
Monocular Depth Estimation from a Single Infrared Image



Abstract
:1. Introduction
2. Related Work
2.1. Self-Supervised Depth Estimation
2.2. Thermal Infrared Camera Vision
3. Materials and Methods
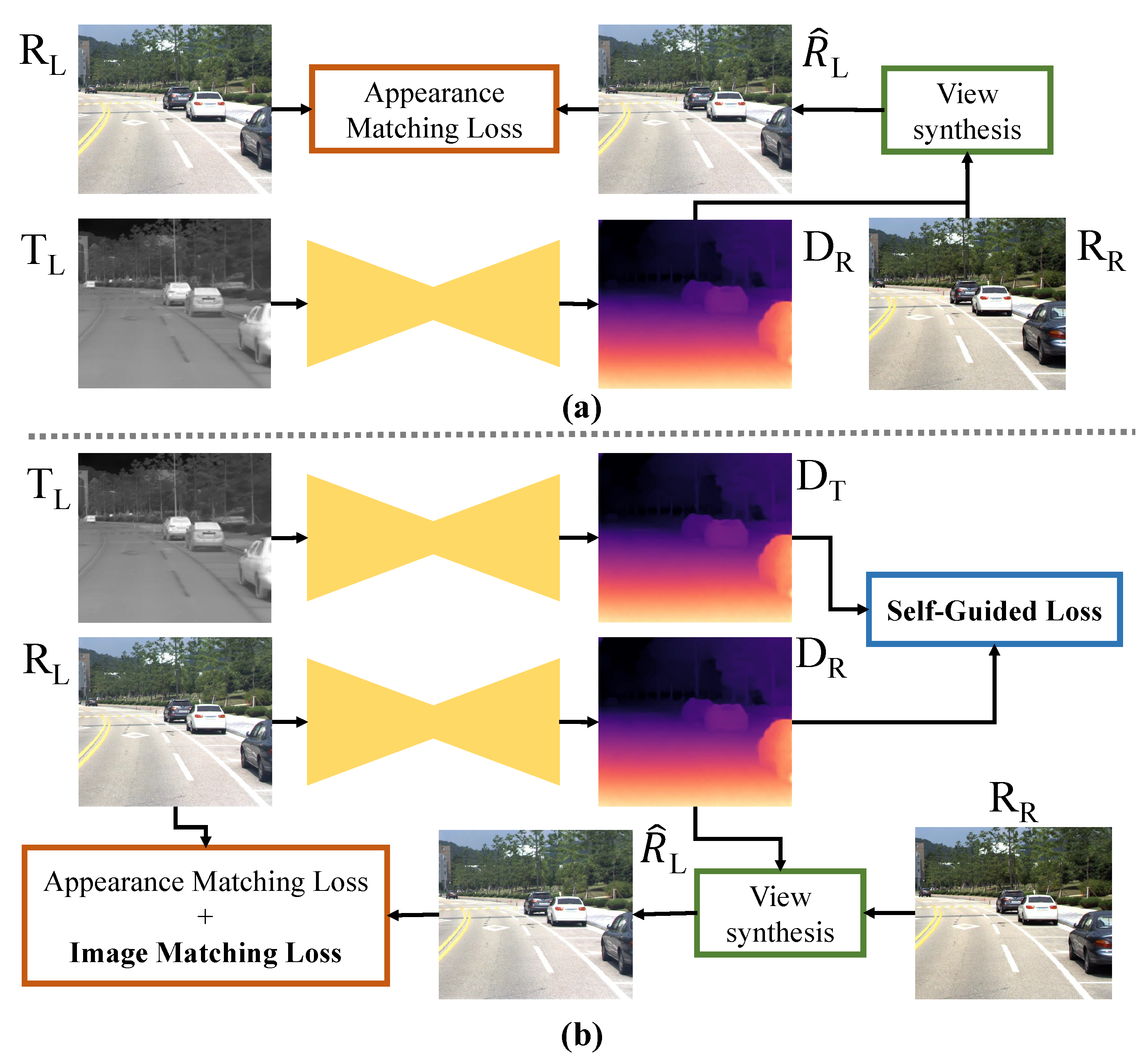
3.1. Self-Guided Framework
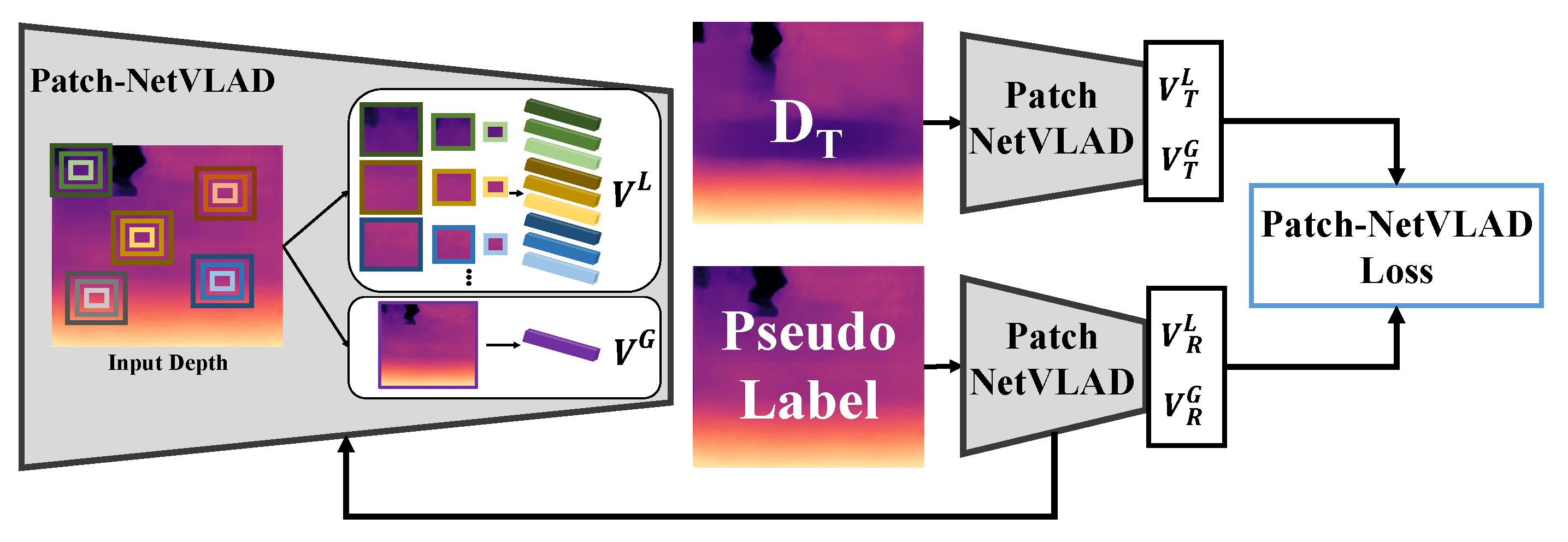
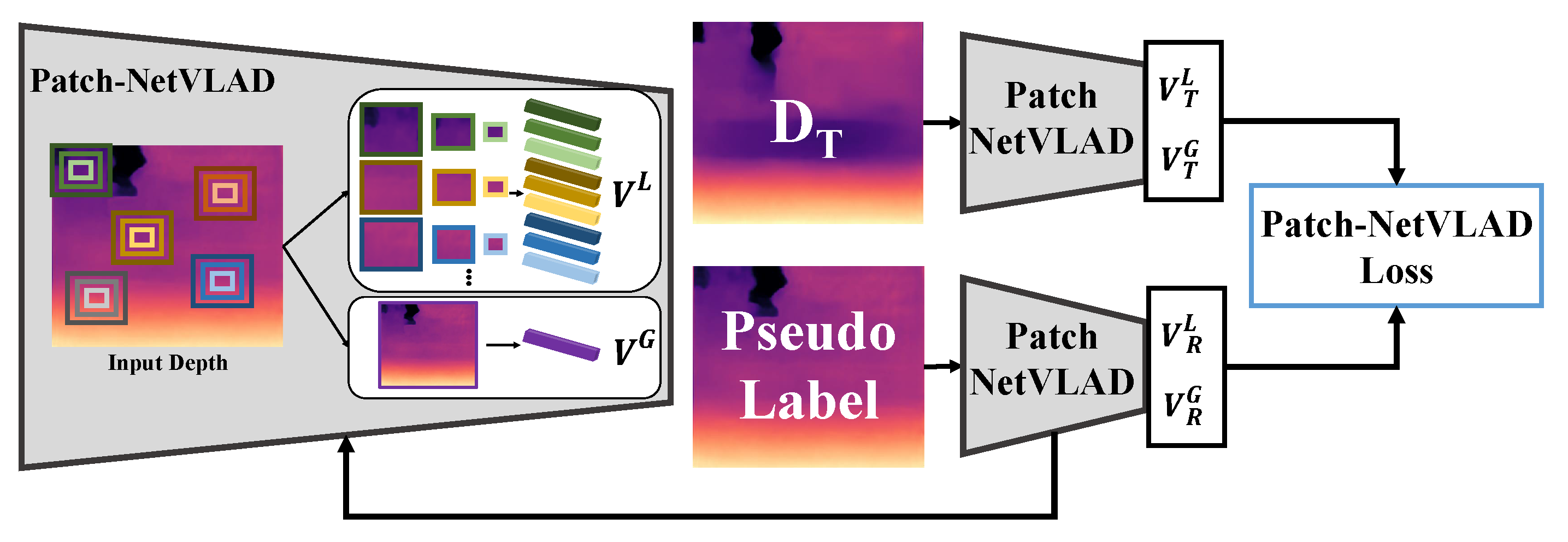
3.2. Patch-NetVLAD Loss
3.3. Image Matching Loss
3.4. Training Loss
4. Experiments and Results
4.1. Dataset
4.2. Implementation Details
4.3. Evaluation Metrics
4.4. Ablation Study
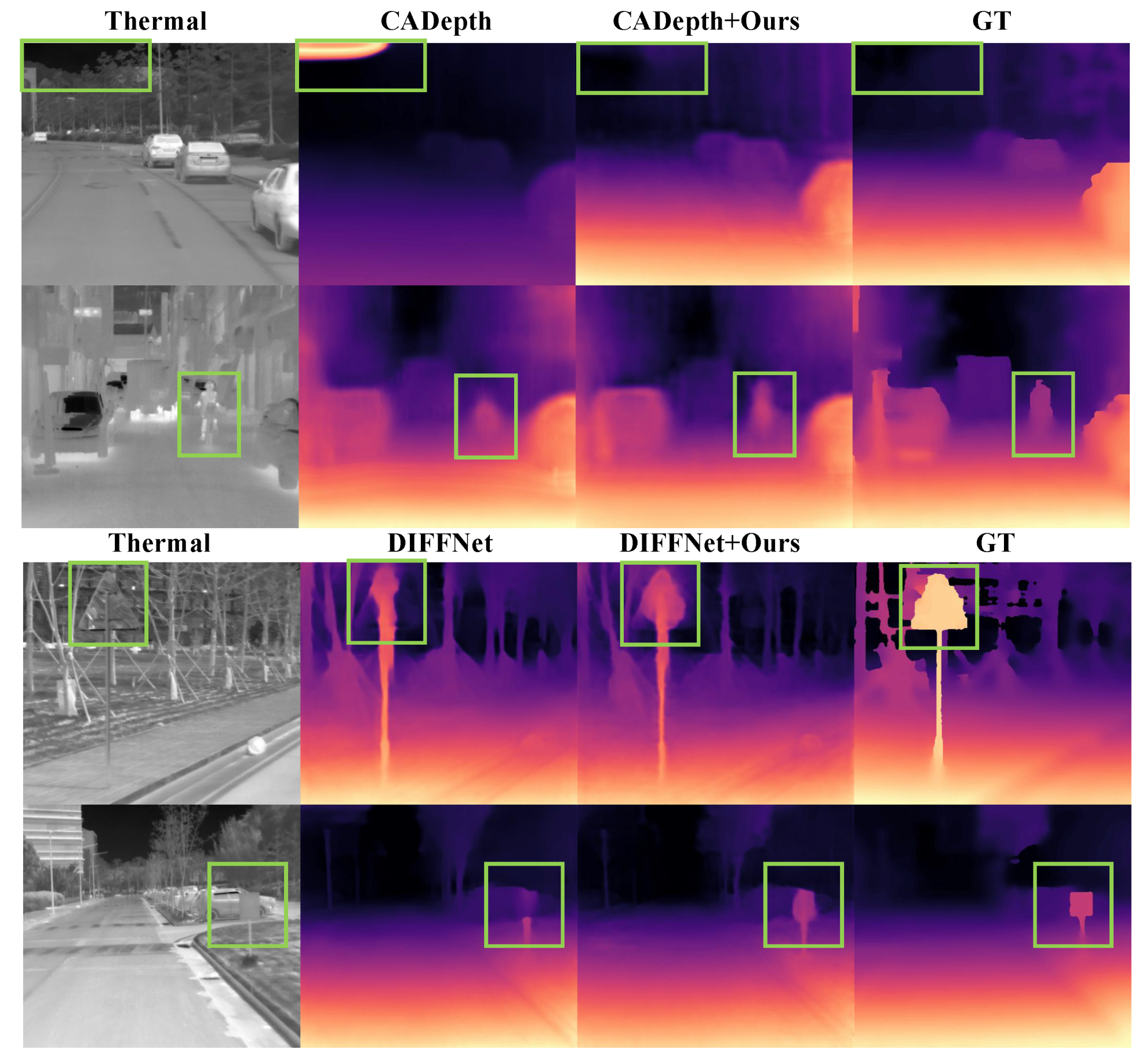
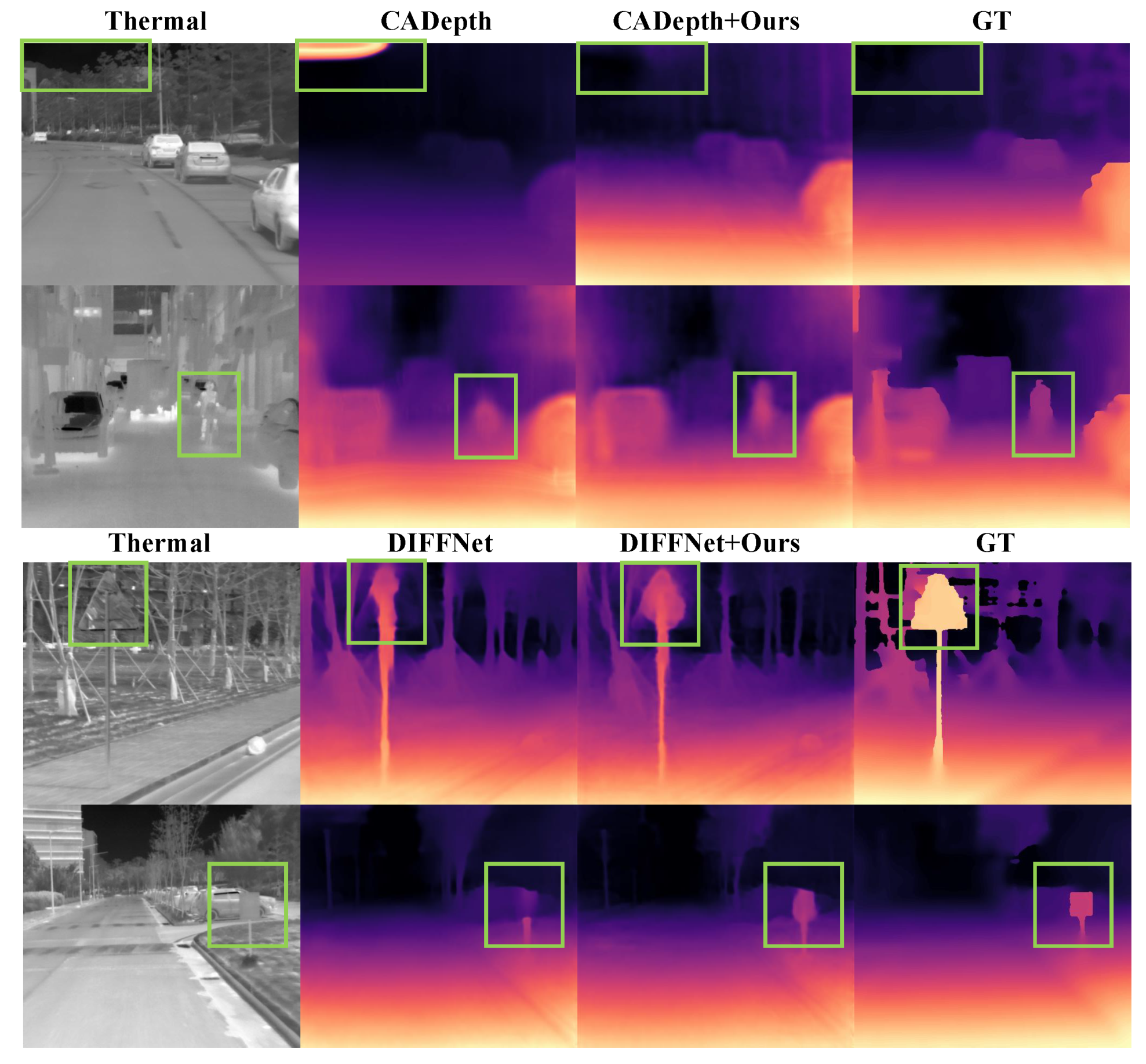
4.5. Depth Estimation Performance
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. Nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Ibáñez, M.B.; Delgado-Kloos, C. Augmented reality for STEM learning: A systematic review. Comput. Educ. 2018, 123, 109–123. [Google Scholar] [CrossRef]
- Bastug, E.; Bennis, M.; Médard, M.; Debbah, M. Toward interconnected virtual reality: Opportunities, challenges, and enablers. IEEE Commun. Mag. 2017, 55, 110–117. [Google Scholar] [CrossRef]
- Bhat, S.F.; Alhashim, I.; Wonka, P. Adabins: Depth estimation using adaptive bins. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021. [Google Scholar]
- Lee, J.H.; Han, M.K.; Ko, D.W.; Suh, I.H. From big to small: Multi-scale local planar guidance for monocular depth estimation. arXiv 2019, arXiv:1907.10326. [Google Scholar]
- Godard, C.; Mac Aodha, O.; Brostow, G.J. Unsupervised monocular depth estimation with left-right consistency. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Gonzalez, J.L.; Kim, M. PLADE-Net: Towards Pixel-Level Accuracy for Self-Supervised Single-View Depth Estimation With Neural Positional Encoding and Distilled Matting Loss. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021. [Google Scholar]
- Godard, C.; Mac Aodha, O.; Firman, M.; Brostow, G.J. Digging into self-supervised monocular depth estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Song, X.; Li, W.; Zhou, D.; Dai, Y.; Fang, J.; Li, H.; Zhang, L. MLDA-Net: Multi-level dual attention-based network for self-supervised monocular depth estimation. IEEE Trans. Image Process. 2021, 30, 4691–4705. [Google Scholar] [CrossRef] [PubMed]
- Guizilini, V.; Ambrus, R.; Pillai, S.; Raventos, A.; Gaidon, A. 3d packing for self-supervised monocular depth estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Hwang, S.; Park, J.; Kim, N.; Choi, Y.; So Kweon, I. Multispectral pedestrian detection: Benchmark dataset and baseline. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Kim, J.; Kim, H.; Kim, T.; Kim, N.; Choi, Y. MLPD: Multi-Label Pedestrian Detector in Multispectral Domain. IEEE Robot. Autom. Lett. 2021, 6, 7846–7853. [Google Scholar] [CrossRef]
- Kim, Y.H.; Shin, U.; Park, J.; Kweon, I.S. MS-UDA: Multi-spectral unsupervised domain adaptation for thermal image semantic segmentation. IEEE Robot. Autom. Lett. 2021, 6, 6497–6504. [Google Scholar] [CrossRef]
- Han, D.; Hwang, Y.; Kim, N.; Choi, Y. Multispectral Domain Invariant Image for Retrieval-based Place Recognition. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Virtual, 31 May–31 August 2020. [Google Scholar]
- Kim, N.; Choi, Y.; Hwang, S.; Kweon, I.S. Multispectral transfer network: Unsupervised depth estimation for all-day vision. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth map prediction from a single image using a multi-scale deep network. arXiv 2014, arXiv:1406.2283. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 694–711. [Google Scholar]
- Hausler, S.; Garg, S.; Xu, M.; Milford, M.; Fischer, T. Patch-netvlad: Multi-scale fusion of locally-global descriptors for place recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021. [Google Scholar]
- Eigen, D.; Fergus, R. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Fu, H.; Gong, M.; Wang, C.; Batmanghelich, K.; Tao, D. Deep ordinal regression network for monocular depth estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Johnston, A.; Carneiro, G. Self-supervised monocular trained depth estimation using self-attention and discrete disparity volume. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 31 May–31 August 2020. [Google Scholar]
- Zhou, T.; Brown, M.; Snavely, N.; Lowe, D.G. Unsupervised learning of depth and ego-motion from video. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Ranjan, A.; Jampani, V.; Balles, L.; Kim, K.; Sun, D.; Wulff, J.; Black, M.J. Competitive collaboration: Joint unsupervised learning of depth, camera motion, optical flow and motion segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Han, D.; Choi, Y. GBNet: Gradient Boosting Network for Monocular Depth Estimation. In Proceedings of the International Conference on Control, Automation and Systems (ICCAS), Jeju, Korea, 12–15 October 2021. [Google Scholar]
- Zhou, H.; Greenwood, D.; Taylor, S. Self-Supervised Monocular Depth Estimation with Internal Feature Fusion. In Proceedings of the British Machine Vision Conference (BMVC), Online, 22–25 November 2021. [Google Scholar]
- Yan, J.; Zhao, H.; Bu, P.; Jin, Y. Channel-Wise Attention-Based Network for Self-Supervised Monocular Depth Estimation. In Proceedings of the British Machine Vision Conference (BMVC), Online, 22–25 November 2021. [Google Scholar]
- Dosovitskiy, A.; Brox, T. Generating images with perceptual similarity metrics based on deep networks. arXiv 2016, arXiv:1602.02644. [Google Scholar]
- Ha, Q.; Watanabe, K.; Karasawa, T.; Ushiku, Y.; Harada, T. MFNet: Towards real-time semantic segmentation for autonomous vehicles with multi-spectral scenes. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017. [Google Scholar]
- Choi, Y.; Kim, N.; Hwang, S.; Kweon, I.S. Thermal image enhancement using convolutional neural network. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 9–14 October 2016. [Google Scholar]
- Ye, M.; Lan, X.; Li, J.; Yuen, P. Hierarchical discriminative learning for visible thermal person re-identification. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Park, T.; Liu, M.Y.; Wang, T.C.; Zhu, J.Y. Semantic image synthesis with spatially-adaptive normalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Arandjelovic, R.; Gronat, P.; Torii, A.; Pajdla, T.; Sivic, J. NetVLAD: CNN architecture for weakly supervised place recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Torii, A.; Sivic, J.; Pajdla, T.; Okutomi, M. Visual place recognition with repetitive structures. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. In Proceedings of the International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef] [Green Version]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SIlog | Input | Abs. Rel | Sqr. Rel | RMSE | RMSE log | |||
|---|---|---|---|---|---|---|---|---|
| - | - | - | - | T | 0.098 | 0.525 | 3.439 | 0.135 |
| ✓ | - | - | - | T | 0.099 | 0.512 | 3.454 | 0.136 |
| - | ✓ | - | - | T | 0.096 | 0.482 | 3.336 | 0.133 |
| - | ✓ | ✓ | - | T | 0.092 | 0.465 | 3.361 | 0.132 |
| - | ✓ | ✓ | ✓ | T | 0.089 | 0.452 | 3.299 | 0.130 |
| - | - | - | - | R | 0.081 | 0.373 | 2.966 | 0.120 |
| Input | Abs. Rel | Sqr. Rel | RMSE | RMSE log | |||
|---|---|---|---|---|---|---|---|
| ✓ | - | - | T | 0.089 | 0.452 | 3.299 | 0.130 |
| ✓ | ✓ | - | T | 0.089 | 0.438 | 3.262 | 0.128 |
| ✓ | ✓ | ✓ | T | 0.086 | 0.431 | 3.261 | 0.127 |
| ✓ | - | - | R | 0.081 | 0.373 | 2.966 | 0.120 |
| ✓ | ✓ | - | R | 0.081 | 0.365 | 2.889 | 0.116 |
| ✓ | ✓ | ✓ | R | 0.079 | 0.350 | 2.877 | 0.116 |
| Method | SGF | Abs. Rel | Sqr. Rel | RMSE | RMSE log | |||
|---|---|---|---|---|---|---|---|---|
| monodepth2 [8] | - | 0.107 | 0.577 | 3.619 | 0.148 | 0.885 | 0.975 | 0.994 |
| monodepth2 [8] | ✓ | 0.098 | 0.515 | 3.529 | 0.145 | 0.888 | 0.977 | 0.994 |
| CADepth [27] | - | 0.109 | 0.720 | 4.277 | 0.201 | 0.882 | 0.970 | 0.989 |
| CADepth [27] | ✓ | 0.105 | 0.581 | 3.782 | 0.153 | 0.883 | 0.973 | 0.993 |
| GBNet [25] | - | 0.095 | 0.483 | 3.430 | 0.135 | 0.911 | 0.980 | 0.995 |
| GBNet [25] | ✓ | 0.091 | 0.442 | 3.256 | 0.128 | 0.916 | 0.984 | 0.996 |
| DIFFNet [26] | - | 0.098 | 0.525 | 3.439 | 0.135 | 0.909 | 0.980 | 0.994 |
| DIFFNet [26] | ✓ | 0.086 | 0.435 | 3.284 | 0.129 | 0.912 | 0.983 | 0.995 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, D.; Choi, Y. Monocular Depth Estimation from a Single Infrared Image. Electronics 2022, 11, 1729. https://doi.org/10.3390/electronics11111729
Han D, Choi Y. Monocular Depth Estimation from a Single Infrared Image. Electronics. 2022; 11(11):1729. https://doi.org/10.3390/electronics11111729
Chicago/Turabian StyleHan, Daechan, and Yukyung Choi. 2022. "Monocular Depth Estimation from a Single Infrared Image" Electronics 11, no. 11: 1729. https://doi.org/10.3390/electronics11111729
APA StyleHan, D., & Choi, Y. (2022). Monocular Depth Estimation from a Single Infrared Image. Electronics, 11(11), 1729. https://doi.org/10.3390/electronics11111729