
A Codec-Unified Deblurring Approach Based on U-Shaped Invertible Network with Sparse Salient Representation in Latent Space

Abstract
:1. Introduction
- Non-codec-unified architectures are not conducive to analyze and reconstruct features efficiently and accurately;
- The unsupervised invertible networks cannot be directly applied to supervised deblurring tasks;
- The massive dimension learning of invertible networks can influence the utilization efficiency of salient detail features.
- A novel framework for image deblurring is proposed using invertible network modules with a codec-unified structure. For the first time, the wavelet invertible network is introduced into the deblurring tasks, making full use of the correlation between coding and decoding to compactly guide the image reconstruction in the latent space;
- A U-shaped multi-level invertible network (UML-IN) is developed by integrating the wavelet invertible networks into a two-branch U-shaped supervised architecture instead of the existing single-branch unsupervised schemes. Therefore, the multi-level feature learning of the two branches corresponds to each other, and the sharp-feature branch explicitly guides the learning of the blur-feature branch in the same level of latent space;
- regularization is applied to alleviate the defect of dimensional redundancy in the original invertible networks. The model invertibility requires the same number of input and output dimensions, which causes information dispersion that is not conducive to represent salient image details. Therefore, we introduce sparse regularization for the learning of latent variables in order to aggregate these high-quality features. The experimental results illustrate that the proposed model achieves excellent performance in a variety of visual perception scenarios.
2. Research Background
3. The Proposed Approach for Image Deblurring
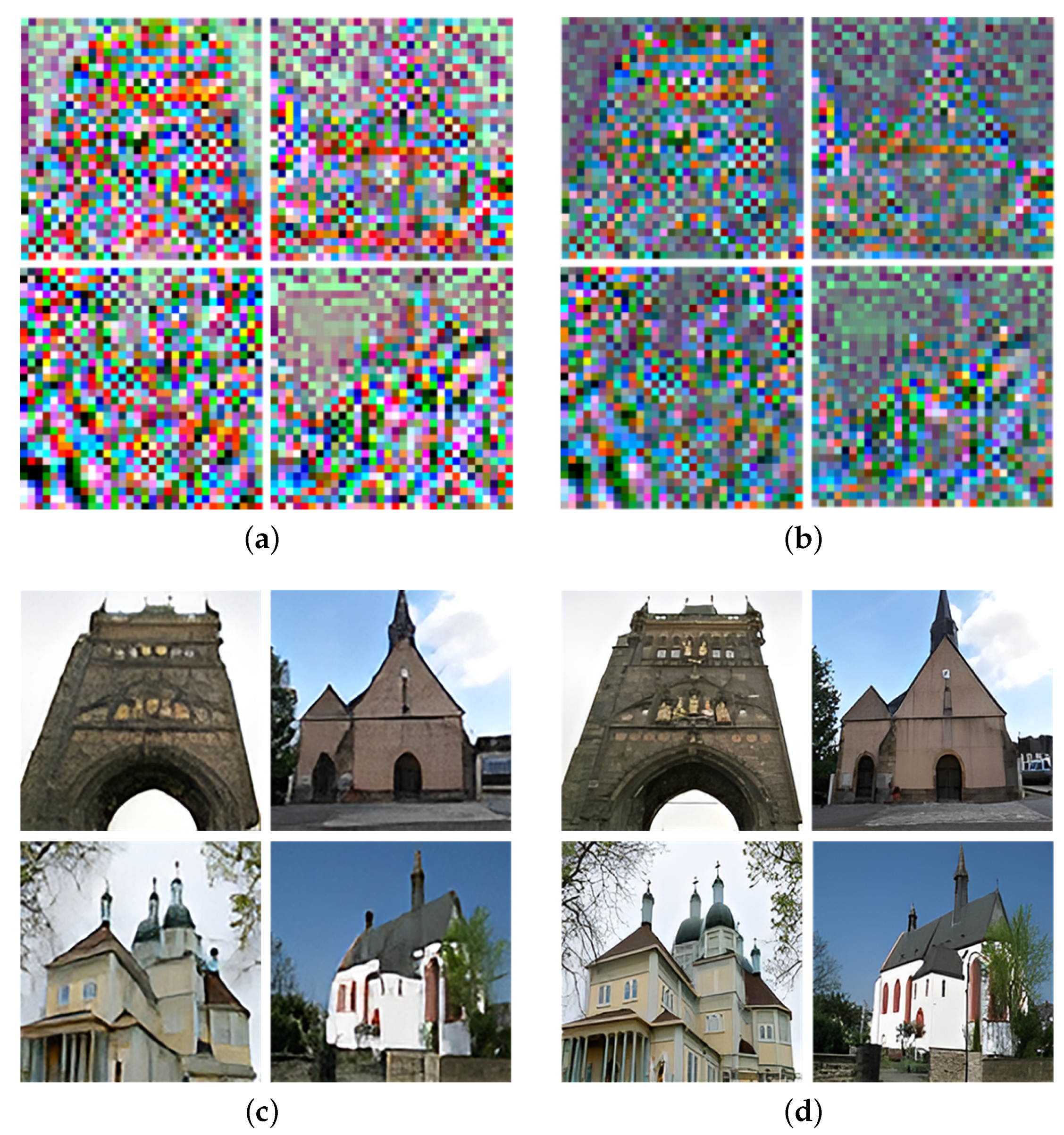
3.1. U-Shaped Architecture Using Invertible Networks
3.2. Hybrid Losses to Guide Detail Reconstruction
3.3. Latent Variable Learning by Regularization
4. Results And Discussion
4.1. Experimental Settings
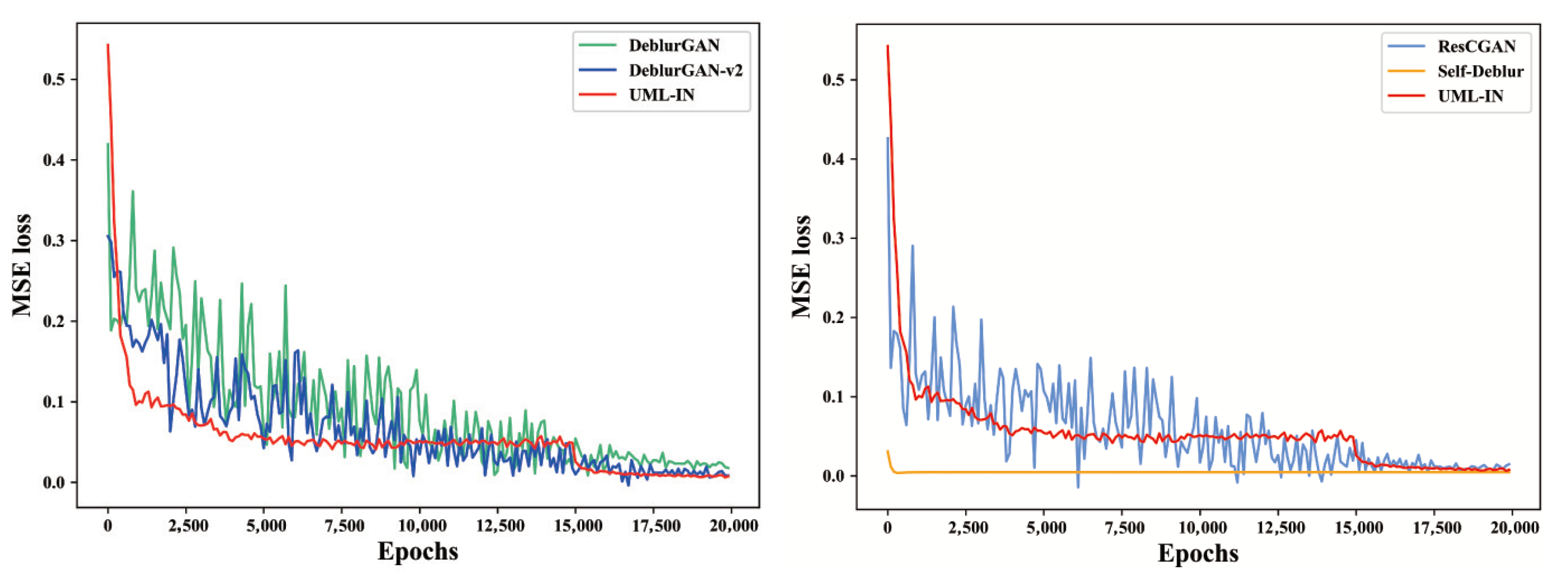
4.2. Comparison of Results on Different Datasets
4.2.1. Experimental Results on CelebA
4.2.2. Experimental Results on LSUN
4.2.3. Experimental Results on GoPro
4.2.4. Experimental Results on Lai
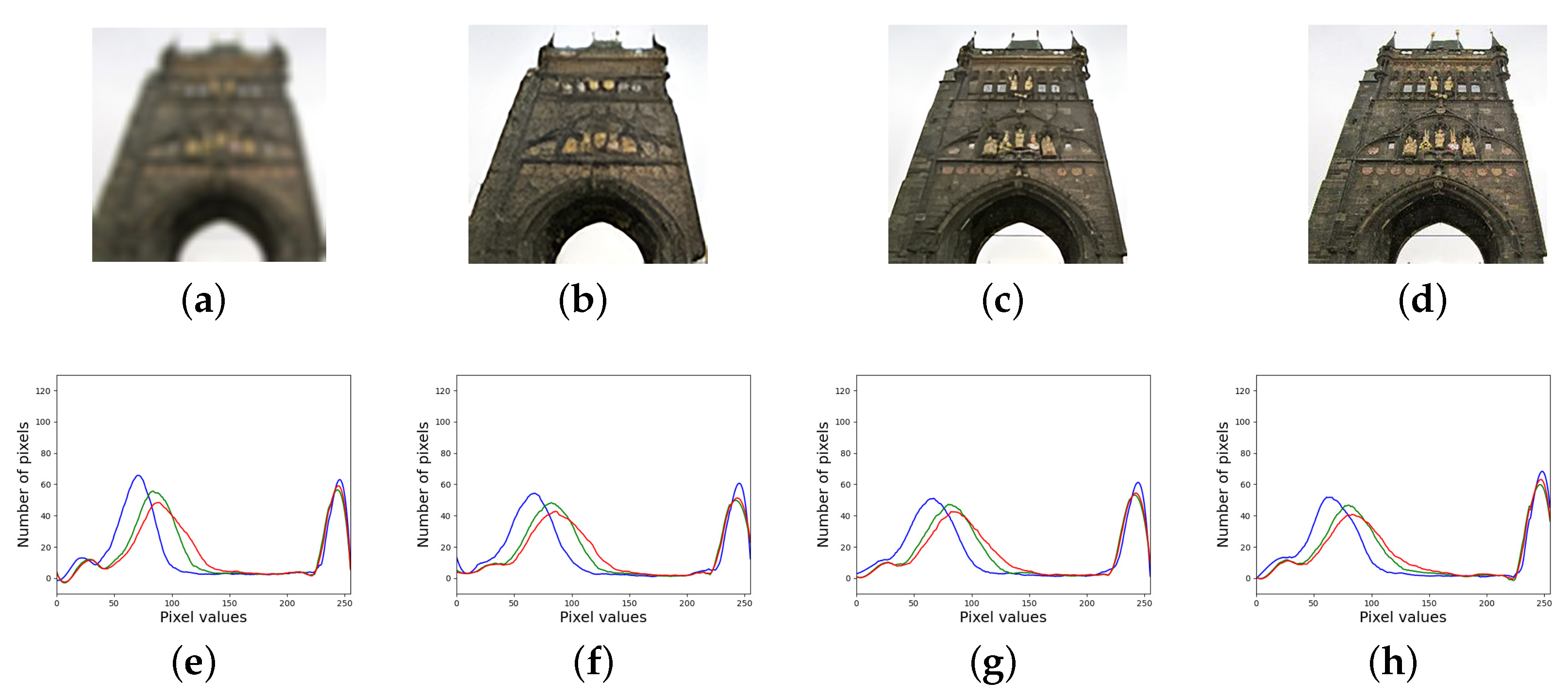
4.3. Ablation Study
4.3.1. Effectiveness of Regular Term
4.3.2. Effectiveness of SSIM Loss
4.4. Empirical Analysis
4.4.1. Models Analysis
4.4.2. Analysis on Various Datasets
4.4.3. Regular Term Analysis
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A. Implementation of the Proposed Model
| Algorithm A1: Training Procedure. |
Input: Blur images: ; Sharp images: . Output: Deblur images:. Initialize .  |
| Algorithm A2: Testing Procedure. |
Input: Blur images: . Output: Deblur images:. Initialize .  |
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Kupyn, O.; Budzan, V.; Mykhailych, M.; Mishkin, D.; Matas, J. Deblurgan: Blind motion deblurring using conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8183–8192. [Google Scholar]
- Krishnan, D.; Tay, T.; Fergus, R. Blind deconvolution using a normalized sparsity measure. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 233–240. [Google Scholar]
- Nan, Y.; Quan, Y.; Ji, H. Variational-EM-based deep learning for noise-blind image deblurring. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 3626–3635. [Google Scholar]
- Zhang, K.; Luo, W.; Zhong, Y.; Ma, L.; Stenger, B.; Liu, W.; Li, H. Deblurring by realistic blurring. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 2737–2746. [Google Scholar]
- Wu, C.; Du, H.; Wu, Q.; Zhang, S. Image Text Deblurring Method Based on Generative Adversarial Network. Electronics 2020, 9, 220. [Google Scholar] [CrossRef] [Green Version]
- Xiang, J.; Ye, P.; Wang, L.; He, M. A novel image-restoration method based on high-order total variation regularization term. Electronics 2019, 8, 867. [Google Scholar] [CrossRef] [Green Version]
- Pan, J.; Bai, H.; Tang, J. Cascaded deep video deblurring using temporal sharpness prior. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 3043–3051. [Google Scholar]
- Nah, S.; Kim, T.H.; Lee, K.M. Deep multi-scale convolutional neural network for dynamic scene deblurring. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3883–3891. [Google Scholar]
- Kupyn, O.; Martyniuk, T.; Wu, J.; Wang, Z. Deblurgan-v2: Deblurring (orders-of-magnitude) faster and better. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 8878–8887. [Google Scholar]
- White, R.L. Image restoration using the damped Richardson-Lucy method. Instrum. Astron. VIII 1994, 2198, 1342–1348. [Google Scholar]
- Hiller, A.D.; Chin, R.T. Iterative Wiener filters for image restoration. In Proceedings of the International Conference on Acoustics, Speech, and Signal Processing, Albuquerque, NM, USA, 3–6 April 1990; pp. 1901–1904. [Google Scholar]
- Pan, J.; Sun, D.; Pfister, H.; Yang, M.H. Blind image deblurring using dark channel prior. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1628–1636. [Google Scholar]
- Hongbo, Z.; Liuyan, R.; Lingling, K.; Xujia, Q.; Meiyu, Z. Single image fast deblurring algorithm based on hyper-Laplacian model. IET Image Process. 2020, 13, 483–490. [Google Scholar] [CrossRef]
- Shin, C.J.; Lee, T.B.; Heo, Y.S. Dual Image Deblurring Using Deep Image Prior. Electronics 2021, 10, 2045. [Google Scholar] [CrossRef]
- Wang, Z.; Ren, J.; Zhang, J.; Luo, P. Image Deblurring Aided by Low-Resolution Events. Electronics 2022, 11, 631. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B. Generative adversarial nets. arXiv 2014, arXiv:1406.2661v1. [Google Scholar]
- Li, C.; Wand, M. Precomputed real-time texture synthesis with markovian generative adversarial networks. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 702–716. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Li, L.; Pan, J.; Lai, W.S.; Gao, C.; Sang, N.; Yang, M.H. Learning a discriminative prior for blind image deblurring. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6616–6625. [Google Scholar]
- Wang, M.; Hou, S.; Li, H.; Li, F. Generative image deblurring based on multi-scaled residual adversary network driven by composed prior-posterior loss. J. Vis. Commun. Image Represent. 2019, 65, 102648. [Google Scholar] [CrossRef]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4401–4410. [Google Scholar]
- Jiang, Z.; Zhang, Y.; Zou, D.; Ren, J.; Lv, J.; Liu, Y. Learning event-based motion deblurring. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 3320–3329. [Google Scholar]
- Yuan, Y.; Su, W.; Ma, D. Efficient Dynamic Scene Deblurring Using Spatially Variant Deconvolution Network With Optical Flow Guided Training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 3552–3561. [Google Scholar]
- Suin, M.; Purohit, K.; Rajagopalan, A.N. Spatially-attentive patch-hierarchical network for adaptive motion deblurring. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 3606–3615. [Google Scholar]
- Nan, Y.; Ji, H. Deep learning for handling kernel/model uncertainty in image deconvolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 2388–2397. [Google Scholar]
- Kaufman, A.; Fattal, R. Deblurring using analysis-synthesis networks pair. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 5811–5820. [Google Scholar]
- An, S.; Roh, H.; Kang, M. Blur Invariant Kernel-Adaptive Network for Single Image Blind Deblurring. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo, Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar]
- Su, J.; Wu, G. f-VAEs: Improve VAEs with conditional flows. arXiv 2018, arXiv:1809.05861. [Google Scholar]
- Ho, J.; Chen, X.; Srinivas, A.; Duan, Y.; Abbeel, P. Flow++: Improving flow-based generative models with variational dequantization and architecture design. Int. Conf. Mach. Learn. 2019, 97, 2722–2730. [Google Scholar]
- Yu, J.J.; Derpanis, K.G.; Brubaker, M.A. Wavelet flow: Fast training of high resolution normalizing flows. Adv. Neural Inf. Process. Syst. 2020, 33, 6184–6196. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical image computing and computer-assisted intervention, Boston, MA, USA, 7–12 June 2015; pp. 234–241. [Google Scholar]
- Dinh, L.; Krueger, D.; Bengio, Y. Nice: Non-linear independent components estimation. arXiv 2014, arXiv:1410.8516. [Google Scholar]
- Dinh, L.; Sohl-Dickstein, J.; Bengio, S. Density estimation using real nvp. arXiv 2016, arXiv:1605.08803. [Google Scholar]
- Kingma, D.P.; Dhariwal, P. Glow: Generative flow with invertible 1 × 1 convolutions. arXiv 2018, arXiv:1807.03039v2. [Google Scholar]
- Ardizzone, L.; Lüth, C.; Kruse, J.; Rother, C.; Köthe, U. Guided image generation with conditional invertible neural networks. arXiv 2019, arXiv:1907.02392. [Google Scholar]
- Lugmayr, A.; Danelljan, M.; Gool, L.V.; Timofte, R. Srflow: Learning the super-resolution space with normalizing flow. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 715–732. [Google Scholar]
- Stephane, M. A Wavelet Tour of Signal Processing; Elsevier: Amsterdam, The Netherlands, 1999. [Google Scholar]
- Denton, E.L.; Chintala, S.; Fergus, R. Deep generative image models using a laplacian pyramid of adversarial networks. arXiv 2015, arXiv:1506.05751v1. [Google Scholar]
- Dosovitskiy, A.; Fischer, P.; Ilg, E.; Hausser, P.; Hazirbas, C.; Golkov, V.; Van Der Smagt, P.; Cremers, D.; Brox, T. Flownet: Learning optical flow with convolutional networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2758–2766. [Google Scholar]
- Eigen, D.; Fergus, R. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2650–2658. [Google Scholar]
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth map prediction from a single image using a multi-scale deep network. arXiv 2014, arXiv:1406.2283v1. [Google Scholar]
- Xu, L.; Zheng, S.; Jia, J. Unnatural L0 sparse representation for natural image deblurring. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1107–1114. [Google Scholar]
- Levin, A.; Weiss, Y.; Dur, F.; Freeman, W.T. Understanding and evaluating blind deconvolution algorithms. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1964–1971. [Google Scholar]
- Xu, L.; Lu, C.; Xu, Y.; Jia, J. Image smoothing via L0 gradient minimization. Acm Trans. Graph. (TOG) 2011, 30, 174. [Google Scholar] [CrossRef] [Green Version]
- Yang, D.Y.; Wu, X.J.; Yin, H.F. Blind image deblurring via enhanced sparse prior. J. Electron. Imaging 2021, 30, 023031. [Google Scholar] [CrossRef]
- Pan, J.; Sun, D.; Pfister, H.; Yang, M. Deblurring Images via Dark Channel Prior. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 2315–2328. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Fang, F.; Wang, T.; Zhang, G. Blind image deblurring with local maximum gradient prior. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 1742–1750. [Google Scholar]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep learning face attributes in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3730–3738. [Google Scholar]
- Yu, F.; Seff, A.; Zhang, Y.; Song, S.; Funkhouser, T.; Xiao, J. Lsun: Construction of a large-scale image dataset using deep learning with humans in the loop. arXiv 2015, arXiv:1506.03365. [Google Scholar]
- Lai, W.S.; Huang, J.B.; Hu, Z.; Ahuja, N.; Yang, M.H. A comparative study for single image blind deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1701–1709. [Google Scholar]
- Ren, D.; Zhang, K.; Wang, Q.; Hu, Q.; Zuo, W. Neural blind deconvolution using deep priors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 3341–3350. [Google Scholar]
- Tran, P.; Tran, A.T.; Phung, Q.; Hoai, M. Explore image deblurring via encoded blur kernel space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11956–11965. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Measurement | GoPro | Lai | CelebA | LSUN | Ground Truth |
|---|---|---|---|---|---|---|
| PSNR | 22.98 | 20.36 | 19.32 | 22.29 | ∞ | |
| DeblurGAN [2] | SSIM | 0.824 | 0.809 | 0.801 | 0.817 | 1 |
| MSE | 0.005 | 0.012 | 0.017 | 0.004 | 0 | |
| PSNR | 23.55 | 19.59 | 21.33 | 22.49 | ∞ | |
| DeblurGAN-V2 [10] | SSIM | 0.835 | 0.791 | 0.828 | 0.832 | 1 |
| MSE | 0.005 | 0.011 | 0.009 | 0.005 | 0 | |
| PSNR | 25.38 | 23.42 | 22.29 | 24.12 | ∞ | |
| ResCGAN [21] | SSIM | 0.898 | 0.887 | 0.839 | 0.915 | 1 |
| MSE | 0.003 | 0.004 | 0.005 | 0.008 | 0 | |
| PSNR | 23.63 | 22.05 | 21.85 | 22.92 | ∞ | |
| Selef-Deblur [52] | SSIM | 0.841 | 0.811 | 0.821 | 0.835 | 1 |
| MSE | 0.004 | 0.004 | 0.004 | 0.005 | 0 | |
| PSNR | 31.29 | 28.81 | 29.23 | 30.04 | ∞ | |
| Tran et al. [53] | SSIM | 0.948 | 0.929 | 0.940 | 0.943 | 1 |
| MSE | 0.002 | 0.003 | 0.001 | 0.001 | 0 | |
| PSNR | 30.98 | 28.64 | 27.15 | 28.72 | ∞ | |
| DED [16] | SSIM | 0.941 | 0.925 | 0.937 | 0.959 | 1 |
| MSE | 0.002 | 0.003 | 0.002 | 0.001 | 0 | |
| PSNR | 32.49 | 29.35 | 31.42 | 32.73 | ∞ | |
| Ours | SSIM | 0.954 | 0.938 | 0.943 | 0.966 | 1 |
| MSE | 0.002 | 0.002 | 0.001 | 0.001 | 0 |
| Method | Measurement | GoPro | Lai | CelebA | LSUN | Ground Truth |
|---|---|---|---|---|---|---|
| PSNR | 18.98 | 17.69 | 20.63 | 22.53 | ∞ | |
| UML-IN | SSIM | 0.642 | 0.707 | 0.809 | 0.826 | 1 |
| MSE | 0.018 | 0.021 | 0.010 | 0.008 | 0 | |
| PSNR | 22.16 | 19.67 | 24.83 | 24.98 | ∞ | |
| UML-IN + SSIM | SSIM | 0.818 | 0.781 | 0.876 | 0.894 | 1 |
| MSE | 0.008 | 0.017 | 0.005 | 0.003 | 0 | |
| PSNR | 30.26 | 28.32 | 29.12 | 31.10 | ∞ | |
| UML-IN + | SSIM | 0.931 | 0.944 | 0.913 | 0.941 | 1 |
| MSE | 0.002 | 0.005 | 0.002 | 0.002 | 0 | |
| PSNR | 32.49 | 29.35 | 31.42 | 32.73 | ∞ | |
| UML-IN + + SSIM | SSIM | 0.954 | 0.938 | 0.943 | 0.966 | 1 |
| MSE | 0.002 | 0.002 | 0.001 | 0.001 | 0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, M.; Wen, T.; Liu, H. A Codec-Unified Deblurring Approach Based on U-Shaped Invertible Network with Sparse Salient Representation in Latent Space. Electronics 2022, 11, 2177. https://doi.org/10.3390/electronics11142177
Wang M, Wen T, Liu H. A Codec-Unified Deblurring Approach Based on U-Shaped Invertible Network with Sparse Salient Representation in Latent Space. Electronics. 2022; 11(14):2177. https://doi.org/10.3390/electronics11142177
Chicago/Turabian StyleWang, Meng, Tao Wen, and Haipeng Liu. 2022. "A Codec-Unified Deblurring Approach Based on U-Shaped Invertible Network with Sparse Salient Representation in Latent Space" Electronics 11, no. 14: 2177. https://doi.org/10.3390/electronics11142177
APA StyleWang, M., Wen, T., & Liu, H. (2022). A Codec-Unified Deblurring Approach Based on U-Shaped Invertible Network with Sparse Salient Representation in Latent Space. Electronics, 11(14), 2177. https://doi.org/10.3390/electronics11142177