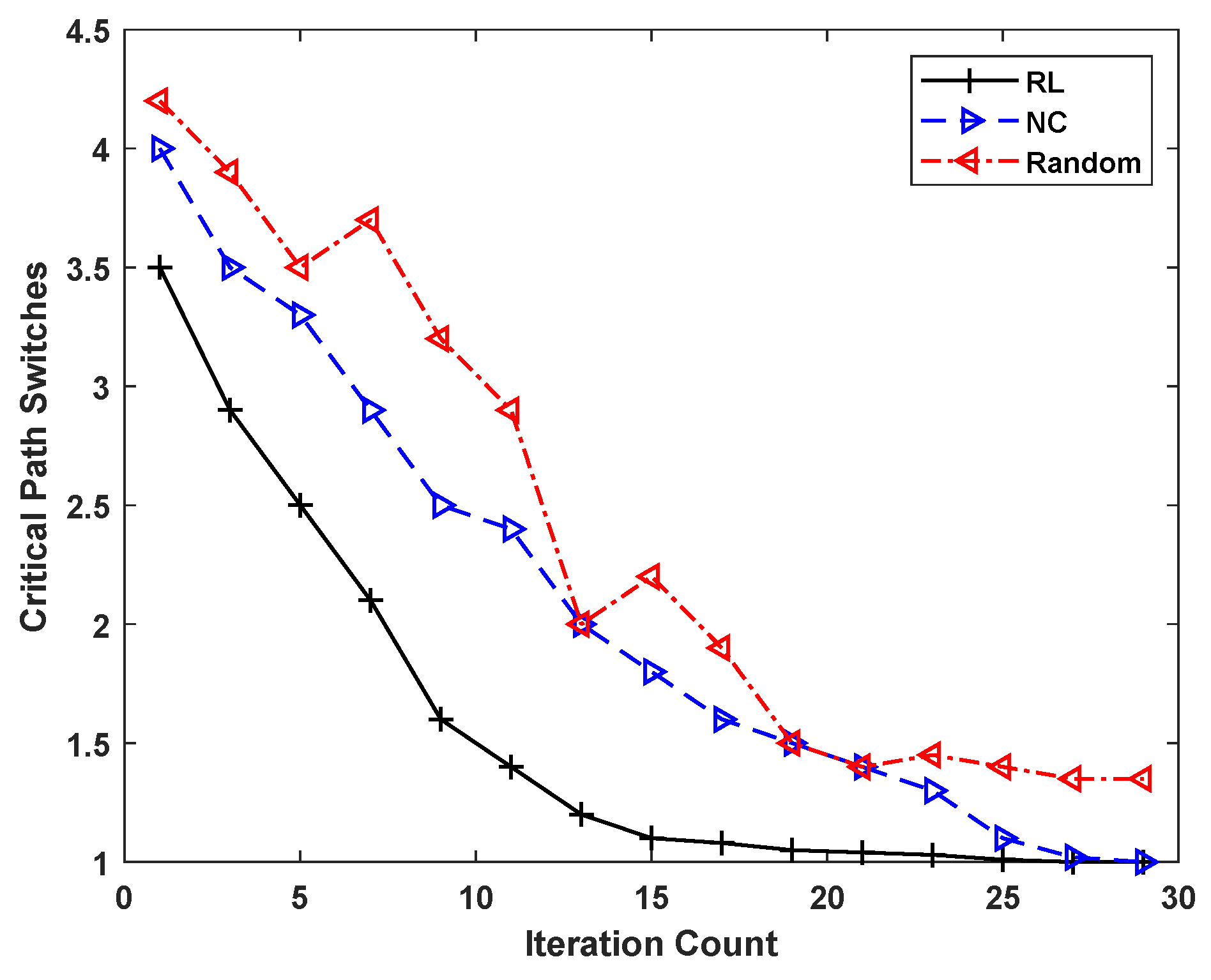
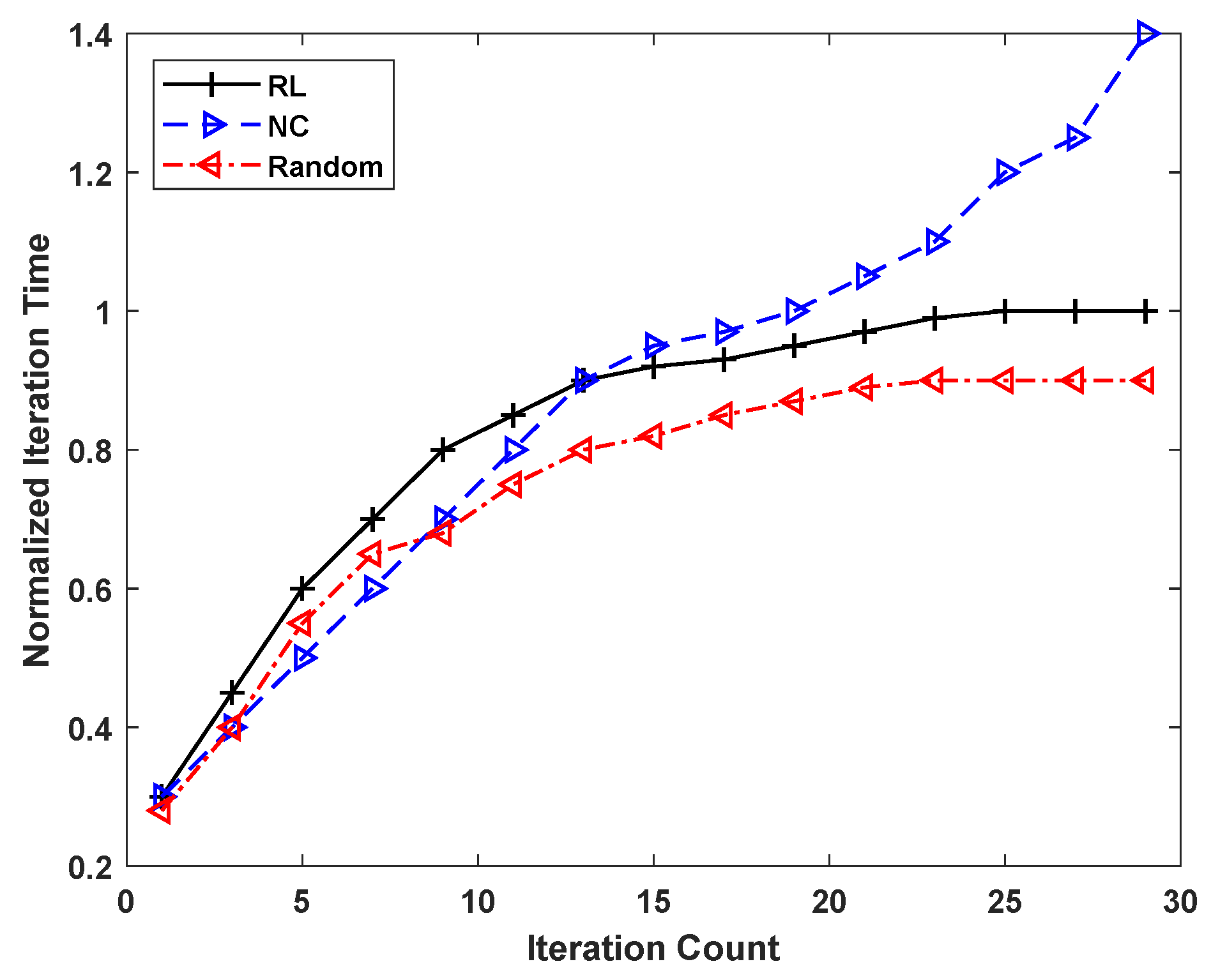
5.3. Comparison Results and Analysis
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Xilinx. Virtex UltraScale+ VU19P FPGA Product Brief. 2021. Available online: https://www.xilinx.com/products/silicon-devices/fpga/virtex-ultrascale-plus.html (accessed on 25 May 2022).
- Intel. Intel Stratix10 GX 10M FPGA Product Description. 2021. Available online: https://www.intel.com/content/www/us/en/products/details/fpga/stratix/10.html (accessed on 25 May 2022).
- Farooq, U.; Mehrez, H. Pre-Silicon Verification Using Multi-FPGA Platforms: A Review. J. Electron. Test. 2021, 37, 7–24. [Google Scholar] [CrossRef]
- Al-hyari, A.; Abuowaimer, Z.; Maarouf, D.; Areibi, S.; Gréwal, G. An Effective FPGA Placement Flow Selection Framework using Machine Learning. In Proceedings of the 2018 30th International Conference on Microelectronics (ICM), Sousse, Tunisia, 16–19 December 2018; pp. 164–167. [Google Scholar]
- Farooq, U.; Alzahrani, B.A. Exploring and optimizing partitioning of large designs for multi-FPGA based prototyping platforms. Computing 2020, 102, 2361–2383. [Google Scholar] [CrossRef]
- Farooq, U.; Parvez, H.; Mehrez, H.; Marrakchi, Z. Exploration of Heterogeneous FPGA Architectures. Int. J. Reconfig. Comput. 2011, 2011, 121404. [Google Scholar] [CrossRef][Green Version]
- Chen, S.C.; Chang, Y.W. FPGA placement and routing. In Proceedings of the 2017 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), Irvine, CA, USA, 13–16 November 2017; pp. 914–921. [Google Scholar]
- Kim, C.; Shin, H. A performance-driven logic emulation system: FPGA network design and performance-driven partitioning. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 1996, 15, 560–568. [Google Scholar] [CrossRef]
- Abuowaimer, Z.; Maarouf, D.; Martin, T.; Foxcroft, J.; Gréwal, G.; Areibi, S.; Vannelli, A. GPlace3.0: Routability-driven analytic placer for UltraScale FPGA architectures. ACM Trans. Des. Autom. Electron. Syst. 2018, 23, 1–33. [Google Scholar] [CrossRef]
- Li, W.; Lin, Y.; Pan, D.Z. elfPlace: Electrostatics-based placement for large-scale heterogeneous fpgas. In Proceedings of the 2019 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), Westminster, CO, USA, 4–7 November 2019; pp. 1–8. [Google Scholar]
- Vercruyce, D.; Vansteenkiste, E.; Stroobandt, D. Liquid: High quality scalable placement for large heterogeneous FPGAs. In Proceedings of the 2017 International Conference on Field Programmable Technology (ICFPT), Melbourne, Australia, 11–13 December 2017; pp. 17–24. [Google Scholar]
- Altan, A.; Hacıoğlu, R. Model predictive control of three-axis gimbal system mounted on UAV for real-time target tracking under external disturbances. Mech. Syst. Signal Process. 2020, 138, 106548. [Google Scholar] [CrossRef]
- Chen, G.; Pui, C.W.; Chow, W.K.; Lam, K.C.; Kuang, J.; Young, E.F.; Yu, B. RippleFPGA: Routability-driven simultaneous packing and placement for modern FPGAs. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2017, 37, 2022–2035. [Google Scholar] [CrossRef]
- Luu, J.; Kuon, I.; Jamieson, P.; Campbell, T.; Ye, A.; Fang, W.M.; Kent, K.; Rose, J. VPR 5.0: FPGA CAD and architecture exploration tools with single-driver routing, heterogeneity and process scaling. ACM Trans. Reconfig. Technol. Syst. 2011, 4, 1–23. [Google Scholar] [CrossRef]
- Kapre, N.; Ng, H.; Teo, K.; Naude, J. Intime: A machine learning approach for efficient selection of fpga cad tool parameters. In Proceedings of the 2015 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 22–24 February 2015; pp. 23–26. [Google Scholar]
- Liao, H.; Zhang, W.; Dong, X.; Poczos, B.; Shimada, K.; Burak Kara, L. A deep reinforcement learning approach for global routing. J. Mech. Des. 2020, 142, 061701. [Google Scholar] [CrossRef]
- Murray, K.E.; Whitty, S.; Liu, S.; Luu, J.; Betz, V. Titan: Enabling large and complex benchmarks in academic CAD. In Proceedings of the 2013 23rd International Conference on Field programmable Logic and Applications, Porto, Portugal, 2–4 September 2013; pp. 1–8. [Google Scholar]
- Inagi, M.; Takashima, Y.; Nakamura, Y. Globally optimal time-multiplexing in inter-FPGA connections for accelerating multi-FPGA systems. In Proceedings of the 2009 International Conference on Field Programmable Logic and Applications, Prague, Czech Republic, 31 August–2 September 2009; pp. 212–217. [Google Scholar] [CrossRef]
- Hauck, S.; DeHon, A. Reconfigurable Computing: The Theory and Practice of FPGA-Based Computation; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2007. [Google Scholar]
- McMurchie, L.; Ebeling, C. Pathfinder: A Negotiation-Based Performance-Driven Router for FPGAs. In Proceedings of the ACM International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 12–14 February 1995; ACM Press: New York, NY, USA; pp. 111–117. [Google Scholar]
- Gréwal, G.; Areibi, S.; Westrik, M.; Abuowaimer, Z.; Zhao, B. Automatic flow selection and quality-of-result estimation for FPGA placement. In Proceedings of the 2017 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), Lake Buena Vista, FL, USA, 29 May–2 June 2017; pp. 115–123. [Google Scholar]
- Wang, L.C.; Abadir, M.S. Data mining in EDA-basic principles, promises, and constraints. In Proceedings of the 2014 51st ACM/EDAC/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 1–5 June 2014; pp. 1–6. [Google Scholar]
- Mametjanov, A.; Balaprakash, P.; Choudary, C.; Hovland, P.D.; Wild, S.M.; Sabin, G. Autotuning FPGA design parameters for performance and power. In Proceedings of the 2015 IEEE 23rd Annual International Symposium on Field-Programmable Custom Computing Machines, Vancouver, BC, Canada, 2–6 May 2015; pp. 84–91. [Google Scholar]
- Kapre, N.; Chandrashekaran, B.; Ng, H.; Teo, K. Driving timing convergence of FPGA designs through machine learning and cloud computing. In Proceedings of the 2015 IEEE 23rd Annual International Symposium on Field-Programmable Custom Computing Machines, Vancouver, BC, Canada, 2–6 May 2015; pp. 119–126. [Google Scholar]
- Chang, W.H.; Lin, C.H.; Mu, S.P.; Chen, L.D.; Tsai, C.H.; Chiu, Y.C.; Chao, M.C.T. Generating routing-driven power distribution networks with machine-learning technique. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2017, 36, 1237–1250. [Google Scholar] [CrossRef]
- Manimegalai, R.; Soumya, E.S.; Muralidharan, V.; Ravindran, B.; Kamakoti, V.; Bhatia, D. Placement and routing for 3D-FPGAs using reinforcement learning and support vector machines. In Proceedings of the 18th International Conference on VLSI Design Held Jointly with 4th International Conference on Embedded Systems Design, Kolkata, India, 3–7 January 2005; pp. 451–456. [Google Scholar]
- Liu, Q.; Gao, M.; Zhang, Q. Knowledge-based neural network model for FPGA logical architecture development. IEEE Trans. Very Large Scale Integr. Syst. 2015, 24, 664–677. [Google Scholar] [CrossRef]
- Neto, W.L.; Austin, M.; Temple, S.; Amaru, L.; Tang, X.; Gaillardon, P.E. LSOracle: A logic synthesis framework driven by artificial intelligence. In Proceedings of the 2019 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), Westminster, CO, USA, 4–7 November 2019; pp. 1–6. [Google Scholar]
- Brayton, R.; Mishchenko, A. ABC: An academic industrial-strength verification tool. In Proceedings of the International Conference on Computer Aided Verification, Edinburgh, UK, 15–19 July 2010; pp. 24–40. [Google Scholar]
- Yu, C.; Xiao, H.; De Micheli, G. Developing synthesis flows without human knowledge. In Proceedings of the 55th Annual Design Automation Conference, San Francisco, CA, USA, 24–29 June 2018; pp. 1–6. [Google Scholar]
- An, M.; Steffan, J.G.; Betz, V. Speeding up FPGA placement: Parallel algorithms and methods. In Proceedings of the 2014 IEEE 22nd Annual International Symposium on Field-Programmable Custom Computing Machines, Boston, MA, USA, 11–13 May 2014; pp. 178–185. [Google Scholar]
- Fobel, C.; Grewal, G.; Stacey, D. A scalable, serially-equivalent, high-quality parallel placement methodology suitable for modern multicore and GPU architectures. In Proceedings of the 2014 24th International Conference on Field Programmable Logic and Applications (FPL), Munich, Germany, 2–4 September 2014; pp. 1–8. [Google Scholar]
- Vorwerk, K.; Kennings, A.; Greene, J.W. Improving simulated annealing-based FPGA placement with directed moves. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2009, 28, 179–192. [Google Scholar] [CrossRef]
- Alhyari, A.; Shamli, A.; Abuwaimer, Z.; Areibi, S.; Grewal, G. A Deep Learning Framework to Predict Routability for FPGA Circuit Placement. In Proceedings of the 2019 29th International Conference on Field Programmable Logic and Applications (FPL), Barcelona, Spain, 8–12 September 2019; pp. 334–341. [Google Scholar]
- He, Z.; Ma, Y.; Zhang, L.; Liao, P.; Wong, N.; Yu, B.; Wong, M.D. Learn to floorplan through acquisition of effective local search heuristics. In Proceedings of the 2020 IEEE 38th International Conference on Computer Design (ICCD), Hartford, CT, USA, 18–21 October 2020; pp. 324–331. [Google Scholar]
- Mirhoseini, A.; Goldie, A.; Yazgan, M.; Jiang, J.; Songhori, E.; Wang, S.; Lee, Y.J.; Johnson, E.; Pathak, O.; Bae, S.; et al. Chip placement with deep reinforcement learning. arXiv 2020, arXiv:2004.10746. [Google Scholar]
- He, Z.; Zhang, L.; Liao, P.; Ma, Y.; Yu, B. Reinforcement learning driven physical synthesis. In Proceedings of the 2020 IEEE 15th International Conference on Solid-State & Integrated Circuit Technology (ICSICT), Kunming, China, 3–6 November 2020; pp. 1–4. [Google Scholar]
- Murray, K.E.; Betz, V. Adaptive FPGA placement optimization via reinforcement learning. In Proceedings of the ACM/IEE Workshop on Machine Learning for CAD (MLCAD19), Canmore, AB, Canada, 3–4 September 2019; pp. 1–6. [Google Scholar]
- Zhao, J.; Liang, T.; Sinha, S.; Zhang, W. Machine learning based routing congestion prediction in FPGA high-level synthesis. In Proceedings of the 2019 Design, Automation & Test in Europe Conference & Exhibition (DATE), Florence, Italy, 25–29 March 2019; pp. 1130–1135. [Google Scholar]
- Szentimrey, H.; Al-Hyari, A.; Foxcroft, J.; Martin, T.; Noel, D.; Grewal, G.; Areibi, S. Machine learning for congestion management and routability prediction within FPGA placement. ACM Trans. Des. Autom. Electron. Syst. 2020, 25, 1–25. [Google Scholar] [CrossRef]
- Goswami, P.; Bhatia, D. Congestion Prediction in FPGA Using Regression Based Learning Methods. Electronics 2021, 10, 1995. [Google Scholar] [CrossRef]
- Farooq, U.; Ul Hasan, N.; Baig, I.; Zghaibeh, M. Efficient FPGA Routing using Reinforcement Learning. In Proceedings of the 2021 12th International Conference on Information and Communication Systems (ICICS), Valencia, Spain, 24–26 May 2021; pp. 106–111. [Google Scholar] [CrossRef]
- Dai, S.; Zhou, Y.; Zhang, H.; Ustun, E.; Young, E.F.; Zhang, Z. Fast and accurate estimation of quality of results in high-level synthesis with machine learning. In Proceedings of the 2018 IEEE 26th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), Boulder, CO, USA, 29 April–1 May 2018; pp. 129–132. [Google Scholar]
- Ferianc, M.; Fan, H.; Chu, R.S.; Stano, J.; Luk, W. Improving performance estimation for fpga-based accelerators for convolutional neural networks. In Proceedings of the International Symposium on Applied Reconfigurable Computing, Toledo, Spain, 1–3 April 2020; pp. 3–13. [Google Scholar]
- Kirkpatrick, S.; Gelatt, C.D., Jr.; Vecchi, M.P. Optimization by Simulated Annealing. Science 1983, 220, 671–680. [Google Scholar] [CrossRef] [PubMed]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Circuit Name | No. of Inputs | No. of Outputs | No. of LUTs (LUT-4) | No. of Multipliers (16 × 16) | No. of Adders (20 + 20) | Function |
|---|---|---|---|---|---|---|
| cf_fir_3_8_8_open | 42 | 18 | 159 | 4 | 3 | Finite Impulse Response (8 bit) |
| cf_fir_7_16_16 | 146 | 35 | 638 | 8 | 14 | Finite Impulse Response (16 bit) |
| cfft16x8 | 20 | 40 | 1511 | - | 26 | Finite Fourier Transform |
| cordic_p2r | 18 | 32 | 803 | - | 43 | Polar to Rectangular |
| cordic_r2p | 34 | 40 | 1328 | - | 52 | Rectangular to Polar |
| fm | 9 | 12 | 1308 | 1 | 19 | Frequency Modulation |
| fm_receiver | 10 | 12 | 910 | 1 | 20 | Frequency Modulation Receiver |
| lms | 18 | 16 | 940 | 10 | 11 | Mean Square |
| reed_solomon | 138 | 128 | 537 | 16 | 16 | Reed Solomon Code |
| Circuit Name | No. of Inputs | No. of Outputs | No. of LUTs (LUT-4) | No. of Multipliers (18 × 18) | Function |
|---|---|---|---|---|---|
| cf_fir_3_8_8_ut | 42 | 22 | 214 | 4 | Finite Impulse Response (8 bit) |
| diffeq_f_systemC | 66 | 99 | 1532 | 4 | Differential Equation |
| fir_scu | 10 | 27 | 1366 | 17 | Finite Impulse Response (16 bit) |
| iir1 | 33 | 30 | 632 | 5 | Infinite Impulse Response (16 bit) |
| iir | 28 | 15 | 392 | 5 | Infinite Impulse Response (8 bit) |
| rs_decoder_1 | 13 | 20 | 1553 | 13 | Decoder |
| rs_decoder_2 | 21 | 20 | 2960 | 9 | Decoder |
| Circuit Name | Routing Time (Sec) | Gain | |
|---|---|---|---|
| NC | RL | ||
| cf_fir_3_8_8_open | 750 | 478 | 36.3 |
| cf_fir_7_16_16 | 2250 | 1512 | 32.8 |
| cfft16x8 | 5945 | 3812 | 35.8 |
| cordic_p2r | 2890 | 2102 | 27.3 |
| cordic_r2p | 4745 | 3012 | 36.5 |
| fm | 4567 | 3012 | 34 |
| fm_receiver | 2765 | 1890 | 31.6 |
| lms | 4456 | 2798 | 37.2 |
| reed_solomon | 1923 | 1190 | 38.1 |
| Average | 3365 | 2201 | 34.6 |
| Circuit Name | Routing Time (Sec) | Gain | |
|---|---|---|---|
| NC | RL | ||
| cf_fir_3_8_8_ut | 798 | 450 | 43.6 |
| diffeq_f_systemC | 6902 | 4412 | 36.1 |
| fir_scu | 4698 | 3102 | 33.9 |
| iir1 | 3892 | 2489 | 36 |
| iir | 1802 | 1198 | 33.5 |
| rs_decoder_1 | 4889 | 3106 | 36.5 |
| rs_decoder_2 | 10,034 | 6789 | 32.3 |
| Average | 4716 | 3078 | 34.7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Baig, I.; Farooq, U. Efficient Detailed Routing for FPGA Back-End Flow Using Reinforcement Learning. Electronics 2022, 11, 2240. https://doi.org/10.3390/electronics11142240
Baig I, Farooq U. Efficient Detailed Routing for FPGA Back-End Flow Using Reinforcement Learning. Electronics. 2022; 11(14):2240. https://doi.org/10.3390/electronics11142240
Chicago/Turabian StyleBaig, Imran, and Umer Farooq. 2022. "Efficient Detailed Routing for FPGA Back-End Flow Using Reinforcement Learning" Electronics 11, no. 14: 2240. https://doi.org/10.3390/electronics11142240
APA StyleBaig, I., & Farooq, U. (2022). Efficient Detailed Routing for FPGA Back-End Flow Using Reinforcement Learning. Electronics, 11(14), 2240. https://doi.org/10.3390/electronics11142240